Automated Scalable Address Generation Patterns for 2-Dimensional Folding Schemes in Radix-2 FFT Implementations


Abstract
:1. Introduction
- a set of methods to generate scalable FFT cores based on an address generation scheme for Field Programmable Gate Array (FPGA) implementation when the vertical folding factor is optimized,
- a mathematical procedure to automatically generate address patterns in FFT computations,
- a set of stride group permutations to guide data flow in hardware architectures, and
- a set of guidelines about space/time tradeoffs for FFT algorithm developers.
2. Mathematical Preliminaries
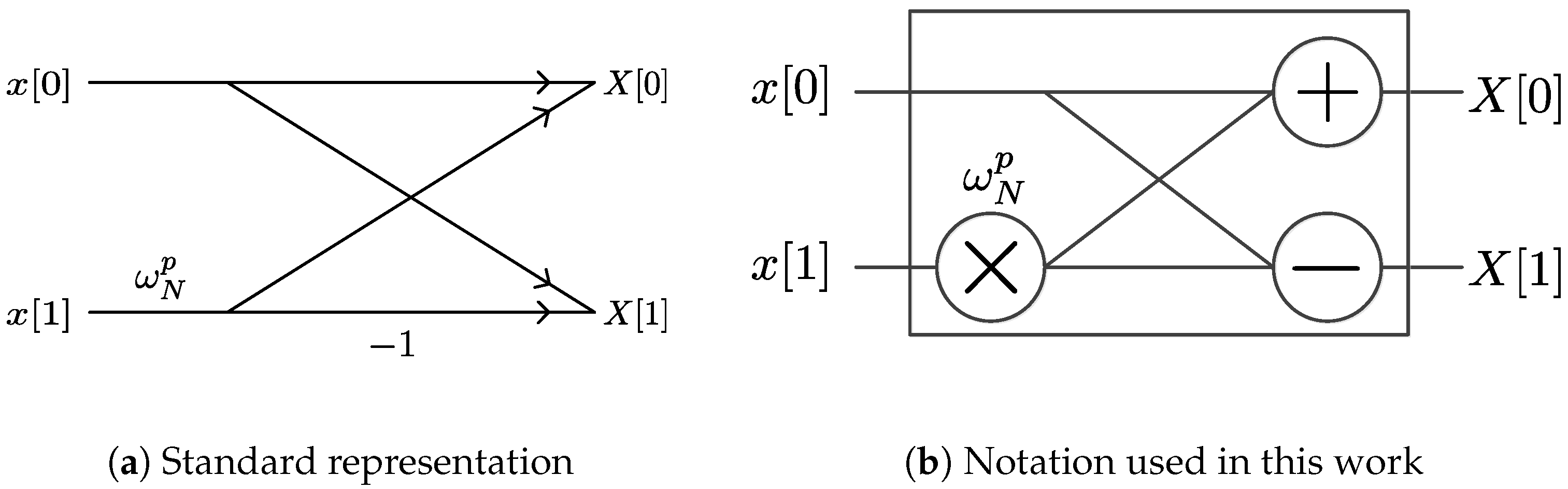
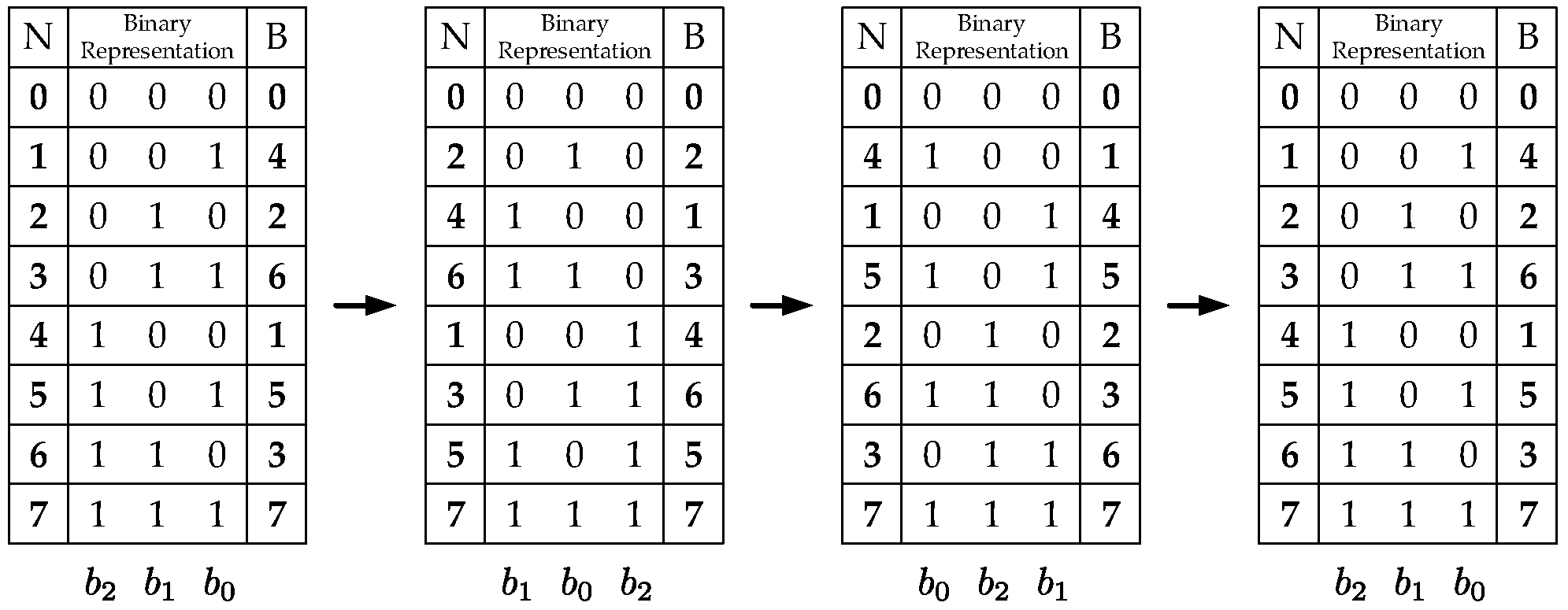
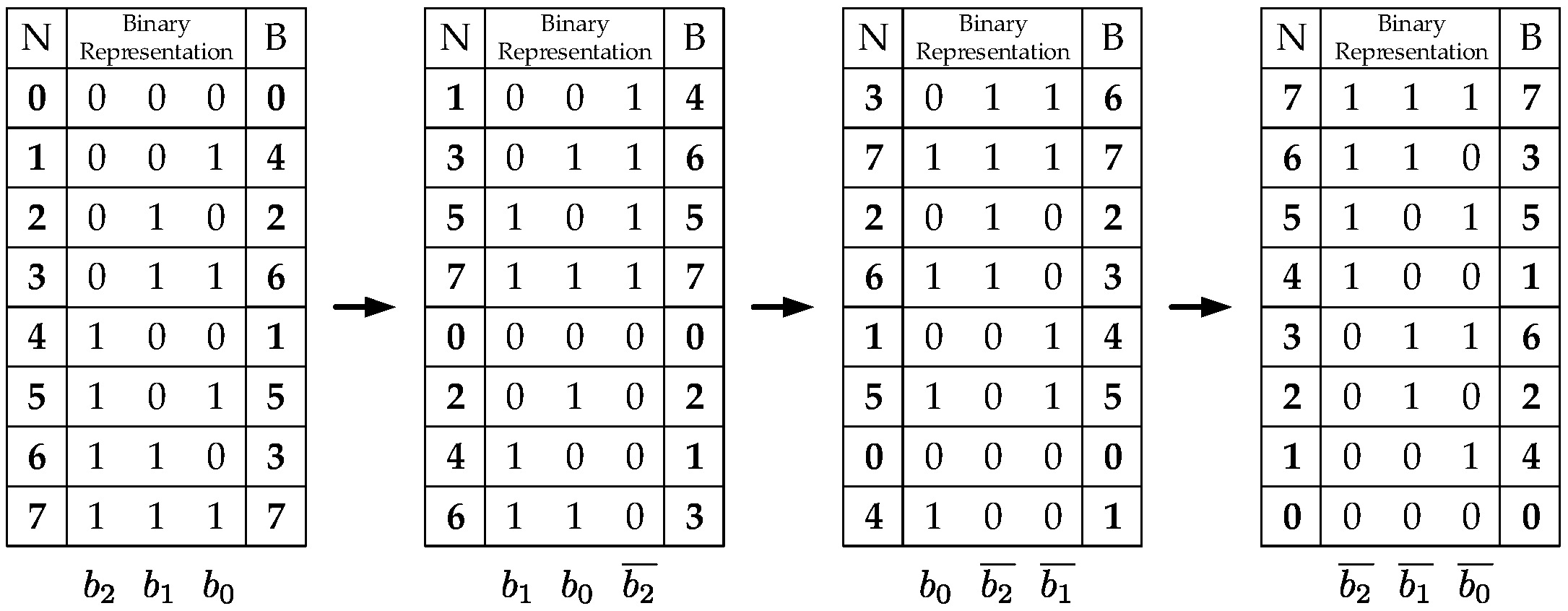
2.1. Definitions
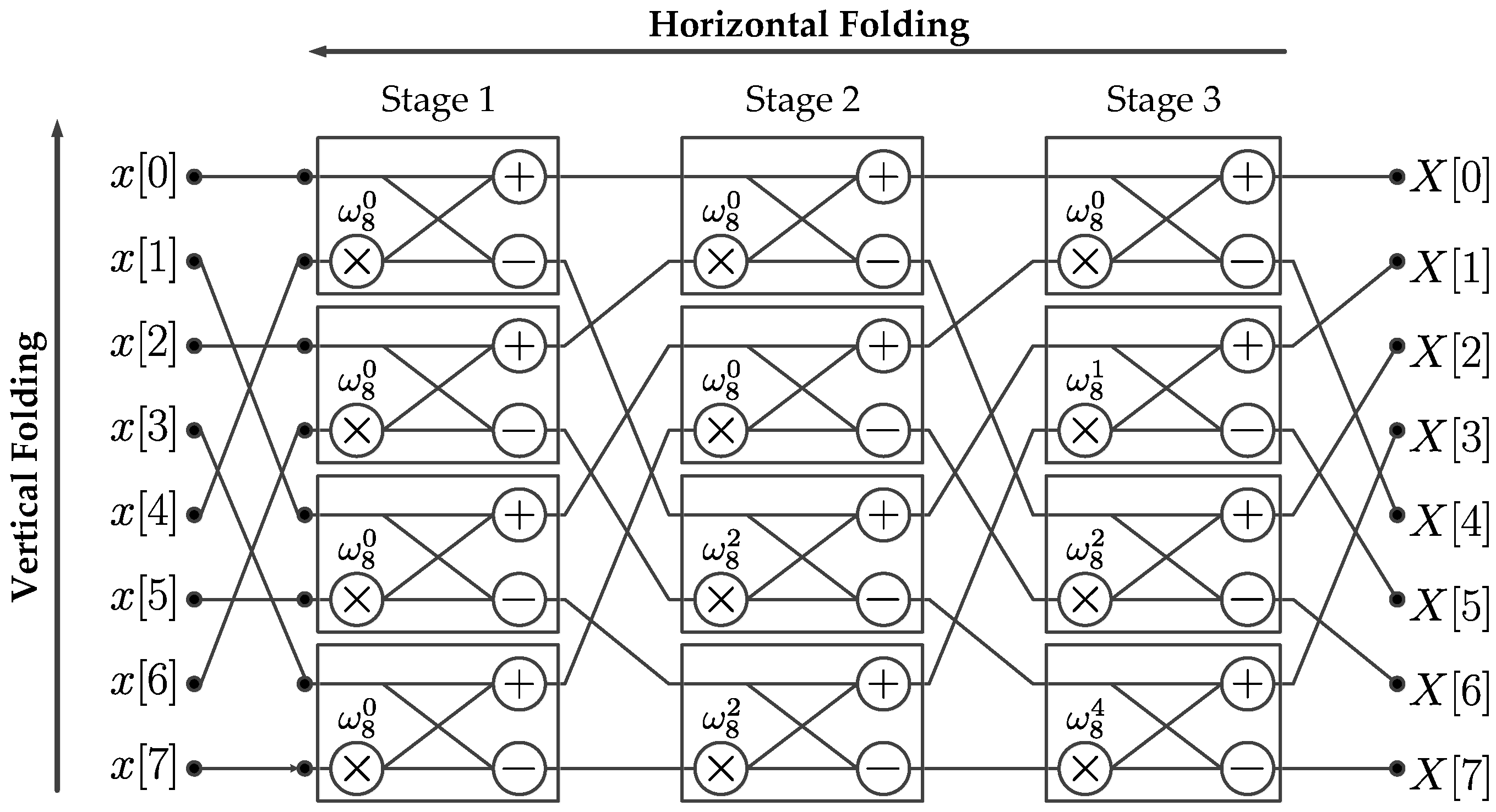
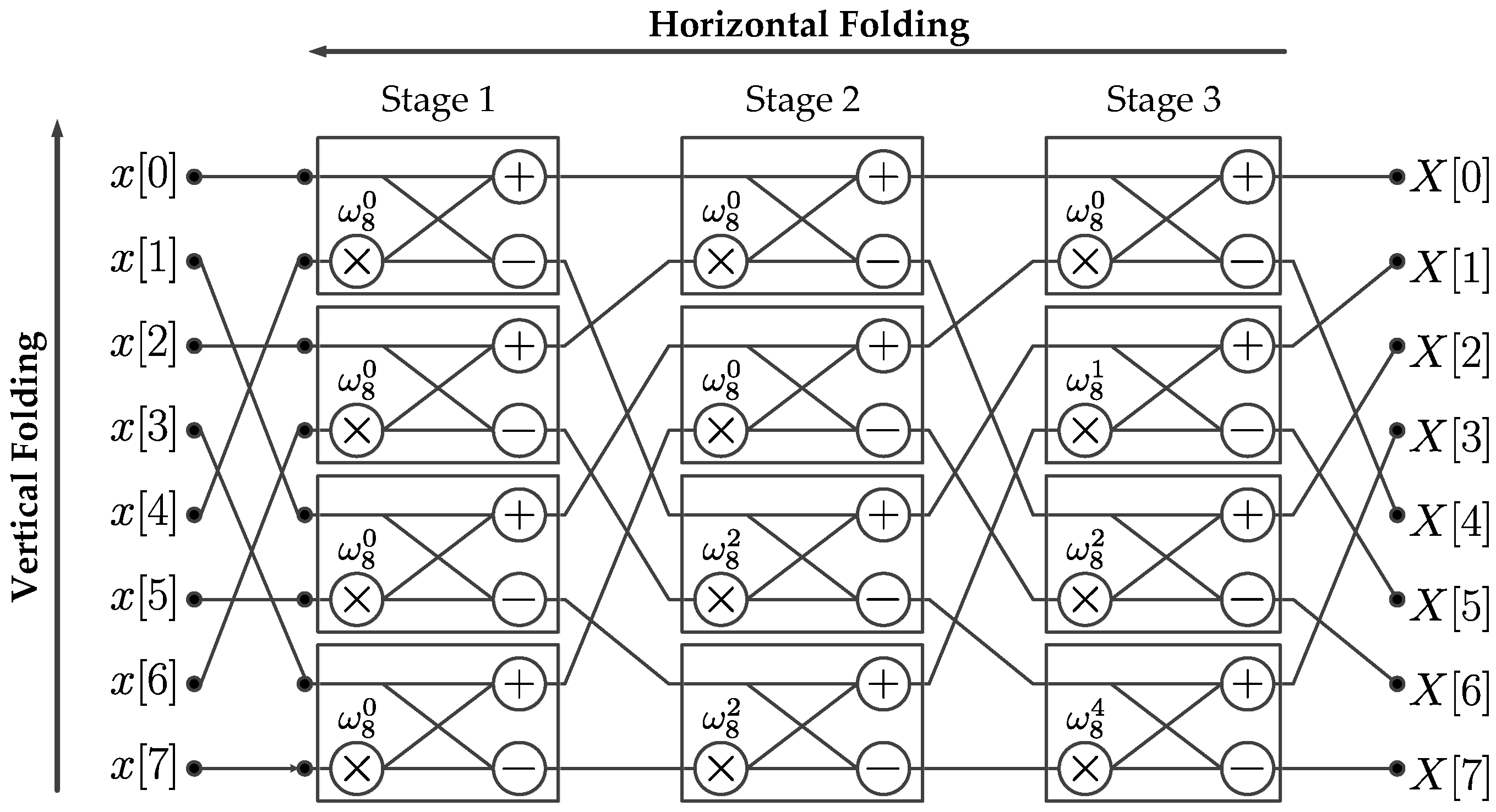
2.2. Kronecker Products Formulation of the Xilinx FFT Radix-2 Burst I/O Architecture
2.3. Kronecker Products Formulation of the Scalable FFT with Address Generation
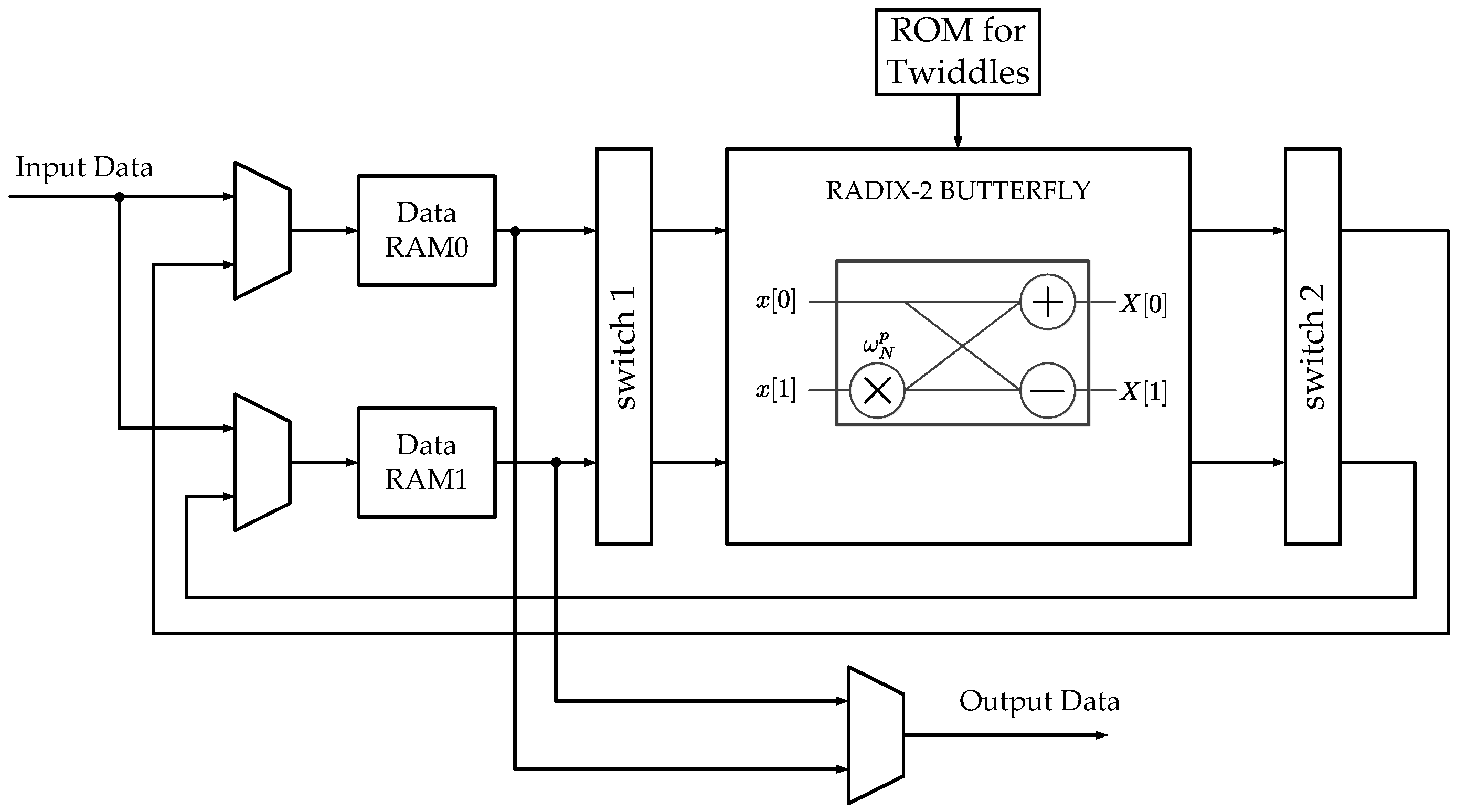
