
Designing Closed-Loop Brain-Machine Interfaces Using Model Predictive Control †



Abstract
:
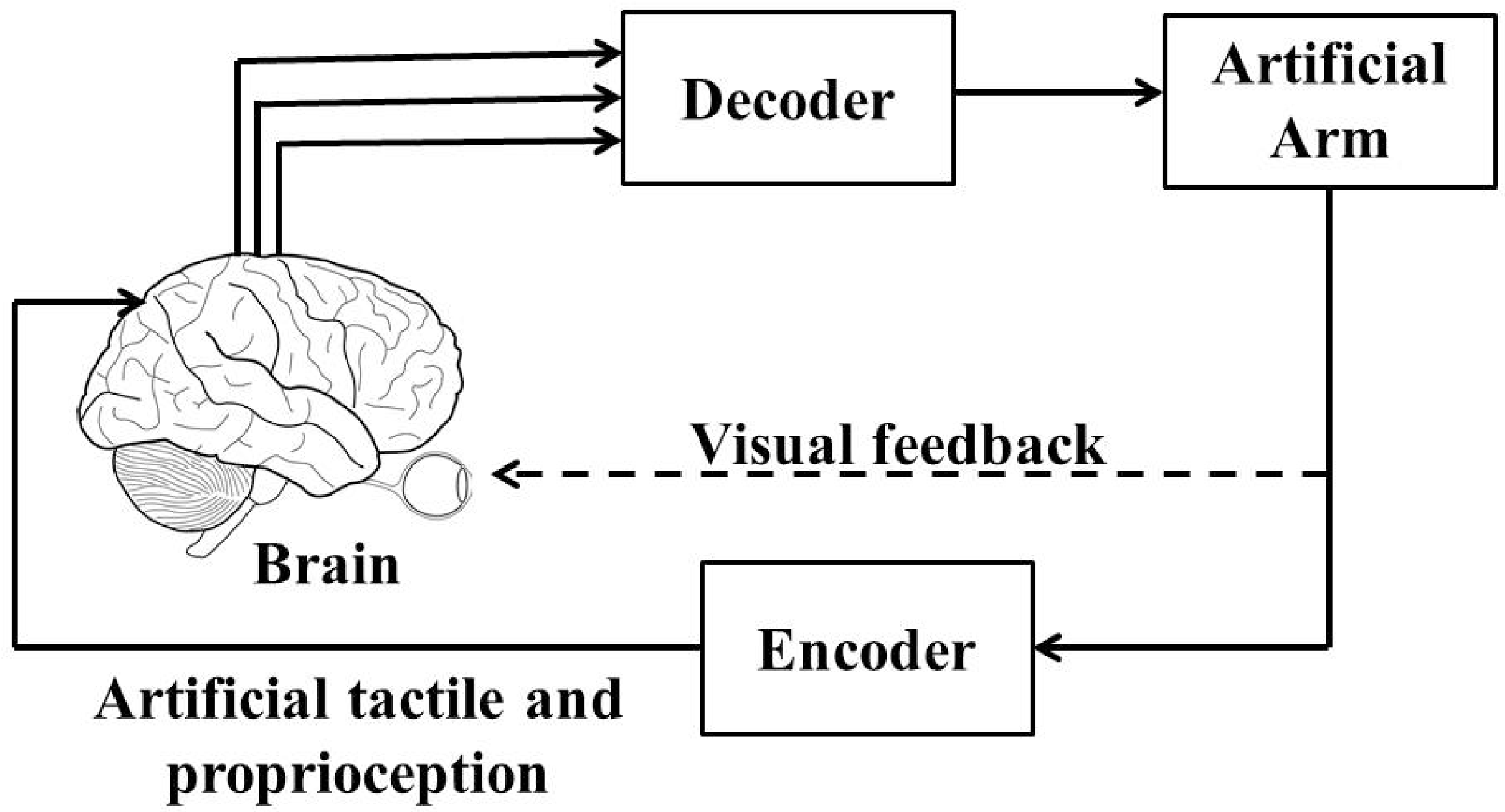
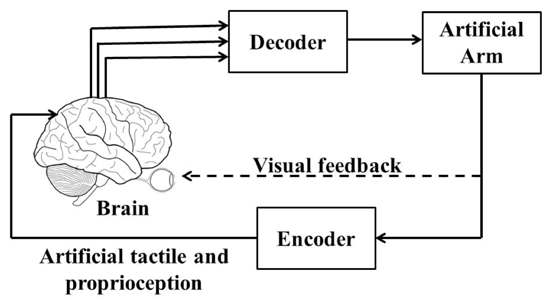{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
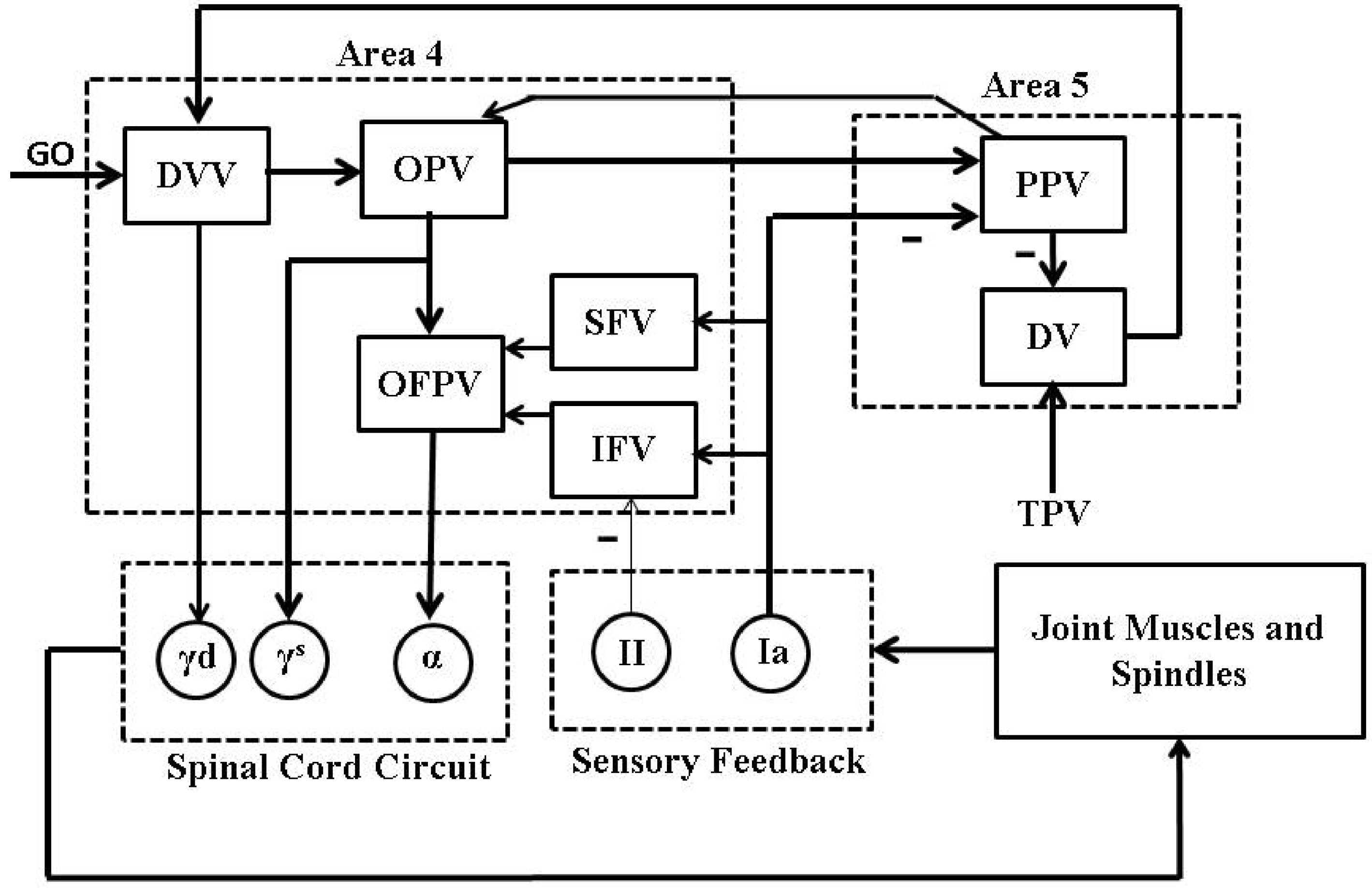
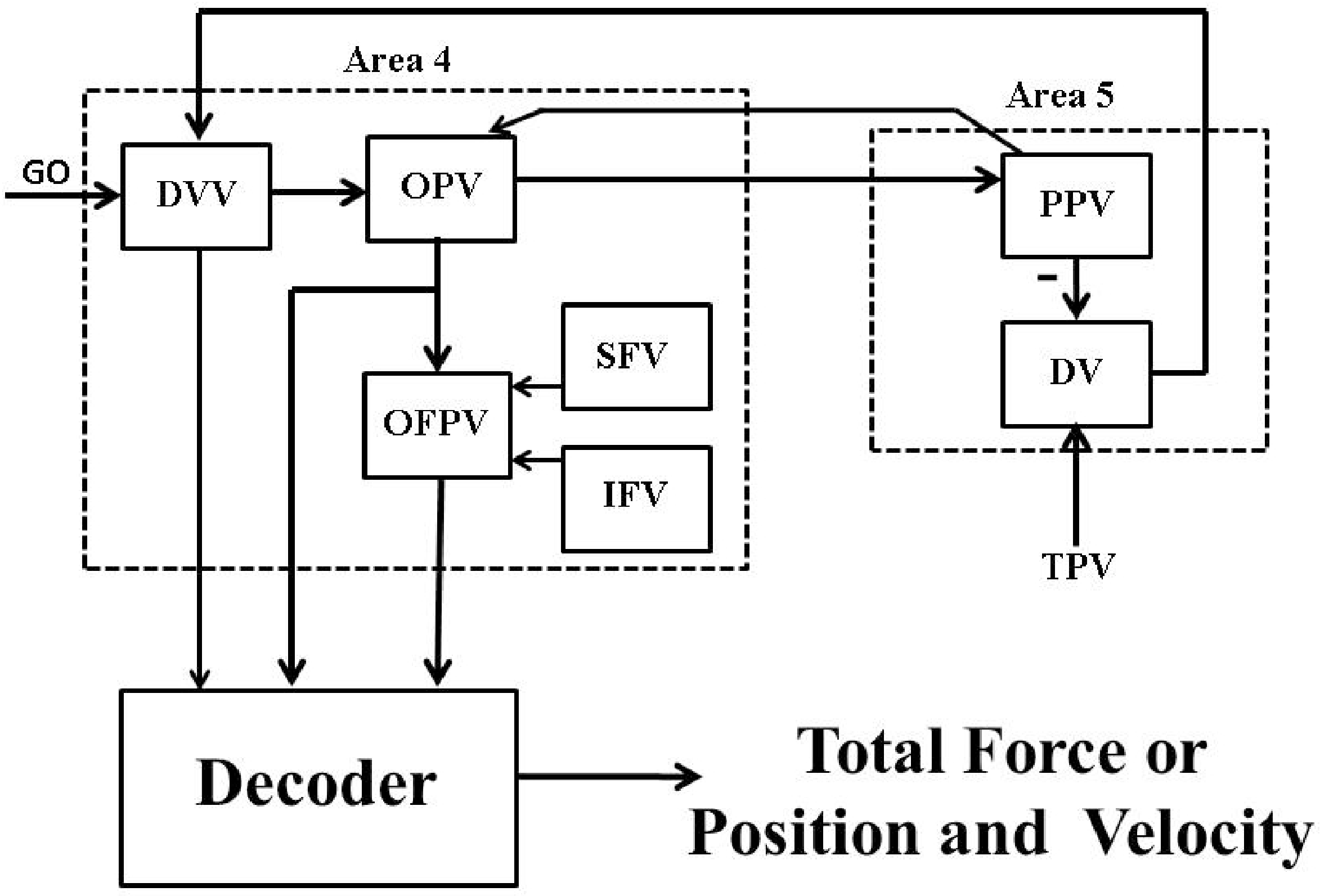
