1. Introduction
Measuring the similarity and dissimilarity between models is crucial in many fields of time series analysis. We limit ourselves to mentioning some applications: clustering time series data (see [
1,
2]), data mining problems (see [
3]), time series classification (see [
4]), selecting between direct and indirect model-based seasonal adjustment (see [
5]), the analysis of Granger causality (see [
6]), comparing autocorrelation structures of multiple time series (see [
7]).
A number of measures of dissimilarity between univariate linear models have been suggested in the literature. Among these, we find the Mahalanobis distance between autoregressive models used in [
8], the autoregressive distances introduced in [
9,
10,
11], the cepstral distance proposed in [
12] to be of note. In this paper, we introduce a distance measure between sets of invertible autoregressive moving average (ARMA) models and we show how it finds application in time series analysis. In particular, two specific applications are described. The first application consists of measuring the distance between two single ARMA series,
x and
y, by means of the proposed distance between portfolios of ARMA models providing reasonably good fits of
x and
y. The second application uses our distance to compute distances between two vector autoregressive (VAR) models once these models are properly represented in terms of univariate ARMA models. The remainder of the paper is organized as follows:
Section 2 presents the distance.
Section 3 shows how this distance can be used. An empirical application is presented in
Section 4.
Section 5 concludes.
2. Proposed Distance
The intrinsic nature of a time series is usually that the observations are dependent or correlated. The autoregressive moving average (ARMA) processes are a very general class of parametric models useful for describing such correlations. For a general reference on ARMA models, see Brockwell and Davis [
13].
We have that
is an ARMA(
p,
q) process if, for every t,
where
and
are polynomials in the lag operator
L, with no common factors, and
is a white noise process with constant variance
. The ARMA process
x is said to be invertible if it admits the representation:
where the AR(∞) operator is defined by
with
.
Let M be the class of ARMA invertible processes and let be a metric on M. Now, we consider the family of all non-empty finite subsets of M. We want to introduce a metric on .
If
S is an element of
and
x is a point of
M, the distance from
x to
S is defined as
Equation (
1) represents the smallest distance between
and any point
. Given a subset
T of
M, let us define the function
that measures the largest among all distances
, with
. However, this function is not symmetric since in general
is not equal to
. Thus, we prefer to define the distance,
, between two finite sets of invertible
ARMA processes,
S and
T, as their Hausdorff distance. Formally, we have:
The distance between two finite sets of invertible
ARMA processes, defined in this way satisfies all the desirable metric properties. In fact, we can prove the following:
Proposition 1. The function defined asis a metric on . Proof. The function (
2) is obviously non-negative and the symmetry follows straight from the definition.
In order to prove the triangle inequality, we note that if
, then
for all
, so there exists
,
such that
. Let
S,
F,
T be three elements of
and put
and
. For each
we have that
and there exists
,
such that
. Analogously, from
there exists
such that
. Since
d is a metric on
M,
It follows that
and
Thus
Finally, we show that
if and only if
. It is clear that if
, then
. Now, we assume that
. This implies that
. It follows that
and hence for every
there exists a
such that
. Since
is a metric on
M, this implies that
. Thus
. In an analogous way, we can show that
. Thus we can conclude that
. The non-negative real-valued function (
2) is a metric on
. ☐
In order to make operative the notion of distance between finite sets of invertible ARMA models introduced above, it is necessary to specify a particular distance
d between invertible ARMA models. If
, following Piccolo [
9], we can consider the Euclidean distance between the corresponding
π-weights sequence,
, that is
where
and
denote the sequences of AR weights of
x and
y, respectively.
The measure
satisfies the following properties:
i. Non-negativity:
ii. Symmetry:
iii. Subadditivity:
We note that the distance between two ARMA processes, measured by
, is allowed to be zero even if they are generated by different white noise processes,
and
.
1 This implies that
is a pseudometric on
M. It follows that also
H, with
, becomes a pseudometric on
.
3. Applications
This section discusses two applications of the distance function defined in (2) in the field of time series analysis.
