
Interval Type-2 Fuzzy Envelope of Proportional Hesitant Fuzzy Linguistic Term Set: Application to Large-Scale Group Decision Making




1
Business School, University of Shanghai for Science and Technology, Shanghai 200093, China
2
Department of Computer Science, University of Jaen, 23071 Jaen, Spain
*
Author to whom correspondence should be addressed.
Mathematics 2022, 10(14), 2368; https://doi.org/10.3390/math10142368
Submission received: 30 May 2022
/
Revised: 28 June 2022
/
Accepted: 4 July 2022
/
Published: 6 July 2022
(This article belongs to the Special Issue New Trends in Fuzzy Sets Theory and Their Extensions)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Large-scale group decision-making (LS-GDM) problems are common in the daily life of human beings. Both information fusion and computing with words (CWW) technologies in LS-GDM suffer from challenges. In the current research, a proportional hesitant fuzzy linguistic term set (PHFLTS) will be applied to capture the preferences of sub-groups in LS-GDM, which decreases the information lost in information fusion processes. Novel fuzzy semantic representation models of PHFLTS, such as type-1 fuzzy envelope and interval type-2 fuzzy envelope, are respectively studied. The application of the proposed fuzzy entropies facilitates the CWW process with the PHFLTS under the framework of a fuzzy linguistic approach. In particular, linguistic uncertainties contained in the PHFLTS can be reflected in a comprehensive way when the type-2 fuzzy envelope is applied, which contributes to the decrease in the information lost during the CWW process. A novel LS-GDM method cooperating with the fuzzy semantic models of PHFLTS is proposed, in which weights for the sub-groups are determined by size, cohesion, and degree of reliability among the sub-groups. Finally, the proposed decision method as well as CWW tools are applied to the process of urban renewal plan selection.
1. Introduction
In the coming era of big data, it is common to collect a massive amount of data from different sources when dealing with a decision problem. People are increasingly more interested in pursuing more general decision results by allowing the attendance of a larger number of participants. A group decision-making problem is called a large-scale decision-making problem (LS-GDM) [1] if more than 20 decision makers take part in the decision-making process. The engagement of more decision makers brings more challenges, and traditional decision-making models for small-scale activities usually fail to meet the application demands of large-scale situations [2]. In the last years, LS-GDM strategies have become a hot research topic: Zhou et al. [3] studied a statistics-based approach for LS-GDM under the incomplete Pythagorean fuzzy information with risk attitude; Wan et al. [4] studied a personalized, individual, semantics-based consensus reaching process for LS-GDM with probabilistic linguistic preference relations; Qin et al. [5] proposed a minimum cost consensus model for a CRP-driven preference optimization analysis in LS-GDM with the Louvain algorithm; Gou and Xu [6] studied non-cooperative behaviors in LS-GDM with linguistic preference orderings; Du et al. [7] studied non-cooperative behavior management in LS-GDM; Song and Hu [8] studied LS-GDM with multiple stakeholders based on probabilistic linguistic preference relation; Li et al. [9] studied CRP in LS-GDM based on bounded confidence and social network; Choi et al. [10] studied circular supply chain management with LS-GDM in the big data era; Li [11] studied big data-driven fuzzy large-scale group decision making in the circular economy environment; Liao et al. [12] studied an interactive consensus-reading model with updated weights of clusters in LS-GDM. Li and Wei [13] introduced a two-stage dynamic influence model to achieve consensus within LS-GDM with incomplete information; Cao et al. [14] studied an LS-GDM method based on topic sentiment analysis to deal with the problem of completely data-driven attribute information acquisition; Zhong et al. provided a non-threshold and a multi-stage hybrid consensus model for multi-attribute LS-GDM in [15] and [16], respectively; Li and Wei [17] provided an LS-GDM approach based on a sub-group weighting model with hesitant fuzzy linguistic information; Gao et al. [18] presented an opinion leader identification method and a clustering-based consensus model for LS-GDM; Zheng et al. [19] studied a hesitant fuzzy linguistic bi-objective clustering method for LS-GDM; Rodríguez et al. studied minimum cost consensus models and a cohesion-driven consensus reaching process for LS-GDM in [20,21], respectively.
Although researchers have made contributions to the enrichment of LS-GDM strategies from different points of view, there are still noticeable challenges that need to be studied, such as: (1) Under linguistic contexts, it is common in LS-GDM to apply linguistic aggregation operators in order to collect sub-group assessments in the decision making process. However, the aggregation of linguistic information at the very beginning leads to heavy information loss; (2) CWW [22,23] in LS-GDM calls for more flexible semantic representation models in order to support information processing with uncertainties, etc. The current research makes an effort to explore efficient LS-GDM methodologies in order to deal with such new challenges.
Noticing that single linguistic terms or 2-tuple values fail to capture the hesitancy of information in decision making, Rodríguez et al. [24] initially introduced the hesitant fuzzy linguistic term set (HFLTS), which can be viewed as an extension model of the hesitant fuzzy set [25,26,27] in linguistic information contexts and uses several consecutive linguistic terms to express the preferences for alternatives in decision making. Several context-free grammars and a structure named comparative linguistic expression (CLE) were proposed [24,28,29]. CLEs can be generated by context-free grammar in order to provide more flexibility to the decision makers and to elicit their preferences, and CLE can be transformed into HFLTS to facilitate the CWW process. To meet complex information extraction requests in decision making, various extension models of HFLTS have been proposed, such as the extended hesitant fuzzy linguistic term set (EHFLTS) [30], which applies non-consecuetive terms to describe the hesitation of decision makers, and the proportional hesitant fuzzy linguistic term set (PHFLTS). Considering the specific structure of PHFLTS, i.e., the proportion of single terms in the term set, is determined by the union of various individuals’ evaluations; thus, it can potentially apply PHFLTS in sub-group information collection and description. In this way, the application of aggregation operators could be avoided, and therefore information loss could be decreased in the information fusion process. Based on this consideration, a novel LS-GDM methodology based on PHFLTS is proposed, in which the preferences collected from decision makers can be in different flexible forms such as single terms, HFLTS, and EHFLTS, while the sub-group evaluations are characterized by PHFLTS.
A fuzzy semantic model represents words or linguistic terms by using fuzzy membership functions [31], which can be characterized by the parameters of these membership functions [32]. It is popular to use fuzzy semantic models in CWW, especially the interval type-2 fuzzy set (IT2-FS), which reflects linguistic uncertainties in a more comprehensive way than the type-1 fuzzy set, and its structure is simpler than the general type-2 fuzzy set. To carry out CWW with single words, researchers have proposed various methodologies for encoding words into IT2-FS: Mendel [33] proposed the person membership function approach and the interval end-points approach to encode words into IT-FS; Liu and Mendel [34] provided an interval approach to encode words into IT2-FS, which requests neither fuzzy set knowledge for the information provider nor symmetric shape for the footprint of uncertainty; Wu and Mendel introduced an enhanced interval approach [35]; in [36], the median interval approach was proposed in which the median boundaries of the range of membership functions are calculated. Recently, researchers have paid attention to methodologies that fuzzy encode HFLTS and its extension models by using fuzzy sets. Liu et al. [29] and Li et al. [37] studied the type-1 fuzzy envelope of HFLTS, which facilitates CWW with HFLTS under the framework of the fuzzy linguistic approach. Liu et al. [38] came up with interval type-2 fuzzy envelopes for HFLTS. However, fuzzy encoding technologies for extensions of HFLTS have rarely been studied. For instance, there is still a large gap in fuzzy semantic representation models of the extended hesitant fuzzy linguistic term set (EHFLTS) [30], the possibility distribution of hesitant fuzzy linguistic information [39], the probabilistic linguistic term set [40], the proportional hesitant fuzzy linguistic term set (PHFLTS) [41], and so on; this causes difficulties in the CWW process, with linguistic expressions being provided in more flexible forms than in single terms. In the current proposal, we apply PHFTS to describe sub-group preferences in LS-GDM, in order to keep as much information as possible in the information fusion process. To carry out the CWW process in LS-GDM with PHFLTS, novel fuzzy semantic representation models, named type-1 and interval type-2 fuzzy envelopes for PHFLTS, will be carefully studied.
