A Matrix-Based Structure for Vario-Scale Vector Representation over a Wide Range of Map Scales: The Case of River Network Data


Abstract
:1. Introduction
2. Relevant Work
2.1. Continous Generalization
2.2. Vario-Scale Data Structure
2.3. Hydrographic Generalization
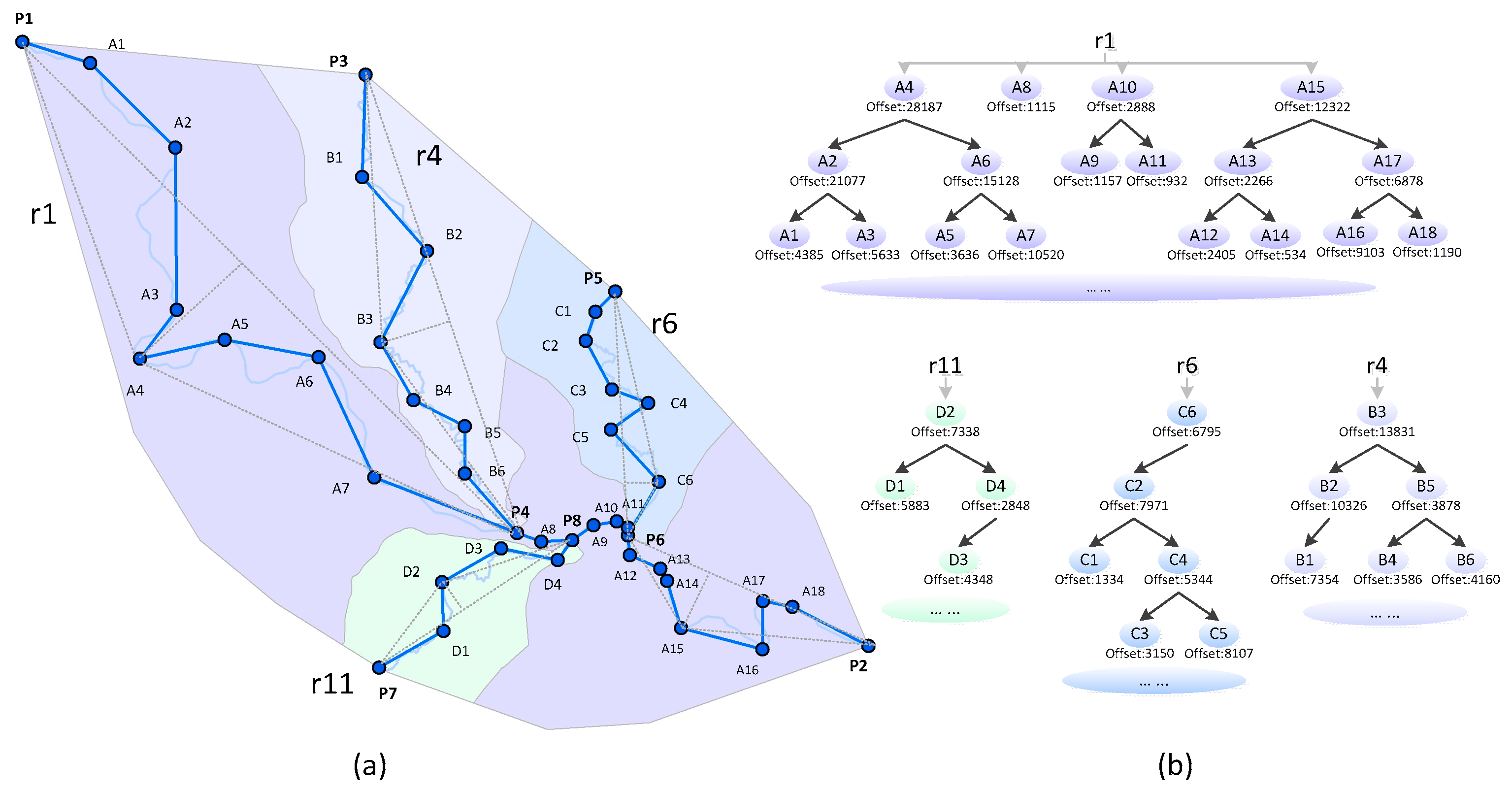
3. Matrix Model for Vario-Scale Representation
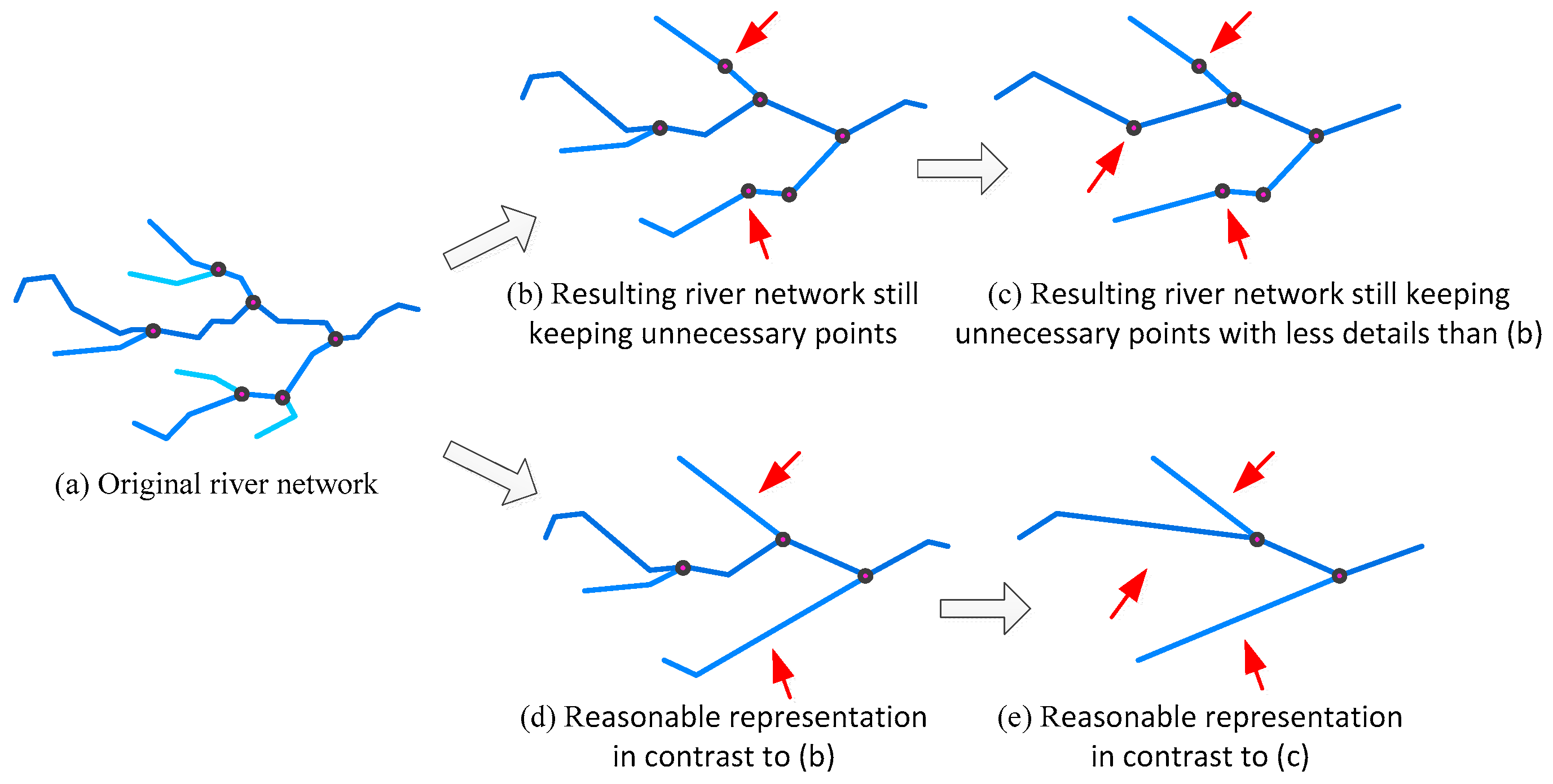
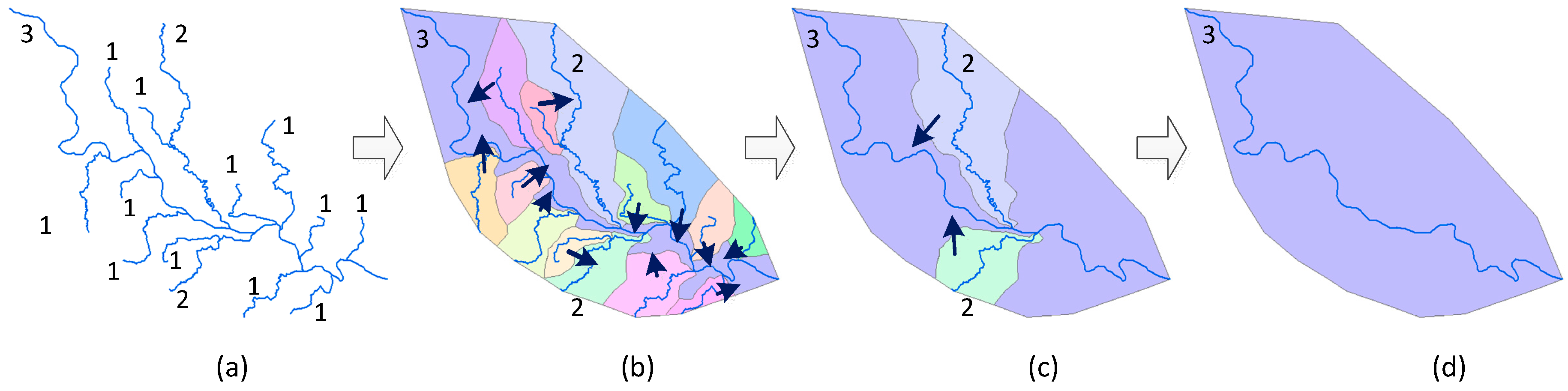
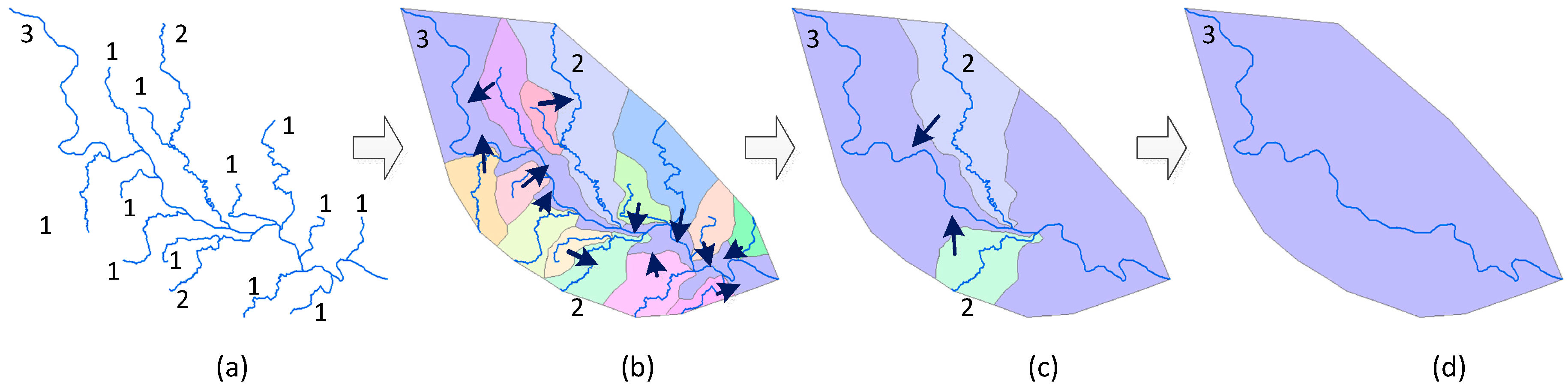
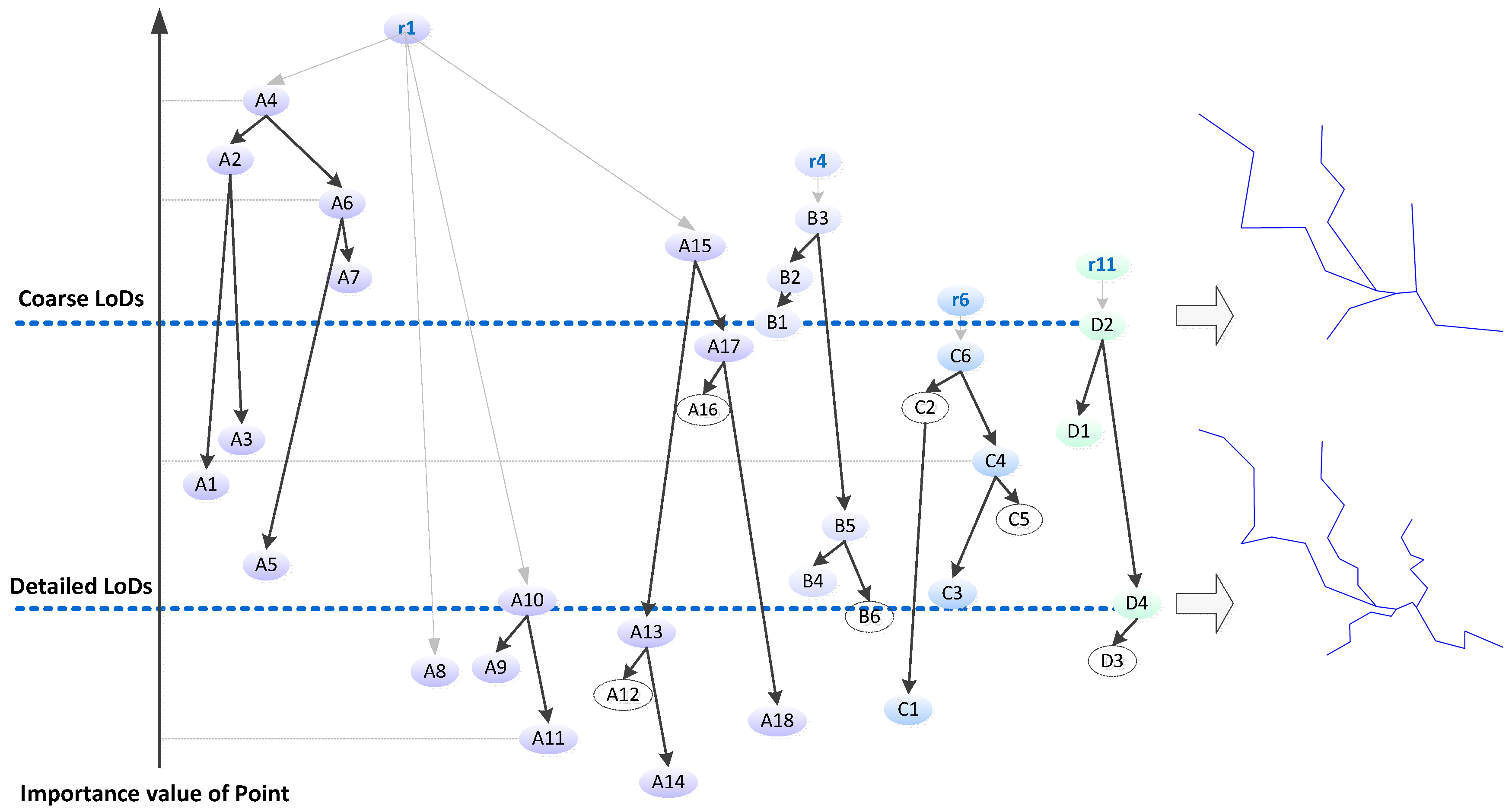
3.1. Hierarchical Construction for Network Pruning
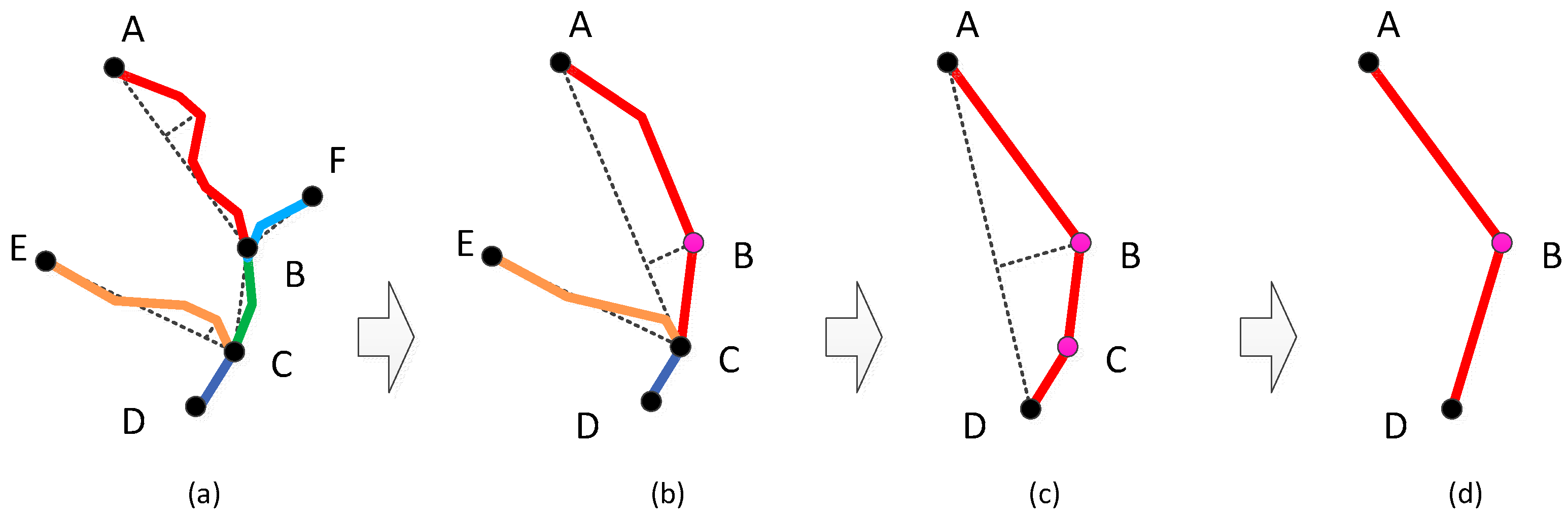
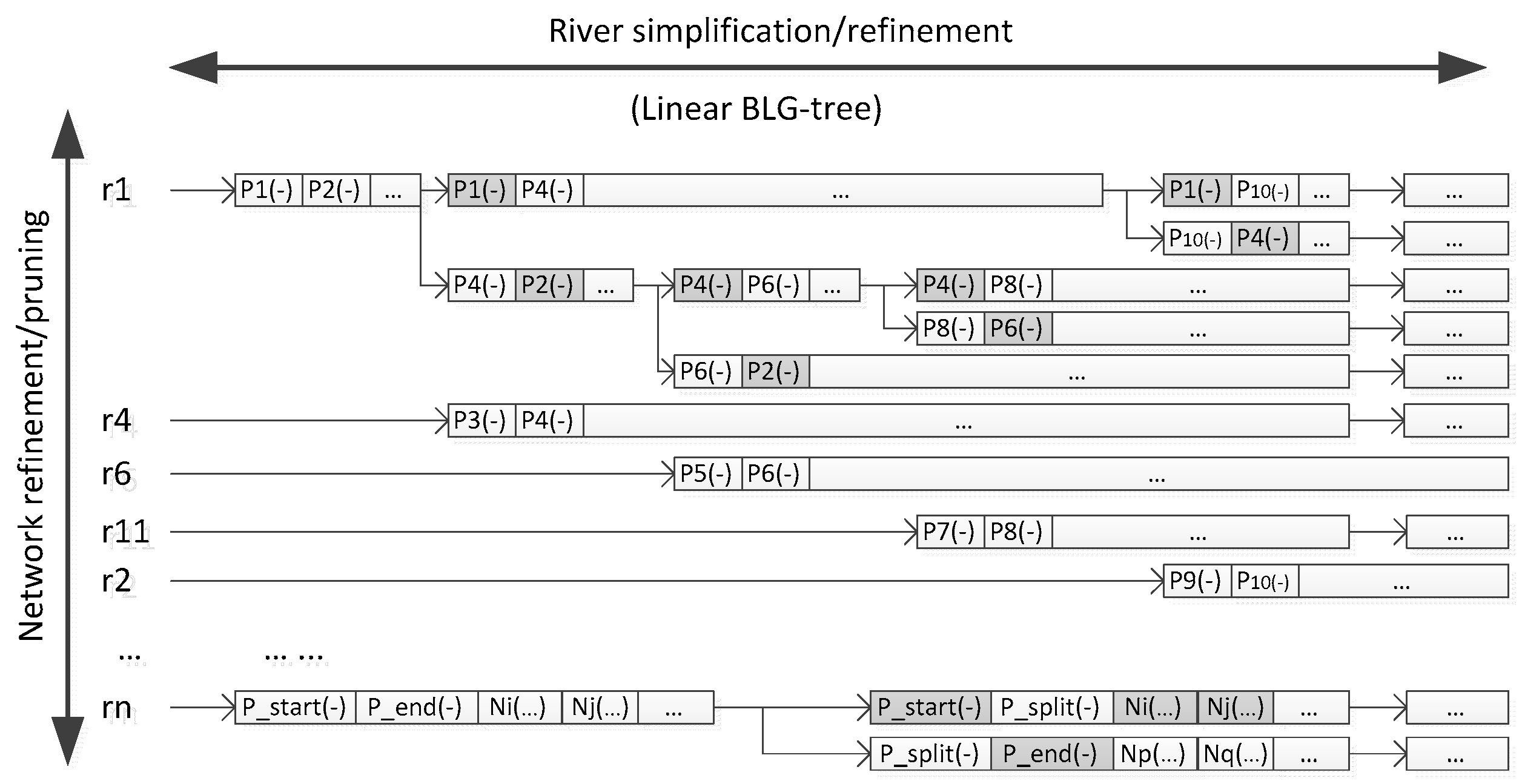
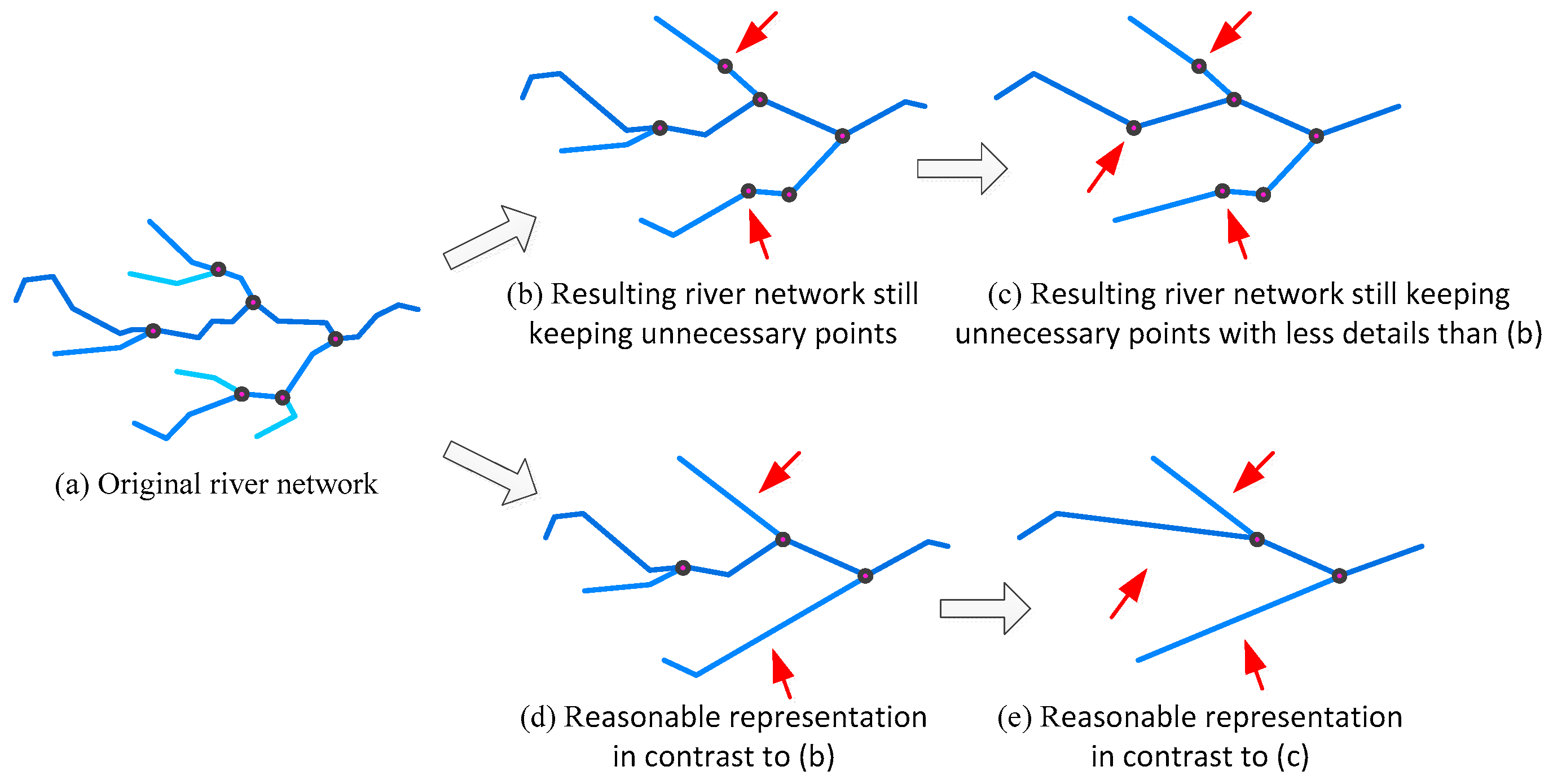
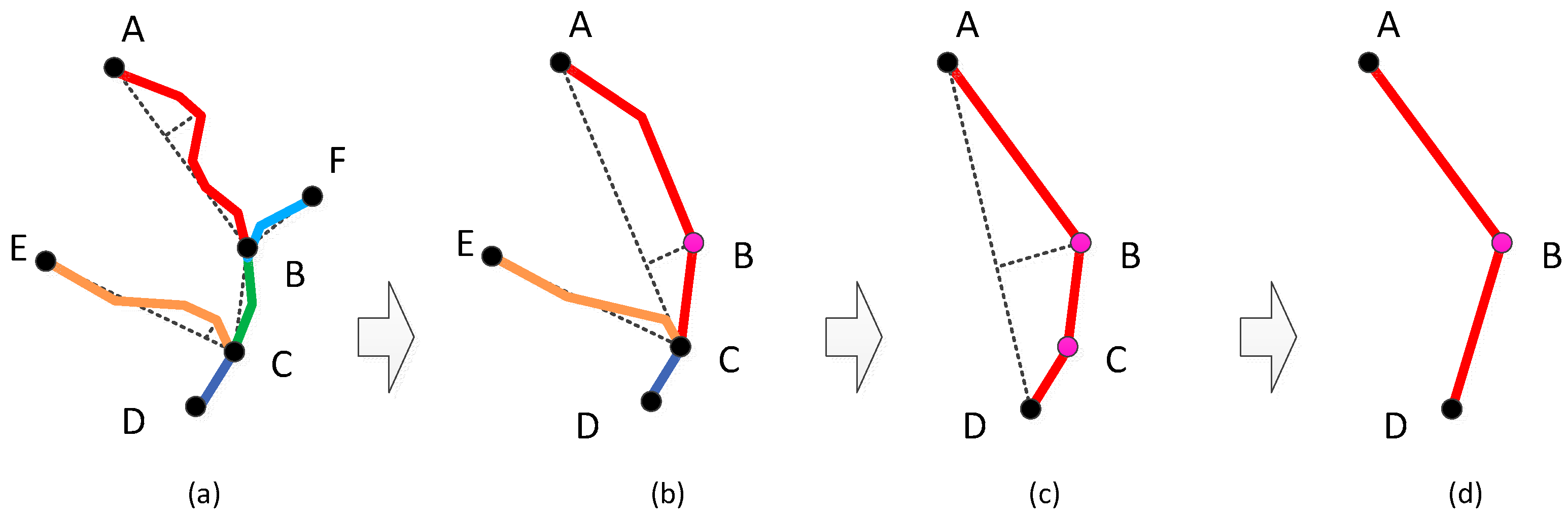
3.2. Hierarchical Construction for River Simplification
