Shared Execution Approach to ε-Distance Join Queries in Dynamic Road Networks


Department of Software, Kyungpook National University, 2559, Gyeongsang-daero, Sangju-si, Gyeongsangbuk-do 37224, Korea
ISPRS Int. J. Geo-Inf. 2018, 7(7), 270; https://doi.org/10.3390/ijgi7070270
Submission received: 30 April 2018
/
Revised: 1 July 2018
/
Accepted: 6 July 2018
/
Published: 10 July 2018
Abstract
:Given a threshold distance ε and two object sets R and S in a road network, an ε-distance join query finds object pairs from R × S that are within the threshold distance ε (e.g., find passenger and taxicab pairs within a five-minute driving distance). Although this is a well-studied problem in the Euclidean space, little attention has been paid to dynamic road networks where the weights of road segments (e.g., travel times) are frequently updated and the distance between two objects is the length of the shortest path connecting them. In this work, we address the problem of ε-distance join queries in dynamic road networks by proposing an optimized ε-distance join algorithm called EDISON, the key concept of which is to cluster adjacent objects of the same type into a group, and then to optimize shared execution for the group to avoid redundant network traversal. The proposed method is intuitive and easy to implement, thereby allowing its simple integration with existing range query algorithms in road networks. We conduct an extensive experimental study using real-world roadmaps to show the efficiency and scalability of our shared execution approach.
1. Introduction
Recent advances in mobile technologies and map-based applications enable users to access a wide range of location-based services such as shortest path queries [1,2,3,4,5,6,7], distance queries [2,3,5,8,9], range queries [3,10], and k-nearest neighbor (kNN) queries [3,7,10,11,12]. Owing to the popularity of map-based applications among users, processing spatial queries in road networks efficiently has become an important research area in recent years. In this work, we address -distance join queries in road networks. Given a threshold distance and two object sets and , an -distance join query explores all object pairs and returns a set of object pairs that are within the threshold distance . The -distance join queries are useful in real-life applications such as data mining and similarity joins [13,14,15,16,17,18]. Therefore, many studies have evaluated the efficiency of -distance join queries in the Euclidean space [19,20] and in the metric space [13,14,15,16,17,18]. These studies focus primarily on designing elegant indexing techniques to avoid scanning the entire dataset repeatedly, and on pruning as many distance computations as possible.
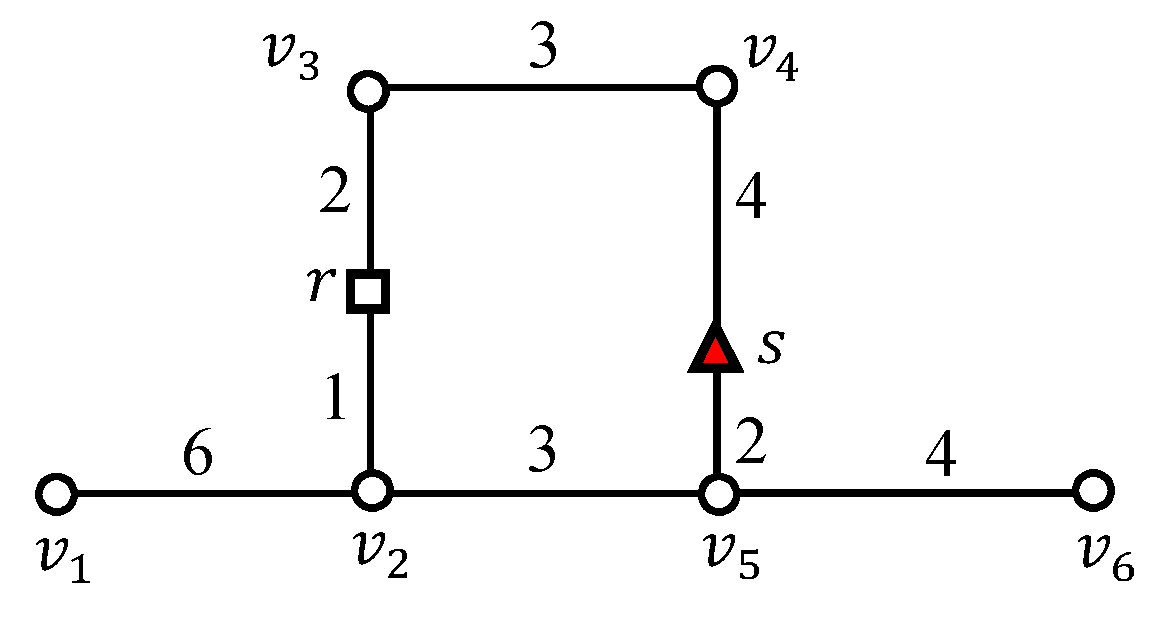
Figure 1 presents an example of dynamic road networks where objects through denote passengers (represented by rectangles), and objects through denote taxicabs (represented by triangles). In this example, an -distance join query for a taxicab company involves sending an available taxicab to each passenger who is located within a five-minute driving distance from the taxicab. The travel time should be frequently updated depending on traffic conditions. For example, at time , taxicab is closer to passenger than taxicab , as shown in Figure 1a. However, as shown in Figure 1b, because the taxicab is in a traffic-congested area, it cannot reach the passenger faster than the taxicab at time .
Owing to the dynamic nature of road networks, many studies have recently addressed a variety of spatial queries in dynamic road networks such as shortest path queries [1,6,21], distance queries [8], and kNN queries [22]. Although there have been a few studies [10,23] on -distance join queries in road networks, they proposed sophisticated index structures and algorithms to boost -distance join queries in static road networks, where the weights of road segments are rarely updated. Specifically, the state-of-the-art solution to -distance join queries in road networks is the distance join algorithm proposed in Reference [23], based on the spatially induced linkage cognizance (SILC) framework introduced in Reference [3]. The algorithm pre-computes the shortest path between each pair of vertices in a road network and stores all paths. This approach is not suitable for dynamic road networks because in these road networks, the weights of road segments are frequently updated, and the pre-computed distances between vertices often become obsolete. Various techniques [24,25,26,27,28,29,30,31,32,33,34] for preserving location privacy in road networks have recently been developed, which focus on moving objects such as vehicles and users, and therefore cannot be applied to the problem studied here.
Therefore, in this study, we propose an optimized -distance join algorithm called EDISON to efficiently support -distance join queries in dynamic road networks, where materialized structures such as the SILC framework cannot be used to dynamically compute the shortest path and distances from a source point to one or more destination points. Intuitively, a simple solution involves computing the distance between every object pair from two datasets. This simple solution is very inefficient, because for each element in an object set , the algorithm must traverse another object set , which can lead to redundant network traversal. The proposed solution is to cluster adjacent objects of the same type into a group and then optimize shared execution for the group to avoid redundant network traversal. Although the shared execution of queries has received much attention [21,35,36,37,38], no shared execution strategy has been applied to evaluate -distance join queries in dynamic road networks to date. The contributions of this study are as follows.
- We propose an efficient -distance join algorithm called EDISON for dynamic road networks that optimizes the shared execution paradigm to accelerate query response times. To the best of our knowledge, this is the first attempt to evaluate -distance join queries effectively in dynamic road networks.
- We design algorithms that reduce the number of range queries required to evaluate -distance join queries in dynamic road networks. The proposed method is intuitive and easy to implement, thereby allowing its simple integration with existing range query algorithms (e.g., [10]) in road networks.
- We conduct extensive experiments under different setups to demonstrate the efficiency and scalability of our approach over conventional solutions.
The remainder of this paper is organized as follows. In Section 2, we review related studies. In Section 3, we provide some background information. We present a simple solution called the naive EDISON method based on shared execution in Section 4. In Section 5, we present an optimized solution that avoids redundant network traversal called the EDISON method. In Section 6, we evaluate our proposed solutions experimentally under different setups by comparing them to a conventional solution. We conclude the paper in Section 7.
2. Related Work
2.1. Dynamic Road Networks
The geographic information system (GIS) community has shown interest in processing spatial queries in road networks, which form an integral aspect of geospatial applications, such as location-based services and locational analysis [1,2,3,5,6,7,10,11,22,23,39,40]. Previous works have studied a variety of spatial queries in road networks, which include shortest path queries [1,2,3,4,5,6,7], distance queries [2,3,5,8,9], range queries [3,10], and kNN queries [3,7,10,11]. The previous studies focused primarily on adopting sophisticated index structures to achieve good performance under the assumption that road networks are stable. For example, Sankaranarayanan et al. [3,4] proposed the SILC and path-coherent pairs decomposition frameworks based on spatial path coherence to determine the shortest path and the shortest distance between every pair of vertices. In particular, the SILC framework can support various queries in road networks including path queries, distance queries, range queries, and kNN queries. Because these frameworks have high pre-computational overhead and space complexity even in static road networks, they are not suitable for processing spatial queries in dynamic road networks where the weights of road segments are often updated. Recently, distance queries [8] and shortest path queries [1,6,21] have been actively studied in dynamic road networks. Techniques for distance queries and shortest path queries cannot be applied directly to processing -distance join queries in dynamic road networks owing to the inconsistent problem requirements. Recently, Arain et al. [24,25,26], Domenic et al. [27], Gustav et al. [28], Kamenyi et al. [29], and Memon et al. [30,31,32,33,34] developed novel techniques for location privacy preservation over road networks. These techniques focus on protecting the location privacy of moving objects in road networks. However, it is inappropriate to extend these location privacy techniques to solve the -distance join problem in dynamic road networks owing to differences in the problem definition.
2.2. -Distance Join Queries
