
Intelligent Distributed Swarm Control for Large-Scale Multi-UAV Systems: A Hierarchical Learning Approach

Department of Electrical and Biomedical Engineering, University of Nevada, Reno, NV 89557, USA
*
Author to whom correspondence should be addressed.
Electronics 2023, 12(1), 89; https://doi.org/10.3390/electronics12010089
Submission received: 11 November 2022
/
Revised: 14 December 2022
/
Accepted: 19 December 2022
/
Published: 26 December 2022
(This article belongs to the Special Issue Advanced Nonlinear and Learning-Based Control Techniques for Complex Dynamical Systems)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:In this paper, a distributed swarm control problem is studied for large-scale multi-agent systems (LS-MASs). Different than classical multi-agent systems, an LS-MAS brings new challenges to control design due to its large number of agents. It might be more difficult for developing the appropriate control to achieve complicated missions such as collective swarming. To address these challenges, a novel mixed game theory is developed with a hierarchical learning algorithm. In the mixed game, the LS-MAS is represented as a multi-group, large-scale leader–follower system. Then, a cooperative game is used to formulate the distributed swarm control for multi-group leaders, and a Stackelberg game is utilized to couple the leaders and their large-scale followers effectively. Using the interaction between leaders and followers, the mean field game is used to continue the collective swarm behavior from leaders to followers smoothly without raising the computational complexity or communication traffic. Moreover, a hierarchical learning algorithm is designed to learn the intelligent optimal distributed swarm control for multi-group leader–follower systems. Specifically, a multi-agent actor–critic algorithm is developed for obtaining the distributed optimal swarm control for multi-group leaders first. Furthermore, an actor–critic–mass method is designed to find the decentralized swarm control for large-scale followers. Eventually, a series of numerical simulations and a Lyapunov stability proof of the closed-loop system are conducted to demonstrate the performance of the developed scheme.
1. Introduction
The concept of swarming in multi-agent systems (MASs) has been adopted from the biological swarming behavior in nature ranging from bacteria to more advanced mammals [1]. Examples of swarming behavior include flock of birds [2], school of fish [3], and cooperation of ants [4], which form groups of MASs to achieve certain tasks such as threatening predators, foraging food, and energy-efficient flying during migration. Over the past few decades, the biological swarm system has been widely adopted by researchers [5,6,7,8,9,10,11,12,13]. A survey of the recent development in the control and optimization of swarm systems was presented in [14]. Aside from that, the cooperative control problem for the swarming system was studied in [15]. Skobelev et al. [16] proposed a prototype system using a swarm of unmanned aerial vehicles (UAVs), which includes coordinated flight plans with reconfiguration in the presence of disruptive events. In [17], a new formation control scheme with smooth distributed consensus control for multi-UAV systems was developed. The authors in [18] proposed intelligent flight decision techniques for UAVs for cooperative target tracking using an end-to-end, cooperative, multi-agent reinforcement learning scheme. Zhao et al. [19] developed a flocking obstacle avoidance algorithm with shared obstacle information. Despite all of these recent efforts, the traditional cooperative control of large-scale multi-agent systems (LS-MASs) suffers from the well-known “Curse of Dimensionality” [20] and communication reliability [21] problem.
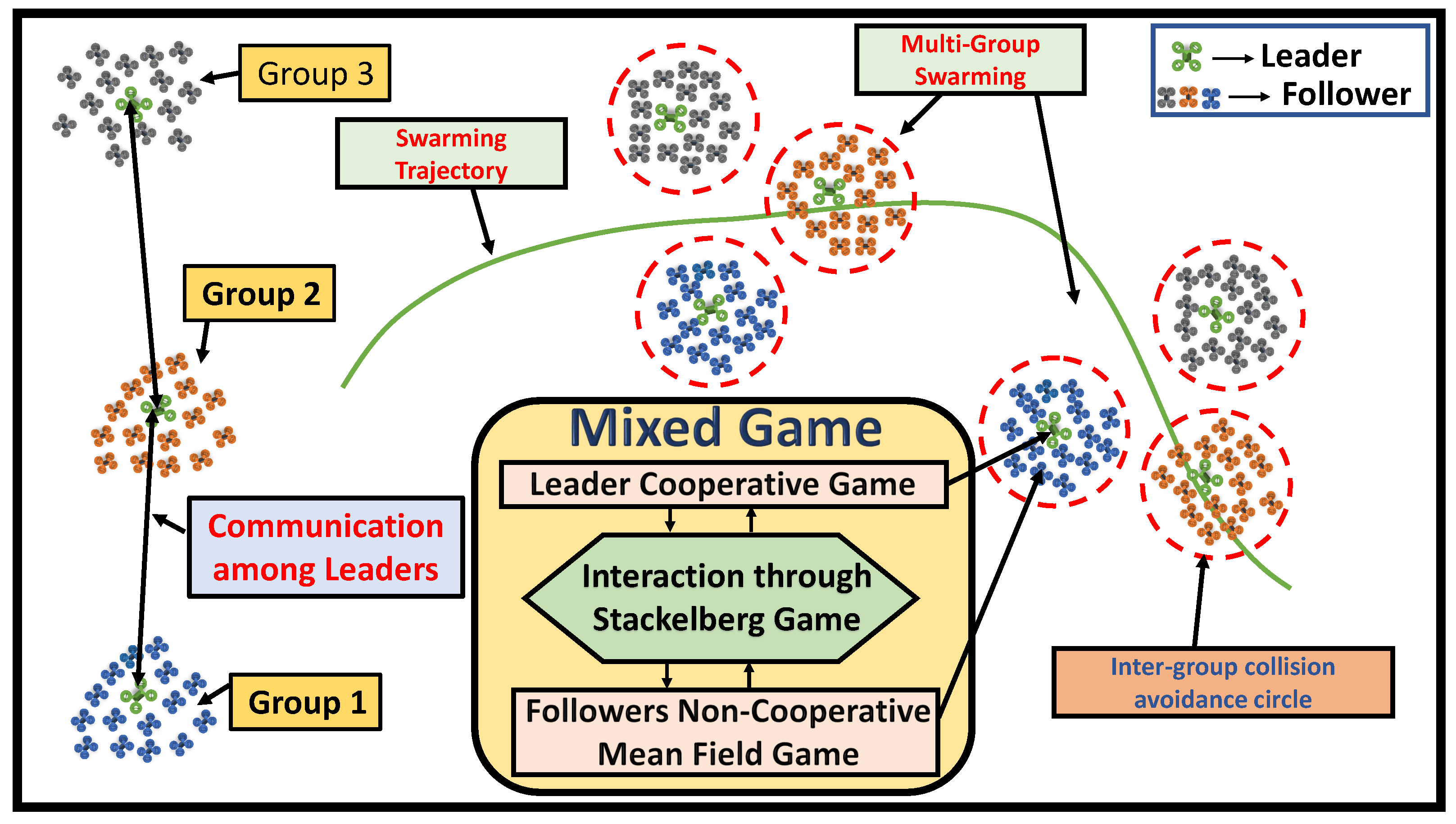
