
A Lightweight 6D Pose Estimation Network Based on Improved Atrous Spatial Pyramid Pooling

 ,
,
Abstract
:1. Introduction
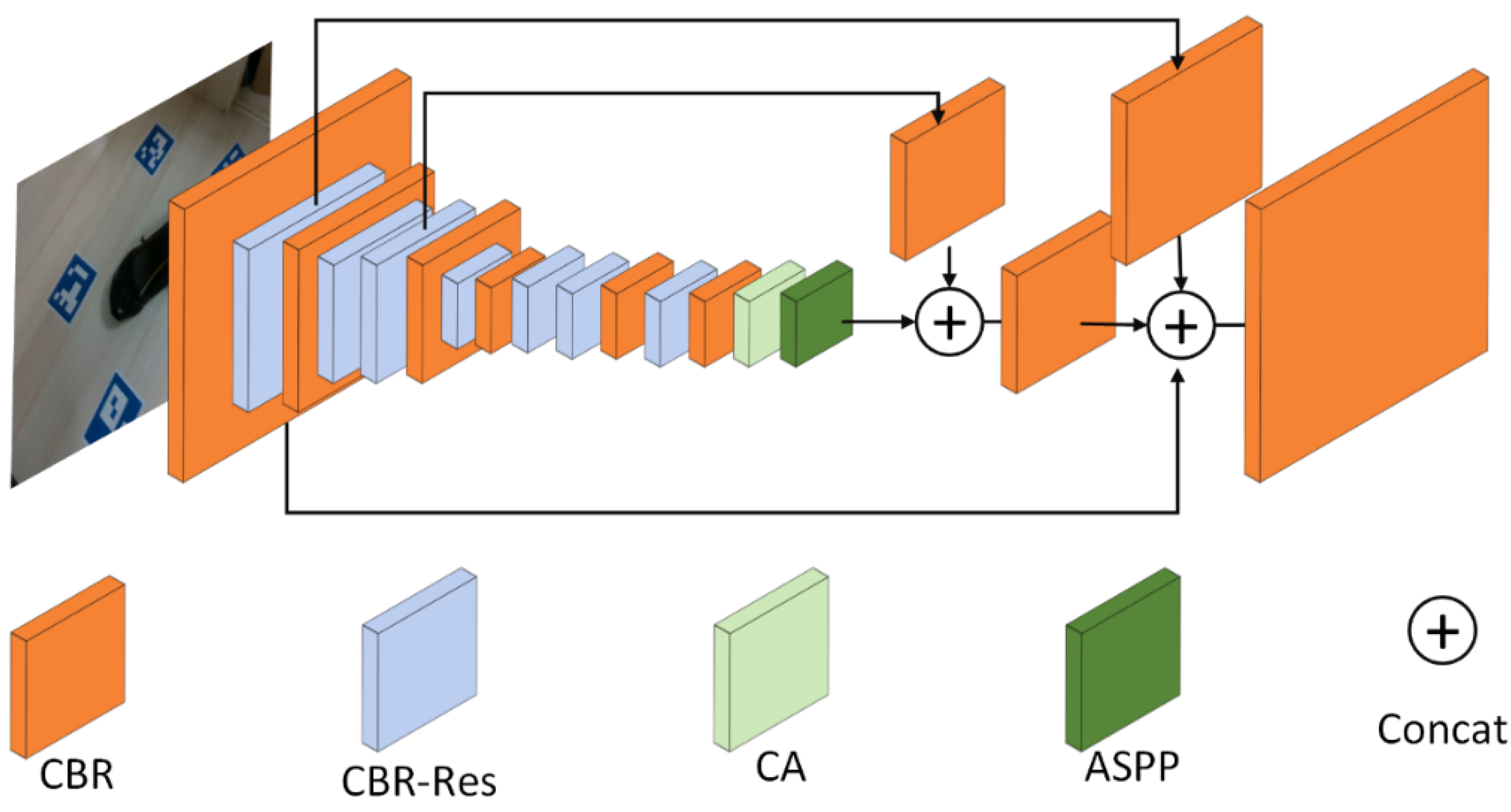
- To reduce the computational cost of 6D object pose estimation, we propose a lightweight model in which residual depth-wise separable convolution is combined with an improved atrous spatial pyramid pooling (ASPP) method.
- We introduce a coordinate attention mechanism and address the issue of object scale variation, which was not considered in the original method. Additionally, we incorporate a multi-scale pyramid pooling module. These enhancements effectively reduce the model’s parameter and computation complexity while significantly improving the pose estimation accuracy for objects with large-scale variations.
- The effectiveness of this lightweight model is validated and analyzed through experiments on both publicly available and self-built datasets.
