A Multi-Objective Particle Swarm Optimization Algorithm Based on Gaussian Mutation and an Improved Learning Strategy


1
School of Computer Science and Information Engineering, Hefei University of Technology, Hefei 230009, China
2
Ningxia Province Key Laboratory of Intelligent Information and Data Processing, North Minzu University, Yinchuan 750021, China
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Mathematics 2019, 7(2), 148; https://doi.org/10.3390/math7020148
Submission received: 8 January 2019
/
Revised: 28 January 2019
/
Accepted: 29 January 2019
/
Published: 4 February 2019
(This article belongs to the Special Issue Evolutionary Algorithms in Intelligent Systems)
Abstract
:Obtaining high convergence and uniform distributions remains a major challenge in most metaheuristic multi-objective optimization problems. In this article, a novel multi-objective particle swarm optimization (PSO) algorithm is proposed based on Gaussian mutation and an improved learning strategy. The approach adopts a Gaussian mutation strategy to improve the uniformity of external archives and current populations. To improve the global optimal solution, different learning strategies are proposed for non-dominated and dominated solutions. An indicator is presented to measure the distribution width of the non-dominated solution set, which is produced by various algorithms. Experiments were performed using eight benchmark test functions. The results illustrate that the multi-objective improved PSO algorithm (MOIPSO) yields better convergence and distributions than the other two algorithms, and the distance width indicator is reasonable and effective.
1. Introduction
Multi-objective optimization problems (MOPs) are very common in engineering and other areas of research, such as economics, finance, production scheduling, and aerospace engineering. It is very difficult to solve these problems because they usually involve several conflicting objectives. Generally, the optimal solution of MOPs is a set of optimal solutions (known as a Pareto optimal set), which differs from the solution of single-objective optimization (with only one optimal solution) [1]. Some classical optimization methods (weighted methods, goal programming methods, etc.) require the problem functions to be differentiable and are required to run multiple times with the hope of finding different solutions. In recent years, the multi-objective optimization evolutionary algorithm (MOEA) has become a popular method for solving MOPs, and it has garnered scholarly interest around the world [2]. Many representative MOEAs, such as multiple objective genetic algorithm (MOGA) [3], non-dominated sorting genetic algorithm II (NSGA-II) [4], strength pareto evolutionary algorithm (SPEA) [5] and pareto archived evolution strategy (PAES) [6], have been presented.
Over the past decade, the particle swarm optimization algorithm (PSO) has been used to solve MOPs, and a number of multi-objective PSO algorithms have been suggested. Some studies have shown that the modified PSO algorithm can effectively solve the MOPs and that the non-dominated solution set of the algorithm is much closer to the true Pareto optimal front. Coello and Pultdo [7] incorporated a special mutation operator that enriches the exploratory capabilities. Sierra and Coello [8] proposed the OMOPSO algorithm, which places the whole population into three subpopulations with the same size and uses different mutation operators within different subpopulations. This algorithm improves the exploration ability of the particles. Reddy and Kumar [9] proposed an elitist-mutation multi-objective PSO (EM-MOPSO) algorithm with a strategic mechanism that effectively explores the feasible search space and speeds up the search for the true Pareto optimal region. Leong and Yen [10] proposed a dynamic population multiple-swarm MOPSO algorithm that uses an adaptive local archive to improve the diversity within each swarm. Yen and Leong [11] also proposed a dynamic population multiple-swarm MOPSO algorithm in which the number of swarms is adaptively adjusted throughout the search process via the proposed dynamic swarm strategy. The strategy allocates an appropriate number of swarms to support convergence and diversity criteria among the swarms as required. Chen, Zou, and Wang [12] presented a multi-objective endocrine particle swarm optimization algorithm (MOEPSO) in which the hormone (RH), released by the endocrine system, is encoded as a particle swarm and is then supervised by the corresponding stimulating hormone. Lin et al. [13] introduced a novel MOPSO algorithm using multiple search strategies (MMOPSO), and a decomposition approach was used to transform MOPs into a set of aggregation problems. Then, each particle was accordingly assigned to optimize each aggregation problem. A multi-objective vortex particle swarm optimization (MOVPSO) method was proposed in [14] based on the emerging properties of a swarm to simulate motion with diversity control via collaborative mechanisms using linear and circular movements. The parallel cell coordinate system (PCCS) in self-adaptive MOPSO [15] is used to select global and personal bests, maintain archives and adjust flight parameters. Knight et al. [16] presented a spreading mechanism to promote diversity in MOPSO. Cheng et al. [17] presented a hybrid multi-objective particle swarm optimization that combines the canonical PSO search with a teaching–learning-based optimization (TLBO) algorithm to promote diversity and improve the search ability. Overall, for any improved MOPSO algorithm, the search ability is determined by the neighbouring topological structure, and the convergence rate depends on the dominance relationship.
In this paper, we introduce a new multi-objective PSO algorithm based on Gaussian mutation and an improved learning strategy to solve MOPs. The main new contributions of this work can be summarized as: (1) Gaussian mutation throw points strategy to improve the uniformity of external archives and current populations; (2) For MOPs, it is difficult to select the value of velocity and update the formula. Unlike other MOPSOs, that often randomly select a solution from the external archive as the global optimal solution , we present different learning strategies to update the individual positions of the non-dominated and dominated solutions; (3) To further measure the distribution width, the indicator is proposed.
The remainder of this paper is organized as follows. In Section 2, we describe the multi-objective optimization. Thereafter, in Section 3, we present a multi-objective improved PSO algorithm (MOIPSO). Section 4 outlines the MOIPSO algorithm. Test problems, performance measures, and the results are provided in Section 5, and the conclusions are presented in Section 6.
