
Predictive Language Processing in Russian Heritage Speakers: Task Effects on Morphosyntactic Prediction in Reading

1
Psychology Department, Middlebury College, Middlebury, VT 05753, USA
2
Center for Language and Brain, HSE University, Moscow 101000, Russia
3
Doctoral Program in Second Language Acquisition, University of Wisconsin-Madison, Madison, WI 53706, USA
4
Department of Psychology, College of Staten Island of the City University of New York, New York, NY 10314, USA
*
Author to whom correspondence should be addressed.
Languages 2024, 9(5), 158; https://doi.org/10.3390/languages9050158
Submission received: 24 January 2024
/
Revised: 4 April 2024
/
Accepted: 8 April 2024
/
Published: 26 April 2024
(This article belongs to the Special Issue Heritage Russian Bilingualism across the Lifespan)
Abstract
:This study investigates the effect of task demands on the predictive processing of morphosyntactic cues (word class, noun/adjective gender, case, and number) in reading among Heritage Speakers of Russian (N = 29), comparing them with Russian language learners (N = 29) and monolingual Russian speakers (N = 63). Following the utility account of bilingual prediction, we hypothesized that the predictive use of morphosyntactic cues would be more evident in a less-demanding reading cloze task (Experiment 1) than in a more-challenging eye-tracking reading task (Experiment 2), and for cues that RHSs regard as more reliable (word class and number vs. gender and case cues). The results confirmed our predictions: In Experiment 1, Heritage Speakers (and L2 learners) used all cues predictively to generate the upcoming lexical item, with higher accuracy for word class and number cues compared to gender and case cues. In Experiment 2, in contrast to monolingual readers, neither Heritage Speakers nor L2 learners used gender cues on adjectives to anticipate the gender of the upcoming noun. The results are discussed in respect to the interplay between task demands, cue weight, oral fluency, and Russian literacy experience.
1. Introduction
Language prediction is considered integral to human language processing across all linguistic levels: lexical (Altmann and Kamide 1999; Grisoni et al. 2017), morphosyntax (Lau et al. 2006; Szewczyk and Schriefers 2013; Van Berkum et al. 2005), phonology, and orthography (DeLong et al. 2005; Dikker et al. 2010; Ito et al. 2018). For example, in the sentence ‘I take my coffee with cream and___,’ most monolingual English speakers can successfully predict both lexical (i.e., activation of a specific lexical item in its grammatical form—‘sugar’) and morphosyntactic (i.e., activation of morphosyntactic features—noun, singular) information from the context of the sentence (Luke and Christianson 2015, 2016).
One of the most recent theories, prediction-by-production (Pickering and Gambi 2018; Pickering and Garrod 2007, 2013) suggests that prediction at different linguistic levels does not occur instantaneously. Instead, skilled monolingual speakers form predictions via a two-phase, production-based mechanism: (1) non-optional spreading activation (or prediction-by-association), during which all target-related concepts are activated in the mental lexicon (Collins and Loftus 1975), and (2) optional covert imitation (prediction-by-production) in which the comprehender pre-activates linguistic input based on the production phases, i.e., they first choose the lexical features of the word (lemma) that received the highest activation, then add morphosyntax and, as the last step, phonology. Thus, the second stage in prediction is identical to the language production process, with only one difference that the comprehender does not overtly produce the expected item—unless, of course, it is a part of the task, as in the cloze tests. When successful, prediction aids language processing: “[comprehenders] preactivate representations that they use when they actually encounter the predicted input. Such preactivation, therefore, allows them to perform some of the processing ahead of time, and therefore explains how prediction facilitates comprehension” (Pickering and Gambi 2018, p. 1003).
While there seems to be a consensus that monolingual speakers anticipate linguistic information while reading or listening (Pickering and Gambi 2018, for a review), there are still no clear-cut conclusions about when and to what extent bilingual speakers engage in prediction in their second language (L2) despite the growing number of studies on the topic. In a recent review that can be considered an update of the seminal review by Kaan (2014), Schlenter (2023) identifies several ‘(un)favorable conditions’ for lexical and morphosyntactic prediction in L2 language comprehension. Beyond L2 proficiency, the overarching factors influencing prediction are the task demands or task-induced processes and strategies that bilinguals employ depending on cognitive effort, material complexity, time constraints, and available resources in each situation (Dussias et al. 2013; Henry et al. 2022; Hopp 2013). Other (un)favorable conditions are related to differences in morphosyntactic cue reliability/availability between the dominant and non-dominant languages. One such condition is the degree of cross-linguistic overlap in morphosyntactic features: the absence or different realization of a feature in the bilinguals’ languages can hinder prediction in the non-dominant language (e.g., the lack of morphological gender marking in English affecting prediction in a gender-marking language, Hopp 2015; Mitsugi and Macwhinney 2016). Another challenge arises from differences in cue weighting between the bilingual languages, where cues in one language may be less reliable or salient compared to the other (e.g., differential weighting of case markings in Hebrew vs. Russian, Meir et al. 2024). According to the utility account of prediction (Kaan and Grüter 2021; Kuperberg and Jaeger 2016), bilinguals ‘evaluate’ the combined favorability of all of these conditions in the form of a cost–benefit analysis. If the cost of the prediction outweighs its benefits for language comprehension, bilinguals may adjust their predictive strategies or abandon prediction altogether.
This study aims to further explore the interplay of these (un)favorable conditions in predictive processing, with a specific focus on prediction in Russian as a Heritage Language (RHL). Our primary goal is to investigate the effects of task demands on morphosyntactic prediction in reading, a task that poses notable challenges for Heritage Speakers (HSs) and about which very little is known regarding prediction. Being exposed to RHL from birth, Heritage Speakers of Russian (RHSs) typically attain relative proficiency in oral language production while still lacking skills in written language processing due to limited experience with the written form of Russian (e.g., Parshina et al. 2021, 2022b). This discrepancy in language skills allows us to test the predictions of prediction-by-production (Pickering and Gambi 2018) and utility accounts (Kaan and Grüter 2021; Kuperberg and Jaeger 2016) together. In particular, a bilingual speaker with fluent production skills, such as an RHS, should be able to complete all stages of prediction and accurately predict the morphosyntactic features of the upcoming linguistic input. However, the utility account of prediction adds that this ability is influenced by the ‘weight’ of the morphosyntactic cue and task demands: RHSs, even with a strong command of oral language, may not exhibit prediction in resource-demanding tasks and in materials with unreliable morphosyntactic cues.
Russian and English can be an optimal language pair to study the prediction in bilingual language processing as a function of cue reliability/availability, due to the contrasting ways in which morphological cues are expressed in Russian compared to English. Russian has three genders (masculine, feminine, and neuter), six noun cases (nominative, accusative, dative, genitive, instrumental, and prepositional cases organized in several declensional classes), and three verb tenses (past, present, future). The nominal modifiers (adjectives, participles, pronouns, and demonstratives) must match the ‘trigger’ noun in gender, case, and number, as well as the verbs in past tense must match the noun in number and gender which is expressed in the agreement by modifier inflections (for review see Corbett 1991; Polinsky 2008). Thus, an adult native speaker of Russian, upon encountering a modifying adjective that carries an overt inflectional marker of the accusative case, masculine gender, and singular number would anticipate a noun in the upcoming linguistic input that matches all three morphological cues. In the sections that follow, we begin with a review of existing knowledge about morphosyntactic prediction in heritage language processing, focusing on task demands and cue weight. We conclude the introduction with the outline of research questions and hypotheses for the current study.
1.1. Morphosyntactic Prediction in Heritage Language
While there has been a notable increase in studies concerning prediction in L2 learners (Schlenter 2023 for review), studies investigating prediction in HSs are still sparse. The findings reported so far are mixed with few studies pointing to the monolingual-like predictive morphosyntactic processing in HL (Fuchs 2022), others indicating delayed utilization of the cues compared to the monolingual control groups (Fuchs 2021) or only selective engagement in prediction that depends on the interplay of various factors (Karaca et al. 2024; Parshina et al. 2022a; Fuchs and Sekerina, forthcoming).
1.1.1. Morphosyntactic Prediction in Spoken Language Comprehension Tasks
The series of Visual World Paradigm (VWP) studies, which involved participants listening to auditory stimuli while their eye movements were recorded as they looked at relevant images, investigated the ability of RHSs to utilize grammatical gender cues for predictive processing. Fuchs and Sekerina (forthcoming) examined English-dominant adult Russian HSs, alongside monolingual adults, assessing their ability to anticipate the grammatical gender of nouns based on gender-marking cues from preceding adjectives and verbs. The findings revealed that RHSs did employ gender cues predictively; however, the effect was significant only for more salient feminine but not less salient/null masculine markers. Several other studies also reported challenges that RHSs encounter in tasks examining noun–adjective gender agreement knowledge, particularly in nouns with opaque gender markers—those with endings that do not clearly indicate grammatical gender (Polinsky 2008; Rodina and Westergaard 2017 in children). Conversely, the number cue in Sekerina (2015, preliminary analysis of the data in Fuchs and Sekerina, forthcoming), particularly the plural marker, was the strongest and most reliable cue in participant groups, with no statistical difference between them.
Two more recent studies (Fuchs 2021, 2022) confirmed the predictive processing of gender cues in adult English-dominant HSs of Spanish and Polish, respectively. In the 2021 study, HSs and a monolingual control group listened to prompts containing a pre-nominal, gender-marked article with either a masculine (le) or feminine (la) gender marker, while being shown two images on display containing lexical items of either matching (match condition: both items match in gender) or mismatching gender (mismatch condition: only one item matches in gender). The analysis of eye movements revealed no significant differences in anticipatory looks between the groups. However, Spanish HSs were slower in fixating the target item compared to the monolingual adult group. In Fuchs’s 2022 study, Polish HSs listened to auditory prompts with prenominal adjectives marked for masculine, feminine, or neuter grammatical genders. Similar to the 2021 study, HSs and the monolingual control group were quicker to fixate on the target lexical item in the mismatch condition than in the match condition. In contrast to the previous study in Fuchs (2021), however, this study did not show quantitative differences between the groups, except in the condition involving feminine target nouns, where HSs increased their fixation speed on the target noun, while the speed of monolinguals remained consistent throughout the experiment. Overall, the results in Fuchs (2022) suggested predictive processing of gender cues in HSs that is on par with the monolingual peers, both qualitatively and quantitatively.
