1. Introduction
Measurement uncertainty relations are quantitative expressions of complementarity. As Bohr often emphasized, the predictions of quantum theory are always relative to some definite experimental arrangement, and these settings often exclude each other. In particular, one has to make a choice of measuring devices, and typically, quantum observables cannot be measured simultaneously. This often used term is actually misleading, because time has nothing to do with it. For a better formulation, recall that quantum experiments are always statistical, so the predictions refer to the frequency with which one will see certain outcomes when the whole experiment is repeated very often. Therefore, the issue is not simultaneous measurement of two observables, but joint measurement in the same shot. That is, a device R is a joint measurement of observable A with outcomes and observable B with outcomes , if it produces outcomes of the form in such a way that if we ignore outcome y, the statistics of the x outcomes is always (i.e., for every input state) the same as obtained with a measurement of A and symmetrically for ignoring x and comparing to B. It is in this sense that non-commuting projection-valued observables fail to be jointly measurable.
However, this is not the end of the story. One is often interested in
approximate joint measurements. One such instance is Heisenberg’s famous
γ-ray microscope [
1], in which a particle’s position is measured by probing it with light of some wavelength
λ, which from the outset sets a scale for the accuracy of this position measurement. Naturally, the particle’s momentum is changed by the Compton scattering, so if we make a momentum measurement on the particles after the interaction, we will find a different distribution from what would have been obtained directly. Note that in this experiment, we get from every particle a position value and a momentum value. Moreover, errors can be quantified by comparing the respective distributions with some ideal reference: the
accuracy of the microscope position measurement is judged by the degree of agreement between the distribution obtained and the one an ideal position measurement would give. Similarly, the
disturbance of momentum is judged by comparing a directly measured distribution with the one after the interaction. The same is true for the
uncontrollable disturbance of momentum. This refers to a scenario where we do not just measure momentum after the interaction, but try to build a device that recovers the momentum in an optimal way, by making an arbitrary measurement on the particle after the interaction, utilizing everything that is known about the microscope, correcting all known systematic errors and even using the outcome of the position measurement. The only requirement is that at the end of the experiment, for each individual shot, some value of momentum must come out. Even then it is impossible to always reproduce the pre-microscope distribution of momentum. The tradeoff between accuracy and disturbance is quantified by a measurement uncertainty relation. Since it simply quantifies the impossibility of a joint exact measurement, it simultaneously gives bounds on how an approximate momentum measurement irretrievably disturbs position. The basic setup is shown in
Figure 1.
Note that in this description of errors, we did not ever bring in a comparison with some hypothetical “true value”. Indeed, it was noted already by Kennard [
2] that such comparisons are problematic in quantum mechanics. Even if one is willing to feign hypotheses about the true value of position, as some hidden variable theorists will, an operational criterion for agreement will always have to be based on statistical criteria,
i.e., the comparison of distributions. Another fundamental feature of this view of errors is that it provides a figure of merit for the comparison of two devices, typically some ideal reference observable and an approximate version of it. An “accuracy”
ε in this sense is a promise that no matter which input state is chosen, the distributions will not deviate by more than
ε. Such a promise does not involve a particular state. This is in contrast to
preparation uncertainty relations, which quantify the impossibility to find a state for which the distributions of two given observables (e.g., position and momentum) are both sharp.
Measurement uncertainty relations in the sense described here were first introduced for position and momentum in [
3] and were initially largely ignored. A bit earlier, an attempt by Ozawa [
4] to quantify error-disturbance tradeoffs with state dependent and somewhat unfortunately chosen [
5] quantities had failed, partly for reasons already pointed out in [
6]. When experiments confirmed some predictions of the Ozawa approach (including the failure of the error-disturbance tradeoff), a debate ensued [
7,
8,
9,
10]. Its unresolved part is whether a meaningful role for Ozawa’s definitions can be found.
Technically, the computation of measurement uncertainty remained hard, since there were no efficient methods to compute sharp bounds in generic cases. A direct computation along the lines of the definition is not feasible, since it involves three nested optimization problems. The only explicit solutions were for qubits [
11,
12,
13], one case of angular momentum [
14] and all cases with phase space symmetry [
7,
15,
16], in which the high symmetry allows the reduction to preparation uncertainty as in [
3,
9]. The main aim of the current paper is to provide efficient algorithms for sharp measurement uncertainty relations of generic observables, even without any symmetry.
