



Reviewing Federated Learning Aggregation Algorithms; Strategies, Contributions, Limitations and Future Perspectives

Abstract
:1. Introduction
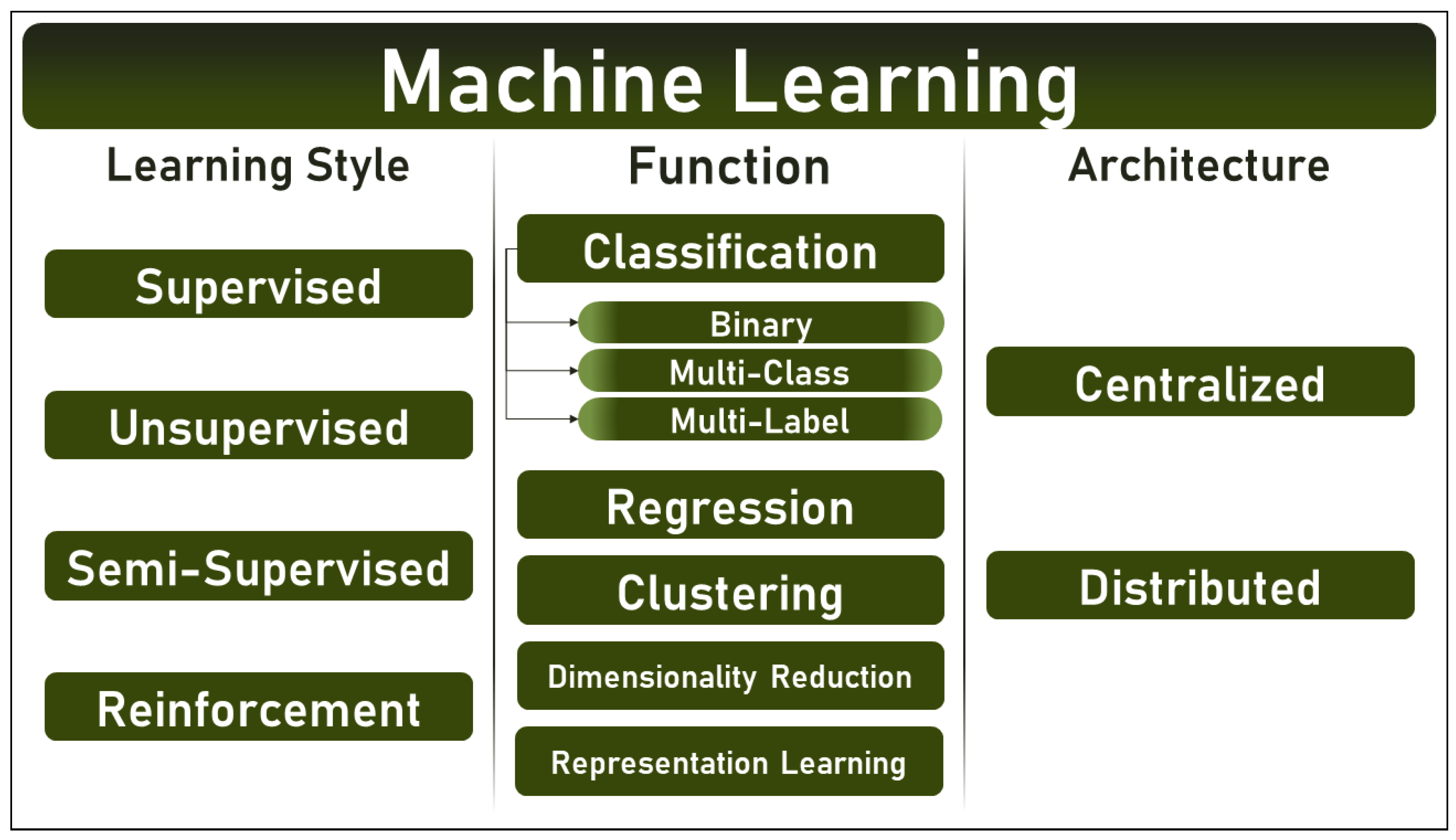
1.1. Machine Learning Techniques: A Taxonomy
1.1.1. Classification per Learning Style
- Supervised Learning: This refers to the types of ML where machines are trained with labeled input and then predict output based on that data. Labeled data means that the input data have been labeled with the corresponding output. The training data serve as a supervisor that teaches the computers how to correctly predict the output. Then it can be described as a process of providing the model ML with appropriate input and output data so that it can identify a function to map the input and output variables;
- Unsupervised Learning: An algorithm that operates only on input data and has no outputs or target variables. Consequently, unlike supervised learning, there is no teacher to correct the model. In other words, it is a collection of problems where a model is used to explain or extract relationships in data;
- Semi-Supervised Learning: This is a form of supervised learning in which the training data includes a small number of labeled instances and a large number of unlabeled examples. It attempts to use all available data, not just the labeled data as in supervised learning;
- Reinforcement Learning: This defines a class of problems where the intelligent model operates in a given environment and must learn how to act based on inputs. This means that there is no given training dataset, but rather a goal or collection of goals for the model to achieve, actions it can take, and feedback on its progress toward the goal. In other words, the goal is to learn what to do, how to map events to actions in order to maximize a numerical reward signal, not dictating to the model what actions to perform, but figuring out through trial and error which activities yield the greatest reward.
1.1.2. Classification per Function
- Classification: the process by which a ML algorithm predicts a discrete output or so-called class. Depending on the type of class to be predicted, this class can be divided into the following groups:
- –
- Binary Classification: refers to algorithms that can predict only one of two labels, e.g., classifying emails as spam or not;
- –
- Multi-Class Classification: refers to algorithms with more than two class labels, where there are no normal and abnormal results. Instead, the examples are classified into one of several known classes;
- –
- Multi-Label Classification: the collection of algorithms that predict the output of a label class, with no limit to how many classes the instance can be assigned to.
- Regression: the process by which a ML algorithm can predict a continuous output or a so-called numerical value;
- Clustering: the process of categorizing a set of data instances or points so that those in the same group are more similar and different from data points in other groups. It is essentially a collection of instances based on their similarity and dissimilarity;
- Dimensionality Reduction: the process of minimizing the number of variables in the supplied data, either by selecting only relevant variables ( feature selection ) or by creating new variables that reflect several others (feature extraction);
- Representation Learning: the process of determining appropriate representations for input data, which often involves dimensionality reduction.
1.1.3. Classification per Architecture
- Centralized Architecture: the traditional ML architecture, where data is collected on a machine running the model;
- Distributed Machine Learning: the ML paradigm that benefits from a decentralized and distributed computing architecture where the ML process is split across different nodes, resulting in a multi-node algorithm and system that provides better performance, higher accuracy, and better scalability for larger input data.
1.2. Machine Learning Challenges
1.2.1. Data Related Challenges
- Data Availability/Accessibility: data may not be available or accessible;
- Data Locality (Data Islands): data are scattered into different and non-related entities;
- Data Readiness: data may be heterogeneous, noisy or imbalanced;
- Data Volume: difficulty of working with datasets that are too large or too small;
- Feature Representation and Selection: selecting the optimal features for best results.
1.2.2. Models Related Challenges
- Accuracy and Performance: increasing the accuracy of the models;
- Model Evaluation: correct evaluation of the performance of the models;
- Variance and Bias: affects the results and confidence;
- Explainability: resolving back-box identity of ML models.
1.2.3. Implementation-Related Challenges
- Real-Time Processing: adapting models to operate in real time;
- Model Selection: selecting the best model suitable for the problem under study;
- Execution Time and Complexity: ML models may require high computational power.
1.2.4. General Challenges
- Users’ Data Privacy and Confidentiality: data are protected by numerous regulations;
- User Technology Adoption and Engagement;
- Ethical Constraints.
1.3. Privacy Criticality: Federated Learning as a Solution
1.4. Article Outline and Contributions
- What is federated machine learning?
- What is aggregation in federated learning?
- What are the different aggregation strategies?
- What is the state of the art in FL aggregation algorithms?
- What possible taxonomy can be established for these algorithms?
- What are the area(s) of contribution for each proposed aggregation algorithms?
- What are the limitations to date in this area?
- What future perspectives can be pursued to improve aggregation in the field FL?
- Differentiating between exchanging model updates, parameters or gradients in FL;
- Explaining aggregation algorithms in federated learning domain;
- Describing aggregation and its different approaches;
- Presenting the state of the art of aggregation algorithms in federated learning;
- Proposing a taxonomy that can be followed in categorizing FL aggregation algorithms;
- Discussing the contributions of each of the available FL aggregation algorithms;
- Studying the limitations of the aforementioned algorithms;
- Examining possible future prospects, which can be used as a starting point for further studies to improve aggregation algorithms in the field of FL.
