
Bit-Weight Adjustment for Bridging Uniform and Non-Uniform Quantization to Build Efficient Image Classifiers

Abstract
:1. Introduction
- We introduce the BWA module to learn the best quantization schemes for each layer, which can be easily optimized through end-to-end training using two different training strategies: incremental training and joint training.
- We combine uniform and non-uniform quantization to benefit from both the hardware friendliness of uniform quantization and the high performance of non-uniform quantization.
2. Related Works
3. Preliminary
3.1. Network Quantization
3.2. Computational Acceleration
4. Method
4.1. Overview
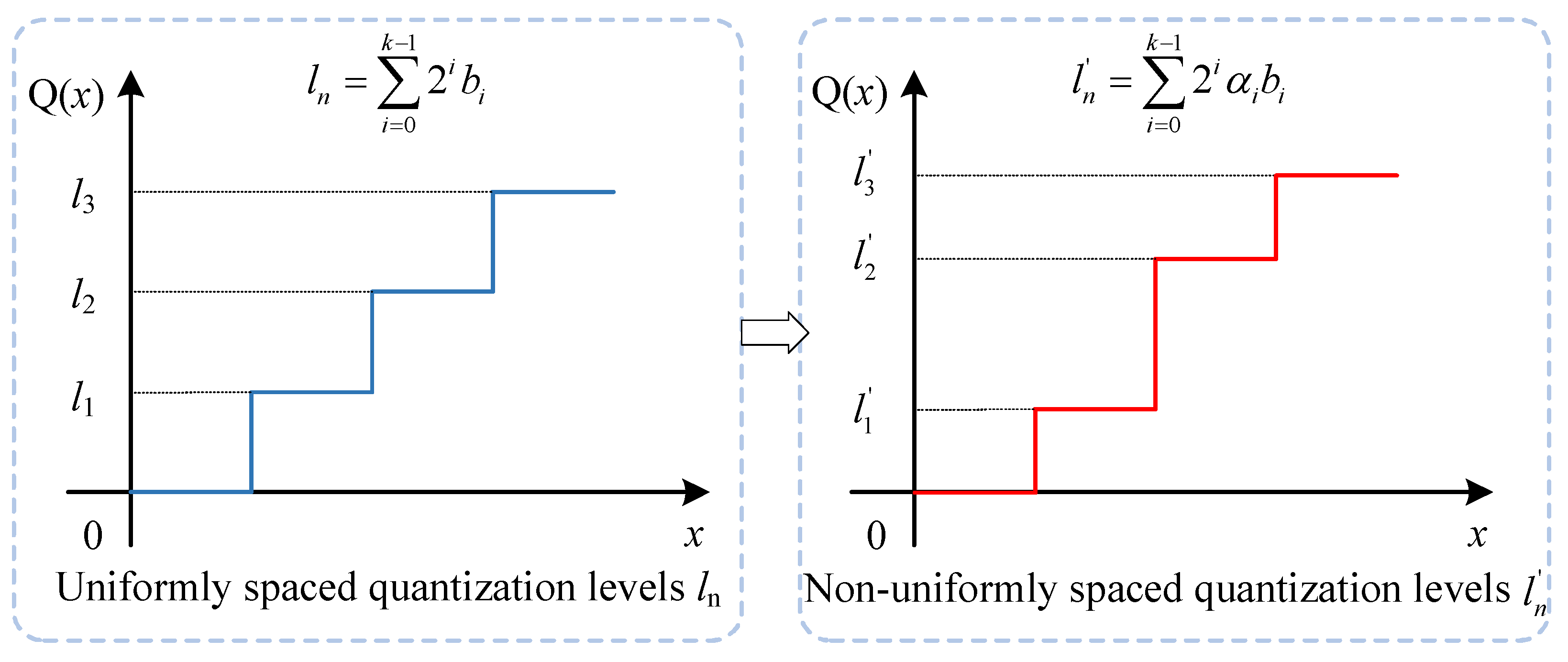
4.2. Quantization Block
4.2.1. Pre-Quantization
4.2.2. Bit-Weight Adjustment Module
4.3. Training Process
| Algorithm 1: Incremental training algorithm |
| Input: Target model , pre-trained low-precision parameters, input data , |
| bit-width k, number of quantization layers L |
| Output: Optimized quantized model |
| Initialize model with pre-trained low-precision parameters; |
| Freeze parameters other than those of BWA modules; |
| for do |
| Apply k-bit pre-quantization to and obtain ; |
| if BWA module exists then |
| Apply BWA module to and obtain using Equation (6) and |
| Equation (8); |
| Forward propagate and obtain ; |