Given a query point , a threshold distance , and a set of objects , a range query retrieves objects that are within the threshold distance from the query point . Several algorithms have been proposed to support range queries in road networks. Papadias et al. [10] proposed the range Euclidean restriction (RER) and range network expansion (RNE) algorithms for processing range queries in road networks. The -distance join query is another important query in road networks. Papadias et al. [10] proposed join Euclidean restriction (JER) and join network expansion (JNE) algorithms to support -distance join queries in road networks. The JER algorithm uses the Euclidean distance as a heuristic to search for object pairs within the threshold distance based on their network distance. Therefore, it performs poorly when the Euclidean distance and the network distance are very different, which is a common scenario in practice. If the edge weight is defined as the travel time in road networks, the Euclidean distance cannot confine the search space unless additional assumptions are made, such as assuming maximum speed. Therefore, JER is not appropriate for processing -distance join queries in dynamic road networks. Sankaranarayanan et al. [23] proposed a distance join algorithm that can support -distance join queries in road networks. The distance join algorithm, based on the SILC framework introduced in [3], exploits the pre-computation of the shortest path between each pair of vertices in a road network and stores all paths in a quad-tree. However, the distance join algorithm in [23] is not suitable for dynamic road networks as it suffers from excessive storage costs for large road networks. The -distance join queries are well studied in the Euclidean space [19,20] and in the metric space [13,14,15,16,17,18]. Nonetheless, all approaches are unsuitable for processing -distance join queries, because they utilize some geometric properties (e.g., MBR [20], plane-sweep [20], and space-filling curve [41]) that are not available for dynamic road networks.
As a means to process a large number of queries in database systems, the shared execution of queries has recently received much attention [35,36,37,38,42]. The key idea of shared query execution is to cluster similar queries (i.e., those that share some common execution path) into a group and then execute the group as a single query in the system. These shared execution methods are found to be effective in many applications involving high load conditions. In this study, we optimize the shared execution strategy to boost -distance join queries in dynamic road networks. Our proposed solution differs from existing studies in several aspects. First, our solution represents the first attempt to evaluate -distance join queries efficiently in dynamic road networks, where materialized index structures (e.g., SILC [3]) cannot be used. Second, our solution considers applying a shared execution strategy to avoid redundant network traversal while processing -distance join queries. Finally, our solution can be implemented easily using the best-known solutions (e.g., RNE [10]) to range queries in road networks, which is considered a desirable property in practice.
3. Preliminaries
Section 3.1 defines the terms and notations that are used in this paper. Section 3.2 defines the -distance join query applied to road networks.
3.1. Definition of Terms and Notations
Road network: We represent a road network by an undirected weighted graph , where , , and indicate the vertex set, the edge set, and the edge distance matrix, respectively. Each edge has a nonnegative weight representing the network distance, such as the travel time.
Classification of vertices: We divide vertices into three categories based on their degree. (1) If the degree of a vertex is larger than or equal to 3, the vertex is referred to as an intersection vertex; (2) If the degree is 2, the vertex is an intermediate vertex; (3) If the degree is 1, the vertex is a terminal vertex.
Vertex sequence and segment: A vertex sequence denotes a path between two vertices and , such that () is either an intersection vertex or a terminal vertex, and the other vertices in the path, are intermediate vertices. The length of a vertex sequence is the total weight of the edges in the vertex sequence. A part of a vertex sequence is referred to as a segment. By definition, a vertex sequence is also a segment.
Table 1 summarizes the symbols used in this paper. Note that to simplify presentation, we use to denote , where adjacent outer objects are located in the same vertex sequence. In this study, we employ the basic concept of clustering adjacent outer objects in a vertex sequence into an outer segment. The advantage of this clustering method is that if we evaluate two range queries at the two end points, and , of an outer segment , we can retrieve inner objects within distance from each outer object without duplicating the network traversal. In other words, the two range queries at and are sufficient to retrieve inner objects within distance from all outer objects in , which is proved in Lemma 1.
Figure 2 shows the difference between the distance and the segment length between two objects and in a road network, where the numbers at the edges indicate the distance between two adjacent points (e.g., ). The shortest path from to is denoted by where the distance between and is in this case. The segment connecting and in the same vertex sequence becomes with length equal to . We recall that is defined for two objects located in the same vertex sequence.
3.2. -Distance Join Query
We consider two object sets and in the road network . For convenience, is referred to as the set of outer objects and is referred to as the set of inner objects. Accordingly, and are referred to as outer and inner objects, respectively.
Definition 1.
(-distance join query): Given a threshold distance and two object sets and , where and , the -distance join query, denoted by , returns the set of all possible pairs of objects from that are within the threshold distance :
Naturally, is a subset of . The -distance join query is commutative, i.e., .
4. Naive Shared Execution for -Distance Join Queries in Road Networks
4.1. Grouping of Objects in a Vertex Sequence
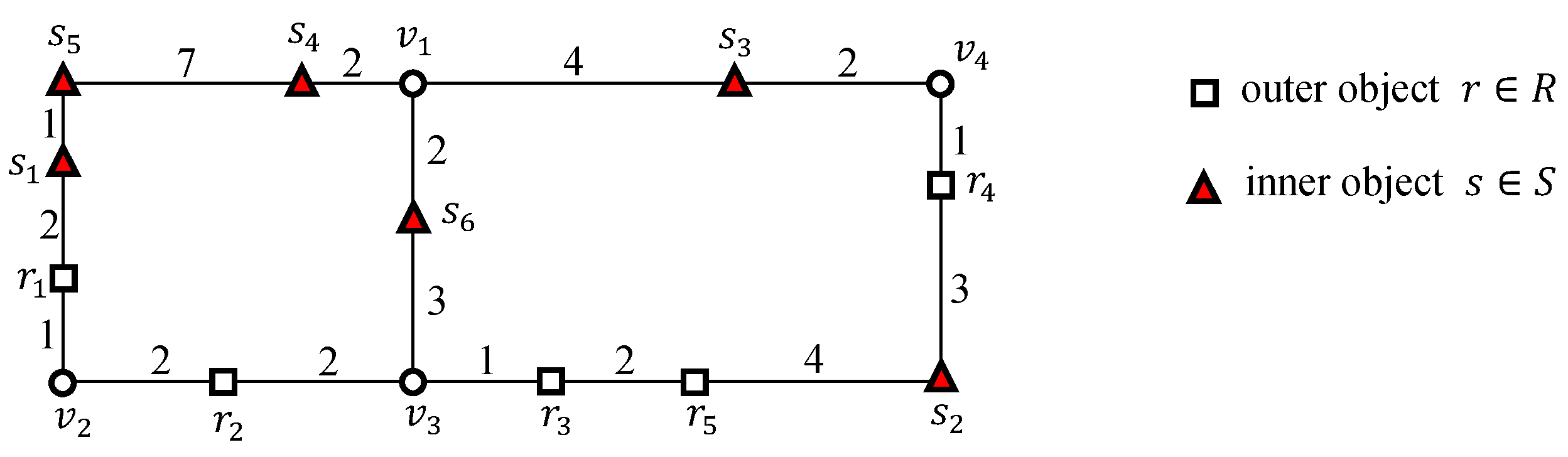
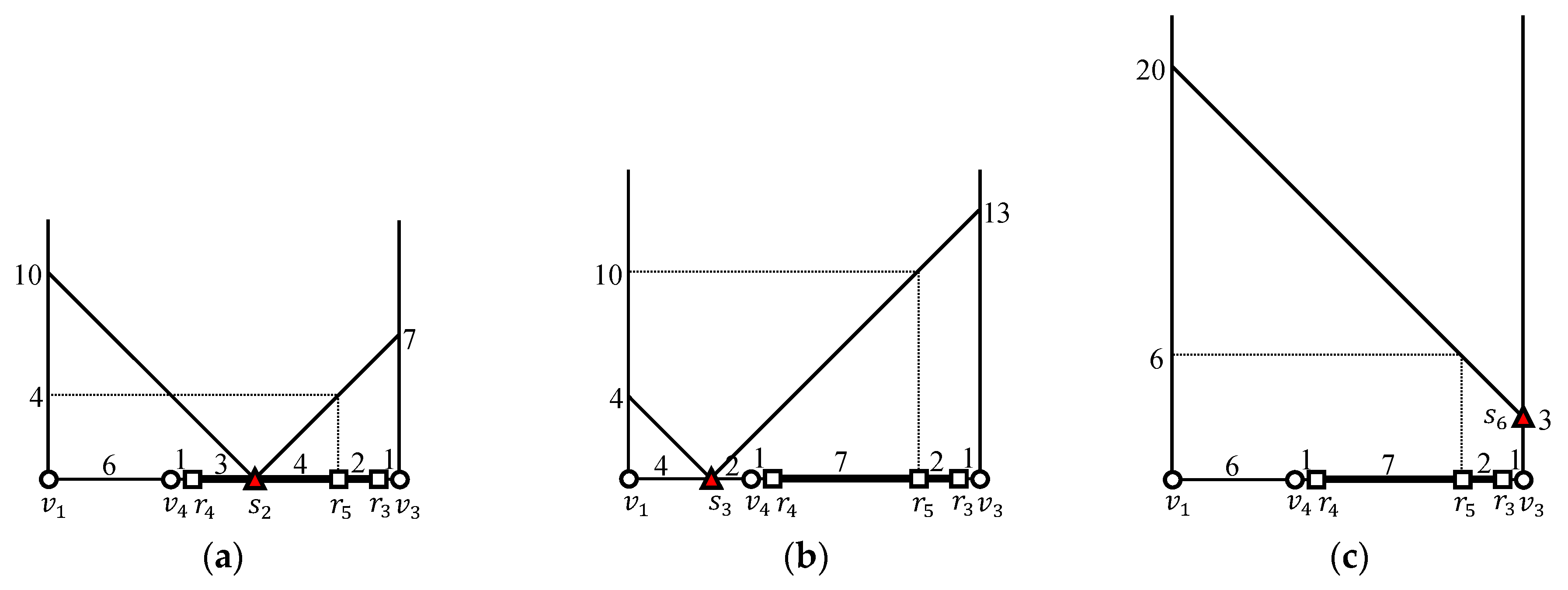
Figure 3 presents an example of an -distance join query in a road network, which will be discussed throughout this section. In this figure, there are five outer objects, through , and six inner objects, through . Given a threshold distance and two object sets and , we consider an -distance join query of the following form: .
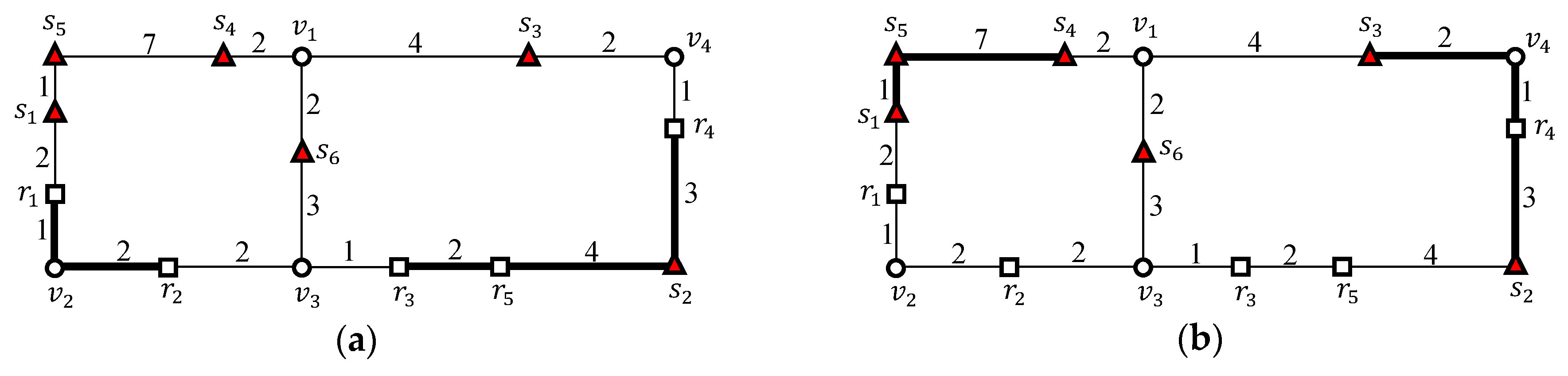
Figure 4 shows the sample grouping of outer objects in a vertex sequence and the sample grouping of inner objects in a vertex sequence. As shown in Figure 4a, two outer objects and in a vertex sequence are grouped into an outer segment , and three outer objects , , and in a vertex sequence are grouped into another outer segment . Similarly, as shown in Figure 4b, three inner objects , , and in a vertex sequence are grouped into an inner segment , and two inner objects and in a vertex sequence are grouped into another inner segment . Therefore, a set of outer objects is transformed into , where is the set of outer segments generated from the outer objects. Similarly, a set of inner objects is transformed into , where is the set of inner segments generated from the inner objects. Without loss of generality, we assume that , because . If , then is evaluated instead of .
4.2. Shared Execution Processing of Grouped Outer Objects
Our shared execution strategy for processing -distance join queries in road networks is motivated by the observation that at most two range queries are sufficient for retrieving inner objects within the threshold distance from each outer object in an outer segment. This observation is formalized in Lemma 1, which states a simple but important fact regarding the shared execution of -distance join queries in road networks—if we evaluate two range queries at outer objects and , which correspond to the two end points of an outer segment , then we can retrieve inner objects within distance from outer objects without duplicating the network traversal. Thus, the two range queries at and are sufficient for retrieving inner objects within distance from the other outer objects .
Lemma 1.
For every outer object , it holds that , where () is the set of inner objects within distance from an outer object (), and is the set of inner objects located in the outer segment (e.g., in Figure 4).
Proof.
We prove Lemma 1 by contradiction. We assume that does not hold, i.e., . Then this implies that there is an inner object such that , i.e., , , and . Clearly, means that . Similarly, means that . Clearly, means that is not located in . Therefore, the shortest path from to passes through either or and the distance from to is determined by . From the previous condition, both and , which leads to . Thus, cannot belong to , which contradicts the assumption that an inner object exists such that . Consequently, it holds that for . □
We determine the inner objects within distance from an outer object among inner objects in . First, we compute the distance from an outer object to an inner object . If there exists a path (i.e., ), then the distance from to is , as shown in Figure 5a. Similarly, if there exists a path (i.e., ), then the distance from to is , as shown in Figure 5b. If the inner object is located in (i.e., ), then the distance from to is , as shown in Figure 5c. Because is the length of the shortest path among multiple paths between and , is computed as follows.
Table 2 explains how to compute the distance from to , where and . The inner object belongs to a combination of , , and , so seven possible cases are considered in total. Clearly, it is trivial to retrieve a set of inner objects that are located in compared with retrieving a set () of inner objects within distance from an outer object ().
4.3. Naive EDISON Algorithm
