1. Introduction
Extending 2D convolutional neural networks (CNNs) to 3D shapes is at the forefront of the field of computer graphics and computer vision. Unlike images represented on a regular grid of discrete values, generalizing CNNs to 3D shapes with irregular structure is very difficult.
Previous work has generalized CNNs to 3D shapes using regular representations: mapping 3D shapes to multiple 2D projections [
1] or 3D voxel grids [
2]. Further important work has involved the direct application of CNNs to the sparse point cloud representation [
3], which has inspired a series of follow-up investigations [
4,
5]. However, the approach can take up a lot of memory or weaken the connectivity of 3D shapes.
In contrast, triangle meshes provide more efficient representation of 3D shapes and have arbitrary connectivity, which is useful for expressing shape details. They approximate a continuous shape via a set of 2D triangles in 3D space, and are widely used in modeling, rendering, animation and other applications. However, this arbitrary connectivity makes the meshes non-uniform, which means that generalizing CNNs to the meshes is difficult.
To the best of our knowledge, most methods use CNNs indirectly by transforming the meshes into other structures, such as manifolds [
6,
7,
8,
9,
10] and graphs [
11,
12], and do not take into account the structural properties of the meshes. For example, PDMeshNet [
13] is a novel method which converts the meshes to primal-dual graphs with the help of graph vertices for convolution and pooling. There are some novel networks that can directly apply CNNs to the meshes. They have in common that they all use local regular connectivity—there are four edges around an edge [
14], and a face has three adjacent faces [
15]. This makes them only construct kernels of a fixed size, which limits the receptive field of convolution. Recently, the SubdivNet [
16] network was proposed, which subdivides the mesh to provide loop subdivision connectivity, with approximate plane properties to facilitate pooling. However, remesh preprocessing is needed and it is difficult to apply directly to meshes with arbitrary connectivity.
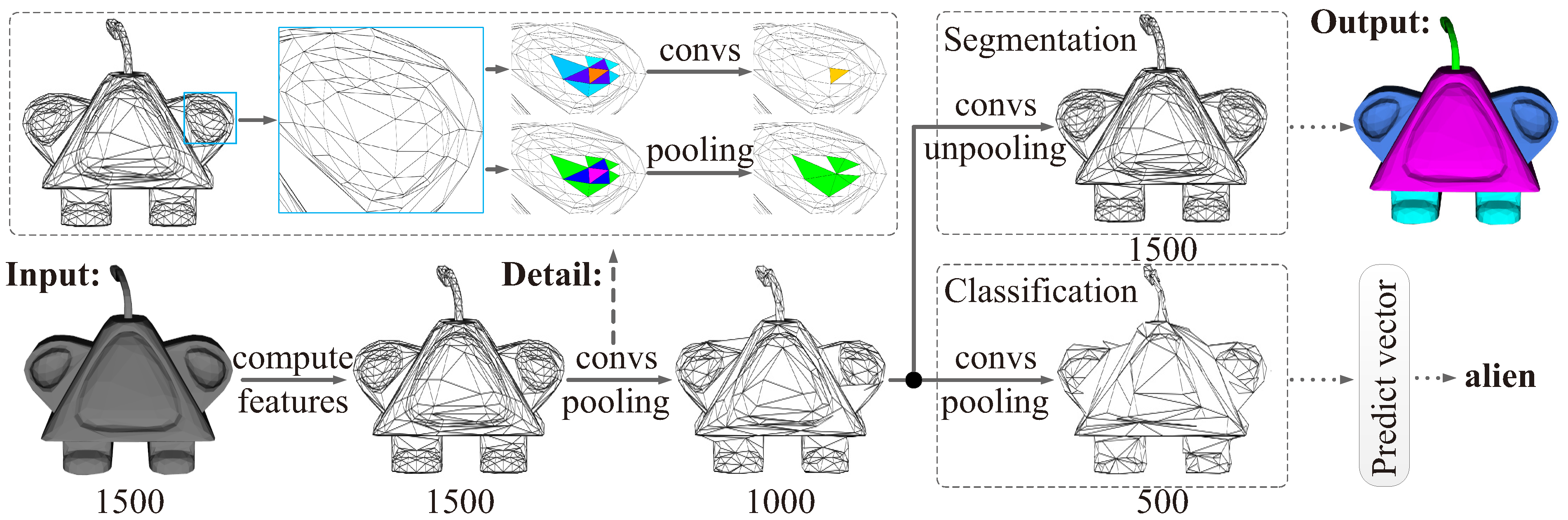
Seeking to tap into the arbitrary connectivity of the watertight mesh, we propose a novel face-based CNN, which bases the convolution and pooling region completely on the arbitrary connectivity. Many experiments undertaken demonstrate that the proposed method performs very well in mesh classification and segmentation. In
Figure 1, some chairs are shown that are accurately segmented with face labels by our method. The main contributions of the proposed technique are the following:
We directly generalize CNNs to the watertight meshes with arbitrary connectivity using faces as the basic elements of the network.