3.1. Distance between Portfolios of ARMA Models
The first application consists of measuring the distance between two univariate ARMA series,
x and
y, by means of the proposed distance between portfolios of ARMA models providing reasonably good fits of
x and
y. The notion of portfolio of ARMA models has been introduced by Poskitt and Tremayne [
14]. When modeling time series data an analyst typically searches over a range of models. Then a single model is usually selected as a satisfactory representation of the true, but unknown, underlying data generating mechanism. However, given that a wrong model may be selected or that a “best” model may not exist anyway (see Chatfield [
15], p. 80), a better strategy could be to allow the possibility that there may be more than one model which may be regarded as a reasonable representation of the data generating mechanism.
Consider a process
that admits an invertible ARMA representation
Following Box and Jenkins [
16], given a realization
, a common model building strategy is to initially select plausible values of
p and
q based on statistics (the Akaike information criterion (AIC), the Bayesian information criterion (BIC), etc.) calculated from the data.
Consider, for example, the BIC criterion
where
is the maximum likelihood estimate of
. Let
and
be the orders of the ARMA selected by using the BIC criterion, that is
where
and
. We denote with
an ARMA(
) model (with
and
) for the process
x and, following Poskitt and Tremayne [
14], we consider the quantity
We note that this quantity is related to the Y parameter introduced and studied in [
17,
18].
When
the ARMA model
is said to be a “close competitor” to the criterion-minimizing ARMA(
) model. The set of closely competing models
is termed a model portfolio for the process
x.
The concept of model portfolio suggests not only that the model minimizing the criterion should be selected but also that any additional specifications closely competing with ARMA() should not be discarded.
Using the Hausdorff distance H, we can evaluate the distance between portfolios of ARMA models. Let x and y be two invertible ARMA processes and let and be the model portfolios of the process x and y, respectively. Since , the distance between the portfolios and is given by .
3.2. Distance between VAR Processes
The vector autoregressive (VAR) process is a generalization of the univariate autoregressive process. The VAR processes has been popularized by Sims [
19]. In this subsection, we will show how the proposed distance can be used to evaluate the distance between VAR processes.
Recall that a
k-dimensional process
is a VAR
process if it can be represented as
where
are
matrices od coefficients and
is a
k-dimensional white noise, with non-singular covariance matrix
. Using the lag operator,
L, we can rewrite the VAR model in the following way
where
.
We have
where
and
are, respectively, the adjoint matrix and the determinant of the matrix
.
Following Zellner and Palm [
20], premultiplying both sides of (
3) by
, we obtain the “final equations”:
For the
ith element of
, expression (
4) becomes
where
denotes the
ith row of the adjoint matrix
.
Since the right-hand side of (
5) is the sum of
k finite moving averages, it can also be represented as a finite moving average
, where
is a white noise process, such that
The coefficients of the polynomial
are found by equating the autocovariances in the two representations. In this way we obtain a non-linear system of
equations in
unknowns
and
. It is important to note that we consider the invertible solution of this system.
Considering (
5) and (
6), the univariate models implied by (
3) are given by
Thus, we can conclude that
where it is well known that
and
. We denote with
this set of univariate ARMA processes. Given two VAR processes,
y and
x, we can obtain their final forms,
and
. Since
, we can calculate
and consider it as distance between the VAR processes
y and
x.
An Illustrative Example
Here, we present an example of the proposed distance. We consider two VAR(1) processes,
y and
x, defined, respectively, by the following equations
with
and
with
where the bivariate white noise processes are such that
The univariate models implied by (
7) are given by:
The univariate models implied by (
8) are:
We have that
,
,
and
, Thus we obtain
.
4. An Empirical Application
To show the applicability of the derived results we consider the following time series:
the northern hemisphere annual temperature anomalies (N);
the southern hemisphere annual temperature anomalies (S);
the annual global land temperature anomalies (L);
the annual global ocean temperature anomalies (O).
