Optical Extreme Learning Machines with Atomic Vapors


1
Center for Applied Photonics, Institute for Systems and Computer Engineering, Technology and Science (INESC TEC), Rua do Campo Alegre, 4169-007 Porto, Portugal
2
Departamento de Física e Astronomia, Faculdade de Ciências da Universidade do Porto, Rua do Campo Alegre, 4169-007 Porto, Portugal
*
Author to whom correspondence should be addressed.
Atoms 2024, 12(2), 10; https://doi.org/10.3390/atoms12020010
Submission received: 8 January 2024
/
Revised: 26 January 2024
/
Accepted: 29 January 2024
/
Published: 6 February 2024
(This article belongs to the Section Cold Atoms, Quantum Gases and Bose-Einstein Condensation)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Extreme learning machines explore nonlinear random projections to perform computing tasks on high-dimensional output spaces. Since training only occurs at the output layer, the approach has the potential to speed up the training process and the capacity to turn any physical system into a computing platform. Yet, requiring strong nonlinear dynamics, optical solutions operating at fast processing rates and low power can be hard to achieve with conventional nonlinear optical materials. In this context, this manuscript explores the possibility of using atomic gases in near-resonant conditions to implement an optical extreme learning machine leveraging their enhanced nonlinear optical properties. Our results suggest that these systems have the potential not only to work as an optical extreme learning machine but also to perform these computations at the few-photon level, paving opportunities for energy-efficient computing solutions.
1. Introduction
In the last decades, the advent of artificial intelligence and neuromorphic architectures has completely reshaped the computing landscape. In particular, the logic procedures and arithmetic operations of the von Neumann paradigm may now be replaced by an alternative optimization-based approach. This establishes opportunities in two distinct directions. On one hand, on the side of algorithms, where rules and strategies are now autonomously inferred from data-driven processes [1]. On the other hand, on the side of the hardware, co-locating processing and memory operations pave for simpler hardware solutions capable of competing with electronic devices [2,3,4].
From the perspective of hardware, one of the most promising architectures is the reservoir computing framework. This design leverages the nonlinear dynamics of a physical system to simplify the transference of neuromorphic concepts to hardware implementations, allowing most physical systems to act as a computing platform. A particular group of reservoir computers that uses neither temporal dependence nor system feedback are Extreme Learning Machines(ELM), which have an architecture closer to a common feed forward network and are typically easier to implement [5,6,7]. In short, an Extreme learning machine exploits an untrained nonlinear random transformation to project each element of an input space onto a high-dimensional output space. The learning process is then performed in this output space, i.e., at the output layer, which reduces the computational load and bypasses the need to fine-tune all the network weights [5].
ELMs and reservoir computers have the potential to simplify the deployment of alternative physical systems as effective computing platforms, from mechanical [8,9] and hydraulic [10,11,12,13] to optical systems [14,15,16,17], with the latter being the main focus of this work. Yet, deploying an effective physical ELM requires control of the relevant nonlinear dynamics [7,18,19]. From the optical computing perspective, this means that one needs optical media with a tunable nonlinear optical response. Nonlinear crystals or thermo-optical media may be explored for that purpose, but their relatively weak nonlinearity may limit their applications, requiring either large propagation distances that forbid miniaturization and increase losses or higher laser power that can be prohibitive from the power efficiency perspective.
In this context, atomic gases in near-resonant conditions may constitute a valuable alternative for the construction of such devices. Indeed, provided with a suitable level structure, one can engineer the light–matter interaction conditions to achieve a tunable optical media with enhanced nonlinear susceptibilities at ultra-low intensities [20,21,22,23]. Motivated by this background, this manuscript explores how such near-resonant media can be utilized for deploying effective optical extreme learning machines (OELM). For that, we will start by modeling the optical response of a typical N-type four-level atomic system to demonstrate how it can be utilized to obtain a highly nonlinear optical medium that is suitable to perform at low-intensity levels. Then, introducing the basic concepts of ELMs, we demonstrate how such configuration can be envisioned and used as a processing solution by using a phase encoding scheme and interferometric processes occurring during the nonlinear optical propagation of an optical beam inside a gas cell. By performing beam propagation numerical simulations under realistic physical conditions, we test the computing capabilities of these systems, demonstrating the importance of controlling the nonlinear properties of the system.