To address these challenges, a mixed game theory is proposed and utilized to formulate the optimal swarming problem for large scale multi-agent systems. The overall structure of the developed mixed game theoretical swarming is shown in Figure 1. First, the LS-MAS is reformulated as a multi-group large-scale leader–follower system by dividing a large number of agents into several subgroups with a leader and a large number of followers in each group. The objective of each group is to achieve optimal distributed swarming behavior. To achieve desired swarming, a mixed game theory was developed by seamlessly integrating (1) the cooperative game [22,23] to ensure the collective swarming behavior among multi-group leaders, where the leaders from each group cooperate with other leaders to maintain the overall multi-group swarming while avoiding inter-group collision, (2) the Stackelberg game [24,25] to connect the leader with its corresponding followers, where a set of coupling functions is introduced by the Stackelberg game in order to maintain leader–follower cohesion in each group, which guarantees that the followers from each group successfully achieve the swarming behavior of their respective leaders, and (3) the mean field game (MFG) [26,27,28] between non-cooperative followers used to continue the collective swarming behavior from the leaders to large-scale followers. The MFG deal involves the “Curse of Dimensionality” and the communication complexity problem of a traditional cooperative game. A probability density function (PDF) (i.e., mass) is employed in the MFG to replace the large number of agents’ state information. Since the mass function has the same dimension as the state space, it eliminates the correlation between rising computing complexity and the agents’ increasing population by reducing the dimension of the cost function.
However, to obtain the mass function, a new partial differential equation (PDE) (i.e., the Fokker–Planck–Kolmogorov (FPK) [29] equation), is adopted. Then, the optimal decentralized swarming control for large-scale followers in each group can be obtained by solving coupled Hamiltonian–Jacobi–Bellman (HJB) and FPK equations [30]. Meanwhile, the distributed optimal swarming control for multi-group leaders can be solved by using the multi-player cooperative HJB equation. However, it is very difficult and even impossible to solve those PDEs in real time due to its complexity and coupling. Hence, adaptive dynamic programming [31] and a reinforcement learning [32] algorithm were adopted. Specifically, a hierarchical learning structure was developed to obtain the optimal swarming control for the multi-group leader–follower system. This includes (1) multi-agent actor–critic-based distributed optimal swarm control for multi-group leaders and (2) actor–critic-mass (ACM)-based decentralized swarm control for large-scale followers. In ACM learning-based control, the actor neural network (NN) is used to approximate the optimal decentralized control, the critic NN is used for approximating the optimal evaluation function, and the mass NN approximates the FPK solution. The main contributions of the article are as follows:
- A novel mixed game theory is developed with cooperative leaders and non-cooperative followers in order to achieve multi-group optimal swarming control which addresses the challenge of the curse of dimensionality and unrealistic communication.
- A hierarchical learning structure with actor–critic-based, leader-distributed swarming and actor–critic–mass-based, large-scale followers decentralized swarming is implemented in real time to learn the solution of the overall intelligent optimal swarming control.
The structure of this paper is as follows. Section 2 provides the significance of the developed algorithm, and Section 3 includes the problem formulation. In Section 4, the novel mixed game hierarchical learning-based intelligent optimal swarming control scheme is developed. Then, the numerical simulation is shown in Section 5 to demonstrate the effectiveness of the proposed design.