The salient features of this proposal are as follows:
- (1)
- In order to decrease the information loss in the preferences collection process, a novel LS-GDM model is proposed, in which PHFLTS is applied to capture sub-group hesitation. Both the cohesion and the degree of reliability of the sub-groups can be reflected and measured based on PHFLTS. A sub-group weight determination scheme is introduced, taking into account relevant factors such as size, cohesion, and reliability of sub-groups, which are synthesized when their weights are determined.
- (2)
- To facilitate the CWW process with PHFLTS in LS-GDM under the framework of the fuzzy linguistic approach, novel fuzzy semantic representation models such as type-1 and interval type-2 fuzzy envelopes for PHFLTS will be initially studied. The current research extends the fuzzy encoding approaches from single words to PHFLTS, which increases the flexibility of linguistic preference expression in LS-GDM and further meets the demands of CWW with less information loss.
- (3)
- Entropy measures of PHFLTS are studied in a comprehensive way in order to evaluate linguistic uncertainties during the construction of the interval type-2 fuzzy envelope for PHFLTS. These explorations help to extend the CWW scheme with interval type-2 fuzzy sets from single words to more complex linguistic expressions.
The rest of this paper is structured as follows: Relative concepts are recalled in Section 2. Axiomatic definitions for fuzzy entropy, hesitant entropy, comprehensive entropy, and total entropy measures of PHFLTS are introduced in Section 3, as well as specific calculation formulae. Schemes for obtaining type-1 and type-2 fuzzy envelopes for PHFLTS are respectively provided in Section 4 and Section 5. A novel LS-GDM method based on PHFLTS and its fuzzy semantic representation models is presented in Section 6. Afterwards, a numerical example applying the proposals in a real-life situation is provided in Section 7. Finally, the conclusions are presented in Section 8, as well as a discussion about future works.
2. Preliminary
In this section, we will recall some basic related concepts such as PHFLTS, interval type-2 fuzzy set, CWW with the fuzzy linguistic approach, and LS-GDM.
2.1. PHFLTS
Traditional linguistic computation techniques for decision making are usually limited to single words. To increase the flexibility for decision makers in providing their preferences or evaluations of alternatives with the use of relatively complex expressions close to human beings’ cognition, the concept of context-free grammar was initially proposed by Rodríguez et al. [24], which generates CLE in a formal way.
Let be a context-free grammar, in which
Three types of CLEs “at most ”, “at least ”, and “between and ” could be generated by using . Every CLE can be transformed into an HFLTS, that is, transformation functions exist to convert CLEs to HFLTSs.
Definition 1
([24]). Let be a linguistic term set; an HFLTS on S is an ordered finite subset of consecutive linguistic terms in S.
The application of HFLTS facilitates the CWW processes with CLE, which allows for the participants’ hesitation among consecutive terms. Later, the concept of HFLTS is extended to deal with non-consecutive linguistic terms, giving rise to the extended HFLTS (EHFLTS).
Definition 2
([30]). Let be a linguistic term set; an EHFLTS on S is an ordered subset of non-consecutive linguistic terms in S, that is,
Another extension of HFLTS, is the concept PHFLTS [41], whose main feature includes the proportional information of each generalized linguistic term. Definitions of a proportional linguistic pair and PHFLTS are reviewed below.
Definition 3
([41]). Let be a finite and totally ordered linguistic term set with odd cardinality, and let be a proportional vector, where represent the proportions for linguistic terms . The binary groups are defined as proportional linguistic pairs.
The proportional linguistic pairs are pairs ordered on S, and they are ranked according to the ordered linguistic terms .
Definition 4
([41]). Let be a linguistic term set. Let be n HFLTSs given by a group of decision makers . A PHFLTS for a linguistic variable θ formed by the union of , namely , is a set of ordered finite proportional linguistic pairs and is expressed as follows:
where is a proportional vector, and denotes the degree of possibility that the alternative carries an assessment value provided by a group of decision makers, with the condition that and .
2.2. Interval Type-2 Fuzzy Set
The type-2 fuzzy set theory has been developed well during the past few decades. Compared with the type-1 fuzzy set, the fuzzy membership degree of a value within the universe is described by an independent fuzzy set instead of a single crisp value. In this way, it reflects information uncertainty in a more comprehensive manner. Compared with the general type-2 fuzzy set, due to the relatively simple structure, the application of the interval type-2 fuzzy set (IT2 FS) is more common in linguistic information encoding.
Definition 5
([42,43,44]). A type-2 fuzzy set in the universe X can be represented by the following equation:
where is the type-2 membership function, and .
If , turns into an IT2FS, which can be rewritten as follows:
where x is the primary variable, u is the secondary variable, and is the primary membership of x.
Footprint of uncertainty () can be presented as the equation below:
An IT2FS is determined by its and
where the secondary grade is 1 at all points of .
The upper membership function (UMF) and the lower membership function (LMF) of are two type-1 fuzzy membership functions that bound . An IT2FS with a trapezoidal could be presented as ; the (shaded area) is shown in Figure 1.
2.3. Fuzzy Linguistic Approach
Most real-life decision-making situations present uncertainty, vagueness, and incomplete information. In modeling information under these conditions, the use of linguistic information has obtained successful results. Among various approaches that model linguistic information, the fuzzy linguistic approach [46] stands out by using linguistic variables characterized by a label and a semantic value or a syntactic value. The intention of the fuzzy linguistic approach is to process information by using the fuzzy set theory and to model the information by using linguistic variables, whose values are usually words or sentences rather than numbers. Linguistic variables are obviously less precise than numbers, therefore they are suitable for describing uncertain information.
CWW is a methodology that uses words or propositions (that are obtained from natural language) as the computation objects [47]. Its main feature is that both the input and the output are linguistic information; however, the computation process is numerical. To facilitate the CWW process with the use of the fuzzy linguistic approach, the syntax and fuzzy semantics of linguistic variables in a linguistic domain could be defined a priori. In this work, we adopt a commonly used strategy, i.e., we directly assume that the semantics of linguistic terms in a linguistic term set S are distributed by triangular fuzzy numbers within an interval [0, 1]. For instance, is shown in Figure 2.
2.4. Large-Scale Group Decision Making under a Linguistic Environment
Large-scale group decision making usually indicates more than 20 decision makers who hold different attitudes regarding a problem, present different opinions concerning alternatives or solutions, and pursue a commonly accepted decision by carrying out a decision making process. Different information domains could be considered under the framework of decision making, including the numerical domain, the interval-valued domain, and the linguistic domain. In this proposal, we focus on LS-GDM under the linguistic environment, which usually consists of the following:
- A problem to be solved;
- A set of alternatives or a set of possible solutions to the problem;
- A set of decision makers who express their preferences with regard to alternatives and try to obtain a common solution to the problem;
- A linguistic domain from which decision makers could build linguistic variables to express their preferences among alternatives/solutions.