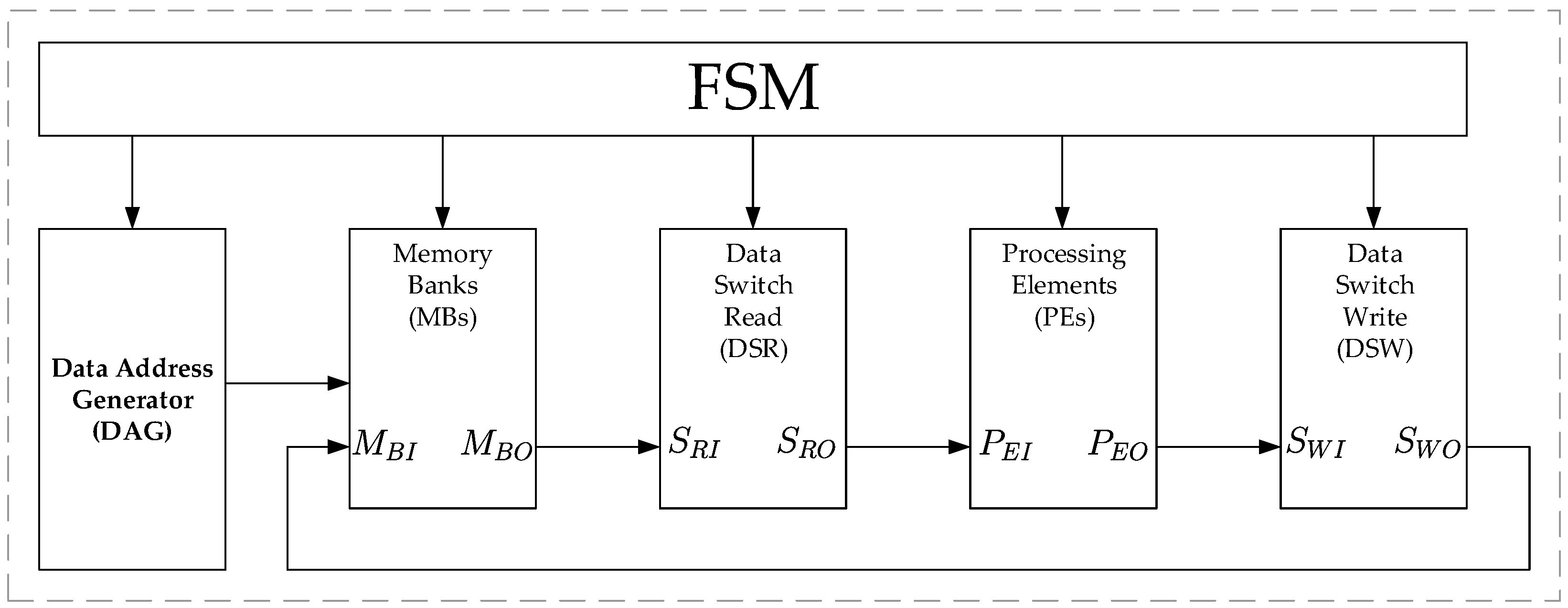
3. Hardware Implementation
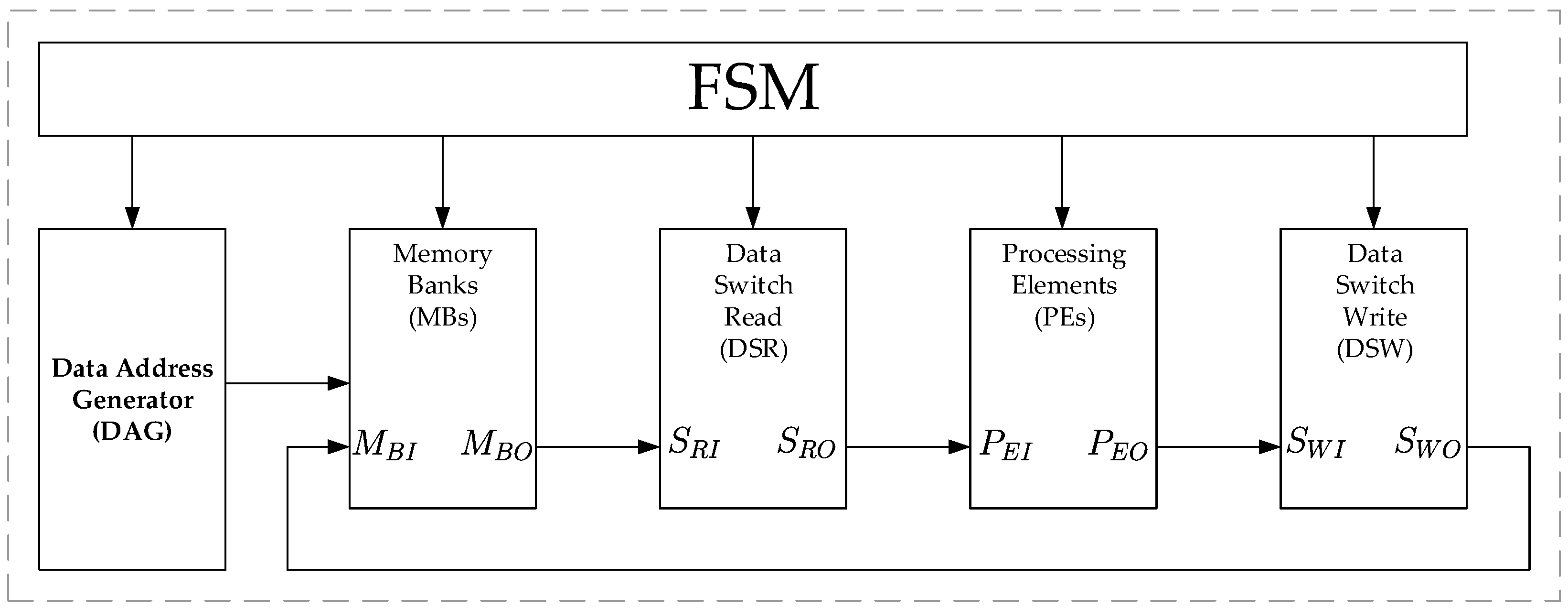
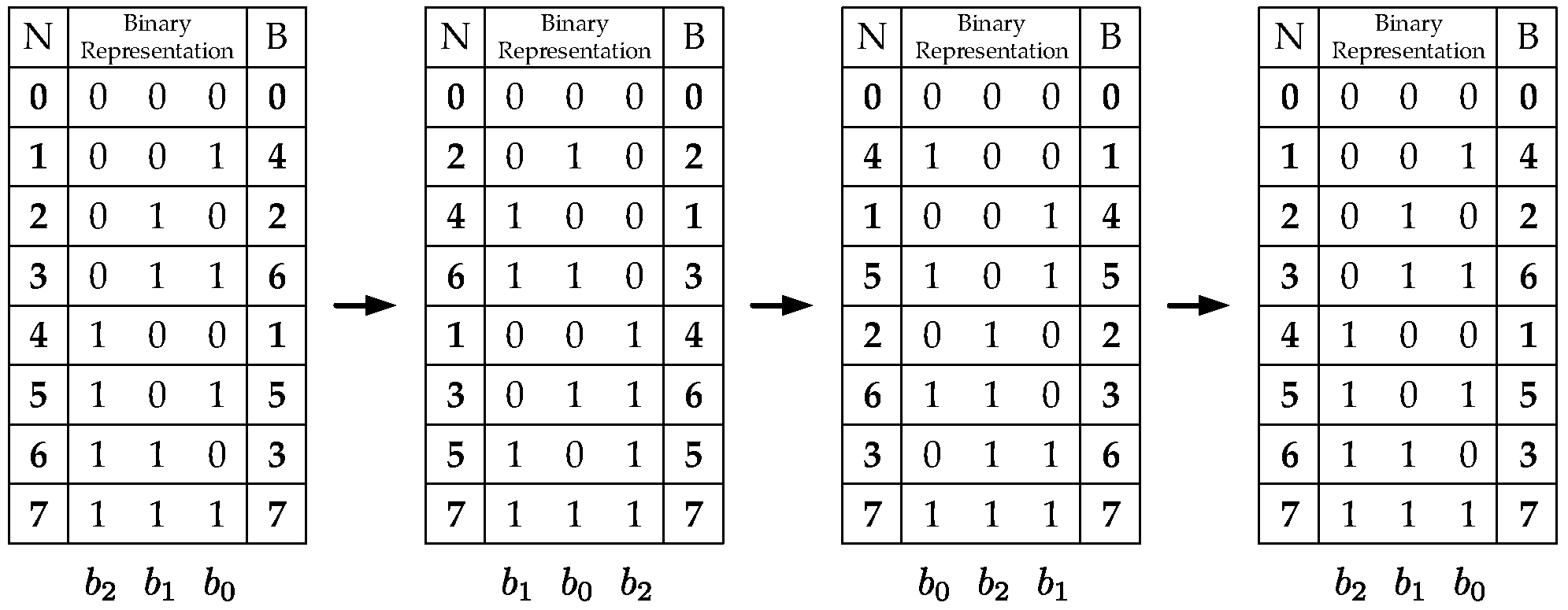
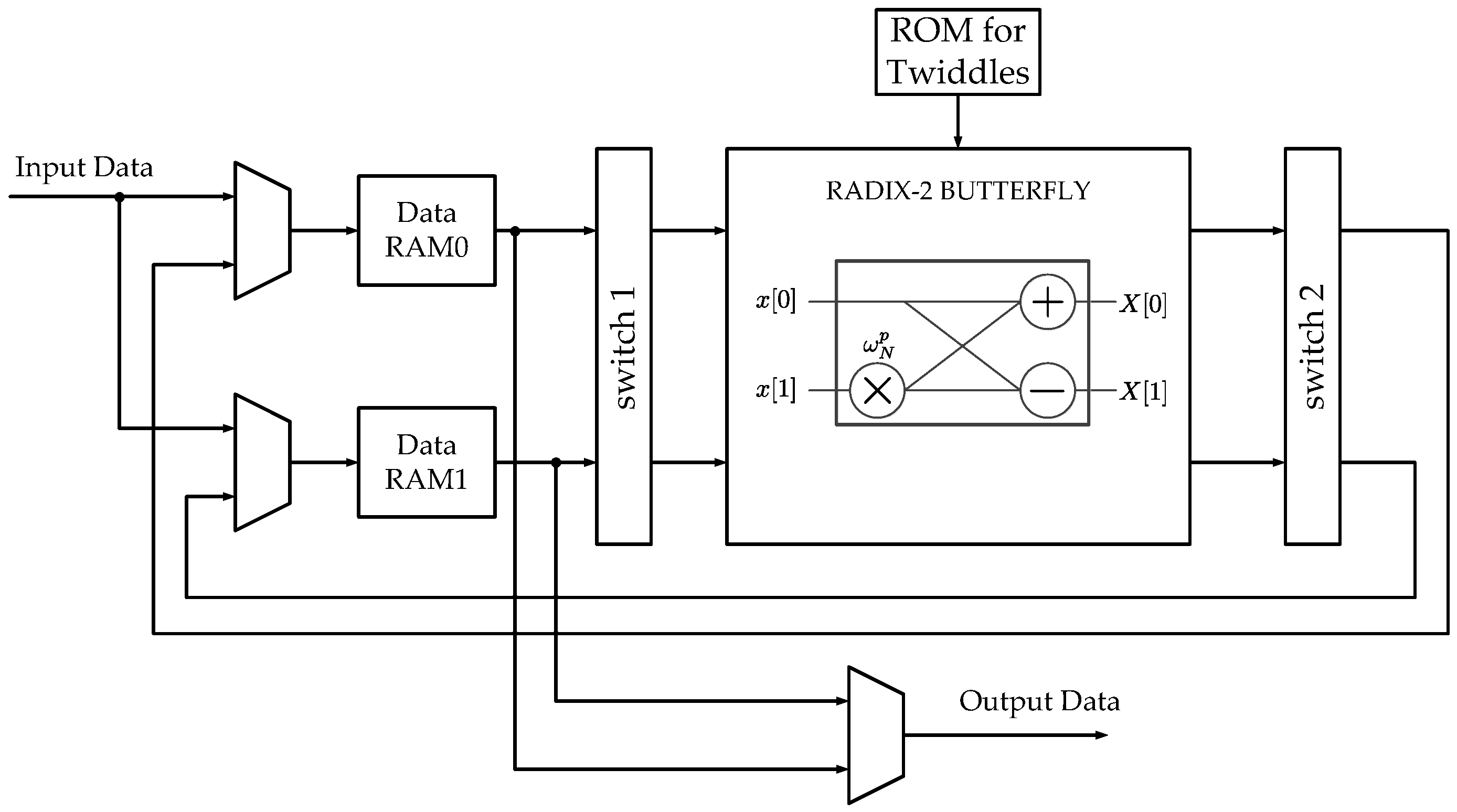
3.1. Data Address Generator
3.2. Phase Factor Scheduling
| Algorithm 1: Twiddle Address. |
| Input: , , Output: Twiddle Pattern for N points and butterflies ; for to do ; for to do ; if is divisible by n and then ; end for to do if is divisible by f then ; end end end ; if then ; end if then ; end end |