These global temperature anomaly data, with respect to the 20th century average, come from the Global Historical Climatology Network-Monthly (GHCN-M) data set and International Comprehensive Ocean-Atmosphere Data Set (ICOADS). The data span is from 1980 to 2012. These time series, shown in
Figure 1, are available at [
21]. Various subsets of this data set have been used in a number of studies (see, for example, [
22,
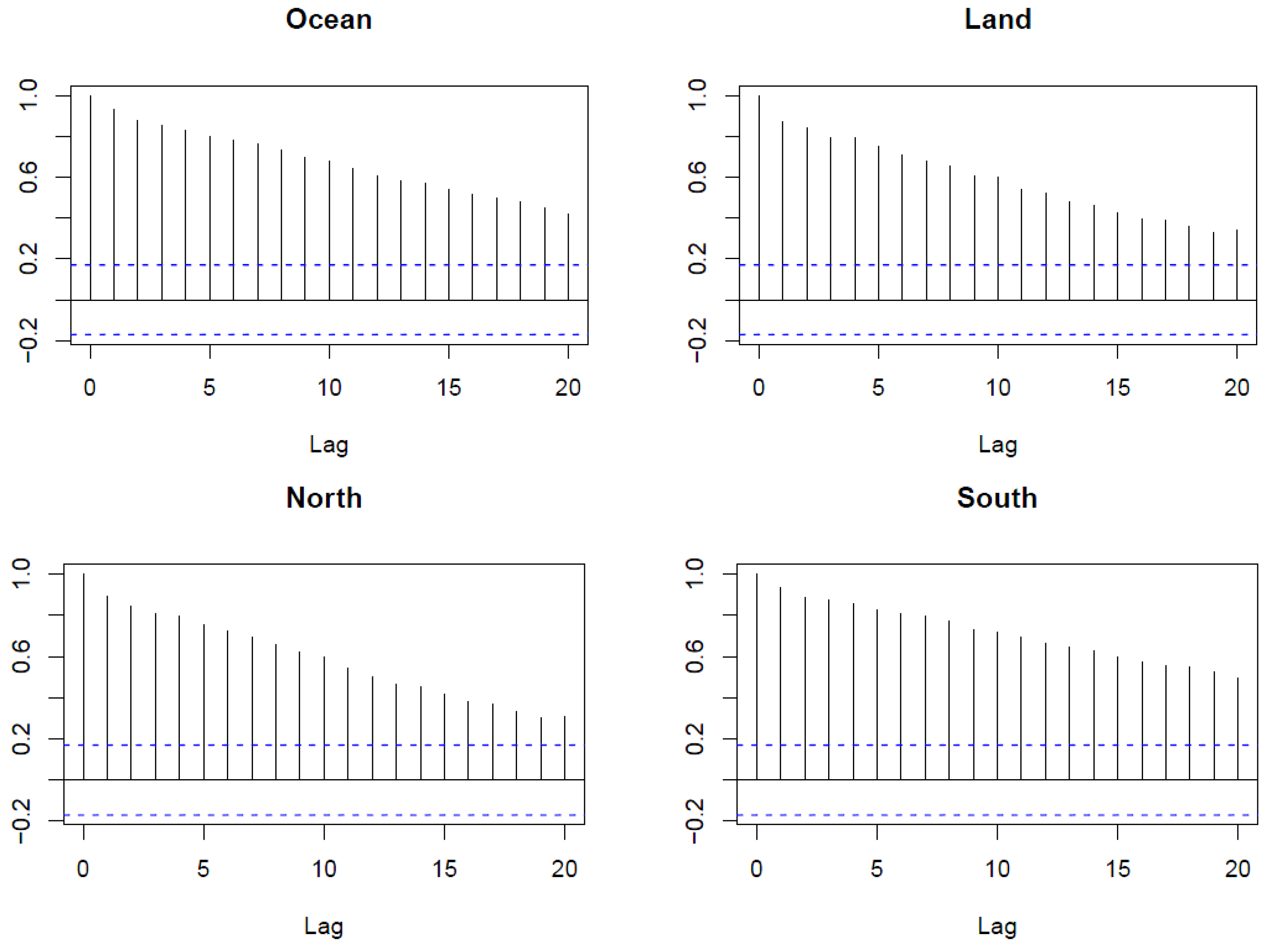
23]). The Auto Correlation Functions (ACFs) of the series and the Cross Correlation Functions (CCFs) are presented in
Figure 2 and
Figure 3, respectively. The ACF plots indicate that the series are nonstationary, since the ACFs decay very slowly.
