1. Introduction
The Belt and Road Initiative encompasses a wide array of countries, populations, and linguistic diversity, encompassing exchanges across multiple technical, cultural, and economic domains. As neighboring countries and key players within the Belt and Road strategy, China and Japan play a crucial role in this endeavor. In 2017, the Japan Research Center for the Belt and Road was established in Tokyo by a group of Japanese scholars. The two countries are significant trading partners; Japan is currently China’s second biggest trading partner, while China is Japan’s largest trading partner. As language is the communication link of cultural and industrial cooperation, the language barrier remains a challenge to enhancing communication between the two countries.
Particularly with the emergence of neural machine translation (NMT) as the leading framework for translation applications, the field of natural language processing (NLP) has undergone substantial advancements. Despite the similarities between Chinese and Japanese, the machine translation of these languages still lacks practical application, and the accuracy of the results is inadequate for practical use.
In recent times, the accelerated advancement of deep learning has been predominantly centered around technological development but with less emphasis on the underlying data class. However, data are the cornerstone of deep learning, and without adequate data, even the most advanced technology is just castles in the air.
Linguistic researchers have recognized the significance of corpus processing methods and means. While spoken corpora are the ideal object of linguistic research, they have not yet been given sufficient attention. The current ad hoc approach to including spoken corpora in a corpus highlights the need for a dedicated Japanese-Chinese spoken language corpus for the exploration of Japanese-Chinese NMT systems in academic research.
