1. Introduction
Multiprocessor architecture such as Multi-Processor System-on-Chip (MPSoC) are increasingly believed to be the major solution for an embedded cloud computing system due to high computing power and parallelism. The multiprocessor architecture of an MPSoC incorporates multiprocessors and other functional units in a single case on a single die. Meanwhile, there is an ongoing trend that diverse emerging safety-critical real-time applications, such as automotive, computer vision, data collection and control applications are running simultaneously on the MPSoCs [
1]. For these safety-related applications, it is imperative that deadlines should be strongly guaranteed. Due to the strong timing requirements and needed predictability guarantees, real-time cloud computing is a complex problem [
2]. To satisfy the timing requirement, task scheduling typically relies on an offline schedule based on the architectures such as TTA (Time Triggered Architecture) such that full predictability is guaranteed [
3]. In the computing systems, time-triggered scheduling, where tasks have to be executed at particular points in real time, is often utilized to form a deterministic schedule. To effectively schedule the applications, the safety-critical systems require more elaborated scheduling strategies to meet timing constraints and the precedence relationships between tasks.
Reducing energy consumption or conducting green computing is a critical issue in deploying and operating cloud platforms. When the safety-related applications are executed on MPSoCs, reducing energy consumption is another concern since high energy consumption translates to shorter lifetime, higher maintenance costs, more heat dissipation, lower reliability, and, in turn, has a negative impact on real-time performance. Therefore, this growing demand to accommodate multiple applications running periodically on the safety/time-critical multiprocessor systems necessitates to develop an efficient scheduling approach to fully exploit the energy-saving potential. The high energy consumption mainly comes from the energy consumption at the processor level. To reduce power dissipation of processors, Dynamic Voltage and Frequency Scaling (DVFS) and Power Mode Management (PMM (Note that PMM is also referred to as ‘Dynamic Power Management (DPM)’ [
4]. This paper uses the more specific term ‘Power Mode Management’ to avoid any confusion.)) are two well established system-level energy management techniques. DVFS reduces the dynamic power consumption by dynamically adjusting voltage or frequency while PMM explores idle intervals of a processor and switches the processor to a sleep mode to reduce the static power.
Lots of research has been done on scheduling for energy optimization in real-time multiprocessor embedded systems [
5,
6,
7,
8,
9,
10,
11]. An application can usually be modeled as a Directed Acyclic Graph (DAG) where nodes denote tasks, and edges represent precedence constraints among tasks. Among these studies, a DAG-based application must be released periodically, whereas tasks in the application can be started aperiodically. In other words, the start time interval between any two consecutive task instances does not need to be fixed to the value of period as long as precedence and deadline constraints can be met. However, such an assumption in these studies is not suitable for the problem of scheduling periodic DAGs on safety/time-critical time-triggered systems. Their solutions in the studies cannot fully guarantee timing predictability and meet the timeliness requirements if the schedulings are not appropriate. Moreover, their methods are merely for single DAG and cannot be directly applied to multiple DAGs.
On the other hand, for a periodic application in time-triggered systems, the scheduling should follow a strictly regular pattern, where besides release time and deadline, the start time of different invocations of a task must be also periodic [
12,
13,
14,
15,
16,
17,
18,
19,
20]. In this case, most research efforts in energy-efficient scheduling on time-triggered multiprocessor systems, which applied mathematical programming techniques such as Integer Linear Programming (ILP), simply and consistently assume that all tasks in the application are strictly periodic [
12,
13,
14,
15,
16,
17,
18]. Their time-triggered scheduling approaches are suitable for the tasks that are designed for periodic samplings and actuations.
Nevertheless, tasks within an application are unnecessarily strictly periodic in reality. Today, newly emerging periodic applications may also consist of tasks that do not generate jobs strictly periodically [
21]. A typical case can be easily found in the real-world automotive application in engine management system, where most tasks in the application are strictly periodic, and the non-strict periodic tasks are the angle synchronous tasks. Here, for the angle synchronous tasks, the inter-arrival time depend on the revolutions per minute and the number of cylinders of the engine [
22,
23]. The non-strict periodic tasks are started with relative deadlines corresponding to around an additional 30 degrees of the crankshaft position, after passing a specific rotation of crankshaft position. Therefore, the oversimplified assumption in previous approaches developed for energy-efficient scheduling may impose excessive constraints and degrades scheduling flexibility of the whole system. Furthermore, from the perspective of energy-saving, the excessive constraints result in unnecessary energy consumption. To make readers easy to follow, a motivating example presented in
Section 4 will illustrate the problem.