3. Entropy Measures of PHFLTS
One of the main focuses of the current research is the development of a fuzzy encoding method for PHFLTS. An important construction precondition of interval type-2 fuzzy encoding is the suitable evaluation of linguistic uncertainty contained in PHFLTS. Therefore, in this section, entropy measures of PHFLTS will be introduced to evaluate linguistic uncertainty. Hesitant and fuzzy entropy are respectively provided to evaluate fuzzy uncertainty and hesitant uncertainty in PHFLTS. Afterwards, comprehensive entropy will be provided based on the synthesis of two other kinds of uncertainty.
For the convenience of defining the fuzzy entropy of PHFLTS, the fuzzy entropy measure of linguistic terms is recalled below.
Definition 6
([48]). A real-valued function is an entropy measure for a linguistic term if it satisfies the following axiomatic requirements:
- (E1)
- , if and only if or .
- (E2)
- , if and only if .
- (E3)
- , if or .
- (E4)
- .
The fuzzy entropy of the linguistic term could be computed with , where the function satisfies the following conditions (1)–(2):
- (1)
- , moreover, .
- (2)
- is strictly monotone increasing when and strictly monotone decreasing when .
In order to construct the hesitant entropy of PHFLTS, we define a function to describe the deviation degree of the linguistic terms contained in a PHFLTS.
Definition 7.
Let be a linguistic term set, let be a PHFLTS defined on S. The deviation function of a PHFLTS, is defined by the following equation:
where l is the cardinality of , and is the index of the linguistic term set .
Remark 1.
If the , then .
This remark declares that the deviation degree reaches the minimum when only one linguistic term exists in a PHFLTS, which is consistent with the cognition of a human being.
With the knowledge reserve above, the axiomatic definitions of the fuzzy and hesitant entropies of PHFLTS are provided below.
Definition 8.
Let be a PHFLTS on S, and be the set of all PHFLTSs on S. Let , be two mappings; if satisfies requirements (F1)–(F5), and satisfies requirements (H1)–(H4), then and are the fuzzy and hesitant entropies of PHFLTS, respectively.
- (F1)
- , if and only if where .
- (F2)
- , if and only if .
- (F3)
- Let as well as be two PHFLTSs on S; if
- and (for , which satisfy ),
- (for and ),
then . - (F4)
- If is a PHFLTS on S, change to to get a new PHFLTS , where , then .
- (F5)
- ,where .
- (H1)
- , if and only if .
- (H2)
- , if .
- (H3)
- , if .
- (H4)
- ,where .
Subsequently, with the introduction of Theorems 1 and 2, we will provide specific formulae to compute the fuzzy and hesitant entropies of PHFLTS, respectively.
Theorem 1.
Suppose that is a PHFLTS on a linguistic term set . Let , where is the fuzzy entropy of linguistic term . Then, is a fuzzy entropy for .
Proof.
- (F1)
- If , then , where . According to the axiomatic definition of the fuzzy entropy of linguistic terms, we know that or , where . Therefore, , where . On the contrary, if , where , then ; that is, .
- (F2)
- Since , we know that if and only if . From the axiomatic definition of the fuzzy entropy of linguistic terms, if and only if , then we know that if and only if .
- (F3)
- If , and are two PHFLTSs on S, , then . If , , then . If , then , and .
- (F4)
- If in is changed to to get a new PHFLTS , where , then ; therefore, , that is, .
- (F5)
- From the axiomatic definition of the fuzzy entropy of linguistic terms, ; therefore, . That is, , where .
□
Theorem 2.
Suppose that is a PHFLTS on a linguistic term set . Let , where is the index of the linguistic term set . Then, is a hesitant entropy for .
Proof.
- (H1)
- If , then , that is, for all , so there is only one term contained in , ; On the contrary, if , then , therefore, .
- (H2)
- If , then , and .
- (H3)
- From the definition of in Equation (7), it is easy to obtain that if .
- (H4)
- Since for all and , we have
□
Based on axiom definitions of fuzzy and hesitant entropies, we propose the axiom definition for the comprehensive entropy of PHFLTS, which reflects the uncertainty contained in a PHFLTS in a more comprehensive way. The formulae for computing comprehensive entropy and specific examples will also be introduced.
Definition 9.
Let
be a PHFLTS on S, and be the set of all PHFLTSs on S. Let and be the fuzzy and hesitant entropies of PHFLTS, respectively. Let be a mapping; if it satisfies the following requirements, then is a comprehensive entropy of PHFLTS.
- (C1)
- , if and only if or .
- (C2)
- , if and only if .
- (C3)
- If and , then .
- (C4)
- , where.
Theorem 3.
Suppose that a function satisfies the following conditions:
- (1)
- , .
- (2)
- is strictly monotone increasing with respect to x and y, respectively,
then is a comprehensive entropy measure of the PHFLTS, .
Example 1.
Let , which satisfies conditions (1) and (2) in Theorem 3, then
where , is a comprehensive entropy measure of PHFLTS, .
There is another approach to synthesizing fuzzy and hesitant entropies. Here, we propose the concept of total entropy.
Definition 10.
Let
be a PHFLTS on S, and be the set of all PHFLTSs on S. Let and be fuzzy and hesitant entropies of PHFLTS, respectively. Let be a mapping; if it satisfies the following requirements, then is a total entropy of PHFLTS.
- (T1)
- , if and only if or .
- (T2)
- , if and only if or .
- (T3)
- If and , then .
- (T4)
- , where.
Theorem 4.
Suppose that function satisfies the following conditions:
- (1)
- , , .
- (2)
- is monotone increasing with respect to x and y, respectively,
then the mapping is a total entropy measure of the PHFLTS, .
Example 2.
Let be a PHFLTS, f be a co-norm such as , , , which satisfies conditions (1) and (2) in Theorem 4, then
is a total entropy measure of .
4. Type-1 Fuzzy Envelope of PHFLTS
In this section, the type-1 fuzzy envelope of an PHFLTS will be built according to the meaning of the corresponding linguistic expressions. To achieve this goal, we first provide the general process of constructing a type-2 fuzzy envelope for all types of PHFLTS. Afterwards, specific methodologies for computing the fuzzy envelope of three types of CLE will be discussed. Finally, the strategies for computing an important parameter that must be applied in order to complete the specific methodologies for achieving the type-1 fuzzy envelope will be provided.
4.1. General Process
In a linguistic term set , every single term () can be assumed to be a triangular membership function . To compute the type-1 fuzzy envelope of an PHFLTS , only the terms for which the proportion contained in the is larger than zero should be aggregated when computing the fuzzy envelope. We use a trapezoidal fuzzy membership function to represent the type-1 fuzzy envelope of PHFLTS . Let , and . Parameters in could be calculated with the following formulas:
if , then ; if , then .
where are aggregation operators, in which the weights are determined by the proportions of the linguistic terms in PHFLTS, and .
if , then ; if , then .
In order to be consistent with the research on the fuzzy envelope of HFLTS in [29], the following two classes of OWA weights will be applied in order to aggregate linguistic terms in the PHFLTS during the process of computing for the type-1 fuzzy envelope.
Definition 11
([49]). Let β be a parameter belonging to the unit interval . The first kind of OWA weights is defined as follows:
The second type of OWA weights is defined as follows:
4.2. Type-1 Fuzzy Envelope of PHFLTS Corresponding to Linguistic Expression “between and "
Suppose that for ∀, where (), we have and , then is regarded as a PHFLTS related to the CLE “between and ". In the type-1 fuzzy envelope of , denoted by , parameters a and d could be determined by and ; b and c are determined by the following procedure:
Reorder the sequence from the largest value to the smallest one in order to obtain a sequence that satisfies .
