RedEdge: A Novel Architecture for Big Data Processing in Mobile Edge Computing Environments


Abstract
:1. Introduction
2. Related Work
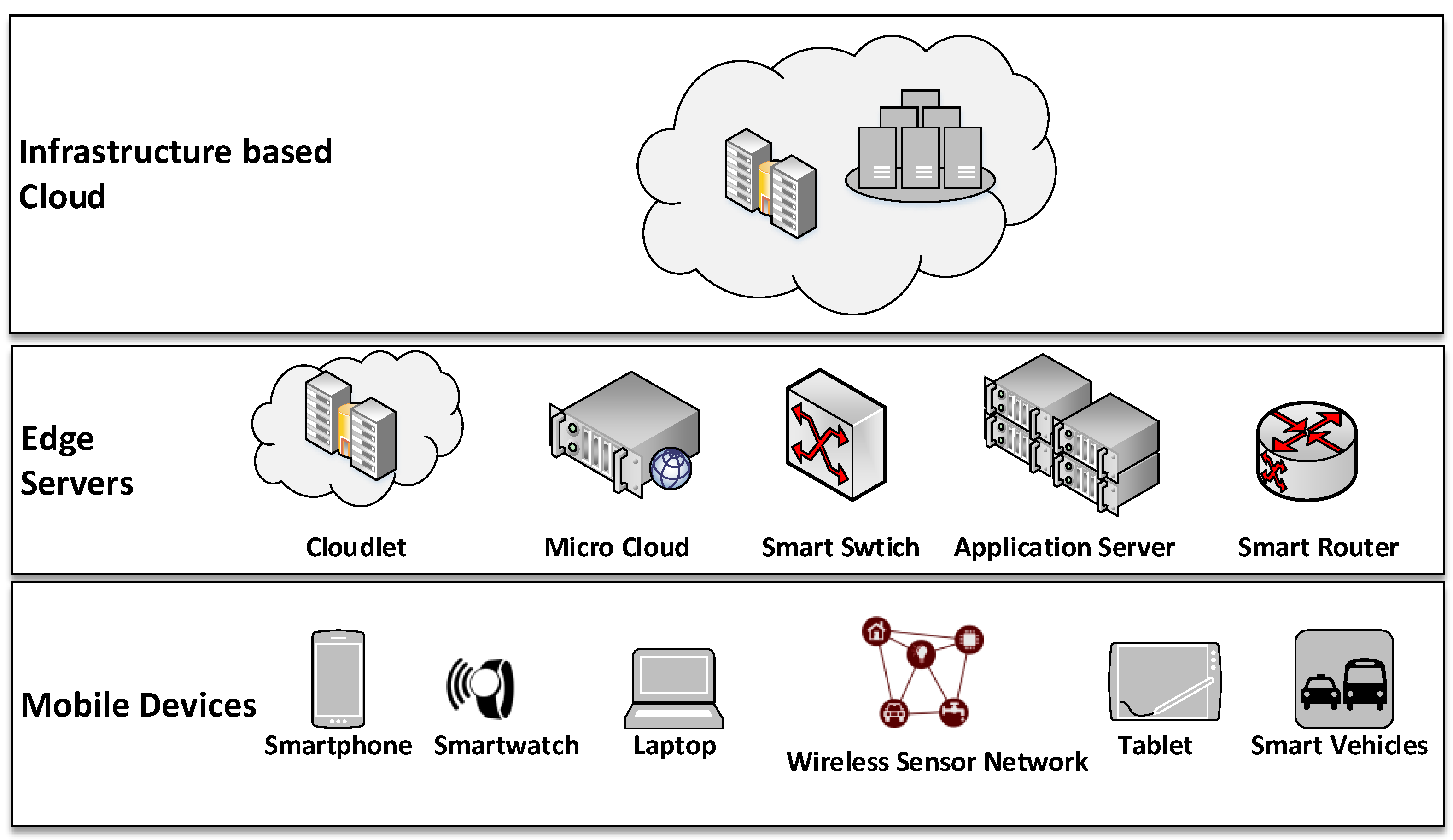
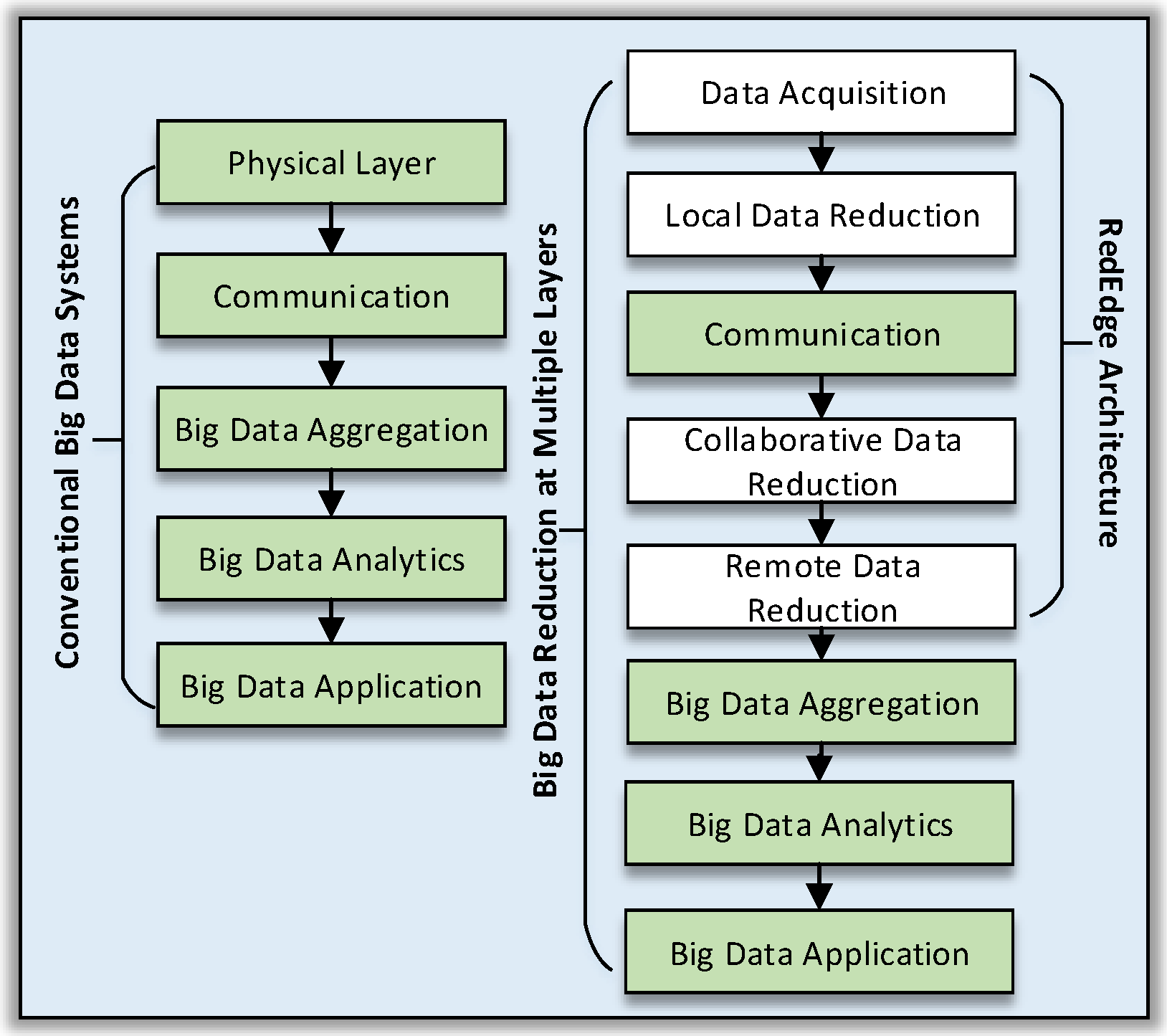
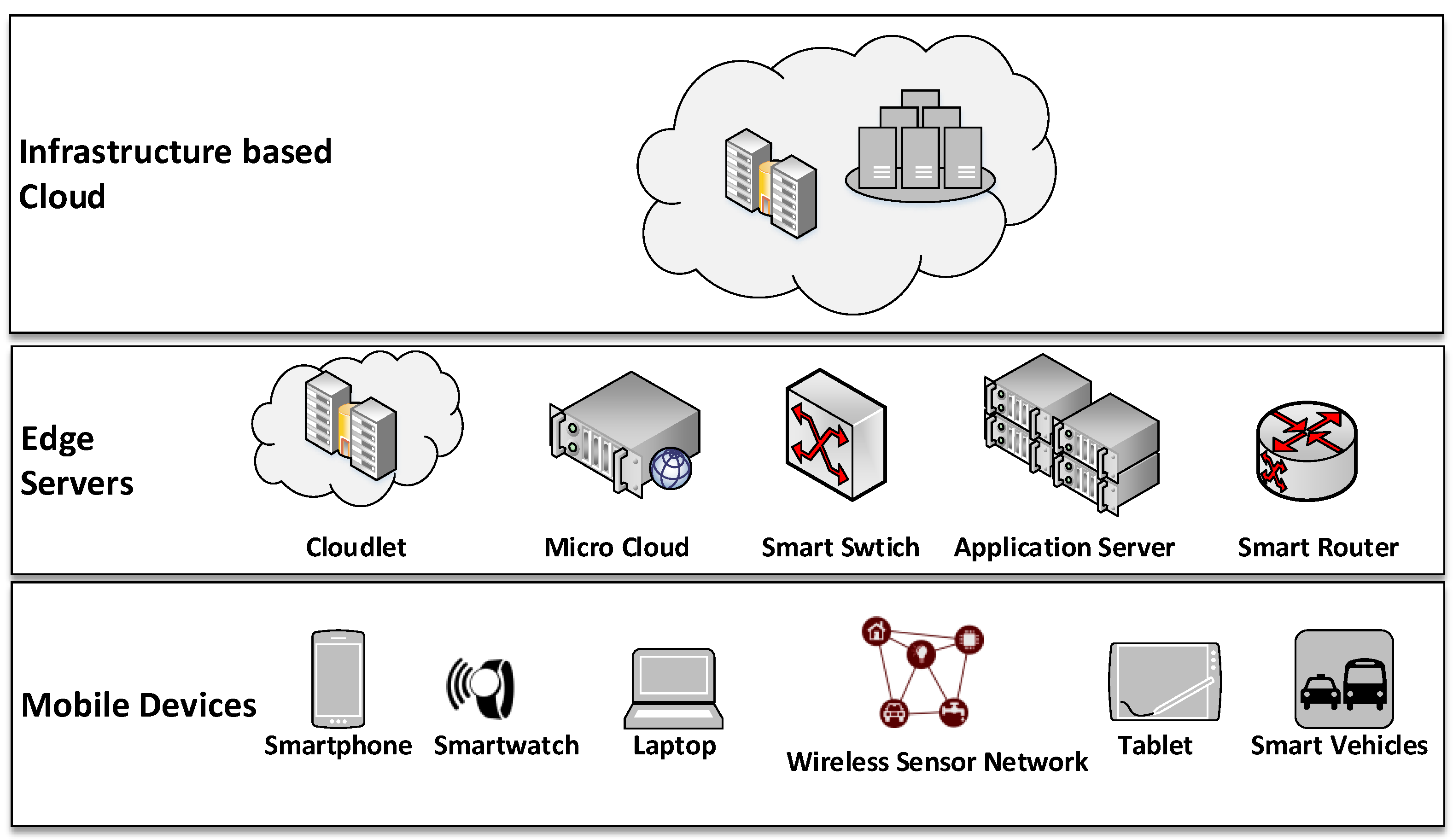
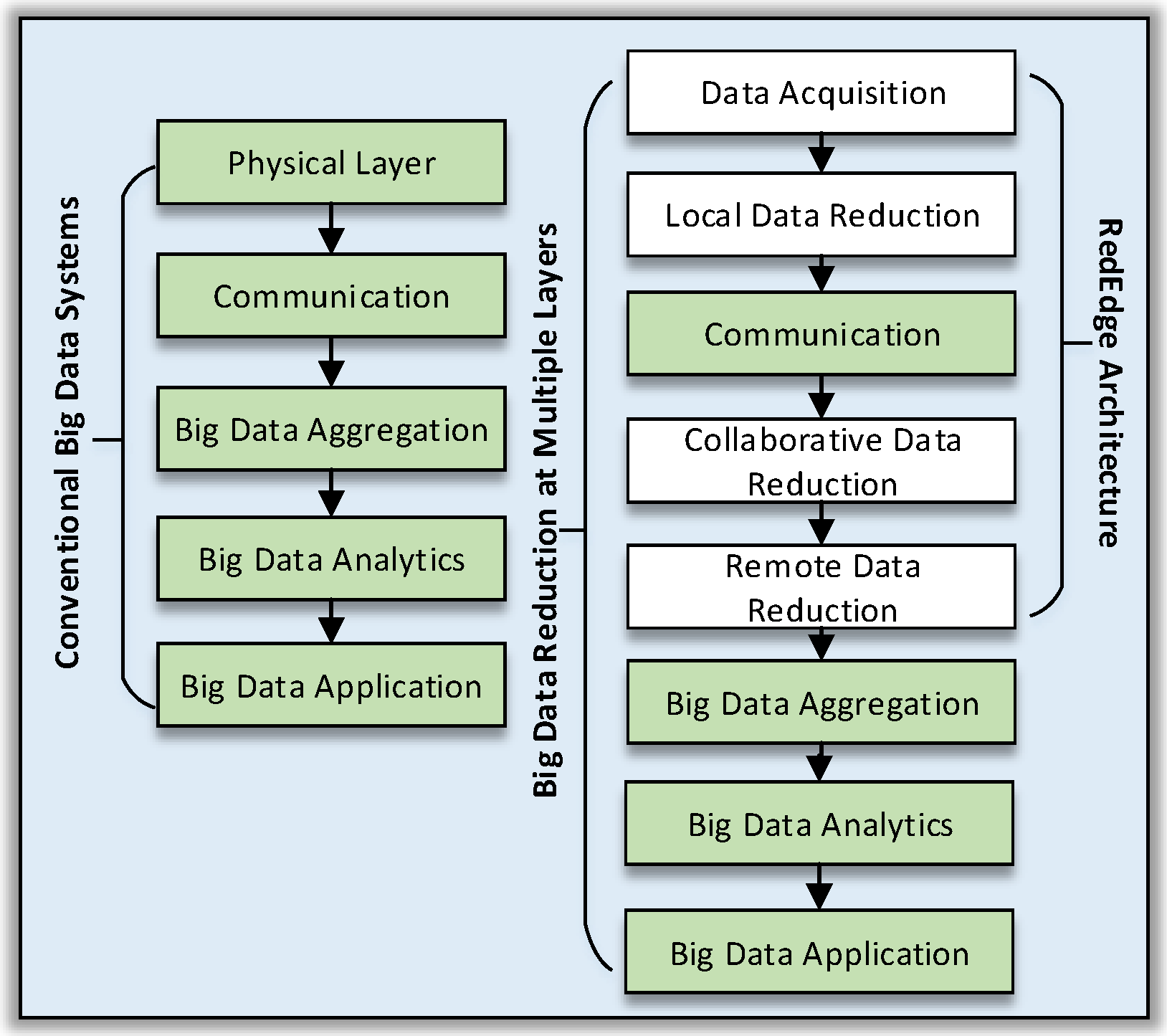
3. The Case for a Multi-Layer Far-Edge Computing Architecture for Big Data Reduction