In this paper, we study the energy-efficient scheduling problem arising from the requirements of safety-related real-time applications when deployed in the context of cloud computing embedded platforms. We focus on the problem of static scheduling multiple periodic applications consisting of both strictly and non-strictly periodic tasks on safety/time-critical time-triggered MPSoCs for energy optimization by employing the two powerful techniques: DVFS and PMM. To reduce energy consumption more effectively, both strictly and non-strictly periodic tasks in time-triggered applications should be correctly addressed. This requires an intelligent scheduling that can capture the strict periodicity of specific tasks. Moreover, the problem becomes more challenging when scheduling for energy minimization by combining DVFS with PMM has to consider periodicity of specific tasks in time-triggered systems. In addition, the energy-efficient scheduling problem becomes more complicated as the number of applications running extends from single to multiple. Our main contributions are summarized as the following:
We consider the unique feature of periodic applications that not all tasks within the applications are strictly periodic in time-triggered systems. A practical task model that can accurately characterize the periodic applications is presented and an energy-efficient scheduling problem based on the model is formulated.
To solve the problem, we present an improved Mixed Integer Linear Programming (MILP) formulation utilizing the flexibility of non-strictly periodic tasks to reduce unnecessary energy overhead. The MILP method can generate the optimal scheduling solutions.
To overcome disadvantage of the MILP method when the size of the problem expands, we further develop a heuristic method, named Hybrid List Tabu-Simulated Annealing with Fine-Tune (HLTSA-FT), which integrates the list-based energy-efficient scheduling and tabu-simulated annealing with a fine-tune algorithm. The heuristic can obtain high-quality solutions in a reasonable time.
We conduct experiments on both synthetic and realistic benchmarks. The experimental results demonstrate the effectiveness of our approach.
It is worth mentioning that, based on the static energy-efficient deterministic schedule (defined in a static configuration file) generated by our proposed methods, the operating system kernel applies it to schedule the partition at its assigned time slot for designing of a practical safety/time-critical partitioned system, where the middleware is integrated to ease interoperability and portability of components to satisfy requirement regarding cost, timeliness, power consumption and so on [
24,
25].
The remainder of this paper is organized as follows:
Section 2 reviews related work in the literature.
Section 3 describes models and defines the studied problem. In
Section 4, we give a motivating example to explain our idea. Our approach is presented in
Section 5. Experimental results are provided in
Section 6. The conclusions are presented in
Section 7.
2. Related Work
Scheduling for energy optimization is a crucial issue in real-time systems [
2,
4]. Energy-efficient scheduling of the DAG-based application on the systems have been extensively studied. To name a few, Baskiyar et al. combined DVFS and decisive path scheduling list scheduling algorithm to achieve two objectives of minimizing finish time and energy consumption [
6]. Liu et al. distributed the slack time over tasks with the DVFS techniques on the critical path to achieve energy savings [
8]. However, they are merely for single DAG-based application. Moreover, these approaches only consider dynamic power consumption, and ignore static power consumption that becomes prominent in the deep submicron domain. In energy-harvesting system, Qiu et al. were devoted to reducing power failures and optimizing the computation and energy efficiency [
26], and the authors in [
27] addressed the scheduling of implicit deadline periodic tasks on a uniprocessor based on the Earliest Deadline First-As Soon As Possible (EDF-ASAP) algorithm. The works in [
28,
29] combined DVFS and PMM to minimize energy consumption for scheduling frame-based tasks. However, their approaches can only address independent tasks in a single-processor system. Kanoun et al. proposed a fully self-adaptive energy-efficient online scheduler for general DAG models for multicore DVFS- and PMM-enabled platforms [
9]. However, the proposed energy-efficient scheduling solution is designed for soft real-time tasks, where missing deadlines is tolerable.
The aforementioned studies are not applicable for safety-critical applications that have the highest level of safety. Furthermore, in these studies, an application is only periodic in terms of its release time and each task within the application can start aperiodically. Obviously, such an assumption is untenable for a time-triggered application in safety/time-critical systems. The scheduling of tasks in time-triggered systems have also been reported in [
13,
14,
18,
19,
20]. Lukasiewycz et al. obtained a schedule for time-triggered distributed automotive systems by a modular framework which provided a symbolic representation used by an ILP solver [
13]. Sagstetter et al. studied the problem of synthesizing schedules for the static time-triggered segment for asynchronous scheduling in current automotive architectures, and proposed an ILP approach to obtain optimal solutions and a greedy heuristic to obtain high quality solutions [
18]. Freier and Chen presented the time-triggered scheduling policies for real-time periodic task model [
19]. Gendy introduced techniques to automate the process of searching for a workable schedule and increase the system predictability [
20]. Unfortunately, these works only focus on enhancing system performance.
