1. Introduction
The human visual system can effectively distinguish objects in different environments and contexts, even under a variety of constraints such as low illumination [
1], color differences [
2], and occlusions [
3,
4]. In addition, objects are key to the understanding of a scene’s context, which lends paramount importance to the estimation of their precise location and classification. This has led computer vision researchers to explore automatic object detection for decades [
5], reaching impressive results particularly in the last few years [
6,
7,
8,
9].
Object detection algorithms attempt to locate general occurrences of one or more predefined classes of objects. In a system designed to detect pedestrians, for instance, an algorithm tries to locate all pedestrians that appear within an image or a video [
3,
10,
11]. In the identification task, however, an algorithm tries to recognize a specific instance of a given class of objects. In the pedestrian example, an identification algorithm wants to determine the identity of each pedestrian previously detected.
Initially, real-time object detection applications were limited to only one object type [
12] at a time, mostly due to hardware limitations. Later on, advancements in object detection techniques led to their increasing adoption in areas that included the manufacturing industry with optical inspections [
13], video surveillance [
14], forensics [
15,
16], medical image analysis [
17,
18,
19], autonomous vehicles [
20], and traffic monitoring [
21]. In the last decade, the use of deep neural networks (DNNs) has completely changed the landscape of the computer vision field [
22]. DNNs have allowed for drastic improvements in image classification, image segmentation, anomaly detection, optical character recognition (OCR), action recognition, image generation, and object detection [
5].
The field of object detection has yielded significant improvements in both efficiency and accuracy. To validate such improvements, new techniques must be assessed against current state-of-the-art approaches, preferably over widely available datasets. However, benchmark datasets and evaluation metrics differ from work to work, often making their comparative assessment confusing and misleading. We identified two main reasons for such confusion in comparative assessments:
There are often differences in bounding box representation formats among different detectors. Boxes could be represented, for instance by their upper-left corner coordinates (x, y) and their absolute dimensions (width, height) in pixels, or by their relative coordinates (, ) and dimensions , with the values normalized by the image size, among others;
Each performance assessment tool implements a set of different metrics, requiring specific formats for the ground-truth and detected bounding boxes.
Even though many tools have been developed to convert the annotated boxes from one format to another, the quality assessment of the final detections still lacks a tool compatible with different bounding box formats and multiple metrics. Our previous work [
23] contributed to the research community in this direction, by presenting a tool which reads ground-truth and detected bounding boxes in a closed format and evaluates the detections using the average precision (AP) and mean average precision (mAP) metrics, as required in the PASCAL Challenge [
24]. In this work that contribution is significantly expanded by incorporating 13 other metrics, as well as by supporting additional annotation formats into the developed open-source toolbox. The new evaluation tool is available at
https://github.com/rafaelpadilla/review_object_detection_metrics. We believe that our work significantly simplifies the task of evaluating object detection algorithms.
This work intends to explain in detail the computation of the most popular metrics used as benchmarks by the research community, particularly in online challenges and competitions, providing their mathematical foundations and a practical example to illustrate their applicability. In order to do so, after a brief contextualization of the object-detection field in
Section 2, the most common annotation formats and assessment metrics are examined in
Section 3 and
Section 4, respectively. A numerical example is provided in
Section 5 illustrating the previous concepts from a practical perspective. Popular metrics are further addressed in
Section 6. In
Section 7 object detection in videos is discussed from an integrated spatio-temporal point of view, and a new metric for videos is provided.
Section 8 presents an open-source and freely distributed toolkit that implements all discussed concepts in a unified and validated way, as verified in
Section 9. Finally,
Section 10 concludes the paper by summarizing its main technical contributions.
2. An Overview of Selected Works on Object Detection
Back in the mid-50s and 60s the first attempts to recognize simple patterns in images were published [
25,
26]. These works identified primitive shapes and convex polygons based on contours. In the mid-80s, more complex shapes started gaining meaning, such as in [
27], which described an automated process to construct a three-dimensional geometric description of an airplane.
To describe more complex objects, instead of characterizing them by their shapes, automated feature extraction methods were developed. Different methods attempted to find important feature points that when combined could describe objects broadly. Robust feature points are represented by distinctive pixels, whose neighborhood describe the same object irrespective of changes in pose, rotation, and illumination. The Harris detector [
28] finds such points in the object corners based on local intensity changes. A local search algorithm using gradients was devised in [
29] to solve the image registration problem, which later was expanded to a tracking algorithm [
30] for identifying important points in videos.
More robust methods were able to identify characteristic pixel points and represent them as feature vectors. The so-called scale invariant feature transform (SIFT) [
31], for instance, applied the difference of Gaussians in several scales coupled with histograms of gradients, yielding characteristic points with features that are robust to scale changes and rotation. Another popular feature detector and descriptor, the speed up robust features (SURF) [
32], was claimed to be faster and more robust than SIFT, and uses a blob detector based on the Hessian matrix for interest point detection and wavelet responses for feature representations.
Feature-point representation methods alone are not able to perform object detection, but can help in extracting a group of keypoints that are used to represent them. In [
33], the SIFT keypoints and features are used to detect humans in images, and in [
34] SIFT was combined with color histograms to classify regions of interest across frames to track objects in videos. Another powerful feature extractor widely applied for object detection is the histogram of oriented gradients (HOG) [
35], which is computed for several image small cells. The histograms of each cell are combined to form the object descriptor, which, associated to a classifier, can perform the object detection task [
35,
36].
The Viola–Jones object detection framework was described in the path-breaking work of [
12]. It could detect a single class object at a rate of 15 frames per second. The proposed algorithm employed a cascade of weak classifiers to process image patches of different sizes, being able to associate bounding boxes to the target object. The Viola–Jones method was first applied to face detection and required extensive training to automatically select a group of Haar-features to represent the target object, thus detecting one class of objects at a time. This framework has been extended to detect other object classes such as pedestrians [
10,
11] and cars [
37].
More recently, with the growth and popularization of deep learning in computer vision problems [
6,
7,
38,
39,
40], object detection algorithms have started to develop from a new perspective [
41,
42]. The traditional feature extraction [
31,
32,
35] phase is performed by convolutional neural networks (CNNs), which are dominating computer vision research in many fields. Due to their spatial invariance, convolutions perform feature extraction spatially and can be combined into layers to produce the desired feature maps. The network end is usually composed of fully connected (FC) layers that can perform classification and regression tasks. The output is then compared to a desired result and the network parameters are adjusted to minimize a given loss function. The advantage of using DNNs in object detection tasks is the fact that their architectures can extract features and predict bounding boxes in the same pipeline, allowing efficient end-to-end training. The more layers a network has, the more complex features it is able to extract, but the more parameters it needs to learn, demanding more computer processing power and data.
When it is not feasible to acquire more real data, data augmentation techniques are used to generate artificial but realistic data. Color and geometric operations and changes inside the target object area are the main actions performed by data augmentation methods for object detection tasks [
43]. The work in [
44] applied generative adversarial networks (GANs) to increase by 10 times the amount of medical chest images to detect patients with COVID-19. In [
45], the number of images was increased by applying filters in astronomy images so as to improve the performance of galaxy detectors.