2. Significance of Mixed Game Theory-Based Intelligent Distributed Swarm Control
The traditional cooperative control [33,34,35] of multi-agent systems requires communication among all agents to achieve optimal control, which encounters issues with significant computational complexity and the requirement of low-latency communication in real time. In particular, when a swarm contains a massive population which is known as an LS-MAS, it suffers from the following challenges: (1) a high-quality communication network is required for exchanging information in an LS-MAS to achieve the conventional cooperative swarming behavior, although in practice, maintaining these communication networks is unrealistic, and (2) each agent must be aware of the states of the other agents to accomplish the desired multi-group swarming behavior. As the number of agents increases, the computational complexity problem increases substantially, which brings about the well-known “Curse of Dimensionality” [20] problem. Aside from that, most of the existing studies focus on the swarming behavior of single-group MASs with a limited number of agents while avoiding multi-group large-scale MASs, whose examples in a practical environment are ubiquitous. For instance, dividing an MAS into multiple groups can help it effectively handle multi-task missions, whereas a single group cannot, such as in predator formation during multi-prey hunting or cooperative searching for multiple objectives. Recently, several studies in MASs addressed this issue to some extent. Zhang et al. [36] developed a type of multi-group formation tracking control, where the agents are divided into several subgroups to form different desired sub-formations. A distributed impulsive control method with and without the input delay for multi-group formation tracking control was presented in [37]. Moreover, collision avoidance among multi-group UAVs was studied in [38]. In this paper, the developed mixed game theory-based distributed control addressed the challenges of the existing single-group traditional multi-agent cooperative control. At first, the large-scale multi-agent system is divided into multiple groups. Then, each group is reformulated with a leader and a large number of followers. The leader from each group plays the cooperative game to achieve the optimal swarming behavior for all the agents and ensure collision avoidance between the group of agents. The leader just needs to know the PDF information of the followers’ group instead of knowing the state information of each follower. This reduces the dimension of the cost function significantly. However, the leaders still need to exchange the state information with other group leaders. The communication cost of exchanging information is still low compared with a large number of agents, as the agents are divided into a few of subgroups. On the other hand, this upper-level communication between leaders significantly ensures the optimal swarming behavior and collision avoidance of the group of agents. In addition, the followers from each group are guided by their respective leaders and play a non-cooperative game inside the group to reduce the computational complexity and communication problem significantly. To validate the effectiveness of the developed algorithm, the performance of the developed method is further compared against the existing traditional cooperative control method in the simulation (Section 5.2).
3. Problem Formulation
Consider an LS-MAS being reformulated as a multi-group large-scale leader–follower system, with each group having a leader with a large number of followers. Then, assume there are M groups with M leaders as well as being the number of followers in the ith group. Next, the dynamics of the leader and follower q in group i are defined as follows.
Leader:
where denotes the system state and denotes the control input. Moreover, denotes independent wiener processes which represents the environmental noise, and is a non-negative parameter. The functions and represent the intrinsic dynamics of the leaders.
Follower:
where is the state and is the control input of the follower q. Moreover, denotes the wiener process. The functions and represent the intrinsic dynamics of the followers.
3.1. Multi-Group Optimal Swarming Control Formulation
In this section, the mixed game theory is designed to formulate the optimal swarming control for multi-group large-scale leader–follower systems. Next, the details of the developed scheme are given as follows:
Collective Swarming among Multi-Group Leaders: To achieve the collective swarming behavior for all groups in the system, a predefined reference trajectory is given to all leaders ahead of the mission. Next, the desired formation vector with respect to the reference trajectory for a group’s ith leader can be denoted as . Then, the desired trajectory for the leader in group i is defined as follows:
Then, the tracking error of the leader i is defined as with the tracking error dynamic as follows:
where and . Additionally, the tracking error function for the leader in group i is given as
where is a matrix. To achieve the common goal for all groups (i.e., the collective swarming behavior), each leader needs to communicate with the leaders in the neighborhood groups to avoid inter-group collisions. Let is a graph that describes the connection among the leaders of M groups, with is an adjacency matrix (i.e., ). In addition, denotes the set of leader vertices, and is the set of edges. The element of the adjacency matrix is defined as if (i.e., the leaders of group i and j are connected); otherwise, . Moreover, we assume that . To define the neighborhood of each leader, sensing and communicating distance is needed. Let denote the communicating distance. Then, the neighborhood set of the leader of group i is defined as follows:
where is a positive definite matrix. Additionally, the communication between group leader i and j can be possible if . Furthermore, collision avoidance between leaders and their respective followers needs to be addressed for multi-group leader–follower swarming control in order to ensure safe path planning and guide the group to their desired swarming movement. The cost function for collision among leaders is
where is a weighting matrix, is a weighting parameter, and . In addition, is the separating distance between leaders i and j, which is chosen so that it always ensures the avoidance of collision between two groups (i.e., collisions between any two leaders and their corresponding followers). Moreover, to achieve collective swarming behavior while avoiding group collision, the cohesion between the leader and large-scale followers needs to be maintained. In this regard, the leader–follower coupling function is introduced as follows.
Leader–Follower Coupling Functions for Swarming: To achieve a group swarming behavior, a set of coupling functions is defined by the Stackelberg game ([24]). The coupling function that forces the leader to keep cohesion with their corresponding followers is defined as follows:
where is the probability density function (PDF) of the large-scale followers’ state in the ith group, is the expected value, and and are the weighting matrix and weighting parameter, respectively. Now, the leader–follower swarming coupling function is
where is a weighting matrix, is a weighting parameter, and is the maximum safe distance of the ith group’s followers. This distance ensures inter-group collision avoidance by keeping the followers within the safe distance limit.
Leader–Follower Coupling Functions for Swarming: The followers from each group track their respective leaders in order to achieve the group swarming behavior. The tracking error of the follower q in group i is derived as , with the tracking error dynamics
where
Now, the followers’ tracking error cost function can be derived as follows:
where is a positive definite matrix. Then, the same group large scale follower collision avoidance function is as follows:
where and are the weighting matrix and weighting parameter, respectively. Moreover, and are positive constants. Furthermore, the cohesion function of the followers with their respective group center can be derived as follows:
with the weighting matrix and weighting parameter . This function helps each follower from the same group to stay close to the other members of the group.
Overall Optimal Swarming Control for Multi-Group LS-MAS: The goal of the leaders is to achieve overall swarming control by minimizing the following cost function.