| else |
| Forward propagate and obtain ; |
| end if |
| end for |
| Backpropagate to update only the parameters of BWA modules; |
| Algorithm 2: Joint training algorithm |
| Input: Target model , pre-trained full precision parameters, input data , |
| bit-width k, number of quantization layers L |
| Output: Quantized model |
| Initialize model with pre-trained full-precision parameters; |
| for do |
| Apply k-bit pre-quantization to and obtain ; |
| if BWA module exists then |
| Apply BWA module to and obtain using Equation (6) and |
| Equation (8); |
| Forward propagate and obtain ; |
| else |
| Forward propagate and obtain ; |
| end if |
| end for |
| Backpropagate to update all trainable parameters of the model; |
5. Experimental Results and Discussion
5.1. Experimental Settings
5.1.1. Dataset
5.1.2. Implementation Details
5.1.3. Training
5.2. Comparison with State of the Art
5.2.1. Results on CIFAR-10
5.2.2. Results on ImageNet
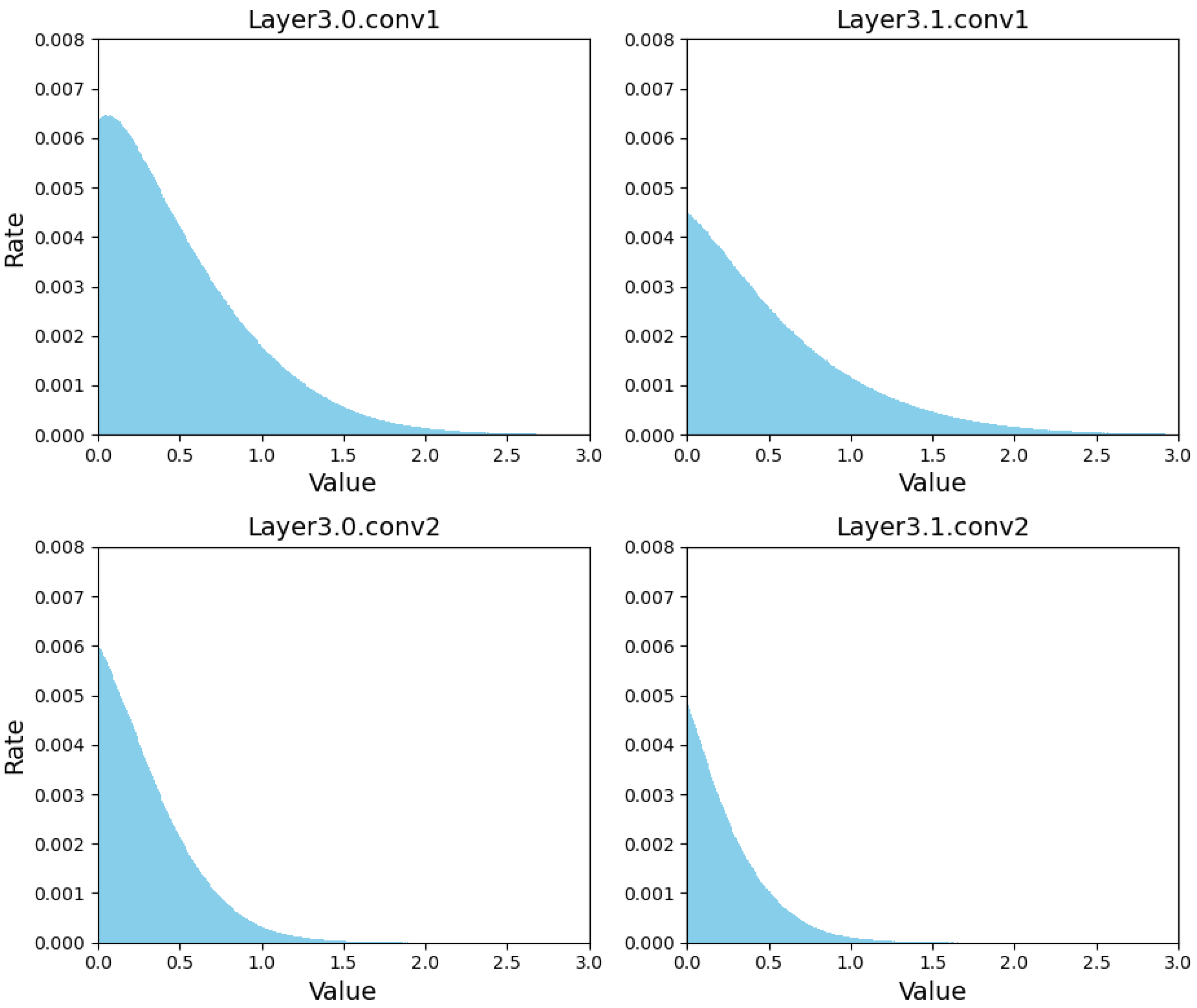
5.3. Ablation Studies
5.3.1. Exploration of Configuration Space
5.3.2. Incorporation of Different Pre-Quantizers
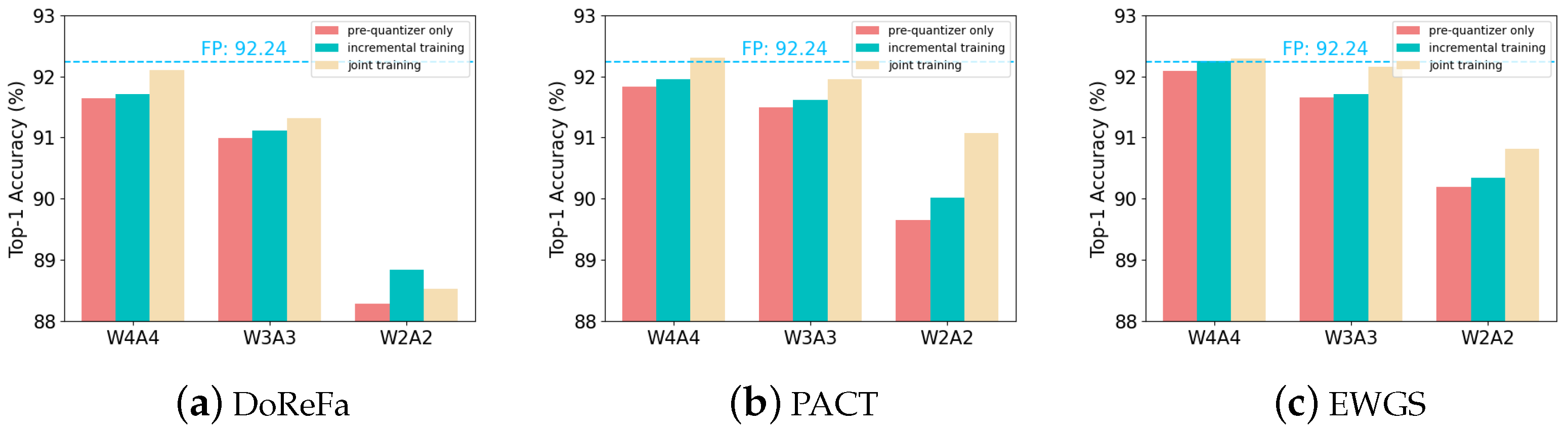
5.3.3. Evaluation of Different Training Strategies
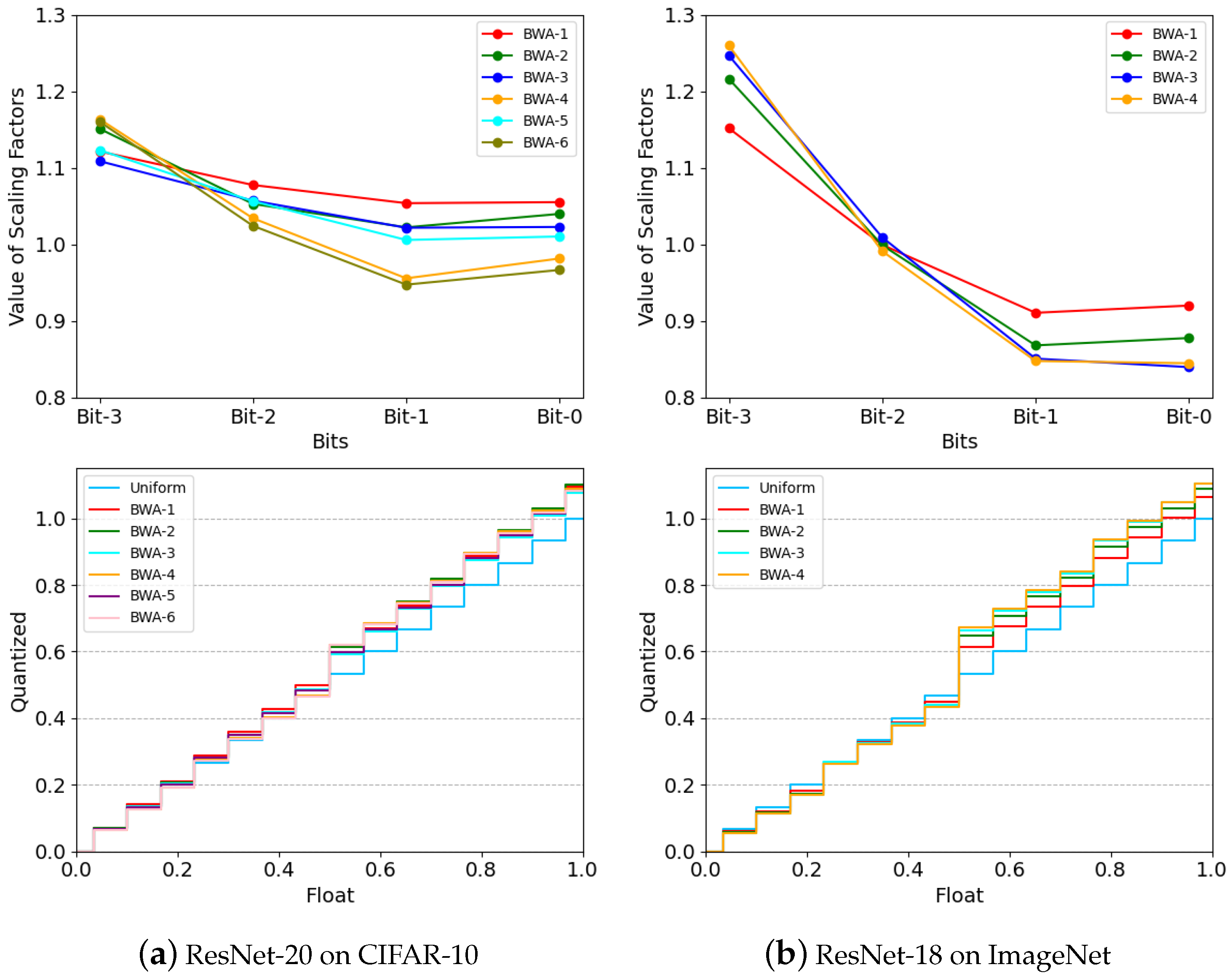
5.4. Analysis of Scaling Factors
5.5. Memory Efficiency and Computational Cost
5.5.1. Memory Efficiency