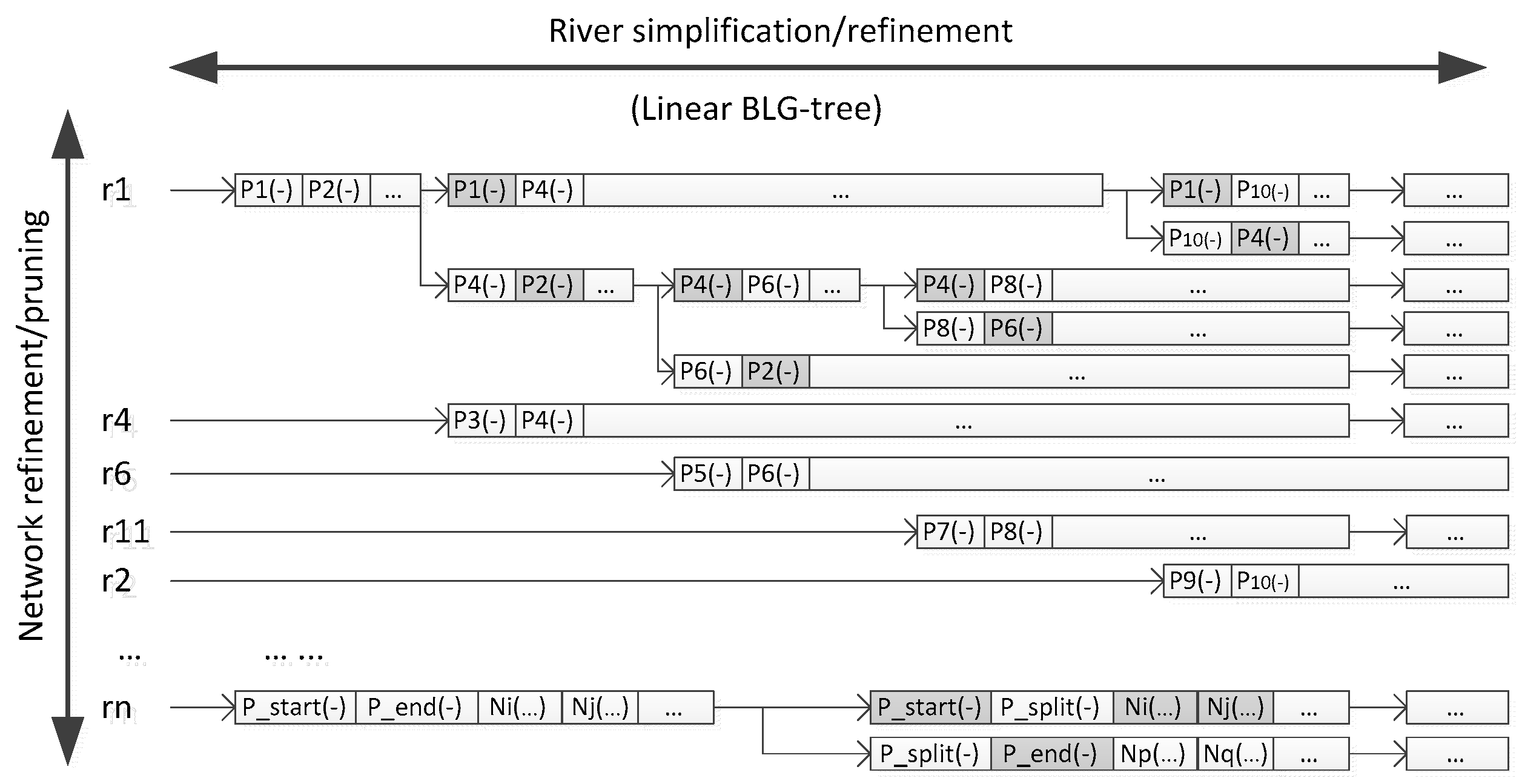
3.3. A Matrix Hybrid: Integration of Network Pruning and River Simplification
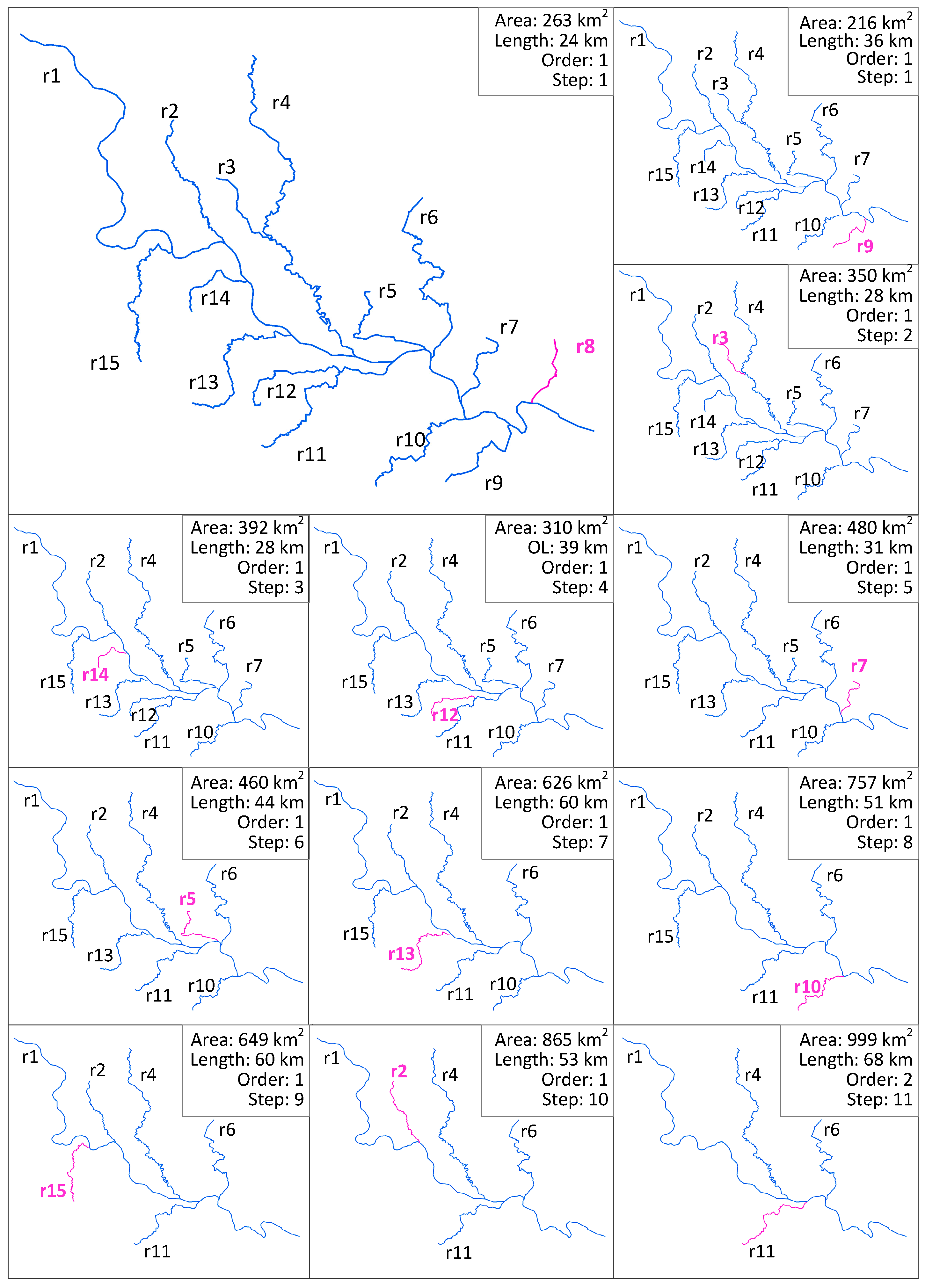
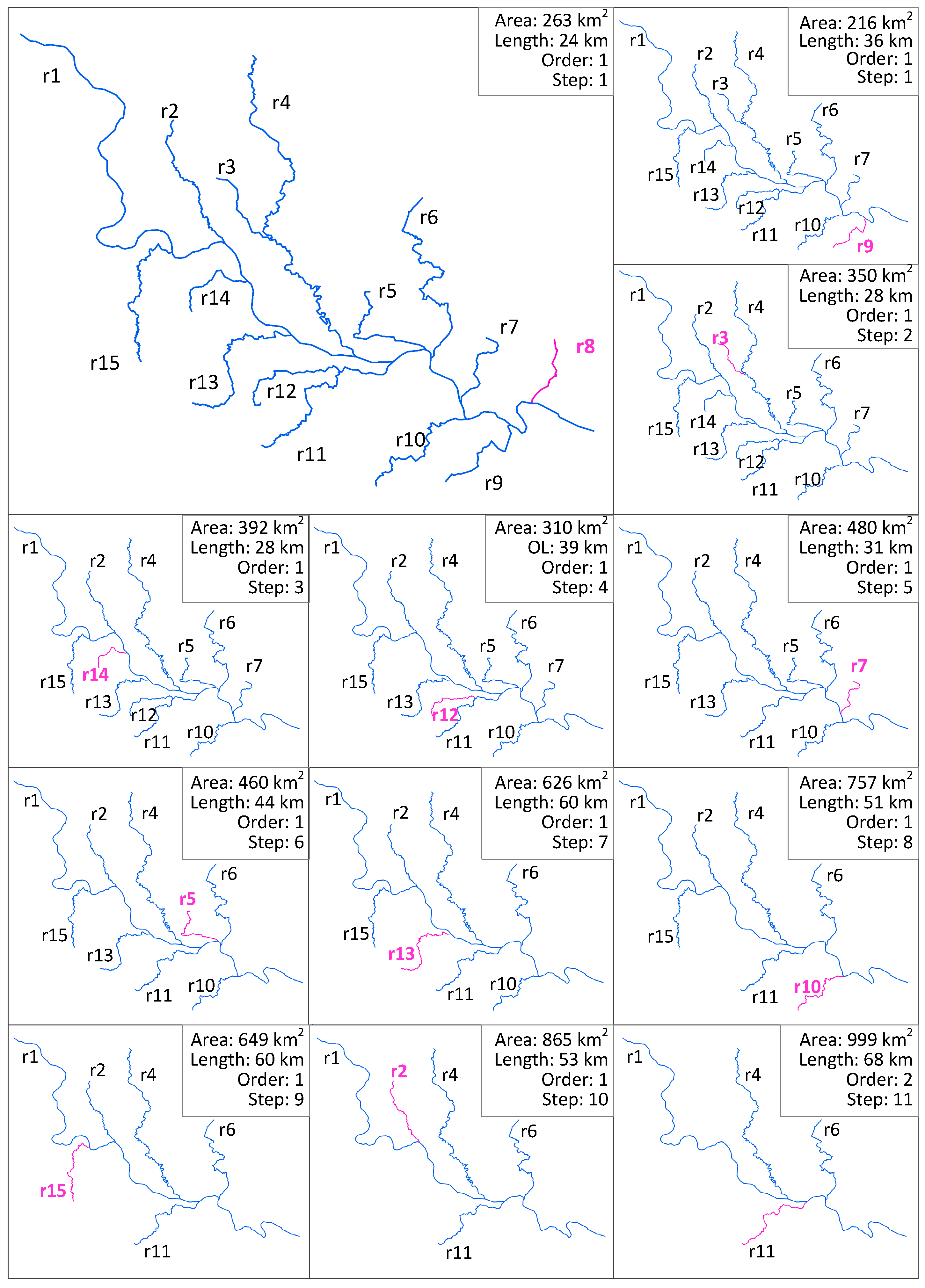
- Construct the linear hierarchy of the river network by sorting the rivers in descending order of importance.
- Select the least important river from the river hierarchy, simplify its shape and construct a corresponding linear BLG tree that refers to the LoDs representation. Identify the river as an eliminated river.
- Check the river hierarchy and search the parent river which is adjacent to the current eliminated river (e.g., r1 is the parent river of r11 in Figure 5), retrieve the related segments (e.g., segment P4P8 and P8P6 of r1), then construct their linear BLG trees.