Algorithm 1 describes the naive EDISON algorithm, which employs the grouping of outer objects and shared execution to reduce query processing time. This algorithm involves two steps. In the first step, adjacent outer objects in a vertex sequence are grouped into an outer segment. Similarly, adjacent inner objects in a vertex sequence are also grouped into an inner segment. In other words, and are transformed into and , respectively. For simplicity, we assume that . If , we simply evaluate , because . In the second step, the naive EDISON algorithm explores each outer segment sequentially to retrieve inner objects that are within distance from each outer object in the outer segment . Depending on the number of outer objects in , there are three possible cases, which the naive EDISON algorithm handles differently: (1) ; (2) ; and (3) . If , a range query is evaluated at because includes an outer object () only. Then, a partial join result is simply obtained from the range query result at , i.e., . The partial join result is added to the -distance join query result , i.e., (lines 8‒10). If , two range queries, and , are evaluated at and , respectively, because includes only two outer objects and . Then, two partial join results and are simply obtained from the range query results and at and , respectively, i.e., and . These partial join results and are added to the -distance join query result , i.e., (lines 11‒14). Finally, if , only two range queries, and , are evaluated at and , respectively, similar to the case of . According to Lemma 1, a partial join result can be obtained from using the shared execution method (lines 15‒19), which is detailed in Lemma 2. This is because the partial join result is the set of object pairs that are within distance , where and , i.e., . Finally, the -distance join query result is returned after all outer segments have been processed (line 20), i.e., for each outer segment . In Lemma 2, we prove the correctness of the naive EDISON algorithm.
| Algorithm 1: Naive_EDISON () | ||||
| Input:: threshold distance, : set of outer objects, : set of inner objects | ||||
| Output:: set of object pairs such that | ||||
| 1 | // is the set of object pairs such that . | |||
| 2 | // Step 1: neighboring outer objects are grouped and neighboring inner objects are also grouped. | |||
| 3 | // Outer objects in a vertex sequence are grouped into an outer segment. | |||
| 4 | // Inner objects in a vertex sequence are grouped into an inner segment. | |||
| 5 | // For simplicity, we assume that . if , we simply evaluate . | |||
| 6 | // Step 2: is evaluated for each outer segment . | |||
| 7 | for each outer segment do | |||
| 8 | ifthen | // means that contains an outer object only. | ||
| 9 | // A range query is evaluated at and its result is . | |||
| 10 | // Note that . | |||
| 11 | else ifthen | // means that contains two outer objects and . | ||
| 12 | // A range query is evaluated at and its result is . | |||
| 13 | // Another range query is evaluated at and its result is . | |||
| 14 | // Note that and . | |||
| 15 | else ifthen | // means that contains more than two outer objects. | ||
| 16 | // A range query is evaluated at and its result is . | |||
| 17 | // Another range query is evaluated at and its result is . | |||
| 18 | // is explained in Algorithm 3. | |||
| 19 | // . | |||
| 20 | return | // stores the result of . | ||
Lemma 2.
The naive EDISON algorithm is correct.
Proof.
We prove the correctness of the naive EDISON algorithm by cases. As shown in Algorithm 1, the naive EDISON algorithm handles the following three cases differently depending on the number of outer objects in an outer segment , namely, (1) , (2) , and (3) . In the first two cases (i.e., and ), a range query is used to retrieve inner objects within distance from each outer object . This is same as a straightforward method used to answer -distance join queries by issuing a range query for each outer object . For , the naive EDISON algorithm evaluates a range query for only an outer object , and adds an object pair to the -distance join query result for each inner object . Therefore, the naive EDISON algorithm is correct for because simply retrieves inner objects within distance from . Similarly, for , the naive EDISON algorithm evaluates two range queries, and , for two outer objects and , respectively. The naive EDISON algorithm then adds an object pair to the -distance join query result for each inner object , and adds an object pair to the -distance join query result for each inner object . Therefore, the naive EDISON algorithm is correct for because and retrieve inner objects within distance from and , respectively.
The proof for the correctness of the naive EDISON algorithm for differs from that for and because the naive EDISON algorithm exploits the shared execution strategy for . Note that the naive EDISON algorithm evaluates only two range queries and for . The key idea of the proof of the correctness for is to compute the distance between an outer object and each candidate inner object without evaluating a range query for , where and . According to Lemma 1, we can retrieve inner objects within distance from every outer object among the candidate inner objects . The distance between and , , determines whether an object pair is included in the -distance join query result. Let us compute the distance between an outer object and candidate inner object . To do so, we consider the two cases, and , as shown in Figure 6a,b, respectively. If , the distance from to is evaluated as because there are two possible paths from to , i.e., and ; otherwise, the distance from to is evaluated as because there are three possible paths from to , i.e., , , and . If , an object pair is included in the -distance join query result; otherwise, the object pair is not included. Therefore, the naive EDISON algorithm is correct for . Consequently, the naive EDISON algorithm is correct for , , and . □
4.4. Evaluation of an Example -Distance Join Query Using the Naive EDISON Algorithm
We discuss how to evaluate the -distance join query in Figure 3 using the naive EDISON algorithm. Recall that , , and are given and that outer objects through are grouped into outer segments and , as shown in Figure 4. Table 3 summarizes the computation of for the naive EDISON algorithm.
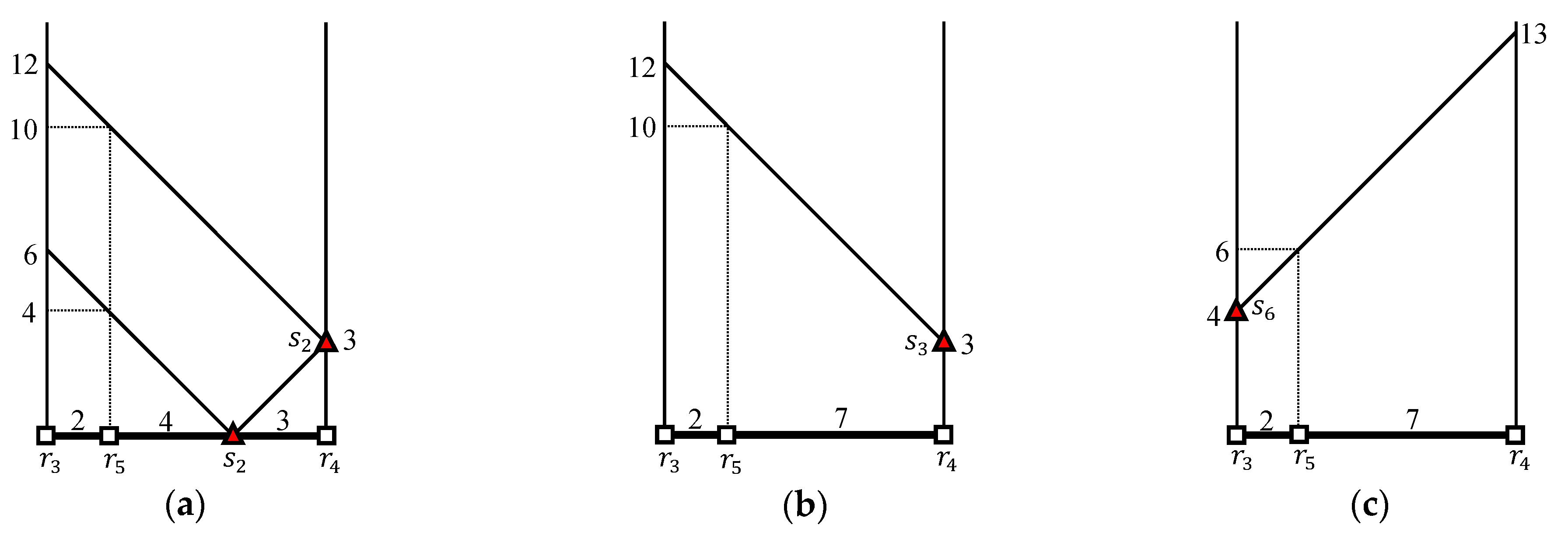
Because Algorithm 1 processes outer segments one by one, we determine inner objects within the threshold distance from each outer object followed by . Two range queries and are evaluated for an outer segment , whose results are and , respectively. Because holds, we can simply obtain the partial join result for , i.e., .
Similarly, two range queries and are evaluated for an outer segment , whose results are and , respectively. Because we have , , and , we can compute the distance from to each candidate inner object and can retrieve inner objects within distance from . For this, we need to compute the distance from to each candidate inner object . Because according to Table 3, the distance from to is , as shown in Figure 7a. Similarly, because according to Table 3, the distance from to is , as shown in Figure 7b. Finally, because according to Table 3, the distance from to is , as shown in Figure 7c. Thus, given that , , and . The partial join result for is obtained by taking the union of the three range query results at , , and , i.e., where , , and . Consequently, we have the result of the -distance join query, i.e., .
5. Optimal Shared Execution for -Distance Join Queries in Road Networks
5.1. Extending Shared Execution Processing to Adjacent Outer Segments
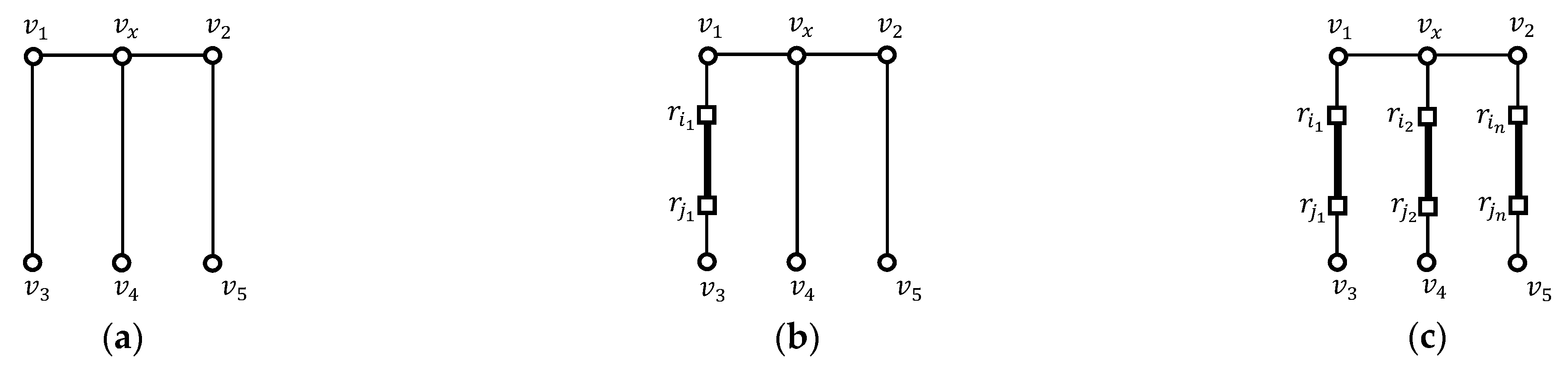
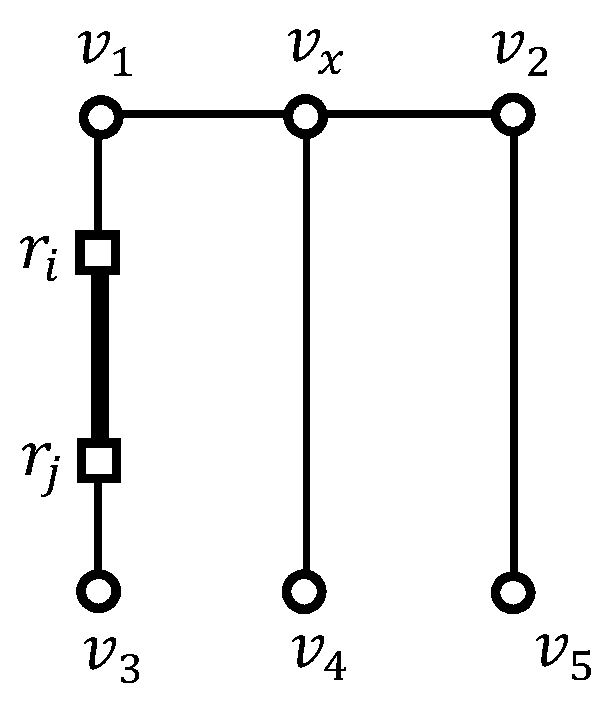
We can extend the shared execution processing to adjacent outer segments. We call this shared execution processing the EDISON method. To this end, we investigate the number of outer segments that belong to adjacent vertex sequences of an intersection vertex. Let be the number of outer segments in vertex sequences adjacent to an intersection vertex . If , as shown in Figure 8a, no range query is issued at . If , as shown in Figure 8b, a range query is issued at . If , as shown in Figure 8c, a range query is issued at , where and . Naturally, if , no range query at is issued. In summary, if , the same shared execution as the naive EDISON algorithm is applied to an outer segment, and if , an extended shared execution is applied to outer segments adjacent to .
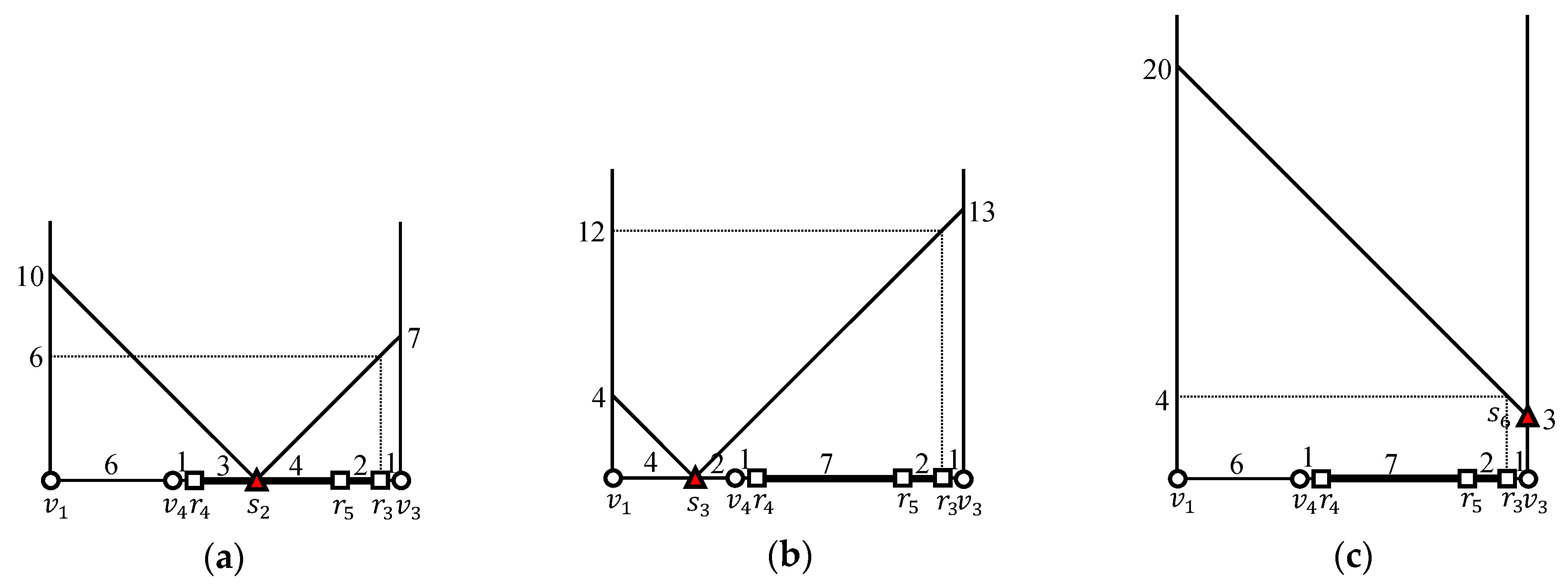
Returning to the example in Figure 3, we reevaluate the -distance join query to demonstrate the effectiveness of considering the shared execution of adjacent outer segments. To answer the -distance join query, the naive EDISON method would evaluate four range queries , ,, and whereas the EDISON method only evaluates the range query at the intersection vertex . This occurs because there are two intersection vertices and , as shown in Figure 4a and we have , , , so .
We present a simple heuristic where no range queries close to terminal vertices are issued. As shown in Figure 9, the example network has one intersection vertex and three terminal vertices , , and . In this figure, the naive EDISON method evaluates two range queries and to answer the -distance join query. However, the EDISON method evaluates only the range query to answer the same -distance join query. This is because holds, and it is sufficient to evaluate the range query rather than the two range queries and .
5.2. EDISON Algorithm
Algorithm 2 describes the EDISON algorithm based on shared execution to avoid redundant range queries while processing -distance join queries. For simplicity, we assume that , because . The EDISON algorithm examines , the number of outer segments adjacent to each intersection vertex , and applies the extended shared execution to outer segments adjacent to if . If , then no range query is issued at . If and , then a range query is issued and its result is saved to , where , assuming that outer segments are adjacent to and that is closer to than for (lines 8‒11).
Next, for each outer segment , we retrieve a set of object pairs within distance from each outer object . We assume that is close to for an outer segment . We consider the following four cases depending on the values of and , where is a vertex sequence containing an outer segment : (1) ; (2) and ; (3) and ; and (4) and . If and , then inner objects within distance from each outer object are retrieved among the candidate inner objects in (lines 13‒16). If and , then inner objects within distance from each outer object are retrieved among the candidate inner objects in (lines 17‒19). If and , then inner objects within distance from each outer object are retrieved among the candidate inner objects in (lines 20‒22). Finally, if and , then inner objects within distance from each outer object are retrieved among the candidate inner objects in (lines 23‒24). A partial join result for is added to the query result . Finally, the -distance join query result is returned after all outer segments have been processed (line 26), i.e., for each outer segment .