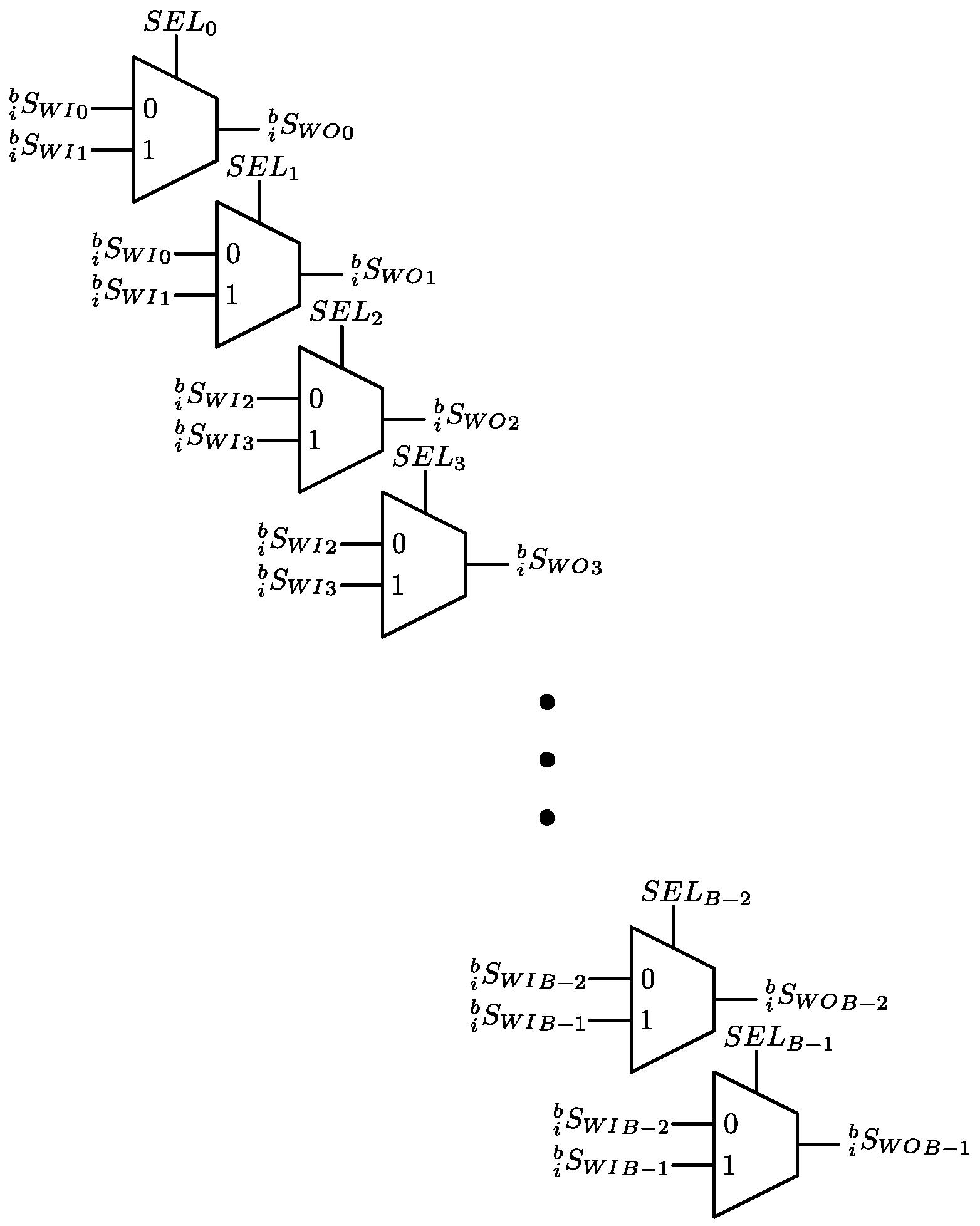
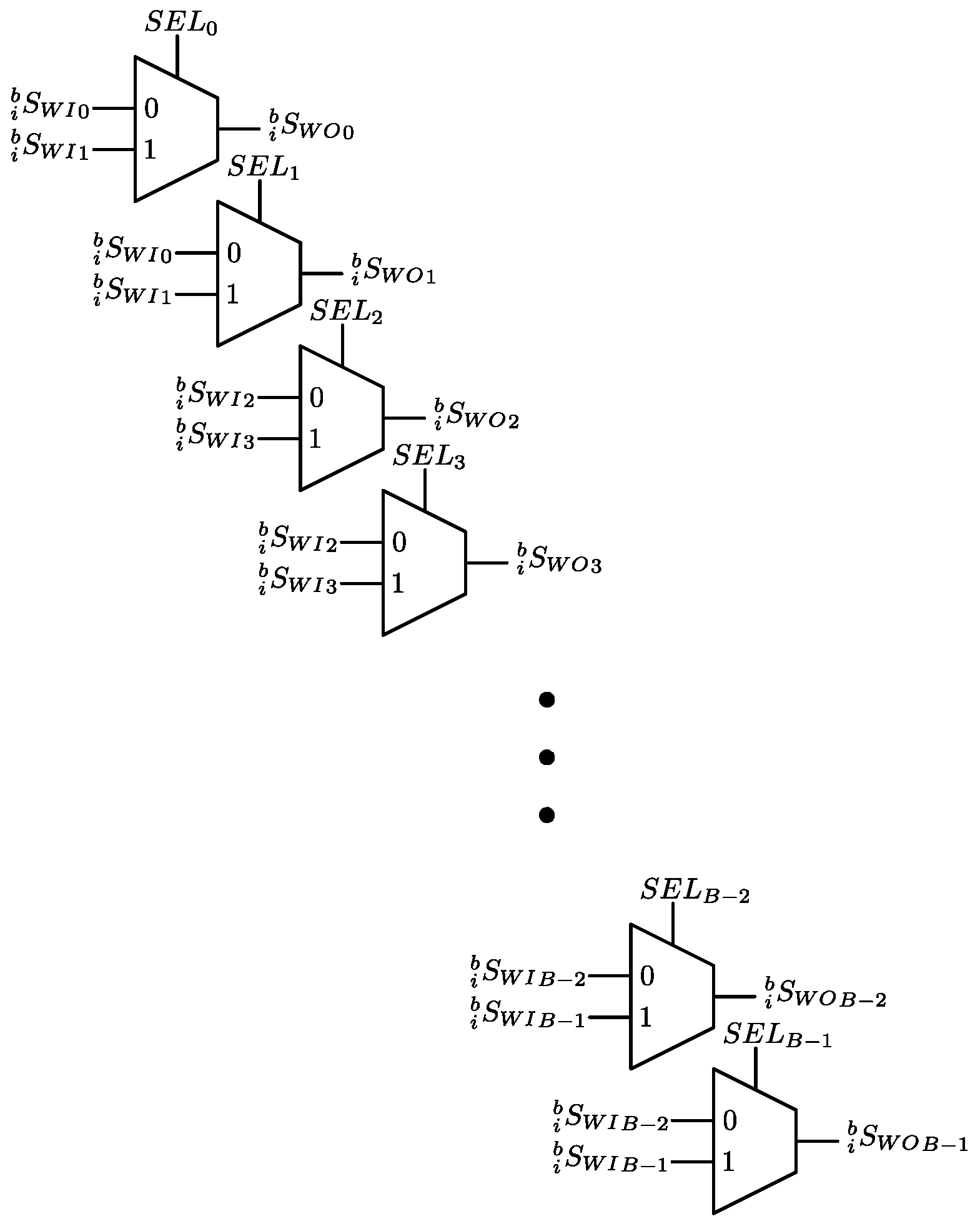
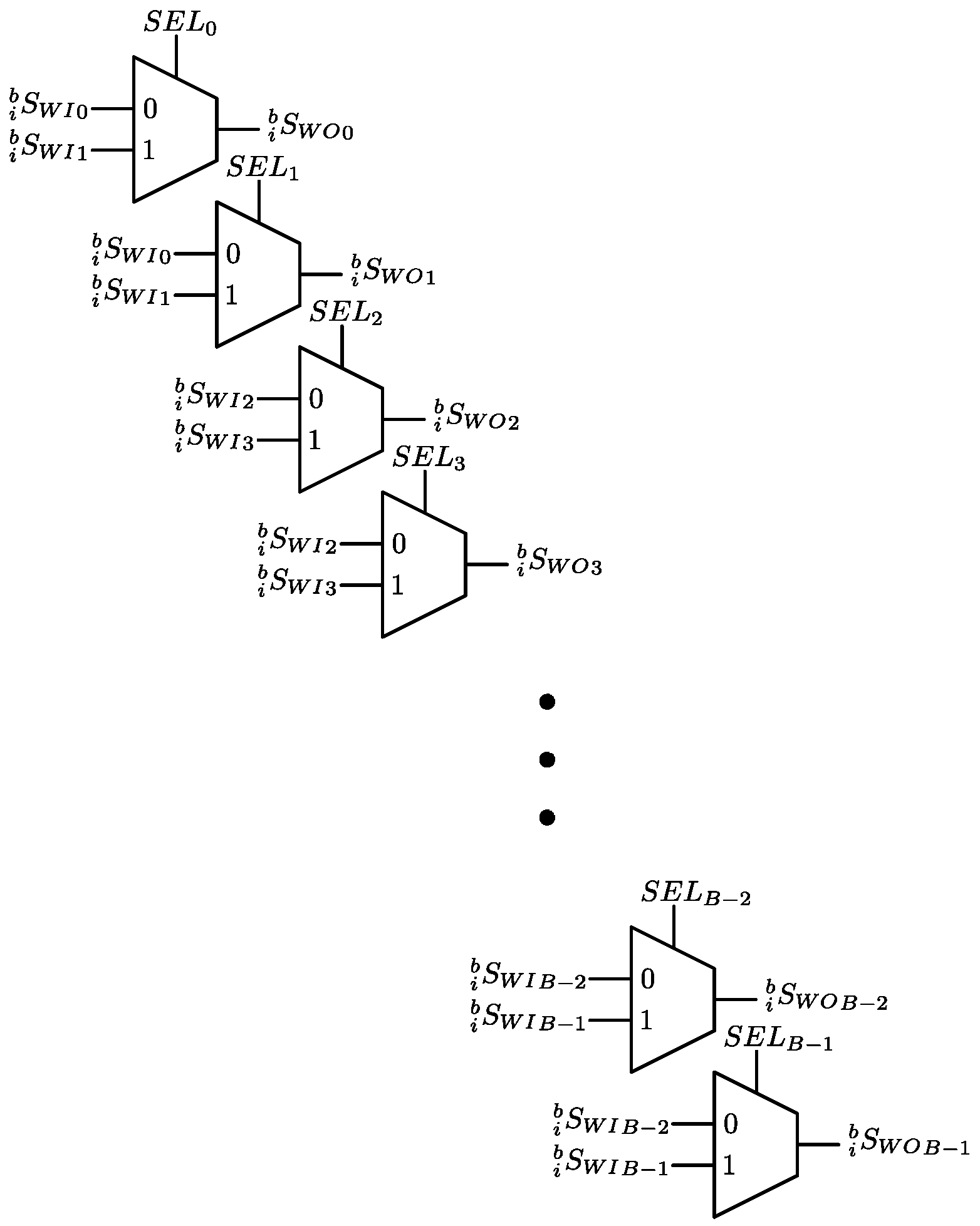
3.3. Data Switch Read (DSR)
3.4. Data Switch Write (DSW)
3.5. Finite State Machine (FSM)
- the output change of the DAG as indicated in Equations (17) and (19),
- the permutation to perform by the DSR and DSW as indicated in Equations (27) and (32),
- the phase factor addresses for the PEs and as indicated in Equation (28),
- the reading and writing process in the MBs as indicated in Equations (25) and (34).
