

Using Dual Spatial Clustering Models for Urban Fringe Areas Extraction Based on Night-time Light Data: Comparison of NPP/VIIRS, Luojia 1-01, and NASA’s Black Marble



Abstract
:1. Introduction
2. Study Area and Data
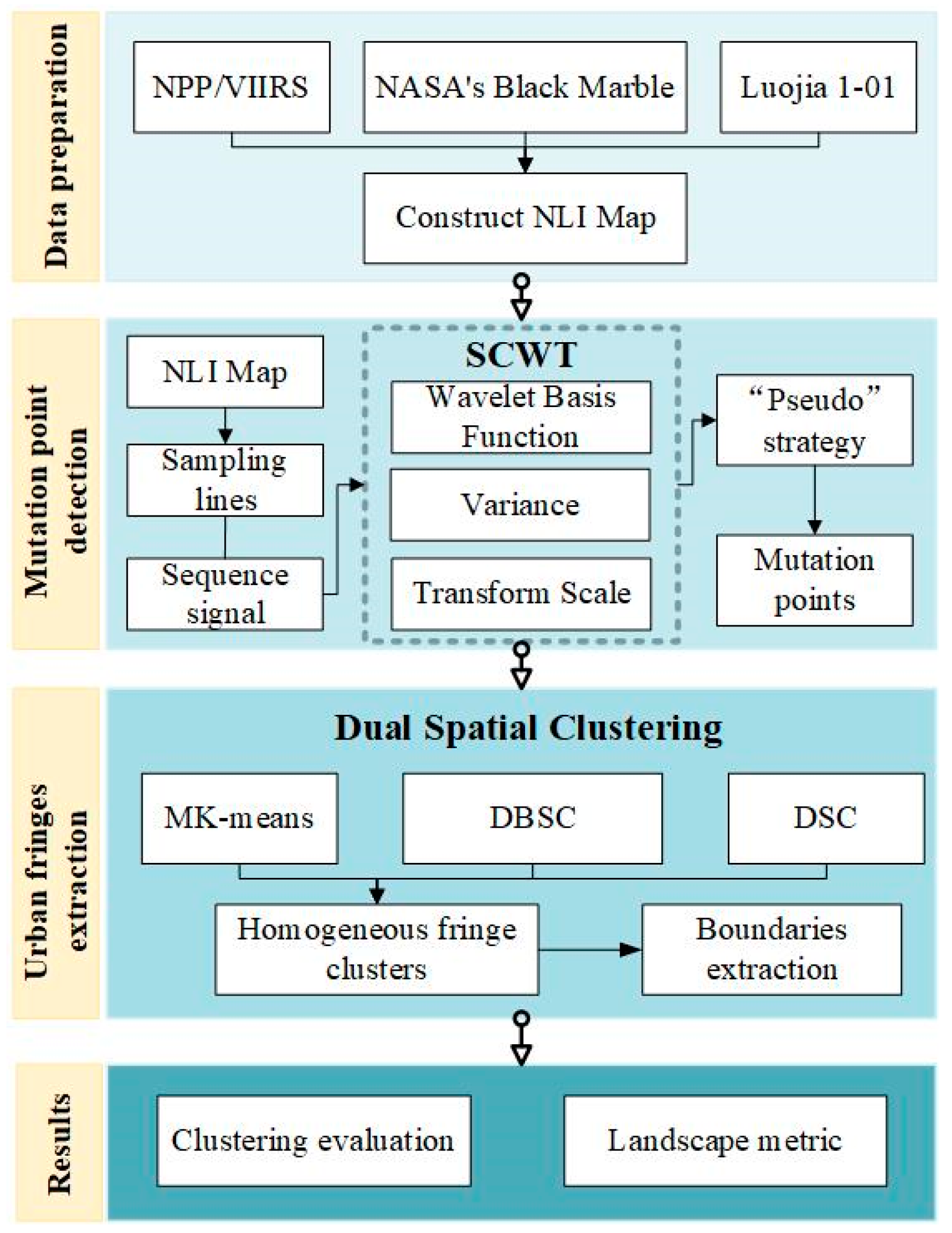
3. Methodology
3.1. The Detection of Mutation Points Using SCWT
3.2. Extraction of Urban Fringe Based on Different Dual Spatial Clustering Methods
3.2.1. Modified k-Means Algorithm (Mk-Means)
3.2.2. Density-Based Spatial Clustering Algorithm (DBSC)
- (1)
- Clustering based on spatial position constraints
- (2)
- Clustering based on non-spatial attribute constraints
3.2.3. DSC Algorithm
- (1)
- Clustering constrained by spatial proximity
- (2)
- Clustering constrained by attribute similarity
3.3. Boundary Extraction of Homogeneous Fringe Clusters
3.4. Evaluation
4. Results
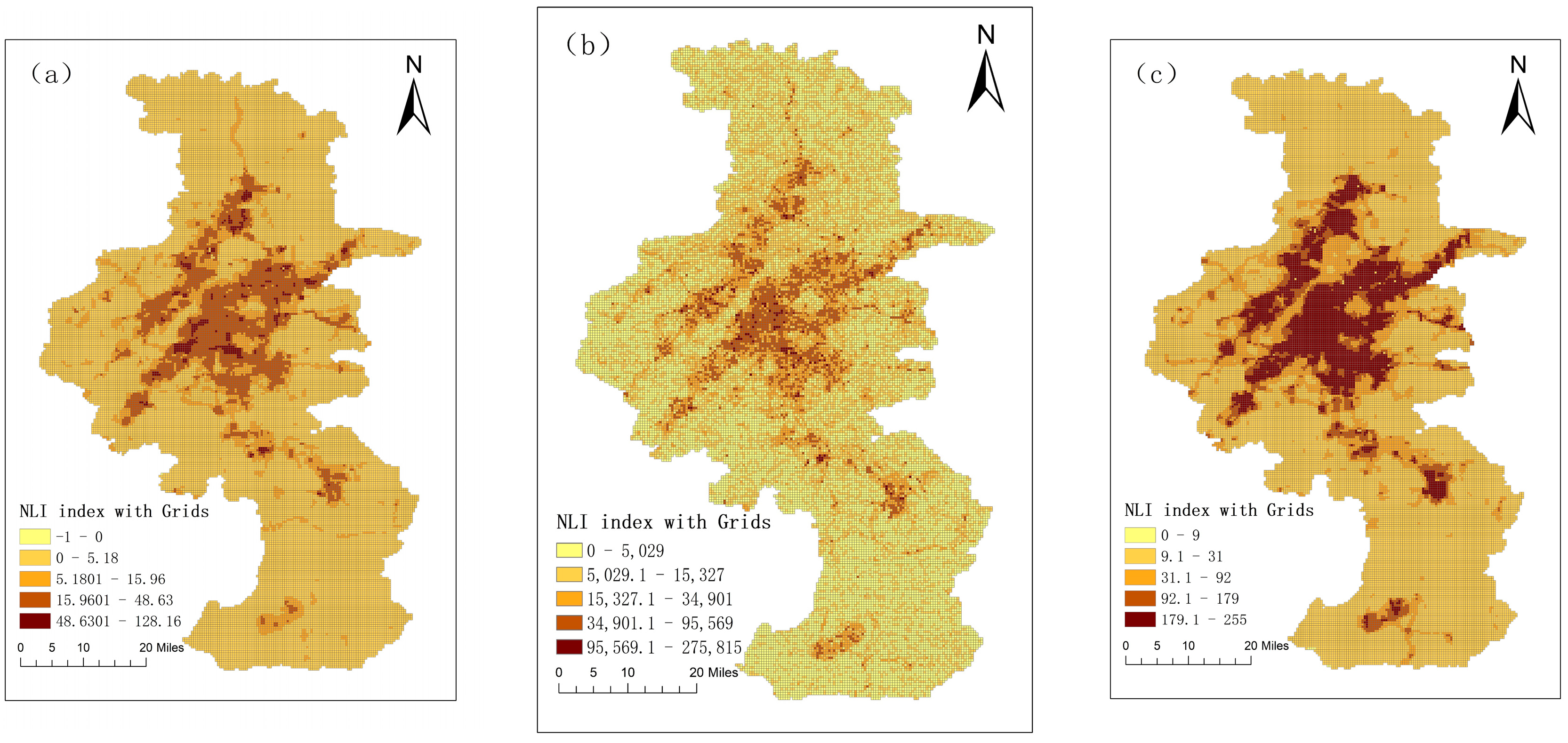
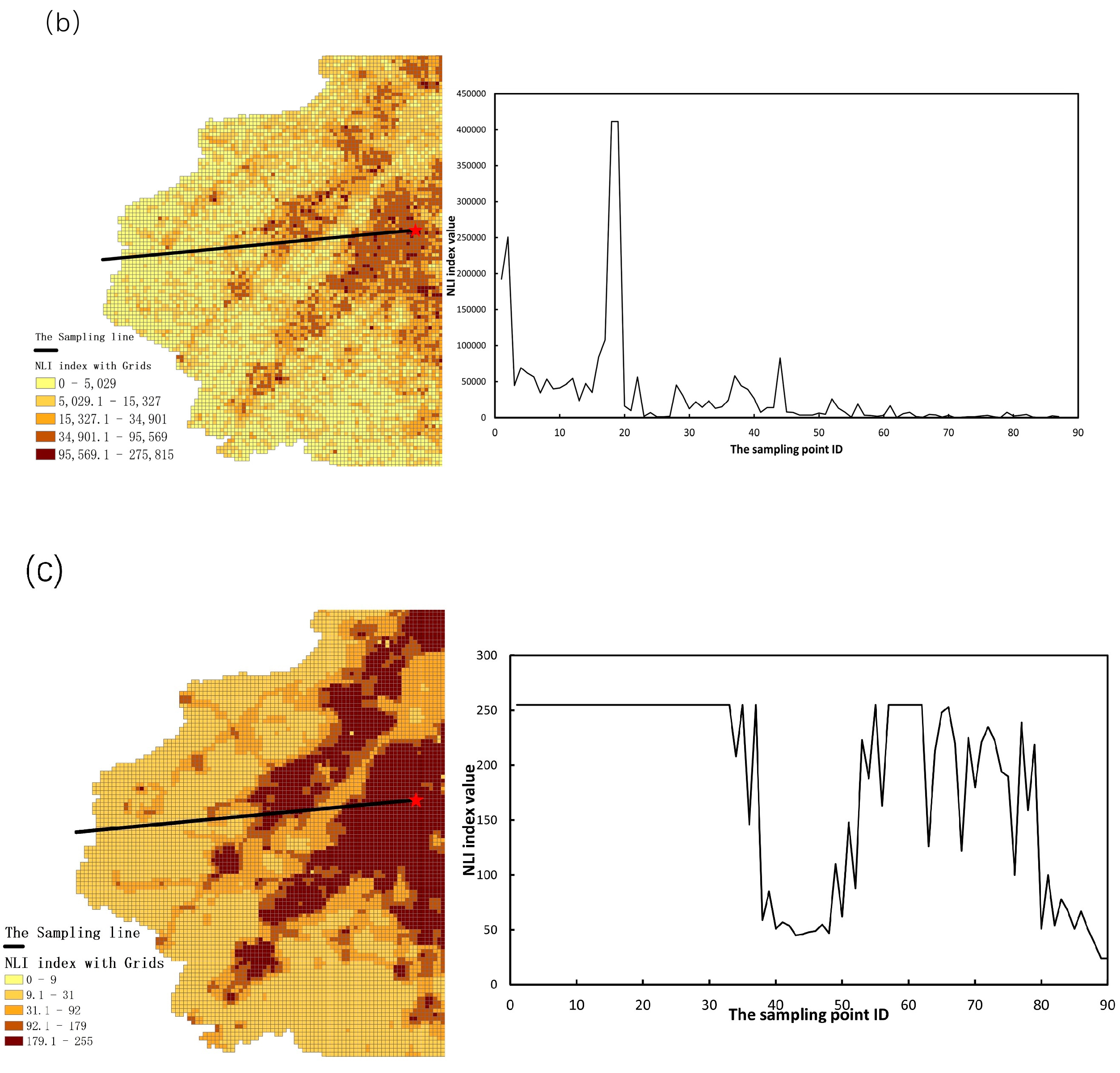
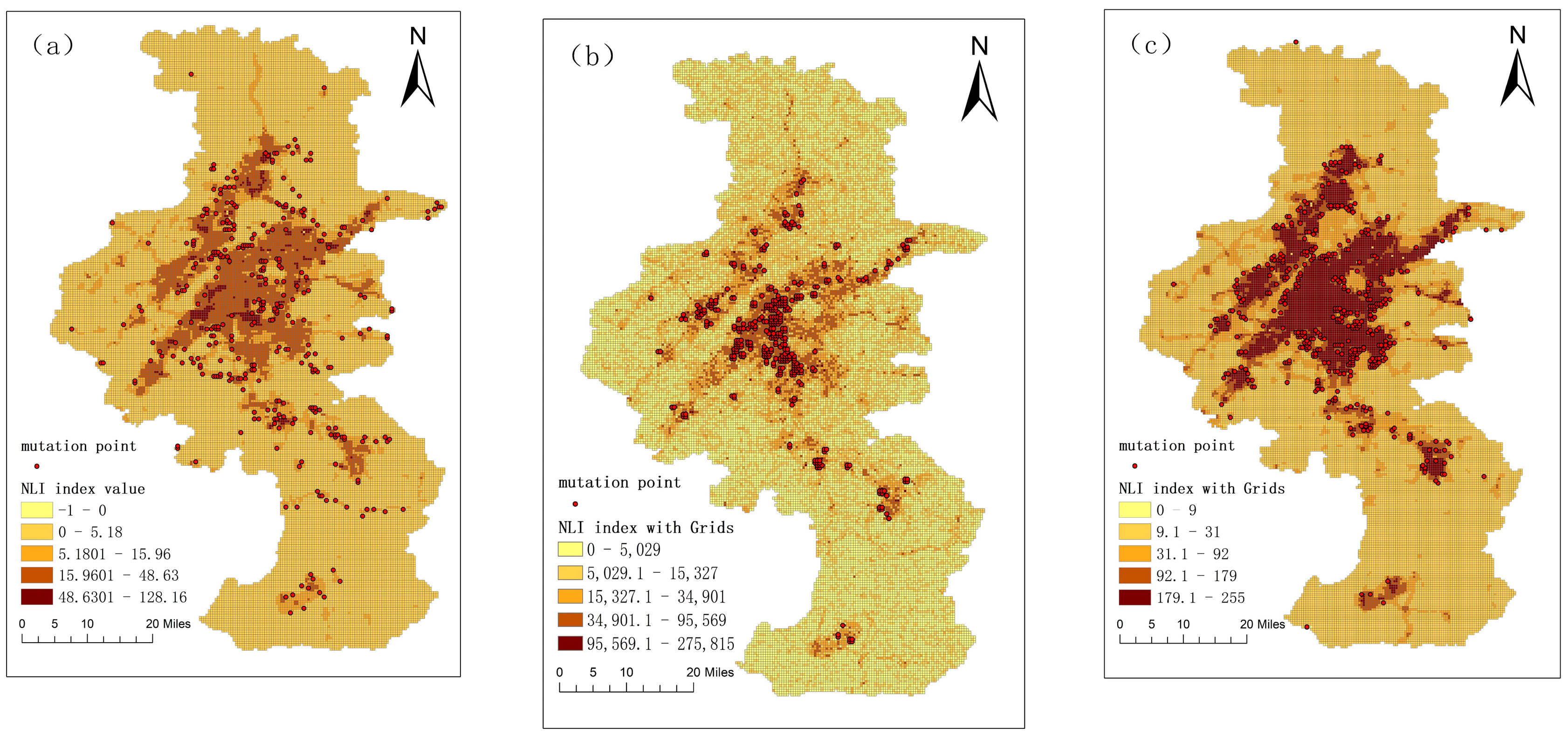
4.1. Mutation Points Detection from Different NTL Sources
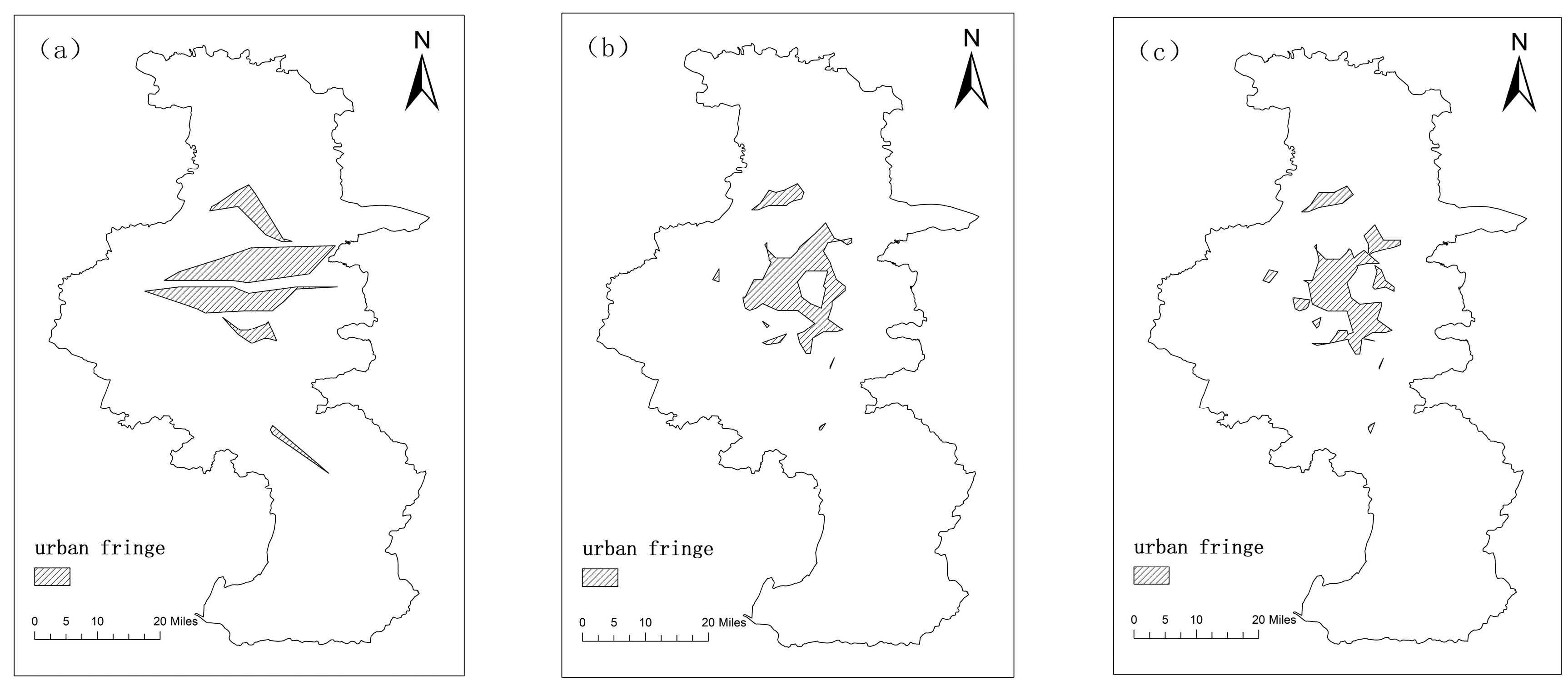
4.2. Urban Fringe Extraction by Different Dual Spatial Clustering Methods
5. Discussion
5.1. NASA’s Black Marble and NPP/VIIRS Data Effectively Captured the Abrupt Change of Urban Fringe Areas with NTL Variations
5.2. DSC Provided a Reliable Approach for Accurately Extracting Urban Fringe Area Using NASA’s Black Marble Data
6. Conclusions
- (1)
- For different algorithms, the MK-Means clustering approach offers a useful perspective on the hierarchical structure and general urbanization differences between regions. However, it fails to detect certain adjacent spatial clusters with different attributes within the clusters, as indicated by more scattered distribution and poorer performance. DBSC fails to differentiate the actual differences between two adjacent clusters as it ignores the tendency of the NLI index. The urban fringe boundaries in the north and south of the Yangtze River basin (i.e., Zhucheng and Jiangbei) are not anticipated to demonstrate a distinct demarcation. The DSC algorithm is suitable for detecting clusters in datasets with an uneven distribution of non-spatial attributes. However, it resulted in the over-segmentation of urban–rural fringes into numerous smaller areas.