The CNN-based object detectors may be cataloged as single-shot or region-based detectors, also known as one- or two-stage detectors, respectively. The single-shot detectors work by splitting the images into a grid of cells. For each cell, they make bounding-box guesses of different scales and aspect ratios. This type of detector prioritizes speed rather than accuracy, aiming to predict both bounding box and class simultaneously. Overfeat [
46] was one of the first single-shot detectors, followed by the single shot multiBox detector (SSD) [
47], and all versions of you only look once (YOLO) [
9,
48,
49,
50,
51]. The region-based detectors perform the detection in two steps. First, they generate a sparse set of region proposals in the image where the objects are supposed to be. The second stage classifies each object proposal and refines its estimated position. The region-based convolutional neural network (R-CNN) [
52] was a pioneer employing CNNs in this last stage, achieving significant gains in accuracy. Later works such as Fast R-CNN [
53], Faster R-CNN [
8], and region-based fully convolutional networks (R-FCN) [
54] suggest changes in R-CNN to improve its speed. The aforementioned detectors have some heuristic and hand-crafted steps such as region feature extraction or non-maximum suppression to remove duplicate detections. In this context, graph neural networks (GNNs) are employed to compute region of interest features in a more efficient way and process the objects simultaneously by modeling them according to their appearance feature and geometry [
55,
56].
Hybrid solutions combining different approaches have been proposed lately and have proved to be more robust in various object-detection applications. The work in [
57] proposes a hybrid solution involving a genetic algorithm and CNNs to classify small objects (structures) presented in microscopy images. Feature descriptors coupled with a cuckoo search algorithm were applied by the authors of [
58] to detect vessels in a marine environment using synthetic aperture radar (SAR) images. This approach was compared to genetic algorithms and neural network models individually, improving precision to nearly 96.2%. Vision-based autonomous vehicles can also benefit from hybrid models as shown in [
59], where a system integrating different approaches was developed to detect and identify pedestrians and to predict their movements. In the context of detecting objects using depth information, the work in [
60] proposes a hybrid attention neural network that incorporates depth and high-level RGB features to produce an attention map to remove background information.
Other works aim to detect the most important region of interest and segment relevant objects using salient object detectors. The work in [
61] proposes a pipeline to separate an input image into a pair of images using content-preserving transforms. Then, each resulting image is passed by an interweaved convolutional neural network, which extracts complementary information of the image pairs and fuses them into the final salient map.
As medical images are acquired with special equipment, they form a very specific type of image [
17]. To detect lesions, organs, and other structures of interest can be crucial for a precise diagnostic. However, most object detection systems are designed for general applications and usually do not perform well in medical images without adaptations [
62]. Detecting anomalies such as glaucoma, breast, and lung lesions, for instance, have been explored from the medical object-detection perspective in [
63,
64]. In the medical field, training and testing data usually have significant differences due to data scarcity and privacy. In order to address this issue, a domain adaptation framework, referred to as clustering CNNs (CLU-CNNs) [
65], has been proposed to improve the generalization capability without specific domain training.
With new object detection methods being constantly released, it is highly desirable that a consensual evaluation procedure is established. To do so, the most common bounding box formats used by public datasets and competitions are revised in the next section.
3. Bounding Box Formats
Given the large, ever growing number of object detectors based on supervised methods in different areas, specific datasets have been built to train these systems. Popular competitions such as the common objects in context (COCO) [
66], PASCAL visual object classes (VOC) [
67], and Open Images Dataset [
68] offer annotated datasets so that participants can train and evaluate their models before submission. Apart from using available datasets, collecting data for a object detection task can be quite challenging, as labeling images and videos is often a manual and quite demanding exercise. The medical field provides a good example of this fact: Developing a database of X-ray, electroencephalography (EEG), magnetoencephalography (MEG), or electrocardiography (ECG) images involves not only high costs for capturing such signals, but also requires expert knowledge to interpret and annotate them.
To ease the object annotation process in images and videos, many tools have been developed to annotate different datasets. Such tools basically offer the same features, such as bounding-box annotations and polygon-like silhouettes, as shown in
Figure 1.
A vast amount of annotation tools are freely available.
Table 1 lists the most popular ones with their respective bounding box output formats.
Some datasets introduced new formats to represent their annotations, which are usually named after the datasets themselves. The PASCAL VOC dataset [
67] established the PASCAL VOC XML format and the COCO dataset [
66] represents their annotations in the COCO format, embodied in a JSON file. Annotation tools also brought further formats. For example, CVAT [
72], a popular annotation tool, outputs bounding boxes in multiple formats, including its own specific XML-based one, named a CVAT format. The most popular bounding box formats shown in
Table 1 are described in more detail. Note that whenever we refer to absolute coordinates, we mean coordinates that are expressed on the image coordinate frame, as opposed to coordinates that are normalized by the image width or image height.
PASCAL VOC: It consists of one XML file for each image containing none, one or multiple bounding boxes. The upper-left and bottom-right pixel coordinates are absolute. Each bounding box also contains a tag representing the class of the object. Extra information about the labeled object can be provided, such as whether, the object extends beyond the bounding box or it is partially occluded. The annotations in the ImageNet [
74] and PASCAL VOC [
67] datasets are provided using the PASCAL VOC format;
COCO: It is represented by a single JSON file containing all bounding boxes of a given dataset. The classes of the objects are listed separately in the categories tag and identified by an id. The image file corresponding to an annotation is also indicated in a separate element (images) that contains its file name and is referenced by an id. The bounding boxes and their object classes are listed in a different element (annotations), with their top-left coordinates being absolute, and with explicit values of width and height;
LabelMe: The bounding-box annotations in this format are inserted in a single JSON file for each image, containing a list of boxes represented by their absolute upper-left and bottom-right coordinates. Besides the class of the object, this format also contains the image data encoded in base64 type, thus making the LabelMe format to consume more storage space than others;
YOLO: One TXT file per image is used in this representation. Each line of the file contains the class id and the bounding box coordinates. An extra file is needed to map the class id to the class name. The bounding box coordinates are not absolute, being represented by the format (). The advantage of representing the boxes in this format is that, if the image dimensions are scaled, the bounding box coordinates do not change, and thus the annotation file does not have to be altered. This type of format is the one preferred by those who annotate images in one resolution and need to scale their dimensions to fulfill the input shape requirement of a specific CNN. The YOLO object detector needs bounding boxes in this format to execute training;
VoTT: This representation of the bounding boxes coordinates and object class is made in a JSON file (one file per image) and the coordinates are expressed as the width, height and upper-left pixel position in absolute coordinates. The Visual Object Tagging Tool (VoTT) produces annotations in this format;
CVAT: It consists of a unique XML file with all bounding boxes in the dataset represented by the upper-left and bottom-right pixel absolute coordinates. This format has been created with the CVAT annotation tool;
TFRecord: This is a serialized representation of the whole dataset containing all images and annotations in a single file. This format is recognized by the Tensorflow library [
75];
Tensorflow Object Detection: This is a CSV file containing all labeled bounding boxes of the dataset. The bounding box format is represented by the upper-left and bottom-right pixel absolute coordinates. This is also a widely used format employed by the Tensorflow library;
Open Images Dataset: This format is associated with the Open Images Dataset [
68] to annotate its ground-truth bounding boxes. All annotations are written in a unique CSV file listing the name of the images and labels, as well as upper-left and bottom-right absolute coordinates of the bounding boxes. Extra information about the labeled object is conveyed by other tags such as, for example,
IsOcclude,
IsGroupOf, and
IsTruncated.
