Military Object Real-Time Detection Technology Combined with Visual Salience and Psychology


Abstract
:1. Introduction
- (1)
- establishing a data set dedicated to military object detection to ensure that the data is sufficient and representative so as to compare and verify the validity of the model;
- (2)
- imitating the human eye vision adaptive adjustment system, thus proposing a new method for image adaptive enhancement is proposed in order to highlight the object, weaken the background, and suppress interference;
- (3)
- establishing a saliency region detection model based on double channel and feature fusion, after being inspired by how human visual information is processed; and,
- (4)
- applying Gestalt’s main theory on visual psychology as a constraint condition to integrate the obtained candidate salient regions and thus to generate a salient map with overall perception;
- (5)
- proposing a new efficient sub-window search method to detect and screen objects and to determine the region where the objects are located on the other hand.
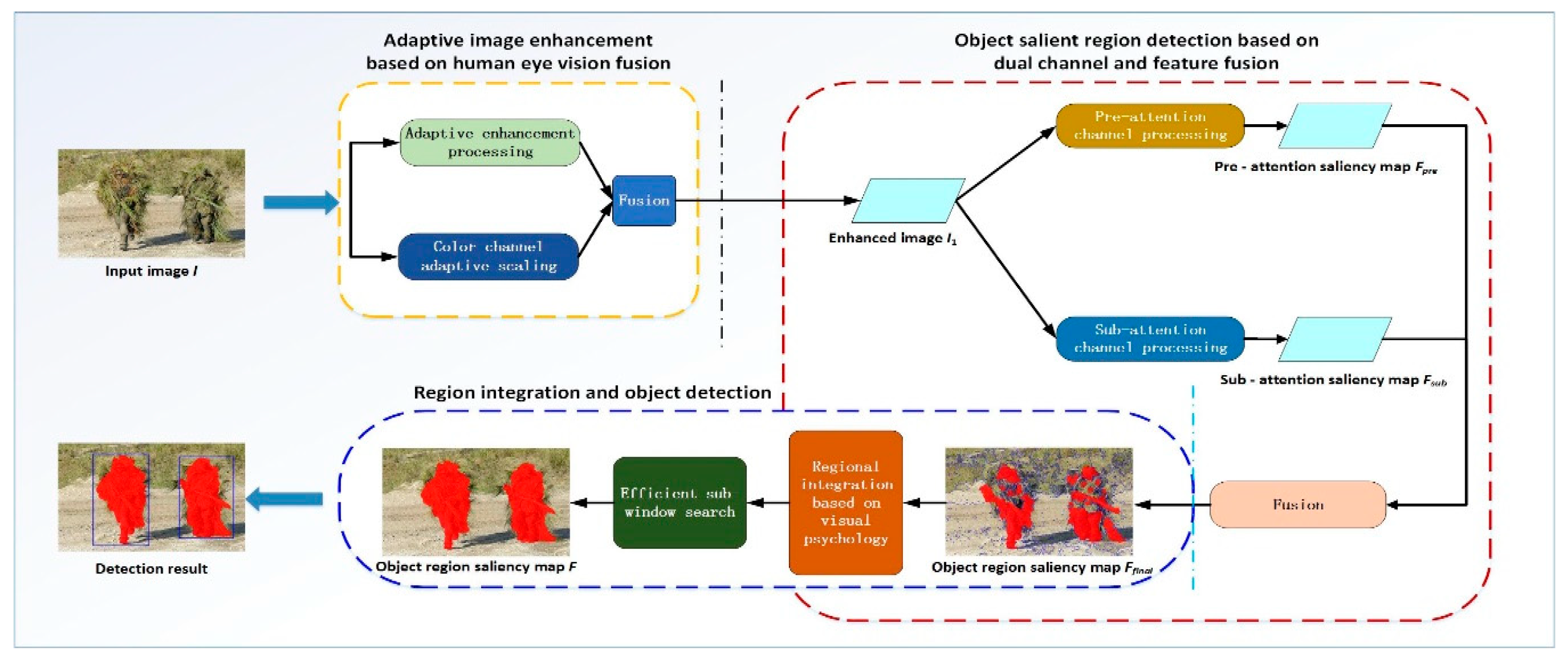
2. Our Model
- (1)
- the image is effectively enhanced by a method based on human eye vision fusion [25] (yellow border section);
- (2)
- a saliency region detection model based on dual channel and feature fusion (red border section) is established, wherein the pre-attention channel processing obtains the pre-attention saliency map Fpre, the sub-processing channel processing obtains the sub-attention saliency map Fsub; then, the two channel detection results are fused to obtain the final saliency map Ffinal; and,
- (3)
- using Gestalt’s main theory of visual psychology as a constraint condition (blue border section), the candidate salient regions that are obtained are integrated to achieve an object segmentation result map F with overall perception. Then, the object (blue border section) is detected and screened by using an efficient sub-window search method to determine the region where the object is located.
