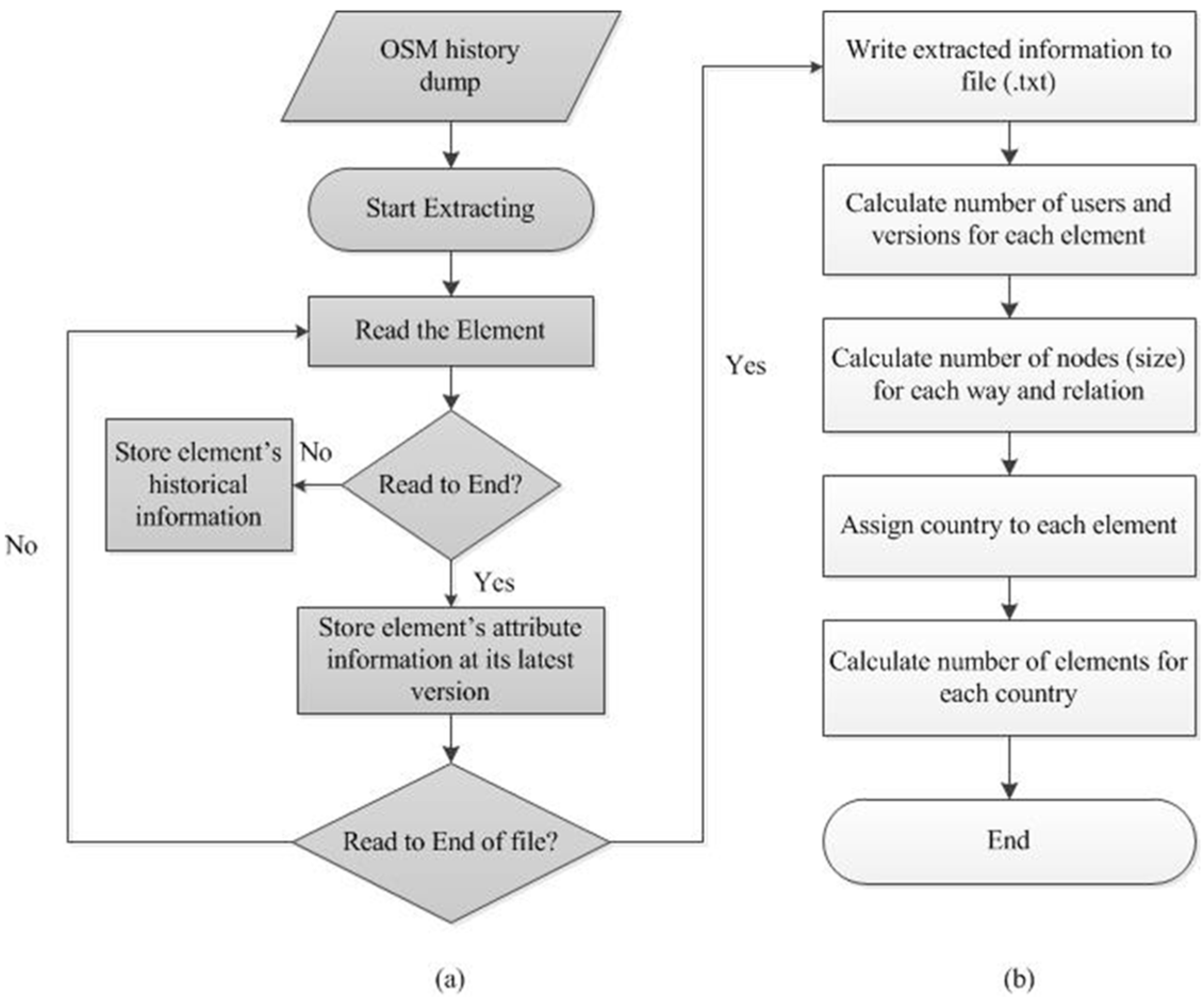
This section presents the results of the scaling analysis on a variety of features based on three aspects in the context of big data including 1 million users, 2.1 billion elements and 2.7 billion contributions (
Figure 2). These three parts constitute an interconnected picture of the OSM data and community. The users contribute to the elements, leading to a great increase in both element volume and complexity, and the user community. Through the contributions, users formed an interconnected collaboration network. The scaling analysis based on power-law detection and head/tail breaks was applied to these three aspects to examine to what extent the scaling pattern of far more small things than large ones was true for the OSM data.
