
An Efficient Ship-Detection Algorithm Based on the Improved YOLOv5
Abstract
:1. Introduction
2. Materials and Methods
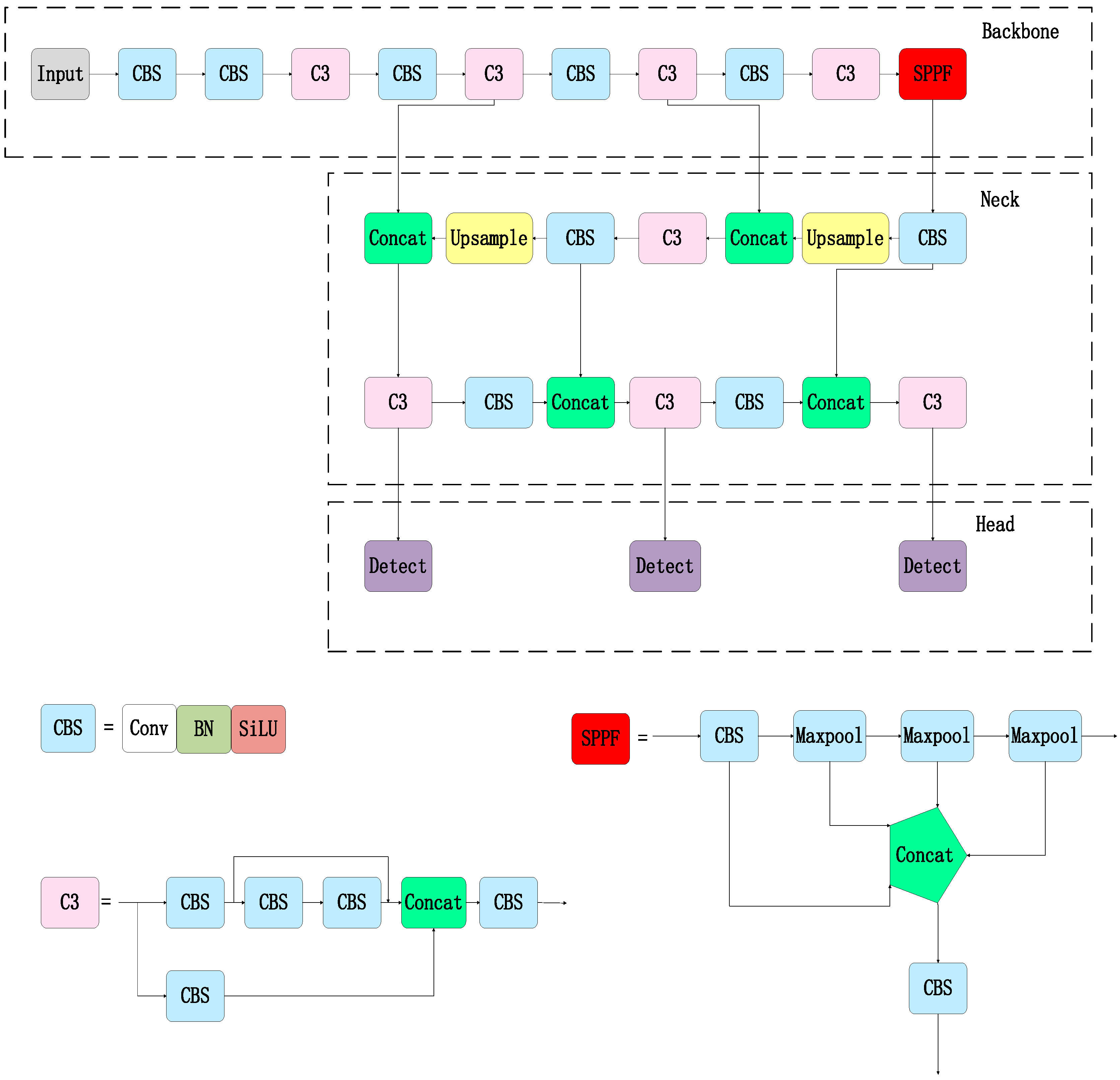
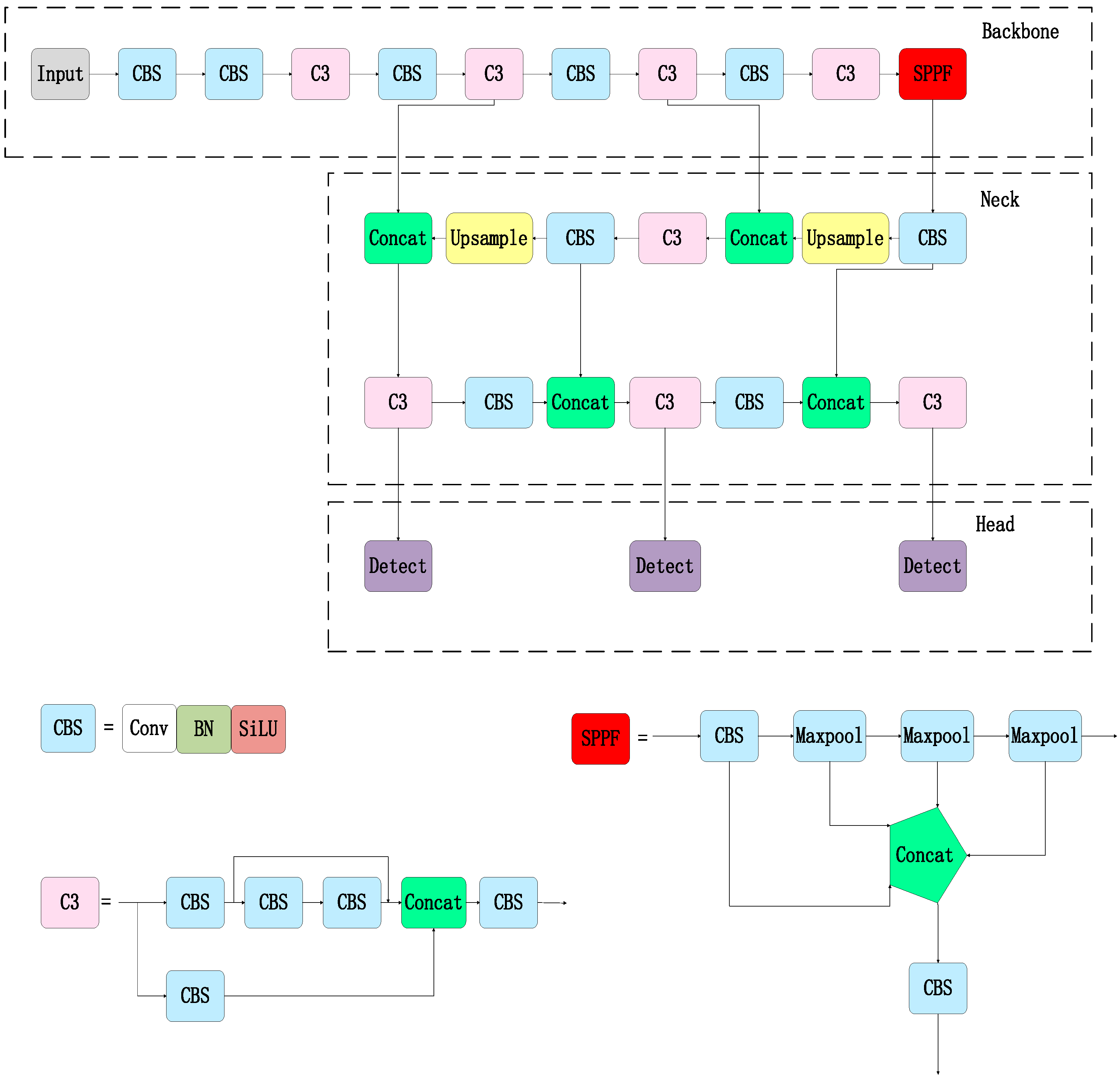
2.1. YOLOv5 Model
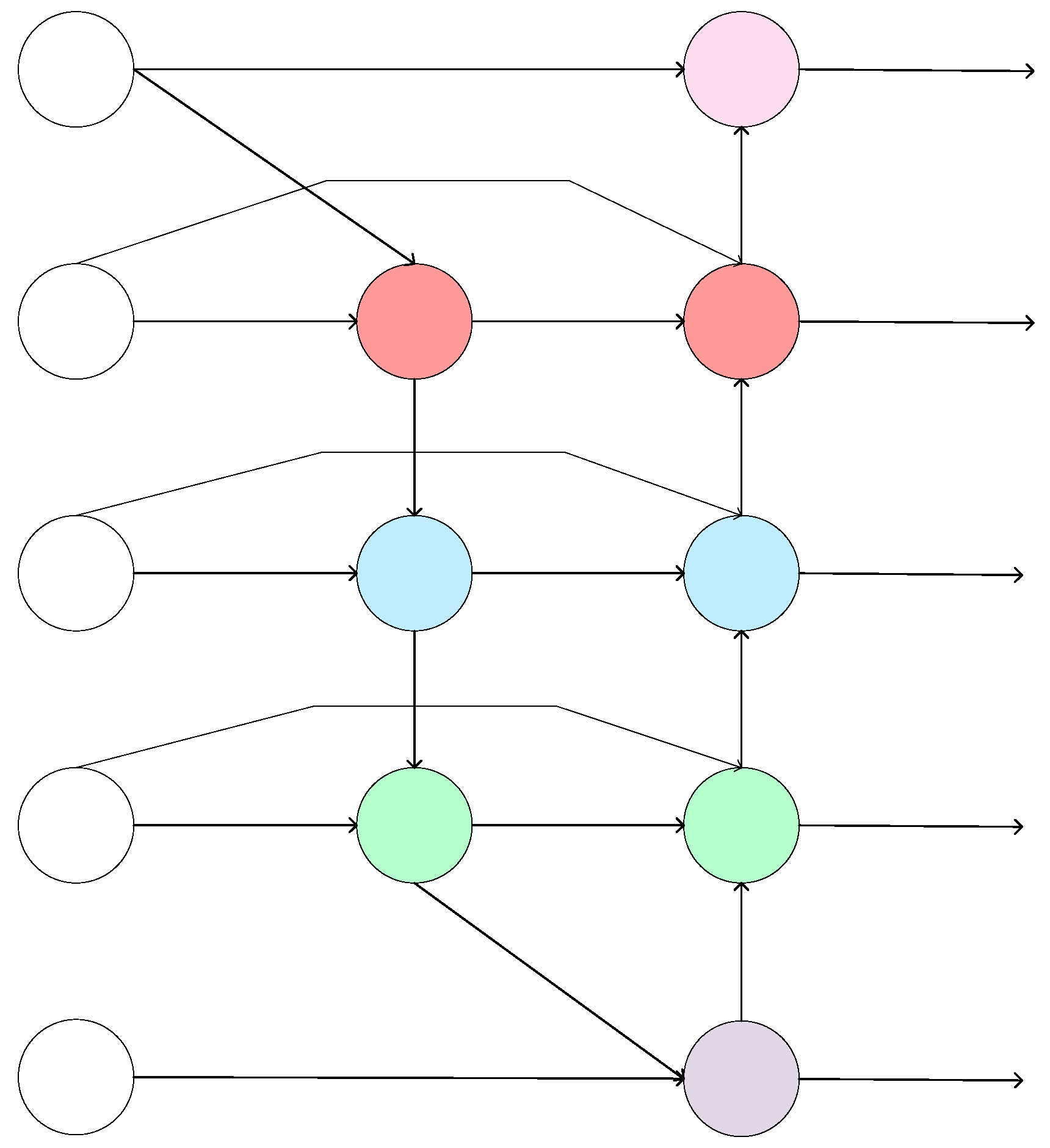
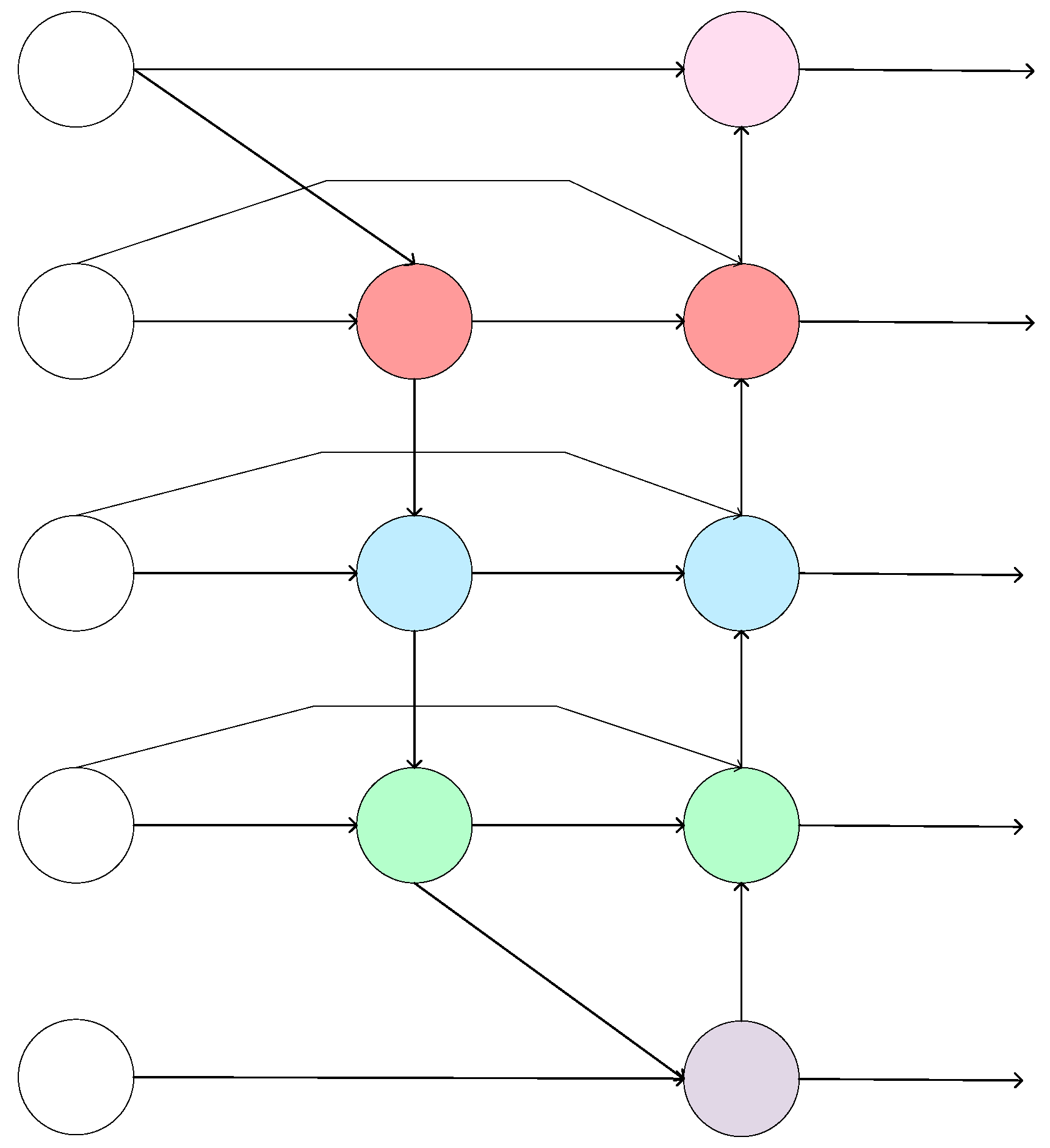
2.2. BiFPN Model
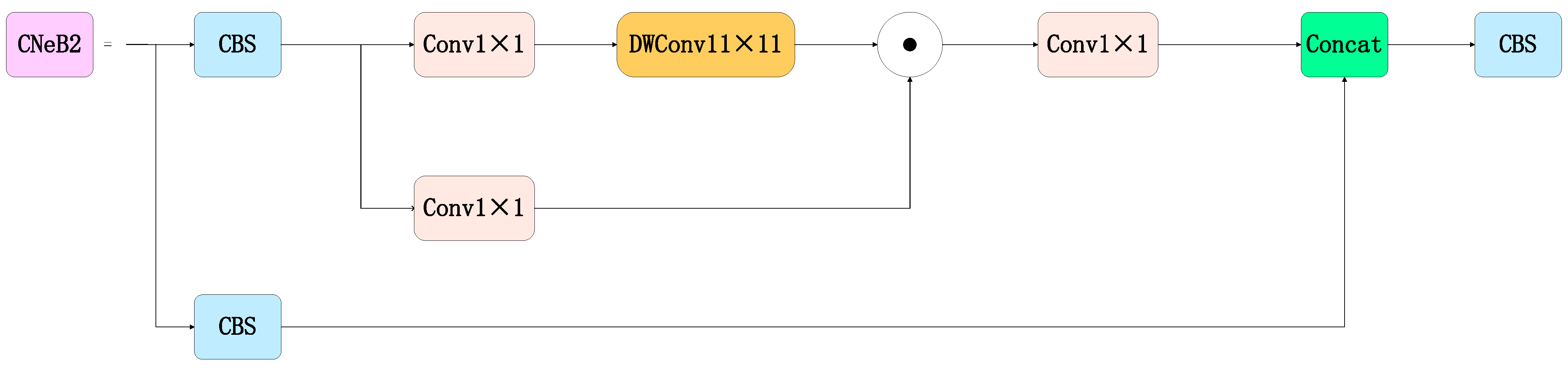
2.3. CNeB2 Module
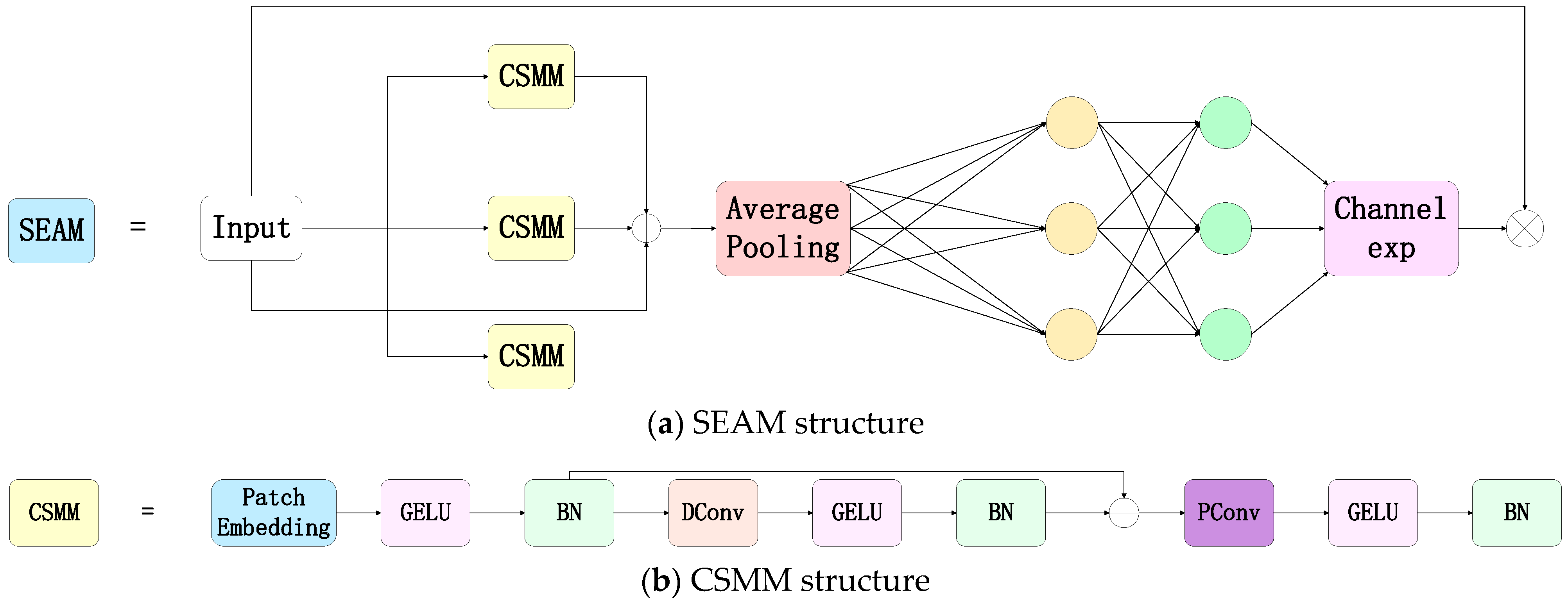
2.4. SEAM
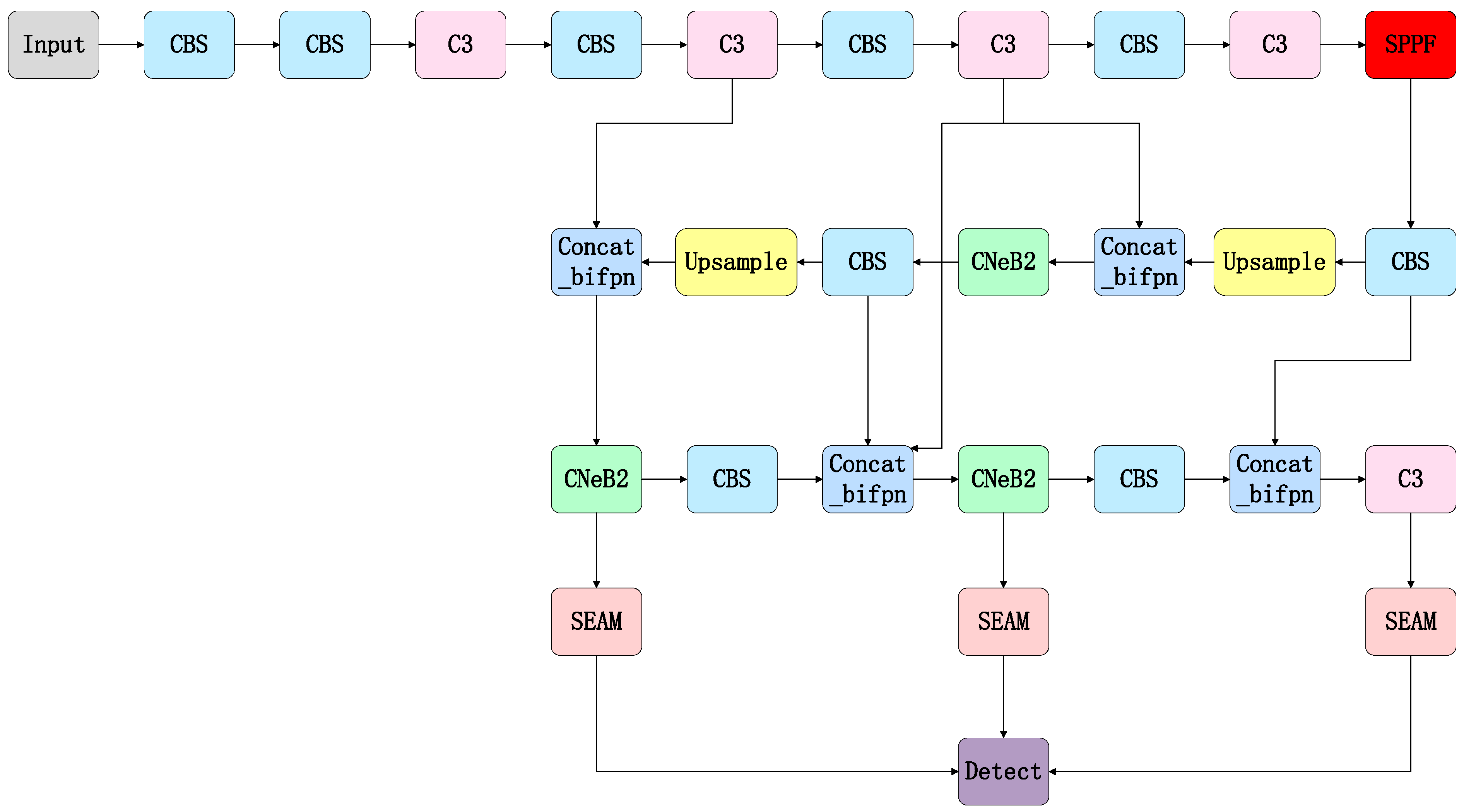
2.5. Proposed Improved Algorithm
3. Experiments
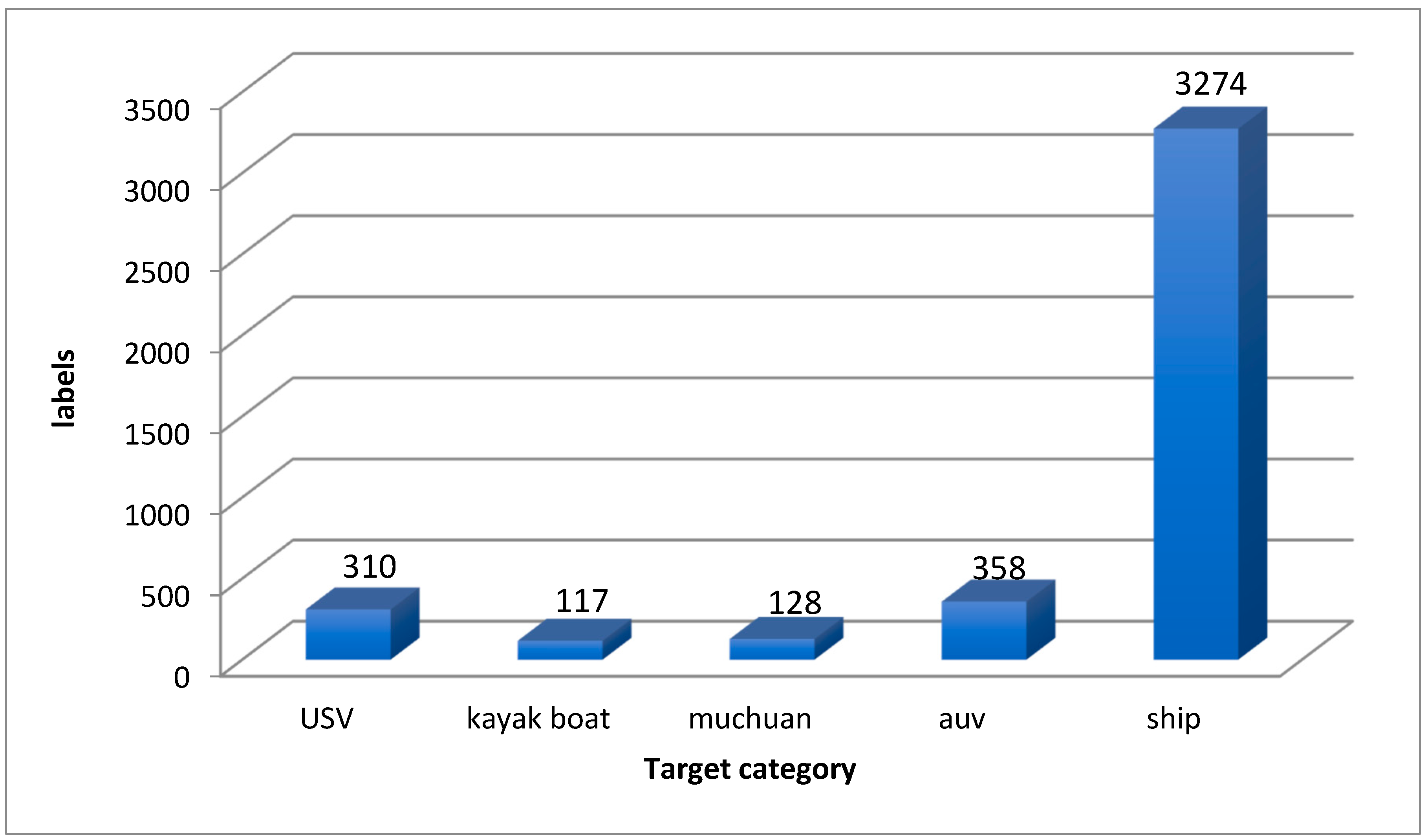
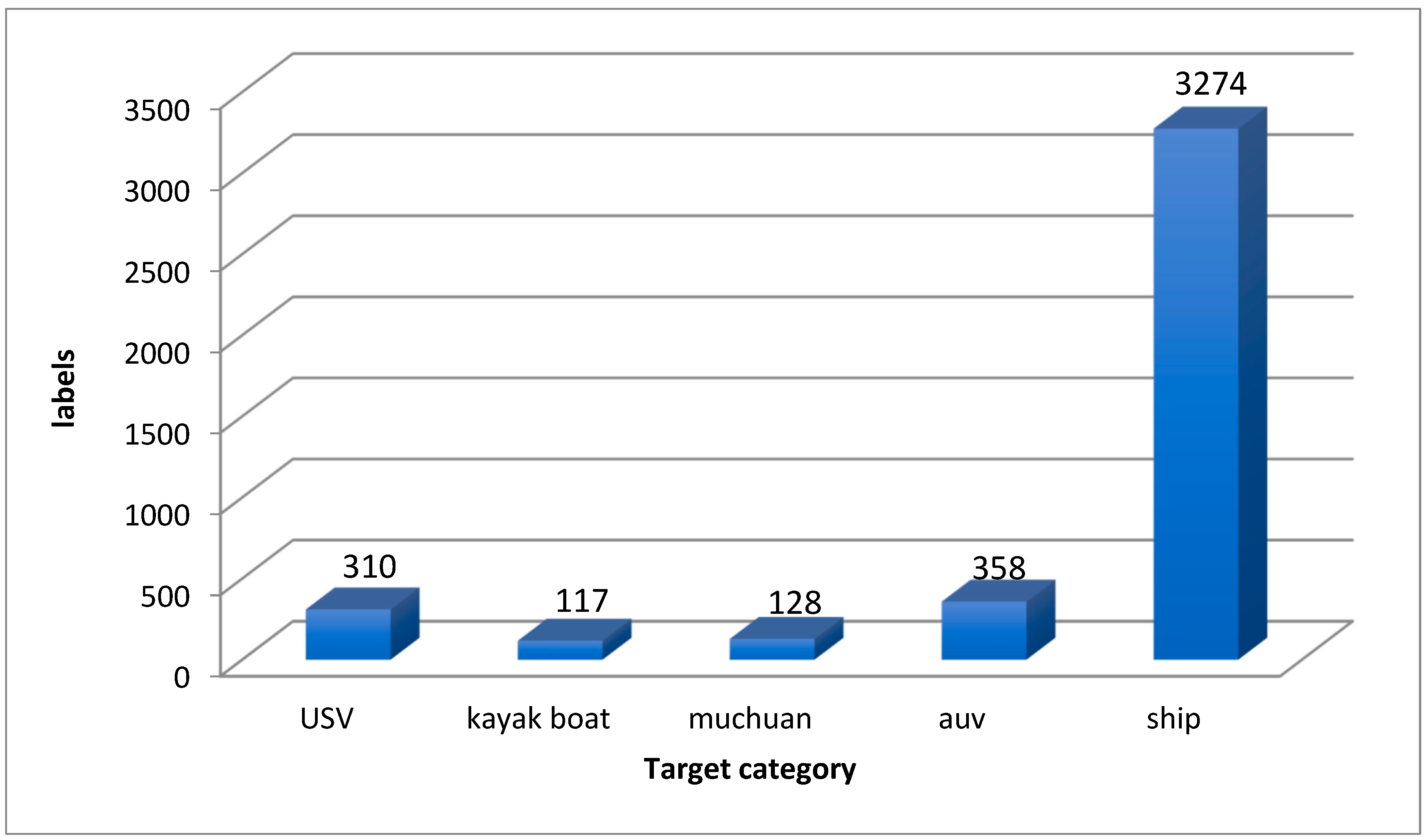
3.1. Experimental Dataset
3.2. Experimental Platform and Parameter Settings
3.3. Experimental Design
3.3.1. Evaluation Indexes
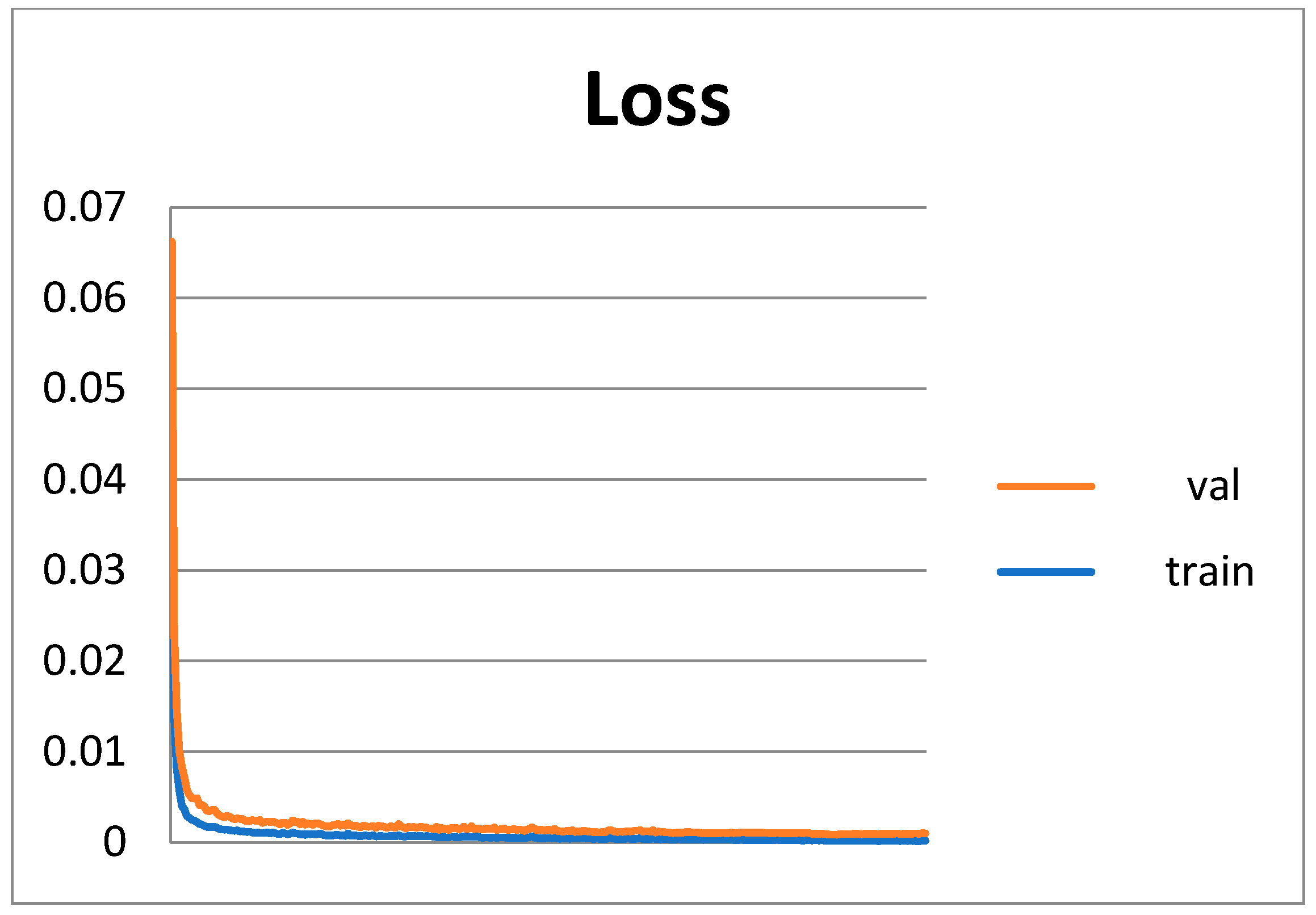
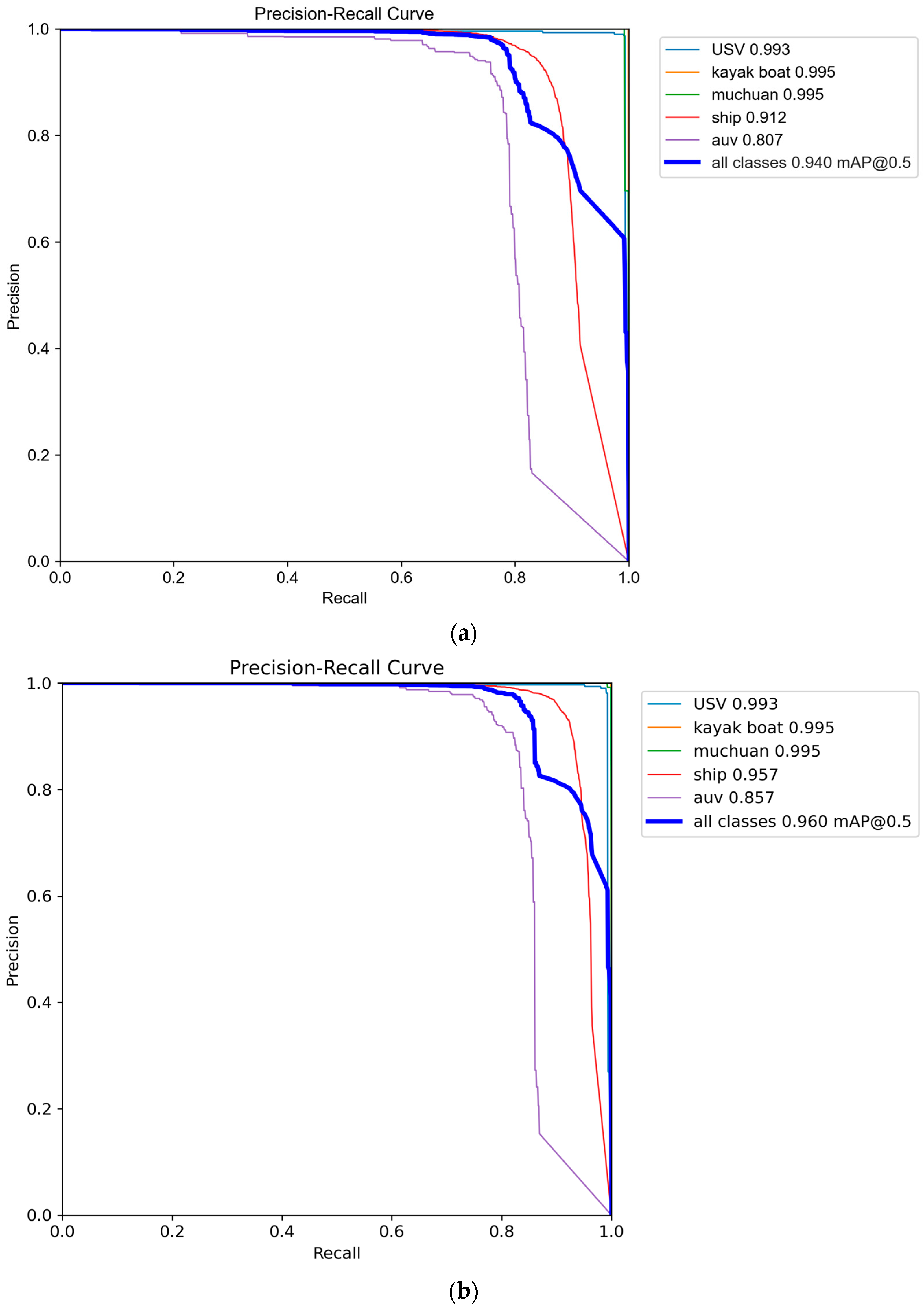
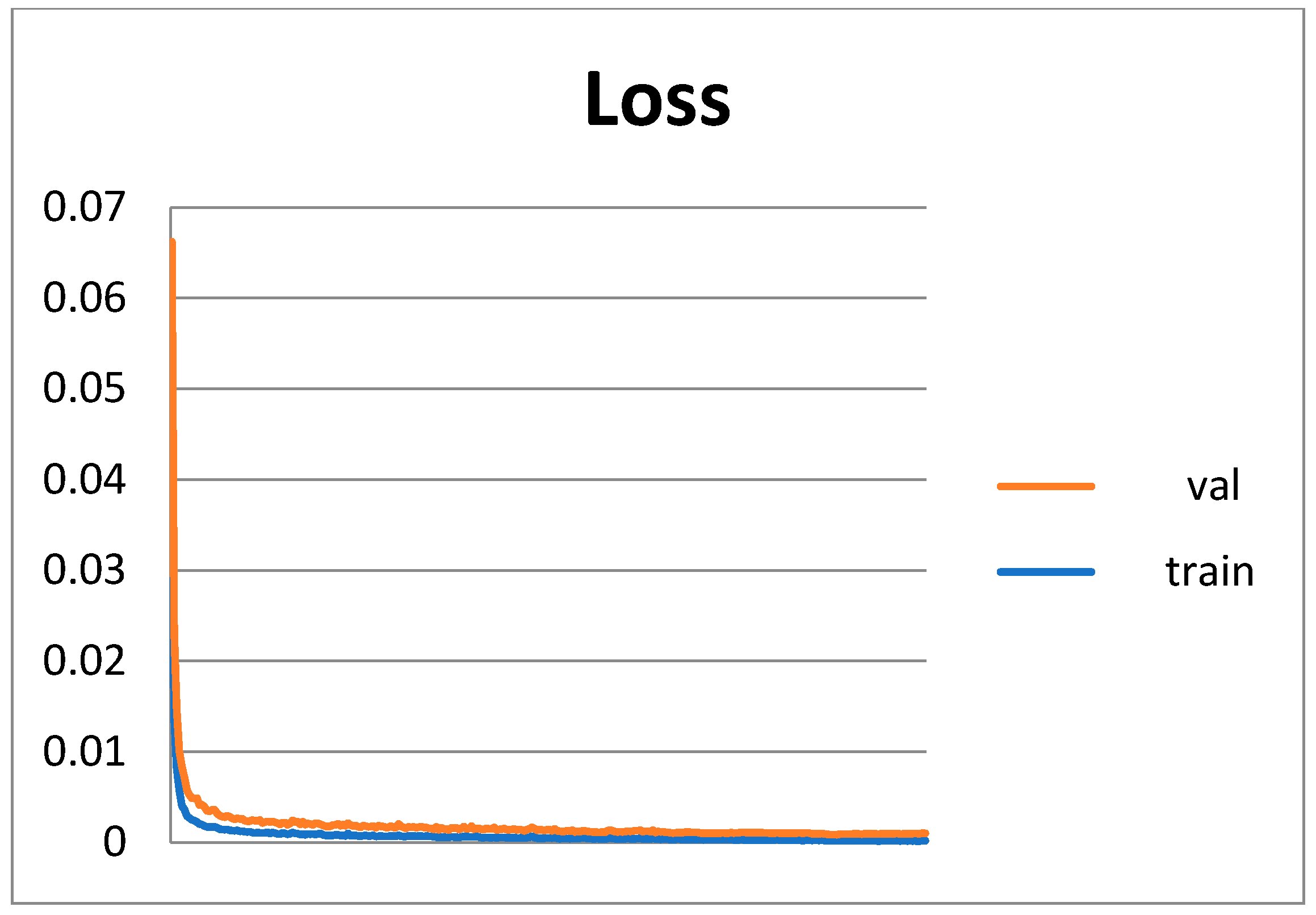
3.3.2. Experimental Results
4. Discussion
4.1. Ablation Experiments
4.2. Comparative Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Laurent, C.; Sébastien, M. On the detection of morphing attacks generated by GANs. In Proceedings of the 2022 International Conference of the Biometrics Special Interest Group, Darmstadt, Germany, 14–16 September 2022. [Google Scholar]
- Gómez, J.K.C.; Puentes, Y.A.N.; Niño, D.D.C.; Acevedo, C.M.D. Detection of Pesticides in Water through an Electronic Tongue and Data Processing Methods. Water 2023, 15, 624. [Google Scholar] [CrossRef]