4.3. Type-1 Fuzzy Envelope of PHFLTS Corresponding to Linguistic Expression “at Least "
Suppose that s.t. , then is regarded as a PHFLTS related to “at least ”. Let be the type-1 fuzzy envelope of . The parameters , , b are determined by the following equation:
where and in Equation (18) is
4.4. Type-1 Fuzzy Envelope of PHFLTS Corresponding to Linguistic Expression “ at Most "
Suppose that s.t. , then is a PHFLTS related to “at most ", the type-1 fuzzy envelope of is , in which , , c is determined by the following equation:
where and in Equation (19) is shown below:
4.5. A Strategy for Determining Parameter in Uncertainty Evaluation for PHFLTS
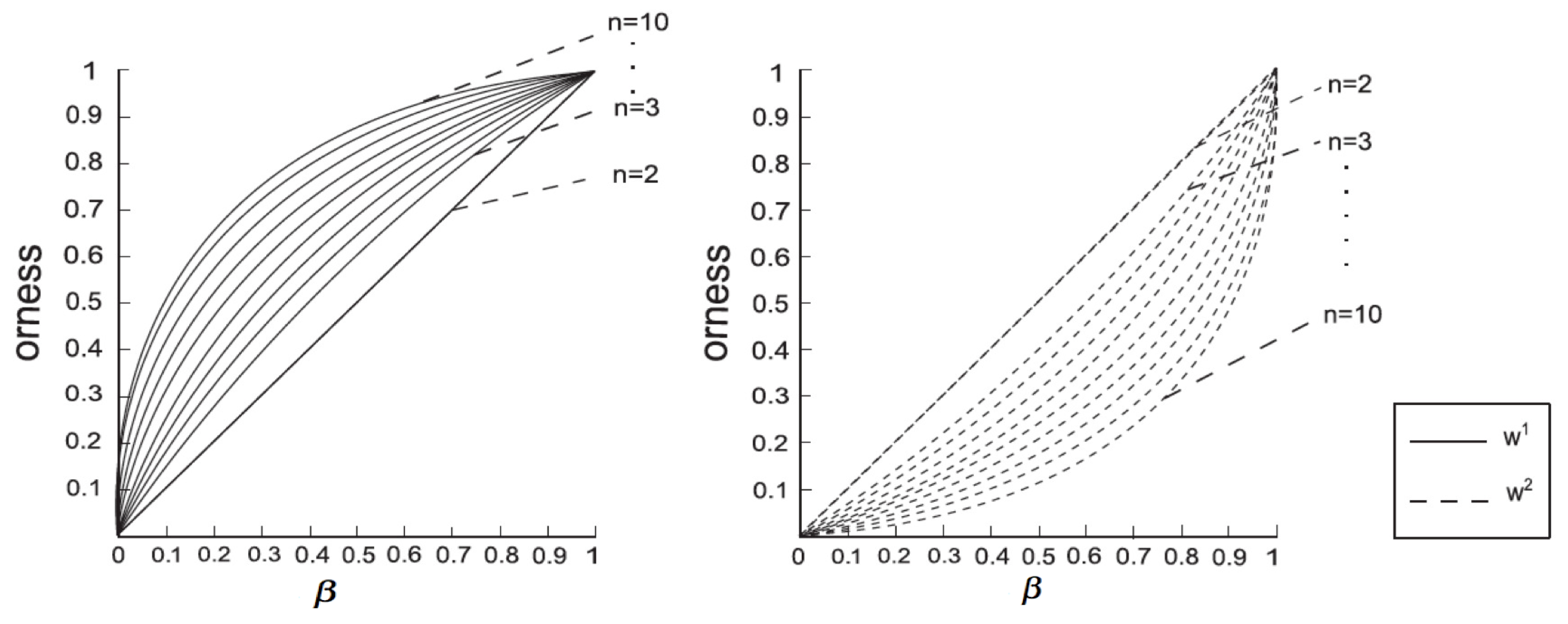
The methodology to obtain the parameter can be different. Here, we only provide one available method that determines according to the number of skip terms in PHFLTS as well as the orness degree. There is a monotone function between the orness degree and the value of in (or ). The relationship could be described by Equations (20) and (21), which is shown in Figure 3:
The principle we adopt in determining the value of the orness degree as well as the value of is the following: “the more skip terms there are contained in a PHFLTS, the lower the orness degree of the group is. On the contrary, the fewer skip terms there are contained in a PHFLTS, the higher the orness degree of the group is”.
Reference [29] discussed how to determine the value of according to the meaning of linguistic expressions when no skip terms exist in an HFLTS. The linguistic expressions can be classified into three types: “at least ”, “at most ”, “between and ”. In the current research, the value of for computing the fuzzy envelope of PHFLTS should not only be determined by the corresponding expressions, but also by the value of skip terms in PHFLTS. If no skip terms exist in a PHFLTS, the orness degree of the decision maker reaches the maximum value, and the parameter can be computed by using the approach in [29]. The more skip terms exist in a PHFLTS, the lower the orness degree of information should be. Considering the relationship between the value of and the orness degree shown in Figure 3, the lower the orness degree is, the smaller the value of should be. From this viewpoint, we can adopt the value of to determine the maximum value of the orness degree; in this way, we can build a scheme that computes according to the number of skipped terms.
Based on the analysis above, a novel strategy determining the value of for the computation of the fuzzy envelope of PHFLTS is provided as follows:
For the convenience of discussion, the value of skipped terms contained in a is denoted by ; therefore, .
- For the PHFLTS corresponding to the expression “at least ”:If , then , which is obtained from in [29], and the orness reaches its maximum, which can be computed by Equations (20) and (21). If , then the orness reaches its minimum, and orness and , which is also computed by Equations (20) and (21). The value of increases from 0 to , while decreases from to 0. A function f can be defined as follows:where , which satisfies the following boundary conditions:Moreover, it is easy to find a linear function that satisfies such conditions:
- For the PHFLTS corresponding to the expression “between and ”:If , then , which is obtained from in [29], and the orness reaches its maximum, which can be computed by Equations (20) and (21). If , then the orness reaches its minimum, orness and , which is also computed by Equations (20) and (21). The value of increases from 0 to , while decreases from to 0. A function f can be defined as follows:where , which satisfies the following boundary conditions:Moreover, it is easy to find a linear function that satisfies such conditions:If , then , which is obtained from in [29], and the orness reaches its maximum, which can be computed by Equations (20) and (21). If , then the orness reaches its minimum, orness and , which is also computed by Equations (20) and (21). The value of increases from 0 to , while decreases from to 0. A function can be defined as follows:where , which satisfies the following boundary conditions:Moreover, it is easy to find a linear function that satisfies such conditions:Lemma 1.If , then .Proof.. Then, if , then . □
- For the PHFLTS corresponding to the expression “at most ”:If , then , which is obtained from in [29], and the orness reaches its maximum, which can be computed by Equations (20) and (21). If , then the orness reaches its minimum, orness and , which is also computed by Equations (20) and (21). The value of increases from 0 to , while decreases from to 0. A function f can be defined as follows:where , which satisfies the following boundary conditions:Moreover, it is easy to find a linear function that satisfies such conditions:
5. Type-2 Fuzzy Envelope of PHFLTS
For the PHFLTS, , transformed from a CLE, , its type-2 fuzzy envelope can be presented as an IT2FS:
whose footprint is
where is the type-1 fuzzy envelope, which should be computed according to the type of linguistic expression. Compared with the type-1 fuzzy envelope, an extra parameter can be determined by in the parameterized representation of trapezoidal IT2FS, , i.e., (see Figure 1) (According to Equations (26) and (27), if and are determined, other parameters can be easily computed based on them. For instance, for a PHFLTS corresponding to “between and ”, we have , , , .).