In order to do that, we restrict the setting in some ways, but allow maximal generality in others. We will restrict to finite dimensional systems and reference observables, which are projection valued and non-degenerate. Thus, each of the ideal observables will basically be given by an orthonormal basis in the same
d-dimensional Hilbert space. The labels of this basis are the outcomes
of the measurement, where
X is a set of
d elements. We could choose all
, but it will help to keep track of things using a separate set for each observable. Moreover, this includes the choice
, the set of eigenvalues of some Hermitian operator. We allow not just two observables, but any finite number
of them. This makes some expressions easier to write down, since the sum of an expression involving observable
A and an analogous one for observable
B becomes an indexed sum. We also allow much generality in the way errors are quantified. In earlier works, we relied on two elements to be chosen for each observable, namely a metric
D on the outcome set and an error exponent
α, distinguishing, say, absolute (
), root-mean-square (
) and maximal (
) deviations. Deviations were then averages of
. Here, we generalize further to an arbitrary
cost function , which we take to be positive and zero exactly on the diagonal (e.g.,
), but not necessarily symmetric. Again, this generality comes mostly as a simplification of notation. For a reference observable
A with outcome set
X and an approximate version
with the same outcome set, this defines an error
. Our aim is to provide algorithms for computing the
uncertainty diagram associated with such data, of which
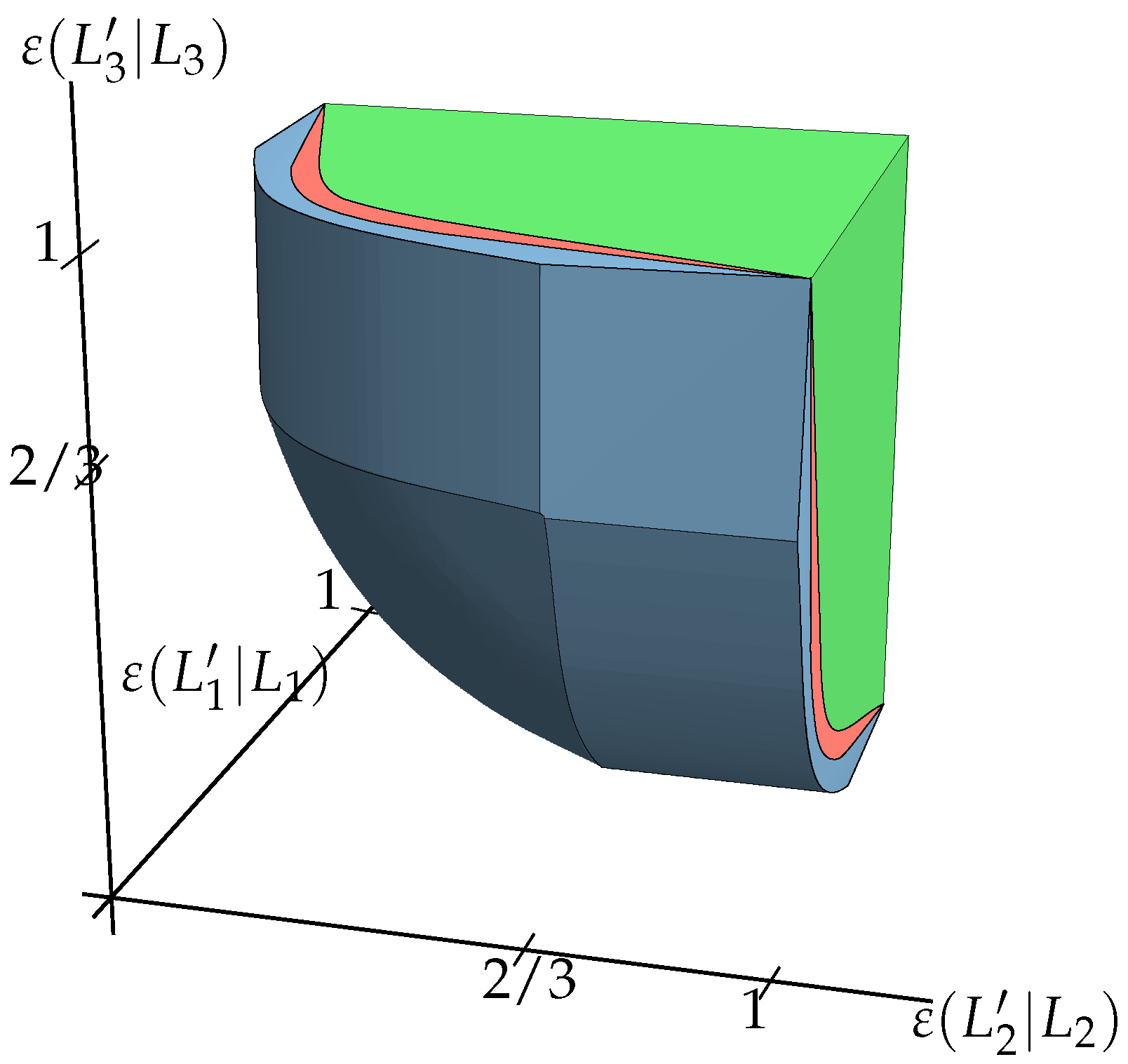
Figure 2 gives an example. The given data for such a diagram are
n projection valued observables
, with outcome sets
, for each of which we are given also a cost function
for quantifying errors. An approximate joint measurement is then an observable
R with outcome set
, and hence, with POVMelements
, where
. By ignoring every output, but one, we get the
n marginal observables:
and a corresponding tuple:
of errors. The set of such tuples, as
R runs over all joint measurements, is the
uncertainty region. The surface bounding this set from below describes the uncertainty tradeoffs. For
, we call it the tradeoff curve. Measurement uncertainty is the phenomenon that, for general reference observables
, the uncertainty region is bounded away from the origin. In principle, there are many ways to express this mathematically, from a complete characterization of the exact tradeoff curve, which is usually hard to get, to bounds that are simpler to state, but suboptimal. Linear bounds will play a special role in this paper.
