

MFFRand: Semantic Segmentation of Point Clouds Based on Multi-Scale Feature Fusion and Multi-Loss Supervision

Abstract
:1. Introduction
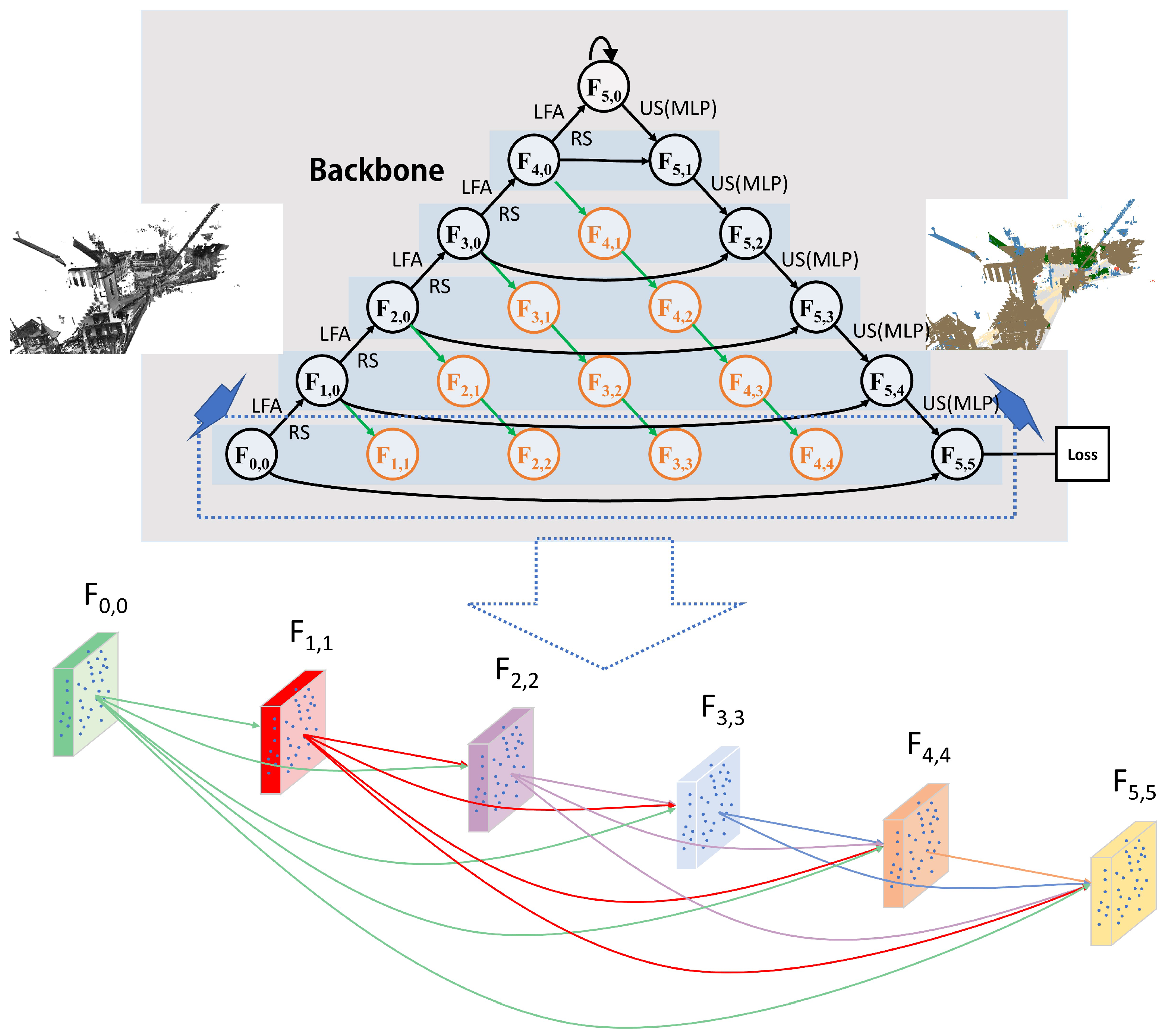
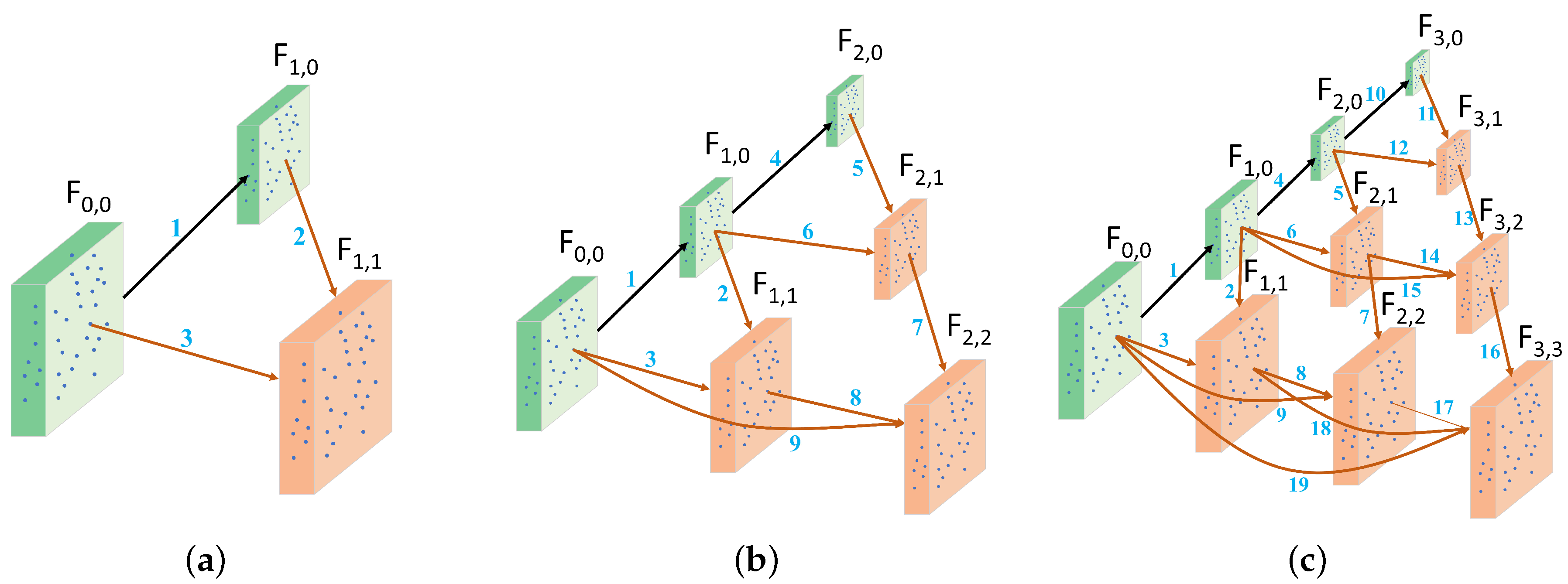
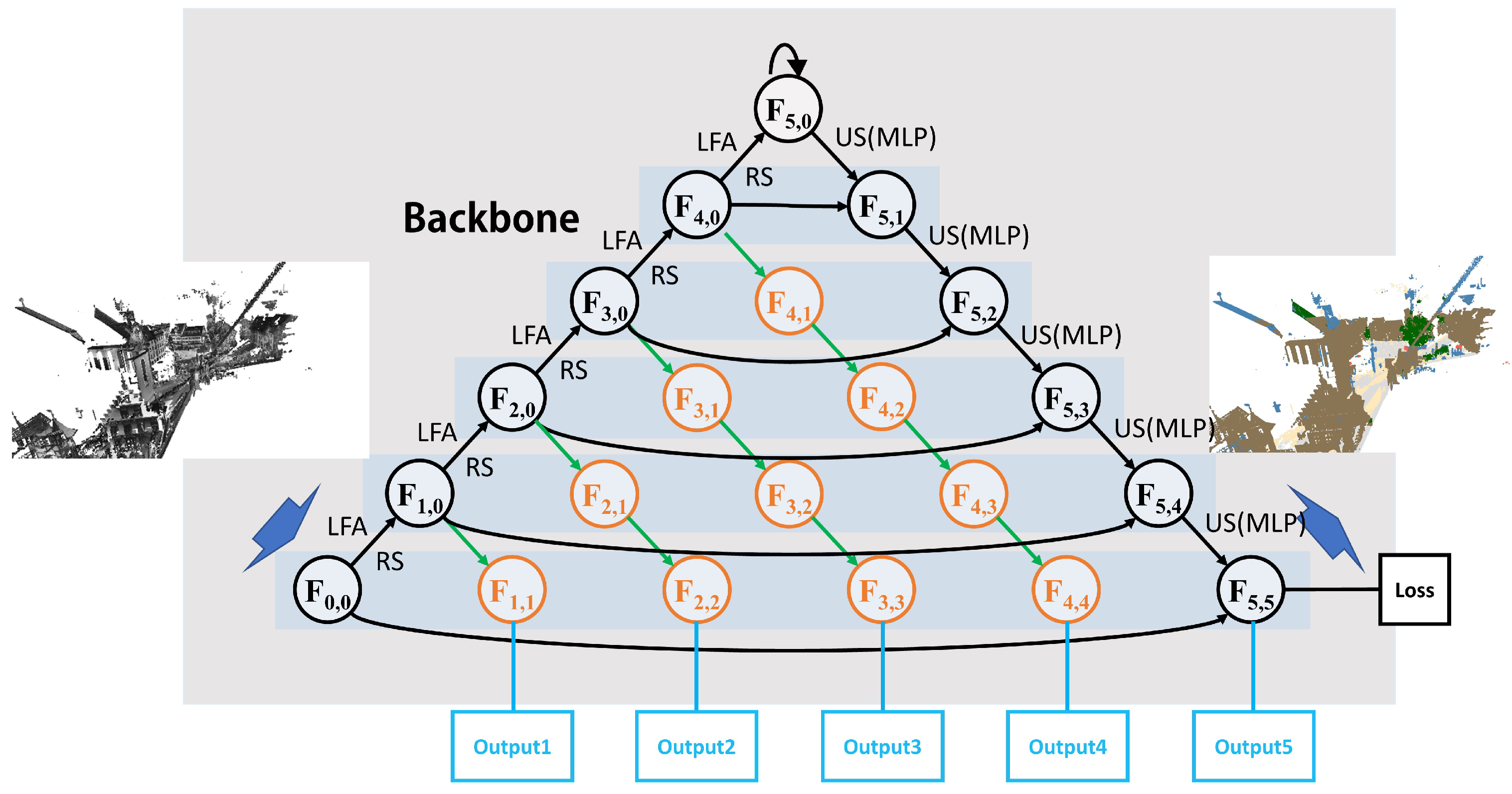
- A multi-scale feature fusion module is proposed, which different levels of encoder-decoders interconnect to achieve effective feature fusion between high and low levels of semantic information.
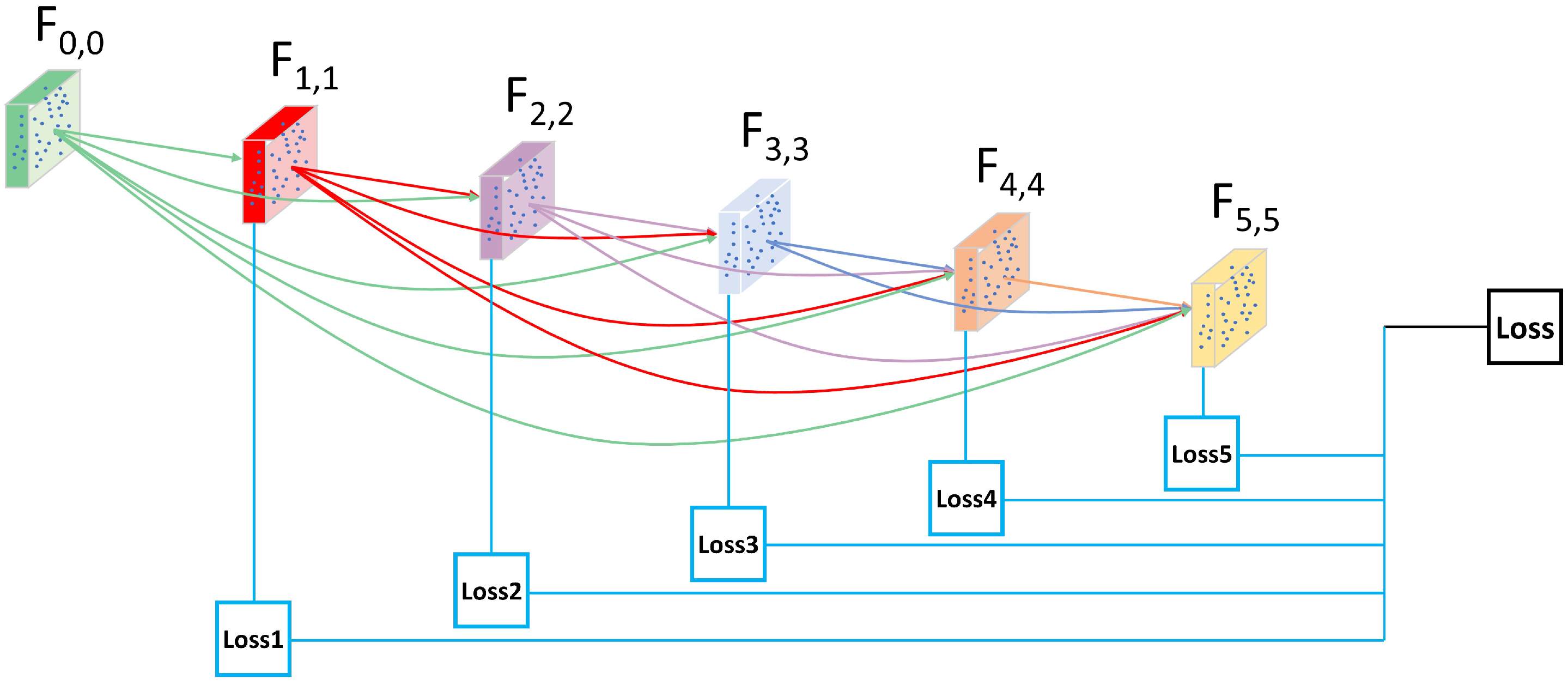
- A multi-loss supervision module is proposed, of which multiple sub-losses connected to different levels of encoder-decoder for supervision of the network training. By this way, the local structures could be trained more sufficiently to achieve better feature fusion, so as to further optimize the final segmentation results.
- The MFFRand allows a one-time training for deep networks to obtain the outputs of network with different depths. This is so that the optimal network depth could be selected according to the results inferred by MFFRand.
2. Related Work
2.1. Projection-Based Methods
2.2. Voxel-Based Methods
2.3. Point-Based Methods
3. Methodology
3.1. Multi-Scale Feature Fusion Module
3.2. Multi-Loss Supervision Module
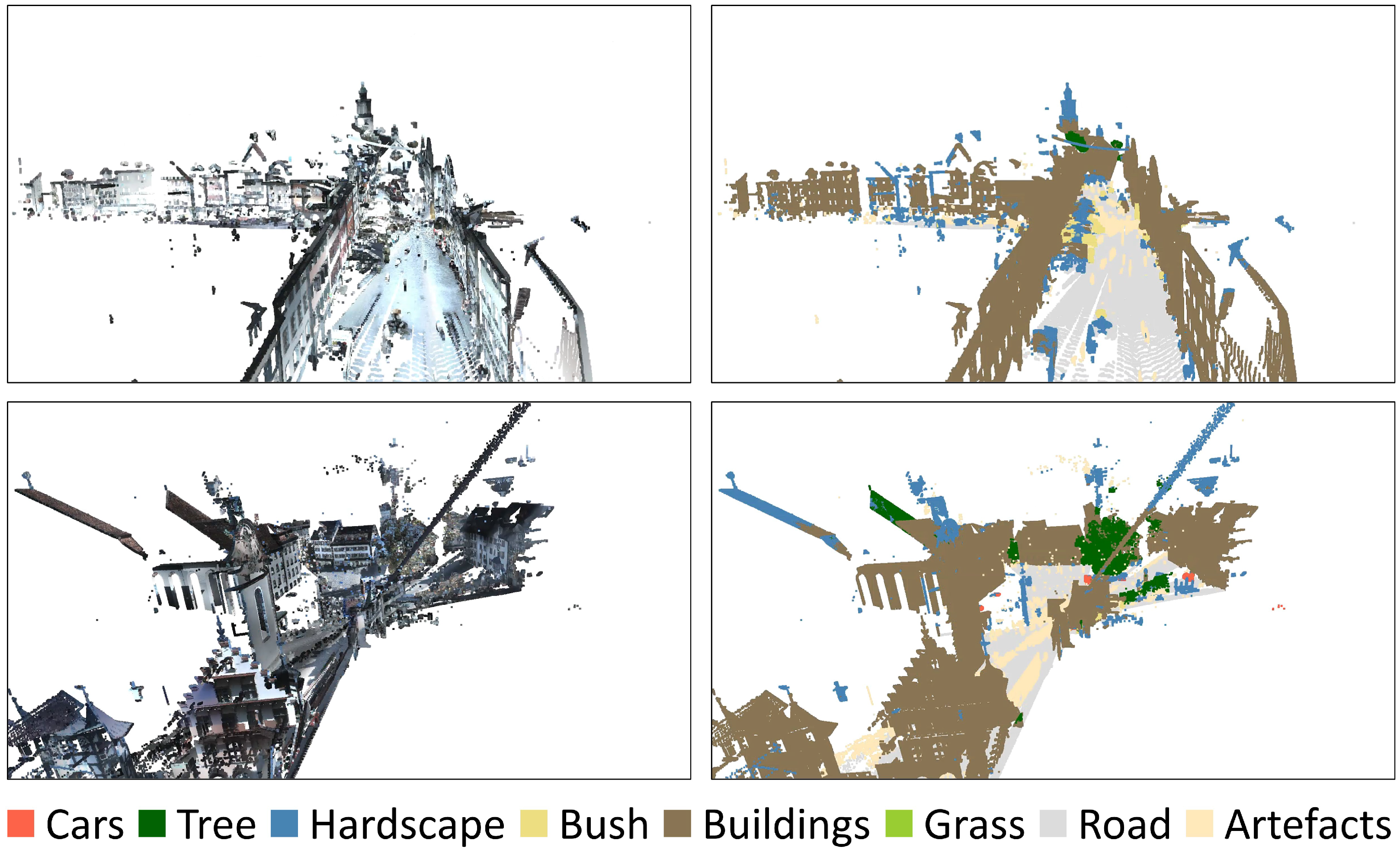
4. Experiments
4.1. Evaluation of mIoU and OA
4.2. Evaluation of Time Consumption
4.3. Ablation Study
- Remove multi-loss supervision module. The better training of local structure in MFFRand could be achieved by the multi-loss supervision module. With the removal of the multi-loss supervision module, the training of the entire network is controlled by the loss function of the deepest encoder-decoder structure.
- Remove multi-feature fusion module (& multi-loss supervision module). This module enables the feature of encoder-decoders could be fused more sufficiently, bridging the semantic gap between the high and low layers effectively. With the removal of the multi-feature fusion module, the encoder and the decoder sub-networks are directly connected to each other through the skip connections.