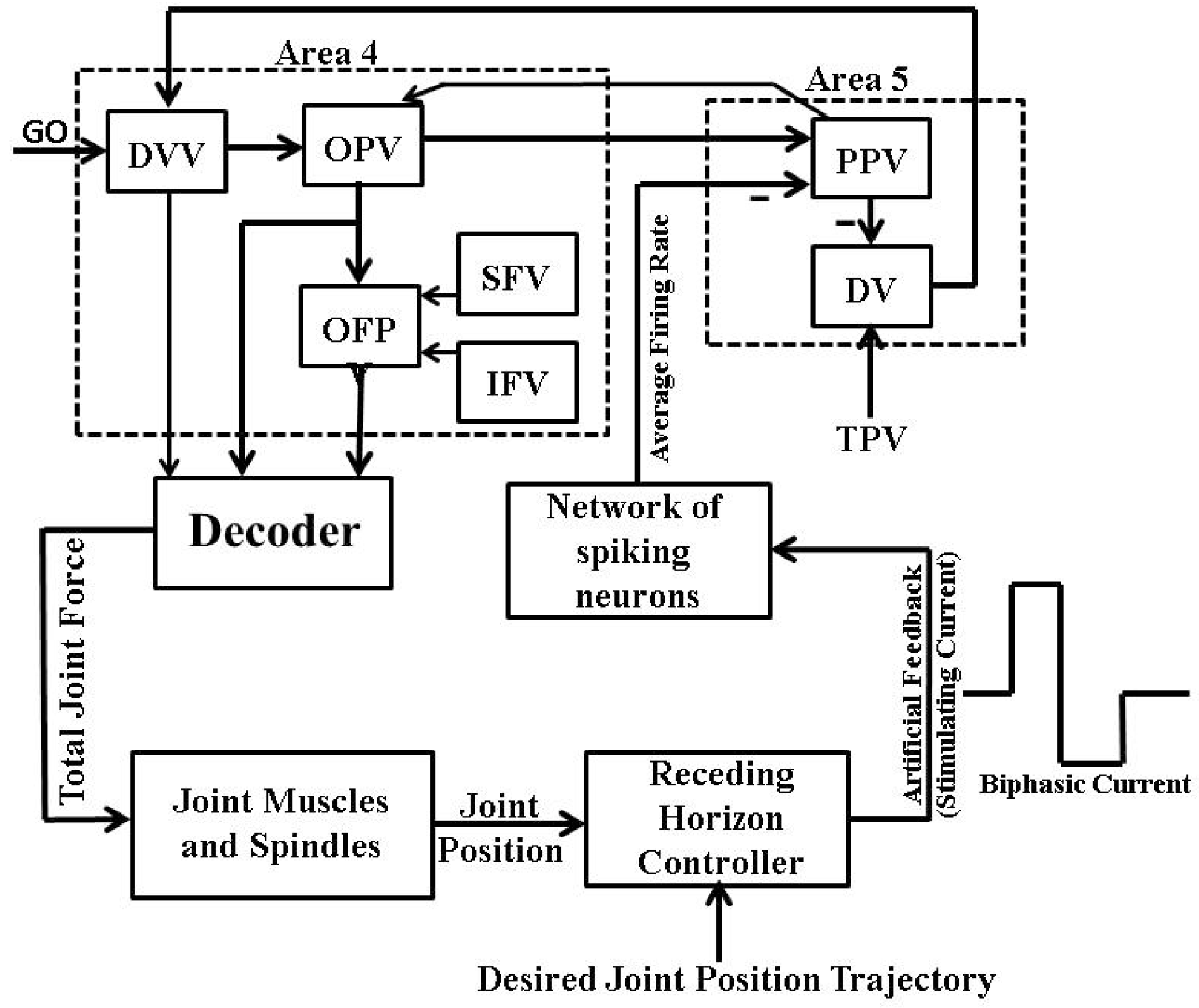
2. Psycho-Physiological Cortical Circuit Model of Single Joint Movement
3. Synthetic Experimental Data Generation for Extension Task
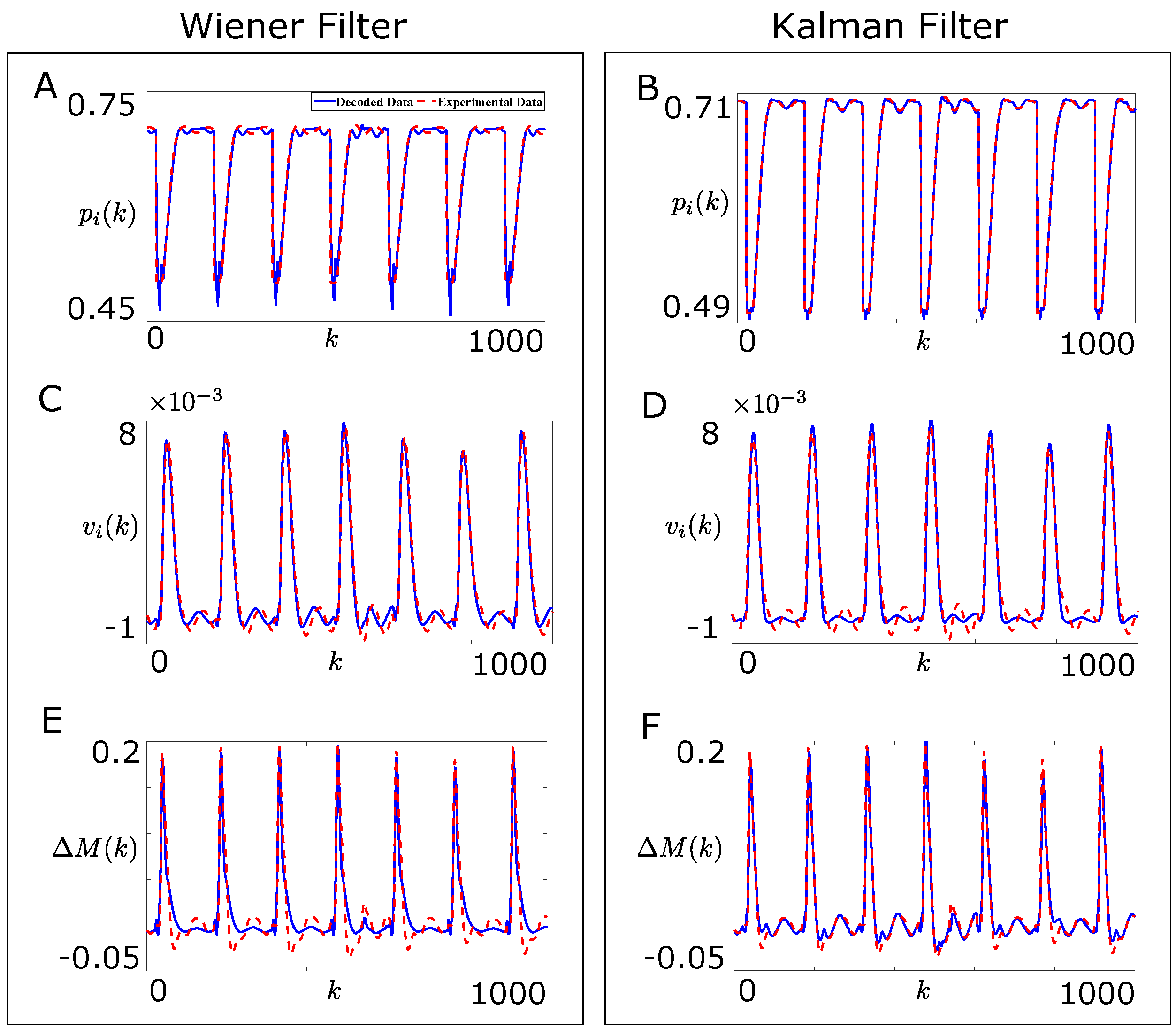
4. Wiener and Kalman Filters Based Decoder Designs