Leader:
where , is the cost function of the ith group leader and is the positive weight matrix. The functions , , and derived in Equations (5), (7), and (8) are the tracking error, collision avoidance, and coupling function of the leader, respectively. Moreover, the objective of the follower q in the group i is to minimize the following cost function to achieve the group swarming behavior.
Follower:
where , is the positive weight matrix and is the initial state of the follower q. The functions , , , and derived in Equations (9) and (11)–(13) are the follower tracking error, coupling, cohesion, and collision avoidance functions, respectively. Here, the initial states of the followers from all groups are subject to a constraint in order to keep the followers inside a specific region defined by the distance . This distance is the radius of an enclosing circle which acts as a collision-avoiding region for the respective groups.
3.2. Mixed Game Theory-Based Multi-Group, Large-Scale Leader–Follower-Distributed Optimal Swarming Control
To achieve the overall swarming behavior for all groups, the overall cost function of the leaders’ (Equation (14)) and followers’ individual cost function (Equation (15)) need to be minimized. Now, the leader-follower Hamiltonian can be obtained using Bellman’s principle of optimality [39] and optimal control [20]. The Hamiltonian of all the leaders is as follows:
with individual leaders distributed Hamiltonian:
The Hamiltonian for the follower q from the ith group is derived as follows:
Now, the multi-group leaders Hamiltonian–Jacobi–Bellman (HJB) equation can be derived from the cooperative game is as follows:
Furthermore, a coupled HJB and Fokker–Planck–Kolmogorov(FPK) equations for the large number of followers, using MFG can be obtained as follows:
Follower (HJB):
Follower (FPK):
Then, according to optimal control theory, the mixed game-based distributed optimal swarming control for a multi-group leader–follower system can be attained as follows:
Leader:
Follower:
Remark 1.
The coupled HJB-FPK equations of the follower and the HJB equation for the leader must be solved in real time in order to determine the optimal control policy. The backward HJB and forward FPK equations, however, are coupled multidimensional nonlinear PDEs that are difficult to solve. Therefore, in this paper, a hierarchical learning-based, multi-actor-critic–mass NN is developed to learn the optimal control online.
4. Hierarchical Learning-Based Intelligent Optimal Distributed Swarming Control
4.1. Hierarchical Learning-Based Control for Multi-Group Leader–Follower Systems
In this section, a hierarchical learning-based actor–critic–mass algorithm (see Figure 2) is developed and explained in detail. It includes (1) multi-agent actor–critic neural networks (NNs) to obtain the cooperative game-based distributed optimal swarm control for multi-group leaders and (2) actor–critic–mass-based decentralized control for large-scale followers within the same game to obtain the mean field game-based swarming. Additionally, the Stackelberg game integrates distributed swarming control for leaders and decentralized control for followers into a unified framework and further obtains the overall distributed intelligent swarming control for multi-group leader–follower systems.
Ideal Actor–Critic Set-up for Leaders:
Ideal Actor–Critic–Mass Set-up for Followers:
where , , , , and are the respective weights for the leader and follower critic, actor, and mass neural network (NN). Also, is the activation function and is the reconstruction error of the respective neural networks. Then, the estimated cost and control functions of the leader are as follows:
Estimated Actor-Critic for Multi-Group Leaders:
Please be aware that the leader from each group collects the estimated PDF from each decentralized follower in the same group. Then, the leader evaluates the statistic average of the received PDF (i.e., ). Next, The residual errors that result from substituting the approximation in Equation (26) into Equation (19) can be utilized to adjust the weights of the leader actor and critic neural networks by using the residual errors given as following equations:
where the estimated Hamiltonian of the leader is defined as
Now, let
and
Then, the estimation error from the Equation (27) is therefore rewritten follows:
Next, the effect of the reconstruction error is considered by substituting the optimal function from Equation (24) to the HJB Equation (19):
By substituting Equation (30) into Equation (29), the following HJB error equation can be obtained with reconstruction error as:
Again, the leader actor NN error is as follows:
where and . In addition, the approximated functions can be represented as follows:
Next, the multi-agent actor–critic NNs for the leader are updated by using residual errors (Equations (31) and (32)) with the gradient descent method as follows.
Actor–Critic Update Laws for Multi-Group Leaders:
Next, the decentralized optimal swarming control for large-scale followers is as follows.
Estimated Actor–Critic Mass for Followers in the Same Group:
The residual error after the substitution of (35) into the HJB and FPK equations (Equations (20) and (21)):
where
Again, let
Similarly, we can obtain
where , and . In addition, we have
Using the residual errors in Equations (43)–(45), the actor–critic-mass NNs for the followers are tuned by using gradient descent method as follows.
Actor–Critic–Mass Update Laws for Followers:
where , , , , and are the learning rates:
Remark 2.
The functions , , , , and must satisfy the persistent excitation (PE) condition [20] in order to let the weights converge.
4.2. Optimal Swarming Control Performance Analysis
The performance of all NNs as well as the closed-loop swarming system stability are given in this section:
Theorem 1.
Let and be updated as Equations (33) and (46) with the learning rates and , respectively. Then, the error between the actual and approximated critic NN weights and as well as the optimal evaluation function approximation errors (i.e., and ) are uniformly ultimately bounded (UUB). Moreover, , , , and are asymptotically stable while the reconstruction errors are sufficiently small. Next, the bounds for the evaluation function approximation errors and are as follows:
Similarly, we have
where and are the Lipschitz constants of the critic activation functions and , respectively. Additionally, can be calculated by taking the average of the mass bound of each follower.
Proof.
See Appendix A. □
Theorem 2.