Research efforts devoted to task scheduling for energy optimization in time-triggered embedded systems have received attention recently. Chen et al. presented ILP formulations and developed two algorithms to address the energy-aware task partitioning and processing unit allocation for periodic real-time tasks [
15]. However, the work only addresses independent tasks, and it is not suitable for the DAG-based applications. For periodic dependent tasks, Pop et al. proposed a constraint logic programming-based approach for time-triggered scheduling and voltage scaling for low-power and fault-tolerance [
16]. Recently, the state-of-the-art work in [
17] introduced a key technique to model the idle interval of the cores by means of MILP. The study proposed a time-triggered scheduling approach to minimize total system energy for a given set of applications represented as DAGs and a mapping of the applications. However, the studies all assume that each task and its instances are started in a strictly periodic pattern. In reality, besides the strictly periodic tasks within time-triggered applications, there also exist non-strictly periodic tasks where each instance of a task does not need to be started periodically [
21,
22,
23]. To the best of our knowledge, Ref. [
21] is the first study that tried to derive better system performance with scheduling both strictly and non-strictly periodic tasks in the safety-critical time-triggered systems. However, their work only focuses on enhancing schedulability, and energy optimization is not involved. In this paper, we address the energy-efficient scheduling problem for periodic time-triggered applications consisting of both strictly and non-strictly periodic tasks.
Methods for scheduling applications on time-triggered multiprocessor systems are mostly based on mathematical programming techniques [
12,
13,
14,
15,
16,
17,
18]. Since scheduling in multiprocessor systems is NP-hard, many heuristics have been developed when the scale of the problem is increased. To schedule multiple DAG-based applications on real-time multiprocessor systems, the studies in [
6,
8,
21,
30,
31,
32,
33,
34] presented a collection of static greedy scheduling heuristics based on list-based scheduling. The list-based scheduling heuristics are generally accepted and can provide effective scheduling solutions and its performance is comparable with other algorithms at lower time complexity. They efficiently reduce the search space by means of greedy strategies. However, due to the greedy nature, they can only address certain cases efficiently and cannot ensure the solution quality for a broad range of problems.
On the other hand, to explore the solution space for a high-quality solution, current practice in many domains such as job shop scheduling [
35], autonomous power systems [
36], distributed scheduling [
37] and energy-efficient scheduling problems in embedded system [
38,
39,
40], favors Tabu Search (TS)/Simulated Annealing (SA) meta-heuristic algorithms. They have shown superiority to the one-shot list scheduling heuristics, despite a higher computational cost. However, both TS and SA have advantages and disadvantages. In general, the SA algorithm is problem-independent, which is analogous to the physical process of annealing. However, it does not keep track of recently visited solutions and needs more iterations to find the best solution. TS algorithm is more efficient in finding the best solution in a given neighborhood, whereas it cannot guarantee convergence and avoid cycling [
35]. Moreover, the algorithms cannot be directly used to solve our problem since the non-strictly periodic tasks in time-triggered applications are ignored (whether a task starts strictly periodic or not has a strong influence on scheduling and total energy consumption of the whole system).
To the best of our knowledge, the heuristic method for our problem is not yet reported. In this paper, we consider to solve the problem by formulating the MILP model to obtain optimal solutions, and further to develop an efficient heuristic algorithm since computation time of the MILP method is intolerable when the problem size increases.
