2. Background
SC has its roots in the 1960s, and it is used for probability representation using digital bit streams [
3,
4]. SC has been successfully applied to many applications like image processing, neural networks, LDPCcodes, factor graphs, fault-tree analysis and in filters [
5,
6,
7,
8,
9,
10]. However, the extensive use of stochastic computation is still limited, because of its long run-time and inaccuracy. Recent improvements have mainly focused on improving the accuracy and performance of the stochastic circuits by sharing consecutive bit streams, sharing the stochastic number generators, using true random generators, exploiting the correlation and using the spectral transform approach for stochastic circuit synthesis [
11,
12,
13,
14,
15,
16,
17]. This paper also explores new methods to improve the accuracy and performance of stochastic circuits.
Figure 1 shows the basic SC circuits. The function implemented by these circuits varies with the number interpretations, i.e., unipolar, bipolar or inverted bipolar (UP, BP, IBP), where unipolar format is used to represent real number
x in the range of
, bipolar is used to represent real number
x between
and IBP is the inverted bipolar format, which is an inversion of BP ranging from
, where the Boolean values zero and one in the Stochastic Number (SN) represent one and
, respectively, rather than
and one in the case of the BP format. One can refer to [
13] for more details on different SN formats.
In SC, a probability value is represented by a binary bit stream of zeroes and ones with specific length
L. To represent a probability value of
, half of the bits in the bit stream of length
L are represented by ones. For example, if
is to be represented by a bit stream of 10 bits, then the 0101010101 bit stream is one way of representing it. The representation of a probability value in SC is not unique, and not all real number’s in the interval
can be exactly represented for a fixed value of
L. Another considerably important factor when representing a stochastic number is the dependency or correlation between the inputs [
19]. This is an important inherent nature of stochastic circuits that limits their performance over certain applications when compared to conventional binary implementations [
20].
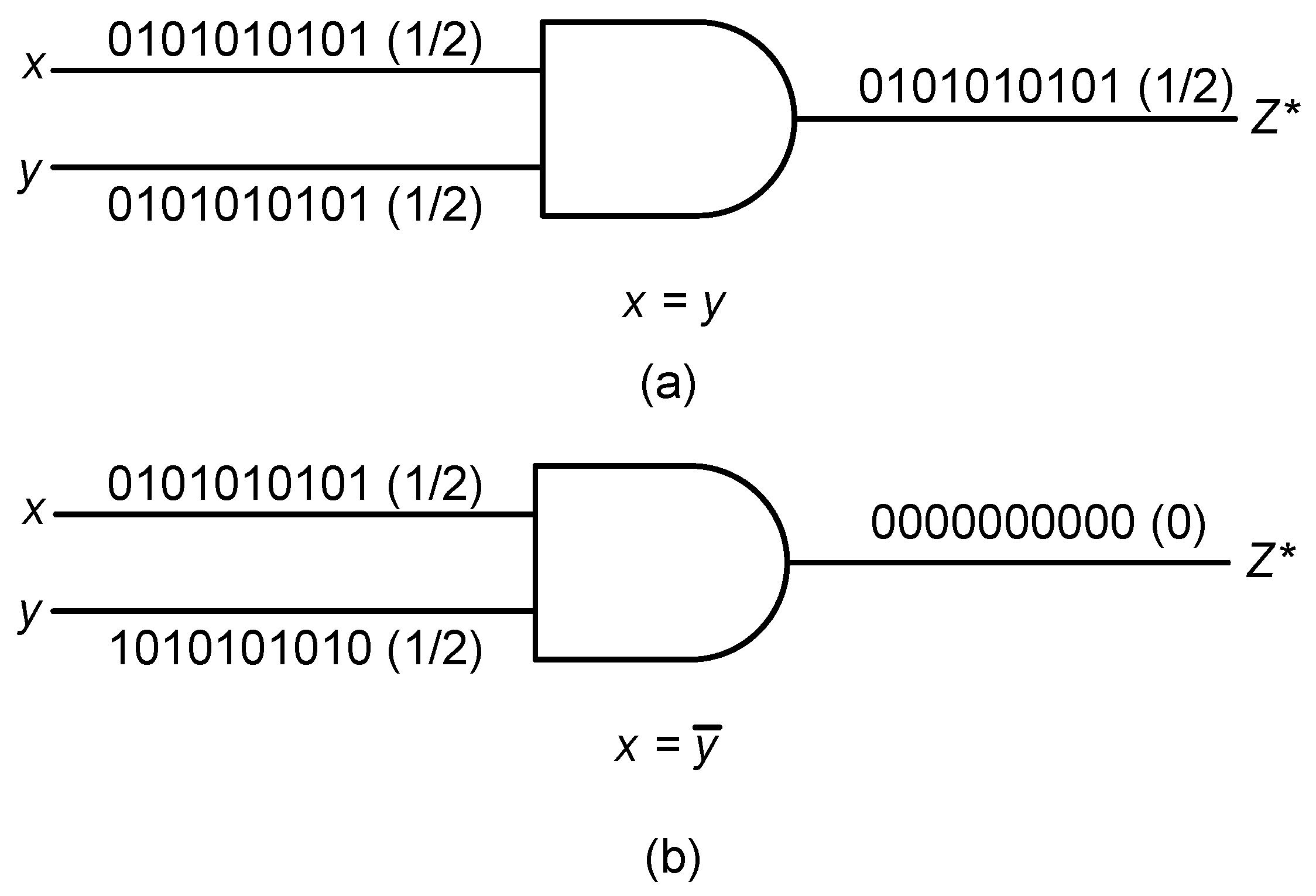
Figure 2 shows two examples where inaccurate results are caused by correlated inputs in the multiplication circuit. This correlation comes from the SNGs, where the SNs generated by SNGs happened to have the same set of sequences of ones and zeros or have some relation among them as shown in
Figure 2. This causes inaccuracy in the output generated, so SNGs are always chosen in such a way that they produce uncorrelated SNs. LFSRs are known to be best-suited for SC and have been used for number generation in many SC designs [
21]. However, the main disadvantages are the number of SNGs must be higher (i.e., for every independent input, the number of SNGs used increases by one) for uncorrelated inputs and need a longer time to operate for accurate and efficient SC [
19].