Let be updated as in Equation (48), where the learning rate . Then, the error between the actual and approximated mass NN weights as well as the mass function approximation errors (i.e., ) are uniformly ultimately bounded (UUB). Moreover, and are asymptotically stable while the reconstruction errors are sufficiently small. The bound for the mass approximation errors is as follows:
Proof.
See Appendix B. □
Theorem 3.
Let and be updated as in Equations (34) and (47), where the learning rates are and , respectively. Then, the error between the actual and approximated actor NN weights and as well as the optimal control approximation errors (i.e., and , respectively) are uniformly ultimately bounded (UUB). Moreover, , , , and are asymptotically stable while the reconstruction errors are sufficiently small. Moreover, the bounds for the actor approximation errors and are as follows:
In addition, we have
where and are the Lipschitz constants of the actor activation functions and , respectively.
Proof.
See Appendix C. □
Next, the closed-loop stability of a multi-group, large-scale leader–follower swarming system with developed hierarchical learning control is analyzed:
Lemma 1.
Theorem 4
(Closed-Loop Stability). Let the leaders’ and followers’ critic, mass, and actor NN weights be updated as in Equations (33)–(48). Additionally, consider the learning rates , , , , and to be greater than zero. Then, , , , , , , , , , , , and are all UUB. Moreover, , , , , , , , , , , , and are asymptotically stable while the reconstruction errors are sufficiently small.
Proof.
See Appendix D. □
5. Simulation Results
The developed mixed game theory and hierarchical learning-based intelligent distributed swarming control algorithm is implemented in a very large-scale unmanned aerial vehicle (UAV) system. The experiment aims to validate the effectiveness of the swarming behavior of multiple UAV groups by using the developed techniques.
5.1. Performance Evaluation of Mixed Game Theory-Based Intelligent Distributed Swarm Control
Let, there are four groups in an area scaled to .
Each group had 1 leader and 500 followers. Each leader was given a predefined time-varying trajectory. Then, to produce the swarming behavior, each leader is tracked by his respective followers. Please note that the leader’s location is known to his corresponding followers.
Next, the selected initial positions of the leaders were , , , and . Moreover, the initial state of the followers from each group was generated using the following normal distribution. Group 1: ; Group 2: ; Group 3: ; and Group 4: .
Next, the time-varying reference trajectory was defined as follows:
Additionally, the intrinsic dynamics of the leaders were selected as follows:
with .
Similarly, the follower’s dynamics could be derived as follows:
with .
Furthermore, the parameters for evaluating the cost functions (Equations (14) and (15)) were defined as , , , , , , , , and . The total simulation time for this experiment was 15 s.
Next, hierarchical learning-based multi-agent actor–critic neural networks for the leaders and actor–critic–mass neural networks for the followers were constructed. The neural networks learning rate parameters were selected as , , , , and .
The trajectories of the multi-group, large-scale UAVs are plotted in Figure 3 for times s, s, s, and s. The red curve represents the reference trajectory for all groups. Moreover, the leader trajectories are shown with green curves in the figure. For the follower trajectories, different colors have been used. Figure 3a shows the initial positions of all the leaders and followers and the reference trajectory. Then, the leaders and followers from all groups begin their motion from the left region and move toward the right region. The trajectories of the UAVs with swarming behavior are shown in Figure 3b–d. These figures clearly show that all the leaders tracked the reference trajectory and the followers tracked their respective leaders while avoiding collisions to achieve the collective swarming behavior.
The tracking performance of the leaders and followers from all the groups is verified in Figure 4 and Figure 5. Figure 4 shows the tracking error of the leaders from all four groups. From this figure, it is clear that the error converged to zero after a certain time period. This implies that the leaders attained the desired swarming behavior as time progressed. We also needed to ensure that each follower could track their respective leaders to achieve the group swarming behavior. In this regard, coupling functions and were used in the leader and follower cost functions to ensure that the followers could stay close to their respective leaders. To verify the performance of the developed method, the tracking errors of the followers with respect to their corresponding leaders are plotted in Figure 5. The average distance of all the followers with respect to their leaders from each group was calculated and plotted in Figure 5a. This figure implies that the tracking errors of the followers from all groups converged to zero over time. To demonstrate the performance clearly, the PDF of the follower tracking error is shown in Figure 5b. The yellow color from time 5 s to 15 s shows the tracking error with higher probability.
The neural network performance was evaluated by demonstrating the HJB equation error of the leader and the HJB and FPK equation errors of the followers. The HJB errors of the leader and the follower 1 in group 1 have been shown in this simulation. In Figure 6, the HJB equation error of the leader of group 1 is plotted. In the figure, it is clear that the error converged to zero with time. A small window is also demonstrated in this figure for time –15 s to observe the performance in detail. This implies the optimality of the leader for achieving the desired swarming behavior. Next, the HJB equation error of follower 1 from group 1 is demonstrated in Figure 7. We can clearly see that the HJB error of the followers converged to 0 after s. These two figures confirm the optimality of all groups. To confirm the convergence of the mean-field swarming error, the FPK equation error for group 1 follower 1 is presented in Figure 8. The FPK error figure validates the follower mean field equation solution.
5.2. Performance Comparison of Mixed Game Theory against Traditional Cooperative Control
Finally, the performance of the developed mixed game theory-based distributed control was compared with the traditional cooperative centralized control [33,34,35] to demonstrate the significance of our method. In this comparison, each group in the cooperative swarm control scheme had 1 leader and 100 followers. The other parameter values used in the cooperative swarm control scheme (e.g., the initial positions) were identical to those used for the mixed game theory-based distributed swarm control scheme. Next, the running cost including the communication costs was evaluated to provide a comparison of the performances. The running cost of the leader for this simulation was defined as
where and is a new term which represents the communication cost of the leader with their followers from group i. Additionally, is the communication cost weight, and is the total number of followers in group i, while represents the communication cost of the leader with other leaders from different groups. Here, is the communication cost weight, and M is the total number of leaders.