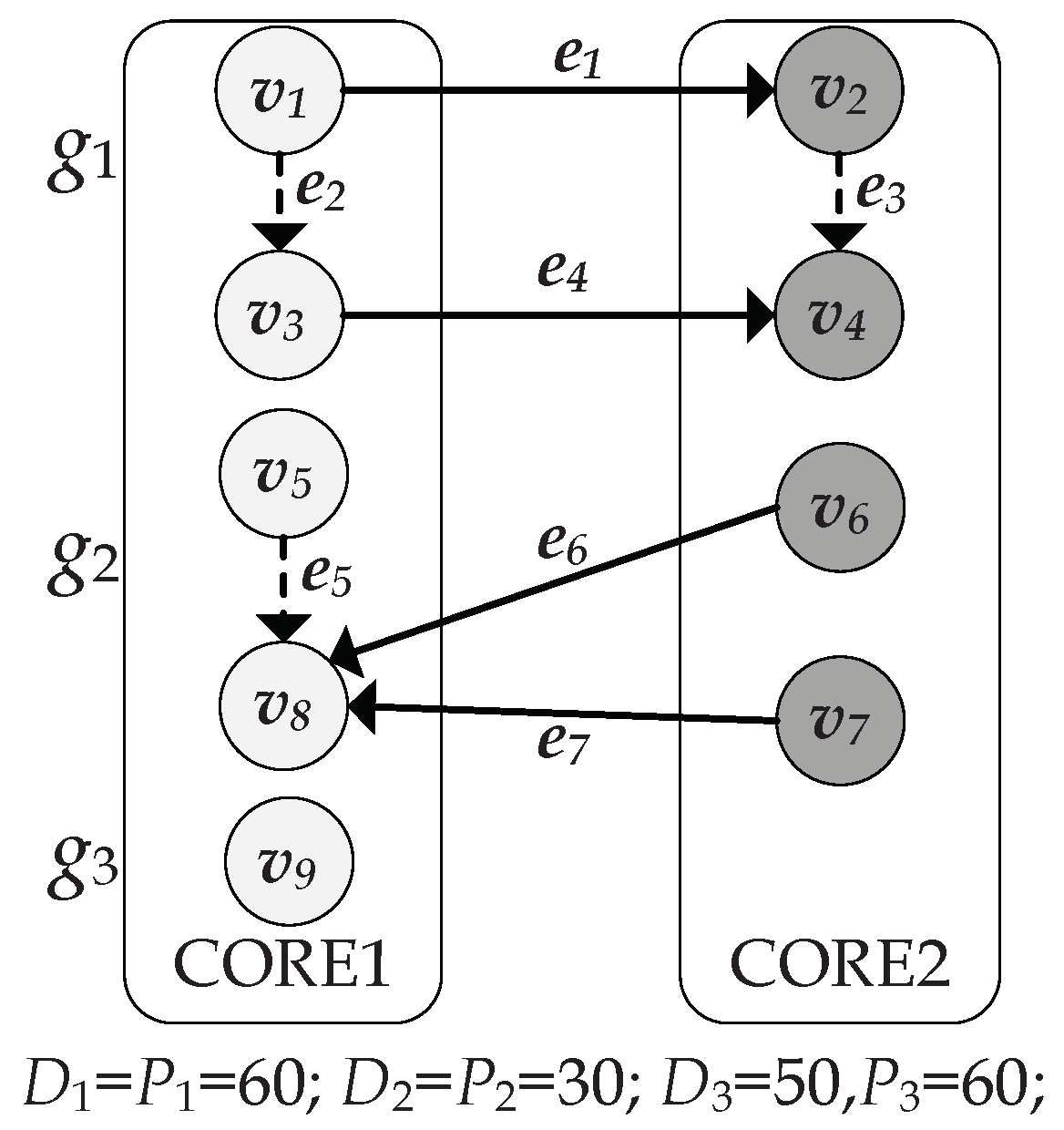
4. Motivating Example
For easy understanding, in this section, we first present a motivating example to show that state-of-the-art energy-efficient scheduling on time-triggered systems may not work well on the problem. Assuming that an MPSoC has CORE1 and CORE2, each with a high frequency level
and a low frequency level
. The total active power of the core under
and
is denoted by
and
. Assuming a set of applications (denoted as
,
and
) and their task mappings on the MPSoC have been given as illustrated in
Figure 4.
is an exact periodic application in which task
,
,
and
are responsible for collecting data from sensors periodically and
is a loose periodic application in which task
,
,
and
are responsible for performing processing data. The edges
,
,
and
indicate their connected tasks are mapped to different cores and the dashed edges
,
and
indicate the corresponding tasks are mapped to the same core. Thus,
,
and
are equal to 0. The periods for
,
and
are 60, 30 and 60, respectively. Task WCETs and power profiles are shown in
Table 2. For simplicity, time unit is 1 ms, power unit is 1 W, and the energy unit is 1 mJ.