- Merge the adjacent segments, construct a new tree for the newly merged segment and insert in front of the original two linear trees. The original linear BLG trees of those adjacent segments are clipped at the relevant LoDs of the eliminated river.
- Repeat steps 2–4 until no rivers are left in the river hierarchy.
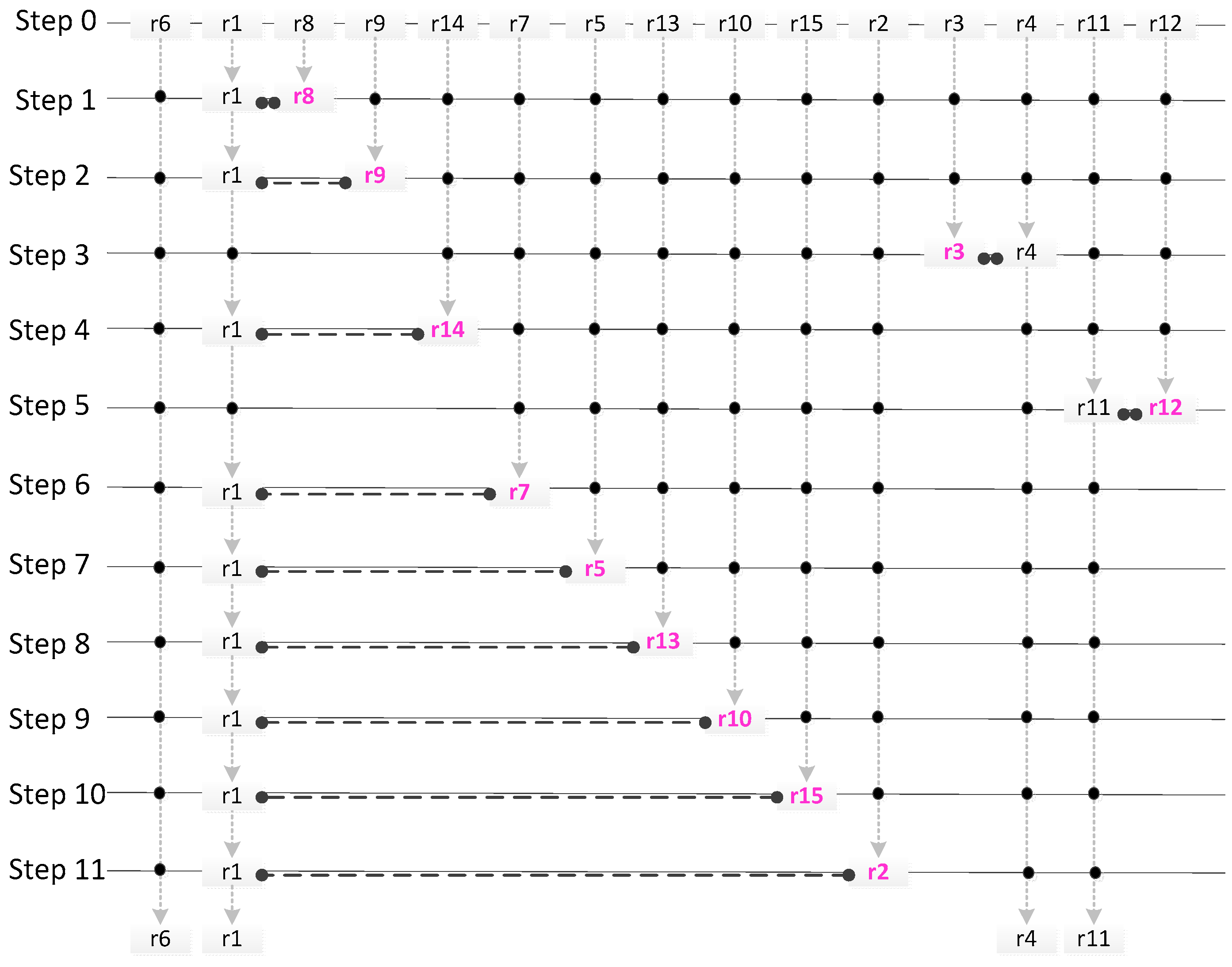
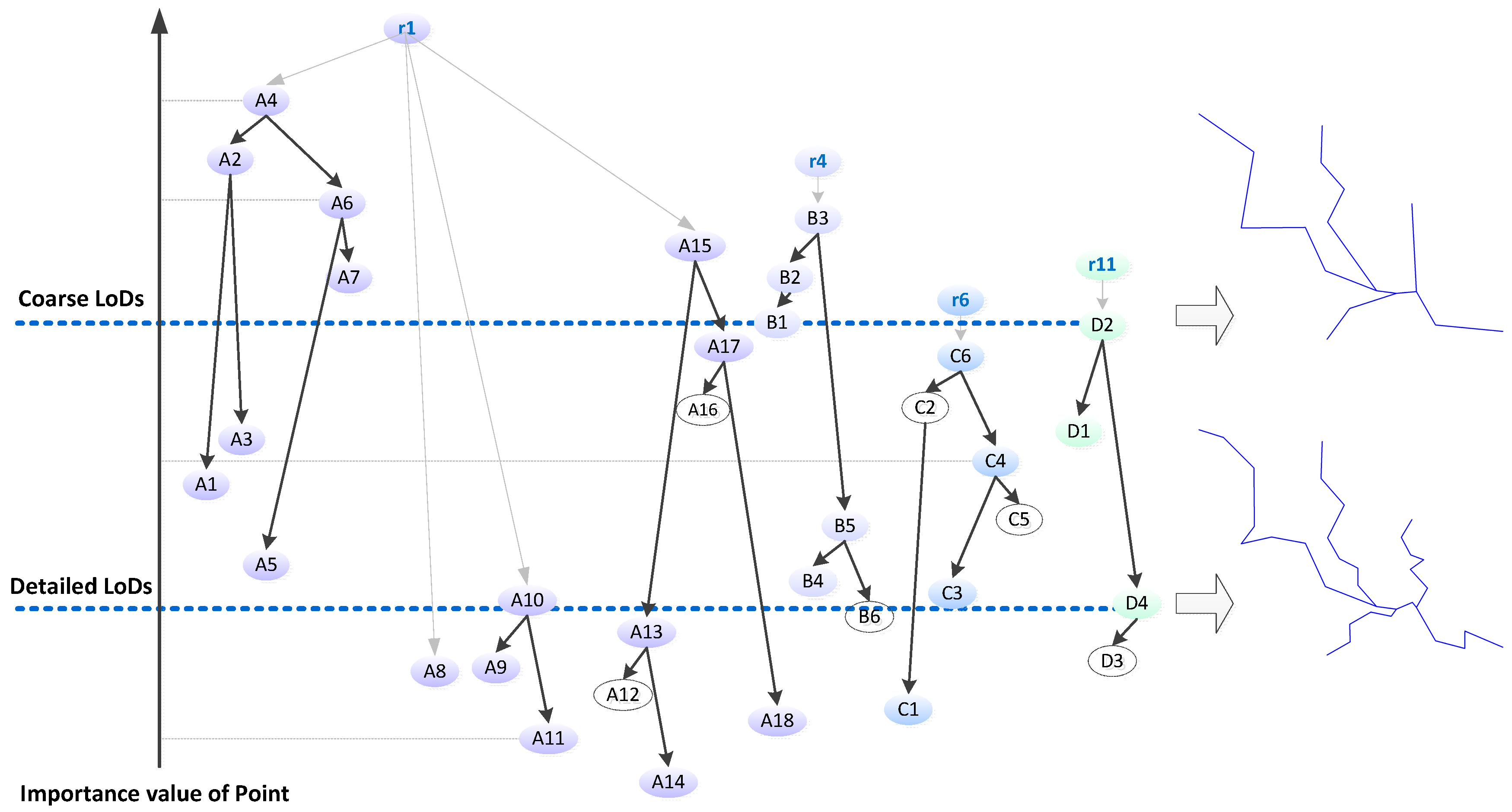
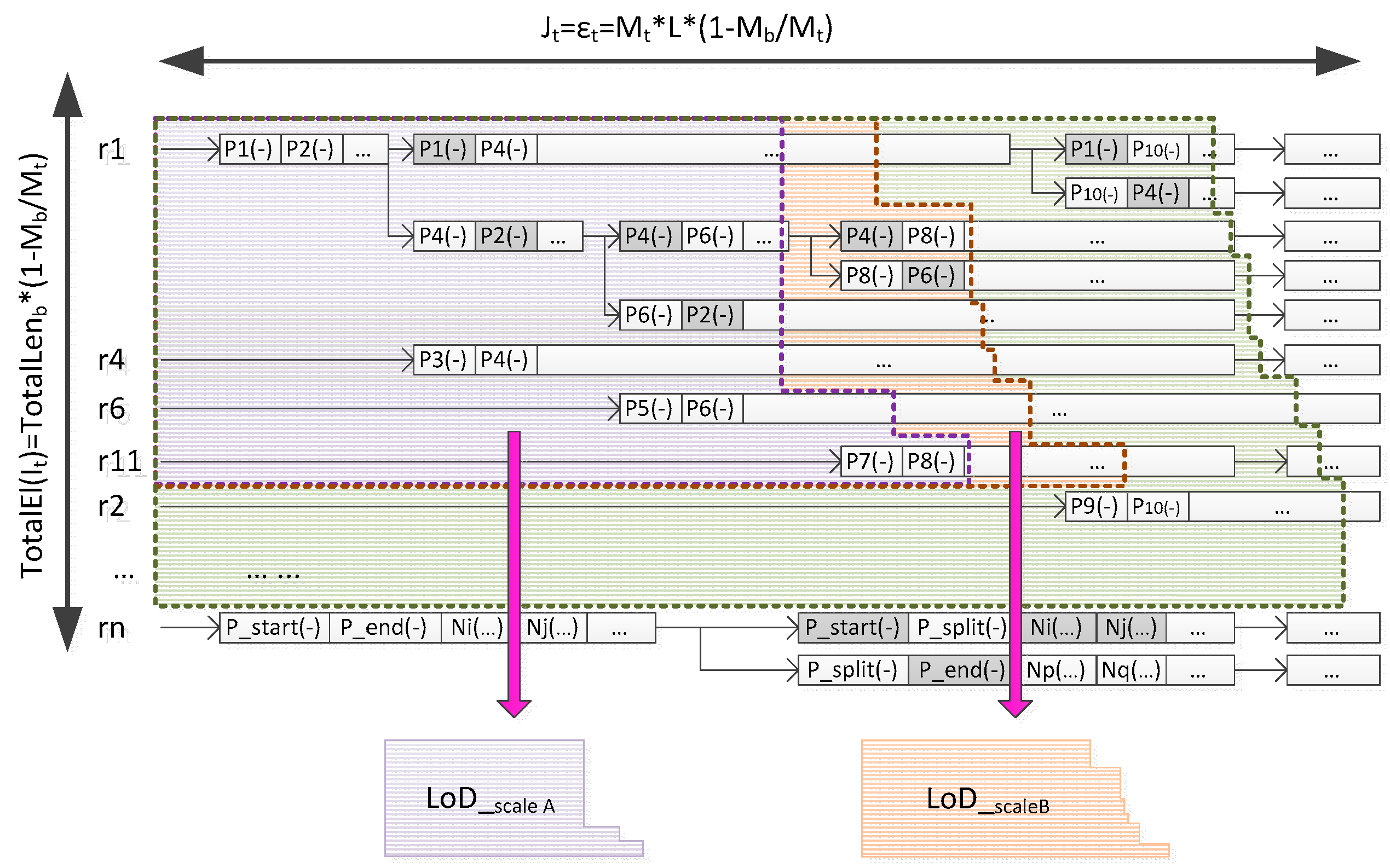
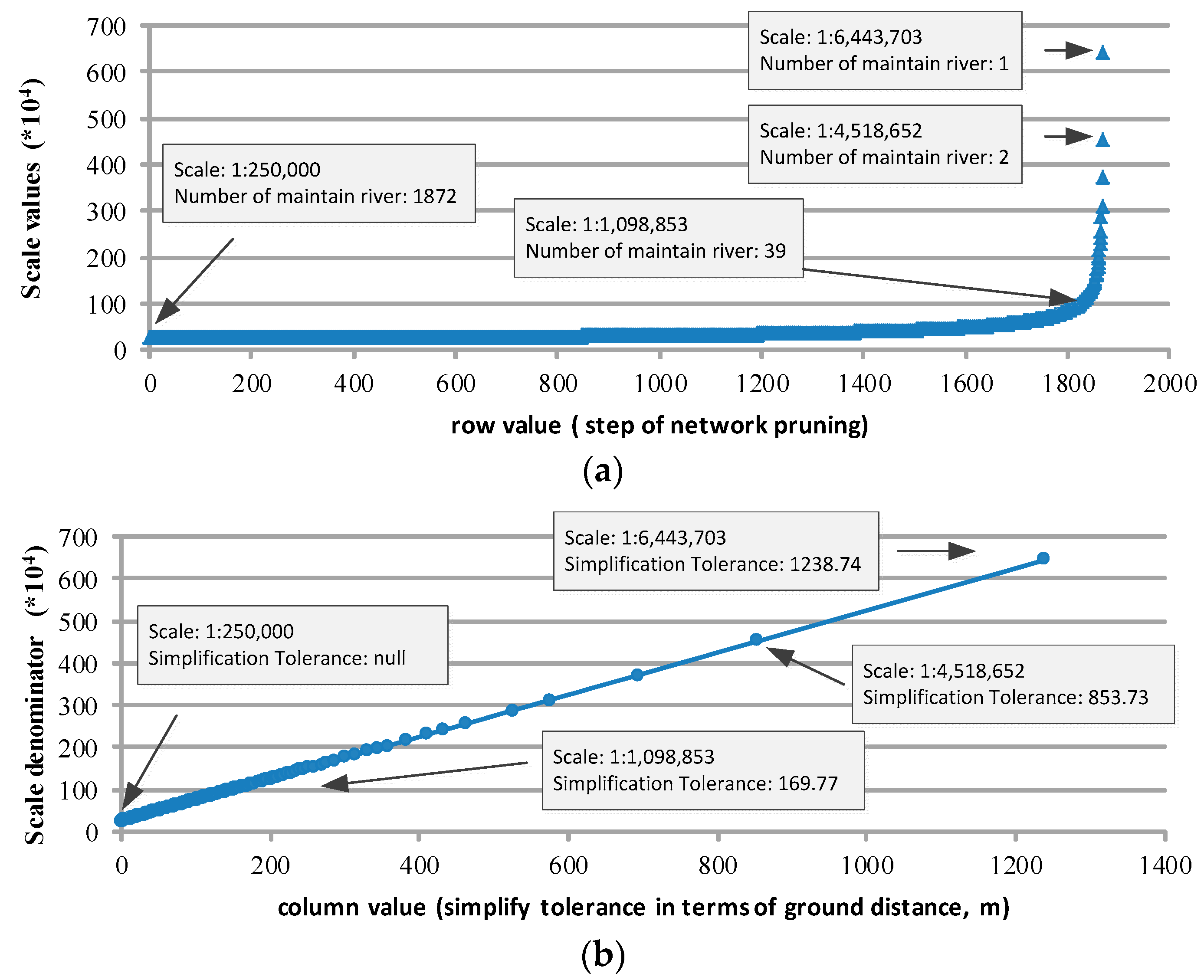
4. Scale Correspondence in the Matrix
4.1. Three Scale Correspondences
4.1.1. Scale Correspondence of the Row
4.1.2. Scale Correspondence of the Column
4.1.3. Scale Linkage between Row and Column
4.2. Parameter Determination
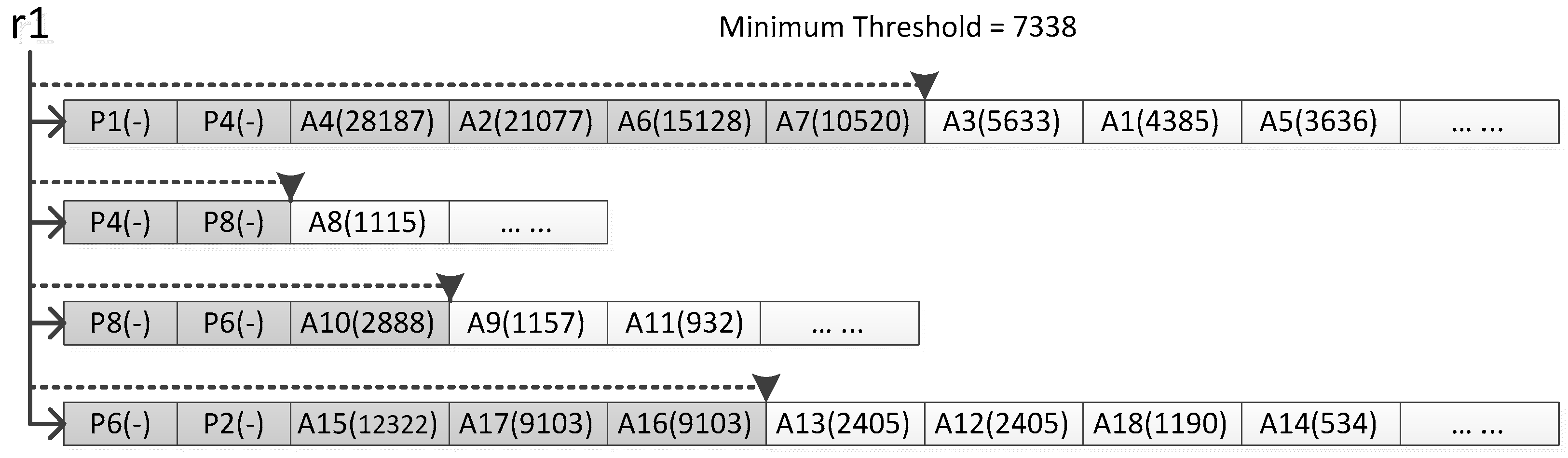