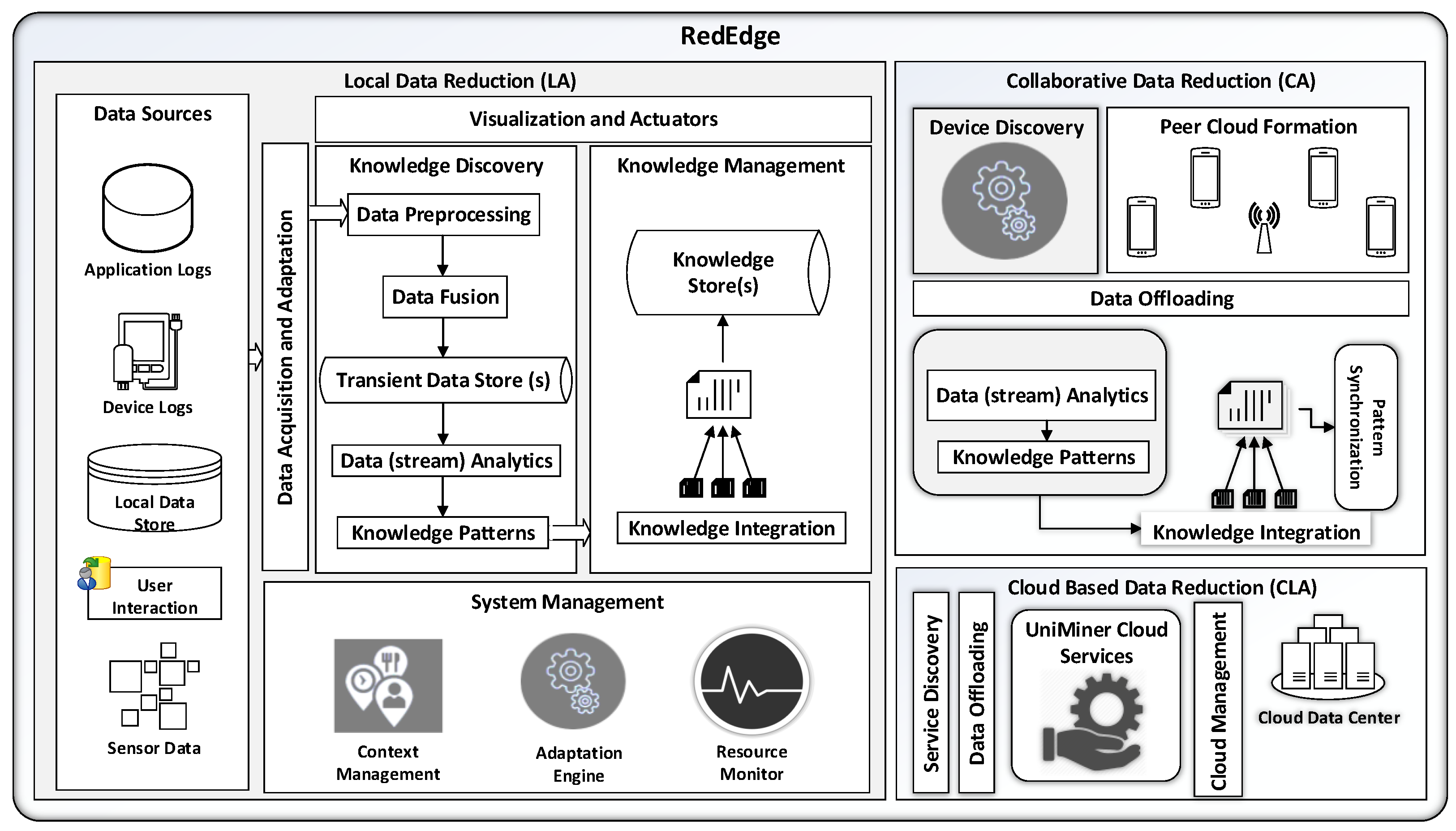
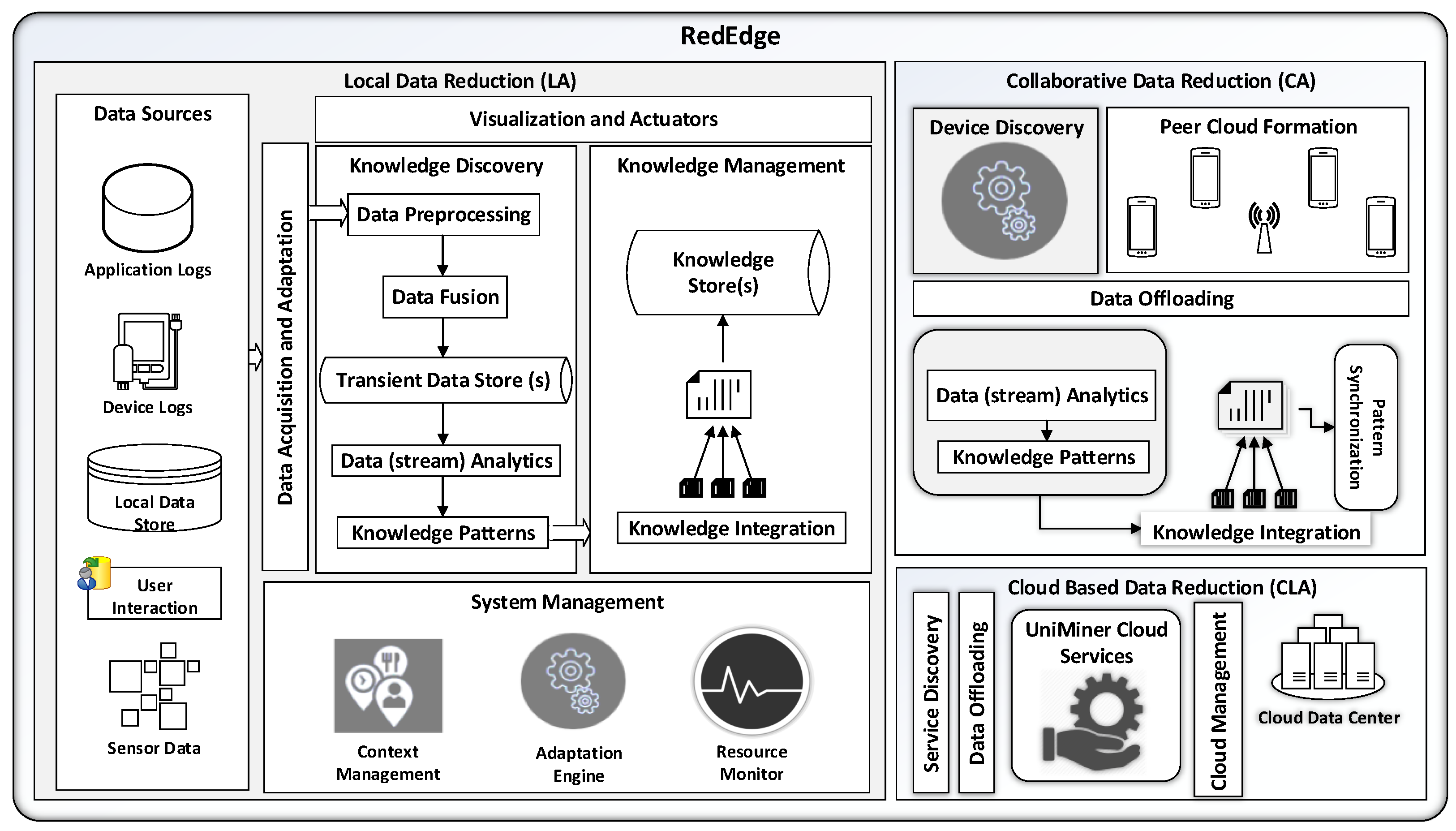
4. RedEdge: An Architecture for Big Data Processing in MECC Environments
4.1. Components and Operations for LA
4.1.1. Data Acquisition and Data Adaptation
4.1.2. Knowledge Discovery
4.1.3. Knowledge Management
4.1.4. System Management
4.1.5. Visualization and Actuation