In this proposal, we will use the equation to evaluate the uncertainty contained in the type-2 fuzzy envelope of a PHFLTS . Several principles are proposed here to determine the value of the parameter :
- (P1)
- if .This principle indicates that the importance degree of hesitancy reaches its highest when all terms appear in the PHFLTS.
- (P2)
- if .This principle indicates that the importance degree of hesitancy reaches its lowest when there is no hesitancy in a PHFLTS.
- (P3)
- if ,and , where .This principle indicates that when a new term is added in a PHFLTS, the importance degree of hesitancy should be increased.
- (P4)
- If , and,,where , and , then .This principle indicates that when two different terms are added in a PHFLTS , the change of is positively related to the fuzzy degree of the added linguistic term.
- (P5)
- .This principle indicates the importance degree of hesitancy should be the same for a PHFLTS and its negative because the hesitancy degree is the same.
Following the five principles above, researchers could easily find different functions to compute the value of the parameter ; here, we only provide a simple function as an example:
Let , for any PHFLTS ,
where
Theorem 5.
The defined by Equation (6) satisfies principles(P1)–(P5).
Proof.
(1) When , it is easy to obtain the following:
. Therefore, .
(2) When , it can be viewed as and ; in this way, .
(3) If , and
, where ,
then , that is, .
(4) If , then , therefore, . That is,
(5) . Since and , we have . Therefore, , that is, .
□
5.1. Comparative Analysis: Type-1 and Type-2 Fuzzy Envelopes of PHFLTS
Type-1 and type-2 fuzzy envelopes will be compared based on computation complexity, information lost, and feasibility.
- (1)
- From the point of view of computation complexity: The main difference is reflected by the parameter determination process. The complexity of type-1 fuzzy envelopes is a bit lower since only four parameters (i.e., the four parameters in ) need to be computed to achieve a trapezoidal fuzzy number as the type-1 fuzzy envelope for PHFLTS, while five parameters (i.e., the five parameters in )) need to be determined to achieve the corresponding type-2 fuzzy envelope for PHFLTS. The extra parameter is determined on the basis of the linguistic uncertainty contained in the PHFLTS, which can be evaluated by using the proposed entropy measures.
- (2)
- From the point of view of information lost: During the past few decades, IT2FS has been a widely accepted tool in the presentation of linguistic information. The current work is an extension study of the fuzzy encoding approach for linguistic information; we extend the IT2FS encoding technique from single words to more complex linguistic expressions. Compared with the type-1 fuzzy envelope, when the type-2 fuzzy envelope is applied, the uncertainties contained in linguistic information can be evaluated by using the proposed comprehensive entropy. Therefore, more information can be reflected and restored during the process of CWW. In this way, the information lost could be decreased, which is the main reason why we recommend the use of the type-2 fuzzy envelope.
- (3)
- From the point of view of feasibility: There are plenty of research that pay attention to decision making based on either type-1 fuzzy sets or type-2 fuzzy sets. Therefore, as long as the fuzzy envelopes of PHFLTSs can be computed, most decision-making problems based on PHFLTS can be transformed into decision-making problems based on type-1 or type-2 fuzzy sets; then, the decision results can be obtained. The proposed fuzzy envelopes allow the CWW process that is based on PHFLTS in decision making follow the framework of the fuzzy linguistic approach. Hence, these two fuzzy representation models can make the CWW process with PHFLTS feasible.
6. An LS-GDM Approach Based on PHFLTS
In this section, the problem formulation and a framework overview of the main decision strategies are introduced. Afterwards, a detailed presentation of an LS-GDM method is provided.
6.1. Problem Formulation
Suppose that there are t decision makers () who provide preferences on n alternatives . A linguistic term set S will be available to decision makers who can apply single terms, HFLTS, CLEs, and EHFLTS as their preferences with flexibility. The aim is to rank the alternatives, and the alternative with the maximum utility value will be selected as the most desirable decision.
6.2. Framework Overview
The decision framework could be stated as written below and is illustrated in Figure 4.
- (1)
- Information collection.At this stage, every decision maker is requested to express their preferences from the alternatives by using single terms or HFLTS or EHFLTS. In this way, the t preference matrix is obtained.
- (2)
- Cluster and information fusion.
- Cluster principle.In order to make a group decision based on the assessments provided from a large group of decision makers, first of all, we should select a suitable cluster approach to classify the large-scale group into several small-scale sub-groups. At this stage, our expectation is to “classify the decision makers who hold similar opinions into one class”.
- Cluster objective.For each alternative with respect to each criteria, group evaluations gathered from all decision makers in a sub-group will form a PHFLTS. This process is called an information-fusion process. We expect the linguistic terms contained in each EHFLT to be consecutive rather than discrete. From the view point of position in the linguistic-term set, linguistic terms contained in each EHFLT should be “the closer, the better”. Meanwhile, we expect the number of linguistic terms in an EHFLT to be “the less, the better". To illustrate this, the sub-group evaluation is more expected than , and is more expected than .Our objective is just to put adjacent linguistic terms together after the classification. Therefore, the similarity of two linguistic terms and could be briefly evaluated by using the euclidean distance between their subscripts i and j.
- Cluster method.In the current research, we suggest the use of the cluster method based on the fuzzy equivalence relationship when the cluster starts with linguistic terms/HFLTSs and results with PHFLTSs. In this way, (1) the fuzzy property of linguistic values could be considered; (2) compared with the fuzzy-c means approach, it can avoid a possible unreasonable cluster result caused by the inappropriate selection of the initial cluster center; (3) the computation process is simple.
- (3)
- Best alternative selection.
- Computation tool.The proposed fuzzy representation models, i.e., fuzzy envelopes of PHFLTS, will be adopted as the computation tool during the CWW process.
- Alternative selection.We will compute the utility values for alternatives and then select the one with the largest utility value as the best selection.
6.3. Method Description
Following the outlines in Section 6.2, a detailed description of the proposed decision method is given.
- Cluster and information fusion.To classify decision makers in an LS-GDM problem into several sub-groups, the cluster scheme based on a fuzzy equivalence relation [50] is extended in order to deal with linguistic decision matrices formed by terms in .
- (1)
- The construction of similarity matrix.Firstly, we should select an approach to compute the similarity between two linguistic decision matrices. Suppose that there are two linguistic decision matrices,where .The similarity between these two matrices is defined as follows:where the parameter k is a positive integer. It can be noticed that the larger the value of k is, the larger the similarity will be. The value of k could be selected and adjusted according to the cluster performance.Remark 2.Suppose that , we can define . More specifically, when only one term exists in , will be the subscript of the linguistic term. For instance, for , we have .There are t decision makers, therefore the similarity matrix is constructed as a matrix:where
- (2)
- Compute the transitive closure and the fuzzy equivalence relationship. If , then is the fuzzy equivalence relationship. Denote .
- (3)
- Choose a threshold value and use the theory to obtain a dynamic cluster result.From the transitive closure , construct a matrix byThe initial selection of the value depends on the expectations from the similarity of the evaluations of decision makers within the sub-groups. It could be adjusted until the expected number of clustered sub-groups is obtained.
- (4)
- Adjust the threshold value and obtain several clusters.If , this means that decision makers and should be clustered into one class. In this way, we obtain different clusters. The cluster result could be easily adjusted by controlling . If the number of clusters is too large, we can decrease the threshold value ; conversely, we can increase the threshold value .
- 2.
- Obtain the sub-group preference matrix.Suppose that the group G is classified into , , ⋯, after the cluster process. There are h decision makers in a sub-group , which are denoted as . The preference provided by the decision maker on over is denoted by .Then, the group preference of on over forms a PHFLTS,where is the number of all terms in , is the number of in all ; repeat terms should not be deleted when and are computed.