4. FPGA Implementation
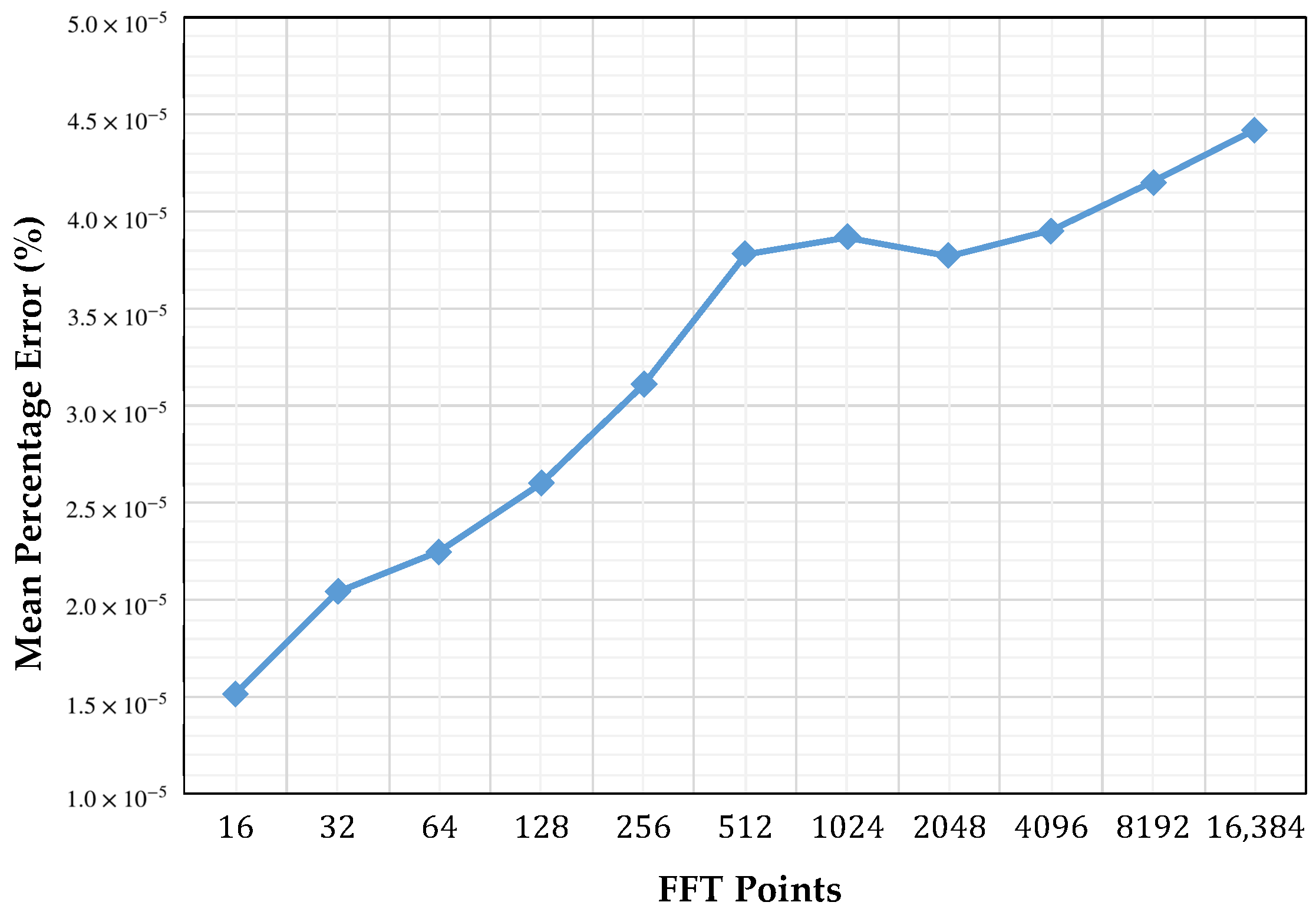
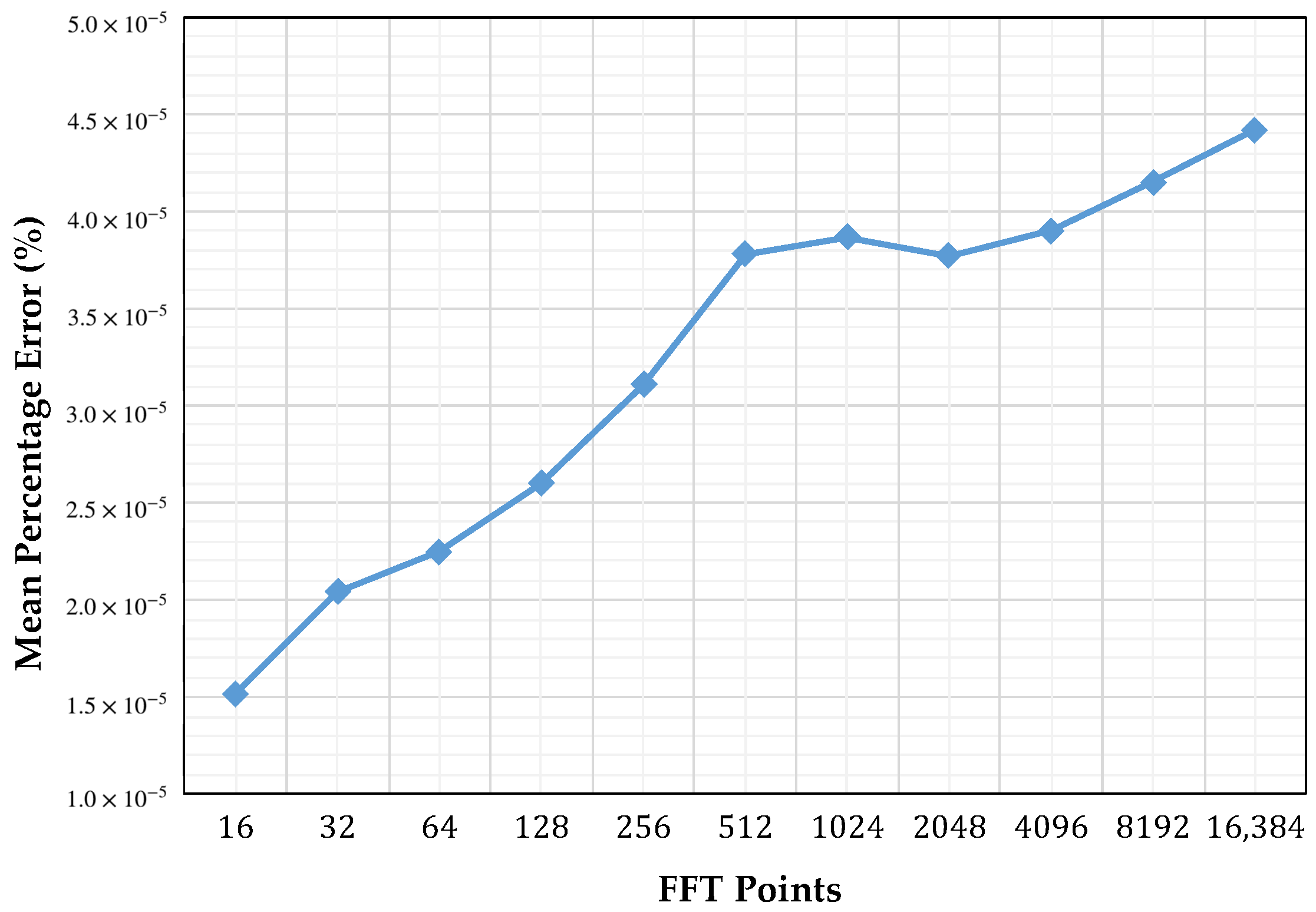
4.1. Validation
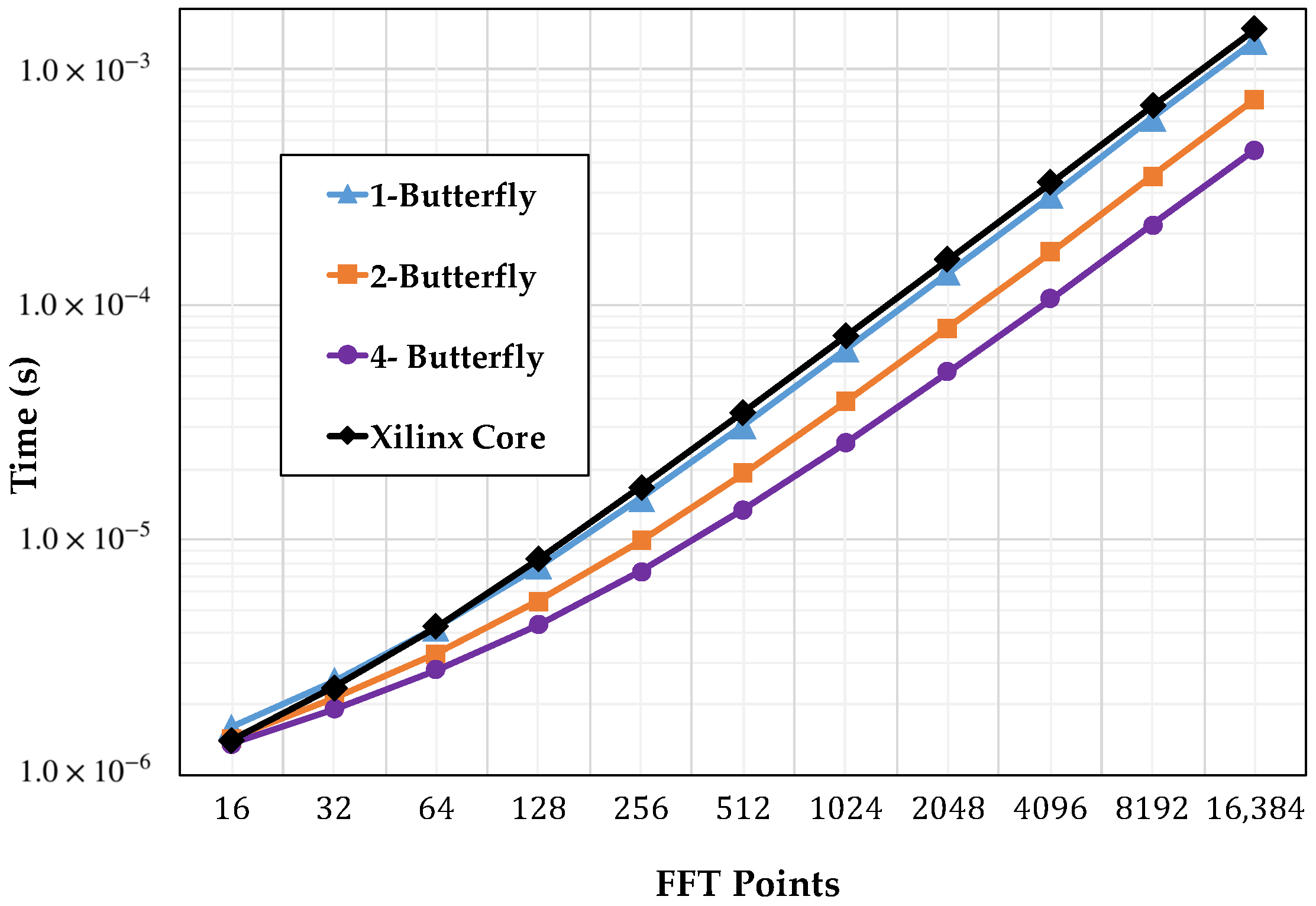
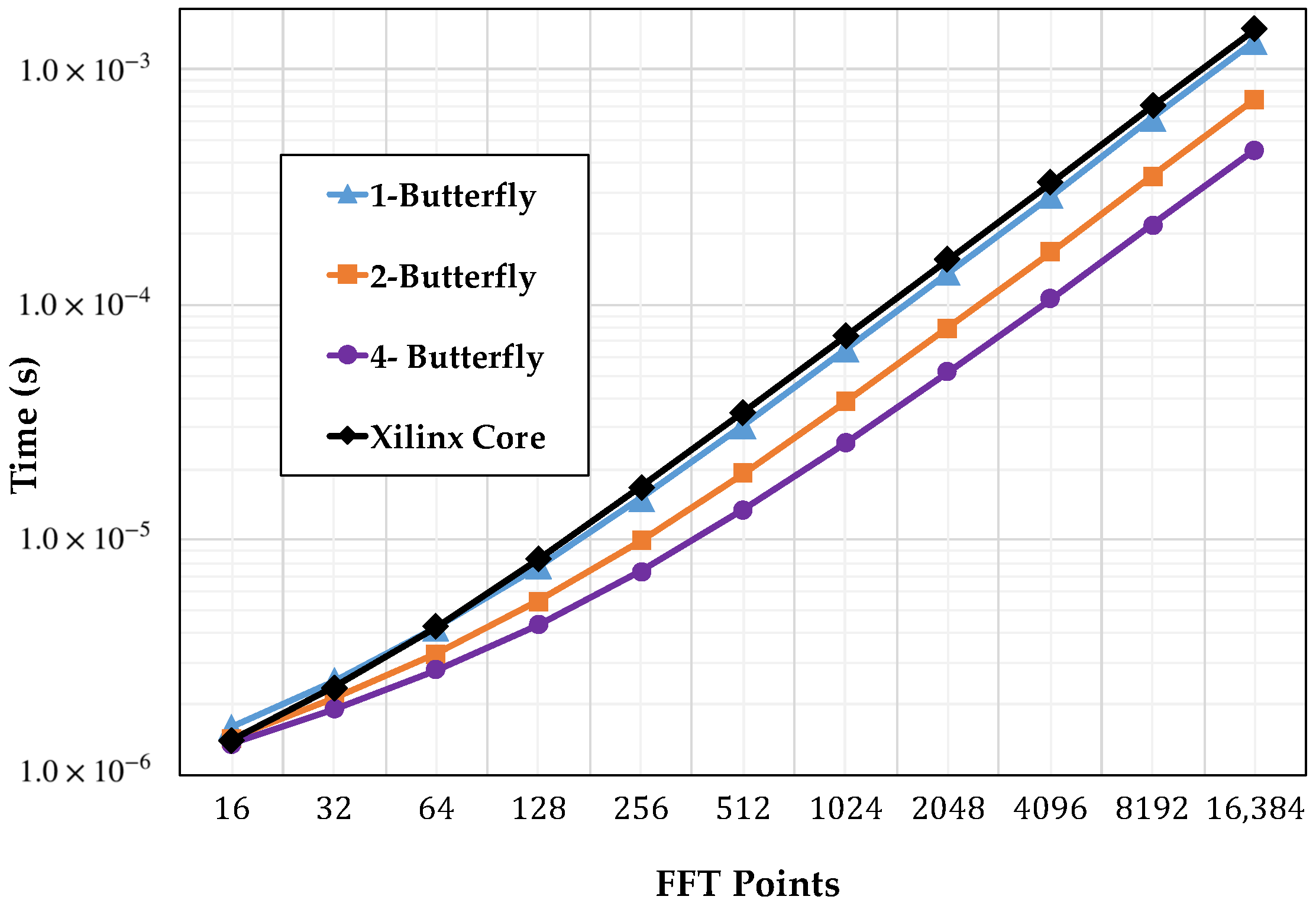
4.2. Timing Performance
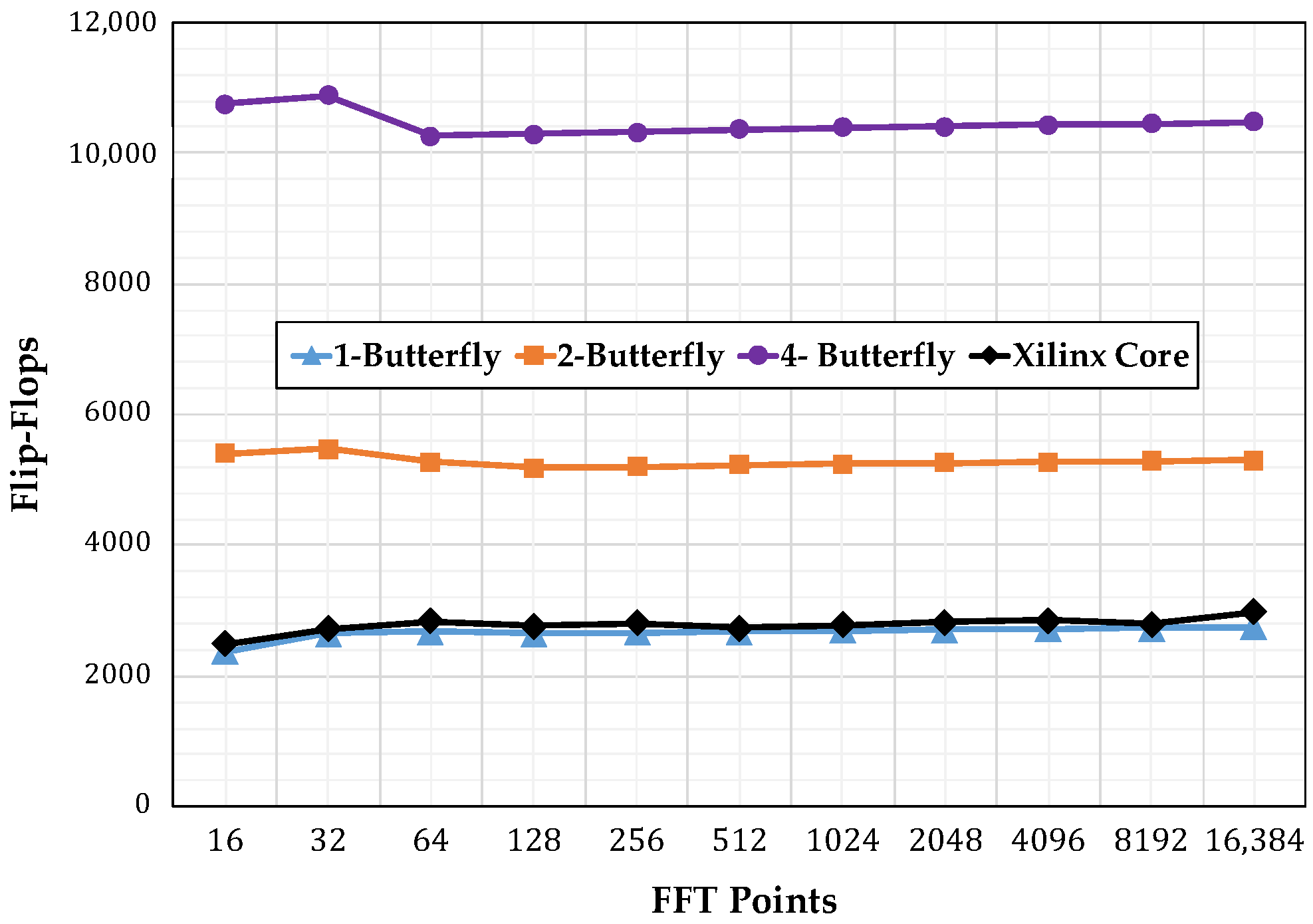
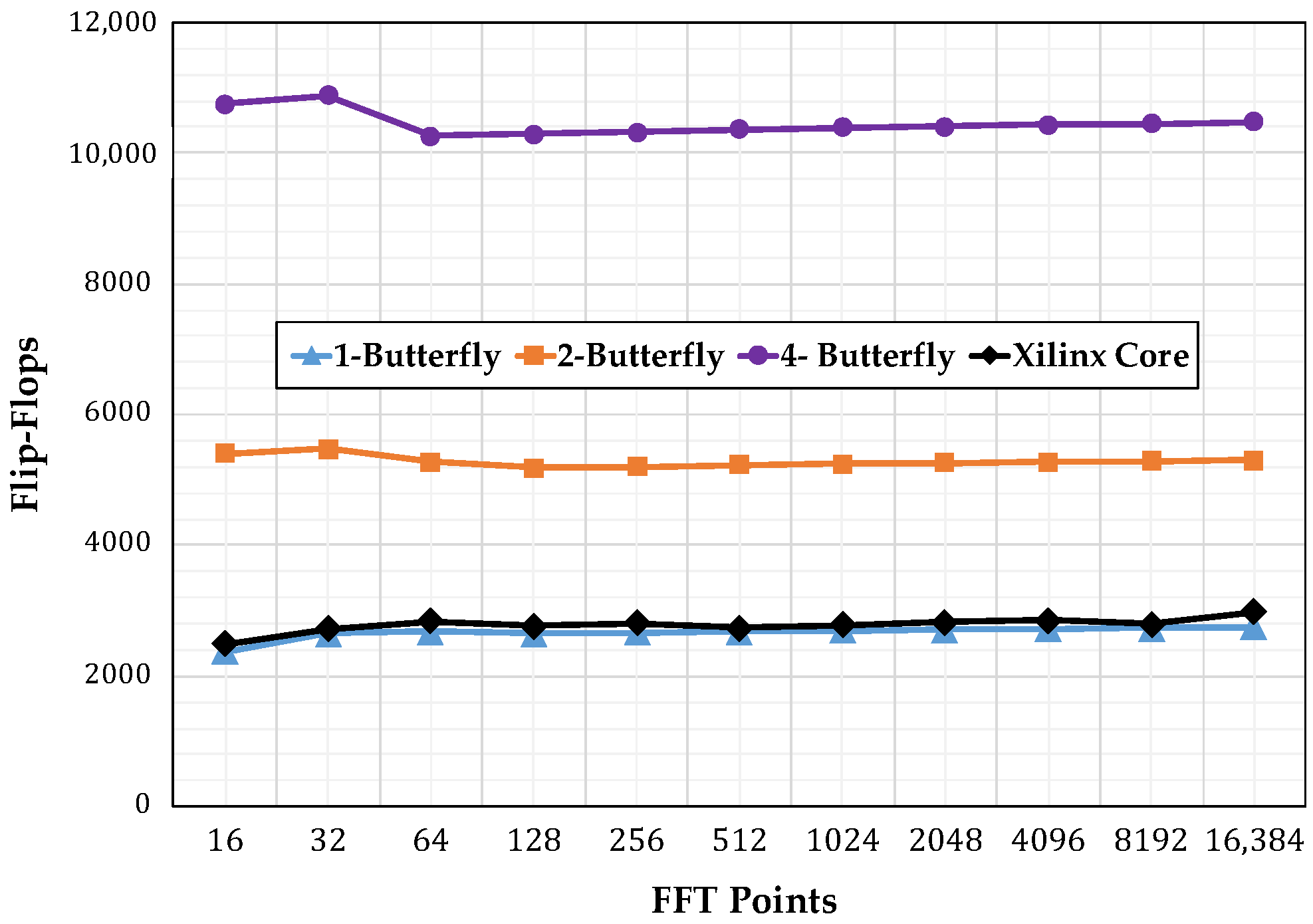
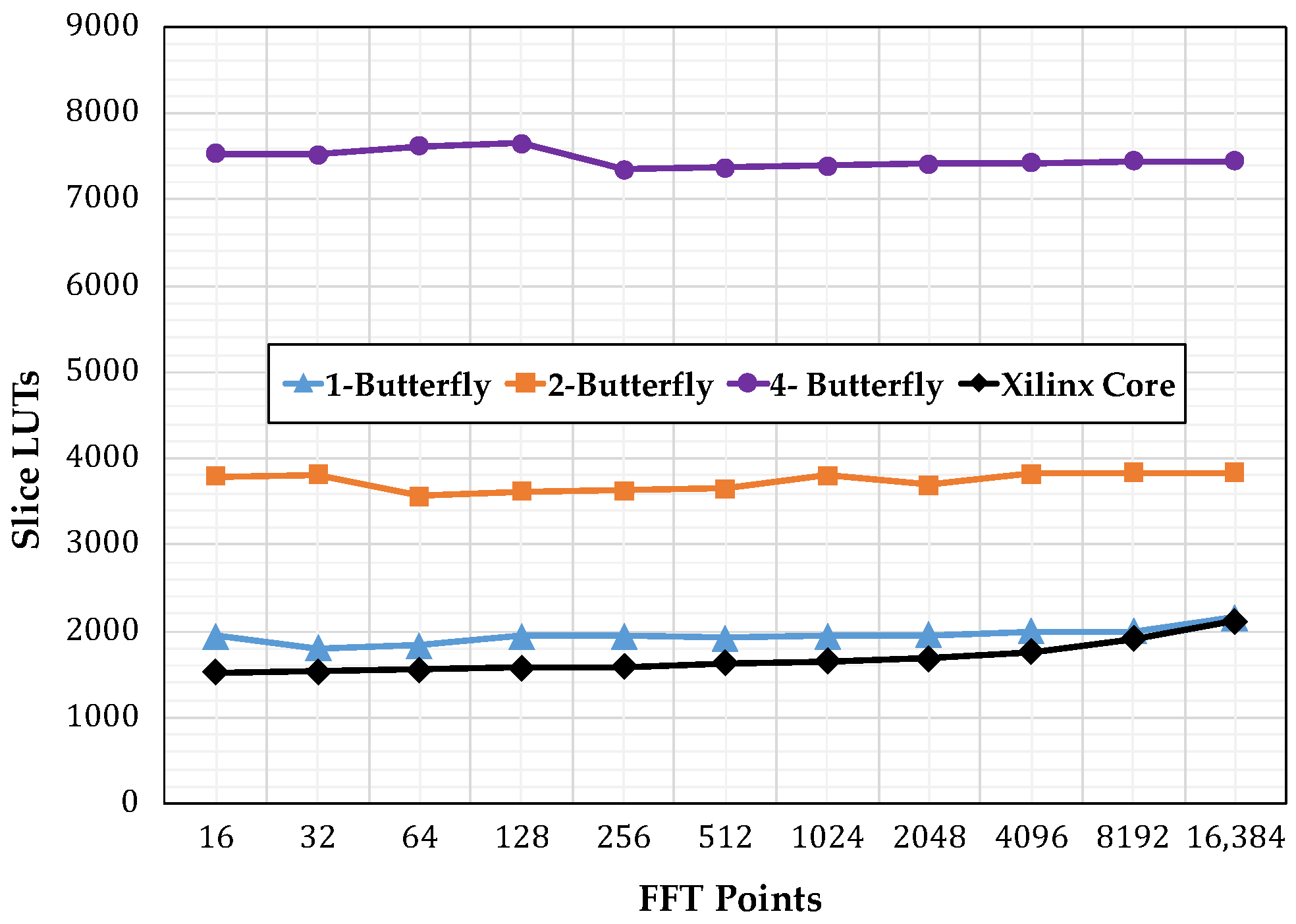
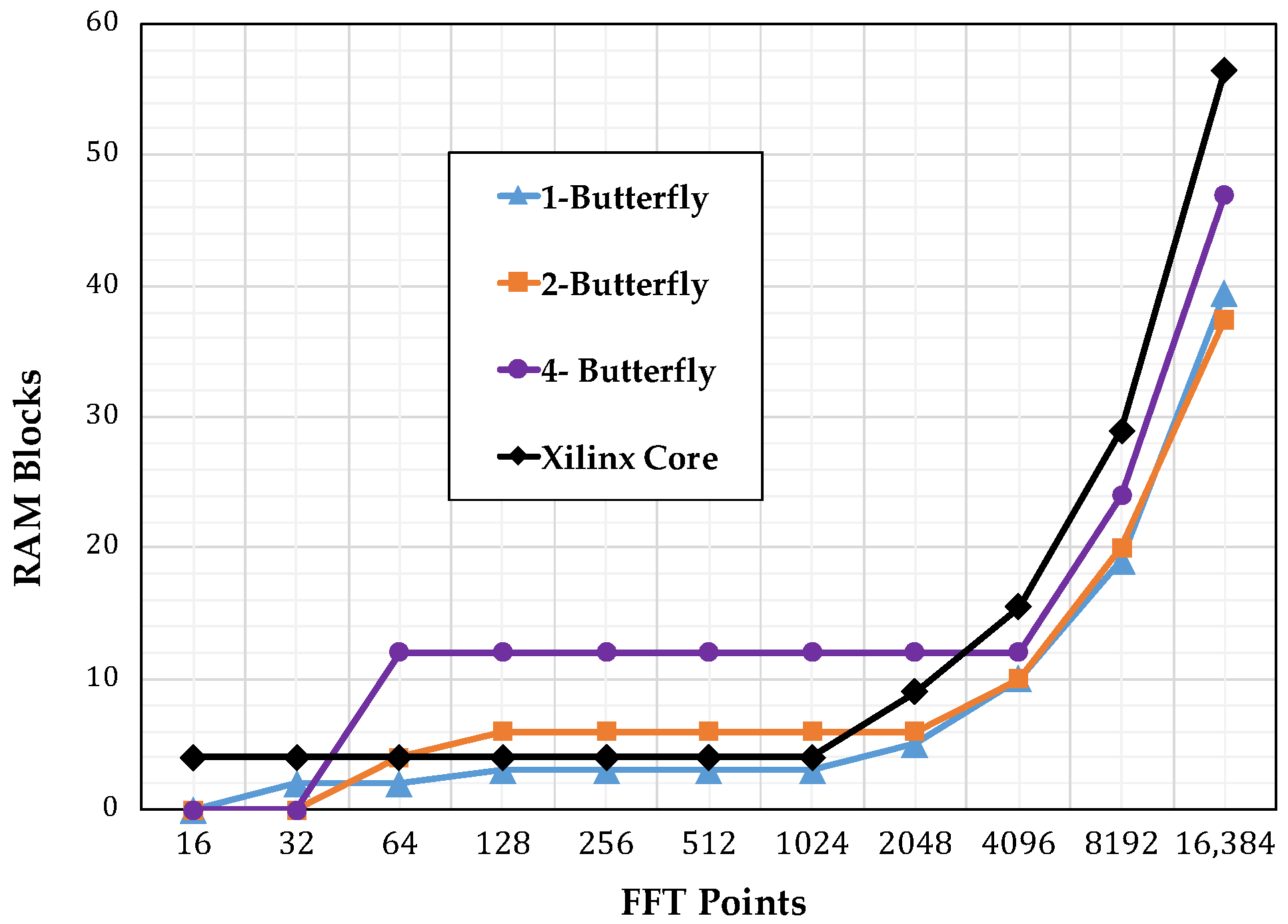
4.3. Resource Consumption
4.4. Analysis
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Cooley, J.W.; Tukey, J. An Algorithm for the Machine Calculation of Complex Fourier Series. Math. Comput. 1965, 19, 297–301. [Google Scholar] [CrossRef]
- Pease, M.C. An Adaptation of the Fast Fourier Transform for Parallel Processing. J. ACM 1968, 15, 252–264. [Google Scholar] [CrossRef]
- Astola, J.; Akopian, D. Architecture-oriented regular algorithms for discrete sine and cosine transforms. IEEE Trans. Signal Process. 1999, 47, 1109–1124. [Google Scholar] [CrossRef]
- Chen, S.; Chen, J.; Wang, K.; Cao, W.; Wang, L. A Permutation Network for Configurable and Scalable FFT Processors. In Proceedings of the IEEE 9th International Conference on ASIC (ASICON), Xiamen, China, 25–28 October 2011; pp. 787–790. [Google Scholar]
- Montaño, V.; Jimenez, M. Design and Implementation of a Scalable Floating-point FFT IP Core for Xilinx FPGAs. In Proceedings of the 53rd IEEE International Midwest Symposium on Circuits and Systems (MWSCAS), Seattle, WA, USA, 1–4 August 2010; pp. 533–536. [Google Scholar]
- Yang, G.; Jung, Y. Scalable FFT Processor for MIMO-OFDM Based SDR Systems. In Proceedings of the 5th IEEE International Symposium on Wireless Pervasive Computing (ISWPC), Modena, Italy, 5–7 May 2010; pp. 517–521. [Google Scholar]
- Johnson, L.G. Conflict Free Memory Addressing for Dedicated FFT Hardware. IEEE Trans. Circuits Syst. II Analog Digit. Signal Process. 1992, 39, 312–316. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, Q.; Ao, T.; Huang, M. Design of Pipelined FFT Processor Based on FPGA. In Proceedings of the Second International Conference on Computer Modeling and Simulation, ICCMS ’10, Hainan, China, 22–24 January 2010; Volume 4, pp. 432–435. [Google Scholar]