2. Materials and Methods: Studying Federated Learning and Aggregation
2.1. Federated Learning: An Overview
2.2. Federated Learning: Technical Perspectives
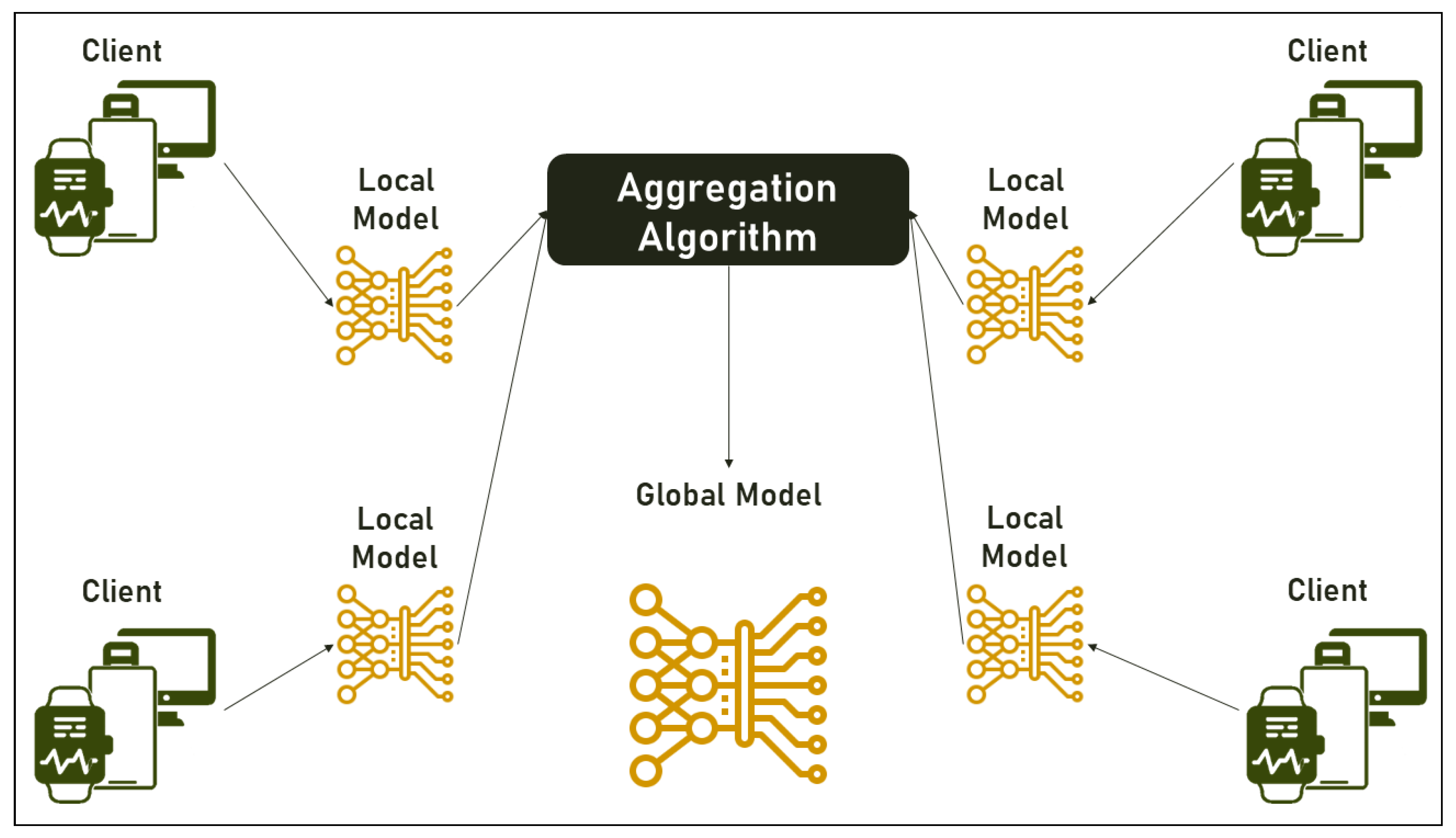
2.2.1. Underlying Architecture
- Central Server: the entity responsible for managing the connections between the entities in the FL environment and for aggregating the knowledge acquired by the FL clients;
- Parties (Clients): all computing devices with data that can be used for training the global model, including but not limited to: personal computers, servers, smartphones, smartwatches, computerized sensor devices, and many more;
- Communication Framework: consists of the tools and devices used to connect servers and parties and can vary between an internal network, an intranet, or even the Internet;
- Aggregation Algorithm: the entity responsible for aggregating the knowledge obtained by the parties after training with their local data and using the aggregated knowledge to update the global model.
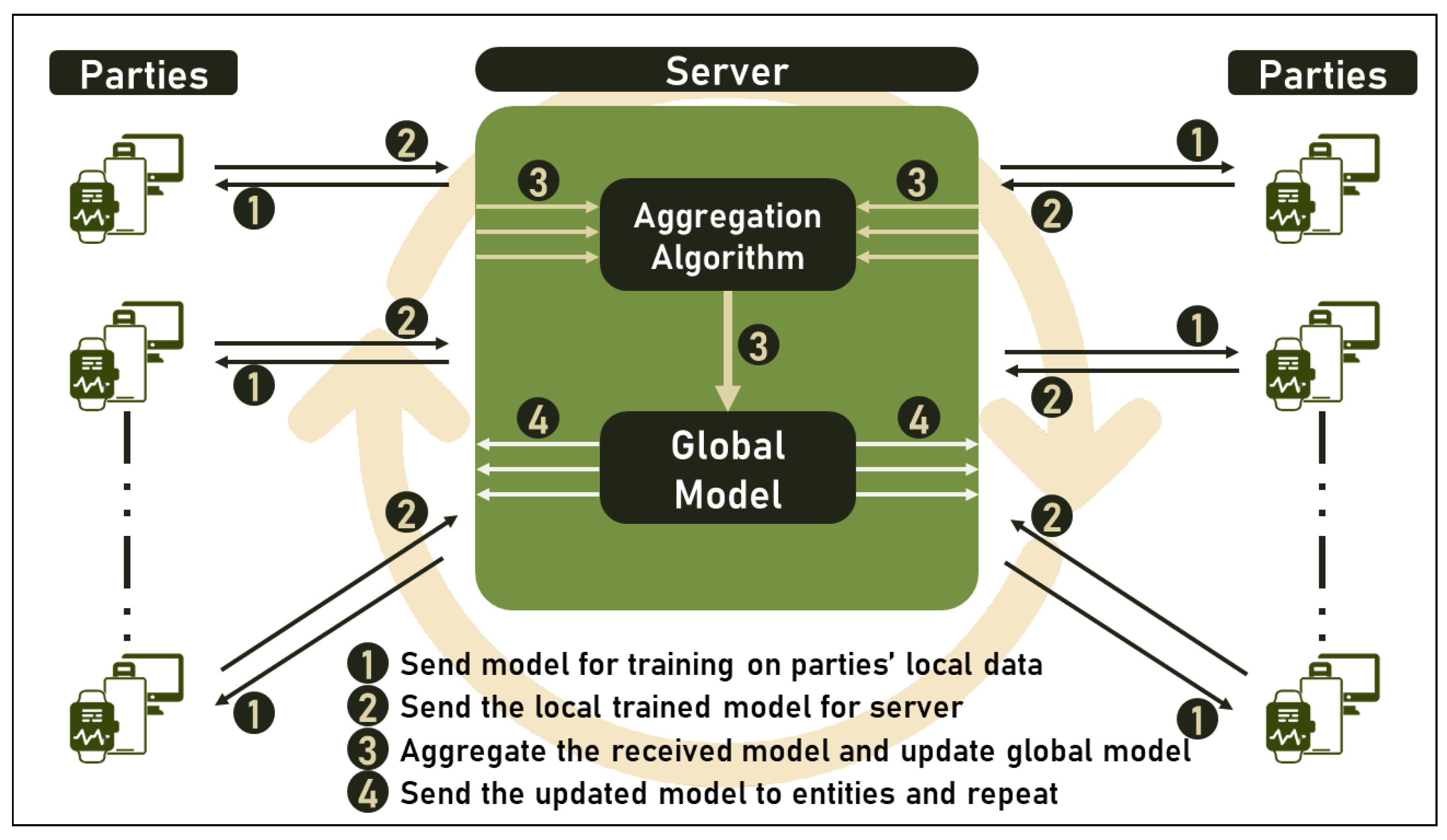
- Central server receives connection from clients and sends them initial global model;
- Parties receive initial copy of model, train it with their local data, and send results back to central server;
- The central server receives the locally trained models, which are aggregated with the correct algorithm;
- The central server updates the global model based on the aggregation results and sends the updated version to the clients;
- Repeat the above steps until the model converges or until the server decides to stop.