- (2)
- For different NTL datasets, the extraction results from NPP/VIIRS data are significantly affected by the light spillover phenomenon, leading to an overestimation of the recognition results with a high concentration of contiguous patches. Luojia 1-01 data did not yield satisfactory results due to a relatively concentrated distribution of mutation points, resulting in a significant amount of missing fringe area information, which could potentially lead to an underestimation of the recognition results. NASA’s Black Marble data with medium and high spatial resolution can better reveal inner-city NTL variations, which can offer valuable insights into localized variations to map urban fringe areas. Notably, when using the Black Marble data combined with DSC clustering, the extraction of urban fringe area boundaries in Nanjing were more precise and accurate.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, X.; Huang, Y.; Xu, X.; Li, X.; Li, X.; Ciais, P.; Lin, P.; Gong, K.; Ziegler, A.D.; Chen, A.; et al. High-spatiotemporal-resolution mapping of global urban change from 1985 to 2015. Nat. Sustain. 2020, 3, 564–570. [Google Scholar] [CrossRef]
- United Nations. World Urbanization Prospects: The 2018 Revision; United Nations Department of Economic and Social Affairs: New York, NY, USA, 2018. [Google Scholar]
- Gant, R.; Robinson, G.; Fazal, S. Land-use change in the ‘edgelands’: Policies and pressures in London’s rural–urban fringe. Land Use Policy 2011, 28, 266–279. [Google Scholar] [CrossRef]
- Peng, J.; Hu, Y.; Liu, Y.; Ma, J.; Zhao, S. A new approach for urban-rural fringe identification: Integrating impervious surface area and spatial continuous wavelet transform. Landsc. Urban Plan 2018, 175, 72–79. [Google Scholar] [CrossRef]
