
Robustness and Complexity in Italian Mid Vowel Contrasts

Department of Linguistics, University of Georgia, Athens, GA 30602, USA
Languages 2024, 9(4), 150; https://doi.org/10.3390/languages9040150
Submission received: 25 August 2023
/
Revised: 5 April 2024
/
Accepted: 8 April 2024
/
Published: 18 April 2024
(This article belongs to the Special Issue Phonetic and Phonological Complexity in Romance Languages)
Abstract
:Accounts of phonological contrast traditionally invoke a binary distinction between unpredictable lexically stored phonemes and contextually predictable allophones, whose patterning reveals speakers’ knowledge about their native language. This paper explores the complexity of contrasts among Italian mid vowels from a multifaceted perspective considering the lexicon, linguistic structure, usage, and regional variety. The Italian mid vowels are marginally contrastive due to a scarcity of minimal pairs alongside variation in phonetic realization. The analysis considers corpus data, which indicate that the marginal contrasts among front vowels vs. back vowels are driven by different sources and forces. Functional loads are low; while front /e ɛ/ have the weakest lexical contrast among all Italian vowels, back /o ɔ/ are separated by somewhat more minimal pairs. Among stressed front vowels, height is predicted by syllable structure and is context-dependent in some Italian varieties. Meanwhile, the height of back mid vowels is predicted by lexical frequency, in line with expectations of phonetic reduction in high-frequency contexts. For both front and back vowels, the phonetic factor of duration predicts vowel height, especially in closed syllables, suggesting its use for contrast enhancement. The results have implications for a proposed formalization of Italian mid vowel variation.
1. Introduction
Theories of phonology include the concept of contrast, referring to meaningful distinctions among sounds whose presence reveals the knowledge speakers possess about the selection and patterning of sounds in their native language. Empirical work on speech production and perception has demonstrated that contrast is a complex phenomenon for speaker/hearers. An adequate characterization of distinctions within a phonological system would extend well beyond the traditional binary of allophones vs. phonemes to encompass gradient degrees of structural contrast (Goldsmith 1995; Hall and Hall 2016) influenced by usage, predictability, lexical evidence, and perceptual distinctness (Hall et al. 2018; Stevenson and Zamuner 2017; Wedel et al. 2018). Native grammatical knowledge includes such gradience. The “phonological status” of a sound is rapidly acquired during learning (Seidl and Cristia 2012), leading to differential processing of phonemes vs. allophones corresponding to detailed knowledge about the phonotactic probabilities of sounds (Auer and Luce 2005) that guides habits of spoken communication.
This article focuses on relationships between speech sounds described as marginal contrasts, as manifest in regional varieties of Italian. Marginal contrasts are pairs of sounds whose phonological relationship is “intermediate” between that of a phonemic contrast, which distinguishes between words in the lexicon, and allophony, in which spoken variants are predictable. Such intermediate relationships are linguistically widespread (see Hall 2013 for a terminological review). They are distinct from “robust” phonemic contrasts, which “create salient and/or numerous minimal pairs in the language and are unwaveringly unpredictable by context—that is, they are not phonologically conditioned. A marginal contrast may underperform in one or both of these categories: it may create few minimal pairs […], partially neutralize […], or be otherwise phonologically conditioned” (Tiegs 2023, p. 15). The existence of marginal contrasts shows that phonological relationships are complex because they are not binary: contrasts lie along a continuum in which sounds are distinct in some dimensions but predictable in others. Given the demonstrable knowledge speaker/hearers possess of these dimensions, phonological theory must be equipped to model this complexity.
One characteristic of marginal contrasts is that they may have a low functional load, meaning that few lexical items can confirm for speaker/hearers that the sounds require separate mental representations. This may be due to the sounds’ rarity, their distribution, or both. Marginal contrasts are relevant for modeling changes in phonological systems because it has been demonstrated that contrasts supported by higher functional load are less likely to be lost in historic time. In a corpus study of 18 mergers across 9 language varieties, Wedel et al. (2013, p. 184) showed that “the more minimal pairs defined by a phoneme pair, the less likely that phoneme pair is to have merged”, thus supporting the hypothesis that functional load is relevant for maintaining phonological distinctions. Nevertheless, not all marginal contrasts are merged: what are their possible outcomes?
Italian is a language argued to have marginal contrasts, particularly in its oppositions of front and back mid vowels, /e ɛ/ and /o ɔ/ (Renwick and Ladd 2016). The functional load of these contrasts has not been previously evaluated with respect to hypotheses about vowel merger, which this paper undertakes in the context of a model of phonological contrast that combines insights from a range of structural and usage-based factors (the Multidimensional Model of Phonemic Robustness, see Section 1.1). Findings of low functional load in the prescriptive Italian lexicon motivate a corpus-based comparison of mid vowels in three types of phonological systems found across Italian regional varieties. These are systems that maintain the mid vowel contrasts, keep them in near-allophony with context-based conditioning, or merge them entirely. It is proposed that these three systems represent possible outcomes of low functional load scenarios. Statistical modeling confirms that Italian mid vowels’ acoustics vary with structural, phonetic, and usage-based factors, but these factors’ interplay is modulated by speakers’ regional phonological system. The results have theoretical implications for the instantiation of a formal phonological model that can successfully treat patterns of variation seen in the data.
1.1. The Multidimensional Model of Phonemic Robustness
A contrast is a pairwise relationship between two sounds. However, the status of a pairwise relation is defined by the union of its members’ distributions within the language. Several characteristics affect the degree to which a given phone is independent of other forces at work in the linguistic system, first characterized for Romanian /ɨ/ (Renwick 2012, 2014). In this Multidimensional Model of Phonemic Robustness (MMPR; Figure 1), different factors contribute positively or negatively to the phonemic robustness of a particular sound. The model here has four types of factors: systemic, phonetic, usage-based, and the single social factor of local salience, which is particularly relevant for studies of Italian variation. On a language-specific basis, an increase in each factor may contribute positively toward robustness, or detract from it. Additional factors, such as social indexation, may also play a role in mental representation, e.g., as characterized by exemplar models of phonology (see Drager and Kirtley 2016 for discussion).
This paper evaluates the Italian mid vowels /e ɛ o ɔ/ with respect to factors enumerated in the MMPR and their potentially complex interactions. The phonetic factor of distinctiveness contributes to these sounds’ salience, as speakers whose local varieties include a mid vowel height contrast maintain a strong separation in F1 between the categories (Renwick and Ladd 2016). Among systemic factors, high type frequency and abundant minimal pairs contribute positively to robustness. Context dependence captures the extent to which a sound is phonotactically or contextually constrained and is argued to negatively affect robustness. This is because contextual knowledge can be employed to infer segmental identity, requiring less dependence on the sound’s phonetic realization to retrieve a lexical item. Turning to usage-based factors, token frequency is evaluated here, via lexical frequency. Finally, the social factor of local salience is treated indirectly by considering the type of phonological system found in each city. In cities whose variety includes a mid vowel contrast, speakers may be aware of each vowel, potentially as a local speech feature, to a greater extent than speakers with five-vowel systems.
1.2. Marginal Contrasts in Romance Languages
Among the vowel systems of Romance languages, numerous marginal contrasts exist. These present a challenge to traditional theories of contrast vs. allophony. They are reviewed below before turning to Italian mid vowels, whose contrasts are analyzed here by simultaneously modeling multiple factors that affect surface realizations.
A longstanding characterization of marginal contrast in Romance comes from Trubetzkoy’s (1939) discussion of French vowel pairs /e ɛ/, /o ɔ/ and /ø œ/. Minimal pairs between the higher and lower vowels exist only in stressed syllables. Later phonetic surveys found that in Parisian French, the contrasts between /e ɛ/ and /o ɔ/ were widely variable and on the decline, with variation in height that could not be tied to systematic factors (Landick 1995). Although the oppositions were largely maintained for both front and back vowels, they were highly variable across participants: speakers maintained /e ɛ/ in 22–93% of minimal pairs, while /o ɔ/ were maintained in 35–94% of pairs (Landick 1995, p. 92). Perceptual evidence for “weakness” comes from Laurentian French, via a study that classified vowel pairs as high-, mid-, or low-contrast, based on the number of lexical contrasts they participate in and the vowels’ acoustic and distributional similarity (Stevenson and Zamuner 2017). An ABX task showed that pairs’ level of contrast predicted listeners’ accuracy, which decreased for low-contrast pairs, and reaction times, which increased for low-contrast pairs; in a subsequent similarity-judgment task, listeners perceived greater distinctions between high-contrast pairs than low-contrast pairs, indicating reduced sensitivity to contrasts supported by few lexical distinctions (Stevenson and Zamuner 2017).
Several varieties of Catalan distinguish /e ɛ/ and /o ɔ/ in stressed syllables. However, there are few minimal pairs, and some words have two normative pronunciations (Recasens 1993). Mid vowel usage varies across dialects (Mora and Nadeu 2012; Wheeler 2005) and within a single dialect, including intra-speaker oscillations (Badia i Margarit 1969). The mid vowels of Catalan have been widely studied at the intersection of psycholinguistics, bilingualism, and sociolinguistics, thanks to the observation (Pallier et al. 1997) that linguistic dominance in Spanish, which lacks /ɛ ɔ/, reduces sensitivity to these height contrasts (see recent overview by Simonet 2018). In a production-based task, Nadeu and Renwick (2016) compared the acoustics of mid vowels against native speakers’ own intuitions of height and found that intuitions do not uniformly correspond to productions; speakers with poor intuitions may exhibit increased acoustic overlap between higher and lower mid vowels. Linking marginal contrast with bilingualism and language change, a large-scale Internet survey showed that speakers with higher Catalan dominance have increased confidence in making and judging height distinctions and that older speakers are more likely to use low /ɛ ɔ/ (Renwick and Nadeu 2018). The survey confirmed a synchronic link between phonological context and mid vowel height: judgments were more confident and consistent in segmental contexts where low mid vowels were historically preferred (Renwick and Nadeu 2018; cf. Wheeler 2005).
It is speculated that marginal contrasts in Catalan are linked to a paucity of minimal pairs, although this has not yet been empirically investigated. A similar supposition exists for Galician, whose mid vowels /e ɛ/ and /o ɔ/ are also affected by increasing contact with Spanish. Results from production and perception tasks found that Galician-dominant speakers have a less-robust front mid contrast compared to their back mid contrast; Amengual and Chamorro (2015) speculate that low functional load and high variability in vowel height may play a role. Functional load is indeed low among mid vowels in European Portuguese, where perceptual results demonstrate an increased processing cost for marginal contrasts: the distinctions between /e ɛ/ and /o ɔ/ induce greater errors in identification alongside increased reaction time compared to point-vowel contrasts (Tiegs 2023). Similar findings were obtained for Brazilian Portuguese among front vowels /e ɛ/ compared to /i e/, where a contrast is more perceptually robust (Silva and Rothe-Neves 2016).
Functional load has also been investigated for the marginally contrastive Romanian central vowels /ɨ ʌ/ (or /ɨ ə/). Minimal pairs like /rɨw/ ‘river’ vs. /rʌw/ ‘bad (m. sg.)’ attest to the phonemic status of each, but the functional load of this contrast is the lowest among all Romanian vowels (Renwick et al. 2016). In careful speech, the vowels’ distinction is maintained, but in other styles, /ɨ/ lowers phonetically to overlap with /ʌ/ (Vasilescu et al. 2016), potentially revealing speakers’ lack of motivation to maintain the contrast. Perceptually, the vowels remain distinct, but /ʌ/ is less salient than /i e ɨ/, being confused most frequently for /ɨ/ with identification rates as low as 77% in some cases (Renwick 2014). The Romanian central vowels typify a marginal contrast: they have very few minimal pairs, and the sounds have low type frequency; both sounds are partially phonologically conditioned; they lie in near-complementary distribution, and are phonetically similar. Their relationship motivates the MMPR, which in the present paper is applied to Italian mid vowels.