2. Propagation of an Optical Beam in an Atomic Media under Near-Resonant Conditions
Regarding the goal of a strong nonlinear optical response, multiple atomic systems with a variety of level structures are known to support such phenomenology through effects related to quantum state coherence [21,22]. For this manuscript, we will focus on a typical 4-level atomic system [23,24,25,26] interacting with three continuous-wave electromagnetic fields, which is widely known in the literature to support giant cross-Kerr nonlinearities even at ultra-low intensity levels [23,24]. In particular, we choose a typical N-type configuration(see Figure 1). First, a weak probe field , with envelope function , center frequency and wave vector couples the levels and . The additional transitions are driven with stronger fields: a second ground state is coupled to the excited state via a control field , with envelope function , center frequency and wave vector ; and a switching field couples the second ground state to a second excited state via , with envelope function , center frequency and wave vector .
Taking a semi-classical approach for the light–matter interaction [27,28] and neglecting the effects of the weaker probe beam on the dynamics of the control and switching fields, the propagation of the optical probe beam equation under the paraxial approximation is given by
In this framework, the coherent light–matter interaction can be accounted for through the polarization density term that oscillates with . For the current atomic medium it can be defined as , where and are the dipole moment for the transition and the population coherence terms of the density matrix operator , respectively, and is the atomic density. To proceed with an analysis, the dynamics of the atomic populations can be modeled by the master equation
where H is the system Hamiltonian given by
where the Lindblad superoperator accounts for all the decoherence processes of the system, and the Rabi frequencies for the transitions are defined as . Using the definition of optical susceptibility , we can simplify the Equation (1) to
Equations (2) and (4) are then coupled through the susceptibility term, which may be obtained by solving the master equation. Assuming the steady-state solution, and by making use of the rotating-wave approximation [28], Equation (2) can be expanded into the form
where stands for a vectorized form of the density matrix, and where and are matrices related with the -independent and dependent parts of the master equation for , respectively. Recovering the weak probe beam assumption, i.e., , a perturbative approach to the weak probe beam gives , obtained iteratively from
starting from the ground state as the zero-th order solution (i.e., , if i or ).
The results for this equation system are straightforward to obtain algebraically, but the general full expressions are typically too cumbersome [26]. Yet, in the simplified limit of negligible dephasing processes between the two ground states, and assuming , and the two-photon resonance condition , it is possible to obtain that
where the second approximation is valid for sufficiently large detunings, and equal amplitudes . Finally, introducing the new variables , , , , the transformation , and the coefficient and dropping the primes, we obtain a dimensionless Nonlinear Schrödinger equation (NSE) to describe the evolution of the probe field as
where the linear coefficient is given by
while the nonlinear term, associated with a self-Kerr effect, is given by
In the context of this work, the NSE model will be utilized to investigate numerically the propagation of a given envelope field that contains the input information encoded in its wavefront. In the next section, we introduce how this propagation can be used to construct an optical computing system to process information by establishing a parallel to an extreme learning machine architecture. Furthermore, leveraging on the controllable parameters of the model, specifically the detuning , we investigate the impact of this choice in the overall performance of our OELM, showcasing the opportunities of using atomic systems for this specific purpose.
3. Building an Optical Extreme Learning Machine
To build an effective optical ELM, we first need to understand the inner workings of this architecture. For this section, we consider the task of predicting a belonging to a space for a total of input states belonging to the feature space (with being the total number of features) and associated with ground-truth targets that belong to a space .
The ELM architecture comprises three stages. First, each input state is projected into an intermediate space as
with G being a nonlinear activation function, the number of output channels, and and the internal weights and bias for each channel. The second step concerns the learning stage. It is performed on this high-dimensional intermediate space and assumes that we can train a linear transformation from to and that matches the target values by minimizing a given loss function. For example, it can be an output weight matrix that belongs to and that under the typical regularized ridge regression can be obtained from minimization of the loss function
considering all the inputs i and associated targets of the training dataset. Note that while the Ridge model is typically suitable for regression tasks, classification is also possible, for example, by converting binary class targets to positive/negative values and keeping the sign of the prediction. Additionally, under the theory of extreme learning machines [5,6,7], it is known that the universal approximation capabilities of this framework require two conditions under the activation function: (i) an infinitely differentiable nonlinear activation function G and (ii) a random distribution of weights [5].