4.1. Wiener Filter Based Decoder Design
4.2. Kalman Filter Based Decoder Design
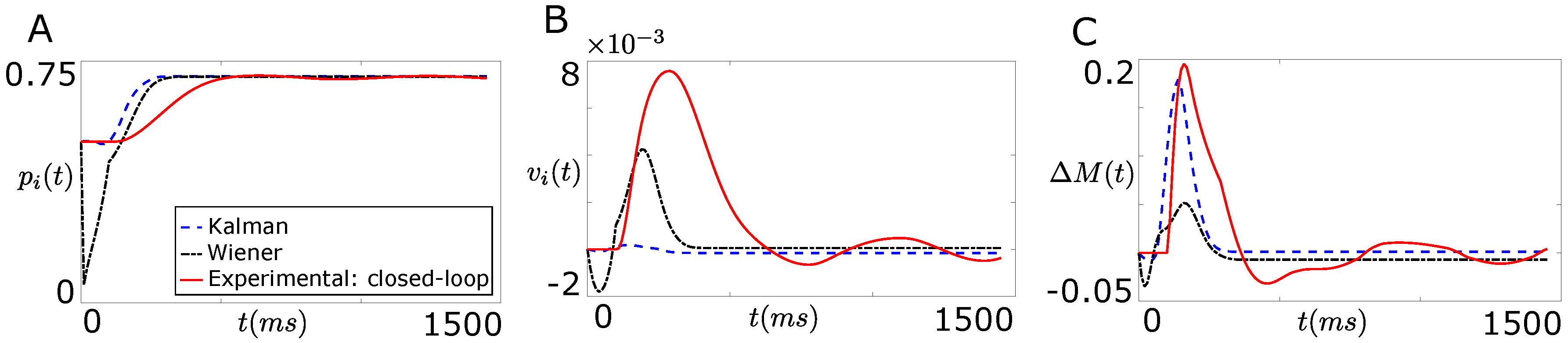
4.3. Comparison of Designed Decoders
5. Need of a Closed-Loop BMI
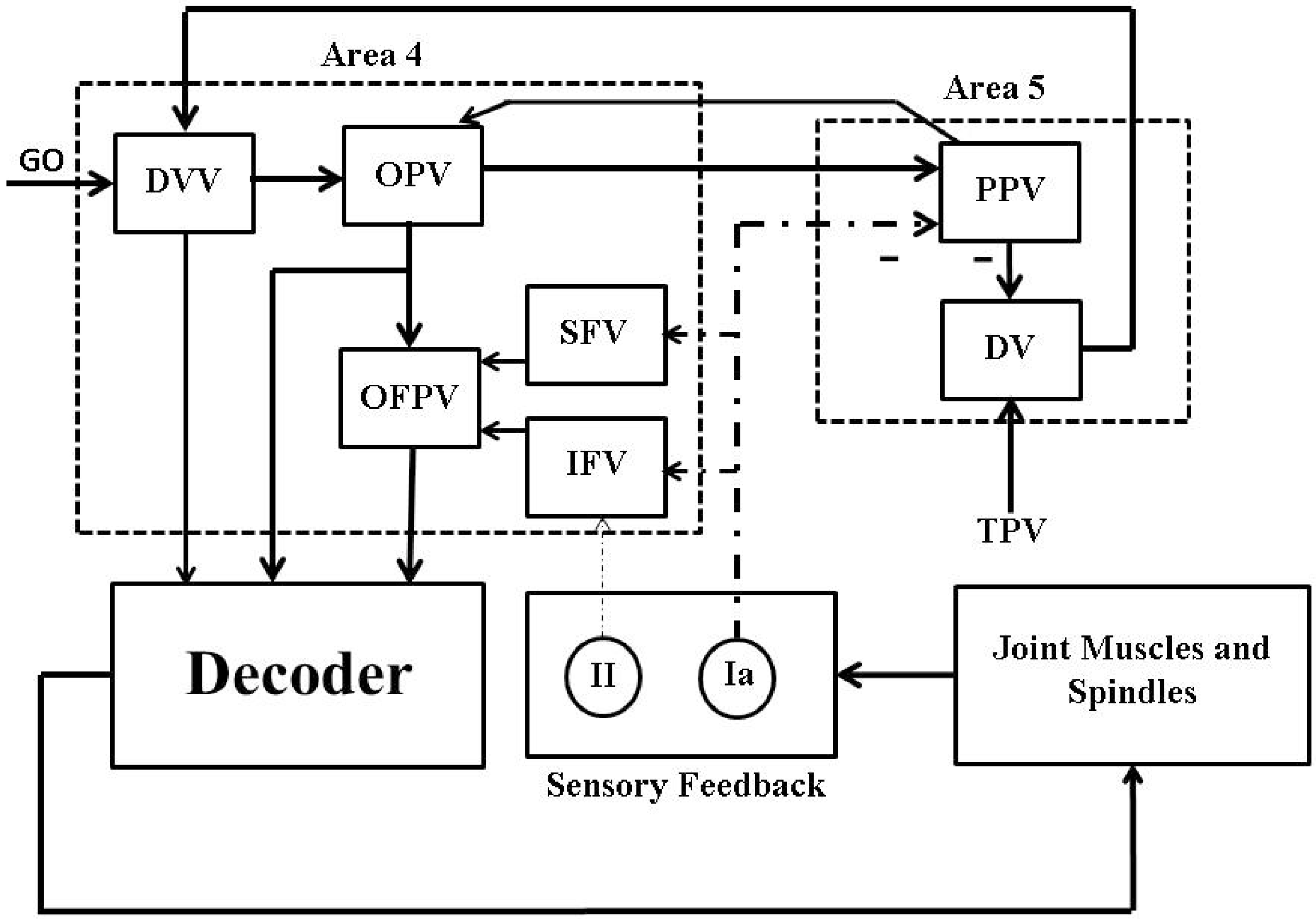
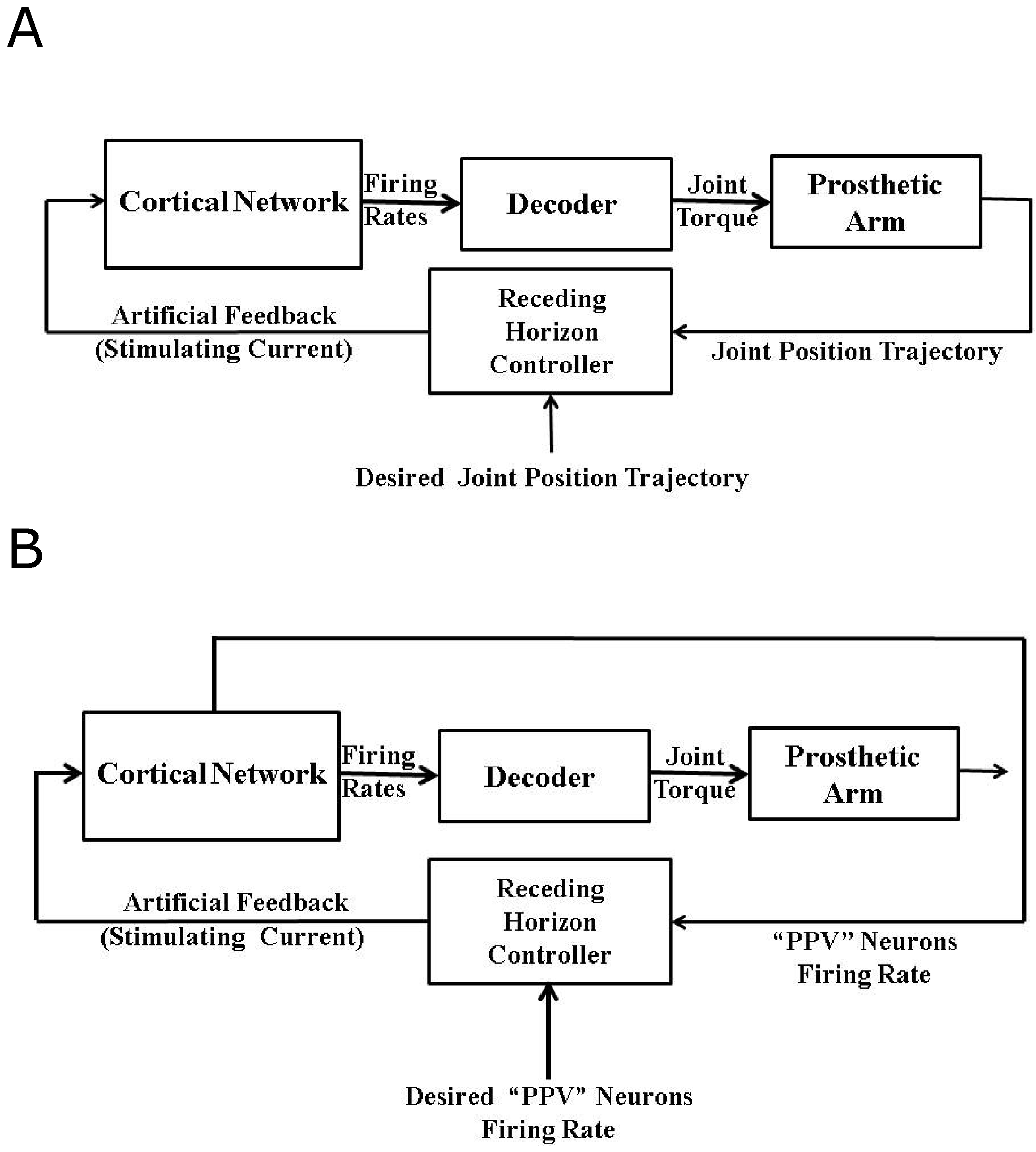
6. Artificial Proprioceptive Feedback Design