2. Related Works
3. Improved Model Based on Atrous Spatial Pyramid Pooling
3.1. Backbone Network
3.1.1. Residual Depth-Wise Separable Network
3.1.2. Improved Atrous Spatial Pyramid Pooling
3.2. Pixel Voting and Pose Estimation
3.3. Training Strategy
4. Experimental Results and Analysis
4.1. Dataset
4.2. Performance Evaluation Metrics
4.3. Experimental Results
4.4. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Viswanathan, D.G. Features from accelerated segment test (fast). In Proceedings of the 10th Workshop on Image Analysis for Multimedia Interactive Services, London, UK, 6–8 May 2009; pp. 6–8. [Google Scholar]
- Mohammad, S.; Morris, T. Binary robust independent elementary feature features for texture segmentation. Adv. Sci. Lett. 2017, 23, 5178–5182. [Google Scholar] [CrossRef]
- Hinterstoisser, S.; Lepetit, V.; Ilic, S.; Holzer, S.; Bradski, G.; Konolige, K. Model based training, detection and pose estimation of texture-less 3D objects in heavily cluttered scenes. In Asian Conference on Computer Vision, Computer Vision—ACCV 2012 Proceedings of the11th Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 548–562. [Google Scholar]
- Kendall, A.; Grimes, M.; Cipolla, R. Posenet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2938–2946. [Google Scholar]
- Li, Y.; Wang, G.; Ji, X.; Xiang, Y.; Fox, D. Deepim: Deep iterative matching for 6d pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 683–698. [Google Scholar]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes. In Proceedings of the Robotics: Science and Systems (RSS), Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar]
- Wang, C.; Xu, D.; Zhu, Y.; Martin-Martin, R.; Lu, C.; Li, F.-F.; Savarese, S. Densefusion: 6d object pose estimation by iterative dense fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3343–3352. [Google Scholar]
- Sundermeyer, M.; Marton, Z.-C.; Durner, M.; Brucker, M. Implicit 3d orientation learning for 6d object detection from rgb images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 699–715. [Google Scholar]
- Wang, G.; Manhardt, F.; Tombari, F.; Ji, X. Gdr-net: Geometry-guided direct regression network for monocular 6d object pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16611–16621. [Google Scholar]
- Rad, M.; Lepetit, V. Bb8: A scalable, accurate, robust to partial occlusion method for predicting the 3d poses of challenging objects without using depth. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3828–3836. [Google Scholar]
- Zhao, Z.; Peng, G.; Wang, H.; Fang, H.-S.; Li, C.; Lu, C. Estimating 6D pose from localizing designated surface keypoints. arXiv 2018, arXiv:1812.01387. [Google Scholar]
- Peng, S.; Liu, Y.; Huang, Q.; Zhou, X.; Bao, H. Pvnet: Pixel-wise voting network for 6dof pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4561–4570. [Google Scholar]
- Park, K.; Patten, T.; Vincze, M. Pix2pose: Pixel-wise coordinate regression of objects for 6d pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Repulic of Korea, 7 October–2 November 2019; pp. 7668–7677. [Google Scholar]
- Chen, B.; Chin, T.J.; Klimavicius, M. Occlusion-robust object pose estimation with holistic representation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 2929–2939. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 7–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zeme, R. Understanding the effective receptive field in deep convolutional neural networks. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; p. 29. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Brachmann, E.; Krull, A.; Michel, F.; Gumhold, S.; Shotton, J.; Rother, C. Learning 6D object pose estimation using 3D object coordinates. In European Conference on Computer Vision, Computer Vision—ECCV 2014, Proceedings of the13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 536–551. [Google Scholar]
- Hodan, T.; Haluza, P.; Obdrzalek, S.; Matas, J.; Lourakis, M.; Zabulis, X. T-LESS: An RGB-D Dataset for 6D Pose Estimation of Texture-Less Objects. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; IEEE: Piscataway, NJ,USA, 2017. [Google Scholar] [CrossRef]