| Algorithm 2: EDISON () | |||||||
| Input: : set of outer objects, : set of inner objects | |||||||
| Output: : set of object pairs such that | |||||||
| 1 | // is the set of object pairs such that . | ||||||
| 2 | // Step 1: neighboring outer objects are grouped and neighboring inner objects are also grouped. | ||||||
| 3 | // Outer objects in a vertex sequence are grouped into an outer segment. | ||||||
| 4 | // Inner objects in a vertex sequence are grouped into an inner segment. | ||||||
| 5 | // For simplicity, we assume that . if , we simply evaluate . | ||||||
| 6 | // Step 2: is evaluated by extending shared execution processing to adjacent outer segments. | ||||||
| 7 | for each intersection vertex do | ||||||
| 8 | if then | // means that more than two outer segments are adjacent to . | |||||
| 9 | // assume that . | ||||||
| 10 | if then | // If , then no range query is evaluated at . | |||||
| 11 | // Otherwise, a range query is evaluated at . | ||||||
| 12 | for each outer segment do | // Assume that () is close to (). | |||||
| 13 | if and then | ||||||
| 14 | // A range query is evaluated at because no range query is issued at . | ||||||
| 15 | // A range query is evaluated at because no range query is issued at . | ||||||
| 16 | |||||||
| 17 | else if and then | ||||||
| 18 | // A range query is evaluated at because no range query is issued at . | ||||||
| 19 | // is reused by outer segments adjacent to . | ||||||
| 20 | else if and then | ||||||
| 21 | // A range query is evaluated at because no range query is issued at . | ||||||
| 22 | // is reused by outer segments adjacent to . | ||||||
| 23 | else if and then | ||||||
| 24 | // () is reused by outer segments adjacent to (). | ||||||
| 25 | // A partial join result for is added to . | ||||||
| 26 | return | // stores the result of . | |||||
Algorithm 3 retrieves a set of object pairs within distance , where and . First, is initialized to the empty set. According to the condition of an inner object , the distance from to is computed (lines 4‒11). Note that in Algorithm 3 may not necessarily be the length of the shortest path from to , as discussed in Section 5.3. If , then the object pair is added to the partial join result (lines 12‒14). Clearly, is returned after all candidate object pairs have been examined (line 15). In Lemma 3, we prove the correctness of the EDISON algorithm.
| Algorithm 3: | |||||
| Input: : threshold distance, : outer segment, : set of candidate inner objects for outer objects in | |||||
| Output: : set of object pairs such that for and | |||||
| 1 | // is the set of object pairs within distance where . | ||||
| 2 | for each outer object do | ||||
| 3 | for each inner object do | ||||
| 4 | // is computed according to the condition of . | ||||
| 5 | if then | ||||
| 6 | else if then | ||||
| 7 | else if then | ||||
| 8 | else if then | ||||
| 9 | else if then | ||||
| 10 | else if then | ||||
| 11 | else if then | ||||
| 12 | // If then an object pair is involved in the query result. | ||||
| 13 | if then | ||||
| 14 | |||||
| 15 | return | // A partial join result for is returned. | |||
Lemma 3.
The EDISON algorithm is correct.
Proof.
We prove the correctness of the EDISON algorithm by cases. As shown in Algorithm 2, the EDISON algorithm handles the following four cases differently depending on the values of and of a vertex sequence containing an outer segment , namely, (1) ; (2) and ; (3) and ; and (4) and . For , two range queries, and , are evaluated at and , respectively. According to Lemma 1, we can retrieve the inner objects within distance from every outer object among the candidate inner objects The EDISON algorithm computes the distance from an outer object to each candidate inner object Because is the length of the shortest path among three possible paths (i.e., , , and if ), it is determined simply depending on the conditions listed in Algorithm 3. Specifically, if , then otherwise, If , an object pair is included in the -distance join query result; otherwise, the object pair is not included. Therefore, the EDISON algorithm is correct for .
For and , two range queries, and , are evaluated at and , respectively, where , assuming that the outer segments are adjacent to , and that is closer to than for . Because and , set of the inner objects within distance from contains set of the inner objects within distance from , where , i.e., . According to Lemma 1, we can retrieve inner objects within distance from every outer object among the candidate inner objects because contains The EDISON algorithm computes the distance from an outer object to each candidate inner object . Because is the length of the shortest path among three possible paths (i.e., , , and if ), it is determined simply depending on the conditions listed in Algorithm 3. Specifically, if , then otherwise, . If , an object pair is included in the -distance join query result; otherwise, the object pair is not included. Therefore, the EDISON algorithm is correct for and . Without loss of generality, the proof of the correctness of the EDISON algorithm for and can be simply obtained by interchanging the roles of and , as well as the roles of and , in the proof for and , which is omitted.
Finally, for and , two range queries, and , are evaluated at and , respectively, where and It is assumed that the outer segments are adjacent to , and that is closer to than for . Because () and , set of the inner objects within distance from contains set of the inner objects within distance from , where , i.e., . According to Lemma 1, we can retrieve the inner objects within distance from every outer object among the candidate inner objects because contains The EDISON algorithm computes the distance from an outer object to each candidate inner object Because is the length of the shortest path among three possible paths (i.e., , , and if ), it is determined simply depending on the conditions listed in Algorithm 3. Specifically, if , then otherwise, . If , an object pair is included in the -distance join query result; otherwise, the object pair is not included. Therefore, the EDISON algorithm is correct for and Consequently, the EDISON algorithm is correct for , and , and , and and □
5.3. Evaluation of an Example -Distance Join Query Using the EDISON Algorithm
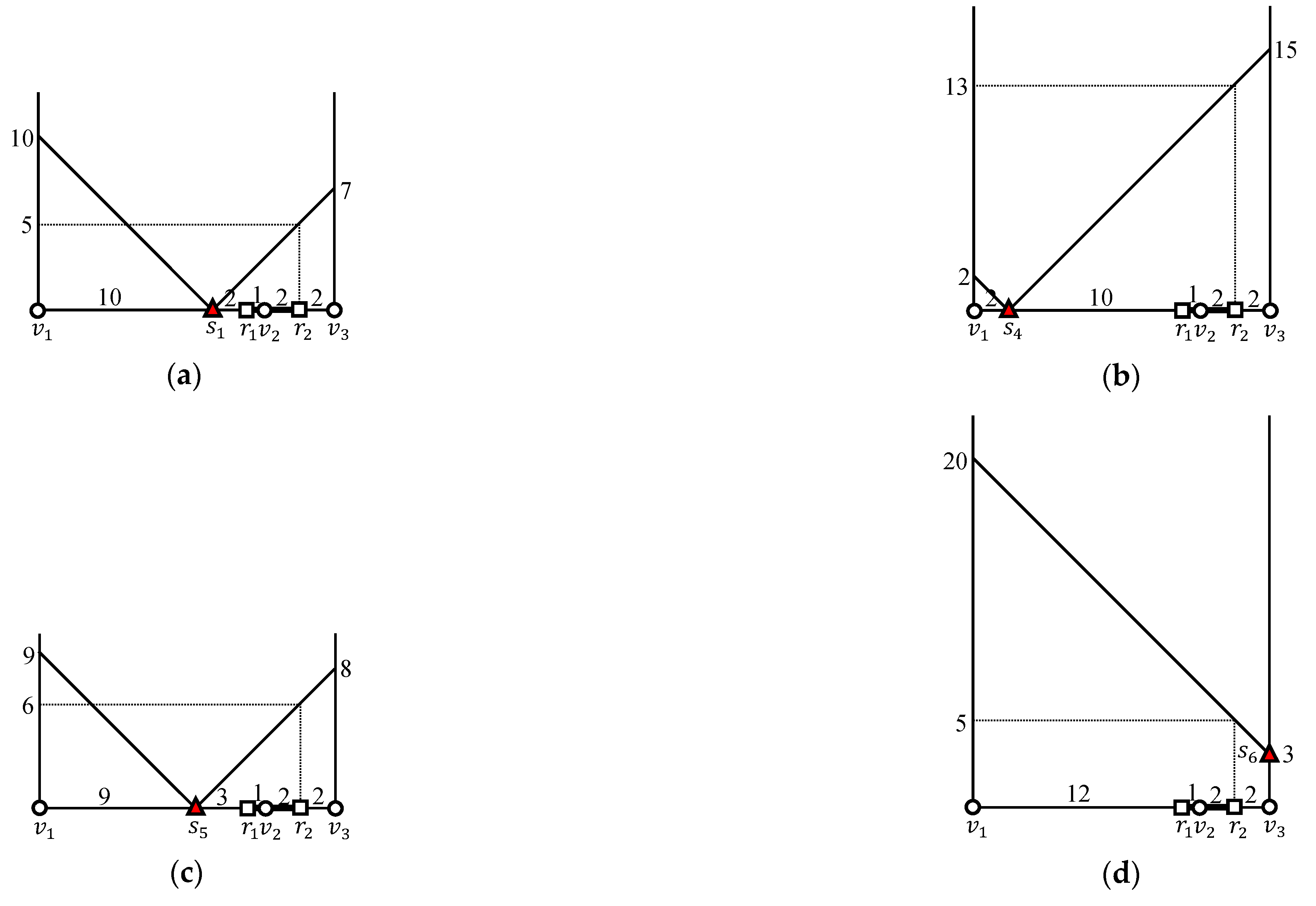
We discuss how to evaluate the -distance join query in Figure 3 using the EDISON algorithm. As shown in Figure 4, and are grouped into and , respectively. Because , we evaluate . There are two intersection vertices, and , both of which are adjacent to and . Therefore, to determine whether range queries at and are evaluated, the EDISON algorithm computes the distances and for the range queries at and , respectively. Because and , the EDISON algorithm evaluates the range query only. Clearly, the range query returns the empty set. Table 4 summarizes the computation of for the EDISON algorithm.
We retrieve inner objects within distance from each outer object among the candidate inner objects, followed by inner objects within distance from each outer object . As shown in Table 4, is the set of candidate inner objects for , and is the set of candidate inner objects for . The EDISON algorithm computes the distance between an outer object and each candidate inner object and finds all qualifying object pairs such that .
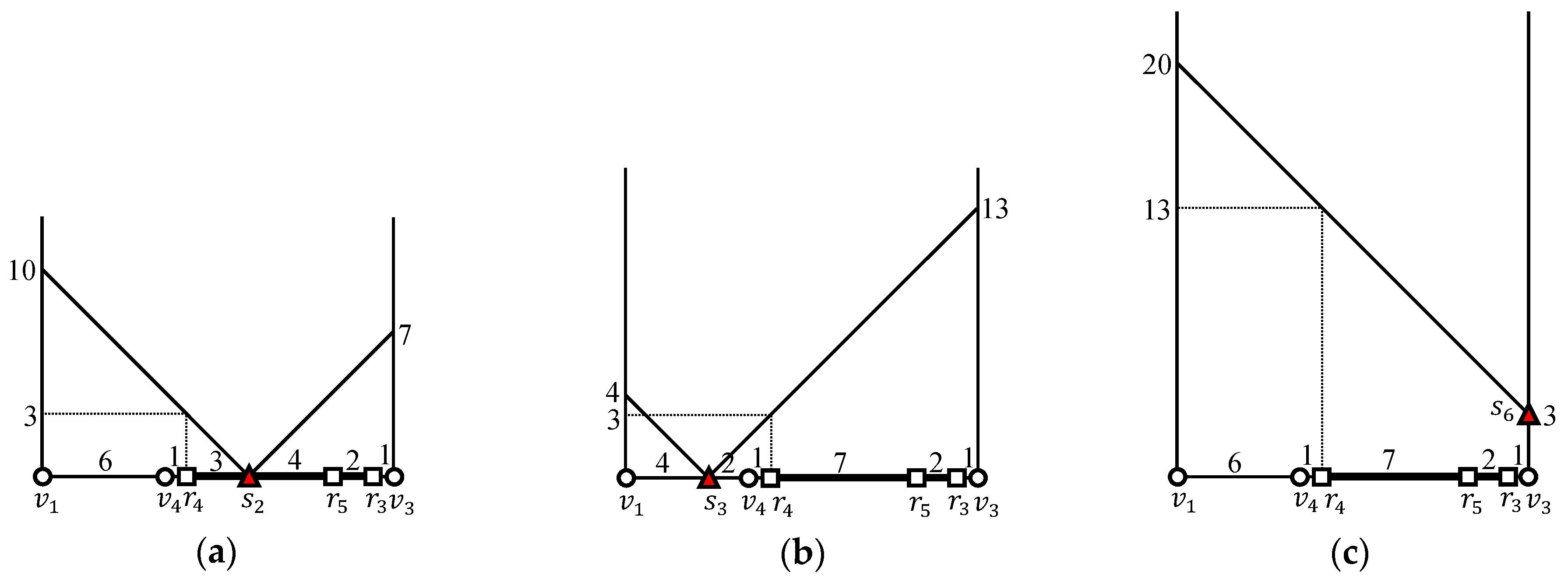
We compute the distance from to each candidate inner object . Because according to Table 4, the distance from to is , as shown in Figure 10a. Because , the distance from to is , as shown in Figure 10b. Similarly, because , the distance from to is , as shown in Figure 10c. Finally, because according to Table 4, the distance from to is , as shown in Figure 10d. Consequently, given that , , , and , and the generated partial join result is .
We compute the distance from to each candidate inner object . Because according to Table 4, the distance from to is , as shown in Figure 11a. Because , the distance from to is , as shown in Figure 11b. In fact, the shortest path from to is , whose length is . However, this deviation from the shortest distance does not affect the query result. Similarly, because , this distance from to is , as shown in Figure 11c. Finally, because according to Table 4, the distance from to is , as shown in Figure 11d. Consequently, given that , , , and , and the generated partial join result is .
We compute the distance from to each candidate inner object . Because according to Table 4, the distance from to is , as shown in Figure 12a. Similarly, because , the distance from to is , as shown in Figure 12b. In fact, the shortest path from to is , whose length is . However, this deviation from the shortest distance does not affect the query result. Finally, because , the distance from to is , as shown in Figure 12c. Consequently, given that , , and , and the generated partial join result is .
We compute the distance from to each candidate inner object . Because according to Table 4, the distance from to is , as shown in Figure 13a. Similarly, because , the distance from to is , as shown in Figure 13b. Finally, because , the distance from to is , as shown in Figure 13c. In fact, the shortest path from to is , whose length is . However, this deviation from the shortest distance does not affect the query result. Consequently, given that , , and , and the generated partial join result is .
We compute the distance from to each candidate inner object . Because according to Table 4, the distance from to is , as shown in Figure 14a. Similarly, because , the distance from to is , as shown in Figure 14b. Finally, because , the distance from to is , as shown in Figure 14c. Consequently, given that , , and , and the generated partial join result is . Finally, we obtain the complete query result .