- Xie, Z.; Du, S.; Lv, J.; Deng, Y.; Jia, S. A Hybrid Prognostics Deep Learning Model for Remaining Useful Life Prediction. Electronics 2021, 10, 39. [Google Scholar] [CrossRef]
- Liu, S.; You, S.; Yin, H.; Lin, Z.; Liu, Y.; Cui, Y.; Yao, W.; Sundaresh, L. Data source authentication for wide–area synchrophasor measurements based on spatial signature extraction and quadratic kernel SVM. Int. J. Electr. Power Energy Syst. 2022, 140, 108083. [Google Scholar] [CrossRef]
- Jason, H.; Lyons, D.M. Wall Detection Via IMU Data Classification In Autonomous Quadcopters. In Proceedings of the 7th International Conference on Control, Automation and Robotics, Singapore, 23–26 April 2021. [Google Scholar]
- Yan, K.; Li, Q.; Li, H.; Wang, H.; Fang, Y.; Xing, L.; Yang, Y.; Bai, H.; Zhou, C. Deep learning–based substation remote construction management and AI automatic violation detection system. IET Gener. Transm. Distrib. 2022, 9, 16. [Google Scholar] [CrossRef]
- Jesse, R.; Polina, D.; Josh, S.; Bryant, T.C.; Ross, M.; Tim, R.; Andrew, M.K. 7 Characterization of Feeder Cattle Behavior Using an Integrated Machine Vision Learning System. J. Anim. Sci. 2022, 100, 23–24. [Google Scholar]
- Oguine, K.J.; Oguine, O.C.; Bisallah, H.I. YOLO v3: Visual and Real–Time Object Detection Model for Smart Surveillance Systems (3s). In Proceedings of the 5th Information Technology for Education and Development, Abuja, Nigeria, 6–8 September 2022. [Google Scholar]