2.2.2. Exchanging Models, Parameters, or Gradients
- Exchanging Models: This is the classical approach, where models are exchanged between server and clients. This approach is very costly in terms of communication and also poses security problems, since the models can be intercepted with malicious intent to extract the data used for training;
- Exchanging Gradients [34,35]: Instead of submitting the entire model to the server, clients in this method submit only the gradients they compute locally. Federated learning with gradient aggregation (FLAG) is another name for this strategy. Each client computes the gradients using its own local data and then submits them to the server, which indicates the direction in which the parameters of the model should be updated to minimize the loss function. After the server collects the gradients, it applies them to the global model. This method has the advantage of both maintaining privacy and reducing communication costs. The divergence of local models is one of the challenges that can arise with this strategy when clients use different learning rates and optimization strategies;
- Exchanging Model Parameters [36,37]: This concept is mainly tied to neural networks where model parameters and weights are usually used interchangeably. Parameters, sometimes called weights, are the values assigned to connections between neurons in a neural network where the input from one layer of neurons is used by the next layer to produce an output, which is then weighted. During training, the weights are adjusted to reduce the discrepancy between the expected and actual output. This method has the potential to reduce the burden of communication costs in an FL environment while maintaining the confidentiality features of the FL approach. However, this method assumes that all clients have the same model architecture, which may not be the case for all implementations, leading to numerous problems. There is also the possibility that the method will not be effective if the client data are too large or if the data are not balanced on the client side;
- Hybrid Approaches: Two or more of the above methods can be combined to form a hybrid strategy that is particularly suited to a particular application or environment. For example, the server can broadcast the initial parameters for the clients to all nodes and then receive updated models from the nodes, which it then combines with its own to create a global model.
2.3. What Is Aggregation in FL?
2.4. Different Approaches of Aggregation
2.4.1. Average Aggregation
2.4.2. Clipped Average Aggregation
2.4.3. Secure Aggregation
2.4.4. Differential Privacy Average Aggregation
2.4.5. Momentum Aggregation
2.4.6. Weighted Aggregation
2.4.7. Bayesian Aggregation
2.4.8. Adversarial Aggregation
2.4.9. Quantization Aggregation