We will consider three ways to build a single error quantity out of the comparison of distributions, denoted by
,
and
. These will be defined in
Section 2. For every choice of observables and cost functions, each will give an uncertainty region, denoted by
,
and
, respectively. Since they are all based on the same cost function
c, they are directly comparable (see
Figure 2). We show in
Section 3 that the three regions are convex and hence characterized completely by linear bounds. In
Section 4, we show how to calculate the optimal linear lower bounds by semidefinite programs. Finally, an
Appendix collects the basic information on the beautiful theory of optimal transport, which is needed in
Section 2.1 and
Section 4.1.
2. Deviation Measures for Observables
Here, we define the measures we use to quantify how well an observable
approximates a desired observable
A. In this section, we do not use the marginal condition Equation (
1), so
is an arbitrary observable with the same outcome set
X as
A,
i.e., we drop all indices
i identifying the different observables. Our error quantities are operational in the sense that each is motivated by an experimental setup, which will in particular provide a natural way to measure them. All error definitions are based on the same cost function
, where
is the “cost” of getting a result
, when
would have been correct. The only assumptions are that
with
iff
.
As described above, we consider a quantum system with Hilbert space . As a reference observable A, we allow any complete von Neumann measurement on this system, that is any observable whose set X of possible measurement outcomes has size and whose POVM elements () are mutually orthogonal projectors of rank 1; we can then also write with an orthonormal basis of . For the approximating observable , the POVM elements (with ) are arbitrary with and .
The comparison will be based on a comparison of output distributions, for which we use the following notations: given a quantum state ρ on this system, i.e., an operator with and , and an observable, such as A, we will denote the outcome distribution by , so . This is a probability distribution on the outcome set X and can be determined physically as the empirical outcome distribution after many experiments.
For comparing just two probability distributions
and
, a canonical choice is the “minimum transport cost”:
where the infimum runs over the set of all
couplings or “transport plans”
of
p to
q,
i.e., the set of all probability distributions
γ satisfying the marginal conditions
and
. The motivations for this notion and the methods to compute it efficiently are described in the
Appendix. Since
X is finite, the infimum is over a compact set, so it is always attained. Moreover, since we assumed
and
, we also have
with equality iff
. If one of the distributions, say
q, is concentrated on a point
, only one coupling exists, namely
. In this case, we abbreviate
, and get:
i.e., the average cost of moving all of the points
x distributed according to
p to
.
2.1. Maximal Measurement Error
The worst case error over
all input states is:
which we call the
maximal error. Note that, like the cost function
c and the transport costs
, the measure
need not be symmetric in its arguments, which is sensible, as the reference and approximating observables have distinct roles. Similar definitions for the deviation of an approximating measurement from an ideal one have been made, for specific cost functions, in [
7,
9] and [
14] before.
The definition Equation (
5) makes sense even if the reference observable
A is not a von Neumann measurement. Instead, the only requirement is that
A and
be general observables with the same (finite) outcome set
X, not necessarily of size
d. All of our results below that involve only the maximal measurement error immediately generalize to this case, as well.
