
A Fast Algorithm for the Computation of HAC Covariance Matrix Estimators †

Abstract
:1. Introduction
2. HAC Covariance Matrix Estimation
2.1. The Estimation Problem
2.2. Application
2.3. The Case of the OLS Estimator
2.4. The Case of the GMM Estimator
3. The Algorithm
- The Toeplitz matrix is given by the first N rows and first N columns of , i.e.,Generally we denote with a sub-matrix of M containing the rows from a to b and the columns from c to d (, and ).
- The necessary product is given byThus, the fast evaluation of permits fast evaluation of .
- 1.
- The eigenvalues are the discrete Fourier transform (DFT) of the column vector c, i.e.,for .
- 2.
- The orthornomal left eigenvectors () are given bywith .
- 3.
- The product , for any , is given by the DFT of x.
- 4.
- The product , for any , is given by the inverse discrete Fourier Transform (IDFT) of x, i.e.,for .
- 1.
- Compute the eigenvalues () of using Equation (34) with
- 2.
- 3.
- For all compute the columns of the matrix . These columns are written as while is the j-th column of . This computation is done in three steps:
- (a)
- Determine given by the DFT of .
- (b)
- Multiply for all the i-th entry of the vector with the eigenvalue , in order to construct .
- (c)
- Determine given by the IDFT of .
- 4.
- Select the upper block of . This upper block results in , i.e.,:
- 5.
- Determine .
4. Alternative Algorithms
- 1.
- Determine and set .
- 2.
- For τ from 1 to b determine according to (40) and update .
- 3.
- Determine .
- 1.
- Determine and set .
- 2.
- For τ from 1 to b determine and update .
- 3.
- Determine .
- 1.
- Construct the symmetric Toeplitz matrix with the first column
- 2.
- Determine .
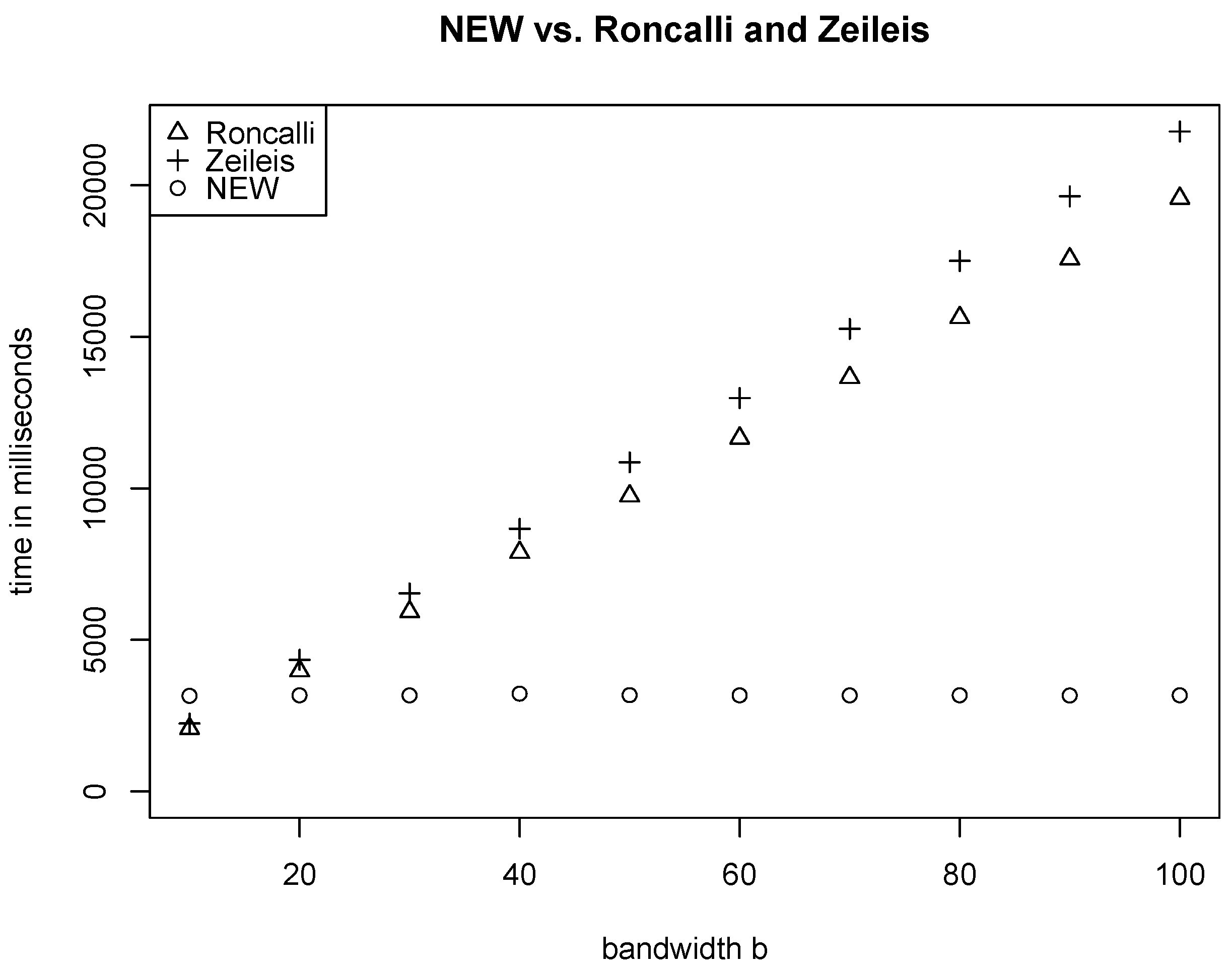
5. Comparing Different Algorithms for the Computation of HAC Covariance Matrix Estimators
- We used the “fftwtools”-package of R for the fft-function. The four algorithms run a little bit faster when using the “compiler”-package of R , but relative computing times are nearly the same.
- Intel i5 2.90 GHz
- 8GB RAM
- R 3.3.2
- Windows 10 Professional 64bit
Author Contributions
Conflicts of Interest
Appendix A. R Codes
Appendix A.1. The R Code for Our New Algorithm

Appendix A.2. The R Code for the Algorithm Proposed by Roncalli

Appendix A.3. The R Code for the Algorithm Proposed by Zeileis

Appendix A.4. The R Code for the Algorithm Proposed by Kyriakoulis

Appendix A.5. The R Code for the Computation of the Weights

References