3. Salient Region Detection Based on Double Channel and Feature Fusion
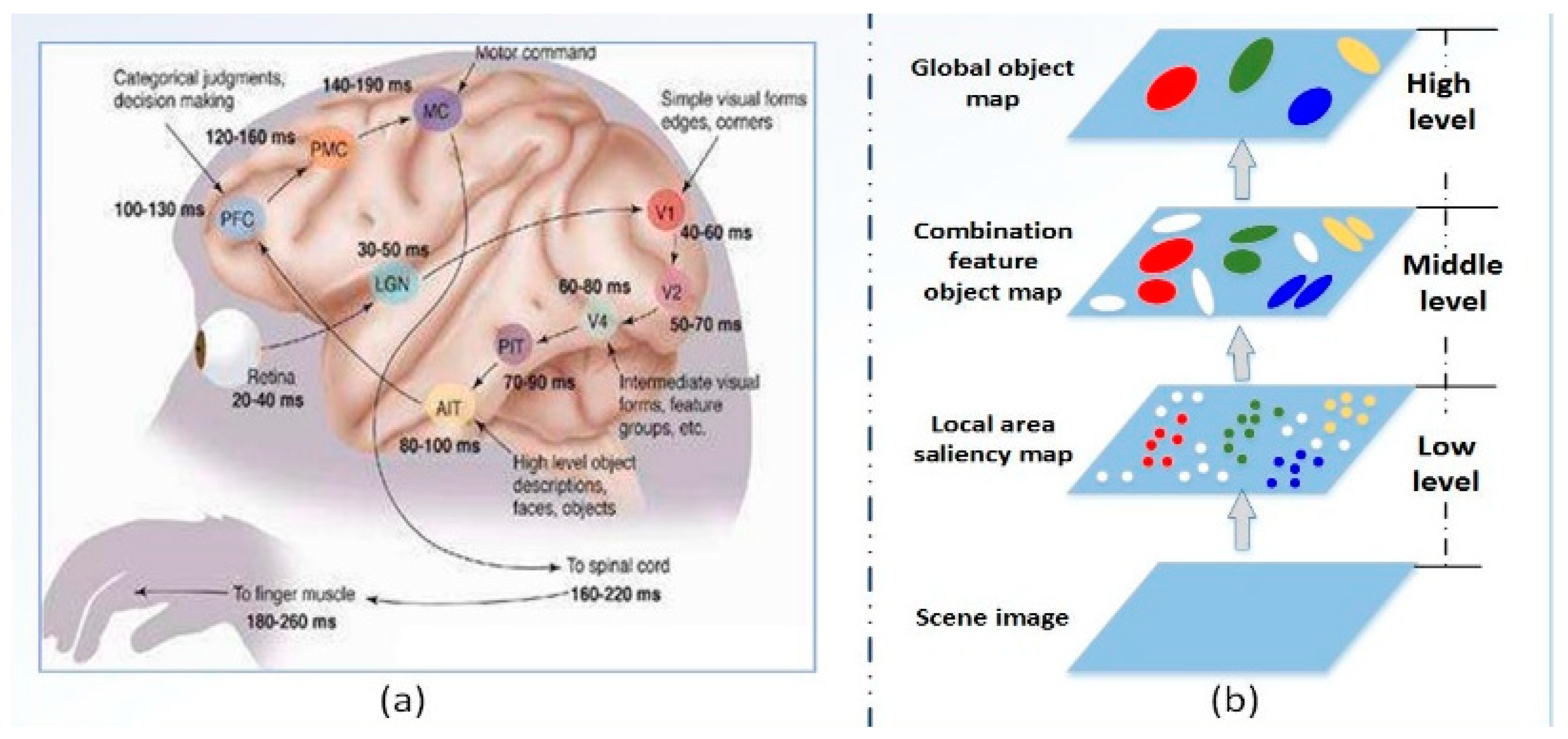
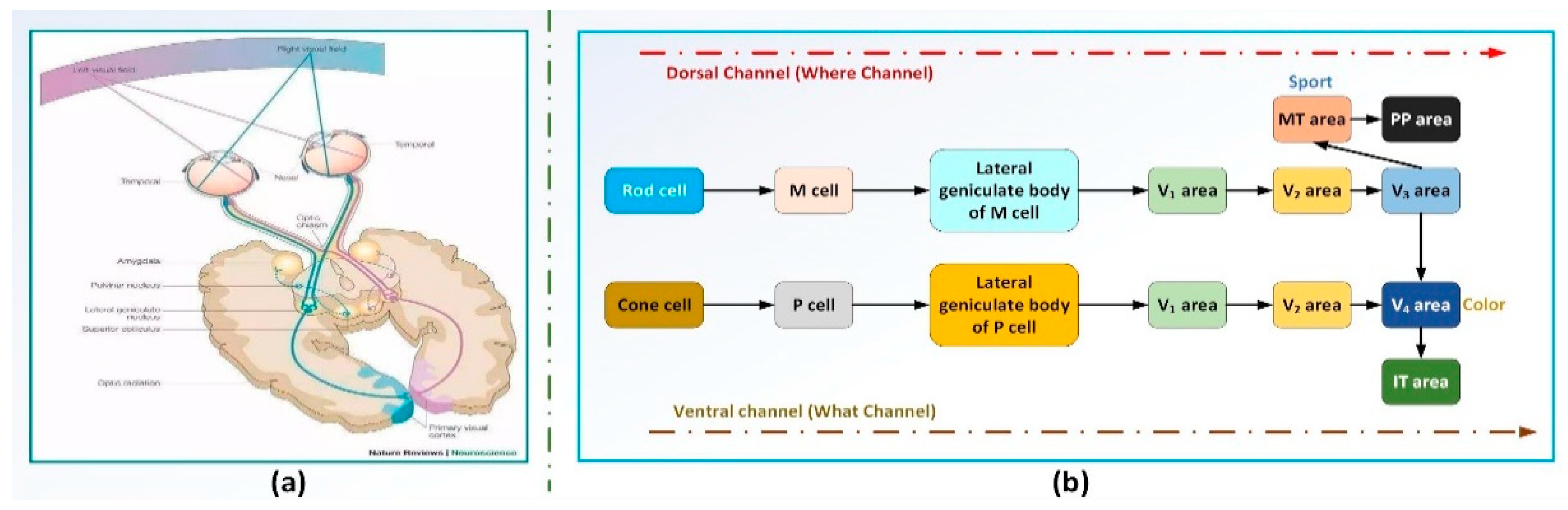
3.1. Human Visual Perception and Processing System
3.2. Salient Region Detection Model Based on Dual Channel and Feature Fusion
- (1)
- Pre-attention channel processing. First, the SLIC super pixel segmentation [29] is performed on the color image, and then sigma features of each region are extracted [30]. While considering the influence of neighborhood contrast, background contrast, spatial distance and region size, a local saliency map is generated, and then the over-all density estimation of each region is extracted to construct a global saliency map. Finally, the local and global saliency maps are fused by exponential weighting to construct a saliency map Fpre.
- (2)
- Sub-attention channel processing. Firstly, multi-resolution processing is carried out on the input image by using a variable-scale Gaussian function to establish a Gaussian pyramid [31]. Then, the color space of the image is transformed according to the color antagonism mechanism. After that, information on such features as color, brightness, and texture orientation of potential objects’ image region is fed back by the pre-paid attention path to be extracted on multiple scales, which leads to the generation of the corresponding feature map by using the central peripheral difference [32] operation. Finally, the saliency of each primary visual feature is measured through inter-layer Gaussian difference processing [33], and the saliency of each feature is integrated between layers, and the saliency map Fsub is calculated by combining the weighted summation method.
- (3)
- Normalizing the pre-attention saliency map and the post-attention saliency map, merging the pre-attention channel and the sub-attention channel, and identifying a salient object region according to the total saliency map Ffinal.