4.2. Components and Operations for CA
4.2.1. Discovering Mobile Edge Devices and Communication Interfaces
4.2.2. Peer to Peer Network Formation
4.2.3. Data Offloading in Mobile Edge Devices
4.2.4. Knowledge Discovery and Pattern Synchronization
4.3. Components and Operations for CLA
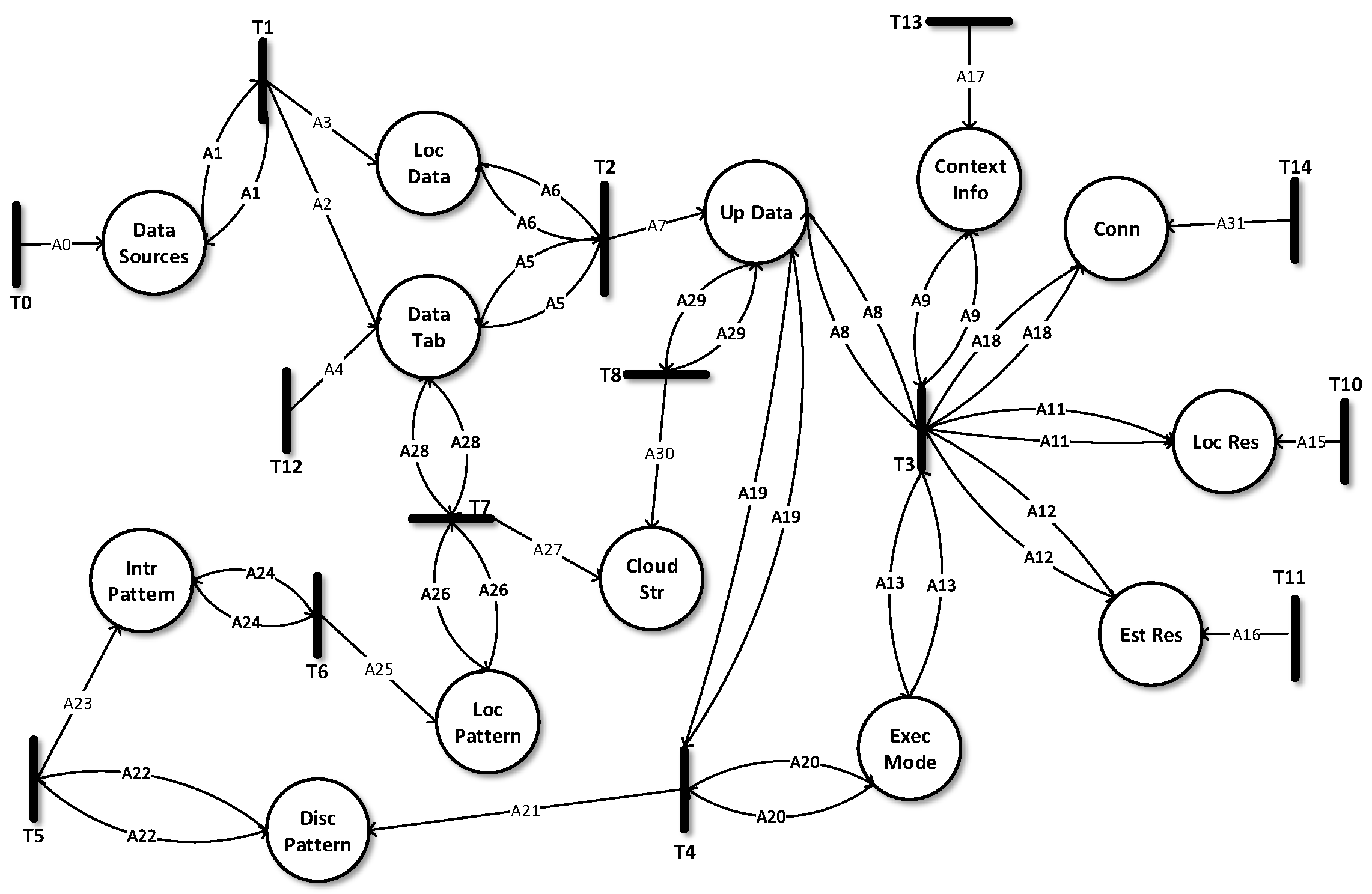
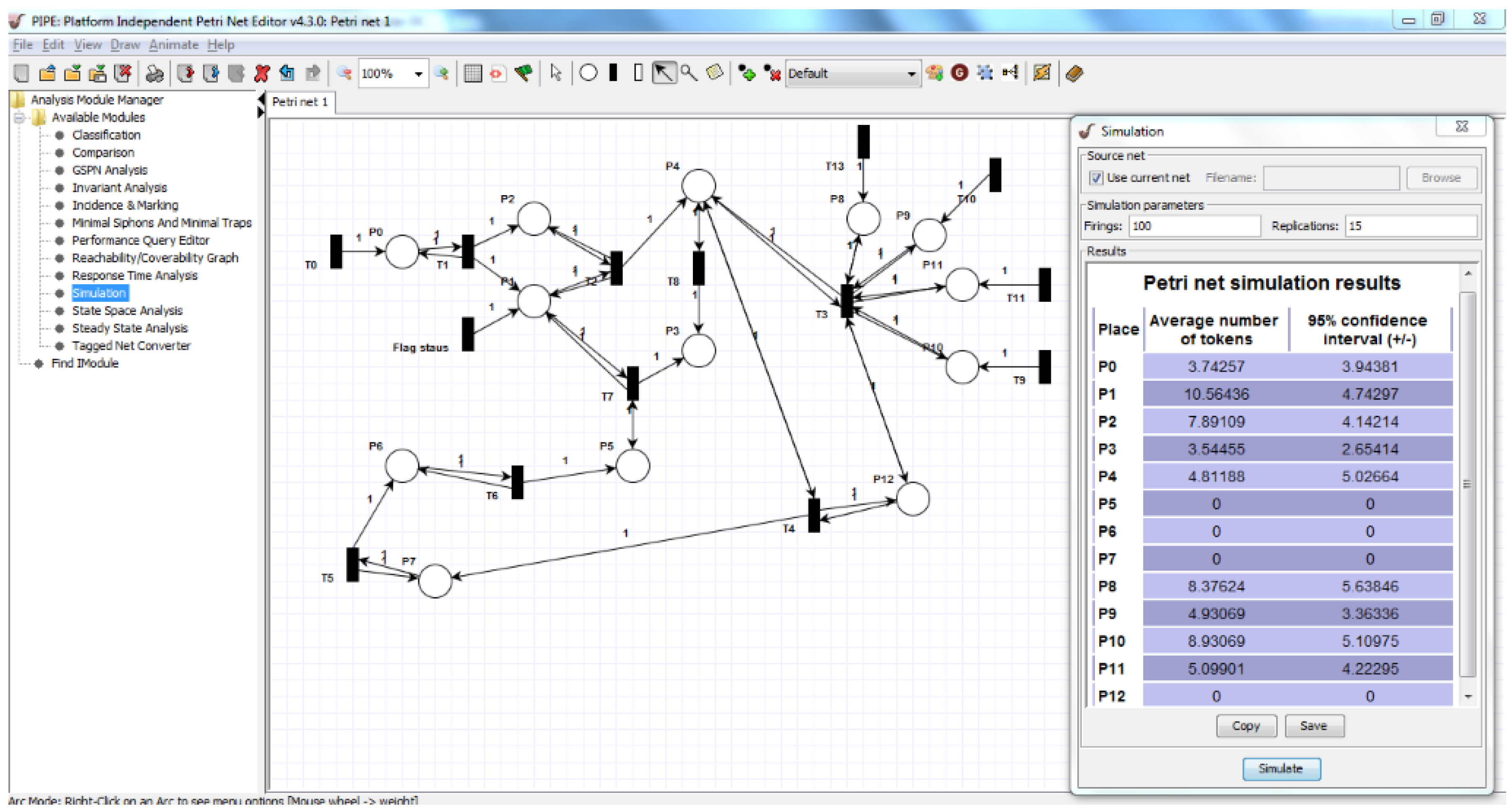