4.4. Evaluation of Output at Different Network Depths
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Qi, C.R.; Su, H.; Nießner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and Multi-view CNNs for Object Classification on 3D Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5648–5656. [Google Scholar]
- Feng, Y.; Zhang, Z.; Zhao, X.; Ji, R.; Gao, Y. GVCNN: Group-view convolutional neural networks for 3D shape recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 264–272. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation, Brisbane, Australia, 21–26 May 2018; pp. 1887–1893. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud. In Proceedings of the 2019 International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; pp. 4376–4382. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–1 October 2015; pp. 922–928. [Google Scholar]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. SEGCloud: Semantic Segmentation of 3D Point Clouds. In Proceedings of the 2017 International Conference on 3D vision, Qingdao, China, 10–12 October 2017; pp. 537–547. [Google Scholar]
- Riegler, G.; Osman Ulusoy, A.; Geiger, A. OctNet: Learning Deep 3D Representations at High Resolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 27 January–1 February 2017; pp. 3577–3586. [Google Scholar]
- Zeng, W.; Gevers, T. 3DContextNet: K-d Tree Guided Hierarchical Learning of Point Clouds Using Local and Global Contextual Cues. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Meng, H.Y.; Gao, L.; Lai, Y.K.; Manocha, D. VV-Net: Voxel VAE Net with Group Convolutions for Point Cloud Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 8500–8508. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 27 January–1 February 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Jiang, M.; Wu, Y.; Zhao, T.; Zhao, Z.; Lu, C. PointSIFT: A SIFT-like network module for 3D point cloud semantic segmentation. arXiv 2018, arXiv:1807.00652. [Google Scholar]