Karaca et al. (2024), on the other hand, observed the differential predictive processing of the morphosyntactic cues based on the cue weight in a VWP study with adult Dutch-dominant HSs of Turkish. In their study, HSs were able to generate correct predictions based on the case-markings cues, but prediction was contingent on additional semantic information provided by the verb in the auditory stimuli. Specifically, predictive processing occurred only in sentences where verbs were positioned in the middle, as opposed to at the end of the sentence. In contrast, monolingual participants utilized case-marking cues predictively in both verb-medial and verb-final sentences. Karaca et al. concluded that their findings align with the utility account of prediction, as outlined by Kaan and Grüter (2021): morphosyntactic cues alone were insufficient for HSs to engage in predictive processing. Overall, the study underscores the significance of additivity in bilingual predictive processing: HSs (and bilinguals in general) benefit from combining morphosyntactic cues with other types of linguistic information such as semantic or prosodic cues (see also Grüter et al. 2020; Henry et al. 2017, 2022). Furthermore, in line with the prediction-by-production account (Pickering and Gambi 2018), Karaca et al. reported the effects of the spoken language experience in HL and written language experience (both in HL and majority language) on predictive processing, emphasizing the role of the language exposure in enhancing predictive abilities in HL.
1.1.2. Morphosyntactic Prediction in Tasks in Written Language Comprehension
To our knowledge, only a limited number of studies have directly (or indirectly) investigated morphosyntactic predictive processing in written heritage language (HL) comprehension. This scarcity is understandable, considering that writing and reading skills in HL often trail behind spoken language comprehension (Carreira and Kagan 2011). Gor (2019) utilized an offline auditory and written grammaticality judgement task in which ungrammatical sentences contained a violation in the agreement of the feature on a target word with the cue on the agreeing/modifying word. The results across both modalities showed RHSs generally were more accurate in grammaticality judgments than L2 learners in most features. In terms of developmental trajectory across the proficiency continuum, for both groups, certain features (e.g., quantification, case) showed progress more rapidly, while others (e.g., verbs of motion, verbal aspect) were slower. However, the study did not differentiate performance by modality, which limits the ability to draw definitive conclusions about the impact of task modality on morphosyntactic knowledge. In a similar grammatical acceptability task, but now in the visual modality only, Laleko (2019) asked RHSs, L2 learners, and monolingual speakers to read 72 sentences containing gender agreement violations between animate nouns and modifying adjectives or the past tense verbs. The study found that the accuracy of gender agreement did not vary significantly between the groups, but only when gender cues were transparent, i.e., when the gender marker unambiguously indicated the grammatical gender of the noun. This finding is consistent with previously reported results from auditory tasks indicating that RHSs experience difficulties using opaque gender cues to pre-activate the respective gender feature (Polinsky 2008).
The study by Parshina et al. (2022a) is the only one to date that has directly investigated online morphosyntactic predictive processing in a reading task. The study involved English-dominant RHSs, L2 learners of Russian, and monolingual children, who read corpus sentences in Russian while their eye movements were recorded. The words in these sentences were tagged for morphosyntactic predictability in terms of word class, noun case, gender, number, as well as verb number and tense based on the prior predictability norming study. Parshina et al. found that RHSs, particularly those with more literacy experience, anticipated certain morphosyntactic features like the word class of upcoming lexical items, as well as noun and verb number. Words with higher morphosyntactic predictability for these features led to shorter fixation durations on them. Curiously, this study followed the design of the prior eye-tracking study with Russian monolingual speakers (Lopukhina et al. 2021) which also analyzed the sensitivity of the monolingual readers to cloze predictability of the words while reading corpus sentences. In contrast to RHSs, monolingual readers showed sensitivity not only to the word class and noun number, but also noun gender, as well as present and future tense for verbs. The selective engagement of RHSs in predicting some morphosyntactic features but not others again supports the utility account (Kaan and Grüter 2021; Kuperberg and Jaeger 2016). In a cognitively demanding task such as reading, where all resources are focused on lexical retrieval, the engagement in prediction may only be beneficial for HSs with higher written HL exposure and when morphosyntactic cues overlap between the dominant language and HL, or serve as reliable cues in HL (e.g., number cue). Conversely, unreliable, non-transparent, infrequent cues or cues that are not present in the dominant language (e.g., gender and case cues) are likely to be ignored in challenging tasks such as reading.
In fact, in respect to cue reliability, it is well-documented now that RHSs experience difficulties in the tasks that examine noun–adjective gender agreement knowledge in nouns with opaque gender markers, that is in the noun with endings that do not clearly identify its grammatical gender assignment (Polinsky 2008; Rodina and Westergaard 2017; Laleko 2018). For instance, in Russian, nouns that end in stressed [a] are typically feminine (e.g., трава ‘grass’), nouns that end in non-palatal consonants are masculine (e.g., стул ‘chair’), and nouns with final stressed [o] are neuter (e.g., кoльцo ‘ring’). While these are transparent nouns, there are also masculine and feminine nouns in Russian that can end with the same palatal and postalveolar consonant, which makes gender cues opaque (e.g., дверь ‘doorFEM’ and зверь ‘beastMASC’). It is likely that due to the lack of input in HL and the absence of grammatical gender in English, RHSs assign gender based on the formal cues (Polinsky 2008). Specifically, RHSs assimilate all nouns ending in a vowel or sound ‘schwa’ as feminine and all nouns that end in consonants as masculine, ‘ignoring’ the other declensional paradigm in which phonologically opaque nouns can be either masculine or feminine.
Overall, past research on predictive morphosyntactic processing in HSs in general and HSs of Russian in particular draws the following picture: similar to monolinguals (and often L2 learners), HSs utilize morphosyntactic cues predictively. However, the extent of their predictive processing depends on the characteristics of these cues and the demands of the task, aligning with the hypotheses of the utility account (Kaan and Grüter 2021; Kuperberg and Jaeger 2016). Assuming HSs have adequate exposure to their HL and fluent production skills, as posited by the prediction-by-production account (Pickering and Gambi 2018), reliable cues present in both languages of a bilingual (e.g., noun number in English and Russian) will lead to predictive processing in HSs that is qualitatively or even quantitatively similar to that of monolinguals. This is particularly likely if the cue is accompanied by additional information (e.g., verb semantics) in a less cognitively demanding task such as VWP study. Conversely, morphosyntactic cues that pose greater challenges for HSs, such as those absent in the dominant language or those that are expressed unreliably (e.g., gender markings in HL Russian that vary in their transparency and are absent in dominant English), especially in cognitively demanding tasks (e.g., reading or writing), are likely to result in HSs opting for selective prediction or no prediction at all.
1.2. Current Study
The current study aims to directly investigate whether RHSs demonstrate differential morphosyntactic prediction based on the task demands and, additionally, characteristics of the morphosyntactic cues. Specifically, we seek answers to the following research questions:
RQ1: Do RHSs demonstrate differential morphosyntactic prediction based on the task demands that are conducted within the same written modality?
RQ2: Does prediction of the morphosyntactic features (word class, noun gender, case, number) differ depending on the cue weight of these features?
RQ3: Do RHSs differ in the prediction abilities in these tasks and features from L2 learners and monolingual speakers?
To answer these questions, we employed two tasks that differed in the allocation of cognitive resources and attention but both required reading. In Experiment 1, we utilized a reading cloze task, where participants generated the target word based on the context of the sentence they read. We considered this task to be cognitively less demanding as the translation of each word in the sentence was available to participants in addition to the assistance in sounding out the words by the research assistant when required (see Method for details). Specifically, we evaluated the ability of RHSs to accurately generate predictions of the target word class (Noun/Adjective) and noun–adjective agreement features (number, case, and gender) in the sentences with highly constraining and low-constraining semantic contexts. In Experiment 2, we employed a more challenging eye-tracking reading task with no additional translation/pronunciation resources available and sentences with neutral context. Experiment 2 exclusively focused on noun–adjective gender agreement prediction. In both tasks, we compared the morphosyntactic prediction abilities of RHSs to those of second-language learners and monolingual Russian controls.
Based on the utility account of prediction in bilingual language processing (Kaan and Grüter 2021; Kuperberg and Jaeger 2016) we hypothesized that RHSs will use all morphosyntactic cues (word class, markings for gender, case, and number) on nouns/adjectives predictively in Experiment 1: morphosyntactic, semantic (from each word and sentence context), and phonological information should aid the pre-activation of relevant features and, thus, result in accurate production of the target word. In respect to specific features, based on what we know about the weight of morphosyntactic cues in HL Russian from the prior research (Gor 2019; Laleko 2018; Parshina et al. 2022a; Sekerina 2015; Fuchs and Sekerina, forthcoming), we expected word class and noun/adjective number to be the cues with the strongest predictive power, likely followed by case cue. In the first Experiment, due to its relative ease, we also anticipated a predictive use of noun/adjective gender cues as HSs were shown previously to use such cues in ‘easier’ tasks such as studies with VWP design or other auditory tasks (Fuchs 2021, 2022; Fuchs and Sekerina, forthcoming; Polinsky 2008).
In addition, based on the previous reading study by Parshina et al. (2022a), we hypothesized that literacy experience with Russian as HL would influence the ability to use the cues predictively, with more experience correlating with higher prediction scores—this applies to L2 learners as well. The impact of production skill (assessed via a self-reported proficiency measure) on predictive processing in this reading task remains exploratory. The prediction-by-production account (Pickering and Gambi 2018) suggests that RHSs, known for fluency in HL production, would outperform L2 learners, resulting in an effect of the production skill on predictive processing in general and an interaction between the production skill score and a participant group in particular. However, the existing literature on HL does not provide a unified consensus on whether such a link between production and prediction exists (Meir et al. 2024; cf. Karaca et al. 2024).