A sort convolution operation of faces is designed, which can obtain a larger receptive field, while preserving the invariance of convolution.
The face collapse is used for pooling, which can extract multi-level and more robust features of meshes.
3. Method
We propose a face-based CNN on triangular meshes with arbitrary connectivity, as shown in
Figure 2. The core of our method has three elements: face feature, described in
Section 3.2, face convolution, described in
Section 3.3, and face pooling, described in
Section 3.4.
3.1. Notation
The mesh can be expressed as
with the set of vertices
, edges
and faces
. We regard the existence of three adjacent faces in a face as the basic attribute of
F, and, for faces with less than three adjacent faces, fill them with the face itself [
15]. We express the face adjacency matrix as
, where
is the number of faces. To resolve the ordering ambiguity, we generate
by sorting the adjacent faces in
from small to large according to the length of the common edge. For instance, in
Figure 3, it can be described as:
where
are the indices of adjacent faces, and after sorting, the original unordered face indexes become the ordered on the right.
3.2. Input Features
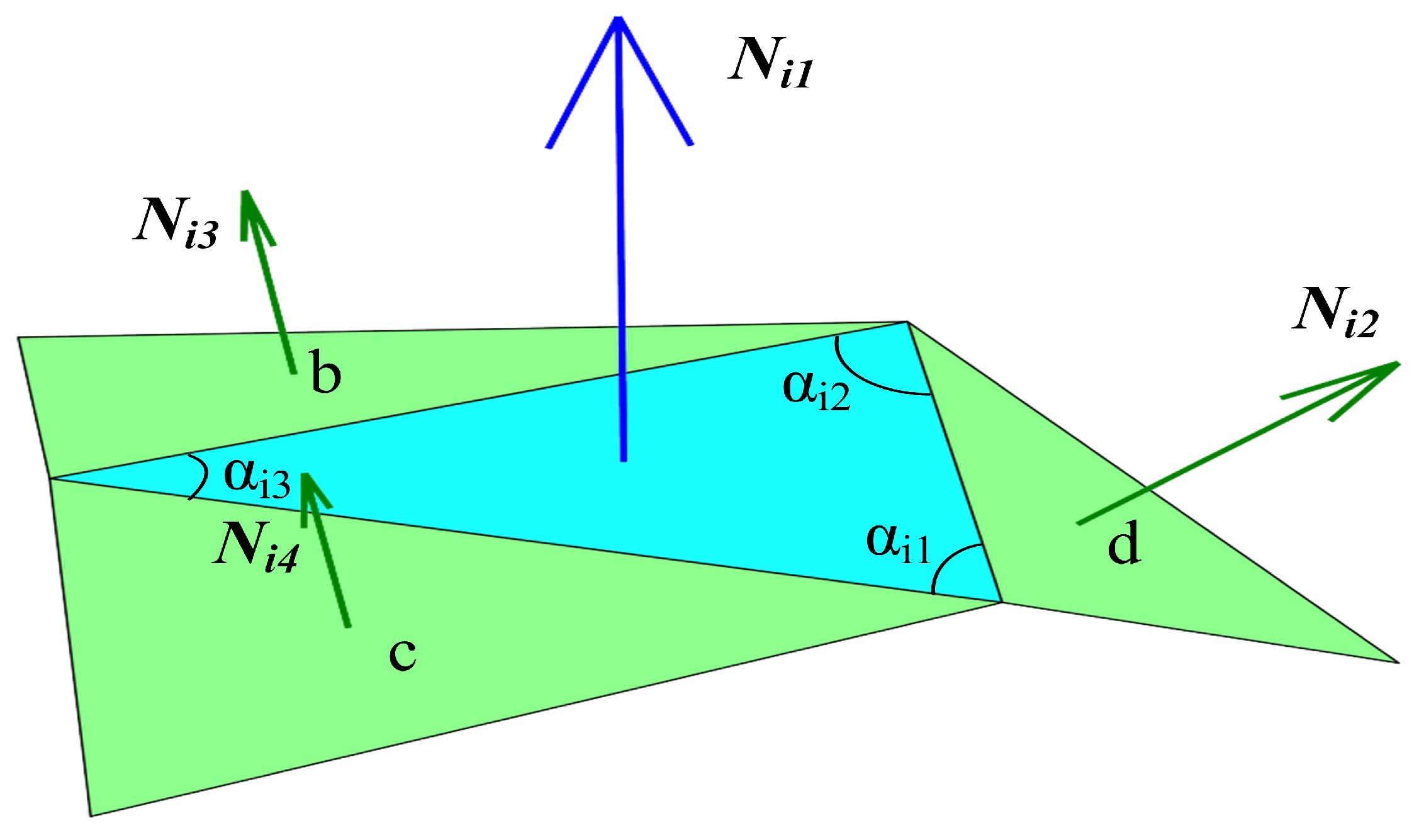
The face feature () is a 10-dimensional vector (, , ), including six dihedral angles, the face area and three internal angles.
Six dihedral angles. Given the the four normal vectors (
) of a face and its adjacent faces shown in
Figure 3, we calculate six dihedral angles using the two combinations of normals according to the order of the faces in
as:
where
∡ is the dihedral angle between normals.
The face area. We normalize the area
of each face according to the total face areas and the number of faces:
which makes the face area insensitive to the scale transformation of the input mesh.
Three internal angles. We sort the internal angles of the face, from small to large, to avoid ambiguity, as shown in
Figure 3, which can be described as:
These features are robust to rotation, translation and scale transformation. Following the approaches of MeshCNN [
14] and PD-MeshNet [
13], we standardize all input features according to their mean and variance.
3.3. Convolution
We define a sorting convolution of faces on the meshes with a one-dimensional convolution kernel. As a consequence of the irregularity of the mesh faces, we need to set the convolution region for each face according to the convolution kernel size k.
In fact, the
F itself and
set a
convolution receptive field for each face. We initialize
with
, then, to obtain a larger region, we continue to add adjacent faces to
according to traversing
in order and add
F to
if
F is not repeated in
. This is stopped when the set number
k is reached. In Algorithm 1, we show how to obtain a larger convolution receptive field of a face in detail.