With the architecture established, we can now discuss how to implement an OELM based on the propagation of an optical beam in our nonlinear optical media. First, we embed each input state into the phase of a given probe beam, namely
where are encoding function and intensity distributions working as embedding states. Then, we let the optical beam propagate inside the media before recovering it at the end , utilizing an intensity sensor (e.g., a camera) for that purpose. Then, taking the pixels as the output channels, we obtain
where a subscript for the right-hand side may for example refer to a pixel position for a sensor of pixels. Establishing a parallel with the definition in Equation (12), it is straightforward to conclude that our nonlinear activation function is provided by a mixed combination of multiple effects, namely the interference of waves and generated patterns when interrogated with an intensity sensor, and the nonlinear evolution of the optical state inside the nonlinear media. Although the first by itself does not warrant the necessary conditions for an ELM with universal approximation capabilities [7,16], it is known that the second may provide them if the strength of the nonlinearity is sufficiently high [7,19].
4. Results
In this section, we present the results of numerical simulations of Equation (9) to explore the performance of an OELM for regression and classification tasks. Additionally, to increase the relevance of the work and maintain a close connection with a real-world implementation—supporting its future experimental implementation in cold or hot atomic gases—we have chosen as the N-type configuration the well-explored hyperfine structure of the D line of , more precisely the levels , , and [29,30]. Realistic physical parameters [29] for this system are: , and for dipole matrix elements; and for decay rates. Also, we consider the wavelengths of the optical fields to be and and a fixed atomic concentration . For the present work, we focus on the self-focusing Kerr regime, meaning that we will restrict our analysis to positive detunings. For the simulations presented below, we utilized in adimensional units (approx. 10 mW/cm2), . We further explore the range of [1, 200] for g meaning that would in practice vary within a range . Encoding states are flattops with waist w = 400 μm and propagate for a total distance of z = 1 cm inside the optical media. This propagation distance is quite realistic from the perspective of hot atoms, as typical vapor cells may feature propagation distances even an order of magnitude larger than that. From the perspective of cold atoms, however, these often involve magneto-optical trapping, and the atomic clouds normally fall within the millimeter range. Nevertheless, we shall also note that the atomic densities may be much higher in this case, and the increased nonlinear response effectively reduces the necessary propagation distance to obtain similar effects.
4.1. Regression of Nonlinear Functions
To understand the computing capabilities of our optical ELM, we first focus on a typical regression task. For the purposes of this work, we have chosen to approximate the function with encoded in the input state as
with the encoding obtained using a min-max normalization of the features (see Figure 2 for spatial distributions and encoding strategy). The additional fixed random phase distribution warrants the generation of speckles in such a short distance and randomness of the projection onto the output space and can be applied experimentally using a spatial light modulator or an optical diffuser, for example. For each state, we propagate it numerically, taking the intensity at (i.e., imaging the intensity at the output plane) and recording a region of interest(ROI) of 60 × 60 pixels around the center . We further downsampled the ROI by averaging regions of 2 × 2 pixels, before randomly choosing superpixels as the output state . Note that the effective dimensionality of the output space may be higher or lower than , and it is associated with multiple factors such as the type of activation function and encoding strategy. Indeed, from a purely theoretical perspective, the only formal statement known is that if the matrix has then it can learn a dataset of elements with zero error, which would imply [5]. Still, this statement does not impose major constraints on performance as one does not require for effective learning [16,19]. Indeed, a higher may be detrimental to performance as it may lead to overfitting issues that must be dealt with using convenient regularization techniques.
To explore this framework, we test the system with the regression of the function . The dataset is comprised of 64 points equally distributed in the interval [−3, 3] with an 80–20% train-test split where a standard Ridge Regression methodology from the sklearn Python library is used to train the output layer [31]. Taking the root mean squared error (RMSE) as an evaluation metric, the results obtained are presented in Figure 3. As we can see, both the the dimensionality of the output space and nonlinear strength g are important for achieving a good performance in the regression task, achieving an error below 5%, meaning that both play a role as hyperparameters of the model. Yet, looking at Figure 3C, one can see that the nonlinear dynamics are more important for achieving a good performance than simply increasing the number of output channels, meaning that the dimensionality is important but not sufficient. Indeed, this becomes evident when computing the error of the noisy dataset (same input data but with 5% random noise added on top of it), for which one sees a decrease in the accuracy of the predictions with the increase in the , which suggest an overfitting of the model with the increase in .
4.2. Classification of the Spiral Dataset
For the second case study, we focused on the typical two-class spiral dataset to obtain a grasp of the classification capabilities of our proposed implementation as well as to obtain a clear picture of its generalization capabilities. Taking the dataset represented in Figure 4, we encoded each pair of features into an input state
with the encodings obtained using a min-max normalization of the features (see Figure 4 for spatial distributions). The associated vector on the output space for each input state was computed following the same strategy as utilized for the regression task.
