
Wind Speed Prediction via Collaborative Filtering on Virtual Edge Expanding Graphs

 , ,
, , 
Abstract
:1. Introduction
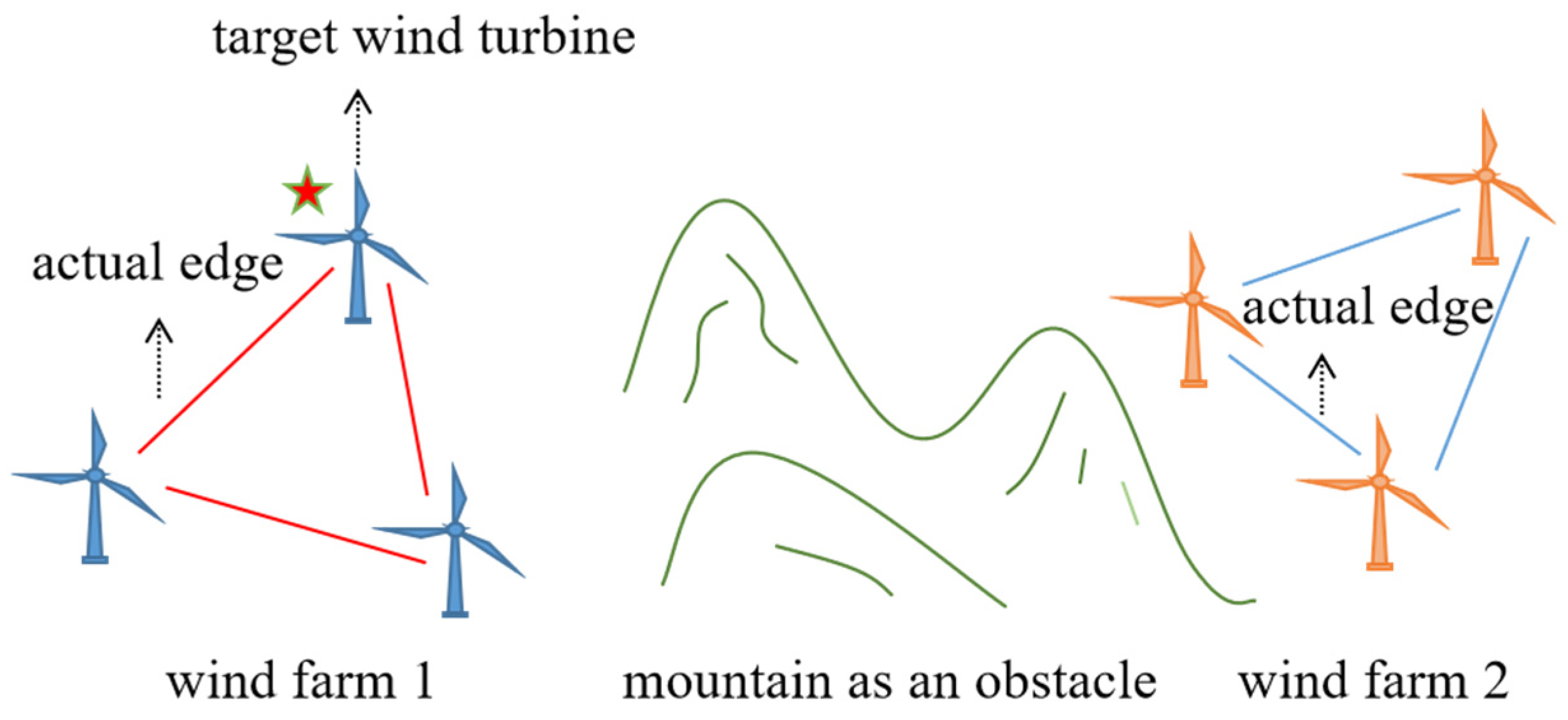
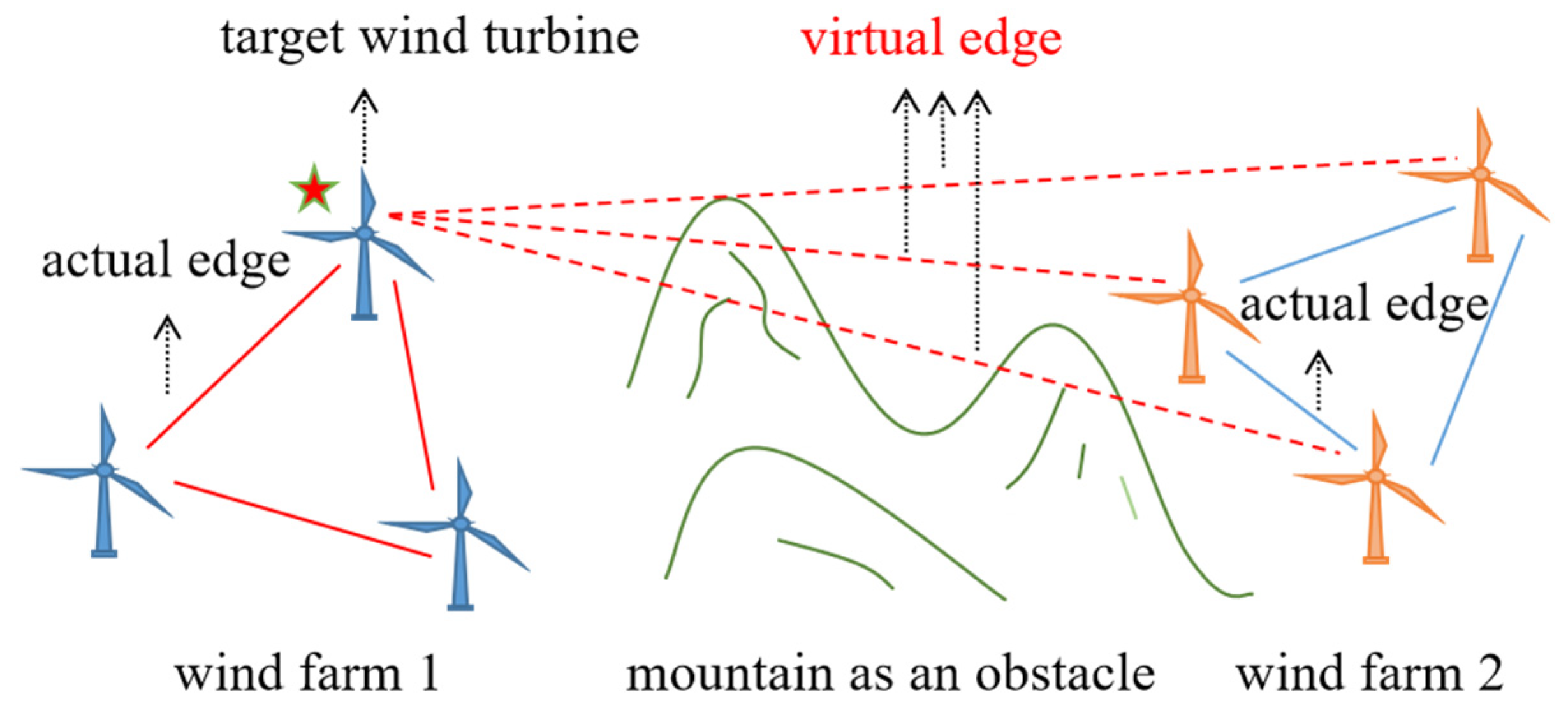
- Aiming at the problem that the datasets used for wind speed prediction often come from the wind turbine to be predicted and the surrounding wind turbines, this paper proposes to extend the meaning of the actual edge, build a virtual edge to connect wind turbines in different areas, and enhance usage dataset size.
- In view of the problem that the spatiotemporal features extracted in wind speed prediction are not sufficient, this paper proposes to use the collaborative filtering algorithm to preprocess the wind speed sequence from the perspective of pattern mining and matching, and then use k-d tree to match the wind speed pattern to effectively extract and integrate the wind speed information.