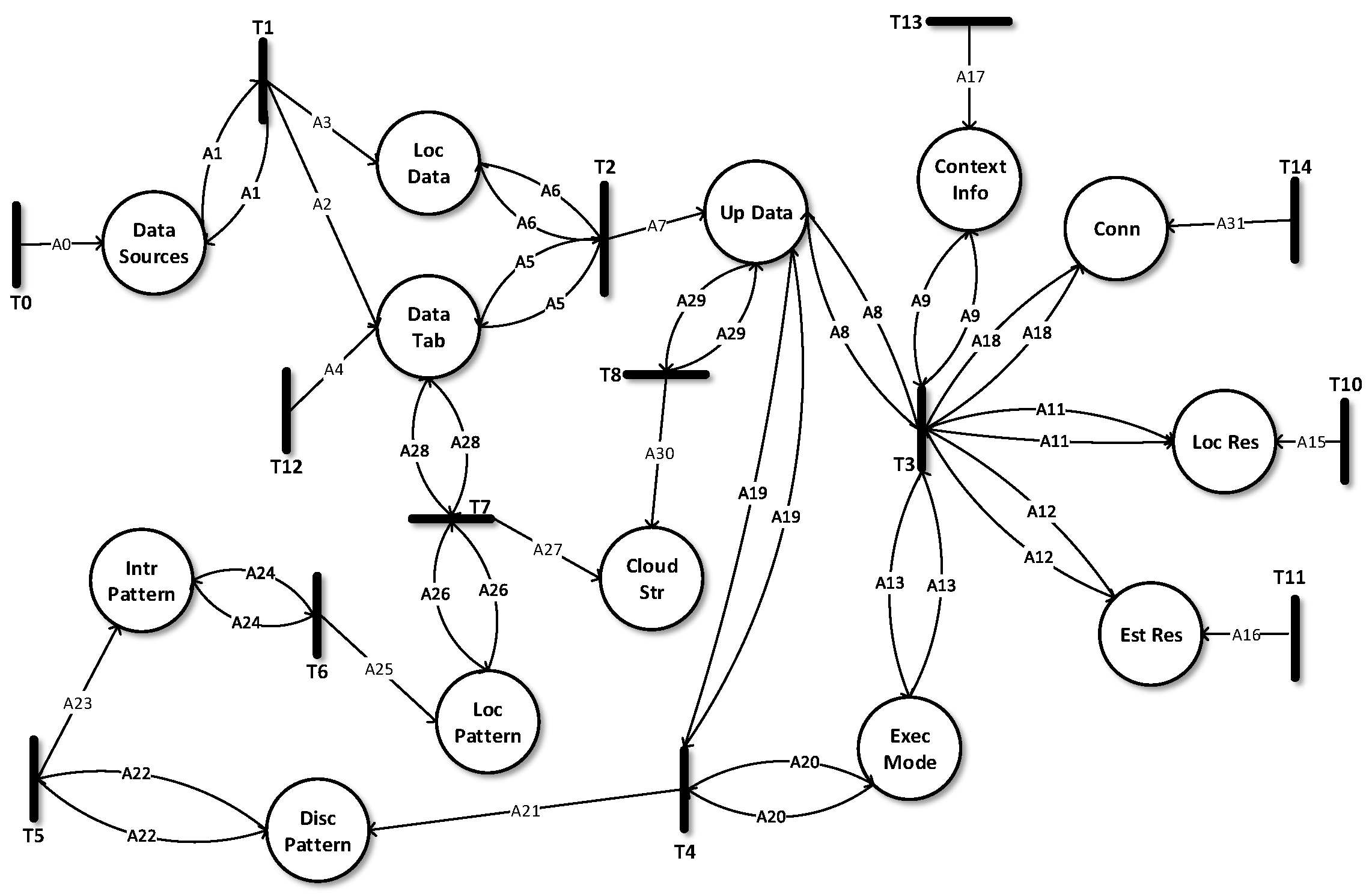
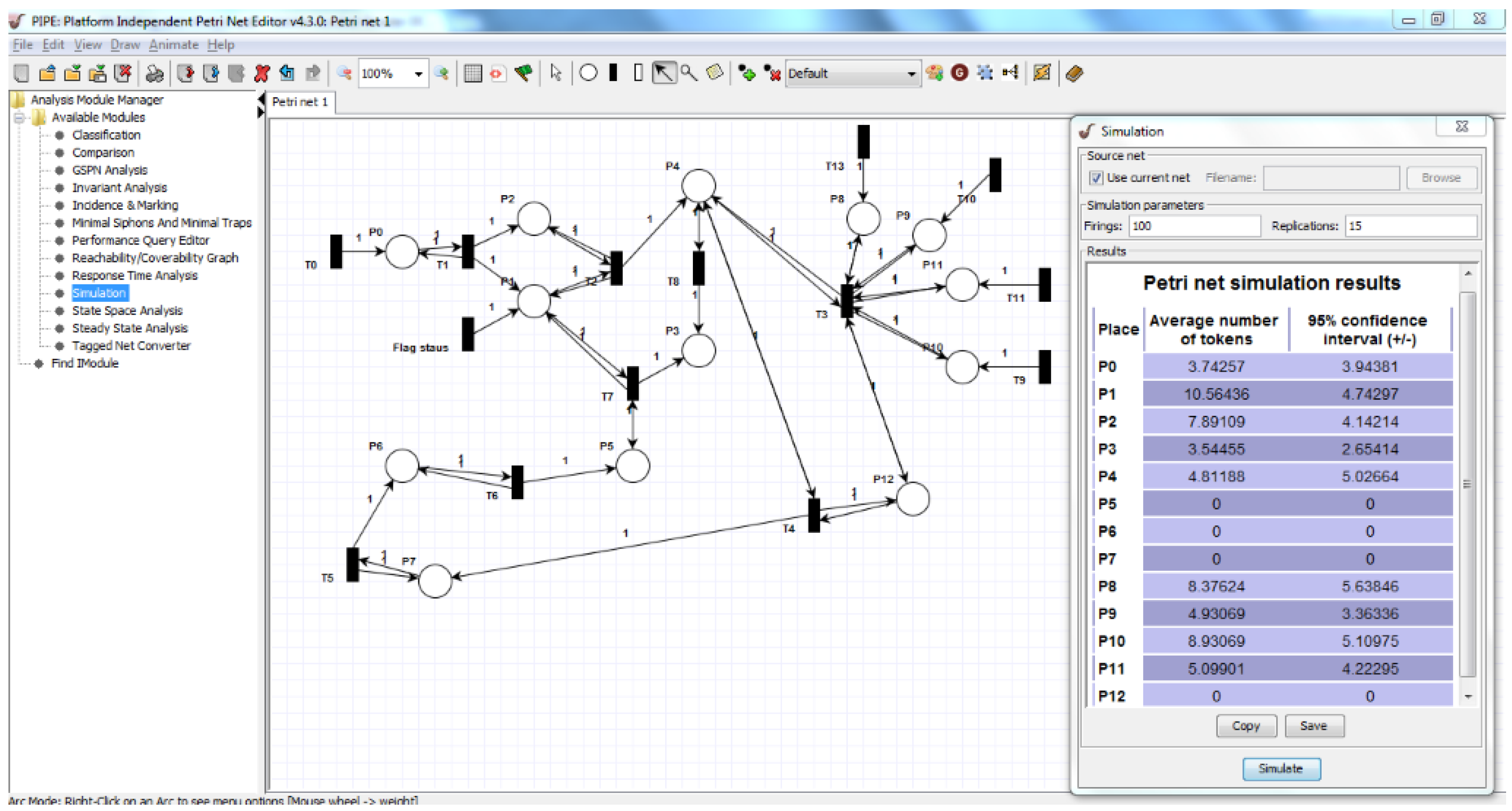
5. Formal Modelling, Analysis and Verification
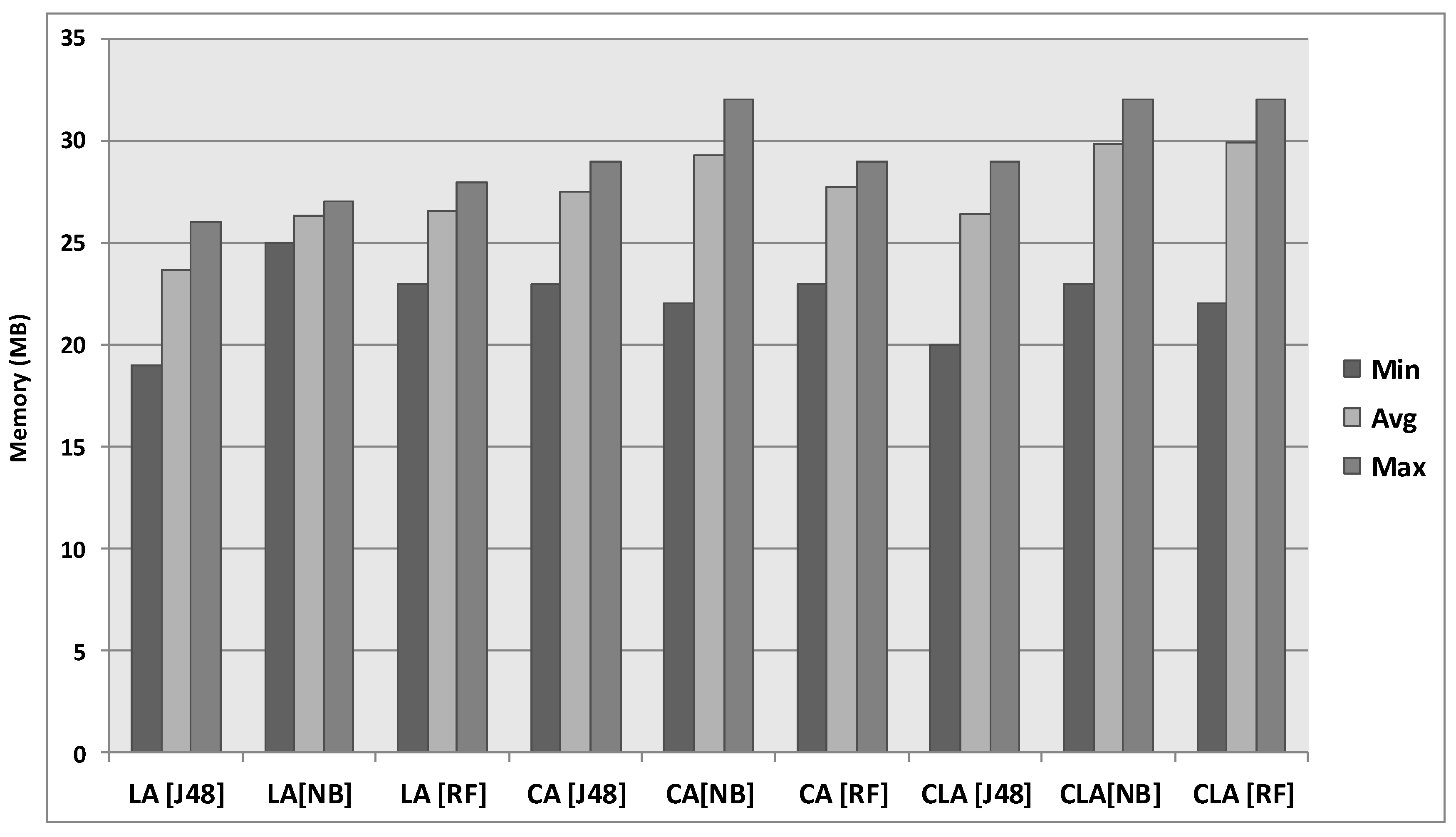
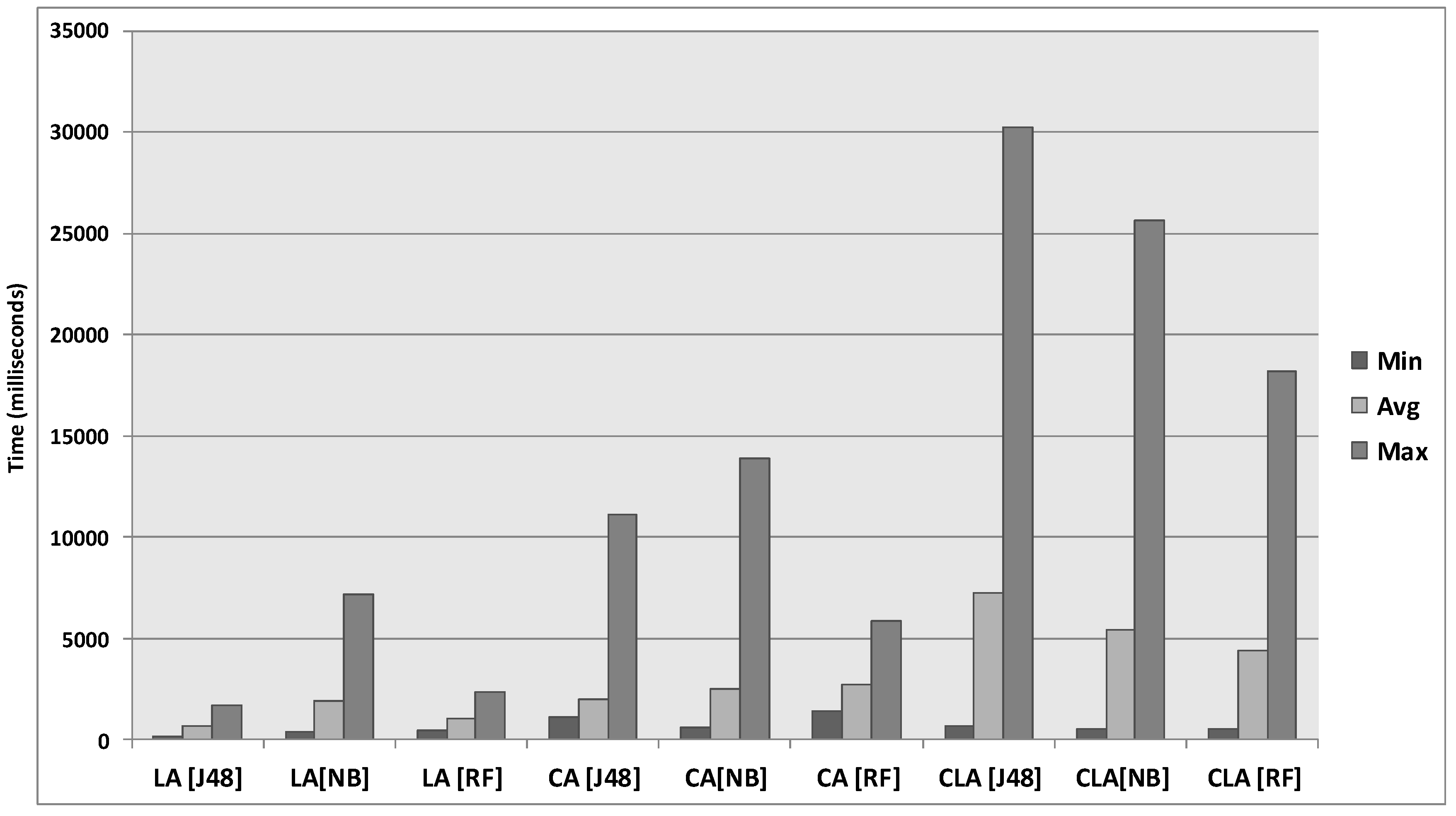
6. Performance Evaluation of the Proposed Data Reduction Strategy
6.1. Big Data Reduction in Participatory Sensing Application