In an eye-tracking reading Experiment 2, we manipulated the grammatical gender of the target noun (feminine vs. masculine) while presenting participants with the set of sentences in which half of the sentences contained gender agreement violations between a noun and the preceding modifying adjective (see Method for details). For Experiment 2, we propose two hypotheses. The first (null) hypothesis is based on (1) the utility account of prediction (Kaan and Grüter 2021; Kuperberg and Jaeger 2016) that suggests that demanding tasks decrease the probability of predictive processing in bilinguals and (2) the knowledge that RHSs (and L2 learners of Russian) typically face challenges in reading in HL (Parshina et al. 2021, 2022b). Consequently, we expected that RHSs and L2 learners would not utilize gender cues to facilitate comprehension, regardless of the cue’s grammatical gender. Alternatively, we explored the possibility that in contrast to RHSs, L2 learners may demonstrate greater sensitivity to gender agreement violations, showing more efficient morphosyntactic prediction compared to HSs, as they received formal instruction and training in Russian gender agreement rules in the school setting.
2. Materials and Methods: Experiment 1
2.1. Participants
A total of 78 participants were recruited to participate in the cloze test: 29 HSs (13 men, MAge = 19.8, range 18–33; MAgeofArrival = 3.5 years), 29 L2 learners (17 men, MAge = 24.4, range 18–43) and 20 monolingual speakers of Russian (2 men, MAge = 21.2, range 17–30). The RHSs and L2 participants were recruited from the mix of two sites: an urban university in New York City and a university in Moscow (Russia); the monolingual participants were recruited online through a social network platform. Before the start of the study, all participants signed the informed consent and bilingual participants completed the language background questionnaire, administered in English (see Table 1, top rows for bilingual participant characteristics). The study was approved by the university’s Institutional Review Board (IRB). Monolingual participants were volunteers, while bilingual participants received $10.
2.2. Materials
2.2.1. Pre-Test Assessments
Before conducting the cloze test with bilingual participants, we assessed their general reading abilities in Russian. Table 1 provides scores for all pre-test assessments. They included:
- Self-reported scores for reading proficiency (scale 1–5);
- Self-reported age of start of reading in Russian (in years);
- Self-assessed daily reading exposure to Russian, including books, text messages, articles, social networks (in hours or minutes);
- Receptive Vocabulary test in Russian (Golovin 2015);
- Russian Word Identification test (Fotekova and Akhutina 2002);
- Russian Oral Reading Fluency test (Kornev 1997)
Participants’ vocabulary size in Russian was assessed via an online version of the Receptive Vocabulary test in Russian (Golovin 2015). The test uses the Computerized Adaptive Testing technique which adapts the next word difficulty (based on the lemma frequency) after each provided response. Note that the test estimates vocabulary size in word families, i.e., it includes the lemma and all its possible word forms into the size calculation. Thus, the average vocabulary size of monolingual Russian speakers aged 20 (to match mean age of HSs) is 60,000 words (Golovin 2015). Russian Word Identification and Russian Oral Reading Fluency tests (Word ID-Rus and ORF-Rus; Fotekova and Akhutina 2002) assess speed and accuracy of grapheme-to-phoneme decoding, reading speed, reading quality, and text comprehension in Russian (see Parshina et al. 2021 for detailed description).
To derive a single measure of the literacy experience in Russian, we conducted a Principal Component Analysis using the FactoMineR package (Lê et al. 2008, built under R version 4.2.3) on all six reading measures. The first principal component, PC, explained 36% of the variability in the data, with the highest contribution by the ORF-Rus test (Kornev 1997), at 34%, and the self-reported reading score at 30%.
2.2.2. Cloze Reading Test
Participants were presented with pairs of sentences in Russian, in which the first sentence (see examples in 1a in Table 2) included either highly or low-constraining semantic context, and the second sentence (see examples in 1b in Table 2) contained the target word which remained constant across conditions. The participants were asked to read the sentences silently but they were allowed to use a translation service or ask for a pronunciation of the words (see Procedure below). After that, participants completed the second sentence with one target word, which was always the last word in the second sentence. In total, the task included 48 pairs of sentences, with 24 experimental items in each condition. These were further divided such that 12 sentences had a noun as the target word, and another 12 sentences had an adjective. Noun and adjective target words varied in length (Mlength = 5.8, SD = 2.1, range = 3–9 letters). All target words (lemmas) were high-frequency words (Mipm = 689.2, SD = 1253, range = 69.5–5414 ipm). While we did not manipulate the target words in morphosyntactic features of interest, they represented all of them (gender: Masc, Fem, Neuter with opaque and transparent gender markings; case: NOM, ACC, GEN, DAT, INSTR, PREP; number: SG, PL). (Table 2).
Before conducting the cloze test with the bilingual groups and monolingual control group, a separate group of 70 monolingual participants (19 men, MAge = 26.9, range 15–52) provided cloze norming data to ensure that constructed sentences elicited the expected lexical items with specific morphosyntactic features. Monolingual participants completed the cloze test in an online survey presented via Google forms. After answering basic demographic questions (age, gender, occupation), participants were presented with the questionnaire that included the first 24 sentences with low-constraining context in the Block 1, followed by 24 highly constraining context sentences in Block 2. For each sentence, the instructions were to complete the sentence with one word that first comes to mind and type it into the blank space. Participants were also instructed to take a 30 min break between the blocks.
The results of the predictability norming study showed that targets in the high-constraining contexts had a high lexical cloze completion probability (i.e., participants guessed the exact target word in a specific word form) (M = 0.80, SD = 0.14), while predictability of the target words in the low constraining contexts was, as expected, significantly lower (M = 0.15, SD = 0.08), t(69)= −30.3, p < 0.001. In respect to morphosyntactic features, all participants performed at ceiling: they were able to generate target word class, gender, case, and number error-free, regardless of the context of the sentence or target word class (M = 1.0, SD = 0.0).
2.3. Procedure
All HSs and L2 learners were tested individually as a part of the study, while monolingual participants followed the same procedure as in the norming study (i.e., online survey). Bilinguals completed one of the versions of the online survey, the presentation of which was counterbalanced: version A contained 12 highly constraining and 12 low constraining sentences in alternating order, while version B contained the remaining stimuli. Thus, a bilingual participant never saw two identical target sentences. Participants were instructed to read stimuli silently, but to say the completion word out loud, which was then typed into the form by the research assistant (native Russian speaker) without changing the pronounced word form. To ensure that participants knew the meaning of all words in the materials prior to the blank space, they were allowed to use the TransOver service (version 1.48, Google extension) which, after double-clicking on the word, provided the translation of the lemma of the word to English. In addition, the research assistant sounded out the words in the sentences if requested by the participant providing additional resource to aid comprehension. Experiment 1 took approximately 45 minutes to complete.
2.4. Results and Discussion
Two Russian-speaking research assistants coded responses as a binary variable: ‘1′ if the response matched the target word in word class, gender, number, and case features; ‘0′ if the response deviated from the target word in these features. Note that in some sentences, constructed to elicit the plural form of the noun or adjective, the gender feature was not coded. Furthermore, even when the participant’s response deviated lexically from the target, it was still coded as ‘1′ if the generated lexical item had matching morphosyntactic features. For instance, in Example 1, if the participant produced the noun другoм (friend SG,MASC,INSTR) instead of the target мужем (husband SG,MASC,INSTR) the response was coded as ‘1′ for all features. The inter-rater reliability Kappa for the word class, gender, case, and number features were 0.96, 0.98, 0.98, and 0.94, respectively. Consensus was reached on all disagreements to arrive at a unified coding of each response.
The descriptive results for the cloze test are presented in Figure 1. In general, all groups showed high morphosyntactic cloze probability, with the monolingual group performing at ceiling (M = 1.0, SD = 0.00), followed by RHSs (M = 0.92, SD = 0.03) and L2 learners (M = 0.88, SD = 0.03).
First, to examine whether there are statistical differences in morphosyntactic cloze probability among groups and features we fitted a generalized linear mixed-effects model using lme4 package (Bates et al. 2015) in R (R Core Team 2021, version 4.2.1) that estimated cloze probability and included the group (treatment-coded, RHSs as a reference level) and the feature (treatment-coded, case as a reference level) as well as the interaction between these predictors. Random structure included random intercept and slope for the feature by sentences and random intercept for participants (addition of other random slopes led to convergence failure). SjPlot package 2.8.3 was used for data visualization and the computation of p-values (Lüdecke 2017). R script, data, and supplementary tables are located in supplementary files.
The model (the output is presented in Table 3) indicated that there was an effect of the group and feature on the cloze probability but no interactions between these predictors. A series of the pairwise comparisons on the data (using emmeans function in R; Lenth 2021, the output of pairwise comparisons is embedded within the R script) showed that the cloze probabilities did not differ between RHSs and L2 learners in any of the features except the word class (est.= 1.04, SE = 0.40, z = 2.6, p = 0.028) in which RHSs anticipated the word class with the higher probability. Both bilingual groups were different in cloze probability from the monolingual controls (ps < 0.001) in all of the features.
In respect to the specific feature prediction within each group, the pairwise comparisons revealed that in bilingual groups, the lowest cloze probabilities were produced when predicting the gender and case of the upcoming item with no difference between these features in either of the bilingual groups (ps = 1.0). The word class and number features elicited significantly higher cloze probabilities for RHSs than case (word class: est. = −1.06, SE = 0.22, z = −4.9, p < 0.001; number: est. = −1.02, SE = 0.22, z = −4.6, p < 0.001) or gender (word class: est. = −0.88, SE = 0.24, z = −3.7, p = 0.001; number: est. = −0.84, SE = 0.24, z = -3.5, p = 0.003), but there was no differences between these features (ps = 1.0). In the L2 learner group, the pattern is similar, i.e., the word class and number did not differ in cloze probabilities (p = 0.384), as well as case and gender (p = 1.0). However, for L2 learners there were also no differences in cloze probability between gender and word class features (p = 0.295).