- For the proposed new wind speed prediction method, this paper constructs a model with LSTM network as the main body, then evaluates the performance of the model through mean square error and root mean square difference, comparing it with some popular wind speed prediction methods. Experiments show that the use of a virtual edge expansion graph and a collaborative filtering algorithm is beneficial to the improvement of the wind speed prediction effect.
2. Related Work
2.1. Common Methods
2.2. Collaborative Filtering
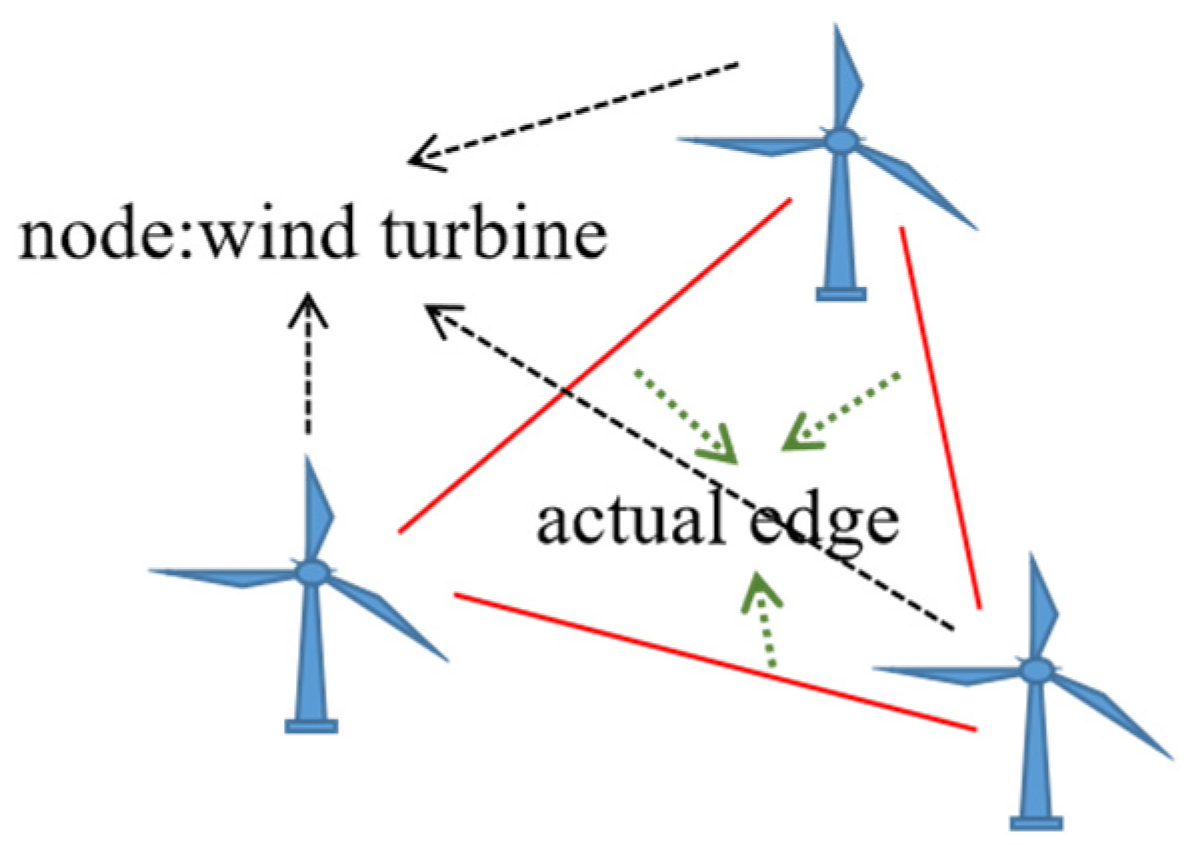
2.3. Wind Farm Graph
3. Method
3.1. Virtual Edge Expansion Graph
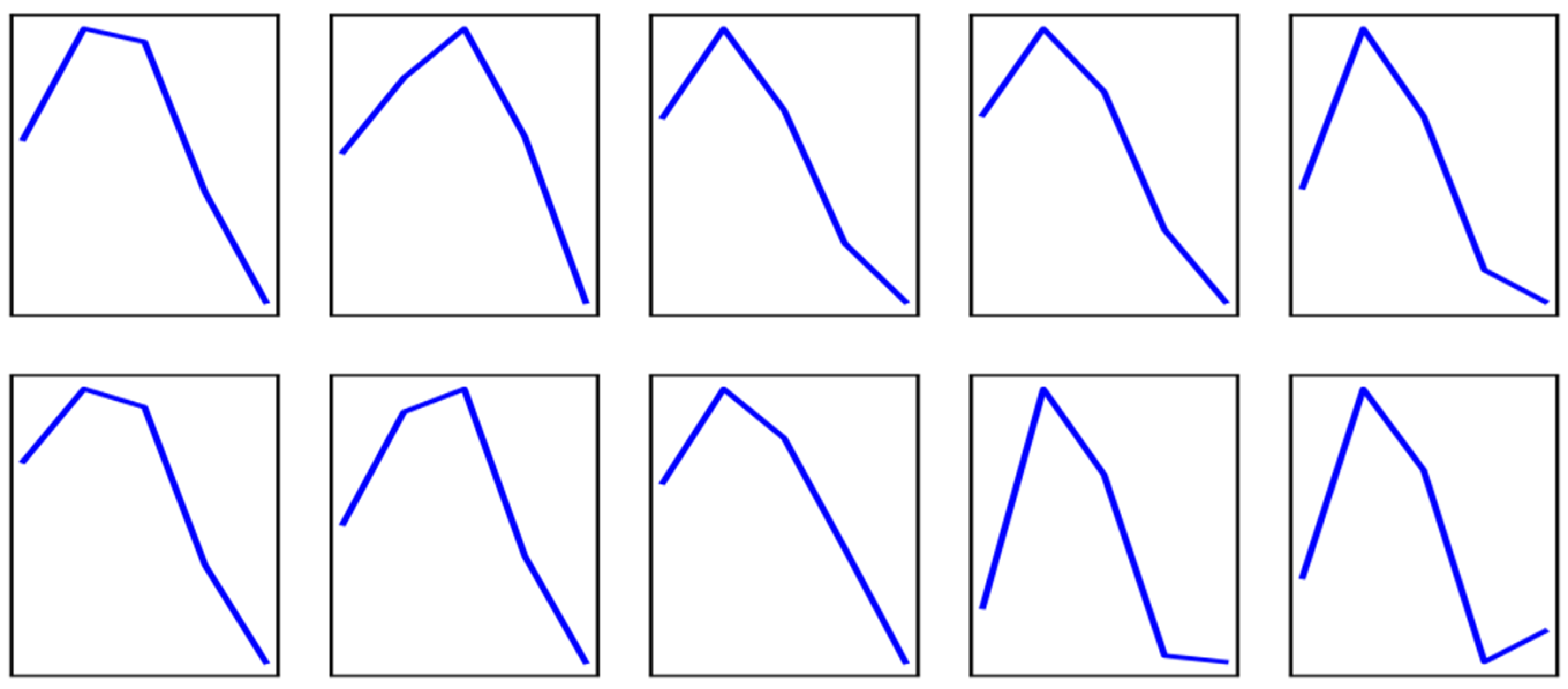
3.2. Wind Speed Sequence Preprocessing
3.3. k-d Tree Implements Collaborative Filtering
- Determine the split domain. The length of the pattern is the dimension of the space, which is assumed to be k. Calculate the data variance of all pattern in dimensions 1 to k, assuming that the data variance in the p dimension is the largest, then the split domain value is p.
- Determine the node-data domain. The patterns are sorted according to the value in the p dimension. The value in the middle is the data point in the node-data domain. Assuming that the pattern is (1, 2, …, pnumber, … k), the median pnumber is the segmentation threshold. Then, the split hyperplane of this node is the plane p = pnumber, which passes through (1, 2, …, pnumber, … k) and is perpendicular to the split = p dimension.
- Determine the left subspace and the right subspace. The dividing hyperplane p = pnumber divides the whole space into two parts: the part of p ≤ pnumber is the left subspace, and the part of p > pnumber is the right subspace. Repeat this process; each split splits the dataset and space into two parts until the space contains only one pattern.
