
Automatic Modulation Classification with Neural Networks via Knowledge Distillation
Abstract
:1. Introduction
2. Materials and Methods
2.1. Basic Principle of Signal Modulation
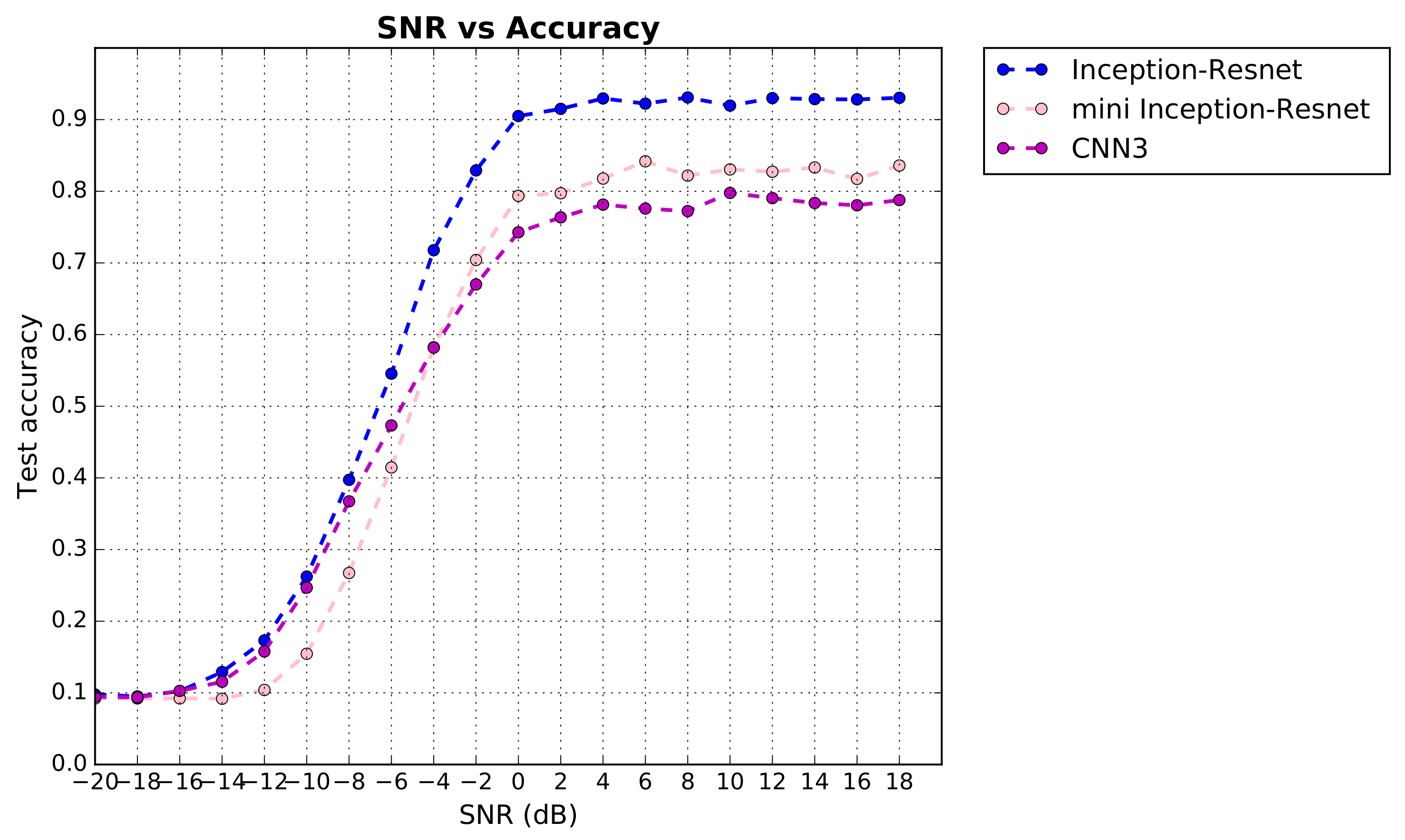
2.2. SNR and Accuracy
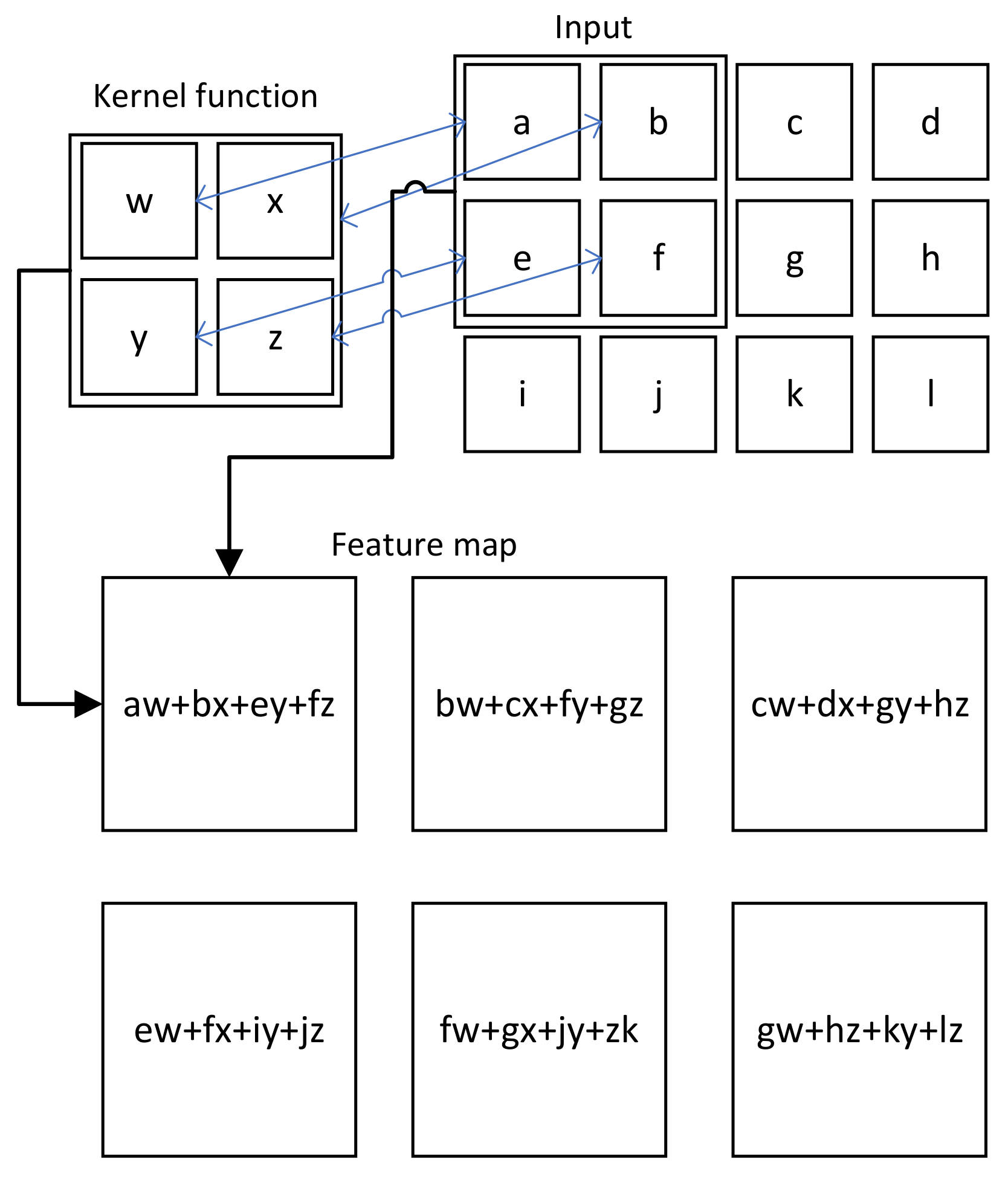
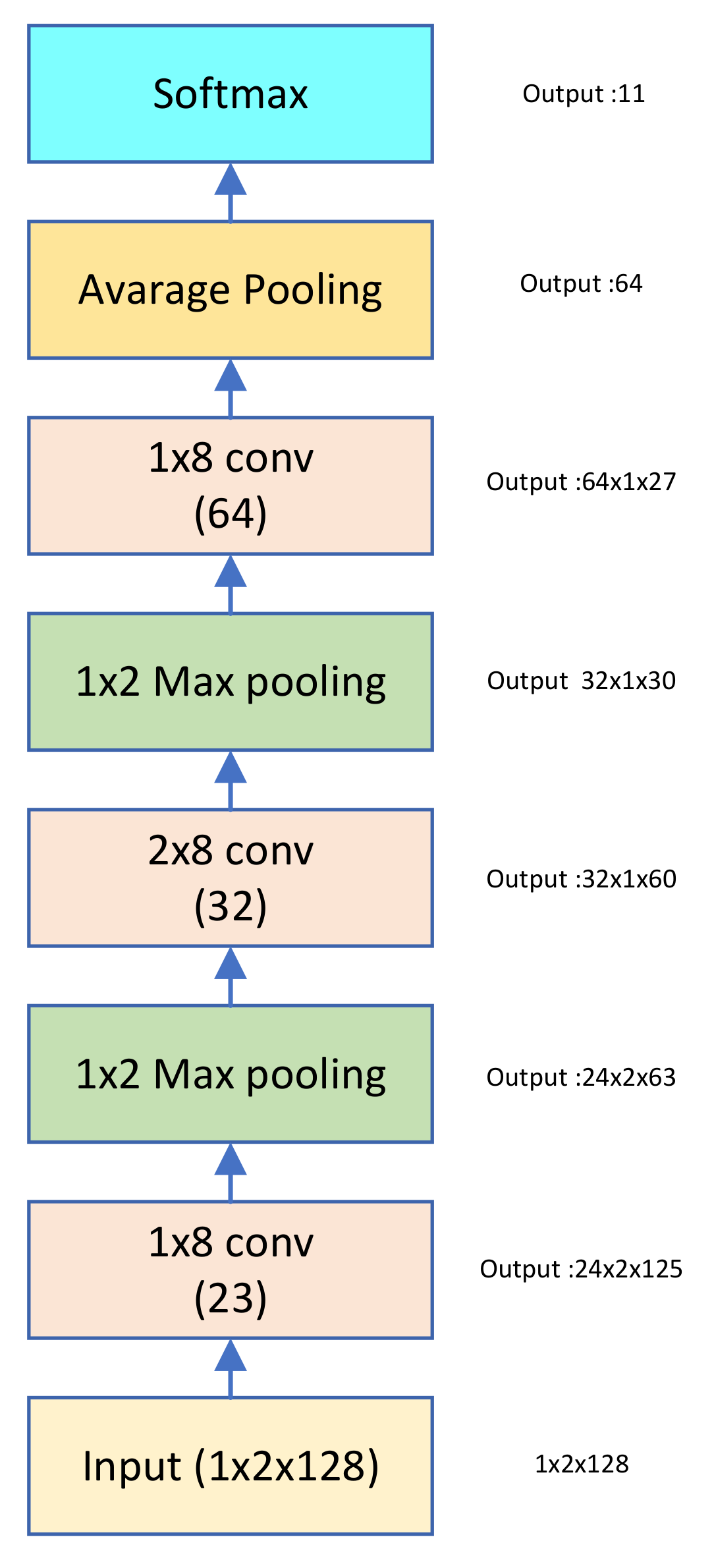
2.3. CNN
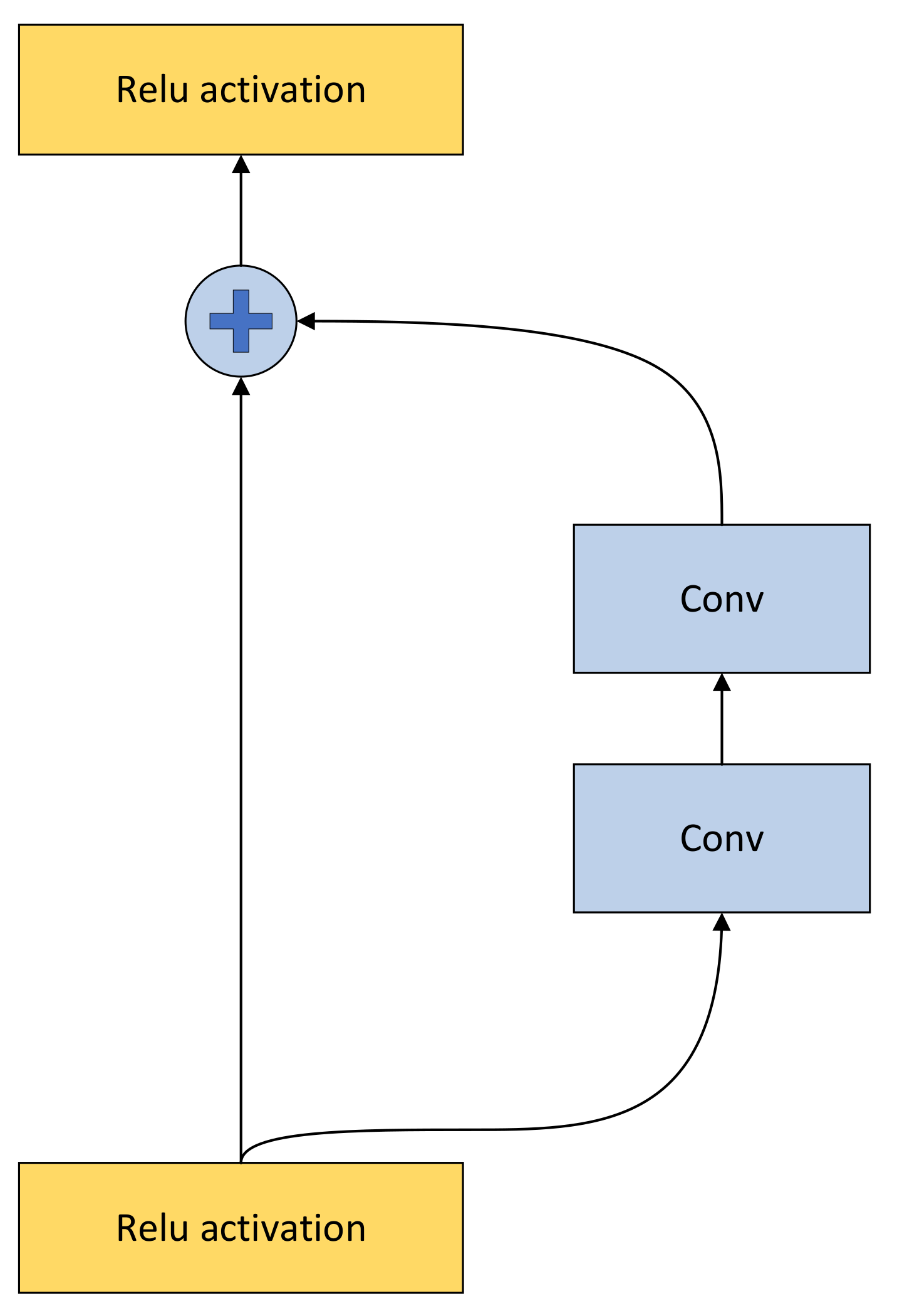
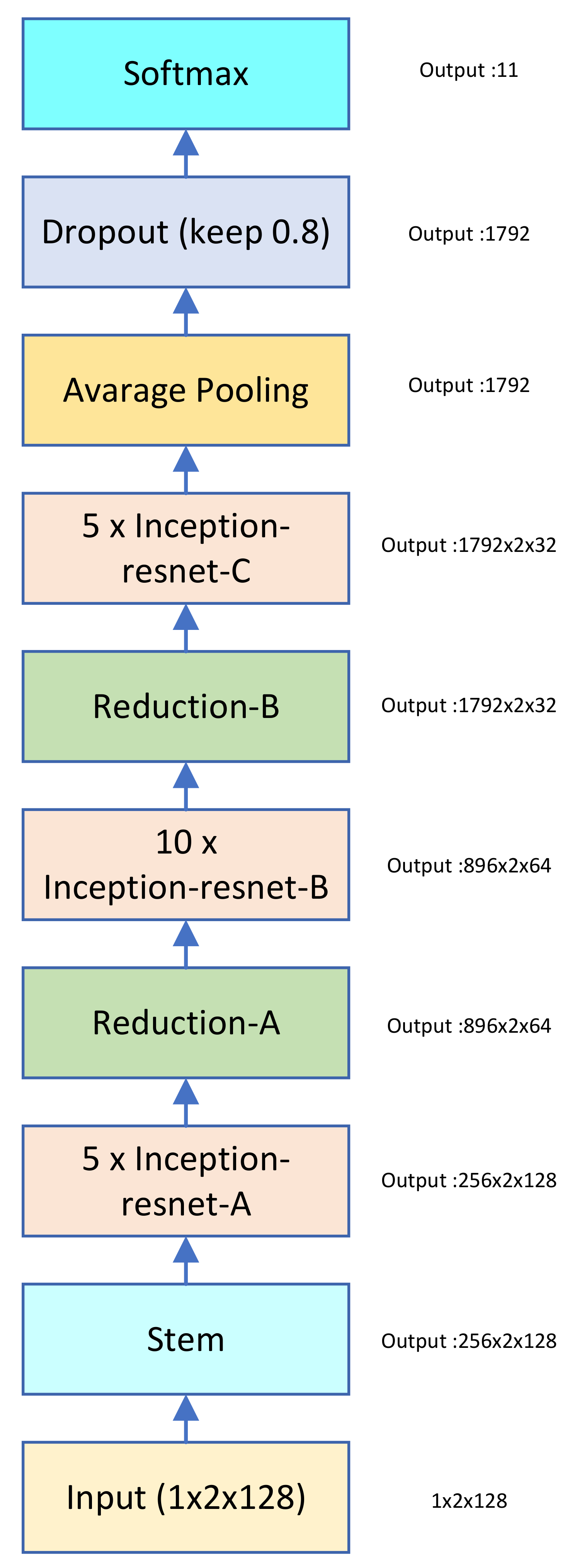
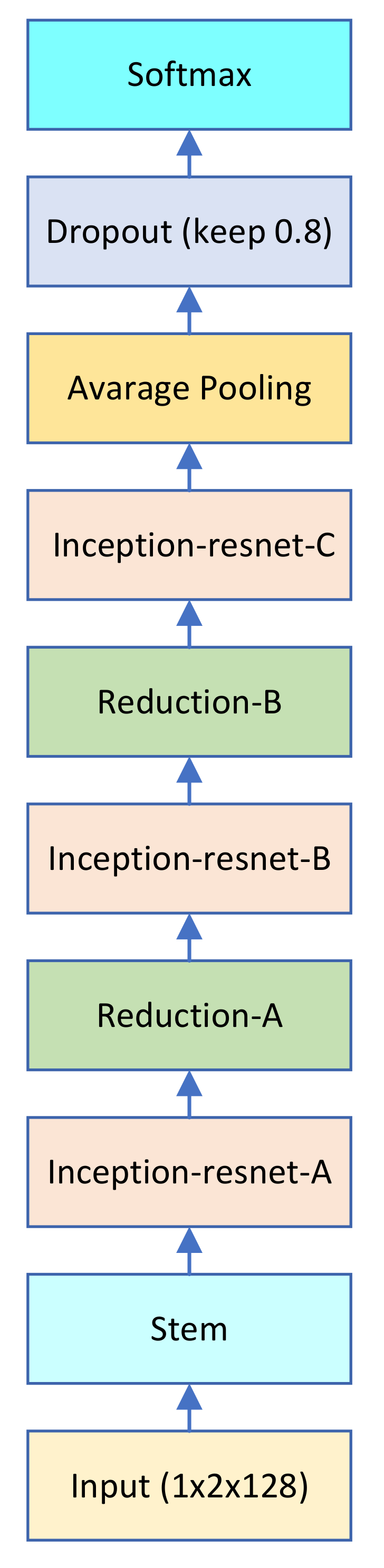
2.4. Residual Network
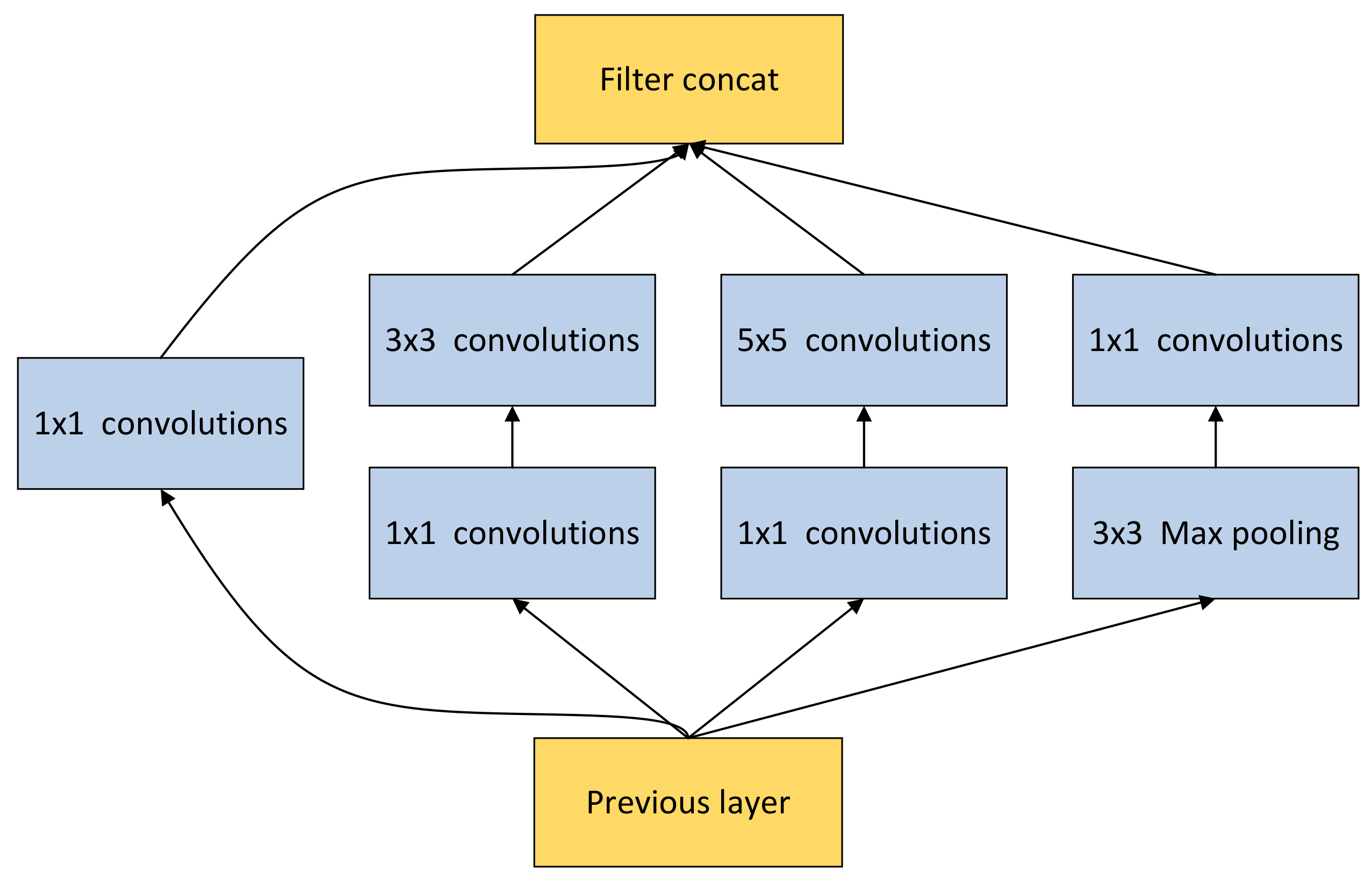
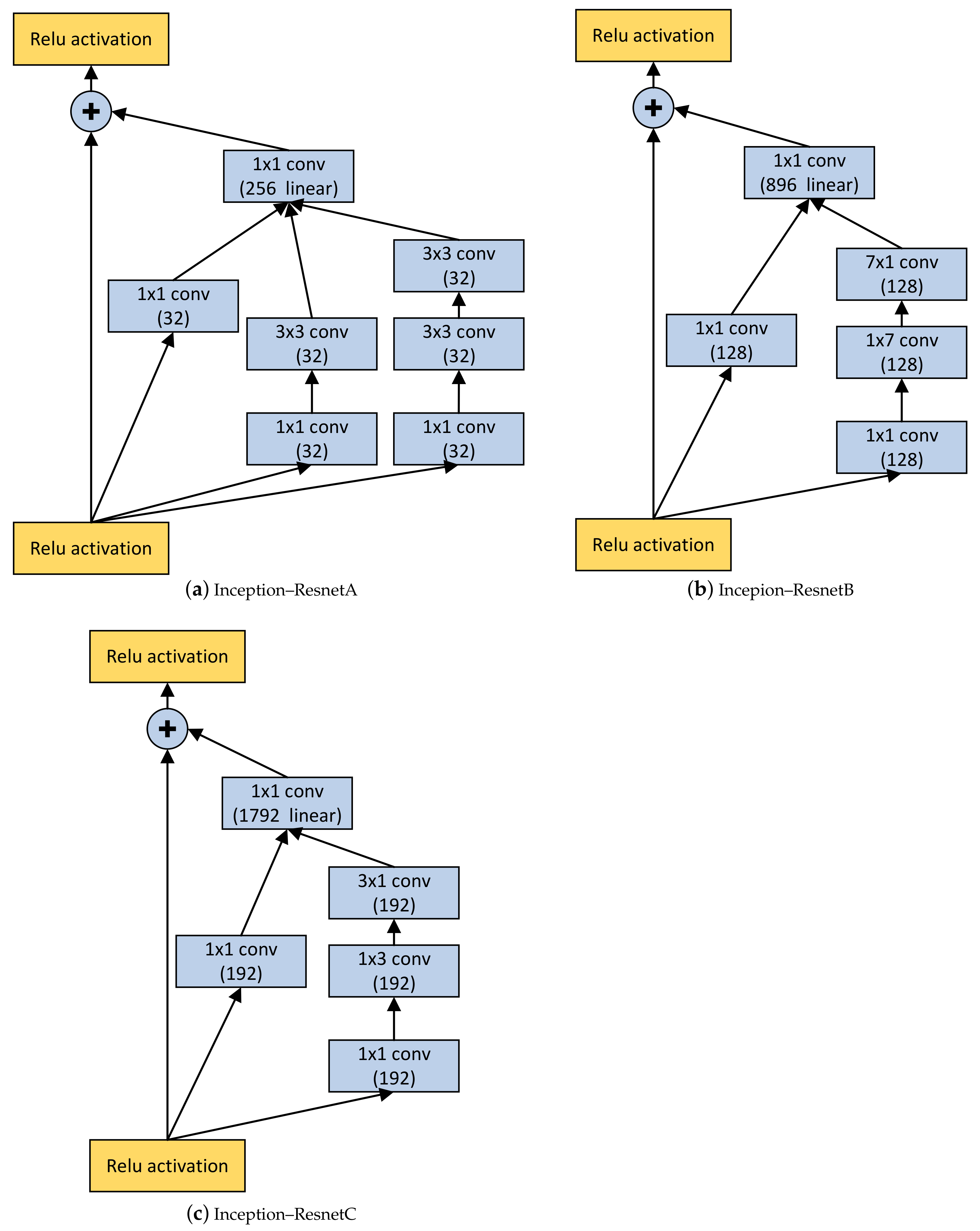
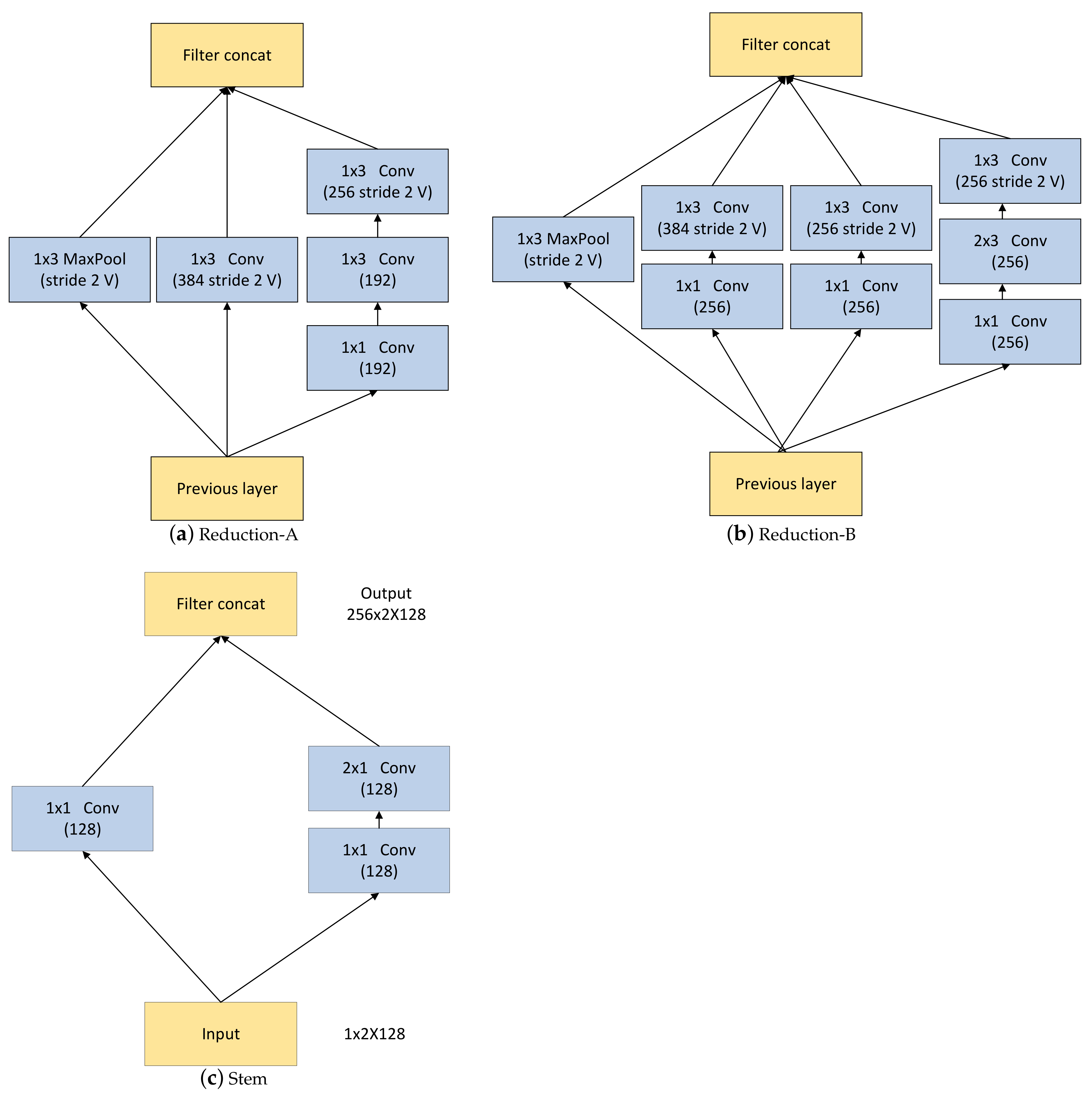
2.5. Inception
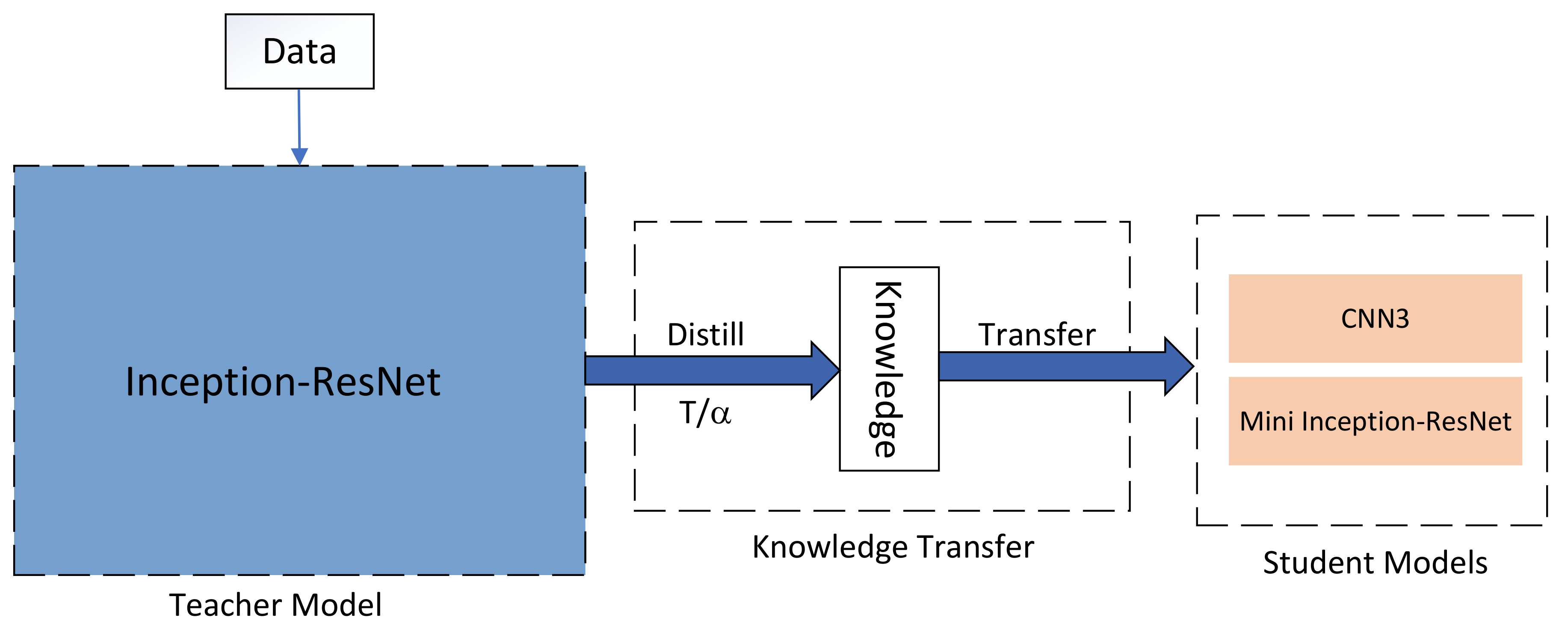
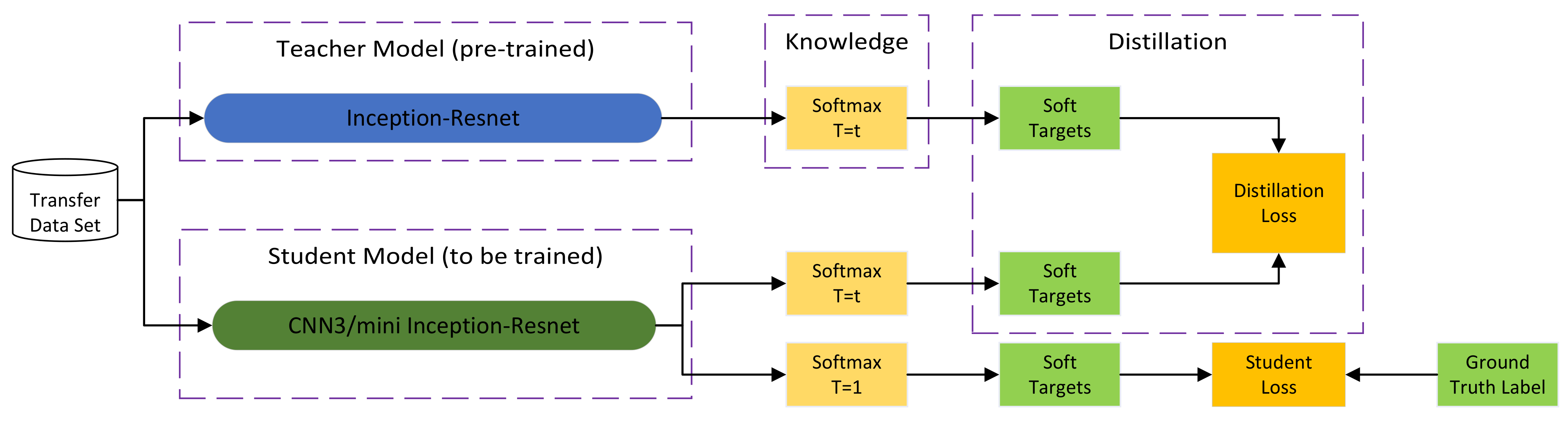
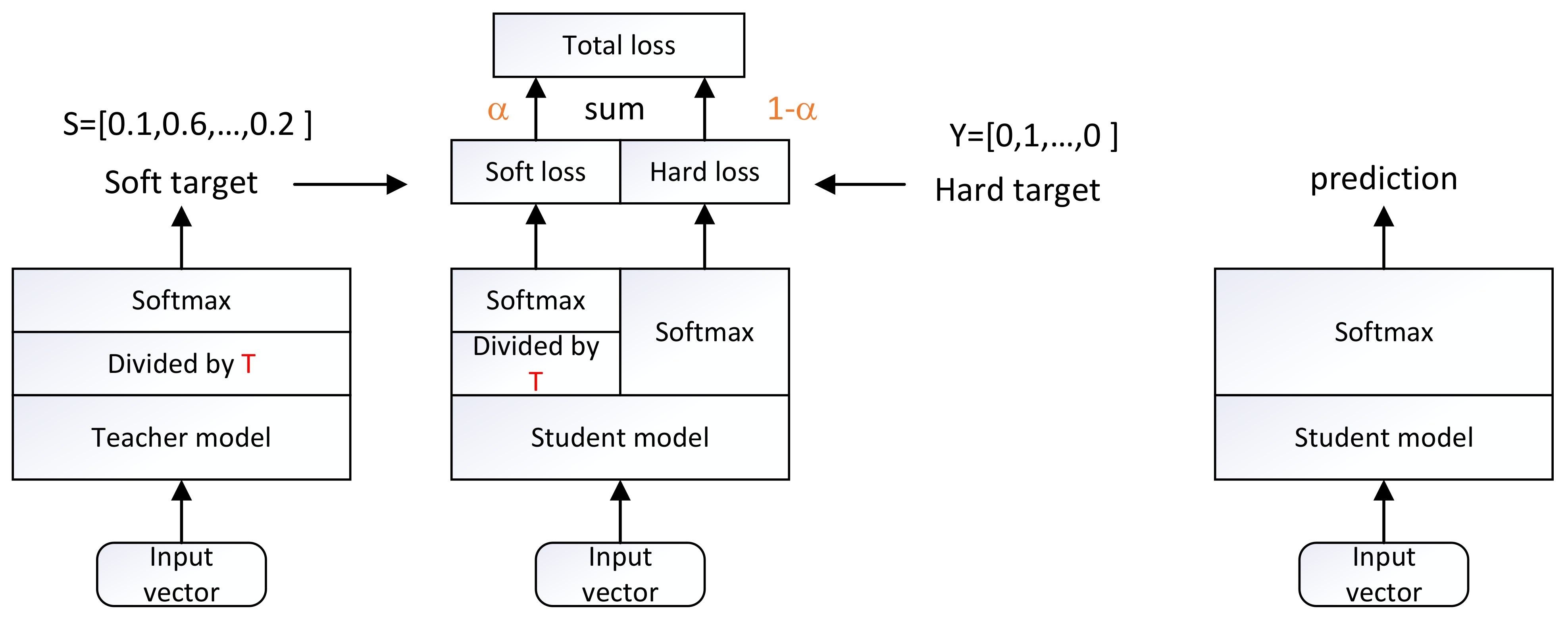
2.6. Knowledge Distillation
3. Experiments
3.1. Structure of the Teacher and Student Network
3.2. Loss Function
3.3. Dataset and Training
3.4. Experimental Procedure
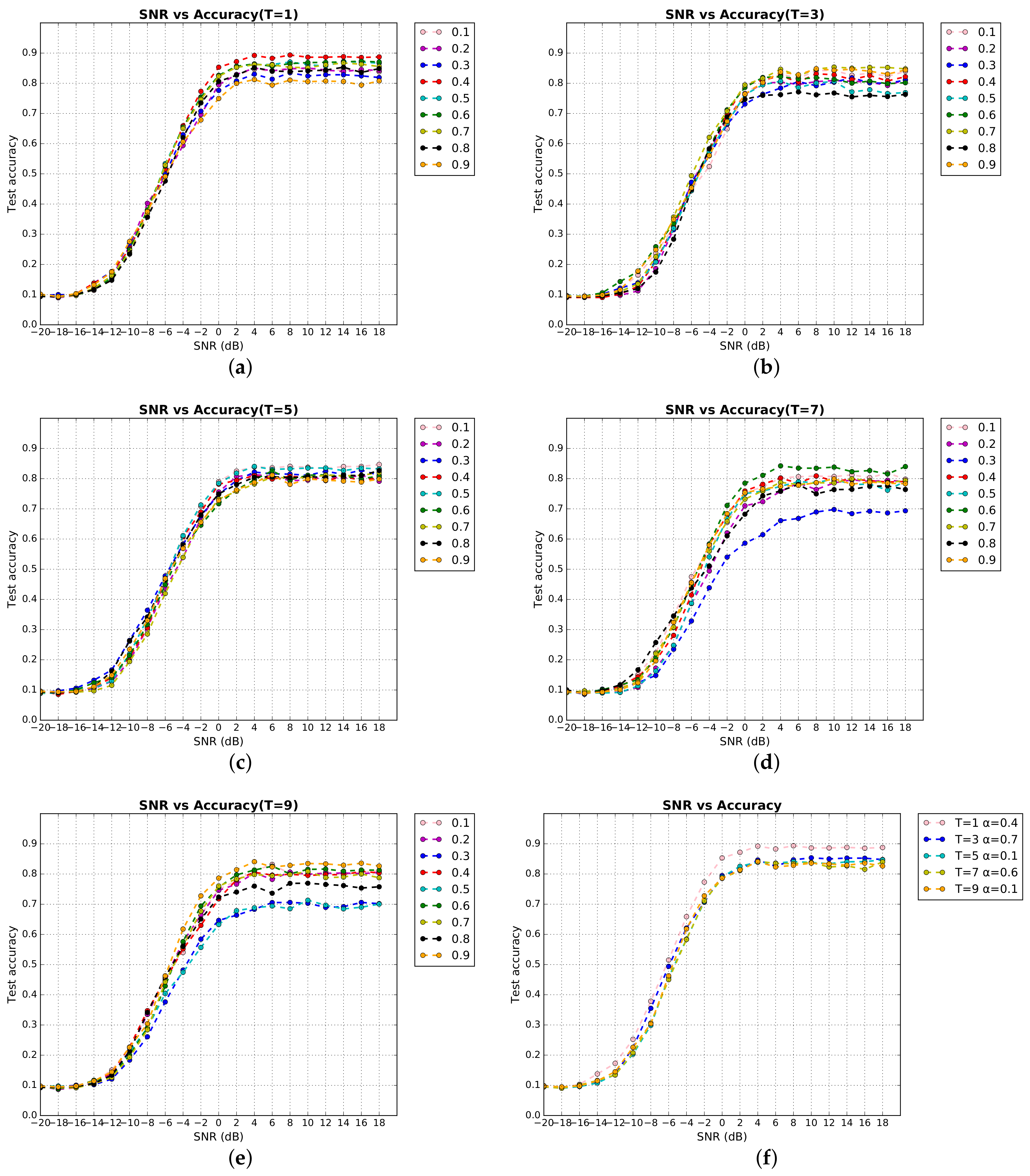
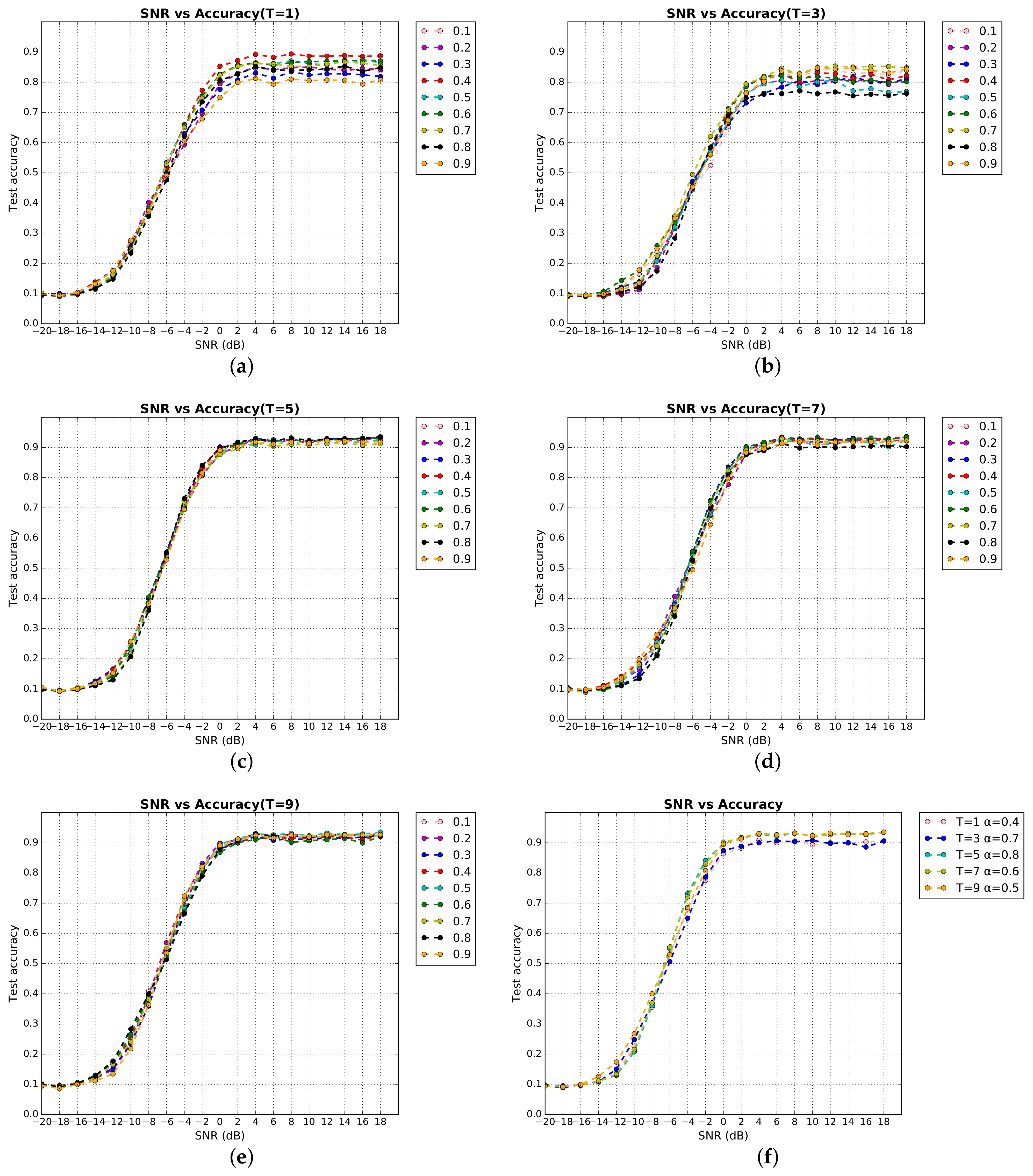
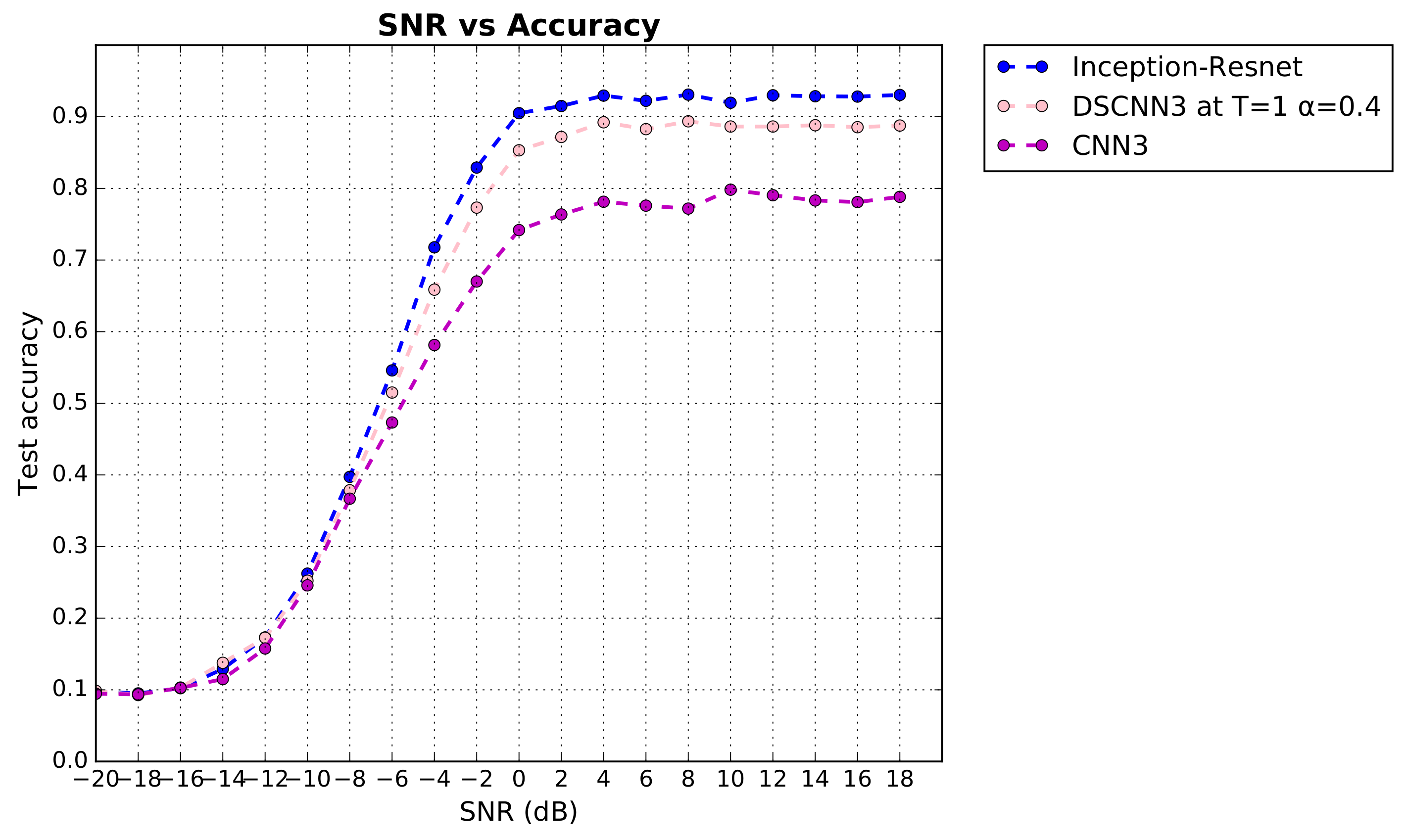
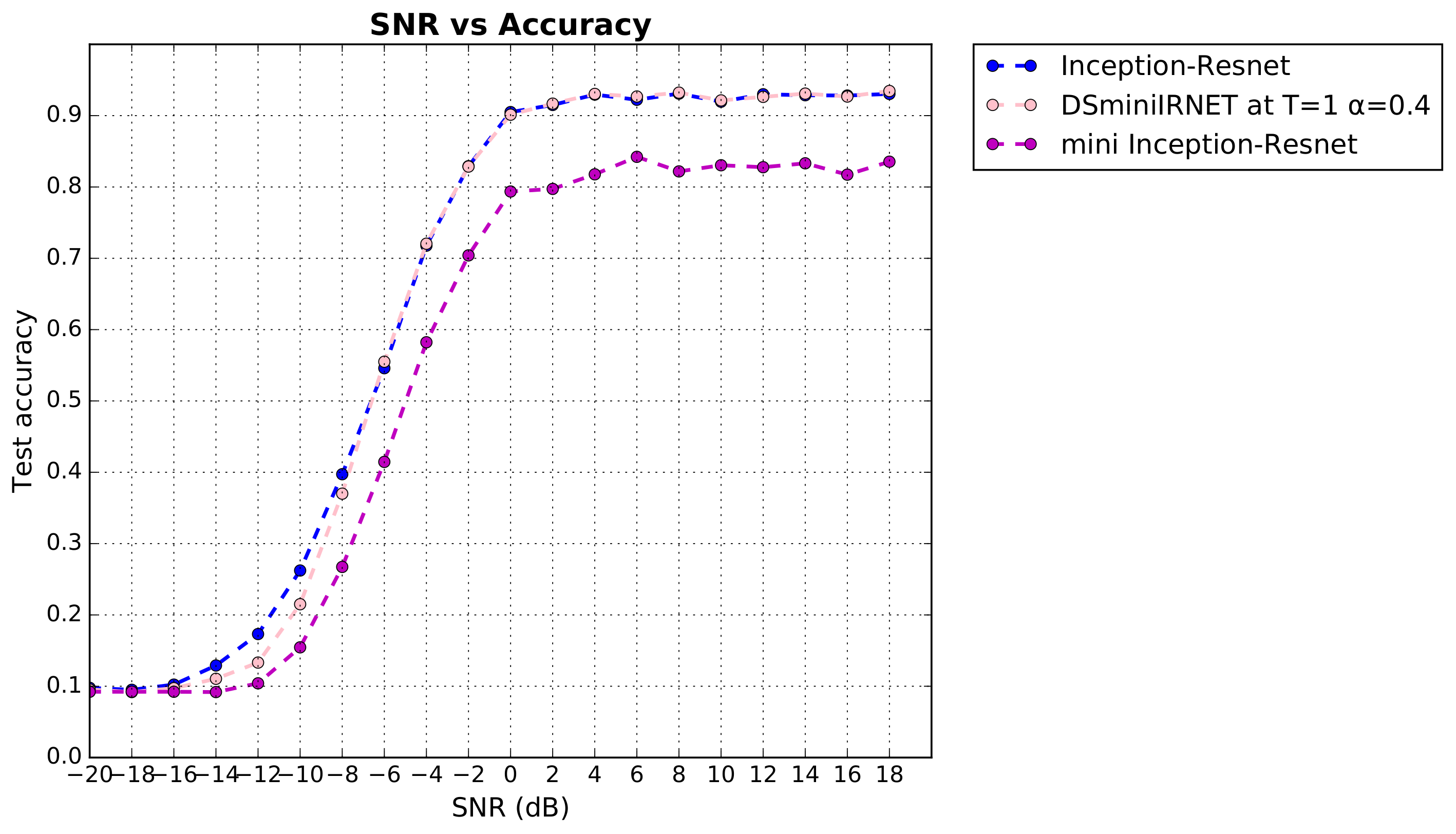
4. Result and Analysis
4.1. Evaluation of Classification