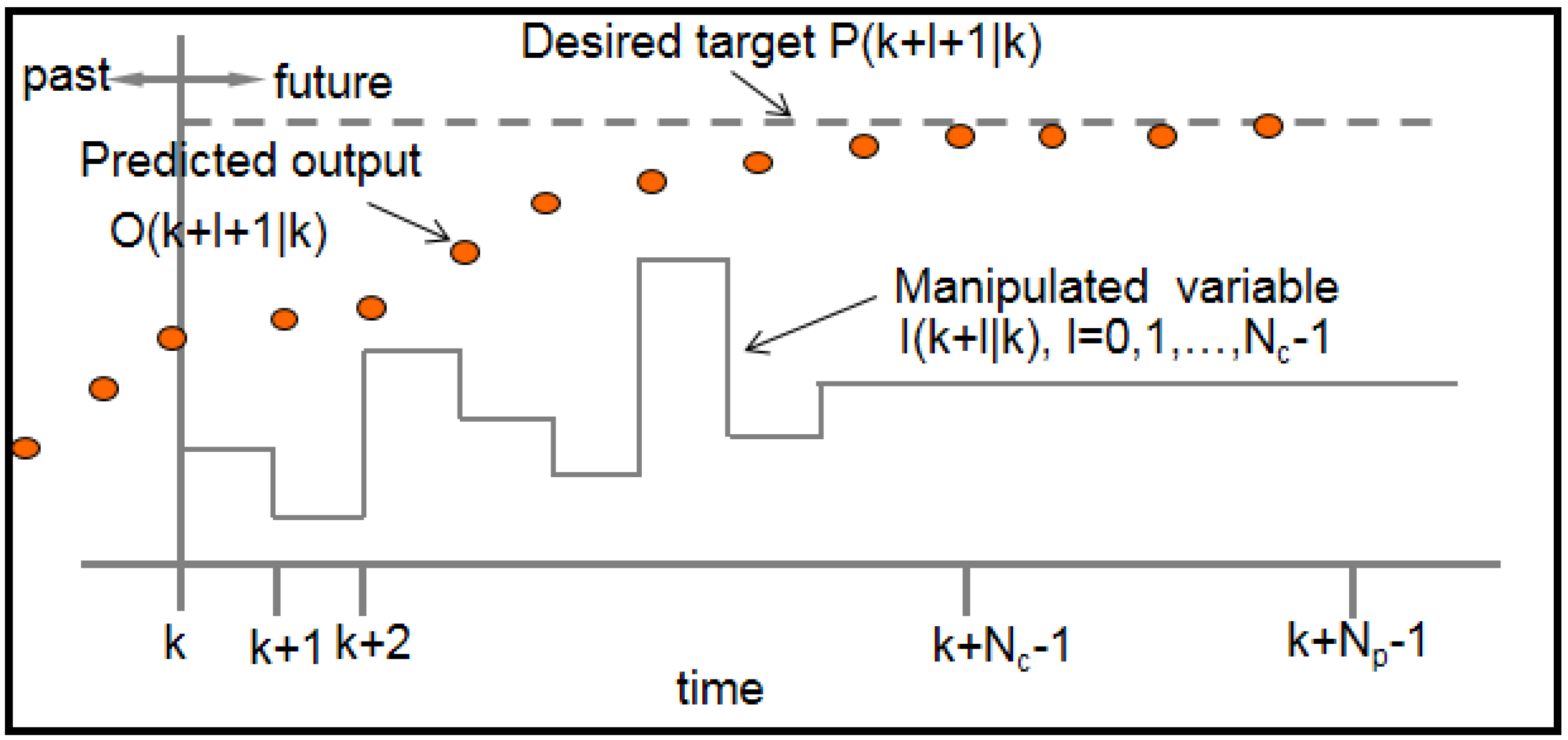
6.1. Model Predictive Control
6.2. Firing Rate Based Closed-Loop BMI Design
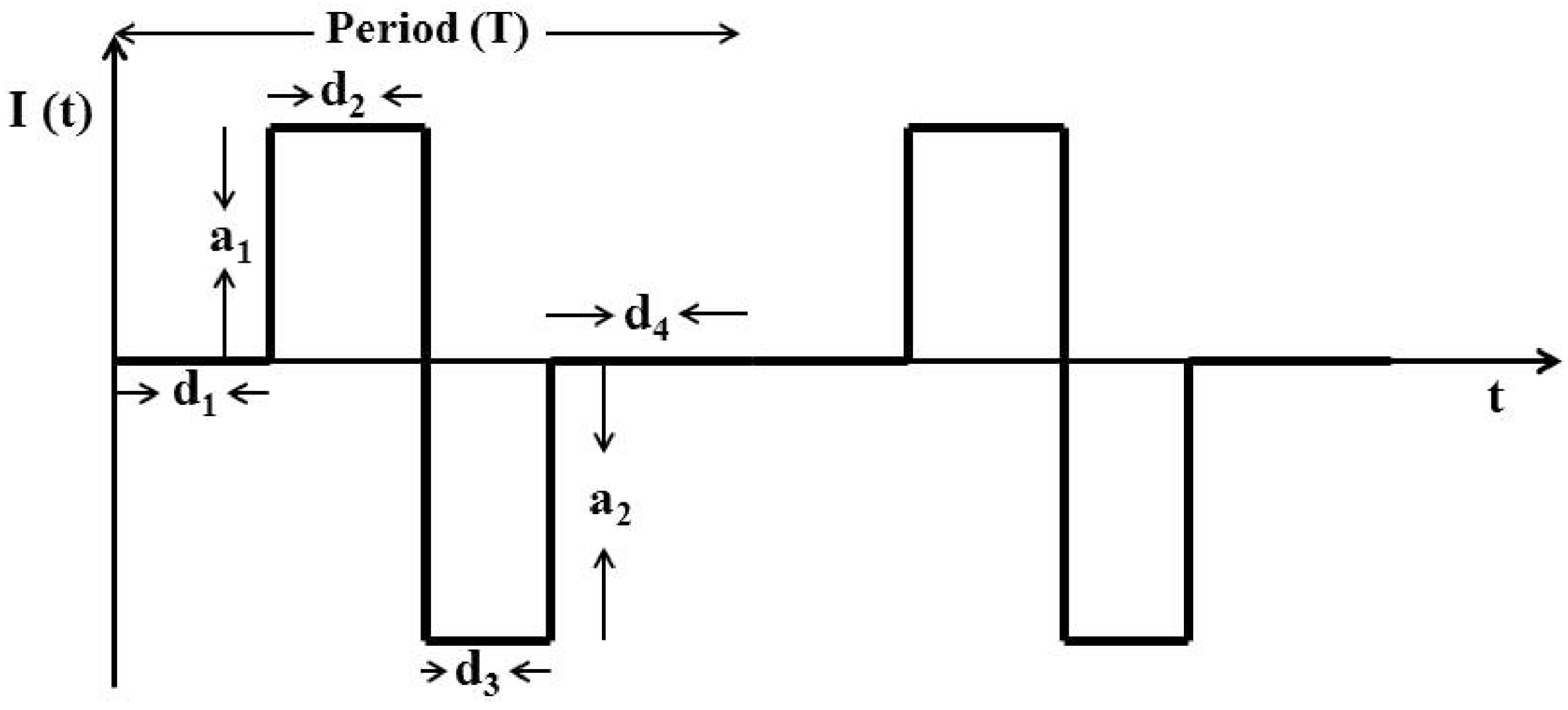
6.3. Intracortical Micro-Stimulation Based Closed-Loop BMI Design
7. Discussion
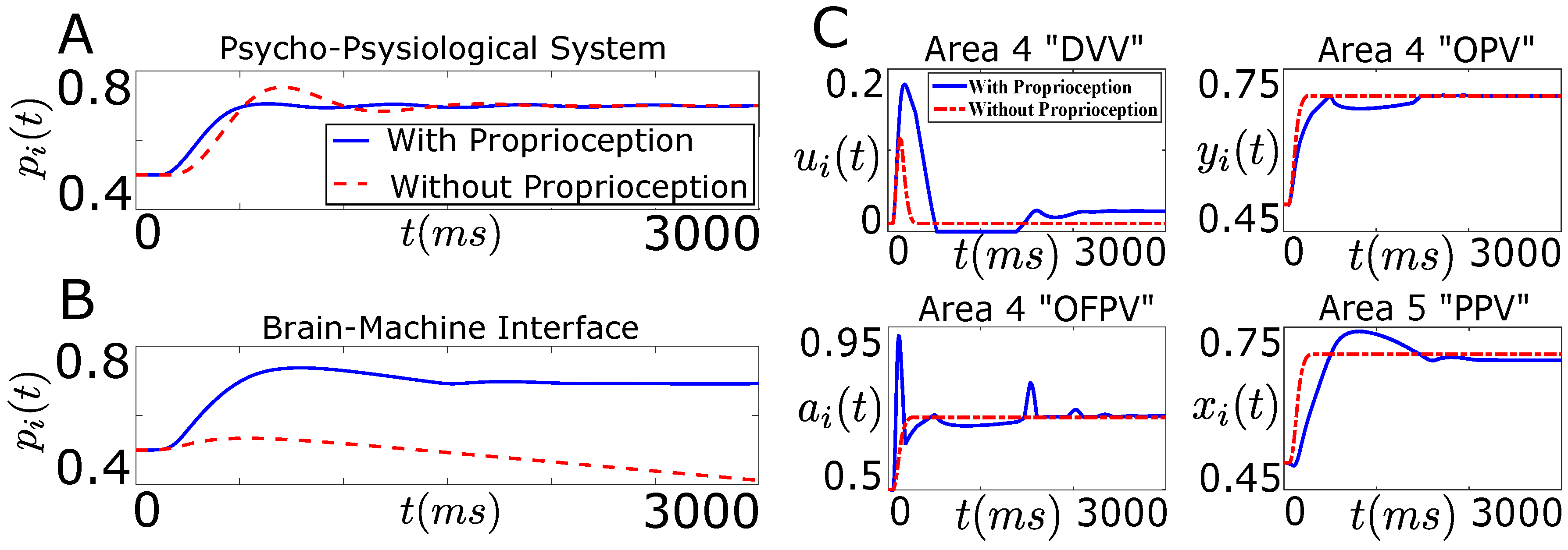