- 3.
- Compute the interval type-2 fuzzy envelopes of PHFLTSs.To avoid confusion, we set rules to compute the fuzzy envelope for according to the corresponding CLEs.
- If , then the interval type-2 fuzzy envelope of the , is computed according to the CLE “ at most ”;
- If , then the interval type-2 fuzzy envelope of the , is computed according to the CLE “ at least ”;
- If , or , then the interval type-2 fuzzy envelope of the , is computed according to the CLE “ between and ”.
Note: For the convenience of discussion, we denote the type-2 fuzzy envelope of PHFLTS, as .
- 4.
- Compute the utility values for alternatives according to the sub-group preference.Suppose that the group decision matrix of a sub-group could be presented as follows:
- 5.
- Determine the weights for sub-groups.Three different factors will be considered when we compute the weights for sub-groups in the proposed decision scheme.
- Size: The more members there are in a sub-group, the larger the weight of this sub-group should be;
- Cohesion[52]: The higher the level of togetherness that the preferences of a sub-group has, the larger the weight of this sub-group should be;
- Reliability: The higher the level of reliability that a sub-group has, the larger the weight of this sub-group should be.
Since size is a commonly used index in sub-group weight determination in LS-GDM, and cohesion has also been proved a useful index in [52] during the sub-group weight determination progress, here, we only explain “the reliability of the assessments of a sub-group”, which is first postulated in the current work in a detailed way. After the cluster process, we hope that the opinions of decision makers within a sub-group are close to each other. Suppose that the gathered preference of this sub-group for one alternative over another alternative is , then we think that the degree of “decision makers in a sub-group are close to each other” is higher than the situation when the gathered preference is . This is because in the former situation, for each decision maker in this sub-group, there is another decision maker who provides a preference that is close to him/her. That is, assessments among the sub-groups are closer, and no obvious inharmonious mechanisms exist. The sub-group is more reliable when the gathered preference is rather than . In summary, the more continuous the linguistic terms in a PHFLTS are, the more reliable the corresponding preference of a sub-group is. On the contrary, the more discrete, the less reliable.Subsequently, we will introduce specific measures to compute the “Size”, “Cohesion”, and “Reliability” of a sub-group when PHFLTSs are applied in LS-MALGDM problems.- Size:The size of sub-group is computed by:where denotes the number of members in sub-group , and denotes the number of members in group G.
- Cohesion:The preference of sub-group for alternative over is a PHFLTS, denoted by the following equation:Let be the index of linguistic term . The cohesion of sub-group on over is computed byThe cohesion of sub-group is computed by
- Reliability:Let be the number of linguistic terms in the PHFLTS, . The preference reliability of sub-group for over is computed byThe reliability of sub-group is computed byThe three indices above are synthesized by using the function below:where are respectively used to control the impact of cohesion and reliability during the process in order to compute the weights of the sub-groups.Finally, the weight for sub-group is computed by the following equation:where f is the number of sub-groups after clustering.
- 6.
- Compute the utility value of alternatives according to the group preferences.
7. Case Study: Application to Urban Renewal Plan Selection
In this section, the proposed LS-GDM methodology is applied to an urban renewal plan selection problem. Detailed solution procedures will be provided after a brief problem description.
7.1. Problem Description
Since the beginning of 2020, the transformation of old areas in Shanghai has been accelerated. So far, 400,000 square meters and about 19,700 households with houses below the secondary old lane have been transformed. As an innovative measure to accelerate the transformation of old areas and urban organic renewal, the Shanghai urban renewal center was officially inaugurated and established on 13 July 2020, mainly promoting the transformation of old areas, old houses, urban villages, and other urban renewal projects. It was noted that decision-making problems were involved in the process of urban renewal, such as the optimizations of the old district reconstruction scheme, the old housing reconstruction scheme, and the urban village project investment scheme. The traditional information processing method obviously cannot meet the requirements of a comprehensive evaluation of the decision-making scheme. The complexity of urban renewal requires that the interests of the government, developers, residents, and other parties must be taken into account. Therefore, most of the decision-making problems faced by the urban renewal task are large-scale group decision-making problems, which need the support of an appropriate group decision-making model and advanced decision-making technology. To select the appropriate targeted plan, suppose that the government invited 30 representatives (denoted by ) from different interests to evaluate four alternatives . These representatives are allowed to provide their preference matrix, with items in the form of HFLTS, EHLFT, or single terms in the linguistic term set (see the fuzzy semantic representation of S in Figure 2). To save space, 30 initial preference matrices (denoted by ) have been included in Appendix A.
7.2. Solution to the Sample Problem
- Cluster and information fusion.There are 30 decision makers who provide evaluations by using the linguistic term set , therefore and . Without loss of generality, we set , , and . According to the classification strategy introduced, the group is classified into five sub-groups, i.e.,, , ,, .
- Obtain sub-group preference matrix.From each sub-group, the evaluations on alternative with parameter are gathered to form a PHFLTS. In this way, the evaluation of the five sub-groups could be obtained as follows.
- Compute the interval type-2 fuzzy envelopes of PHFLTSs.The context-free grammar in [24] will be applied during the process of computing the interval type-2 fuzzy envelopes of PHFLTSs. Let be the type-2 fuzzy envelope of a PHFLTS, . Following the scheme introduced in Section 4, to compute parameters for the PHFLTS corresponding to the CLE “at least ", the parameter is calculated by using Equation (22); for the PHFLTS corresponding to the CLE “between and ", the parameters and are calculated by using Equation (23) and Equation (24), respectively; for the PHFLTS corresponding to the CLE “at most ", the parameter is calculated by using Equation (25). Following the scheme introduced in Section 5, to compute parameter , it is necessary to evaluate the uncertainty contained in PHFLTS; we also adopt the comprehensive entropy to calculate the uncertainties, where is computed by Equations (28) and (29). In this way, we can compute the interval type-2 fuzzy envelope of each PHFLTS; the evaluations obtained from the five sub-groups are fuzzy-encoded and presented below.
- Compute the utility values of alternatives according to the sub-group preference.By applying Equation (36), we obtain the following:;;;.
- Determine the weights for sub-groups.
- Decision result calculation.By applying Equation (45), we obtain the following: , , , and ; then, alternative is the decision result.
- Numerical ComparisonFollowing the same weight-determination scheme and decision-making strategy, if the type-1 fuzzy envelope of PHFLTS is applied in this LS-GDM problem, by applying the magnitude [53] of the trapezoidal fuzzy number as the rank value, the utility values can be computed as , , , and . It is obvious that , and therefore the best alternative is also , which is consistent with the result when the type-2 fuzzy envelope is applied. However, since IT2FS can restore more linguistic uncertainty than the type-1 fuzzy set, the application of the proposed type-2 fuzzy envelope will contribute to a more precise result in specific decision-making situations (see more detailed discussions in Section 5.1).
8. Conclusions and Future Works
LS-GDM problems widely exist in daily life, which brings challenges to both the information-fusion process and the CWW process. In the current proposal, the application of PHFLTS in sub-group preference description avoids the use of aggregation operators at the very beginning of decision making. In this way, it decreases information loss during the information-fusion process. Fuzzy envelopes have been constructed, and the application of the proposed linguistic information representation models facilitates the CWW process with PHFLTS under the framework of the fuzzy linguistic approach. The proposed type-2 fuzzy envelope contributes to the development of the fuzzy encoding technique, from single words to more complex linguistic forms, i.e., PHFLTS, which facilitates the flexibility of decision makers in expressing their preferences in decision making.