![Electronics 11 02466 i001]()
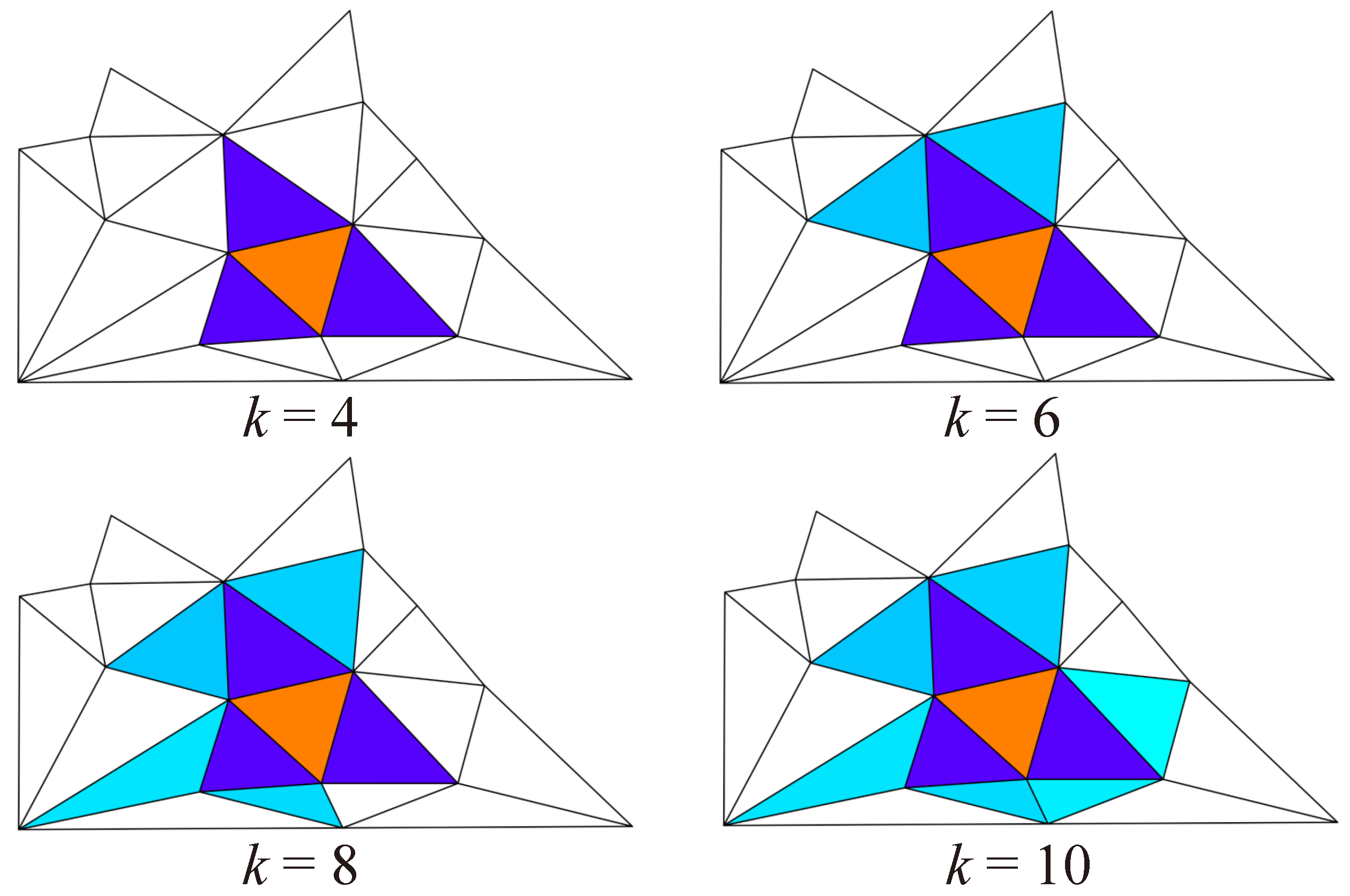
The receptive field for different
k is shown in
Figure 4; it can be seen that
k = 4 and
k = 10 are similar to the one ring and two ring receptive fields of 2D convolution. This construction method for the convolution receptive field can be extended to arbitrary polygonal meshes. The convolution result
is given by:
where
is the
nth learnable parameter in a convolution kernel, and
is the feature of the
nth face in
. The
are sorted in
. No matter how the meshes rotate,
will not change. So this convolution operation is rotation invariant.