1.3. Sources and Evidence of Marginal Contrast in Italian
Italian is standardly described as having a seven-vowel system, /i e ɛ a ɔ o u/ (Rogers and d’Arcangeli 2004), in which /e o/ are close mids or high mid vowels, and /ɛ ɔ/ are open mids or low mid vowels. This is derived from the seven-vowel Pan Romance system /i e ɛ a ɔ o u/, which underpins many Romance varieties and is the product of the “Great Merger” (Alkire and Rosen 2010) of Latin’s 10-vowel, quantity-based system. The Pan-Romance high mid vowels passed into Italian largely unchanged, as /e/ and /o/. They underwent raising to /i/ and /u/ in certain phonological contexts, reducing the number of lexical items with stressed mid vowels. The low mid vowels /ɛ/ and /ɔ/ are retained, particularly in closed syllables, but they diphthongize to /jɛ/ and /wɔ/ in some open syllables and raise to high mid vowels before palatal /ɲ/. As in other Romance languages, the Italian mid vowels are contrastive only in stressed syllables, neutralizing to [e o] elsewhere.
A consequence of these historical trends is that the contrastive distribution of the high and low mid vowels is largely restricted to stressed closed syllables. Vowel quality is therefore partially context-dependent. Another crucial factor in the present analysis is regional variation in spoken Italian, which affects vowel inventory, lexical specification of mid vowels, and whether or how they are phonologically conditioned.
1.3.1. Regional Variation in Italy: Regiolects and the Construct of “Standard Italian”
Although prescriptive descriptions of “Standard Italian” exist, such a variety is not spoken natively by any sizeable portion of the population. Multiple models for standard Italian pronunciation have been proposed since the early 20th century, as detailed by Crocco (2017). Recently the “modern neutral Italian pronunciation” has emerged; it “admits more variation than traditional norms do because it accepts forms that have been rejected by the reference models but have become widespread” (Crocco 2017, p. 93). For lexical input choices, as in earlier standard models, the explicit target in this model is central Italian. Most major dictionaries reflect lexical choices of Florentine and/or Roman Italian, with some indication of variation where permitted by orthography (De Mauro 2000).
Contemporary sociolinguistic accounts of Italian (e.g., Cerruti 2011; Cerruti et al. 2017) characterize a longtime situation of linguistic contact between local languages (mutually unintelligible dialetti) and “standard” Italian superimposed via education and mass media, particularly between the two World Wars (De Mauro 1976, pp. 143–44). At-home communication in Italian has since become more common, and in place of dialects, a set of regiolects has arisen, developed from the advergence of dialect and standard forms (Cerruti and Regis 2014). These variants include regional lexical, morphosyntactic, and phonological characteristics. The main social axis of variation in the Italian language is thus geographical rather than across classes or stylistic situations (Cerruti 2011).
Italy has four major regional areas, each of which may be further subdivided: a northern variety centered around Milan; a central variety with Florence and Rome as its foci; a southern variety characterized by Naples; and Sardinian (De Mauro 1976; cf. Vietti 2019). These share linguistic features, particularly phonological ones, including their treatment of mid vowels—although their lexical specifications are known to simply vary from city to city (Calamai 2017; Bertinetto and Loporcaro 2005; De Pascale et al. 2017). In Central Italian, four mid vowels are maintained. However, in many Northern cities and in some Southern varieties, surface realizations are at least partially determined by phonological context. In particular, low mid vowels may be restricted to closed syllables. A separate trend is the merger of high mid and low mid vowels, leading to a five-vowel system in the lexicon and on the surface.
1.3.2. Evidence for Marginal Contrast in Italian
Under a traditional phonological account, the Italian front mid vowels /e ɛ/ are contrastive, as are the back mid vowels /o ɔ/. Canonical minimal pairs include venti [ˈventi] ‘twenty’ vs. [ˈvɛnti] ‘winds (n.)’ and foro [ˈforo] ‘hole’ vs. [ˈfɔro] ‘forum.’ However, several pieces of evidence demonstrate that these height-based distinctions are marginal. A major factor is variation in their phonetic realization. This is exemplified for mid vowels in (1) and (2) via phonetic transcriptions of sentences produced under laboratory conditions by speakers in Corpora e Lessici dell’Italiano Parlato e Scritto (CLIPS; Albano Leoni et al. 2007).
- (1)
- Examples drawn from CLIPS, as transcribed in Crocco (2017, (1)). Bold indicates stressed mid vowels. The orthographic sentence is Maria dovrebbe stare più attenta a scuola, “Maria should pay more attention at school”.
[maˈria doˈvrɛbːe ˈstare ˈpju aˈtːɛnta a ˈskwɔla] Standard speaker [maˈria doˈvrɛbːe ˈstare ˈpju aˈtːenta a ˈskwɒla] Milanese speaker [maˈria doˈvrɛbːe ˈstare ˈɸju aˈtːɛnta a ˈskwɔla] Florentine speaker [maˈria doˈvrɛbːe ˈstare ˈp̬ju aˈtːɛnta a ˈskwɔla] Roman speaker [maˈria doˈvrebːe ˈstare ˈpːju aˈtːɛnta a ˈskwola] Neapolitan speaker - (2)
- Examples drawn from CLIPS, as transcribed in Crocco (2017, (2)). Bold indicates stressed mid vowels. The orthographic sentence is Un mese di vacanza passa in fretta, “A month of vacation passes quickly”.
[uˈmːeze di vaˈkanʦa ˈpasːa iɱ ˈfretːa] Standard speaker [uˈmːeze di vaˈkanʦa ˈpasːa iɱ ˈfrɛtːa] Milanese speaker [uˈmːeze di vaˈxanʦa ˈpasːa iɱ ˈfretːa] Florentine speaker [uˈmːese di vaˈk̬anʦa ˈpasːa iɱ ˈfretːa] Roman speaker [uˈmːese di vaˈkanʦa ˈpasːa iɱ ˈfretːa] Neapolitan speaker
Mid vowel contrasts in Italian are not reinforced by orthography, because spelling does not distinguish them, and vowel quality is subject to regionally influenced interpretation (Crocco 2017). Prescriptive works have argued that learners of Italian can ignore the mid vowel distinctions (Rebora 1958), and dictionaries acknowledge that stressed mid vowel quality is variable in some words (De Mauro 2000), because systematic regional variation affects mid vowel height (Bertinetto and Loporcaro 2005) and because “oscillations” are possible for individual words within a regional variety (Canepari 1980). Calamai (2017, p. 223) concurs that few dependable mid vowel minimal pairs exist, even within a single region, describing this state of affairs as the “vagueness of standard phonology”.
Several studies have recently investigated mid vowel contrasts in Italian. Renwick and Ladd (2016) quantitatively investigated the relationship between native Italians’ mid vowel intuitions and their pronunciations. In an acoustic study of stressed vowels in laboratory speech, F1/F2 values were extracted from productions by 17 speakers (14 female), producing 5571 mid vowel tokens. Each participant subsequently provided phonological intuitions based on introspection for the stressed mid vowel in each target word. These responses were compared both with prescriptive quality and with speakers’ own acoustics. There was widespread variability in phonolexical mappings. Speakers consistently distinguished [e] from [ɛ] and [o] from [ɔ] in pronunciation, exhibiting seven distinct phonetic vowels, and they were generally aware of their own productions. However, all speakers exhibited production-judgment mismatches, suggesting weakness in lexical intuitions. The results were strongly affected by speakers’ regional variety: intuitions of talkers from Rome and Florence matched the dictionary closely, while Northerners showed the influence of phonological context on their judgments, and two Southern speakers used five phonetic vowels with little correspondence between phonetics and intuition. In fact, speakers could be sorted by regional variety based on mid vowel judgments alone. For each speaker in Renwick and Ladd’s (2016) study, their 100 mid vowel judgments were compared to the prescriptive standard. Patterns of (mis)matches in that dataset sorted speakers broadly into Northern, Central, and Southern groupings (Cohn and Renwick 2021, Figure 3), confirming systematic regional variation.
The strong effects of region on mid vowel realizations motivated additional analyses that fully consider the role of geographic variation. Using data from CLIPS, a large-scale study evaluated the realization of stressed mid vowels in specific lexical items across 15 Italian cities (Renwick 2021). It found that some words consistently have stressed high mid vowels (e.g., sedici [ˈseditʃi] ‘sixteen’, dove [ˈdove] ‘where’), while others pattern consistently as stressed low mid vowels (e.g., bella [ˈbɛlːa] ‘beautiful (f. sg.)’, nove [ˈnɔve] ‘nine’). However, many words are realized variably, such as in the penultimate syllables of aspetti ‘wait (2sg.)’ or conosci ‘know (2sg.)’. Words with variable realizations sometimes follow regional patterns of phonological conditioning, meaning, for instance, that front vowels are realized as [ɛ] in closed syllables; nonetheless, the overwhelming picture is one of widespread but lexically specific variation. Data from CLIPS provide evidence for variability both within and across cities (Renwick 2021), which is consistent with earlier findings of intraspeaker variability (Renwick and Ladd 2016). The present paper returns to this CLIPS dataset in search of evidence for systematicity within this phonetic variation.
1.4. Road Map: Sources of Mid Vowel Variation across Italy
Previous work has shown that Italian mid vowels are variably implemented across and within regional varieties and individual speakers. Canonical lexical specifications (e.g., the dictionary) have limited predictive power of mid vowel height. At the same time, individual speakers can maintain the contrasts, and there is little evidence that seven-vowel systems are being lost. What, then, predicts the height of an Italian mid vowel?
We first consider the characteristics of contrast within the Italian lexicon from a cross-varietal perspective, which motivates a more detailed analysis of regional varieties. At the cross-varietal level, lexical distinctions are evaluated by quantifying the relative frequencies of vowels alongside functional load among vowel contrasts. The low functional loads attributed to mid vowel contrasts in the prescriptive lexicon indicate a scenario ripe for language change along the lines of Wedel et al. (2013). An acoustic analysis is then conducted of data from 15 Italian cities. Its central hypothesis is that mid vowels’ acoustics, particularly their first formant (F1) as a correlate of height, vary systematically under the influence of systemic, usage-based, phonetic, and regional factors. The relative contribution of each factor is tested in linear mixed-effects models of F1 in front mid and back mid vowels, and these are evaluated through the lens of the Multidimensional Model of Phonemic Robustness.