In the near future, the following research will be carried out:
- Interval type-2 fuzzy encoding techniques need to be further developed, from single words to more flexible linguistic expressions.
- The fuzzy encoding technology for linguistic expressions in various forms still need to be further developed in the near future.
- More strategies adopting PHFLTS to solve LS-GDM problems need to be explored in order to pursue a suitable decision result in a flexible way.
- Consensus models need to be studied under the framework of LS-LSGDM with PHFLTS.
Author Contributions
Supervision, L.M.; Validation, R.M.R. and L.M.; Writing (original draft), Y.L.; Writing (review and editing), R.M.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China (grant number 62006154), Spanish Ministry of Economy and Competitiveness through the Spanish National Research Project (grant number PGC2018-099402-B-I00), the Postdoctoral Fellowship Ramón y Cajal (grant number RYC-2017-21978), and the FEDER-UJA Project (grant number 1380637).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Decision Matrices
References
- Hong, C.X.; Rong, L. Improved clustering algorithm and its application in complex huge group decision-making. Syst. Eng. Electron. 2006, 28, 1695–1699. [Google Scholar]
- Palomares, I.; Martínez, L.; Herrera, F. A Consensus Model to Detect and Manage Noncooperative Behaviors in Large-Scale Group Decision Making. IEEE Trans. Fuzzy Syst. 2014, 22, 516–530. [Google Scholar] [CrossRef]
- Zhou, Y.; Zheng, C.; Goh, M. Statistics-based approach for large-scale group decision-making under incomplete Pythagorean fuzzy information with risk attitude. Knowl.-Based Syst. 2021, 235, 107654. [Google Scholar] [CrossRef]
- Wan, S.P.; Yan, J.; Dong, J.Y. Personalized individual semantics based consensus reaching process for large-scale group decision making with probabilistic linguistic preference relations and application to COVID-19 surveillance. Expert Syst. Appl. 2021, 191, 116328. [Google Scholar] [CrossRef]
- Qin, J.; Li, M.; Liang, Y. Minimum cost consensus model for CRP-driven preference optimization analysis in large-scale group decision making using Louvain algorithm. Inf. Fusion 2022, 50, 121–136. [Google Scholar] [CrossRef]
- Gou, X.; Xu, Z. Managing noncooperative behaviors in large-scale group decision-making with linguistic preference orderings: The application in Internet Venture Capital. Inf. Fusion 2021, 69, 142–155. [Google Scholar] [CrossRef]
- Du, Z.; Yu, S.M.; Xu, X. Managing noncooperative behaviors in large-scale group decision-making: Integration of independent and supervised consensus-reaching models. Inf. Sci. 2020, 531, 119–138. [Google Scholar] [CrossRef]
- Song, Y.; Hu, J. Large-scale group decision making with multiple stakeholders based on probabilistic linguistic preference relation. Appl. Soft Comput. 2019, 80, 712–722. [Google Scholar] [CrossRef]
- Li, Y.; Kou, G.; Peng, Y. Consensus reaching process in large-scale group decision making based on bounded confidence and social network. Eur. J. Oper. Res. 2022, 303, 790–802. [Google Scholar] [CrossRef]
- Choi, T.M.; Yue, C. Circular supply chain management with large scale group decision making in the big data era: The macro-micro model. Technol. Forecast. Soc. Chang. 2021, 169, 120791. [Google Scholar] [CrossRef]
- Li, X. Big data-driven fuzzy large-scale group decision making (LSGDM) in circular economy environment. Technol. Forecast. Soc. Chang. 2022, 175, 121285. [Google Scholar]
- Liao, H.; Wu, Z.; Tang, M.; Wan, Z. An interactive consensus reaching model with updated weights of clusters in large-scale group decision making. Eng. Appl. Artif. Intell. 2022, 107, 104532. [Google Scholar] [CrossRef]
- Li, S.; Wei, C. A two-stage dynamic influence model-achieving decision-making consensus within large scale groups operating with incomplete information - ScienceDirect. Knowl.-Based Syst. 2020, 189, 105132. [Google Scholar] [CrossRef]
- Cao, J.; Xu, X.; Yin, X.; Pan, B. A Risky Large Group Emergency Decision-making Method Based on Topic Sentiment Analysis. Expert Syst. Appl. 2022, 195, 116527. [Google Scholar] [CrossRef]
- Zhong, X.; Xu, X.; Pan, B. A non-threshold consensus model based on the minimum cost and maximum consensus-increasing for multi-attribute large group decision-making. Inf. Fusion 2022, 77, 90–106. [Google Scholar] [CrossRef]
- Zhong, X.; Xu, X.; Yin, X. A multi-stage hybrid consensus reaching model for multi-attribute large group decision-making: Integrating cardinal consensus and ordinal consensus—ScienceDirect. Comput. Ind. Eng. 2021, 158, 107443. [Google Scholar] [CrossRef]
- Li, S.; Wei, C. A large scale group decision making approach in healthcare service based on sub-group weighting model and hesitant fuzzy linguistic information. Comput. Ind. Eng. 2020, 144, 106444. [Google Scholar] [CrossRef]
- Gao, P.; Jing, H.; Xu, Y. A k-core decomposition-based opinion leaders identifying method and clustering-based consensus model for large-scale group decision making. Comput. Ind. Eng. 2020, 150, 106842. [Google Scholar] [CrossRef]
- Zheng, Y.; Xu, Z.; He, Y.; Tian, Y. A hesitant fuzzy linguistic bi-objective clustering method for large-scale group decision-making. Expert Syst. Appl. 2021, 168, 114355. [Google Scholar] [CrossRef]
- Rodríguez, R.M.; Labella, A.; Nunez Cacho, P.; Molina-Moreno, V.; Martínez, L. A comprehensive minimum cost consensus model for large scale group decision making for circular economy measurement. Technol. Forecast. Soc. Chang. 2022, 175, 121391. [Google Scholar] [CrossRef]
- Rodríguez, R.M.; Labella, A.; Sesma-Sara, M.; Bustince, H.; Martínez, L. A Cohesion-driven Consensus Reaching Process for Large Scale Group Decision Making under a Hesitant Fuzzy Linguistic Term Sets Environment. Comput. Ind. Eng. 2021, 155, 107158. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy logic = computing with words. IEEE Trans. Fuzzy Syst. 1996, 4, 103–111. [Google Scholar] [CrossRef] [Green Version]
- Zadeh, L.A. From Computing with Numbers to Computing with Words. Ann. N. Y. Acad. Sci. 2001, 929, 221–252. [Google Scholar] [CrossRef] [PubMed]
- Rodríguez, R.M.; Martínez, L.; Herrera, F. Hesitant fuzzy linguistic term sets for decision making. IEEE Trans. Fuzzy Syst. 2012, 20, 109–119. [Google Scholar] [CrossRef]
- Torra, V. Hesitant fuzzy sets. Int. J. Intell. Syst. 2010, 25, 529–539. [Google Scholar] [CrossRef]
- Verma, R. Operations on hesitant fuzzy sets: Some new results. J. Intell. Fuzzy Syst. 2015, 29, 43–52. [Google Scholar] [CrossRef]