3.2.1. Pre-Attention Channel Based on Fused Saliency Map
3.2.2. Sub-Attention Channel Based on Gaussian Pyramid and Feature Fusion
3.2.3. Gross Saliency Map
4. Regional Integration of Visual Overall Perception Based on Gestalt
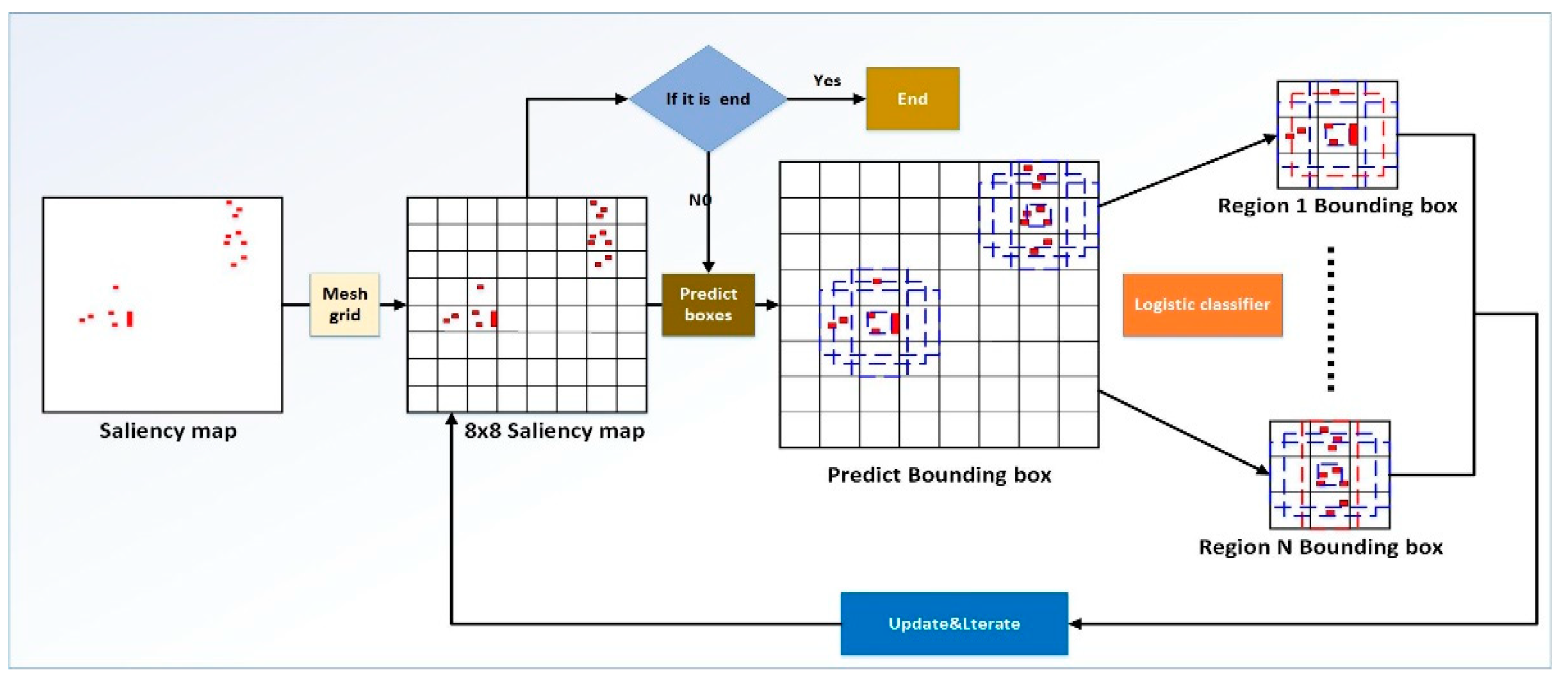
4.1. Efficient Sub-Window Search
4.2. Regional Integration Based on Visual Overall Perception
- (1)
- simplification: excluding the unimportant part of the background from the image, only preserving the necessary components, such as the object, so as to achieve the simplification of the vision;
- (2)
- the relationship between the subject and the background: the feature of the scene will affect the parsing of the subject and the background in the scene, when a small object (or color block) overlaps with the larger object, we incline to the view that small objects are the main body and the big object is the background;
- (3)
- the global and the local: the whole of the experience organized by the perceptual activity, in nature, is not equal to the simple linear superposition of the part;
- (4)
- closeness: referring to the situation in which individual visual unit is infinitely close so that they form a large and unified whole;
- (5)
- closed-up: closed figures are often regarded as a whole; and,
- (6)
- incomplete or irregular graphics: they are often regarded as a similar regular pattern.