4.2. Computation Complexity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AMC | Automatic modulation classification |
| GPUs | Graphic processing units |
| KD | Knowledge Distillation |
| DSCNN3 | CNN3 after knowledge distillation |
| DSminiIRNET | mini Inception–Resnet after knowledge distillation |
References
- O’Shea, T.; Hoydis, J. An Introduction to Deep Learning for the Physical Layer. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 563–575. [Google Scholar] [CrossRef]
- Dobre, O.; Abdi, A.; Bar-Ness, Y.; Su, W. Survey of automatic modulation classification techniques: Classical approaches and new trends. IET Commun. 2007, 1, 137. [Google Scholar] [CrossRef]
- O’Shea, T.J.; Corgan, J.; Clancy, T.C. Convolutional Radio Modulation Recognition Networks. arXiv 2016, arXiv:1602.04105. [Google Scholar]
- Kim, B.; Kim, J.; Chae, H.; Yoon, D.; Choi, J.W. Deep neural network-based automatic modulation classification technique. In Proceedings of the 2016 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea, 19–21 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 579–582. [Google Scholar] [CrossRef]
- West, N.E.; O’Shea, T. Deep architectures for modulation recognition. In Proceedings of the 2017 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Baltimore, MD, USA, 6–9 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, H.; Sang, Z.; Xu, L.; Cao, C.; Gulliver, T.A. Modulation Classification of Underwater Communication with Deep Learning Network. Comput. Intell. Neurosci. 2019, 2019, 8039632. [Google Scholar] [CrossRef]
- Zhang, J.; Cabric, D.; Wang, F.; Zhong, Z. Cooperative Modulation Classification for Multipath Fading Channels via Expectation-Maximization. IEEE Trans. Wirel. Commun. 2017, 16, 6698–6711. [Google Scholar] [CrossRef]
- Liu, X.; Yang, D.; Gamal, A.E. Deep Neural Network Architectures for Modulation Classification. arXiv 2018, arXiv:1712.00443. [Google Scholar]
- O’Shea, T.J.; Roy, T.; Clancy, T.C. Over-the-Air Deep Learning Based Radio Signal Classification. IEEE J. Sel. Top. Signal Process. 2018, 12, 168–179. [Google Scholar] [CrossRef]
- Zeng, Y.; Zhang, M.; Han, F.; Gong, Y.; Zhang, J. Spectrum Analysis and Convolutional Neural Network for Automatic Modulation Recognition. IEEE Wirel. Commun. Lett. 2019, 8, 929–932. [Google Scholar] [CrossRef]