- Li, J.; Chen, B.M.; Lee, G.H. SO-Net: Self-Organizing Network for Point Cloud Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9397–9406. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11108–11117. [Google Scholar]
- Liang, Z.; Yang, M.; Deng, L.; Wang, C.; Wang, B. Hierarchical Depthwise Graph Convolutional Neural Network for 3D Semantic Segmentation of Point Clouds. In Proceedings of the 2019 International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; pp. 8152–8158. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-scale point cloud semantic segmentation with superpoint graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4558–4567. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 6411–6420. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 27 January–1 February 2017; pp. 2117–2125. [Google Scholar]
- Lee, C.Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-supervised nets. In Proceedings of the Artificial Intelligence and Statistics, PMLR, San Diego, CA, USA, 9–12 May 2015; pp. 562–570. [Google Scholar]
- Ke, L.; Chang, M.C.; Qi, H.; Lyu, S. Multi-scale structure-aware network for human pose estimation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 713–728. [Google Scholar]
- Zhang, Y.; Zhou, Z.; David, P.; Yue, X.; Xi, Z.; Gong, B.; Foroosh, H. PolarNet: An Improved Grid Representation for Online LiDAR Point Clouds Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9601–9610. [Google Scholar]
- Peng, K.; Fei, J.; Yang, K.; Roitberg, A.; Zhang, J.; Bieder, F.; Heidenreich, P.; Stiller, C.; Stiefelhagen, R. MASS: Multi-Attentional Semantic Segmentation of LiDAR Data for Dense Top-View Understanding. IEEE Trans. Intell. Transp. Syst. 2022, 23, 15824–15840. [Google Scholar] [CrossRef]
- Lyu, Y.; Huang, X.; Zhang, Z. Learning to Segment 3D Point Clouds in 2D Image Space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12255–12264. [Google Scholar]