- Kabra, K.; Xiong, A.; Li, W.; Luo, M.; Lu, W.; Garcia, R.; Vijay, D.; Yu, J.; Tang, M.; Yu, T.; et al. Deep object detection for waterbird monitoring using aerial imagery. In Proceedings of the 21st IEEE International Conference on Machine Learning and Applications, Nassau, Bahamas, 12–15 December 2022. [Google Scholar]
- Li, L.; Guo, X.; Wang, Y.; Ma, J.; Jiao, L.; Fang, L.; Xu, L. Region NMS–based deep network for gigapixel level pedestrian detection with two–step cropping. Neurocomputing 2022, 468, 482–491. [Google Scholar] [CrossRef]
- Maji, D.; Nagori, S.; Mathew, M.; Poddar, D. YOLO–Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Gilroy, S.; Jones, E.; Glavin, M. Overcoming Occlusion in the Automotive Environment—A Review. IEEE Trans. Intell. Transp. Syst. 2021, 22, 23–35. [Google Scholar] [CrossRef]
- Chen, N.; Li, M.; Yuan, H.; Su, X.; Li, Y. Survey of pedestrian detection with occlusion. Complex Intell. Syst. 2021, 7, 577–587. [Google Scholar]
- Zhang, J.; Liu, C.; Wang, B.; Chen, C.; He, J.; Zhou, Y.; Li, J. An infrared pedestrian detection method based on segmentation and domain adaptation learning. Comput. Electr. Eng. 2022, 99, 107781. [Google Scholar] [CrossRef]
- Alotaibi, M.F.; Omri, M.; Khalek, S.A.; Khalil, E.; Mansour, R.F. Computational Intelligence–Based Harmony Search Algorithm for Real–Time Object Detection and Tracking in Video Surveillance Systems. Mathematics 2022, 10, 733. [Google Scholar] [CrossRef]
- Leira, F.S.; Helgesen, H.H.; Johansen, T.A.; Fossen, T.I. Object detection, recognition, and tracking from UAVs using a thermal camera. J. Field Robot. 2021, 38, 242–267. [Google Scholar] [CrossRef]