- Wu, P.; Sun, B.; Su, S.; Wei, J.; Zhao, J.; Wen, X. Automatic Modulation Classification Based on Deep Learning for Software-Defined Radio. Math. Probl. Eng. 2020, 2020, 2678310. [Google Scholar] [CrossRef]
- Liu, R.; Guo, Y.; Zhu, S. Modulation Recognition Method of Complex Modulation Signal Based on Convolution Neural Network. In Proceedings of the 2020 IEEE 9th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 11–13 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1179–1184. [Google Scholar] [CrossRef]
- Jiao, J.; Sun, X.; Zhang, Y.; Liu, L.; Shao, J.; Lyu, J.; Fang, L. Modulation Recognition of Radio Signals Based on Edge Computing and Convolutional Neural Network. J. Commun. Inf. Netw. 2021, 6, 280–300. [Google Scholar] [CrossRef]
- Snoap, J.A.; Popescu, D.C.; Spooner, C.M. On Deep Learning Classification of Digitally Modulated Signals Using Raw I/Q Data. In Proceedings of the 2022 IEEE 19th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 8–11 January 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 441–444. [Google Scholar] [CrossRef]
- Chen, Y.H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks. IEEE J. Solid-State Circuits 2017, 52, 127–138. [Google Scholar] [CrossRef]
- Raina, R.; Madhavan, A.; Ng, A.Y. Large-scale deep unsupervised learning using graphics processors. In Proceedings of the 26th Annual International Conference on Machine Learning-ICML’09, Montreal, QC, Canada, 14–18 June 2009; ACM Press: Montreal, QC, Canada, 2009; pp. 1–8. [Google Scholar] [CrossRef]
- He, K.; Sun, J. Convolutional Neural Networks at Constrained Time Cost. arXiv 2014, arXiv:1412.1710. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge Distillation: A Survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Janveja, I.; Nambi, A.; Bannur, S.; Gupta, S.; Padmanabhan, V. Insight: Monitoring the state of the driver in low-light using smartphones. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–29. [Google Scholar] [CrossRef]
- Chen, R.; Ai, H.; Shang, C.; Chen, L.; Zhuang, Z. Learning lightweight pedestrian detector with hierarchical knowledge distillation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1645–1649. [Google Scholar]