- Li, L.; Zhu, S.; Fu, H.; Tan, P.; Tai, C.L. End-to-End Learning Local Multi-View Descriptors for 3D Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1919–1928. [Google Scholar]
- Peng, B.; Yu, Z.; Lei, J.; Song, J. Attention-guided fusion network of point cloud and multiple views for 3D shape recognition. In Proceedings of the 2020 IEEE International Conference on Visual Communications and Image Processing, Virtual Conference, 1–4 December 2020; pp. 185–188. [Google Scholar]
- Nie, W.; Zhao, Y.; Song, D.; Gao, Y. DAN: Deep-Attention Network for 3D Shape Recognition. IEEE Trans. Image Process. 2021, 30, 4371–4383. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Zhou, D.; Zhao, Y.; Nie, W.; Su, Y. MV-LFN: Multi-view based local information fusion network for 3D shape recognition. Vis. Inform. 2021, 5, 114–119. [Google Scholar] [CrossRef]
- Que, Z.; Lu, G.; Xu, D. VoxelContext-Net: An Octree based Framework for Point Cloud Compression. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 6042–6051. [Google Scholar]
- Zhu, Z.; Li, X.; Xu, J.; Yuan, J.; Tao, J. Unstructured road segmentation based on road boundary enhancement point-cylinder network using LiDAR sensor. Remote Sens. 2021, 13, 495. [Google Scholar] [CrossRef]
- Zhou, H.; Zhu, X.; Song, X.; Ma, Y.; Wang, Z.; Li, H.; Lin, D. Cylinder3D: An Effective 3D Framework for Driving-scene LiDAR Semantic Segmentation. arXiv 2020, arXiv:2008.01550. [Google Scholar]
- Han, L.; Zheng, T.; Xu, L.; Fang, L. OccuSeg: Occupancy-Aware 3D Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2940–2949. [Google Scholar]
- Chew, A.W.Z.; Ji, A.; Zhang, L. Large-scale 3D point-cloud semantic segmentation of urban and rural scenes using data volume decomposition coupled with pipeline parallelism. Autom. Constr. 2022, 133, 103995. [Google Scholar] [CrossRef]