Figure 2.
Three aspects of the study in the context of big data.
4.1. On Users and Elements
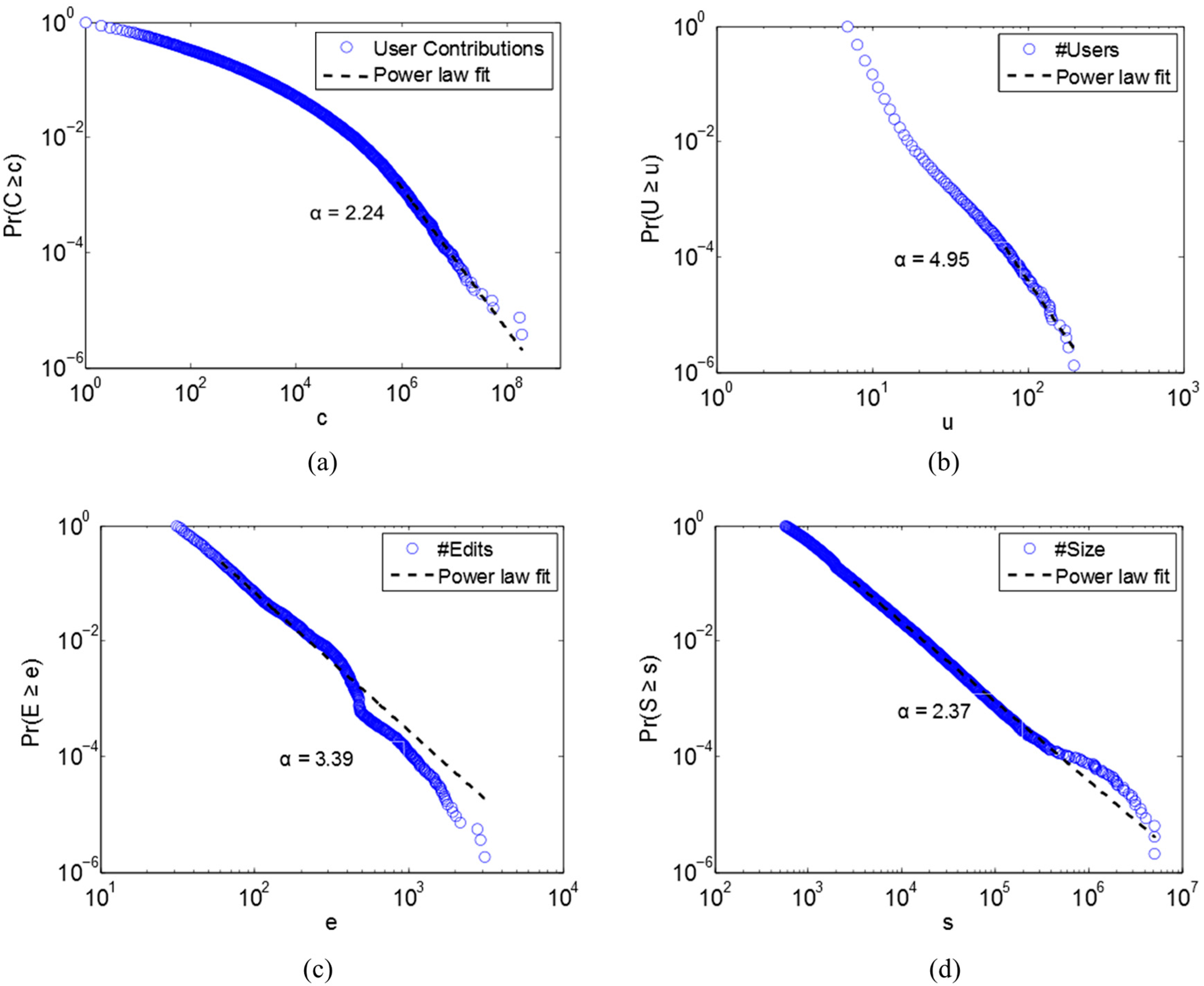
We first investigated users based on their number of contributions. The investigation was based on how many unique element IDs can one user contribute to. These contributions include both creating and editing. A total of 268,227 users made contributions. The number of each user’s contributions exhibited a power-law distribution, with an accepted
α of 2.24 and
p value of 0.26 (
Figure 3a). By applying the head/tail breaks, we derive the scaling hierarchy of these numbers, indicated by the ht-index of 7 and very low percentages for each head (<30%). This means the strikingly scaling pattern recurs 6 times of this data (
Table 1). This apparent scaling pattern indicates that only a very small number of users contributed the majority of OSM elements. In other words, there are far more inactive users than active ones.