6. Performance Study
In this section, we report on an empirical analysis of our proposed solution. We present our experimental settings in Section 6.1, followed by our experimental results in Section 6.2.
6.1. Experimental Settings
For the performance study, we use three real-world road networks [43], which are described in Table 5. These real-world road networks have different sizes and are part of the US’s road network. Table 6 shows the range of each variable used in the experiments with defaults indicated in bold. For convenience, each dimension of the data universe is normalized independently to unit length, such that the threshold distance is in the range of . The positions of both the outer objects and the inner objects follow either centroid or uniform distributions. The centroid dataset is generated to resemble the real-world data. First, 10 centroids are selected randomly. The objects around each centroid follow a normal distribution, where the mean is set to the centroid and the standard deviation is set to 1% of the side length of the data universe. In each experiment, we vary one or two of the parameters within the range shown in Table 6, while keeping other parameters at default values. The outer objects and the inner objects follow the centroid distribution unless stated otherwise.
We implement and evaluate two versions of our proposed solution, i.e., the naive EDISON and EDISON methods. As a benchmark for our proposed method, we use a baseline method that computes the range query of every outer object using the RNE algorithm [10]. A comparison with the pre-computed distance-based solution [23] and the Euclidean distance-based solution (e.g., JER [10]) is beyond the scope of this study, because these methods cannot support frequent network traffic updates.
All algorithms are implemented in C++ in Microsoft Visual Studio 2015, and they use common subroutines for similar tasks. We conduct experiments on a desktop computer running Windows 10 with a 4 GHz processor and 32 GB of memory. We believe that indexing structures of all techniques should be memory resident to ensure responsive query processing, which is assumed in many recent studies [5,11] and is crucial to online map services and commercial navigation systems. We determine the average values based on 10 repetitions of the experiments for each algorithm.
6.2. Experimental Results
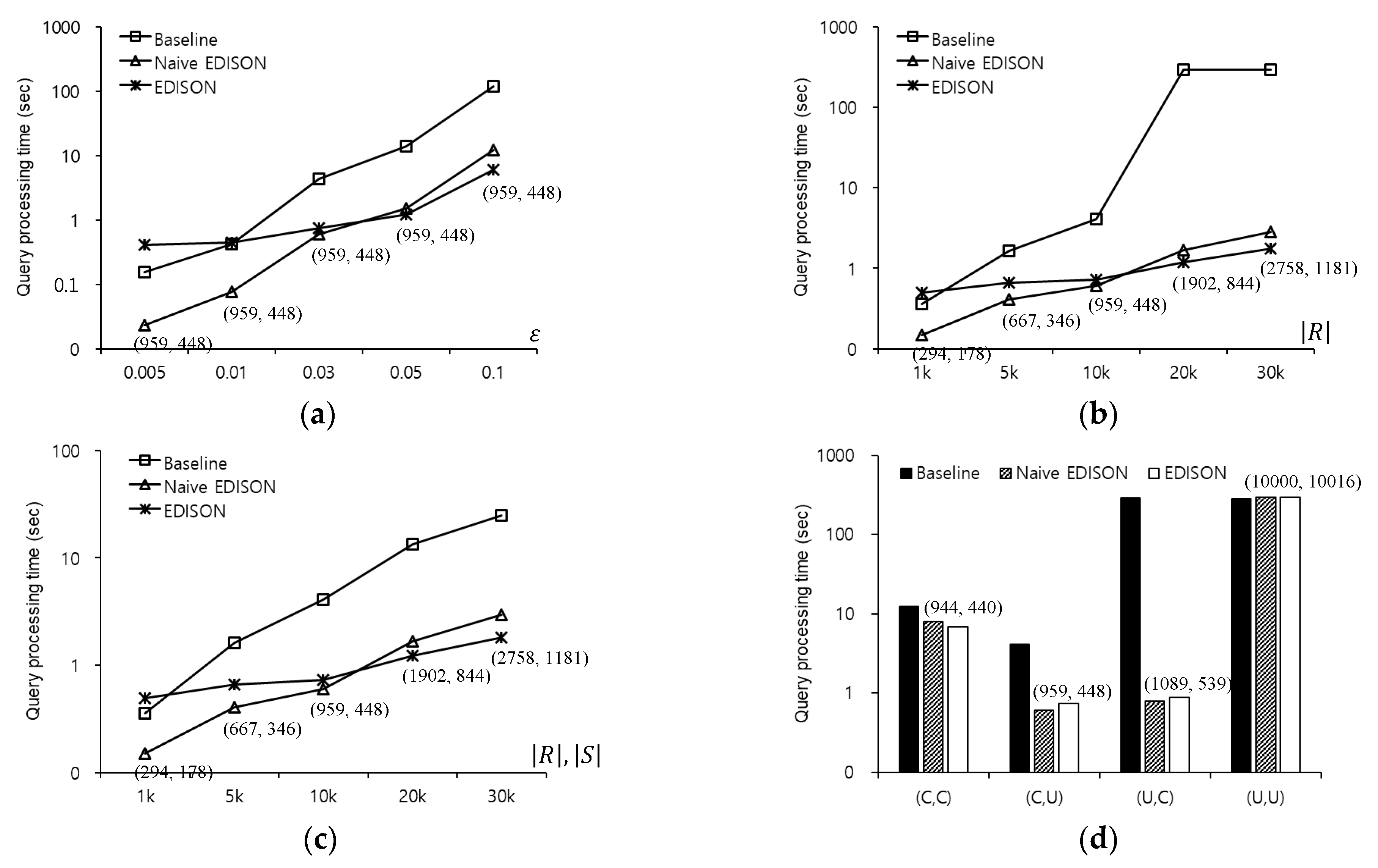
Figure 15 compares the query processing times using the baseline, naive EDISON, and EDISON methods to evaluate -distance join queries in the CAL roadmap, where each chart illustrates the effect of changing one or two of the parameters in Table 6. The first and the second values in parentheses indicate the number of range queries that are evaluated by the naive EDISON and EDISON methods, respectively. The numbers of range queries evaluated by the baseline method are omitted, because these numbers become , i.e., the cardinality of the smaller dataset between and . Figure 15a shows the query processing time as a function of the threshold distance . Although the EDISON method shows the worst performance for , the processing times using the baseline and the naive EDISON methods increase more rapidly with the value of than those using the EDISON method. This implies that the shared execution of the EDISON method is more effective for a large threshold distance . The baseline, naive EDISON, and EDISON methods evaluate a total of 10,000 range queries, 959 range queries, and 448 range queries, respectively. Figure 15b shows the query processing time as a function of the number of outer objects, while the number of inner objects is fixed at . The EDISON method is less sensitive to variations in than the other methods, although it shows the worst performance at . Owing to the benefit of the shared execution processing, the numbers of range queries evaluated by the naive EDISON and EDISON methods increase slightly with .
Figure 15c shows the query processing time as a function of both the number of outer objects and the number of inner objects. The naive EDISON method outperforms the EDISON method for whereas the latter outperforms the former for . This indicates that the EDISON method optimizes the shared execution processing more effectively than the naive EDISON method for large datasets. Clearly, the baseline method shows the worst performance in most cases. Figure 15d shows the query processing time for various distributions of outer objects and inner objects, where each ordered pair (i.e., , , , and ) denotes a combination of the distributions of outer objects and inner objects. Because shared execution processing is favorable for non-uniform distributions of objects, the naive EDISON and EDISON methods significantly outperform the baseline method for , , and . However, the processing times of the naive EDISON and EDISON methods for are very similar to the baseline method. This is because both the outer objects and the inner objects are widely scattered, which hinders shared execution processing.
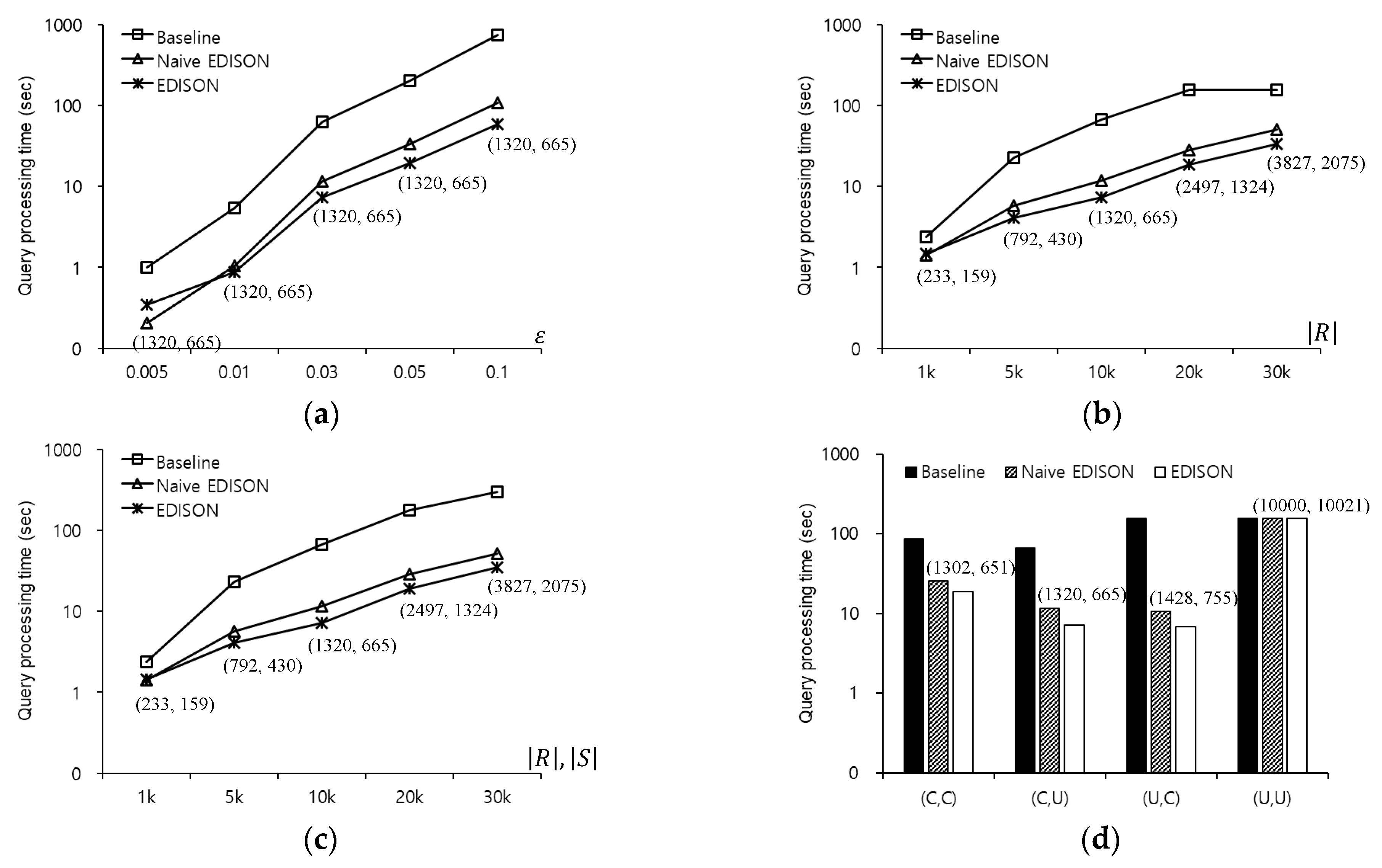
Figure 16 compares the query processing times using the baseline, naive EDISON, and EDISON methods to evaluate -distance join queries in the FLA roadmap. Figure 16a shows the query processing time as a function of , when varies between 0.005 and 0.1. The EDISON method achieves the best performance for , because it evaluates the smallest number of range queries among the three methods. The baseline, naive EDISON, and EDISON methods evaluate 10,000 range queries, 1320 range queries, and 665 range queries, respectively. Figure 16b shows the query processing time as a function of , when varies between 1000 and 30,000. The EDISON method clearly outperforms the other methods for . Due to shared execution processing, the naive EDISON and EDISON methods are less sensitive to changes in than the baseline method. Figure 16c shows the query processing time as a function of and , when () varies between 1000 and 30,000. The EDISON method clearly outperforms the other methods for . Figure 16d shows the query processing time for various distributions of outer objects and inner objects. The naive EDISON and EDISON methods significantly outperform the baseline method for , , and , whereas the former methods show similar performance to the latter method for for the same reason as in the CAL case.
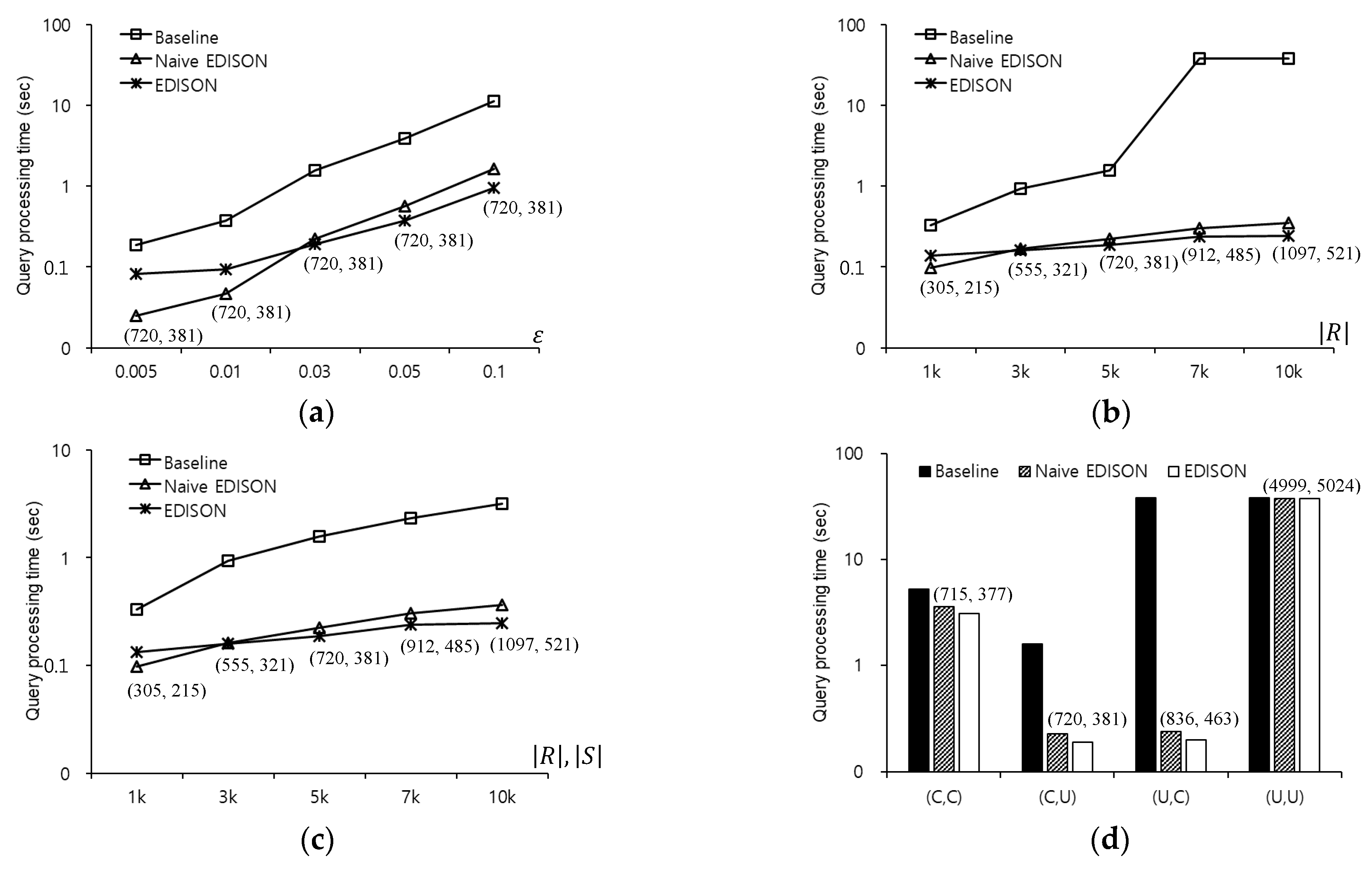
Figure 17 compares the query processing times using the baseline, naive EDISON, and EDISON methods to evaluate -distance join queries in the COL roadmap. Figure 17a shows the query processing time as a function of , when varies between 0.005 and 0.1. The naive EDISON and EDISON methods significantly outperform the baseline method in all cases. Specifically, the query processing time of the EDISON method is up to 11 times shorter than the baseline method at . The naive EDISON method significantly outperforms the EDISON method for , whereas the latter outperforms the former for . This indicates that the EDISON method is less sensitive to changes in than the naive EDISON method. Figure 17b shows the query processing time as a function of , when varies between 1000 and 10,000. The naive EDISON and EDISON methods significantly outperform the baseline method in all cases and the former methods are less sensitive to changes in than the latter method. This indicates that the performance difference between the EDISON method and the baseline method increases rapidly with . Specifically, the query processing time of the EDISON method is up to 155 times shorter than the baseline method at . Figure 17c shows the query processing time as a function of and , when () varies between 1000 and 10,000. The naive EDISON method outperforms the EDISON method at , whereas the latter outperforms the former for and the performance difference between the two methods increases with . and . This implies that the EDISON method scales better with and than the naive EDISON method. Figure 17d shows the query processing time for various distributions of outer objects and inner objects. The naive EDISON and EDISON methods significantly outperform the baseline method for , , and . However, all methods show similar performance when the outer objects and the inner objects follow uniform distributions . This is expected because both the outer objects and inner objects are widely scattered for , which obstructs shared execution processing of the naive EDISON and EDISON methods.
7. Conclusions
In this study, we investigated the efficient processing of -distance join queries in dynamic road networks. We proposed a cost-effective solution called EDISON that optimizes the shared execution method to avoid redundant network traversal. We implemented and evaluated a baseline method and two versions of EDISON, i.e., the naive EDISON and EDISON methods. The experiments are based on several real-world roadmaps and involve a wide range of parameter values. The experimental results are summarized as follows: (1) the naive EDISON and EDISON methods significantly outperform the baseline method; (2) the naive EDISON and EDISON methods are typically comparable in terms of query processing time; (3) the EDISON method scales better with increasing number of objects and threshold distance than the naive EDISON method. In future work, we plan to extend the shared execution approach used here to the problems of processing sophisticated spatial queries over road networks, such as multi-way distance join queries [44] and aggregate k-farthest neighbor queries [45,46]. These problems have not been adequately addressed with regard to road networks despite their importance.
Author Contributions
H.-J.C. designed the study, performed the experiments, and wrote the paper.
Funding