- Cheng, R.; Razani, R.; Taghavi, E.; Li, E.; Liu, B. (AF)2-S3Net: Attentive Feature Fusion with Adaptive Feature Selection for Sparse Semantic Segmentation Network. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 12542–12551. [Google Scholar]
- Zhao, H.; Jiang, L.; Fu, C.W.; Jia, J. PointWeb: Enhancing Local Neighborhood Features for Point Cloud Processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 January 2019; pp. 5565–5573. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution on X-transformed points. In Advances in Neural Information Processing Systems 31; Neural Information Processing Systems Foundation, Inc.: Montreal, QC, Canada, 2018. [Google Scholar]
- Lei, H.; Akhtar, N.; Mian, A. SegGCN: Efficient 3D Point Cloud Segmentation with Fuzzy Spherical Kernel. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11611–11620. [Google Scholar]
- Lu, T.; Wang, L.; Wu, G. CGA-Net: Category Guided Aggregation for Point Cloud Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 11688–11697. [Google Scholar]
- Zeng, Z.; Xu, Y.; Xie, Z.; Tang, W.; Wan, J.; Wu, W. LEARD-Net: Semantic segmentation for large-scale point cloud scene. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102953. [Google Scholar] [CrossRef]
- Qiu, S.; Anwar, S.; Barnes, N. Semantic Segmentation for Real Point Cloud Scenes via Bilateral Augmentation and Adaptive Fusion. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 1757–1767. [Google Scholar]
- Fan, S.; Dong, Q.; Zhu, F.; Lv, Y.; Ye, P.; Wang, F.Y. SCF-Net: Learning Spatial Contextual Features for Large-Scale Point Cloud Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14504–14513. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 27 January–1 February 2017; pp. 4700–4708. [Google Scholar]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Semantic3d.net: A new large-scale point cloud classification benchmark. arXiv 2017, arXiv:1704.03847. [Google Scholar] [CrossRef] [Green Version]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3D Semantic Parsing of Large-Scale Indoor Spaces. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1534–1543. [Google Scholar]