2. Relative Frequencies and Functional Load of Italian Vowels
Some marginal contrasts involve a large disparity in type or token frequency between members of the contrast. Low frequency is argued to contribute to marginal contrast, especially because rare sounds participate in fewer minimal pairs than frequent sounds can. To test whether this extends to Italian, type and token frequency are calculated here for vowels as represented in the prescriptive Italian lexicon. Data are drawn from the PhonItalia project (Goslin et al. 2014), an open-access phonological database whose 120,000 Italian lexical items are associated with phonological transcriptions and annotated for features like stress and syllable boundaries. Among the datasets available within PhonItalia is its phones table, which compiles type and token frequencies for the 29 vowels and consonants assumed by the lexicon.1
Functional load (Hockett 1966; Surendran and Niyogi 2006) is a measure of how much lexical differentiation is carried out by a pair of sounds. It is meaningful for discussions of contrast due to its link with the likelihood of phonological merger in historical time (Wedel et al. 2013). Low functional load is a diagnostic of marginal contrast and may help account for situations in which a lexical contrast is not consistently maintained. Functional loads have been previously provided for Italian (Oh et al. 2015), but without contrast-specific comparisons. For such an analysis, the input was phonetic transcriptions of individual lexical items gathered from PhonItalia (Goslin et al. 2014). Functional loads were calculated using Phonological Corpus Tools 1.5.1 (PCT; Hall et al. 2019) with its type-based Change in Entropy metric. This method evaluates how entropy would change in the system if two or more segments merged (Surendran and Niyogi 2003): the greater the increase in entropy associated with homophony, the higher the functional load. PCT was also used to count minimal pairs between vowels in the dataset.2
Since mid vowels neutralize in unstressed syllables of Italian, it might be desirable to separately calculate functional loads for stressed vs. unstressed syllables. That is beyond the combined technical capacity of the PhonItalia dataset and PCT’s current algorithms, as they do not support differential marking and processing of stressed vs. unstressed vowels. Therefore, the functional loads presented here represent the entire lexicon without considering positional alternations. Furthermore, the lexicon under evaluation is not specific to a regional variety but instead represents a prescriptive standard serving as a baseline illustration. Some regional varieties, such as Central Italian, may have lexicons similar to PhonItalia, while others may deviate further.
2.1. How Frequent Is Each Vowel across Italian Words?
In Table 1 and Figure 2, vowels are ordered from most to least frequent based on tabulations of PhonItalia’s lexical items. The high mid vowels /o e/ are quite frequent in Italian, but low mid /ɛ/ and /ɔ/ are the two rarest vowels in the language, especially because they do not appear in unstressed syllables (which are included here).
2.2. Functional Loads of Italian Vowels
A typical characteristic of marginal contrasts is a low functional load, which is a quantitative measure of lexical differentiation generated by a pair of sounds. Table 2 and Table 3 reflect functional load calculations and minimal pair counts, respectively, for all possible pairs of Italian monophthongs as captured by PhonItalia. The tables show that /e, ɛ/ have the lowest functional load across all twenty-one comparisons, a value of 0.001, with only 70 minimal pairs.3 The back mid vowels /o, ɔ/ have roughly the 9th-lowest functional load, and 346 minimal pairs. Thus, while type and token frequencies (Table 1) rank /ɛ/ above /ɔ/, this ranking is reversed in calculations of functional load. Although the back vowels’ contrast is clearly better supported by this analysis, their functional load is not high compared to the number of minimal pairs separating /i e/ or /a o/. One takeaway is that front and back vowels have different distributions with respect to their functional load.
The results from functional load show that within the Italian lexicon, there is little lexical support for the maintenance of mid vowel contrasts, especially among front vowels /e ɛ/. As modeled by Wedel et al. (2013, p. 183), “when a phoneme plays a greater role in distinguishing words, it is more resistant to merger processes”. In Italian, the mid vowels do not play this role with each other. Given their phonetic proximity and orthographic similarity, as well as historical asymmetries in their distribution introduced by regular sound change, it is unsurprising that only a subset of varieties (e.g., Roma, Firenze) preserve a lexical distinction. Other varieties (Milano, Bari) maintain a phonetic distinction with contextual conditioning, and many areas (Torino, Lecce) have merged the mid vowels entirely. This trio of mid vowel treatments represents three possible outcomes for contrasts with low functional load. The following sections, via a corpus study, explore the phonetic realization of stressed mid vowels in such systems.
3. Corpus Analysis of Mid Vowel Variation: Methods and Predictors
This section lays the groundwork for an acoustic study of mid vowel variation in Italian regional varieties. We draw predictions about phonetic behavior from lexical statistics of functional load and from the MMPR. Regional varieties are divided into three groups: those with a fully functional mid vowel contrast, those with a conditioned contrast, and those with merged mid vowels. We predict that the degree of contrast functionality is manifest in the acoustics, as outlined for specific predictors below. Where functional load is concerned, we predict that the asymmetry in values across front and back vowels leads to different sources of systematic variation across the vowel space.
3.1. Dataset and Acoustic Analysis
Phonetic analysis was conducted using data from Corpora e lessici dell’italiano parlato e scritto, or CLIPS (Albano Leoni et al. 2007), which includes 16 speakers from each of 15 Italian cities (see Table 4; 240 speakers total) and contains ~100 h of speech. Since a focus of the corpus was geographic coverage rather than potential sociolinguistic variation, its speaker sample was restricted to people between the ages of 18–30, balanced for male/female gender, having a high school diploma or some university education, who came from a middle/upper-middle class background (Sobrero 2006). Participants were natives of the city or province where they were recorded, and typically, their parents were also. The CLIPS project spanned 1999–2005 (Albano Leoni et al. 2007), meaning that its speakers were born between approximately 1969 and 1987. CLIPS speakers are representatives of Italian regional variety speech. This is confirmed by the results of a study using portions of its Map Task recordings in a verbal guise study exploring listeners’ attitudes toward speech from Lombardy, Tuscany, Lazio, and Campania, which revealed significant differences in responses based on speaker origin (De Pascale et al. 2017).
CLIPS is one of the largest freely available corpora of Italian, and it contains both dialogues and monologues. The lettura frasi “read sentences” portion of the corpus is used here; in this task, individual speakers read aloud twenty sentences of increasing length, with a total of 272 unique words, produced under laboratory conditions. The audio (in .wav format) and transcription were force-aligned using WebMAUS (Kisler et al. 2016) and hand-corrected to ensure boundary placement accuracy at the segmental level. Formant values (F1, F2) were extracted at the midpoint of all vowels using Praat (Boersma and Weenink 2021). For all vowels, outliers were filtered for female and male speakers separately based on Mahalanobis distance (Mahalanobis 1936; Labov et al. 2013), a non-dimensional Euclidean distance, resulting in the exclusion of approximately 2.25% of tokens. Stressed vowels were isolated and normalized to Z-scores (Lobanov 1971) at the level of individual speaker. The data set was further narrowed to mid vowels, leaving 31,523 stressed mid vowel tokens for analysis.
3.2. Systemic Factors for Italian Mid Vowels
When studying the contrastive properties of sounds, it is relevant to know which sounds are assigned to each lexical item. In a small-scale, controlled study (Renwick and Ladd 2016; Nadeu and Renwick 2016), it is possible to query native speakers’ lexical intuitions, for comparison against the phonetics of their speech. Meanwhile, a strength of CLIPS is its wide geographic coverage and large speaker count, but these properties eliminate the possibility of directly investigating phonological intuitions. Instead, mid vowel heights from a prescriptive dictionary standard (De Mauro and Mancini 2000) were used to label each word, solely as a method of comparison. It should be noted that prescriptive values of lexical vowel quality are expected to vary across cities, but they serve as a baseline against which to evaluate phonolexical variation across and within varieties of Italian.
Another factor that may affect vowel quality is an item’s status as a function word: words like che ‘that (conj.),’ ne (a partitive clitic), o ‘or,’ tre ‘three,’ per ‘for,’ te (2sg clitic), e ‘and,’ se ‘him/herself’ are monosyllables, but typically do not receive stress and thus are expected to be realized with a high mid vowel [e]. To evaluate these items’ variability while controlling for their separate structural status, all words in the dataset were binarily coded as content vs. function. This factor is included in statistical modeling (see §5).
The status and implementation of a contrast within a language is a systemic factor. Each CLIPS city was coded according to its vowel system’s contrast type based on descriptions in Canepari (1980) and Maiden and Parry (1997). Cities were classified as exhibiting (a) a Full Contrast, in which both high mid and low mid vowels are present without phonological conditioning; (b) a Conditioned Contrast, in which high mid and low mid vowels are present but contextually restricted; or (c) a Merged vowel system, in which high mid and low mid vowels are not independent categories lexically or phonetically. Each city’s classification is listed in Table 4, but in the Results, each contrast type is exemplified by two cities. These represent northern, central, and southern varieties and are bolded in Table 4. It is hypothesized that phonetics of mid vowels from cities with a Full Contrast are more strongly predicted by prescriptive vowel quality than those from Conditioned Contrast cities—where height is mediated by syllable structure. In Merged cities, prescriptive quality is hypothesized not to influence phonetic mid vowel height.
3.3. Usage-Based Factor: Lexical Frequency
Lexical frequency data were acquired from the SUBTLEX-IT dataset (Crepaldi et al. 2015), which is built from subtitles of filmed entertainment and includes 517,564 unique items annotated for part of speech, lemma, and measures of relative frequency. The frequency measure used here is log-transformed term frequency, i.e., log10(frequency count/total words). The lexical frequency of each word in the CLIPS read sentences dataset was extracted from SUBTLEX-IT as a measure of its usage in typical spoken Italian. Calculating the frequencies of words in real-world situations is challenging, as frequency may vary across styles (formal vs. informal communication) or modalities (written vs. spoken language). In this case, the use of filmed entertainment focuses on spoken scenarios, making it appropriate for comparison against a spoken-language corpus; since most movies and TV programs are scripted, SUBTLEX-IT is furthermore an appropriate comparison for the read-sentences portion of CLIPS, which is not conversational speech. For future investigations of conversational speech, an approach based on context frequency (Raymond and Brown 2012) could be fruitful, alongside consideration of vowels’ frequency of occurrence in different phonotactic constructions (e.g., syllable structures).
High lexical frequency is typically associated with reduction in speech, particularly via shortened duration (Bell et al. 2009; Meunier and Espesser 2011), but additionally via raising and centralization of vowels in high-frequency words; conversely, low-frequency words are associated with hyperarticulation (Wright 2004). For F1, a decrease is expected at high lexical frequencies, corresponding to a reduced degree of jaw aperture.
3.4. Phonetic Factor: Duration
In many languages, vowel height is intrinsically linked to duration, meaning that (all else being equal) phonetically lower vowels have longer durations (Peterson and Lehiste 1960; Esposito 2002 for Italian). Vowel duration in Italian also varies predictably, increasing under stress, particularly in open syllables, especially in penultimate position (D’Imperio and Rosenthall 1999), with durational reduction in unstressed syllables (Savy and Cutugno 1998). The phonetically grounded explanation for the relationship between vowel height and duration is that greater jaw movement, and thus greater time, is required to reach lower vowel targets. This leads to a hypothesis that duration and F1 are positively correlated in mid vowels, with the mitigating factor of syllable structure, since the presence of a coda consonant reduces the preceding vowel’s duration in Italian (Farnetani and Kori 1986). To evaluate relationships between vowel quality and factors affecting vowel length, vowel duration (sec) was measured.
4. Results of Corpus Study
In this section, several relationships are evaluated between the acoustics of Italian mid vowels and characteristics of the words from which they are drawn, including their word-level variability and the relevance of prescriptive height (Section 4.1) and lexical frequency (Section 4.2). Links between vowels’ acoustic height and durations are evaluated in Section 4.3.
4.1. Lexical Specification vs. Regional Variation
Based on lexical information alone, mid vowel height is largely unpredictable. While some lexical items are consistently realized with high mid or low mid vowels, most words are highly variable (Renwick 2021). However, how much variation is due to regional differences in lexical specifications or phonological systems? Turning to acoustic results from CLIPS, we consider descriptively the relationship between acoustics and lexical vowel quality as specified by an Italian dictionary, Garzanti (De Mauro and Mancini 2000). Figure 3 presents summarized data for stressed front and back mid vowels from the six Italian cities bolded in Table 4. Words’ normalized F1 and F2 values are averaged and plotted, differentiated by color and symbol according to prescriptive height. If the dictionary is a reasonable match for mid vowel height, then each plot should contain four clusters of words corresponding to those prescriptive heights. This is true in Figure 3 for Roma: with few exceptions, words specified by Garzanti as high mid are realized higher in the vowel space. This pattern does not occur elsewhere. Bergamo and Bari trend toward higher vowels in open syllables and lower realizations in closed-syllable words, regardless of dictionary height. Turning to the back vowels, Roma, Napoli, and Bergamo show a tendency to match the dictionary: words with prescriptive high mid [o] are higher in the vowel space than those with prescriptive low mid [ɔ]. However, this trend does not hold for Torino, Bari, or Lecce.
