
On Some Extended Block Krylov Based Methods for Large Scale Nonsymmetric Stein Matrix Equations

1
Laboratory LAMAI, University of Cadi Ayyad, Marrakesh 40000, Morocco
2
LMPA, 50 rue F. Buisson, ULCO Calais, Calais 62228 , France
3
ENSA d’EL Jadida, University Chouaib Doukkali, EL Jadida 24002, Morocco
*
Author to whom correspondence should be addressed.
Mathematics 2017, 5(2), 21; https://doi.org/10.3390/math5020021
Submission received: 22 December 2016
/
Revised: 15 March 2017
/
Accepted: 17 March 2017
/
Published: 27 March 2017
(This article belongs to the Special Issue Numerical Linear Algebra with Applications)
Abstract
:In the present paper, we consider the large scale Stein matrix equation with a low-rank constant term . These matrix equations appear in many applications in discrete-time control problems, filtering and image restoration and others. The proposed methods are based on projection onto the extended block Krylov subspace with a Galerkin approach (GA) or with the minimization of the norm of the residual. We give some results on the residual and error norms and report some numerical experiments.
1. Introduction
In this paper, we are interested in the numerical solution of large scale nonsymmetric Stein matrix equations of the form:
where A and B are real, sparse and square matrices of size and respectively, and E and F are matrices of size and , respectively.
Stein matrix equations play an important role in many problems in control and filtering theory for discrete-time large-scale dynamical systems, in each step of Newton’s method for discrete-time algebraic Riccati equations, model reduction problems, image restoration techniques and other problems [1,2,3,4,5,6,7,8,9,10].
Direct methods for solving the matrix Equation (1), such as those proposed by Bartels–Stewart [11] and the Hessenberg–Schur [12] algorithms, are attractive if the matrices are of small size. For a general overview of numerical methods for solving the Stein matrix equation [1,2,13].
The Stein matrix Equation (1) can be formulated as an large linear system using the Kronecker formulation:
where is the vector obtained by stacking all the columns of the matrix X, is the n-by-n identity matrix, and the Kronecker product of two matrices A and B is defined by where . This product satisfies the properties , and . Then, the matrix Equation (1) has a unique solution if and only if for all and , where denotes the spectrum of the matrix A. Throughout the paper, we assume that this condition is satisfied. Moreover, if both A and B are Schur stable, i.e., and lie in the open unit disc, and then the solution of Equation (1) can be expressed as the following infinite matrix series:
To solve large linear matrix equations, several Krylov subspace projection methods have been proposed (see, e.g., [1,13,14,15,16,17,18,19,20,21,22,23,24] and the references therein). The main idea developed in these methods is to use a block Krylov subspace or an extended block Krylov subspace and then project the original large matrix equation onto these Krylov subspaces using a Galerkin condition or a minimization property of the obtained residual. Hence, we will be interested in these two procedures to get approximate solutions to the solution of the Stein matrix Equation (1). The rest of the paper is organized as follows. In the next section, we recall the extended block Krylov subspace and the extended block Arnoldi (EBA) algorithm with some properties. In Section 3, we will apply the Galerkin approach (GA) to Stein matrix equations by using the extended Krylov subspaces. In Section 4, we define the minimal residual (MR) method for Stein matrix equations by using the extended Krylov subspaces. We finally present some numerical experiments in Section 5.
2. The Extended Block Krylov Subspace Algorithm
In this section, we recall the EBA algorithm applied to where . The block Krylov subspace associated with is defined as:
The extended block Krylov subspace associated with the pair is given as:
The EBA Algorithm 1 is defined as follows [15,16,18,23]:
| Algorithm 1. The Extended Block Arnoldi (EBA) Algorithm |
|
This algorithm allows us to construct an orthonormal matrix that is a basis of the block extended Krylov subspace . The restriction of the matrix A to the block extended Krylov subspace is given by .
3. Galerkin-Based Methods
In this section, we will apply the Galerkin projection method to obtain low-rank approximate solutions of the nonsymmetric Stein matrix Equation (1). This approach has been applied for Lyapunov, Sylvester or Riccati matrix equations [1,14,15,19,20,21,23,25,26].
3.1. The Case: Both A and B Are Large Matrices
We consider here a nonsymmetric Stein matrix equation, where A and B are large and sparse matrices with and . We project the initial problem by using the extended block Krylov subspaces and associated with the pairs and , respectively, and get orthonormal bases and . We then consider approximate solutions of the Stein matrix Equation (1) that have the low-rank form:
where and .
The matrix is determined from the following Galerkin orthogonality condition:
Now, replacing in Equation (4), we obtain the reduced Stein matrix equation:
where , ,
Assuming that for any and , the solution of the low-order Stein Equation (5) can be obtained by a direct method such as those described in [11]. The following result on the norm of the residual allows us to stop the iterations without having to compute the approximation .
Theorem 1.
Let be the approximation obtained at step m by the EBA algorithm. Then, the Frobenius norm of the residual associated to the approximation is given by:
where and:
Proof.