2.4.10. Hierarchical Aggregation
2.4.11. Personalized Aggregation
2.4.12. Ensemble Bases Aggregation
3. Results: FL Aggregation Algorithm Implementations
3.1. State of the Art
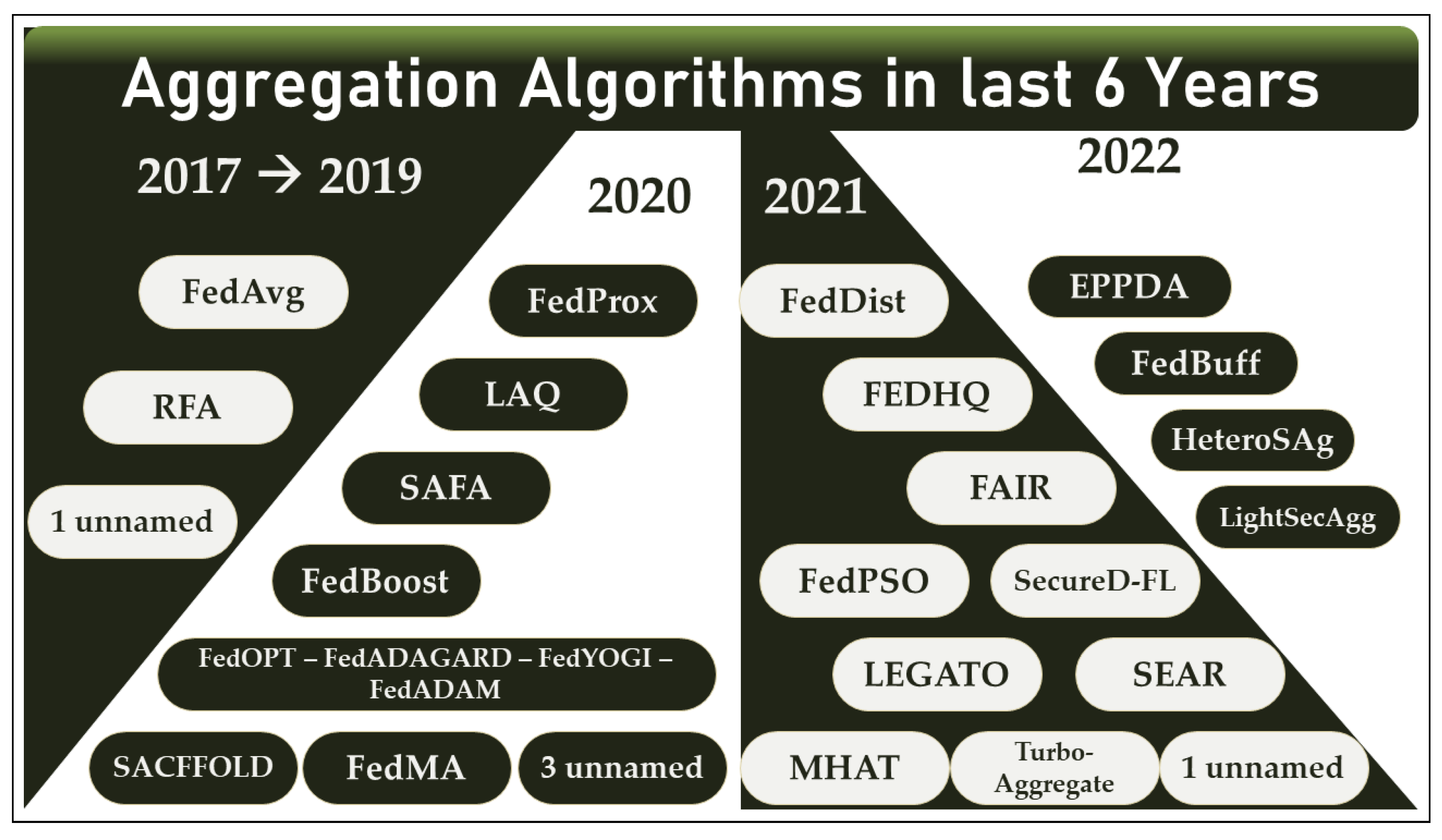
3.1.1. “2017–2019”: Introducing FL to the Market
3.1.2. “2020”: A Big Step
3.1.3. “2021”: FL toward More Enhancements
3.1.4. “2022”: The Journey Continues
3.2. FL Aggregation Algorithm Implementations Taxonomy
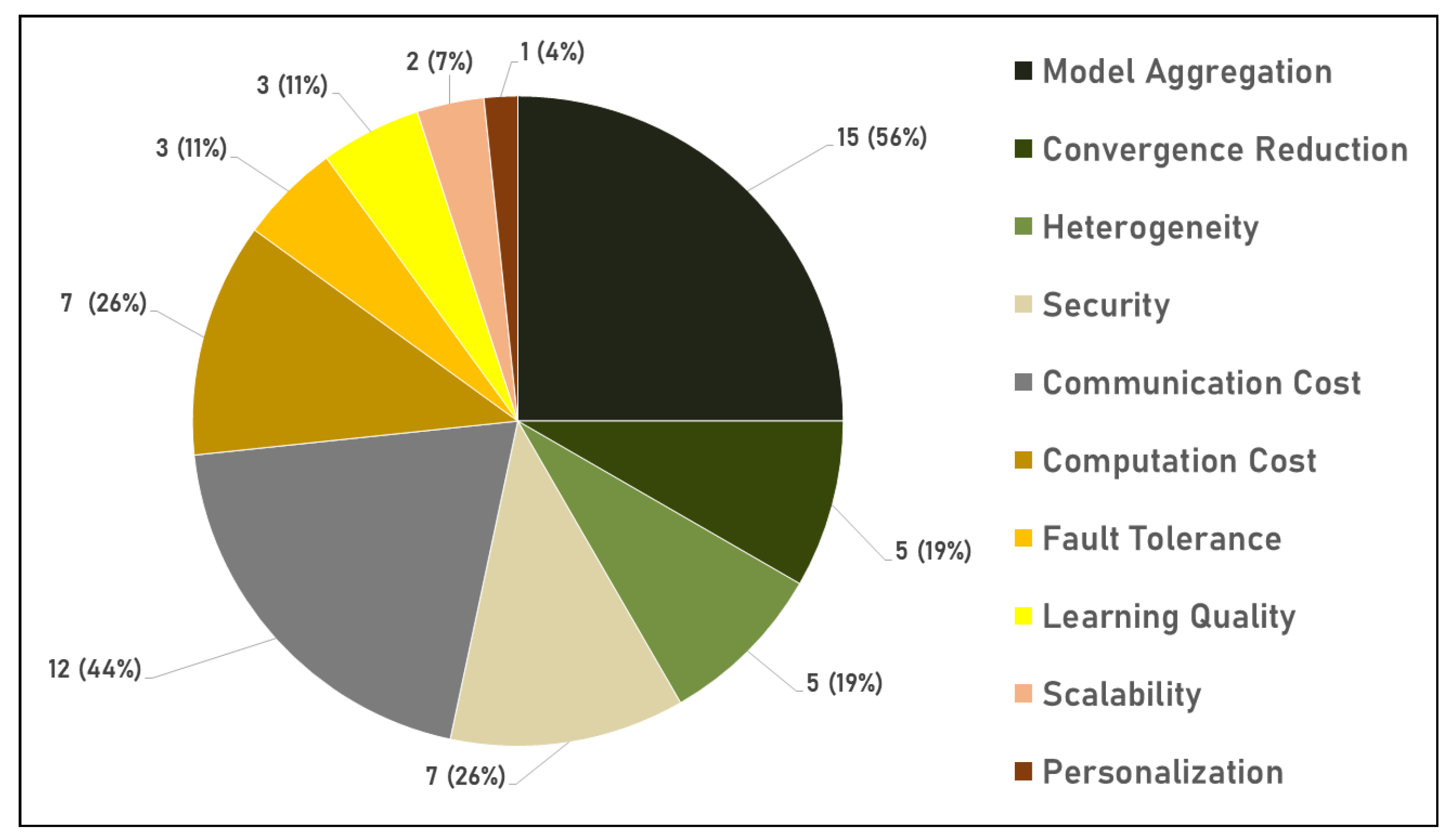
3.2.1. Classification by Area of Contribution
- Improving model aggregation;
- Reducing convergence;
- Handling heterogeneity;
- Enhancing security;
- Reducing communication and computation cost;
- Handling users’ failures (fault tolerance);
- Boosting learning quality;
- Supporting scalability, personalization and generalization.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Given Name | Model Aggregation | Convergence Reduction | Heterogeneity | Security | Communication Cost | Computation Cost | Fault Tolerance | Learning Quality | Scalability | Personalization |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [38] | 2017 | FedAVG | 🗸 | |||||||||
| [50] | 2017 | - | 🗸 | 🗸 | ||||||||
| [51] | 2019 | RFA | 🗸 | 🗸 | ||||||||
| [52] | 2020 | SCAFFOLD | 🗸 | 🗸 | 🗸 | |||||||
| [53] | 2020 | FedOPT | 🗸 | 🗸 | 🗸 | |||||||
| FedADAGAR | ||||||||||||
| FedYOGI | ||||||||||||
| FedADAM | ||||||||||||
| [54] | 2020 | FedBoost | 🗸 | |||||||||
| [55] | 2020 | FedProx | 🗸 | 🗸 | ||||||||
| [56] | 2020 | FedMA | 🗸 | 🗸 | ||||||||
| [57] | 2020 | - | 🗸 | 🗸 | 🗸 | |||||||
| [58] | 2020 | - | 🗸 | 🗸 | ||||||||
| [59] | 2020 | - | 🗸 | 🗸 | ||||||||
| [60] | 2020 | LAQ | 🗸 | |||||||||
| [61] | 2020 | SAFA | 🗸 | 🗸 | 🗸 | 🗸 | ||||||
| [62] | 2021 | FedDist | 🗸 | 🗸 | ||||||||
| [46] | 2021 | FEDHQ | 🗸 | 🗸 | ||||||||
| [63] | 2021 | FAIR | 🗸 | 🗸 | ||||||||
| [64] | 2021 | FedPSO | 🗸 | 🗸 | ||||||||
| [65] | 2021 | LEGATO | 🗸 | 🗸 | 🗸 | 🗸 | ||||||
| [66] | 2021 | MHAT | 🗸 | 🗸 | 🗸 | |||||||
| [67] | 2021 | - | 🗸 | |||||||||
| [68] | 2021 | - | 🗸 | 🗸 | 🗸 | |||||||
| [69] | 2021 | SEAR | 🗸 | 🗸 | ||||||||
| [70] | 2021 | Turbo-Aggregate | 🗸 | 🗸 | 🗸 | |||||||
| [71] | 2022 | EPPDA | 🗸 | 🗸 | ||||||||
| [72] | 2022 | FedBuff | 🗸 | |||||||||
| [73] | 2022 | HeteroSAg | 🗸 | 🗸 | 🗸 | |||||||
| [74] | 2022 | LightSecAgg | 🗸 | 🗸 |
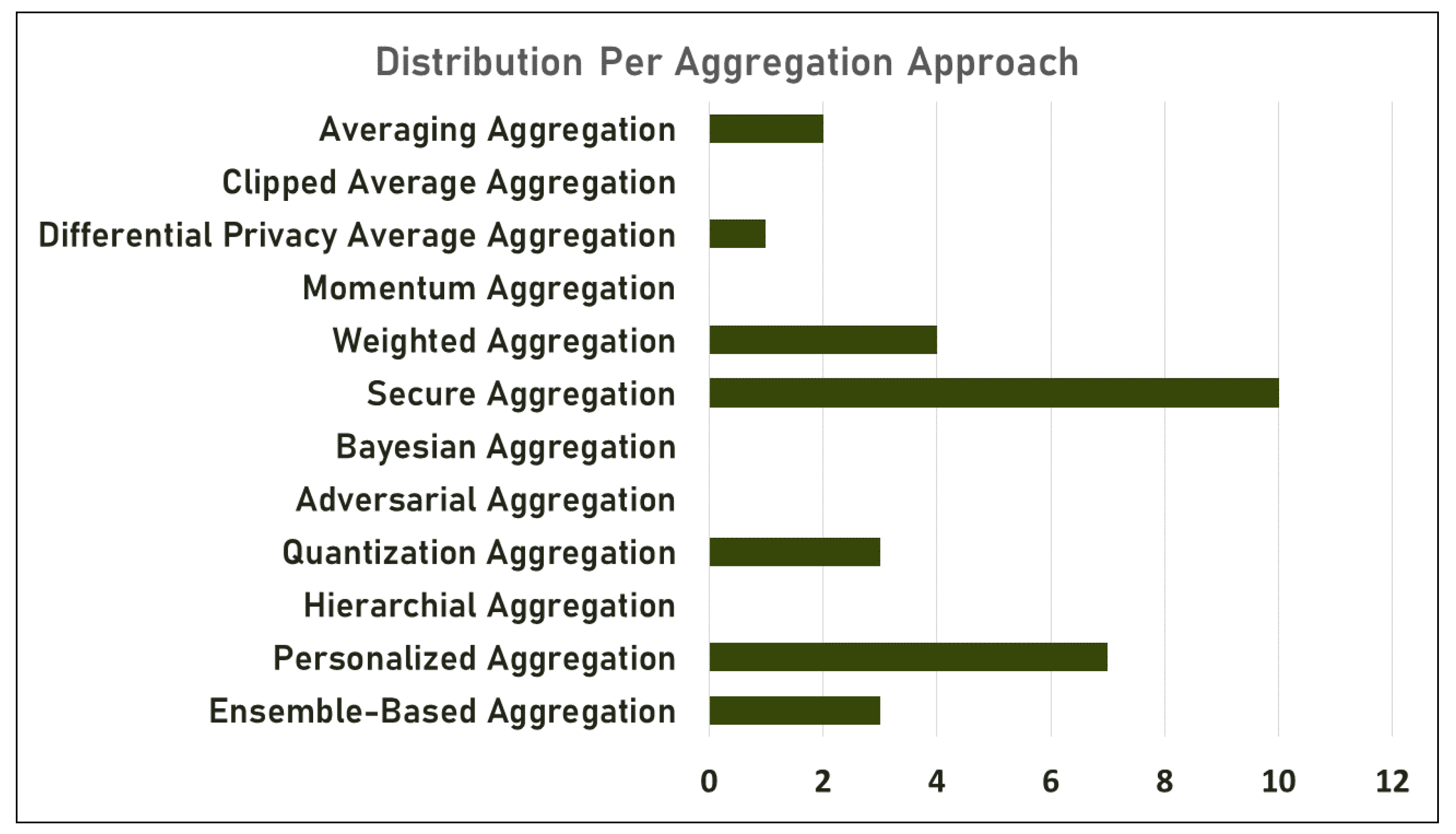
3.2.2. Classification by the Aggregation Approach
4. Discussion
4.1. Contributions of Aggregation Algorithms
4.1.1. Aggregation
- Suffering from ’client-drift’ and convergence;
- Tuning difficulty;
- High communication and computation cost;
- Significant variability in clients’ system characteristics;
- Non-identically distributed data across the network;
- Heterogeneity of devices, users and network channels;
- Sensitivity to local models;
- Scalability issues.