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korean government (MSIP) (NRF-2016R1A2B4009793).
Conflicts of Interest
The author declares no conflict of interest.
References
- Delling, D.; Goldberg, A.V.; Pajor, T.; Werneck, R.F. Customizable route planning in road networks. Transp. Sci. 2017, 51, 566–591. [Google Scholar] [CrossRef]
- Samet, H.; Sankaranarayanan, J.; Alborzi, H. Scalable network distance browsing in spatial databases. In Proceedings of the International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008. [Google Scholar]
- Sankaranarayanan, J.; Alborzi, H.; Samet, H. Efficient query processing on spatial networks. In Proceedings of the International Workshop on Geographic Information Systems, Bremen, Germany, 4–5 November 2005. [Google Scholar]
- Sankaranarayanan, J.; Samet, H.; Alborzi, H. Path oracles for spatial networks. PVLDB 2009, 2, 1210–1221. [Google Scholar] [CrossRef] [Green Version]
- Wu, L.; Xiao, X.; Deng, D.; Cong, G.; Zhu, A.D.; Zhou, S. Shortest path and distance queries on road networks: An experimental evaluation. PVLDB 2012, 5, 406–417. [Google Scholar] [CrossRef]
- Zhang, D.; Yang, D.; Wang, Y.; Tan, K.-L.; Cao, J.; Shen, H.T. Distributed shortest path query processing on dynamic road networks. VLDB J. 2017, 26, 399–419. [Google Scholar] [CrossRef]
- Zhong, R.; Li, G.; Tan, K.-L.; Zhou, L.; Gong, Z. G-tree: An efficient and scalable index for spatial search on road networks. IEEE Trans. Knowl. Data Eng. 2015, 27, 2175–2189. [Google Scholar] [CrossRef]
- D’Angelo, G.; D’Emidio, M.; Frigioni, D. Distance queries in large-scale fully dynamic complex networks. In Proceedings of the International Workshop on Combinatorial Algorithms, Helsinki, Finland, 17–19 August 2016. [Google Scholar]
- Sankaranarayanan, J.; Samet, H. Query processing using distance oracles for spatial networks. IEEE Trans. Knowl. Data Eng. 2010, 22, 1158–1175. [Google Scholar] [CrossRef]
- Papadias, D.; Zhang, J.; Mamoulis, N.; Tao, Y. Query processing in road network databases. In Proceedings of the International Conference on Very Large Data Bases, Berlin, Germany, 9–12 September 2003. [Google Scholar]
- Abeywickrama, T.; Cheema, M.A.; Taniar, D. k-Nearest neighbors on road networks: A journey in experimentation and in-memory implementation. PVLDB 2016, 9, 492–503. [Google Scholar] [CrossRef]
- Luo, S.; Kao, B.; Li, G.; Hu, J.; Cheng, R.; Zheng, Y. TOAIN: A throughput optimizing adaptive index for answering dynamic knn queries on road networks. PVLDB 2018, 11, 594–606. [Google Scholar]
- Chaudhuri, S.; Ganti, V.; Kaushik, R. A primitive operator for similarity joins in data cleaning. In Proceedings of the International Conference on Data Engineering, Atlanta, GA, USA, 3–8 April 2006. [Google Scholar]
- Deng, D.; Li, G.; Hao, S.; Wang, J.; Feng, J. MassJoin: A mapreduce-based method for scalable string similarity joins. In Proceedings of the International Conference on Data Engineering, Chicago, IL, USA, 31 March–4 April 2014. [Google Scholar]
- Metwally, A.; Faloutsos, C. V-SMART-Join: A scalable mapreduce framework for all-pair similarity joins of multisets and vectors. PVLDB 2012, 5, 704–715. [Google Scholar] [CrossRef]
- Sarma, A.D.; He, Y.; Chaudhuri, S. ClusterJoin: A similarity joins framework using map-reduce. PVLDB 2014, 7, 1059–1070. [Google Scholar]
- Vernica, R.; Carey, M.J.; Li, C. Efficient parallel set-similarity joins using mapreduce. In Proceedings of the International Conference on Management of Data, Indianapolis, IN, USA, 6–10 June 2010. [Google Scholar]
- Wang, Y.; Metwally, A.; Parthasarathy, S. Scalable all-pairs similarity search in metric spaces. In Proceedings of the International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013. [Google Scholar]
- Hjaltason, G.R.; Samet, H. Incremental distance join algorithms for spatial databases. In Proceedings of the International Conference on Management of Data, Seattle, WA, USA, 2–4 June 1998. [Google Scholar]
- Shin, H.; Moon, B.; Lee, S. Adaptive and incremental processing for distance join queries. IEEE Trans. Knowl. Data Eng. 2003, 15, 1561–1578. [Google Scholar] [CrossRef]
- Mahmud, H.; Amin, A.M.; Ali, M.E.; Hashem, T.; Nutanong, S. A group based approach for path queries in road networks. In Proceedings of the International Symposium on Spatial and Temporal Databases, Munich, Germany, 21–23 August 2013. [Google Scholar]
- Mouratidis, K.; Yiu, M.L.; Papadias, D.; Mamoulis, N. Continuous nearest neighbor monitoring in road networks. In Proceedings of the International Conference on Very Large Data Bases, Seoul, Korea, 12–15 September 2006. [Google Scholar]
- Sankaranarayanan, J.; Alborzi, H.; Samet, H. Distance join queries on spatial networks. In Proceedings of the International Symposium on Geographic Information Systems, Arlington, VA, USA, 10–11 November 2006. [Google Scholar]
- Arain, Q.A.; Deng, Z.; Memon, I.; Zubedi, A.; Jiao, J.; Ashraf, A.; Khan, M.S. Privacy protection with dynamic pseudonym-based multiple mix-zones over road networks. China Commun. 2017, 14, 89–100. [Google Scholar] [CrossRef]
- Arain, Q.A.; Memon, I.; Deng, Z.; Memon, M.H.; Mangi, F.A.; Zubedi, A. Location monitoring approach: Multiple mix-zones with location privacy protection based on traffic flow over road networks. Multimedia Tools Appl. 2018, 77, 5563–5607. [Google Scholar] [CrossRef]
- Arain, Q.A.; Uqaili, M.A.; Deng, Z.; Memon, I.; Jiao, J.; Shaikh, M.A.; Zubedi, A.; Ashraf, A.; Arain, U.A. Clustering based energy efficient and communication protocol for multiple mix-zones over road networks. Wirel. Pers. Commun. 2017, 95, 411–428. [Google Scholar] [CrossRef]
- Domenic, M.K.; Wang, Y.; Zhang, F.; Memon, I.; Gustav, Y.H. Preserving users’ privacy for continuous query services in road networks. In Proceedings of the International Conference on Information Management, Innovation Management and Industrial Engineering, Xi’an, China, 23–24 November 2013. [Google Scholar]
- Gustav, Y.H.; Wang, Y.; Domenic, M.K.; Zhang, F.; Memon, I. Velocity similarity anonymization for continuous query Location based services. In Proceedings of the International Conference on Computational Problem-Solving, Jiuzhai, China, 26–28 October 2013. [Google Scholar]
- Kamenyi, D.M.; Wang, Y.; Zhang, F.; Memon, I. Authenticated privacy preserving for continuous query in location based services. J. Comput. Inform. Syst. 2013, 9, 9857–9864. [Google Scholar]
- Memon, I. Distance and clustering-based energy-efficient pseudonyms changing strategy over road network. Int. J. Commun. Syst. 2018, 31, 1–22. [Google Scholar] [CrossRef]
- Memon, I. Authentication user’s privacy: An integrating location privacy protection algorithm for secure moving objects in location based services. Wirel. Pers. Commun. 2015, 82, 1585–1600. [Google Scholar] [CrossRef]
- Memon, I.; Arain, Q.A. Dynamic path privacy protection framework for continuous query service over road networks. World Wide Web 2017, 20, 639–672. [Google Scholar] [CrossRef]
- Memon, I.; Arain, Q.A.; Zubedi, A.; Mangi, F.A. DPMM: Dynamic pseudonym-based multiple mix-zones generation for mobile traveler. Multimedia Tools Appl. 2017, 76, 24359–24388. [Google Scholar] [CrossRef]
- Memon, I.; Chen, L.; Arain, Q.A.; Memon, H.; Chen, G. Pseudonym changing strategy with multiple mix zones for trajectory privacy protection in road networks. Int. J. Commun. Syst. 2018, 31, 1–44. [Google Scholar] [CrossRef]
- Ali, M.E.; Tanin, E.; Zhang, R.; Kulik, L. A motion-aware approach for efficient evaluation of continuous queries on 3D object databases. VLDB J. 2010, 19, 603–632. [Google Scholar] [CrossRef]
- Giannikis, G.; Alonso, G.; Kossmann, D. SharedDB: Killing one thousand queries with one stone. PVLDB 2012, 5, 526–537. [Google Scholar] [CrossRef]
- Thomsen, J.R.; Yiu, M.L.; Jensen, C.S. Effective caching of shortest paths for location-based services. In Proceedings of the International Conference on Management of Data, Scottsdale, AZ, USA, 20–24 May 2012. [Google Scholar]
- Zhang, D.; Chow, C.-Y.; Li, Q.; Zhang, X.; Xu, Y. SMashQ: Spatial mashup framework for k-nn queries in time-dependent road networks. Distrib. Parall. Databases 2013, 31, 259–287. [Google Scholar] [CrossRef]
- Brinkhoff, T.; Kriegel, H.-P.; Seeger, B. Efficient processing of spatial joins using r-trees. In Proceedings of the International Conference on Management of Data, Washington, DC, USA, 26–28 May 1993. [Google Scholar]
- Chen, C.; Sun, W.; Zheng, B.; Mao, D.; Liu, W. An incremental approach to closest pair queries in spatial networks using best-first search. In Proceedings of the International Conference on Database and Expert Systems Applications, Toulouse, France, 29 August–2 September 2011. [Google Scholar]
- Koudas, N.; Sevcik, K.C. High dimensional similarity joins: Algorithms and performance evaluation. IEEE Trans. Knowl. Data Eng. 2000, 12, 3–18. [Google Scholar] [CrossRef]
- Makreshanski, D.; Giannikis, G.; Alonso, G.; Kossmann, D. MQJoin: Efficient shared execution of main-memory joins. PVLDB 2016, 9, 480–491. [Google Scholar] [CrossRef]
- 9th DIMACS Implementation Challenge: Shortest Paths. Available online: http://www.dis.uniroma1.it/challenge9/download.shtml (accessed on 15 June 2018).
- Corral, A.; Manolopoulos, Y.; Theodoridis, Y.; Vassilakopoulos, M. Multi-way distance join queries in spatial databases. GeoInformatica 2004, 8, 373–402. [Google Scholar] [CrossRef]
- Gao, Y.; Shou, L.; Chen, K.; Chen, G. Aggregate farthest-neighbor queries over spatial data. In Proceedings of the International Conference on Database Systems for Advanced Applications, Hong Kong, China, 22–25 April 2011. [Google Scholar]
- Wang, H.; Zheng, K.; Su, H.; Wang, J.; Sadiq, S.; Zhou, X. Efficient aggregate farthest neighbour query processing on road networks. In Proceedings of the Australasian Database Conference, Brisbane, Australia, 14–16 July 2014. [Google Scholar]
Figure 1.
Example of dynamic road networks (a) traffic condition at time ; (b) traffic condition at time .
Figure 1.
Example of dynamic road networks (a) traffic condition at time ; (b) traffic condition at time .