The proof is similar to the one given at proposition 6 in [17]. ☐
In the following result, we give an upper bound for the norm of the error .
Theorem 2.
Assume that and , and let be the exact solution of projected Stein matrix Equation (5) and be the approximate solution given by running m steps of the EBA algorithm. Then:
Proof.
The proof is similar to the one given at Theorem 2 in [27]. ☐
The approximate solution can be given as a product of two matrices of low rank. Consider the singular value decomposition of the matrix:
where is the diagonal matrix of the singular values of sorted in decreasing order. Let and be the matrices of the first l columns of and respectively, corresponding to the l singular values of magnitude greater than some tolerance. We obtain the truncated singular value decomposition:
where . Setting , and it follows that:
This is very important for large problems when one doesn’t need to compute and store the approximation at each iteration.
The GA is given in Algorithm 2:
| Algorithm 2. Galerkin Approach (GA) for the Stein Matrix Equations |
|
In the next section, we consider the case where the matrix A is large while B has a moderate or a small size.
3.2. The Case: A Large and B Small
In this section, we consider the Stein matrix equation:
where E is a matrix of size with .
In this case, we will consider approximations of the exact solution X as:
where is the orthonormal basis obtained by applying the extended block Krylov subspace . The orthogonality Galerkin condition gives:
where is the m-th residual given by . Therefore, we obtain the projected Stein matrix equation:
where and .
The next result gives a useful expression of the norm of the residual.
Theorem 3.
Proof.
The residual is given by . Since E is belonging to , then . Using the relation , we have:
As the matrix is orthogonal and , we have:
Therefore:
☐
This result is very important because it allows us to calculate the Frobenius norm of without having to compute the approximate solution.
Next, we give a result showing that the error is an exact solution of a perturbed Stein matrix equation.
Theorem 4.
Let be the approximate solution of Equation (9) obtained after m iterations of the EBA algorithm. Then:
where
Proof.
We can now state the following result, which gives an upper bound for the norm of the error.
Theorem 5.
If and , then we have:
Proof.
In the next section, we present projection methods based on extended block Krylov subspaces and MR property.
4. Minimal Residual Method for Large Scale Stein Matrix Equations
In this section, we present a MR method for solving large scale Stein matrix equations. A MR method for solving large scale Lyapunov matrix equation is given in [22].
4.1. The Case: Both A and B Are Large
Instead of using a Galerkin condition as we explained in the preceding section, we consider here approximate solutions satisfying the following minimization property:
We have the following result.
Theorem 6.
The solution of the the minimization problem:
is given by:
where solves the following low dimentional minimization problem:
with and , the factorization of E and F, respectively.
Proof.
We have:
☐
One advantage of using the minimization approach is the fact that the projected problem (24) always has a solution that is not the case when one uses a GA.
The main problem is now how to solve the reduced order minimization problem (24). One possibility is the use of the preconditioned global conjugate gradient (PGCG) method.
4.2. The Preconditioned Global CG Method for Solving the Reduced Minimization Problem
In this section, we adopt the preconditioned conjugate gradient method (PCG) [28,29] to solve the reduced minimization problem (24). The normal equation associated with (24) is given by:
where:
Notice that is the adjoint of the linear operator with respect to the Frobenius inner product is given by:
and:
We can decompose the matrices and as follows:
where and represent the last rows of the matrices and , respectively. Therefore, the normal Equation (25) can be written as:
Considering the singular value decomposition (SVD) of the matrices and :
we get the eigendecomposition:
where , and .
Let and , and then the normal Equation (26) is now expressed as:
where and . This expression suggests that one can use the first part as a preconditioner, that is, the matrix operator:
It can be seen that the expression (29) corresponds to the normal equation of the following matrix operator:
where and . Then, the preconditioned global CG algorithm is obtained by applying the preconditioner (30) to the normal equation associated with the matrix linear operator defined by Equation (31). This is summarized in Algorithm 3.
| Algorithm 3. The Preconditioned Global Conjugate Gradient (PGCG) Algorithm. |
|
Notice that the use of the preconditioner requires the solution, at each iteration, of a Stein equation. As the matrices and of these Stein matrix equations are diagonal matrices, this reduces the costs.
The MR Algorithm 4 for the Stein matrix equations is summarized as follows:
| Algorithm 4. The Minimal Residual (MR) Method for Nonsymmetric Stein Matrix Equations |
4.3. The Case: A Large and B Small
In this subsection, we apply the MR norm method to the nonsymmetric Stein Equation (9) in the case A large and B small. The approximate solution is given by:
with:
We have the following result, which is not difficult to prove.
Theorem 7.
The solution of the minimization problem:
is given by:
where:
with being the decomposition of E.
5. Numerical Experiments
In this section, we present some numerical experiments of large and sparse Stein matrix equations. We compared EBA-MR and EBA-GA methods. For the GA and at each iteration m, we solved the projected Stein matrix equations by using the Bartels–Stewart algorithm [11]. When solving the minimization reduced problem by the PGCG, we stopped the iterations when the relative norm of the residual was less than or when a maximum of iterations was achieved. The algorithms were coded in Matlab 8.0 (2014). The stopping criterion used for EBA-MR and GA was or a maximum of iterations was achieved.