As each dataset is annotated using a specific format, works tend to employ the evaluation tools provided along with the datasets to assess their performance. Therefore, their results are dependent on the specific metric implementation associated with the used dataset. For example, the PASCAL VOC dataset employs the PASCAL VOC annotation format, which provides a MATLAB code implementing the metrics AP and mAP (intersection over union (IOU)=.50). This tends to inhibit the use of other metrics to report results obtained for this particular dataset.
Table 2 lists popular object detection methods along with the datasets and the 14 different metrics used to report their results, namely: AP@[.5:.05:.95],
[email protected],
[email protected], AP
S, AP
M, AP
L, AR
1, AR
10, AR
100, AR
S, AR
M, AR
L, mAP (IOU=.50), and AP.
As the evaluation metrics are directly associated with a given annotation format, almost all works report their results only for the metrics implemented for the benchmarking dataset. For example, mAP (IOU=.50) is reported when the PASCAL VOC dataset is used, while AP@[.5:.05:.95] is applied to report results on the COCO dataset. If a work uses the COCO dataset to train a model and wants to evaluate their results with the PASCAL VOC tool, it will be necessary to convert the ground-truth COCO JSON format to the PASCAL VOC XML format. This scenario discourages the use of such cross-dataset assessments, which have become quite rare in the object detection literature.
An example of confusions that may arise in such a scenario is given by the fact that some works affirm that the metrics
[email protected] and mAP (IOU=.50) are the same [
54], which may not always be true. The origins of such misunderstandings are the differences in how each tool computes the corresponding metrics. The next section deals with this problem by detailing the implementations of the several object detection metrics and pointing out their differences.
4. Performance Metrics
Challenges and online competitions have pushed forward the frontier of the object detection field, improving results for specific datasets in every new edition. To validate the submitted results, each competition applies a specific metric to rank the submitted detections. These assessment criteria have also been used by the research community to report and compare object detection methods using different datasets as illustrated in
Table 2. Among the popular metrics to report the results, this section will cover those used by the most popular competitions, namely Open Images RVC [
81], COCO Detection Challenge [
82], VOC Challenge [
24], Datalab Cup [
83], Google AI Open Images challenge [
84], Lyft 3D Object Detection for Autonomous Vehicles [
85], and City Intelligence Hackathon [
86]. Object detectors aim to predict the location of objects of a given class in an image or video with a high confidence. They do so by placing bounding boxes to identify the positions of the objects. Therefore, a detection is represented by a set of three attributes: The object class, the corresponding bounding box, and the confidence score, usually given by a value between 0 and 1 showing how confident the detector is about that prediction. The assessment is done based on:
A set of ground-truth bounding boxes representing the rectangular areas of an image containing objects of the class to be detected, and
a set of detections predicted by a model, each one consisting of a bounding box, a class, and a confidence value.
Detection evaluation metrics are used to quantify the performance of detection algorithms in different areas and fields [
87,
88]. In the case of object detection, the employed evaluation metrics measure how close the detected bounding boxes are to the ground-truth bounding boxes. This measurement is done independently for each object class, by assessing the amount of overlap of the predicted and ground-truth areas.
Consider a target object to be detected represented by a ground-truth bounding box
and the detected area represented by a predicted bounding box
. Without taking into account a confidence level, a perfect match is considered when the area and location of the predicted and ground-truth boxes are the same. These two conditions are assessed by the intersection over union (IOU), a measurement based on the Jaccard Index, a coefficient of similarity for two sets of data [
89]. In the object detection scope, the IOU is equal to the area of the overlap (intersection) between the predicted bounding box
and the ground-truth bounding box
divided by the area of their union, that is:
as illustrated in
Figure 2.
A perfect match occurs when and, if both bounding boxes do not intercept each other, . The closer to 1 the IOU gets, the better the detection is considered. As object detectors also perform the classification of each bounding box, only ground-truth and detected boxes of the same class are comparable through the IOU.
By setting an IOU threshold, a metric can be more or less restrictive on considering detections as correct or incorrect. An IOU threshold closer to 1 is more restrictive as it requires almost-perfect detections, while an IOU threshold closer to, but different than 0 is more flexible, considering as detections even small overlaps between
and
. IOU values are usually expressed in percentages, and the most used threshold values are
and
. In
Section 4.1,
Section 4.2, and
Section 4.4 the IOU is used to define the metrics that are most relevant to object detection.
4.1. Precision and Recall
Let us consider a detector that assumes that every possible rectangular region of the image contains a target object (this would be done by placing bounding boxes of all possible sizes centered in every image pixel). If there is one object to be detected, the detector would correctly find it by one of the many predicted bounding boxes. That is not an efficient way to detect objects, as many wrong predictions are made as well. Conversely, a detector which never generates any bounding box, will never have a miss-detection. These extreme examples highlight two important concepts, referred as precision and recall, are further explained below.
Precision is the ability of a model to identify only relevant objects. It is the percentage of correct positive predictions. Recall is the ability of a model to find all relevant cases (all ground-truth bounding boxes). It is the percentage of correct positive predictions among all given ground truths. To calculate the precision and recall values, each detected bounding box must first be classified as:
True positive (TP): A correct detection of a ground-truth bounding box;
False positive (FP): An incorrect detection of a non-existing object or a misplaced detection of an existing object;
False negative (FN): An undetected ground-truth bounding box.
Assuming there is a dataset with
G ground-truths and a model that outputs
N detections, of which
S are correct (
), the concepts of precision and recall can be formally expressed as:
4.2. Average Precision
As discussed above, the output of an object detector is characterized by a bounding box, a class, and a confidence interval. The confidence level can be taken into account in the precision and recall calculations by considering as positive detections only those whose confidence is larger than a confidence threshold
. The detections whose confidence level is smaller than
are considered as negatives. By doing so, one may rewrite Equations (
2) and (
3) to consider this dependence on the confidence threshold
as:
Both TP
and FP
are decreasing functions of
, as a larger
reduces the number of positive detections. Conversely, FN
is an increasing function of
, since less positive detections imply a larger number of negative detections. In addition,
does not depend on
and is a constant equal to the number of all the ground truths. Therefore, from Equation (
5), the recall
is a decreasing function of
. On the other hand, nothing can be said a priori about the precision
, since both the numerator and denominator of Equation (
4) are decreasing functions of
, and indeed the graph of
tends to exhibit a zig-zag behavior in practical cases, as later illustrated in
Section 5.
In practice, a good object detector should find all ground-truth objects (≡ high recall), while identifying only relevant objects (≡ high precision). Therefore, a particular object detector can be considered good if, when the confidence threshold decreases, its precision remains high as its recall increases. Hence, a large area under the curve (AUC) tends to indicate both high precision and high recall. Unfortunately, in practical cases, the precision × recall plot is often not monotonic, being zigzag-like instead, which poses challenges to an accurate measurement of its AUC.
The average precision (AP) is a metric based on the area under a curve that has been pre-processed to eliminate the zig-zag behavior. It summarizes this precision-recall trade-off dictated by confidence levels of the predicted bounding boxes.
To compute the AP, one starts by ordering the
K different confidence values
output by the object detector as:
Since the values also have a one-to-one, monotonic correspondence with , which has a one-to-one, monotonic, correspondence with the index k, then the curve is not continuous but sampled at the discrete points , leading to the set of pairs ( indexed by k.