Figure 9 shows the performance of the developed algorithm in terms of the running cost for the leader in group 1. From Figure 9, it is clear that the performance of our approach against the cooperative multi-agent centralized approach was better after a certain amount of time. In the beginning, the cost of the cooperative game-based optimal solution was lower. However, the developed algorithm slowly outperformed the cooperative game-based algorithm. The main reason for this is that the cost function of cooperative centralized swarm control is penalized for high amounts of communication between the leader and the followers in the same group. Similarly, the performance of the developed mixed game theory-based distributed swarm control algorithm for the follower in the same group is shown.
The running cost of the follower is defined as
with , being a new term which represents the communication cost of follower q from group i. In addition, is the communication cost weight, and is the total number of followers in group i. Similar to Figure 9, the performance of the developed distributed swarm algorithm in terms of the running costs for the followers in group 1 are demonstrated in Figure 10. The cost of the cooperative centralized approach was penalized here because of the communication among a large number of followers in the same group. From Figure 9 and Figure 10, it is clear that the developed algorithm outperformed the traditional cooperative centralized approach.
6. Conclusions
This paper developed mixed game-based distributed intelligent swarming control along with a hierarchical learning algorithm for multi-group, large-scale leader–follower systems. To attain the collective swarming behavior for a large number of agents, a mixed game theory was designed which included a cooperative game to ensure collective swarming behavior among the multi-group leaders, a Stackelberg game to bond the group leader with its large-scale followers, and a mean field game to continue the collective swarming behavior to all the followers without raising computational complexity by breaking the “Curse of Dimensionality”. Moreover, a hierarchical learning-based actor–critic algorithm was designed to achieve the solution of intelligent optimal swarming control. This structure includes the multi-agent actor–critic neural networks to learn the distributed swarm control for multi-group leaders and actor–critic–mass-based neural networks to learn decentralized swarm control for the large-scale followers. The developed mixed game-based intelligent swarm control optimizes the collective swarming behavior and also adapts to uncertainties in the dynamic environment. Finally, the effectiveness of the developed techniques was validated through Lyapunov analysis and numerical simulations.
Author Contributions
Conceptualization, S.D. and H.X.; methodology, S.D. and H.X.; software, S.D.; validation, S.D. and H.X.; formal analysis, S.D. and H.X.; investigation, H.X.; resources, H.X.; data curation, S.D.; writing—original draft preparation, S.D.; writing—review and editing, H.X.; visualization, S.D.; supervision, H.X.; project administration, H.X.; funding acquisition, H.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Science Foundation grant number 2144646.
Data Availability Statement
Data sharing not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Theorem 1
Leader Critic NN: Consider the following Lyapunov function candidate:
In addition, the first derivative of the leader–critic NN estimated weight from Equation (33) can be obtained as follows:
According to the Lyapunov stability analysis, we take the first derivative of Equation (A1) and substitute the leader–critic NN weight estimation error dynamic from Equation (A2):
Then, we let
Next, the triangle inequality properties are applied to Equation (A4):
Now, Equation (A5) can be simplified using :
Here, and are the Lipschitz constants, and is a mass estimation bound.
The leader–critic NN weight estimation error will be UUB, and the bound is
This completes the proof.
Follower Critic NN: Consider the following Lyapunov function candidate:
Additionally, the first derivative of the leader–critic NN estimated weight from Equation (47) can be obtained as follows:
According to Lyapunov stability analysis, we take the first derivative of Equation (A19) and substitute the follower–critic NN weight estimation error dynamic from Equation (A11):
Then, we let
Next, the triangle inequality properties are applied to Equation (A13):
Now, Equation (A14) can be simplified as follows:
By dropping several negative terms, the derivation can be simplified to
where
Here, , , and are the Lipschitz constants, and is the mass estimation bound.
The follower–critic NN weight estimation error will be UUB, and the bound is
This completes the proof.
Appendix B. Proof of Theorem 2
Consider the Lyapunov function candidate
Additionally, the first derivative of the mass NN estimated weight from (48) can be obtained as follows:
According to Lyapunov stability analysis, we take the first derivative of Equation (A19) and substitute in the mass NN weight estimation error dynamic from Equation (A20):
Let
Now, the triangle inequality properties are applied to Equation (A22):
Next, Equation (A23) can be simplified as follows:
Here, is the Lipschitz constant, and is the critic estimation error bound. The mass NN weight estimation error will be UUB, and the bound is
This completes the proof.
Appendix C. Proof of Theorem 3
Consider the Lyapunov function candidate for the leader
The first derivative of the leader–actor NN estimated weight from (34) can be obtained:
According to the Lyapunov stability analysis, we take the first derivative of Equation (A28) and substitute Equation (A29):
Let
After applying the triangle inequality property, Equation (A31) can be written as follows:
Here, is the critic estimation error bound. The actor NN weight estimation error will be UUB, and the bound is
Similarly, we can derive the bound for the follower–actor NN:
where
Here, represents the Lipschitz constants, is the mass estimation bound, and is the critic estimation error bound. The follower–actor NN weight estimation error will be UUB, and the bound is
This completes the proof.