- Ong, J.; Vo, B.; Kim, D.Y.; Nordholm, S. A Bayesian Filter for Multi–View 3D Multi–Object Tracking with Occlusion Handling. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2246–2263. [Google Scholar] [CrossRef] [PubMed]
- Zeng, D.; Veldhuis, R.; Spreeuwers, L. A survey of face recognition techniques under occlusion. IET Biom. 2021, 10, 581–606. [Google Scholar] [CrossRef]
- Yang, T.; Wu, J.; Liu, L.; Chang, X.; Feng, G. VTD–Net: Depth Face Forgery Oriented Video Tampering Detection based on Convolutional Neural Network. In Proceedings of the 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020. [Google Scholar]
- Shi, Y.; Guo, Y.; Mi, Z.; Li, X. Stereo CenterNet–based 3D object detection for autonomous driving. Neurocomputing 2022, 471, 219–229. [Google Scholar] [CrossRef]
- Zhou, Z.; Du, L.; Ye, X.; Zou, Z.; Tan, X.; Zhang, L.; Xue, X.; Feng, J. SGM3D: Stereo Guided Monocular 3D Object Detection. IEEE Robot. Autom. Lett. 2022, 7, 10478–10485. [Google Scholar] [CrossRef]
- Jiang, H.; Lu, Y.; Chen, S. Research on 3D Point Cloud Object Detection Algorithm for Autonomous Driving. Math. Probl. Eng. 2022, 2022, 8151805. [Google Scholar] [CrossRef]
- Pillai, U.K.; Valles, D. An Initial Deep CNN Design Approach for Identification of Vehicle Color and Type for Amber and Silver Alerts. In Proceedings of the 2021 IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 27–30 January 2021. [Google Scholar]