We will build portfolios of ARMA models for these four series, and hence, by estimating the models for each portfolio, an estimate of the Hausdorff distance
H among our time series will be obtained. Preliminarily, we have used the augmented Dickey Fuller (ADF) test in order to establish whether the considered series are stationary or non-stationary. We concluded that all four temperature time series are integrated of order one. These results are consistent with those obtained by Stern and Kaufmann ([
24]), Liu and Rodriguez ([
25]) and Mills ([
26]). Now, in order to build a model portfolio for the considered time series, we identify ARMA models for the first differences of our time series. Bayesian Information Criterion (BIC) has been used to find the appropriate orders
p and
q of the AR and MA polynomials respectively.
The BIC values has been calculated for the ARMA(
) models with
.
Table 1 shows the orders (
) of ARMA models (for each time series) for which the value of the BIC, has been found to be minimum. The residual plots, reported in
Figure 4, indicate no presence of serial correlation on the error term. The obtained portfolios of ARMA models for the four differenced series are:
,
,
,
.
By estimating the models for each portfolio, an estimate of the Hausdorff distance
H is obtained.
Table 2 summarizes the results.
According to our notion of distance, the dynamic structure of the ocean temperature (O) and the dynamic structure of the southern temperature (S) seem to be very similar. On the contrary, both the series, O and S, seem to be very distant by the land temperature (L) and by the northern hemisphere temperature (N). Instead, a smaller distance separates the series L and N. The big thermal inertia of oceans, together with the uneven distribution of the land and sea (the Southern Hemisphere contains 80.9 percent water and 19.1 percent land, while the Northern Hemisphere is 60.7 percent water and 39.3 percent land) represents a possible explanation of our results. This conclusion is attractive since it links a statistical result to a physical mechanism.
5. Conclusions
This manuscript focuses on measuring the distance between two finite sets of invertible ARMA processes using the Hausdorff distance. In order to make this distance operative, a dissimilarity measure between two single ARMA processes (the AR metric) is considered. Of course other dissimilarity measures, e.g., the Mahalanobis distance between autoregressive models or the cepstral distance, could be used. We have chosen the AR metric since it is simple to compute and it is robust with respect to the presence of anomalous behavior in the data. Further, it is implemented for both stationary and non-stationary time series.
In order to show the usefulness of the proposed distance, two specific applications have been described. The first application consists of measuring the distance between two single ARMA series, let’s say x and y, by means of the Hausdorff distance between portfolios of ARMA models providing reasonably good fits of x and y. The second application uses the Hausdorff distance to compute distances between two VAR processes once these models are properly represented in terms of univariate ARMA processes. An empirical application is also presented.
Acknowledgments
We thank three anonymous reviewers and Diane Bergman for their constructive comments, which helped us to improve the manuscript.
Conflicts of Interest
The author declares no conflict of interest.