- D.W.K. Andrews. “Heteroskedasticity and Autocorrelation Consistent Covariance Matrix Estimation.” Econometrica 59 (1991): 817–858. [Google Scholar] [CrossRef]
- A. Zeileis. “Object-oriented Computation of Sandwich Estimators.” J. Stat. Softw. 16 (2006): 1–16. [Google Scholar] [CrossRef]
- H. White. Estimation, Inference and Specification Analysis, 1st ed. Cambridge, UK: Cambridge University Press, 1994. [Google Scholar]
- W.K. Newey, and K.D. West. “A Simple, Positive Semi-Definite, Heteroskedasticity and Autocorrelation Consistent Covariance Matrix.” Econometrica 55 (1987): 703–708. [Google Scholar] [CrossRef]
- H. White. “A Heteroskedasticity-Consistent Covariance Matrix Estimator and a Direct Test for Heteroskedasticity.” Econometrica 48 (1980): 817–838. [Google Scholar] [CrossRef]
- J.G. MacKinnon, and H. White. “Some heteroskedasticity-consistent covariance matrix estimators with improved finite sample properties.” J. Econom. 29 (1985): 305–325. [Google Scholar] [CrossRef]
- G.H. Jowett. “The Comparison of Means of Sets of Observations from Sections of Independent Stochastic Series.” J. R. Stat. Soc. 17 (1955): 208–227. [Google Scholar]
- E.J. Hannan. “The Variance of the Mean of a Stationary Process.” J. R. Stat. Soc. 19 (1957): 282–285. [Google Scholar]
- D.R. Brillinger. “Confidence Intervals for the Crosscovariance Function.” Sel. Stat. Can. 5 (1979): 1–16. [Google Scholar]
- F. Cribari-Neto, and S.G. Zarkos. “Econometric and Statistical Computing Using Ox.” Comput. Econ. 21 (2003): 277–295. [Google Scholar] [CrossRef]
- A.T.A. Wood, and G. Chan. “Simulation of Stationary Gaussian Processes in [0, 1]d.” J. Comput. Graph. Stat. 3 (1994): 409–432. [Google Scholar] [CrossRef]
- A.N. Jensen, and M.O. Nielsen. “A Fast Fractional Difference Algorithm.” J. Time Ser. Anal. 35 (2014): 428–436. [Google Scholar] [CrossRef]
- T. Roncalli. TSM–Time Series and Wavelets for Finance. Paris, France: Ritme Informatique, 1996. [Google Scholar]
- Aptech Systems. GAUSS. Chandler, AZ, USA: Aptech Systems Inc., 2014. [Google Scholar]
- A. Zeileis. “Econometric Computing with HC and HAC Covariance Matrix Estimators.” J. Stat. Softw. 11 (2004): 1–17. [Google Scholar] [CrossRef]
- R Development Core Team. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing, 2016. [Google Scholar]
- K. Kyriakoulis. The GMM Toolbox. 2005. Available online: http://personalpages.manchester.ac.uk/staff/Alastair.Hall/GMMGUI.html (accessed on 13 January 2017).