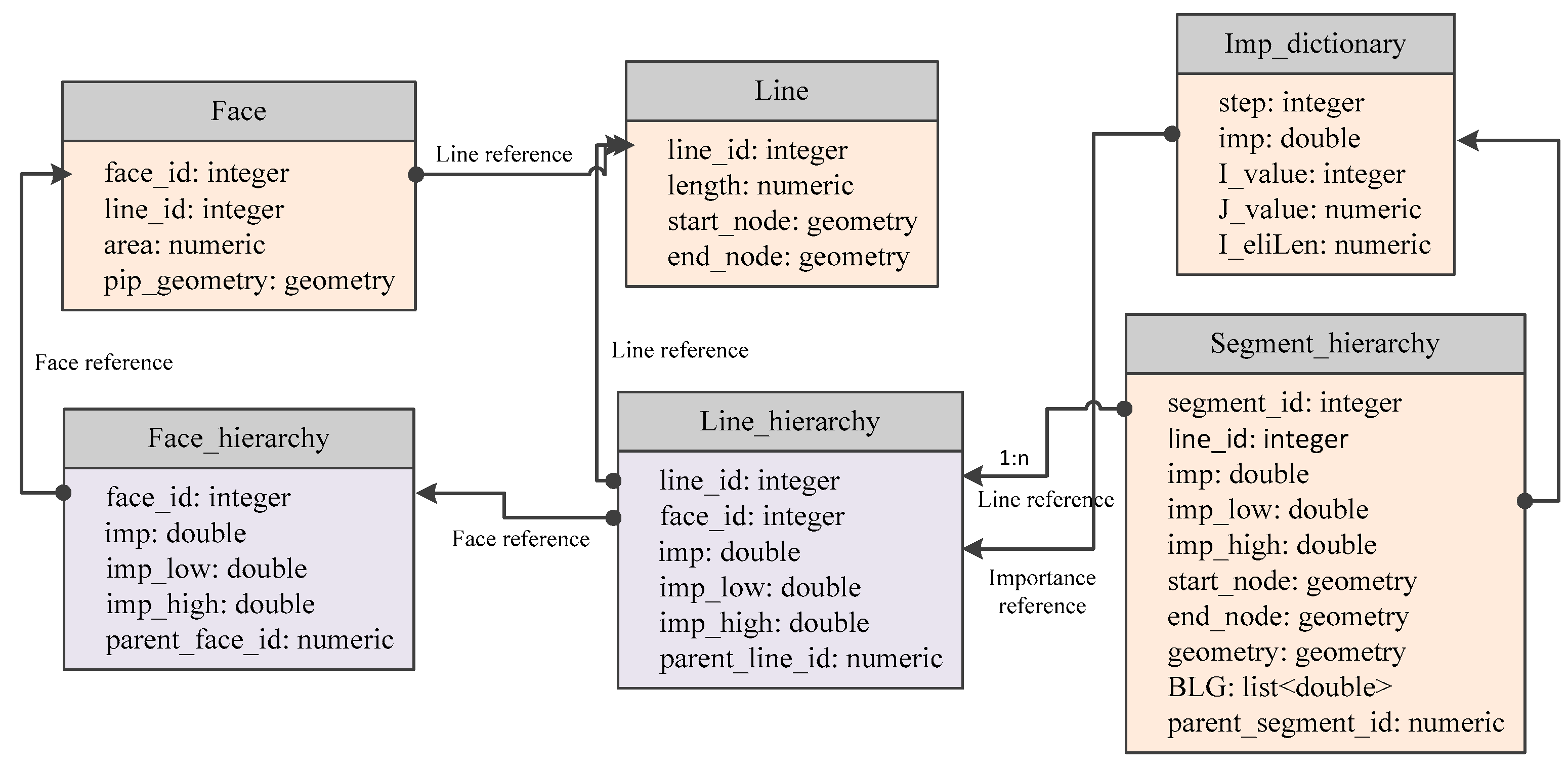
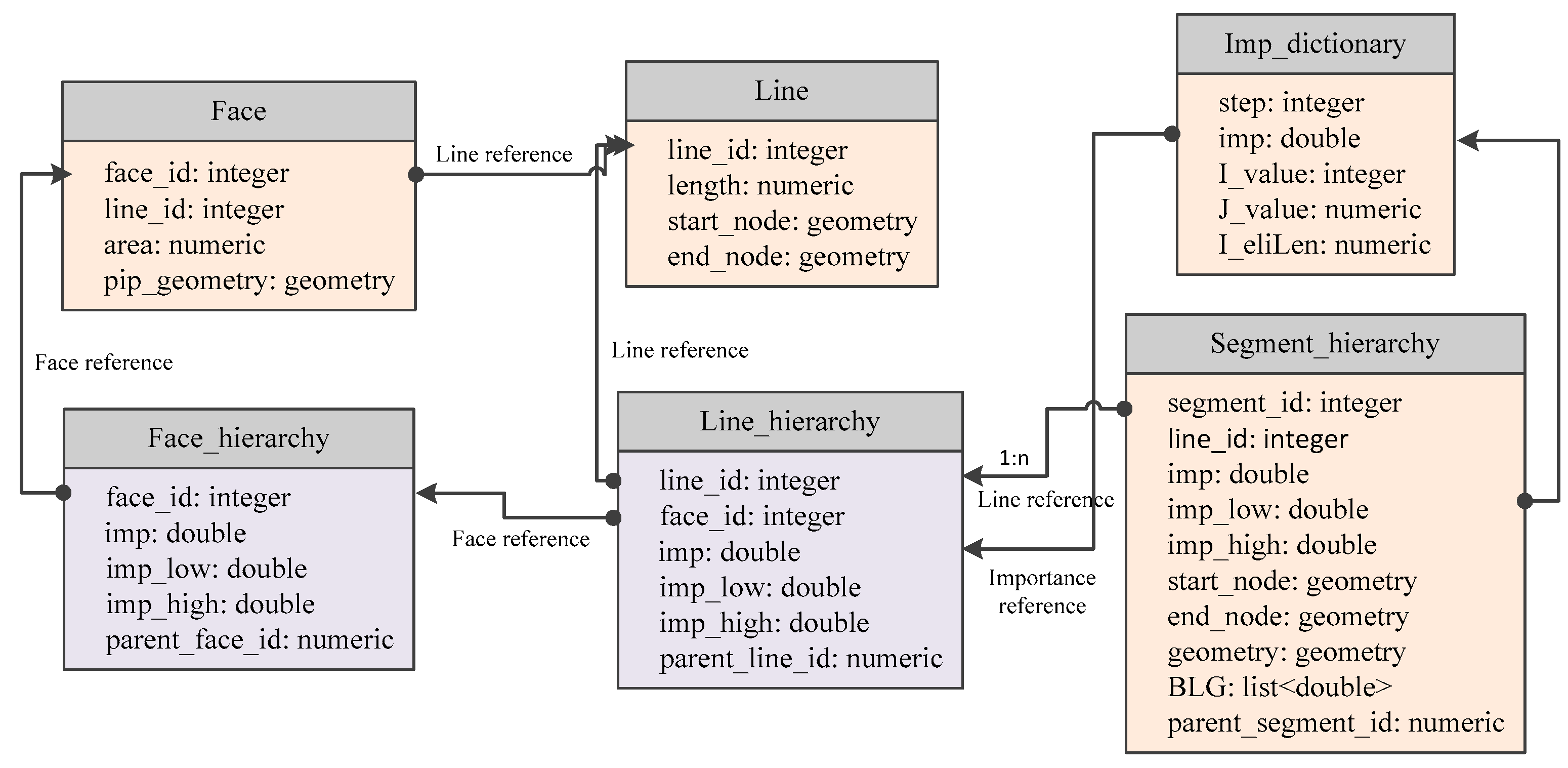
5. Vario-Scale Data Structure Based on the Matrix
- Face refers to the watershed area represented in the polygon. Table Face records the area, and the length of the related river.
- Line refers to the river that is comprised of a few segments.
- Table Face_hierarchy records the importance values of the watershed area. The column imp records the importance value for each record, and the columns imp_low and imp_high indicate the importance range. Parent face refers to the watershed area which the current watershed area merges with.
- Table Line_hierarchy is joined with table Line and Face_hierarchy by line_id and face_id.