5. Experience & Analysis
5.1. Experience Condition and Dataset
5.2. Experimental Design
5.3. Analysis of the Algorithm Performance of Object Saliency Map
5.4. Comparative Analysis of Significant Graph Generation Algorithms
5.4.1. Evaluation Index
5.4.2. Comparison of Visual Effects
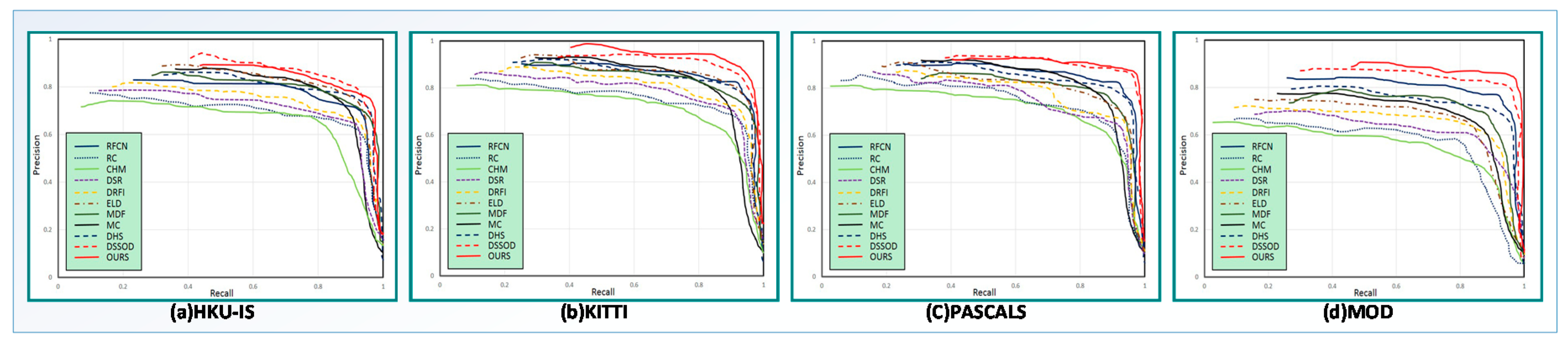
5.4.3. PR Curve
5.4.4. F-Measure & MAE
5.5. Comparative Analysis of Algorithm Detection Results
- (1)
- Establish an optimal one-to-one correspondence between goals and hypothetical results. The Euclidean distance is used to calculate the spatial position correspondence between the real object and the hypothetical object. The threshold T of the Euclidean distance is set to the distance between the centers of the hypothesis and the least overlap of the objects. The number of objects for completing the correspondence is NT, and the number of missed objects is LP = n − NT.
- (2)
- After the mutual correspondence between the objects is completed, we divide the test results into two categories according to d, which is in accordance with the real object and the hypothetical object. The two categories are: accurate detection, which occurs when there are same categories; and, misdetection, which occurs when there are different categories. The number of objects accurately detected by statistics is TR, and the number of objects for statistical misdetection is TW. When we compare the number of real objects n with the number of objects detected m, and if n < m, there is a case of false alarms, and the number of false objects is FP = m − NT.
- (3)
- From the statistical results of step 2, we can measure the detection effect of the algorithm by calculating the false alarm rate, missed alarm rate, detection rate, and false detection rate of the algorithm.