- Plötz, T.; Guan, Y. Deep learning for human activity recognition in mobile computing. Computer 2018, 51, 50–59. [Google Scholar] [CrossRef]
- Nagel, M.; Fournarakis, M.; Amjad, R.A.; Bondarenko, Y.; van Baalen, M.; Blankevoort, T. A white paper on neural network quantization. arXiv 2021, arXiv:2106.08295. [Google Scholar]
- Wu, R.T.; Singla, A.; Jahanshahi, M.R.; Bertino, E.; Ko, B.J.; Verma, D. Pruning deep convolutional neural networks for efficient edge computing in condition assessment of infrastructures. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 774–789. [Google Scholar] [CrossRef]
- Khan, M.S.; Alam, K.N.; Dhruba, A.R.; Zunair, H.; Mohammed, N. Knowledge distillation approach towards melanoma detection. Comput. Biol. Med. 2022, 146, 105581. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Aboamer, M.A.; Sikkandar, M.Y.; Gupta, S.; Vives, L.; Joshi, K.; Omarov, B.; Singh, S.K. An Investigation in Analyzing the Food Quality Well-Being for Lung Cancer Using Blockchain through CNN. J. Food Qual. 2022, 2022, 5845870. [Google Scholar] [CrossRef]
- Agarwal, C.; Kaur, I.; Yadav, S. Hybrid CNN-SVM Model for Face Mask Detector to Protect from COVID-19. In Artificial Intelligence on Medical Data; Springer: Berlin/Heidelberg, Germany, 2023; pp. 419–426. [Google Scholar]