- Table Imp_dictionary stores the stepwise process of network pruning. The column imp records the importance value of eliminating rivers for each step. The I_value equals to step and is added for illustration purposes referring to the row of the matrix. The J_value is the simplified tolerance when a less important river is eliminated and two adjacent segments are merged. The I_eliLen means the summed length of all the removed rivers, i.e., in Section 4.1.
- Table Segment_hierarchy stores the process of segment simplification and mergers. A record refers to either an original river segment or a new segment merged from two adjacent segments. The BLG is a list of offset distance of the points in each segment. The parent_segment_id indicates the id of its next river segment going down the river.
- In the able Segment_hierarchy, the imp_low of segment equals the imp_high of eliminated river that causes the creation of the current segment. For an original river segment, the value of imp_low is 0. The imp_high of segment equals the imp_high of eliminated rivers, which lead the current segment to merge with another.
- Step 1:
- calculate the summed length of eliminated rivers for desired scale by Equation (2);
- Step 2:
- look up the importance value of rivers and the simplification tolerance in table Imp_dictionary;
- Step 3:
- retrieve the rivers that have and from table Line_hierarchy;
- Step 4:
- retrieve the segments which have , and from the table Segment_hierarchy; and
- Step 5:
- reconstruct the river network using and under the condition that points of each segment have a larger BLG value than .