Now one defines an ordered set of reference recall values
,
The AP is computed using the two ordered sets in Equations (
6) and (
7). But before computing AP, the precision × recall pairs have to be interpolated such that the resulting precision × recall curve is monotonic. The resulting interpolated curve is defined by a continuous function
, where
is a real value contained in the interval
, defined as:
where
is defined in Equation (
6) and
is the recall value for the confidence
, computed according to Equation (
5). The precision value interpolated at recall
R corresponds to the maximum precision
whose corresponding recall value is greater than or equal to
R. Note that an interpolation using a polynomial fitting would not be convenient in this case, since a polynomial interpolation cannot guarantee that the resulting interpolated curve is monotonic.
Now one is ready to compute AP by sampling
at the
N reference recall values
defined in Equation (
7). The AP is the area under the
curve calculated by a Riemann integral of
using the
K recall values from the set
in Equation (
7) as sampling points, that is,
where
is defined in Equation (
8) and
is given by Equation (
12), with
and
.
There are basically two approaches to compute this Riemann integral: The N-point interpolation and the all-point interpolation, as detailed below.
4.2.1. N-Point Interpolation
In the
N-point interpolation, the set of reference recall values
for the computation of the Riemann integral in Equation (
9) are equally spaced in the interval
, that is,
and thus the expression for AP becomes:
Actually the
N-point interpolation as defined by Equation (
11) computes an AP value which is equal to the value computed by the Riemann integral in Equation (
9) multiplied by
.
Popular applications of this interpolation method use
as in the competition [
82] and
as initially adopted by the competition [
24], which was later changed to the all-point interpolation method.
4.2.2. All-Point Interpolation
For the computation of AP using the so-called all-point interpolation, here referred to as
, as the set values
used to compute the Riemann integral in Equation (
9) corresponds exactly to the set of recall values computed considering all
K confidence levels
in Equation (
6), with the confidences
and
added so that the points
and
are considered in Equation (
9). More precisely,
where
is given by Equation (
5) with
and
.
Using this definition of
in Equation (
12),
is computed using Equation (
9). In the all-point interpolation, instead of using the precision observed at only a few points, the AP is obtained by interpolating the precision at each recall level. The Pascal Challenge [
24] adopts the all-point interpolation method to compute the average precision.
4.3. Mean Average Precision
Regardless of the interpolation method, AP is obtained individually for each class. In large datasets with many classes, it is useful to have a unique metric that is able to represent the exactness of the detections among all classes. For such cases, the mean average precision (mAP) is computed, which is simply the average AP over all classes [
8,
47], that is,
where
is the AP value for the
i-th class and
C is the total number of classes being evaluated.
4.4. Average Recall
The average recall (AR) [
90] is another evaluation metric used to measure the assertiveness of object detectors for a given class. Unlike the average precision, the confidences of the estimated detections are not taken into account in AR computation. This turns all detections into positive ones, which is equivalent to setting the confidence threshold as
in Equations (
4) and (
5).
The AR metric makes an evaluation at a large range of IOU thresholds, by taking into account all recall values obtained for IOU thresholds in the interval . An IOU of 0.5 can be interpreted as a rough localization of an object and is the least acceptable IOU by most of the metrics, and an IOU equal to 1 is equivalent to the perfect location of the detected object. Therefore, by averaging recall values in the interval , the model is evaluated on the condition of the object location being considerably accurate.
Let
o be the IOU overlap between a ground truth and a detected bounding box as computed by Equation (
1), and
a function that retrieves the recall for a given IOU
o. The AR is defined as twice the area under the
curve for the IOU interval
, that is,
The authors in [
90] also give a straightforward equation for the computation of the above integral from the discrete sample set, as twice the average of the excess IOU for all the ground-truths, that is,
where
denotes the best IOU obtained for a given ground truth
i and
G is the total number of ground-truths.
Interestingly, COCO also reports the AR, although its definition does not match exactly that in Equation (
15). Instead, what is reported as the COCO AR is the average of the maximum obtained recall across several IOU thresholds. To do so one first defines a set of
O IOU thresholds:
Then, letting
be the precision × recall points for a confidence
, given the IOU threshold
, the COCO AR is computed as:
that is, the average of the largest recall values such that the precision is greater than zero for each IOU threshold, and
as defined in Equation (
6). Effectively, this yields a coarse approximation of the original integral in Equation (
14), provided that the IOU threshold set
covers an adequate range of overlaps.
4.5. Mean Average Recall
As the AR is calculated individually for each class, similarly to what is done to compute mAP, a unique AR value can be obtained considering the mean AR among all classes, that is:
In the sequel, a practical example illustrates the differences reflected in the final result depending on the chosen method.
5. A Numerical Example
Considering the set of 12 images in
Figure 3, each image, except (a), (g), and (j), has at least one target object of the class
cat, whose ground-truth locations are delimited by the green rectangles. There is a total of 12 target objects limited by the green boxes. Images (b), (e), and (f) have each two ground-truth samples of the target class. An object detector predicted 12 objects represented by the red rectangles (labeled with letters ‘A’ to ‘L’) with their associated confidence levels being represented as percentages also shown close to the corresponding boxes. From the above, images (a), (g), and (j) are expected to have no detection, and images (b), (e), and (f) are expected to have two detections each.
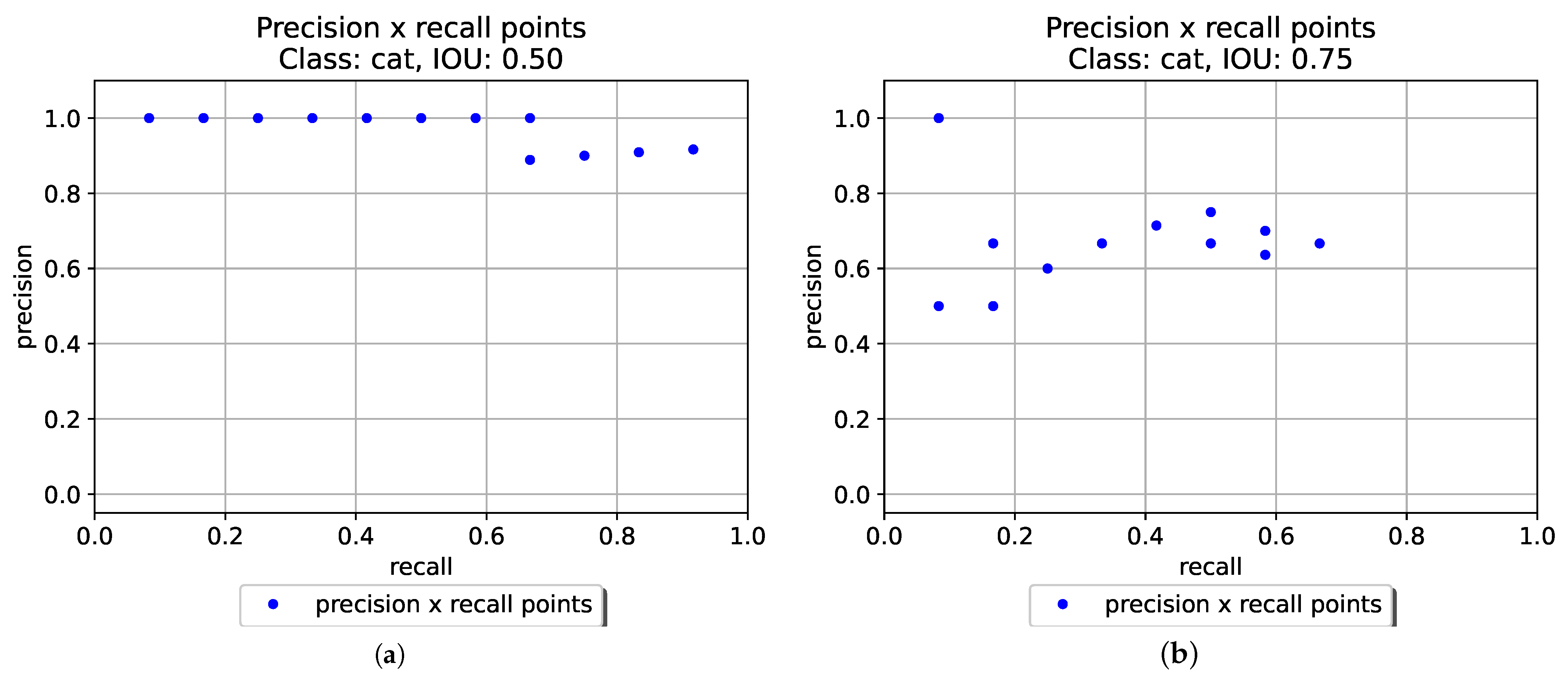
All things considered, to evaluate the precision and recall of the 12 detections it is necessary to establish an IOU threshold t, which will classify each detection as TP or FP. In this example, let us first consider as TP the detections with , that is .