Table 1.
Head/tail breaks statistics for user contributions (Note: # = number, % = percentage).
Table 1.
Head/tail breaks statistics for user contributions (Note: # = number, % = percentage).
| # Sum | # Head | % Head | # Tail | % Tail | Mean |
|---|
| 268,227 | 13,241 | 4% | 254,986 | 96% | 10,232 |
| 13,241 | 1825 | 13% | 11,416 | 87% | 199,020 |
| 1825 | 307 | 16% | 1518 | 84% | 1,164,797 |
| 307 | 48 | 15% | 259 | 85% | 4,751,085 |
| 48 | 8 | 16% | 40 | 84% | 18,843,785 |
| 8 | 2 | 25% | 6 | 75% | 69,899,060 |
Secondly, we looked at different attributes of elements. Each element is characterized by the number of users, edits and size respectively. Specifically, the number of users for each element indicates that how many users contribute to it, given by the number of unique user ids of this element. Note that the contribution includes both creation and edit; the number of edits can be directly obtained by the maximum version number of this element, since it equals to maximum version number minus one. The number of size refers to how many unique node ids it contains. The size of each node element is always 1; the size of each way element equals to the number of its unique comprising points; the size of each relation element is determined by the number of unique points its member contains: node, way or relation (these three members do not always exist simultaneously in one relation). Because some relation elements can have other relation element(s) as its member(s), it is difficult to calculate those relation elements’ sizes when they mutually contain each other as their member(s). There were 4356 relation elements excluded because of such complicated structures. Considering the elements of 2.1 billion studied, we believe that the 4356 excluded would not affect much on our results.
Next, we applied head/tail breaks to the above three aspects. All three derived ht-indices were very high (>10), and most of the head percentages were small (<30 percent; see detailed results in the
Appendix). It indicates that there are far more small elements than large ones. Power-law detection was further applied on the data of the top hierarchical levels of each category (
Table 2). The “filtered” data was the proxy of the whole since the scaling pattern remains at each level. Only the number of element size passed the power law test (
Figure 3d). The number of element users and edits can still be considered as heavy-tailed distributed as observed from the
Figure 3b and 3c that each plot is close to a straight line at logarithm scales, therefore we think that the entire dataset of three aspects possess a strong scaling property. We also examined the evolution of data on a yearly basis and found that heterogeneity was no different from the data as a whole. In other words, the data for the previous years are all heavy-tail distributed, but vary with different ht-indices.
Table 2.
Summarized statistics on OpenStreetMap (OSM) elements on top hierarchies in three categories.
Table 2.
Summarized statistics on OpenStreetMap (OSM) elements on top hierarchies in three categories.
| | # Elements | Max | Min | α | p |
|---|
| User | 745,943 | 197 | 7 | 4.95 | 0 |
| Edit | 548,914 | 3084 | 31 | 3.39 | 0.006 |
| Size | 479,004 | 5,118,276 | 564 | 2.37 | 0.13 |
Figure 3.
Power-law distributions of user contributions: (
a) number of users; (
b) number of edits; and (
c) number of sizes (
d) of each element. The data for (b), (c), and (d) are selected from the top hierarchies of all elements. (b) and (c) are not power-law distributed because both α values are larger than 3, but they are heavy-tailed, illustrated by the high ht-index shown in the
Appendix.
Figure 3.
Power-law distributions of user contributions: (
a) number of users; (
b) number of edits; and (
c) number of sizes (
d) of each element. The data for (b), (c), and (d) are selected from the top hierarchies of all elements. (b) and (c) are not power-law distributed because both α values are larger than 3, but they are heavy-tailed, illustrated by the high ht-index shown in the
Appendix.