- Polychronakis, N.; Reisis, D.; Tsilis, E.; Zokas, I. Conflict free, parallel memory access for radix-2 FFT processors. In Proceedings of the 19th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Seville, Spain, 9–12 December 2012; pp. 973–976. [Google Scholar]
- Huang, S.J.; Chen, S.G. A High-Throughput Radix-16 FFT Processor With Parallel and Normal Input/Output Ordering for IEEE 802.15.3c Systems. IEEE Trans. Circuits Syst. I Regul. Papers 2012, 59, 1752–1765. [Google Scholar] [CrossRef]
- Chen, J.; Hu, J.; Lee, S.; Sobelman, G.E. Hardware Efficient Mixed Radix-25/16/9 FFT for LTE Systems. IEEE Trans. Large Scale Integr. (VLSI) Syst. 2015, 23, 221–229. [Google Scholar] [CrossRef]
- Garrido, M.; Sanchez, M.A.; Lopez-Vallejo, M.L.; Grajal, J. A 4096-Point Radix-4 Memory-Based FFT Using DSP Slices. IEEE Trans. Large Scale Integr. (VLSI) Syst. 2017, 25, 375–379. [Google Scholar] [CrossRef]
- Xing, Q.J.; Ma, Z.G.; Xu, Y.K. A Novel Conflict-Free Parallel Memory Access Scheme for FFT Processors. IEEE Trans. Circuits Syst. II Express Briefs 2017, 64, 1347–1351. [Google Scholar] [CrossRef]
- Xia, K.F.; Wu, B.; Xiong, T.; Ye, T.C. A Memory-Based FFT Processor Design With Generalized Efficient Conflict-Free Address Schemes. IEEE Trans. Large Scale Integr. (VLSI) Syst. 2017, 25, 1919–1929. [Google Scholar] [CrossRef]
- Gautam, V.; Ray, K.; Haddow, P. Hardware efficient design of Variable Length FFT Processor. In Proceedings of the 2011 IEEE 14th International Symposium on Design and Diagnostics of Electronic Circuits Systems (DDECS), Cottbus, Germany, 13–15 April 2011; pp. 309–312. [Google Scholar]
- Tsai, P.Y.; Lin, C.Y. A Generalized Conflict-Free Memory Addressing Scheme for Continuous-Flow Parallel-Processing FFT Processors With Rescheduling. IEEE Trans. Large Scale Integr. (VLSI) Syst. 2011, 19, 2290–2302. [Google Scholar] [CrossRef]
- Xiao, X.; Oruklu, E.; Saniie, J. An Efficient FFT Engine With Reduced Addressing Logic. IEEE Trans. Circuits Syst. II Express Briefs 2008, 55, 1149–1153. [Google Scholar] [CrossRef]
- Shome, S.; Ahesh, A.; Gupta, D.; Vadali, S. Architectural Design of a Highly Programmable Radix-2 FFT Processor with Efficient Addressing Logic. In Proceedings of the International Conference on Devices, Circuits and Systems (ICDCS), Coimbatore, India, 15–16 March 2012; pp. 516–521. [Google Scholar]