As stated before, AP is a metric that integrates precision and recall in different confidence values. Thus, it is necessary to count the amount of TP and FP classifications given the different confidence levels.
Table 3 presents each detection from our example sorted by their confidence levels. In this table, columns ∑TP
and ∑FP
are the accumulated TPs and FPs, respectively, whose corresponding confidence levels are larger than or equal to the confidence
specified in the second column of the table. Precision (
) and recall (
) values are calculated based on Equations (
4) and (
5), respectively. In this example a detection is considered as a TP only if its IOU is larger than 50%, and in this case the column ‘IOU > 0.5?’ is marked as ‘Yes’, otherwise it is marked as ‘No’ and is considered an FP. In this example, all detections overlap some ground-truth with
, except detection ‘J’, which is not overlapping any ground-truth, so there is no IOU to be computed in this case.
Some detectors can output one detection overlapping multiple ground truths, as seen in the image from
Figure 3b with detections ‘A’ and ‘B’. As detection ‘A’ has a higher confidence than ‘B’ (
), ‘A’ has the preference over ‘B’ to match the ground-truth, so ‘A’ is associated with the ground truth which gives the highest IOU.
Figure 4c,d show the two possible associations that ‘A’ can have, ending up with the first one, which presents a higher IOU. Detection ‘B’ is left with the remaining ground truth in
Figure 4f. Another similar situation where one detection could be associated with more than one ground truth is faced by detection ‘E’ in
Figure 3e. The application of the same rule results in matching detection ‘E’ with the ground truth whose IOU is the highest, represented by the fairer cat, at the bottom of the image.
By choosing a more restrictive IOU threshold, different precision
and recall
values can be obtained.
Table 4 computes the precision and recall values with a more strict IOU threshold of
. By that, it is noticeable the occurrence of more FP detections and less TP detections, thus reducing both the precision
and recall
values.
Graphical representations of the
×
values presented in
Table 3 and
Table 4 can be seen in
Figure 5. By comparing both curves, one may note that for this example:
With a less restrictive IOU threshold (), higher recall values can be obtained with the highest precision. In other words, the detector can retrieve about of the total ground truths without any miss detection.
Using , the detector is more sensitive to different confidence values . This is explained by the more accentuated monotonic behavior for this IOU threshold.
Regardless the IOU threshold applied, this detector can never retrieve
of the ground truths (
) for any confidence value
. This is due to the fact that the algorithm failed to output any bounding box for one of the ground truths in
Figure 3e.
Note that
Figure 5 suggests that an IOU threshold of
is less affected by different confidence levels. The graph for the lowest IOU threshold (
) shows that when confidence levels
are high, the precision
does not vary, being equal to the maximum (1.0) for most of confidence values
. However, in order to detect more objects (increasing the recall
), it is necessary to set a lower confidence threshold
, which reduces the precision at most by
. On the other hand, considering the highest IOU threshold (
), the detector can retrieve half of the target objects (recall =
) with a precision of
.
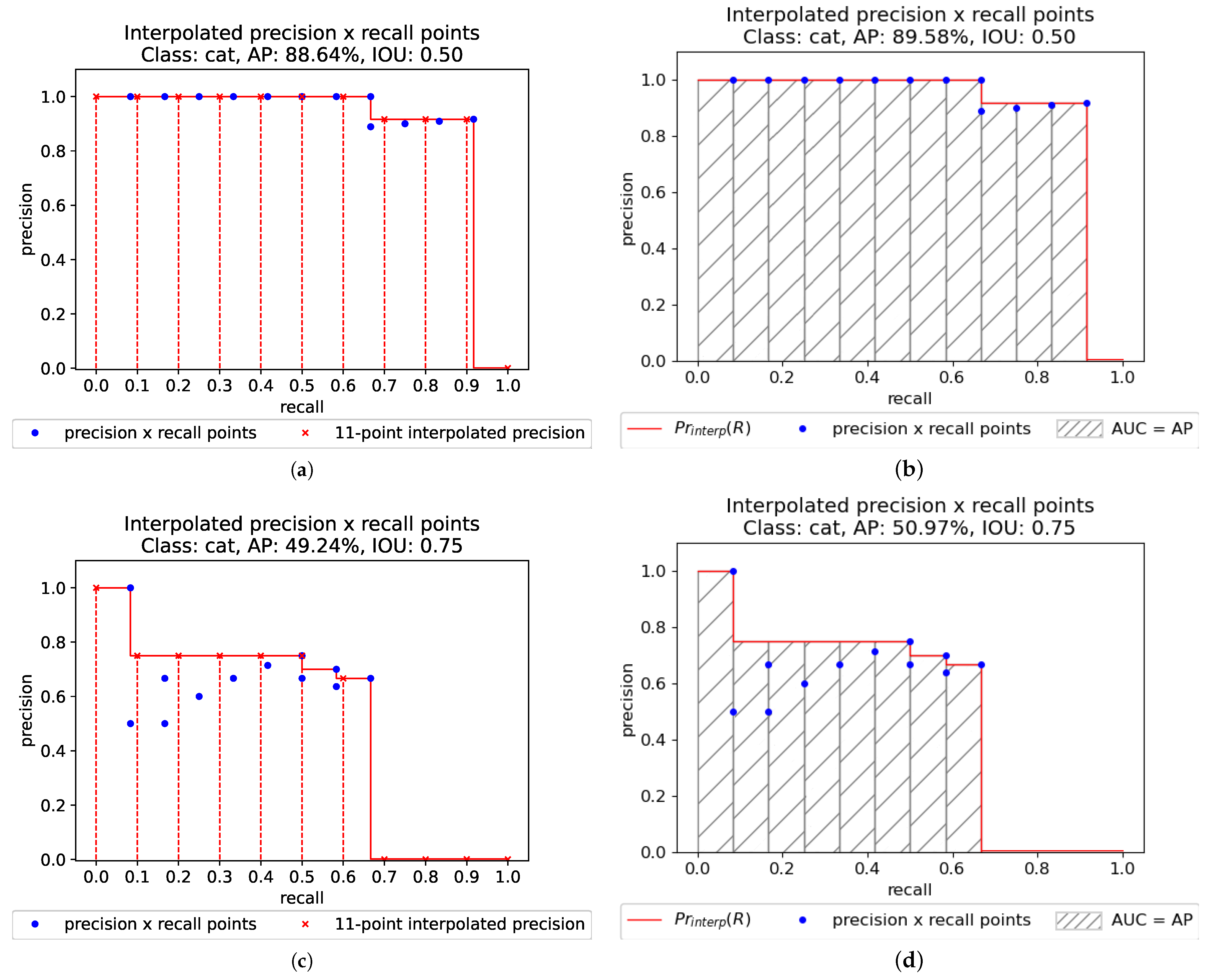
As previously explained, different methods can be applied to estimate the average precision, that is, the area under the precision × recall curve. To obtain AP using the
N-point interpolation in Equation (
11) with
points, the area under the
curve is computed as the average of the interpolated precision
(Equation (
9)) samples considering the sampling recall points
R at
in the set
(Equation (
10)). On the other hand, to obtain AP using the all-point interpolation approach, the area under the
curve is computed by the Riemann integral in Equation (
9), sampling the recall points
R at
coincident with the
values given by the last column of
Table 3 or of
Table 4 (Equation (
12)). The results can be seen in
Figure 6. When an IOU threshold
was applied, the 11-point interpolation method obtained
while the all-point interpolation method resulted in a slightly higher AP, reaching
. Similarly, for an IOU threshold
, the 11-point interpolation method obtained
and the all-point interpolation obtained
.
