
DMFF-Net: Densely Macroscopic Feature Fusion Network for Fast Magnetic Resonance Image Reconstruction

Abstract
1. Introduction
- (1)
- We designed a new encoding and decoding network, and reconstructed high-quality MR images from undersampled images from coarse to fine by adopting three-stage processing.
- (2)
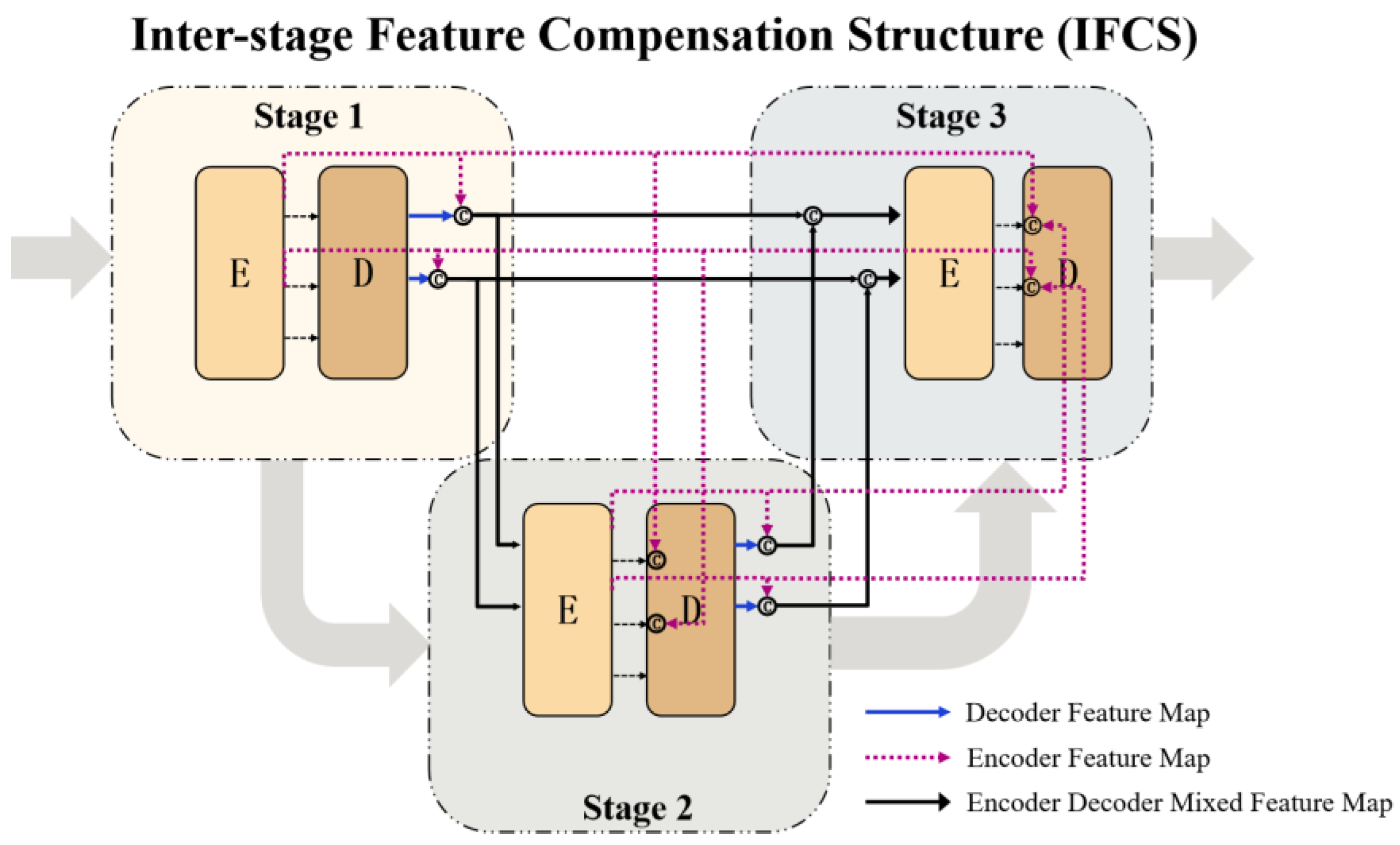
- We propose an inter-stage feature compensation structure (IFCS), which improves the utilization efficiency of features and enhances the encoding and decoding ability by compensating for different encoder and decoder features in different stages. The structure has achieved a significant breakthrough in terms of performance.
- (3)
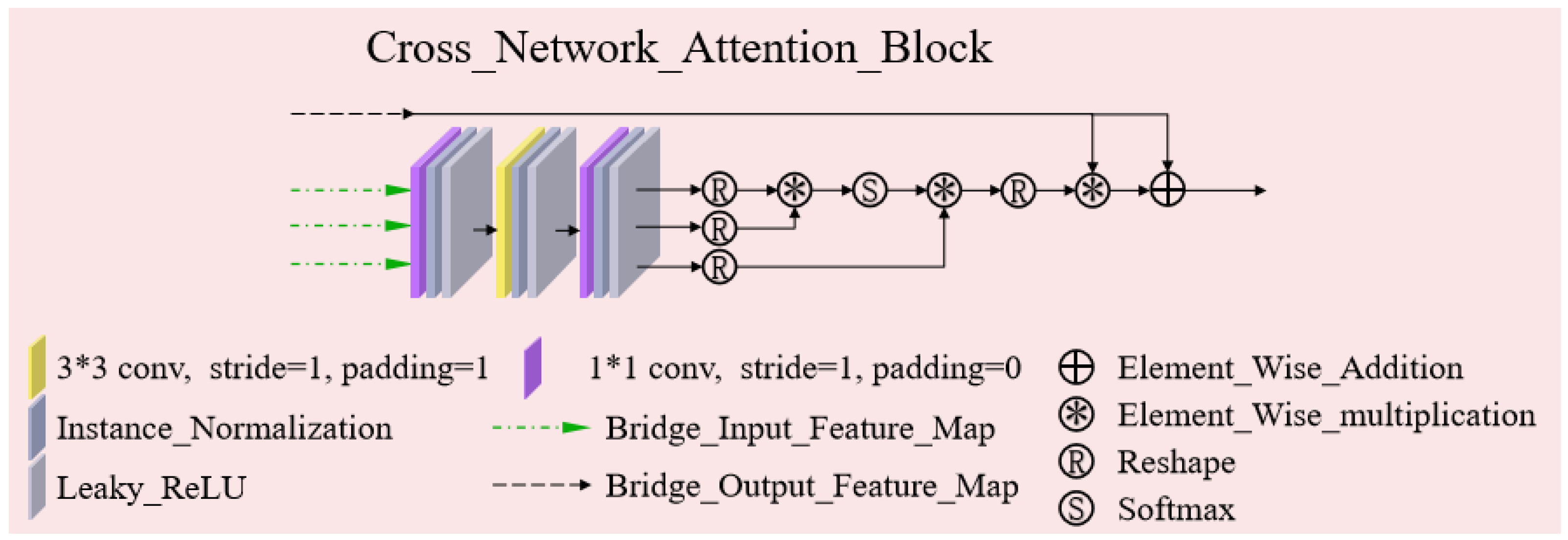
- Inspired by the self-attention mechanism, we designed a cross network attention block (CNAB), which creatively fuses cross-network features to obtain a global receptive field and further improves the image reconstruction quality.