- Chen, J.; Kakillioglu, B.; Velipasalar, S. Background-Aware 3-D Point Cloud Segmentation With Dynamic Point Feature Aggregation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5703112. [Google Scholar] [CrossRef]
- Zhang, Z.; Hua, B.S.; Yeung, S.K. ShellNet: Efficient Point Cloud Convolutional Neural Networks Using Concentric Shells Statistics. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 1607–1616. [Google Scholar]
- Liu, C.; Zeng, D.; Akbar, A.; Wu, H.; Jia, S.; Xu, Z.; Yue, H. Context-Aware Network for Semantic Segmentation toward Large-Scale Point Clouds in Urban Environments. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5703915. [Google Scholar] [CrossRef]
- Xie, L.; Furuhata, T.; Shimada, K. Multi-Resolution Graph Neural Network for Large-Scale Pointcloud Segmentation. arXiv 2020, arXiv:2009.08924. [Google Scholar]
- Roynard, X.; Deschaud, J.E.; Goulette, F. Classification of point cloud scenes with multiscale voxel deep network. arXiv 2018, arXiv:1804.03583. [Google Scholar]
- Wu, W.; Qi, Z.; Fuxin, L. PointConv: Deep Convolutional Networks on 3D Point Clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 January 2019; pp. 9613–9622. [Google Scholar]
- Ma, Y.; Guo, Y.; Liu, H.; Lei, Y.; Wen, G. Global Context Reasoning for Semantic Segmentation of 3D Point Clouds. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 2920–2929. [Google Scholar]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph Attention Convolution for Point Cloud Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 January 2019; pp. 10288–10297. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 9297–9307. [Google Scholar]