Utilizing the logistic regression as a classification model, we followed the same 80–20% train-test subset division procedure and varied the number of channels and the nonlinear strength g, obtaining the results depicted in Figure 5. As in the regression task, the results again suggest that the output dimensionality and nonlinear strength of the physical system are both important parameters, but only the nonlinear strength warrants good accuracy. In ideal conditions, train and test accuracies above 90% can be achieved, meaning that the model is not overfitting and validating our conceptual proposal as an effective OELM capable of performing nonlinear classification tasks.
To finalize, Figure 5 also presents the accuracy for predictions on a noisy dataset, i.e., propagating states with 5% random noise added on top of the initial state. As the performance does not vary significantly, it suggests that the classification model is robust and may generalize well for unseen data. Indeed, a better insight into model generalization capabilities may be achieved by performing numerical simulations for each point covering a rectangular grid with and , and predicting the associated label at each point using the previously trained model for . Figure 6 depicts the obtained results, showing that a correct spiral-like separation of the data is possible for the sufficiently high nonlinear regime of the reservoir, demonstrating that generalization is possible but tightly connected with the strength of the nonlinearity.
5. Discussion and Concluding Remarks
The present manuscript reports a strategy to enable a physical implementation of an OELM using the nonlinear optical properties of atomic vapors in near-resonant conditions. The proposed implementation focuses on the use of an N-type configuration and the propagation of a weak probe beam assisted by strong coupling and switching fields. Following a perturbative approach, we derived an effective model for the propagation of a weak probe optical beam in the form of a nonlinear Schrödinger equation. Then, leveraging an encoding strategy based on the spatial modulation of the phase of the input probe beam, we established a connection between the physical system and the ELM architecture, demonstrating how one can benefit from the strong nonlinear optical properties of near-resonant optical media to enable an optical implementation of an ELM. Additionally, by offering the possibility to control the nonlinearity strength with external parameters such as detuning or field intensity, the system presents an interesting playground to explore the crossover between linear and nonlinear response and to assess its impact on the performance of an optical ELM. The numerical results presented demonstrate how combining a sufficiently large output dimensional space with strong nonlinear dynamics performs regression and classification of nonlinear problems. To approximate experimental conditions, realistic physical values, together with synthetic noise, are used to obtain the numerical results. Therefore, it is plausible to expect similar observations in experimental setups, which are soon to be explored.
Compared to previous results in the literature, we would also like to highlight two interesting research directions for future works. On the one hand, the possible physical deployment of the system would allow us not only to confirm the predictions described here but also to explore the connections, benefits, and drawbacks of the proposed architecture against previous all-optical processing hardware implementations. In particular, it would be very interesting to compare the performance of this machine with other architectures, such as diffractive deep neural networks [32] and specifically with those exploiting the use of rubidium as a nonlinear activation function [33]. On the other hand, theoretical research at the level of the activation functions for such optical machines would be very beneficial for understanding the possible computing capacity of the all-optical ELMs for more complex problems such as chaotic series prediction. In particular, we anticipate that some insightful connections may be made with the recently proposed next-generation reservoir computer architecture [34].
Finally, putting the results in perspective by comparing them with previous approaches in free space [14,16], the system presented here benefits from the fact that the nonlinearity does not reside solely in the measurement of the intensity of the field at the output plane (commonly performed with an electronic element such as a camera) but also on the propagation itself, which can be controlled externally. These findings pave an important step for all-optical computing schemes and for establishing atomic vapors as possible building blocks of fast and robust neuromorphic all-optical computers.
Author Contributions
N.A.S.: Conceptualization, methodology, investigation, writing; T.D.F.: writing—reviewing and editing; V.R.: writing—reviewing and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This work is financed by National Funds through the Portuguese funding agency, FCT—Fundação para a Ciência e a Tecnologia, within the project UIDB/50014/2020. T.D.F. is supported by FCT—Fundação para a Ciência e a Tecnologia through Grant No. SFRH/BD/145119/2019.
