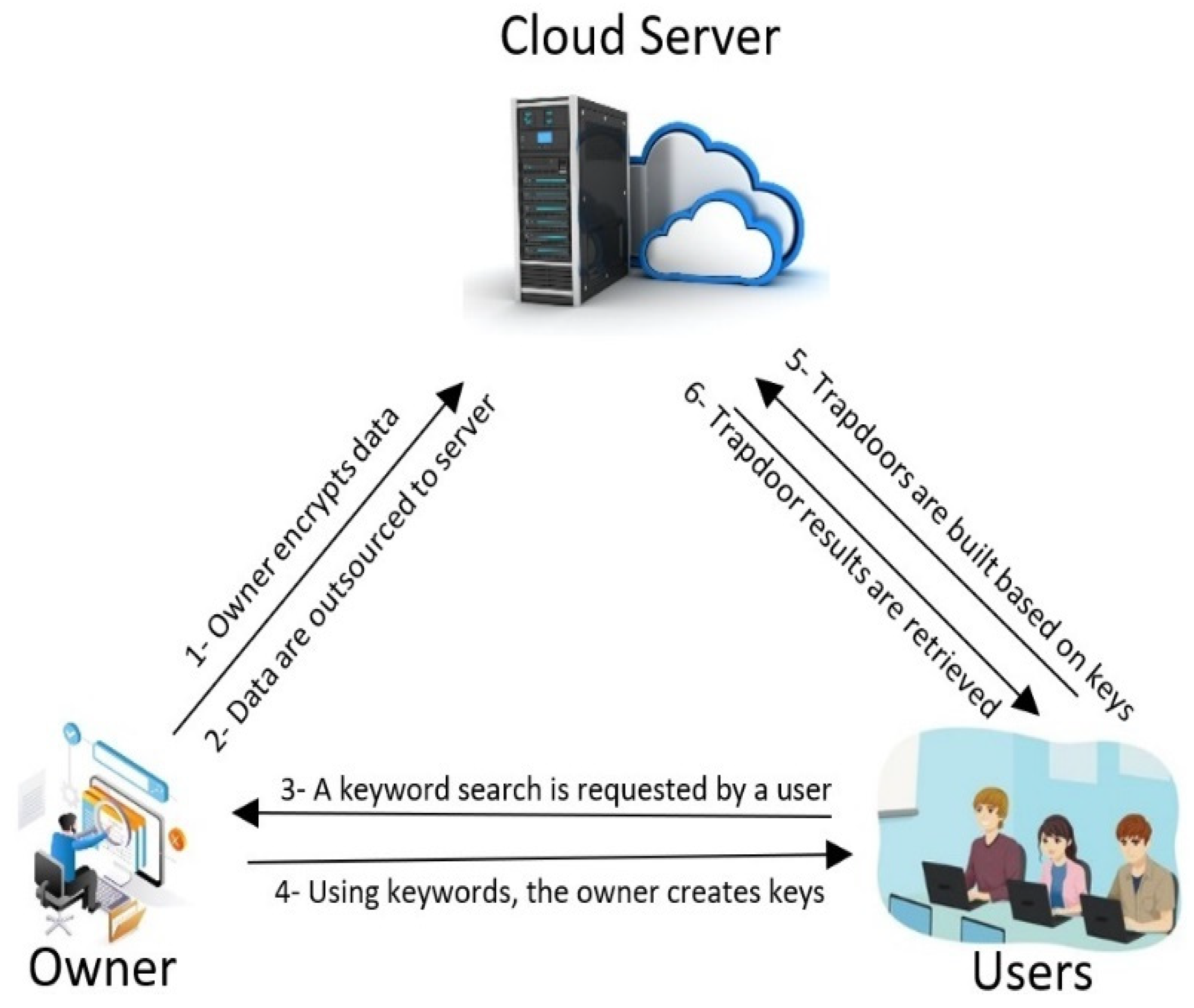
6.1. Comparison of the Performance of Our Scheme
Proof of Theorem 1. In our scheme, the transcript is performed as follows: At each update request, data are stored as () pairs in the encrypted database EDB on the server. EDB is initially empty. Also included are lists of locations of encrypted values retrieved from the server when a keyword is searched for. We assume that is the total length of the transcript. The simulator operates as follows. On starting, creates an empty EDB and an empty list. By randomly sampling from , calculates () during an update query. Let the timestamp of the update be , and let t be the time it occurred. An entry in is stored as ). Null entries are returned for timestamps that do not correspond to updates. Leakage functions such as and are used in the simulator during a keyword search. Using , the timestamps of previously updated keywords are derived based on the timestamps of updates from , represented as , and the addresses are sent to the server as they are stored in for The inference of document identifiers containing the search keyword from is carried out by the . This is carried out when a keyword search is completed. is used here to prove the security of our scheme. □
|
|
| 1: |
|
| 2: |
|
| 3: |
|
| 4: |
|
| 5: |
|
| 6: |
|
| 7: |
|
| 11: |
|
| 12: |
|
. This hybrid is the same as for the previous game, except for one difference. A keyword’s value
is computed during an update for
and is either zero or one, and the values are chosen randomly from the range of the function
.