- Tang, H.; Liu, Z.; Zhao, S.; Lin, Y.; Lin, J.; Wang, H.; Han, S. Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution. In Proceedings of the European Conference on Computer Vision, Edinburgh, UK, 23–28 August 2020; pp. 685–702. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| mIoU (%) | OA (%) | Ceil. | Floor | Wall | Beam | Col. | Wind. | Door | Table | Chair | Sofa | Book. | Board | Clut. | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DPFA [46] | 61.7 | 89.2 | 94.6 | 98.0 | 79.2 | 40.7 | 36.6 | 52.2 | 70.8 | 65.9 | 74.7 | 27.7 | 49.8 | 51.6 | 60.6 |
| PointCNN [37] | 65.4 | 88.1 | 94.8 | 97.3 | 75.8 | 63.3 | 51.7 | 58.4 | 57.2 | 71.6 | 69.1 | 39.1 | 61.2 | 52.2 | 58.6 |
| PointWeb [36] | 66.7 | 87.3 | 93.5 | 94.2 | 80.8 | 52.4 | 41.3 | 64.9 | 68.1 | 71.4 | 67.0 | 50.3 | 62.7 | 62.2 | 58.5 |
| ShellNet [47] | 66.8 | 87.1 | 90.2 | 93.6 | 79.9 | 60.4 | 44.1 | 64.9 | 52.9 | 71.6 | 84.7 | 53.8 | 64.6 | 48.6 | 59.4 |
| Liu et al. [48] | 68.3 | 88.6 | 93.5 | 96.0 | 81.5 | 42.6 | 46.3 | 61.0 | 74.1 | 67.4 | 82.7 | 63.5 | 59.5 | 56.6 | 62.9 |
| MuGNet [49] | 69.8 | 88.5 | 92.0 | 95.7 | 82.5 | 64.4 | 60.1 | 60.7 | 69.7 | 82.6 | 70.3 | 64.4 | 52.1 | 52.8 | 60.6 |
| RandLA-Net [15] | 70.0 | 88.0 | 93.1 | 96.1 | 80.6 | 62.4 | 48.0 | 64.4 | 69.4 | 69.4 | 76.4 | 60.0 | 64.2 | 65.9 | 60.1 |
| KPConv [18] | 70.6 | - | 93.6 | 92.4 | 83.1 | 63.9 | 54.3 | 66.1 | 76.6 | 57.8 | 64.0 | 69.3 | 74.9 | 61.3 | 60.3 |
| MFFRand (ours) | 71.1 | 88.9 | 93.9 | 94.4 | 83.6 | 64.8 | 54.7 | 62.7 | 68.2 | 71.7 | 79.3 | 65.5 | 64.2 | 58.8 | 63.1 |
| mIoU (%) | OA (%) | Man-Made | Natural | High Veg | Low Veg | Building | Hard Scape | Scanning Art | Cars | |
|---|---|---|---|---|---|---|---|---|---|---|
| SEGCloud [7] | 61.3 | 88.1 | 83.9 | 66.0 | 86.0 | 40.5 | 91.1 | 30.9 | 27.5 | 64.3 |
| MSDeepVoxNet [50] | 65.3 | 88.4 | 83.0 | 67.2 | 83.8 | 36.7 | 92.4 | 31.3 | 50.0 | 78.2 |
| PointConv [51] | 69.2 | 91.8 | 92.2 | 79.2 | 73.1 | 62.7 | 92.0 | 28.7 | 43.1 | 82.3 |
| ShellNet [47] | 69.3 | 93.2 | 96.3 | 90.4 | 83.9 | 41.0 | 94.2 | 34.7 | 43.9 | 70.2 |
| PointGCR [52] | 69.5 | 92.1 | 93.8 | 80.0 | 64.4 | 66.4 | 93.2 | 39.2 | 34.3 | 85.3 |