6.2. System Development Platform and Real-World Experiment Settings
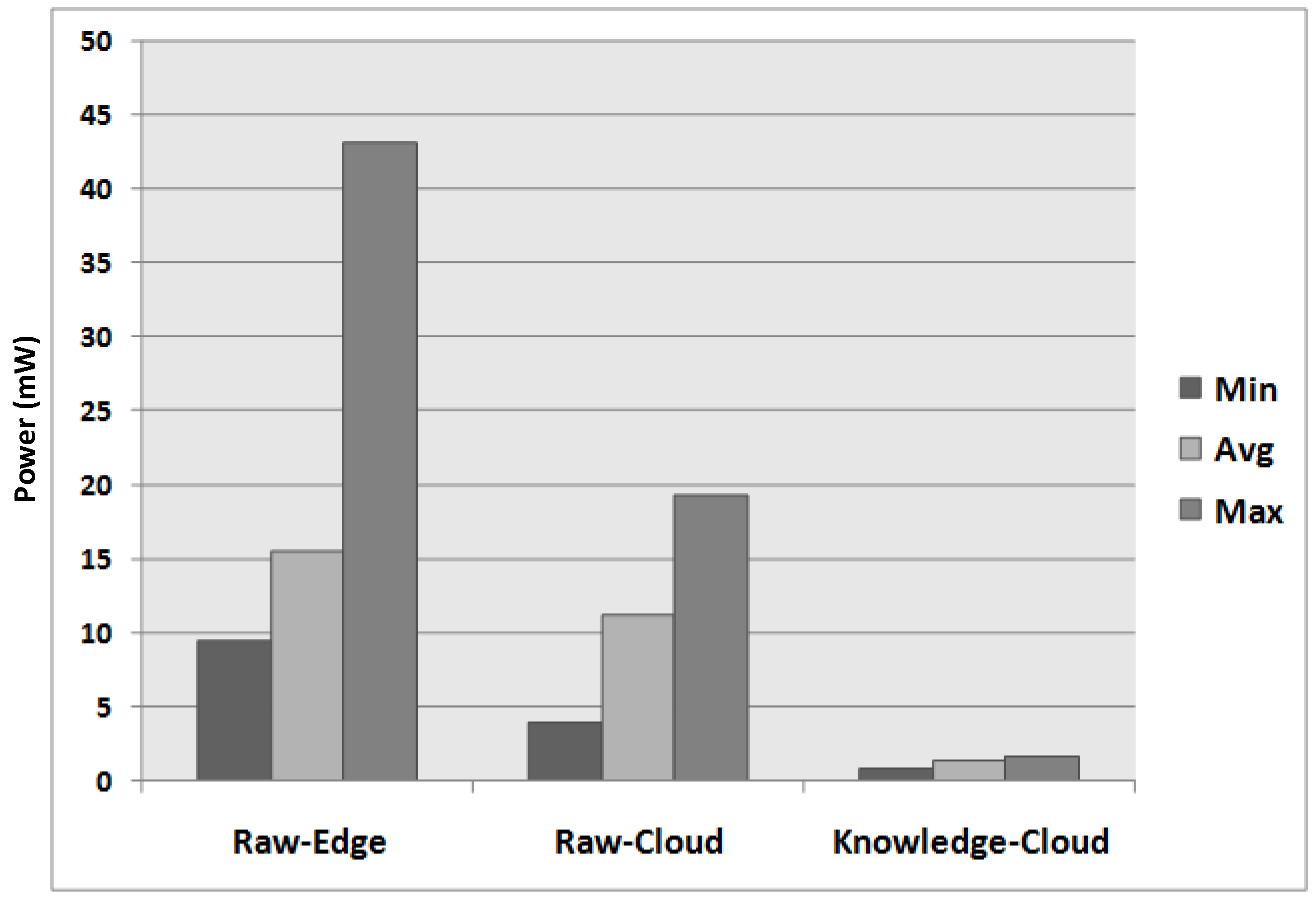
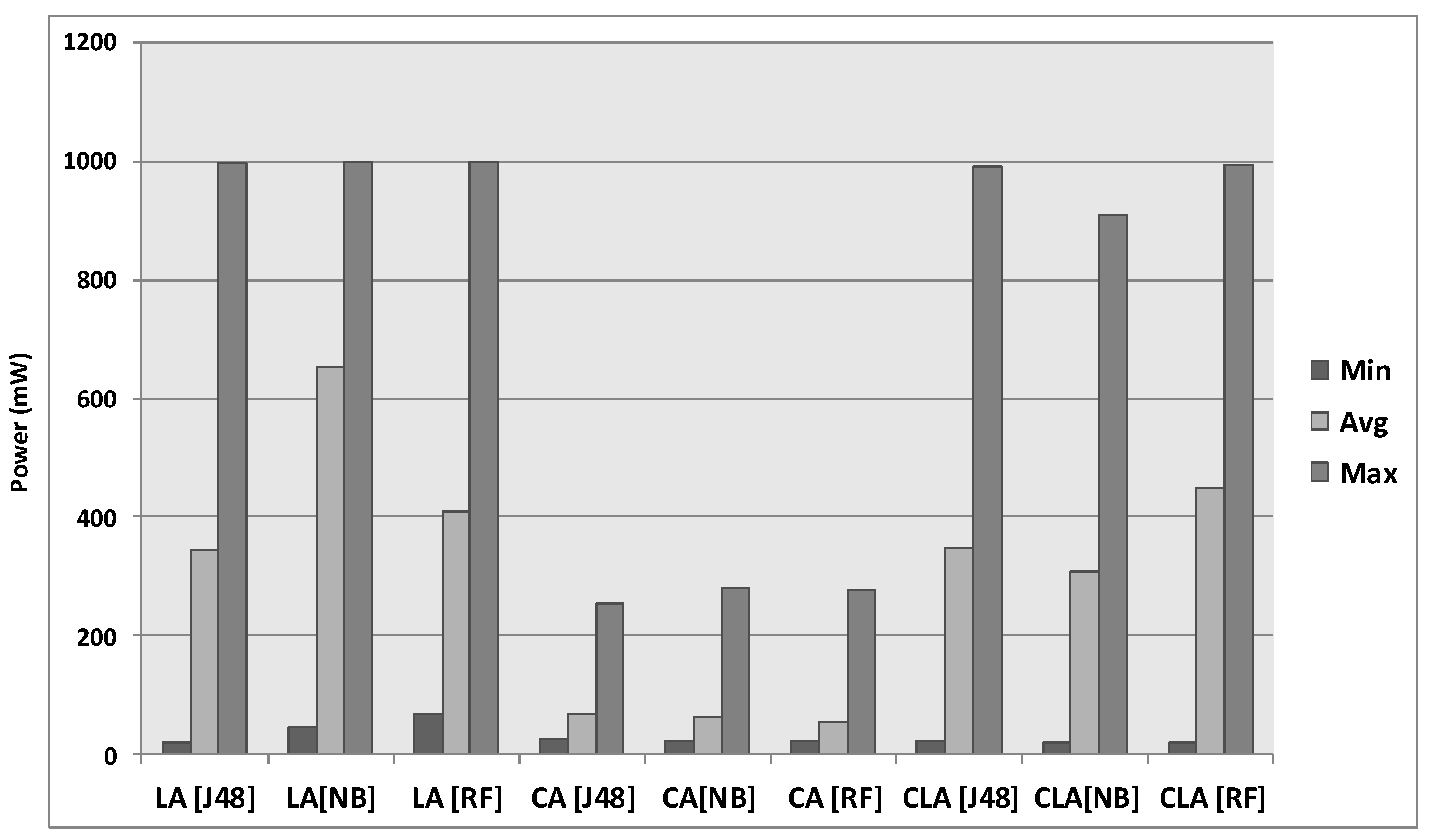
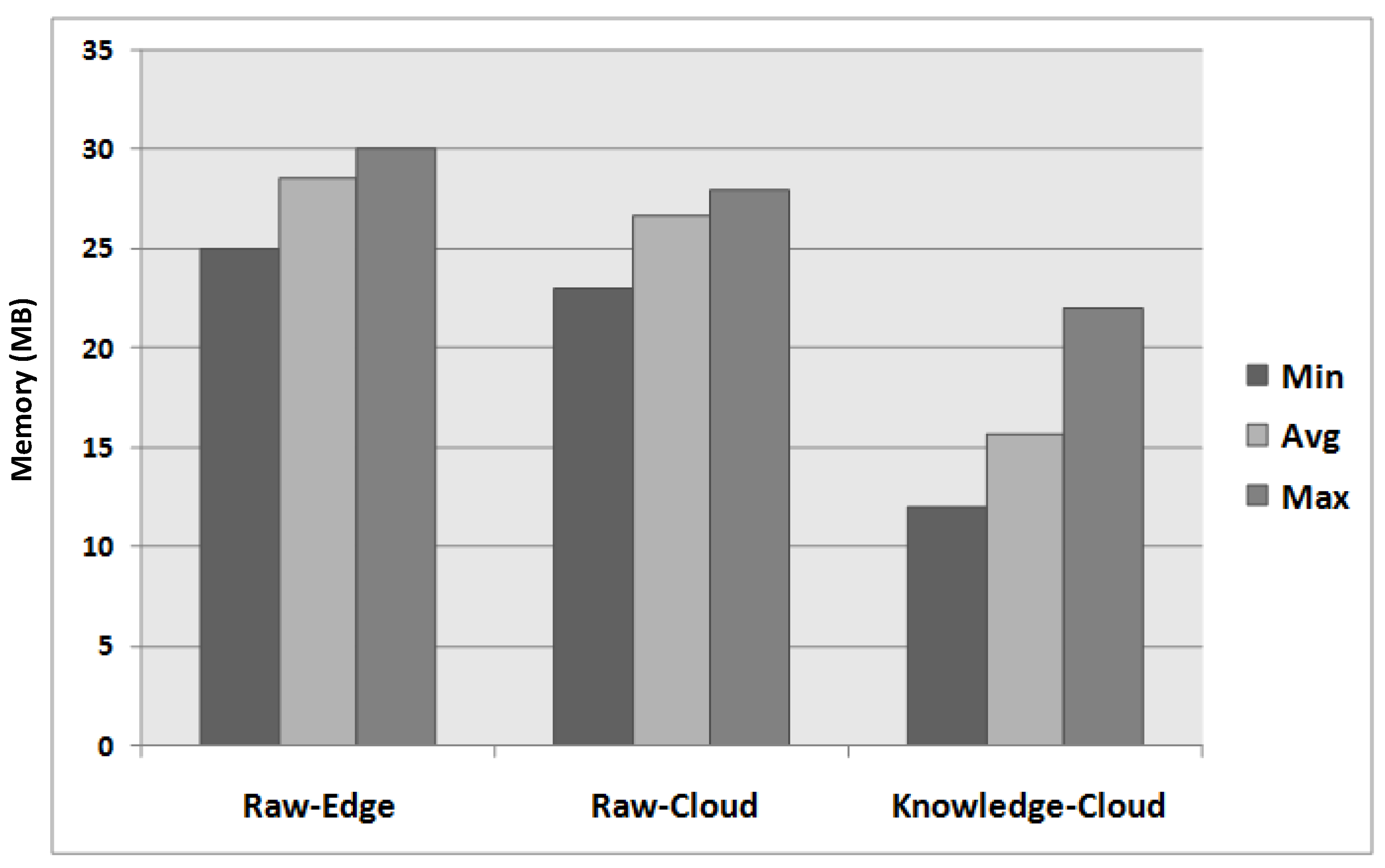
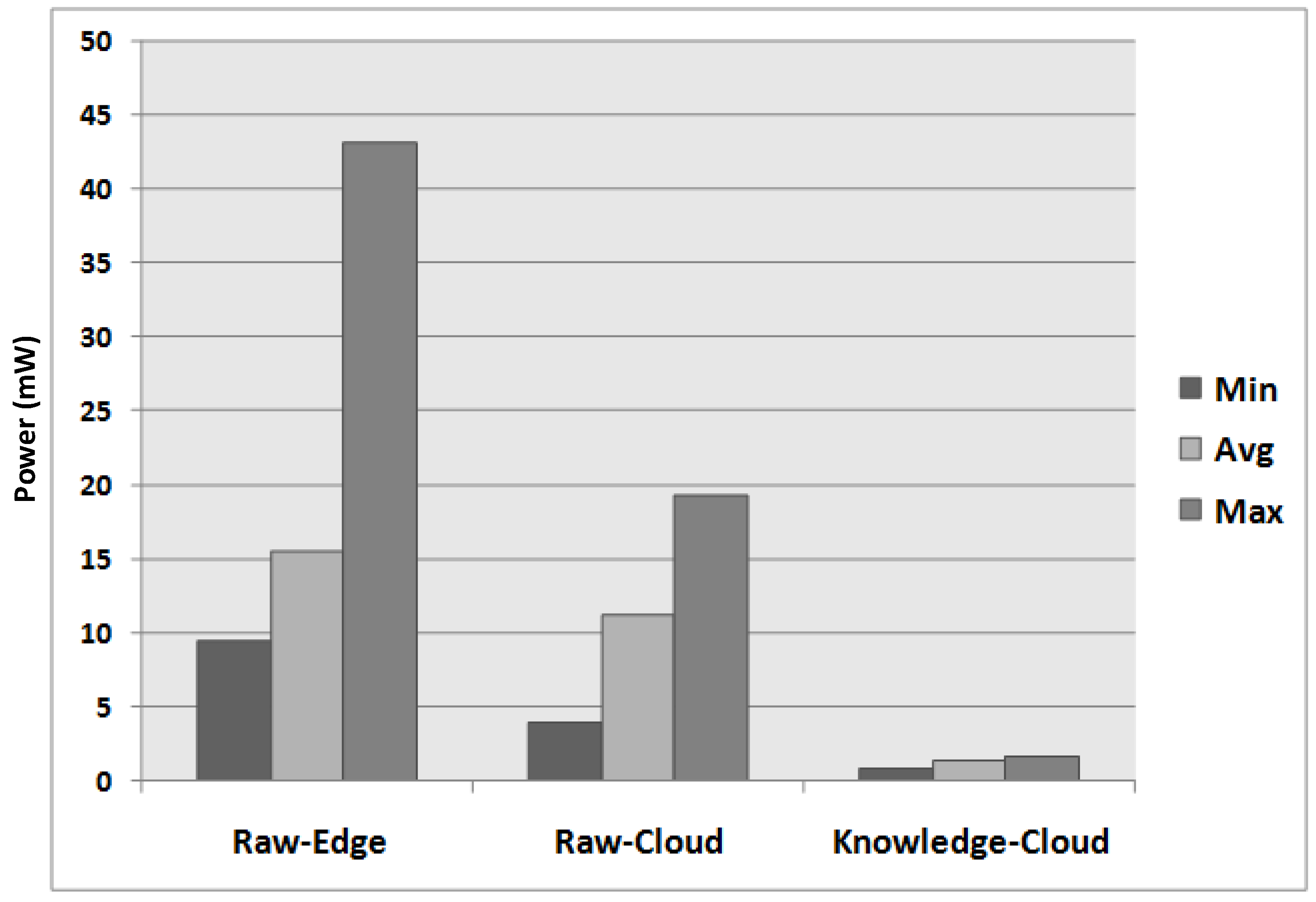
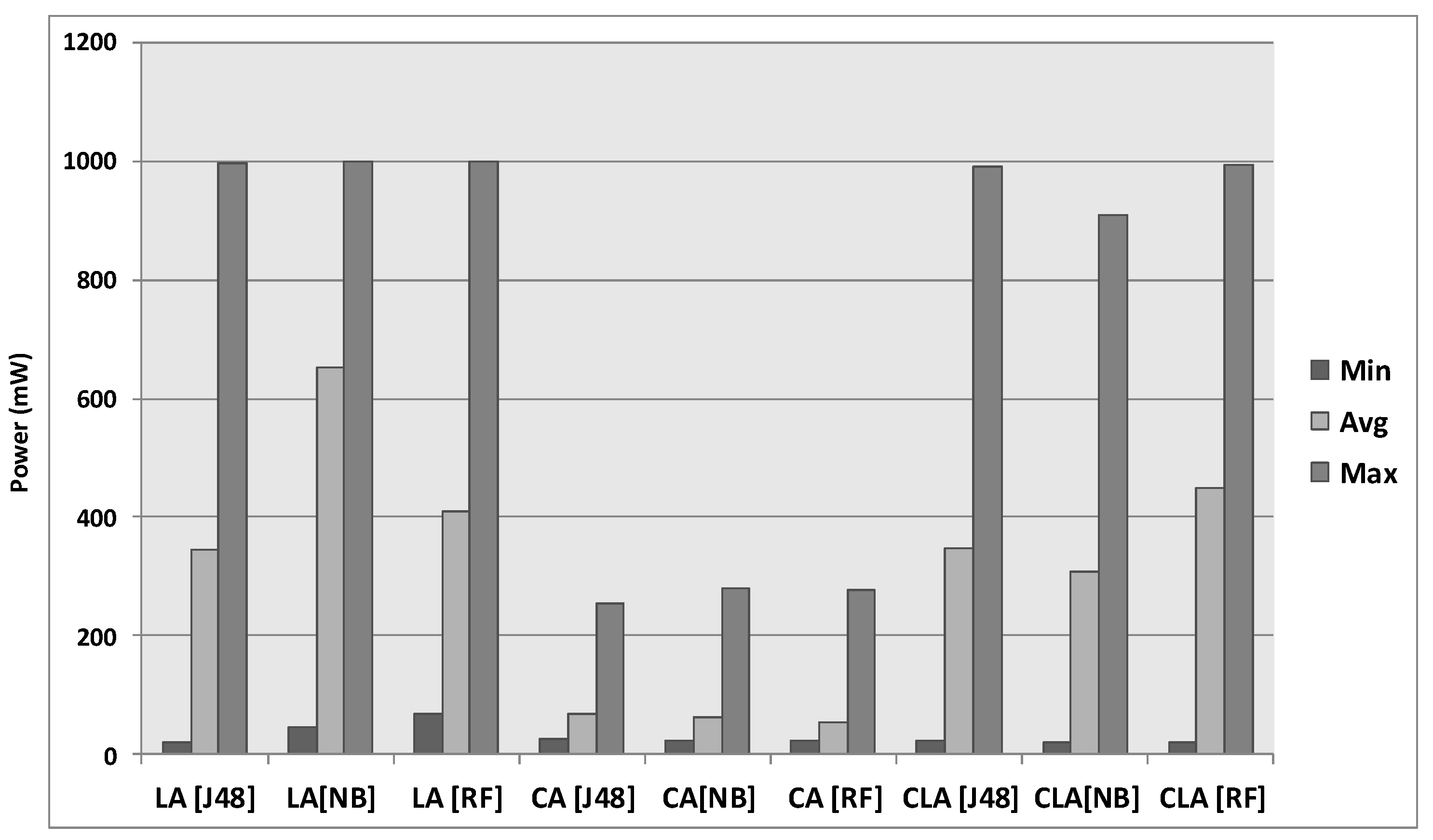
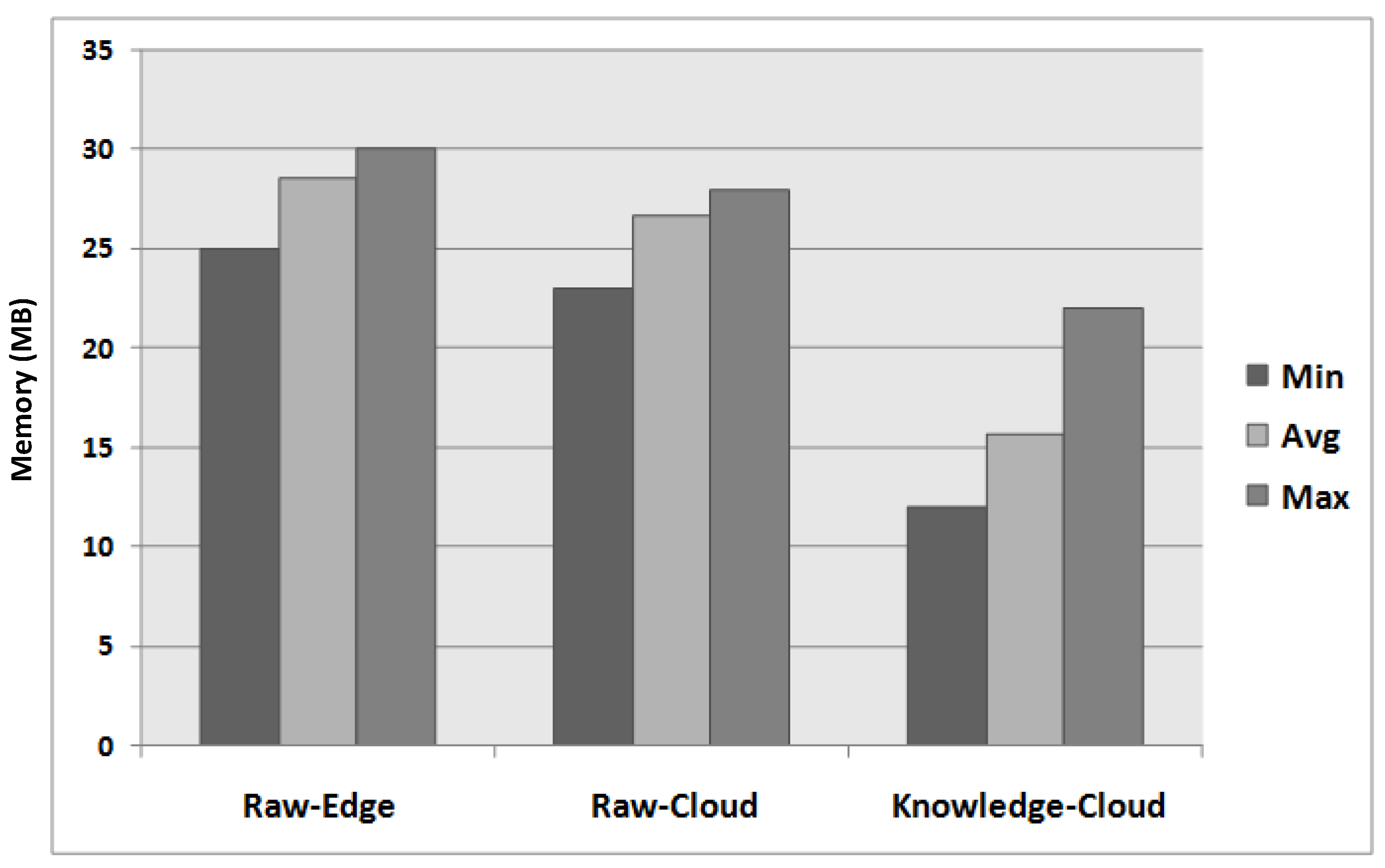
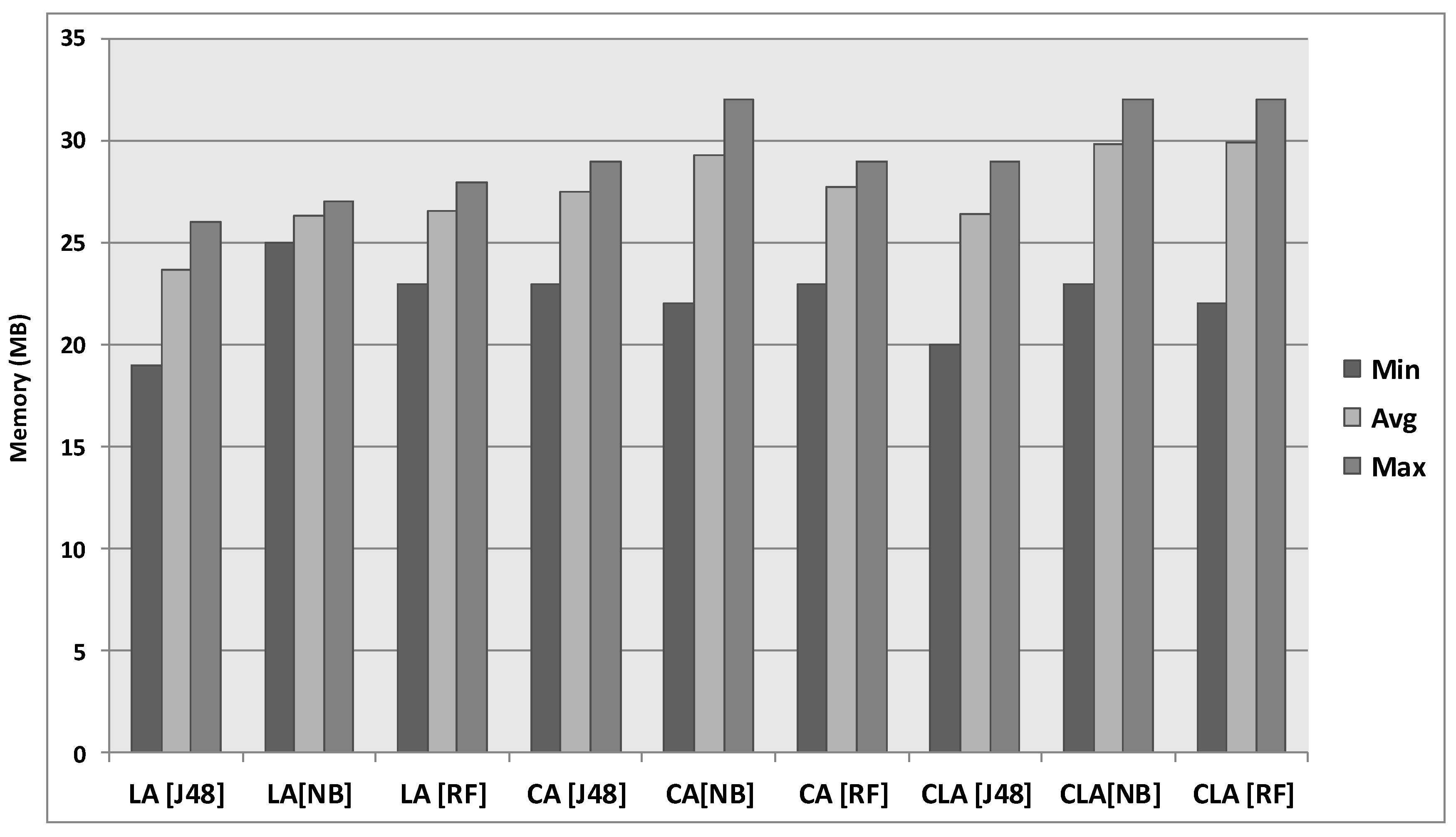
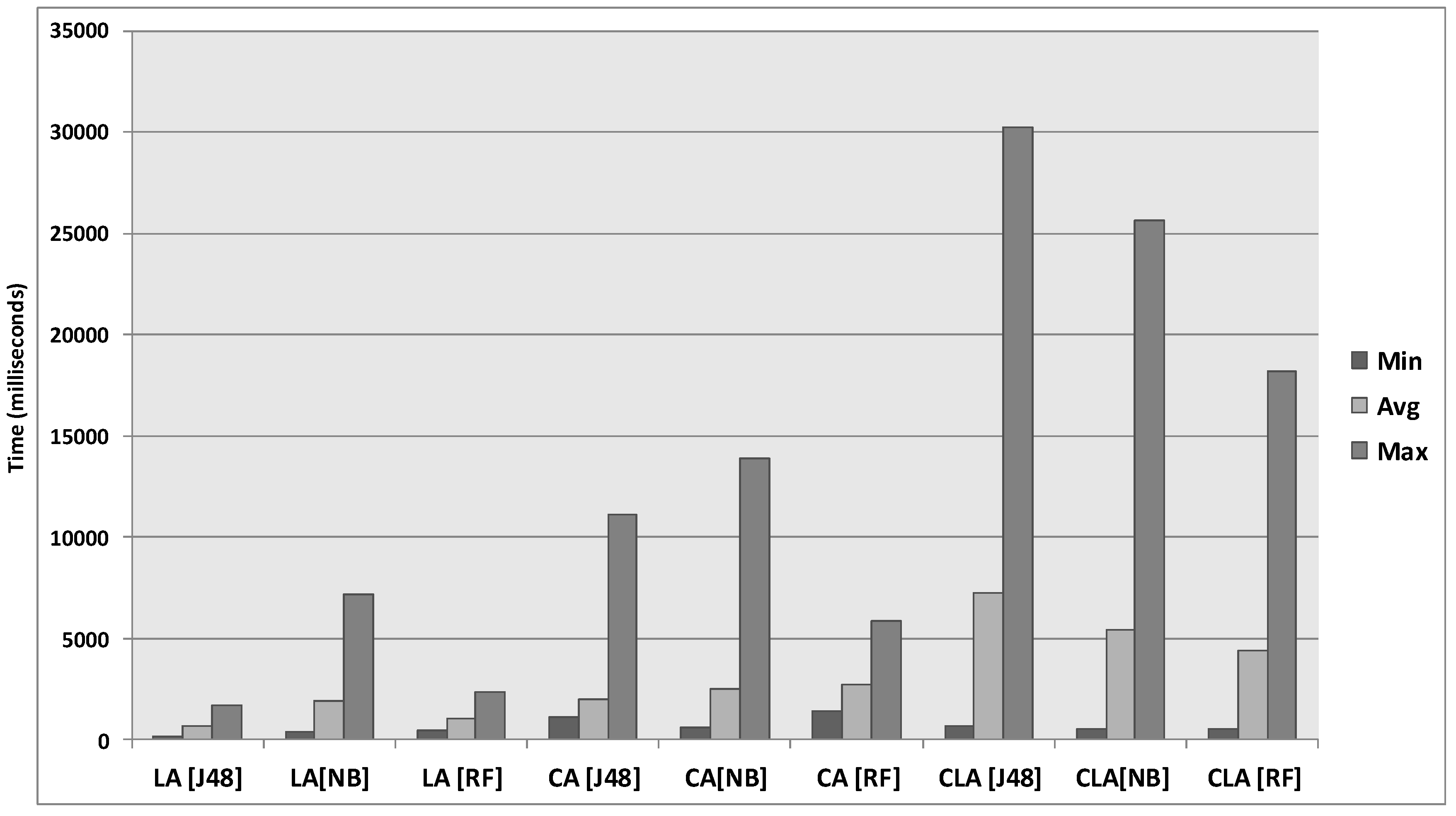
6.3. Results of the Real-World Experiment
- The architecture enables controlling the velocity of incoming data streams in big data systems. The data acquisition and adaptation module of RedEdge enable setting the speed of data collection according to the application requirements and provide mechanisms to acquire data streams from multiple data sources.