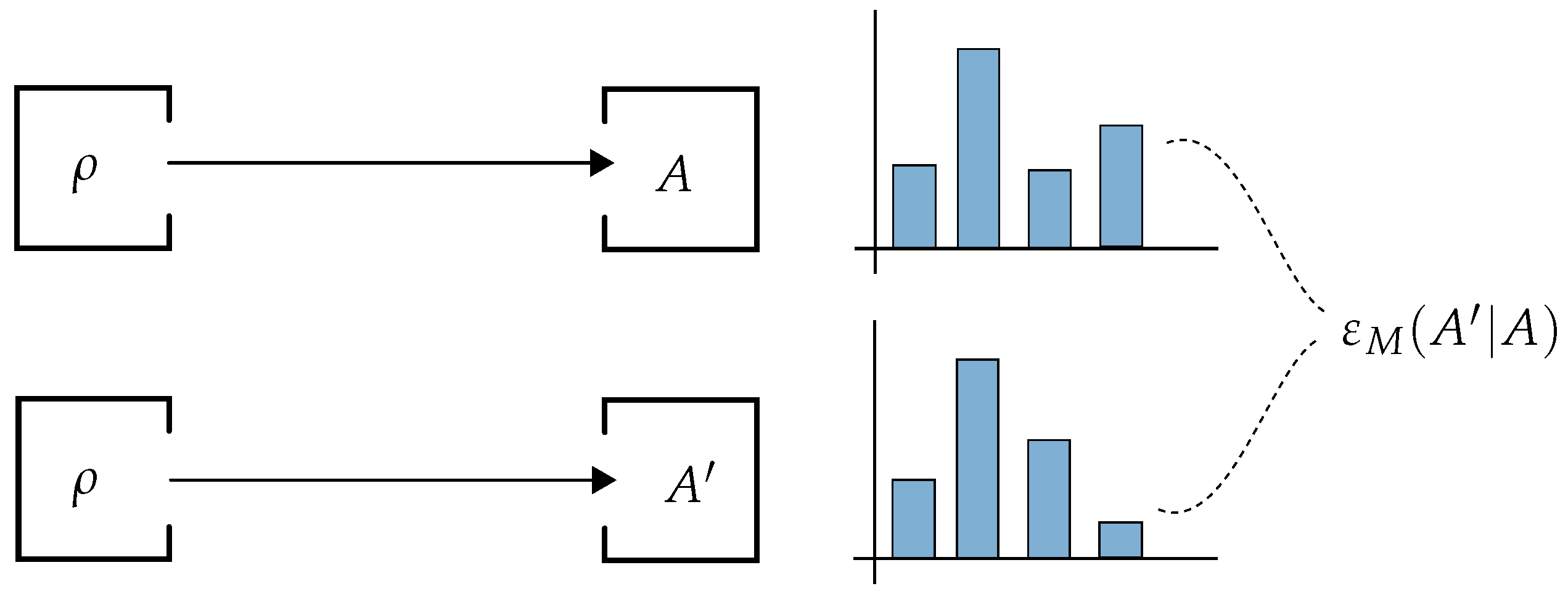
One can see that it is expensive to determine the quantity
experimentally according to the definition: one would have to measure and compare (see
Figure 3) the outcome statistics
and
for all possible input states
ρ, which form a continuous set. The following definition of observable deviation alleviates this burden.
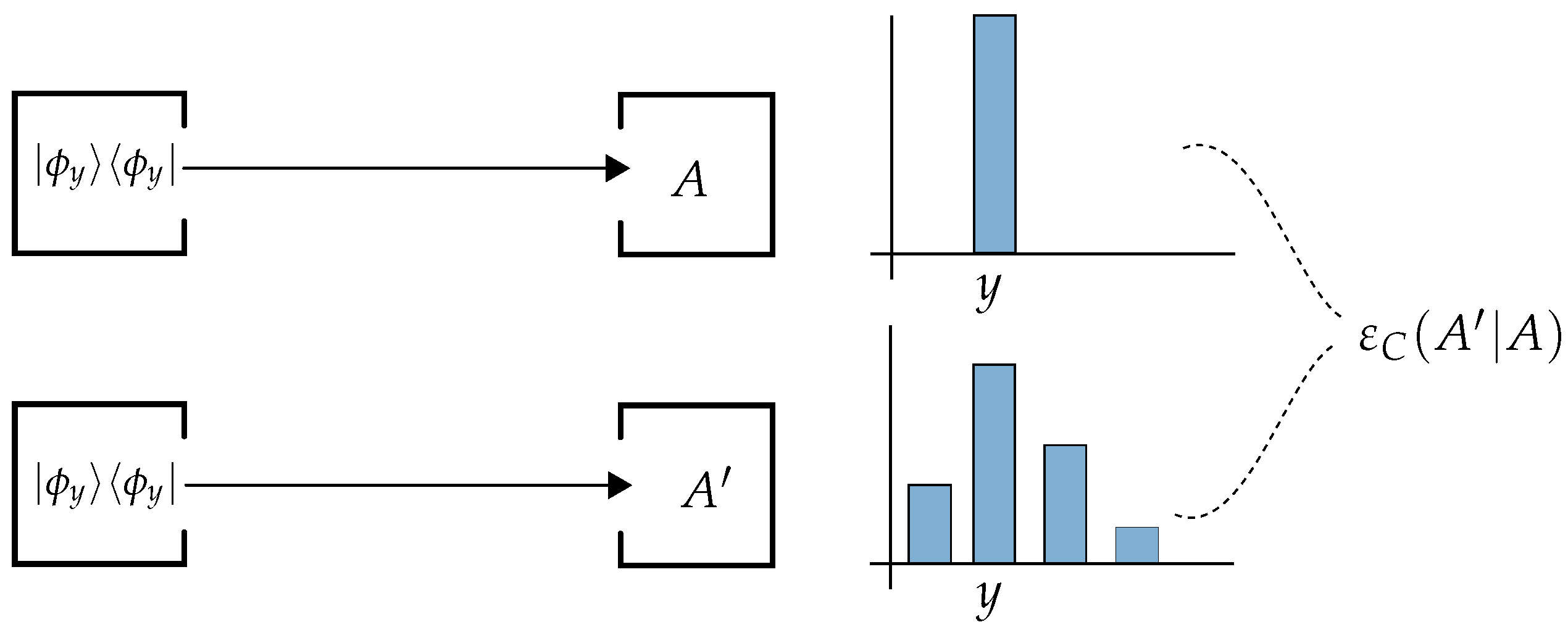
2.2. Calibration Error
Calibration (see
Figure 4) is a process by which one tests a measuring device on inputs (or measured objects) for which the “true value” is known. Even in quantum mechanics, we can set this up by demanding that the measurement of the reference observable on the input state gives a sharp value
y. In a general scenario with continuous outcomes, this can only be asked with a finite error
δ, which goes to zero at the end [
7], but in the present finite scenario, we can just demand
. Since, for every outcome
y of a von Neumann measurement, there is only one state with this property (namely
), we can simplify even further, and define the
calibration error by:
Note that the calibration idea only makes sense when there are sufficiently many states for which the reference observable has deterministic outcomes, i.e., for projective observables A.
A closely related quantity has recently been proposed by Appleby [
10]. It is formulated for real valued quantities with cost function
and has the virtue that it can be expressed entirely in terms of first and second moments of the probability distributions involved. Therefore, for any
ρ, let
m and
v be the mean and variance of
and
the mean quadratic deviation of
from
m. Then, Appleby defines:
Here, we added the square to make Appleby’s quantity comparable to our variance-like (rather than standard deviation-like) quantities and chose the letter
D, because Appleby calls this the
D-error. Since in the supremum, we have also the states for which
A has a sharp distribution (
i.e.,
), we clearly have
. On the other hand, let
and
. Then, one easily checks that
, so
is a pricing scheme in the sense defined in the
Appendix. Therefore:
Maximizing this expression over
t gives exactly Equation (
7). Therefore,
2.3. Entangled Reference Error
In quantum information theory, a standard way of providing a reference state for later comparison is by applying a channel or observable to one half of a maximally-entangled system. Two observables would be compared by measuring them (or suitable modifications) on the two parts of a maximally-entangled system (see