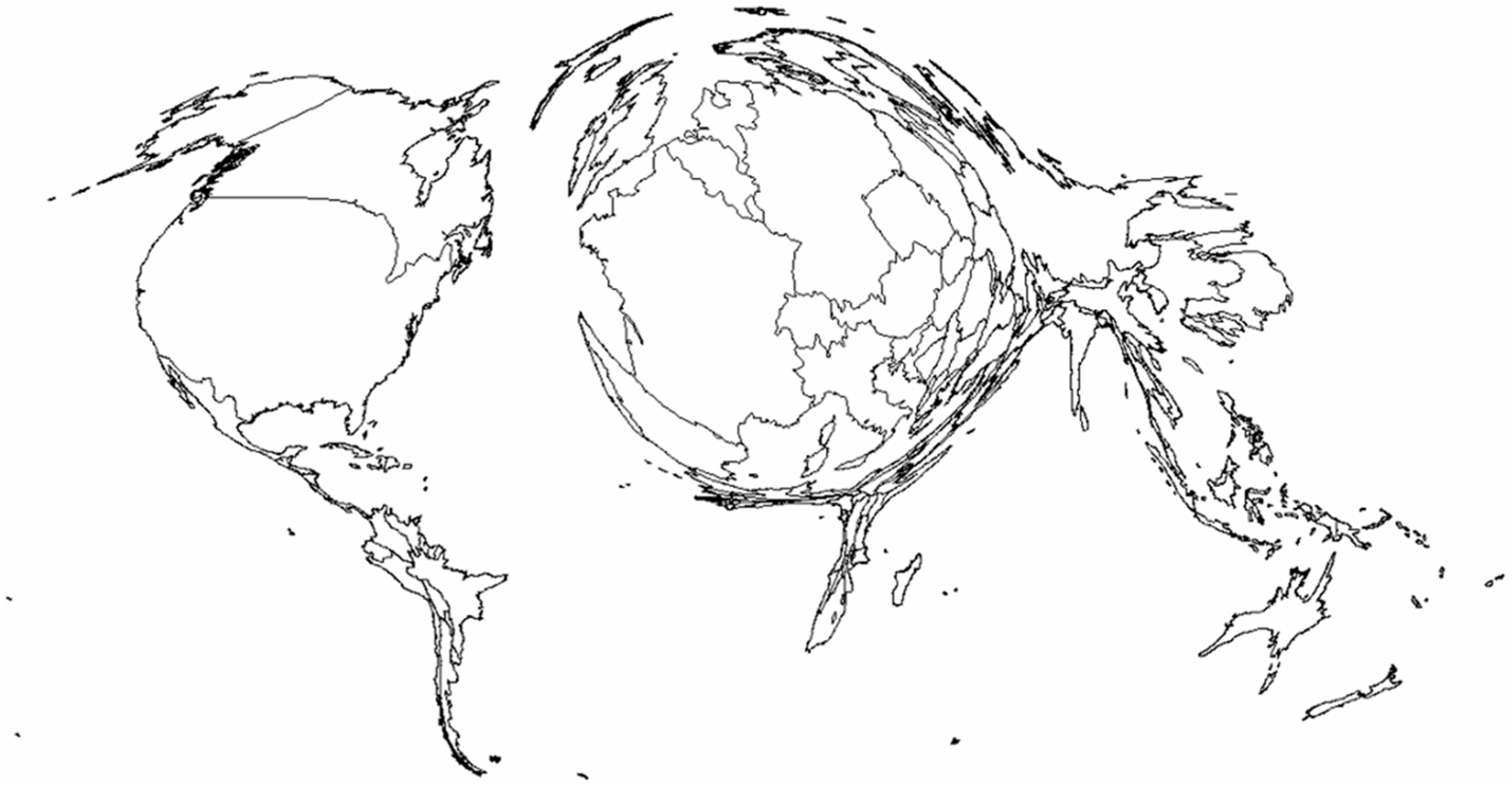
We further inspected the spatial distribution of the elements,
i.e., how many the elements are located in each country. We computed and assigned to each country the number of elements and the aggregated attribute values of each aspect. As results, the data of all the three aspects are very power-law distributed (
Table 3), which indicate that there are far more small countries than large ones all over the world in terms of the elements, users and contributions and it further implies that the high variation of quality and completeness of OSM database from country to country through different elements concentrations. The cartogram shows the resulting country sizes (
Figure 4), of which the top 5 countries are US, France, Canada, Germany and Russia. These countries are also the top 5 ones in terms of aggregated numbers of users, edits and size, but with a slightly different ranking (Canada and Germany switch positions).
Table 3.
Summarized statistics of elements at country level.
Table 3.