entries are maintained in a list
. In the case where the
i-th operation is an update, the entry
will be used to save the sampled random values along with the operation input
for
1, …,
. If it is not an update operation, the entry will contain a null value. When searching for a particular keyword
, the game initiates a scan of
to find entries that are a match for
. Subsequently, the game sends the associated
Addr values to the server and awaits a response. Afterward, the game conducts another scan of
to infer
, which denotes the collection of documents that currently hold
. This set is then transmitted to the server.
The security of the
ensures that
cannot be differentiated from
, since the
is never evaluated with the same input during updates in
. The game referred to as
is formally defined in
Figure 3a, and utilizes the
Sim simulator as described above. It is evident that the generated transcript adheres to the same probability distribution as the one created during
.
This is because the leakage functions correspond to identical values computed in that game, and when a uniformly random value
is selected, the resulting
also follows a uniform random distribution.
|
|
| 1: |
|
| 2: |
|
| 3: |
|
| 4: |
|
| 5: |
|
| 6: |
|
| 7: |
|
| 11: |
|
| 12: |
|
In regard to the accuracy of our approach, it should be mentioned that if is not a pseudorandom function (as it is in our implementation), there is a possibility of collisions arising when calculating and for various and pairs. This probability can be significantly reduced by expanding the range of .
6.2. Performance Evaluation
The
[
23] and
[
24] share similarities with our proposed approach in terms of achieving privacy for multiple users, and we, therefore, compared the execution times of these algorithms. This comparison included evaluating the time taken for index generation, client storage, and the search process. We carried out these experiments on a single computer, and the encrypted database was kept in the memory of the same computer, without the need for a WAN network. Two computers in different countries (Iraq and the UAE) were used to calculate the round-trip time for the data, and the result was approximately 2 ms. Our main focus was to calculate the time spent on searching and updating operations, in addition to the communication size and the amount of storage required for each plan on the client side.
To implement the proposed scheme and assess its efficiency, we used the Java language on the Windows 11 operating system, with an x64-based processor. The comparison schemes were applied to a real dataset called
[
31]. The selected ranges in the experimental evaluation, including dataset size, dictionary size, and other parameters, are pivotal for comprehending the performance and generalizability of the proposed (DSSE) scheme in real-world scenarios. The dataset comprises an extensive collection of textual email exchanges among Enron employees. Notably, the dataset is characterized by its considerable size, offering a diverse and realistic sample that proves valuable for testing information retrieval systems. The test results were obtained on a computer equipped with an Intel(R) Core(TM) i5-10210U CPU @ 1.60GHz 2.11 GHz, 8GB of RAM, and a 512 GB SSD hard disk. To enable a comparative analysis of our proposed scheme with existing ones, the time cost and running time results for SSMDO and Al-Najafy, as reported in [
24], have been referenced.