- Zhao, P.; Zhang, M. Informal suburbanization in Beijing: An investigation of informal gated communities on the urban fringe. Habitat Int. 2018, 77, 130–142. [Google Scholar] [CrossRef]
- Lyu, Y.; Wang, M.; Zou, Y.; Wu, C. Mapping trade-offs among urban fringe land use functions to accurately support spatial planning. Sci. Total Environ. 2022, 802, 149915. [Google Scholar] [CrossRef]
- Zhou, Y.; Smith, S.; Zhao, K.; Imhoff, M.; Thomson, A.; Bond-Lamberty, B.; Elvidge, C. A global map of urban extent from nightlights. Environ. Res. Lett. 2015, 10, 054011. [Google Scholar] [CrossRef]
- Yang, Y.; Ma, M.; Tan, C.; Li, W. Spatial Recognition of the Urban-Rural Fringe of Beijing Using DMSP/OLS Nighttime Light Data. Remote Sens. 2017, 9, 114. [Google Scholar] [CrossRef]
- Feng, Z.; Peng, J.; Wu, J. Using DMSP/OLS nighttime light data and K–means method to identify urban–rural fringe of megacities. Habitat Int. 2020, 103, 102227. [Google Scholar] [CrossRef]
- Zheng, Q.; Seto, K.; Zhou, Y.; You, S.; Weng, Q. Nighttime light remote sensing for urban applications: Progress, challenges, and prospects. ISPRS J. Photogramm. Remote Sens. 2023, 202, 125–141. [Google Scholar] [CrossRef]
- Elvidge, C.; Baugh, K.; Kihn, E.; Kroehl, H.; Davis, E. Mapping city lights with nighttime data from the DMSP operational linescan system. Photogramm. Eng. Remote Sens. 1997, 63, 727–734. [Google Scholar]
- Wang, Z.; Rom’an, M.; Kalb, V.; Miller, S.; Zhang, J.; Shrestha, R. Quantifying uncertainties in nighttime light retrievals from Suomi-NPP and NOAA-20 VIIRS Day/Night Band data. Remote Sens. Environ. 2021, 263, 112557. [Google Scholar] [CrossRef]
- Sanchez de Miguel, A.; Kyba, C.; Aube, M.; Zamorano, J.; Cardiel, N.; Tapia, C.; Gaston, K. Colour remote sensing of the impact of artiffcial light at night (I): The potential of the International Space Station and other DSLR-based platforms. Remote Sens. Environ. 2019, 224, 92–103. [Google Scholar] [CrossRef]
- Li, X.; Li, X.; Li, D.; He, X.; Jendryke, M. A preliminary investigation of Luojia-1 night-time light imagery. Remote Sens. Lett. 2019, 10, 526–535. [Google Scholar] [CrossRef]