4.1.2. Convergence Reduction
4.1.3. Heterogeneity
4.1.4. Security
4.1.5. Communication Cost
4.1.6. Computation Cost
4.1.7. Fault Tolerance
4.1.8. Learning Quality
4.1.9. Scalability
4.1.10. Personalization
- Ability to handle heterogeneous data and hardware;
- Capability to adapt for the network settings such as bandwidth on the client’s side;
- Other factors.
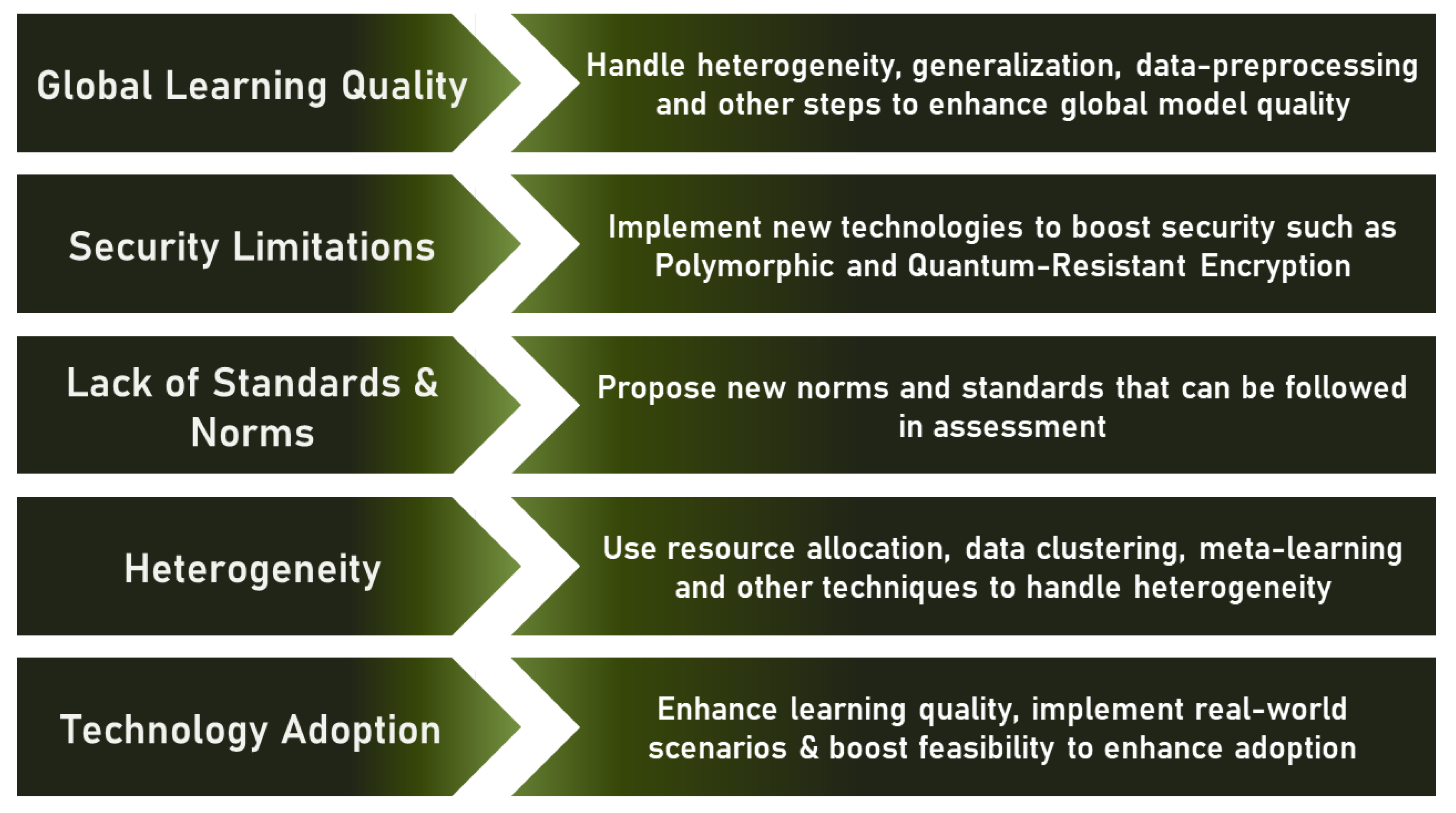
4.2. Further Limitations
4.2.1. Global Model Quality
4.2.2. Security Limitations
- Poisoning attacks: these are conducted by injecting noise into the FL system, and are also split into two categories:
- –
- Data poisoning attacks: these are the most common attacks against ML models and can be either targeted toward a specific class or non-targeted. In a targeted attack, the noisy records of a specific target class are injected into local data so that the learned model will act badly on this class;
- –
- Model poisoning attacks: these are similar to data poisoning attacks, where the adversary tries to poison the local models instead of the local data.
- Inference attacks: in some scenarios, it is possible to infer, conclude, or restore the party local data from the model updates during the learning process;
- Backdoor attacks: secure averaging allows parties to be anonymous during the model update process. Using the same functionality, a party or group of parties can introduce backdoor functionality in in FL global model. Then, a malicious entity can use the backdoor to mislabel certain tasks such as choosing a specific label for a data instance with specific characteristics. For sure, the proportion of the compromised devices and FL model capacity affects in the intensity of such attacks.
4.2.3. Evaluation Complexity and Lack of Standards
4.2.4. Software and Hardware Heterogeneity
4.2.5. User Adoption
4.3. Future Perspectives
4.3.1. Boost Learning Quality
4.3.2. Improving Security and Privacy
4.3.3. Proposing Standards and Norms
4.3.4. Enhance Heterogeneity Handling Abilities
- Resource Allocation [94]: This involves the optimal distribution of computational load and communication bandwidth among clients, taking into account their capabilities and limitations. This can reduce the impact of heterogeneity, minimize training time, and improve the convergence and accuracy of the model;
- Data Clustering: Implemented by grouping clients into clusters based on the similarity of their data distribution or other criteria, this allows the system to leverage the similarities between devices and reduce the impact of heterogeneity;
- Meta-Learning [95]: This involves determining the optimal learning algorithm or hyperparameters for each client based on its past performance or other metadata. This helps to adapt to client heterogeneity and also improves the overall performance and scalability of the federated learning process.
4.3.5. Boost Technology Adoption into Real-Word Scenarios
4.3.6. Integrate Different Areas of Contribution
4.3.7. Embedding Latest Technologies into FL: Quantum Computing as an Example
- Speeding Up Computation: Quantum computers are capable of solving certain tasks much faster than traditional computers, such as factoring large numbers or scanning unsorted databases. Quantum computers could potentially help speed up the training of machine learning models in the context of federated learning, especially for complicated tasks or large datasets. This could improve the efficiency and feasibility of federated learning for real-world applications;
- Quantum Communication: Quantum communication technologies, such as quantum teleportation and quantum key distribution, could be used to securely transfer model changes between nodes of the federated learning system. This could improve the privacy and security of federated learning, which is one of its main advantages;
- Quantum Encryption: Quantum encryption technology, such as quantum key distribution, could be used to improve the security of communications between nodes of the federated learning system. This could be particularly useful in federated learning environments where privacy and security are critical;
- Improved Optimization: Some optimization problems, such as training machine learning models, can be solved more effectively by using quantum technologies. As a result, federated learning algorithms can become more efficient and effective.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Stearns, P.N. The Industrial Revolution in World History; Routledge: Oxfordshire, UK, 2020. [Google Scholar]
- Campbell-Kelly, M. Computer, Student Economy Edition: A History of the Information Machine; Routledge: Oxfordshire, UK, 2018. [Google Scholar]
- Moor, J. The Dartmouth College artificial intelligence conference: The next fifty years. AI Mag. 2006, 27, 87. [Google Scholar]
- Frankish, K.; Ramsey, W.M. (Eds.) The Cambridge Handbook of Artificial Intelligence; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Aggarwal, K.; Mijwil, M.M.; Al-Mistarehi, A.H.; Alomari, S.; Gök, M.; Alaabdin, A.M.Z.; Abdulrhman, S.H. Has the future started? The current growth of artificial intelligence, Machine Learning, and deep learning. Iraqi J. Comput. Sci. Math. 2022, 3, 115–123. [Google Scholar]
- Bell, J. What Is Machine Learning? In Machine Learning and the City: Applications in Architecture and Urban Design; John Wiley & Sons: Hoboken, NJ, USA, 2022; pp. 207–216. [Google Scholar]
- Hardt, M.; Benjamin, R. Patterns, predictions, and actions: A story about Machine Learning. arXiv 2021, arXiv:2102.05242. [Google Scholar]
- Sarker, I.H. Machine learning: Algorithms, real-world applications and research directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef] [PubMed]
- Sharma, N.; Sharma, R.; Jindal, N. Machine learning and deep learning applications-a vision. Glob. Transit. Proc. 2021, 2, 24–28. [Google Scholar] [CrossRef]
- Pallathadka, H.; Mustafa, M.; Sanchez, D.T.; Sajja, G.S.; Gour, S.; Naved, M. Impact of machine learning on management, healthcare and agriculture. Mater. Today Proc. 2023, 80, 2803–2806. [Google Scholar] [CrossRef]
- Ghazal, T.M.; Hasan, M.K.; Alshurideh, M.T.; Alzoubi, H.M.; Ahmad, M.; Akbar, S.S.; Al Kurdi, B.; Akour, I.A. IoT for smart cities: Machine learning approaches in smart healthcare—A review. Future Internet 2021, 13, 218. [Google Scholar] [CrossRef]
- Moshawrab, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Smart Wearables for the Detection of Cardiovascular Diseases: A Systematic Literature Review. Sensors 2023, 23, 828. [Google Scholar] [CrossRef]
- Zantalis, F.; Koulouras, G.; Karabetsos, S.; Kandris, D. A review of Machine Learning and IoT in smart transportation. Future Internet 2019, 11, 94. [Google Scholar] [CrossRef]
- Xin, Y.; Kong, L.; Liu, Z.; Chen, Y.; Li, Y.; Zhu, H.; Gao, M.; Hou, H.; Wang, C. Machine learning and deep learning methods for cybersecurity. IEEE Access 2018, 6, 35365–35381. [Google Scholar] [CrossRef]
- Nagarhalli, T.P.; Vaze, V.; Rana, N.K. Impact of machine learning in natural language processing: A review. In Proceedings of the Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 1529–1534. [Google Scholar]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [PubMed]
- Larrañaga, P.; Atienza, D.; Diaz-Rozo, J.; Ogbechie, A.; Puerto-Santana, C.; Bielza, C. Industrial Applications of Machine Learning; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Verbraeken, J.; Wolting, M.; Katzy, J.; Kloppenburg, J.; Verbelen, T.; Rellermeyer, J.S. A survey on distributed Machine Learning. ACM Comput. Surv. 2020, 53, 1–33. [Google Scholar] [CrossRef]