- Lian, J.; Wang, D.; Zhu, S.; Wu, Y.; Li, C. Transformer–Based Attention Network for Vehicle Re–Identification. Electronics 2022, 11, 1016. [Google Scholar] [CrossRef]
- Hu, R.; Ma, W.; Lin, W.; Chen, X.; Zhong, Z.; Zeng, C. Technology Topic Identification and Trend Prediction of New Energy Vehicle Using LDA Modeling. Complexity 2022, 2022, 9373911. [Google Scholar] [CrossRef]
- Chen, X.; Lv, J.; Fang, Y.; Du, S. Online detection of surface defects based on improved YOLOV3. Sensors 2022, 22, 817. [Google Scholar] [CrossRef]
- Dmitriev, S.F.; Malikov, V.; Ishkov, A.; Voinash, S.; Kalimullin, M.; Marat, S.; Liliya, N. Ultra–Compact Eddy Current Transducer for Corrosion Defect Search in Steel Pipes. Mater. Sci. Forum 2022, 1049, 282–288. [Google Scholar] [CrossRef]
- Ma, W.; Gong, C.; Xu, S.; Zhang, X. Multi–scale spatial context–based semantic edge detection. Inf. Fusion 2020, 64, 238–251. [Google Scholar] [CrossRef]
- Li, J.; Wang, P.; Ni, C.; Rong, W. Loop Closure Detection Based on Image Semantic Segmentation in Indoor Environment. Math. Probl. Eng. 2022, 2022, 7765479. [Google Scholar] [CrossRef]
- Sheng, L.; Min, Z.; Xi, C.; Liang, W.; Xu, M.; Wang, H. Hyperspectral Anomaly Detection via Dual Dictionaries Construction Guided by Two–Stage Complementary Decision. Remote Sens. 2022, 14, 1784. [Google Scholar]
- Lin, S.; Zhang, M.; Cheng, X.; Zhou, K.; Zhao, S. Hyperspectral Anomaly Detection via Sparse Representation and Collaborative Representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 946–961. [Google Scholar] [CrossRef]