5.5.2. Computational Cost
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 630–645. [Google Scholar]
- Condés, I.; Fernández-Conde, J.; Perdices, E.; Cañas, J.M. Robust Person Identification and Following in a Mobile Robot Based on Deep Learning and Optical Tracking. Electronics 2023, 12, 4424. [Google Scholar] [CrossRef]
- Zhang, R.; Zhu, Z.; Li, L.; Bai, Y.; Shi, J. BFE-Net: Object Detection with Bidirectional Feature Enhancement. Electronics 2023, 12, 4531. [Google Scholar] [CrossRef]
- Liang, C.; Yang, J.; Du, R.; Hu, W.; Tie, Y. Non-Uniform Motion Aggregation with Graph Convolutional Networks for Skeleton-Based Human Action Recognition. Electronics 2023, 12, 4466. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 1, pp. 1097–1105. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. In Proceedings of the 4th International Conference on Learning Representations, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Park, S.; Lee, J.; Mo, S.; Shin, J. Lookahead: A far-sighted alternative of magnitude-based pruning. In Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Polino, A.; Pascanu, R.; Alistarh, D. Model compression via distillation and quantization. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhou, S.; Wu, Y.; Ni, Z.; Zhou, X.; Wen, H.; Zou, Y. Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv 2016, arXiv:1606.06160. [Google Scholar]
- Choi, J.; Wang, Z.; Venkataramani, S.; Chuang, P.I.J.; Srinivasan, V.; Gopalakrishnan, K. Pact: Parameterized clipping activation for quantized neural networks. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gong, R.; Liu, X.; Jiang, S.; Li, T.; Hu, P.; Lin, J.; Yu, F.; Yan, J. Differentiable soft quantization: Bridging full-precision and low-bit neural networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4852–4861. [Google Scholar]
- Zhang, D.; Yang, J.; Ye, D.; Hua, G. Lq-nets: Learned quantization for highly accurate and compact deep neural networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 365–382. [Google Scholar]
- Lin, X.; Zhao, C.; Pan, W. Towards accurate binary convolutional neural network. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Qu, Z.; Zhou, Z.; Cheng, Y.; Thiele, L. Adaptive loss-aware quantization for multi-bit networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7988–7997. [Google Scholar]
- Jung, S.; Son, C.; Lee, S.; Son, J.; Han, J.J.; Kwak, Y.; Hwang, S.J.; Choi, C. Learning to quantize deep networks by optimizing quantization intervals with task loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4350–4359. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf (accessed on 10 April 2023).