- MathWorks. MATLAB. Natick, MA, USA: The MathWorks Inc., 2014. [Google Scholar]
- E. Zivot. “Practical Issues in the Analysis of Univariate GARCH Models.” In Handbook of Financial Time Series. Edited by T.G. Andersen, R.A. Davis, J.P. Kreiß and T. Mikosch. Berlin/Heidelberg, Germany: Springer-Verlag, 2009, pp. 113–155. [Google Scholar]
- E. Ruiz. “Quasi-Maximum Likelihood Estimation of Stochastic Volatility Models.” J. Econom. 63 (1994): 289–306. [Google Scholar] [CrossRef] [Green Version]
- E. Renault. “Moment-Based Estimation of Stochastic Volatility Models.” In Handbook of Financial Time Series. Edited by T.G. Andersen, R.A. Davis, J.P. Kreiß and T. Mikosch. Berlin/Heidelberg, Germany: Springer-Verlag, 2009, pp. 269–311. [Google Scholar]
- E. Bacry, A. Kozhemyak, and J.F. Muzy. “Continuous Cascade Models for Asset Returns.” J. Econ. Dyn. Control 32 (2008): 156–199. [Google Scholar] [CrossRef]
- T. Lux. “The Markov-Switching Multifractal Model of Asset Returns: GMM Estimation and Linear Forecasting of Volatility.” J. Bus. Econ. Stat. 26 (2008): 194–210. [Google Scholar] [CrossRef]
- E. Bacry, A. Kozhemyak, and J.F. Muzy. “Log-Normal Continuous Cascade Model of Asset Returns: Aggregation Properties and Estimation.” Quant. Finance 13 (2013): 795–818. [Google Scholar] [CrossRef]
- P. Chaussé, and D. Xu. “GMM Estimation of a Realized Stochastic Volatility Model: A Monte Carlo Study.” Econom. Rev., 2016. [Google Scholar] [CrossRef]
- T. Lux, L. Morales-Arias, and C. Sattarhoff. “Forecasting Daily Variations of Stock Index Returns with a Multifractal Model of Realized Volatility.” J. Forecast. 33 (2014): 532–541. [Google Scholar] [CrossRef]
- R.J. Smith. “Automatic positive semidefinite HAC covariance matrix and GMM estimation.” Econom. Theory 21 (2005): 158–170. [Google Scholar] [CrossRef]
- A.R. Hall. Generalized Method of Moments, 1st ed. Advanced Texts in Econometrics; Oxford, UK: Oxford University Press, 2005. [Google Scholar]
- C.F. Van Loan. Computational Frameworks for the Fast Fourier Transform. Frontiers in Applied Mathematics; Philadelphia, PA, USA: Society for Industrial and Applied Mathematics, 1992. [Google Scholar]
- P.J. Brockwell, and R.A. Davis. Time Series: Theory and Methods, 2nd ed. Springer Series in Statistics; New York, NY, USA: Heidelberg, Germany: Springer, 2006. [Google Scholar]
- R.M. Gray. “Toeplitz and Circulant Matrices: A review.” Found. Trends Commun. Inf. Theory 2 (2006): 155–239. [Google Scholar] [CrossRef]