4.2. Usage: Vowel Acoustics vs. Lexical Frequency
Lexical frequency data for words in CLIPS were drawn from SUBTLEX-IT (Crepaldi et al. 2015) and compared to vowel acoustics, with the hypothesis that increasing frequency is associated with reduction (Bybee 2003). Focusing on height, the acoustic reduction would produce smaller first-formant values and vowel raising. Across all cities, correlations were tested between lexical frequency and normalized F1. Significant negative correlations were found between F1 and frequency for both front vowels (r = −0.144, t(16,918) = −18.955, p ~ 0) and back vowels (r = −0.158, t(14,601) = −19.31, p ~ 0). These relationships indicate that as usage frequency increases, normalized F1 declines, as hypothesized. They are illustrated in Figure 4 (front vowels) and Figure 5 (back vowels) for six cities. Separate trend lines are shown for vowels in closed vs. open syllables since syllable structure determines height, particularly for Conditioned systems. Figure 5 shows that, especially in closed syllables, there is a strong effect of frequency on height across all cities.
4.3. Phonetic Factors: Vowel Height vs. Duration
In addition to formant values, phonological vowel height may be cued by duration, with the basic expectation that lower vowels have intrinsically longer duration due to the biomechanics of their articulation. Correlations were tested between normalized F1 and duration (sec) in stressed penultimate syllables across all cities combined, but separately for vowels in open vs. closed syllables.4 For front vowels, there is no significant correlation between F1 and duration in open syllables (p > 0.05), but in closed syllables, a significant positive correlation is obtained (r = 0.29, t(5352) = 21.925, p ~ 0), as illustrated in Figure 6. For back vowels, illustrated in Figure 7, significant positive correlations exist between F1 and duration in both open syllables (r = 0.21, t(4712) = 14.61, p ~ 0) and closed syllables (r = 0.16, t(3468) = 9.6383, p ~ 0). Particularly for front vowels, the divergence in patterns between open and closed syllables suggests that duration may function as a cue to both vowel height and syllable stress in the closed-syllable context. As pointed out by Gordon (2002, p. 73), “in languages [such as Italian] without phonemic vowel length, contrasts based on vowel quality can safely be accompanied by large differences in duration without endangering any phonemic length contrasts”.
5. Modeling Mid Vowel Height with Linear Mixed-Effects Regression
While §4 descriptively characterized the individual relationships between Italian mid vowel height and various structural, usage-based, and phonetic factors, this section models height as a combination of those factors. This helps determine whether multiple relationships hold simultaneously, or whether instead some relationships are insignificant once others are controlled for. Linear mixed-effects modeling is used to explore the relationships between vowel quality and individual factors.
In this exploratory analysis, the dependent variable is normalized values of F1. The same model was applied to stressed front and back vowel tokens separately for Full Contrast, Conditioned Contrast, and Merged data (six models total). Categorical variables were treatment-coded. The reference level for dictionary height is “low mid”; the reference level for type, referring to content vs. function, is “content”, and the reference level for syllable structure is “open”. Models were fit via maximum likelihood estimation using lmer in R’s lme4 package (Bates and Maechler 2009), alongside lmerTest (Kuznetsova et al. 2013) for calculation of p-values. Model selection was supported by the examination and minimization of Akaike Information Criterion (AIC) and Bayesian information criterion (BIC) values. The model is characterized in (3).
- (3)
- Linear mixed-effects model structure
F1.z ~ # dependent variable F2.z + log10_frequency + # continuous fixed effects dictionary height + type + # categorical fixed effects duration*structure + # interaction term (1|City) + (1|Word) + (1|Speaker) # random intercept terms
Models including random slopes were attempted (e.g., for Speaker by duration), but they failed to converge. When applied to back vowels in Conditioned Contrast systems, the model in (3) converged but produced a singular fit, which occurs when some combination of linear effects within the model has a variance close to zero. Inspection of random effects for this model indicated that variance due to the random intercept of City was vanishingly small (σ2 = 1.882 × 10−11). When City was excluded from the model for Conditioned Contrasts’ back vowels, singularity no longer occurred, and model comparison indicated little change in AIC and no significant detriment in performance (model with City, AIC = 4410.9, model without City, AIC = 4408.9; Χ2(1) = 0, p = 1). Following recommendations for constructing mixed-effects models (Barr et al. 2013), this reduced model was maximal.
Results of Linear Mixed-Effects Modeling
A selection of model summary information is shown in Table 5 for front vowel models and Table 6 for back vowel models. In each model, a range of factors significantly predicts the height of mid vowels. Several significant predictors are shared across front and back, including normalized F2: the negative estimates for front vowels and positive estimates for back vowels show that vowels with lower F1 (greater height) have more peripheral positions in the front/back dimension (p < 0.001). Significantly greater duration is predicted for vowels with higher F1 (lower height; p < 0.001). In three models, the prescriptive lexical specification of vowel height is significant: words classified by the dictionary as high mid vowels have significantly lower F1 (greater height) than low mids (p < 0.01). In the model for Conditioned Contrast front vowels, however, dictionary height has no significant predictive power for F1 (β = −0.116, p = 0.098); the same is true for both Merged models (front: β = −0.102, p = 0.742, back: β = −0.039, p = 0.573).
In models for Full Contrast and Conditioned Contrast systems, the main effect of syllable structure is insignificant (p > 0.05), but its interaction with duration is significant for these systems’ models of front vowels (p < 0.001). In Full Contrast and Conditioned Contrast systems, as duration increases in closed syllables, F1 also increases, indicating a lowering toward [ɛ] at longer durations. Among Conditioned Contrast back vowels and in Merged systems, syllable structure does not mitigate durational effects (p > 0.05).
The distinction between content and function words has limited effect. For front vowels in Merged systems, function words are associated with lower F1 (p < 0.05), indicating the expected tendency toward [e]. For back vowels in Full Contrast systems only, function words are associated with slightly higher F1 (β = 0.283, p < 0.05). This runs contra to typical expectations of phonetic reduction in unstressed function words. Turning to usage, log10 frequency is not a significant predictor for front vowels (p > 0.05), but it is for back vowels, where in Full Contrast (p < 0.01), Conditioned Contrast (p < 0.001), and Merged (p < 0.01) systems, a negative estimate is found. This confirms that for back vowels, high lexical frequency predicts lower F1 (greater height), matching Figure 5.
To summarize, for all models, estimates generally indicate the expected effects of formant covariation (F1 and F2) and relative hyperarticulation at lower speech rates, alongside phonetic effects owing to syllable structure. However, where the models diverge, evidence suggests that front mid vowels have greater systematic variation based on phonetic durational constraints, while back mid vowels vary to a greater extent with the usage-based factor of lexical frequency. Additionally, the F1 of vowels is not significantly predicted by prescriptive vowel height in Merged systems or among front vowels in Conditioned Contrast systems. This confirms that such cities’ lexicons diverge sharply from prescriptive norms. Instead, to the extent that Merged systems’ vowel qualities are predictable, they vary according to duration and function-word status or lexical frequency. Front vowel height in Conditioned systems, on the other hand, is strongly determined by the interaction of syllable structure and duration, whose effect is of larger magnitude (β = 3.344, p < 0.001) than in Full Contrast systems (β = 1.349, p < 0.001).
The contribution of these predictors to variation in the acoustic data was checked by model comparison. This process confirms that all models outperform simpler nested models lacking fixed effects for syllable structure, regional contrast, duration, and lexical frequency (Full Contrast: front vowels, Χ2(4) = 436.82, p < 0.001; back vowels: Χ2(4) = 123.6, p < 0.001. Conditioned Contrast: front vowels, Χ2(4) = 343.84, p < 0.001; back vowels: Χ2(5) = 56.026, p < 0.001. Merged: front vowels, Χ2(5) = 241.46, p < 0.001; back vowels: Χ2(5) = 92.409, p < 0.001).
Goodness-of-fit was evaluated following recommendations by Sonderegger (2023). For models of Full Contrast systems, marginal R2, including only fixed effects, was 0.38 for front vowels and 0.23 for back vowels; conditional R2, which includes random effects’ adjustments, was much higher at 0.63 for front vowels and 0.46 for back vowels. For Conditioned Contrast systems, marginal R2 was 0.34 for front vowels and 0.30 for back vowels (conditional R2 0.62 and 0.54, respectively). For Merged systems, marginal R2 was 0.163 for front vowels and 0.105 for back vowels (conditional R2 0.524 and 0.436). These goodness-of-fit statistics indicate that each model does have predictive power, especially when fixed effects and random effects for speaker, word, and city are included. Modeling is more successful for systems that maintain some mid vowel distinction (Full or Conditioned), where prescriptive quality and/or syllable structure are influential, but they account for less variation in Merged systems, where phonetic and usage-based factors are the primary predictors. The boost in goodness-of-fit that is achieved by considering random effects (conditional R2) indicates the presence of variation across speakers, words, and cities. This echoes previous findings that some Italian words are more variable than others, even within cities (Watt et al. 2023, Figure 12.2), but a detailed investigation of this variation and its potential social underpinnings is left for future research.
6. Discussion
6.1. Summary of Findings
This paper has presented a multifaceted analysis of contrasts among Italian mid vowels /e ɛ/ and /o ɔ/. We now interpret its results in terms of the structural, usage-based, phonetic, and social factors in the MMPR. While both front and back mid vowels in Italian meet some criteria for marginal contrast, the implementation and degree of marginality differ across the front and back mid vowels. Within the prescriptive lexicon, there are discrepancies in these vowels’ lexical frequencies: the high mid vowels /e o/ are more frequent than their low mid counterparts /ɛ ɔ/, which are two of Italian’s rarest vowels, canonically subject to neutralization in unstressed syllables. This type of imbalance is arguably part and parcel with natural language phenomena since power laws apply to the frequency distributions of individual phonemes (Macklin-Cordes and Round 2020). However, marginal contrasts are often characterized by an imbalance in frequencies or by the rarity of one or both sounds (Hall 2013). The functional loads of the front and back mid vowel contrasts are among the lowest in Italian; notably, the front mid contrast is weaker (supported by 70 minimal pairs) than the back mid contrast (supported by 300 minimal pairs). This disparity may predict an asymmetry in perceptual distinctions, like that found for Galician, where the front mid contrast is less robust than the back mid contrast (Amengual and Chamorro 2015). This is worth testing in future work.
The distributional divergence of front and back spurred hypotheses that the vowels’ phonetic contrasts would be shaped by different systemic, usage-based, and phonetic factors. Prescriptive lexical specifications are more relevant for some varieties than others: mid vowels in Full Contrast systems covary with dictionary standards, but in Conditioned systems, the relevance of syllable structure, especially for front vowels, eliminates a significant link to prescriptive height. Among Merged systems, mid vowel height is phonetically unrelated to the dictionary. Turning to usage, we find that for back vowels, across phonological systems, height is related to lexical frequency, in line with expectations of phonetic reduction in high-frequency contexts. Considering the phonetic factor of duration in relation to F1, modeling shows that lower vowels generally appear at greater durations, aligning with expectations of intrinsic phonetic length. The strength of this relationship, however, depends on syllable structure and vowel backness. The strongest relationships are found for front vowels having low F1 in closed syllables (where short durations are expected). This suggests that duration is a secondary phonetic cue to phonological height and that the extent of lengthening by low mid vowels should be seen as a contrast enhancement strategy (Stevens and Keyser 2010; Storme 2019). Finally, although the factor of social salience is not directly analyzed here, it is accounted for by the inclusion of the City as a modeling predictor and is treated visually in city-specific plots.