- (4)
- The experiment shows that our network achieves good performance, which is superior to many previous reconstruction methods and achieves a competitive result in the FastMRI Public Leader board published by Facebook [18].
2. Related Works
2.1. Some Methods in the Field of MR Image Reconstruction
2.2. Attention Mechanism
2.3. Encoder and Decoder Network Structure Based on U-Net
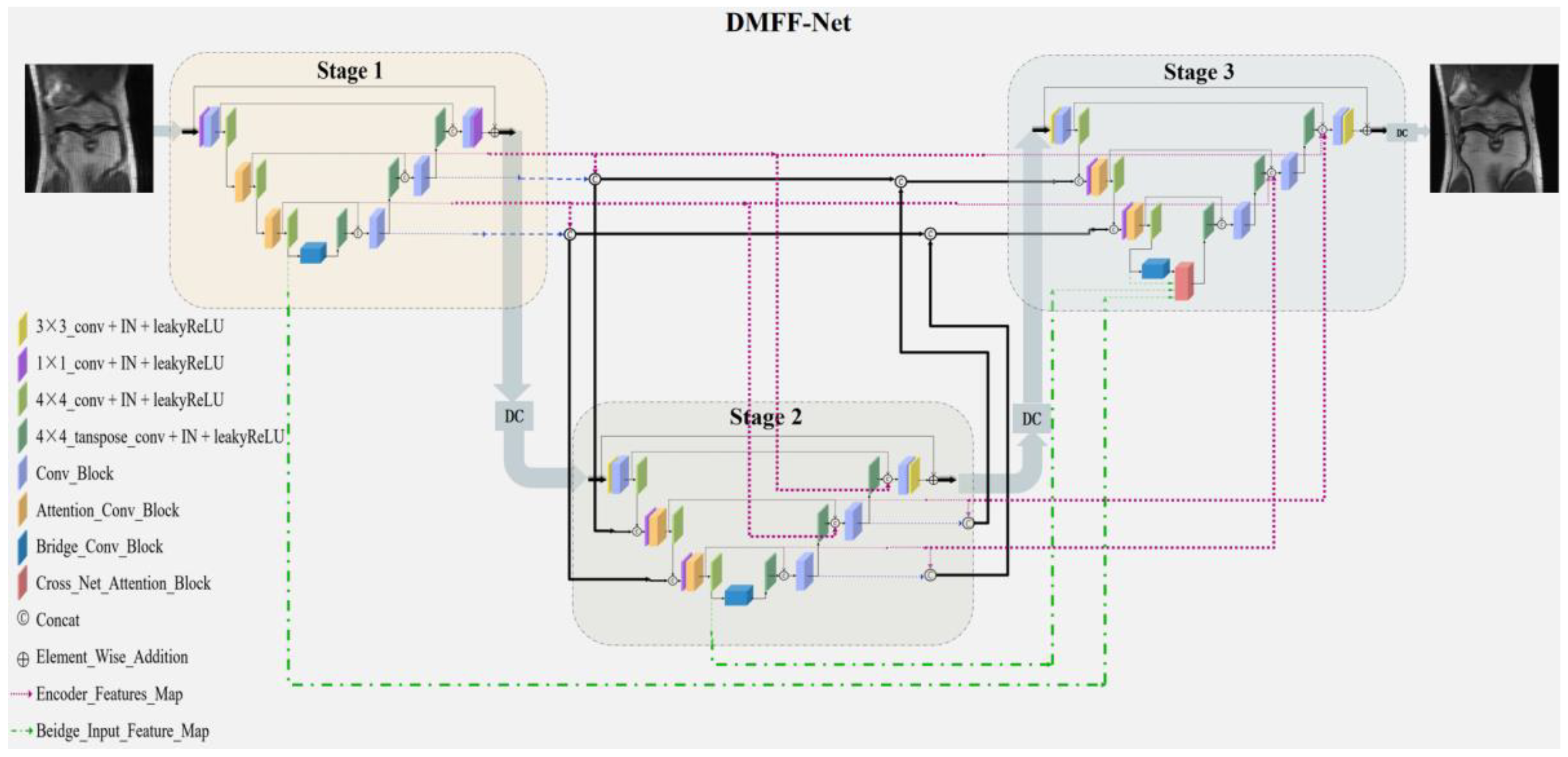
3. DMFF-Net
3.1. Three-Stage Sub-Network Reconstruction
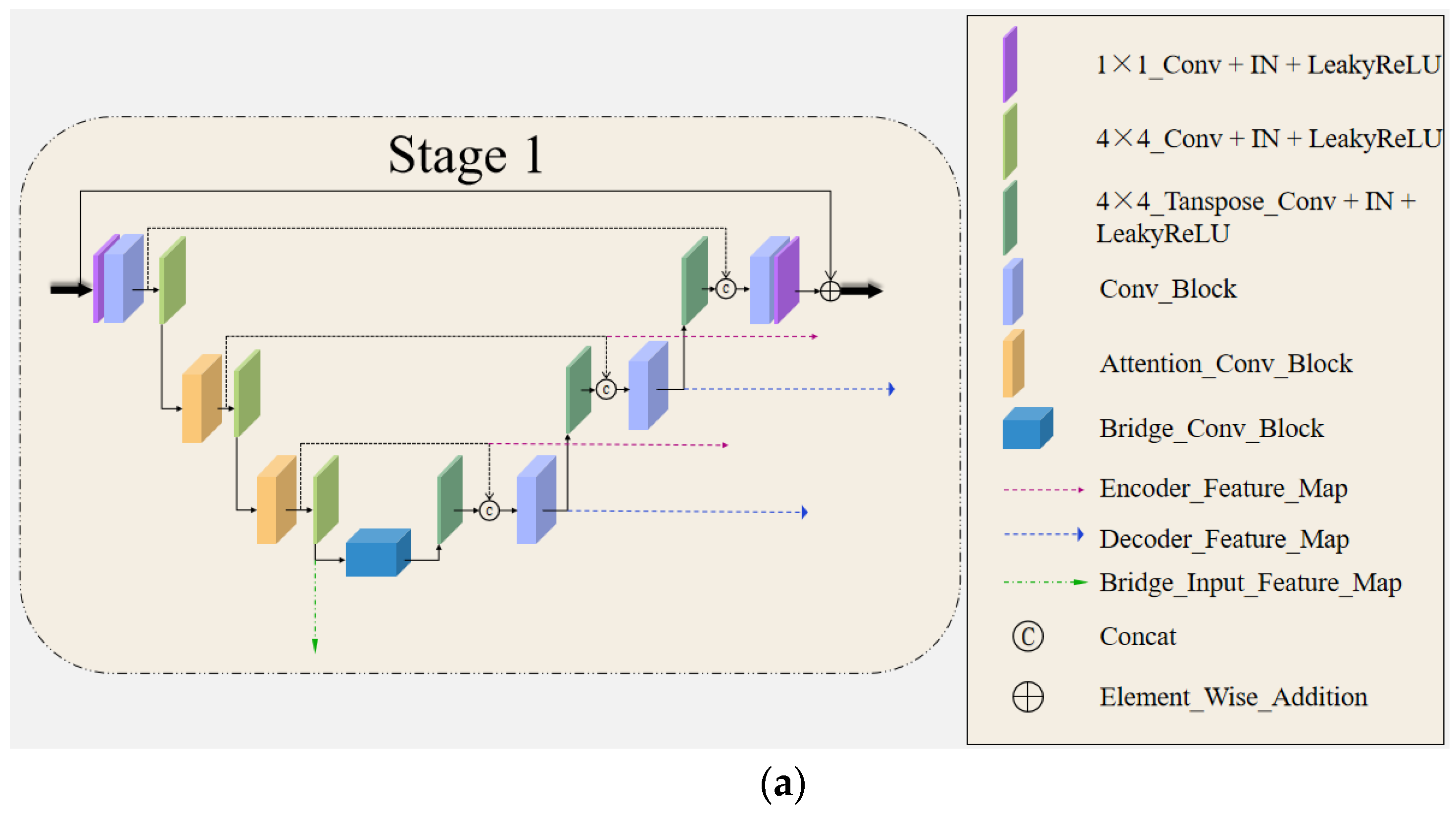
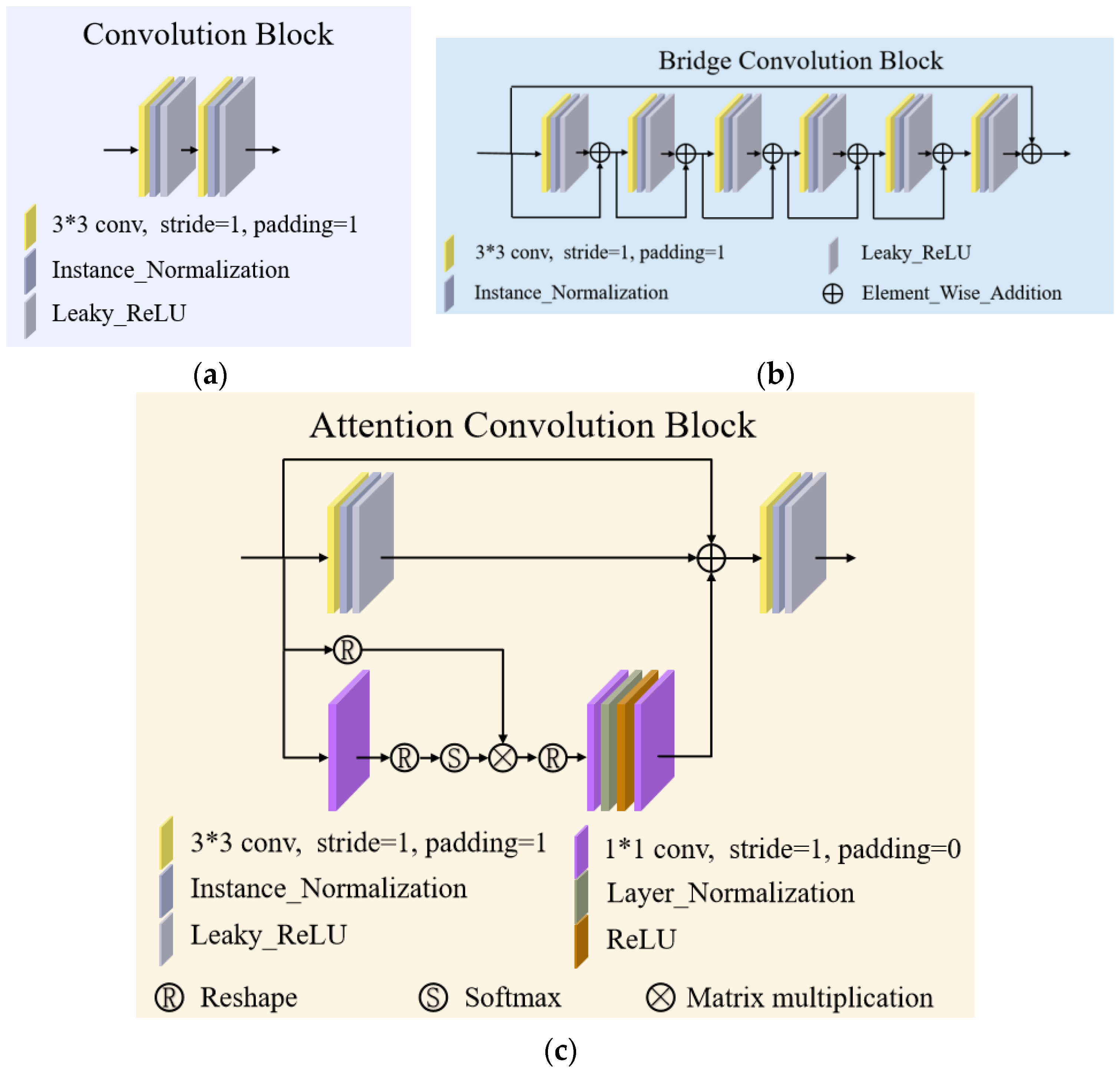
3.1.1. Stage One
- Attention Convolution Block (ACB)
- Bridge Convolution Block (BCB)
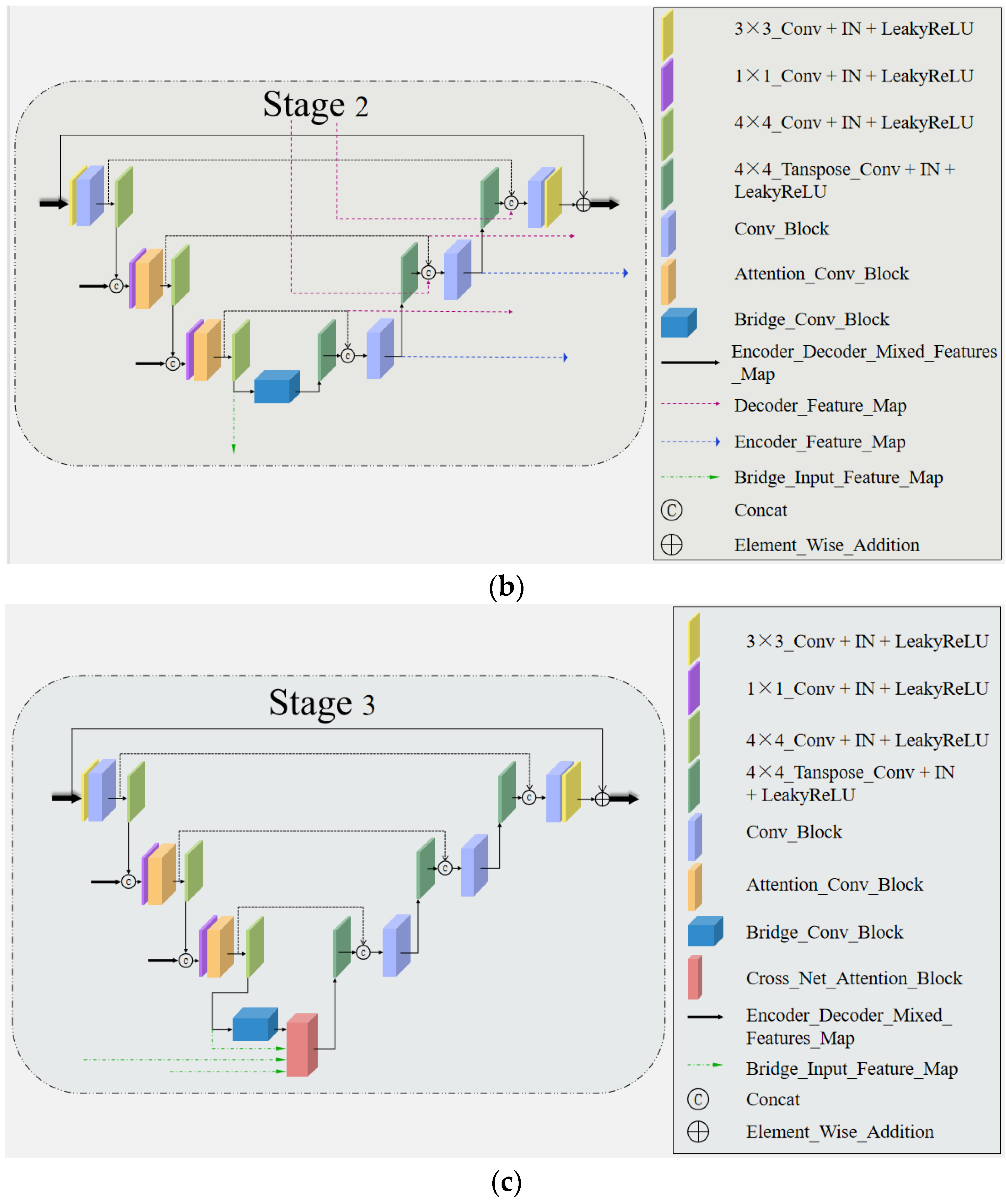
3.1.2. Stage Two
3.1.3. Stage Three
3.2. Inter-Stage Feature Compensation Structure (IFCS)