Figure 5). Let us denote the entangled vector by
. Since later, we will look at several distinct reference observables, the basis kets
in this expression have no special relation to
A or its eigenbasis
. We denote by
the transpose of an operator
X in the
basis, and by
the observable with POVM elements
, where
is the complex conjugate of
in
-basis. These transposes are needed due to the well-known relation
. We now consider an experiment, in which
is measured on the first part and
on the second part of the entangled system, so we get the outcome pair
with probability:
As
A is a complete von Neumann measurement, this probability distribution is concentrated on the diagonal (
) iff
,
i.e., there are no errors of
relative to
A. Averaging with the error costs, we get a quantity we call the
entangled reference error:
Note that this quantity is measured as a single expectation value in the experiment with source Ω. Moreover, when we later want to measure different such deviations for the various marginals, the source and the tested joint measurement device can be kept fixed, and only the various reference observables acting on the second part need to be adapted suitably.
2.4. Summary and Comparison
The quantities
,
and
constitute three different ways to quantify the deviation of an observable
from a projective reference observable
A. Nevertheless, they are all based on the same distance-like measure, the cost function
c on the outcome set
X. Therefore, it makes sense to compare them quantitatively. Indeed, they are ordered as follows:
Here, the first inequality follows by restricting the supremum Equation (
5) to states that are sharp for
A and the second by noting that the Equation (
6) is the maximum of a function of
y, of which Equation (
10) is the average.
Moreover, as we argued before in Equation (
10),
if and only if
, which is hence equivalent also to
and
.
3. Convexity of Uncertainty Diagrams
For two observables
and
with the same outcome set, we can easily realize their mixture or convex combination
by flipping a coin with probability
t for heads in each instance and then apply
when heads is up and
otherwise. In terms of POVM elements, this reads
. We show first that this mixing operation does not increase the error quantities from
Section 2.
