

Infrared Dim and Small Target Sequence Dataset Generation Method Based on Generative Adversarial Networks
 ,
,
Abstract
:1. Introduction
2. Related Principles
2.1. Infrared Background Generation Based on an Improved Deep Convolutional Generative Adversarial Network
2.1.1. Deep Convolutional Generative Adversarial Networks
2.1.2. ISD-DCGAN Networks
2.2. Target–Background Image Sequence Construction Based on Improved Conditional Generative Adversarial Networks
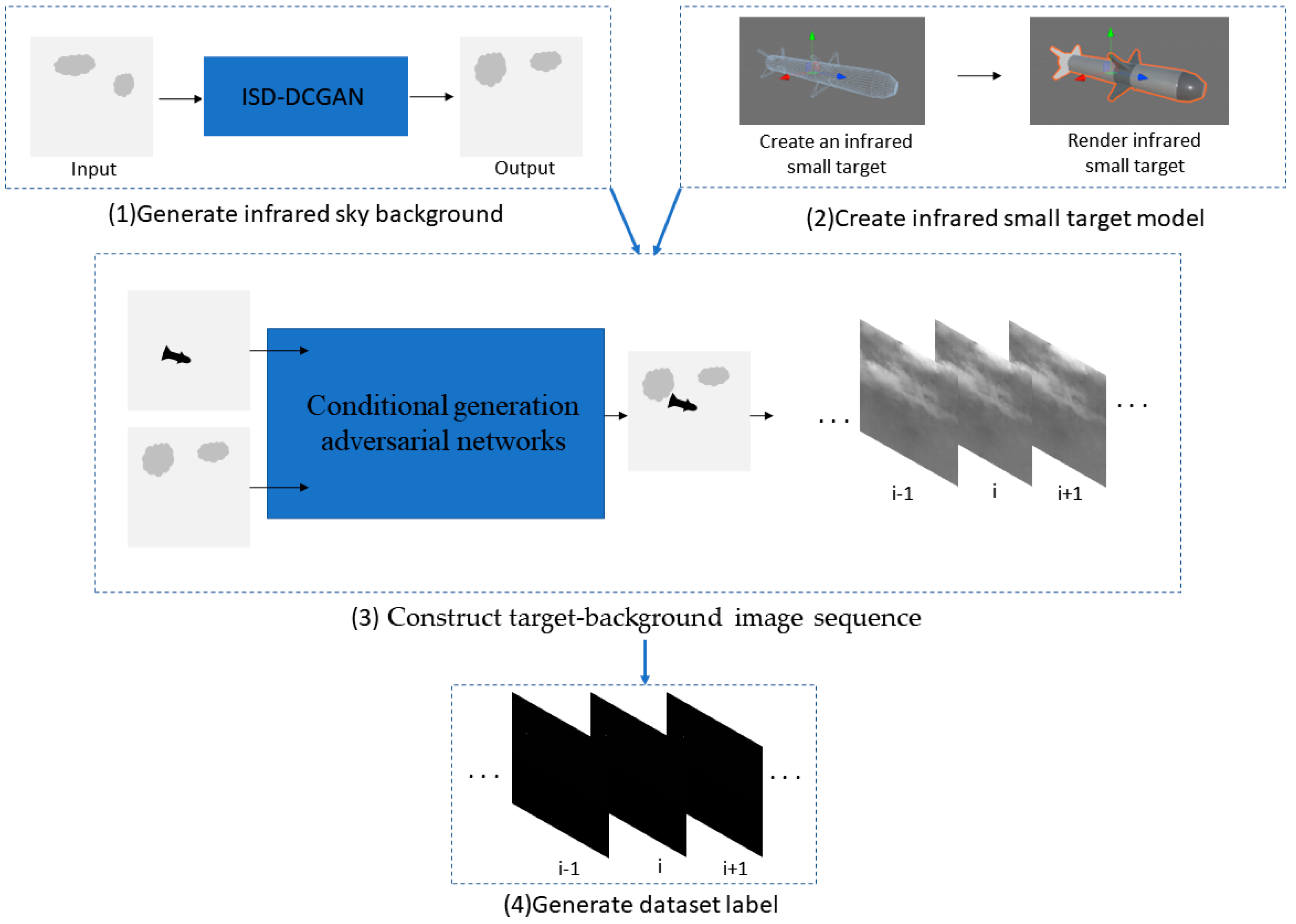
3. Method
3.1. Generating an Infrared Sky Background
3.2. Creating an Infrared Small Target Model
3.3. Constructing a Target–Background Image Sequence and Generating Datasets
3.4. Generating Dataset Labels
4. Experiments
4.1. Experimental Results
4.2. Experimental Evaluation
4.2.1. Comparison between DCGAN and ISD-DCGAN
4.2.2. Structure Similarity Index Measure
4.2.3. Comparative Analysis with Other Datasets
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Deng, L.; Zhang, J.; Xu, G.; Zhu, H. Infrared small target detection via adaptive M-estimator ring top-hat transformation. Pattern Recognit. 2021, 112, 107729. [Google Scholar] [CrossRef]
- Bae, T.W. Small target detection using bilateral filter and temporal cross product in infrared images. Infrared Phys. Technol. 2011, 54, 403–411. [Google Scholar] [CrossRef]
- Chen, C.P.; Li, H.; Wei, Y.; Xia, T.; Tang, Y.Y. A Local Contrast Method for Small Infrared Target Detection. IEEE Trans. Geosci. Remote Sens. 2014, 52, 574–581. [Google Scholar] [CrossRef]
- Han, J.; Ma, Y.; Zhou, B.; Fan, F.; Liang, K.; Fang, Y. A Robust Infrared Small Target Detection Algorithm Based on Human Visual System. IEEE Geosci. Remote Sens. Lett. 2014, 11, 2168–2172. [Google Scholar]
- Han, J.H.; Liang, K.; Zhou, B.; Zhu, X.Y.; Zhao, J.; Zhao, L.L. Infrared Small Target Detection Utilizing the Multiscale Relative Local Contrast Measure. IEEE Trans. Geosci. Remote Sens. 2018, 15, 612–616. [Google Scholar] [CrossRef]
- Wei, Y.; You, X.; Li, H. Multiscale patch-based contrast measure for small infrared target detection. Pattern Recognit. 2016, 58, 216–226. [Google Scholar] [CrossRef]
- Deng, H.; Sun, X.; Liu, M.; Ye, C.; Zhou, X. Small Infrared Target Detection Based on Weighted Local Difference Measure. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4204–4214. [Google Scholar] [CrossRef]
- Zhang, L.; Peng, L.; Zhang, T.; Cao, S.; Peng, Z. Infrared small target detection via non-convex rank approximation minimization joint l2,1 norm. Remote Sens. 2018, 10, 1821. [Google Scholar] [CrossRef]