3.3. Cross Network Attention Block (CNAB)
3.4. Data Consistency Module
4. Implementation and Experiments
4.1. Dataset
4.2. Loss Function
4.3. Implementation Details
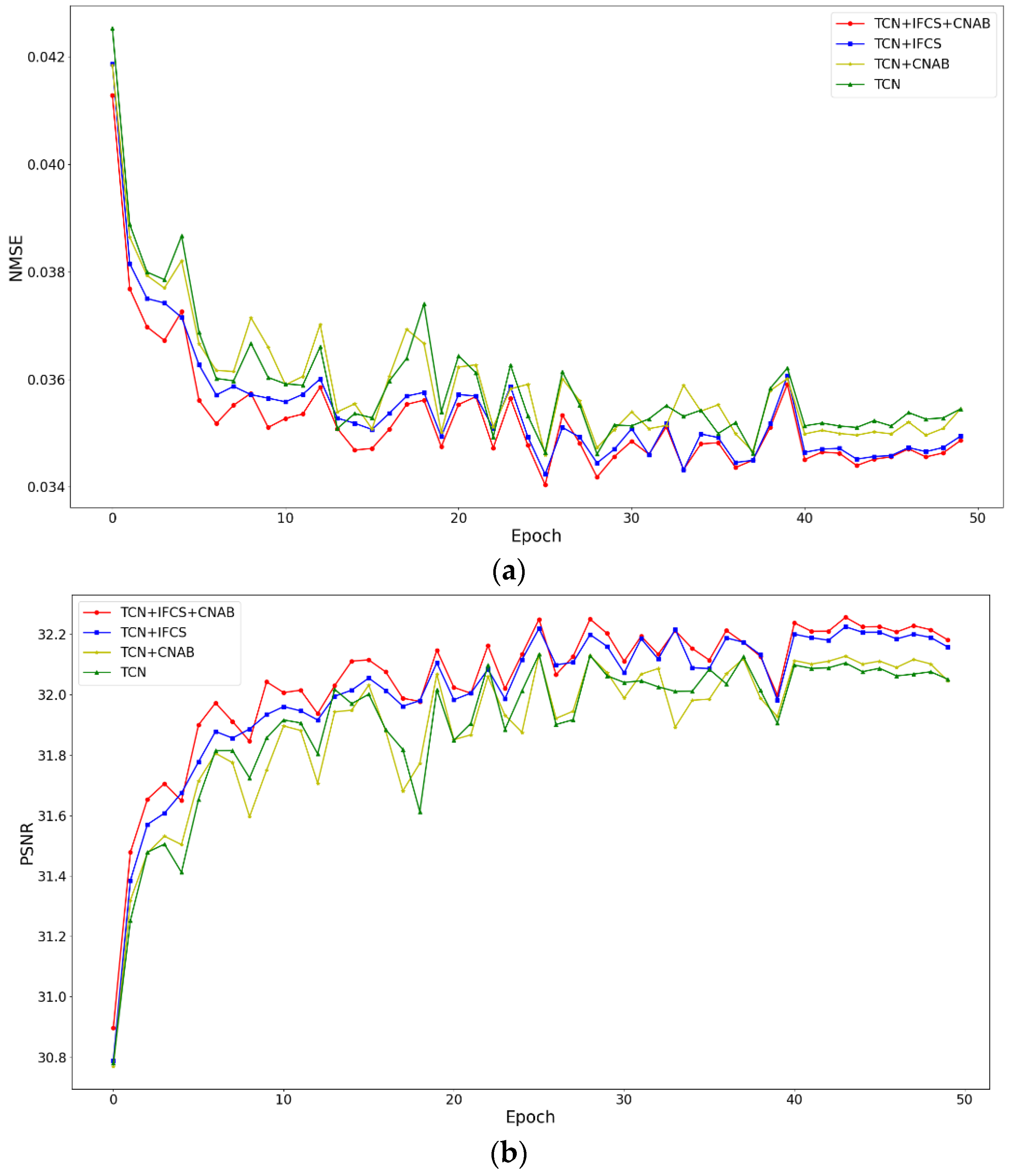
4.4. Ablation Study
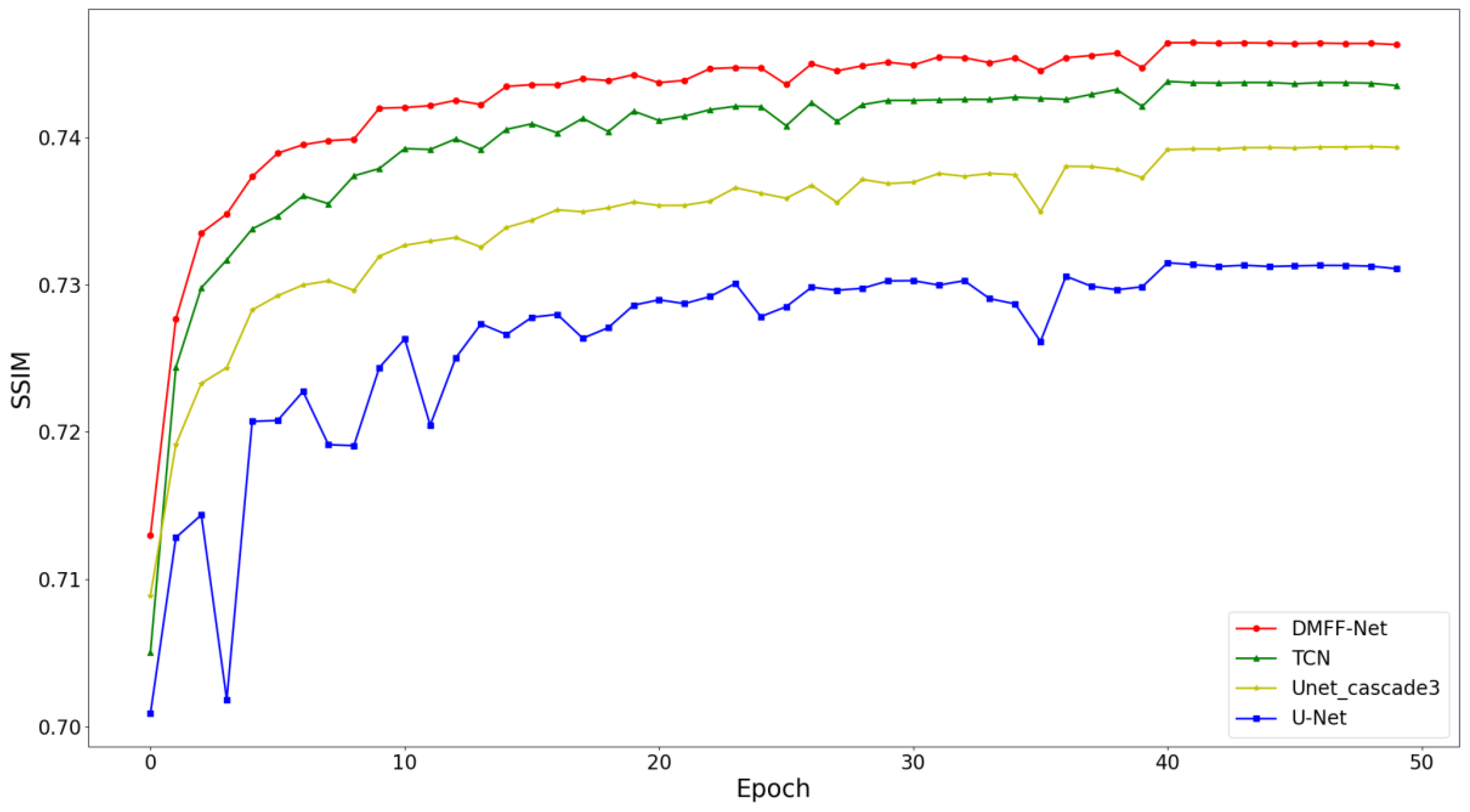
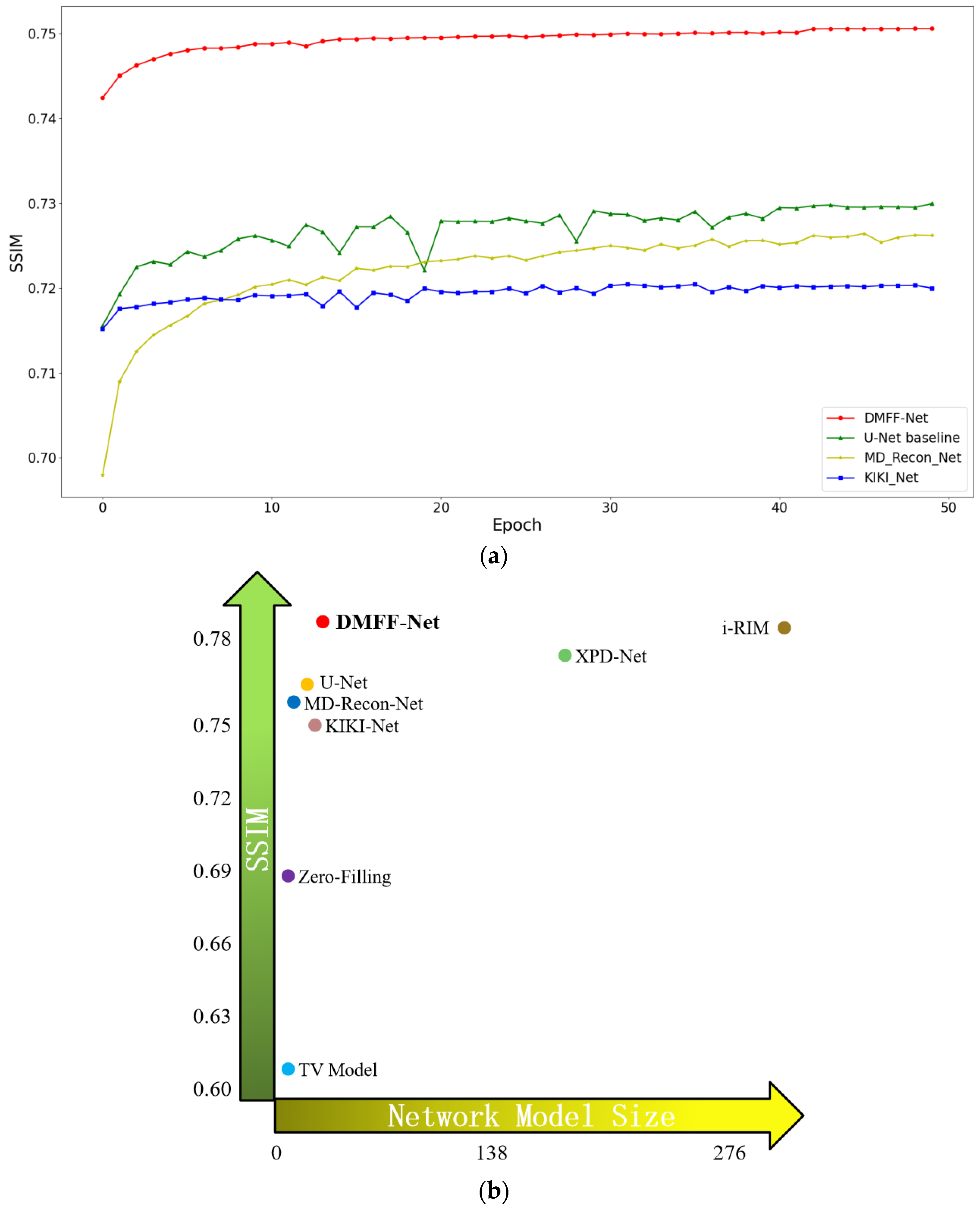
4.5. Comparisons with State-of-the-Art Methods
4.5.1. Comparisons on Validation Set
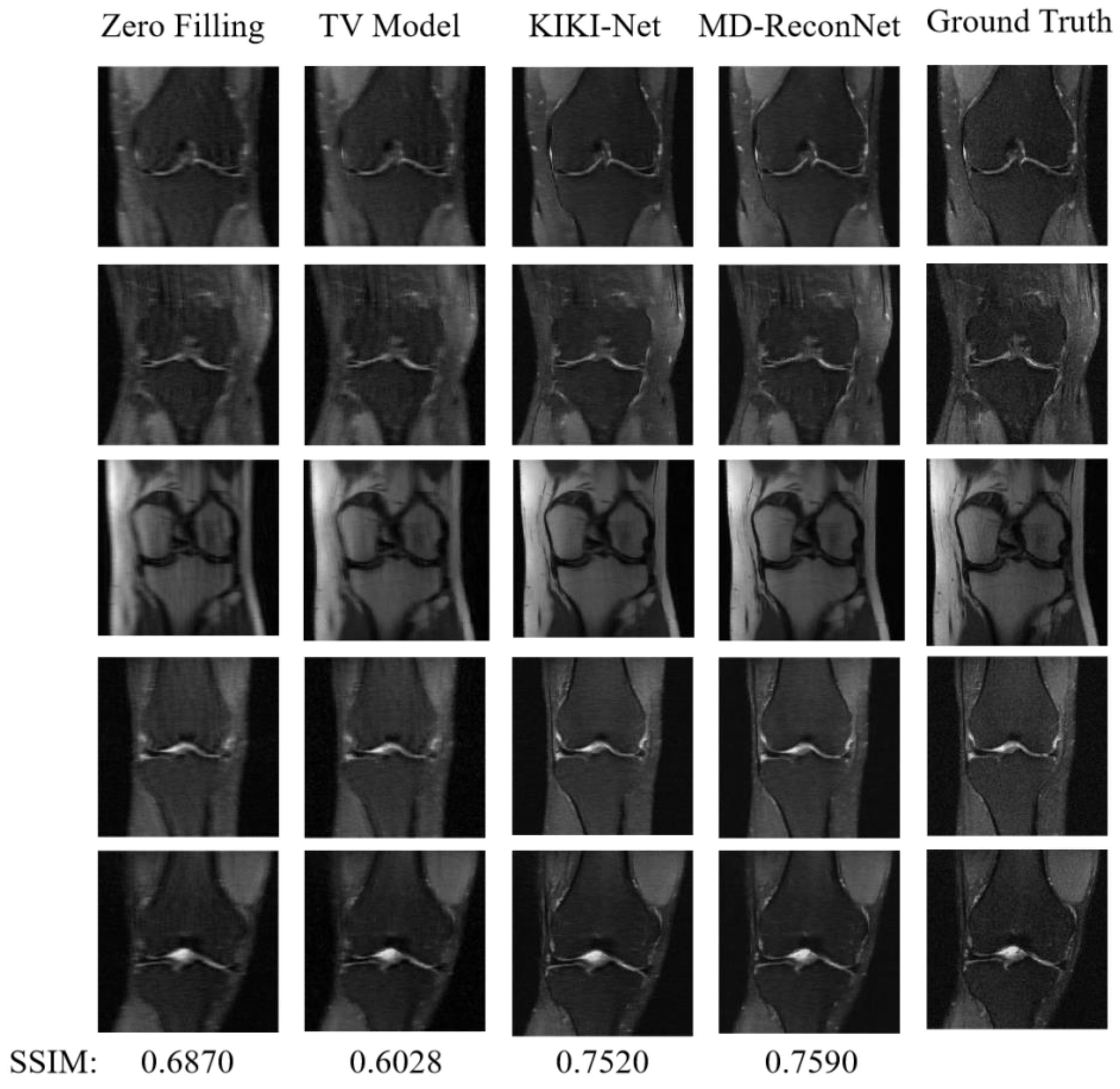
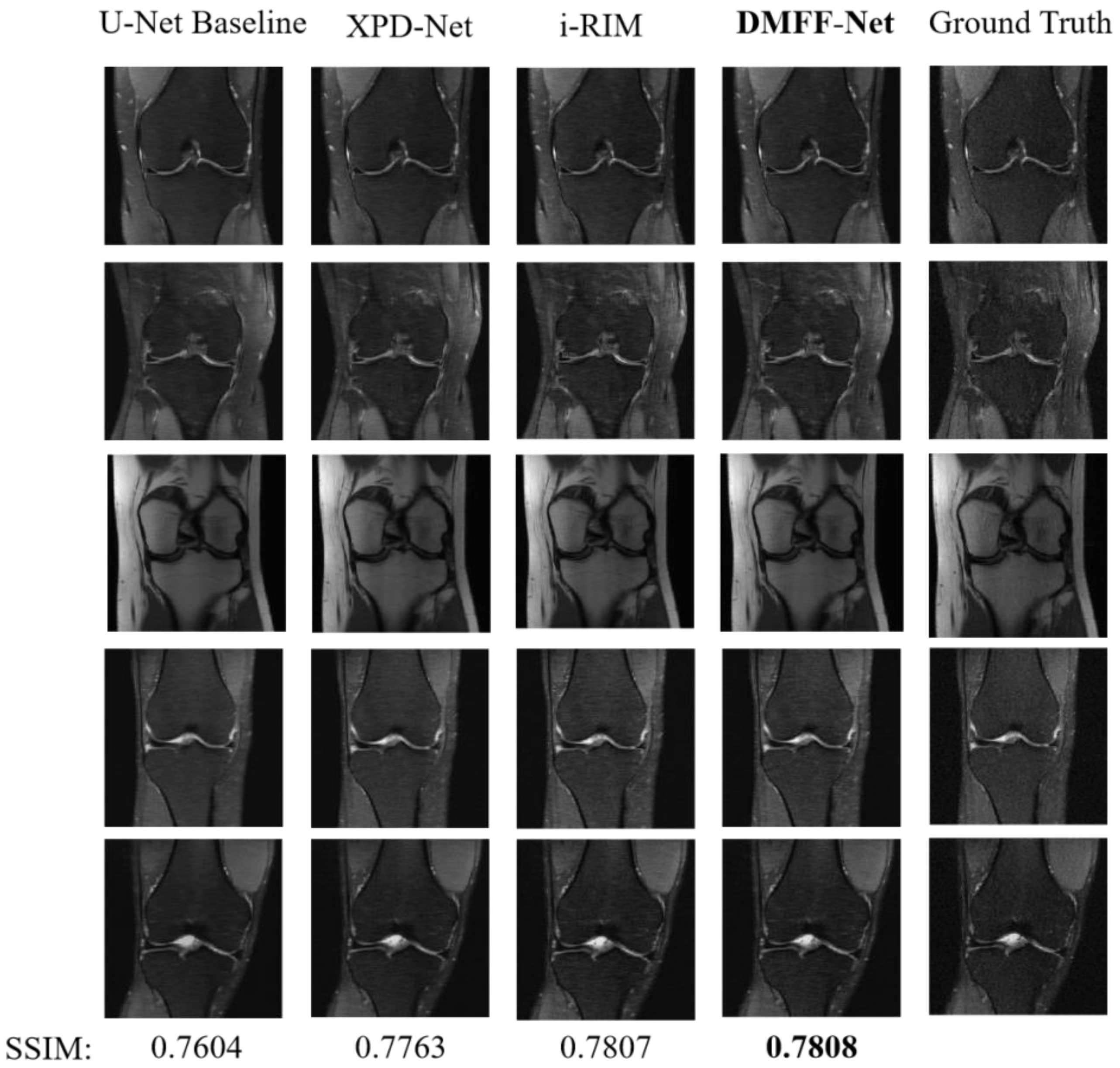
4.5.2. Comparisons on Test Set
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pal, A.; Rathi, Y. A review of deep learning methods for MRI reconstruction. arXiv 2021, arXiv:2109.08618. [Google Scholar]