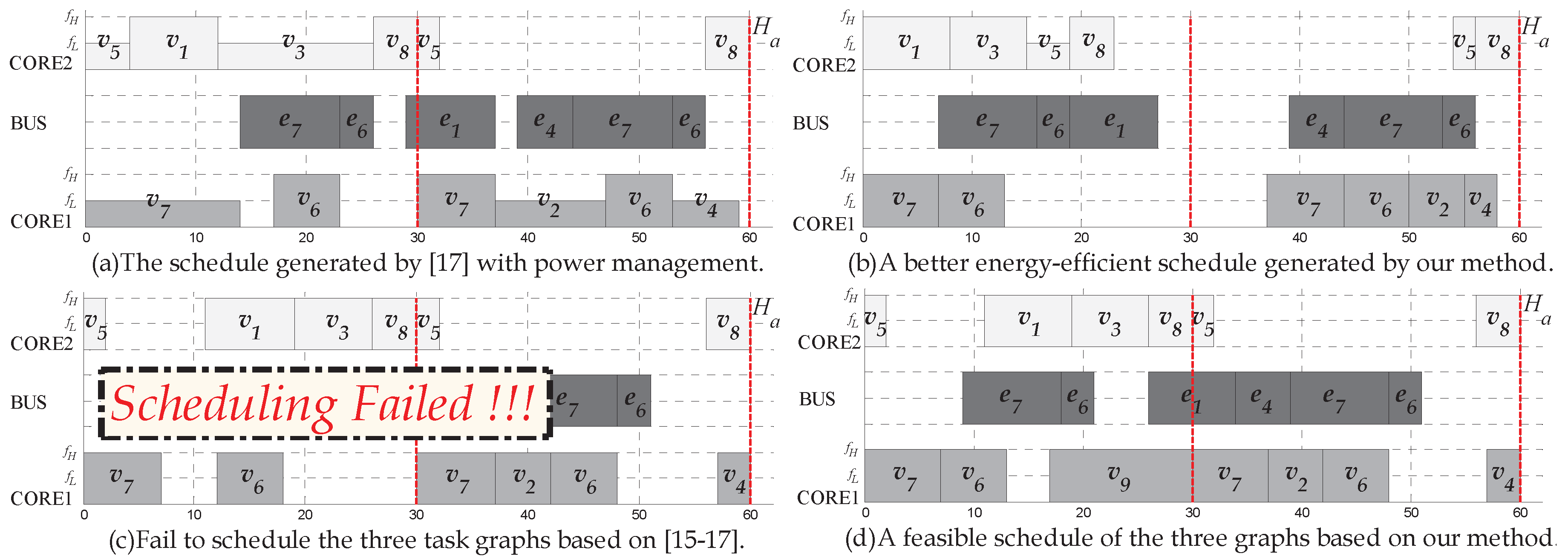
The hyper-period
is 60 if we schedule
and
. In one hyper-period,
and
are released 1 and 2 times, respectively, as well as each task within its application. Based on the assumptions that the start time interval of any two successive instances of a task must be fixed in previous works [
15,
16,
17], the scheduling for energy minimization is shown in
Figure 5a. In the schedule, the horizontal axis represents the time, and the heights of task blocks represent the frequency level. The start time interval between two consecutive task instances (
,
), (
,
), (
,
) and (
,
) in
are equal to 30. The average power consumption in
can be calculated as 0.854 W.
In contrast to the scheduling from
Figure 5a, the schedule generated by our method in
Figure 5b shows a better scheduling for energy-efficiency that the average power consumption in
is 0.784 W. In the schedule, the start time interval between task pair (
,
), (
,
), (
,
) and (
,
) in
do not have such the strict constraint of periodicity, as
is a loose periodic application. Due to the flexibility of those non-strictly periodic tasks in the scheduling, increase of total core sleep time and decrease of energy overhead from mode switching can achieve about 8.2% total energy savings compared with
Figure 5a.
Assuming that
is a exact periodic application in which
is responsible for data transformation, we then consider to schedule the three task graphs,
,
and
. The hyper-period is still 60. We find that scheduling the task graphs based on the simplistic assumptions in [
15,
16,
17] would fail as shown in
Figure 5c, as their methods impose overly strict constraints on the task instances within
. For example, the start time of the two task instances
and
are 12 and 42, respectively, such that the start time interval between these two task instances is fixed as 30. Thus,
cannot be scheduled in a hyper period since the size of
is 6 and the size of
is 13. However, there actually exists a feasible schedule as shown in
Figure 5d. For the non-strictly periodic task
in
, the constraint regarding the periodic interval between the start time of
and its next instance
is unnecessary. In the schedule, the two task instances,
and
start at 7 and 42, respectively, and thus
can be scheduled at 17.
From the above results, one can observe that the previous studies which do not consider characteristics of non-strictly periodic tasks may result in more energy consumption and even degradation of the schedulability of the whole system. For our problem in this paper, to reduce energy consumption more effectively, a scheduling approach which is aware of the periodicity of specific tasks and utilizes the flexibility of non-strictly periodic tasks is desired.
5. The Proposed Methods
This section presents the energy-efficient scheduling approach jointly with DVFS and PMM techniques for multiple periodic applications consisting of strictly and non-strictly periodic tasks. With consideration of strictness of tasks’ periodicity, we formulate a MILP model to solve the problem and to obtain an optimal scheduling in which the system total energy consumption is the minimum. Then, we develop a heuristic algorithm when the MILP formulation cannot be used to efficiently solve large scale instances.