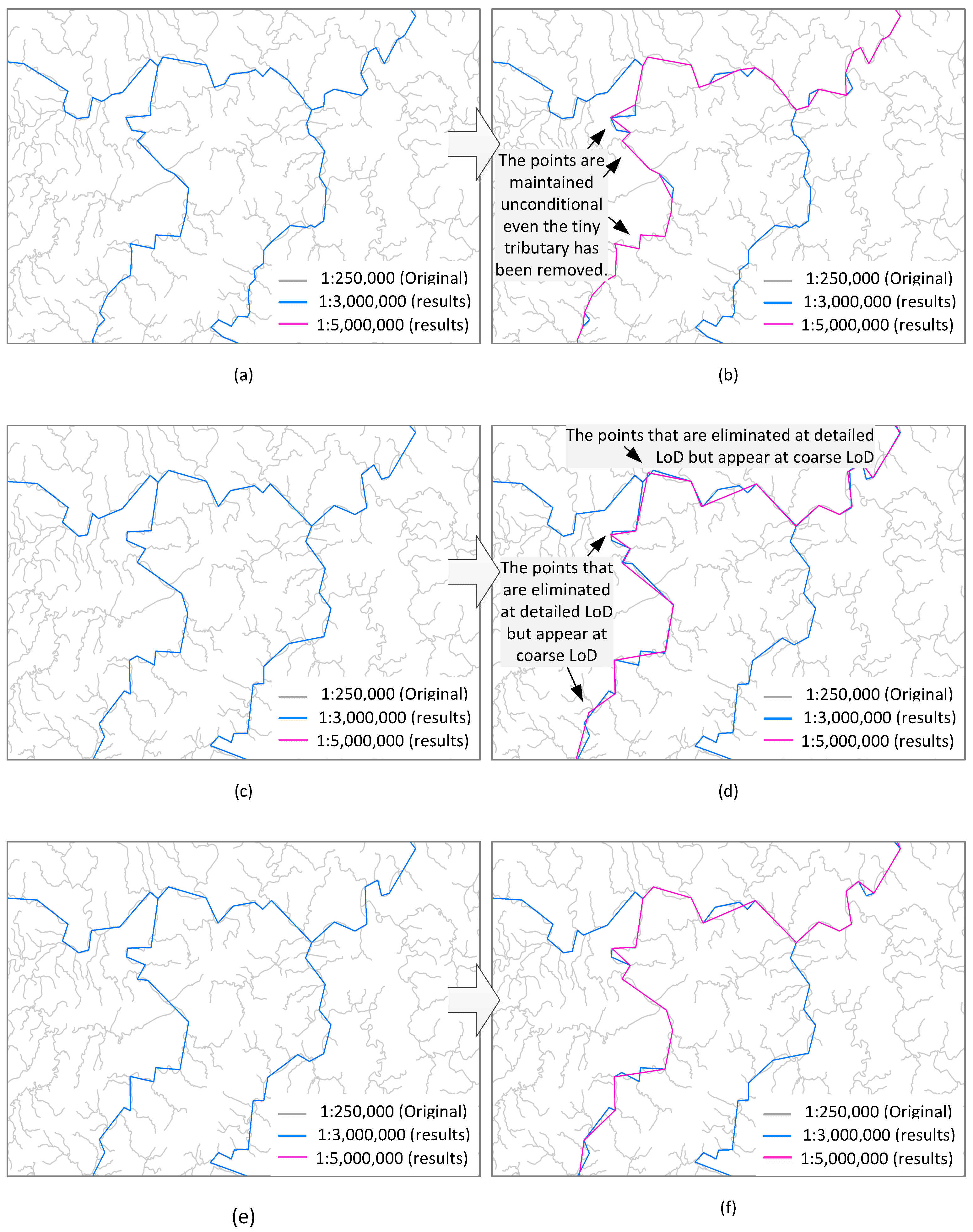
6. Empirical Study and Discussion
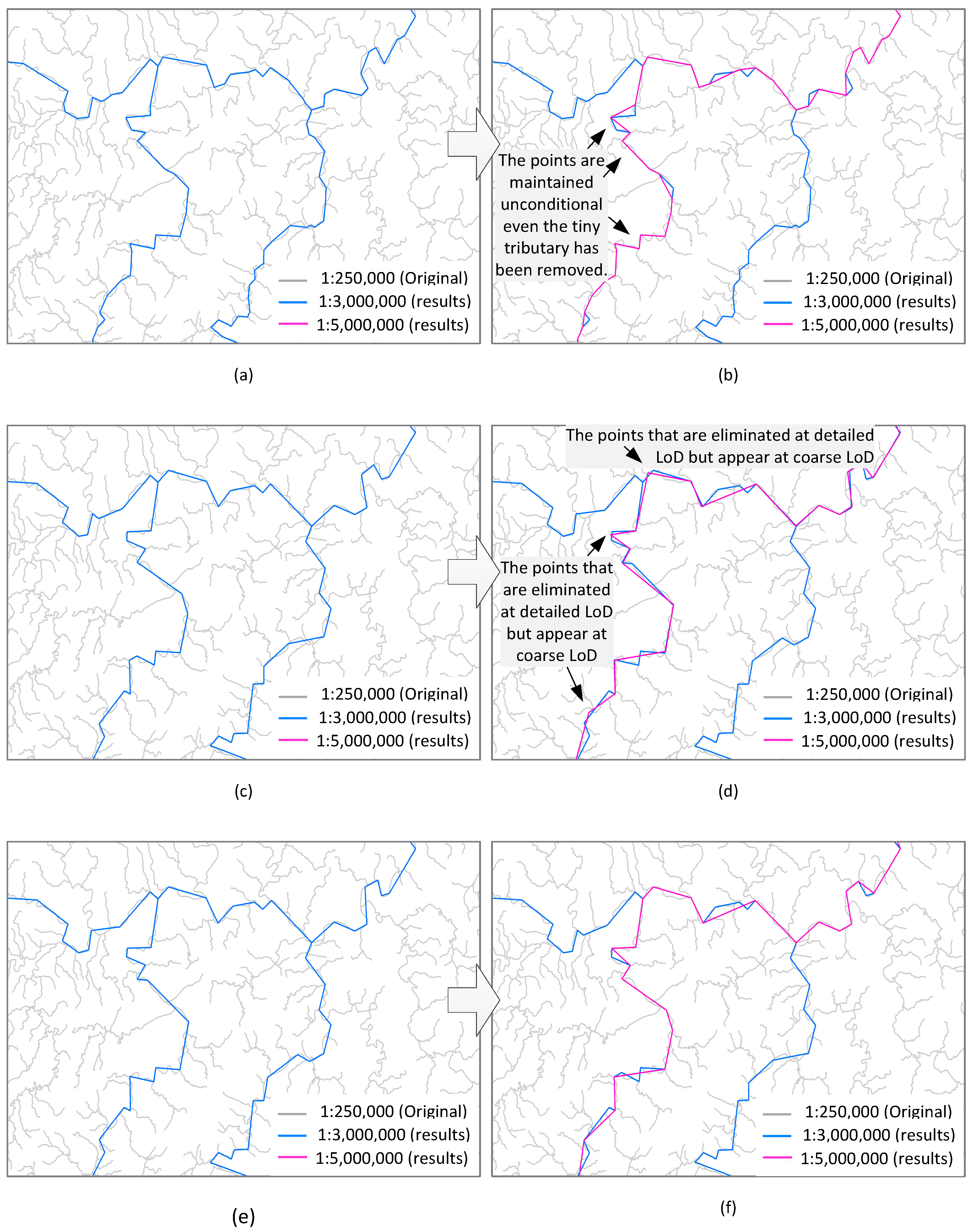
6.1. Generalization Quality
6.2. Data Storage
6.3. Scale Scope
7. Conclusions and Future Work
- The proposed matrix fit the complex transformation of the river network, when different generalization operations, i.e., network pruning and river simplification, were involved (or any other generalization operators that could deliver data as a sequence of LoDs by setting appropriate parameters). Compared with traditional methods that conduct generalization operations in sequence, the matrix-base method provided the best results by integrating the operation in combination.
- Taking advantage of the proposed matrix, the LoDs data at an arbitrary scale were retrieved. In contrast to the MRDBs, where LoDs are stored as multiple versions separately and only limited scales are available, the storage of LoDs data based on a vario-scale matrix was much smaller.
- The proposed matrix enabled the vario-scale representation of a river network across a wide scale range. The large scale depended on the original data, which was used to establish the matrix. Theoretically, the smallest scale was the map scale when only one river was left.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Haklay, M.; Singleton, A.; Parker, C. Web mapping 2.0: The neogeography of the geoweb. Geogr. Compass 2008, 2, 2011–2039. [Google Scholar] [CrossRef]
- Batty, M.; Hudson-Smith, A.; Milton, R.; Crooks, A. Map mashups, web 2.0 and the GIS revolution. Ann. GIS 2010, 16, 1–13. [Google Scholar] [CrossRef]
- Jones, C.B.; Ware, J.M. Map generalization in the web age. Int. J. Geogr. Inf. Sci. 2005, 19, 859–870. [Google Scholar] [CrossRef]
- Vrotsou, K.; Janetzko, H.; Navarra, C.; Fuchs, G.; Spretke, D.; Mansmann, F.; Andrienko, N.; Andrienko, G. Simplifly: A methodology for simplification and thematic enhancement of trajectories. IEEE Trans. Vis. Comput. Graph. 2015, 21, 107–121. [Google Scholar] [CrossRef] [PubMed]
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Regnauld, N.; McMaster, R.B. Chapter 3—A synoptic view of generalisation operators. In Generalisation of Geographic Information; Mackaness, W.A., Ruas, A., Sarjakoski, L.T., Eds.; Elsevier Science B.V.: Amsterdam, The Netherlands, 2007; pp. 37–66. [Google Scholar]
- Foerster, T.; Stoter, J.; Kobben, B. Towards a formal classification of generalization operators. In Proceedings of the 23rd International Cartographic Conference, Moscow, Russia, 4–10 August 2007. [Google Scholar]
- Stanislawski, L.V.; Buttenfield, B.P.; Bereuter, P.; Savino, S.; Brewer, C.A. Generalisation operators. In Abstracting Geographic Information in a Data Rich World: Methodologies and Applications of Map Generalisation; Burghardt, D., Duchêne, C., Mackaness, W., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 157–195. [Google Scholar]
- Roth, R.E.; Brewer, C.A. A typology of operators for maintaining legible map designs at multiple scales. Cartogr. Perspect. 2011, 68, 29–64. [Google Scholar] [CrossRef]
- Stanislawski, L.V. Feature pruning by upstream drainage area to support automated generalization of the united states national hydrography dataset. Comput. Environ. Urban Syst. 2009, 33, 325–333. [Google Scholar] [CrossRef]
- Ai, T.; Ai, B.; Huang, Y. Multi-scale representation of hydrographic network data for progressive transmission over web. In Proceedings of the 24th International Cartographic Conference, Santiago, Chile, 15–21 November 2009. [Google Scholar]
- Thomson, R.C.; Richardson, D.E. The ‘good continuity’ principle of perceptual organisation applied to the generalisation of road networks. In Proceedings of the 19th International Cartographic Conference, Ottawa, ON, Canada, 14–21 August 1999. [Google Scholar]
- Ai, T. The drainage network extraction from contour lines for contour line generalization. ISPRS J. Photogramm. Remote Sens. 2007, 62, 93–103. [Google Scholar] [CrossRef]
- Brewer, C.A.; Buttenfield, B.P. Framing guidelines for multi-scale map design using databases at multiple resolutions. Cartogr. Geogr. Inf. Sci. 2007, 34, 3–15. [Google Scholar] [CrossRef]
- Cecconi, A.; Weibel, R.; Barrault, M. Improving automated generalisation for on-demand web mapping by multiscale databases. In Advances in Spatial Data Handling; Richardson, D., Oosterom, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 515–531. [Google Scholar]
- Neun, M.; Burghardt, D.; Weibel, R. Web service approaches for providing enriched data structures to generalisation operators. Int. J. Geogr. Inf. Sci. 2008, 22, 133–165. [Google Scholar] [CrossRef]
- Buttenfield, B.P.; Stanislawski, L.V.; Brewer, C.A. Adapting generalization tools to physiographic diversity for the united states national hydrography dataset. Cartogr. Geogr. Inf. Sci. 2011, 38, 289–301. [Google Scholar] [CrossRef]
- Stoter, J.; Post, M.; van Altena, V.; Nijhuis, R.; Bruns, B. Fully automated generalization of a 1:50k map from 1:10k data. Cartogr. Geogr. Inf. Sci. 2014, 41, 1–13. [Google Scholar] [CrossRef]
- Touya, G.; Girres, J. Scalemaster 2.0: A scalemaster extension to monitor automatic multi-scales generalizations. Cartogr. Geogr. Inf. Sci. 2013, 40, 192–200. [Google Scholar] [CrossRef]
- Töpfer, F.; Pillewizer, W. The principles of selection. Cartogr. J. 1966, 3, 10–16. [Google Scholar] [CrossRef]
- Douglas, D.H.; Peucker, T.K. Algorithms for the reduction of the number of points required to represent a digitized line or its caricature. Cartogr. Int. J. Geogr. Inf. Geovis. 1973, 10, 112–122. [Google Scholar] [CrossRef]
- Wang, Z.; Müller, J.C. Line generalization based on analysis of shape characteristics. Cartogr. Geogr. Inf. Syst. 1998, 25, 3–15. [Google Scholar] [CrossRef]
- Ai, T.H.; Zhou, Q.; Zhang, X.; Huang, Y.F.; Zhou, M.J. A simplification of ria coastline with geomorphologic characteristics preserved. Mar. Geod. 2014, 37, 167–186. [Google Scholar] [CrossRef]
- Van Oosterom, P. Semantic modelling an vario-scale geo-information. In Proceedings of the 5th International Workshop on Semantics and Conceptual Issues in Geographical Information Systems: SeCoGIS 2011, Brussels, Belgium, 1 November 2011. [Google Scholar]
- Meijers, M.; Stoter, J.; Van Oosterom, P. Comparing the vario-scale approach with a discrete multi-representation based approach for automated generalisation of topographic data. In Proceedings of the 15th Workshop of the ICA commission on Generalisation and Multiple Representation, Istanbul, Turkey, 13–14 September 2012. [Google Scholar]
- Sester, M.; Brenner, C. Continuous Generalization for Visualization on Small Mobile Devices; Springer: Berlin/Heidelberg, Germany, 2005; pp. 188–193. [Google Scholar]
- Sester, M.; Brenner, C. A vocabulary for a multiscale process description for fast transmission and continuous visualization of spatial data. Comput. Geosci. 2009, 35, 2177–2184. [Google Scholar] [CrossRef]
- Nöllenburg, M.; Merrick, D.; Wolff, A.; Benkert, M. Morphing polylines: A step towards continuous generalization. Comput. Environ. Urban Syst. 2008, 32, 248–260. [Google Scholar] [CrossRef]
- Peng, D.; Wolff, A.; Haunert, J.-H. Continuous generalization of administrative boundaries based on compatible triangulations. In Geospatial Data in a Changing World: Selected Papers of the 19th Agile Conference on Geographic Information Science; Sarjakoski, T., Santos, M.Y., Sarjakoski, L.T., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 399–415. [Google Scholar]