Figure 2.
Example where and .

Figure 3.
Example of an -distance join query in a road network.

Figure 4.
Grouping outer and inner objects (a) and ; (b) and .

Figure 5.
Determination of the distance from to (a) If , then ; (b) If , then ; (c) If , then .

Figure 6.
Computation of the distance from to (a) If , ; (b) If , .

Figure 7.
Computation of the distance from to (a) ; (b) ; (c) .

Figure 8.
Investigating the number of outer segments adjacent to an intersection vertex (a) ; (b) ; (c) .
Figure 8.
Investigating the number of outer segments adjacent to an intersection vertex (a) ; (b) ; (c) .

Figure 9.
Simple heuristic .

Figure 10.
Computation of the distance from to (a) ; (b) ; (c) ; (d) .

Figure 11.
Computation of the distance from to (a) ; (b) ; (c) ; (d) .

Figure 12.
Computation of the distance from to (a) ; (b) ; (c) .

Figure 13.
Computation of the distance from to (a) ; (b) ; (c) .

Figure 14.
Computation of the distance from to (a) ; (b) ; (c) .

Figure 15.
Comparison of the baseline, naive EDISON, and EDISON methods for CAL (a) varying ; (b) varying ; (c) varying and ; (d) varying the distributions of objects.
Figure 15.
Comparison of the baseline, naive EDISON, and EDISON methods for CAL (a) varying ; (b) varying ; (c) varying and ; (d) varying the distributions of objects.