5.1. MILP Method
ILP-based methods have the advantages of reachable optimality and easy access to various solving tools. We aim to find an energy-efficient time-triggered scheduling and a v/f assignment of all tasks in given an MPSoC, multiple DAGs and task mapping, such that the total system energy consumption is minimized under timing constraints. To obtain optimal energy-efficient scheduling solutions for pre-mapped tasks with consideration of strictness of tasks’ periodicity, we now develop our MILP formulation for the problem based on the practical models defined in
Section 3. We build up our MILP formulation step by step, including v/f selection constraints, deadline constraints, periodicity constraints for the strictly periodic tasks, precedence constraints, non-preemption constraints, and an objective function. Firstly, we define the following variables:
: binary variable, = 1 if v/f level of task is l and = 0 otherwise,
: Start time of computation task
: Start time of communication task ( transfer data to ),
: binary variable, = 1 if task executes before task and = 0, otherwise.
Then, given task graphs and task mappings, we formulate the MILP model as follows:
Subject to
Voltage or frequency selection constraints for each task as we use inter-task DVFS:
Deadline constraints (
denotes time overheads for DVFS and task switch on core
m):
According to strictness of the tasks’s periodicity, we separately determine the start time of these tasks and their instances in
. Therefore, for the strictly periodic tasks belonging to the time-triggered applications within one hyper-period
, the periodic constraints can be represented as follows:
For any non-strictly periodic task and its instances in , the periodic constraint is unnecessary, that is, the interval between the start time of two consecutive instances of the task is no longer fixed as .
Dependency constraints for computation tasks (e.g., source task
and target task
mapped to the same core:
Dependency constraints for tasks (e.g., source task and target task mapped to different cores.
(a)
can be started only after
completes:
(b)
can be started only after
completes:
Any two computation task instances mapped to the same core must not overlap in time, as well as the communication tasks in the bus. They can only be executed sequentially. Assume task
and task
are two task instances, and
is a constant far greater than
. To guarantee either task
can run after task
finishes, or vice versa, the non-preemption constraint can be expressed as follows:
The two formulas are also applicable to communication tasks mapped to the bus. The differences between computation and communication tasks are that execution time of computation tasks are variable, while communication time of communication tasks are constant. We can get real computational time of the task on the specified core and real communication cost between the dependent tasks, as task mapping has been given. In addition, communication tasks can be overlapped with the computation tasks independent on them.
To formulate the time interval (
) of any two adjacent tasks on each core
m in one hyper-period
, we use the interval modelling technique in [
17]. The readers interested in the detailed steps of modeling can refer to [
17]. Then, according to the definition of
, for each time interval
on the core, we have
where
refers to a binary variable in the decision array
, representing whether the core should remain idle mode
or enter into sleep mode
. Assuming there are
N tasks on the core in
, the total idle and sleep interval (
and
) can be represented as follows:
The total energy overheads of mode switch for the core can be calculated as follows:
Note that the step function introduced by
in Equation (
19) and the multiplication of
and binary variable
in Equations (
20) and (
21) are nonlinear equations. Such problems can be solved by commercial or open-source ILP solvers after linearization. Solutions to similar problems have been presented in [
46]. We now present the linearization process for our problem.
To linearize the multiplication of
, we define a new variable
, such that
. It is obvious that
. The multiplication can be linearized as the following constraints:
The step function introduced by
in Equation (
19) can be transformed to the following constraint:
In Equation (
26), the multiplication of
are linearized by using Equations (
23)–(
25).
Based on these formulations, lastly, we can obtain an optimal scheduling and minimum overall energy consumption by solving the MILP model with ILP solver.
Limitation of the MILP-based method: Though we can obtain an optimal solution by solving the MILP formulation with modern ILP solvers, it is time-consuming to search the optimal solution for our problem. Specifically, to construct time interval for each task instance in one hyper-period, the time interval modeling in the previously discussed MILP-based method particularly yields a large number of variables, and results in dramatically increased exploration space. The problem may even not be solved because of memory overflow when input size of tasks to be scheduled is large. To address this, we propose an efficient heuristic algorithm to reduce the exponentially increasing scale in
Section 5.2.