- G.H. Golub, and C.F. van Loan. Matrix Computations, 3rd ed. Johns Hopkins Series in the Mathematical Sciences; Baltimore, MD, USA: Johns Hopkins University Press, 1996. [Google Scholar]
- P.R. Hansen, Z. Huang, and H.H. Shek. “Realized GARCH: A Joint Model for Returns and Realized Measures of Volatility.” J. Appl. Econom. 27 (2012): 877–906. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| New Algorithm | Roncalli | Zeileis | Kyriakoulis | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N | q | q | q | q | |||||||||
| 10 | 20 | 30 | 10 | 20 | 30 | 10 | 20 | 30 | 10 | 20 | 30 | ||
| 5000 | 11 | 24 | 31 | 21 | 76 | 156 | 24 | 89 | 165 | 1404 | 1603 | 1806 | |
| 10,000 | 25 | 54 | 74 | 49 | 166 | 334 | 54 | 173 | 340 | 5654 | 6827 | 7398 | |
| 50,000 | 125 | 319 | 447 | 267 | 905 | 1738 | 291 | 947 | 1797 | ||||
| 100,000 | 287 | 642 | 892 | 571 | 1893 | 3521 | 635 | 2066 | 3685 | ||||
| 200,000 | 628 | 1195 | 1768 | 1185 | 3855 | 7313 | 1280 | 4321 | 7538 | ||||
| 500,000 | 1523 | 3006 | 4485 | 2963 | 9628 | 18,145 | 3260 | 9849 | 18,929 | ||||
| 1,000,000 | 3201 | 6727 | 9809 | 5862 | 18,497 | 36,687 | 6545 | 19,627 | 37,678 | ||||
| 5000 | 9 | 22 | 31 | 46 | 149 | 320 | 56 | 160 | 342 | 1388 | 1606 | 1807 | |
| 10,000 | 27 | 49 | 75 | 95 | 324 | 646 | 108 | 344 | 672 | 6067 | 6526 | 7375 | |
| 50,000 | 121 | 319 | 446 | 547 | 1850 | 3530 | 595 | 1950 | 3704 | ||||
| 100,000 | 330 | 579 | 851 | 1108 | 3746 | 6971 | 1238 | 4016 | 7242 | ||||
| 200,000 | 626 | 1254 | 1823 | 2326 | 7765 | 14,474 | 2550 | 8255 | 14,974 | ||||
| 500,000 | 1502 | 2977 | 4682 | 6081 | 19,021 | 36,469 | 6427 | 19,807 | 37,544 | ||||
| 1,000,000 | 3150 | 6398 | 9833 | 11,565 | 36,816 | 72,326 | 12,972 | 39,166 | 74,822 | ||||
| 5000 | 10 | 25 | 34 | 78 | 248 | 512 | 88 | 266 | 539 | 1382 | 1609 | 1907 | |
| 10,000 | 27 | 52 | 76 | 156 | 546 | 1065 | 178 | 589 | 1148 | 5770 | 6832 | 7699 | |
| 50,000 | 121 | 319 | 454 | 950 | 2990 | 5917 | 1025 | 3336 | 6380 | ||||
| 100,000 | 331 | 580 | 927 | 1832 | 6204 | 11,650 | 2063 | 6532 | 12,068 | ||||
| 200,000 | 630 | 1250 | 1749 | 3884 | 12,687 | 24,201 | 4172 | 13,598 | 25,489 | ||||
| 500,000 | 1511 | 2991 | 4872 | 9763 | 31,210 | 60,453 | 10,753 | 33,047 | 62,455 | ||||
| 1,000,000 | 3177 | 6441 | 9855 | 19,424 | 62,593 | 121,815 | 21,667 | 65,241 | 125,517 | ||||
| Roncalli | Zeileis | Kyriakoulis | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| N | q | q | q | |||||||
| 10 | 20 | 30 | 10 | 20 | 30 | 10 | 20 | 30 | ||
| 5000 | 1.99 | 3.09 | 5.09 | 2.24 | 3.65 | 5.38 | 45.73 | 74.84 | 23.89 | |
| 10,000 | 1.94 | 3.08 | 4.50 | 2.17 | 3.22 | 4.58 | 76.24 | 140.40 | 44.61 | |