- The value of big data matters rather than blindly collecting data streams in cloud data centres. The knowledge discovery module of RedEdge enables improving the quality of big data streams. The module provides functionality to convert raw data streams into knowledge patterns, hence improving the quality of collected data streams. For example, in our use case application, the conversion of raw sensor readings into meaningful activities improves the quality of data streams.
- Handling a voluminous amount of big data is quite challenging and requires laborious efforts in order to perform data deduplication, data indexing, storage, retrieval and data cleaning operations for big data analytics. The three-level data reduction facilitates reducing the sheer volume of big data in order to ease the big data management operations. For example, our use-case application reduced the data volume about 13 times as compared with raw data transmission in cloud data centres.
- Conventionally, big data systems do not provide the local view of knowledge patterns near the data sources [55]. The visualization and actuation module of RedEdge ensures local knowledge availability in order to control the data sharing by mobile users.
- The architecture reduced big data streams near the data sources, hence lowering the bandwidth utilization cost. The cost is incurred in terms of data plans consumed by individual users, as well as the bandwidth utilization during in-network data movement in cloud data centres.
- The data reduction near the data sources is highly beneficial in order to reduce the operational cost of big data systems. Governments and enterprises do not need to purchase extra data storage and data processing facilities. Alternatively, the cloud service providers can lower the operational cost due to less storage and processing requirements.
7. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Buyya, R.; Yeo, C.S.; Venugopal, S.; Broberg, J.; Brandic, I. Cloud computing and emerging IT platforms: Vision, hype, and reality for delivering computing as the 5th u0tility. Future Gener. Comput. Syst. 2009, 25, 599–616. [Google Scholar] [CrossRef]
- Rehman, M.H.; Chang, V.; Batool, A.; Wah, T.Y. Big data reduction framework for value creation in sustainable enterprises. Int. J. Inf. Manag. 2016, 36, 917–928. [Google Scholar] [CrossRef]
- Shuja, J.; Gani, A.; Rehman, M.H.; Ahmed, E.; Madani, S.A.; Khan, M.K.; Ko, K. Towards native code offloading based MCC frameworks for multimedia applications: A survey. J. Netw. Comput. Appl. 2016, 75, 335–354. [Google Scholar] [CrossRef]
- Siddiqa, A.; TargioHashem, I.A.; Yaqoob, I.; Marjani, M.; Shamshirband, S.; Gani, A.; Nasaruddin, F. A Survey of big data management: Taxonomy and state-of-the-art. J. Netw. Comput. Appl. 2016, 71, 151–166. [Google Scholar] [CrossRef]
- Rehman, M.H.; Liew, C.S.; Abbas, A.; Jayaraman, P.P.; Wah, T.Y.; Khan, S.U. Big Data Reduction Methods: A Survey. Data Sci. Eng. 2016, 1, 265–284. [Google Scholar] [CrossRef]
- Trovati, M. Reduced topologically real-world networks: A big-data approach. Int. J. Distrib. Syst. Technol. 2015, 6, 13–27. [Google Scholar] [CrossRef]
- Patty, J.W.; Penn, E.M. Analyzing big data: Social choice and measurement. PS Political Sci. Politics 2015, 48, 95–101. [Google Scholar] [CrossRef]
- Yang, C.; Zhang, X.; Zhong, C.; Liu, C.; Pei, J.; Ramamohanarao, K.; Chen, J. A spatiotemporal compression based approach for efficient big data processing on cloud. J. Comput. Syst. Sci. 2014, 80, 1563–1583. [Google Scholar] [CrossRef]
- Wang, W.; Lu, D.; Zhou, X.; Zhang, B.; Mu, J. Statistical wavelet-based anomaly detection in big data with compressive sensing. EURASIP J. Wirel. Commun. Netw. 2013, 2013, 1–6. [Google Scholar] [CrossRef]
- Fu, Y.; Jiang, H.; Xiao, N. A scalable inline cluster deduplication framework for big data protection. In Middleware 2012; Springer: New York, NY, USA, 2012; pp. 354–373. [Google Scholar]
- Dong, W.; Douglis, F.; Li, K.; Patterson, R.H.; Reddy, S.; Shilane, P. Tradeoffs in Scalable Data Routing for Deduplication Clusters. Available online: https://www.usenix.org/legacy/events/fast11/tech/full_papers/Dong.pdf (accessed on 15 August 2017).
- Zerbino, D.R.; Birney, E. Velvet: Algorithms for de novo short read assembly using de Bruijn graphs. Genome Res. 2008, 18, 821–829. [Google Scholar] [CrossRef] [PubMed]
- Lin, M.S.; Chiu, C.Y.; Lee, Y.J.; Pao, H.K. Malicious URL filtering—A big data application. In Proceedings of the IEEE International Conference on Big Data, Silicon Valley, CA, USA, 6–9 October 2013; pp. 589–596. [Google Scholar]
- Leung, C.K.S.; MacKinnon, R.K.; Jiang, F. Reducing the search space for big data mining for interesting patterns from uncertain data. In Proceedings of the IEEE International Conference on Big Data, Washington, DC, USA, 27–30 October 2014; pp. 315–322. [Google Scholar]
- Jiang, P.; Winkley, J.; Zhao, C.; Munnoch, R.; Min, G.; Yang, L.T. An intelligent information forwarder for healthcare big data systems with distributed wearable sensors. IEEE Syst. J. 2016, 10, 1147–1159. [Google Scholar] [CrossRef]
- Akhbar, F.; Chang, V.; Yao, Y.; Muñoz, V.M. Outlook on moving of computing services towards the data sources. Int. J. Inf. Manag. 2016, 36, 645–652. [Google Scholar] [CrossRef]
- Li, C.S.; Darema, F.; Chang, V. Distributed behaviour model orchestration in cognitive Internet of Things solution. Ent. Inf. Sys. 2017. [Google Scholar] [CrossRef]
- Mital, M.; Chang, V.; Choudhary, P.; Pani, A.; Sun, Z. Adoption of cloud based Internet of Things in India: A multiple theory perspective. Int. J. Inf. Manag. 2016. [Google Scholar] [CrossRef]
- Satyanarayanan, M.; Simoens, P.; Xiao, Y.; Pillai, P.; Chen, Z.; Ha, K.; Hu, W.; Amos, B. Edge Analytics in the Internet of Things. IEEE Pervasive Comput. 2015, 14, 24–31. [Google Scholar] [CrossRef]
- Bonomi, F.; Milito, R.; Zhu, J.; Addepalli, S. Fog computing and its role in the Internet of Things. In Proceedings of the MCC Workshop on Mobile Cloud Computing, Helsinki, Finland, 13–17 August 2012; pp. 13–16. [Google Scholar]
- Drolia, U.; Martins, R.P.; Tan, J.; Chheda, A.; Sanghavi, M.; Gandhi, R.; Narasimhan, P. The Case for Mobile Edge-Clouds. In Proceedings of the IEEE 10th International Conference on Ubiquitous Intelligence and Computing and 10th International Conference on Autonomic and Trusted Computing (UIC/ATC), Vietri sul Mare, Italy, 18–21 December 2013; pp. 209–215. [Google Scholar]
- Ha, K.; Satyanarayanan, M. OpenStack++ for Cloudlet Deployment. Available online: http://reports-archive.adm.cs.cmu.edu/cs2015.html (accessed on 10 August 2017).
