Malicious Node Detection Using a Dual Threshold in Wireless Sensor Networks

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background
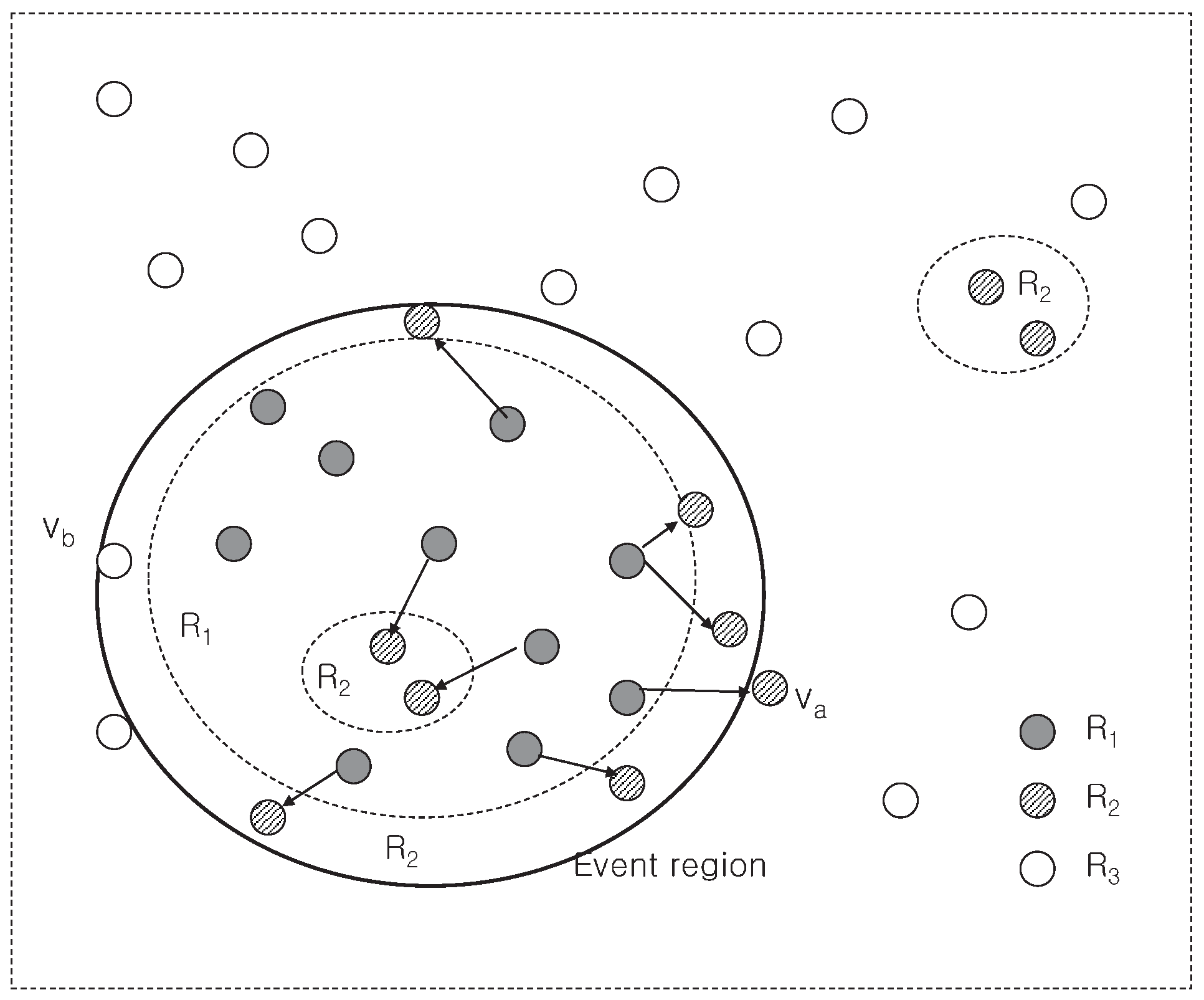
2.1. Network Model and Event Model
2.2. Fault Model
3. Malicious Node Detection Using a Dual Threshold
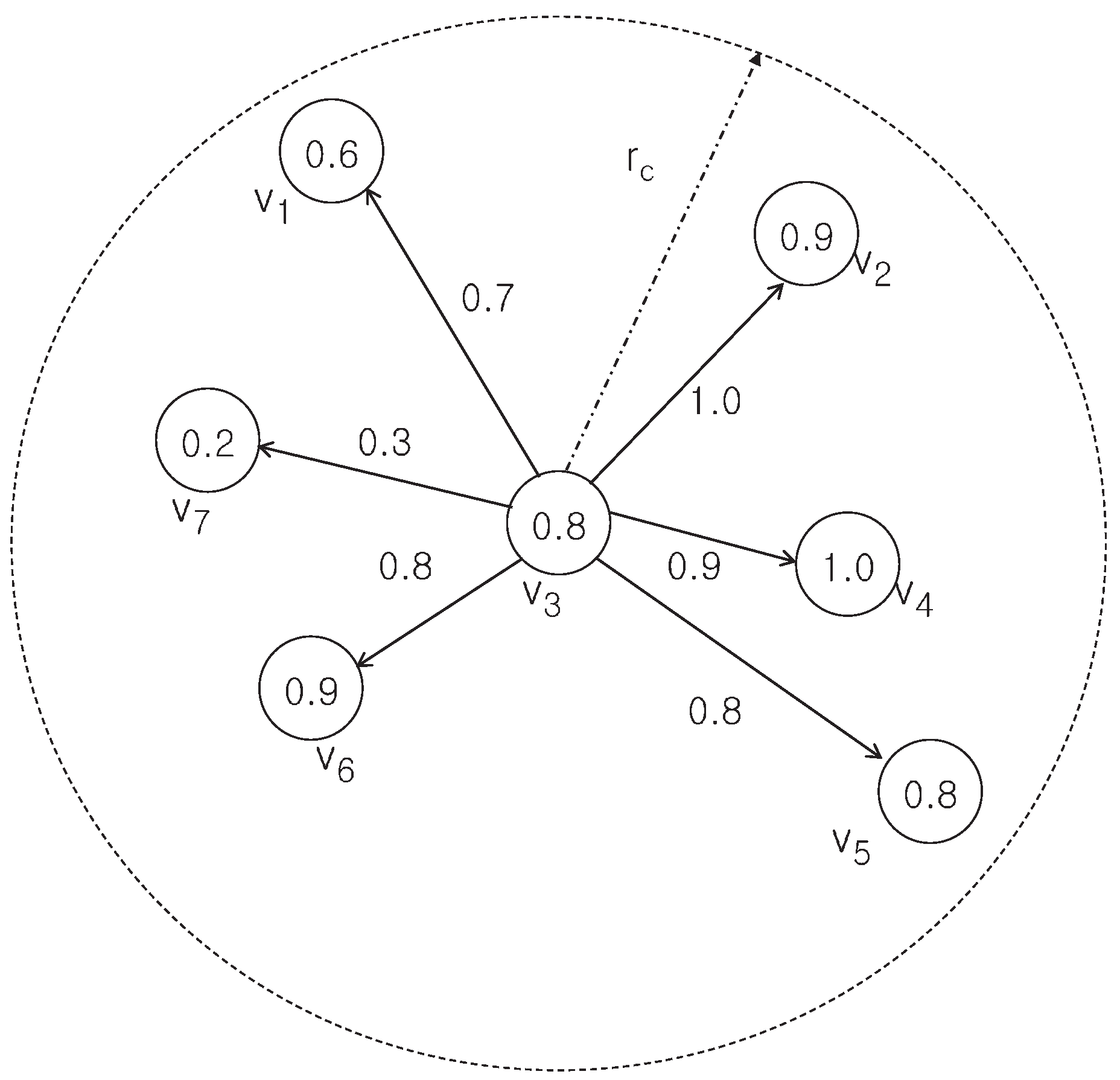
3.1. Representation of Node Trusts Using a Digraph
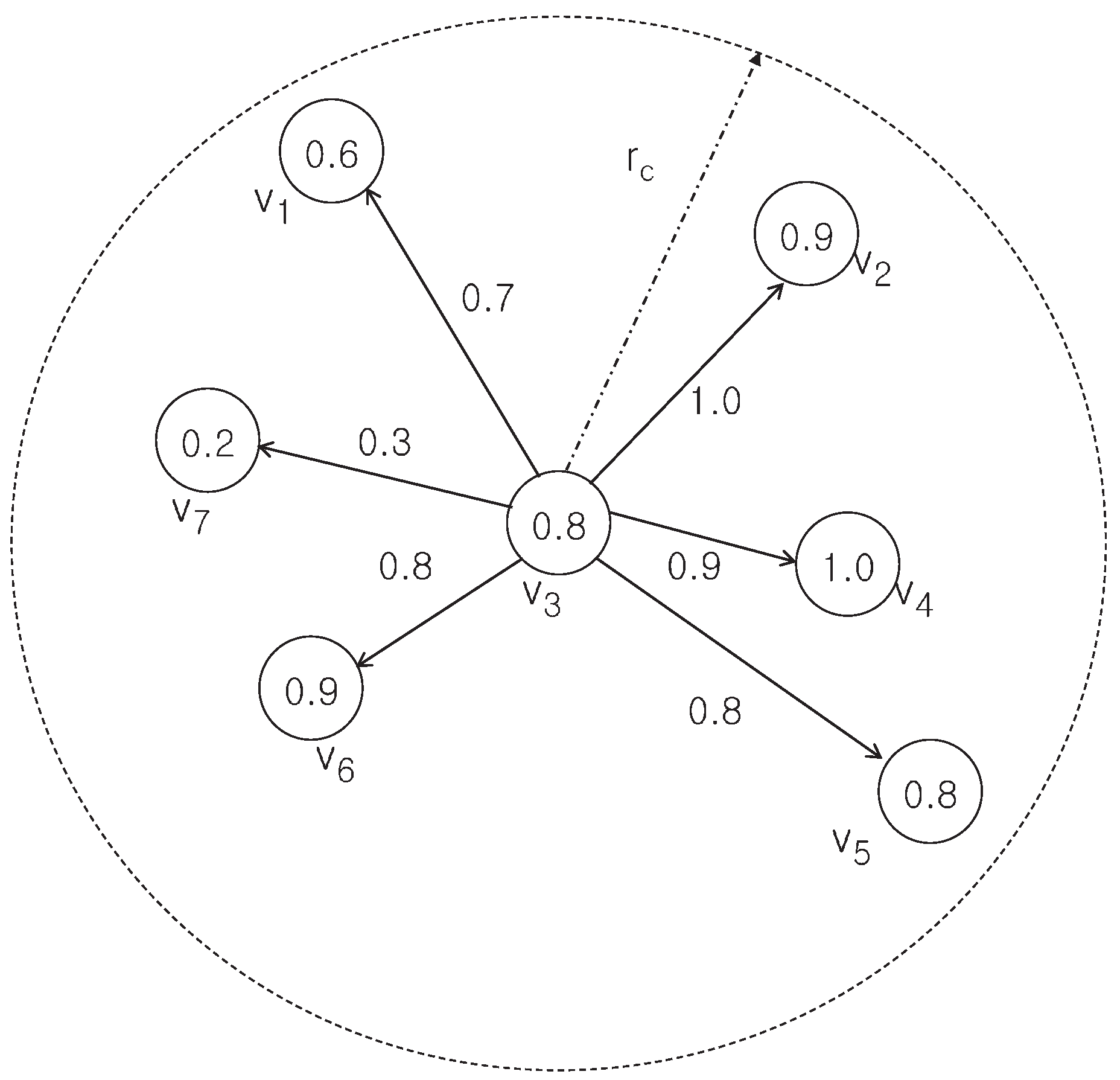
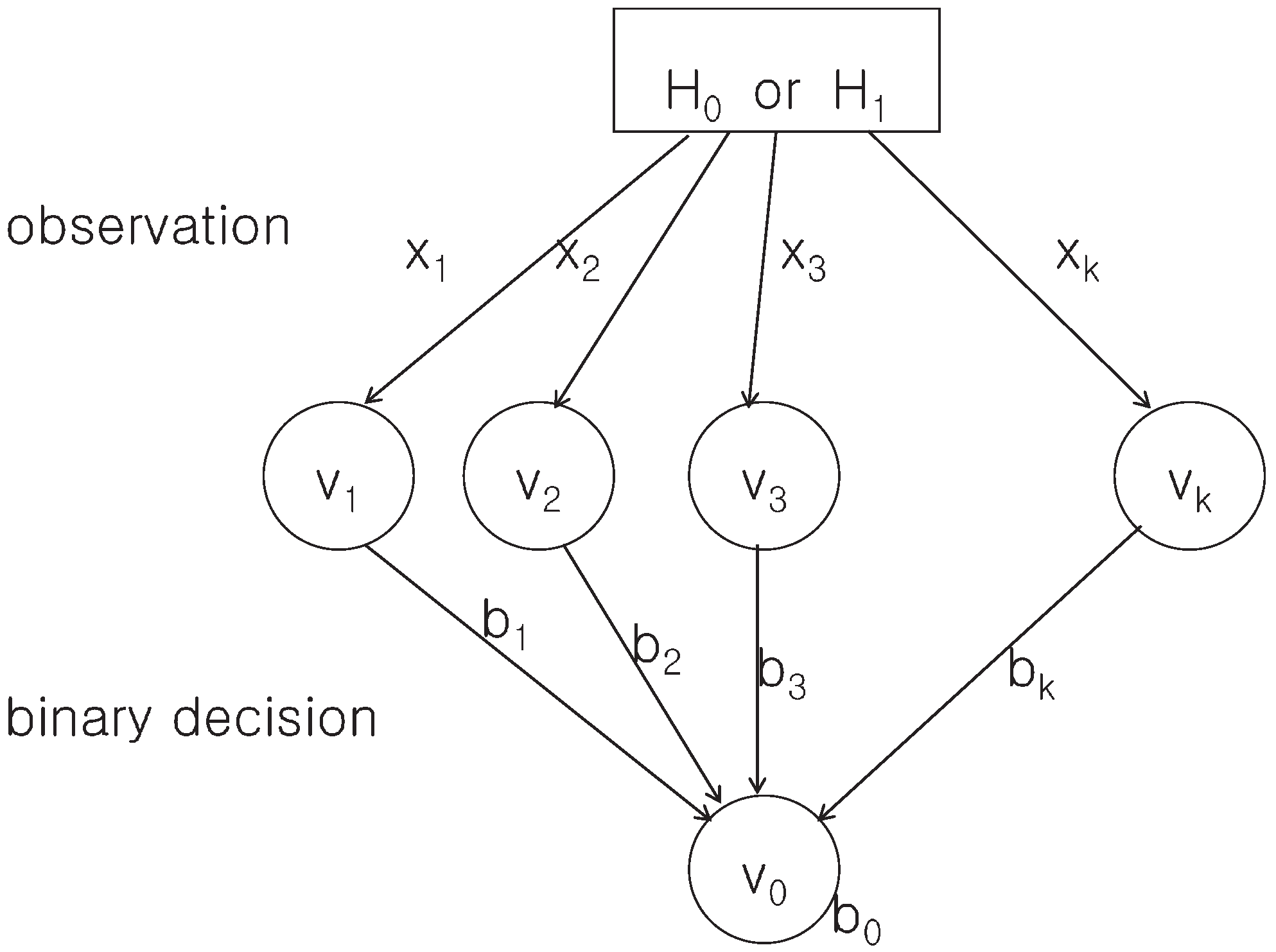
3.2. Modeling Event Detection Problem
3.3. Event Detection Using a Dual Threshold
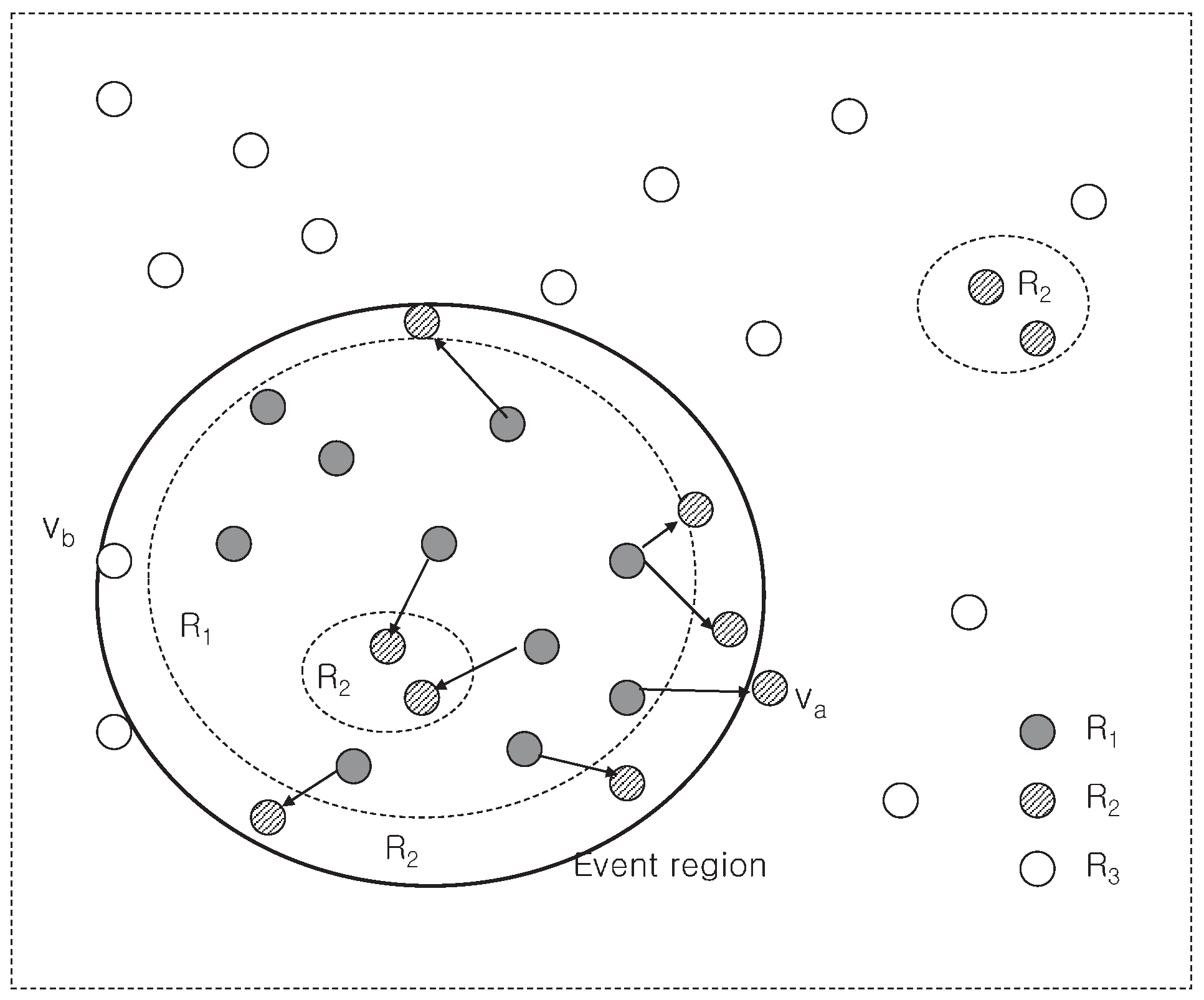
3.4. Updating Trust Values to Detect Malicious Nodes
| Malicious Node Detection Scheme |
| 1. Obtain the sensor readings of neighbors of |
| 2. Compute at each node |
| 3. Divide the n nodes into three groups , and |
| if |
| if |
| otherwise |