| Algorithm 1 Wind speed prediction method based on collaborative filtering |
| Input: Wind power dataset; Output: Mean square error and root mean square error. 1. Load wind speed data and divide training set and test set for each set of wind speed series. 2. Perform pattern mining, preprocessing of the training set and test set, dividing wind speed data into two sets, X and Y. 3. Perform pattern matching, using the k-d tree to filter out the top-k patterns with the highest similarity, return the index and distance, and splice yi and distance together to generate a new pattern, set M. 4. Perform model training. Input the set M into the model, and train the model by continuously reducing the value of the loss function until convergence occurs. 5. Perform the wind speed forecast. Send the test set to the model to predict and evaluate the effect of the model with mean square error and root mean square error. |
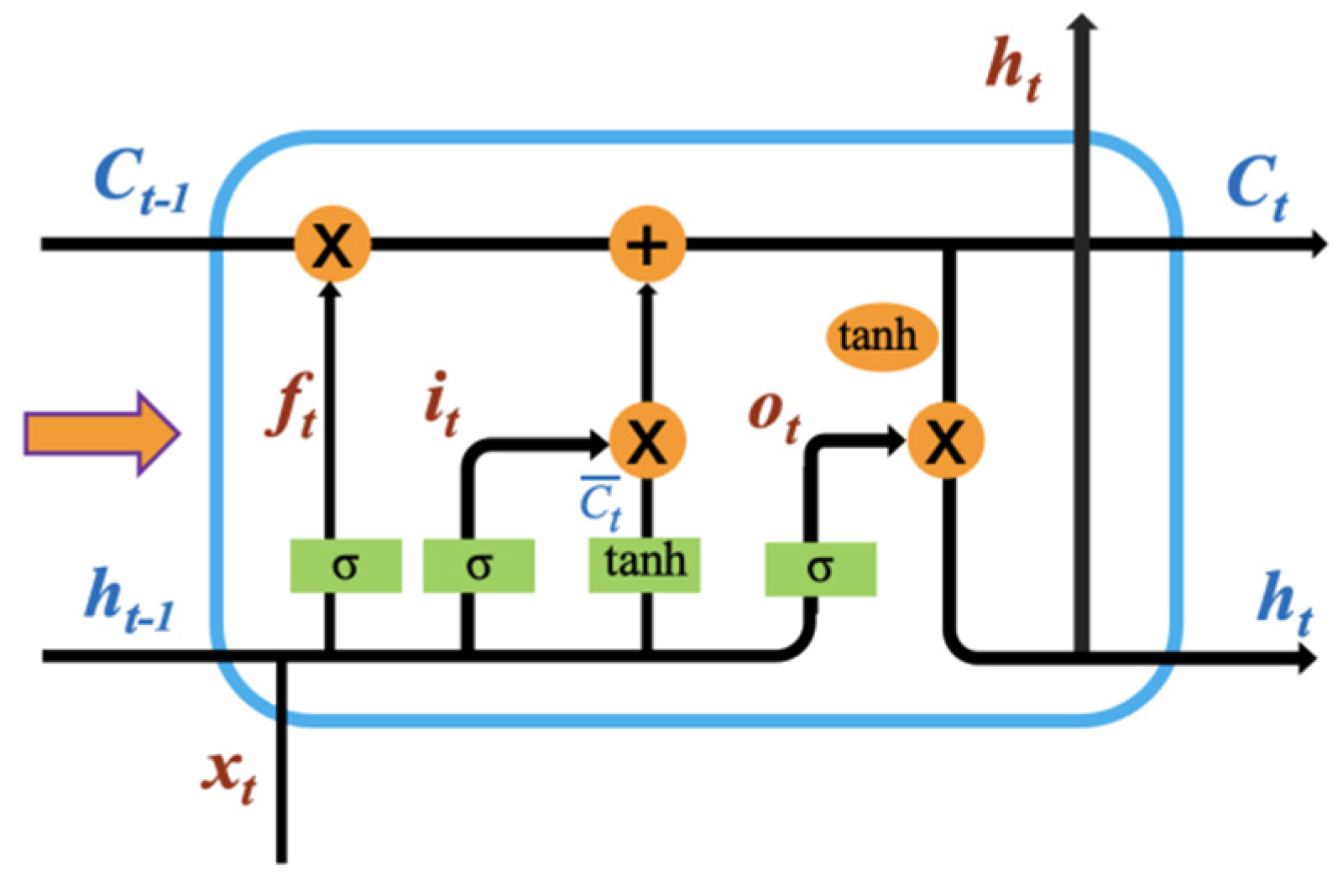
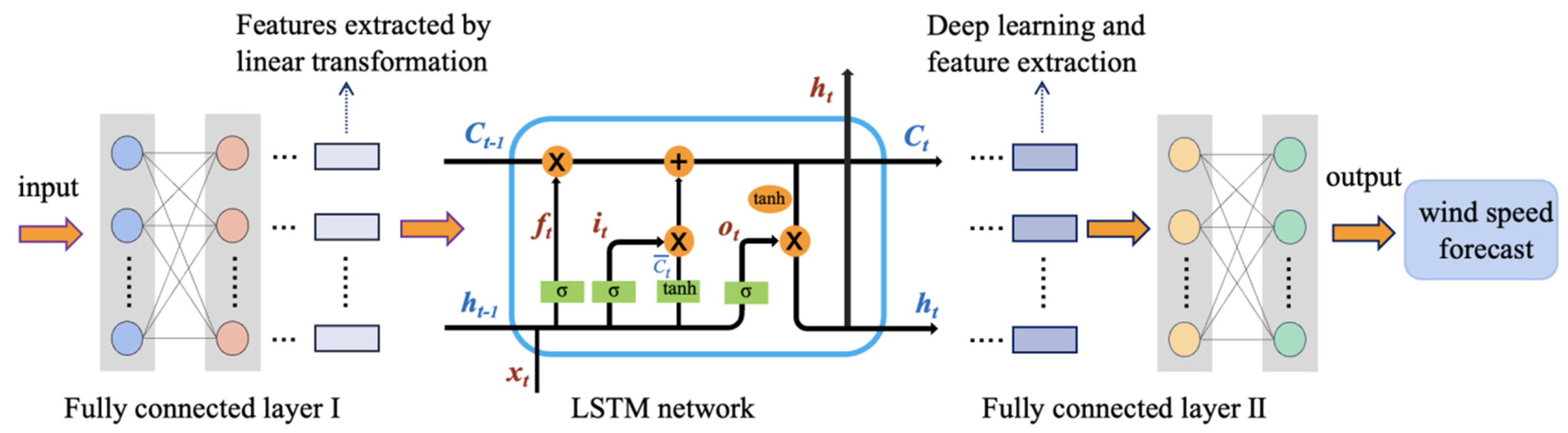
3.4. Wind Speed Prediction Model Structure
4. Experiments
4.1. Datasets and Evaluation Metrics
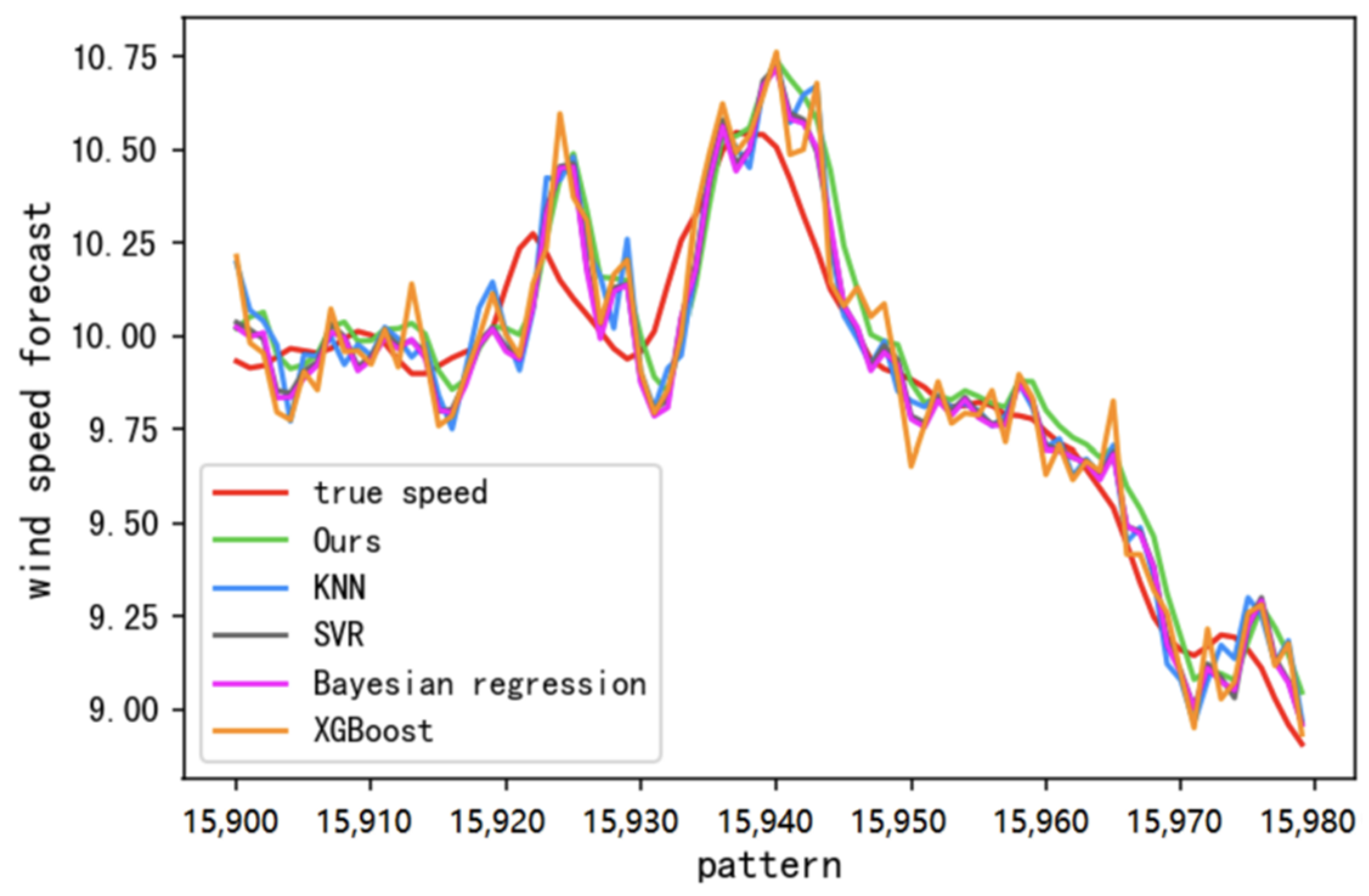
4.2. Experimental Results and Analysis
- KNN [41]: It is a commonly used data mining algorithm. The basic principle is to find k points similar to the point to be predicted through a distance metric relationship, and then perform regression prediction based on these k points.
- SVR [42]: It is an important branch of support vector machine leraning, based on finding a hyperplane such that the distance from all data to this hyperplane is minimized; it is often used in regression problems.
- Bayesian regression [43]: The basic idea is to treat the dataset and parameters as a known distribution, predicting the posterior probability distribution based on the known prior probability distribution of historical observations.