The creation of a Japanese-Chinese spoken language corpus will generate substantial interest among researchers of Japanese-Chinese NMT, promoting advancements in the field and providing crucial information and experience for bilingual information processing and subsequent research. The objective of this research pursuit is to address the language barrier in Japanese-Chinese communication and improve mutual understanding.
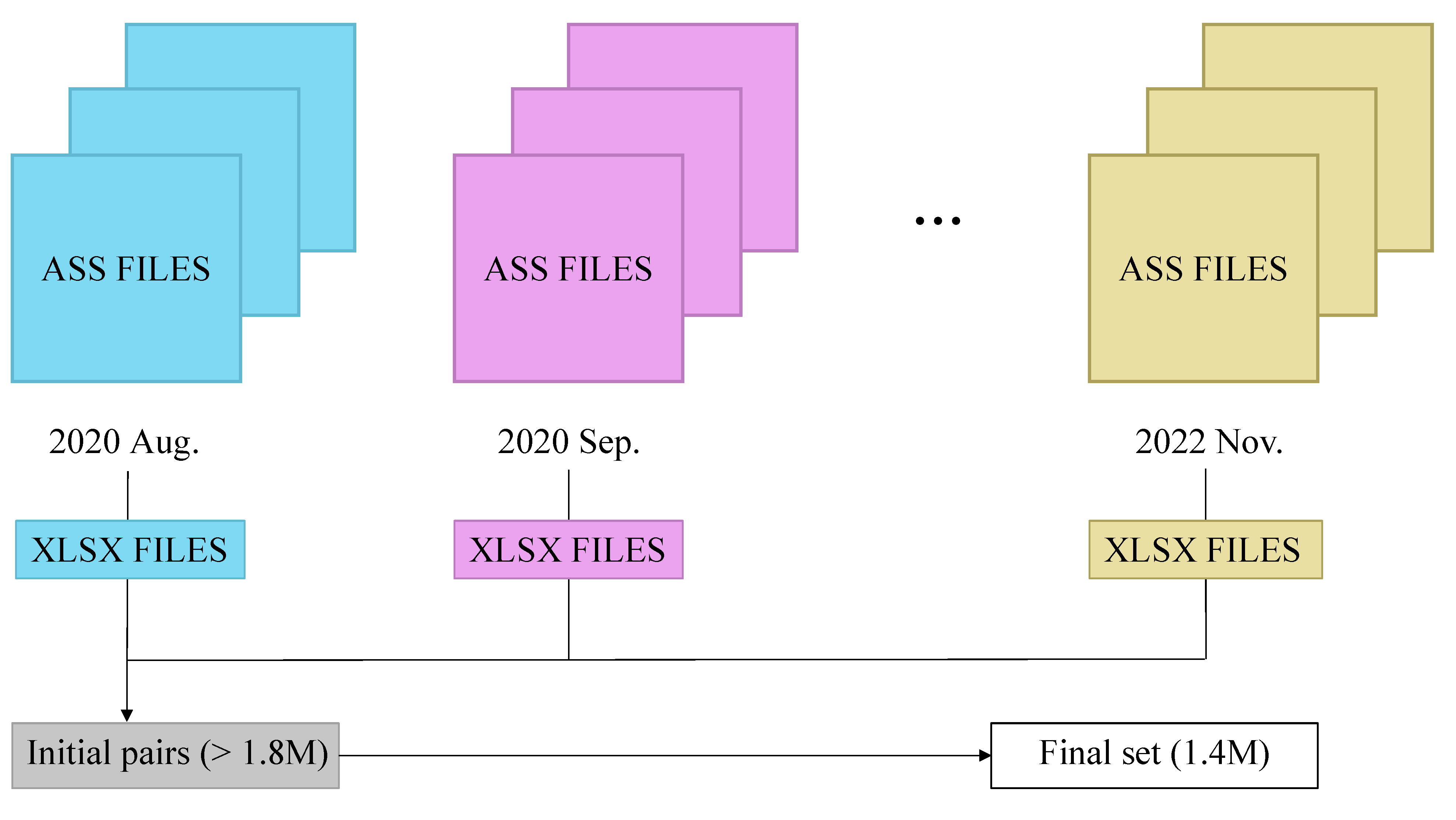
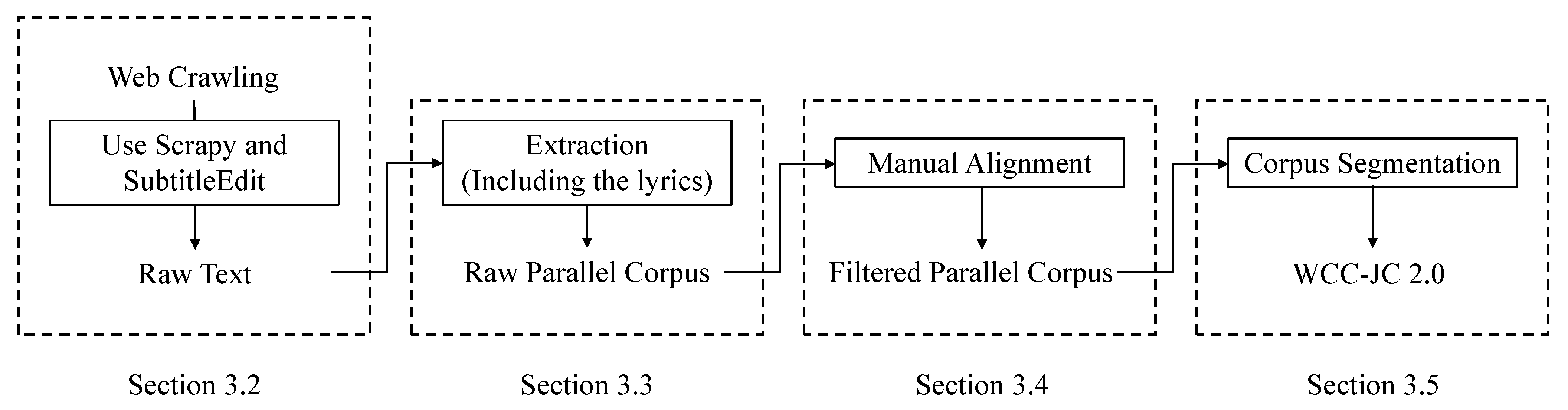
In the present study, our overarching objective is to advance Japanese-Chinese NMT by constructing a Japanese-Chinese spoken language corpus. In our previous study, we collected approximately 753,000 Japanese-Chinese sentence pairs from the Web and created the Web-Crawled Corpus of Japanese and Chinese (WCC-JC 1.0) [
1]. However, the results of translation tests and manual evaluations indicated that WCC-JC 1.0 was inferior in quantity and quality compared with other corpora. To address these shortcomings, we carefully analyzed the limitations of WCC-JC 1.0 and applied extensive manual alignment efforts to the collected corpus texts. As a result, WCC-JC 2.0, now the world’s largest free Japanese-Chinese bilingual corpus, was created with approximately 1.4 million sentence pairs ( an 87% increase in the aggregate number of sentences). The improved translation test results and manual evaluations demonstrate the effectiveness of WCC-JC 2.0 compared with its predecessor WCC-JC 1.0.
The subsequent parts of this article are logically outlined as follows. We will present related works in
Section 2, describe the construction of WCC-JC 2.0 in
Section 3, report the experimental framework and results in
Section 4, discuss the legality of WCC-JC 2.0 in
Section 5, and conclude by expounding on the scholarly contributions and charting the course for future research endeavors in
Section 6.