- Liu, Y.; Leong, A.T.; Zhao, Y.; Xiao, L.; Mak, H.K.; Tsang, A.C.; Lau, G.K.; Leung, G.K.; Wu, E.X. A low-cost and shielding-free ultra-low-field brain MRI scanner. Nat. Commun. 2021, 12, 7238. [Google Scholar] [CrossRef]
- Donoho, D.L. Compressed Sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Sodickson, D.K. Spatial encoding using multiple RF coils: SMASH imaging and parallel MRI. In Methods in Biomedical Magnetic Resonance Imaging and Spectroscopy; John Wiley & Sons Ltd.: Chichester, UK, 2000; pp. 239–250. [Google Scholar] [CrossRef]
- Griswold, M.A.; Jakob, P.M.; Heidemann, R.M.; Nittka, M.; Jellus, V.; Wang, J.; Kiefer, B.; Haase, A. Generalized Autocalibrating Partially Parallel Acquisitions (GRAPPA). Magn. Reson. Med. 2002, 47, 1202–1210. [Google Scholar] [CrossRef] [PubMed]
- Pruessmann, K.P.; Weiger, M.; Scheidegger, M.B.; Boesiger, P. SENSE: Sensitivity encoding for fast MRI. Magn. Reason. Med. 1999, 42, 952–962. [Google Scholar] [CrossRef]
- Wang, S.; Xiao, T.; Liu, Q.; Zheng, H. Deep Learning for Fast MR Imaging: A Review for Learning Reconstruction from Incomplete K-space Data. Biomed. Signal Process. Control 2021, 68, 102579. [Google Scholar] [CrossRef]
- Varoquaux, G.; Cheplygina, V. Machine learning for medical imaging: Methodological failures and recommendations for the future. npj Digit. Med. 2022, 5, 48. [Google Scholar] [CrossRef]
- Protonotarios, N.E.; Katsamenis, I.; Sykiotis, S.; Dikaios, N.; Kastis, G.A.; Chatziioannou, S.N.; Doulamis, A. A few-shot U-Net deep learning model for lung cancer lesion segmentation via PET/CT imaging. Biomed. Phys. Eng. Express 2022, 8, 025019. [Google Scholar] [CrossRef]