In all of the examples, the coefficients of the matrices E and F were random values uniformly distributed on .
Example 1.
In this first example, the matrices A and B are obtained from the centered finite difference discretization of the operators:
on the unit square with homogeneous Dirichlet boundary conditions. The number of inner grid points in each direction was and for the operators and , respectively. The matrices A and B were obtained from the discretization of the operator and with the dimensions and , respectively. The discretization of the operator and yields matrices extracted from the Lyapack package [30] using the command fdm_2d_matrix and denoted as A = fdm(n0,’f_1(x,y)’,’f_2(x,y)’,’f(x,y)’). In this example, and , respectively, and are named as and with , , , , and . For this experiment, we used .
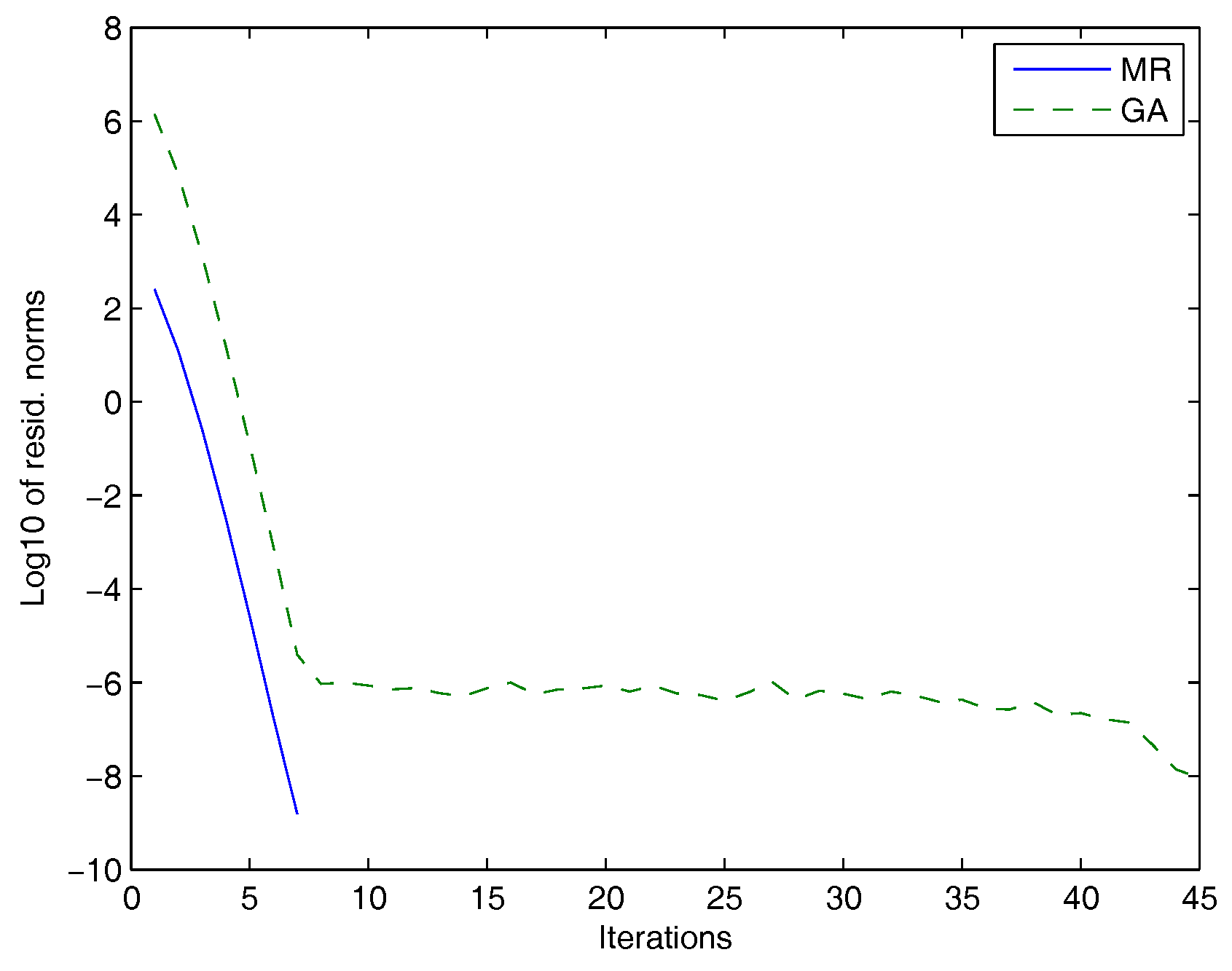
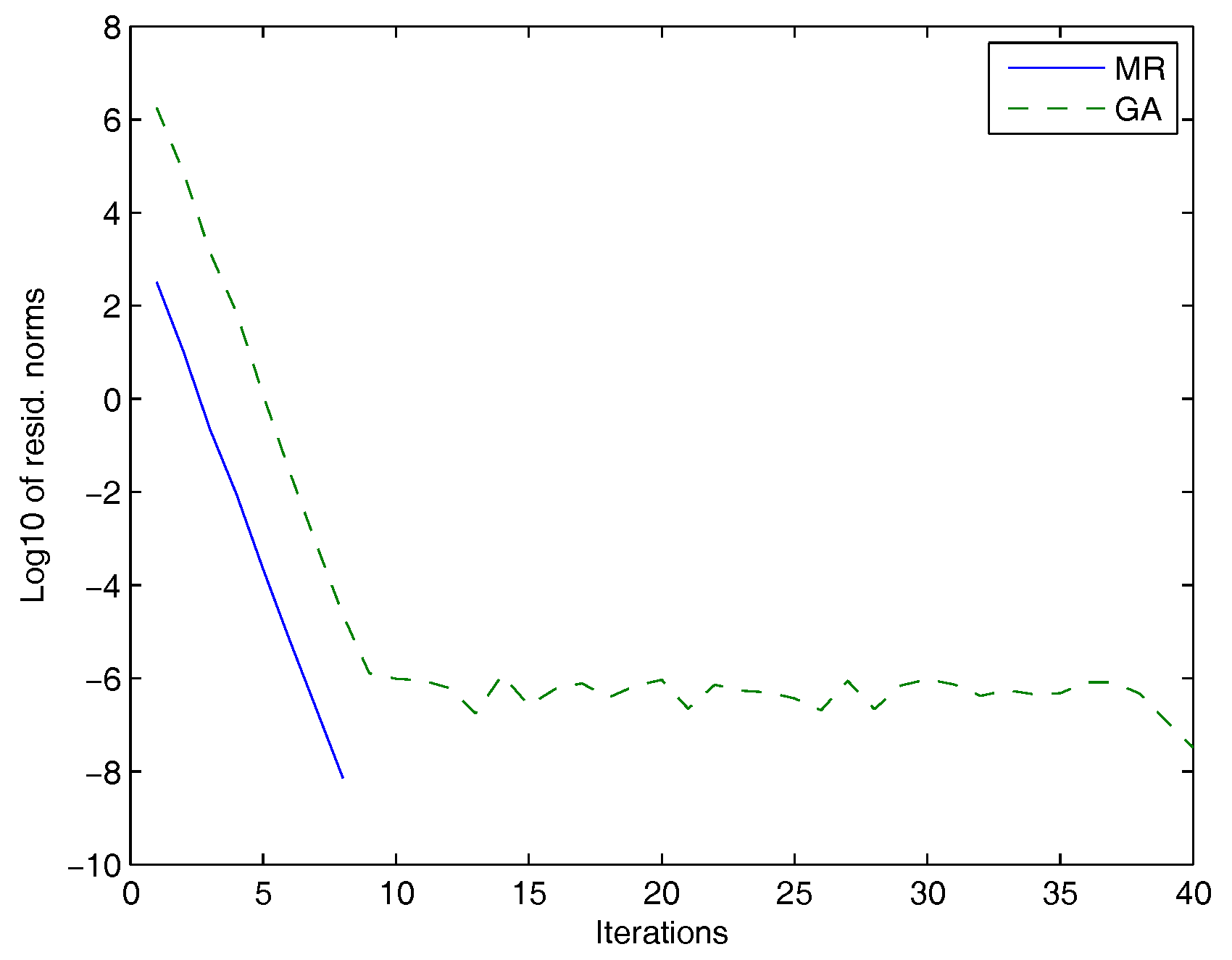
In Figure 1, we plotted the Frobenius norms of the residuals versus the number of iterations for the MR and the GAs.
In Table 1, we compared the performances of the MR method and the GA. For both methods, we listed the residual norms, the maximum number of iteration and the corresponding execution time.
Example 2.
For the second set of experiments, we considered matrices from the University of Florida Sparse Matrix Collection [31] and from the Harwell Boeing Collection (http://math.nist.gov/MatrixMarket).