- Zhang, T.; Wu, H.; Liu, Y.; Peng, L.; Yang, C.; Peng, Z.; Zhang, T. Infrared small target detection based on non-convex optimization with Lp-norm constraint. Remote Sens. 2019, 11, 559. [Google Scholar] [CrossRef]
- Tz, A.; Zp, A.; Hao, W.A.; Yh, A.; Cl, B.; Cy, A. Infrared small target detection via self-regularized weighted sparse model. Neurocomputing 2021, 420, 124–148. [Google Scholar]
- Zhang, C.; He, Y.; Tang, Q.; Chen, Z.; Mu, T. Infrared Small target detection via interpatch correlation enhancement and joint local visual saliency prior. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5001314. [Google Scholar] [CrossRef]
- Cao, Z.; Kong, X.; Zhu, Q.; Cao, S.; Peng, Z. Infrared dim target detection via mode-k1k2 extension tensor tubal rank under complex ocean environment. ISPRS J. Photogramm. Remote Sens. 2021, 181, 167–190. [Google Scholar] [CrossRef]
- Zhang, P.; Zhang, L.; Wang, X.; Shen, F.; Pu, T.; Fei, C. Edge and Corner Awareness-Based Spatial-Temporal Tensor Model for Infrared Small-Target Detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10708–10724. [Google Scholar] [CrossRef]
- Kong, X.; Yang, C.; Cao, S.; Li, C.; Peng, Z. Infrared small target detection via nonconvex tensor fibered rank approximation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 3068465. [Google Scholar] [CrossRef]
- Wang, H.; Zhou, L.; Wang, L. Miss Detection vs. False Alarm: Adversarial Learning for Small Object Segmentation in Infrared Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8509–8518. [Google Scholar]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Asymmetric contextual modulation for infrared small target detection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 950–959. [Google Scholar]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Attentional local contrast networks for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9813–9824. [Google Scholar] [CrossRef]
- Li, B.; Xiao, C.; Wang, L.; Wang, Y.; Lin, Z.; Li, M.; An, W.; Guo, Y. Dense nested attention network for infrared small target detection. IEEE Trans. Image Process. 2023, 32, 1745–1758. [Google Scholar]
- Zhang, T.; Cao, S.; Pu, T.; Peng, Z. Agpcnet: Attention-guided pyramid context networks for infrared small target detection. arXiv 2021, arXiv:2111.03580. [Google Scholar]
- Wang, K.W.; Du, S.Y.; Liu, C.X.; Cao, Z.G. Interior Attention-Aware Network for Infrared Small Target Detection. IEEE Geosci. Remote Sens. 2022, 60, 5002013. [Google Scholar] [CrossRef]