When a lower IOU threshold t was considered ( as opposed to ), the AP was considerably increased in both interpolation approaches. This is caused by the increase in the TP detections, due to a lower IOU threshold.
If focus is shifted towards how well localized the detections are, irrespective of their confidence values, it is sensible to consult the AR metrics (Equations (
14)–(
18)). Computing twice the average excess IOU for the samples in this practical example as in Equation (
15), yields
, while computing the average max recall across the standard COCO IOU thresholds, that is
, as in Equation (
17), yields
. As the latter computation effectively does a coarser quantization of the IOU space, the two AR figures differ slightly. The next section enlists and briefly describes which variations of the metrics based on AP and AR are more frequently employed in the literature. In most cases they are the result of combinations of different IOU thresholds and interpolation methods.
7. Evaluating Object Detection in Videos
Many works in the literature use the mAP as a metric to evaluate the performance of object detection models in video sequences [
92,
93,
94,
95,
96,
97,
98]. In this case, the frames are evaluated independently, ignoring the spatio-temporal characteristics of the objects presented in the scene. The authors of [
92] categorized the ground-truth objects according to their motion speed. This is done by measuring the average IOU score of the current frame and the nearby
frames. In this context, in addition to mAP, they also reported the mAP over the slow, medium, and fast groups, denoted as mAP(slow), mAP(medium), and mAP(fast), respectively.
In some applications, the latency in the identification of the objects of interest plays a crucial role in how well the overall system will perform. Detection delay, defined as the number of frames between the first occurrence of an object in the scene and its first detection, then becomes an important measurement for time-critical systems. The authors in [
99] claim that AP is not sufficient to quantify the temporal behavior of detectors, and propose a complementary metric, the average delay (AD), averaging the mean detection delay over multiple false positive ratio thresholds, and over different object sizes, yielding a metric that fits well for systems that rely on timely detections. While the cost of detection latency is significant for a somewhat niche set of tasks, the inclusion of time information for video detection metrics can be useful to assess system behaviors that would otherwise be elusive when only the standard, frame level AP metric is used.
7.1. Spatio-Temporal Tube Average Precision
As discussed above, the aforementioned metrics are all used on an image or frame level. However, when dealing with videos, one may be interested in evaluating the model performance at the whole video level. In this work, we propose an extension of the AP metric to evaluate video object detection models that we refer to as spatio-temporal tube AP (STT-AP). As in AP, a threshold over the IOU is also used to determine whether the detections are correct or not. However, instead of using two types of overlaps (spatial and temporal), we extend the standard IOU definition to consider the spatio-temporal tubes generated by the detection and of the ground truth. This metric, that integrates spatial and temporal localizations, is concise, yet expressive.
Instead of considering each detection of the same object independently along the frames, the spatial bounding boxes of the same object are concatenated along the temporal dimension, forming a spatio-temporal tube, which is the video analogous to an image bounding box. A spatio-temporal tube
of an object
o is the spatio-temporal region defined as the concatenation of the bounding boxes of this object from each frame of a video, that is:
where
is the bounding box of the object
o in frame
k of the video that is constituted of
Q frames indexed by
.
Using spatio-temporal tubes, the concept of IOU used in object detection in images (see
Section 4) can be naturally extended to videos. Considering a ground-truth spatio-temporal tube
and a predicted spatio-temporal tube
, the spatio-temporal tube IOU (STT-IOU) measures the ratio of the overlapping to the union of the “discrete volume” between
and
, such that:
as illustrated in
Figure 7.
In this way, an object is considered a TP if the STT-IOU is equal or greater than a chosen threshold. As in the conventional AP, this metric may be as rigorous as desired. The closer to 1 it is, the more well-located the predicted tube must be to be considered a TP.