Data Availability Statement
The data used for the production of this manuscript can be made available upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ELM | Extreme Learning Machine |
| OELM | Optical Extreme Learning Machine |
| NSE | Nonlinear Schrödinger equation |
| ROI | Region of Interest |
| RMSE | Root Mean Squared Error |
References
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Tanaka, G.; Yamane, T.; Héroux, J.B.; Nakane, R.; Kanazawa, N.; Takeda, S.; Numata, H.; Nakano, D.; Hirose, A. Recent advances in physical reservoir computing: A review. Neural Netw. 2019, 115, 100–123. [Google Scholar] [CrossRef]
- Shalf, J. The future of computing beyond Moore’s Law. Philos. Trans. R. Soc. A 2020, 378, 20190061. [Google Scholar] [CrossRef]
- Ballarini, D.; Gianfrate, A.; Panico, R.; Opala, A.; Ghosh, S.; Dominici, L.; Ardizzone, V.; De Giorgi, M.; Lerario, G.; Gigli, G.; et al. Polaritonic neuromorphic computing outperforms linear classifiers. Nano Lett. 2020, 20, 3506–3512. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2011, 42, 513–529. [Google Scholar] [CrossRef]
- Marcucci, G.; Pierangeli, D.; Conti, C. Theory of neuromorphic computing by waves: Machine learning by rogue waves, dispersive shocks, and solitons. Phys. Rev. Lett. 2020, 125, 093901. [Google Scholar] [CrossRef]
- Coulombe, J.C.; York, M.C.; Sylvestre, J. Computing with networks of nonlinear mechanical oscillators. PLoS ONE 2017, 12, e0178663. [Google Scholar] [CrossRef]
- Mandal, S.; Sinha, S.; Shrimali, M.D. Machine-learning potential of a single pendulum. Phys. Rev. E 2022, 105, 054203. [Google Scholar] [CrossRef]
- Jaeger, H.; Haas, H. Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication. Science 2004, 304, 78–80. [Google Scholar] [CrossRef]
- Goto, K.; Nakajima, K.; Notsu, H. Twin vortex computer in fluid flow. New J. Phys. 2021, 23, 063051. [Google Scholar] [CrossRef]
- Maksymov, I.S.; Pototsky, A. Reservoir computing based on solitary-like waves dynamics of liquid film flows: A proof of concept. Europhys. Lett. 2023, 142, 43001. [Google Scholar] [CrossRef]
- Maksymov, I.S. Analogue and physical reservoir computing using water waves: Applications in power engineering and beyond. Energies 2023, 16, 5366. [Google Scholar] [CrossRef]
- Pierangeli, D.; Marcucci, G.; Conti, C. Photonic extreme learning machine by free-space optical propagation. Photonics Res. 2021, 9, 1446–1454. [Google Scholar] [CrossRef]
- Lupo, A.; Butschek, L.; Massar, S. Photonic extreme learning machine based on frequency multiplexing. Opt. Express 2021, 29, 28257–28276. [Google Scholar] [CrossRef]
- Silva, D.; Ferreira, T.; Moreira, F.C.; Rosa, C.C.; Guerreiro, A.; Silva, N.A. Exploring the hidden dimensions of an optical extreme learning machine. J. Eur. Opt. Soc. 2023, 19, 8. [Google Scholar] [CrossRef]
- Xu, B.; Huang, Y.; Fang, Y.; Wang, Z.; Yu, S.; Xu, R. Recent progress of neuromorphic computing based on silicon photonics: Electronic–photonic Co-design, device, and architecture. Photonics 2022, 9, 698. [Google Scholar] [CrossRef]
- Yildirim, M.; Oguz, I.; Kaufmann, F.; Escalé, M.R.; Grange, R.; Psaltis, D.; Moser, C. Nonlinear optical feature generator for machine learning. APL Photonics 2023, 8, 106104. [Google Scholar] [CrossRef]
- Silva, N.A.; Ferreira, T.D.; Guerreiro, A. Reservoir computing with solitons. New J. Phys. 2021, 23, 023013. [Google Scholar] [CrossRef]
- Hang, C.; Konotop, V. Spatial solitons in a three-level atomic medium supported by a laguerre-gaussian control beam. Phys. Rev. A 2011, 83, 053845. [Google Scholar] [CrossRef]
- Fleischhauer, M.; Imamoglu, A.; Marangos, J.P. Electromagnetically induced transparency: Optics in coherent media. Rev. Mod. Phys. 2005, 77, 633. [Google Scholar] [CrossRef]
- Wang, H.; Goorskey, D.; Xiao, M. Enhanced Kerr nonlinearity via atomic coherence in a three-level atomic system. Phys. Rev. Lett. 2001, 87, 073601. [Google Scholar] [CrossRef] [PubMed]
- Michinel, H.; Paz-Alonso, M.J.; Pérez-García, V.M. Turning light into a liquid via atomic coherence. Phys. Rev. Lett. 2006, 96, 023903. [Google Scholar] [CrossRef] [PubMed]
- Alexandrescu, A.; Michinel, H.; Pérez-García, V.M. Liquidlike dynamics of optical beams in tailored coherent media. Phys. Rev. A 2009, 79, 013833. [Google Scholar] [CrossRef]
- Sheng, J.; Yang, X.; Wu, H.; Xiao, M. Modified self-Kerr-nonlinearity in a four-level N-type atomic system. Phys. Rev. A 2011, 84, 053820. [Google Scholar] [CrossRef]
- Silva, N.A.; Mendonça, J.; Guerreiro, A. Persistent currents of superfluidic light in a four-level coherent atomic medium. JOSA B 2017, 34, 2220–2226. [Google Scholar] [CrossRef]
- Rand, S.C. Lectures on Light: Nonlinear and Quantum Optics Using the Density Matrix; Oxford University Press: Oxford, UK, 2016. [Google Scholar]
- Meystre, P.; Scully, M.O. Quantum Optics; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Steck, D.A. Rubidium 87 D Line Data. 2001. Available online: https://www.steck.us/alkalidata/rubidium85numbers.pdf (accessed on 12 December 2023).