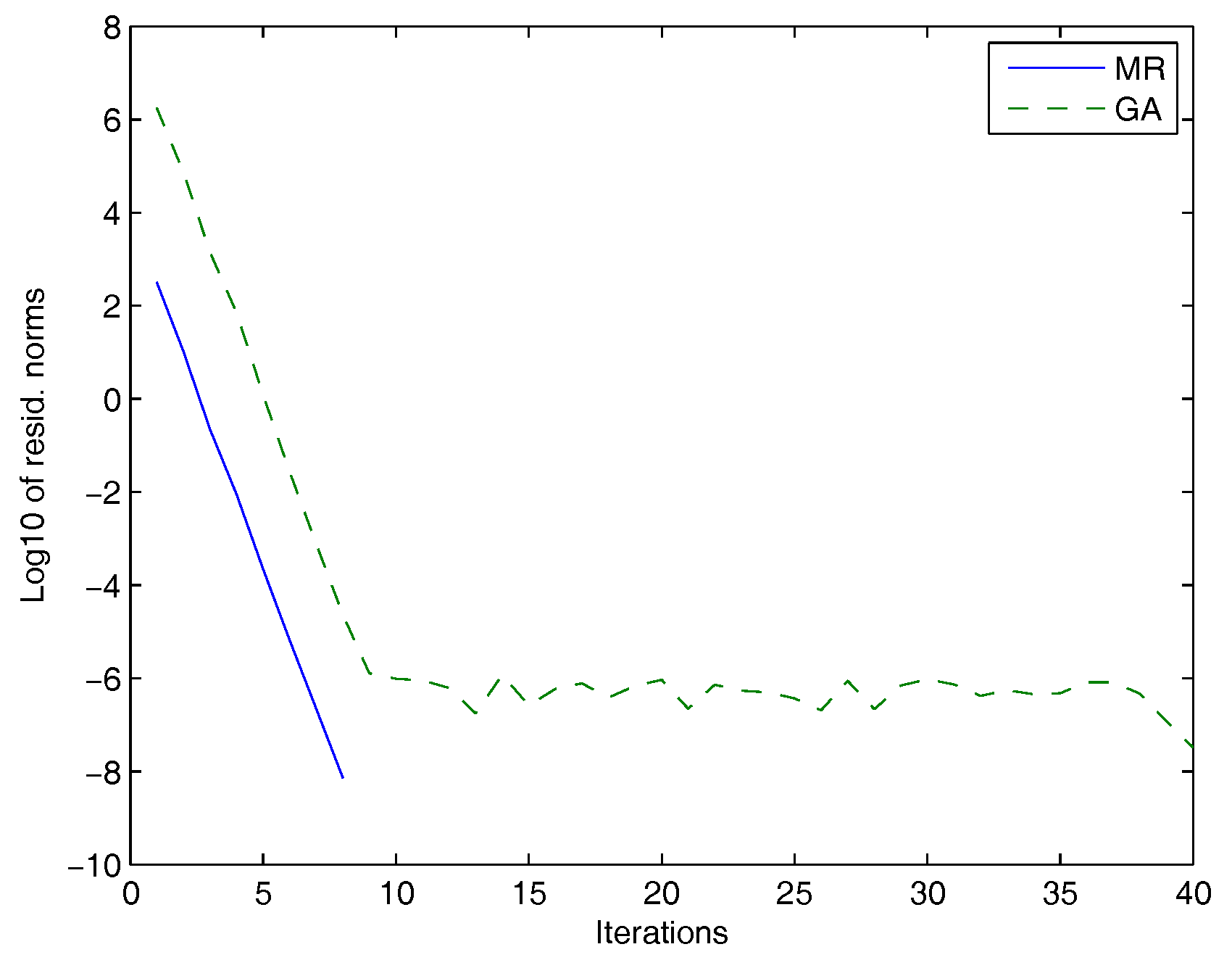
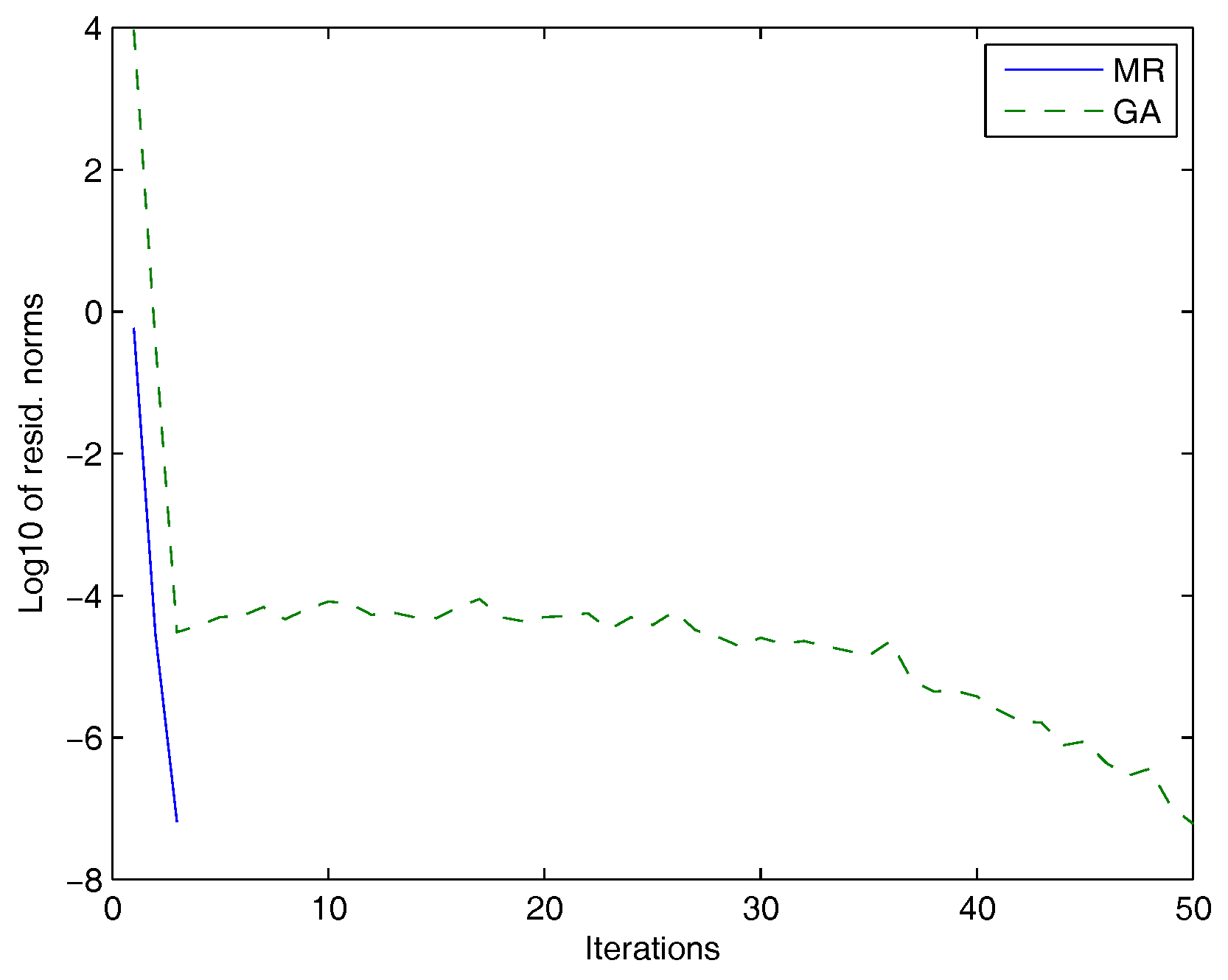
In Table 2, we compared the performances of the MR method and the GA. For both methods, we listed the residual norms, the maximum number of iterations and the corresponding execution time.
6. Conclusions
We presented in this paper two iterative methods for computing numerical solutions for large scale Stein matrix equations with low rank right-hand sides. The proposed methods are based on projection onto extended block Krylov subspaces with a Galerkin or a minimal residual approach. The approximate solutions are given as products of two low rank matrices and allow for saving memory for large problems. The numerical experiments show that the proposed Krylov-based methods are effective for large and sparse matrices.
Author Contributions
Authors have contributed equally in the mathematical part, the editorial as well as the experimental part.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bouhamidi, A.; Heyouni, M.; Jbilou, K. Block Arnoldi-based methods for large scale discrete-time algebraic Riccati equations. J. Comput. Appl. Math. 2011, 236, 1531–1542. [Google Scholar] [CrossRef]
- Bouhamidi, A.; Jbilou, K. Sylvester Tikhonov-regularization methods in image restoration. J. Comput. Appl. Math. 2007, 206, 86–98. [Google Scholar] [CrossRef]
- Zhou, B.; Lam, J.; Duan, G.-R. On Smith-type iterative algorithms for the Stein matrix equation. Appl. Math. Lett. 2009, 22, 1038–1044. [Google Scholar] [CrossRef]
- Zhou, B.; Lam, J.; Duan, G.-R. Toward solution of matrix equation X = Af (X)B + C. Linear Algebra Appl. 2011, 435, 1370–1398. [Google Scholar] [CrossRef]
- Zhou, B.; Duan, G.-R.; Lam, J. Positive definite solutions of the nonlinear matrix equation. Appl. Math. Comput. 2013, 219, 7377–7391. [Google Scholar] [CrossRef]
- Li, Z.-Y.; Zhou, B.; Lam, J. Towards positive definite solutions of a class of nonlinear matrix equations. Appl. Math. Comput. 2014, 237, 546–559. [Google Scholar] [CrossRef]
- Van Dooren, P. Gramian Based Model Reduction of Large-Scale Dynamical Systems. In Numerical Analysis; Chapman and Hall/CRC Press: London, UK, 2000; pp. 231–247. [Google Scholar]