- Kawauchi, K.; Furuya, S.; Hirata, K.; Katoh, C.; Manabe, O.; Kobayashi, K.; Shiga, T. A convolutional neural network-based system to classify patients using FDG PET/CT examinations. BMC Cancer 2020, 20, 227. [Google Scholar] [CrossRef]
- Kumar, A.; Fulham, M.; Feng, D.; Kim, J. Co-learning feature fusion maps from PET-CT images of lung cancer. IEEE Trans. Med. Imaging 2019, 39, 204–217. [Google Scholar] [CrossRef]
- Arabi, H.; AkhavanAllaf, A.; Sanaat, A.; Shiri, I.; Zaidi, H. The promise of artificial intelligence and deep learning in PET and SPECT imaging. Phys. Med. 2021, 83, 122–137. [Google Scholar] [CrossRef]
- Cho, C.; Lee, Y.H.; Park, J.; Lee, S. A Self-Spatial Adaptive Weighting Based U-Net for Image Segmentation. Electronics 2021, 10, 348. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net Architecture for Multimodal Biomedical Image Segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef]
- Jha, D.; Smedsrud, P.H.; Riegler, M.A.; Johansen, D.; Lange, T.D.; Halvorsen, P.; Johansen, H.D. ResUNet++: An Advanced Architecture for Medical Image Segmentation. In Proceedings of the 2019 IEEE International Symposium on Multimedia, San Diego, CA, USA, 9–11 December 2019; pp. 225–2255. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2020, 39, 1856–1867. [Google Scholar] [CrossRef]
- Facebook AI, NYU Langone Health. FastMRI Single-Coil Knee Public Leader Board. Available online: https://fastmri.org/leaderboards/ (accessed on 3 November 2022).