- Safronova, M.; Safronova, U. Critically evaluated theoretical energies, lifetimes, hyperfine constants, and multipole polarizabilities in Rb 87. Phys. Rev. A 2011, 83, 052508. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Zuo, Y.; Li, B.; Zhao, Y.; Jiang, Y.; Chen, Y.C.; Chen, P.; Jo, G.B.; Liu, J.; Du, S. All-optical neural network with nonlinear activation functions. Optica 2019, 6, 1132–1137. [Google Scholar] [CrossRef]
- Zuo, Y.; Zhao, Y.; Chen, Y.C.; Du, S.; Liu, J. Scalability of all-optical neural networks based on spatial light modulators. Phys. Rev. Appl. 2021, 15, 054034. [Google Scholar] [CrossRef]
- Gauthier, D.J.; Bollt, E.; Griffith, A.; Barbosa, W.A. Next generation reservoir computing. Nat. Commun. 2021, 12, 5564. [Google Scholar] [CrossRef] [PubMed]
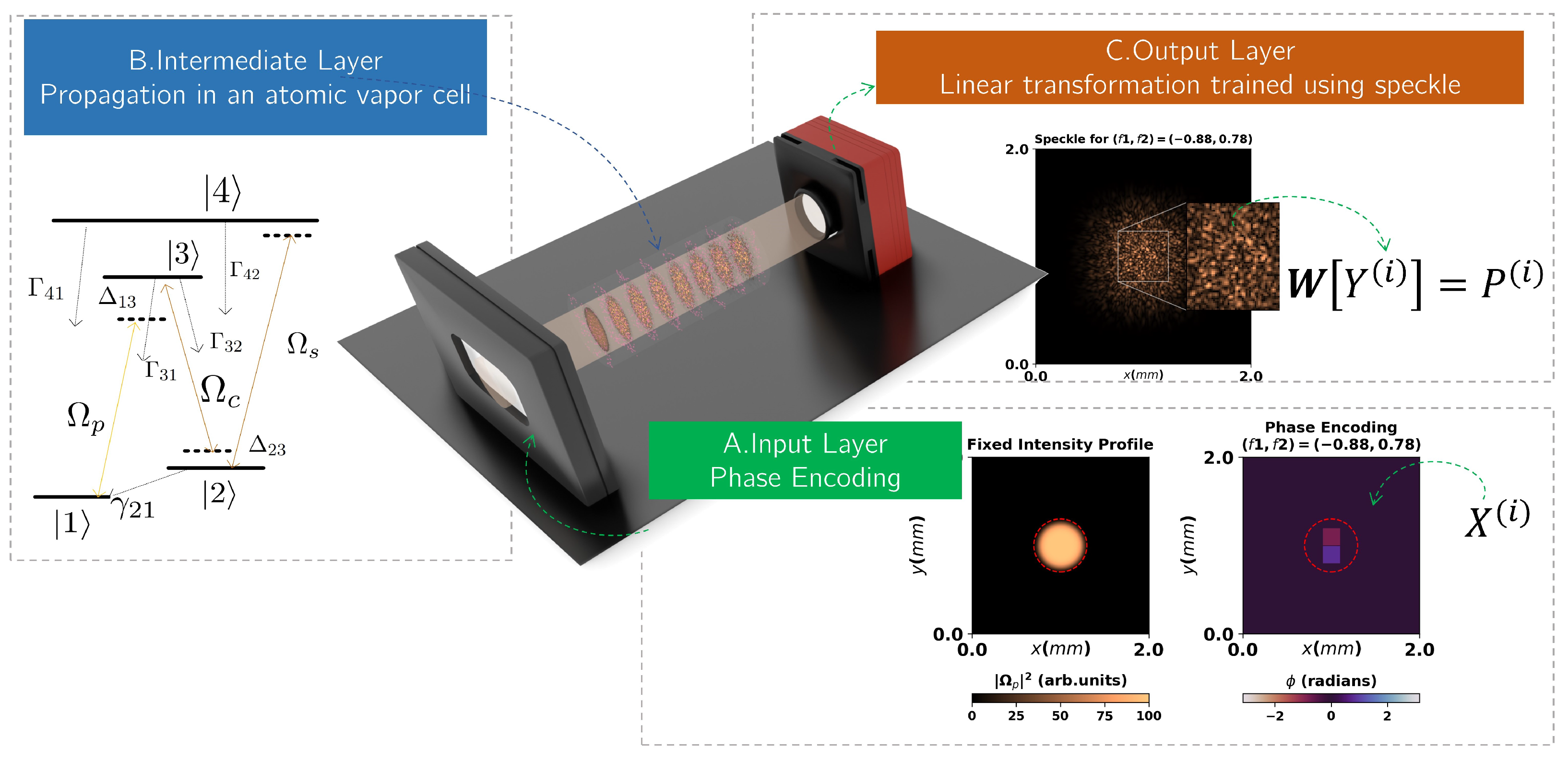
Figure 1.
Schematic of the purposed optical extreme learning configuration (exaggerated scales for illustration purposes). (A) Each input of the dataset is encoded into the phase profile of the incident flat top weak probe beam , which can be achieved with a spatial light modulator, for example. (B) The