- Datta, B.N. Numerical Methods for Linear Control Systems; Academic Press: New York, NY, USA, 2003. [Google Scholar]
- Datta, B.N.; Datta, K. Theoretical and computational aspects of some linear algebra problems in control theory. In Computational and Combinatorial Methods in Systems Theory; Byrnes, C.I., Lindquist, A., Eds.; Elsevier: Amsterdam, The Netherlands, 1986; pp. 201–212. [Google Scholar]
- Calvetti, D.; Levenberg, N.; Reichel, L. Iterative methods for X − AXB = C. J. Comput. Appl. Math. 1997, 86, 73–101. [Google Scholar] [CrossRef]
- Bartels, R.H.; Stewart, G.W. Solution of the matrix equation A X + X B = C, Algorithm 432. Commun. ACM 1972, 15, 820–826. [Google Scholar] [CrossRef]
- Golub, G.H.; Nash, S.; van Loan, C. A Hessenberg Schur method for the problem AX + XB = C. IEEE Trans. Autom. Control 1979, 24, 909–913. [Google Scholar] [CrossRef]
- Simoncini, V. Computational methods for linear matrix equations. SIAM Rev. 2016, 58, 377–441. [Google Scholar] [CrossRef]
- Agoujil, S.; Bentbib, A.H.; Jbilou, K.; Sadek, E.L.M. A minimal residual norm method for large-scale Sylvester matrix equations. Elect. Trans. Numer. Anal. 2014, 43, 45–59. [Google Scholar]
- Bentbib, A.H.; Jbilou, K.; Sadek, E.M. On some Krylov subspace based methods for large-scale nonsymmetric algebraic Riccati problems. Comput. Math. Appl. 2015, 2555–2565. [Google Scholar] [CrossRef]
- Druskin, V.; Knizhnerman, L. Extended Krylov subspaces: Approximation of the matrix square root and related functions. SIAM J. Matrix Anal. Appl. 1998, 19, 755–771. [Google Scholar] [CrossRef]
- El Guennouni, A.; Jbilou, K.; Riquet, A.J. Block Krylov subspace methods for solving large Sylvester equations. Numer. Algorithms 2002, 29, 75–96. [Google Scholar] [CrossRef]
- Heyouni, M. Extended Arnoldi methods for large low-rank Sylvester matrix equations. Appl. Numer. Math. 2010, 60, 1171–1182. [Google Scholar] [CrossRef]
- Jaimoukha, I.M.; Kasenally, E.M. Krylov subspace methods for solving large Lyapunov equations. SIAM J. Numer. Anal. 1994, 31, 227–251. [Google Scholar] [CrossRef]
- Jbilou, K. Low-rank approximate solution to large Sylvester matrix equations. Appl. Math. Comput. 2006, 177, 365–376. [Google Scholar] [CrossRef]
