


Econometrics 2026, 14(2), 25; https://doi.org/10.3390/econometrics14020025 - 16 May 2026
Abstract
►
Show Figures
This study investigates the short-term and long-term impacts of gross domestic product (GDP), inflation, foreign capital flows, trade balance and interest rate on stock market performance in Saudi Arabia for the period 1990–2023. The autoregressive distributed lag (ARDL) approach and error correction model
[...] Read more.
This study investigates the short-term and long-term impacts of gross domestic product (GDP), inflation, foreign capital flows, trade balance and interest rate on stock market performance in Saudi Arabia for the period 1990–2023. The autoregressive distributed lag (ARDL) approach and error correction model (ECM) are employed to empirically examine the short-run and long-run relationships. The ARDL-ECM technique is effective for analyzing cointegration and assessing adjustment processes. Additionally, impulse response function (IRF) analysis based on the vector autoregression (VAR) model, estimated using these macroeconomic indicators, is applied in this paper. This study provides novel insights and addresses emerging gaps in the literature concerning Saudi Arabia as a developing economy. The long-term relationship in the bounds test results confirms its existence. In the long run, inflation and interest rate exert a statistically significant negative effect on stock market performance, while the trade balance has a significant positive impact. GDP and foreign capital inflows do not exhibit statistically significant long-run effects. Short-run dynamics indicate persistence in stock market performance along with significant effects from inflation and interest rate changes, while GDP and foreign capital inflows remain statistically insignificant in the long-run scenario. Forecast error variance decomposition (FEVD) results show that approximately 68.5% of the variation in market performance is explained by its own shocks, followed by foreign capital flows (16.3%) and inflation (8.4%). While foreign capital flow does not exhibit statistical significance in the ARDL long-run estimates, its contribution in variance decomposition highlights its role as an important source of external shocks. These findings are relevant to various stakeholders, including investors and policymakers. Additionally, policy emphasis should be placed on controlling inflation and maintaining stable interest rates while improving trade balance conditions. Although foreign capital flow does not show a direct long-run effect, its role in influencing market variability suggests the need for a stable and well-regulated investment environment.
Full article

Figure 1











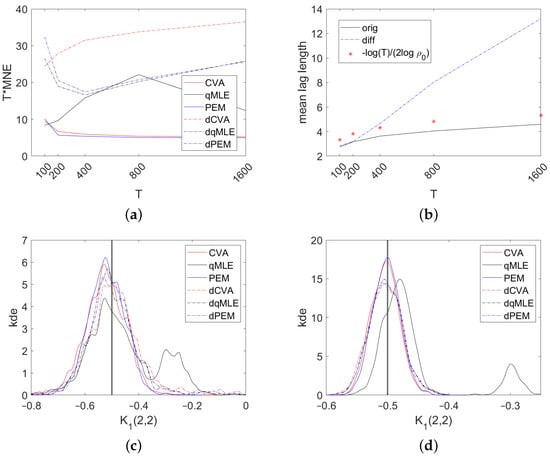

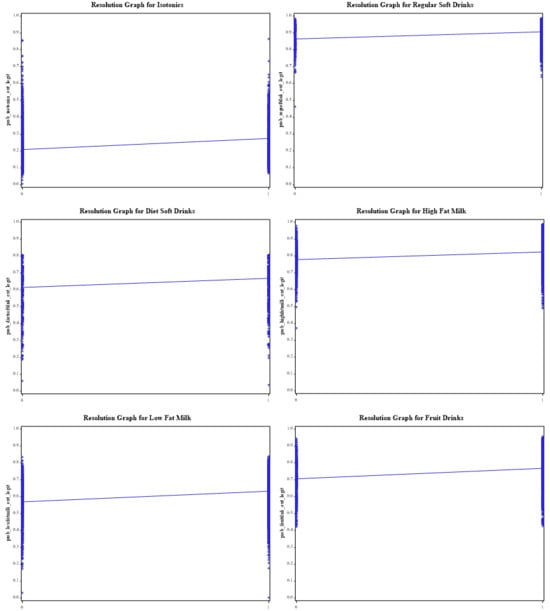

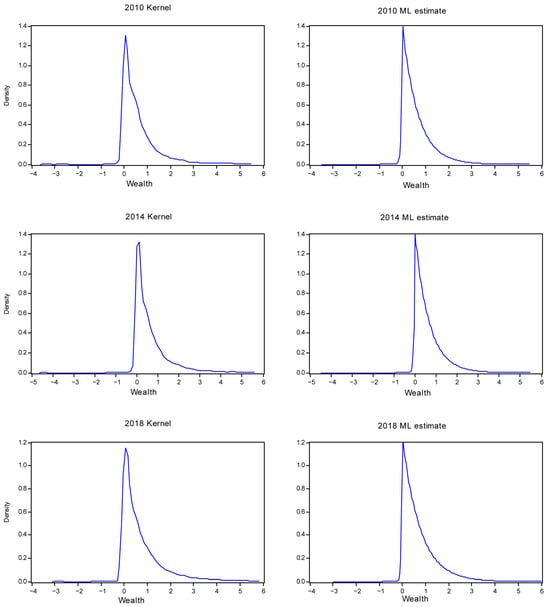




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}