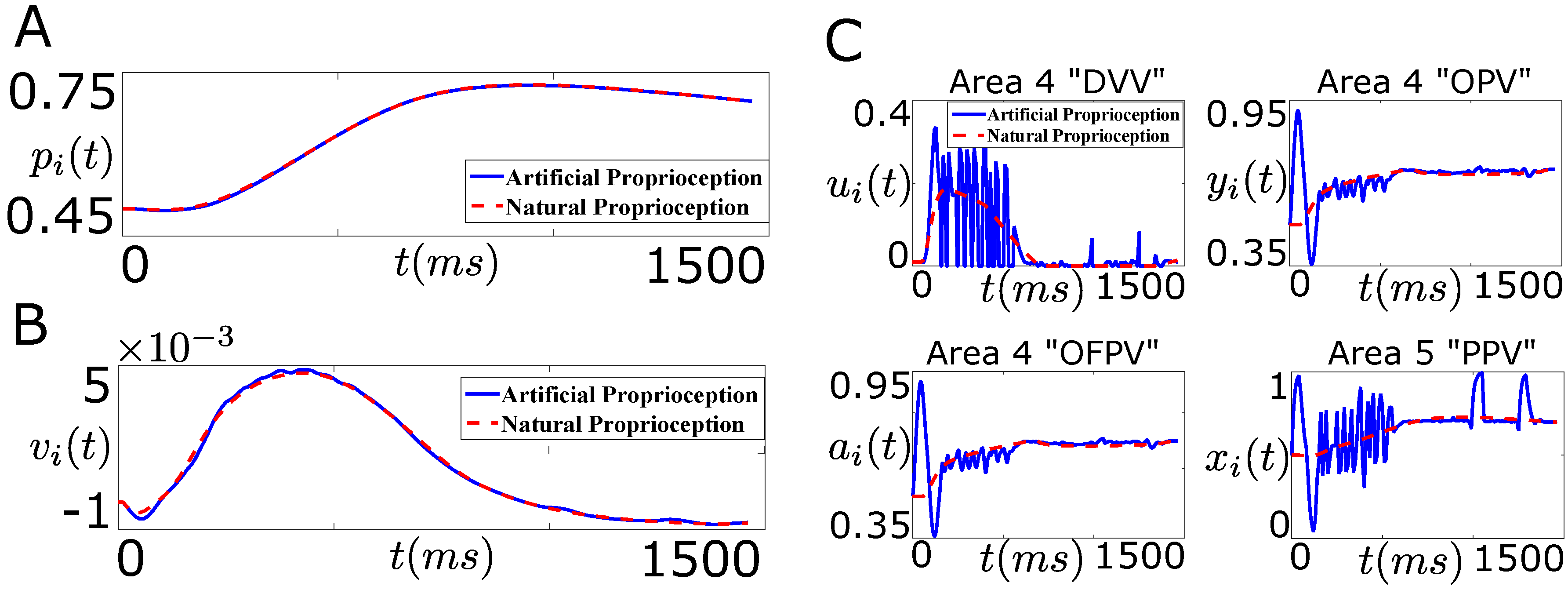
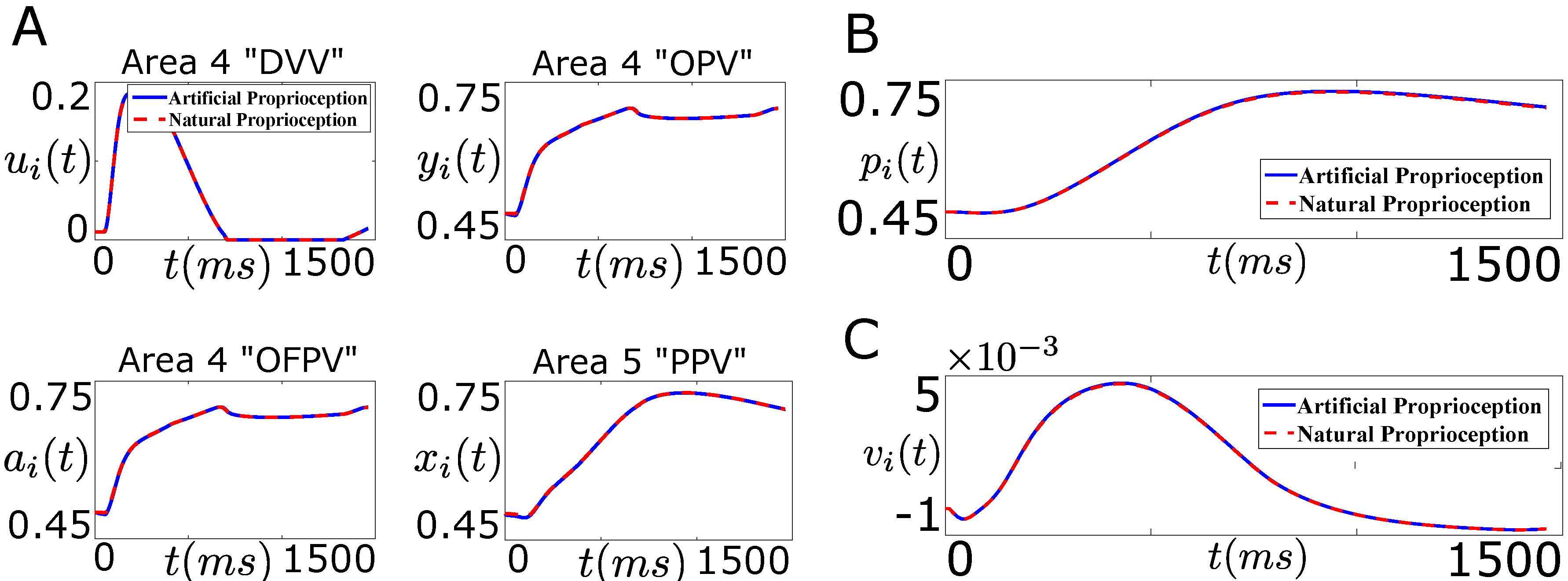
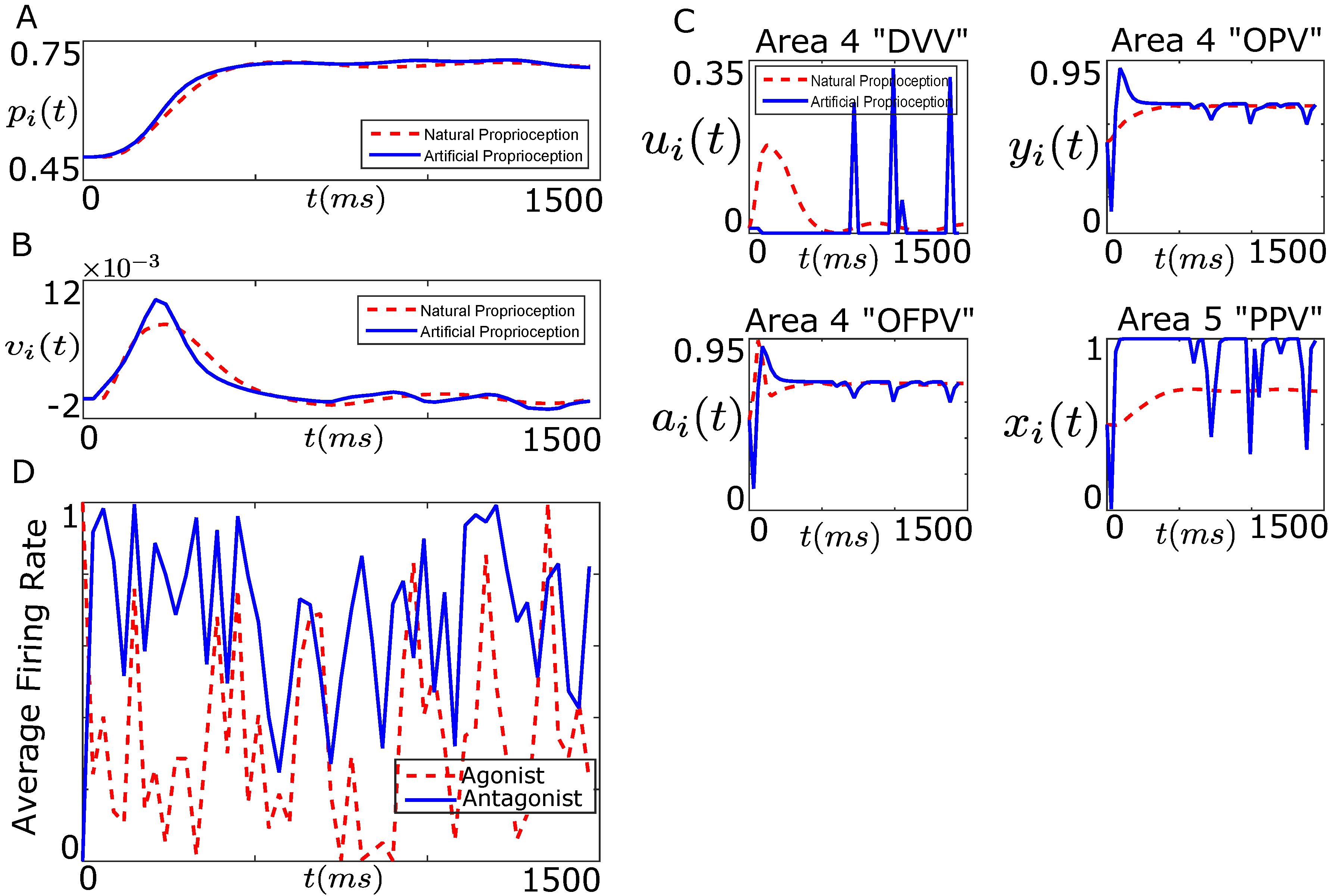
7.1. Tracking Firing Rate of Neurons which Encode Sensory Information Recovers the Natural Performance of BMI
7.2. Generalization beyond Tracking Problems
7.3. Limitations
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
Appendix A.1 Model Parameters for Recurrent Spiking Networks (Equation (23))
Appendix A.2 Particle Swarm Optimization Algorithm
- Position in the -dimensional search space (constraints set) ;
- Best position that it has individually found ;
- Velocity .