5.6. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sun, Y.; Chang, T.; Wang, Q.; Kong, D.; Dai, W. A method for image detection of tank armor objects based on hierarchical multi-scale convolution feature extraction. J. Ordnance Eng. 2017, 38, 1681–1691. [Google Scholar]
- Dollar, P.; Appel, R.; Belongie, S.; Perona, P. Fast feature pyramids for object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 32–45. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Wang, J.; Yuan, Z.; Wu, Y.; Zheng, N.; Li, S. Salient object detection: a discriminative regional feature integration approach. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2083–2090. [Google Scholar]
- Schneiderman, H. Feature-centric evaluation for efficient cascaded object detection. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2004), Washington, DC, USA, 27 June–2 July 2004; Volume 2, pp. II-29–II-36. [Google Scholar]
- Li, L.; Huang, W.; Gu, I.Y.-H.; Tian, Q. Statistical modeling of complex backgrounds for foreground object detection. IEEE Trans. Image Process. 2004, 13, 1459–1472. [Google Scholar] [CrossRef] [PubMed]
- Prasad, D.K.; Rajan, D.; Rachmawati, L.; Rajabally, E.; Quek, C. Video Processing from electro-optical sensors for object detection and tracking in a maritime environment: A Survey. IEEE Trans. Intell. Trans. Syst. 2017, 18, 1993–2016. [Google Scholar] [CrossRef]
- Savaş, M.F.; Demirel, H.; Erkal, B. Moving object detection using an adaptive background subtraction method based on block-based structure in dynamic scene. Optik 2018, 168, 605–618. [Google Scholar] [CrossRef]
- Sultani, W.; Mokhtari, S.; Yun, H.B. Automatic pavement object detection using superpixel segmentation combined with conditional random field. IEEE Trans. Intell. Trans. Syst. 2018, 19, 2076–2085. [Google Scholar] [CrossRef]
- Zhang, C.; Xie, Y.; Liu, D.; Wang, L. Fast threshold image segmentation based on 2D fuzzy fisher and random local optimized QPSO. IEEE Trans. Image Process. 2017, 26, 1355–1362. [Google Scholar] [CrossRef] [PubMed]
- Druzhkov, P.N.; Kustikova, V.D. A survey of deep learning methods and software tools for image classification and object detection. Pattern Recognit. Image Anal. 2016, 26, 9–15. [Google Scholar] [CrossRef]
- Ghesu, F.C.; Krubasik, E.; Georgescu, B.; Singh, V.; Zheng, Y.; Hornegger, J.; Comaniciu, D. Marginal space deep learning: efficient architecture for volumetric image parsing. IEEE Trans. Med. Imaging 2016, 35, 1217–1228. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Li, Y.; Wu, G.; Luo, J. Multi-modal deep feature learning for RGB-D object detection. Pattern Recognit. 2017, 72, 300–313. [Google Scholar] [CrossRef]
- Schölkopf, B.; Platt, J.; Hofmann, T. Graph-based visual saliency. In Proceedings of the 19th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; MIT Press: Cambridge, MA, USA, 2006; pp. 545–552. [Google Scholar]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–26 June 2009; pp. 1597–1604. [Google Scholar]
- Cheng, M.M.; Mitra, N.J.; Huang, X.; Torr, P.H.S.; Hu, S.M. Global contrast based salient region detection. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 569–582. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Li, Y.; Shen, C.; Dick, A.; Hengel, A.V.D. Contextual hypergraph modeling for salient object detection. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 3328–3335. [Google Scholar]
- Li, X.; Lu, H.; Zhang, L.; Ruan, X.; Yang, M.H. Saliency detection via dense and sparse reconstruction. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2976–2983. [Google Scholar]
- Hou, Q.; Cheng, M.M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P.H.S. Deeply supervised salient object detection with short connections. IEEE Trans. Pattern Anal. Mach. Intell. 2018. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Wang, L.; Lu, H.; Zhang, P.; Ruan, X. Saliency detection with recurrent fully convolutional networks. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; Volume 9908. [Google Scholar]
- Dresp, B.; Grossberg, S. Contour integration across polarities and spatial gaps: From local contrast filtering to global grouping. Vis. Res. 1997, 37, 913–924. [Google Scholar] [CrossRef]
- Dresp, B.; Durand, S.; Grossberg, S. Depth perception from pairs of stimuli with overlapping cues in 2-D displays. Spat. Vis. 2002, 15, 255–276. [Google Scholar] [CrossRef] [PubMed]
- Dresp-Langley, B.; Grossberg, S. Neural computation of surface border ownership and relative surface depth from ambiguous contrast inputs. Front. Psychol. 2016, 7, 1102. [Google Scholar] [CrossRef] [PubMed]
- Grillspector, K.; Malach, R. The human visual cortex. Ann. Rev. Neurosci. 2004, 27, 649–677. [Google Scholar] [CrossRef] [PubMed]
- Blog. Available online: https://blog.csdn.net/shuzfan/article/details/78586307 (accessed on 6 August 2018).
- Wagemans, J.; Feldman, J.; Gepshtein, S.; Kimchi, R.; Pomerantz, J.R.; van der Helm, P.A.; van Leeuwen, C. A century of gestalt psychology in visual perception II. conceptual and theoretical foundations. Psychol. Bull. 2012, 138, 1218–1252. [Google Scholar] [CrossRef] [PubMed]
- Lee, T.S. Image representation using 2D Gabor wavelets. IEEE Trans. Pattern Anal. Mach. Intell. 1996, 18, 959–971. [Google Scholar] [Green Version]
- Zhihu. Available online: https://zhuanlan.zhihu.com/p/21905116 (accessed on 6 August 2018).