3.4. Pooling
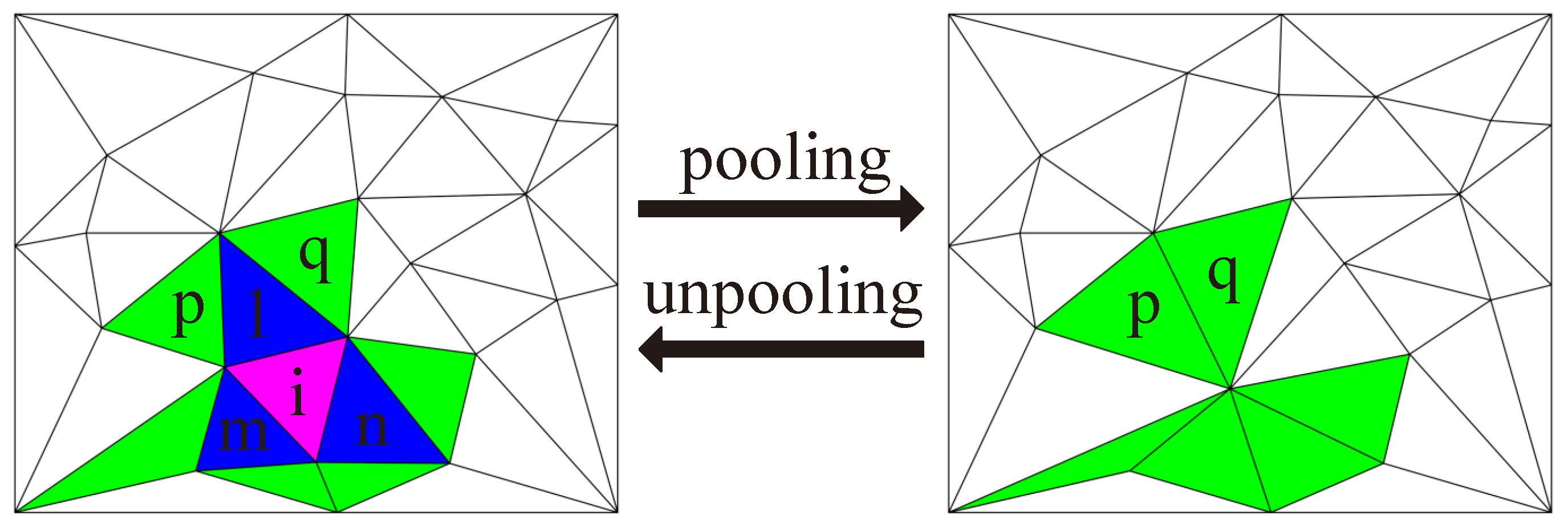
We take the face collapse as the face pooling, which can be applied to the meshes with arbitrary connectivity. As shown in
Figure 5, we set the collection of colored faces as the pooling region; it is evident that the face pooling depends only on the basic attributes of the mesh face.
First, we select disjoint pooling regions in order according to the face weight
w. With reference to the tradition mesh simplification methods, we compute
w as the difference between the features of the faces and the adjacent faces. The calculation method of each face weight
is given by:
Then the faces are collapsed for pooling in sequence, which are arranged in ascending order by w. It should be noted that the pooling changes the structure of the meshes; therefore, we need to update at the same time.
We use the number of faces as the stop criterion, and aggregate the features according to the connectivity of the faces. In
Figure 5, the aggregation of features can be defined as:
where
are the indices of the corresponding faces marked.
Finally, as a result of the reduction in the number of faces, it is necessary to index them and update again. If k of the next layer is more than four, we need to reconstruct . The collapse of faces may produce non-manifold faces, which we allow. However, non-manifold faces, and their surrounding faces, cannot participate in the next pooling.
3.5. Unpooling
For face unpooling, which is the inverse operation of pooling, we can restore the features of each face from the aggregated features. We obtain the , which is saved before pooling, for the next convolution operation. It should be noted that the unpooling operation, and its corresponding pooling operation, which we designed, are reversible.
During pooling, we save the feature mapping matrix, which maps the original face features before pooling, to the new face features after pooling. We can directly use its inverse matrix to restore the higher resolution features. Similar to the aggregation of features in pooling, as shown in
Figure 5, the diffusion of aggregated features can be defined as:
where
and
are calculated in the same way as
, which are the mean features of its two adjacent green faces.