Figure 16.
Comparison of the baseline, naive EDISON, and EDISON methods for FLA (a) varying ; (b) varying ; (c) varying and ; (d) varying the distributions of objects.
Figure 16.
Comparison of the baseline, naive EDISON, and EDISON methods for FLA (a) varying ; (b) varying ; (c) varying and ; (d) varying the distributions of objects.

Figure 17.
Comparison of the baseline, naive EDISON, and EDISON methods for COL (a) varying ; (b) varying ; (c) varying and ; (d) varying the distributions of objects.
Figure 17.
Comparison of the baseline, naive EDISON, and EDISON methods for COL (a) varying ; (b) varying ; (c) varying and ; (d) varying the distributions of objects.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
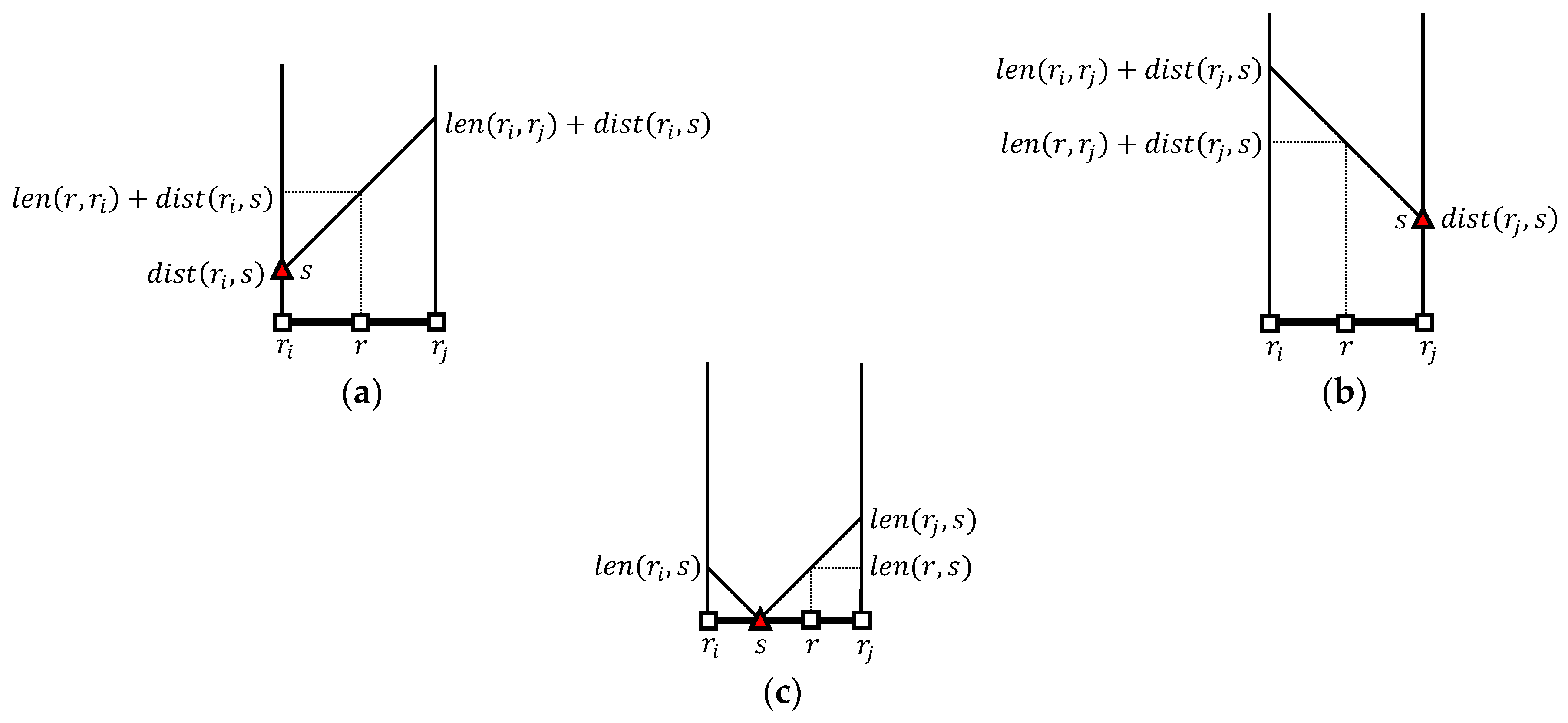{kind=link}
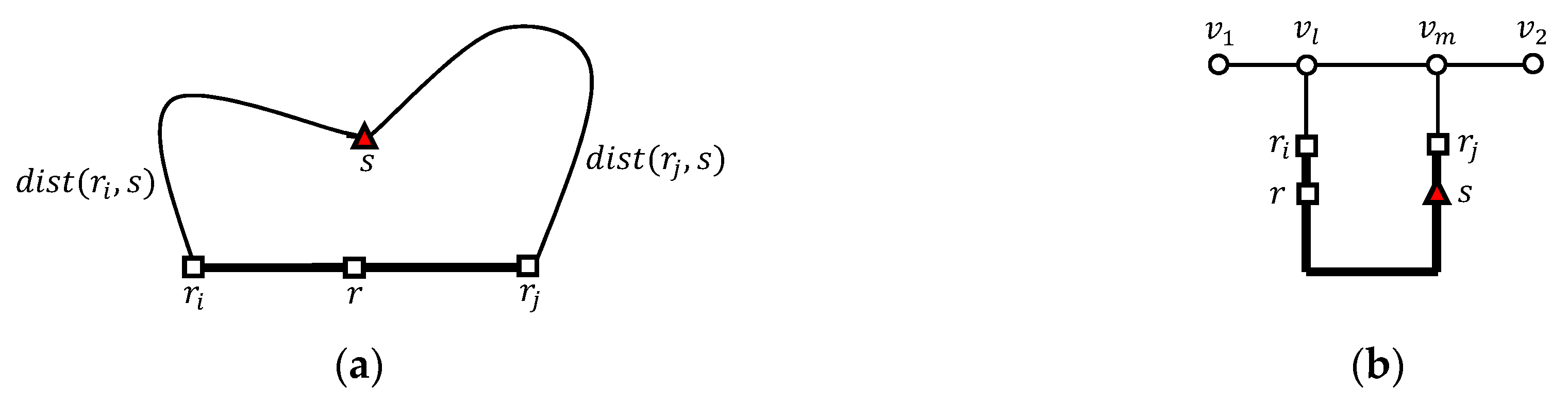{kind=link}
{kind=link}
{kind=link}
{kind=link}
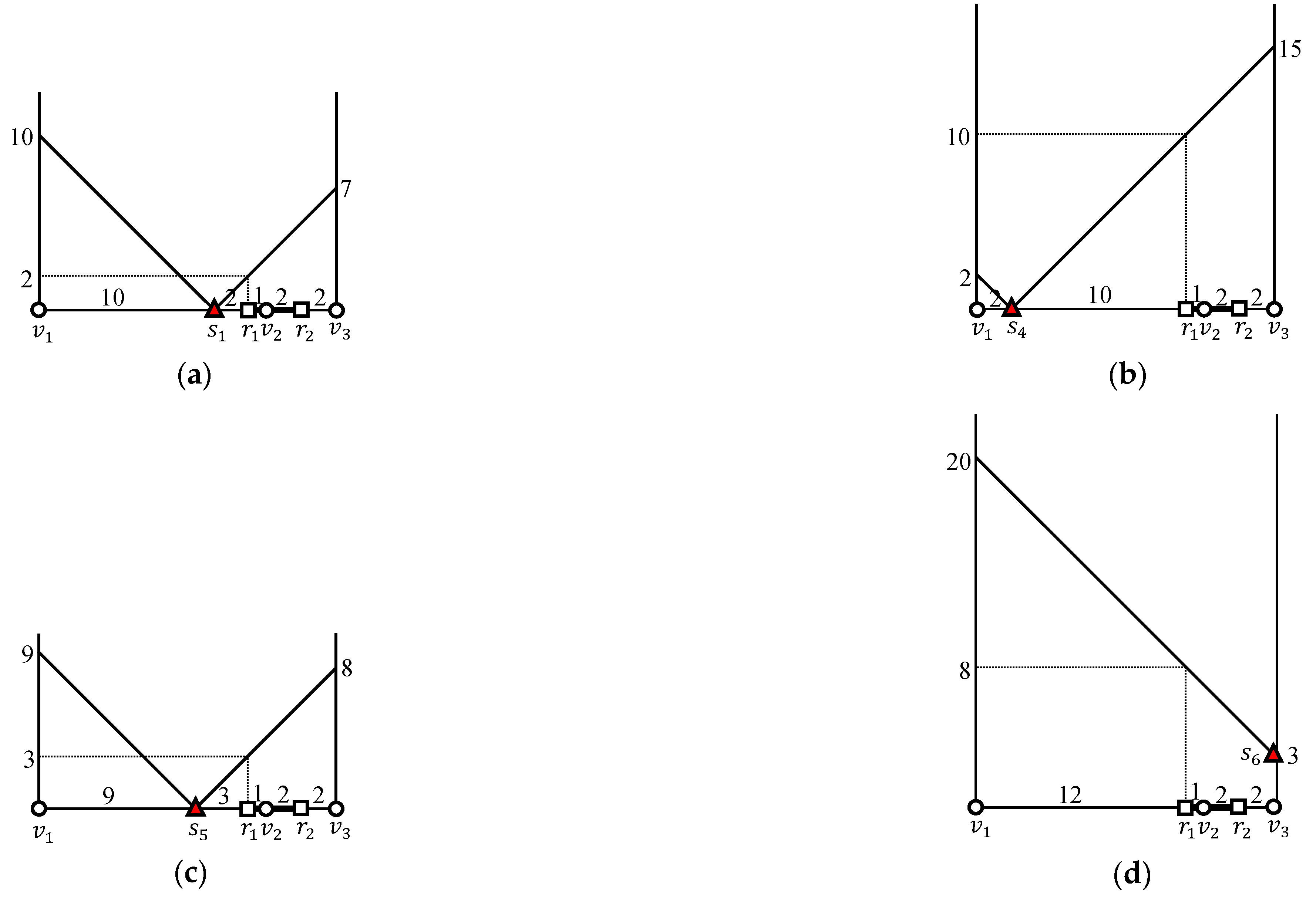{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Symbols and their meaning.
| Symbol | Definition |
|---|---|
| Threshold distance | |
| Query distance at a point such that | |
| Outer object | |
| Inner object | |
| Length of the shortest path connecting two points and in the road network | |
| Length of the segment connecting two points and , such that both and are located in the same vertex sequence | |
| Vertex sequence where and are not intermediate vertices and the other vertices, , are intermediate vertices | |
| Outer segment that consists of outer objects in a vertex sequence | |
| Set of inner objects within distance from a point , i.e., | |
| Set of inner objects in a segment , i.e., | |
| Range query that returns a set of inner objects within distance from a point | |
| Number of outer segments in vertex sequences adjacent to an intersection vertex |
Table 2.
Computation of for and .
| Condition | |
|---|---|
Table 3.
Computation of using the naive EDISON algorithm.
Table 4.
Computation of using the EDISON algorithm.
Table 5.
Real-world roadmaps.
| Name | Description | Number of Vertices | Number of Edges | Number of Vertex Sequences |
|---|---|---|---|---|
| CAL | California and Nevada | 1,890,815 | 2,315,222 | 1,794,708 |
| FLA | Florida | 1,070,376 | 1,343,951 | 1,100,675 |
| COL | Colorado | 435,666 | 521,200 | 374,355 |
Table 6.
Experimental parameter settings.
| Parameter | Range |
|---|---|
| Threshold distance () | 0.005, 0.01, 0.03, 0.05, 0.1 |
| Numbers of outer objects () and inner objects () | 1, 5, 10, 20, 30 () for CAL and FLA 1, 3, 5, 7, 10 () for COL |
| Distributions of outer objects | (C)entroid, (U)niform |
| Distributions of inner objects | (C)entroid, (U)niform |
| Real-world roadmaps | CAL, FLA, COL |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Cho, H.-J. Shared Execution Approach to ε-Distance Join Queries in Dynamic Road Networks. ISPRS Int. J. Geo-Inf. 2018, 7, 270. https://doi.org/10.3390/ijgi7070270
AMA Style
Cho H-J. Shared Execution Approach to ε-Distance Join Queries in Dynamic Road Networks. ISPRS International Journal of Geo-Information. 2018; 7(7):270. https://doi.org/10.3390/ijgi7070270
Chicago/Turabian StyleCho, Hyung-Ju. 2018. "Shared Execution Approach to ε-Distance Join Queries in Dynamic Road Networks" ISPRS International Journal of Geo-Information 7, no. 7: 270. https://doi.org/10.3390/ijgi7070270
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.