The magnitudes of the beta coefficients from linear modeling imply ranking relationships in an adequate phonological grammar, to be formalized in a constraint-based theory such as Optimality Theory. We turn briefly to a proposed sketch for such an analysis.
6.2. Toward a Formalization of Italian Marginal Contrasts
Marginal contrasts increase the complexity of phonological relationships beyond a traditional binary. Theoretical approaches have not yet settled on a single formalism for incorporating these intermediate relationships, which are technically phonemic but largely allophonic. In Italian, multiple types of forces act on mid vowels, leading to word-specific variation and high variability in pronunciation. One method of formally treating variable surface forms is a Maximum Entropy model (Goldwater and Johnson 2003), in which probabilities from real-world data are used to derive phonological constraint weights. In such an approach, lower-ranked constraints may “gang up” (Pater 2009) to disrupt faithful outputs. Systems like Italian may be subject to disruption of faithfulness due to weakened lexical representations, as signaled by low functional load.
For Italian, it would be ideal to formalize a typological comparison between Full Contrast and Conditioned Contrast systems. A restriction on high mid vowels in closed syllables would be heavily weighted in Conditioned systems but not in Full Contrast varieties. Specific constraints privileging low mid vowels in closed syllables could follow the Contrast Enhancement approach of Storme (2019), who extends Dispersion Theory (Flemming 2004) in a typological account of Closed-Syllable Laxing and Open-Syllable Tensing. Given the relevance of both grammatical and extragrammatical factors to Italian mid vowel quality, the introduction of scaling factors (Coetzee and Kawahara 2013; Coetzee 2016) for duration and usage will improve weighted constraints’ fit to patterns of variation. Cumulative constraints within “noisy” grammars are likely to extend successfully to Italian because they have been used to model gradient patterns in the realization of French schwa (Smith and Pater 2020), as well as repair strategies for French word-final clusters (Griffiths 2022). Given the variable but predictable nature of Italian mid vowel variation, the next step is formalization in such a MaxEnt model.
7. Conclusions
Gradient contrasts, and in particular marginal contrasts, are complex. Characterizing their representation and realization in native speech requires information about the lexicon and the sounds’ distribution within it, particularly whether the sounds are common or rare and whether they are context-dependent. Especially in cases where one member of a contrast is more frequent than the other or where usage may affect phonetic quality, functional factors like lexical frequency may also influence the surface form. As a result, marginal contrasts are rarely accommodated in formalizations.
Despite this complexity, it is worthwhile to model marginal contrasts. The potential impacts are at least two-fold. First, there is a typological impact. Marginal contrasts are very common among vowel systems in the Romance languages, and they also exist in heavily studied languages like English (for instance, the caught-cot distinction). They are therefore probably widespread in the world’s languages, where their distributions are readily acquired by learners. Accounting for their effects on production and perception can help us better understand the cognitive requirements of spoken communication and the limits of phonological grammar. The second reason to formalize marginal contrast is its relevance to sound change, a force that many linguists seek to model. Where marginal contrasts are active, there is a reduced need for native speakers to rely on lexical information to distinguish pairs of sounds. Instead, distributional or contextual information can become crucial. In combination with low functional load and usage-based pressures, this may lead to sound change by reshaping the phonemic inventory. Future work will pursue the formalization of marginal contrasts in Italian and other languages, using weighted constraints to account for the complex array of influences on their realization.
Funding
This research was undertaken with support from a Willson Center Fellowship from the University of Georgia’s Willson Center for Humanities & Arts.
Institutional Review Board Statement
Not applicable: this study did not require the collection of new data from humans or animals.
Informed Consent Statement
Not applicable.
Data Availability Statement
The CLIPS recordings, including those analyzed here, are available via http://www.clips.unina.it/it/ (accessed on 7 April 2024). Additional data presented in this study are available upon request.
Acknowledgments
The author thanks the editors and reviewers for their guidance. She is also grateful for discussion with Madeline Gilbert, Joshua M. Griffiths, and the organizers and audiences at the 53rd Linguistic Symposium on Romance Languages in Paris, France.
Conflicts of Interest
The author declares no conflicts of interest.
| 1 | “Type frequency measures […] refer to the number of times a particular unit (phoneme, syllable, etc.) occurs within the words of the lexicon, with each word counted once. Token frequency (identified by the field TokenF, with the natural log of this value found in the field LnTokenF) refers to the number of times a unit occurs in the words of the language taking into account the frequency of the words” (Goslin et al. 2014, p. 875). |
| 2 | In PCT, functional load was calculated twice, using Algorithm: Change in Entropy and Minimal Pairs. All settings were identical across both algorithms as follows. Distinguished homophones: false. Minimal pair count: true minimal pairs. Transcription tier: transcription. Pronunciation variants: canonical form. Minimum word frequency: 0. Environments: none. For documentation, see: https://corpustools.readthedocs.io/en/latest/functional_load.html (accessed on 7 April 2024). |
| 3 | By comparison, the functional load for the marginal Romanian contrast /ɨ ʌ/ is 0.0004 (Renwick et al. 2016). |
| 4 | Penultimate syllables were modeled here because penultimate stress was the most common pattern in this dataset, representing stress patterns of Italian more broadly (Borrelli 2002), but also because previous exploratory analyses indicated that the relationship between F1 and duration was strongest in penultimate syllables (Renwick 2018). |
References
- Albano Leoni, Federico, Francesco Cutugno, Renata Savy, Valentina Caniparoli, Leandro D’Anna, Ester Paone, Rosa Giordano, Olga Manfrellotti, Massimo Petrillo, and Aurelio De Rosa. 2007. Corpora e Lessici dell’Italiano Parlato e Scritto. Available online: http://www.clips.unina.it/ (accessed on 7 April 2024).
- Alkire, Ti, and Carol Rosen. 2010. Romance Languages: A Historical Introduction. Cambridge: Cambridge University Press. [Google Scholar]
- Amengual, Mark, and Pilar Chamorro. 2015. The Effects of Language Dominance in the Perception and Production of the Galician Mid Vowel Contrasts. Phonetica 72: 207–36. [Google Scholar] [CrossRef] [PubMed]
- Auer, Edward T., Jr., and Paul A. Luce. 2005. Probabilistic Phonotactics in Spoken Word Recognition. In The Handbook of Speech Perception. Edited by David B. Pisoni and Robert E. Remez. Hoboken: John Wiley & Sons, pp. 610–30. [Google Scholar]
- Badia i Margarit, Antoni M. 1969. Algunes mostres de les igualacions E = e i O = o en el català parlat de Barcelona. In Sons i Fonemes de la Llengua Catalana. Barcelona: Publicacions de la Universitat de Barcelona, pp. 97–103. [Google Scholar]
- Barr, Dale J., Roger Levy, Christoph Scheepers, and Harry J. Tily. 2013. Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language 68: 255–78. [Google Scholar] [CrossRef] [PubMed]
- Bates, David, and Martin Maechler. 2009. lme4: Linear Mixed-Effects Models Using S4 Classes. Available online: https://cran.r-project.org/web/packages/lme4/index.html (accessed on 7 April 2024).
- Bell, Alan, Jason M. Brenier, Michelle Gregory, Cynthia Girand, and Dan Jurafsky. 2009. Predictability effects on durations of content and function words in conversational English. Journal of Memory and Language 60: 92–111. [Google Scholar] [CrossRef]
- Bertinetto, Pier Marco, and Michele Loporcaro. 2005. The sound pattern of Standard Italian, as compared with the varieties spoken in Florence, Milan and Rome. Journal of the International Phonetic Association 35: 131–51. [Google Scholar] [CrossRef]
- Boersma, Paul, and David Weenink. 2021. Praat: Doing Phonetics by Computer [Computer Program], Version 6.2.03. Available online: http://www.praat.org (accessed on 7 April 2024).
- Borrelli, Doris Angel. 2002. Raddoppiamento Sintattico in Italian: A Synchronic and Diachronic Cross-Dialectical Study. Abingdon: Routledge. [Google Scholar]
- Bybee, Joan. 2003. Phonology and Language Use. Cambridge: Cambridge University Press. [Google Scholar]
- Calamai, Silvia. 2017. Tuscan between standard and vernacular: A sociophonetic perspective. In Towards a New Standard: Theoretical and Empirical Studies on the Restandardization of Italian. Edited by Massimo Cerruti, Claudia Crocco and Stefania Marzo. Boston: De Gruyter, pp. 213–41. [Google Scholar]
- Canepari, Luciano. 1980. Italiano Standard e Pronunce Regionali. Padua: CLUEP. [Google Scholar]
- Cerruti, Massimo. 2011. Regional varieties of Italian in the linguistic repertoire. International Journal of the Sociology of Language 210: 9–28. [Google Scholar] [CrossRef]
- Cerruti, Massimo, and Riccardo Regis. 2014. Standardization patterns and dialect/standard convergence: A northwestern Italian perspective. Language in Society 43: 83–111. [Google Scholar] [CrossRef]
- Cerruti, Massimo, Claudia Crocco, and Stefania Marzo. 2017. On the development of a new standard norm in Italian. In Towards a New Standard: Theoretical and Empirical Studies on the Restandardization of Italian. Edited by Massimo Cerruti, Claudia Crocco and Stefania Marzo. Boston: De Gruyter, pp. 3–28. [Google Scholar]
- Coetzee, Andries W. 2016. A comprehensive model of phonological variation: Grammatical and non-grammatical factors in variable nasal place assimilation. Phonology 33: 211–46. [Google Scholar] [CrossRef]
- Coetzee, Andries W., and Shigeto Kawahara. 2013. Frequency biases in phonological variation. Natural Language & Linguistic Theory 31: 47–89. [Google Scholar] [CrossRef]
- Cohn, Abigail C., and Margaret E. L. Renwick. 2021. Embracing multidimensionality in phonological analysis. The Linguistic Review 38: 101–39. [Google Scholar] [CrossRef]