Summarized statistics of elements at country level.
| | max | min | α | p |
|---|
| #Element | 401,137,304 | 836 | 1.74 | 0.87 |
| #User | 598,175,441 | 951 | 1.74 | 0.82 |
| #Edit | 636,597,363 | 969 | 1.73 | 0.71 |
| #Size | 898,145,600 | 1408 | 1.69 | 0.67 |
Figure 4.
The cartogram showing the spatial distribution of global OSM elements at country level.
Figure 4.
The cartogram showing the spatial distribution of global OSM elements at country level.
4.2. On Co-Contribution Network
Having examined the users and elements, we subsequently studied the scaling pattern in the collaboration network of the OSM users. The social relationship utilized in this research is co-contribution relationship since friend relationship like other social platforms (e.g., Facebook) is undocumented in OSM history. The collaboration or co-contribution relationship is established in the OSM data archive when more than one user contributes to the same element. In other words, we considered that user has such relationship with others if they either create or edit the same element. This approach is different from the one defined by Mooney and Corcoran [
4,
18] who consider only the edit interaction and also the sequence of edits. In this regard, we construct a “co-contribution network” rather than co-edit network. As
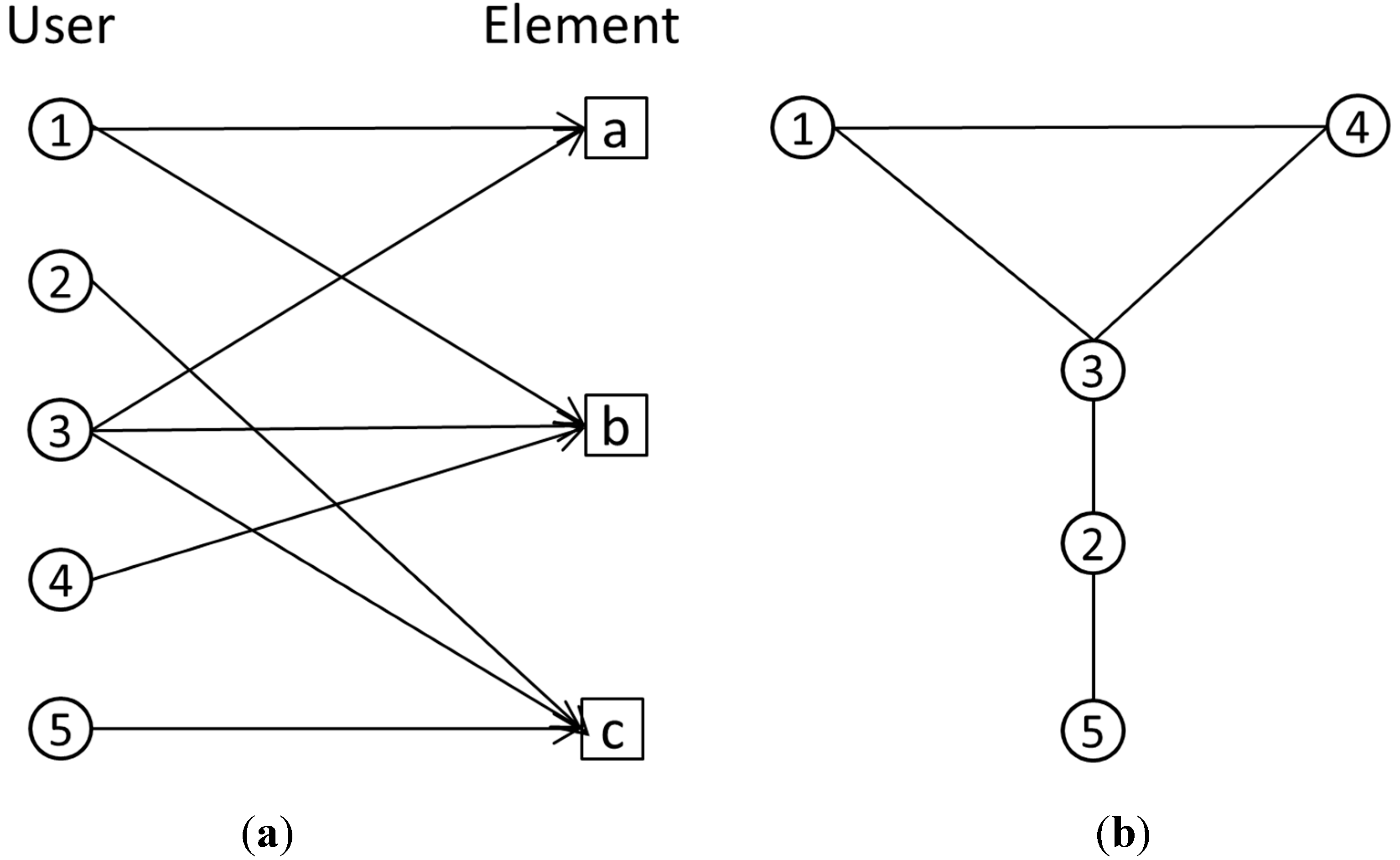
Figure 5a shows, assuming that user 1, 3 and 4 make contributions to element b, there are co-contribution relationships between every two of them, so that the resulting network (
Figure 5b) can be obtained. Note that this paper considers only the binary network, which consists of undirected and unweighted edges.