Metrics include index generation time, measuring the efficiency of the setup process; search process efficiency, evaluating the time complexity of the search algorithm; communication overhead, quantifying data transmission during operations; storage requirements, analyzing client-side storage; and round-trip time for data transfer, simulating real-world scenarios. The Enron [
31] dataset served as the foundation for evaluations, conducting experiments on computers across various countries to authentically assess communication expenditures. Recognized as an authentic database and a live illustration of the system’s application in a real-world environment, this approach allowed for a comprehensive and realistic evaluation of the system’s performance. The results, analyzed in the experimental evaluation, reveal the DSSE scheme’s remarkable efficiency in index generation, outperforming existing methodologies. The search process efficiency, communication overhead, and storage requirements demonstrate the lightweight nature of the design. The round-trip time for data transfer showcases the scheme’s practicality in a distributed environment. The DSSE scheme ensures privacy preservation and exhibits superior efficiency. The comprehensive experimental evaluation validates the approach, with future work focusing on enhancing system security through a verification mechanism for the authenticity and integrity of results.
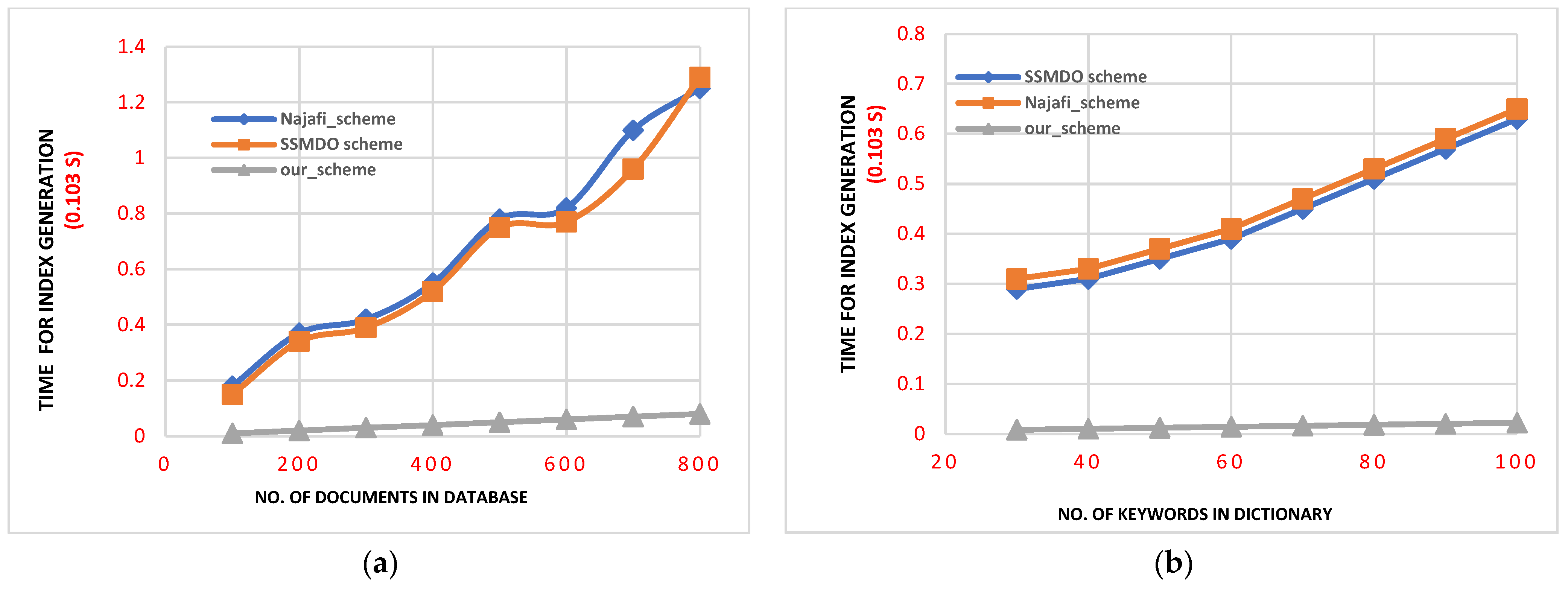
Index generation. In the proposed scheme, the encrypted index is created by performing a continuous update process for each keyword. The index is represented as a set of ordered pairs consisting of a value and a key. We note that our scheme utilizes symmetric encryption. The updating procedure exhibits a time complexity of , indicating that as the size of the encrypted index increases, the required time for the process does not escalate linearly. This aspect is straightforward in our scheme. In the and methodologies for constructing encrypted indexes, the index data structure comprises two numerical components along with a vector component. It also keeps track of the size of the dictionary used in the system.