Lemma 1. For the error quantity , is a convex function of B, i.e., for and : Proof. The basic fact used here is that the pointwise supremum of affine functions (i.e., those for which equality holds in the definition of a convex function) is convex. This is geometrically obvious and easily verified from the definitions. Hence, we only have to check that each of the error quantities is indeed represented as a supremum of functions, which are affine in the observable B.
For
, we even get an affine function, because Equation (
10) is linear in
. For
, Equation (
6) has the required form. For
, Equation (
5) is a supremum, but the function
is defined as an infimum. However, we can use the duality theory described in the
Appendix to write it instead as a supremum over pricing schemes, of an expression that is just the expectation of
plus a constant and, therefore, an affine function. Finally, for Appleby’s case Equation (
7), we get the same supremum, but over the subset of pricing schemes (the quadratic ones). ☐
The convexity of the error quantities distinguishes measurement from preparation uncertainty. Indeed, the variances appearing in preparation uncertainty relations are typically concave functions, because they arise from minimizing the expectation of over m. Consequently, the preparation uncertainty regions may have gaps and non-trivial behavior on the side of large variances. The following proposition will show that measurement uncertainty regions are better behaved.
For every cost function
c on a set
X, we can define a “radius”
, the largest transportation cost from the uniform distribution (the “center” of the set of probability distributions) and a “diameter”
, the largest transportation cost between any two distributions:
Proposition 2. Let n observables and cost functions be given, and define and . Then, for , the uncertainty regions is a convex set and has the following (monotonicity) property: when and are such that , then .
Proof. Let us first clarify how to make the worst possible measurement
B, according to the various error criteria, for which we go back to the setting of
Section 2, with just one observable
A and cost function
c. In all cases, the worst measurement is one with constant and deterministic output,
i.e.,
. For
and
, such a measurement will have
, and we can choose
to make this equal to
. For
, we get instead the average, which is maximized by
.
We can now make a given joint measurement
R worse by replacing it partly by a bad one, say for the first observable
. That is, we set, for
,
Then, all marginals
for
are unchanged, but
. Now, as
λ changes from zero to one, the point in the uncertainty diagram will move continuously in the first coordinate direction from
to the point in which the first coordinate is replaced by its maximum value (see
Figure 6 (left)). Obviously, the same holds for every other coordinate direction, which proves the monotonicity statement of the proposition.
Let
and
be two observables, and let
be their mixture. For proving the convexity of
, we will have to show that every point on the line between
and
can be attained by a tuple of errors corresponding to some allowed observable (see
Figure 6 (right)). Now, lemma 1 tells us that every component of
is convex, which implies that
. However, by monotonicity, this also means that
is in
again, which shows the convexity of
. ☐
Example: Phase Space Pairs
As is plainly visible from
Figure 2, the three error criteria considered here usually give different results. However, under suitable circumstances, they all coincide. This is the case for conjugate pairs related by Fourier transform [
15]. The techniques needed to show this are the same as for the standard position/momentum case [
9,
17] and, in addition, imply that the region for preparation uncertainty is also the same.
In the finite case, there is not much to choose: we have to start from a finite abelian group, which we think of as position space, and its dual group, which is then the analogue of momentum space. The unitary connecting the two observables is the finite Fourier associated with the group. The cost function needs to be translation invariant,
i.e.,
. Then, by an averaging argument, we find for all error measures that a covariant phase space observable minimizes measurement uncertainty (all three versions). The marginals of such an observable can be simulated by first doing the corresponding reference measurement and then adding some random noise. This implies [
14] that
. However, we know more about this noise: it is independent of the input state, so that the average and the maximum of the noise (as a function of the input) coincide,
i.e.,
. Finally, we know that the noise of the position marginal is distributed according to the position distribution of a certain quantum state, which is, up to normalization and a unitary parity inversion, the POVM element of the covariant phase space observable at the origin. The same holds for the momentum noise. However, then the two noise quantities are exactly related like the position and momentum distributions of a state, and the tradeoff curve for that problem is exactly preparation uncertainty, with variance criteria based on the same cost function.