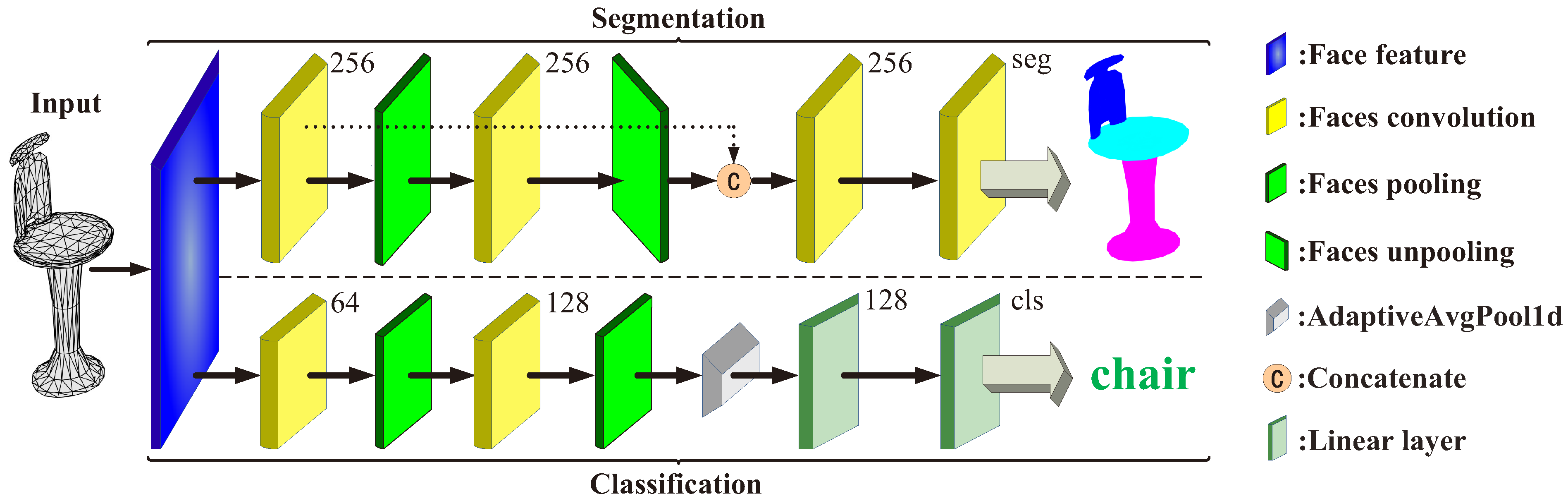
3.6. Network Architecture
Our proposed face convolution and pooling are similar to the edge convolution and pooling of MeshCNN [
14], which can directly apply classical 2D CNNs to the meshes, such as ResNet [
27] or U-Net [
28]. As shown in
Figure 6, our network architecture only makes a slight modification to MeshCNN [
14], by reducing the number of convolution layers and pooling by half. We set
for each convolution layer.
For segmentation, each face convolution has three residual convolutions and the last two face convolutions have an additional convolution layer to reduce the number of feature channels. The convolution parameters are [256, 256, 256, seg]. The pooling parameters are [1000, 700] or [1500, 1000], depending on the number of faces. For classification, each face convolution has a residual convolution. The convolution, MLP and pooling parameters are [64, 128], [128, cls] and [500, 400, 300]. Obviously, we only use 18 and 4 convolution layers for segmentation and classification. The above parameters are the numbers of output channels and face numbers after pooling. The seg and cls are the numbers of segmentation and classification. For the other details, we use the same configurations as MeshCNN [
14].