| GACNet [53] | 70.8 | 91.9 | 86.4 | 77.7 | 88.5 | 60.6 | 94.2 | 37.3 | 43.5 | 77.8 |
| RandLA-Net [15] | 72.7 | 92.7 | 96.4 | 83.9 | 85.1 | 40.1 | 94.8 | 46.4 | 61.4 | 73.8 |
| KPConv [18] | 72.8 | 92.8 | 92.9 | 88.6 | 82.4 | 42.4 | 93.2 | 38.5 | 64.5 | 80.1 |
| MFFRand (ours) | 74.8 | 93.7 | 97.2 | 91.9 | 84.2 | 47.8 | 94.0 | 38.8 | 66.6 | 77.8 |
| Total Time (seconds) | |
|---|---|
| SPVNAS | 617.33 (8.07 frame/s) |
| RandLA-Net | 169.5 (29.39 frame/s) |
| MFFRand (ours) | 170.4 (29.23 frame/s) |
| mIoU (%) | |
|---|---|
| MFFRand | 74.8 |
| Remove multi-loss supervision module | 73.8 |
| Remove multi-scale feature fusion module & multi-loss supervision module (RandLA-Net) | 72.7 |
| Number of Network Layers | mIoU of RandLA-Net (%) | mIoU of MFFRand (%) |
|---|---|---|
| 3 | 53.03 | 53.73 |
| 4 | 67.63 | 67.63 |
| 5 | 72.70 | 74.07 |
| 6 | 72.70 | 74.80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miao, Z.; Song, S.; Tang, P.; Chen, J.; Hu, J.; Gong, Y. MFFRand: Semantic Segmentation of Point Clouds Based on Multi-Scale Feature Fusion and Multi-Loss Supervision. Electronics 2022, 11, 3626. https://doi.org/10.3390/electronics11213626
Miao Z, Song S, Tang P, Chen J, Hu J, Gong Y. MFFRand: Semantic Segmentation of Point Clouds Based on Multi-Scale Feature Fusion and Multi-Loss Supervision. Electronics. 2022; 11(21):3626. https://doi.org/10.3390/electronics11213626
Chicago/Turabian StyleMiao, Zhiqing, Shaojing Song, Pan Tang, Jian Chen, Jinyan Hu, and Yumei Gong. 2022. "MFFRand: Semantic Segmentation of Point Clouds Based on Multi-Scale Feature Fusion and Multi-Loss Supervision" Electronics 11, no. 21: 3626. https://doi.org/10.3390/electronics11213626
APA StyleMiao, Z., Song, S., Tang, P., Chen, J., Hu, J., & Gong, Y. (2022). MFFRand: Semantic Segmentation of Point Clouds Based on Multi-Scale Feature Fusion and Multi-Loss Supervision. Electronics, 11(21), 3626. https://doi.org/10.3390/electronics11213626