- XGBoost [44]: It is essentially an iterative decision tree algorithm, which is improved based on the gradient boosting tree (GBDT), which effectively avoids overfitting and improves the speed and accuracy of the model.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jørgensen, K.L.; Shaker, H.R. Wind Power Forecasting Using Machine Learning: State of the Art, Trends and Challenges. In Proceedings of the 2020 IEEE 8th International Conference on Smart Energy Grid Engineering (SEGE), Oshawa, ON, Canada, 12–14 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 44–50. [Google Scholar] [CrossRef]
- Liu, H.; Yang, R.; Wang, T.; Zhang, L. A hybrid neural network model for short-term wind speed forecasting based on decomposition, multi-learner ensemble, and adaptive multiple error corrections. Renew. Energy 2021, 165, 573–594. [Google Scholar] [CrossRef]
- Chen, X.; Lai, C.S.; Ng WW, Y.; Pan, K.; Lai, L.L.; Zhong, C. A stochastic sensitivity-based multi-objective optimization method for short-term wind speed interval prediction. Int. J. Mach. Learn. Cybern. 2021, 12, 2579–2590. [Google Scholar] [CrossRef]
- Zhao, X.; Liu, J.; Yu, D.; Chang, J. One-day-ahead probabilistic wind speed forecast based on optimized numerical weather prediction data. Energy Convers. Manag. 2018, 164, 560–569. [Google Scholar] [CrossRef]
- Moreno, S.R.; da Silva, R.G.; Mariani, V.C.; Santos, C.L.D. Multi-step wind speed forecasting based on hybrid multi-stage decomposition model and long short-term memory neural network. Energy Convers. Manag. 2020, 213, 112869. [Google Scholar] [CrossRef]
- Senthil, K.P. Improved prediction of wind speed using machine learning. EAI Endorsed Trans. Energy Web 2019, 6, e2. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Guo, Z.H.; Su, Z.Y.; Zhao, Z.Y.; Xiao, X.; Liu, F. An improved multi-step forecasting model based on WRF ensembles and creative fuzzy systems for wind speed. Appl. Energy 2016, 162, 808–826. [Google Scholar] [CrossRef]
- Yan, J.; Li, K.; Bai, E.; Zhao, X.; Xue, Y.; Foley, A.M. Analytical iterative multistep interval forecasts of wind generation based on TLGP. IEEE Trans. Sustain. Energy 2018, 10, 625–636. [Google Scholar] [CrossRef] [Green Version]
- Erdem, E.; Shi, J. ARMA based approaches for forecasting the tuple of wind speed and direction. Appl. Energy 2011, 88, 1405–1414. [Google Scholar] [CrossRef]
- Singh, S.N.; Mohapatra, A. Repeated wavelet transform based ARIMA model for very short-term wind speed forecasting. Renew. Energy 2019, 136, 758–768. [Google Scholar] [CrossRef]
- Aly HH, H. An intelligent hybrid model of neuro Wavelet, time series and Recurrent Kalman Filter for wind speed forecasting. Sustain. Energy Technol. Assess. 2020, 41, 100802. [Google Scholar] [CrossRef]
- Li, W.; Jia, X.; Li, X.; Wang, Y.; Lee, J. A Markov model for short term wind speed prediction by integrating the wind acceleration information. Renew. Energy 2021, 164, 242–253. [Google Scholar] [CrossRef]
- Chen, K.; Yu, J. Short-term wind speed prediction using an unscented Kalman filter based state-space support vector regression approach. Appl. Energy 2014, 113, 690–705. [Google Scholar] [CrossRef]
- Wen, Y.; Song, M.; Wang, J. A combined AR-kNN model for short-term wind speed forecasting. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 6342–6346. [Google Scholar] [CrossRef]
- Samadianfard, S.; Hashemi, S.; Kargar, K.; Izadyar, M.; Mostafaeipour, A.; Mosavi, A.; Shamshirband, S. Wind speed prediction using a hybrid model of the multi-layer perceptron and whale optimization algorithm. Energy Rep. 2020, 6, 1147–1159. [Google Scholar] [CrossRef]
- Jin, D.; You, X.; Li, W.; He, D.; Cui, P.; Fogelman-Soulié, F.; Chakraborty, T. Incorporating network embedding into markov random field for better community detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 160–167. [Google Scholar] [CrossRef]