2. Related Works
The limitations of early English word frequency dictionaries have been subject to extensive scholarly discourse in the existing body of literature. In a study by Leech et al., the authors recognized the limitations in terms of sample size and breadth of early English word frequency dictionaries [
2]. To overcome these limitations, the authors investigated the written and spoken English found in the British National Corpus, culminating in the development of frequency dictionaries for the major languages spoken worldwide.
Contrary to other areas of linguistics, forensic linguistics research remains entrenched in traditional, intuition-driven, and retrospective methodologies. Ting, in his study, combined the features of parallel corpora and current forensic linguistics to examine the potential of applying parallel corpora to forensic linguistics. He explored this concept from six different perspectives [
3].
Tiedemann presented a dictionary-based strategy that leveraged automatic word alignment to enhance the alignment quality compared with the synonym-based approach [
4]. By adopting this approach, the quality of alignment during the construction of a parallel corpus that uses translated subtitles is significantly enhanced.
From a linguistic perspective, spoken corpora are deemed to be the primary objects of research. However, to date, such corpora remain scarce. The determination of content is also a crucial consideration when constructing a spoken corpus. Cermák successfully tackled this challenge by transforming the pivotal dissimilarities between spoken and written texts into pragmatic parameters, thereby facilitating the creation of a spoken corpus [
5].
Aziz et al. proposed a novel approach to subtitle translation and assessed its efficacy through the implementation of two strategies for translating and compressing subtitles from English to Portuguese [
6]. The results of the experiments revealed that fine-tuning the model parameters in the translation system can lead to improvements over an unconstrained baseline. Furthermore, the final translation quality can be further enhanced by incorporating specific model components that guide the translation process. In this investigation, the translation quality was meticulously evaluated through the process of human post-editing.
Wang et al. undertook a research investigation on the refinement of word segmentation in machine translation using a corpus with word alignments that were manually annotated [
7]. The corpus was annotated to align words to the smallest translation unit. The findings of the study shed light on the effectiveness of utilizing a word alignment corpus with manual annotations to improve word segmentation in machine translation.
Adolphs et al. explored the area of spoken language corpus linguistics, analyzing both monomodal and multimodal spoken language corpora [
8]. They explored the obstacles faced during the design, development, and application of spoken language corpora. The authors emphasized the importance of spoken language corpora in revealing unique patterns of language use, which has significant implications for both the description of language use patterns and the field of applied linguistics.
Liu et al. proposed an unsupervised word alignment method for a manually aligned Chinese-English parallel corpus, which contains approximately 40,000 sentence pairs [
9] (
https://nlp.csai.tsinghua.edu.cn/~ly/systems/TsinghuaAligner/TsinghuaAligner.html (accessed on 10 November 2022)). The proposed method’s effectiveness in aligning words between Chinese and English languages was demonstrated using this corpus.
Tiedemann established a vast collection of parallel corpora, OPUS [
10], which encompasses over 200 languages and dialects. This corpus comprises roughly 3.2 billion sentences and sentence fragments representing over 28 billion tokens and draws data from various sources and domains. The data within OPUS can be conveniently downloaded in a uniform data format, facilitating their use in research.
The ASPEC-JC corpus was curated by means of manual translation of Japanese scientific articles into Chinese, with the articles being either under the ownership of the Japan Science and Technology Agency (JST) or preserved in Japan’s largest electronic platform for academic journals (J-STAGE) [
11].
The utilization of alternative translations in subtitle translation has been underexplored. To address this issue, Tiedemann proposed a methodology that leverages time-based alignment and lexical resynchronization techniques in combination with BLEU score metrics to categorize substitute translation versions into groups, employing the measures of edit distance and heuristics [
12]. The implementation of this approach resulted in a substantial number of sentence-aligned translation alternatives, providing a solution to the challenges posed by spelling errors, incomplete or corrupted data files, or misaligned subtitles in the corpus of subtitles.
Wee et al. conducted research on the impact of dialogue-specific aspects, such as dialog acts, speaker, gender, and text register, and the impact of fictional dialogues on the efficacy of machine translation systems was assessed [
13]. They constructed and published a corpus of multilingual movie dialogues and found that the BLEU values between categories were significantly larger than expected. As a result of this, it was hypothesized and demonstrated that adapting machine translation systems to dialogue acts and text registers could enhance their performance when translating fictional dialogue.
A significant amount of conversational data is necessary for the training and optimization of neural models used for dialogue generation, which are often obtained from chat forums or movie subtitles. However, these data can sometimes lack multiple references, making them difficult to utilize. To address this challenge, Lison et al. put forward a weighting model with the aim of enhancing the effectiveness of neural conversational models, as shown through evaluation with unsupervised metrics [
14].