- Stocker, A.A.; Simoncelli, E.P. Noise characteristics and prior expectations in human visual speed perception. Nat. Neurosci. 2006, 9, 578–585. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kastner, S.; Pinsk, M.A. Visual attention as a multilevel selection process. Cognit. Affect. Behav. Neurosci. 2004, 4, 483–500. [Google Scholar] [CrossRef] [Green Version]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.T.; Liu, Z.X.; Jiang, N. Object segmentation of infrared image based on fused saliency map and efficient subwindow search. Acta Autom. Sin. 2018, 11, 274–282. [Google Scholar]
- Lan, Z.; Lin, M.; Li, X.; Hauptmann, A.G.; Raj, B. Beyond gaussian pyramid: Multi-skip feature stacking for action recognition. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 204–212. [Google Scholar]
- Cacioppo, J.T.; Petty, R.E.; Kao, C.F.; Rodriguez, R. Central and peripheral routes to persuasion: An individual difference perspective. J. Person. Soc. Psychol. 1986, 51, 1032–1043. [Google Scholar] [CrossRef]
- Tuzel, O.; Porikli, F.; Meer, P. Region Covariance: A fast descriptor for detection and classification. In Computer Vision—ECCV 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 589–600. [Google Scholar]
- Cela-Conde, C.J.; Marty, G.; Maestú, F.; Ortiz, T.; Munar, E.; Fernández, A.; Roca, M.; Rosselló, J.; Quesney, F. Activation of the prefrontal cortex in the human visual aesthetic perception. Proc. Natl. Acad. Sci. USA 2004, 101, 6321–6325. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liang, D. Research on Human Eye Optical System and Visual Attention Mechanism. Ph.D. Thesis, Zhejiang University, Hangzhou, China, 2017. [Google Scholar]
- Hong, X.; Chang, H.; Shan, S.; Chen, X.; Gao, W. Sigma Set: A small second order statistical region descriptor. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–26 June 2009; pp. 1802–1809. [Google Scholar]
- Lauinger, N. The two axes of the human eye and inversion of the retinal layers: The basis for the interpretation of the retina as a phase grating optical, cellular 3D chip. J. Biol. Phys. 1993, 19, 243–257. [Google Scholar] [CrossRef]
- Dong, L.; Wesseloo, J.; Potvin, Y.; Li, X. Discrimination of mine seismic events and blasts using the fisher classifier, naive bayesian classifier and logistic regression. Rock Mech. Rock Eng. 2016, 49, 183–211. [Google Scholar] [CrossRef]
- Fang, Z.; Cui, R.; Jin, W. Video saliency detection algorithm based on bio-visual features and visual psychology. Acta Phys. Sin. 2017, 66, 319–332. [Google Scholar]
- Liu, T.; Sun, J.; Zheng, N.-N.; Tang, X.; Shum, H.-Y. Learning to detect a salient object. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 353–367. [Google Scholar] [PubMed]
- Li, G.; Yu, Y. Visual saliency based on multiscale deep features. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5455–5463. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Hou, X.; Koch, C.; Rehg, J.M.; Yuille, A.L. The secrets of salient object segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 280–287. [Google Scholar]
- Che, Z.; Zhai, G.; Min, X. A hierarchical saliency detection approach for bokeh images. In Proceedings of the 2015 IEEE 17th International Workshop on Multimedia Signal Processing (MMSP), Xiamen, China, 19–21 October 2015; pp. 1–6. [Google Scholar]
- Zhao, R.; Ouyang, W.; Li, H.; Wang, X. Saliency detection by multi-context deep learning. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1265–1274. [Google Scholar]