- Dong, Z.; Yao, Z.; Arfeen, D.; Gholami, A.; Mahoney, M.W.; Keutzer, K. Hawq-v2: Hessian aware trace-weighted quantization of neural networks. In Proceedings of the Conference on Neural Information Processing Systems, Virtual Event, 6–12 December 2020; Volume 33, pp. 18518–18529. [Google Scholar]
- Lee, J.; Kim, D.; Ham, B. Network quantization with element-wise gradient scaling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6448–6457. [Google Scholar]
- Miyashita, D.; Lee, E.H.; Murmann, B. Convolutional neural networks using logarithmic data representation. arXiv 2016, arXiv:1603.01025. [Google Scholar]
- Xu, J.; Huan, Y.; Jin, Y.; Chu, H.; Zheng, L.R.; Zou, Z. Base-reconfigurable segmented logarithmic quantization and hardware design for deep neural networks. J. Signal Process. Syst. 2020, 92, 1263–1276. [Google Scholar] [CrossRef]
- Zhou, A.; Yao, A.; Guo, Y.; Xu, L.; Chen, Y. Incremental network quantization: Towards lossless cnns with low-precision weights. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Lee, E.H.; Miyashita, D.; Chai, E.; Murmann, B.; Wong, S.S. Lognet: Energy-efficient neural networks using logarithmic computation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 5–9 March 2017; pp. 5900–5904. [Google Scholar]
- Lee, S.; Sim, H.; Choi, J.; Lee, J. Successive log quantization for cost-efficient neural networks using stochastic computing. In Proceedings of the 56th ACM/IEEE Design Automation Conference (DAC), Las Vegas, NV, USA, 2–6 June 2019; pp. 1–6. [Google Scholar]
- Xu, C.; Yao, J.; Lin, Z.; Ou, W.; Cao, Y.; Wang, Z.; Zha, H. Alternating multi-bit quantization for recurrent neural networks. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Li, Z.; Ni, B.; Zhang, W.; Yang, X.; Gao, W. Performance guaranteed network acceleration via high-order residual quantization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2584–2592. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Yang, H.; Duan, L.; Chen, Y.; Li, H. BSQ: Exploring bit-level sparsity for mixed-precision neural network quantization. In Proceedings of the 9th International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Yamamoto, K. Learnable companding quantization for accurate low-bit neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5029–5038. [Google Scholar]
- Wang, L.; Dong, X.; Wang, Y.; Liu, L.; An, W.; Guo, Y.K. Learnable Lookup Table for Neural Network Quantization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12413–12423. [Google Scholar]
- Lin, S.T.; Li, Z.; Cheng, Y.H.; Kuo, H.W.; Lu, C.C.; Tang, K.T. LG-LSQ: Learned Gradient Linear Symmetric Quantization. arXiv 2022, arXiv:2202.09009. [Google Scholar]
- Xu, K.; Lee, A.H.X.; Zhao, Z.; Wang, Z.; Wu, M.; Lin, W. MetaGrad: Adaptive Gradient Quantization with Hypernetworks. arXiv 2023, arXiv:2303.02347. [Google Scholar]