- Lim, J.; Astrid, M.; Yoon, H.; Lee, S. Small Object Detection using Context and Attention. In Proceedings of the 2021 International Conference on Artificial Intelligence in Information and Communication, Jeju Island, Republic of Korea, 13–16 April 2021. [Google Scholar]
- Deng, C.; Wang, M.; Liu, L.; Liu, Y. Extended Feature Pyramid Network for Small Object Detection. IEEE Trans. Multimed. 2020, 24, 1968–1979. [Google Scholar] [CrossRef]
- Li, W.; Wei, Y.; Lyu, S.; Chang, M.C. Simultaneous multi–person tracking and activity recognition based on cohesive cluster search. Comput. Vis. Image Underst. 2022, 214, 214. [Google Scholar] [CrossRef]
- Wang, Z.; Xie, Q.; Wei, M.; Long, K.; Wang, J. Multi–feature Fusion VoteNet for 3D Object Detection. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–17. [Google Scholar] [CrossRef]
- Zhora, G. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise–IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Feng, H.; Jie, S.; Hang, M.; Wang, R.; Fang, F.; Zhang, G. A novel framework on intelligent detection for module defects of PV plant combining the visible and infrared images. Sol. Energy 2022, 236, 406–416. [Google Scholar]
- Zhou, Q.; Liu, H.; Qiu, Y.; Zheng, W. Object Detection for Construction Waste Based on an Improved YOLOv5 Model. Sustainability 2023, 15, 681. [Google Scholar] [CrossRef]