When the circuit size, power and computation time of SC are considered, the main contributions for these factors to vary significantly are the SNGs. The number of SNGs is proportional to the area of a stochastic circuit, contributing to about 80% of the circuit area. The power consumed by SC mainly depends on the number of clock cycles the circuit uses for computation, which in turn, depends on the SNG properties. The computation time can be limited by SNGs due to their inherent properties such as random number fluctuations. The computation time increases exponentially with the linear increase in accuracy, hence the need to address basic questions such as: What is the minimum number of clock cycles needed to run, so the probability value is represented correctly? What is the effect of random noise fluctuations in a sequence of stochastic operations? Answers to these questions may help in decreasing the computation time drastically. SC has another disadvantage over the binary implementation as all the operations in the SC are single staged; therefore, conventional techniques such as pipelining to improve the throughput cannot be applied [
18].
This paper is organized as follows.
Section 3 gives the background of the LD sequences and LUT-based method implemented.
Section 4 discusses the parallel implementation of SNGs and the different stages used in the parallel implementation of SNGs for parallel stochastic computing.
Section 5 discusses the simulation results comparing the proposed SNG with the pseudo-random number generators (LFSRs). An analysis of the convergence rate of the proposed SNG with that of the LFSR is given. A discussion of the application of the proposed serial and parallel SNG in edge detection and the multiplication circuit and the specification of the advantages over the LFSR implementation is given. Finally,
Section 6 provides the conclusion.
3. Proposed LUT-Based Method for LD Sequence Generation
In the proposed approach, SNGs are designed to leverage LUTs, which are the distributed memory elements of the FPGAs. The primary focuses of this paper are on decreasing the power consumed, improving the accuracy, reducing the number of random fluctuations and reducing the execution time by parallel implementation using the proposed LUT-based Quasi-SNG (QSNG). FPGAs are the target hardware implemented in this design for their abundant availability of LUTs and their inherent parallel nature. Among various applications, LUTs are used in digital signal processing algorithms, where multiplication is done with a fixed set of coefficients that are already pre-computed and stored in the LUT, so they can be used without computing them each time [
22]. The same concept is used in this paper, where pre-computed fixed direction vectors are multiplied with a binary number to get the desired sequence. The LUT-based method is used to develop stochastic bit numbers by using Quasi-Monte Carlo (QMC) methods [
23]. The LD sequences in the literature are used to develop these stochastic numbers. The main advantage gained over the use of LFSRs is that LD sequences do not suffer from random fluctuations as the zeros and ones are uniformly spaced [
2]. This is unlike LFSRs, where the zero and ones are non-uniformly spaced. The idea behind the LD sequences is to let the fraction of the points within any subset of
be as close as possible, such that the low-discrepancy points will spread over
as uniformly as possible, reducing gaps and clustering points.