- Liu, H.; Elkerdawy, S.; Ray, N.; Elhoushi, M. Layer importance estimation with imprinting for neural network quantization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2408–2417. [Google Scholar]
- Li, Y.; Dong, X.; Wang, W. Additive powers-of-two quantization: An efficient non-uniform discretization for neural networks. In Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Esser, S.K.; McKinstry, J.L.; Bablani, D.; Appuswamy, R.; Modha, D.S. Learned step size quantization. In Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Bhalgat, Y.; Lee, J.; Nagel, M.; Blankevoort, T.; Kwak, N. Lsq+: Improving low-bit quantization through learnable offsets and better initialization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 696–697. [Google Scholar]
- Kim, D.; Lee, J.; Ham, B. Distance-aware Quantization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5271–5280. [Google Scholar]
- Tang, C.; Ouyang, K.; Wang, Z.; Zhu, Y.; Wang, Y.; Ji, W.Z.; Zhu, W. Mixed-Precision Neural Network Quantization via Learned Layer-wise Importance. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 259–275. [Google Scholar]
- Tang, C.; Ouyang, K.; Chai, Z.; Bai, Y.; Meng, Y.; Wang, Z.; Zhu, W. SEAM: Searching Transferable Mixed-Precision Quantization Policy through Large Margin Regularization. In Proceedings of the 31st ACM International Conference on Multimedia, Vancouver, BC, Canada, 7–10 June 2023. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Year | Bit Width (W/A) | Acc. (%) |
|---|---|---|---|
| LQ-Net [13] | 2018 | 32/32 | 92.10 |
| 3/3 | 91.60 (−0.50) | ||
| 2/2 | 90.20 (−1.90) | ||
| BSQ [30] | 2021 | 32/32 | 92.62 |
| 3/2.9 | 92.16 (−0.46) | ||
| 2/1.7 | 90.19 (−2.43) | ||
| APoT [36] | 2020 | 32/32 | 92.96 |
| 4/4 | 92.45 (−0.49) | ||
| 3/3 | 92.49 (−0.45) | ||
| 2/2 | 90.93 (−2.03) | ||
| APoT+LIEI [35] | 2021 | 32/32 | 92.96 |
| 3.85/3.85 | 92.82 (−0.14) | ||
| 2.3/2.7 | 91.65 (−1.31) | ||
| 1.65/2.4 | 90.64 (−2.32) | ||
| LCQ [31] | 2021 | 32/32 | 93.40 |
| 4/4 | 93.20 (−0.20) | ||
| 3/3 | 92.80 (−0.60) | ||
| 2/2 | 91.80 (−1.60) | ||
| EWGS [20] | 2021 | 32/32 | 92.24 |
| 4/4 | 92.09 (−0.15) | ||
| 3/3 | 91.65 (−0.59) | ||
| 2/2 | 90.20 (−2.02) | ||
| LLT [32] | 2022 | 32/32 | 92.96 |
| 4/4 | 92.71 (−0.25) | ||
| 3/3 | 92.17 (−0.79) | ||
| 2/2 | 90.63 (−2.33) | ||
| LG-LSQ [33] | 2022 | 32/32 | 92.74 |
| 4/4 | 92.55 (−0.19) | ||
| MetaGrad [34] | 2023 | 32/32 | 91.36 |
| 4/4 | 91.20 (−0.16) | ||
| EWGS+BWA (Ours) | - | 32/32 | 92.24 |
| 4/4 | 92.29 (+0.05) | ||
| 3/3 | 92.16 (−0.08) | ||
| 2/2 | 90.81 (−1.43) |
| Method | Year | Bit Width (W/A) | |||
|---|---|---|---|---|---|
| 2/2 | 3/3 | 4/4 | 32/32 | ||
| PACT [11] | 2018 | 64.40 (−5.80) | 68.10 (−2.10) | 69.20 (−1.00) | 70.20 |
| LQ-Net [13] | 2018 | 64.90 (−5.40) | 68.20 (−2.10) | 69.30 (−1.00) | 70.30 |
| QIL [16] | 2019 | 65.70 (−4.50) | 69.20 (−1.00) | 70.10 (−0.10) | 70.20 |
| DSQ [12] | 2019 | 65.20 (−4.70) | 68.70 (−1.20) | 69.60 (−0.30) | 69.90 |