Next, to estimate the effect of the target morphosyntactic features as well as individual difference factors on the cloze probability for bilingual groups, we ran four generalized linear mixed-effects models (separately for each feature) with cloze probability as a binary outcome and random intercept and slope for sentences and random intercept for participants. In each model, we included fixed predictors of group (sum-contrast coded) and its two-way interaction with the Age of Arrival (AoA), daily Russian language exposure, Russian literacy experience score, and production skills score. We also included a three-way interaction between the group, word class of the target (Noun vs. Adj; sum-contrast coded) and context (highly vs. low-constraining; sum-contrast coded). All continuous fixed predictors were scaled and centered.
The full output of all generalized linear models is presented in Table S1 in the Supplementary Materials. They indicate no difference in cloze probability for any of the morphosyntactic features between RHSs and L2 learners, suggesting the word class effect that we found in the model 1 (Table 3) could be due to other factors that were not tested in that model, such as Russian literacy experience. In fact, for both bilingual groups, more Russian literacy experience led to the higher cloze probabilities in all features except number: word class (est. = 1.12, SE = 0.03, z = 4.15, p = 0.001), case (est. = 0.06, SE = 0.02, z = 3.01, p = 0.042), and gender (est. = 0.08, SE = 0.02, z = 3.83, p = 0.002). In addition, both bilingual groups showed higher cloze probability when the target word was noun compared to adjective (est. = −0.08, SE = 0.02, z = −3.56, p = 0.006). Finally, there was a significant interaction between production skills (i.e., self-estimated speaking score) and the group (est. = 0.09, SE = 0.02, z = 3.96, p = 0.001) for the case cloze probability. The follow-up visualization showed the crossover interaction: the better production skill increased the cloze probability in case feature for RHSs but decreased it for L2 learners.
In sum, our results indicate that all groups successfully generated the expected morphosyntactic features in this reading task. The monolingual control group performed at ceiling while RHSs and L2 learners did not differ in their performance with overall high cloze probabilities for all features, among which the target word class and number were produced with the highest accuracy and the gender and case with the lowest. For both bilingual groups, greater Russian literacy experience aided morphosyntactic prediction, and for both groups it was easier to generate nouns than adjectives. The only evidence of the impact of the production skills was for the case feature and it appeared that it only aided RHSs group while hindering the performance of the L2 learners.
3. Materials and Methods: Experiment 2
3.1. Participants
All bilingual readers from Experiment 1 participated in Experiment 2 (29 HSs and 29 L2 learners). We additionally collected eye-tracking data from 43 monolingual adults (15 men, MAge = 24.4, range 18–44). Monolingual speakers were recruited from the university in Moscow (Russia) and an urban university in New York City (immigrated less than 3 years before the data collection date).
3.2. Materials
The materials for the eye-tracking task included 33 filler sentences and 32 experimental sentences involving gender agreement between a noun and a modifying adjective. The experiment employed a 2 × 2 within-participant design manipulating a noun’s gender (Masc vs. Fem) and grammaticality (grammatical vs. ungrammatical), with 8 sentences per condition (see examples in 2a and 2b). All experimental sentences consisted of 11 words, organized in such a way that the adjective was always the 4th word in the sentence, the target noun was on the 8th position, and there was a prepositional phrase between the modifying adjective and the target noun. Such sentence structure enabled us to avoid parafoveal preview of the target and, thus, examine predictive processing as opposed to integration of the information (i.e., the input being already processed). All adjectives were high-frequency words (>50 ipm) and all target nouns were either high-frequency words (Mfreq= 172.0 ipm) (Lyashevskaya and Sharov 2009) or were cognates in English (e.g., гитара [gitara] ‘guitar’). The target nouns were also balanced in phonological transparency of gender cue (transparent vs. opaque).
| (2) | a. | Grammatical, MASC | ||||||
| В углу | стoит | черный | с тoнким | экранoм | телевизop. | Хoчешь егo пoсмoтреть? | ||
| In corner | stays | blackMASC | with thin | screen | televisionMASC | Want it watch? | ||
| ‘There is a black TV with thin screen in the corner. Do you want to watch it?’ | ||||||||
| b. | Ungrammatical, MASC: | |||||||
| В углу | стoит | черная | с тoнким | экранoм | телевизop. | Хoчешь егo пoсмoтреть? | ||
| In corner | stays | blackFEM | with thin | screen | televisionMASC | Want it watch? | ||
| ‘There is a black TV with thin screen in the corner. Do you want to watch it?’ | ||||||||
The measures of interest to investigate prediction included early reading time measures on the target noun: first-fixation duration (FFD), single-fixation duration (SFD), and gaze duration (GD). These measures capture the earliest lexical processing stages (grapheme-to-phoneme conversion and word recognition) (Rayner 2009). The increase in fixation durations in these measures in ungrammatical condition signifies the delay in the lexical processing, likely stemming from the detection of the disagreement between the preactivated gender feature and its realization on the target noun. We additionally looked at the total reading time per word (TT) that is considered a late reading time measure. TT reflects late-lexical processing stages and signals difficulties in post-lexical information integration and reanalysis rather than morphosyntactic prediction.
3.3. Procedure
Eye movements were recorded via Eyelink 1000+ eye tracker (SR Research, Ltd., SR Research, Ottawa, ON, Canada) on the BenQ XL2411Z 144 Hz monitor (resolution: 1920 × 1080 pix) controlled by a ThinkStation computer. The right eye was tracked at 1000 Hz rate. Before the start, all participants’ eye gaze was calibrated with a 9-point calibration procedure that was repeated after every 15 sentences. Each trial started with the drift correction at the position of the first letter in the sentence presented for 500 ms. After reading the sentence, participants were instructed to look at the red dot at the lower-right-hand corner of the screen. When the fixation was identified by the eye-tracker at that location, participants were presented with the multiple-choice question to access comprehension and attention allocation (e.g., for example in (2) ‘Where was the TV in the room?’ with two answer options: ‘in the corner/in the middle’). After clicking on one of the alternatives, the trial proceeded to the next sentence.
All sentences appeared on the screen individually against a light grey background. Sentences were presented in pseudo-randomized order and distributed over 2 Blocks with 33 sentences each so that participants never saw the matched sentences from grammatical and ungrammatical conditions within the same Block. Participants took a 5 min break between the Blocks. Experiment 2 took approximately 40 minutes to complete.
3.4. Results and Discussion
For all analyses, only sentences with correct answers to the comprehension questions were analyzed (monolingual adults: Maccuracy = 95%; HSs: Maccuracy = 91%; L2 learners: Maccuracy = 86%). Fixations and saccades were extracted from eye-movement data following the algorithm from the Data Viewer package (SR Research, Ltd.), and all fixations shorter than 100 ms were removed from the data. Table 4 presents means and standard deviations for the dependent measures for the two groups of bilingual readers and monolingual Russian adults in grammatical and ungrammatical conditions.
To investigate the effects of grammaticality and gender within each group, we fitted a series of linear mixed-effect models for target nouns for each of the dependent eye-movement measures. In addition to grammaticality (sum-contrast coded), gender cue (sum-contrast coded), and the interaction among these factors, we added word length (scaled and centered), word frequency (log-transformed) and Block number (to account for practice effect) as fixed predictors. Random factors included random intercepts and slopes for sentences and participants for all models where it was possible (i.e., the model converged). All continuous dependent measures were log-transformed to reduce the skewness of the distribution. Reported p-values were corrected for multiple comparisons.
The results of all LMMs for all duration measures and all groups are presented in Supplementary Tables S2–S4). In general, we found that RHSs and L2 learners did not notice grammatical errors in sentences, evident through the absence of the grammaticality effect on any of the eye-movement measures. Monolingual readers, in contrast, were sensitive to grammaticality manipulation and fixated the target noun longer in ungrammatical sentences in early (SFD: est. = −0.04, SE = 0.01, t = −3.46, p = 0.001) and late eye-movement duration measures (TT: est. = −0.08, SE = 0.02, t = −4.3, p < 0.001). In addition, we asked all participants after the completion of the task whether they noticed that some of the sentences were grammatically incorrect. All of the monolingual participants and none of the bilingual readers responded positively.
To summarize: as expected, monolingual participants were sensitive to the grammaticality manipulation. The stimuli with morphosyntactic violations elicited longer fixations in early and late measures, indicative of predictive morphosyntactic processing of gender cues as well as of likely revision of the morphosyntactic information in the ungrammatical condition. For RHSs and L2 learners, we did not observe either the use of gender cues for anticipation of the gender of the upcoming noun, nor the reanalysis of the morphosyntactic information in the gender agreement violation condition. In fact, both bilingual groups produced very similar reading patterns in grammatical and ungrammatical conditions that are likely to reflect the general difficulties with word recognition and information integration in reading in the non-dominant language.
4. General Discussion
In this study, we examined the task effects on the predictive processing of several morphosyntactic features in written language comprehension in Russian as a heritage language. We also compared the prediction skills to L2 learners of Russian and monolingual Russian readers.
In Experiment 1, in which we employed a less demanding cloze probability reading task, both bilingual groups produced overall high cloze probabilities (0.92 and 0.88 for RHSs and L2 learners, respectively), with no difference between the groups. As expected, monolingual readers outperformed both groups, accurately predicting all features regardless of the semantic constraints of the sentence or word class of the target. RHSs and L2 learners generated word class and number of the target lexical item with higher accuracy compared to gender or case, and they were more accurate in producing nouns compared to adjectives. Finally, for both bilingual groups higher Russian literacy increased the probability of prediction of all features except number. A more challenging eye-tracking reading Experiment 2 was designed to assess the ability of HSs, L2 learners, (and monolingual speakers as a control group) to predict the inflectional morphology of the upcoming target noun based on the gender cue of the modifying adjective. In this setup, in contrast to the monolingual group, RHSs and L2 learners showed no evidence of prediction. Below we discuss these findings in respect to the research questions and hypotheses outlined in Section 1.2.