Figure 3 shows the comparison of pseudo-random points (LFSR implementation) and LD points (Sobol sequence) in the unit square. LD points shows even and uniform coverage of the area of interest as shown and are to converge faster when applied to SC.
The widely-used sequences that fall under the LD sequence category are the Halton sequence, Sobol sequence, Faure sequence and Niederreiter sequence [
23,
25,
26]. Generating these sequences is usually software based because the hardware implementation of all these sequences is not suited for SC due to their complexity in construction [
2]. This disadvantage of LD sequences is mitigated fully by the proposed LUT-based approach. The main difference in generating the LD sequences lies in the construction of their direction vectors [
23]. Each sequence has a specific type of algorithm to compute these, and the uniformity of the sequence depends on the way these direction vectors are computed. In this paper, LUT-based SNGs were designed using three LD sequences including Halton, Sobol and Niederreiter. The digital method was chosen to design these sequences, restricting the base value to binary base two. For a detailed explanation about the sequences mentioned above, refer to [
23].
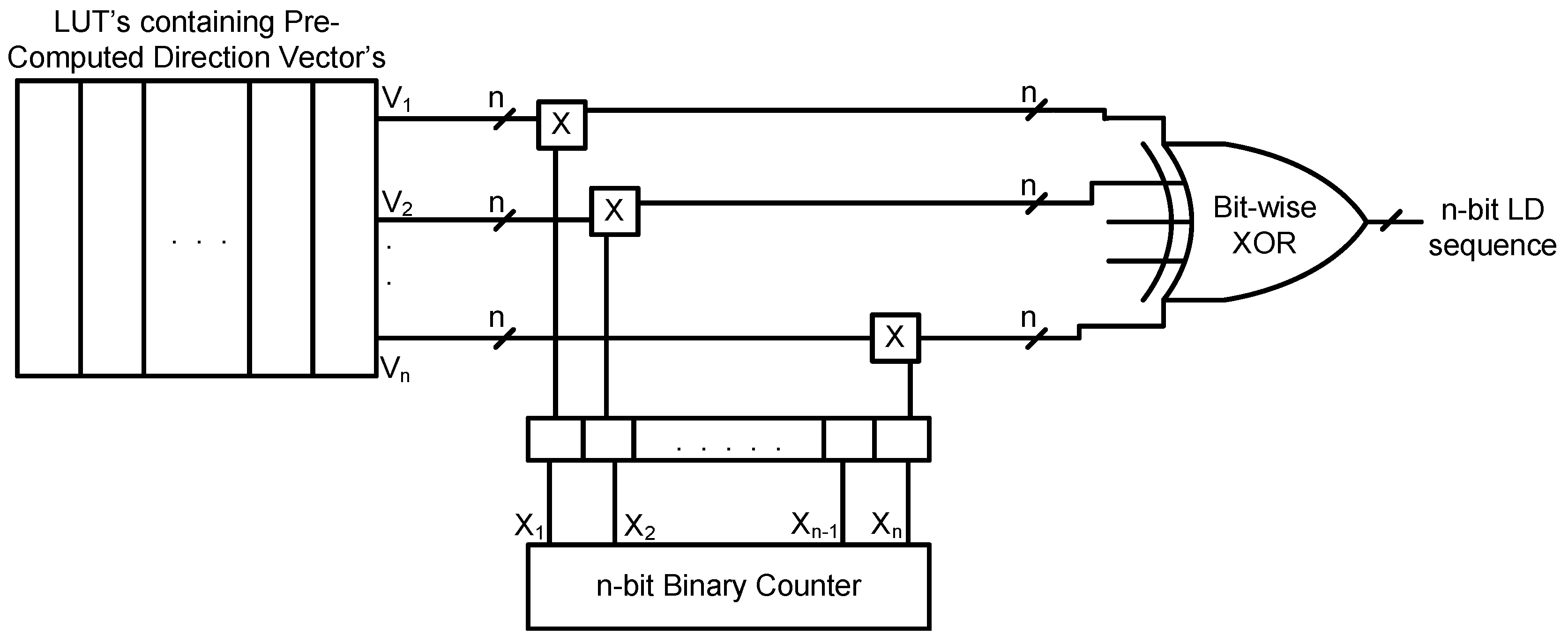
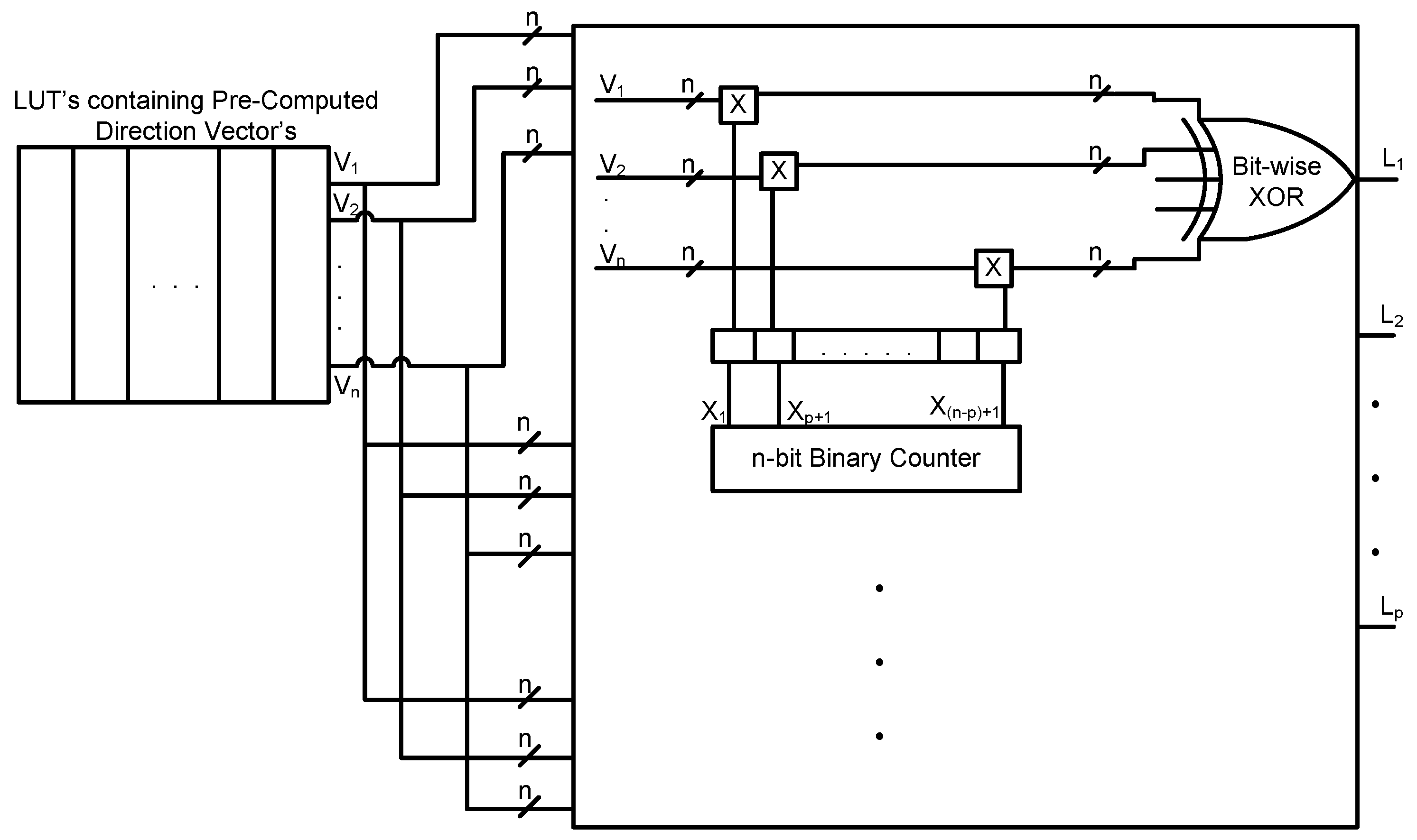
The general structure used for generation of the LD sequence using binary base two is as shown in
Figure 4. It contains RAM to store the direction vectors, a multiplication circuit and bit-wise XOR gates. In the multiplication circuit, every bit from the counter output is multiplied by each
n-bit direction vector, stored in the RAM, to generate
n-bit intermediate direction vectors. These
n-bit intermediate direction vectors are then bit-wise XORed (i.e., modulo-two addition) to generate an
n-bit LD sequence.