- Duan, J.; Zuo, H.; Bai, Y.; Chang, M.; Chen, B. Short-term wind speed forecasting using recurrent neural networks with error correction. Energy 2020, 217, 119397. [Google Scholar] [CrossRef]
- Ehsan, M.A.; Shahirinia, A.; Zhang, N.; Oladunni, T. Wind Speed Prediction and Visualization Using Long Short-Term Memory Networks (LSTM). In Proceedings of the 2020 10th International Conference on Information Science and Technology (ICIST), Plymouth, UK, 9–15 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 234–240. [Google Scholar] [CrossRef]
- Trebing, K.; Mehrkanoon, S. Wind speed prediction using multidimensional convolutional neural networks. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, Australia, 1–4 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 713–720. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, H.; Tao, S. Hybrid deep graph convolutional networks. Int. J. Mach. Learn. Cybern. 2022, 11, 1–17. [Google Scholar] [CrossRef]
- Ding, G.; Qin, L. Study on the prediction of stock price based on the associated network model of LSTM. Int. J. Mach. Learn. Cybern. 2020, 11, 1307–1317. [Google Scholar] [CrossRef] [Green Version]
- Du, B.; Peng, H.; Wang, S.; Bhuiyan MZ, A.; Wang, L.; Gong, Q.; Li, J. Deep irregular convolutional residual LSTM for urban traffic passenger flows prediction. IEEE Trans. Intell. Transp. Syst. 2019, 21, 972–985. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, M.; Li, H. Urban traffic flow forecast based on FastGCRNN. J. Adv. Transp. 2020, 2020, 8859538. [Google Scholar] [CrossRef]
- Peng, H.; Wang, H.; Du, B.; Bhuiyan, M.Z.A.; Ma, H.; Liu, J.; Yu, P.S. Spatial temporal incidence dynamic graph neural networks for traffic flow forecasting. Inf. Sci. 2020, 521, 277–290. [Google Scholar] [CrossRef]
- Cheng, L.; Zang, H.; Xu, Y.; Wei, Z.; Sun, G. Augmented Convolutional Network for Wind Power Prediction: A New Recurrent Architecture Design With Spatial-Temporal Image Inputs. IEEE Trans. Ind. Inform. 2021, 17, 6981–6993. [Google Scholar] [CrossRef]
- Jiajun, H.; Chuanjin, Y.; Yongle, L.; Huoyue, X. Ultra-short term wind prediction with wavelet transform, deep belief network and ensemble learning. Energy Convers. Manag. 2020, 205, 112418. [Google Scholar] [CrossRef]
- Abedinia, O.; Lotfi, M.; Sobhani, B.; Shafie-khah, M.; Catalao, J.P.S. Improved EMD-based complex prediction model for wind power forecasting. IEEE Trans. Sustain. Energy 2020, 11, 2790–2802. [Google Scholar] [CrossRef]
- Hu, H.; Wang, L.; Tao, R. Wind speed forecasting based on variational mode decomposition and improved echo state network. Renew. Energy 2021, 164, 729–751. [Google Scholar] [CrossRef]
- Chen, Y.; Dong, Z.; Wang, Y.; Su, J.; Han, Z.; Zhou, D.; Bao, Y. Short-term wind speed predicting framework based on EEMD-GA-LSTM method under large scaled wind history. Energy Convers. Manag. 2021, 227, 113559. [Google Scholar] [CrossRef]
- Chao, G.; Luo, Y.; Ding, W. Recent advances in supervised dimension reduction: A survey. Mach. Learn. Knowl. Extr. 2019, 1, 20. [Google Scholar] [CrossRef] [Green Version]
- Saxena, A.; Prasad, M.; Gupta, A.; Bharill, N.; Prakash, O.P.; Tiwari, A.; Tiwari, M.E.; Ding, W.; Lin, C.T. A review of clustering techniques and developments. Neurocomputing 2017, 267, 664–681. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Q.; Chen, J.; Shi, D.; Zhu, L.; Bai, X.; Duan, X.; Liu, Y. Learning temporal and spatial correlations jointly: A unified framework for wind speed prediction. IEEE Trans. Sustain. Energy 2019, 11, 509–523. [Google Scholar] [CrossRef]
- Tao, H.; Lu, X. On comparing six optimization algorithms for network-based wind speed forecasting. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 8843–8850. [Google Scholar] [CrossRef]
- Subramaniam Nachimuthu, D.; Banerjee, A.; Karuppaiah, J. Multi-step wind speed and wind power forecasting using variational momentum factor and deep learning based intelligent neural network models. Concurr. Comput. Pract. Exp. 2022, 34, e6772. [Google Scholar] [CrossRef]