4.1. Task Effects on Morphosyntactic Prediction in HL Reading
To begin with, based on the utility account of prediction (Kaan and Grüter 2021; Kuperberg and Jaeger 2016), which considers task difficulty as one of the crucial factors affecting bilingual prediction, we expected that in the ‘easier’ reading task in Experiment 1, RHSs would use all cues (word class, gender, case, and number) predictively. Given the high cloze probabilities for all these features (ranging for RHSs from 0.87 to 0.96; for L2 learners from 0.83 to 0.92), we suggest that our findings confirm this hypothesis. By comparison, in the study with monolingual adult speakers of Russian who also performed a cloze reading task, the same features elicited comparable or even lower cloze probabilities (word class for nouns 0.76, for adjectives 0.35, noun case and number 0.86, and gender 0.62) (Lopukhina et al. 2021). This difference is not surprising, however, considering the differences in materials and methods between the two studies. Participants in Lopukhina et al. (2021) performed a cumulative cloze test with sentences from the Russian Sentence Corpus (Laurinavichyute et al. 2019), guessing each word starting from the first, as opposed to providing only the last word in this study. Additionally, sentences in the corpus varied in syntactic structure complexity and word frequencies, while the sentences in this study were designed to be read by bilingual participants and thus contained simpler sentences with high-frequency words.
We also suggest that the results of this study corroborate the importance of the additivity factor in bilingual predictive processing (Karaca et al. 2024). The additional resources made available to our participants, such as the translation and pronunciation of words, likely aided in the morphosyntactic prediction for all features. This indicates that for literate HSs, prediction is not restricted to the auditory modality: when favorable conditions are met (Schlenter 2023), HSs engage in morphosyntactic prediction in written language comprehension. These findings align with the results in Parshina et al. (2022a), who reported that in a corpus-reading eye-tracking study RHSs were also sensitive to morphosyntactic predictability of word class, noun, and verb number. Curiously, in the present study the context of the sentence (highly or low-constraining) did not affect the cloze probabilities in any of the features, indicating that RHSs were indeed utilizing the morphosyntactic information available in the sentence, regardless of the sentential constraints.
The stark difference in prediction comes when we look at the results of Experiment 2, confirming our null hypothesis of no prediction in bilingual readers. The purpose of this experiment was to further explore morphosyntactic prediction abilities in RHSs by measuring their sensitivity to gender agreement violations in a more challenging task but within the same written domain. To reiterate, we did not find evidence that RHSs (or L2 learners) can anticipate the gender of the noun based on the gender marker of the modifying adjective in any of the eye-movement measures, regardless of the gender of the cue (Fem vs. Masc). In contrast, the effect of grammaticality was present in our control monolingual group, evident in early (single-fixation duration) and late eye-movement (total reading time) measures. Remember that early measures reflect the first stages of lexical access (i.e., grapheme-to-phoneme conversion and word recognition), while late measures indicate post-lexical processing (i.e., reanalysis and recovery from difficulties in morphosyntactic processing or semantic integration, Rayner 2009; Roberts and Siyanova-Chanturia 2013). Thus, we suggest that the effect of the grammaticality condition on the early eye-tracking measure (increase in SFD) is likely to signal the eye-movement behavior stemming from prediction violation, while increase in the total reading time indicates that monolinguals spent more time on the word, trying to integrate the morphosyntactic information and perform a reanalysis.
This absence of predictive processing of gender cues in Experiment 2 in bilinguals provides evidence for the task effect, as such gender prediction was present in the easier reading task in Experiment 1. Notably, RHSs in Parshina et al. (2022a) also were not sensitive to gender cues in corpus-reading eye-tracking tasks, although a strong effect was observed for word class and number feature (discussed below). However, in contrast, RHSs in Laleko (2019) successfully identified gender agreement violations for transparent nouns in the offline acceptability rating reading task. We posit that this discrepancy in results can be attributed to task demands again, or, more precisely, to task-induced strategies (Schlenter 2023): in the acceptability rating task, participants might be primed to anticipate grammaticality violations in the sentences, leading them to strategically allocate attention and processing resources for their detection. Consequently, in more naturalistic reading tasks, such as in the present study or in Parshina et al. (2022a), it is plausible that bilinguals prioritize processing resources for lexical retrieval (Parshina et al. 2021), focusing mainly on lexical–semantic information. As the utility account (Kaan and Grüter 2021; Kuperberg and Jaeger 2016) and the additive principle predicts, when cue unreliability is added to the task difficulty, prediction is not beneficial for language comprehension.
4.2. Morphosyntactic Cue Weight in Prediction
Based on what we know about the ‘weight’ of morphosyntactic cues in RHL from the previous studies with RHSs (adults: Fuchs and Sekerina, forthcoming; Gor 2019; Laleko 2018, 2019; Parshina et al. 2022a; Polinsky 2008; Sekerina 2015; RHS children: Meir et al. 2024; Mitrofanova et al. 2018; Rodina and Westergaard 2017), we hypothesized that RHSs in our study would form the most accurate predictions for word class and word number features, followed by case and gender features. The combined results from Experiment 1 and Experiment 2 support this hypothesis.
First, we observed high accuracy in producing the target word class for both bilingual groups (RHSs: 0.95, L2 learners: 0.88) in Experiment 1, although the accuracy was higher in the production of nouns than adjectives. Following the discussion in Parshina et al. (2022a), who also reported RHSs’ sensitivity to word class predictability in reading corpus sentences, we suggest that the prediction of word class based on the syntactic information available in the sentence is a skill that can be transferred from the prediction in dominant English. Specifically, since morphosyntactic prediction in general is a common and accessible process in the dominant language (Luke and Christianson 2016), bilinguals can transfer the word class prediction as a general language processing skill to the non-dominant language by relying on the syntactic and semantic information of the sentence. The possible explanation for the greater prediction of nouns over adjectives might lie in the sentence structure we used in Experiment 1. In many sentences, the words with morphosyntactic cues preceding the target noun were adjacent to it, whereas the words carrying cues for the target adjective were positioned earlier in the sentence (see examples in (1)), creating the need to carry the information in memory over till the end of the sentence and thus creating additional processing effort.
We also observed highly accurate generation of the target number on nouns and adjectives in Experiment 1 (RHSs: 0.95, L2 learners: 0.92), consistent with previous findings in spoken (Sekerina 2015) and written language comprehension (Gor 2019; Parshina et al. 2022a). The presence of the predictive use of number in reading corpus sentences in Parshina et al. (2022a) suggests that the prediction is due to the characteristics of the cue rather than task effects. It is likely that RHSs consider number feature as a reliable cue that also has cross-linguistic overlap with the dominant language, and thus this feature is ‘opted in’ for prediction, aligning with the utility account (Kaan and Grüter 2021; Kuperberg and Jaeger 2016). Case and gender cues, on the other hand, are weighted as less reliable, as evident in lower cloze probabilities in Experiment 1 and the absence of gender prediction in Experiment 2. RHSs weigh these cues as less reliable and only use them predictively in less demanding tasks.
4.3. The Group Differences in Prediction: RHSs vs. L2 Learners and Monolingual Readers
In Experiment 1, we did not observe any quantitative differences in morphosyntactic cloze probabilities between RHSs and L2 learners of Russian in any of the features, although both groups were not as accurate in predictions as their monolingual counterparts who performed at ceiling. Thus, even in an easy reading task, although the accuracy of prediction of bilinguals was high, it was still not on par with monolingual prediction. The explanation is intuitive. The reduced exposure to Russian, especially in written modality, in bilingual readers plays a role. In fact, in parallel to findings in Karaca et al. (2024) and Parshina et al. (2022a), the Russian literacy experience score was a significant factor influencing prediction in both RHSs and L2 learners. The higher the literacy score was, the higher the accuracy of predicting all features except number was. Notably, contrary to the prediction-by-production account (Pickering and Gambi 2018) that suggests RHSs would perform better in the task due to greater production skills (assessed via a self-reported measure), we did not find a strong link between production and prediction in this study. The only interaction effect we observed was in generating the case of the upcoming noun or adjective, wherein higher production scores increased accuracy of case prediction in RHSs but decreased it in L2 learners. While the result is intriguing, we should apply caution in attributing theoretical implications to it. It is likely that the self-report measure of the production skill that we used in the current study may not accurately reflect the true linguistic competence of the participants (see discussion in Limitations section).
In Experiment 2, a similar trend to Experiment 1 is revealed: RHSs and L2 learners perform on par, while monolingual adults were the only group to show sensitivity to gender agreement violations. Initially, as an alternative hypothesis, we expected that L2 learners in our study would also be sensitive to gender agreement violations due to explicit classroom instructions on gender agreement in Russian. However, this prediction was not confirmed. The finding that L2 learners do not detect morphosyntactic violations in reading, of course, is not novel (Dowens et al. 2010; Keating 2009; Sabourin and Stowe 2008), but they do, nevertheless, contradict some other reported results (Foote 2011; Foucart and Frenck-Mestre 2012; Hopp 2006; Lim and Christianson 2015). Interestingly, there seems to be a common denominator in these opposing findings: L2 speakers often show morphosyntactic prediction in local domains (e.g., when the disagreeing adjective is immediately adjacent to the head noun) but fail to detect agreement errors when the violation spans beyond the immediate domain (as in our study). While some researchers appeal to working memory limitations in bilingual processing (e.g., Foucart and Frenck-Mestre 2012; Keating 2009), it is also likely that in local domains, L2 learners can parafoveally preview the upcoming word (Pickering and Gambi 2018, for discussion). In this scenario, positive results in these studies reflect the process of information integration rather than prediction, per se.
To summarize, we suggest that the results of the current study, when placed within the context of previous research in predictive processing in Heritage Speakers, provide further evidence supporting the utility account of prediction (Kaan and Grüter 2021; Kuperberg and Jaeger 2016). Like their monolingual counterparts, RHSs (and L2 learners of Russian) engage in morphosyntactic prediction to facilitate language comprehension, even in tasks that are notoriously challenging for HSs, such as reading. However, the extent of this engagement is contingent on the interplay of several factors including but not limited to task demands, morphosyntactic cue weight, and literacy experience with Russian. Given sufficient exposure to written materials in the heritage language, in combination with access to additional information (e.g., semantics and phonology), and reliable morphosyntactic cues, RHSs ‘opt in’ for prediction.