This can be expressed by using a mathematical expression as shown in the equation below [
23]:
where ⊕ denotes binary addition or XOR operation,
is the binary representation of
,
represents the direction vectors and
N represents the
N-th number in the respective LD sequence; for example
represents the eighth number in a Sobol sequence, which is computed by using
n direction vectors and an
n-bit counter, when Sobol sequence direction vectors are used [
23]. Sobol and Niederreiter sequences belong to the general class of digital sequences, and their LD sequence generation can be expressed by the above digital method [
25,
27]. The Halton sequences belong to the simplest form of LD sequences, and their construction does not have a general form as mentioned above in Equation (
1). In the above Equation (
1),
are called the direction vectors and are defined as the constant values that have to be multiplied with the counter output to generate the desired LD sequence as shown in
Figure 4. These values do not change throughout the operation of the circuit; hence, for the generation of Halton LD sequences, defining the direction vectors to fit into the above equation of the general digital method of LD sequence is necessary to generalize the hardware structure for the LD sequences mentioned in the paper.
Halton sequences are defined as the generalized form of van der Corput sequences, which use a distinct prime base for every dimension. The
Halton point
is defined as
[
26]. Upon closer inspection of the summation, we define
to be nothing, but the base
b representation of
, and
is the base b term, which has to be multiplied with
for the generation of each sequence depending on the value of
k. The term
is a constant term, and the value does not change with the change in the value of
k; hence, these terms are defined as direction vectors and fit into the general form represented above to generate an LD sequence by choosing the base
. Sobol and Niederreiter sequences have specific algorithms to calculate the direction vectors that fit into Equation (
1) to generate the LD sequence. In this paper, algorithms reported in papers [
25] and [
23] are used to pre-calculate direction vectors. An important point to note in this implementation is that the number of sequences generated is limited by using only
R base
b direction vectors of
R bits, which are capable of representing a value of
in base
b [
23]. For example, to generate a stochastic bit length of 256, the generation of only initial 256 LD sequences is required. For this process, eight-bit length direction vectors, which are capable of generating an eight-bit length LD sequence every clock cycle, are needed. The maximum value they can represent is
, limiting the size of the counter. For the above 256 initial sequences, an eight-bit counter is needed to count from zero to 255.
After generation, the LD sequence numbers are sent to the comparator where they are compared with the input value to generate an equivalent stochastic number. The size of the proposed SNG depends on the stochastic bit length L of the circuit, as well as the number of inputs to the stochastic circuit. For a stochastic bit length of 256, it is necessary to use an eight-bit binary counter and a memory space of 64 bits to store eight direction vectors each of an eight-bit length. Independent stochastic inputs require different direction vectors; as the number of independent stochastic inputs increases, the memory space required to store these direction vectors increases. LUT-based SNGs were implemented for 256-, 512-, 1024- and 2048-bit lengths on the Xilinx Virtex 4-SFFPGA (XC4VLX15) device and synthesized using the Xilinx ISE tool. In this paper, a general form of implementation was presented, and further optimization of the circuit has been left for a future study. Table 2 clearly shows that the LD sequence generators make use of more hardware when compared to the LFSRs, but the convergence and the accuracy obtained from LD sequences are superior enough to justify this extra hardware utilization (explained in the following sections).