Wang et al. presented a new de-duplication algorithm for web pages, which utilizes TF-IDF and the distance of word vectors to enhance the performance of web page de-duplication during the construction of a corpus of semantically annotated natural language via a cloud-based service infrastructure [
15].
Levshina conducted a quantitative analysis of online film subtitles, considering them as a separate mode of communication [
16]. The study contrasted movie subtitles translated into English from other languages with two prominent English language corpora representing spoken and written language—British and American English. The findings of this study, based on an analysis of n-gram frequencies, indicated that the subtitles were not significantly dissimilar from other variants of the English language, closely resembling informal spoken language in both forms of English used in the United Kingdom and the United States. Additionally, the language used in subtitles was observed to be more emotionally charged and expressive when compared with typical conversations.
Love et al. created the Spoken British National Corpus 2014, a comprehensive collection of 11.5 million words of conversational British English spoken by native speakers from various regions of the UK [
17]. The paper highlights the crucial steps involved in creating the corpus, with a particular emphasis on ensuring the sensitivity of the data collection process and implementing innovative techniques.
In English for Specific Purposes (ESP) education, a corpus provides a wealth of examples for students and can assist in guiding them toward the right texts that fit their specific needs. Chen et al. investigated the challenges and solutions in creating a corpus for ESP, with the aim of transforming traditional teaching methods into a student-centered approach to learning [
18].
The OpenSubtitles2018 corpus was a rich resource for multilingual parallel movie subtitle data, comprising 3.7 million subtitles across 60 different languages [
19,
20]. To improve the alignment quality, the authors proposed a sophisticated regression model and employed its scores to filter the parallel corpus, thus effectively eliminating low-quality alignment results. This approach improved the overall quality of the corpus, making it an even more valuable resource for cross-linguistic studies and machine translation research.
In order to meet the needs of various biomedical research, Ren et al. developed a precision medicine corpus that stores a more comprehensive collection of medical knowledge, enriching the biomedical corpus and promoting research in the field of biomedical text mining [
21].
Davies presented the creation and utilization of the television shows and movies corpora, both of which are available at English-Corpora.org [
22]. The television shows corpus consists of a collection of 75,000 episodes’ subtitles. The subtitles cover a time span ranging from the 1950s to the 2010s and were obtained from 6 English-speaking countries, totaling 325 million words. The movies corpus contains subtitles from 25,000 motion pictures, covering 200 million words in the same 6 countries and time period. These corpora provide a unique opportunity to compare very informal language from different periods.
Doi et al. devised an innovative and extensive corpus for English-Japanese simultaneous interpretation (SI) and compared it to offline translation [
23]. They analyzed the differences in terms of latency, quality, and word order. The results showed that the data from experienced interpreters were of better quality and that a larger latency negatively impacted the quality of the corpus.
Meftah et al. created the King Saud University Emotions (KSUEmotions) corpus, the inaugural Arabic emotion corpus accessible to the public, which encompasses emotional speeches from speakers originating from Syria, Saudi Arabia, and Yemen [
24]. The corpus consists of emotions such as neutral, joy, sorrow, astonishment, and rage. The authors conducted a significant number of validation experiments to assess the corpus.
Xu emphasized the crucial role that big data crawl-based language-networked corpora now play in practical applications and language research [
25]. The research emphasized that the utilization of linguistic databases has evolved into an essential research tool across all domains of language research, proving indispensable for natural language researchers, lexicographers, and language scientists alike.
Duszkin et al. presented the design principles of 10 parallel pair translation corpora and the parallel CLARIN-PL corpus of the Slavic and Baltic languages [
26]. These corpora possess unique features, including resource selection, preprocessing, manual sentence-level segmentation, lemmatization, annotation, and metadata, which were constructed based on these design principles. The paper highlighted the importance of well-designed corpora in facilitating and advancing language research.
Liu et al. constructed a comprehensive spoken English corpus, the Spoken BNC2014, which contains 11.5 million words of conversational data collected from native British English speakers across the UK [
27]. As one of the UK’s largest spoken English corpora, this corpus is a valuable resource for linguistic work and natural language processing.
Using Mark Davies’ mega-corpora, Ha’s study examined the lexical profile of informal spoken English [
28]. The findings indicated that vocabulary knowledge at the 3000 and 5000 word frequency levels was required to comprehend 95% and 98% of the words in general scripted dialogues, respectively. The research revealed that soap operas demand less vocabulary than TV shows and movies.