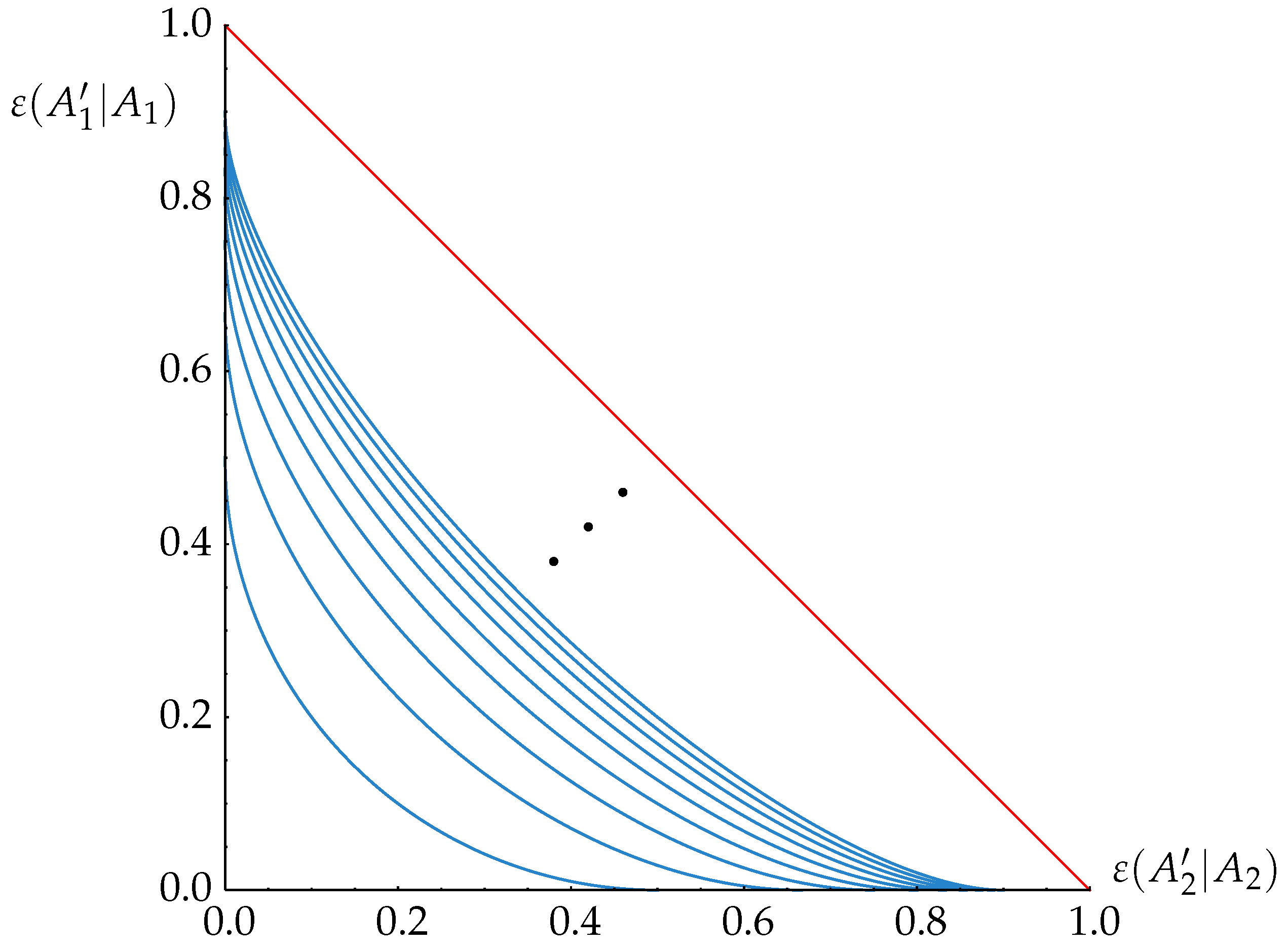
If we choose the discrete metric for
c, the uncertainty region depends only on the number
d of elements in the group we started from [
15]. The largest
ε for all quantities is the distance from a maximally-mixed state to any pure state, which is
. The exact tradeoff curve is then an ellipse, touching the axes at the points
and
. The resulting family of curves, parameterized by
d, is shown in
Figure 7. In general, however, the tradeoff curve requires the solution of a non-trivial family of ground state problems and cannot be given in closed form. For bit strings of length
n and the cost, some convex function of Hamming distance there is an expression for large
n [
15].
4. Computing Uncertainty Regions via Semidefinite Programming
We show here how the uncertainty regions, and therefore, optimal uncertainty relations, corresponding to each of the three error measures can actually be computed, for any given set of projective observables
and cost functions
. Our algorithms will come in the form of semidefinite programs (SDPs) [
18,
19], facilitating efficient numerical computation of the uncertainty regions via the many existing program packages to solve SDPs. Moreover, the accuracy of such numerical results can be rigorously certified via the duality theory of SDPs. To obtain the illustrations in this paper, we used the CVX package [
20,
21] under MATLAB.