| 4. If 0, then H = 1 (i.e., an event) |
| Determine that is an event node if () or (, , ) |
| If 0, then H = 0 (i.e., no-event) |
| 5. Update weights, and , accordingly |
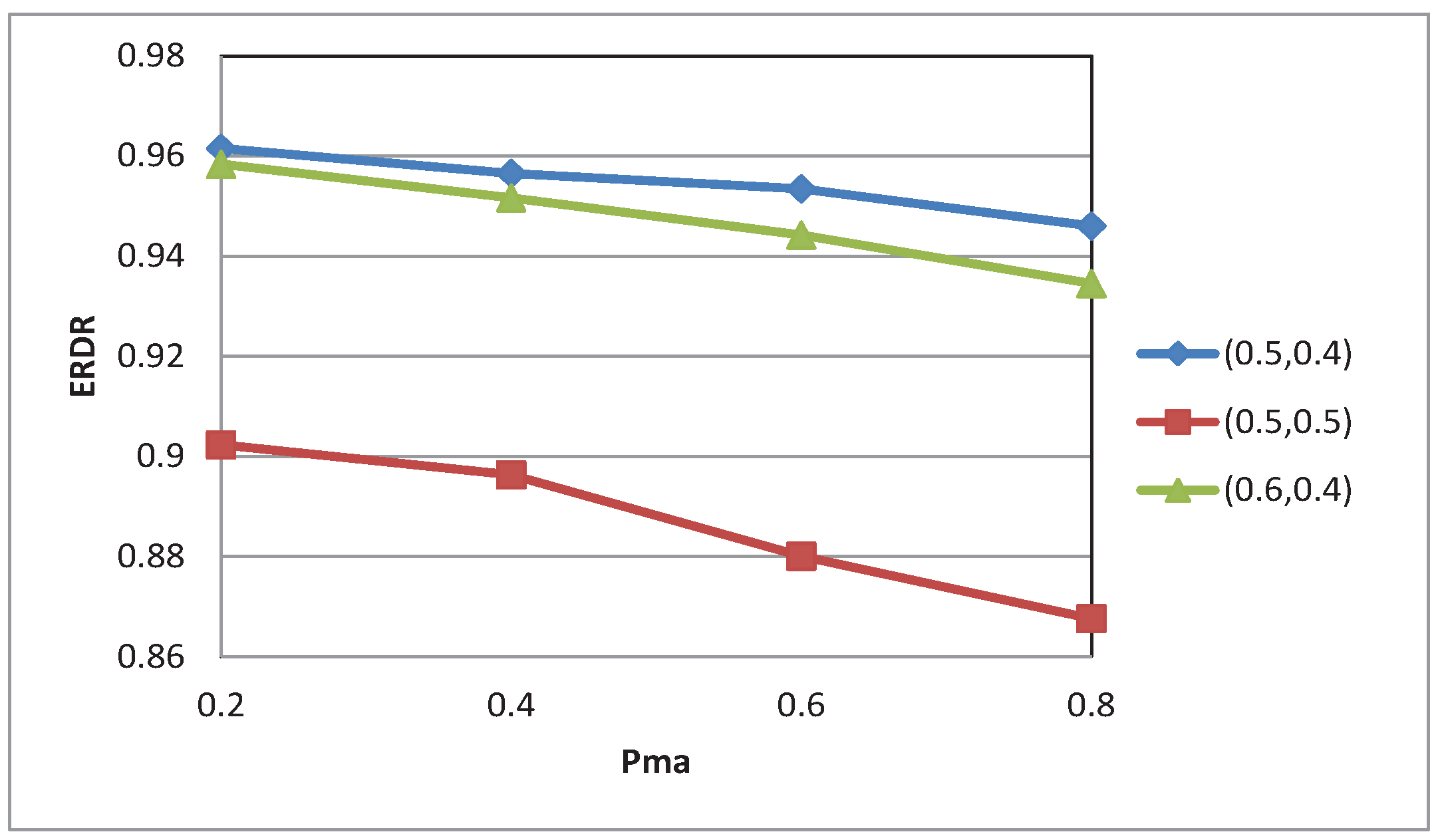
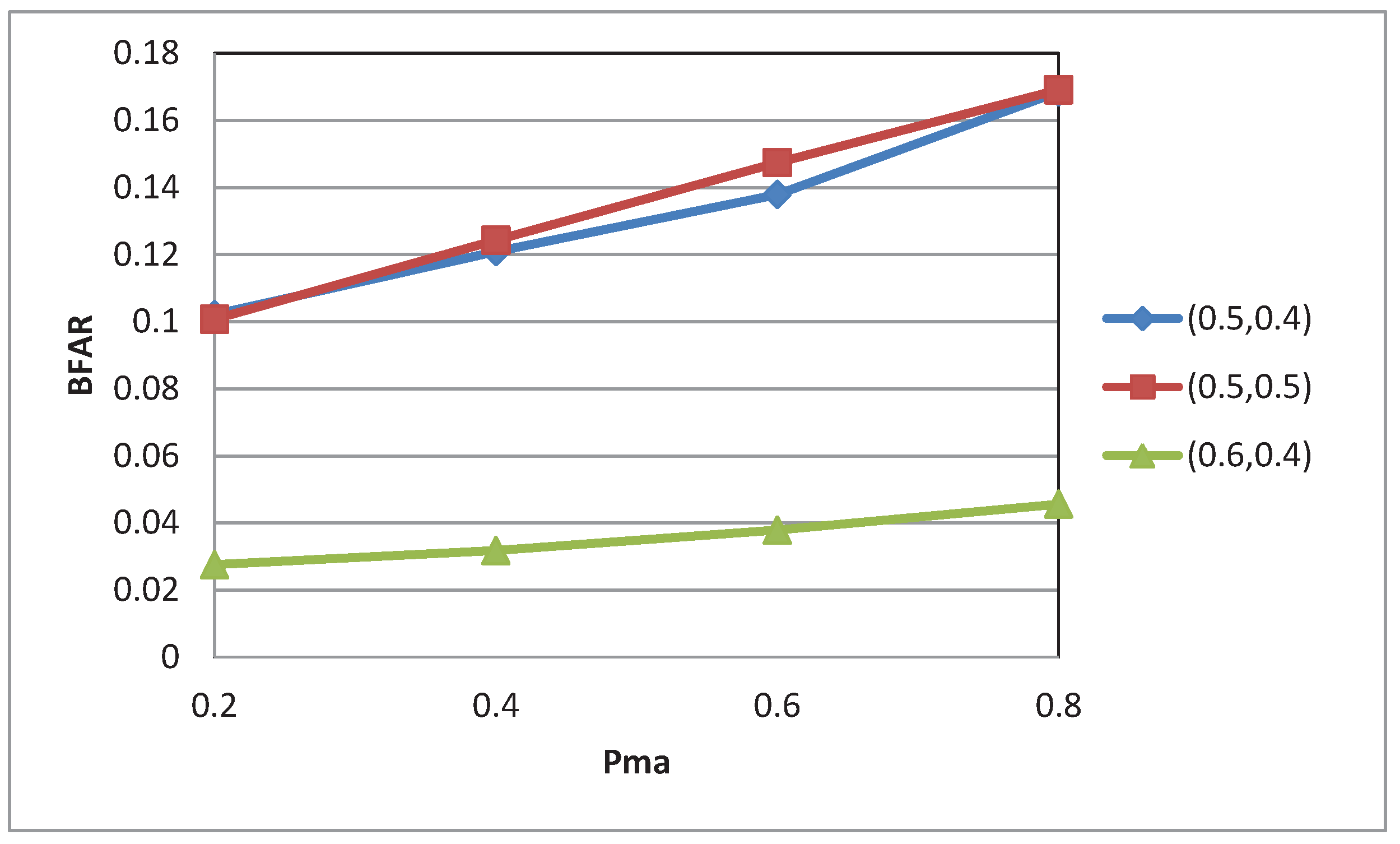
4. Performance Evaluation
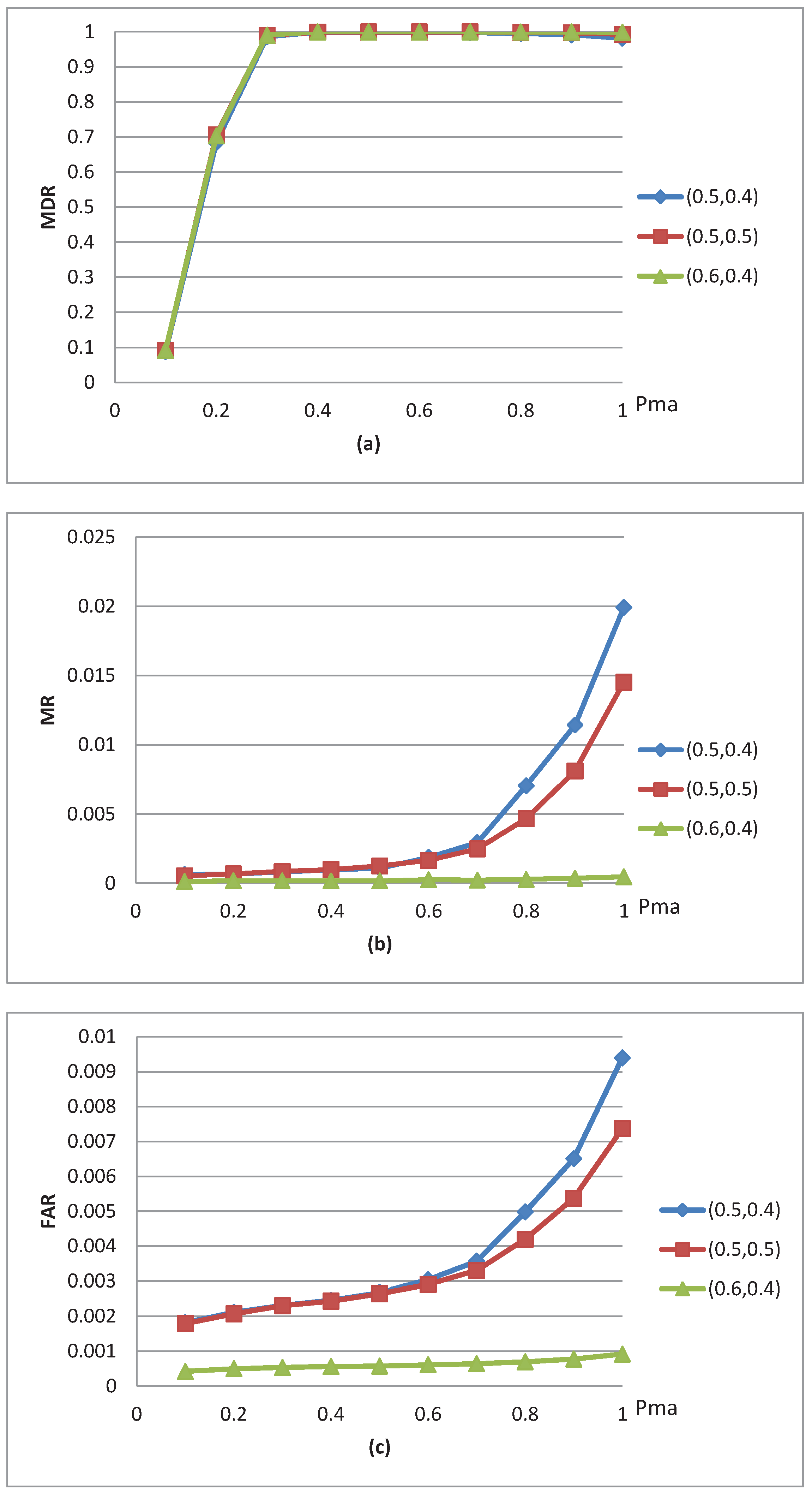
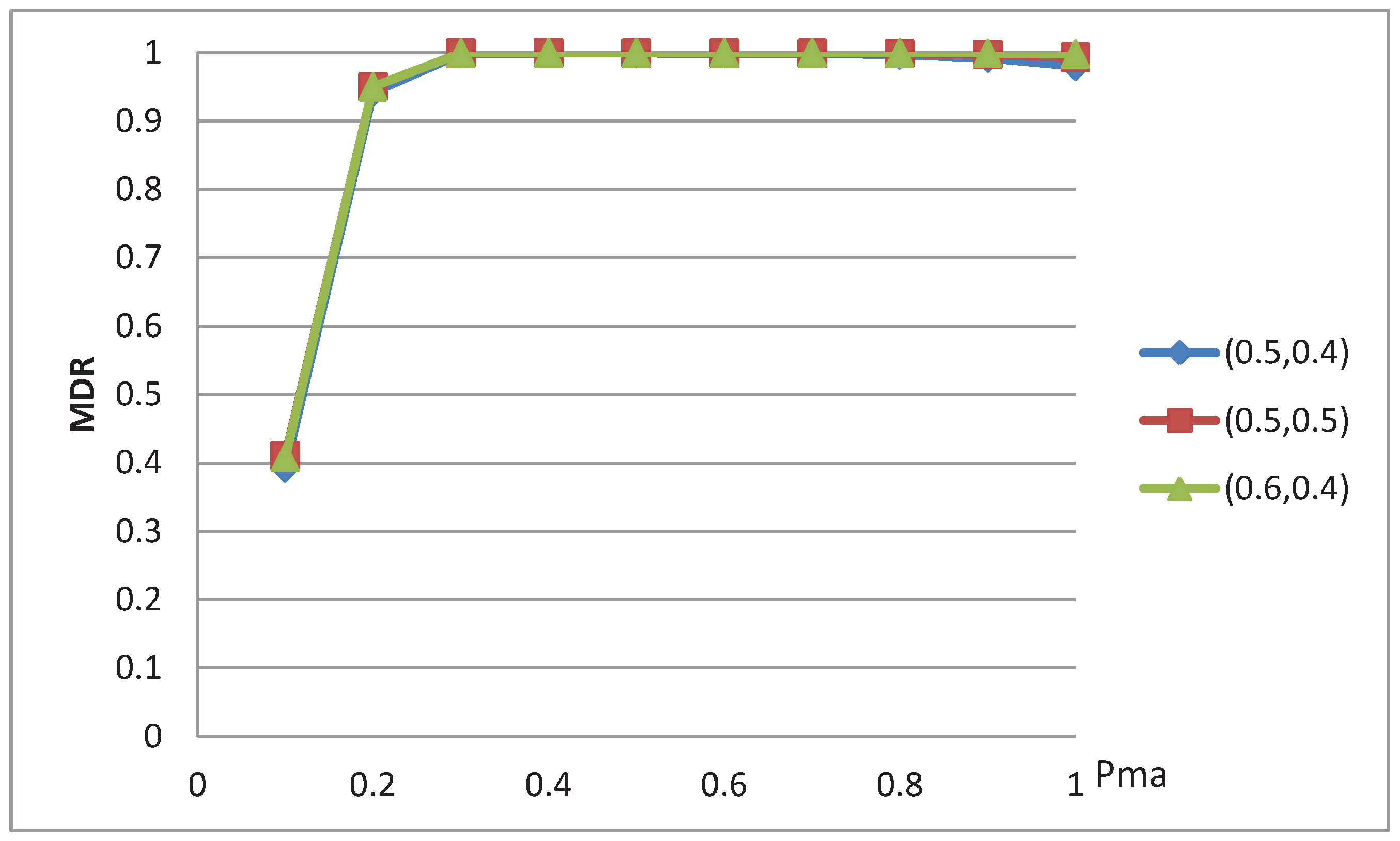
4.1. Simulation Setup
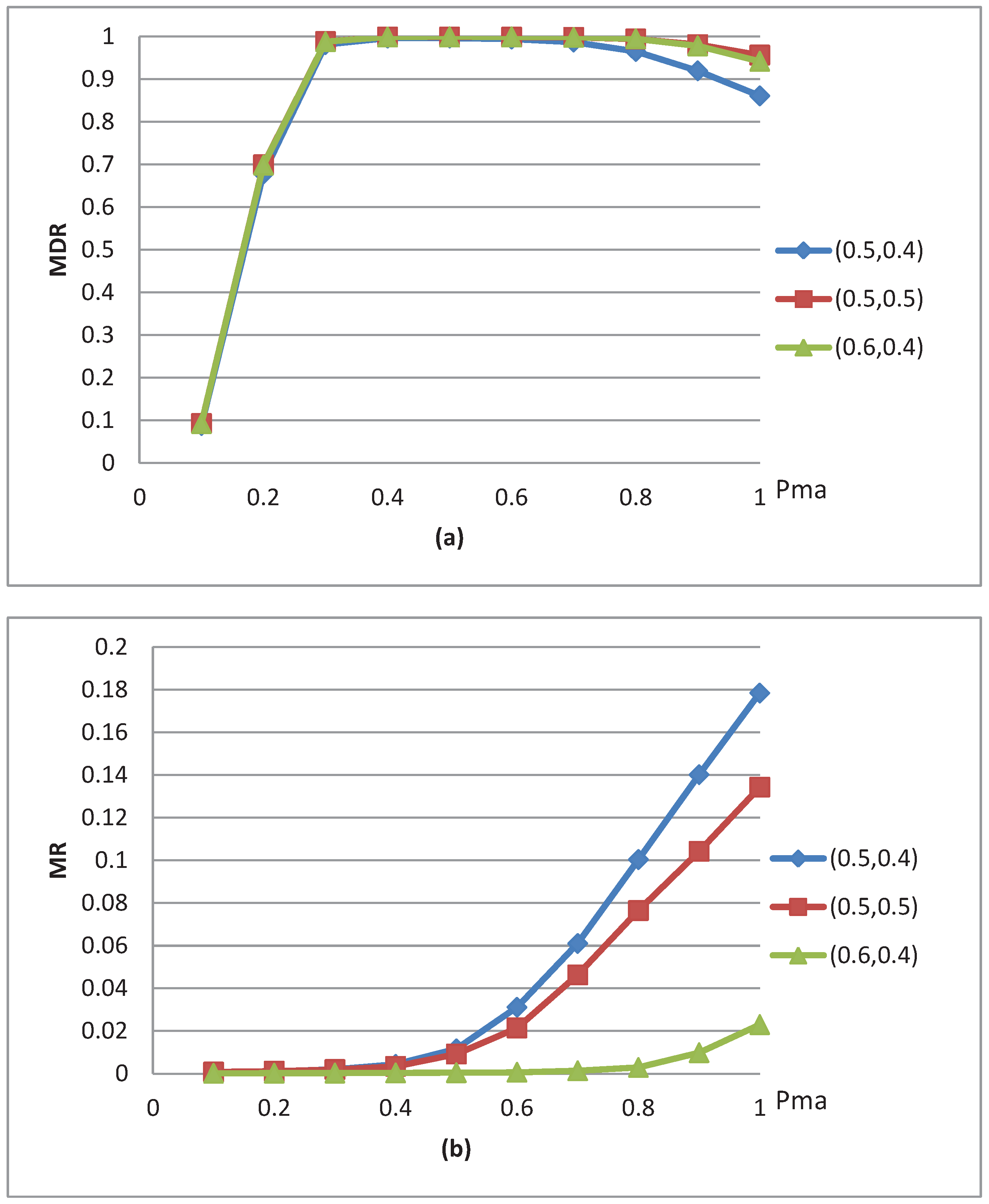
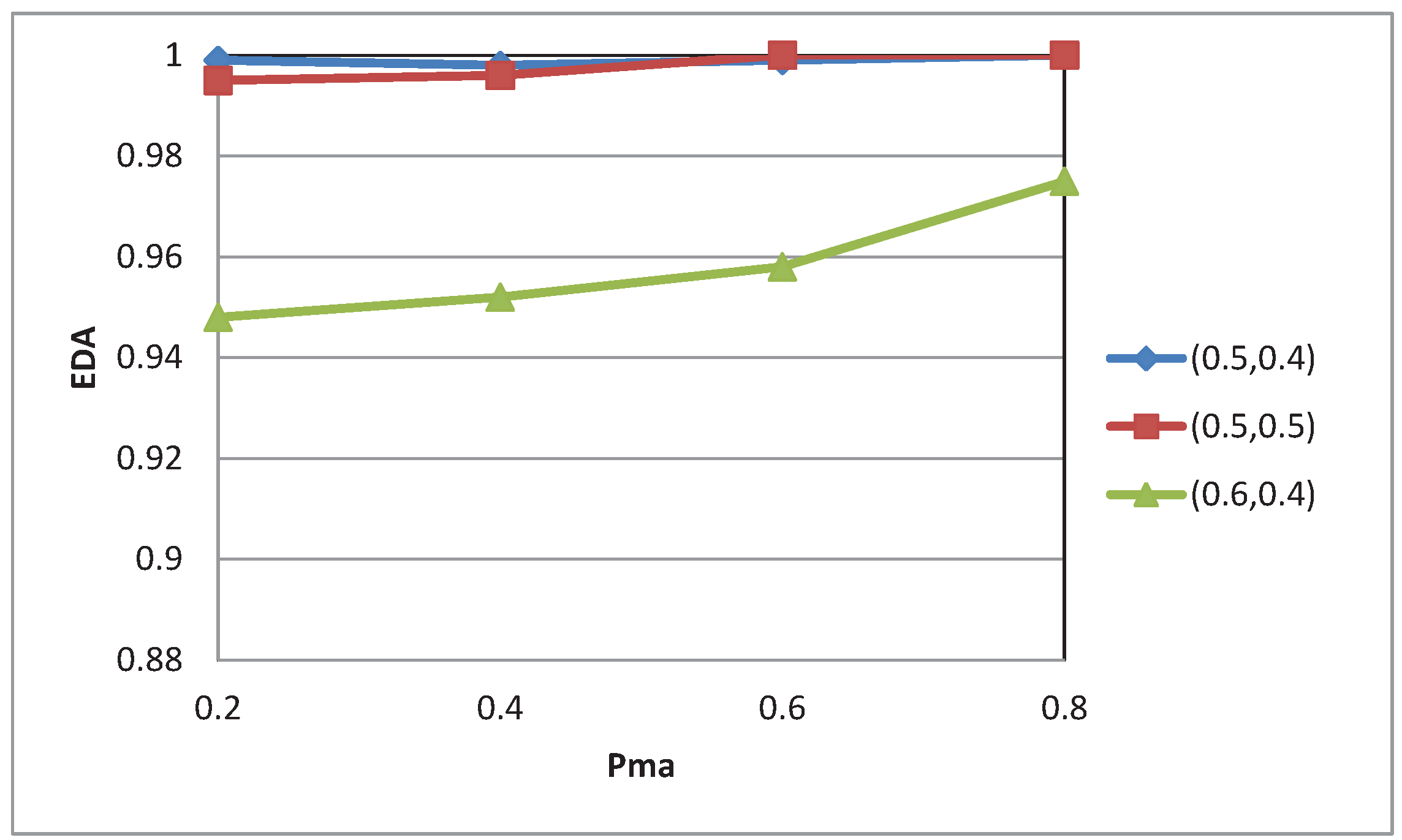
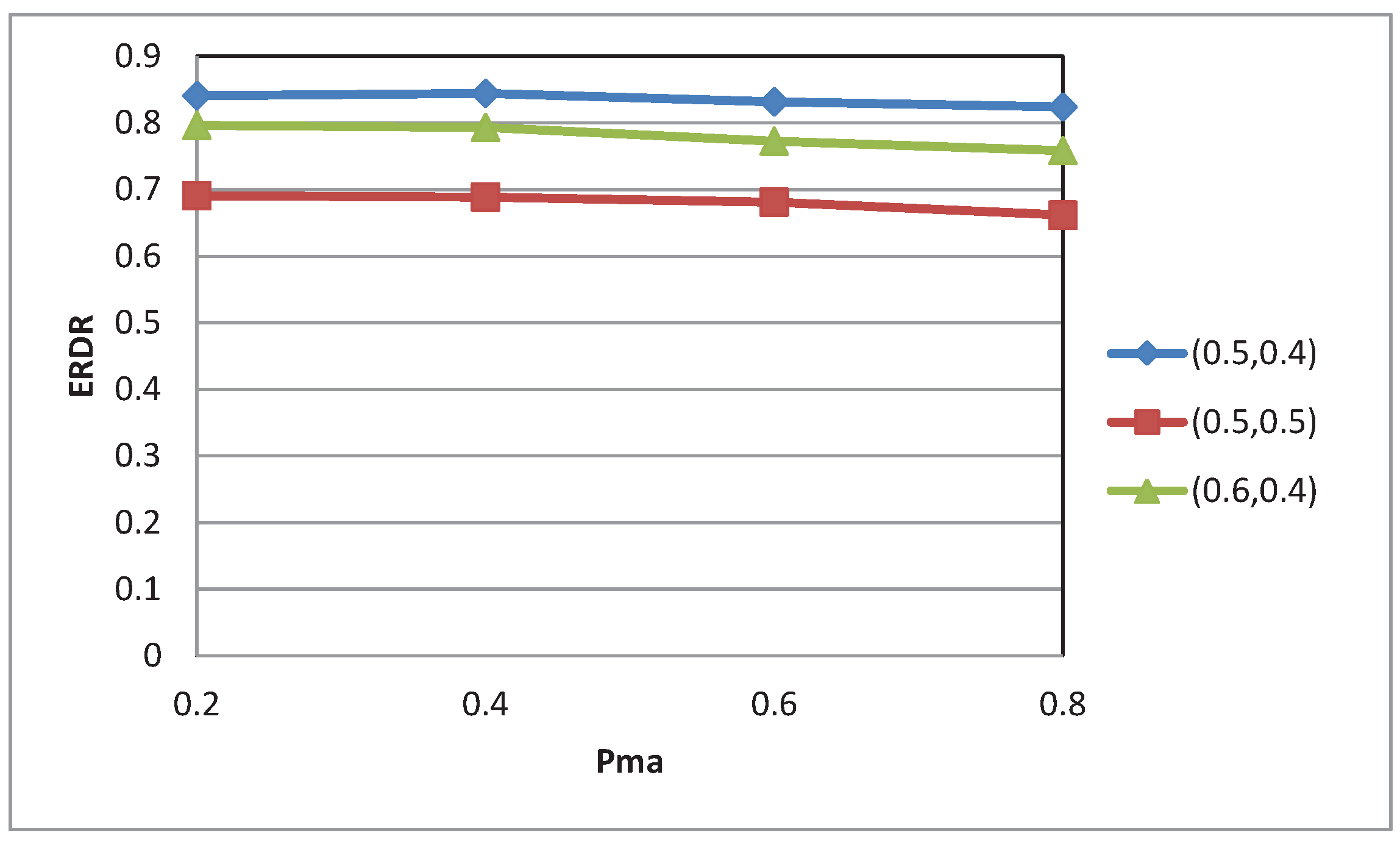
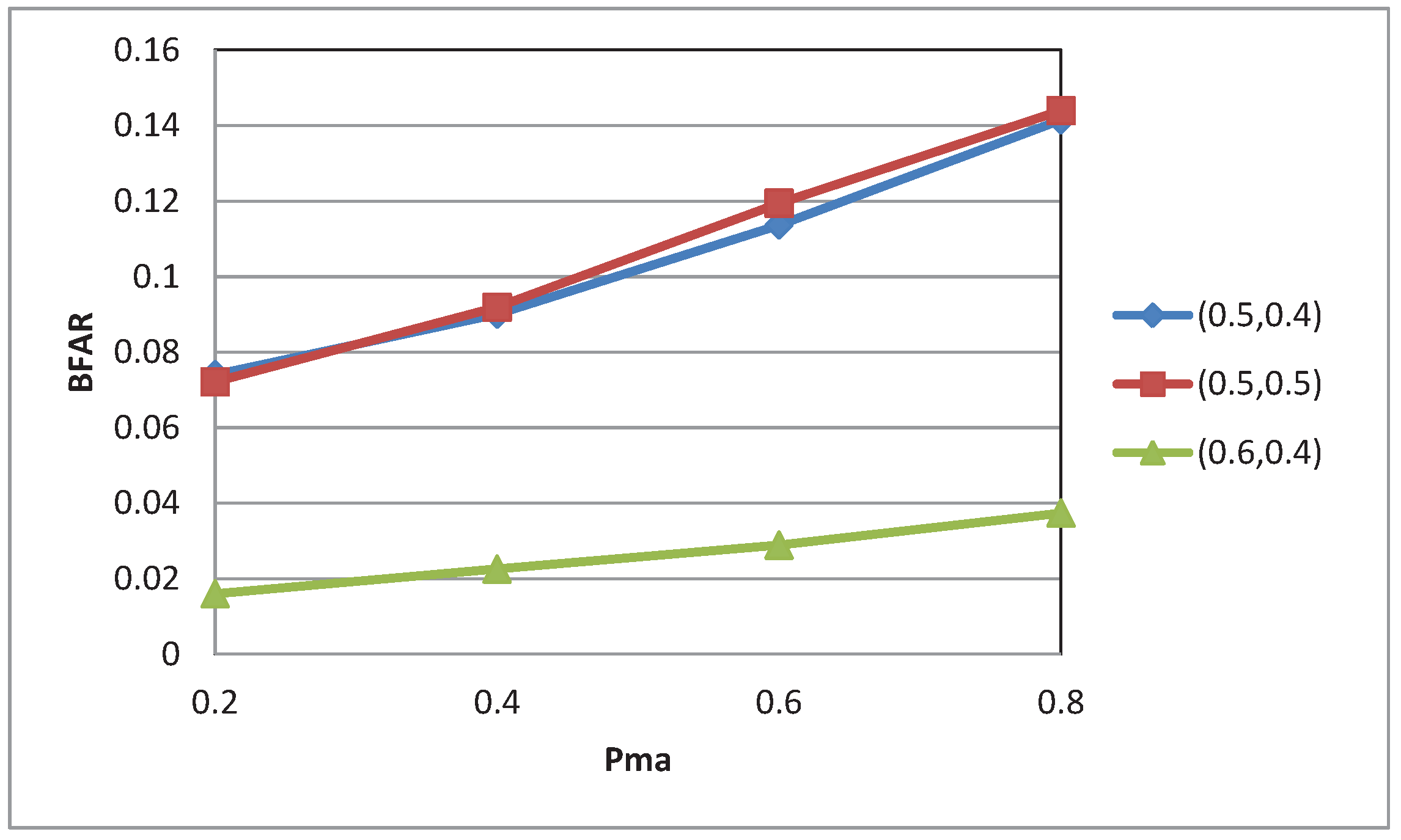
4.2. Experimental Results
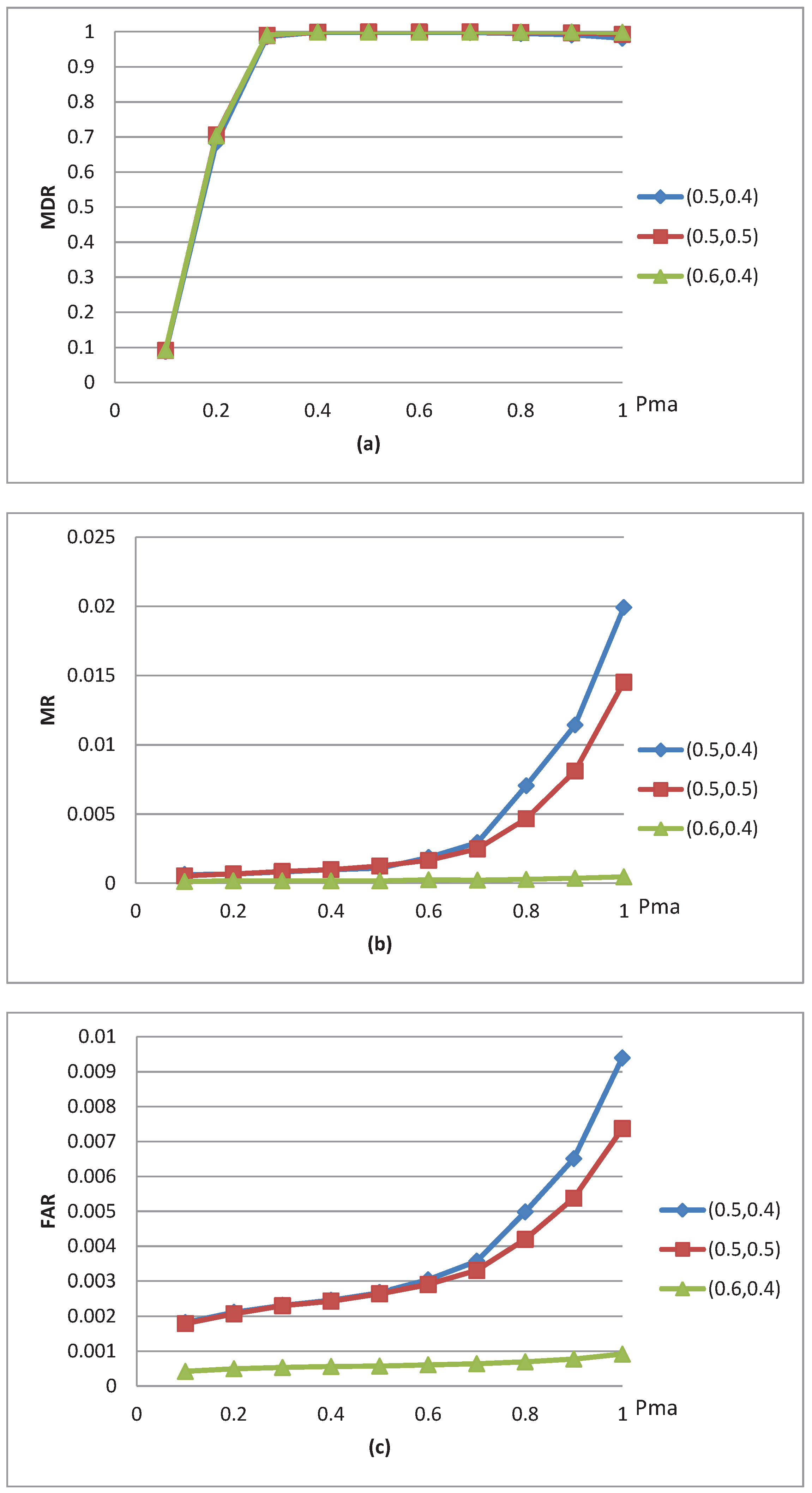
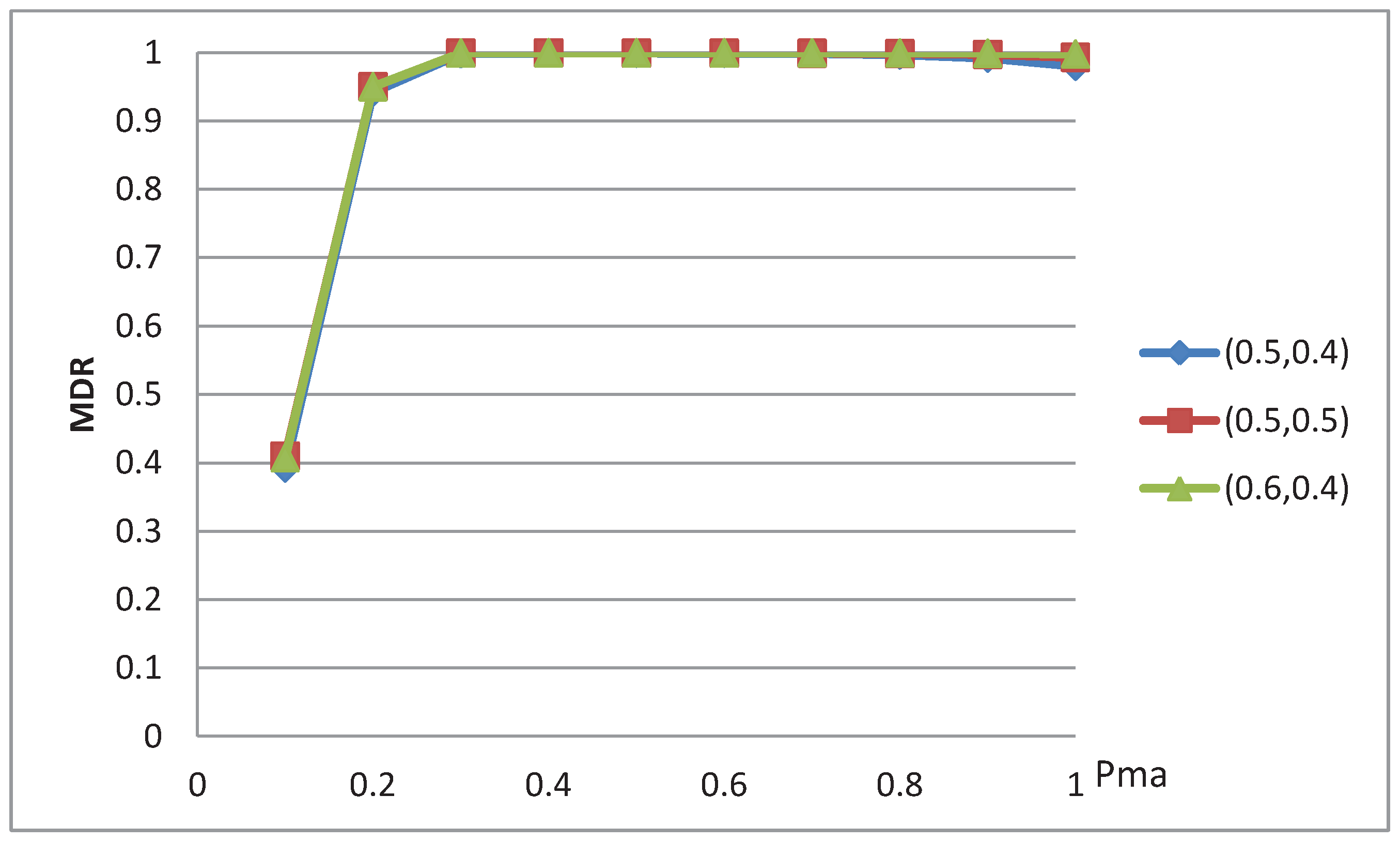
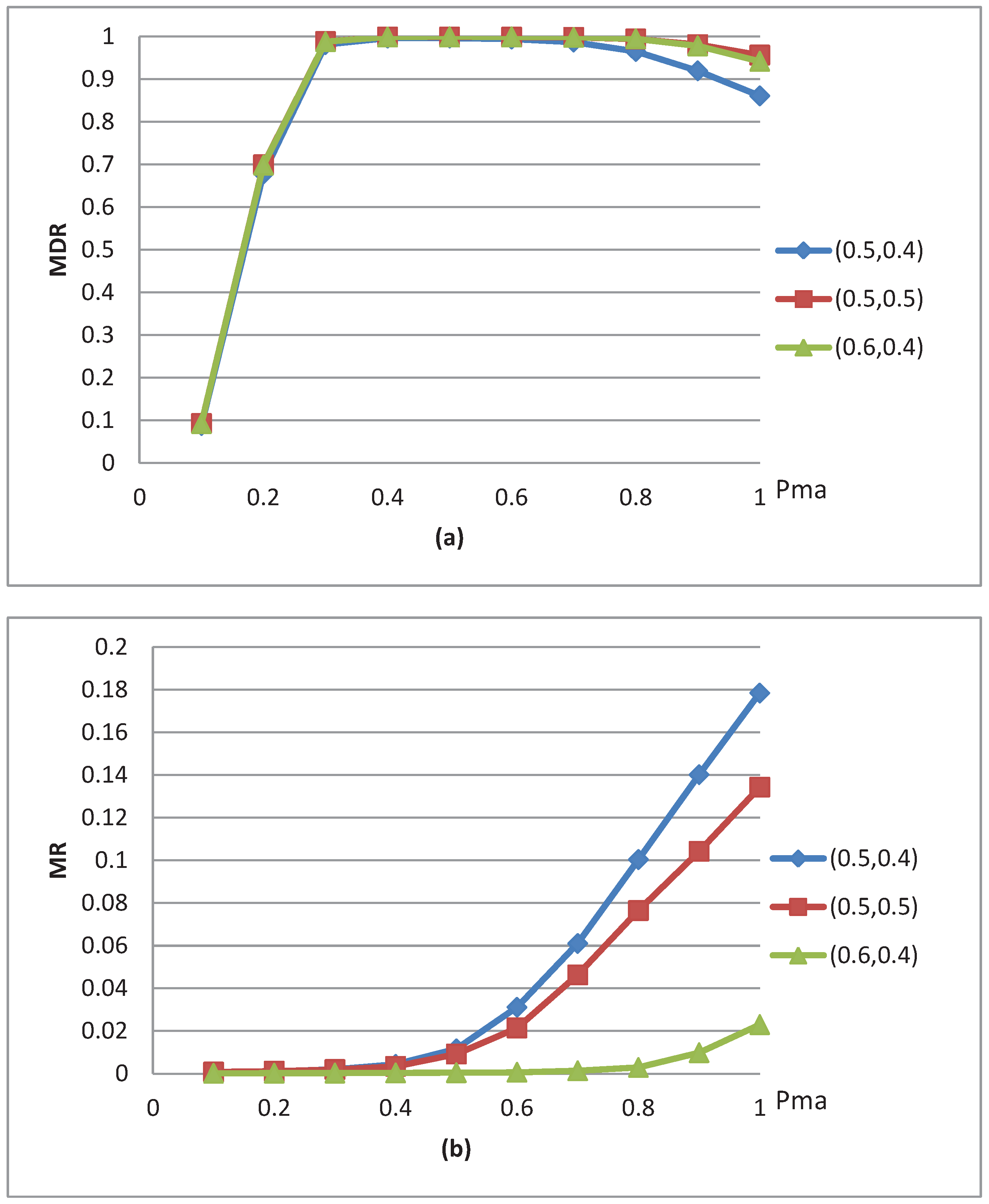
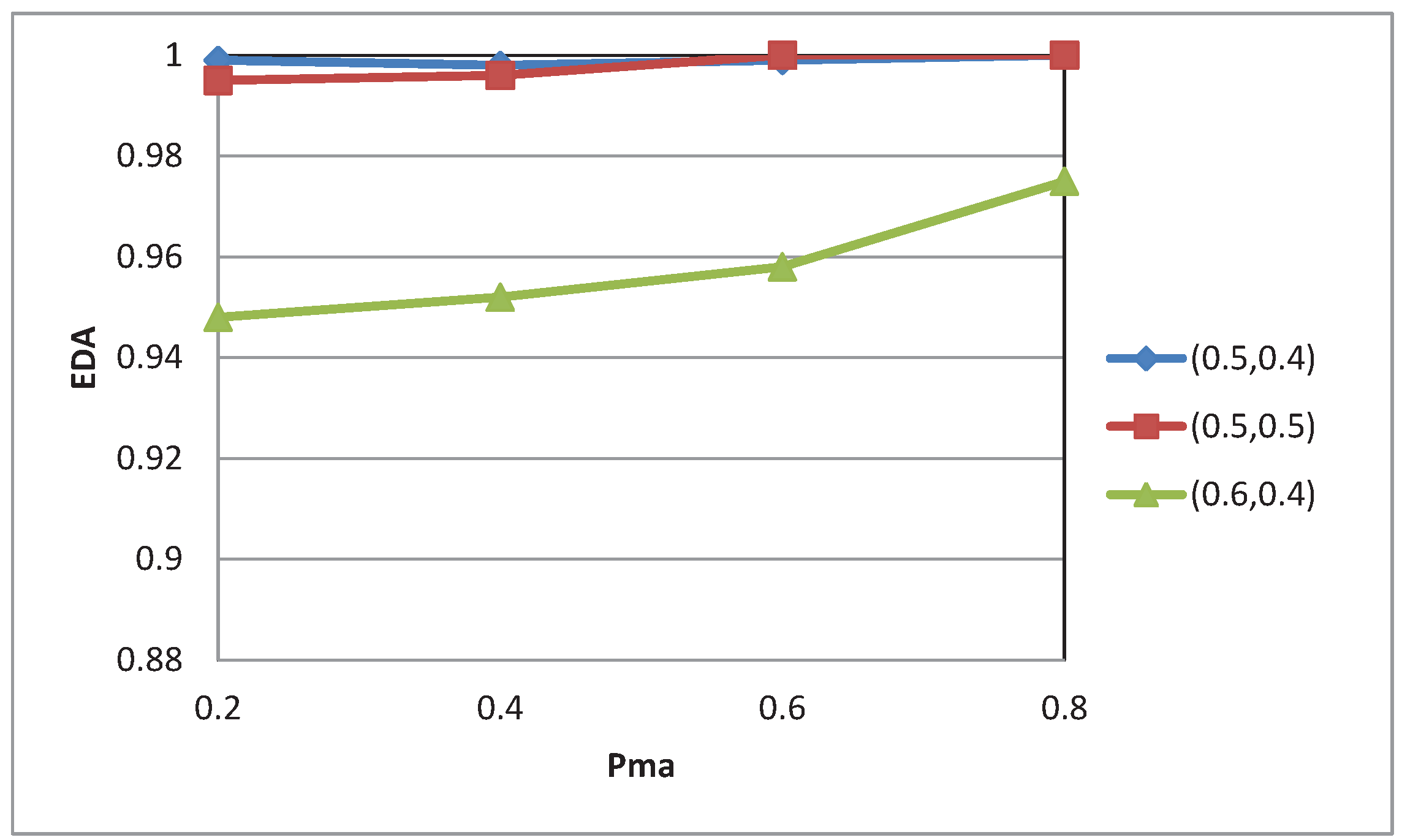

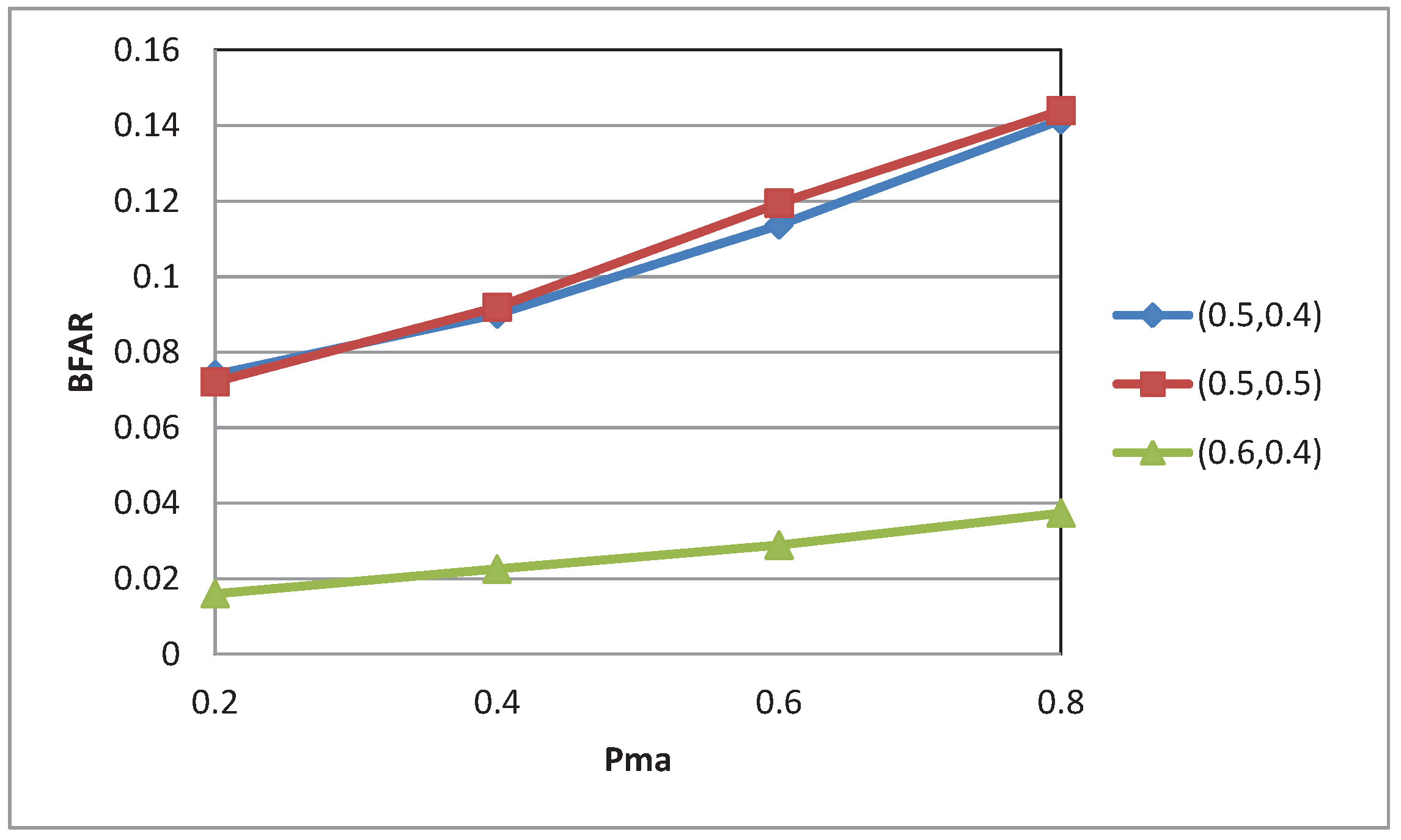
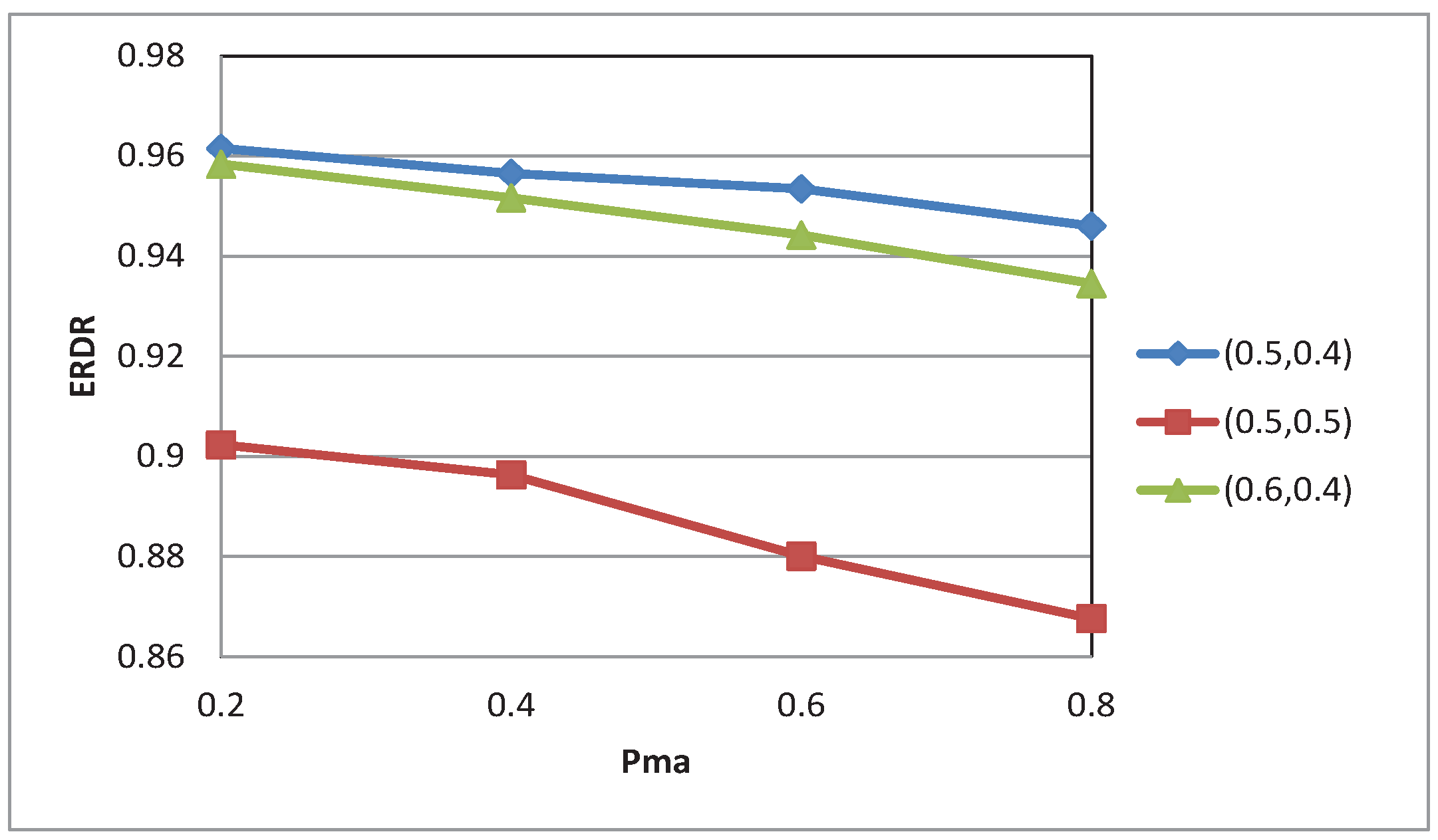