- Yang, B.; Purves, R.; Weibel, R. Variable-resolution compression of vector data. GeoInformatica 2008, 12, 357–376. [Google Scholar] [CrossRef]
- Dilo, A.; van Oosterom, P.; Hofman, A. Constrained tgap for generalization between scales: The case of dutch topographic data. Comput. Environ. Urban Syst. 2009, 33, 388–402. [Google Scholar] [CrossRef]
- Haunert, J.-H.; Dilo, A.; van Oosterom, P. Constrained set-up of the tgap structure for progressive vector data transfer. Comput. Geosci. 2009, 35, 2191–2203. [Google Scholar] [CrossRef]
- Van Oosterom, P. Variable-scale topological data structures suitable for progressive data transfer: The gap-face tree and gap-edge forest. Cartogr. Geogr. Inf. Sci. 2005, 32, 331–346. [Google Scholar] [CrossRef]
- Van Oosterom, P.; Meijers, M. Vario-scale data structures supporting smooth zoom and progressive transfer of 2d and 3d data. Int. J. Geogr. Inf. Sci. 2013, 28, 455–478. [Google Scholar] [CrossRef]
- Huang, L.; Meijers, M.; Šuba, R.; van Oosterom, P. Engineering web maps with gradual content zoom based on streaming vector data. ISPRS J. Photogramm. Ermote Sens. 2016, 114, 274–293. [Google Scholar] [CrossRef]
- Van Oosterom, P. A reactive data structure for geographic information systems. In Proceedings of the International Symposium on Computer-Assisted Cartography, Baltimore, MD, USA, 2–7 April 1989; pp. 665–674. [Google Scholar]
- Van Oosterom, P. A storage structure for a multi-scale database: The reactive-tree. Comput. Environ. Urban Syst. 1992, 16, 239–247. [Google Scholar] [CrossRef]
- Yang, W.; Li, J. A method for rapid transmission of multi-scale vector river data via the internet. Geod. Geodyn. 2012, 3, 34–41. [Google Scholar]
- Harrie, L.; Weibel, R. Chapter 4—Modelling the overall process of generalisation. In Generalisation of Geographic Information; Ruas, A., Sarjakoski, L.T., Eds.; Elsevier Science B.V.: Amsterdam, The Netherlands, 2007; pp. 67–87. [Google Scholar]
- Brewer, C.A.; Buttenfield, B.P.; Usery, E.L. Evaluating generalizations of hydrography in differing terrains for the national map of the united states. In Proceedings of the 24th International Cartographic Conference, Santiago, Chile, 15–21 November 2009. [Google Scholar]
- Thomson, R.C.; Brooks, R. Efficient generalisation and abstraction of network data using perceptual grouping. In Proceedings of the 5th International Conference on GeoComputation, Ottawa, ON, Canada, 14–21 August 2000; pp. 23–25. [Google Scholar]
- Sen, A.; Gokgoz, T.; Sester, M. Model generalization of two different drainage patterns by self-organizing maps. Cartogr. Geogr. Inf. Sci. 2014, 41, 151–165. [Google Scholar] [CrossRef]
- Ai, T.; Liu, Y.; Chen, J. The hierarchical watershed partitioning and data simplification of river network. In Progress in Spatial Data Handling: 12th International Symposium on Spatial Data Handling; Riedl, A., Kainz, W., Elmes, G.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Horton, R.E. Erosional development of streams and their drainage basins; hydrophysical approach to quantitative morphology. Geol. Soc. Am. Bull. 1945, 56, 807–813. [Google Scholar] [CrossRef]
- Dong, P. Generating and updating multiplicatively weighted voronoi diagrams for point, line and polygon features in gis. Comput. Geosci. 2008, 34, 411–421. [Google Scholar] [CrossRef]
- Gökgöz, T.; Sen, A.; Memduhoglu, A.; Hacar, M. A new algorithm for cartographic simplification of streams and lakes using deviation angles and error bands. ISPRS Int. J. Geo-Inf. 2015, 4, 2185–2204. [Google Scholar] [CrossRef]
- Ai, T.; Ke, S.; Yang, M.; Li, J. Envelope generation and simplification of polylines using delaunay triangulation. Int. J. Geogr. Inf. Sci. 2016, 31, 1–23. [Google Scholar] [CrossRef]
- Shi, W.; Cheung, C.K. Performance evaluation of line simplification algorithms for vector generalization. Cartogr. J. 2006, 43, 27–44. [Google Scholar] [CrossRef]
- Meijers, M. Variable-Scale Geo-Information. Ph.D. Thesis, Delft University of Technology, Delft, The Netherlands, 16 December 2011. [Google Scholar]
- Li, Z.; Openshaw, S. Algorithms for automated line generalization based on a natural principle of objective generalization. Int. J. Geogr. Inf. Sci. 1992, 6, 373–389. [Google Scholar] [CrossRef]
- Li, Z.; Openshaw, S. A natural principle for objective generalization of digital map data. Cartogr. Geogr. Inf. Syst. 1993, 20, 19–29. [Google Scholar] [CrossRef]
- Muller, J.C. Optimum point density and compaction rates for the representation of graphic lines. In Proceedings of the Eighth International Symposium on Computer-Assisted Cartography, Baltimore, MD, USA, 29 March–3 April 1987. [Google Scholar]
- Chen, J.; Hu, Y.; Li, Z.; Zhao, R.; Meng, L. Selective omission of road features based on mesh density for automatic map generalization. Int. J. Geogr. Inf. Sci. 2009, 23, 1013–1032. [Google Scholar] [CrossRef]
- Li, Z.; Zhou, Q. Integration of linear and areal hierarchies for continuous multi-scale representation of road networks. Int. J. Geogr. Inf. Sci. 2012, 26, 855–880. [Google Scholar] [CrossRef]
- Amos, T. Features of similarity. Psychol. Rev. 1977, 84, 327–352. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Length Compression (%) | Point Compression (%) | Ratio of New Points 1 (%) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Matrix-Based | SimpleSelGen | SelectSimpGen | Matrix-Based | SimpleSelGen | SelectSimpGen | Matrix-Based | SimpleSelGen | SelectSimpGen | |
| 1:250,000 | - | - | - | - | - | - | - | - | - |
| 1:500,000 | 6.46 | 7.26 | 6.46 | 6.46 | 6.46 | 7.26 | 0 | 0 | 0 |
| 1:1,000,000 | 1.40 | 2.01 | 1.41 | 1.40 | 1.41 | 2.01 | 0 | 0 | 17.88 |
| 1:2,000,000 | 0.34 | 0.73 | 0.34 | 0.34 | 0.34 | 0.73 | 0 | 0 | 13.42 |
| 1:3,000,000 | 0.14 | 0.42 | 0.14 | 0.14 | 0.14 | 0.42 | 0 | 0 | 9.46 |
| 1:4,000,000 | 0.10 | 0.41 | 0.10 | 0.10 | 0.10 | 0.41 | 0 | 0 | 6.22 |
| 1:5,000,000 | 0.06 | 0.23 | 0.06 | 0.06 | 0.06 | 0.23 | 0 | 0 | 23.81 |
| 1:6,000,000 | 0.05 | 0.23 | 0.05 | 0.05 | 0.05 | 0.23 | 0 | 0 | 0 |
| (a) | ||||
| Execution Time (s) | Data Amount (MB) | |||
| Matrix-Based Method | MRDB 1 | Matrix-Based Method | MRDB | |
| Vario-scale | 29.62 | - | 11.73 | 13.32 |
| 1:250,000 | - | - | - | 12 |
| 1:500,000 | - | - | - | 0.94 |
| 1:1,000,000 | - | - | - | 0.38 |
| (b) | ||||
| Execution Time (s) | Data Amount (MB) | |||
| Matrix-Based Method | MRDB | Matrix-Based Method | MRDB | |
| 1:250,000 | 0.18 | 2.3 | 8.9 | 12 |
| 1:500,000 | 0.46 | 0.12 | 1.05 | 0.94 |
| 1:1,000,000 | 0.07 | 0.06 | 0.02 | 0.38 |
| 1:2,000,000 | 0.05 | - | 0.05 | - |
| 1:3,000,000 | 0.04 | - | 0.02 | - |
| 1:4,000,000 | 0.03 | - | 0.02 | - |
| 1:5,000,000 | 0.03 | - | 0.02 | - |
| 1:6,000,000 | 0.03 | - | 0.02 | - |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, L.; Ai, T.; Oosterom, P.V.; Yan, X.; Yang, M. A Matrix-Based Structure for Vario-Scale Vector Representation over a Wide Range of Map Scales: The Case of River Network Data. ISPRS Int. J. Geo-Inf. 2017, 6, 218. https://doi.org/10.3390/ijgi6070218
Huang L, Ai T, Oosterom PV, Yan X, Yang M. A Matrix-Based Structure for Vario-Scale Vector Representation over a Wide Range of Map Scales: The Case of River Network Data. ISPRS International Journal of Geo-Information. 2017; 6(7):218. https://doi.org/10.3390/ijgi6070218
Chicago/Turabian StyleHuang, Lina, Tinghua Ai, Peter Van Oosterom, Xiongfeng Yan, and Min Yang. 2017. "A Matrix-Based Structure for Vario-Scale Vector Representation over a Wide Range of Map Scales: The Case of River Network Data" ISPRS International Journal of Geo-Information 6, no. 7: 218. https://doi.org/10.3390/ijgi6070218