| Algorithm 1 |
|
| Algorithm 2 Offline stage |
|
| Online stage, for each : |
|
References
- Nicolelis, M.A.L.; Lebedev, M.A. Principles of neural ensemble physiology underlying the operation of brain-machine interfaces. Nat. Rev. 2009, 10, 530–540. [Google Scholar] [CrossRef] [PubMed]
- Moritz, C.T.; Perlmutter, S.I.; Fetz, E.E. Direct control of paralyzed muscles by cortical neurons. Nature 2008, 486, 639–643. [Google Scholar] [CrossRef] [PubMed]
- Doherty, J.E.; Lebedev, M.A.; Ifft, P.J.; Zhuang, K.Z.; Shokur, S.; Bleuler, H.; Nicolelis, M.A.L. Active tactile exploration using a brain-machine-brain interface. Nature 2011, 479, 228–231. [Google Scholar] [CrossRef] [PubMed]
- Hochberg, L.R.; Serruya, M.D.; Friehs, G.M.; Mukand, J.A.; Saleh, M.; Caplan, A.H.; Branner, A.; Chen, D.; Penn, R.D.; Donoghue, J.P. Neuronal ensemble control of prosthetic devices by a human with tetraplegia. Nature 2006, 442, 164–171. [Google Scholar] [CrossRef] [PubMed]
- Velliste, M.; Perel, S.; Spalding, M.C.; Whitford, A.S.; Schwartz, A.B. Cortical control of a prosthetic arm for self-feeding. Nature 2008, 453, 1098–1101. [Google Scholar] [CrossRef] [PubMed]
- Koyoma, S.; Chase, S.M.; Whitford, A.S.; Velliste, M.; Schwartz, A.B.; Kass, R.E. Comparison of brain-computer interface decoding algorithms in open-loop and closed-loop control. J. Comput. Neurosci. 2010, 29, 73–87. [Google Scholar] [CrossRef] [PubMed]
- Héliot, R.; Ganguly, K.; Jimenez, J.; Carmena, J.M. Learning in closed-loop brain–machine interfaces: Modeling and experimental validation. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2010, 40, 1387–1397. [Google Scholar] [CrossRef] [PubMed]
- Cunnigham, J.P.; Nuyujukian, P.; Gilja, V.; Chestek, C.A.; Ryu, S.I.; Shenoy, K.V. A closed-loop human simulator for investigating the role of feedback-control in Brain Machine Interfaces. J. Neurophysiol. 2011, 105, 1932–1949. [Google Scholar] [CrossRef] [PubMed]
- Moritz, C.T.; Fetz, E.E. Volitional control of single cortical neurons in a brain-machine interface. J. Neural Eng. 2011, 8, 025017. [Google Scholar] [CrossRef] [PubMed]
- Hochberg, L.R.; Bacher, D.; Jarosiewicz, B.; Masse, N.Y.; Simeral, J.D.; Vogel, J.; Haddadin, S.; Liu, J.; Cash, S.S.; van der Smagt, P.; et al. Reach and grasp by people with tetraplegia using a neurally controlled robotic arm. Nature 2012, 485, 372–375. [Google Scholar] [CrossRef] [PubMed]
- Ethier, C.; Oby, E.R.; Bauman, M.J.; Miller, L.E. Restoration of grasp following paralysis through brain-controlled stimulation of muscles. Nature 2012, 485, 368–371. [Google Scholar] [CrossRef] [PubMed]
- Scherberger, H. Neural control of motor prostheses. Curr. Opin. Neurobiol. 2009, 19, 629–633. [Google Scholar] [CrossRef] [PubMed]
- Suminski, A.J.; Tkach, D.C.; Fagg, A.H.; Hatsopoulos, N.G. Incorporating feedback from multiple sensory modalities enhances brain-machine interface control. J. Neurosci. 2010, 30, 16777–16787. [Google Scholar] [CrossRef] [PubMed]
- Weber, D.J.; London, B.M.; Hokanson, J.A.; Ayers, C.A.; Gaunt, R.A.; Torres, R.R.; Zaaimi, B.; Miller, L.E. Limb-state information encoded by peripheral and central somatosensory neurons: Implications for an afferent interface. IEEE Trans. Neural Syst. Rehabil. Eng. 2011, 19, 501–513. [Google Scholar] [CrossRef] [PubMed]
- Dadarlat, M.C.; O’Doherty, J.E.; Sabes, P.N. A learning-based approach to artificial sensory feedback leads to optimal integration. Nat. Neurosci. 2015, 18, 138–144. [Google Scholar] [CrossRef] [PubMed]
- Kumar, G.; Aggarwal, V.; Thakor, N.V.; Schieber, M.H.; Kothare, M.V. An optimal control problem in closed-loop neuroprostheses. In Proceedings of the 2011 50th IEEE Conference on Decision and Control and European Control Conference (CDC-ECC), Orlando, FL, USA, 12–15 December 2011; pp. 53–58.
- Lagang, M.; Srinivasan, L. Stochastic optimal control as a theory of brain-machine interface operation. Neural Comput. 2013, 25, 374–417. [Google Scholar] [CrossRef] [PubMed]
- Benyamini, M.; Zacksenhouse, M. Optimal feedback control successfully explains changes in neural modulations during experiments with brain-machine interfaces. Front. Syst. Neurosci. 2015, 9, 71. [Google Scholar] [CrossRef] [PubMed]
- Kumar, G.; Schieber, M.H.; Thakor, N.V.; Kothare, M.V. Designing closed-loop brain-machine interfaces using optimal receding horizon control. In Proceedings of the 2013 American Control Conference, Washington, DC, USA, 17–19 June 2013; pp. 5029–5034.
- Pan, H.; Ding, B.; Zhong, W.; Kumar, G.; Kothare, M.V. Designing Closed-loop Brain-Machine Interfaces with Network of Spiking Neurons Using MPC Strategy. In Proceedings of the 2015 American Control Conference, Chicago, IL, USA, 1–3 July 2015; pp. 2543–2548.