- Panayiotou, T.; Savvas, G.; Tomkos, I.; Ellinas, G. Centralized and distributed Machine Learning-based QoT estimation for sliceable optical networks. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–7. [Google Scholar]
- Zhou, L.; Pan, S.; Wang, J.; Vasilakos, A.V. Machine learning on big data: Opportunities andchallenges. Neurocomputing 2017, 237, 350–361. [Google Scholar] [CrossRef]
- Wuest, T.; Weimer, D.; Irgens, C.; Thoben, K.D. Machine learning in manufacturing: Advantages, challenges, and applications. Prod. Manuf. Res. 2016, 4, 23–45. [Google Scholar] [CrossRef]
- Injadat, M.; Moubayed, A.; Nassif, A.B.; Shami, A. Machine learning towards intelligent systems:applications, challenges, and opportunities. Artif. Intell. Rev. 2021, 54, 3299–3348. [Google Scholar] [CrossRef]
- Char, D.S.; Shah, N.H.; Magnus, D. Implementing Machine Learning in health care—Addressingethical challenges. N. Engl. J. Med. 2018, 378, 981. [Google Scholar] [CrossRef]
- Albrecht, J.P. How the GDPR will change the world. Eur. Data Prot. Law Rev. 2016, 2, 287. [Google Scholar] [CrossRef]
- Parasol, M. The impact of China’s 2016 Cyber Security Law on foreign technology firms, and onChina’s big data and Smart City dreams. Comput. Law Secur. Rev. 2018, 34, 67–98. [Google Scholar] [CrossRef]
- IBM. Security Cost of Data Breach Report. 2021. Available online: https://www.ibm.com/downloads/cas/ojdvqgry (accessed on 1 March 2023).
- Konečný, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Moshawrab, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Reviewing Federated Machine Learning and Its Use in Diseases Prediction. Sensors 2023, 23, 2112. [Google Scholar] [CrossRef]
- Malekijoo, A.; Fadaeieslam, M.J.; Malekijou, H.; Homayounfar, M.; Alizadeh-Shabdiz, F.; Rawassizadeh, R. Fedzip: A compression framework for communication-efficient federated learning. arXiv 2021, arXiv:2102.01593. [Google Scholar]
- Liu, Z.; Guo, J.; Yang, W.; Fan, J.; Lam, K.-Y.; Zhao, J. Privacy-Preserving Aggregation in Federated Learning: A Survey. IEEE Trans. Big Data 2022. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on Federated Learning. Knowl.-Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Li, Q.; Wen, Z.; Wu, Z.; Hu, S.; Wang, N.; Li, Y.; Liu, X.; He, B. A survey on Federated Learning systems: Vision, hype and reality for data privacy and protection. IEEE Trans. Knowl. Data Eng. 2021, 35, 3347–3366. [Google Scholar] [CrossRef]
- Jiang, J.; Hu, L. Decentralised Federated Learning with adaptive partial gradient aggregation. CAAI Trans. Intell. Technol. 2020, 5, 230–236. [Google Scholar] [CrossRef]
- Yao, X.; Huang, T.; Zhang, R.X.; Li, R.; Sun, L. Federated learning with unbiased gradient aggregation and controllable meta updating. arXiv 2019, arXiv:1910.08234. [Google Scholar]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef]
- Cheng, B.; Titterington, D.M. Neural networks: A review from a statistical perspective. Stat. Sci. 1994, 9, 2–30. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics PMLR, Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Wang, T.; Zheng, Z.; Lin, F. Federated Learning Framew Ork Based on Trimmed Mean Aggregation Rules. SSRN Electron. J. 2022. [Google Scholar] [CrossRef]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for Federated Learning on user-held data. arXiv 2016, arXiv:1611.04482. [Google Scholar]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Jin, S.; Tony, Q.S.Q.; Poor, H.V. Federated learning with differential privacy: Algorithms and performance analysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3454–3469. [Google Scholar] [CrossRef]
- Xu, J.; Wang, S.; Wang, L.; Yao, A.C.C. Fedcm: Federated learning with client-level momentum. arXiv 2021, arXiv:2106.10874. [Google Scholar]
- Reyes, J.; Di Jorio, L.; Low-Kam, C.; Kersten-Oertel, M. Precision-weighted Federated Learning. arXiv 2021, arXiv:2107.09627. [Google Scholar]
- West, M. Bayesian aggregation. J. R. Stat. Soc. Ser. A 1984, 147, 600–607. [Google Scholar] [CrossRef]
- Kerkouche, R.; Ács, G.; Castelluccia, C. Federated learning in adversarial settings. arXiv 2020, arXiv:2010.07808. [Google Scholar]
- Chen, S.; Shen, C.; Zhang, L.; Tang, Y. Dynamic aggregation for heterogeneous quantization in Federated Learning. IEEE Trans. Wirel. Commun. 2021, 20, 6804–6819. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, J.; Song, S.; Letaief, K.B. Hierarchical quantized Federated Learning: Convergence analysis and system design. arXiv 2021, arXiv:2103.14272. [Google Scholar]
- Ma, X.; Zhang, J.; Guo, S.; Xu, W. Layer-wised model aggregation for personalized Federated Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10092–10101. [Google Scholar]
- Chen, H.Y.; Chao, W.L. Fedbe: Making bayesian model ensemble applicable to Federated Learning. arXiv 2020, arXiv:2009.01974. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving Machine Learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1175–1191. [Google Scholar]
- Pillutla, K.; Kakade, S.M.; Harchaoui, Z. Robust aggregation for Federated Learning. IEEE Trans. Signal Process. 2022, 70, 1142–1154. [Google Scholar] [CrossRef]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.; Suresh, A.T. Scaffold: Stochastic controlled averaging for Federated Learning. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 5132–5143. [Google Scholar]
- Reddi, S.; Charles, Z.; Zaheer, M.; Garrett, Z.; Rush, K.; Konečný, J.; Kumar, S.; McMahan, H.B. Adaptive federated optimization. arXiv 2020, arXiv:2003.00295. [Google Scholar]
- Hamer, J.; Mohri, M.; Suresh, A.T. Fedboost: A communication-efficient algorithm for Federated Learning. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 3973–3983. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Wang, H.; Yurochkin, M.; Sun, Y.; Papailiopoulos, D.; Khazaeni, Y. Federated learning with matched averaging. arXiv 2020, arXiv:2002.06440. [Google Scholar]
- Guo, H.; Liu, A.; Lau, V.K. Analog gradient aggregation for Federated Learning over wireless networks: Customized design and convergence analysis. IEEE Internet Things J. 2020, 8, 197–210. [Google Scholar] [CrossRef]
- Choi, B.; Sohn, J.Y.; Han, D.J.; Moon, J. Communication-computation efficient secure aggregation for Federated Learning. arXiv 2020, arXiv:2012.05433. [Google Scholar]
- Ye, D.; Yu, R.; Pan, M.; Han, Z. Federated learning in vehicular edge computing: A selective model aggregation approach. IEEE Access 2020, 8, 23920–23935. [Google Scholar] [CrossRef]
- Sun, J.; Chen, T.; Giannakis, G.B.; Yang, Q.; Yang, Z. Lazily aggregated quantized gradient innovation for communication-efficient Federated Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2031–2044. [Google Scholar] [CrossRef]
- Wu, W.; He, L.; Lin, W.; Mao, R.; Maple, C.; Jarvis, S. SAFA: A semi-asynchronous protocol for fast Federated Learning with low overhead. IEEE Trans. Comput. 2020, 70, 655–668. [Google Scholar] [CrossRef]
- Sannara, E.K.; Portet, F.; Lalanda, P.; German, V.E.G.A. A Federated Learning aggregation algorithm for pervasive computing: Evaluation and comparison. In Proceedings of the 2021 IEEE International Conference on Pervasive Computing and Communications (PerCom), Kassel, Germany, 22–26 March 2021; pp. 1–10. [Google Scholar]
- Deng, Y.; Lyu, F.; Ren, J.; Chen, Y.C.; Yang, P.; Zhou, Y.; Zhang, Y. Fair: Quality-aware Federated Learning with precise user incentive and model aggregation. In Proceedings of the IEEE INFOCOM 2021-IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar]