- Lee, G.; Tai, Y.W.; Kim, J. Deep saliency with encoded low level distance map and high level features. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 660–668. [Google Scholar]
- Liu, N.; Han, J. DHSNet: Deep hierarchical saliency network for salient object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 678–686. [Google Scholar]
- Li, G.; Yu, Y. Deep contrast learning for salient object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 478–487. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Shen, Z.; Liu, Z.; Li, J.; Jiang, Y.G.; Chen, Y.; Xue, X. DSOD: Learning deeply supervised object detectors from Scratch. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1937–1945. [Google Scholar]
- Zhang, J.; Huang, M.; Jin, X.; Li, X. A real-time chinese traffic sign detection algorithm based on modified YOLOv2. Algorithms 2017, 10, 127. [Google Scholar] [CrossRef]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. SSD: Deconvolutional single shot detector. arXiv, 2017; arXiv:1701.06659. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | PASCALS | HKU-IS | KITTI | MSRA-B | MOD | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Fβ | MAE | Fβ | MAE | Fβ | MAE | Fβ | MAE | Fβ | MAE | |
| RFCN | 0.862 | 0.127 | 0.879 | 0.081 | 0.816 | 0.235 | 0.938 | 0.079 | 0.825 | 0.229 |
| RC | 0.631 | 0.245 | 0.716 | 0.185 | 0.698 | 0.276 | 0.803 | 0.159 | 0.612 | 0.375 |
| CHM | 0.611 | 0.275 | 0.696 | 0.205 | 0.678 | 0.289 | 0.793 | 0.168 | 0.601 | 0.383 |
| DSR | 0.627 | 0.255 | 0.703 | 0.235 | 0.692 | 0.279 | 0.801 | 0.16 | 0.608 | 0.379 |
| DRFI | 0.812 | 0.149 | 0.819 | 0.131 | 0.801 | 0.255 | 0.938 | 0.079 | 0.725 | 0.279 |
| ELD | 0.768 | 0.121 | 0.843 | 0.073 | 0.816 | 0.168 | 0.913 | 0.041 | 0.795 | 0.208 |
| MDF | 0.765 | 0.147 | 0.859 | 0.131 | 0.798 | 0.169 | 0.884 | 0.115 | 0.763 | 0.265 |
| MC | 0.723 | 0.149 | 0.792 | 0.103 | 0.732 | 0.185 | 0.872 | 0.063 | 0.691 | 0.325 |
| DHS | 0.819 | 0.101 | 0.892 | 0.052 | 0.785 | 0.201 | 0.906 | 0.058 | 0.739 | 0.298 |
| DSSOD | 0.83 | 0.08 | 0.913 | 0.039 | 0.896 | 0.045 | 0.927 | 0.028 | 0.803 | 0.196 |
| OURS | 0.852 | 0.061 | 0.896 | 0.041 | 0.912 | 0.031 | 0.915 | 0.068 | 0.875 | 0.082 |
| Methods | Dataset | Pf (%) | Pm (%) | Pd (%) | Pe (%) | Time (s) |
|---|---|---|---|---|---|---|
| Faster R-CNN | KITTI | 11.21 | 13.34 | 60.32 | 15.13 | 0.076 |
| MOD | 16.25 | 15.38 | 50.83 | 17.54 | 0.086 | |
| DSOD300 | KITTI | 14.48 | 15.91 | 63.38 | 6.23 | 0.017 |
| MOD | 18.95 | 19.28 | 51.42 | 10.35 | 0.021 | |
| YOLO V2 544 | KITTI | 13.31 | 12.29 | 59.84 | 14.56 | 0.022 |
| MOD | 15.17 | 15.49 | 49.45 | 19.89 | 0.026 | |
| DSSD | KITTI | 9.53 | 10.69 | 66.25 | 13.53 | 0.018 |
| MOD | 16.24 | 13.19 | 55.16 | 15.41 | 0.028 | |
| OURS | KITTI | 4.19 | 3.13 | 90.47 | 2.21 | 0.106 |
| MOD | 6.16 | 5.37 | 82.05 | 6.42 | 0.185 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hua, X.; Wang, X.; Wang, D.; Huang, J.; Hu, X. Military Object Real-Time Detection Technology Combined with Visual Salience and Psychology. Electronics 2018, 7, 216. https://doi.org/10.3390/electronics7100216
Hua X, Wang X, Wang D, Huang J, Hu X. Military Object Real-Time Detection Technology Combined with Visual Salience and Psychology. Electronics. 2018; 7(10):216. https://doi.org/10.3390/electronics7100216
Chicago/Turabian StyleHua, Xia, Xinqing Wang, Dong Wang, Jie Huang, and Xiaodong Hu. 2018. "Military Object Real-Time Detection Technology Combined with Visual Salience and Psychology" Electronics 7, no. 10: 216. https://doi.org/10.3390/electronics7100216