References
- E.A. Maharaj. “Clusters of time series.” J. Classif. 17 (2000): 297–314. [Google Scholar] [CrossRef]
- T. Liao. “Clustering time series data—A survey.” Pattern Recognit. 38 (2005): 1857–1874. [Google Scholar] [CrossRef]
- R. Agrawal, C. Faloutsos, and A. Swami. “Efficient similarity search in sequence databases.” In Proceedings of the 4th International Conference on Data Organization and Algorithms FODO ’93, Chicago, IL, USA, 13–15 October 1993; New York, NY, USA: Springer Verlag, 1993. Number 730 in Lecture Notes in Computer Science. pp. 69–84. [Google Scholar]
- J. Caiado, N. Crato, and D. Peña. “A periodogram-based metric for time series classification.” Comput. Stat. Data Anal. 50 (2006): 2668–2684. [Google Scholar] [CrossRef] [Green Version]
- E. Otranto, and U. Triacca. “Measures to evaluate the discrepancy between direct and indirect model-based seasonal adjustment.” J. Off. Stat. 18 (2002): 551–530. [Google Scholar]
- F. Di Iorio, and U. Triacca. “Testing for Granger non-causality using the autoregressive metric.” Econ. Model. 33 (2013): 120–125. [Google Scholar] [CrossRef] [Green Version]
- L. Jin. “Comparing autocorrelation structures of multiple time series via the maximum distance between two groups of time series.” J. Stat. Comput. Simul. 85 (2015): 3535–3548. [Google Scholar] [CrossRef]
- P.J. Thomson, and P. de Souza. “Speech recognition using LPC distance measures.” In Handbook of Statistics 5 Time Series in the Time Domain. Edited by E.J. Hannan, P.R. Krishnaiah and M.M. Rao. Amsterdam, The Netherlands: North Holland, 1985, pp. 389–412. [Google Scholar]
- D. Piccolo. “A distance measure for classifying ARIMA models.” J. Time Ser. Anal. 11 (1990): 153–164. [Google Scholar] [CrossRef]
- M. Corduas, and D. Piccolo. “Time series clustering and classification by the autoregressive metric.” Comput. Stat. Data Anal. 52 (2008): 1860–1872. [Google Scholar] [CrossRef]
- E.A. Maharaj. “A significance test for classifying ARMA models.” J. Stat. Comput. Simul. 54 (1996): 305–331. [Google Scholar] [CrossRef]
- R.J. Martin. “A metric for ARMA processes.” IEEE Trans. Signal Proces. 48 (2000): 1164–1170. [Google Scholar] [CrossRef]
- P. Brockwell, and R. Davies. Time Series: Theory and Methods, 2nd ed. New York, NY, USA: Springer-Verlag, 1991. [Google Scholar]
- D.S. Poskitt, and A.R. Tremayne. “Determining a portfolio of linear time series models.” Biometrika 74 (1987): 125–137. [Google Scholar] [CrossRef]
- C. Chatfield. Time-Series Forecasting. London, UK: Chapman & Hall, 2000. [Google Scholar]
- G.E.P. Box, and G.M. Jenkins. Time Series Analysis: Forecasting and Control. San Francisco, CA, USA: Holden-Day, 1970. [Google Scholar]
- D. Faranda, B. Dubrulle, F. Daviaud, and F.M.E. Pons. “Probing turbulence intermittency via autoregressive moving-average models.” Phys. Rev. E 90 (2014): 061001. [Google Scholar] [CrossRef] [PubMed]
- D. Faranda, F.M.E. Pons, E. Giachino, S. Vaienti, and B. Dubrulle. “Early warnings indicators of financial crises via auto regressive moving average models.” Commun. Nonlinear Sci. Numer. Simul. 29 (2015): 233–239. [Google Scholar] [CrossRef]
- A. Sims. “Macroeconomics and reality.” Econometrica 48 (1980): 1–48. [Google Scholar] [CrossRef]
- A. Zellner, and F. Palm. “Time series analysis and simultaneous equation econometric models.” J. Econom. 2 (1974): 17–54. [Google Scholar] [CrossRef]
- “Climate at a Glance.” NOAA. Available online: http://www.ncdc.noaa.gov/cag/time-series/global (accessed on 10 June 2016).
- K.E. Trenberth. “Has there been a hiatus? ” Science 6249 (2015): 691–692. [Google Scholar] [CrossRef] [PubMed]
- U. Triacca, A. Pasini, and A. Attanasio. “Measuring persistence in time series of temperature anomalies.” Theor. Appl. Climatol. 118 (2014): 491–495. [Google Scholar] [CrossRef]
- D.I. Stern, and R.K. Kaufmann. “Econometric analysis of global climate change.” Environ. Model. Softw. 14 (1999): 597–605. [Google Scholar] [CrossRef]
- H. Liu, and G. Rodríguez. “Human activities and global warming: A cointegration analysis.” Environ. Model. Softw. 20 (2005): 761–773. [Google Scholar] [CrossRef] [Green Version]
- T.C. Mills. “Breaks and unit roots in global and hemispheric temperatures: An updated analysis.” Clim. Chang. 118 (2013): 745–755. [Google Scholar] [CrossRef]
© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license ( http://creativecommons.org/licenses/by/4.0/).








{kind=link}
{kind=link}
{kind=link}
{kind=link}