probe beam propagates inside a cell filled with an atomic vapor with a N-type 4-level atomic system, which acts as the intermediate layer of the OELM. (C) After the propagation, the speckle pattern is recovered at the end, with the pixel intensity values being utilized as the output state for training the linear transformation that completes the extreme learning machine architecture.
Figure 1.
Schematic of the purposed optical extreme learning configuration (exaggerated scales for illustration purposes). (A) Each input of the dataset is encoded into the phase profile of the incident flat top weak probe beam , which can be achieved with a spatial light modulator, for example. (B) The probe beam propagates inside a cell filled with an atomic vapor with a N-type 4-level atomic system, which acts as the intermediate layer of the OELM. (C) After the propagation, the speckle pattern is recovered at the end, with the pixel intensity values being utilized as the output state for training the linear transformation that completes the extreme learning machine architecture.

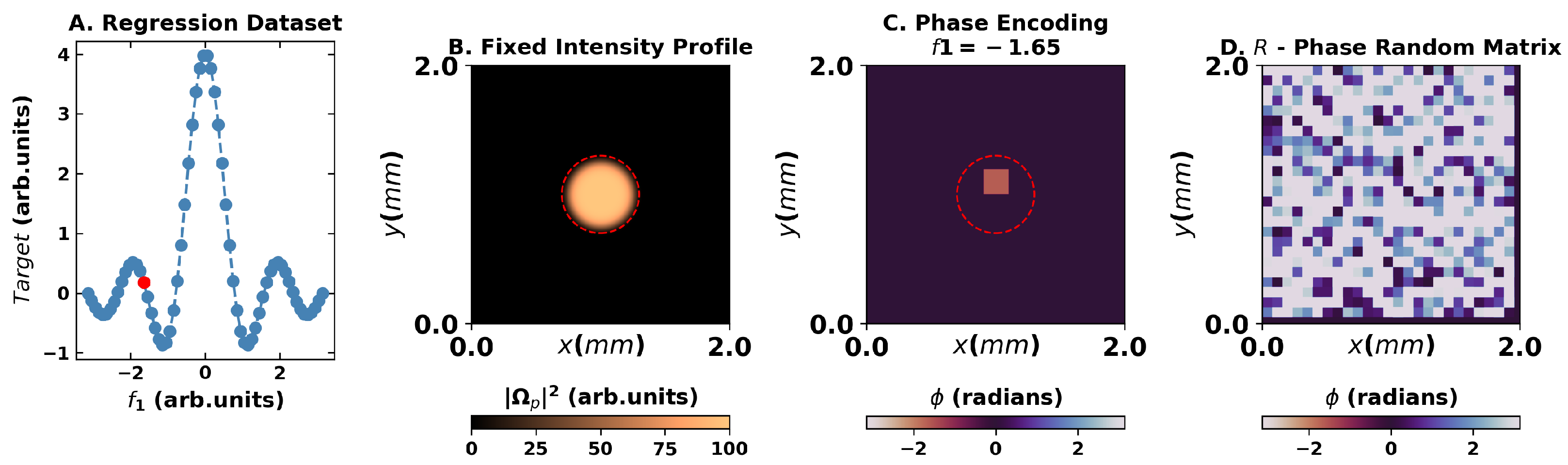
Figure 2.