- Zheng, Q.; Weng, Q.; Huang, L.; Wang, K.; Deng, J.; Jiang, R.; Gan, M. A new source of multi-spectral high spatial resolution night-time light imagery—JL1-3B. Remote Sens. Environ. 2018, 215, 300–312. [Google Scholar] [CrossRef]
- Lin, Z.; Jiao, W.; Liu, H.; Long, T.; Liu, Y.; Wei, S.; Liu, M. Modelling the public perception of urban public space lighting based on SDGSAT-1 glimmer imagery. Sustain. Cities Soc. 2022, 88, 104272. [Google Scholar] [CrossRef]
- Zheng, Q.; Weng, Q.; Wang, K. Developing a new cross-sensor calibration model for DMSP-OLS and Suomi-NPP VIIRS night-light imageries. ISPRS J. Photogramm. Remote Sens. 2019, 153, 36–47. [Google Scholar] [CrossRef]
- Li, X.; Li, D.; Xu, H.; Wu, C. Intercalibration between DMSP/OLS and VIIRS night- time light images to evaluate city light dynamics of Syria’s major human settlement during Syrian Civil War. Int. J. Remote Sens. 2017, 38, 5934–5951. [Google Scholar] [CrossRef]
- Elvidge, C.; Baugh, K.; Zhizhin, M.; Hsu, F. Why VIIRS data are superior to DMSP for mapping nighttime lights. Proc. Asia-Pacifc Adv. Netw. 2013, 35, 62. [Google Scholar] [CrossRef]
- Elvidge, C.; Baugh, K.; Zhizhin, M.; Hsu, F.; Ghosh, T. VIIRS night-time lights. Int. J. Remote Sens. 2017, 38, 5860–5879. [Google Scholar] [CrossRef]
- Roman, M.; Wang, Z.; Sun, Q.; Kalb, V.; Miller, S.; Molthan, A.; Masuoka, E. NASA’s Black Marble nighttime lights product suite. Remote Sens. Environ. 2018, 210, 113–143. [Google Scholar] [CrossRef]
- Wang, Z.; Shrestha, R.; Roma´n, M.; Kalb, V. NASA’s black marble multi- angle nighttime lights temporal composites. IEEE Geosci. Rem. Sens. Lett. 2022, 19, 1–5. [Google Scholar]
- Li, T.; Zhu, Z.; Wang, Z.; Román, M.O.; Kalb, V.L.; Zhao, Y. Continuous monitoring of nighttime light changes based on daily NASAʹs Black Marble product suite. Remote Sens. Environ. 2022, 282, 113269. [Google Scholar] [CrossRef]
- Masek, J.G.; Lindsay, F.E.; Goward, S.N. Dynamics of urban growth in the Washington DC metropolitan area, 1973–1996, from Landsat observations. Int. J. Remote Sens. 2000, 21, 3473–3486. [Google Scholar] [CrossRef]