- Park, S.; Suh, Y.; Lee, J. Fedpso: Federated Learning using particle swarm optimization to reduce communication costs. Sensors 2021, 21, 600. [Google Scholar] [CrossRef]
- Varma, K.; Zhou, Y.; Baracaldo, N.; Anwar, A. Legato: A layerwise gradient aggregation algorithm for mitigating byzantine attacks in Federated Learning. In Proceedings of the 2021 IEEE 14th International Conference on Cloud Computing (CLOUD), Chicago, IL, USA, 5–11 September 2021; pp. 272–277. [Google Scholar]
- Hu, L.; Yan, H.; Li, L.; Pan, Z.; Liu, X.; Zhang, Z. MHAT: An efficient model-heterogenous aggregation training scheme for Federated Learning. Inf. Sci. 2021, 560, 493–503. [Google Scholar] [CrossRef]
- Jeon, B.; Ferdous, S.M.; Rahman, M.R.; Walid, A. Privacy-preserving decentralized aggregation for Federated Learning. In Proceedings of the IEEE INFOCOM 2021-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Virtual, 9–12 May 2021; pp. 1–6. [Google Scholar]
- Wang, Y.; Kantarci, B. Reputation-enabled Federated Learning model aggregation in mobile platforms. In Proceedings of the ICC 2021-IEEE International Conference on Communications, Xiamen, China, 28–30 July 2021; pp. 1–6. [Google Scholar]
- Zhao, L.; Jiang, J.; Feng, B.; Wang, Q.; Shen, C.; Li, Q. Sear: Secure and efficient aggregation for byzantine-robust Federated Learning. IEEE Trans. Dependable Secur. Comput. 2021, 19, 3329–3342. [Google Scholar] [CrossRef]
- So, J.; Güler, B.; Avestimehr, A.S. Turbo-aggregate: Breaking the quadratic aggregation barrier in secure Federated Learning. IEEE J. Sel. Areas Inf. Theory 2021, 2, 479–489. [Google Scholar] [CrossRef]
- Avizienis, A.; Laprie, J.-C.; Randell, B.; Landwehr, C. Basic concepts and taxonomy of dependable and secure computing. IEEE Trans. Dependable Secur. Comput. 2014, 1, 11–33. [Google Scholar] [CrossRef]
- Nguyen, J.; Malik, K.; Zhan, H.; Yousefpour, A.; Rabbat, M.; Malek, M.; Huba, D. Federated learning with buffered asynchronous aggregation. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Virtual, 28–30 March 2022; pp. 3581–3607. [Google Scholar]
- Elkordy, A.R.; Avestimehr, A.S. HeteroSAg: Secure aggregation with heterogeneous quantization in Federated Learning. IEEE Trans. Commun. 2022, 70, 2372–2386. [Google Scholar] [CrossRef]
- So, J.; He, C.; Yang, C.S.; Li, S.; Yu, Q.; E Ali, R.; Guler, B.; Avestimehrm, S. Lightsecagg: A lightweight and versatile design for secure aggregation in Federated Learning. Proc. Mach. Learn. Syst. 2022, 4, 694–720. [Google Scholar]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Rahman, K.J.; Ahmed, F.; Akhter, N.; Hasan, M.; Amin, R.; Aziz, K.E.; Islam, A.K.M.M.; Mukta, M.S.H.; Islam, A.K.M.N. Challenges, applications and design aspects of Federated Learning: A survey. IEEE Access 2021, 9, 124682–124700. [Google Scholar] [CrossRef]
- Lynch, J.F. Analysis and application of adaptive sampling. In Proceedings of the Nineteenth ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Dallas, TX, USA, 15–17 May 2000; pp. 260–267. [Google Scholar]
- He, B.; Huang, J.X.; Zhou, X. Modeling term proximity for probabilistic information retrieval models. Inf. Sci. 2011, 181, 3017–3031. [Google Scholar] [CrossRef]
- Zhu, H.; Xu, J.; Liu, S.; Jin, Y. Federated learning on non-IID data: A survey. Neurocomputing 2021, 465, 371–390. [Google Scholar] [CrossRef]
- Lyu, L.; Yu, H.; Yang, Q. Threats to Federated Learning: A survey. arXiv 2020, arXiv:2003.02133. [Google Scholar]
- Weiszfeld, E.; Plastria, F. On the point for which the sum of the distances to n given points is minimum. Ann. Oper. Res. 2009, 167, 7–41. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends® Mach. Learn. 2011, 3, 1–122. [Google Scholar]
- Chakrabarti, S.; Knauth, T.; Kuvaiskii, D.; Steiner, M.; Vij, M. Trusted execution environment with intel sgx. In Responsible Genomic Data Sharing; Academic Press: Cambridge, MA, USA, 2020; pp. 161–190. [Google Scholar]
- Benaloh, J.C. Secret sharing homomorphisms: Keeping shares of a secret secret. In Advances in Cryptology—CRYPTO’86: Proceedings; Springer: Berlin/Heidelberg, Germany, 2000; pp. 251–260. [Google Scholar]
- Müller, T.; Rousselle, F.; Keller, A.; Novák, J. Neural control variates. Acm Trans. Graph. (TOG) 2020, 39, 1–19. [Google Scholar] [CrossRef]
- Ketkar, N.; Ketkar, N. Stochastic gradient descent. In Deep Learning with Python: A Hands-On Introduction; Apress: Berkeley, CA, USA, 2017; pp. 113–132. [Google Scholar]
- Boenisch, F.; Sperl, P.; Böttinger, K. Gradient masking and the underestimated robustness threats of differential privacy in deep learning. arXiv 2021, arXiv:2105.07985. [Google Scholar]
- Dai, W.; Zhou, Y.; Dong, N.; Zhang, H.; Xing, E.P. Toward understanding the impact of staleness in distributed Machine Learning. arXiv 2018, arXiv:1810.03264. [Google Scholar]
- Moshawrab, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Cardiovascular Events Prediction using Artificial Intelligence Models and Heart Rate Variability. Procedia Comput. Sci. 2022, 203, 231–238. [Google Scholar] [CrossRef]
- Moshawrab, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Predicting Cardiovascular Events with Machine Learning Models and Heart Rate Variability. Int. J. Ubiquitous Syst. Pervasive Netw. (JUSPN) 2023, 18, 49–59. [Google Scholar]
- Lamport, L.; Shostak, R.; Pease, M. The Byzantine generals problem. In Concurrency: The Works of Leslie Lamport; Transactions on Programming Languages and Systems; ACM: New York, NY, USA, 2019; pp. 203–226. [Google Scholar]
- Booher, D.D.; Cambou, B.; Carlson, A.H.; Philabaum, C. Dynamic key generation for polymorphic encryption. In Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 7–9 January 2019; pp. 482–487. [Google Scholar]
- Vella, H. The Race for Quantum-Resistant Cryptography [quantum-cyber security]. Eng. Technol. 2022, 17, 56–59. [Google Scholar] [CrossRef]
- Jamil, B.; Ijaz, H.; Shojafar, M.; Munir, K.; Buyya, R. Resource allocation and task scheduling in fog computing and internet of everything environments: A taxonomy, review, and future directions. ACM Comput. Surv. (CSUR) 2022, 54, 1–38. [Google Scholar] [CrossRef]
- Feng, Y.; Chen, J.; Xie, J.; Zhang, T.; Lv, H.; Pan, T. Meta-learning as a promising approach for few-shot cross-domain fault diagnosis: Algorithms, applications, and prospects. Knowl.-Based Syst. 2022, 235, 107646. [Google Scholar] [CrossRef]
- Moshawrab, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Smart Wearables for the Detection of Occupational Physical Fatigue: A Literature Review. Sensors 2022, 22, 7472. [Google Scholar] [CrossRef] [PubMed]
- Yin, H.L.; Fu, Y.; Li, C.L.; Weng, C.X.; Li, B.H.; Gu, J.; Lu, Y.-S.; Huang, S.; Chen, Z.-B. Experimental quantum secure network with digital signatures and encryption. arXiv 2021, arXiv:2107.14089. [Google Scholar] [CrossRef] [PubMed]
- Xie, Y.M.; Lu, Y.S.; Weng, C.X.; Cao, X.Y.; Jia, Z.Y.; Bao, Y.; Wang, Y.; Fu, Y.; Yin, H.-L.; Chen, Z.-B. Breaking the rate-loss bound of quantum key distribution with asynchronous two-photon interference. PRX Quantum 2022, 3, 020315. [Google Scholar] [CrossRef]
- Liu, Z.P.; Zhou, M.G.; Liu, W.B.; Li, C.L.; Gu, J.; Yin, H.L.; Chen, Z.B. Automated machine learning for secure key rate in discrete-modulated continuous-variable quantum key distribution. Opt. Express 2022, 30, 15024–15036. [Google Scholar] [CrossRef] [PubMed]








| Field of Implementation |
|---|
| E-commerce and product recommendations [8,9] |
| Image, speech, and pattern recognition [8,9] |
| User behavior analytics and context-aware smartphone applications [8,9] |
| Healthcare services [10,11,12] |