Figure 5.
Illustration of co-contribution relationship. Users’ contributions to elements are represented as a bi-partite graph (a), which is transformed into a co-contribution network (b).
Figure 5.
Illustration of co-contribution relationship. Users’ contributions to elements are represented as a bi-partite graph (a), which is transformed into a co-contribution network (b).
Following the rule of co-contribution relationship, we built up the network based on the entire history of all the elements to better illustrate engagement in the OSM community [
19]. The resulting social graph consists of 248,070 nodes and 6,446,086 edges. The node degree of this network is power-law distributed and has an ht-index of 10 (
Table 4), indicating that the network is extremely scale-free.
Figure 6 shows the “filtered” network comprising 477 nodes of the top 5 hierarchies as the representative of the entire network, from which the underlying scaling pattern is clearly uncovered. We further examine the networks of previous years from 2005 in order to see if scaling pattern persists all the time during the evolution of the OSM community in terms of contributions. As results, except that no existence of such network between the years of 2005 and 2006, the evolution of co-contribution networks is with a nonlinear growth of both nodes and edges from 2007 onwards and becomes increasingly scaling which is indicated by the power-law fitting metrics and overall increasingly large ht-index of each year (
Table 5).
Table 4.
Head/tail breaks statistics for node degree of co-contribution network in 2013.
Table 4.
Head/tail breaks statistics for node degree of co-contribution network in 2013.
| # nodes | # head | % head | # tail | % tail | mean |
|---|
| 248,070 | 33,504 | 13% | 214,566 | 87% | 51.97 |
| 33,504 | 7267 | 21% | 26,237 | 79% | 322.08 |
| 7267 | 1820 | 25% | 5447 | 75% | 1037.53 |
| 1820 | 477 | 26% | 1343 | 74% | 2486.16 |
| 477 | 137 | 28% | 340 | 72% | 5181.7 |
| 137 | 40 | 29% | 97 | 71% | 9474.48 |
| 40 | 11 | 27% | 29 | 73% | 16,102.82 |