- Jubayer, F.; Soeb, J.; Mojumder, A.; Paul, M.; Barua, P.; Kayshar, S.; Akter, S.S.; Rahman, M.; Islam, A. Detection of mold on the food surface using YOLOv5. Curr. Res. Food Sci. 2021, 4, 724–728. [Google Scholar] [CrossRef] [PubMed]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Yu, Z.; Huang, H.; Chen, W.; Su, Y.; Liu, Y.; Wang, X. YOLO–FaceV2: A Scale and Occlusion Aware Face Detector. arXiv 2022, arXiv:2208.02019. [Google Scholar]
- Hou, Q.; Lu, C.; Cheng, M.; Feng, J. Conv2Former: A Simple Transformer–Style ConvNet for Visual Recognition. arXiv 2022, arXiv:2211.11943. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | mAP (%) | FPS (Frame/s) |
|---|---|---|
| YOLOv5s | 94.0 | 67.56 |
| YOLOv5s + BiFPN | 94.8 | 65.36 |
| YOLOv5s + SEAM | 94.3 | 66.67 |
| YOLOv5s + CNeB2 | 94.4 | 72.46 |
| YOLOv5s + BiFPN + SEAM | 95 | 64.12 |
| YOLOv5s + BiFPN + CNeB2 | 95.5 | 71.42 |
| YOLOv5s + CNeB2 + SEAM | 94.6 | 70.92 |
| YOLOv5s + BiFPN + CNeB2 + SEAM | 96 | 66.23 |
| Algorithm | USV (%) | Kayak Boat (%) | Muchuan (%) | Ship (%) | AUV (%) | mAP (%) | FPS (Frame/s) |
|---|---|---|---|---|---|---|---|
| Faster R-CNN | 70.4 | 94.2 | 97.8 | 43.1 | 59.2 | 72.9 | 19.84 |
| SSD | 90.8 | 95.6 | 92.4 | 81.2 | 74.1 | 86.8 | 30.64 |
| YOLOv4 | 88.2 | 99.8 | 100.0 | 85.4 | 79.6 | 90.6 | 28.11 |
| YOLOv5 | 99.3 | 99.5 | 99.5 | 91.2 | 80.7 | 94.0 | 67.56 |
| YOLOv7 | 95.8 | 99.5 | 97.5 | 91.2 | 79.4 | 92.7 | 61.35 |
| Ours | 99.3 | 99.5 | 99.5 | 95.7 | 85.7 | 96.0 | 66.23 |
| Algorithm | USV (%) | Kayak Boat (%) | Muchuan (%) | Ship (%) | AUV (%) | All (%) |
|---|---|---|---|---|---|---|
| Faster R-CNN | 41.4 | 51.9 | 59.2 | 59.7 | 60.2 | 54.5 |