| Traffic prediction and transportation [8,13] |
| Internet of things (IoT) and smart cities [13] |
| Cybersecurity and threat intelligence [14] |
| Natural language processing and sentiment analysis [15] |
| Sustainable agriculture [16] |
| Industrial applications [17] |
| Type | Concept | Advantages | Disadvantages |
|---|---|---|---|
| Exchanging Models | Models are sent between server and clients | Ease of implementation | High communication cost Less secure |
| Exchanging Gradients | Only gradients are exchanged between entities | Lower communication cost Higher security | Local models divergence |
| Exchanging Model Parameters | Only weight and parameters are exchanged | Lower communication cost Higher security | Limitation to neural networks Unified client model architecture Not effective with big or imbalanced data |
| Hybrid Approach | Merging two or more of the above approaches | Fit for specific cases | Generated frameworks may not be re-used |
| Approach | Main Concept | Advantages | Disadvantages |
|---|---|---|---|
| Average Aggregation | Average the clients updates | Simple and easy to implement Can improve model accuracy | Sensitive to outliers and malicious clients May not perform well in cases of non-IID data |
| Clipped Average Aggregation | Clip the model updates to a predefined range before taking the average | Reduces the effect of outliers and malicious clients Can improve model accuracy | More computationally intensive |
| Secure Aggregation | Use techniques such as homomorphic encryption or secure multi-party computation to ensure privacy | Provides a high level of privacy protection Can still achieve good model accuracy | May be computationally expensive and slower than other aggregation methods Requires careful implementation and management of security protocols |
| Differential Privacy Average Aggregation | Add random noise to the model updates before aggregation to ensure privacy | Provides a high level of privacy protection | May be slower and less efficient than other aggregation methods The level of noise added can impact model accuracy |
| Momentum Aggregation | Add a momentum term to the model updates before aggregation to improve convergence speed | Can improve convergence speed and reduce the impact of noisy or slow clients | May be sensitive to the choice of momentum term and the level of noise in the updates |
| Weighted Aggregation | Weight the contributions of different clients based on performance or other factors | Can improve model accuracy by giving more weight to more reliable or representative clients | Requires careful calibration of weights and may be sensitive to bias or noise in performance metrics |
| Bayesian Aggregation | Use Bayesian inference to aggregate model updates and take uncertainty into account | Can improve model generalization and reduce overfitting | Can be computationally expensive and require large amounts of data The Bayesian model assumptions may not hold for all types of data |
| Adversarial Aggregation | Detect and mitigate the impact of malicious clients or outlier model updates | Can improve model accuracy and reduce the impact of malicious clients | May be computationally expensive and require sophisticated detection and mitigation techniques |
| Quantization | Reduce the bit representation of model updates before transmission | Can improve communication efficiency and reduce bandwidth requirements | May introduce quantization error that can impact model accuracy The level of quantization needs to be carefully chosen |
| Hierarchical Aggregation | Perform aggregation at different levels of a hierarchical structure | Can improve communication efficiency by performing local aggregation at lower levels | Requires a well-defined hierarchical structure and careful management of data and aggregation protocols |
| Personalized Aggregation | Takes clients’ unique characteristics into account | Improves model performance by adapting to individual client data | Maintains privacy, but may require additional communication and computational overhead |
| Ensemble-based Aggregation | Aggregate the model updates of multiple models trained on different subsets of the data | Can improve model accuracy by leveraging the diversity of the models | May be computationally expensive and require careful management of the ensemble models |
| Ref. | Year | Given Name | Aggregation Approach |
|---|---|---|---|
| [38] | 2017 | FedAVG | Averaging Aggregation |
| [50] | 2017 | - | Secure Aggregation |
| [51] | 2019 | RFA | Averaging Aggregation |
| [52] | 2020 | SCAFFOLD | Secure Aggregation |
| [53] | 2020 | FedOPT | Weighted Aggregation |
| FedADAGAR | Differential Privacy Average Aggregation | ||
| FedYOGI | Personalized Aggregation | ||
| FedADAM | - | ||
| [54] | 2020 | FedBoost | Ensemble-Based Aggregation |
| [55] | 2020 | FedProx | Weighted Aggregation |
| [56] | 2020 | FedMA | Personalized Aggregation |
| [57] | 2020 | - | Personalized Aggregation |
| [58] | 2020 | - | Secure Aggregation |
| [59] | 2020 | - | Personalized Aggregation |
| [60] | 2020 | LAQ | Quantization Aggregation |
| [61] | 2020 | SAFA | Secure Aggregation |
| [62] | 2021 | FedDist | Weighted Aggregation |
| [46] | 2021 | FEDHQ | Quantization Aggregation |
| [63] | 2021 | FAIR | Personalized Aggregation |
| [64] | 2021 | FedPSO | Ensemble-Based Aggregation |
| [65] | 2021 | LEGATO | Personalized Aggregation |
| [66] | 2021 | MHAT | Personalized Aggregation |
| [67] | 2021 | - | Secure Aggregation |
| [68] | 2021 | - | Weighted Aggregation |
| [69] | 2021 | SEAR | Secure Aggregation |
| [70] | 2021 | Turbo-Aggregate | Secure Aggregation |
| Personalized Aggregation | |||
| [71] | 2022 | EPPDA | Secure Aggregation |
| [72] | 2022 | FedBuff | Ensemble-Based Aggregation |
| [73] | 2022 | HeteroSAg | Secure Aggregation |
| Quantized Aggregation | |||
| [74] | 2022 | LightSecAgg | Secure Aggregation |
| Ref. | Mechanism |
|---|---|
| [50] | Secure vector summing strategy |
| [51] | Using geometric median estimated using a Weiszfeld-type algorithm |
| [67] | Refined form of the alternating direction multiplier (ADMM) |
| [69] | Hardware-based trusted execution environment instead of complex cryptographic tools |
| [71] | Homomorphisms of the secret exchange |
| [73] | Masking each user’s model update |
| Ref. | Mechanism |
|---|---|
| [50,60,73] | Quantization |
| [52] | Exchanging the control variate term |
| [56] | Matched averaging |
| [57] | Analog network coding technique |
| [59] | Selective aggregation |
| [61] | Semi-asynchronous protocol |
| [64] | Particle swarm optimization (PSO) |
| [65] | Gradient aggregation on a per-layer basis |
| [54,58] | Model compression |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moshawrab, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Reviewing Federated Learning Aggregation Algorithms; Strategies, Contributions, Limitations and Future Perspectives. Electronics 2023, 12, 2287. https://doi.org/10.3390/electronics12102287
Moshawrab M, Adda M, Bouzouane A, Ibrahim H, Raad A. Reviewing Federated Learning Aggregation Algorithms; Strategies, Contributions, Limitations and Future Perspectives. Electronics. 2023; 12(10):2287. https://doi.org/10.3390/electronics12102287
Chicago/Turabian StyleMoshawrab, Mohammad, Mehdi Adda, Abdenour Bouzouane, Hussein Ibrahim, and Ali Raad. 2023. "Reviewing Federated Learning Aggregation Algorithms; Strategies, Contributions, Limitations and Future Perspectives" Electronics 12, no. 10: 2287. https://doi.org/10.3390/electronics12102287