5. Limitations and Future Directions
This study is not without limitations. Firstly, the results revealed only a weak link between the production skills of our bilingual participants and morphosyntactic prediction. While it may indeed be that morphosyntactic prediction in RHSs is not related to oral fluency, contrary to the prediction-by-production account (Pickering and Gambi 2018), we hypothesize that the type of assessment we used (self-reported speaking skills on a 5-point Likert scale) may not be a sufficient or reliable measure to support the relationship. Therefore, the possible direction of future investigations is to employ an objective assessment of oral fluency in Russian to further explore the link between prediction and production in heritage language processing.
Another promising direction that could provide insight into the task effects on morphosyntactic prediction in heritage language processing is to directly compare the prediction of morphosyntactic features, including verbal agreement, in spoken and written language comprehension. This could be done using tasks that are identical in methods, analogous to the design of the study by Gor 2019 (i.e., listening and reading grammaticality judgement tasks). Any differences in the predictive use of cues in this scenario would identify features that are influenced by the modality of the task, independent of the cue weight.
Thirdly, it would be informative to examine the extent to which differences in script affect prediction abilities in bilingual sentence reading. Previous research (Parshina et al. 2021) has shown that RHSs often struggle with the grapheme-phoneme decoding process when reading in RHL. Therefore, the differences between alphabets could have potentially contributed to the lack of prediction in Experiment 2 (recall that in Experiment 1, RHSs had the opportunity to hear the pronunciation of the words when needed): resources are allocated to the grapheme conversion process rather than to morphosyntactic analysis. Moving forward, studying language pairs with the same script (e.g., German–English, Spanish–English) could enhance our understanding of the impact of script differences on prediction in HL reading. Similarly, further studies are needed to investigate whether prediction in reading is a general cognitive skill that can be transferred from L1 to L2 reading (e.g., Mor and Prior 2022 found no evidence of such transfer) in the same way that variance in fluency in L2 reading can be explained by oculomotor behavior in L1 reading (Kuperman et al. 2023).
Finally, our study found that RHSs (and L2 learners) used case cues predictively in Experiment 1, yet the cloze probabilities for these cues were the lowest among all features. This may be attributed to the relatively low weight of the cue for predictive processing: the declensional case system in Russian is complex and syncretic (see Slioussar et al. 2022 for the study in adult native Russian speakers), and, moreover, it is not present in the dominant English language. Interestingly, Meir et al. (2024) reported that young RHSs with Hebrew as their majority language were able to anticipate the upcoming agent/patient in a sentence based on the accusative case cue, performing on par with the monolingual Russian control group and even outperforming their monolingual counterparts in Hebrew. The authors speculated that this was due to the cue weight in Russian and its successful transfer to predictive processing in Hebrew. Therefore, conducting a reading study with adult HSs whose dominant and heritage languages both have a case system (e.g., German–Russian HSs) would provide valuable insights into the interaction between cue weight in the dominant language and its transferability to the heritage language in written language processing.
In general, the syncretism of number/gender morphological expressions and the declensional case system in Russian undoubtedly presents challenges in assessing cue weight in prediction. Considerable effort was made in this study to create stimuli that minimize the effect of syncretism on the predictive abilities of RHSs (e.g., selecting high-frequency target words likely familiar to bilingual participants, adding a second cue (such as все [‘all’]) to potentially ambiguous cues regarding the number feature, spelling е with diacritic marks (ё) to indicate a singular number). However, the occurrence of syncretic morphological cues was not experimentally controlled, which might have influenced the ‘weighing’ mechanism of RHL prediction. A study with carefully controlled forms, therefore, would enhance our understanding of how this inherent characteristic of the Russian grammatical system affects cue weight for prediction.
Supplementary Materials
The following supporting information can be downloaded at: https://osf.io/vuchq/?view_only=44e818744eed4d45b2b38c74ca0b04a3 (assessed on 4 April 2024), R script; data; Table S1: The GLMMs summary for the morphosyntactic cloze probability and its interaction with the individual difference factors for HSs and L2 learners.; Table S2: Summary of (g)LMMs for the dependent measures for monolingual group for the target noun in the Experiment 2.; Table S3: Summary of (g)LMMs for the duration measures for RHSs group for the target noun in the Experiment 2; Table S4: Summary of (g)LMMs for the duration measures for L2 learner group for the target noun in the Experiment 2.
Author Contributions
Conceptualization, O.P. and I.A.S.; methodology, O.P. and I.A.S.; formal analysis, O.P and L.G.; data curation, N.L., O.P. and L.G; writing—original draft preparation, O.P.; writing—review and editing, O.P. and I.A.S.; visualization, O.P.; supervision, I.A.S. All authors have read and agreed to the published version of the manuscript.
Funding
The contributions of Olga Parshina and Nina Ladinskaya are an output of a research project implemented as part of the Basic Research Program at the National Research University Higher School of Economics (HSE University).
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki, and approved by the Institutional Review Board of City University of New York, College of Staten Island (protocol code 2019-0076 05/21/2019).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Data and R script can be found at the OSF project page https://osf.io/vuchq/?view_only=44e818744eed4d45b2b38c74ca0b04a3 (assessed on 4 April 2024).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Altmann, Gerry T. M., and Yuki Kamide. 1999. Incremental interpretation at verbs: Restricting the domain of subsequent reference. Cognition 73: 247–64. [Google Scholar] [CrossRef]
- Bates, Douglas, Martin Mächler, Ben Bolker, and Steve Walker. 2015. Fitting Linear Mixed-Effects Models Using lme4. Journal of Statistical Software 67: 1–48. [Google Scholar] [CrossRef]
- Carreira, Maria, and Olga Kagan. 2011. The results of the National Heritage Language Survey: Implications for teaching, curriculum design, and professional development. Foreign Language Annals 44: 40–64. [Google Scholar] [CrossRef]
- Collins, Allan. M., and Elizabeth F. Loftus. 1975. A spreading-activation theory of semantic processing. Psychological Review 82: 407–28. [Google Scholar] [CrossRef]
- Corbett, Greville. 1991. Gender. Cambridge, UK: Cambridge University Press. [Google Scholar]
- DeLong, Katherine A., Thomas P. Urbach, and Marta Kutas. 2005. Probabilistic word pre-activation during language comprehension inferred from electrical brain activity. Nature Neuroscience 8: 1117–21. [Google Scholar] [CrossRef] [PubMed]
- Dikker, Suzanne, Hugh Rabagliati, Thomas A. Farmer, and Lina Pylkkänen. 2010. Early occipital sensitivity to syntactic category is based on form typicality. Psychological Science 21: 629–34. [Google Scholar] [CrossRef]
- Dowens, Margaret G., Marta Vergara, Horacio A. Barber, and Manuel Carreiras. 2010. Morphosyntactic processing in late second-language learners. Journal of Cognitive Neuroscience 22: 1870–87. [Google Scholar] [CrossRef]
- Dussias, Paola, Jorge Valdés Kroff, Rosa Guzzardo Tamargo, and Chip Gerfen. 2013. When gender and looking go hand in hand: Grammatical gender processing In L2 Spanish. Studies in Second Language Acquisition 35: 353–87. [Google Scholar] [CrossRef]
- Foote, Rebecca. 2011. Integrated knowledge of agreement in early and late English-Spanish bilinguals. Applied Psycholinguistics 32: 187–220. [Google Scholar] [CrossRef]
- Fotekova, Tatiana A., and Tatiana V. Akhutina. 2002. Diagnostika Rečevyx Narušenij škol’nikov s Ispol’zovaniem Nejropsixologičeskix Metodov [Diagnosis of Speech Disorders by Neuropsychological Method]. Moscow: Arkti. (In Russian) [Google Scholar]
- Foucart, Alice, and Cheryl Frenck-Mestre. 2012. Can late L2 learners acquire new grammatical features? Evidence from ERPs and eye-tracking. Journal of Memory and Language 66: 226–48. [Google Scholar] [CrossRef]
- Fuchs, Zuzanna. 2021. Facilitative use of grammatical gender in Heritage Spanish. Linguistic Approaches to Bilingualism 12: 845–71. [Google Scholar] [CrossRef]
- Fuchs, Zuzanna. 2022. Eye tracking evidence for heritage speakers’ access to abstract syntactic agreement features in real-time processing. Frontiers in Psychology 13: 960376. [Google Scholar] [CrossRef] [PubMed]
- Fuchs, Zuzanna, and Irina A. Sekerina. Forthcoming. New Evidence for the Role of Morphological Markedness of Gender Agreement Cues in Monolingual and Heritage-Bilingual Facilitative Processing. Los Angeles: Linguistics Department, University of Southern California, Unpublished manuscript.