4. Parallel Implementation of Proposed SNGs for SC
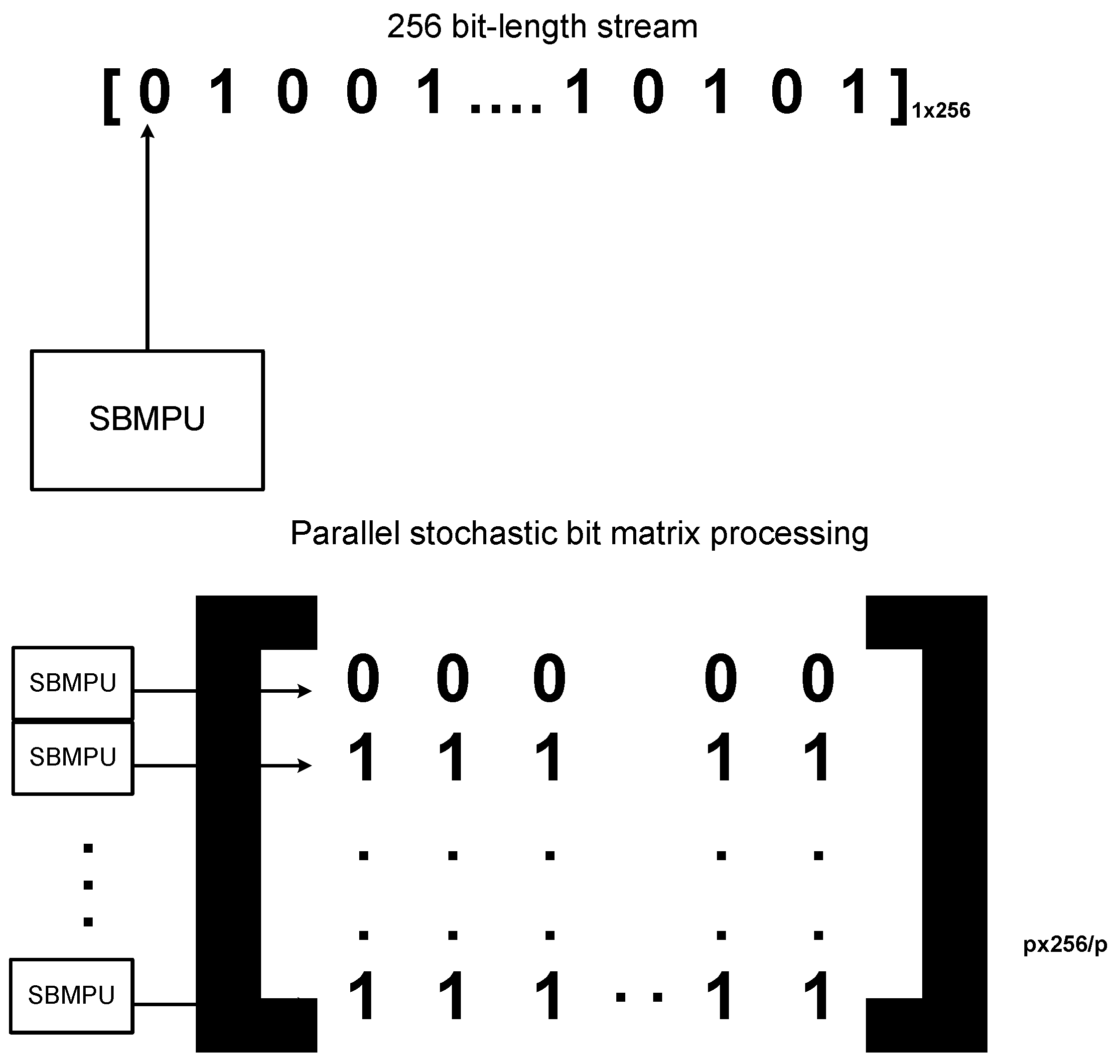
The proposed parallel implementation of the SNGs was designed to generate LD sequence numbers in parallel. These LD sequence numbers generated in parallel were used to generate stochastic bits in parallel. These stochastic numbers, generated in parallel, are termed as Stochastic Bit Vectors (SBVs), and the parallel processing used to generate the sequence is termed as Stochastic Bit Matrix (SBM) processing. Consider a 256-bit length stochastic bit matrix, this design generates
p initial bits every clock cycle of the SBM, instead of generating one bit of the SBM. This is shown in a vector form in
Figure 5, which shows that for one stochastic bit generation using a single SBM Processing Unit (SBMPU), 256 clock cycles are needed to generate a 256-bit length SBM. By duplicating
p SBMPUs in parallel, it is also possible to generate
p stochastic bits of the SBM in just one clock cycle. Hence,
clock cycles are needed for generating a 256-bit length, thus saving the execution time of the operation as
p increases.