Additionally, previous research has extensively cited a multitude of relevant studies [
1].
For the purposes of organization and clarity, these studies have been sorted chronologically. A summarized table (
Table 1) is also provided to categorize the related works based on three aspects: (1) spoken corpus; (2) corpus construction; and (3) corpus applications.
The prior research has highlighted the crucial significance of spoken corpora, corpus construction, and their applications in driving forward the field of NLP. These insights motivated us to create a Japanese-Chinese spoken language corpus for NMT, which can have significant practical implications for overcoming the challenge of limited corpus resources.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
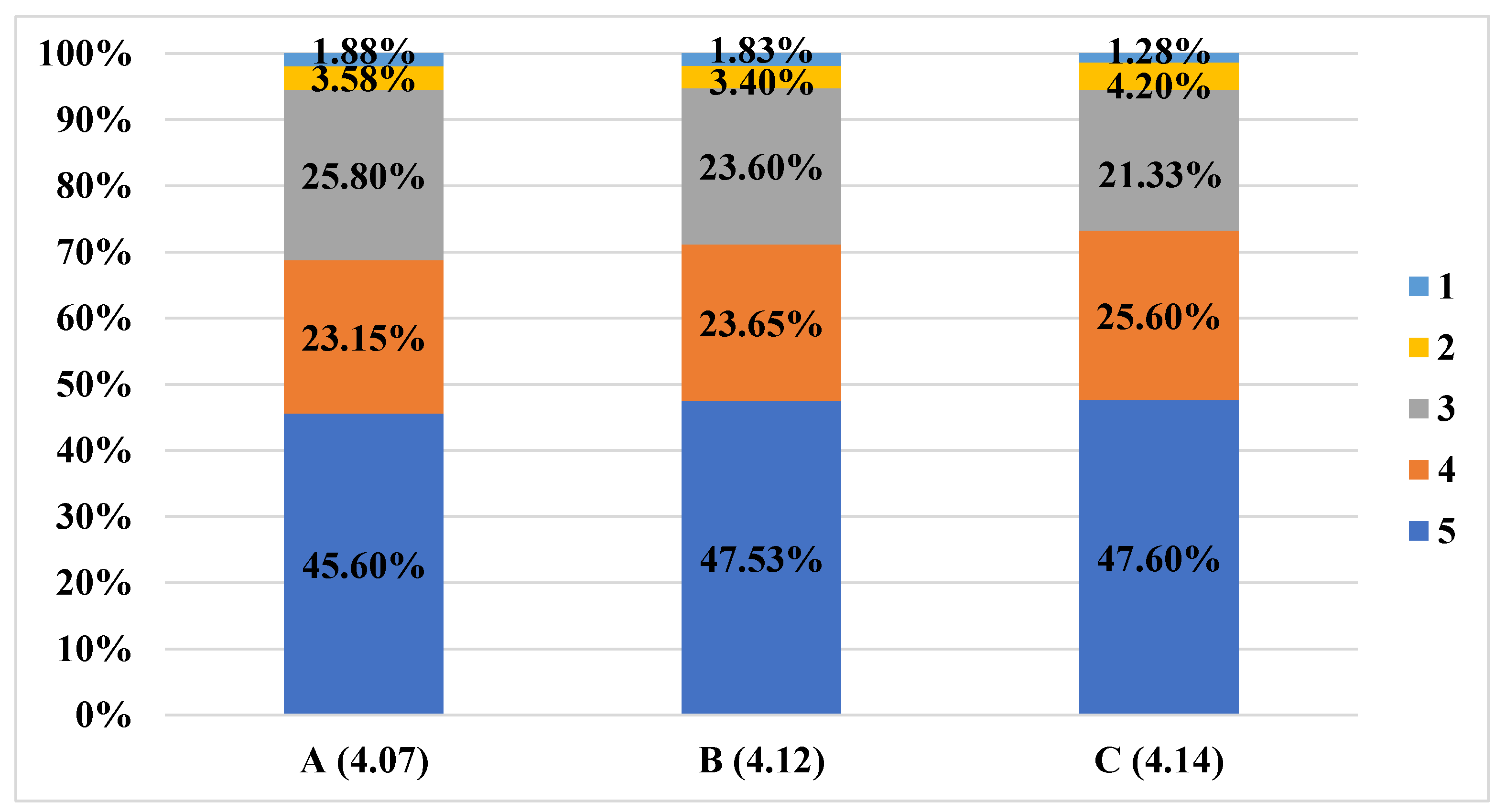{kind=link}