The approach has two additional numerical components in the index structure, meaning that more exponentiation operations need to be performed. The time it takes to generate the index is influenced by two factors: the number of documents in the dataset and the total number of keywords defined in the system.
From
Figure 2, we can see the variations in the time it takes to generate an index due to changes in these two factors across the three different schemes (
, and our proposed scheme). By comparing the diagrams, we can see that our scheme performs the index generation process in a shorter amount of time than the other schemes, indicating that it is the most efficient in terms of index generation.
Figure 2 shows the time taken to generate an encrypted index in two different scenarios.
Figure 2a shows the impact of varying the dataset size while keeping the dictionary size constant at
n = 50, while
Figure 2b shows the effect of varying the dictionary size while maintaining a constant dataset size of
m = 262. The figures provide insights into how the index generation time changes in relation to these factors.
Trapdoor generation. It should be noted that the schemes under comparison outperform our proposed scheme for trapdoor generation. This distinction arises from the fact that our scheme calculates the locations of values in the encrypted database for a specific keyword at the client before initiating the search query for that keyword. In contrast, in our scheme, the time expended by the server in retrieving results is notably quicker than in comparable schemes. This discrepancy underscores the efficiency of our scheme in the subsequent comparison.
Search process. The selection of dataset size and dictionary size for experimental variations is a nuanced process influenced by practical considerations and relevance to real-world scenarios. The chosen ranges (100 to 800 for dataset size and 30 to 100 for the number of keywords) are motivated by several factors. They may reflect realistic expectations in the application domain, mirroring document or record quantities in a typical database, and the diversity of searchable terms. Additionally, the ranges enable scalability assessments, testing the system’s performance with varying dataset and dictionary sizes. Considerations for resource constraints, trade-off analysis, benchmarking against other schemes, and statistical significance underscore the deliberate and comprehensive nature of the experimental design.
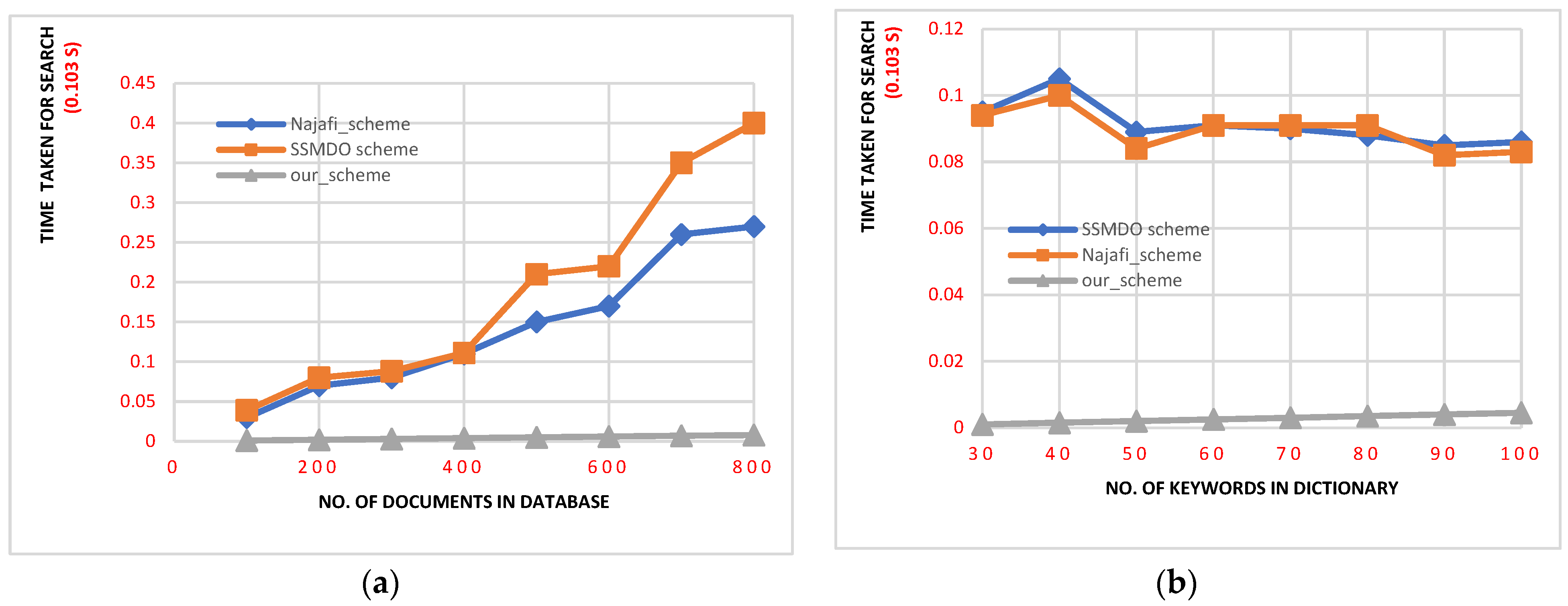
The figures presented above illustrate a direct correlation between the size of the result set and the corresponding search time across all schemes, indicating a linear increase in search time as result size grows. Bilinear pairing plays an important role in the search algorithm for both the