- Tartakovsky, A.; Kligys, S.; Petrov, A. Adaptive sequential algorithms for detecting targets in a heavy IR clutter. In Proceedings of the SPIE’s International Symposium on Optical Science, Engineering, and Instrumentation, Denver, CO, USA, 18–23 July 1999. [Google Scholar]
- van den Oord, A.; Kalchbrenner, N.; Kavukcuoglu, K. Pixel Recurrent Neural Networks. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1747–1756. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139–144. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5907–5915. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Uddin, M.S.; Hoque, R.; Islam, K.A.; Kwan, C.; Gribben, D.; Li, J. Converting Optical Videos to Infrared Videos Using Attention GAN and Its Impact on Target Detection and Classification Performance. Remote Sens. 2021, 13, 3257. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Dong, T.; Shang, W.; Zhu, H. Naive Bayesian Classifier Based on the Improved Feature Weighting Algorithm. In Advanced Research on Computer Science and Information Engineering; Shen, G., Huang, X., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 142–147. [Google Scholar]
- Zhang, Y.; Fang, Q.; Qian, S.; Xu, C. Knowledge-aware Attentive Wasserstein Adversarial Dialogue Response Generation. ACM Trans. Intell. Syst. Technol. 2020, 11, 37. [Google Scholar] [CrossRef]
- Zhou, W.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) NIR | (b) NIR with Added Noise | (c) FIR | (d) Dataset Labels | |
|---|---|---|---|---|
| Single target |  |  |  |  |
| Multiple targets |  |  |  |  |
| Model | Data Set | ||
|---|---|---|---|
| IAANET | MDvsFA | 0.642 | 0.811 |
| IAANET | Ours | 0.705 | 0.753 |
| AGPCNET | MDvsFA | 0.593 | 0.282 |
| AGPCNET | Ours | 0.634 | 0.244 |
| DNANET | MDvsFA | 0.883 | 0.883 |
| DNANET | Ours | 0.904 | 0.794 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Lin, W.; Shen, Z.; Zhang, D.; Xu, B.; Wang, K.; Chen, J. Infrared Dim and Small Target Sequence Dataset Generation Method Based on Generative Adversarial Networks. Electronics 2023, 12, 3625. https://doi.org/10.3390/electronics12173625
Zhang L, Lin W, Shen Z, Zhang D, Xu B, Wang K, Chen J. Infrared Dim and Small Target Sequence Dataset Generation Method Based on Generative Adversarial Networks. Electronics. 2023; 12(17):3625. https://doi.org/10.3390/electronics12173625
Chicago/Turabian StyleZhang, Leihong, Weihong Lin, Zimin Shen, Dawei Zhang, Banglian Xu, Kaimin Wang, and Jian Chen. 2023. "Infrared Dim and Small Target Sequence Dataset Generation Method Based on Generative Adversarial Networks" Electronics 12, no. 17: 3625. https://doi.org/10.3390/electronics12173625