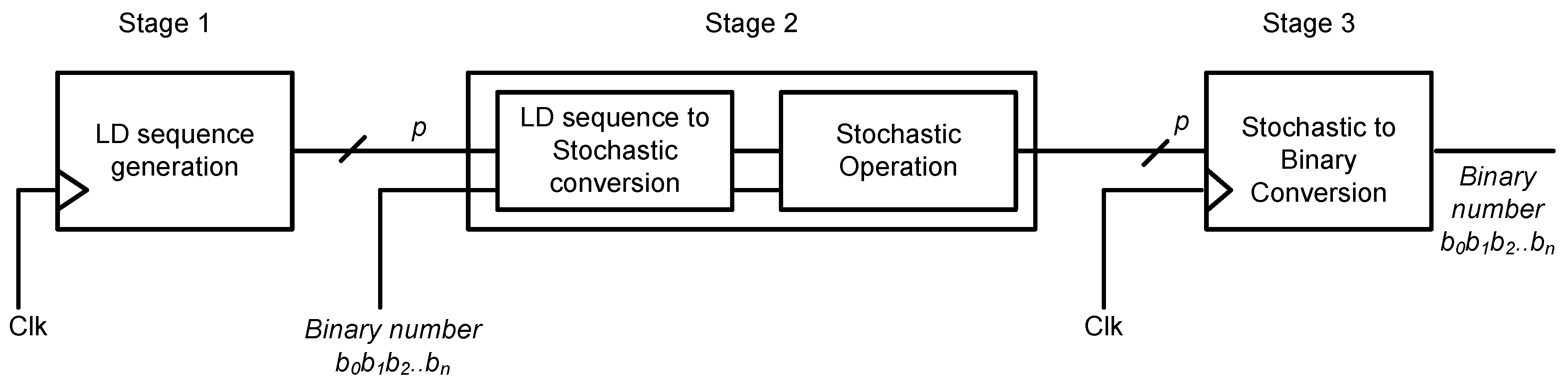
The structure of the parallel implementation of the circuit is shown in
Figure 6. The parallel implementation of the proposed SNGs is done in three stages. The first stage is where the LD sequence numbers are generated in parallel. The second stage is where the stochastic bit streams are generated in parallel using comparators and sent to the stochastic circuit for SC. Finally, the third stage is where the stochastic output is converted back to a binary output by counting the number of ones. A combinational circuit is implemented for the conversion of stochastic to binary number by counting the number of ones in the SN by making use of the Hamming weight counter principle [
28].
4.1. First Stage
The first initial
p LD sequence numbers are generated in parallel depending on the degree of parallelism. The general structure of the implementation is as shown in
Figure 7. Here, the entire structure is not duplicated, but the part of the SNG that generates the LD sequence number is duplicated to reduce the area overhead. The degree of parallelism determines the amount of hardware utilized. Counters, which follow a specific sequence of counting, are used to implement the SNGs in parallel. For example, to generate the first initial eight sub-sequences in parallel of a 256-bit stream length, use eight eight-bit counters, which count by eight. The first counter follows the sequence
, and the second counter follows the sequence
in the same way as the eighth counter follows the sequence
. Therefore, in the first clock cycle, the eight counters hold the value from zero to seven, which means that the first eight LD sequence numbers are generated in parallel. In the second clock cycle, the counters are incremented by one to hold the value eight to 15, and the next eight LD sequence numbers are generated. These generated sequences are then sent to the parallel comparator units where they are compared with the input probability value to generate the stochastic bits in parallel. This implementation generates a sequence for a single input in parallel. For multiple inputs, different direction vectors can be used, while the circuit for the generation of the LD sequence is the same.
4.2. Second Stage
The second stage consists of the generation of the stochastic bit stream and the stochastic operation. For the generation of the stochastic bit stream, the LD sequences generated in parallel are sent to the comparators, which are also in parallel, such that multiple sequences are compared simultaneously to generate a stochastic bit stream in parallel. For example, to generate eight-bits of the stochastic bit stream, use eight comparators where each sequence is compared with the binary probability value to generate the first eight bits of the SN at the same time. This is termed as eight-bit SBV generation using an eight SBM processing in one clock cycle by replicating the SBM circuit eight times. Similarly, to generate 16 SBV’s, 16 SBM processing is done in one clock cycle replicating the SBM circuit 16 times.