SSMDO and
Najafi schemes; however, this imposes a significant computational overhead, and the frequency of its application directly impacts the time complexity of the search algorithm. From
Figure 3, we can observe how the time complexity changes for each scheme as we increase two key factors: the dataset size and the dictionary size. For all of the executions, our scheme consistently outperformed the
Najafi scheme, which is the only other scheme with the same type of information leakage. The predominant portion of the time is allocated to client-side operations within our proposed scheme, with the server primarily tasked with retrieving precomputed location results, thus minimizing its computational workload.
Figure 3a demonstrates that as the dataset size increases, the time cost of the search process also increases almost linearly. Interestingly, despite using the same number of pairings, the
and
schemes show a steeper increase in the search time cost compared to our scheme. This suggests that the search algorithm used in our approach is more efficient. Furthermore,
Figure 3b shows that the time cost of the search algorithm remains relatively independent of the size of the dictionary; in other words, the size of the dictionary does not significantly impact the time required for the search process. Overall, these findings highlight the efficiency and effectiveness of the proposed scheme’s search algorithm in comparison to the
and
schemes, considering the computational overhead of the bilinear pairing map. This result is not surprising, since the
and
schemes rely on bilinear pairings to achieve privacy in both directions, whereas our scheme uses symmetric encryption.
Figure 3 shows the time taken for a search operation, measured in terms of the time cost.
Figure 3 is divided into two parts:
Figure 3a represents the variations in search time with different dataset sizes while maintaining a constant dictionary size of
n = 50, and
Figure 3b showcases the changes in search time with different dictionary sizes while keeping the dataset size constant at
m = 262. These figures help us understand how the search time is influenced by these factors.
Figure 3.
(a) The relationship between search time and different dataset sizes, holding a constant dictionary size of n = 50. (b) The impact of various dictionary sizes on search time, with a fixed dataset size of m = 262.
Figure 3.
(a) The relationship between search time and different dataset sizes, holding a constant dictionary size of n = 50. (b) The impact of various dictionary sizes on search time, with a fixed dataset size of m = 262.


 ,
, 




{kind=link}
{kind=link}
{kind=link}