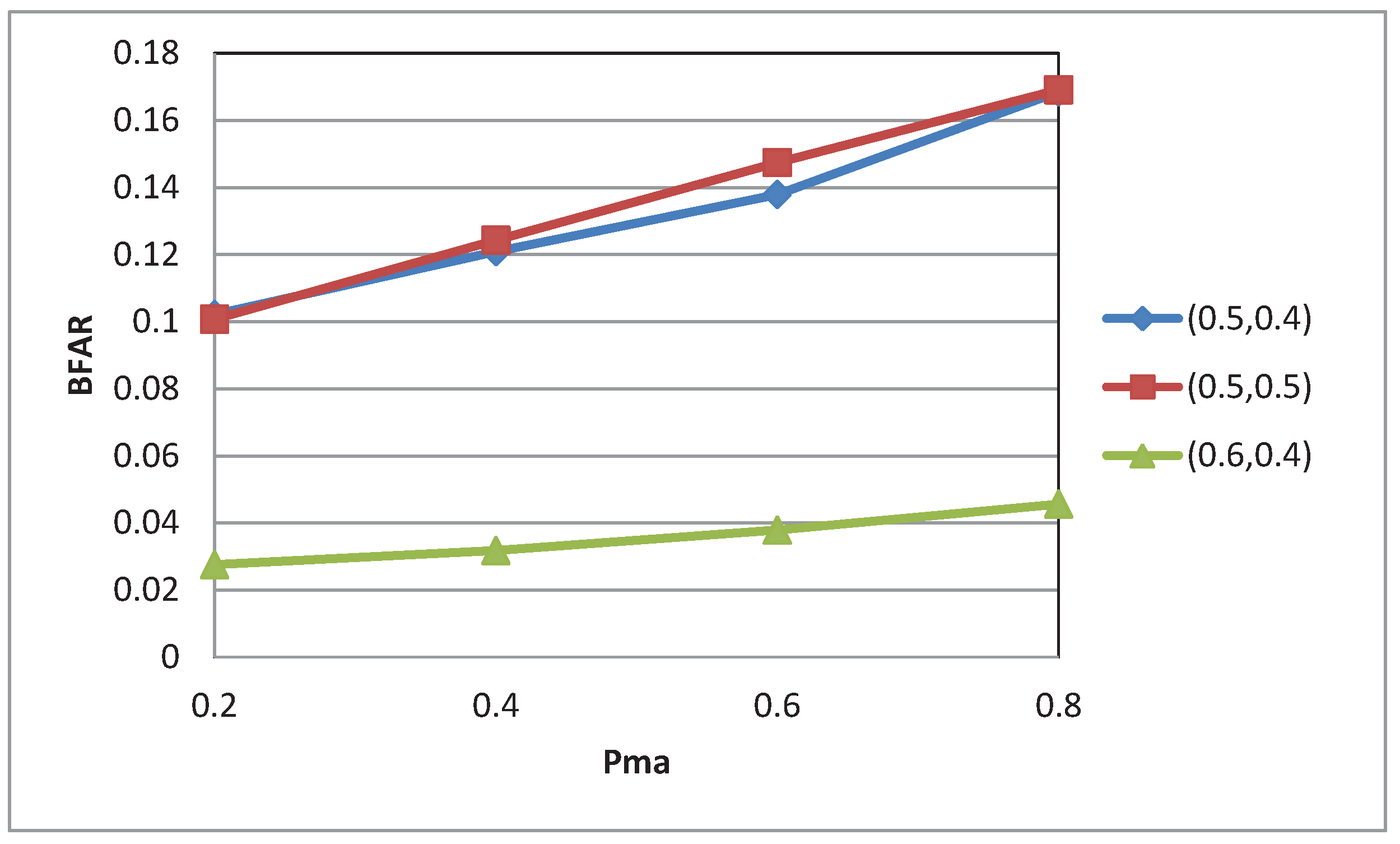
5. Conclusions
Acknowledgments
References
- Akyildiz, I.F.; Su, W.; Sankarasubramaniam, Y.; Cyirci, E. Wireless sensor networks: A survey. Comput. Netw. 2002, 38, 393–422. [Google Scholar] [CrossRef]
- Mainwaring, A.; Polaste, J.; Szewczyk, R.; Culler, D.; Anderson, J. Wireless Sensor Networks for Habitat Monitoring. In Proceedings of the ACM International Workshop on Wireless Sensor Networks and Applications, Atlanta, GA, USA, 28 September 2002; pp. 88–97.
- Yu, M.; Mokhtar, H.; Merabti, M. Fault management in wireless sensor networks. IEEE Wirel. Commun. 2007, 14, 13–19. [Google Scholar] [CrossRef]
- Xu, X.; Zhou, B.; Wan, J. Tree Topology Based Fault Diagnosis in Wireless Sensor Networks. In Proceedings of the International Conference on Wirleess Networks and Infomation Systems, Shanghai, China, 28–29 December 2009; pp. 65–69.