- Ayinala, M.; Lao, Y.; Parhi, K. An In-Place FFT Architecture for Real-Valued Signals. IEEE Trans. Circuits Syst. II Express Briefs 2013, 60, 652–656. [Google Scholar] [CrossRef]
- Qian, Z.; Margala, M. A Novel Coefficient Address Generation Algorithm for Split-Radix FFT (Abstract Only). In Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, California, USA, 22–24 February 2015; ACM: New York, NY, USA, 2015; p. 273. [Google Scholar]
- Yang, C.; Chen, H.; Liu, S.; Ma, S. A New Memory Address Transformation for Continuous-Flow FFT Processors with SIMD Extension. In Proceedings of the CCF National Conference on Compujter Engineering and Technology, Hefei, China, 18–20 October 2015; Xu, W., Xiao, L., Li, J., Zhang, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 51–60. [Google Scholar]
- Milder, P.; Franchetti, F.; Hoe, J.C.; Püschel, M. Computer Generation of Hardware for Linear Digital Signal Processing Transforms. ACM Trans. Des. Autom. Electron. Syst. 2012, 17, 15. [Google Scholar] [CrossRef]
- Richardson, S.; Marković, D.; Danowitz, A.; Brunhaver, J.; Horowitz, M. Building Conflict-Free FFT Schedules. IEEE Trans. Circuits Syst. I Regul. Papers 2015, 62, 1146–1155. [Google Scholar] [CrossRef]
- Loan, C.F.V. The ubiquitous Kronecker product. J. Comput. Appl. Math. 2000, 123, 85–100. [Google Scholar] [CrossRef]
- Johnson, J.; Johnson, R.; Rodriguez, D.; Tolimieri, R. A Methodology for Designing, Modifying, and Implementing Fourier Transform Algorithms on Various Architectures. Circuits Syst. Signal Process 1990, 9, 450–500. [Google Scholar]
- Rodriguez, D.A. On Tensor Products Formulations of Additive Fast Fourier Transform Algorithms and Their Implementations. Ph.D. Thesis, City University of New York, New York, NY, USA, 1988. [Google Scholar]
- Xilinx, Inc. Available online: https://www.xilinx.com/support/documentation/ip_documentation/xfft/v9_0/pg109-xfft.pdf (accessed on 20 October 2017).
- Polo, A.; Jimenez, M.; Marquez, D.; Rodriguez, D. An Address Generator Approach to the Hardware Implementation of a Scalable Pease FFT Core. In Proceedings of the IEEE 55th International Midwest Symposium on Circuits and Systems (MWSCAS), Boise, ID, USA, 5–8 August 2012; pp. 832–835. [Google Scholar]