- Wang, X.; Li, X.; Feng, Z.; Fang, Y. Methods on defining the urban fringe area of Beijing. In Proceedings of the International Symposium on Digital Earth International Society for Optics and Photonics, Beijing, China, 3 November 2010; Volume 7840. [Google Scholar]
- Imhoff, M.; Zhang, P.; Wolfe, R.; Bounoua, L. Remote sensing of the urban heat island effect across biomes in the continental USA. Remote Sens. Environ. 2010, 114, 504–513. [Google Scholar] [CrossRef]
- Qian, J.; Zhou, Y.; Yang, X. Confirmation of urban fringe area based on remote sensing and message entropy: A case study of Jingzhou, Hubei Province. Resour. Environ. 2007, 16, 451–455. (In Chinese) [Google Scholar]
- Peng, J.; Zhao, S.; Liu, Y.; Tian, L. Identifying the urbanrural fringe using wavelet transform and kernel density estimation: A case study in beijing city, China. Environ. Model. Softw. 2016, 83, 286–302. [Google Scholar] [CrossRef]
- Zhou, Y.; Smith, S.; Elvidge, C.; Zhao, K.; Thomson, A.; Imhoff, M. A cluster-based method to map urban area from DMSP/OLS nightlights. Remote Sens. Environ. 2014, 147, 173–185. [Google Scholar] [CrossRef]
- Zhu, J.; Lang, Z.; Yang, J.; Wang, M.; Zheng, J.; Na, J. Integrating Spatial Heterogeneity to Identify the Urban Fringe Area Based on NPP/VIIRS Nighttime Light Data and Dual Spatial Clustering. Remote Sens. 2022, 14, 6126. [Google Scholar] [CrossRef]
- Yang, J.; Dong, J.; Sun, Y.; Zhu, J.; Huang, Y.; Yang, S. A constraint-based approach for identifying the urban–rural fringe of polycentric cities using multi-sourced data. Int. J. Geogr. Sci. 2021, 36, 114–136. [Google Scholar] [CrossRef]
- Liu, Q.L.; Deng, M.; Shi, Y.; Wang, J.Q. A density-based spatial clustering algorithm considering both spatial proximity and attribute similarity. Comput. Geosci. 2012, 46, 296–309. [Google Scholar] [CrossRef]
- Lin, C.; Liu, K.; Chen, M. Dual clustering: Integrating data clustering over optimization and constraint domains. IEEE T. Knowl. Data En. 2005, 17, 628–637. [Google Scholar]