5.2. Heuristic Algorithm
In this section, we develop a heuristic algorithm, named Hybrid List Tabu-Simulated Annealing with Fine-Tune (HLTSA-FT). Different from the TS/SA algorithm mentioned in
Section 2, the proposed algorithm has the following innovations: (1) the HLTSA-FT integrates list scheduling with TS/SA to take advantage of both algorithms and to mitigate their adverse effects. Based on our problem, the decomposition and solution process is iteratively guided by the HLTSA-FT algorithm that employs the proper intensification and diversification mechanism. In HLTSA-FT, the SA supplemented with a tabu list can reduce the number of revisiting old solutions and cover a broader range of solutions; (2) list-based scheduling performed in the List-based and Periodicity-aware Energy-efficient Scheduling (LPES) function can efficiently obtain feasible solutions for our problem; (3) in addition, solutions can be further improved by applying problem specific and heuristic information to guide the process of optimization. Specifically, a fine-tune phase performed in the
function is presented to make minor adjustments of the accepted solution to find a better solution more rapidly. Therefore, the total number of iterations can be reduced and solution quality can be improved. The details of HLTSA-FT are given in Algorithm 1. Three main steps in the algorithm are:
Initialization. The step (in Lines 1–3) first sets appropriate parameters including the initial temperature , the maximum number of iterations , the maximum number of consecutive rejections , the cooling factor and the maximum length of the tabu list . Then, the algorithm builds with length of , and sets aspiration criterion A. The function generates an initial solution (v/f assignment for each task instance in ) as the starting point of optimization process. Since a good initial solution can accelerate the convergence process, the function integrates the MILP model of a relaxed formulation (e.g., by neglecting the idle and sleep interval formulations). is evaluated and the current optimal energy consumption is denoted as . The aspiration criterion accepts the move provided that its total energy is lower than that of the best solution found so far. It helps with restricting the search from being trapped at a solution surrounded by tabu neighbors. The tabu list stores recently visited solutions and helps saving considerable computation time by avoiding revisits.
Iteration. In each iteration (in Lines 5–26), the function (Line 5) generates neighborhood by applying a small perturbation (swap move) to current solution . In our context, v/f assignments for the tasks are in a neighbourhood. is generated in two steps: (i) select two tasks; and (ii) swap their v/f levels. Then, is checked for feasibility (i.e., if constraints mentioned above are met) by function. If the solution is not in the tabu list or satisfies the aspiration criterion, it is selected. Otherwise, a new solution is regenerated. Then, the solution is translated to an energy-efficient schedule by using the function (Line 6). The solution which consumes less energy will always be accepted, and when is an inferior solution, it may still be accepted with a probability where T is the annealing temperature at current iteration. This transition probability can help the algorithm to escape from local optima. Once accepted, is put in the tabu list and the current solution is updated by replacing with for next iteration. Then, the FT phase (Line 16) will performed to fine-tune the accepted . Otherwise, the solution is discarded with plus 1. The algorithm then decreases the temperature and continues to the next iteration.
| Algorithm 1: The HLTSA-FT Heuristic Algorithm |
![Electronics 07 00098 i001]() |
Stopping Criteria. The search procedure will be stopped if the number of iterations or the variable reaches the predefined value. The variable stores the current number of continuous rejections, and it represents that no superior solution exists in the neighborhood and the search has reached a near optimal solution once reaches .
In the next two subsections, we give a detailed description of the and .
5.2.1. LPES
To obtain a feasible scheduling for energy reduction efficiently, the scheduling for our problem needs to addresses two aspects. First, a priority assignment (i.e., execution order of tasks) must satisfy the corresponding constraints (including deadline and precedence constraints for each task graph, and periodicity constraints for the strictly periodic tasks) in the schedule, and maximize the total interval available for energy management. Second, the intervals need to be allocated efficiently to reduce energy consumption. In this paper, we apply the List-based and Periodicity-aware Energy-efficient Scheduling (LPES) method. The first aspect is addressed through bottom level (b-level) based priority assignment. The second aspect is addressed through a modified simple MILP model whose number of variables is only linear with the number of tasks.