- Lee, M.H.; Choi, Y.-H. Fault detection of wireless sensor networks. Comput. Commun. 2008, 31, 3469–3475. [Google Scholar] [CrossRef]
- Rajasegarar, S.; Leckie, C.; Palaniswami, M. Anomaly detection in wireless sensor networks. IEEE Wire. Commun. 2008, 15, 34–40. [Google Scholar] [CrossRef]
- Krishnamachari, B.; Iyengar, S. Distributed Bayesian algorithms for fault-tolerant event region detection in wireless sensor networks. IEEE Trans. Comput. 2004, 53, 241–250. [Google Scholar] [CrossRef]
- Ding, M.; Chen, D.; Xing, K.; Cheng, X. Localized Fault-tolerant Event Boundary Detection in Sensor Networks. In Proceedings of the IEEE International Conference on Computer Communications, Miami, FL, USA, 13–17 March 2005; pp. 902–913.
- Luo, X.; Dong, M.; Huang, Y. On distributed fault-tolerant detection in wireless sensor networks. IEEE Trans. Comput. 2006, 55, 58–70. [Google Scholar] [CrossRef]
- Li, C.-R.; Liang, C.-K. A fault-tolerant event boundary detection algorithm in sensor networks. LNCS 2008, 5200, 406–414. [Google Scholar]
- Xiang, Y.; Li, H.; Xie, Z.; Li, P. Distributed Weighting Fault-Tolerant Algorithm for Event Region Detection in Wireless Sensor Networks. In Proceedings of the International Conference on Communications, Circuits and Systems, Changsha, China, 25–27 May 2008; pp. 414–418.
- Cui, X.; Li, Q.; Zhao, B. Data discrimination in fault-prone sensor networks. Wirel. Sens. Netw. 2010, 12, 285–292. [Google Scholar] [CrossRef]
- Curiac, D.I.; Banias, O.; Dragan, F.; Volosencu, C.; Dranga, O. Malicious Node Detection in Wireless Sensor Networks Using an