- Zakharov, S.; Shugurov, I.; Ilic, S. Dpod: 6d pose object detector and refiner. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Repulic of Korea, 7 October–2 November 2019; pp. 1941–1950. [Google Scholar]
- Gupta, A.; Medhi, J.; Chattopadhyay, A.; Gupta, V. End-to-end differentiable 6DoF object pose estimation with local and global constraints. arXiv 2020, arXiv:2011.11078. [Google Scholar]
- Iwase, S.; Liu, X.; Khirodkar, R.; Yokota, R.; Kitani, K.M. Repose: Fast 6d object pose refinement via deep texture rendering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3303–3312. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Without Refinement | Refinement | ||||||
|---|---|---|---|---|---|---|---|
| Method | Zhao | PVNet | DPOD [24] | SSPE [25] | Ours | DPOD+ | RePose [26] |
| Ape | 41.2 | 43.62 | 53.28 | 52.5 | 67.05 | 87.70 | 79.5 |
| Benchvice | 85.7 | 99.90 | 95.34 | - | 98.46 | 98.50 | 100.0 |
| Cam | 78.9 | 86.86 | 90.36 | - | 88.24 | 96.10 | 99.2 |
| Can | 85.2 | 95.47 | 94.10 | 99.2 | 97.65 | 99.70 | 99.8 |
| Cat | 73.9 | 79.34 | 60.38 | 88.5 | 85.86 | 94.70 | 97.9 |
| Driller | 77.0 | 96.43 | 97.72 | 98.8 | 93.66 | 98.80 | 99.0 |
| Duck | 42.7 | 52.58 | 66.01 | 68.7 | 75.24 | 86.30 | 80.3 |
| Eggbox + | 78.9 | 99.15 | 99.72 | 100.0 | 99.72 | 99.90 | 100 |
| Glue + | 72.5 | 95.66 | 93.83 | 98.5 | 75.86 | 96.80 | 98.3 |
| Hole puncher | 63.9 | 81.92 | 65.83 | 88.1 | 79.46 | 86.90 | 96.9 |
| Iron | 94.4 | 98.88 | 99.80 | - | 95.23 | 100.0 | 100.0 |
| Lamp | 98.1 | 99.33 | 88.11 | - | 98.85 | 96.80 | 99.8 |
| Phone | 51.0 | 92.41 | 74.24 | - | 87.90 | 94.70 | 98.9 |
| Aircraft | - | 71.72 | - | - | 79.80 | - | - |
| Car | - | 83.17 | - | - | 97.34 | - | - |
| Average | 72.6 | 85.09 | 82.98 | 86.8 | 88.02 | 95.15 | 96.1 |
| BB8 | YOLO-6D | PVNet | Ours | |
|---|---|---|---|---|
| Ape | 95.3 | 92.10 | 99.23 | 100.0 |
| Bench vice | 80.0 | 95.06 | 99.81 | 99.52 |
| Cam | 80.9 | 93.24 | 99.21 | 99.22 |
| Jar | 84.1 | 97.44 | 99.90 | 99.90 |
| Cat | 97.0 | 97.41 | 99.30 | 99.60 |
| Driller | 74.1 | 79.41 | 96.92 | 98.82 |
| Duck | 81.2 | 94.65 | 98.02 | 99.05 |
| Eggbox + | 87.9 | 90.33 | 99.34 | 98.87 |
| Glue + | 89.0 | 96.53 | 98.45 | 98.85 |
| Hole puncher | 90.5 | 92.86 | 100.0 | 99.62 |
| Iron | 78.9 | 82.94 | 99.18 | 98.98 |
| Lamp | 74.4 | 76.87 | 98.27 | 97.70 |
| Phone | 77.6 | 86.07 | 99.42 | 99.52 |
| Average | 83.9 | 90.37 | 99.00 | 99.20 |
| ADD | 2D Projection | Params | Computational Cost | Time | |
|---|---|---|---|---|---|
| DC10 | 54.81 | 96.57 | 0.7 M | 16.3 B | 7.03 ms |
| DC11 | 54.51 | 97.16 | 0.8 M | 16.7 B | 7.18 ms |
| DC15 | 65.69 | 98.33 | 2.5 M | 21.9 B | 9.13 ms |
| DC10 + CA | 63.43 | 98.33 | 0.7 M | 16.3 B | 7.15 ms |
| DC11 + CA | 62.84 | 98.43 | 0.8 M | 16.7 B | 7.31 ms |
| DC11 + Res | 62.06 | 97.45 | 0.8 M | 16.7 B | 7.36 ms |
| DC13 + Res | 68.33 | 98.63 | 1.3 M | 16.1 B | 7.61 ms |
| DC13 + Res + CA | 77.65 | 99.12 | 4 M | 27.2 B | 11.67 ms |
| DC13 + Res + CA + ASPP | 88.24 | 99.22 | 5.5 M | 49.8 B | 14.10 ms |
| Params | Computational Cost | Weight Size | GPU Frame Computation Time | |
|---|---|---|---|---|
| PVNet | 13.0 M | 72.7 B | 148 MB | 13.34 ms |
| Ours | 5.5 M | 49.8 B | 63 MB | 14.10 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, F.; Tang, X.; Wu, Y.; Wang, Y.; Chen, H.; Wang, G.; Liao, J. A Lightweight 6D Pose Estimation Network Based on Improved Atrous Spatial Pyramid Pooling. Electronics 2024, 13, 1321. https://doi.org/10.3390/electronics13071321
Wang F, Tang X, Wu Y, Wang Y, Chen H, Wang G, Liao J. A Lightweight 6D Pose Estimation Network Based on Improved Atrous Spatial Pyramid Pooling. Electronics. 2024; 13(7):1321. https://doi.org/10.3390/electronics13071321
Chicago/Turabian StyleWang, Fupan, Xiaohang Tang, Yadong Wu, Yinfan Wang, Huarong Chen, Guijuan Wang, and Jing Liao. 2024. "A Lightweight 6D Pose Estimation Network Based on Improved Atrous Spatial Pyramid Pooling" Electronics 13, no. 7: 1321. https://doi.org/10.3390/electronics13071321
APA StyleWang, F., Tang, X., Wu, Y., Wang, Y., Chen, H., Wang, G., & Liao, J. (2024). A Lightweight 6D Pose Estimation Network Based on Improved Atrous Spatial Pyramid Pooling. Electronics, 13(7), 1321. https://doi.org/10.3390/electronics13071321