- Crepaldi, Davide, Simone Amenta, Mandera Pawel, Emmanuel Keuleers, and Marc Brysbaert. 2015. SUBTLEX-IT. Subtitle-based word frequency estimates for Italian. Paper presented at the Annual Meeting of the Italian Association for Experimental Psychology, Rovereto, Italy, September 10–12. [Google Scholar]
- Crocco, Claudia. 2017. Everyone has an accent. Standard Italian and regional pronunciation. In Towards a New Standard: Theoretical and Empirical Studies on the Restandardization of Italian. Edited by Massimo Cerruti, Claudia Crocco and Stefania Marzo. Boston: De Gruyter, pp. 89–117. [Google Scholar]
- De Mauro, Tullio. 1976. Storia Linguistica dell’Italia unita. Roma and Bari: Laterza. [Google Scholar]
- De Mauro, Tullio. 2000. Il Dizionario della Lingua Italiana. Torino: Paravia. [Google Scholar]
- De Mauro, Tullio, and Marco Mancini. 2000. Dizionario Etimologico. Milan: Garzanti Linguistica. [Google Scholar]
- De Pascale, Stefano, Stefania Marzo, and Dirk Speelman. 2017. Evaluating regional variation in Italian: Towards a change in standard language ideology? In Towards a New Standard: Theoretical and Empirical Studies on the Restandardization of Italian. Edited by Massimo Cerruti, Claudia Crocco and Stefania Marzo. Boston: De Gruyter, pp. 118–41. [Google Scholar]
- D’Imperio, Mariapaola, and Sam Rosenthall. 1999. Phonetics and phonology of main stress in Italian. Phonology 16: 1–28. [Google Scholar] [CrossRef]
- Drager, Katie, and M. Joelle Kirtley. 2016. Awareness, salience, and stereotypes in exemplar-based models of speech production and perception. In Awareness and Control in Sociolinguistic Research. Edited by Anna Babel. Cambridge: Cambridge University Press, pp. 1–24. [Google Scholar]
- Esposito, Anna. 2002. On vowel height and consonantal voicing effects: Data from Italian. Phonetica 59: 197–231. [Google Scholar] [CrossRef] [PubMed]
- Farnetani, Edda, and Shiro Kori. 1986. Effects of syllable and word structure on segmental durations in spoken Italian. Speech Communication 5: 17–34. [Google Scholar] [CrossRef]
- Flemming, Edward. 2004. Contrast and perceptual distinctiveness. In Phonetically Based Phonology. Edited by Bruce Hayes, Robert Kirchner and Donca Steriade. Cambridge: Cambridge University Press, pp. 232–76. [Google Scholar]
- Goldsmith, John A. 1995. Phonological Theory. In The Handbook of Phonological Theory. Edited by John A. Goldsmith. Cambridge: Blackwell Publishers, pp. 1–23. [Google Scholar]
- Goldwater, Sharon, and Mark Johnson. 2003. Learning OT constraint rankings using a maximum entropy model. In Proceedings of the Stockholm Workshop on Variation within Optimality Theory. Edited by Jennifer Spenader, Aners Eriksson and Östen Dahl. Stockholm: Stockholm University Department of Linguistics, pp. 111–20. [Google Scholar]
- Gordon, Matthew. 2002. A Phonetically Driven Account of Syllable Weight. Language 78: 51–80. [Google Scholar] [CrossRef]
- Goslin, Jeremy, Claudia Galluzzi, and Cristina Romani. 2014. PhonItalia: A phonological lexicon for Italian. Behavior Research Methods 46: 872–86. [Google Scholar] [CrossRef] [PubMed]
- Griffiths, Joshua M. 2022. Competing repair strategies for word-final obstruent-liquid clusters in northern metropolitan French. Journal of French Language Studies 32: 1–24. [Google Scholar] [CrossRef]
- Hall, Daniel Currie, and Kathleen Currie Hall. 2016. Marginal contrasts and the Contrastivist Hypothesis. Glossa: A Journal of General Linguistics 1: 50. [Google Scholar] [CrossRef]
- Hall, Kathleen Currie. 2013. A typology of intermediate phonological relationships. The Linguistic Review 30: 215–75. [Google Scholar] [CrossRef]
- Hall, Kathleen Currie, Elizabeth Hume, T. Florian Jaeger, and Andrew Wedel. 2018. The role of predictability in shaping phonological patterns. Linguistics Vanguard 4: 20170027. [Google Scholar] [CrossRef]
- Hall, Kathleen Currie, J. Scott Mackie, and Roger Yu-Hsiang Lo. 2019. Phonological CorpusTools: Software for doing phonological analysis on transcribed corpora. International Journal of Corpus Linguistics 24: 522–35. [Google Scholar] [CrossRef]
- Hockett, Charles Francis. 1966. The Quantification of Functional Load: A Linguistic Problem. Oxford: Memorandum. [Google Scholar]
- Kisler, Thomas, Uwe D. Reichel, Florian Schiel, Christoph Draxler, Bernhard Jackl, and Nina Pörner. 2016. BAS Speech Science Web Services–An Update on Current Developments. Paper presented at the 10th International Conference on Language Resources and Evaluation (LREC 2016), Portorož, Slovenia, May 23–28; pp. 3880–85. [Google Scholar]
- Kuznetsova, Alexandra, Per Bruun Brockhoff, and Rune Haubo Bojesen Christensen. 2013. lmerTest: Tests for Random and Fixed Effects for Linear Mixed Effect Models (lmer Objects of lme4 Package). R Package Version 2–0. Available online: https://cran.r-project.org/web/packages/lmerTest/index.html (accessed on 7 April 2024).
- Labov, William, Ingrid Rosenfelder, and Josef Fruehwald. 2013. One hundred years of sound change in Philadelphia: Linear incrementation, reversal, and reanalysis. Language 89: 30–65. [Google Scholar] [CrossRef]
- Landick, Marie. 1995. The mid-vowels in figures: Hard facts. French Review 69: 88–102. [Google Scholar]
- Lobanov, Boris M. 1971. Classification of Russian vowels spoken by different speakers. The Journal of the Acoustical Society of America 49: 606–8. [Google Scholar] [CrossRef]
- Macklin-Cordes, Jayden L., and Erich R. Round. 2020. Re-evaluating Phoneme Frequencies. Frontiers in Psychology 11: 570895. [Google Scholar] [CrossRef] [PubMed]
- Mahalanobis, Prasanta Chandra. 1936. On the generalized distance in statistics. In Proceedings of the National Institute of Sciences of India. Calcutta: National Institute of Sciences, vol. 2, pp. 49–55. Available online: http://ci.nii.ac.jp/naid/10004710165/ (accessed on 7 April 2024).
- Maiden, Martin, and Mair Parry, eds. 1997. The Dialects of Italy. London: Routledge. [Google Scholar]
- Meunier, Christine, and Robert Espesser. 2011. Vowel reduction in conversational speech in French: The role of lexical factors. Journal of Phonetics 39: 271–78. [Google Scholar] [CrossRef]
- Mora, Joan C., and Marianna Nadeu. 2012. L2 effects on the perception and production of a native vowel contrast in early bilinguals. International Journal of Bilingualism 16: 484–500. [Google Scholar] [CrossRef]
- Nadeu, Marianna, and Margaret E. L. Renwick. 2016. Variation in the lexical distribution and implementation of phonetically similar phonemes in Catalan. Journal of Phonetics 58: 22–47. [Google Scholar] [CrossRef]
- Oh, Yoon Mi, Christophe Coupé, Egidio Marsico, and François Pellegrino. 2015. Bridging phonological system and lexicon: Insights from a corpus study of functional load. Journal of Phonetics 53: 153–76. [Google Scholar] [CrossRef]
- Pallier, Christophe, Laura Bosch, and Núria Sebastián-Gallés. 1997. A limit on behavioral plasticity in speech perception. Cognition 64: B9–B17. [Google Scholar] [CrossRef]
- Pater, Joe. 2009. Weighted Constraints in Generative Linguistics. Cognitive Science 33: 999–1035. [Google Scholar] [CrossRef]
- Peterson, Gordon E., and Ilse Lehiste. 1960. Duration of syllable nuclei in English. Journal of the Acoustical Society of America 32: 693–703. [Google Scholar] [CrossRef]
- Raymond, William D., and Esther L. Brown. 2012. Are effects of word frequency effects of context of use? An analysis of initial fricative reduction in Spanish. In Frequency Effects in Language Learning and Processing. Edited by Stefan Th Gries and Dagmar Divjak. Berlin: Walter de Gruyter, pp. 35–52. [Google Scholar]
- Rebora, Piero. 1958. Cassell’s Italian-English, English-Italian Dictionary. London: Cassell. [Google Scholar]
- Recasens, Daniel. 1993. Fonètica i Fonologia. Barcelona: Enciclopèdia Catalana. [Google Scholar]
- Renwick, Margaret E. L. 2012. Vowels of Romanian: Historical, Phonological and Phonetic Studies. Ph.D. dissertation, Cornell University, Ithaca, NY, USA. [Google Scholar]
- Renwick, Margaret E. L. 2014. The Phonetics and Phonology of Contrast: The Case of the Romanian Vowel System. Berlin and Boston: De Gruyter Mouton. [Google Scholar]
- Renwick, Margaret E. L. 2018. Phonetic Implementation of Mid Vowel Contrasts across Italian Varieties. Poster presented at BAAP 2018. Canterbury: British Association of Academic Phoneticians. [Google Scholar]
- Renwick, Margaret E. L. 2021. Mid vowel variation and contrast in regional Standard Italian. In Sound Change in Romance: Phonetic and Phonological Issues (LINCOM Studies in Romance Linguistics 84). Edited by Daniel Recasens and Fernando Sánchez-Miret. Munich: LINCOM Europa, pp. 115–37. [Google Scholar]
- Renwick, Margaret E. L., and D. Robert Ladd. 2016. Phonetic Distinctiveness vs. Lexical Contrastiveness in Non-Robust Phonemic Contrasts. Laboratory Phonology 7: 1–29. [Google Scholar] [CrossRef]
- Renwick, Margaret E. L., and Marianna Nadeu. 2018. A Survey of Phonological Mid Vowel Intuitions in Central Catalan. Language and Speech 62: 164–204. [Google Scholar] [CrossRef] [PubMed]
- Renwick, Margaret E. L., Ioana Vasilescu, Camille Dutrey, Lori Lamel, and Bianca Vieru. 2016. Marginal Contrast Among Romanian Vowels: Evidence from ASR and Functional Load. Proceedings of Interspeech 2016, 2433–37. [Google Scholar] [CrossRef]
- Rogers, Derek, and Luciana d’Arcangeli. 2004. Italian. Journal of the International Phonetic Association 34: 117–21. [Google Scholar] [CrossRef]
- Savy, Renata, and Francesco Cutugno. 1998. Hypospeech, vowel reduction, centralization: How do they interact in diaphasic variations. In Proceedings of the XVIth International Congress of Linguists. Oxford: Pergamon. [Google Scholar]
- Seidl, Amanda, and Alejandrina Cristia. 2012. Infants’ Learning of Phonological Status. Frontiers in Psychology 3: 448. [Google Scholar] [CrossRef] [PubMed]
- Silva, Daniel Márcio Rodrigues, and Rui Rothe-Neves. 2016. Perception of height and categorization of Brazilian Portuguese front vowels. DELTA: Documentação de Estudos em Lingüística Teórica e Aplicada 32: 355–73. [Google Scholar] [CrossRef]
- Simonet, Miquel. 2018. Phonetic behavior in proficient bilinguals: Insights from the Catalan–Spanish contact situation. In Romance Phonetics and Phonology. Edited by Mark Gibson and Juana Gil. Oxford: Oxford University Press, pp. 395–406. [Google Scholar] [CrossRef]
- Smith, Brian W., and Joe Pater. 2020. French schwa and gradient cumulativity. Glossa: A Journal of General Linguistics 5: 24. [Google Scholar] [CrossRef]
- Sobrero, Alberto. 2006. Definizione delle Caratteristiche Generali del Corpus: Informatori, Località. Available online: http://www.clips.unina.it/it/documenti/1_scelta_informatori_e_localita.pdf (accessed on 7 April 2024).