Sample Availability: Samples of the compounds ...... are available from the authors. |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Twiddle Address | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 |
| 2 | 0 | 0 | 0 | 0 | 4 | 4 | 4 | 4 | 8 | 8 | 8 | 8 | 12 | 12 | 12 | 12 |
| 3 | 0 | 0 | 2 | 2 | 4 | 4 | 6 | 6 | 8 | 8 | 10 | 10 | 12 | 12 | 14 | 14 |
| 4 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| Stage | Twiddle Address | |||||||
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 1 | 0 | 0 | 0 | 0 | 8 | 8 | 8 | 8 |
| 0 | 0 | 0 | 0 | 8 | 8 | 8 | 8 | |
| 2 | 0 | 0 | 4 | 4 | 8 | 8 | 12 | 12 |
| 0 | 0 | 4 | 4 | 8 | 8 | 12 | 12 | |
| 3 | 0 | 2 | 4 | 6 | 8 | 10 | 12 | 14 |
| 0 | 2 | 4 | 6 | 8 | 10 | 12 | 14 | |
| 4 | 0 | 2 | 4 | 6 | 8 | 10 | 12 | 14 |
| 1 | 3 | 5 | 7 | 9 | 11 | 13 | 15 | |
| a β = 1 | b β = 2 | c β = 4 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Stage | s | f | n | Stage | s | f | n | Stage | s | f | n |
| 0 | 16 | 16 | 8 | 0 | 16 | 8 | 8 | 0 | 16 | 4 | 8 |
| 1 | 8 | 8 | 4 | 1 | 8 | 4 | 4 | 1 | 8 | 2 | 4 |
| 2 | 4 | 4 | 2 | 2 | 4 | 2 | 2 | 2 | 4 | 1 | 2 |
| 3 | 2 | 2 | 1 | 3 | 2 | 1 | 1 | 3 | 4 | 1 | 1 |
| 4 | 1 | 1 | 0 | 4 | 1 | 1 | 0 | 4 | 4 | 1 | 0 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Minotta, F.; Jimenez, M.; Rodriguez, D. Automated Scalable Address Generation Patterns for 2-Dimensional Folding Schemes in Radix-2 FFT Implementations. Electronics 2018, 7, 33. https://doi.org/10.3390/electronics7030033
Minotta F, Jimenez M, Rodriguez D. Automated Scalable Address Generation Patterns for 2-Dimensional Folding Schemes in Radix-2 FFT Implementations. Electronics. 2018; 7(3):33. https://doi.org/10.3390/electronics7030033
Chicago/Turabian StyleMinotta, Felipe, Manuel Jimenez, and Domingo Rodriguez. 2018. "Automated Scalable Address Generation Patterns for 2-Dimensional Folding Schemes in Radix-2 FFT Implementations" Electronics 7, no. 3: 33. https://doi.org/10.3390/electronics7030033
APA StyleMinotta, F., Jimenez, M., & Rodriguez, D. (2018). Automated Scalable Address Generation Patterns for 2-Dimensional Folding Schemes in Radix-2 FFT Implementations. Electronics, 7(3), 33. https://doi.org/10.3390/electronics7030033