- Xie, Y.; Li, Q. A Review of Deep Learning Methods for Compressed Sensing Image Reconstruction and Its Medical Applications. Electronics 2022, 11, 586. [Google Scholar] [CrossRef]
- Zbontar, J.; Knoll, F.; Sriram, A.; Murrell, T.; Huang, Z.; Muckley, M.J.; Defazio, A.; Stern, R.; Johnson, P.; Bruno, M.; et al. FastMRI: An Open Dataset and Benchmarks for Accelerated MRI. arXiv 2018, arXiv:1811.08839. [Google Scholar]
- Eo, T.; Jun, Y.; Kim, T.; Jang, J.; Lee, H.; Hwang, D. KIKI-net: Cross-domain Convolutional Neural Networks for Reconstructing Undersampled Magnetic Resonance Images. Magn. Reason. Med. 2018, 80, 2188–2201. [Google Scholar] [CrossRef]
- Ran, M.; Xia, W.; Huang, Y.; Lu, Z.; Bao, P.; Liu, Y.; Sun, H.; Zhou, J.; Zhang, Y. MD-Recon-Net: A Parallel Dual-Domain Convolutional Neural Network for Compressed Sensing MRI. IEEE Trans. Radiat. Plasma Med. Sci. 2021, 5, 120–135. [Google Scholar] [CrossRef]
- Ramzi, Z.; Ciuciu, P.; Starck, J.L. XPDNet for MRI Reconstruction: An Application to the 2020 FastMRI Challenge. arXiv 2020, arXiv:2010.07290. [Google Scholar]
- Putzky, P.; Karkalousos, D.; Teuwen, J.; Miriakov, N.; Bakker, B.; Caan, M.; Welling, M. I-RIM Applied to the FastMRI Challenge. arXiv 2019, arXiv:1910.08952. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-Local Networks Meet Squeeze-Excitation Networks and Beyond. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop, Seoul, Republic of Korea, 27–28 October 2019; pp. 1971–1980. [Google Scholar]
- Sriram, A.; Zbontar, J.; Murrell, T.; Defazio, A.; Zitnick, C.L.; Yakubova, N.; Knoll, F.; Johnson, P. End-to-End Variational Networks for Accelerated MRI Reconstruction. In Proceedings of the Medical Image Computing and Computer Assisted Intervention; Martel, A.L., Abolmaesumi, P., Stoyanov, D., Mateus, D., Zuluaga, M.A., Zhou, S.K., Racoceanu, D., Jos-kowicz, L., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 64–73. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Knoll, F.; Zbontar, J.; Sriram, A.; Muckley, M.J.; Bruno, M.; Defazio, A.; Parente, M.; Geras, K.J.; Katsnelson, J.; Chandarana, H.; et al. FastMRI: A Publicly Available Raw k-Space and DICOM Dataset of Knee Images for Accelerated MR Image Reconstruction Using Machine Learning. Radiol. Artif. Intell. 2020, 2, e190007. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TCN | IFCS | CNAB | NMSE | PSNR | SSIM |
|---|---|---|---|---|---|
| √ | 0.03545 | 32.05 | 0.7435 | ||
| √ | √ | 0.03494 | 32.16 | 0.7457 | |
| √ | √ | 0.03545 | 32.05 | 0.7442 | |
| √ | √ | √ | 0.03486 | 32.18 | 0.7463 |
| NMSE | PSNR | SSIM | |
|---|---|---|---|
| U-Net | 0.03828 | 31.39 | 0.7313 |
| U-Net_cascade3 | 0.03599 | 31.92 | 0.7393 |
| TCN | 0.03545 | 32.05 | 0.7435 |
| DMFF-Net | 0.03486 | 32.18 | 0.7463 |
| Parameters | NMSE | PSNR | SSIM | |
|---|---|---|---|---|
| Zero Filling | -- | 0.0438 | 30.5 | 0.6870 |
| TV-Model [20] | -- | 0.0479 | 30.7 | 0.6028 |
| KIKI-Net [21] | 1.25 M | 0.0296 | 32.8 | 0.7520 |
| MD-Recon-Net [22] | 0.3 M | 0.0272 | 33.3 | 0.7590 |
| U-Net Baseline [20] | 7.8 M | 0.0271 | 33.2 | 0.7604 |
| XPD-Net [23] | 155 M | 0.0251 | 33.9 | 0.7763 |
| i-RIM [24] | 275 M | 0.0271 | 33.7 | 0.7807 |
| DMFF-Net | 18.7 M | 0.0271 | 33.7 | 0.7808 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Z.; Pang, Y.; Sun, Y.; Liu, X. DMFF-Net: Densely Macroscopic Feature Fusion Network for Fast Magnetic Resonance Image Reconstruction. Electronics 2022, 11, 3862. https://doi.org/10.3390/electronics11233862
Sun Z, Pang Y, Sun Y, Liu X. DMFF-Net: Densely Macroscopic Feature Fusion Network for Fast Magnetic Resonance Image Reconstruction. Electronics. 2022; 11(23):3862. https://doi.org/10.3390/electronics11233862
Chicago/Turabian StyleSun, Zhicheng, Yanwei Pang, Yong Sun, and Xiaohan Liu. 2022. "DMFF-Net: Densely Macroscopic Feature Fusion Network for Fast Magnetic Resonance Image Reconstruction" Electronics 11, no. 23: 3862. https://doi.org/10.3390/electronics11233862
APA StyleSun, Z., Pang, Y., Sun, Y., & Liu, X. (2022). DMFF-Net: Densely Macroscopic Feature Fusion Network for Fast Magnetic Resonance Image Reconstruction. Electronics, 11(23), 3862. https://doi.org/10.3390/electronics11233862