| 11 | 3 | 27% | 8 | 73% | 26,460.73 |
| 3 | 1 | 33% | 2 | 67% | 47,980.33 |
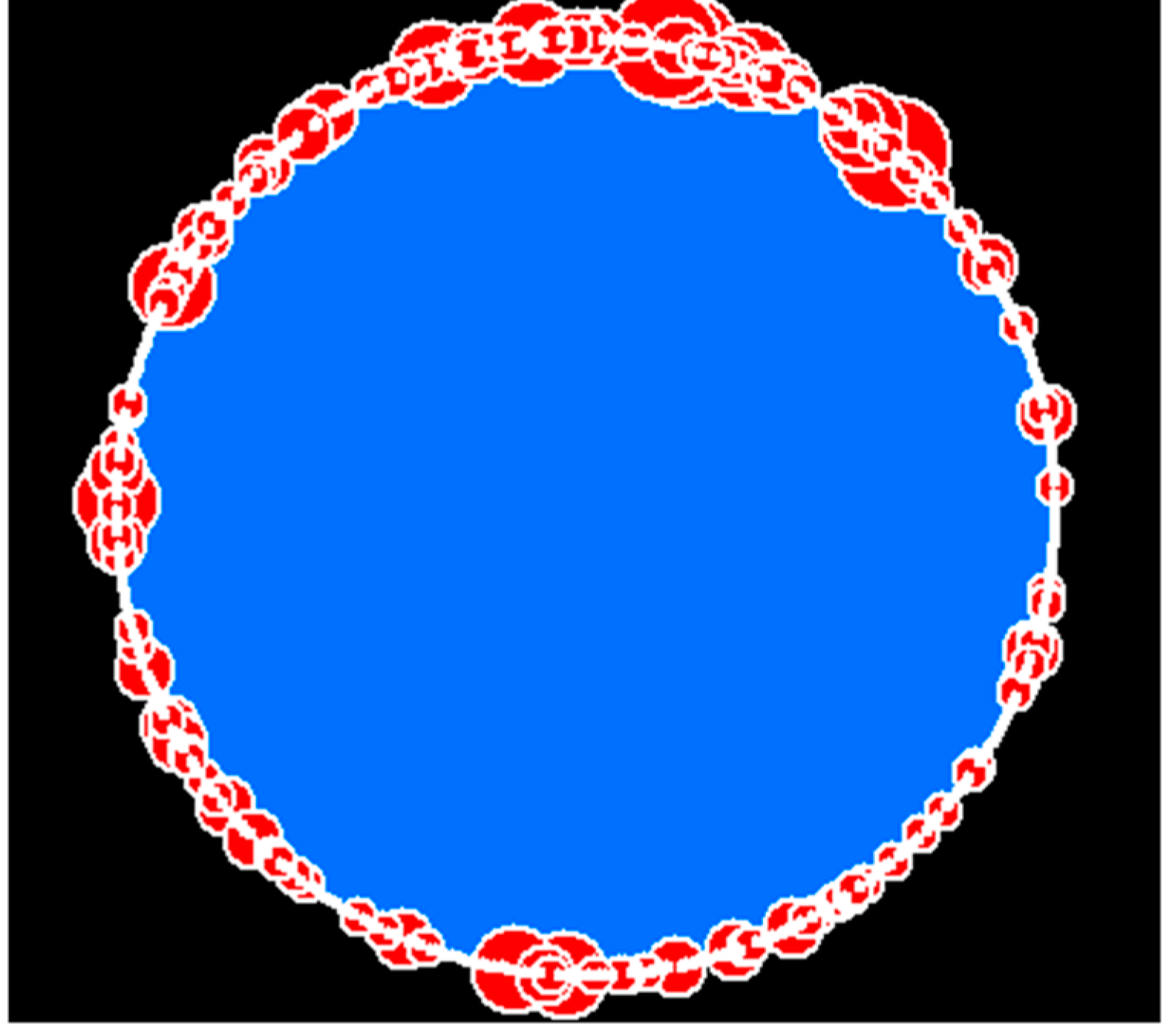
Figure 6.
The co-contribution network for the top five hierarchical levels involving 477 nodes and 80,957 edges. The scaling hierarchy of far more small nodes than larger ones is indicated by the size of red dots.
Figure 6.
The co-contribution network for the top five hierarchical levels involving 477 nodes and 80,957 edges. The scaling hierarchy of far more small nodes than larger ones is indicated by the size of red dots.
Table 5.
Scaling analysis results of co-contribution networks from 2007 to 2013.
Table 5.
Scaling analysis results of co-contribution networks from 2007 to 2013.
| | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 |
|---|
| # of nodes | 3856 | 25,133 | 60,231 | 101,364 | 159,747 | 240,119 | 248,070 |
| # of edges | 29,701 | 418,077 | 1,306,154 | 2,415,319 | 3,954,826 | 6,192,510 | 6,446,086 |
| max-degree | 802 | 5449 | 15,052 | 30,816 | 51,501 | 65,190 | 65,876 |
| ht-index | 8 | 7 | 9 | 9 | 9 | 10 | 10 |
| α | 2.8 | 2.68 | 2.57 | 2.59 | 2.64 | 2.53 | 2.91 |
| p | 0.46 | 0.65 | 0.18 | 0.14 | 0.06 | 0 | 0.2 |
We also developed some insights into OSM community in term of user collaboration from the derived co-contribution network. Comparing to the collaboration network of English Wikipedia [
20,
21,
22], it has the same scaling pattern of far more inactive users than active ones. In addition, the network also has some high density concentrations, especially among those highly active users. Specifically, each user averagely collaborates with around other 52 users in the whole network and those high degree users even have collaboration with almost every other. We further select two global location-based social networks (Gowalla and Brightkite) for comparison (data are available at [
23]) and find that the co-contribution network is much denser than them regarding to both the whole and sampled (nodes of top hierarchies) network.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