- Jbilou, K.; Riquet, A.J. Projection methods for large Lyapunov matrix equations. Linear Algebra Appl. 2006, 415, 344–358. [Google Scholar] [CrossRef]
- Lin, Y.; Simoncini, V. Minimal residual methods for large scale Lyapunov equations. Appl. Numer. Math. 2013, 72, 52–71. [Google Scholar] [CrossRef]
- Simoncini, V. A new iterative method for solving large-scale Lyapunov matrix equations. SIAM J. Sci. Comput. 2007, 29, 1268–1288. [Google Scholar] [CrossRef]
- Jagels, C.; Reichel, L. Recursion relations for the extended Krylov subspace method. Linear Algebra Appl. 2011, 434, 1716–1732. [Google Scholar] [CrossRef]
- Heyouni, M.; Jbilou, K. An extended Block Arnoldi algorithm for large-scale solutions of the continuous-time algebraic Riccati equation. Elect. Trans. Numer. Anal. 2009, 33, 53–62. [Google Scholar]
- Saad, Y. Numerical solution of large Lyapunov equations. In Signal Processing, Scattering, Operator Theory and Numerical Methods; Kaashoek, M.A., van Shuppen, J.H., Ran, A.C., Eds.; Birkhaser: Boston, MA, USA, 1990; pp. 503–511. [Google Scholar]
- Bouhamidi, A.; Hached, M.; Heyouni, M.; Jbilou, K. A preconditioned block Arnoldi method for large Sylvester matrix equations. Numer. Linear Algebra Appl. 2011, 20, 208–219. [Google Scholar] [CrossRef]
- Saad, Y. Iterative Methods for Sparse Linear Systems, 2nd ed.; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2003. [Google Scholar]
- Saad, Y.; Yeung, M.; Erhel, J.; Guyomarc’h, F. A deflated version of the conjugate gradient algorithm. SIAM J. Sci. Comput. 2000, 21, 1909–1926. [Google Scholar] [CrossRef]
- Penzl, T. LYAPACK A MATLAB Toolbox for Large Lyapunov and Riccati Equations, Model Reduction Problems, and Linear-Quadratic Optimal Control Problems. Available online: http://www.tu-chemintz.de/sfb393/lyapack (Accessed on 10 June 2016).
- Davis, T. The University of Florida Sparse Matrix Collection, NA Digest, Volume 97, No. 23, 7 June 1997. Available online: http://www.cise.ufl.edu/research/sparse/matrices (Accessed on 10 June 2016).
Figure 1.
Galerkin approach (GA): dashed line, minimal residual (MR): solid line.

Figure 2.
GA: dashed line, MR: solid line.