List scheduling is a type of scheduling heuristics in which ready tasks are assigned priorities and ordered in a descending order of priority. A ready task is a task whose predecessors have finished executing. Each time, the task with the highest priority is selected for scheduling. If more than one task has the same priority, ties are broken using the strategy such as the random selection method. Priority assignment based on the b-level has been adopted in energy-aware multiprocessor scheduling. The b-level of a task is defined as the length of the longest path from the beginning of the task to the bottom of the task graph. As we focus on multi-DAGs in our problem, we define the b-level of task
and its next instance
within
as:
We calculate b-level values of all tasks and their instances, and sort them in a list which is ordered in descending order. The higher the value of b-level, the higher the priority of the task. An example is shown as below:
Example 1. Consider the case given in the form of two task graphs and in Figure 4. The b-level of tasks in are shown in Table 3. Thus, execution order of tasks on CORE1 and CORE2 are denoted as {} and {}, respectively. Based on the given priority and v/f assignment for each task, a scheduling with PMM should be generated to reduce total energy consumption. The time interval can be directly modeled as the following:
Assuming that there are
N task instances on a core
m in a hyper-period
, all these tasks are stored in a task list represented as
where tasks are ordered in descending order of their priorities. As the tasks in the first hyper-period shown in
Figure 6, the time interval between any two adjacent tasks,
and
, can be directly calculated as:
where
and
denote start time and finish time of task
, respectively. As we focus on task scheduling in one hyper-period and task execution are repeated in each hyper-period, there are
N time intervals. The last time interval
between task
and task
is calculated as
.
In the time interval modeling in
Section 5.1, a large number of intermediate integer variables are used to check timing information of every task instance to determine the closest task instance for a task instance. While compared with the time interval modeling in [
17], the number of constraints and many decision variables (e.g.,
and
,) and the intermediate variables (e.g.,
,
, and
in [
17]) have been greatly reduced. After obtaining each idle time
, we use the ILP solver to obtain an energy-efficient scheduling.
5.2.2. FT
To find solutions that can further reduce energy consumption, a fine-grained adjustment of the neighborhood range is performed for the accepted solution (line 16 in Algorithm 1). We now present the details of FT phase. The core idea of FT is to increase the potential energy savings by tuning priorities that still satisfy corresponding constraints of task graphs (not blindly or randomly adjusting priorities). In this study, for the strictly periodic tasks, their priorities remain unchanged since the strictness of periodicity of task start time limits the possibility of adjustment within a hyper-period. The non-strictly periodic task instances in do not have to follow the strict condition that all tasks need to be started periodically; thus, they have space for execution-order adjustment. On the other hand, the tasks that have the same b-level value (tie-breaking tasks) also have chances to adjust their priorities. We focus on these tasks that may have better schedule flexibility and, correspondingly, make full use of it to achieve more energy savings. The pseudo-code of the FT is listed in Algorithm 2.
| Algorithm 2: The FT Algorithm |
![Electronics 07 00098 i002]() |
In Algorithm 2, firstly, the priority assignments of tasks on each core are recorded according to the accepted solution . Then, the FT keeps strictly periodic tasks unchanged. For tie-breaking and non-strictly periodic tasks, it adjusts and records their priorities in possible priority assignment array by using function. Next, for each element in , the algorithm performs . In each iteration, the feasible solution (checked for feasibility by function) that can reduce the energy consumption is stored. Finally, the tasks are adjusted iteratively until no improvement can be achieved. Note that FT can be used directly in the optimization process to find an optimal solution quickly if the initial solution is good. The FT scheme is illustrated through the following example.
Example 2. In Example 1, the initial execution order of tasks on CORE1 and CORE2 are {} and {}, respectively. Among them, task and task are tie breaking tasks, and tasks belonging to application are non-strictly periodic. Thus, they can be adjusted (swapped) as long as the precedence constraints are guaranteed. The corresponding schedule after FT can be seen in Figure 5b, execution order of tasks on CORE1 and CORE2 are {} and {}, respectively. The improvement of power consumption on the system after FT is, therefore, 8.2%. 7. Conclusions
This paper has investigated the problem of scheduling a set of periodic applications for energy optimization on safety/time-critical time-triggered systems. In the applications, besides strictly periodic tasks, there also exist non-strictly periodic tasks in which different invocations of a task can start aperiodically. We present a practical task model to characterize the strictness of the task’s periodicity, and formulate a novel scheduling problem for energy optimization based on the model. To address the problem, we first propose an improved MILP model to obtain energy-efficient scheduling. Although the MILP method can generate optimal solutions, its solution computation time grows exponentially with the number of inputs. Therefore, we further develop an HLTSA-FT algorithm to reduce complexity and efficiently obtain a high-quality solution within a reasonable time. Extensive evaluations on both synthetic and realistic benchmarks have demonstrated the effectiveness of our improved MILP method and the HLTSA-FT algorithm, compared with the existing studies.
Some issues are taken into account in our future work. In this paper, we assume that task mappings are given as a fixed input. For a higher energy efficiency, mapping and scheduling on time-triggered multiprocessor systems need to be integrated since they are inter-dependent. Currently, we are working on solving this problem. Furthermore, we intend to study how to integrate our approaches with online scheduling methods on the realistic safety/time-critical multiprocessor systems to leverage system-wide energy consumption.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}