The SBM processing circuit involves only that part of the LD sequence generator capable of generating the sequence (i.e., the multiplication and the bit-wise XOR structure) and an LD sequence to the stochastic conversion unit (i.e., comparator); the LUTs used are shared among the parallel SBM processing units as they are constant values that do not change during the execution cycle. The generated stochastic bits by SBM processing are then sent for computation and then to the stochastic to binary conversion stage for final output. See
Figure 8 for the parallel structure of the stochastic bit stream generators. The number of comparators used depends on the degree of parallelism implemented. Hence, the degree of parallelism determines the hardware utilized.
4.3. Third Stage
The final stage in a stochastic computation is to create the binary output, which is generated by using STB conversion units, which are comprised of a counter that counts the number of ones in the stochastic bit-stream. If the output stochastic bits generated are eight bits per clock cycle, it is necessary to count the number of ones in the initial eight-bits within one clock cycle; this is not possible by using a single counter circuit with the same clock period. In this paper, an STB conversion unit is used that converts the parallel stochastic output into a binary number by using simple adder circuits. This circuit can count the number of ones in a parallel bit stream by using the Hamming weight counter principle [
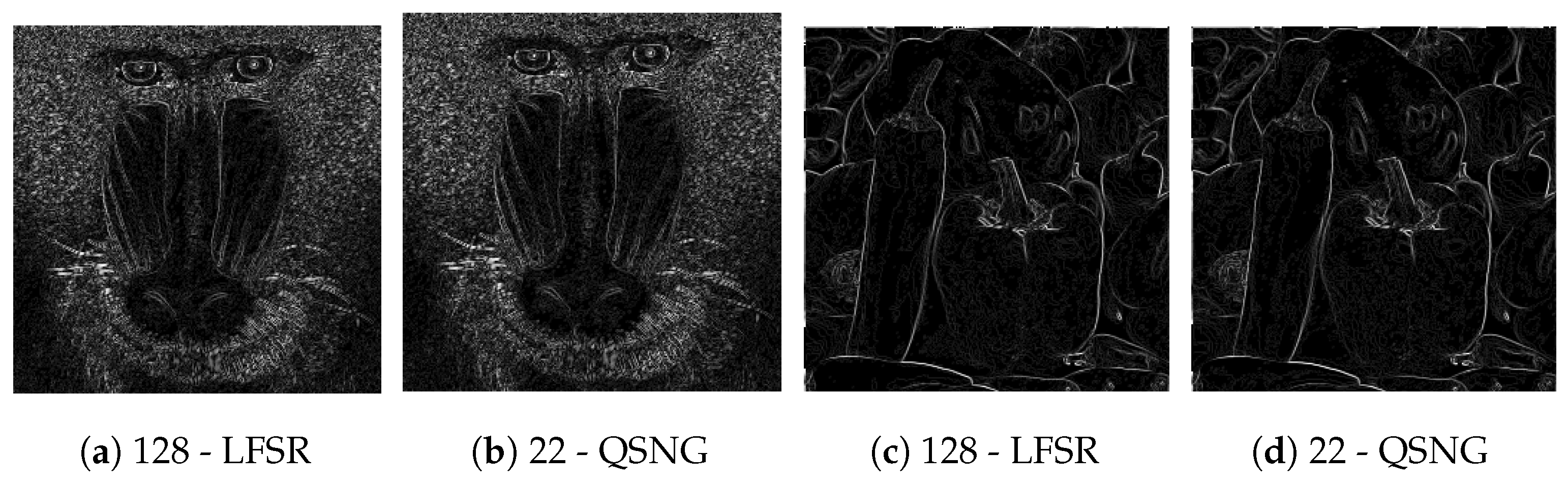
28]. The structure of the STB conversion unit for counting the number of ones in eight parallel stochastic bits of a 256-bit stream length consists of four half adders, two two-bit adders, a three-bit adder, an eight-bit register and a four-bit adder. An eight-bit register is used to store the previous count value, and it is updated every clock cycle with the new value (i.e., the number of ones in the stochastic bit stream). To count the number of ones in 16 stochastic bits of a 256-bit stream length, eight half adders, four two-bit adders, two three-bit adders, an eight-bit register and an eight-bit adder are required. Therefore, the size of the STB conversion unit increases with the number of parallel bits generated. The scalability issue of the STB conversion unit may not be a major concern as the proposed approach mainly targets image processing applications where the word length for many operations is less than 16 bits. The next section presents the simulation results of both the parallel and the serial implementation of the LUT-based LD sequence SNGs.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}