- Sonderegger, Morgan. 2023. Regression Modeling for Linguistic Data. Cambridge: MIT Press. [Google Scholar]
- Stevens, Kenneth Noble, and Samuel Jay Keyser. 2010. Quantal theory, enhancement and overlap. Journal of Phonetics 38: 10–19. [Google Scholar] [CrossRef]
- Stevenson, Sophia, and Tania Zamuner. 2017. Gradient phonological relationships: Evidence from vowels in French. Glossa: A Journal of General Linguistics 2: 58. [Google Scholar] [CrossRef]
- Storme, Benjamin. 2019. Contrast enhancement as motivation for closed syllable laxing and open syllable tensing. Phonology 36: 303–40. [Google Scholar] [CrossRef]
- Surendran, Dinoj, and Partha Niyogi. 2003. Measuring the Functional Load of Phonological Contrasts. arXiv arXiv:cs/0311036. [Google Scholar]
- Surendran, Dinoj, and Partha Niyogi. 2006. Quantifying the functional load of phonemic oppositions, distinctive features, and suprasegmentals. In Competing Models of Linguistic Change: Evolution and Beyond. Edited by Ole Nedergaard Thomsen. Amsterdam and Philadelphia: John Benjamins Publishing Company, pp. 43–58. [Google Scholar]
- Tiegs, Jessica. 2023. Processing Consequences of Marginal Contrastivity in Romance Phonology. Ph.D. thesis, The University of Arizona, Tucson, AZ, USA. [Google Scholar]
- Trubetzkoy, Nikolai Sergeevich. 1939. Principles of Phonology. Translated by Christiane Baltaxe. Berkeley: University of California Press. [Google Scholar]
- Vasilescu, Ioana, Margaret E. L. Renwick, Camille Dutrey, Lori Lamel, and Bianca Vieru. 2016. Réalisation phonétique et contraste phonologique marginal: Une étude automatique des voyelles du roumain. In Actes de la Conférence Conjointe JEP-TALN-RECITAL 2016. Paris: AFCP–ATALA, vol. 1, pp. 597–606. [Google Scholar]
- Vietti, Alessandro. 2019. Phonological Variation and Change in Italian. In Oxford Research Encyclopedia of Linguistics. Oxford: Oxford University Press. [Google Scholar] [CrossRef]
- Vietti, Alessandro, and Daniela Mereu. 2023. Mid vowels at the crossroads between standard and regional Italian. Sociolinguistica 37: 17–39. [Google Scholar] [CrossRef]
- Watt, Dominic, Margaret E. L. Renwick, and Joseph A. Stanley. 2023. Sociophonetics and dialectology. In The Routledge Handbook of Sociophonetics. Edited by Christopher Strelluf. London: Routledge, pp. 263–84. [Google Scholar]
- Wedel, Andrew, Abby Kaplan, and Scott Jackson. 2013. High functional load inhibits phonological contrast loss: A corpus study. Cognition 128: 179–86. [Google Scholar] [CrossRef]
- Wedel, Andrew, Noah Nelson, and Rebecca Sharp. 2018. The phonetic specificity of contrastive hyperarticulation in natural speech. Journal of Memory and Language 100: 61–88. [Google Scholar] [CrossRef]
- Wheeler, Max. 2005. The Phonology of Catalan. Oxford: Oxford University Press. [Google Scholar]
- Wright, Richard. 2004. Factors of lexical competition in vowel articulation. In Phonetic Interpretation: Papers in Laboratory Phonology VI. Edited by John Local, Richard Ogden and Rosalind Temple. Cambridge: Cambridge University Press, pp. 75–87. [Google Scholar]
Figure 1.
The multidimensional model of phonemic robustness.

Figure 2.
Type frequency counts of vowels across the Italian lexicon (PhonItalia).

Figure 3.
Mean normalized F1, F2 per word in stressed vowels across six Italian cities. Symbols indicate prescriptive vowel height and are assigned as an arbitrary comparative standard without accounting for regional lexical assignment, based on De Mauro and Mancini (2000). Color indicates syllable structure: open syllables have no coda consonant, while closed syllables have a coda.
Figure 3.
Mean normalized F1, F2 per word in stressed vowels across six Italian cities. Symbols indicate prescriptive vowel height and are assigned as an arbitrary comparative standard without accounting for regional lexical assignment, based on De Mauro and Mancini (2000). Color indicates syllable structure: open syllables have no coda consonant, while closed syllables have a coda.

Figure 4.
Mean normalized F1 per word vs. lexical frequency in stressed front vowels across six Italian cities. Regression lines apply to open vs. closed-syllable vowels.
Figure 4.
Mean normalized F1 per word vs. lexical frequency in stressed front vowels across six Italian cities. Regression lines apply to open vs. closed-syllable vowels.

Figure 5.
Mean normalized F1 per word vs. lexical frequency in stressed back vowels across six Italian cities. Regression lines apply to open vs. closed-syllable vowels.
Figure 5.
Mean normalized F1 per word vs. lexical frequency in stressed back vowels across six Italian cities. Regression lines apply to open vs. closed-syllable vowels.

Figure 6.
Normalized F1 vs. duration in stressed front vowel tokens across six Italian cities. Regression lines apply to open vs. closed-syllable tokens.
Figure 6.
Normalized F1 vs. duration in stressed front vowel tokens across six Italian cities. Regression lines apply to open vs. closed-syllable tokens.

Figure 7.
Normalized F1 vs. duration in stressed back vowel tokens across six Italian cities. Regression lines apply to open vs. closed-syllable tokens.
Figure 7.
Normalized F1 vs. duration in stressed back vowel tokens across six Italian cities. Regression lines apply to open vs. closed-syllable tokens.


{kind=link}
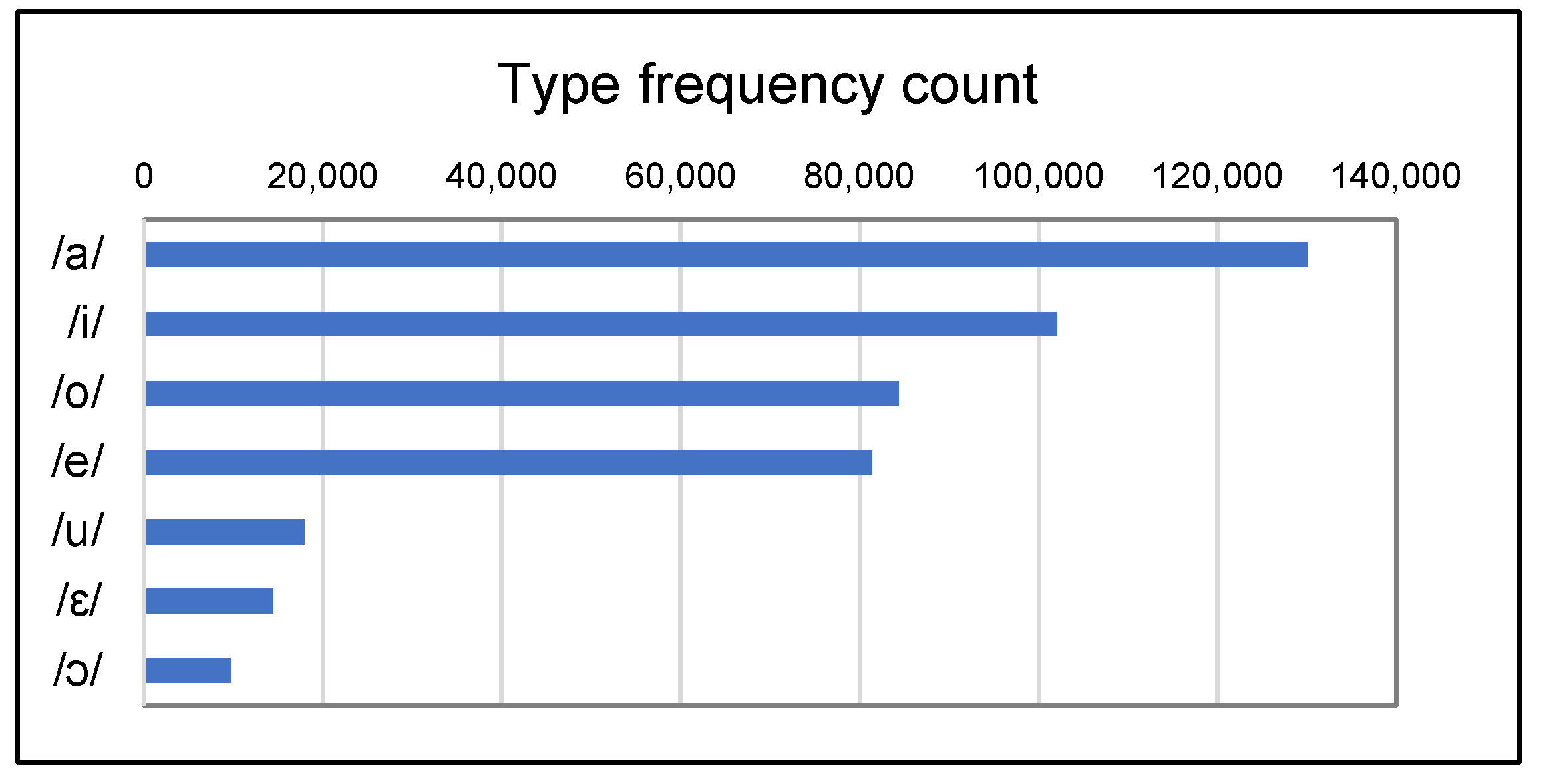{kind=link}
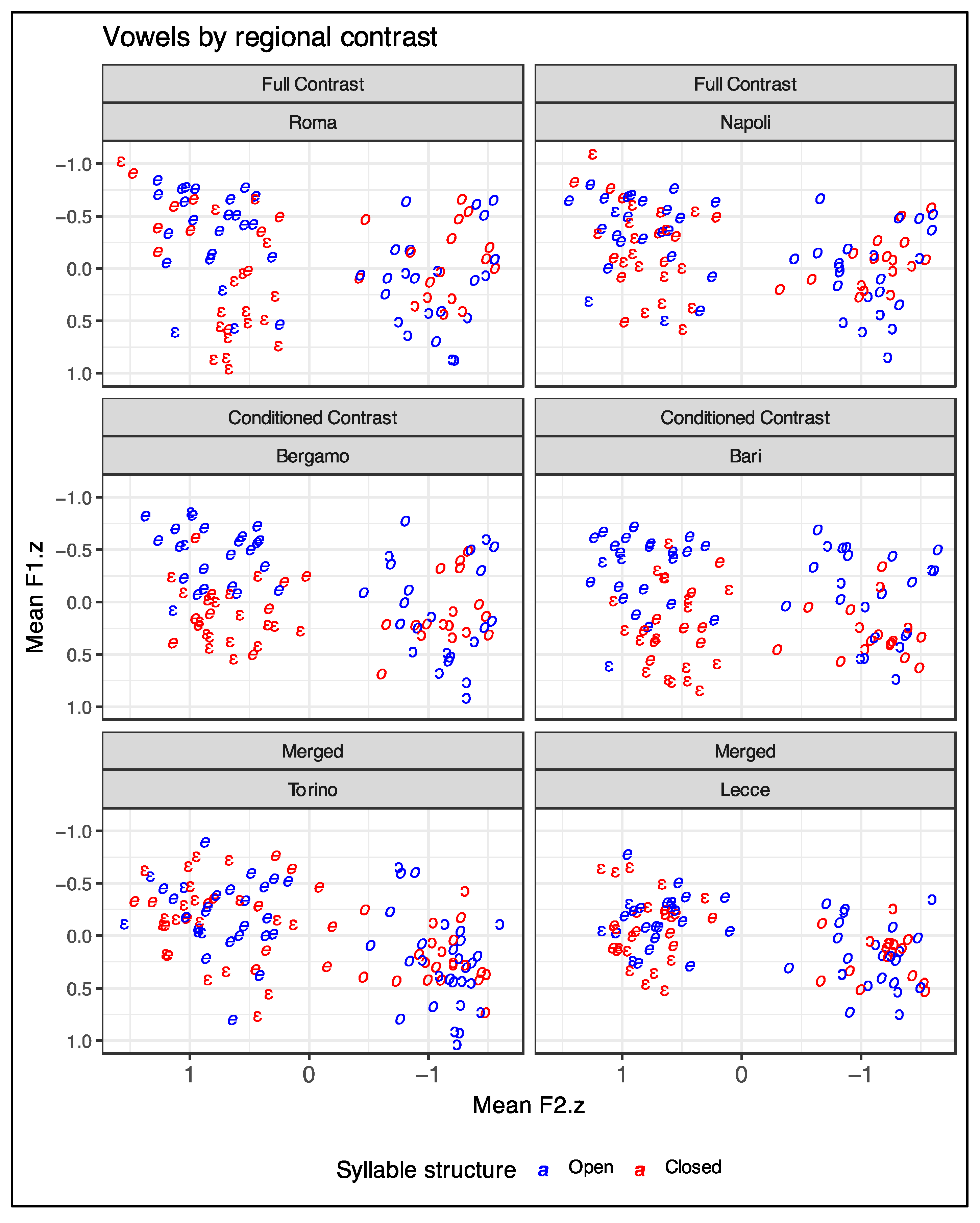{kind=link}