- Dibbo, S.V.; Cheung, W.; Vhaduri, S. On-phone CNN model-based implicit authentication to secure IoT wearables. In The Fifth International Conference on Safety and Security with IoT; Springer: Berlin/Heidelberg, Germany, 2023; pp. 19–34. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:1512.00567. [Google Scholar]
- Li, H. Exploring Knowledge Distillation of Deep Neural Networks for Efficient Hardware Solutions; CS230 Course Report; University of Stanford: Stanford, CA, USA, 2018. [Google Scholar]
- O’shea, T.J.; West, N. Radio machine learning dataset generation with gnu radio. In Proceedings of the GNU Radio Conference, Charlotte, NC, USA, 20–24 September 2016; Volume 1. [Google Scholar]
- Xu, B.; Wang, W.; Falzon, G.; Kwan, P.; Guo, L.; Sun, Z.; Li, C. Livestock classification and counting in quadcopter aerial images using Mask R-CNN. Int. J. Remote Sens. 2020, 41, 8121–8142. [Google Scholar] [CrossRef] [Green Version]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Inception–Resnet | mini-Inception–Resnet | CNN3 | |
|---|---|---|---|
| before KD | 0.9309 | 0.8418 | 0.7981 |
| after KD | 0.9359 | 0.8936 |
| Network | Estimated Total Size (MB) | Total Parameters | FLOPs |
|---|---|---|---|
| Inception–Resnet | 311.77 | 32,353,675 | 3,232,437,248 |
| mini Inception–Resnet | 39.69 | 3,995,787 | 449,975,296 |
| CNN3 | 0.37 | 30,179 | 1,257,360 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Liu, C. Automatic Modulation Classification with Neural Networks via Knowledge Distillation. Electronics 2022, 11, 3018. https://doi.org/10.3390/electronics11193018
Wang S, Liu C. Automatic Modulation Classification with Neural Networks via Knowledge Distillation. Electronics. 2022; 11(19):3018. https://doi.org/10.3390/electronics11193018
Chicago/Turabian StyleWang, Shuai, and Chunwu Liu. 2022. "Automatic Modulation Classification with Neural Networks via Knowledge Distillation" Electronics 11, no. 19: 3018. https://doi.org/10.3390/electronics11193018
APA StyleWang, S., & Liu, C. (2022). Automatic Modulation Classification with Neural Networks via Knowledge Distillation. Electronics, 11(19), 3018. https://doi.org/10.3390/electronics11193018