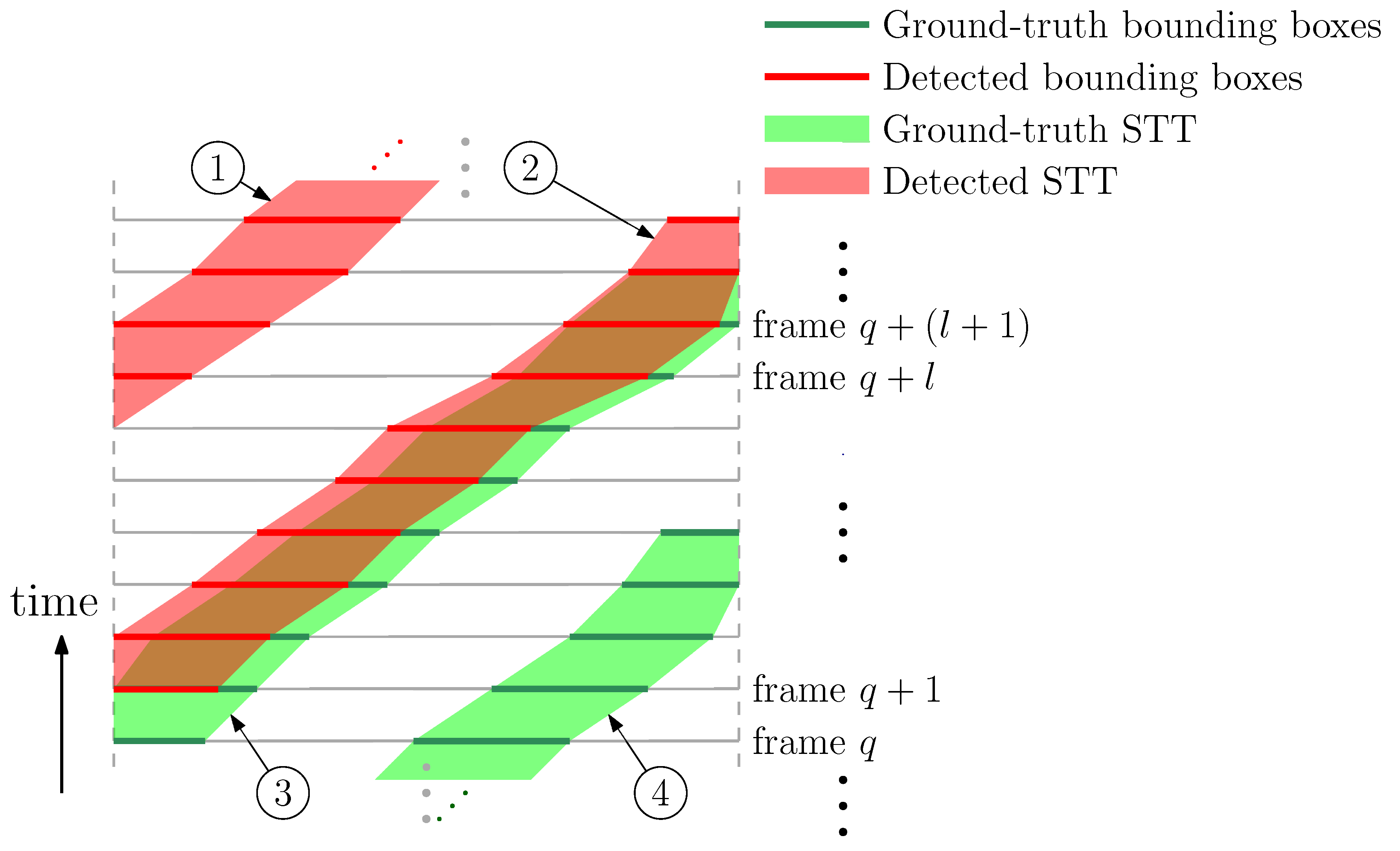
Figure 8 illustrates four different STTs. The STTs in red are detected STTs and the STTs in green are ground-truth STTs. The STT in (1) constitutes an FP case, and the STT in (2) may be a TP case (depending on the STT-IOU), as it intersects the corresponding ground-truths STT (3). Since there is no detection corresponding to the ground-truth STT (4), it is an FN.
Based on these definitions, the proposed STT-AP metric follows the AP: For each class, each ground-truth tube is associated with the predicted tube of the same class that presents the highest STT-IOU scores (since it is higher than the threshold). The ground-truth tubes not associated with a predicted tube are FNs and the predicted tubes not associated with a ground-truth tube are FPs. Then, the spatio-temporal tube predictions are ranked according to the predicted confidence level (from the highest to the lowest), irrespective of correctness. Since the STT-AP evaluates the detection of an object in the video as a whole, the confidence level assumed for a spatio-temporal tube is the average confidence of the bounding boxes corresponding to each of its constituent frames. After that, the all-point interpolation (
Section 4.2.2) is performed allowing one to compute the proposed STT-AP. This procedure may be repeated and averaged for all classes in the database, yielding the so-called mean STT-AP (mSTT-AP). From Equation (
21) one can readily see that the computational cost per frame of the SST-AP is similar to the one of the frame-by-frame mAP.
8. An Open-Source Toolbox
This paper focuses on explaining and comparing the different metrics and formats currently used in object detection, detailing the specifications and pointing out the particularities of each metric variation. The existing tools provided by popular competitions [
24,
81,
82,
83,
84,
85] are not adequate to evaluate metrics using annotations in formats that are different from their native ones. Thus, to complement the analysis of the metrics presented here, the authors have developed and released an open-source toolkit as a reliable source of object detection metrics for the academic community and researchers.
With more than 3100 stars and 740 forks, our previously available tool for object detection assessment [
100] has received positive feedback from the community and researchers. It has also been used as the official tool in competition [
86], adopted in 3rd-party libraries such as [
101], and parts of our code have been used by many other works such as in YoloV5 [
9]. Besides the significant acceptance by the community, we have received many requests to expand the tool in order to support new metrics and bounding box formats. Such demands motivated us to offer more evaluation metrics, to accept more bounding box formats, and to present a novel metric for object detection in videos.
This tool implements the same metrics used by the most popular competitions and object-detection benchmark researches. This implementation does not require modifications of the detection model to match complicated input formats, avoiding conversions to XML, JSON, CSV, or other file types. It supports more than eight different kinds of annotation formats, including the ones presented in
Table 1. To ensure the accuracy of the results, the implementation strictly followed the metric definitions and the output results were carefully validated against the ones of the official implementations.
Developed in Phython and supporting 14 object detection metrics for images, this work also incorporates the novel spatio-temporal metric described in
Section 7.1 to evaluate detected object in videos aggregating some of the concepts applied to evaluate detections in images. From a practical point of view, the tool can also be adapted and expanded to support new metrics and formats. The expanded project distributed with this paper can be accessed at
https://github.com/rafaelpadilla/review_object_detection_metrics [
102].
9. Metrics Evaluation in a Practical Example
In this section, we use different object detection metrics to evaluate YOLOv5 model [
9]. The chosen model was trained with the COCO dataset and was applied in the training/validation PASCAL VOC 2012 dataset [
67]. Intentionally different datasets were used to train and evaluate the model to evidence the potential of our tool to deal with different ground-truth and detected bounding-box formats. For this experiment, the annotations of the ground-truth boxes are in PASCAL VOC format containing 20 classes of objects, while the model was trained with COCO dataset and was able to detect objects in 80 classes, predicting detections in text files in the YOLO format.
By using our tool, one can quickly obtain 14 different metrics without the necessity to convert files to specific formats. As some classes of the ground-truth dataset are tagged differently by the detector (e.g., PASCAL VOC class tvmonitor is referred to as tv in COCO dataset), the only required work is to provide a text file listing the names of the classes in the ground-truth format. This way the evaluation tool can recognize that the detected object airplane should be evaluated as aeroplane.
A total of
of images from the train/val PASCAL VOC 2012 dataset containing
objects of 20 classes were evaluated by the YOLOV5 model to detect objects in 80 different classes. A total of
detections were detected by the model.