- Golovin, Grigory V. 2015. Izmerenie passivnogo slovarnogo zapasa russkogo yazyka [Receptive vocabulary size measurement for Russian language]. Socio-Ipsiholingvisticheskie Issledovaniya [Socio-Psycholinguistic Research] 3: 148–59. [Google Scholar]
- Gor, Kira. 2019. Morphosyntactic knowledge in late second language learners and heritage speakers of Russian. Heritage Language Journal 16: 124–50. [Google Scholar] [CrossRef]
- Grisoni, Luigi, Tally M. Miller, and Friedemann Pulvermüller. 2017. Neural correlates of semantic prediction and resolution in sentence processing. The Journal of Neuroscience 37: 4848–58. [Google Scholar] [CrossRef] [PubMed]
- Grüter, Theres, Elaine Lau, and Wenyi Ling. 2020. How classifiers facilitate predictive processing in L1 and L2 Chinese: The role of semantic and grammatical cues. Language, Cognition and Neuroscience 35: 221–34. [Google Scholar] [CrossRef]
- Henry, Nick, Holger Hopp, and Carrie N. Jackson. 2017. Cue additivity and adaptivity in predictive processing. Language, Cognition and Neuroscience 32: 1229–49. [Google Scholar] [CrossRef]
- Henry, Nick, Holger Hopp, and Carrie N. Jackson. 2022. Cue coalitions and additivity in predictive processing: The interaction between case and prosody in L2 German. Second Language Research 38: 397–422. [Google Scholar] [CrossRef]
- Hopp, Holger. 2006. Syntactic features and reanalysis in near-native processing. Second Language Research 22: 369–97. [Google Scholar] [CrossRef]
- Hopp, Holger. 2013. Grammatical gender in adult L2 acquisition: Relations between lexical and syntactic variability. Second Language Research 29: 33–56. [Google Scholar] [CrossRef]
- Hopp, Holger. 2015. Semantics and morphosyntax in predictive L2 sentence processing. International Review of Applied Linguistics in Language Teaching 53: 277–306. [Google Scholar] [CrossRef]
- Ito, Aine, Martin J. Pickering, and Martin Corley. 2018. Investigating the time–course of phonological prediction in native and non–native speakers of English: A visual world eye-tracking study. Journal of Memory and Language 98: 1–11. [Google Scholar] [CrossRef]
- Kaan, Edith. 2014. Predictive sentence processing in L2 and L1: What is different? Linguistic Approaches to Bilingualism 4: 257–82. [Google Scholar] [CrossRef]
- Kaan, Edith, and Theres Grüter. 2021. Prediction in second language processing and learning: Advances and directions. In Prediction in Second Language Processing and Learning. Edited by Edith Kaan and Theres Grüter. Amsterdam and Philadelphia: John Benjamins Publishing Company, pp. 2–24. [Google Scholar]
- Karaca, Figen, Susanne Brouwer, Sharon Unsworth, and Falk Huettig. 2024. Morphosyntactic predictive processing in adult heritage speakers: Effects of cue availability and spoken and written language experience. Language, Cognition and Neuroscience 39: 118–35. [Google Scholar] [CrossRef]
- Keating, Gregory D. 2009. Sensitivity to violations of gender agreement in native and nonnative Spanish: An eye-movement investigation. Language Learning 59: 503–35. [Google Scholar] [CrossRef]
- Kornev, Alexander N. 1997. Hapyшeниe чтeния и пиcьмa y дeтeй: Учeбнo-мeтoдичecкoe пocoбиe [Reading and Writing Disorders in Children: Study Guide]. Saint Petersburg: M and M. [Google Scholar]
- Kuperberg, Gina R., and T. Florian Jaeger. 2016. What do we mean by prediction in language comprehension? Language, Cognition and Neuroscience 31: 32–59. [Google Scholar] [CrossRef] [PubMed]
- Kuperman, Victor, Noam Siegelman, Sascha Schroeder, Cengiz Acartürk, Svetlana Alexeeva, Simona Amenta, Raymond Bertram, Rolando Bonandrini, Marc Brysbaert, Daria Chernova, and et al. 2023. Text reading in English as a second language: Evidence from the Multilingual Eye-Movements Corpus. Studies in Second Language Acquisition 45: 3–37. [Google Scholar] [CrossRef]
- Laleko, Oksana. 2018. What is difficult about grammatical gender? Evidence from heritage Russian. Journal of Language Contact 11: 233–67. [Google Scholar] [CrossRef]
- Laleko, Oksana. 2019. Resolving indeterminacy in gender agreement: Comparing Heritage Speakers and L2 Learners of Russian. Heritage Language Journal 16: 151–81. [Google Scholar] [CrossRef]
- Lau, Ellen, Clare Stroud, Silke Plesch, and Colin Phillips. 2006. The role of structural prediction in rapid syntactic analysis. Brain and Language 98: 74–88. [Google Scholar] [CrossRef]
- Laurinavichyute, Anna K., Irina A. Sekerina, Svetlana Alexeeva, Kristine Bagdasaryan, and Reinhold Kliegl. 2019. Russian Sentence Corpus: Benchmark measures of eye movements in reading in Russian. Behavior Research Methods 51: 1161–78. [Google Scholar] [CrossRef] [PubMed]
- Lê, Sébastien, Julie Josse, and François Husson. 2008. FactoMineR: An R Package for Multivariate Analysis. Journal of Statistical Software 25: 1–18. [Google Scholar] [CrossRef]
- Lenth, Russell V. 2021. emmeans: Estimated Marginal Means, aka Least-Squares Means, (R Package Version 1.6.1); Available online: https://CRAN.R-project.org/package=emmeans (accessed on 4 April 2024).
- Lim, Jung H., and Kiel Christianson. 2015. Second language sensitivity to agreement errors: Evidence from eye movements during comprehension and translation. Applied Psycholinguistics 36: 1283–315. [Google Scholar] [CrossRef]
- Lopukhina, Anastasiya, Konstantin Lopukhin, and Anna Laurinavichyute. 2021. Morphosyntactic but not lexical corpus-based probabilities can substitute for cloze probabilities in reading experiments. PLoS ONE 16: e0246133. [Google Scholar] [CrossRef] [PubMed]
- Lüdecke, Daniel. 2017. sjPlot: Data Visualization for Statistics in Social Science (R Package Version 2.3.3). Available online: https://CRAN.Rproject.org/package=sjPlot (accessed on 4 April 2024).
- Luke, Steven G., and Kiel Christianson. 2015. Predicting inflectional morphology from context. Language, Cognition and Neuroscience 30: 735–48. [Google Scholar] [CrossRef]
- Luke, Steven G., and Kiel Christianson. 2016. Limits on lexical prediction during reading. Cognitive Psychology 88: 22–60. [Google Scholar] [CrossRef] [PubMed]
- Lyashevskaya, Olga N., and Sergey A. Sharov. 2009. Chastotnyj Slovar’ Sovremennogo Russkogo Jazyka (na Materialakh Natsional’nogo Korpusa Russkogo Jazyka) [Frequency Dictionary of Modern Russian (Based on the Materials of the Russian National Corpus)]. Moscow: Azbukovnik. [Google Scholar] [CrossRef]
- Meir, Natalia, Olga Parshina, and Irina A. Sekerina. 2024. Prediction in bilingual sentence processing: Is it linked to production? Linguistic Approaches to Bilingualism. [Google Scholar] [CrossRef]
- Mitrofanova, Natalia, Yulia Rodina, Olga Urek, and Marit Westergaard. 2018. Bilinguals’ sensitivity to grammatical gender cues in Russian: The role of cumulative input, proficiency, and dominance. Frontiers in Psychology 9: 1894. [Google Scholar] [CrossRef]
- Mitsugi, Sanako, and Brian Macwhinney. 2016. The use of case marking for predictive processing in second language Japanese. Bilingualism: Language and Cognition 19: 19–35. [Google Scholar] [CrossRef]
- Mor, Billy, and Anat Prior. 2022. Frequency and predictability effects in first and second language of different script bilinguals. Journal of Experimental Psychology: Learning, Memory, and Cognition 48: 1363–83. [Google Scholar] [CrossRef] [PubMed]
- Parshina, Olga, Anna K. Laurinavichyute, and Irina A. Sekerina. 2021. Eye-movement benchmarks in Heritage Language reading. Bilingualism: Language and Cognition 24: 69–82. [Google Scholar] [CrossRef]
- Parshina, Olga, Anastasiya Lopukhina, and Irina A. Sekerina. 2022a. Can heritage speakers predict lexical and morphosyntactic information in reading? Languages 7: 60. [Google Scholar] [CrossRef]
- Parshina, Olga, Irina A. Sekerina, Anastasiya Lopukhina, and von Titus Der Malsburg. 2022b. Monolingual and bilingual reading processes in Russian: An exploratory scanpath analysis. Reading Research Quarterly 57: 469–92. [Google Scholar] [CrossRef]
- Pickering, Martin J., and Chiara Gambi. 2018. Predicting while comprehending language: A theory and review. Psychological Bulletin 144: 1002–44. [Google Scholar] [CrossRef] [PubMed]
- Pickering, Martin J., and Simon Garrod. 2007. Do people use language production to make predictions during comprehension? Trends in Cognitive Sciences 11: 105–10. [Google Scholar] [CrossRef] [PubMed]
- Pickering, Martin J., and Simon Garrod. 2013. An integrated theory of language production and comprehension. Behavioral and Brain Sciences 36: 329–47. [Google Scholar] [CrossRef]
- Polinsky, Maria. 2008. Gender under incomplete acquisition: Heritage speakers’ knowledge of noun categorization. Heritage Language Journal 6: 40–71. [Google Scholar] [CrossRef]
- R Core Team. 2021. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 4 April 2024).
- Rayner, Keith. 2009. Eye movements and attention in reading, scene perception, and visual search. The Quarterly Journal of Experimental Psychology 62: 1457–506. [Google Scholar] [CrossRef]
- Roberts, Leah, and Anna Siyanova-Chanturia. 2013. Using eye-tracking to investigate topics in L2 acquisition and L2 processing. Studies in Second Language Acquisition 35: 213–35. [Google Scholar] [CrossRef]
- Rodina, Yulia, and Marit Westergaard. 2017. Grammatical gender in bilingual Norwegian–Russian acquisition: The role of input and transparency. Bilingualism: Language and Cognition 20: 197–214. [Google Scholar] [CrossRef]
- Sabourin, Laura, and Laurie A. Stowe. 2008. Second language processing: When are first and second languages processed similarly? Second Language Research 24: 397–430. [Google Scholar] [CrossRef]
- Schlenter, Judith. 2023. Prediction in bilingual sentence processing: How prediction differs in a later learned language from a first language. Bilingualism: Language and Cognition 26: 253–67. [Google Scholar] [CrossRef]
- Sekerina, Irina A. 2015. Predictions, fast and slow. Linguistic Approaches to Bilingualism 5: 532–36. [Google Scholar] [CrossRef]
- Slioussar, Natalia, Varvara Magomedova, and Polina Makarova. 2022. The role of case syncretism in agreement attraction: A comprehension study. Frontiers in Psychology 13: 829112. [Google Scholar] [CrossRef] [PubMed]
- Szewczyk, Jakub M., and Herbert Schriefers. 2013. Prediction in language comprehension beyond specific words: An ERP study on sentence comprehension in Polish. Journal of Memory and Language 68: 297–314. [Google Scholar] [CrossRef]
- Van Berkum, Jos J. A., Collin M. Brown, Pienie Zwitserlood, Valesca Kooijman, and Peter Hagoort. 2005. Anticipating Upcoming Words in Discourse: Evidence From ERPs and Reading Times. Journal of Experimental Psychology: Learning, Memory, and Cognition 31: 443–67. [Google Scholar] [CrossRef]
Figure 1.