- Bullock, D.; Cisek, P.; Grossberg, S. Cortical Networks for Control of Voluntary Arm Movements under Variable Force Conditions. Cerebral Cortex 1998, 8, 48–62. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.P.; Sanchez, J.C.; Rao, Y.N.; Erdogmus, D.; Carmena, J.M.; Lebedev, M.A.; Nicolelis, M.A.L.; Principe, J.C. A comparison of optimal MIMO linear and nonlinear models for brain-machine interfaces. J. Neural Eng. 2006, 3, 145–161. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; Mumford, D.; Gao, Y.; Bienenstock, E.; Donoghue, J.P. Modeling and decoding motor cortical activity using a switching Kalman filter. IEEE Trans. Biomed. Eng. 2004, 51, 933–942. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; Black, M.J.; Mumford, D.; Gao, Y.; Bienenstock, E.; Donoghue, J.P. Bayesian population decoding of motor cortical activity using a Kalman filter. Neural Comput. 2006, 18, 80–118. [Google Scholar] [CrossRef] [PubMed]
- Mulliken, G.H.; Musallam, S.; Anderson, R.A. Decoding trajectories from posterior parietal cortex ensembles. J. Neurosci. 2008, 28, 12913–12926. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; O’Doherty, J.E.; Hanson, T.L.; Lebedev, M.A.; Henriquez, C.S.; Nicolelis, M.A.L. Unscented Kalman Filter for Brain-Machine Interfaces. PLoS ONE 2009, 4, e6243. [Google Scholar] [CrossRef] [PubMed]
- Dangi, S.; Gowda, S.; Héliot, R.; Carmena, J.M. Adaptive Kalman filtering for closed-loop Brain-Machine Interface systems. In Proceedings of the 2011 5th International IEEE/EMBS Conference on Neural Engineering (NER), Cancun, Mexico, 27 April–1 May 2011; pp. 609–612.
- Gilja, V.; Nuyujukian, P.; Chestek, C.A.; Cunningham, J.P.; Yu, B.M.; Fan, J.M.; Churchland, M.K.; Kaufman, M.T.; Kao, J.C.; Ryu, S.I.; et al. A high-performance neural prosthesis enabled by control algorithm design. Nature Neurosci. 2012, 15, 1752–1757. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, V.; Acharya, S.; Tenore, F.; Shin, H.C.; Cummings, R.E.; Schieber, M.H.; Thakor, N.V. Asynchronous decoding of dexterous finger movements using M1 neurons. IEEE Trans. Neural Syst. Rehabil. Eng. 2008, 16, 3–14. [Google Scholar] [CrossRef] [PubMed]
- Sussillo, D.; Nuyujukian, P.; Fan, J.M.; Kao, J.C.; Stavisky, S.D.; Ryu, S.I.; Shenoy, K.V. A recurrent neural networks for closed-loop intracortical brain-machine interface decoders. J. Neural Eng. 2012, 9, 026027. [Google Scholar] [CrossRef] [PubMed]
- Bizzi, E.; Accornero, N.; Chapple, W.; Hogan, W. Posture control and trajectory formation during arm movement. J. Neurosci. 1984, 4, 2738–2744. [Google Scholar] [PubMed]
- Hanson, T.L.; Omarsson, B.; O’Doherty, J.E.; Peikon, I.A.; Lebedev, M.A.; Nicolelis, M.A.L. High-side digitally current controlled biphasic bipolar microstimulator. IEEE Trans. Neural Syst. Rehabil. Eng. 2012, 20, 331–340. [Google Scholar] [CrossRef] [PubMed]
- Gerstner, W.; Kistler, W.M. Spiking Neuron Models: Single Neurons, Populations, Plasticity; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Merrill, D.R.; Bikson, M.; Jeffreys, J.G.R. Electrical stimulation of excitation tissue: Design of efficacious and safe protocols. J. Neurosci. Methods 2005, 141, 171–198. [Google Scholar] [CrossRef] [PubMed]
- Davidovics, N.S.; Fridman, G.Y.; Chiang, B.; Santina, C.C.D. Effects of biphasic current pulse frequency, amplitude, duration, and interphase gap on eye movement responses to prosthetic electrical stimulation of the vestibular nerve. IEEE Trans. Neural Syst. Rehabil. Eng. 2011, 19, 84–94. [Google Scholar] [CrossRef] [PubMed]
- Cogan, S. Neural stimulation and recording electrodes. Annu. Rev. Biomed. Eng. 2008, 10, 275–309. [Google Scholar] [CrossRef] [PubMed]
- Rakos, M.; Freudenschuss, B.; Girsch, W.; Hofer, C.; Kaus, J.; Meiners, T.; Paternostro, T.; Mayr, W. Electromyogram-controlled functional electrical stimulation for treatment of the paralyzed upper extremity. Artif. Organs 1999, 23, 466–469. [Google Scholar] [CrossRef] [PubMed]
- Micera, S.; Keller, T.; Lawrence, M.; Morari, M.; Popovic, D.B. Wearable neural prostheses. IEEE Eng. Med. Biol. Mag. 2010, 29, 64–69. [Google Scholar] [CrossRef] [PubMed]
- Butson, C.R.; McIntyre, C.C. Differences among implanted pulse generator waveforms cause variations in the neural response to deep brain stimulation. Clin. Neurophysiol. 2007, 118, 1889–1894. [Google Scholar] [CrossRef] [PubMed]
- Watanabe, T.; Kikuchi, H.; Fukushima, T.; Tomita, H.; Sugano, E.; Kurino, H.; Tanaka, T.; Tamai, M.; Koyanagi, M. Novel retinal prosthesis system with three dimensionally stacked LSI chip. In Proceedings of the 36th European Solid-State Device Research Conference, Montreux, Switzerland, 19–21 September 2006; pp. 327–330.
- Todorov, E. Optimality principles in sensorimotor control. Nat. Neurosci. 2004, 7, 907–915. [Google Scholar] [CrossRef] [PubMed]
- Bratton, D.; Kennedy, J. Defining a standard for particle swarm optimization. In Proceedings of the Swarm Intelligence Symposium, Honolulu, HI, USA, 1–5 April 2007; pp. 120–127.
- Wei-Min, Z.; Shao-Jun, L.; Feng, Q. θ-PSO: A new strategy of particle swarm optimization. J. Zhejiang Univ. Sci. A 2008, 9, 786–790. [Google Scholar] [CrossRef]
- Shi, Y.; Eberhart, R. A modified particle swarm optimizer. In Proceedings of the 1998 IEEE International Conference on Evolutionary Computation, IEEE World Congress on Computational Intelligence, Anchorage, AK, USA, 4–9 May 1998; pp. 69–73.














© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumar, G.; Kothare, M.V.; Thakor, N.V.; Schieber, M.H.; Pan, H.; Ding, B.; Zhong, W. Designing Closed-Loop Brain-Machine Interfaces Using Model Predictive Control. Technologies 2016, 4, 18. https://doi.org/10.3390/technologies4020018
Kumar G, Kothare MV, Thakor NV, Schieber MH, Pan H, Ding B, Zhong W. Designing Closed-Loop Brain-Machine Interfaces Using Model Predictive Control. Technologies. 2016; 4(2):18. https://doi.org/10.3390/technologies4020018
Chicago/Turabian StyleKumar, Gautam, Mayuresh V. Kothare, Nitish V. Thakor, Marc H. Schieber, Hongguang Pan, Baocang Ding, and Weimin Zhong. 2016. "Designing Closed-Loop Brain-Machine Interfaces Using Model Predictive Control" Technologies 4, no. 2: 18. https://doi.org/10.3390/technologies4020018
APA StyleKumar, G., Kothare, M. V., Thakor, N. V., Schieber, M. H., Pan, H., Ding, B., & Zhong, W. (2016). Designing Closed-Loop Brain-Machine Interfaces Using Model Predictive Control. Technologies, 4(2), 18. https://doi.org/10.3390/technologies4020018