- Zhu, J.; Zheng, J.; Di, S.; Wang, S.; Yang, J. A dual spatial clustering method in the presence of heterogeneity and noise. Trans. GIS 2020, 24, 1799–1826. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, X.; Liu, D.; Liu, L. An adaptive dual clustering algorithm based on hierarchical structure: A case study of settlement zoning. Trans. GIS 2017, 21, 916–933. [Google Scholar] [CrossRef]
- Zhu, J.; Sun, Y. Building an Urban Spatial Structure from Urban Land Use Data: An Example Using Automated Recognition of the City Centre. ISPRS Int. J. Geo-Inf. 2017, 6, 122. [Google Scholar] [CrossRef]
- Gao, C.; Feng, Y.; Tong, X.; Lei, Z.K.; Chen, S.R.; Zhai, S.T. Modeling urban growth using spatially heterogeneous cellular automata models: Comparison of spatial lag, spatial error and GWR. Comput. Enviro. Urban 2020, 81, 101459. [Google Scholar] [CrossRef]
- Li, J.; Peng, B.; Liu, S.; Ye, H.; Zhang, Z.; Nie, X. An accurate fringe extraction model of small-and medium-sized urban areas using multi-source data. Front. Environ. Sci. 2023, 11, 1118953. [Google Scholar] [CrossRef]
- Estivill-Castro, V.; Lee, I. Argument free clustering for large spatial point-data sets via boundary extraction from Delaunay Diagram. Comput. Environ. Urban 2002, 6, 315–334. [Google Scholar] [CrossRef]
- Pakhira, M.K.; Bandyopadhyay, S.; Maulik, U. Validity index for crisp and fuzzy clusters. Pattern Recognit. 2004, 37, 487–501. [Google Scholar] [CrossRef]
- Peethambaran, J.; Muthuganapathy, R. A non-parametric approach to shape reconstruction from planar point sets through Delaunay filtering. Comput. Aided Des. 2015, 62, 164–175. [Google Scholar] [CrossRef]
- Halkidi, M.; Batistakis, Y.; Vazirgiannis, M. Clustering validity checking methods: Part II. ACM Sigmod Rec. 2002, 31, 19–27. [Google Scholar] [CrossRef]
- Dai, J.; Dong, J.; Yang, S.; Sun, Y. Identification method of urban fringe area based on spatial mutation characteristics. J. Geo-Inf. Sci. 2021, 23, 1401–1421. [Google Scholar]