Appendix D. Proof of Theorem 4
Consider the Lyapunov function to be
By taking the first derivative and substituting Lemma 1 and Theorems 1–3 given in Equations (A7), (A16), (A25), (A33), and (A35), we have
where and are the Lipschitz constants of the dynamic equations and , respectively. Now, by substituting Equations (49)–(53) into Equation (A38), Equation (A38) can be represented and simplified as follows:
where
In addition, let
The derivation of the Lyapunov function is less than zero outside a compact set; in other words, we have
This completes the proof.
References
- Topaz, C.M.; Bertozzi, A.L. Swarming patterns in a two-dimensional kinematic model for biological groups. SIAM J. Appl. Math. 2004, 65, 152–174. [Google Scholar] [CrossRef]
- Okubo, A. Dynamical aspects of animal grouping: Swarms, schools, flocks, and herds. Adv. Biophys. 1986, 22, 1–94. [Google Scholar] [CrossRef] [PubMed]
- Toner, J.; Tu, Y. Flocks, herds, and schools: A quantitative theory of flocking. Phys. Rev. E 1998, 58, 4828. [Google Scholar] [CrossRef] [Green Version]
- Kube, C.R.; Bonabeau, E. Cooperative transport by ants and robots. Robot. Auton. Syst. 2000, 30, 85–101. [Google Scholar] [CrossRef]
- Li, W.; Shen, W. Swarm behavior control of mobile multi-robots with wireless sensor networks. J. Netw. Comput. Appl. 2011, 34, 1398–1407. [Google Scholar] [CrossRef]
- Cao, L.; Cai, Y.; Yue, Y. Swarm intelligence-based performance optimization for mobile wireless sensor networks: Survey, challenges, and future directions. IEEE Access 2019, 7, 161524–161553. [Google Scholar] [CrossRef]
- Berman, S.; Halász, A.; Hsieh, M.A.; Kumar, V. Optimized stochastic policies for task allocation in swarms of robots. IEEE Trans. Robot. 2009, 25, 927–937. [Google Scholar] [CrossRef] [Green Version]
- Bayındır, L. A review of swarm robotics tasks. Neurocomputing 2016, 172, 292–321. [Google Scholar] [CrossRef]
- Jevtic, A.; Gutiérrez, A.; Andina, D.; Jamshidi, M. Distributed bees algorithm for task allocation in swarm of robots. IEEE Syst. J. 2011, 6, 296–304. [Google Scholar] [CrossRef] [Green Version]
- Engelen, S.; Gill, E.; Verhoeven, C. On the reliability, availability, and throughput of satellite swarms. IEEE Trans. Aerosp. Electron. Syst. 2014, 50, 1027–1037. [Google Scholar] [CrossRef]
- Xu, D.; Zhang, X.; Zhu, Z.; Chen, C.; Yang, P. Behavior-based formation control of swarm robots. Math. Probl. Eng. 2014, 2014, 205759. [Google Scholar] [CrossRef] [Green Version]
- Soni, A.; Hu, H. Formation control for a fleet of autonomous ground vehicles: A survey. Robotics 2018, 7, 67. [Google Scholar] [CrossRef] [Green Version]
- Tahir, A.; Böling, J.; Haghbayan, M.H.; Toivonen, H.T.; Plosila, J. Swarms of unmanned aerial vehicles—A survey. J. Ind. Inf. Integr. 2019, 16, 100106. [Google Scholar] [CrossRef]
- Zhu, B.; Xie, L.; Han, D. Recent developments in control and optimization of swarm systems: A brief survey. In Proceedings of the 2016 12th IEEE international conference on control and automation (ICCA), Kathmandu, Nepal, 1–3 June 2016; pp. 19–24. [Google Scholar]
- Lan, X.; Liu, Y.; Zhao, Z. Cooperative control for swarming systems based on reinforcement learning in unknown dynamic environment. Neurocomputing 2020, 410, 410–418. [Google Scholar] [CrossRef]
- Skobelev, P.; Budaev, D.; Gusev, N.; Voschuk, G. Designing multi-agent swarm of uav for precise agriculture. In Proceedings of the International Conference on Practical Applications of Agents and Multi-Agent Systems, Toledo, Spain, 20–22 June 2018; pp. 47–59. [Google Scholar]
- Kada, B.; Khalid, M.; Shaikh, M.S. Distributed cooperative control of autonomous multi-agent UAV systems using smooth control. J. Syst. Eng. Electron. 2020, 31, 1297–1307. [Google Scholar] [CrossRef]
- Xia, Z.; Du, J.; Wang, J.; Jiang, C.; Ren, Y.; Li, G.; Han, Z. Multi-Agent Reinforcement Learning Aided Intelligent UAV Swarm for Target Tracking. IEEE Trans. Veh. Technol. 2022, 71, 931–945. [Google Scholar] [CrossRef]
- Zhao, W.; Chu, H.; Zhang, M.; Sun, T.; Guo, L. Flocking control of fixed-wing UAVs with cooperative obstacle avoidance capability. IEEE Access 2019, 7, 17798–17808. [Google Scholar] [CrossRef]
- Zhou, Z.; Xu, H. A Novel Mean-Field-Game-Type Optimal Control for Very Large-Scale Multiagent Systems. IEEE Trans. Cybern. 2022, 52, 5197–5208. [Google Scholar] [CrossRef]
- Mehlfuhrer, C.; Caban, S.; Rupp, M. Cellular system physical layer throughput: How far off are we from the Shannon bound? IEEE Wirel. Commun. 2011, 18, 54–63. [Google Scholar] [CrossRef]
- Branzei, R.; Dimitrov, D.; Tijs, S. Models in Cooperative Game Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008; Volume 556. [Google Scholar]
- Gulzar, M.M.; Rizvi, S.T.H.; Javed, M.Y.; Munir, U.; Asif, H. Multi-agent cooperative control consensus: A comparative review. Electronics 2018, 7, 22. [Google Scholar] [CrossRef]