| ALQ [15] | 2020 | 66.40 (−3.40) | - | - | 69.8 |
| LSQ [37] | 2020 | 66.80 (−3.30) | 69.30 (−0.80) | 70.70 (+0.60) | 70.10 |
| LSQ+ [38] | 2020 | 66.70 (−3.40) | 69.40 (−0.70) | 70.80 (+0.70) | 70.10 |
| APOT [36] | 2020 | 67.10 (−3.10) | 69.70 (−0.50) | - | 70.20 |
| DAQ [39] | 2021 | 66.90 (−3.00) | 69.60 (−0.30) | 70.50 (+0.60) | 69.90 |
| EWGS [20] | 2021 | 66.52 (−3.13) | 69.46 (−0.19) | 70.39 (+0.74) | 69.65 |
| LIMPQ [40] | 2022 | - | 69.00 (−0.60) | 70.10 (+0.50) | 69.60 |
| LLT [32] | 2022 | 66.00 (−3.80) | 69.50 (−0.30) | 70.40 (+0.60) | 69.80 |
| SEAM [41] | 2023 | - | 70.00 (−0.50) | 70.80 (+0.30) | 70.50 |
| EWGS+BWA (Ours) | - | 66.57 (−3.08) | 69.56 (−0.09) | 70.55 (+0.90) | 69.65 |
| No. | Layers with BWA | Layers without BWA | Acc. (%) | Gain (%) |
|---|---|---|---|---|
| I | - | 1–18 | 90.99 | - |
| II | 1–18 | - | 91.32 | 0.33 |
| III | 1–6 | 7–18 | 91.28 | 0.29 |
| IV | 7–12 | 1–6, 13–18 | 91.25 | 0.26 |
| V | 13–18 | 1–12 | 91.35 | 0.36 |
| VI | 15–18 | 1–14 | 91.18 | 0.19 |
| Method | Bit Width (W/A) | ||
|---|---|---|---|
| 2/2 | 3/3 | 4/4 | |
| DoReFa [10] | 88.29 | 90.99 | 91.64 |
| DoReFa+BWA | 88.53 | 91.32 | 92.10 |
| PACT [11] | 89.65 | 91.49 | 91.83 |
| PACT+BWA | 91.08 | 91.95 | 92.30 |
| EWGS [20] | 90.2 | 91.65 | 92.09 |
| EWGS+BWA | 90.81 | 92.16 | 92.29 |
| Model | Bit Width (W/A) | Model Size (MB) | Memory Access (MB) |
|---|---|---|---|
| ResNet-18 | 32/32 | 44.59 | 6985.09 |
| 4/4 | 5.61 | 1282.73 | |
| 3/3 | 4.22 | 1079.08 | |
| 2/2 | 2.83 | 875.42 | |
| ResNet-20 | 32/32 | 1.03 | 157.55 |
| 4/4 | 0.13 | 22.21 | |
| 3/3 | 0.10 | 17.38 | |
| 2/2 | 0.07 | 12.55 |
| Model | Method | Params |
|---|---|---|
| ResNet-18 | Uniform | 11,689,603 |
| Ours | 11,689,619 (+0.001%) | |
| ResNet-20 | Uniform | 269,934 |
| Ours | 269,958 (+0.089%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.; Duan, Y.; Ding, R.; Wang, Q.; Wang, Q.; Qin, J.; Liu, H. Bit-Weight Adjustment for Bridging Uniform and Non-Uniform Quantization to Build Efficient Image Classifiers. Electronics 2023, 12, 5043. https://doi.org/10.3390/electronics12245043
Zhou X, Duan Y, Ding R, Wang Q, Wang Q, Qin J, Liu H. Bit-Weight Adjustment for Bridging Uniform and Non-Uniform Quantization to Build Efficient Image Classifiers. Electronics. 2023; 12(24):5043. https://doi.org/10.3390/electronics12245043
Chicago/Turabian StyleZhou, Xichuan, Yunmo Duan, Rui Ding, Qianchuan Wang, Qi Wang, Jian Qin, and Haijun Liu. 2023. "Bit-Weight Adjustment for Bridging Uniform and Non-Uniform Quantization to Build Efficient Image Classifiers" Electronics 12, no. 24: 5043. https://doi.org/10.3390/electronics12245043
APA StyleZhou, X., Duan, Y., Ding, R., Wang, Q., Wang, Q., Qin, J., & Liu, H. (2023). Bit-Weight Adjustment for Bridging Uniform and Non-Uniform Quantization to Build Efficient Image Classifiers. Electronics, 12(24), 5043. https://doi.org/10.3390/electronics12245043