- Yang, J.; Huang, X. The 30 m annual land cover dataset and its dynamics in China from 1990 to 2019. Earth Syst. Sci. Data 2021, 13, 3907–3925. [Google Scholar] [CrossRef]
- Li, F.; Yan, Q.; Zou, Y.; Liu, B. Extraction Accuracy of Urban Built-up Area Based on Nighttime Light Data and POI: A Case Study of Luojia 1-01 and NPP/VIIRS Nighttime Light Images. Geomat. Inf. Sci. Wuhan University 2021, 46, 825–835. [Google Scholar]
- Fagan, W.F.; Fortin, M.J.; Soykan, C. Integrating edge detection and dynamic modeling in quantitative analyses of eco-logical boundaries. BioScience 2003, 53, 730–738. [Google Scholar] [CrossRef]
- Mallet, S. A Wavelet Tour of Signal Processing: The Sparse Way, 3rd ed.; Academic Press: New York, NY, USA, 2008. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Indicator | Connotation |
|---|---|---|
| Clustering evaluation | represents the number of entities in the dataset, represents the number of clusters, denotes the number of entities in cluster , represents the centroid of cluster , and represents the centroid of the dataset. | The RS index value ranges between 0 and 1, where 0 indicates no difference between clusters, while 1 indicates significant differences between clusters. |
| Landscape pattern | represents the total area of the landscape type, and represents the total number of patches for the landscape type. | PD represents the quantity of specific land use patches within a given area. It serves as a comparative metric for landscapes of varying sizes and plays a crucial role in describing landscape fragmentation. A higher value indicates a higher degree of landscape fragmentation. |
represents the total length of the boundaries of a specific land use type, while represents the total area of that land use type. | The LSI can indicate the complexity of patches, which comprehensively reflects the size and heterogeneity of land classes. The LSI has a range of values from 1 to ∞, where a higher value indicates a more irregular patch shape. | |