As all of our uncertainty regions
(for
) are convex and closed (
Section 3), they are completely characterized by their supporting hyperplanes (for a reference to convex geometry, see [
22]). Due to the monotonicity property stated in Proposition 2, some of these hyperplanes just cut off the set parallel along the planes
. The only hyperplanes of interest are those with nonnegative normal vectors
(see
Figure 8). Each hyperplane is completely specified by its “offset”
away from the origin, and this function determines
:
In fact, due to homogeneity , we can restrict everywhere to the subset of vectors that, for example, satisfy , suggesting an interpretation of the as weights of the different uncertainties . Our algorithms will, besides evaluating , also allow one to compute a (approximate) minimizer , so that one can plot the boundary of the uncertainty region by sampling over , which is how the figures in this paper were obtained.
Let us further note that knowledge of for some immediately yields a quantitative uncertainty relation: every error tuple attainable via a joint measurement is constrained by the affine inequality , meaning that some weighted average of the attainable error quantities cannot become too small. When is strictly positive, this excludes in particular the zero error point . The obtained uncertainty relations are optimal in the sense that there exists , which attains strict equality .
Having reduced the computation of an uncertainty region essentially to determining (possibly along with an optimizer ), we now treat each case in turn.
4.1. Computing the Uncertainty Region
On the face of it, the computation of the offset
looks daunting: expanding the definitions, we obtain:
where the infimum runs over all joint measurements
R with outcome set
, inducing the marginal observables
according to Equation (
1), and the supremum over all sets of
n quantum states
and where the transport costs
are given as a further infimum Equation (
3) over the couplings
of
and
.
The first simplification is to replace the infimum over each coupling
, via a dual representation of the transport costs, by a maximum over
optimal pricing schemes , which are certain pairs of functions
, where
α runs over some finite label set
. The characterization and computation of the pairs
, which depend only on the chosen cost function
on
, are described in the
Appendix. The simplified expression for the optimal transport costs is then:
We can then continue our computation of
:
where
denotes the maximum eigenvalue of a Hermitian operator
. Note that
, which one can also recognize as the dual formulation of the convex optimization
over density matrices, so that:
We obtain thus a single constrained minimization:
Making the constraints on the POVM elements
of the joint observable
R explicit and expressing the marginal observables
directly in terms of them by Equation (
1), we finally obtain the following SDP representation for the quantity
:
The derivation above shows further that, when , the attaining the infimum equals , where is the marginal coming from a corresponding optimal joint measurement . Since numerical SDP solvers usually output an (approximate) optimal variable assignment, one obtains in this way directly a boundary point of when all are strictly positive. If vanishes, a corresponding boundary point can be computed via from an optimal assignment for the POVM elements .
For completeness, we also display the corresponding dual program [
18] (note that strong duality holds and the optima of both the primal and the dual problem are attained):
4.2. Computing the Uncertainty Region
To compute the offset function
for the calibration uncertainty region
, we use the last form in Equation (
6) and recall that the projectors onto the sharp eigenstates of
(see
Section 2.2) are exactly the POVM elements
for
:
where again, the infimum runs over all joint measurements
R, inducing the marginals
, and we have turned, for each
, the maximum over
y into a linear optimization over probabilities
(
) subject to the normalization constraint
. In the last step, we have made the
explicit via Equation (
1).
The first main step towards a tractable form is von Neumann’s minimax theorem [
23,
24]: as the sets of joint measurements
R and of probabilities
are both convex and the optimization function is an affine function of
R and, separately, also an affine function of the
, we can interchange the infimum and the supremum:
The second main step is to use SDP duality [
19] to turn the constrained infimum over
R into a supremum, abbreviating the POVM elements as
:
which is very similar to a dual formulation often employed in optimal ambiguous state discrimination [
25,
26].
Putting everything together, we arrive at the following SDP representation for the offset quantity
:
The dual SDP program reads (again, strong duality holds, and both optima are attained):
This dual version can immediately be recognized as a translation of Equation (
26) into SDP form, via an alternative way of expressing the maximum over
y (or via the linear programming dual of
from Equation (
28)).
To compute a boundary point
of
lying on the supporting hyperplane with normal vector
, it is best to solve the dual SDP Equation (
32) and to obtain
from an (approximate) optimal assignment of the
. Again, this works when
, whereas otherwise, one can compute
from an optimal assignment of the
. From many primal-dual numerical SDP solvers (such as CVX [
20,
21]), one can alternatively obtain optimal POVM elements
also from solving the primal SDP Equation (
31) as optimal dual variables corresponding to the constraints
and compute
from there.
4.3. Computing the Uncertainty Region
As one can see by comparing the last expressions in the defining Equations (
6) and (
10), respectively, the evaluation of
is quite similar to Equation (
26), except that the maximum over
y is replaced by a uniform average over
y. This simply corresponds to fixing
for all
in Equation (
28), instead of taking the supremum. Therefore, the primal and dual SDPs for the offset
are:
and:
The computation of a corresponding boundary point is similar as above.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