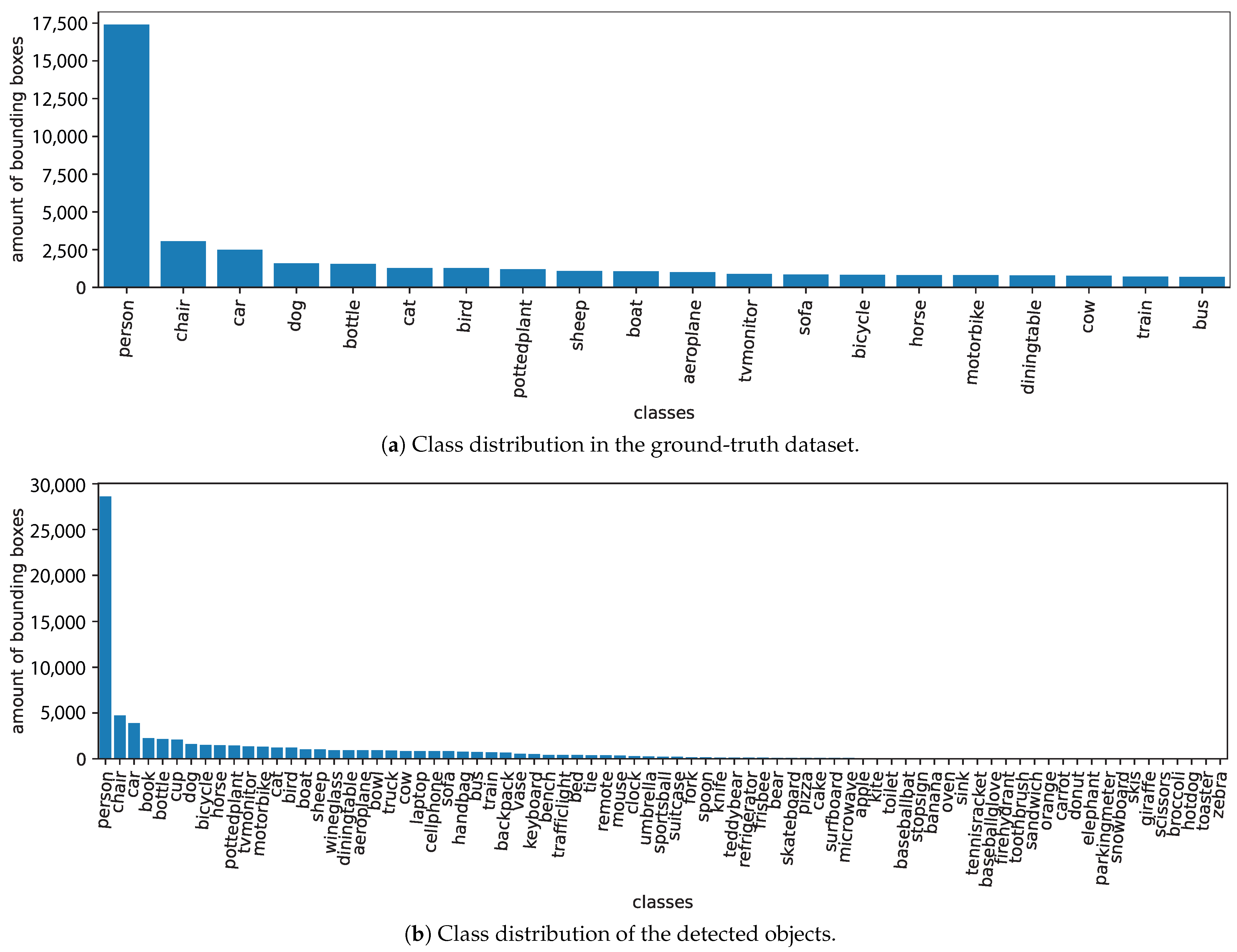
Figure 9 compares the distribution of ground-truth and detected objects per class. Due to the difference of classes in the training and testing datasets, many predicted classes are not in the ground-truth set, so detections of the extra classes are ignored by the metrics.
The AP results for each class are presented in
Table 5. The highest AP values over all classes were obtained when the AUC was measured with the 11-point interpolation method and an IOU threshold of
, resulting in
. As expected for all cases, a more rigorous IOU threshold (
) resulted in a smaller AP. Comparing the individual AP results among all classes, the most difficult object for all interpolation methods was the
potted plant, having an AP not higher than
for an IOU threshold of
and an AP not higher than
with an IOU threshold of
.
The results obtained by the variations which apply AP and AR with different sizes and quantity of objects per image are summarized in
Table 6.
Even if the same interpolation technique is applied, the results may vary depending on the IOU threshold. Similarly, different interpolations with the same IOU threshold may also lead to distinct results.
The metrics considering objects in different scales are useful to compare the assertiveness of detections in datasets containing objects of different scales. In the COCO dataset, for instance, roughly of the objects are considered small (area < pixels), are considered medium ( < area < pixels), and are considered large (area > pixels). This explains the vast amount of works using this dataset to report their results.


 ,
, 













{kind=link}
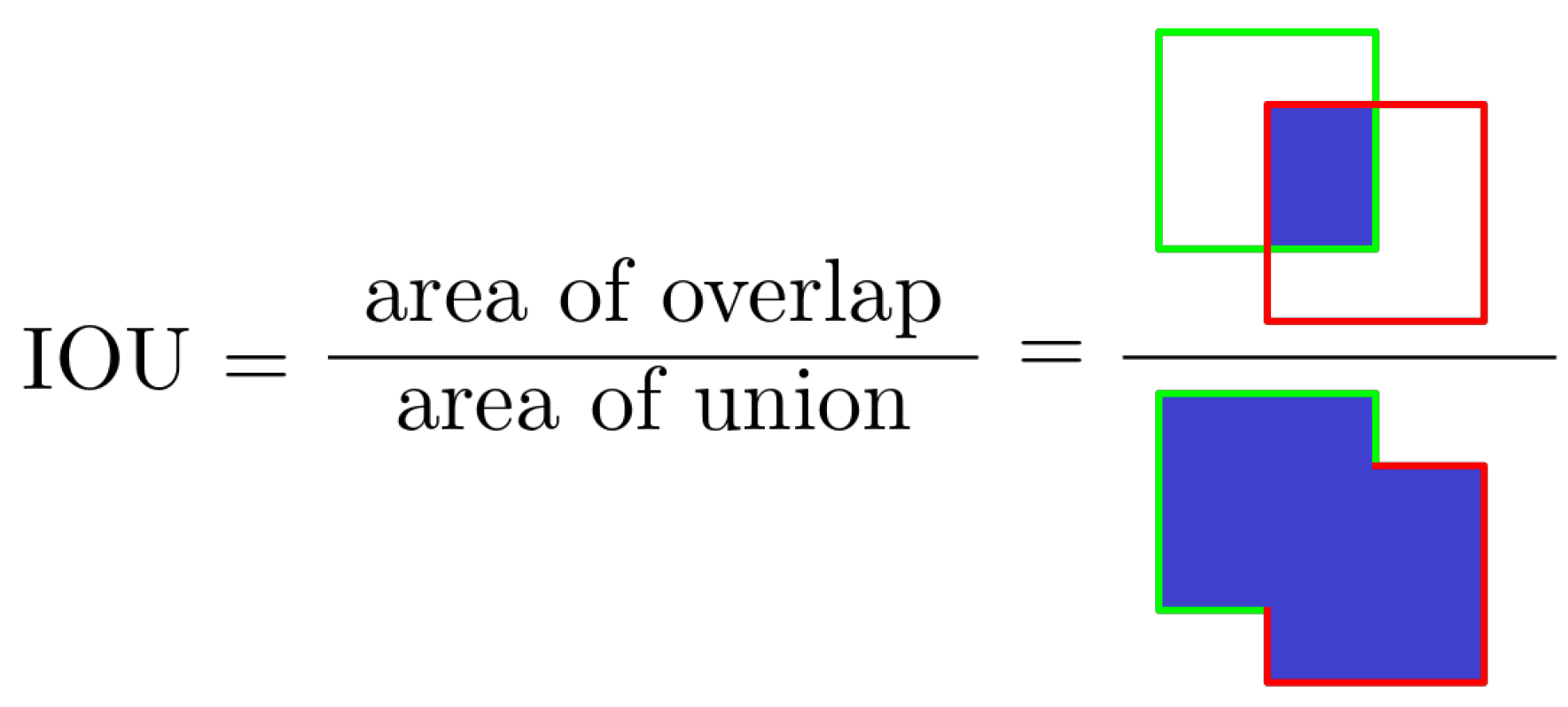{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}