represents the proportion of type within the entire landscape, and represents the total number of landscape types, ranging from [0, ∞). | The SHDI is a metric that measures the complexity and heterogeneity of different types of patches within a landscape. When , the SHDI is 0, indicating that the region has only one type of patch. As SHDI increases, it tends to be a more uniform distribution of different patch types throughout the landscape. |
| NTL Data | Algorithms | Statistical Information | ||||
|---|---|---|---|---|---|---|
| NC | NN | MEANV | SDMV | CV | ||
| Luojia 1-01 | MK-Means | 7 | 0 | 15,844.372 | 6199.354 | 0.391 |
| DBSC | 24 | 44 | 17,281.492 | 27,256.439 | 1.577 | |
| DSC | 33 | 37 | 31,146.359 | 78,428.949 | 2.518 | |
| NPP/VIIRS | MK-Means | 7 | 0 | 4.437 | 0.754 | 0.168 |
| DBSC | 6 | 15 | 2.920 | 0.704 | 0.241 | |
| DSC | 13 | 16 | 16.012 | 18.027 | 1.126 | |
| NASA’s Black Marble | MK-Means | 7 | 0 | 131.933 | 14.771 | 0.112 |
| DBSC | 29 | 17 | 175.540 | 67.517 | 0.385 | |
| DSC | 34 | 23 | 98.674 | 66.554 | 0.674 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, J.; Lang, Z.; Wang, S.; Zhu, M.; Na, J.; Zheng, J. Using Dual Spatial Clustering Models for Urban Fringe Areas Extraction Based on Night-time Light Data: Comparison of NPP/VIIRS, Luojia 1-01, and NASA’s Black Marble. ISPRS Int. J. Geo-Inf. 2023, 12, 408. https://doi.org/10.3390/ijgi12100408
Zhu J, Lang Z, Wang S, Zhu M, Na J, Zheng J. Using Dual Spatial Clustering Models for Urban Fringe Areas Extraction Based on Night-time Light Data: Comparison of NPP/VIIRS, Luojia 1-01, and NASA’s Black Marble. ISPRS International Journal of Geo-Information. 2023; 12(10):408. https://doi.org/10.3390/ijgi12100408
Chicago/Turabian StyleZhu, Jie, Ziqi Lang, Shu Wang, Mengyao Zhu, Jiaming Na, and Jiazhu Zheng. 2023. "Using Dual Spatial Clustering Models for Urban Fringe Areas Extraction Based on Night-time Light Data: Comparison of NPP/VIIRS, Luojia 1-01, and NASA’s Black Marble" ISPRS International Journal of Geo-Information 12, no. 10: 408. https://doi.org/10.3390/ijgi12100408