- Luan, T.H.; Gao, L.; Li, Z.; Xiang, Y.; Sun, L. Fog Computing: Focusing on Mobile Users at the Edge. arXiv, 2015; arXiv:1502.01815. [Google Scholar]
- Rehman, M.H.; Liew, C.S.; Wah, T.Y. Frequent pattern mining in mobile devices: A feasibility study. In Proceedings of the International Conference on Information Technology and Multimedia (ICIMU), Putrajaya, Malaysia, 18–20 November 2014; pp. 351–356. [Google Scholar]
- Rehman, M.H.; Batool, A.; Liew, C.S.; Teh, Y.W.; Khan, A.U.R. Execution Models for Mobile Data Analytics. IT Prof. 2017, 19, 24–30. [Google Scholar] [CrossRef]
- Rehman, M.H.; Liew, C.S.; Wah, T.Y. UniMiner: Towards a unified framework for data mining. In Proceedings of the 4th World Congress on Information and Communication Technologies (WICT), Malacca, Malaysia, 8–10 December 2014; pp. 134–139. [Google Scholar]
- Trovati, M.; Bessis, N. An influence assessment method based on co-occurrence for topologically reduced big data sets. Soft Comput. 2016, 20, 2021–2030. [Google Scholar] [CrossRef] [Green Version]
- Trovati, M.; Asimakopoulou, E.; Bessis, N. An analytical tool to map big data to networks with reduced topologies. In Proceedings of the International Conference on Intelligent Networking and Collaborative Systems (INCoS), Salerno, Italy, 10–12 September 2014; pp. 411–414. [Google Scholar]
- Jalali, B.; Asghari, M.H. The anamorphic stretch transform, putting the squeeze on big data. Opt. Photonics News 2014, 25, 24–31. [Google Scholar] [CrossRef]
- Ackermann, K.; Angus, S.D. A resource efficient big data analysis method for the social sciences: The case of global IP activity. Procedia Comput. Sci. 2014, 29, 2360–2369. [Google Scholar] [CrossRef]
- Zou, H.; Yu, Y.; Tang, W.; Chen, H.W.M. Flexanalytics: A flexible data analytics framework for big data applications with I/O performance improvement. Big Data Res. 2014, 1, 4–13. [Google Scholar] [CrossRef]
- Xia, W.; Jiang, H.; Feng, D.; Hua, Y. SiLo: A Similarity-Locality based Near-Exact Deduplication Scheme with Low RAM Overhead and High Throughput. In Proceedings of the USENIX Annual Technical Conference, Portland, OR, USA, 15–17 June 2011. [Google Scholar]
- Cheng, Y.; Jiang, P.; Peng, Y. Increasing big data front end processing efficiency via locality sensitive Bloom filter for elderly healthcare. In Proceedings of the IEEE Symposium on Computational Intelligence in Big Data (CIBD), Orlando, FL, USA, 9–12 December 2014; pp. 1–8. [Google Scholar]
- Hillman, C.; Ahmad, Y.; Whitehorn, M.; Cobley, A. Near real-time processing of proteomics data using Hadoop. Big Data 2014, 2, 44–49. [Google Scholar] [CrossRef] [PubMed]
- Sugumaran, R.; Burnett, J.; Blinkmann, A. Big 3d spatial data processing using cloud computing environment. In Proceedings of the 1st ACM SIGSPATIAL International Workshop on Analytics for Big Geospatial Data, Redondo Beach, CA, USA, 7–9 November 2012; pp. 20–22. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Hoi, S.C.; Wang, J.; Zhao, P.; Jin, R. Online feature selection for mining big data. In Proceedings of the 1st International Workshop on Big Data, Streams and Heterogeneous Source Mining: Algorithms, Systems, Programming Models and Applications, Beijing, China, 12–16 August 2012; pp. 93–100. [Google Scholar]
- Qiu, J.; Zhang, B. Mammoth Data in the Cloud: Clustering Social Images. In Cloud Computer and Big Data; IoS Press: Amsterdam, The Nederlands, 2013; pp. 231–246. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Cichocki, A. Era of big data processing: A new approach via tensor networks and tensor decompositions. arXiv, 2014; arXiv:1403.2048. [Google Scholar]
- Azar, A.T.; Hassanien, A.E. Dimensionality reduction of medical big data using neural-fuzzy classifier. Soft Comput. 2014, 19, 1115–1127. [Google Scholar] [CrossRef]
- Stateczny, A.; Wlodarczyk-Sielicka, M. Self-organizing artificial neural networks into hydrographic big data reduction process. In Rough Sets and Intelligent Systems Paradigms; Springer: Berlin, Germany, 2014; pp. 335–342. [Google Scholar]
- Rágyanszki, A.; Gerlei, K.Z.; Surányi, A.; Kelemen, A.; Jensen, S.J.K.; Csizmadia, I.G.; Viskolcz, B. Big data reduction by fitting mathematical functions: A search for appropriate functions to fit Ramachandran surfaces. Chem. Phys. Lett. 2015, 625, 91–97. [Google Scholar] [CrossRef]
- Rehman, M.H.; Liew, C.S.; Iqbal, A.; Wah, T.Y.; Jayaraman, P.P. Opportunistic Computation Offloading in Mobile Edge Cloud Computing Environments. In Proceedings of the 17th IEEE International Conference on Mobile Data Management, Porto, Portugal, 13–17 June 2016. [Google Scholar]
- Klas, G.I. Fog Computing and Mobile Edge Cloud Gain Momentum Open Fog Consortium, ETSI MEC and Cloudlets. Available online: http://yucianga.info/wp-content/uploads/2015/11/15-11-22-Fog-computing-and-mobile-edge-cloud-gain-momentum-%E2%80%93-Open-Fog-Consortium-ETSI-MEC-Cloudlets-v1.pdf (accessed on 10 August 2017).
- Lin, B.S.P.; Lin, F.J.; Tung, L.P. The Roles of 5G Mobile Broadband in the Development of IoT, Big Data, Cloud and SDN. Commun. Netw. 2016, 8, 9. [Google Scholar] [CrossRef]
- Ferreira, D.; Dey, A.K.; Kostakos, V. Understanding human-smartphone concerns: A study of battery life. In Pervasive Computing; Springer: Berlin, Germany, 2011; pp. 19–33. [Google Scholar]
- Diaz, M. Petri Nets: Fundamental Models, Verification and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- De Moura, L.; Bjørner, N. Satisfiability modulo theories: An appetizer. In Formal Methods: Foundations and Applications; Springer: Berlin, Germany, 2009; pp. 23–36. [Google Scholar]
- De Moura, L.; Bjorner, N. Z3: An efficient SMT solver. In Proceedings of the International conference on Tools and Algorithms for the Construction and Analysis of Systems, Budapest, Hungary, 29 March–6 April 2008; pp. 337–340. [Google Scholar]
- Othman, M.; Ali, M.; Khan, A.N.; Madani, S.A.; Khan, A.U.R. Pirax: Framework for application piracy control in mobile cloud environment. J. Supercomput. 2014, 68, 753–776. [Google Scholar]
- Abid, S.; Othman, M.; Shah, N.; Ali, M.; Khan, A. 3D-RP: A DHT-based routing protocol for MANETs. Comput. J. 2014, 58, 258–279. [Google Scholar] [CrossRef]
- Bonet, P.; Lladó, C.M.; Puijaner, R.; Knottenbelt, W.J. PIPE v2.5: A Petri Net Tool for Performance Modelling. Available online: http://pubs-dev.doc.ic.ac.uk/pipe-clei/pipe-clei.pdf (accessed on 15 August 2017).
- Liu, S.; Zeng, R.; Sun, Z.; He, X. Bounded Model Checking High Level Petri Nets in PIPE+ Verifier. In Formal Methods and Software Engineering; Springer: Berlin, Germany, 2014; pp. 348–363. [Google Scholar]
- Rehman, M.H.U.; Sun, L.C.; Wah, T.Y.; Khan, M.K. Towards next-generation heterogeneous mobile data stream mining applications: Opportunities, challenges, and future research directions. J. Netw. Comput. Appl. 2017, 79, 1–24. [Google Scholar] [CrossRef]
- Daghighi, B.; Kiah, M.L.M.; Shamshirband, S.; Rehman, M.H.U. Toward secure group communication in wireless mobile environments: Issues, solutions, and challenges. J. Netw. Comput. Appl. 2015, 50, 1–14. [Google Scholar] [CrossRef]
- Daghighi, B.; Kiah, M.L.M.; Iqbal, S.; Rehman, M.H.; Martin, K. Host mobility key management in dynamic secure group communication. Wirel. Netw. 2017. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | Descriptions |
|---|---|
| T_stamp | A DateTime type representing date and time |
| F_name | A string type representing unprocessed data file name |
| DS_ID | A string type representing name of data source |
| Chunk_ID | A string type representing data chunk code generated by system |
| Flag_status | An integer type representing status of data chunks (unprocessed, processed, processing) |
| Location | A string type representing the name and GPS coordinates of a location |
| Charging | A Boolean type representing the charging status of mobile edge device |
| Locked | A Boolean type representing the lock status of mobile edge device |
| Calling | A Boolean type representing the call status of mobile edge device |
| Internet | A Boolean type representing the availability status of active Internet interfaces |
| Dev_ID | A string type representing the device_id based on International Mobile Equipment Identity(IMEI) of mobile edge device |
| Mem | An integer type representing maximum memory in the mobile edge device |
| Storage | An integer type representing maximum storage in the mobile edge device |
| App_ID | A string type representing application_id in the mobile edge device |
| Avlb_Loc_storage | An integer type representing available local storage in the mobile edge device |
| Avlb_SD_card | An integer type representing available storage on the SD-card in the mobile edge device |
| Wifi | A string type representing availability and connectivity through Wi-Fi |
| GSM | A string type representing availability and connectivity status through GSM |
| BT | A string type representing availability and connectivity through Bluetooth |
| BL | A string type representing availability and connectivity through Bluetooth Low Energy |
| Exec_mode | A string type representing the current execution mode of the system |
| Pattern_attribute | A string type representing multiple attributes of extracted patterns (types of patterns, number of patterns, quality of patterns) |
| Places | Mappings |
|---|---|
| (Data Sources) | (T_stamp × F_name × DS_ID) |
| (Loc Data) | (T_stamp × F_name × DS_ID) |
| (Data Tab) | (Chunk_ID × Flag_status × DS_ID × F_name) |
| (Up Data) | (Chunk_ID × Flag_status × DS_ID) |
| (Context Info) | (T_stamp × Location × Charging × Calling × Internet × Locked) |
| (Conn) | (Dev_ID × Mem × Storage) |
| (Local Res) | (T_stamp × Mem × Avlb_Loc_storage × Avlb_SD_Card × Wifi × GSM × BT × BL) |
| (Est Res) | (App_ID × Mem × Storage) |
| (Exec Mode) | (Exec_mode) |
| (Disc Pattern) | (Chunk_ID × Pattern_attributes) |
| (Intr Pattern) | (Chunk_ID × Pattern_attributes) |
| (Loc Pattern) | (Chunk_ID × Pattern_attributes) |
| (Cloud Str) | (Chunk_ID × DS_ID × Pattern_attributes) |
| Places | T0 | T1 | T10 | T11 | T6 | T5 | T4 | T12 | T2 | T7 | T8 | T3 | T13 | T14 | T19 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (Data Sources) | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| (Loc Data) | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| (Exec Mode) | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| (Loc Pattern) | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| (Intr Pattern) | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| (Disc Pattern) | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| (Data Tab) | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| (Up Data) | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| (Cloud Str) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| (Context Info) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| (Conn.) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| (Loc Res) | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| (Est Res) | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| Places | T0 | T1 | T10 | T11 | T6 | T5 | T4 | T12 | T2 | T7 | T8 | T3 | T13 | T14 | T19 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (Data Sources) | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| (Loc Data) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| (Exec Mode) | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| (Loc Pattern) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| (Intr Pattern) | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| (Disc Pattern) | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| (Data Tab) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| (Up Data) | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| (Cloud Str) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| (Context Info) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| (Conn.) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| (Loc Res) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| (Est Res) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| Places | Minimum Threshold | Maximum Threshold | ||
|---|---|---|---|---|
| Average No. of Tokens | 95% Confidence | Average No. of Tokens | 95% Confidence | |
| (Data Sources) | 3.5135 | 1.7770 | 334.8233 | 18.1603 |
| (Loc Data) | 2.9189 | 0.6936 | 354.3783 | 27.6568 |
| (Exec Mode) | 4.2703 | 0.6006 | 684.8284 | 38.9546 |
| (Loc Pattern) | 2.1892 | 1.2426 | 342.7440 | 20.0734 |
| (Intr Pattern) | 1.72973 | 1.15794 | 675.6431 | 41.8029 |
| (Disc Pattern) | 2.4054 | 1.1550 | 340.9338 | 20.8442 |
| (Data Tab) | 0.4595 | 2.18681 | 323.2102 | 31.7452 |
| (Up Data) | 1.0270 | 1.4271 | 332.9073 | 32.9875 |
| (Cloud Str) | 1.5405 | 0.4962 | 305.2618 | 28.0542 |
| (Context Info) | 0.9729 | 1.0296 | 320.1321 | 30.2847 |
| (Conn.) | 1.0270 | 0 | 1.0001 | 0 |
| (Loc Res) | 0.5405 | 0.7352 | 339.9139 | 31.5361 |
| (Est Res) | 0.3514 | 0.5164 | 327.8112 | 25.2031 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Habib ur Rehman, M.; Jayaraman, P.P.; Malik, S.U.R.; Khan, A.U.R.; Medhat Gaber, M. RedEdge: A Novel Architecture for Big Data Processing in Mobile Edge Computing Environments. J. Sens. Actuator Netw. 2017, 6, 17. https://doi.org/10.3390/jsan6030017
Habib ur Rehman M, Jayaraman PP, Malik SUR, Khan AUR, Medhat Gaber M. RedEdge: A Novel Architecture for Big Data Processing in Mobile Edge Computing Environments. Journal of Sensor and Actuator Networks. 2017; 6(3):17. https://doi.org/10.3390/jsan6030017
Chicago/Turabian StyleHabib ur Rehman, Muhammad, Prem Prakash Jayaraman, Saif Ur Rehman Malik, Atta Ur Rehman Khan, and Mohamed Medhat Gaber. 2017. "RedEdge: A Novel Architecture for Big Data Processing in Mobile Edge Computing Environments" Journal of Sensor and Actuator Networks 6, no. 3: 17. https://doi.org/10.3390/jsan6030017