Autoregression Technique. In Proceedings of the 3rd International Conference on Networking and Services, Athens, Greece, 19–25 June 2007; p. 83.
- Pires, W.R., Jr.; Figueiredo, T.; Wong, H.; Loureiro, A. Malicious Node Detection in Wireless Sensor Networks. In Proceedings of the 18th International Parallel and Distributed Processing Symposiuim, Santa Fe, NM, USA, 26–30 April 2004.
- Xiao, X.-Y.; Peng, W.-C.; Hung, C.-C.; Lee, W.-C. Using Sensor Ranks for In-network Detection of Faulty Readings in Wireless Sensor Networks. In Proceedings of the International Workshop Data Engieering for Wireless and Mobile Access, Beijing, China, 10 June 2007; pp. 1–8.
- Atakli, I.M.; Hu, H.; Chen, Y.; Ku, W.-S.; Su, Z. Malicious Node Detection in Wireless Sensor Networks Using Weighted Trust Evaluation. In Proceedings of the 2008 Spring Simulation Multiconference, Ottawa, Canada, 14-17 April 2008; pp. 836–842.
- Hu, H.; Chen, Y.; Ku, W.-S.; Su, Z.; Chen, C.-H. Weighted trust evaluation-based malicious node detection for wireless sensor networks. Int. J. Inf. Comput. Security 2009, 3, 132–149. [Google Scholar] [CrossRef]
- Ju, L.; Li, H.; Liu, Y.; Xue, W.; Li, K.; Chi, Z. An Improved Detection Scheme Based on Weighted Trust Evaluation for Wireless Sensor Networks. In Proceedings of the 5th International Conference on Ubiquitous Information Technologies and Applications, Hainan, China, 16–18 December 2010; pp. 1–6.
- Momani, M.; Challa, S. Survey of trust models in different network domain. Int. J. Ad hoc Sens. Ubiquitous Comput. (IJASUC) 2010, 1, 1–19. [Google Scholar] [CrossRef]
- Momani, M.; Challa, S.; Alhmouz, R. Can We Trust Trusted Nodes in Wireless Sensor Networks? In Proceedings of the International Conference Computer and Communication Engineering, Kuala Lumpur, Malaysia, 13–15 May 2008; pp. 1227–1232.
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Lim, S.Y.; Choi, Y.-H. Malicious Node Detection Using a Dual Threshold in Wireless Sensor Networks. J. Sens. Actuator Netw. 2013, 2, 70-84. https://doi.org/10.3390/jsan2010070
Lim SY, Choi Y-H. Malicious Node Detection Using a Dual Threshold in Wireless Sensor Networks. Journal of Sensor and Actuator Networks. 2013; 2(1):70-84. https://doi.org/10.3390/jsan2010070
Chicago/Turabian StyleLim, Sung Yul, and Yoon-Hwa Choi. 2013. "Malicious Node Detection Using a Dual Threshold in Wireless Sensor Networks" Journal of Sensor and Actuator Networks 2, no. 1: 70-84. https://doi.org/10.3390/jsan2010070