Cloze probability as a function of the morphosyntactic feature by group in Experiment 1. Error bars show standard error of the mean.
Figure 1.
Cloze probability as a function of the morphosyntactic feature by group in Experiment 1. Error bars show standard error of the mean.
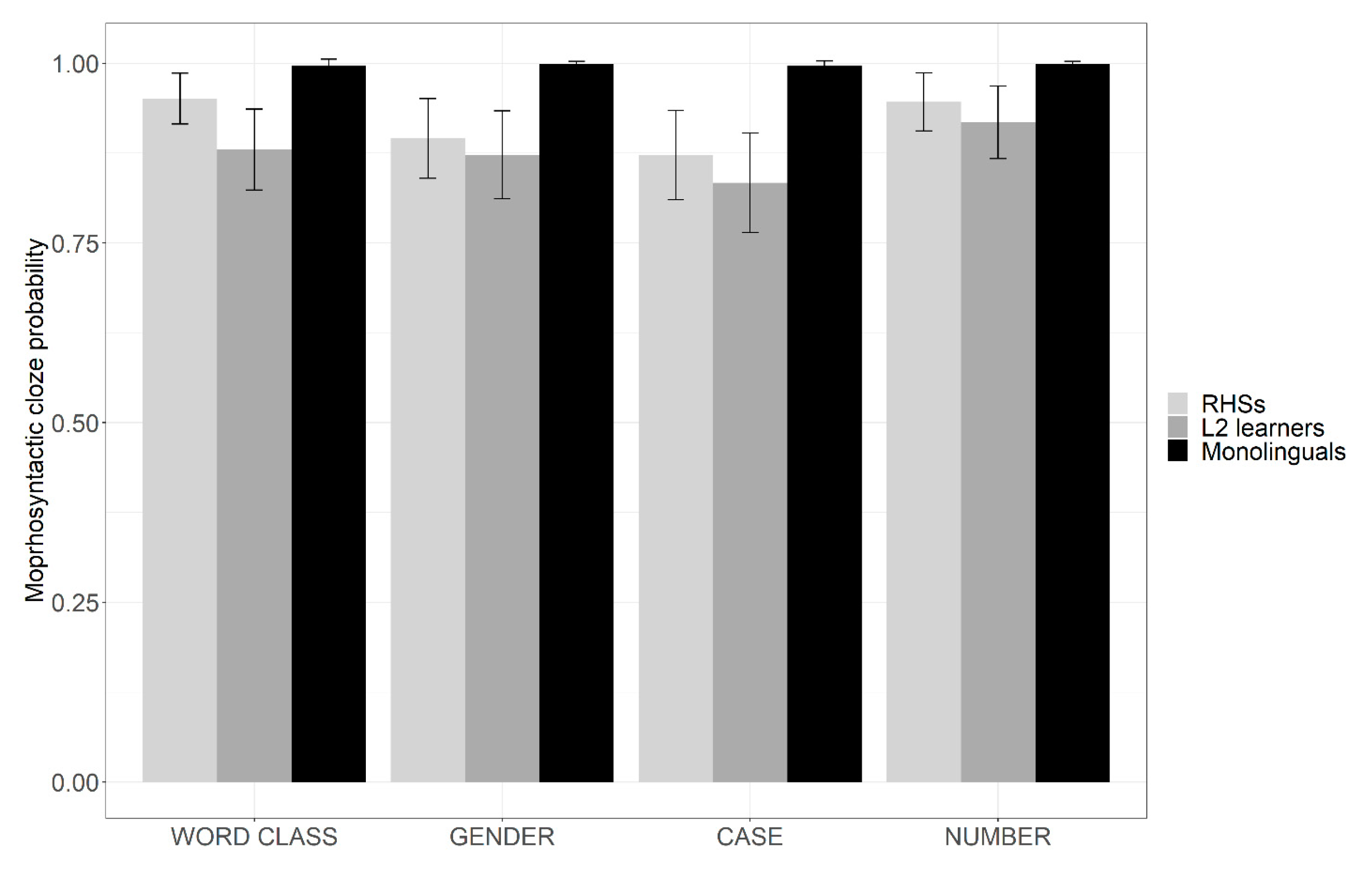

{kind=link}
Table 1.
Bilingual participant characteristics and average scores for performance on reading assessment tasks.
Table 1.
Bilingual participant characteristics and average scores for performance on reading assessment tasks.
| RHSs Mean (SD) | L2 Learners Mean (SD) | |
|---|---|---|
| N | 29 | 29 |
| Age (y.o) | 19.8 (2.9) | 24.4 (5.8) |
| Gender (men:women) | 13:16 | 17:12 |
| Age of Arrival to USA (years) | 3.5 (5.4) | 0.41 (1.7) |
| Vocabulary size in Russian (word count in thousands) | 23.1 (13.1) | 29.1 (23.0) |
| Daily Russian language exposure (%) | 27.6 (25.6) | 17.3 (22.3) |
| Daily reading exposure to Russian (min) | 30–60 | 30–60 |
| Age when started reading in Russian (years) | 7.2 (5.1) | 19.3 (4.3) |
| Self-reported proficiency measures in Russian (scale 1–5, with 5 the highest) | ||
| Comprehension | 3.8 (1.1) | 2.9 (0.98) |
| Speaking | 3.7 (1.0) | 2.7 (0.81) |
| Reading | 2.8 (1.0) | 2.6 (0.79) |
| Writing | 2.6 (1.2) | 2.9 (0.70) |
Table 2.
Examples of sentences in Experiment 1.
| Target Word Class | Highly Constraining Context | Low-Constraining Context |
|---|---|---|
| Noun |
|
|
| Adj |
|
|
Table 3.
Parameter estimates for GLMM: cloze probability by group and morphosyntactic feature (Bonferroni correction applied). Significant effects are highlighted in bold.
Table 3.
Parameter estimates for GLMM: cloze probability by group and morphosyntactic feature (Bonferroni correction applied). Significant effects are highlighted in bold.
| Cloze Probability | ||||
|---|---|---|---|---|
| Predictors | Log-Odds | SE | CI | p |
| (Intercept) | 2.47 | 0.29 | 1.89–3.05 | <0.001 |
| L2 learners | −0.50 | 0.37 | −1.23–0.24 | 1.000 |
| Monolinguals | 5.65 | 1.43 | 2.84–8.46 | 0.001 |
| Gender | 0.18 | 0.21 | −0.22–0.59 | 1.000 |
| Number | 1.02 | 0.22 | 0.59–1.46 | <0.001 |
| Word Class | 1.07 | 0.22 | 0.64–1.50 | <0.001 |
| L2 learners * Gender | −0.07 | 0.28 | −0.63–0.49 | 1.000 |
| Monolinguals * Gender | 0.85 | 1.19 | −1.48–3.19 | 1.000 |
| L2 learners * Number | −0.12 | 0.30 | −0.71–0.47 | 1.000 |
| Monolinguals * Number | 0.10 | 1.19 | −2.24–2.43 | 1.000 |
| L2 learners * Word Class | −0.55 | 0.29 | −1.11–0.01 | 0.662 |
| Monolinguals * Word Class | −1.06 | 0.86 | −2.75–0.63 | 1.000 |
| Random effects | ||||
| σ2 | 3.29 | |||
| τ00 subject | 1.30 | |||
| τ00 SENT_ID | 0.89 | |||
| τ11 SENT_ID L2 learners | 0.42 | |||
| τ11 SENT_ID.Monolinguals | 6.67 | |||
| ρ01 SENT_ID L2 learners | −0.22 | |||
| ρ01 SENT_ID. Monolinguals | −0.54 | |||
| Observations | 8365 | |||
| Marginal R2/Conditional R2 | 0.549/0.796 | |||
* Denotes interaction effect.
Table 4.
Descriptive characteristics of eye movements for grammatical and ungrammatical conditions in three groups of readers (SD in parentheses). Significant differences between grammatical and ungrammatical conditions within the group are in bold.
Table 4.
Descriptive characteristics of eye movements for grammatical and ungrammatical conditions in three groups of readers (SD in parentheses). Significant differences between grammatical and ungrammatical conditions within the group are in bold.
| Duration (ms) | Monolinguals | RHSs | L2 Learners | |||
|---|---|---|---|---|---|---|
| Grammatical | Ungrammatical | Grammatical | Ungrammatical | Grammatical | Ungrammatical | |
| First-Fixation | 227 (58) | 220 (73) | 368 (133) | 369 (137) | 338 (82) | 350 (138) |
| Single-Fixation | 226 (39) | 246 (48) | 381 (152) | 399 (125) | 386 (113) | 418 (115) |
| Gaze Duration | 260 (64) | 277 (65) | 851 (450) | 782 (330) | 643 (215) | 630 (189) |
| Total Reading Time | 335 (148) | 387 (165) | 1261 (714) | 1229 (745) | 973 (393) | 938 (345) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Parshina, O.; Ladinskaya, N.; Gault, L.; Sekerina, I.A. Predictive Language Processing in Russian Heritage Speakers: Task Effects on Morphosyntactic Prediction in Reading. Languages 2024, 9, 158. https://doi.org/10.3390/languages9050158
AMA Style
Parshina O, Ladinskaya N, Gault L, Sekerina IA. Predictive Language Processing in Russian Heritage Speakers: Task Effects on Morphosyntactic Prediction in Reading. Languages. 2024; 9(5):158. https://doi.org/10.3390/languages9050158
Chicago/Turabian StyleParshina, Olga, Nina Ladinskaya, Lidia Gault, and Irina A. Sekerina. 2024. "Predictive Language Processing in Russian Heritage Speakers: Task Effects on Morphosyntactic Prediction in Reading" Languages 9, no. 5: 158. https://doi.org/10.3390/languages9050158