| 50,000 | 2.14 | 2.83 | 3.89 | 2.33 | 2.96 | 4.02 | ||||
| 100,000 | 1.99 | 2.95 | 3.95 | 2.21 | 3.22 | 4.13 | ||||
| 200,000 | 1.89 | 3.23 | 4.14 | 2.04 | 3.61 | 4.26 | ||||
| 500,000 | 1.95 | 3.20 | 4.05 | 2.14 | 3.28 | 4.22 | ||||
| 1,000,000 | 1.83 | 2.75 | 3.74 | 2.04 | 2.92 | 3.84 | ||||
| 5000 | 4.92 | 6.90 | 10.35 | 6.00 | 7.39 | 11.06 | 44.84 | 35.22 | 12.10 | |
| 10,000 | 3.51 | 6.67 | 8.59 | 4.01 | 7.06 | 8.93 | 80.65 | 68.75 | 22.75 | |
| 50,000 | 4.54 | 5.80 | 7.92 | 4.94 | 6.11 | 8.31 | ||||
| 100,000 | 3.35 | 6.47 | 8.19 | 3.75 | 6.93 | 8.51 | ||||
| 200,000 | 3.72 | 6.19 | 7.94 | 4.08 | 6.58 | 8.21 | ||||
| 500,000 | 4.05 | 6.39 | 7.79 | 4.28 | 6.65 | 8.02 | ||||
| 1,000,000 | 3.67 | 5.75 | 7.36 | 4.12 | 6.12 | 7.61 | ||||
| 5000 | 7.85 | 9.84 | 15.03 | 8.78 | 10.54 | 15.82 | 40.56 | 20.50 | 7.68 | |
| 10,000 | 5.70 | 10.58 | 14.08 | 6.48 | 11.42 | 15.17 | 76.24 | 43.68 | 14.11 | |
| 50,000 | 7.88 | 9.37 | 13.02 | 8.50 | 10.45 | 14.04 | ||||
| 100,000 | 5.54 | 10.70 | 12.57 | 6.24 | 11.27 | 13.02 | ||||
| 200,000 | 6.17 | 10.15 | 13.83 | 6.62 | 10.88 | 14.57 | ||||
| 500,000 | 6.46 | 10.44 | 12.41 | 7.11 | 11.05 | 12.82 | ||||
| 1,000,000 | 6.11 | 9.72 | 12.36 | 6.82 | 10.13 | 12.74 | ||||
| Time in Minutes | ||||||
|---|---|---|---|---|---|---|
| Chaussé and Xu | Hansen et al. | Lux et al. | ||||
| one est. | full est. | one est. | full est. | “turbulent” | “full” | |
| Roncalli | 1.38 | 33.03 | 1.67 | 193.40 | 17.31 | 35.80 |
| Zeileis | 1.47 | 35.23 | 1.68 | 195.20 | 19.71 | 40.41 |
| NEW | 0.39 | 9.32 | 0.66 | 76.42 | 10.55 | 22.84 |
| gain in time NEW vs. Roncalli | 0.99 | 23.70 | 1.01 | 116.98 | 6.76 | 12.96 |
| gain in time NEW vs. Zeileis | 1.08 | 25.91 | 1.02 | 118.78 | 9.16 | 17.57 |
© 2017 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Heberle, J.; Sattarhoff, C. A Fast Algorithm for the Computation of HAC Covariance Matrix Estimators. Econometrics 2017, 5, 9. https://doi.org/10.3390/econometrics5010009
Heberle J, Sattarhoff C. A Fast Algorithm for the Computation of HAC Covariance Matrix Estimators. Econometrics. 2017; 5(1):9. https://doi.org/10.3390/econometrics5010009
Chicago/Turabian StyleHeberle, Jochen, and Cristina Sattarhoff. 2017. "A Fast Algorithm for the Computation of HAC Covariance Matrix Estimators" Econometrics 5, no. 1: 9. https://doi.org/10.3390/econometrics5010009
APA StyleHeberle, J., & Sattarhoff, C. (2017). A Fast Algorithm for the Computation of HAC Covariance Matrix Estimators. Econometrics, 5(1), 9. https://doi.org/10.3390/econometrics5010009