- Zhang, Z.; Ye, L.; Qin, H.; Liu, Y.; Wang, C.; Yu, X.; Li, J. Wind speed prediction method using shared weight long short-term memory network and Gaussian process regression. Appl. Energy 2019, 247, 270–284. [Google Scholar] [CrossRef]
- Ekstrand, M.D.; Riedl, J.T.; Konstan, J.A. Collaborative Filtering Recommender Systems. In Foundations and Trends in Human-Computer Interaction; Now Publishers Inc.: Boston, MA, USA, 2011. [Google Scholar] [CrossRef]
- Ding, L.; Han, B.; Wang, S.; Li, X.; Song, B. User-centered recommendation using US-ELM based on dynamic graph model in E-commerce. Int. J. Mach. Learn. Cybern. 2019, 10, 693–703. [Google Scholar] [CrossRef]
- Das, J.; Majumder, S.; Gupta, P.; Mali, K. Collaborative recommendations using hierarchical clustering based on Kd trees and quadtrees. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2019, 27, 637–668. [Google Scholar] [CrossRef]
- Chen, F.; Wang, Y.C.; Wang, B.; Kuo, C.C.J. Graph representation learning: A survey. APSIPA Trans. Signal Inf. Process. 2020, 9, E15. [Google Scholar] [CrossRef]
- Graves, A. Supervised Sequence Labelling with Recurrent Neural Networks; Studies in Computational Intelligence; Springer: Cham, Switzerland, 2012. [Google Scholar] [CrossRef] [Green Version]
- Martínez, F.; Frías, M.P.; Pérez, M.D.; Rivera, A.J. A methodology for applying k-nearest neighbor to time series forecasting. Artif. Intell. Rev. 2019, 52, 2019–2037. [Google Scholar] [CrossRef]
- Santamaría-Bonfil, G.; Reyes-Ballesteros, A.; Gershenson, C. Wind speed forecasting for wind farms: A method based on support vector regression. Renew. Energy 2016, 85, 790–809. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, H.; Srinivasan, D.; Hu, Q. Robust functional regression for wind speed forecasting based on Sparse Bayesian learning. Renew. Energy 2019, 132, 43–60. [Google Scholar] [CrossRef]
- Phan, Q.T.; Wu, Y.K.; Phan, Q.D. A Hybrid Wind Power Forecasting Model with XGBoost, Data Preprocessing Considering Different NWPs. Appl. Sci. 2021, 11, 1100. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
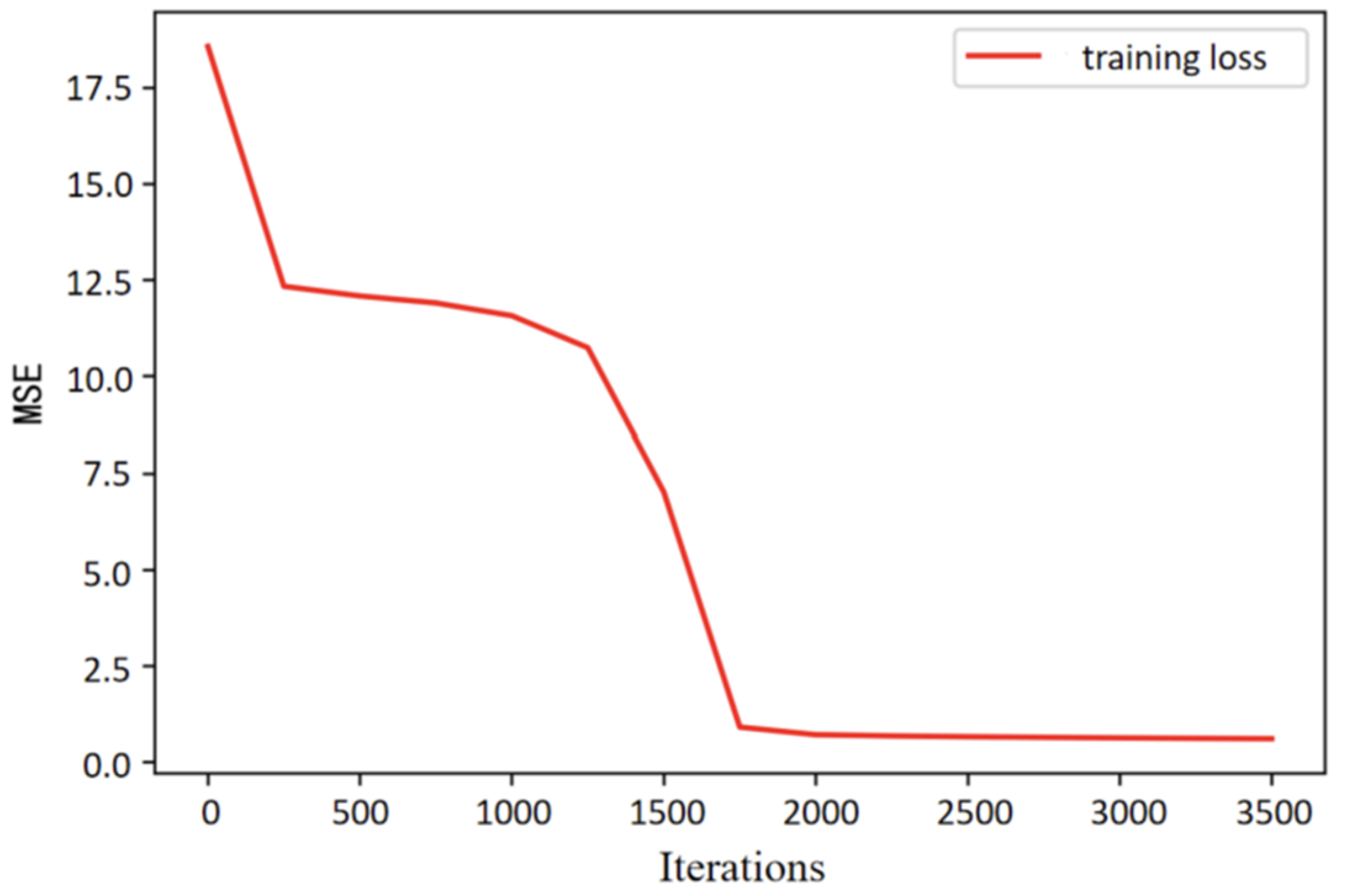{kind=link}
| Pattern Length | 3 | 5 | 7 | 9 | 11 | 13 | 15 |
|---|---|---|---|---|---|---|---|
| MSE | 0.3885 | 0.3446 | 0.3165 | 0.3019 | 0.3205 | 0.3442 | 0.3955 |
| RMSE | 0.6233 | 0.5870 | 0.5625 | 0.5494 | 0.5661 | 0.5867 | 0.6288 |
| Algorithms | Euclidean | Manhattan | Chebyshev |
|---|---|---|---|
| MSE | 0.3019 | 0.3217 | 0.3150 |
| RMSE | 0.5494 | 0.5671 | 0.5612 |
| Time (s) | 949.56 | 880.21 | 2200.72 |
| Whether to Expand the Graph with Virtual Edges | Yes | No |
|---|---|---|
| MSE | 0.2743 | 0.3083 |
| RMSE | 0.5237 | 0.5552 |
| Time (s) | 892.94 | 677.64 |
| Whether to Use Collaborative Filtering | Yes | No |
|---|---|---|
| MSE | 0.2743 | 0.3752 |
| RMSE | 0.5237 | 0.6125 |
| Time (s) | 892.94 | 726.64 |
| Models | Ours | KNN | SVR | Bayesian Regression | XGBoost |
|---|---|---|---|---|---|
| MSE | 0.2636 | 0.3153 | 0.2988 | 0.2915 | 0.3229 |
| RMSE | 0.5134 | 0.5615 | 0.5466 | 0.5399 | 0.5682 |
| Time (s) | 3168.11 | 1040.26 | 1447.17 | 1377.97 | 1889.08 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ying, X.; Zhao, K.; Liu, Z.; Gao, J.; He, D.; Li, X.; Xiong, W. Wind Speed Prediction via Collaborative Filtering on Virtual Edge Expanding Graphs. Mathematics 2022, 10, 1943. https://doi.org/10.3390/math10111943
Ying X, Zhao K, Liu Z, Gao J, He D, Li X, Xiong W. Wind Speed Prediction via Collaborative Filtering on Virtual Edge Expanding Graphs. Mathematics. 2022; 10(11):1943. https://doi.org/10.3390/math10111943
Chicago/Turabian StyleYing, Xiang, Keke Zhao, Zhiqiang Liu, Jie Gao, Dongxiao He, Xuewei Li, and Wei Xiong. 2022. "Wind Speed Prediction via Collaborative Filtering on Virtual Edge Expanding Graphs" Mathematics 10, no. 11: 1943. https://doi.org/10.3390/math10111943