| SSD | 92.9 | 100.0 | 100.0 | 96.1 | 97.3 | 97.3 |
| YOLOv4 | 95.4 | 100.0 | 100.0 | 88.5 | 85.7 | 93.9 |
| YOLOv5 | 98.8 | 99.1 | 100.0 | 91.3 | 94.0 | 96.6 |
| YOLOv7 | 91.2 | 95.4 | 95.3 | 67.7 | 87.5 | 90.9 |
| Ours | 99.0 | 99.0 | 99.8 | 96.4 | 96.8 | 98.2 |
| Algorithm | USV (%) | Kayak Boat (%) | Muchuan (%) | Ship (%) | AUV (%) | All (%) |
|---|---|---|---|---|---|---|
| Faster R-CNN | 74.0 | 97.6 | 100.0 | 45.3 | 58.4 | 75.0 |
| SSD | 62.8 | 92.6 | 64.0 | 50.9 | 35.6 | 61.2 |
| YOLOv4 | 84.6 | 95.2 | 97.6 | 81.8 | 71.3 | 86.1 |
| YOLOv5 | 99.0 | 100.0 | 99.2 | 85.6 | 74.1 | 91.6 |
| YOLOv7 | 80.6 | 98.3 | 95.3 | 75.4 | 47.5 | 77.9 |
| Ours | 98.9 | 100.0 | 99.2 | 89.9 | 76.0 | 92.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Pan, Q.; Lu, D.; Zhang, Y. An Efficient Ship-Detection Algorithm Based on the Improved YOLOv5. Electronics 2023, 12, 3600. https://doi.org/10.3390/electronics12173600
Wang J, Pan Q, Lu D, Zhang Y. An Efficient Ship-Detection Algorithm Based on the Improved YOLOv5. Electronics. 2023; 12(17):3600. https://doi.org/10.3390/electronics12173600
Chicago/Turabian StyleWang, Jia, Qiaoruo Pan, Daohua Lu, and Yushuang Zhang. 2023. "An Efficient Ship-Detection Algorithm Based on the Improved YOLOv5" Electronics 12, no. 17: 3600. https://doi.org/10.3390/electronics12173600
APA StyleWang, J., Pan, Q., Lu, D., & Zhang, Y. (2023). An Efficient Ship-Detection Algorithm Based on the Improved YOLOv5. Electronics, 12(17), 3600. https://doi.org/10.3390/electronics12173600