- Zhou, Z.; Xu, H. Decentralized Adaptive Optimal Tracking Control for Massive Autonomous Vehicle Systems With Heterogeneous Dynamics: A Stackelberg Game. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 5654–5663. [Google Scholar] [CrossRef]
- Yu, M.; Hong, S.H. A Real-Time Demand-Response Algorithm for Smart Grids: A Stackelberg Game Approach. IEEE Trans. Smart Grid 2016, 7, 879–888. [Google Scholar] [CrossRef]
- Cardaliaguet, P.; Porretta, A. An introduction to mean field game theory. In Mean Field Games; Springer: Berlin/Heidelberg, Germany, 2020; pp. 1–158. [Google Scholar]
- Yang, Y.; Luo, R.; Li, M.; Zhou, M.; Zhang, W.; Wang, J. Mean field multi-agent reinforcement learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5571–5580. [Google Scholar]
- Shiri, H.; Park, J.; Bennis, M. Massive autonomous UAV path planning: A neural network based mean-field game theoretic approach. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Bogachev, V.I.; Krylov, N.V.; Röckner, M.; Shaposhnikov, S.V. Fokker–Planck–Kolmogorov Equations; American Mathematical Society: Providence, RI, USA, 2022; Volume 207. [Google Scholar]
- Peng, S. Stochastic hamilton–jacobi–bellman equations. SIAM J. Control Optim. 1992, 30, 284–304. [Google Scholar] [CrossRef]
- Murray, J.J.; Cox, C.J.; Lendaris, G.G.; Saeks, R. Adaptive dynamic programming. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2002, 32, 140–153. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef] [Green Version]
- Ju, C.; Son, H.I. Multiple UAV systems for agricultural applications: Control, implementation, and evaluation. Electronics 2018, 7, 162. [Google Scholar] [CrossRef] [Green Version]
- Gupta, J.K.; Egorov, M.; Kochenderfer, M. Cooperative multi-agent control using deep reinforcement learning. In Proceedings of the International Conference on Autonomous Agents and Multiagent Systems, Sao Paulo, Brazil, 8–12 May 2017; pp. 66–83. [Google Scholar]
- Oroojlooy, A.; Hajinezhad, D. A review of cooperative multi-agent deep reinforcement learning. Appl. Intell. 2022, 1–46. [Google Scholar] [CrossRef]
- Zhang, S.; Li, T.; Cheng, X.; Li, J.; Xue, B. Multi-Group Formation Tracking Control for Second-Order Nonlinear Multi-Agent Systems Using Adaptive Neural Networks. IEEE Access 2021, 9, 168207–168215. [Google Scholar] [CrossRef]
- Wu, Z.; Liu, X.; Sun, J.; Wang, X. Multi-group formation tracking control via impulsive strategy. Neurocomputing 2020, 411, 487–497. [Google Scholar] [CrossRef]
- Luo, L.; Wang, X.; Ma, J.; Ong, Y.S. Grpavoid: Multigroup collision-avoidance control and optimization for UAV swarm. IEEE Trans. Cybern. 2021. [Google Scholar] [CrossRef]
- Lewis, F.L.; Vrabie, D.; Vamvoudakis, K.G. Reinforcement learning and feedback control: Using natural decision methods to design optimal adaptive controllers. IEEE Control. Syst. Mag. 2012, 32, 76–105. [Google Scholar]
Figure 1.
An illustration of mixed game-based leader–follower multi-group swarming.

Figure 2.
Mixed game-based hierarchical learning structure.

Figure 3.
Large-scale leader–follower multi-group swarming. The reference trajectory is denoted by a red curve, the green curve represents the leader trajectory, and the Followers are represented with multiple colors.
Figure 3.
Large-scale leader–follower multi-group swarming. The reference trajectory is denoted by a red curve, the green curve represents the leader trajectory, and the Followers are represented with multiple colors.

Figure 4.
The tracking errors for the leaders.

Figure 5.
The tracking errors and the tracking error PDF of the followers.

Figure 6.
HJB equation error of the leader in group 1.

Figure 7.
HJB equation error of follower 1 in group 1.

Figure 8.
FPK equation error of follower 1 in group 1.

Figure 9.
Leader running cost for developed mixed game theory-based distributed approach and the traditional cooperative game-based centralized approach.
Figure 9.
Leader running cost for developed mixed game theory-based distributed approach and the traditional cooperative game-based centralized approach.

Figure 10.
Follower running cost for developed mixed game theory-based distributed approach and the traditional cooperative game-based centralized approach.
Figure 10.
Follower running cost for developed mixed game theory-based distributed approach and the traditional cooperative game-based centralized approach.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Dey, S.; Xu, H. Intelligent Distributed Swarm Control for Large-Scale Multi-UAV Systems: A Hierarchical Learning Approach. Electronics 2023, 12, 89. https://doi.org/10.3390/electronics12010089
AMA Style
Dey S, Xu H. Intelligent Distributed Swarm Control for Large-Scale Multi-UAV Systems: A Hierarchical Learning Approach. Electronics. 2023; 12(1):89. https://doi.org/10.3390/electronics12010089
Chicago/Turabian StyleDey, Shawon, and Hao Xu. 2023. "Intelligent Distributed Swarm Control for Large-Scale Multi-UAV Systems: A Hierarchical Learning Approach" Electronics 12, no. 1: 89. https://doi.org/10.3390/electronics12010089
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.