- Hu, J.; Yang, Y.; Zhang, X.; Chen, X. Similarity and entropy measures for hesitant fuzzy sets. Int. Trans. Oper. Res. 2018, 25, 857–886. [Google Scholar] [CrossRef] [Green Version]
- Rodríguez, R.M.; Martínez, L.; Herrera, F. A group decision making model dealing with comparative linguistic expressions based on hesitant fuzzy linguistic term sets. Inf. Sci. 2013, 241, 28–42. [Google Scholar] [CrossRef]
- Liu, H.; Rodríguez, R.M. A fuzzy envelope for hesitant fuzzy linguistic term set and its application to multicriteria decision making. Inf. Sci. 2014, 258, 220–238. [Google Scholar] [CrossRef]
- Wang, H. Extended hesitant fuzzy linguistic term sets and their aggregation in group decision making. Int. J. Comput. Intell. Syst. 2015, 8, 14–33. [Google Scholar]
- Rodríguez, R.M.; Martínez, L. An analysis of symbolic linguistic computing models in decision making. Int. J. Gen. Syst. 2013, 42, 121–136. [Google Scholar] [CrossRef]
- Bonissone, P.P.; Decker, K.S. Selecting Uncertainty Calculi and Granularity: An Experiment in Trading-Off Precision and Complexity. Mach. Intell. Pattern Recognit. 1986, 4, 217–247. [Google Scholar]
- Mendel, J.M. Computing with words and its relationships with fuzzistics. Inf. Sci. 2007, 6, 988–1006. [Google Scholar] [CrossRef]
- Liu, F.; Mendel, J.M. Encoding Words Into Interval Type-2 Fuzzy Sets Using an Interval Approach. IEEE Trans. Fuzzy Syst. 2009, 16, 1503–1521. [Google Scholar] [CrossRef]
- Wu, D.; Mendel, J.M.; Coupland, S. Enhanced Interval Approach for Encoding Words Into Interval Type-2 Fuzzy Sets and Its Convergence Analysis. IEEE Trans. Fuzzy Syst. 2011, 20, 499–513. [Google Scholar]
- Tahayori, H.; Sadeghian, A. Median interval approach to model words with interval type-2 fuzzy sets. Int. J. Adv. Intell. Paradig. 2012, 4, 313–336. [Google Scholar] [CrossRef]
- Li, C.C.; Rodríguez, R.M.; Martínez, L.; Dong, Y.; Herrera, F. Personalized individual semantics based on consistency in hesitant linguistic group decision making with comparative linguistic expressions. Knowl. Based Syst. 2018, 145, 156–165. [Google Scholar] [CrossRef]
- Liu, Y.; Rodríguez, R.M.; Hagras, H.; Liu, H.; Qin, K.; Martínez, L. Type-2 fuzzy envelope of hesitant fuzzy linguistic term set: A new representation model of comparative linguistic expression. IEEE Trans. Fuzzy Syst. 2019, 27, 2312–2326. [Google Scholar] [CrossRef]
- Wu, Z.B.; Xu, J.P. Possibility distribution-based approach for MAGDM with hesitant fuzzy linguistic information. IEEE Trans. Cybern. 2016, 46, 694–705. [Google Scholar] [CrossRef]
- Pang, Q.; Wang, H.; Xu, Z. Probabilistic Linguistic Term Sets in Multi-Attribute Group Decision Making. Inf. Sci. 2016, 369, 128–143. [Google Scholar] [CrossRef]
- Chen, Z.S.; Chin, K.S.; Li, Y.L.; Yang, Y. Proportional hesitant fuzzy linguistic term set for multiple criteria group decision making. Inf. Sci. 2016, 357, 61–87. [Google Scholar] [CrossRef]
- Mendel, J.M. Type-2 fuzzy sets and systems: An overview. Comput. Intell. Mag. IEEE 2007, 2, 20–29. [Google Scholar] [CrossRef]
- Mendel, J.M.; Hagras, H.; Bustince, H.; Herrera, F. Comments on “Interval Type-2 Fuzzy Sets are Generalization of Interval-Valued Fuzzy Sets: Towards a Wide View on Their Relationship”. IEEE Trans. Fuzzy Syst. 2016, 24, 249–250. [Google Scholar] [CrossRef] [Green Version]
- Mendel, J.M.; Rajati, M.R.; Sussner, P. On clarifying some definitions and notations used for type-2 fuzzy sets as well as some recommended changes. Inf. Sci. 2016, 340, 337–345. [Google Scholar] [CrossRef]
- Wu, D.; Mendel, J.M. A comparative study of ranking methods, similarity measures and uncertainty measures for interval type-2 fuzzy sets. Inf. Sci. 2008, 179, 1169–1192. [Google Scholar] [CrossRef]
- Zadeh, L. The concept of a linguistic variable and its application to approximate reasoning-I, II, III. Inf. Sci. 1975, 8, 199–249, 301–357, 43–80. [Google Scholar] [CrossRef]
- Mendel, J.M.; Zadeh, L.A.; Trillas, E.; Yager, R.; Lawry, J.; Hagras, H.; Guadarrama, S. What Computing with Words Means to Me [Discussion Forum]. Comput. Intell. Mag. IEEE 2010, 5, 20–26. [Google Scholar] [CrossRef]
- Wei, C.; Rodríguez, R.M.; Martínez, L. Uncertainty Measures of Extended Hesitant Fuzzy Linguistic Term Sets. IEEE Trans. Fuzzy Syst. 2018, 26, 1763–1768. [Google Scholar] [CrossRef]
- Fileva, D.; Yagerb, R.R. On the issue of obtaining OWA operator weights. Fuzzy Sets Syst. 1998, 94, 157–169. [Google Scholar] [CrossRef]
- Klir, G.J.; Yuan, B. Fuzzy Sets and Fuzzy Logic—Theory and Applications; Prentice Hall PTR: Upper Saddle River, NJ, USA, 1995. [Google Scholar]
- Lee, L.W.; Chen, S.M. Fuzzy multiple attributes group decision-making based on the extension of TOPSIS method and interval type-2 fuzzy sets. In Proceedings of the 2008 International Conference on Machine Learning and Cybernetics, San Diego, CA, USA, 11–13 December 2008; Volume 6, pp. 3260–3265. [Google Scholar]
- Rodríguez, R.M.; Labella, Á.; Tré, G.D.; Martínez, L. A large scale consensus reaching process managing group hesitation. Knowl.-Based Syst. 2018, 159, 86–97. [Google Scholar] [CrossRef]
- Abbasbandy, S.; Hajjari, T. A new approach for ranking of trapezoidal fuzzy numbers. Comput. Math. Appl. 2009, 57, 413–419. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
FOU for a trapezoidal IT2FS [45].
Figure 1.
FOU for a trapezoidal IT2FS [45].

Figure 2.
A linguistic term set .

Figure 3.
Functional relationship between the orness measure and parameter of and (adapted from [49]).
Figure 3.
Functional relationship between the orness measure and parameter of and (adapted from [49]).

Figure 4.
Large-scale muti-attribute linguistic group decision making.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Liu, Y.; Rodríguez, R.M.; Martínez, L. Interval Type-2 Fuzzy Envelope of Proportional Hesitant Fuzzy Linguistic Term Set: Application to Large-Scale Group Decision Making. Mathematics 2022, 10, 2368. https://doi.org/10.3390/math10142368
AMA Style
Liu Y, Rodríguez RM, Martínez L. Interval Type-2 Fuzzy Envelope of Proportional Hesitant Fuzzy Linguistic Term Set: Application to Large-Scale Group Decision Making. Mathematics. 2022; 10(14):2368. https://doi.org/10.3390/math10142368
Chicago/Turabian StyleLiu, Yaya, Rosa M. Rodríguez, and Luis Martínez. 2022. "Interval Type-2 Fuzzy Envelope of Proportional Hesitant Fuzzy Linguistic Term Set: Application to Large-Scale Group Decision Making" Mathematics 10, no. 14: 2368. https://doi.org/10.3390/math10142368
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.