{kind=link}
{kind=link}
{kind=link}
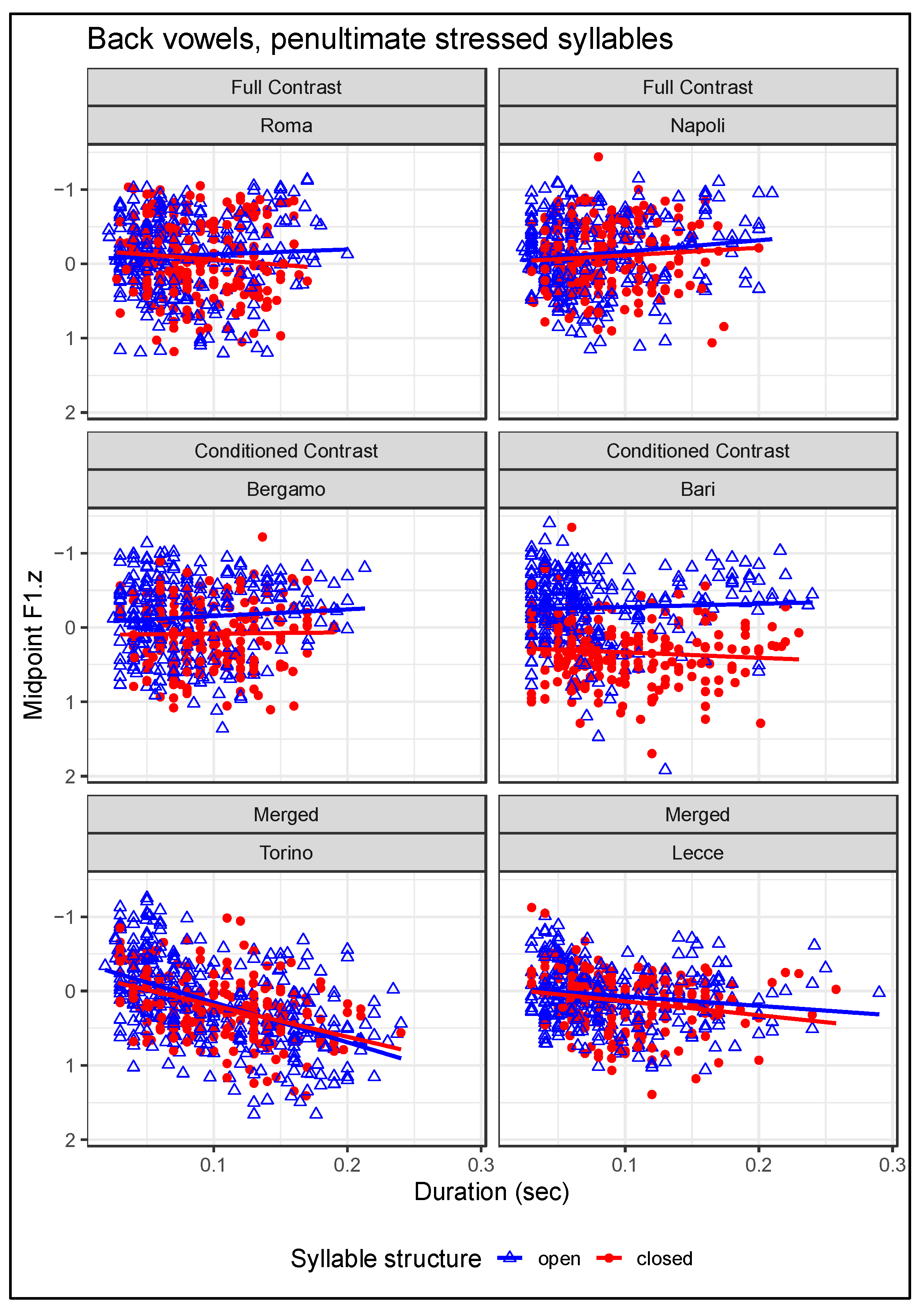{kind=link}
Table 1.
Type and token frequencies of vowels across the Italian lexicon (PhonItalia).
| Vowel | Type Frequency | Token Frequency | Example |
|---|---|---|---|
| /a/ | 0.168 | 0.161 | /ˈrata/ ‘installment’ |
| /i/ | 0.132 | 0.121 | /ˈmite/ ‘mild’ |
| /o/ | 0.109 | 0.114 | /ˈdove/ ‘where’ |
| /e/ | 0.105 | 0.126 | /ˈrete/ ‘net’ |
| /u/ | 0.023 | 0.031 | /ˈmuto/ ‘mute (m.sg.)’ |
| /ɛ/ | 0.019 | 0.028 | /ˈmɛta/ ‘destination’ |
| /ɔ/ | 0.012 | 0.016 | /ˈmɔto/ ‘motion’ |
Table 2.
Functional load of Italian vowel contrasts: Change in Entropy algorithm (PhonItalia).
| Vowels | e | ɛ | a | ɔ | o | u |
|---|---|---|---|---|---|---|
| i | 0.127 | 0.004 | 0.110 | 0.008 | 0.121 | 0.005 |
| e | 0.001 | 0.122 | 0.006 | 0.078 | 0.004 | |
| ɛ | 0.007 | 0.002 | 0.002 | 0.003 | ||
| a | 0.017 | 0.133 | 0.008 | |||
| ɔ | 0.006 | 0.003 |
Table 3.
Minimal pair counts for Italian vowel contrasts (PhonItalia).
| Vowels | e | ɛ | a | ɔ | o | u |
|---|---|---|---|---|---|---|
| i | 7872 | 251 | 6716 | 536 | 7516 | 333 |
| e | 70 | 7132 | 390 | 4895 | 277 | |
| ɛ | 455 | 146 | 130 | 164 | ||
| a | 1103 | 8224 | 489 | |||
| ɔ | 346 | 175 |
Table 4.
Classification of mid vowel contrast type; bold cities are exemplified in Results.
| City in CLIPS | Region | Regional Contrast Type |
|---|---|---|
| Cagliari | Sardegna | Full contrast |
| Firenze | Toscana | Full contrast |
| Genova 1 | Liguria | Full contrast |
| Napoli | Campania | Full contrast |
| Perugia | Umbria | Full contrast |
| Roma | Lazio | Full contrast |
| Venezia | Veneto | Full contrast |
| Bari | Puglia | Conditioned contrast |
| Bergamo | Lombardia | Conditioned contrast |
| Milano | Lombardia | Conditioned contrast |
| Parma | Emilia-Romagna | Conditioned contrast |
| Catanzaro | Calabria | Merged |
| Lecce | Puglia | Merged |
| Palermo | Sicilia | Merged |
| Torino | Piemonte | Merged |
1 Genova’s variety may have a Conditioned contrast, as Vietti and Mereu (2023, p. 5) note it “probably” has only 5 phonemes without indicating a merger. Descriptive acoustic results from CLIPS, however, do not indicate the effects of syllable structure on vowel height.
Table 5.
Parameter estimates (β) and standard errors (SE) of linear effects for F1 of front mid vowels, modeled separately by contrast type. Significance (p-value) is indicated for each predictor by: * (p < 0.05), ** (p < 0.01), *** (p < 0.001).
Table 5.
Parameter estimates (β) and standard errors (SE) of linear effects for F1 of front mid vowels, modeled separately by contrast type. Significance (p-value) is indicated for each predictor by: * (p < 0.05), ** (p < 0.01), *** (p < 0.001).
| Full Contrast | Conditioned Contrast | Merged Contrast | ||||
|---|---|---|---|---|---|---|
| Predictor | β | SE | β | SE | β | SE |
| Intercept | 0.201 | 0.110 | –0.016 | 0.118 | –0.102 | 0.114 |
| Normalized F2 | –0.585 *** | 0.012 | –0.513 *** | 0.016 | –0.273 *** | 0.016 |
| Dictionary height = high mid | –0.297 ** | 0.093 | –0.116 | 0.098 | 0.029 | 0.088 |
| Duration (sec) | 3.609 *** | 0.244 | 3.062 *** | 0.322 | 3.486 *** | 0.270 |
| Structure = Closed | –0.040 | 0.087 | –0.080 | 0.094 | 0.055 | 0.085 |
| Log10 Frequency | 0.040 | 0.042 | 0.026 | 0.044 | 0.058 | 0.040 |
| Type = Function | –0.205 | 0.121 | –0.168 | 0.127 | –0.279 * | 0.115 |
| Duration × Structure = Closed | 1.349 *** | 0.366 | 3.344 *** | 0.488 | –0.156 | 0.419 |
Table 6.
Parameter estimates (β) and standard errors (SE) of linear effects for F1 of back mid vowels, modeled separately by contrast type. Significance (p-value) is indicated for each predictor by: * (p < 0.05), ** (p < 0.01), *** (p < 0.001). The Conditioned Contrast model lacks a random intercept for City, which accounted for no variance.
Table 6.
Parameter estimates (β) and standard errors (SE) of linear effects for F1 of back mid vowels, modeled separately by contrast type. Significance (p-value) is indicated for each predictor by: * (p < 0.05), ** (p < 0.01), *** (p < 0.001). The Conditioned Contrast model lacks a random intercept for City, which accounted for no variance.
| Full Contrast | Conditioned Contrast | Merged Contrast | ||||
|---|---|---|---|---|---|---|
| Predictor | β | SE | β | SE | β | SE |
| Intercept | 0.195 * | 0.089 | 0.243 * | 0.103 | –0.039 | 0.991 |
| Normalized F2 | 0.240 *** | 0.019 | 0.205 *** | 0.026 | 0.093 *** | 0.025 |
| Dictionary height = high mid | –0.432 *** | 0.069 | –0.533 *** | 0.079 | –0.042 | 0.075 |
| Duration (sec) | 2.414 *** | 0.264 | 1.447 *** | 0.326 | 2.051 *** | 0.275 |
| Structure = Closed | –0.096 | 0.079 | –0.001 | 0.093 | –0.087 | 0.086 |
| Log10 Frequency | –0.116 ** | 0.035 | –0.175 *** | 0.040 | –0.115 ** | 0.038 |
| Type = Function | 0.283 * | 0.138 | 0.262 | 0.157 | 0.153 | 0.148 |
| Duration × Structure = Closed | –0.262 | 0.405 | 0.487 | 0.503 | 0.215 | 0.430 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Renwick, M.E.L. Robustness and Complexity in Italian Mid Vowel Contrasts. Languages 2024, 9, 150. https://doi.org/10.3390/languages9040150
AMA Style
Renwick MEL. Robustness and Complexity in Italian Mid Vowel Contrasts. Languages. 2024; 9(4):150. https://doi.org/10.3390/languages9040150
Chicago/Turabian StyleRenwick, Margaret E. L. 2024. "Robustness and Complexity in Italian Mid Vowel Contrasts" Languages 9, no. 4: 150. https://doi.org/10.3390/languages9040150