5. Conclusions
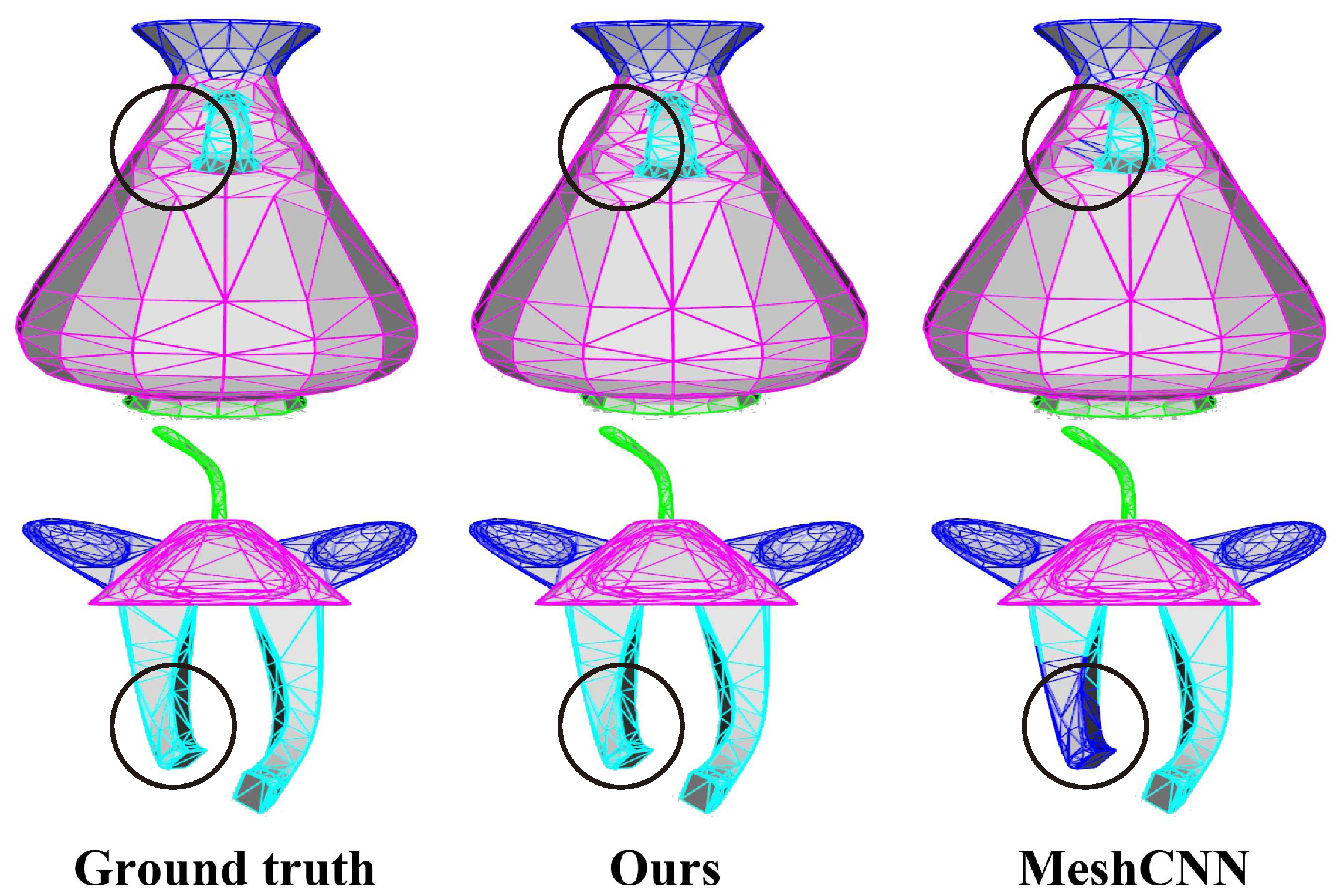
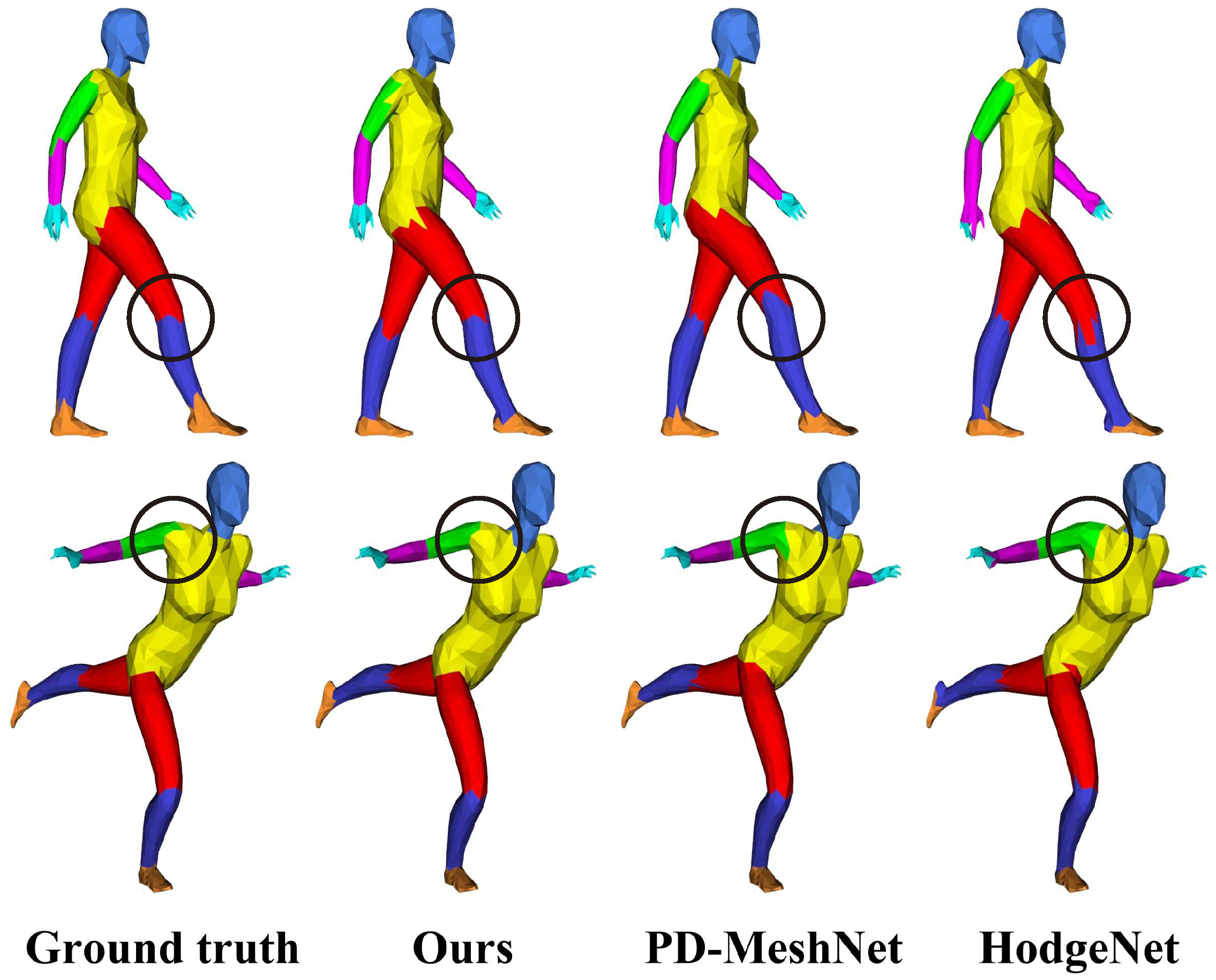
This paper introduces a novel deep learning method involving the direct application of CNNs to the watertight meshes with arbitrary connectivity. The face is used as the basic element for feature extraction, convolution and pooling. Sorting is used to deal with the irregularity of the meshes and the order ambiguity of face convolution, and learnable face simplification is used to extract multi-level features. Classification and segmentation experiments undertaken demonstrated its effectiveness and that its simple implementation enabled straightforward application to various mesh analysis tasks.
Future work. Non-watertightness and high resolution of the mesh are two obstacles to the application of our method. A common solution is to make the meshes watertight and to simplify them, referencing MeshCNN [
14], and then to perform various mesh analysis tasks. An avenue for future research is to explore post-processing methods to simplify the meshes, such as the application of boundary smoothing to mesh segmentation [
23]. In addition, how to improve different mesh analysis tasks, using correspondingly more advanced network architectures, is a potential area for further research.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}