Overview of the encoding for the regression task for dataset and targets presented in (A). Panel (B) presents the flattop intensity of the probe beam utilized, whereas (C) presents one feature of the encoding scheme in the phase of the wavefront for the point highlighted in red in the first panel. (D) A constant random matrix on the phase is also applied to the wavefront to warrant the speckle formation.
Figure 2.
Overview of the encoding for the regression task for dataset and targets presented in (A). Panel (B) presents the flattop intensity of the probe beam utilized, whereas (C) presents one feature of the encoding scheme in the phase of the wavefront for the point highlighted in red in the first panel. (D) A constant random matrix on the phase is also applied to the wavefront to warrant the speckle formation.

Figure 3.
Results for the regression task with the optical ELM measured with the root mean squared error (RMSE) metric. (A) Change in performance with the increase in output channels with fixed . (B) Varying performance with the increase in the nonlinearity parameter g for a fixed . (C) Performance on the test dataset with varying g and shows a clear increasing performance tendency for stronger nonlinearities and larger output spaces.
Figure 3.
Results for the regression task with the optical ELM measured with the root mean squared error (RMSE) metric. (A) Change in performance with the increase in output channels with fixed . (B) Varying performance with the increase in the nonlinearity parameter g for a fixed . (C) Performance on the test dataset with varying g and shows a clear increasing performance tendency for stronger nonlinearities and larger output spaces.

Figure 4.
Overview of the encoding for the classification task for dataset and targets presented in (A). Panel (B) presents the flattop intensity of the probe beam utilized, whereas (C) presents a two-feature encoding scheme in the phase of the wavefront for the point highlighted in red in panel (A). (D) A constant random matrix on the phase is also applied to the wavefront to warrant the speckle formation.
Figure 4.
Overview of the encoding for the classification task for dataset and targets presented in (A). Panel (B) presents the flattop intensity of the probe beam utilized, whereas (C) presents a two-feature encoding scheme in the phase of the wavefront for the point highlighted in red in panel (A). (D) A constant random matrix on the phase is also applied to the wavefront to warrant the speckle formation.

Figure 5.
Results for the classification task with the optical ELM. (A) Change in performance with the increase in output channels with fixed . (B) Varying performance with the increase in the nonlinearity parameter g for a fixed . (C) Performance on the test dataset with varying g and shows a clear increasing performance tendency for stronger nonlinearities and larger output spaces.
Figure 5.
Results for the classification task with the optical ELM. (A) Change in performance with the increase in output channels with fixed . (B) Varying performance with the increase in the nonlinearity parameter g for a fixed . (C) Performance on the test dataset with varying g and shows a clear increasing performance tendency for stronger nonlinearities and larger output spaces.

Figure 6.
Results for the two-spiral classification task with the optical ELM, regarding the generalization capabilities of the model for two distinct nonlinear parameters, (A) and (B) .
Figure 6.
Results for the two-spiral classification task with the optical ELM, regarding the generalization capabilities of the model for two distinct nonlinear parameters, (A) and (B) .

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Silva, N.A.; Rocha, V.; Ferreira, T.D. Optical Extreme Learning Machines with Atomic Vapors. Atoms 2024, 12, 10. https://doi.org/10.3390/atoms12020010
AMA Style
Silva NA, Rocha V, Ferreira TD. Optical Extreme Learning Machines with Atomic Vapors. Atoms. 2024; 12(2):10. https://doi.org/10.3390/atoms12020010
Chicago/Turabian StyleSilva, Nuno A., Vicente Rocha, and Tiago D. Ferreira. 2024. "Optical Extreme Learning Machines with Atomic Vapors" Atoms 12, no. 2: 10. https://doi.org/10.3390/atoms12020010
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.