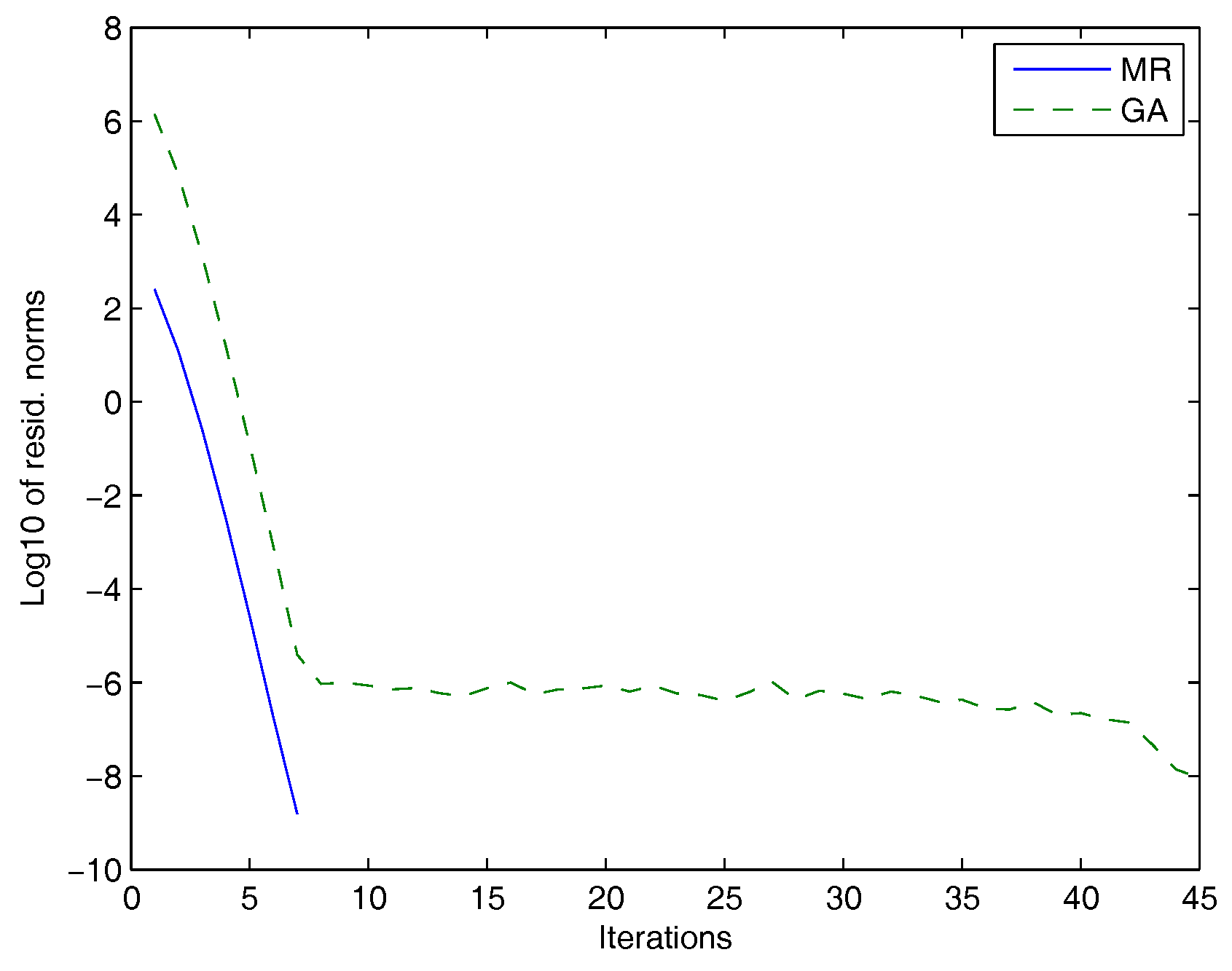
Figure 3.
GA: dashed line, MR: solid line.

{kind=link}
{kind=link}
{kind=link}
Table 1.
Results for Example 1.
| Test Problem | Method | Iterations | Residual Norm | Times (s) |
|---|---|---|---|---|
| , , | GA | 43 | 7.56 × 10 | 4.80 |
| MR | 3 | 1.87 | ||
| 10,000, , | GA | 45 | 26.52 | |
| MR | 3 | 3.75 | ||
| 12,100, , | GA | 49 | 12.96 | |
| MR | 3 | 3.63 |
Table 2.
Results for Example 5.2.
| Test Problem | Method | Iterations | Residual Norm | Time (s) |
|---|---|---|---|---|
| , , , A = pde2961 | GA | 45 | 3.7440 | |
| and B = fdm | MR | 7 | 1.0296 | |
| , , , A = Thermal | GA | 40 | 10.1245 | |
| and B = fdm | MR | 8 | 7.3008 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Bentbib, A.H.; Jbilou, K.; Sadek, E.M. On Some Extended Block Krylov Based Methods for Large Scale Nonsymmetric Stein Matrix Equations. Mathematics 2017, 5, 21. https://doi.org/10.3390/math5020021
AMA Style
Bentbib AH, Jbilou K, Sadek EM. On Some Extended Block Krylov Based Methods for Large Scale Nonsymmetric Stein Matrix Equations. Mathematics. 2017; 5(2):21. https://doi.org/10.3390/math5020021
Chicago/Turabian StyleBentbib, Abdeslem Hafid, Khalide Jbilou, and EL Mostafa Sadek. 2017. "On Some Extended Block Krylov Based Methods for Large Scale Nonsymmetric Stein Matrix Equations" Mathematics 5, no. 2: 21. https://doi.org/10.3390/math5020021
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.