2. Description of Multi-Objective Optimization Problems
A general minimization problem of m objectives can be mathematically stated as follows:
Given , where n is the dimension of decision variable space D. Additionally,
where is the objective function vector, Y is the objective variable space, is the i-th inequality constraint, and is the j-th equality constraint.
Multiple objectives are included in MOPs, therefore, it is not possible to find a single solution that can optimize all objectives. Generally, improving one objective may cause the performance of the other objectives to decrease. Therefore, the conventional concept of single-objective optimality does not hold, and we must find a solution that is a compromize based on all objectives, i.e., the Pareto optimality. Based on the aforementioned reasons, some important definitions are given as follows for MOPs [18,19]:
Definition 1.
(Pareto dominance) The vector dominates the vector if and only if the next statement is verified. and , denoted as .
Definition 2.
(Pareto optimality) A solution is a Pareto optimal solution if there is not another that satisfies .
Definition 3.
(Pareto optimal set) The Pareto optimal set is defined as the set of all Pareto optimal solutions.
Definition 4.
(Pareto optimal front) The Pareto front consists of the values of the objectives corresponding to the solutions in the Pareto optimal set.
3. An Introduction to the Multi-Objective Improved PSO
3.1. Main Aspects of the Standard PSO Algorithm
PSO was first presented by Kennedy and Eberhart in 1995 [20]. It is a random optimization algorithm based on swarm aptitude. The theory behind PSO comes from research on the behaviour of a bird swarm catching food. Compared with genetic algorithms, it has a simple construction, can be easily implemented, and has few adjustable parameters (Algorithm 1).
Let n be the dimension of the search space, be the current position of the i-th particle in the swarm, be the best position of the i-th particle at that time, and be the best position that the whole swarm has visited. The rate of the velocity of the i-th particle is denoted as .
| Algorithm 1: Standard particle swarm optimization [20] |
| Step 1: Initialize a population of particles , such that each particle has a random position vector and a velocity vector . Set parameters and , the maximum number of generations , and the generation number . Step 2: Calculate the fitness of all the particles in . Step 3: Renew the positions and velocities of particles based on the following equations: Step 5: (Termination examination) If the termination criterion is satisfied, then output the global optimal position and the fitness value. Otherwise, let and return to Step 2. |
3.2. Main Aspects of the Multi-Objective Improved PSO Algorithm (MOIPSO)
3.2.1. Elitist Archive and Crowding Entropy
Since Zitzler introduced SPEA with an elitist reservation mechanism in 1999 [5], many new algorithms have adopted a similar elitist reservation mechanism. Namely, they provide an external archive to store all the non-dominated solutions that have been found. The elitist reservation mechanism is also adopted in this article. As the evolution progresses, the non-dominated solutions in the current archive may not be the non-dominated solutions in the entire evolutionary process, therefore, the archive must be updated. The easiest updating method compares each solution with the current archive at each generation, which allows for the input of better solutions into the archive. The specific archive update rules are as follows [21]: (I) If the new solution dominates one or more solutions of the external archive, the new solution enters the archive, and the dominated solutions are deleted from the archive; (II) If the new solution is dominated by one or more solutions in the external archive, then the new solution is rejected; (III) If the new solution and the solutions in the external archive are not dominated by each other, then the new solution is a non-dominated solution and enters the archive. However, because of the storage space and computational efficiency, the external archive is not infinite. When the archive reaches its maximum size, the largest crowding degree solution will be deleted.
For the crowding distance measure, we cite the crowding entropy in the literature [21]. This method combines the crowded distance and distribution entropy, and the method accurately measures the crowding degree of the solution.
Crowding entropy is defined as follows:
where is the distribution entropy of the i-th solution to the j-th objective function. Specifically, is defined as , where , , and . Variables and are the distances from the i-th solution to the lower and upper adjacent solutions for the j-th objective function, and are the maximum and minimum values of the j-th objective function, and m is the number of objective functions.
Thus, the smaller the crowding entropy, the more crowded the archive. For each objective function, the boundary solutions are assigned infinite crowding entropy values. All other intermediate solutions are assigned crowding entropy values according to Equation (4).
3.2.2. Gaussian Mutation Strategy
Gaussian mutation is a very popular way to improve the particle swarm optimization algorithm. Higashi et al. [22] integrate a Gaussian mutation used for GA into PSO, and leave a certain ambiguity in the transition to the next generation due to Gaussian mutation. This method is used to solve the single-objective optimization problem, and carries on each individual variation in the current population. For the multi-objective problems, Coelho et al. [23] used Gaussian mutation to update the velocity update formula, but they only replaced the uniform random number R with a Gaussian random number in the velocity formula. Liang et al. [24] also introduced Gaussian mutation, which will have a certain probability to initialize the particle adjacent to the target particle. Meanwhile, this will randomly initialize the particles beyond the range to increase the utilization rate of particles. To further improve the performance of the solutions from the MOPs, this paper presents a new Gaussian mutation throw point strategy, which involves the throwing of points into external archives and the current population. The details of the strategy are as follows.
1. Throw points at sparse positions in the external archive to produce a thickened point set (TPS).
For MOPs, researchers hope that the non-dominated solution set is evenly distributed in the true Pareto front, but the solution sets of many methods yield uneven distributions. To increase the number of solutions at sparse positions and make the distribution of the solution set more uniform, we define the crowding degree of the solution in the external archive based on the crowding entropy and use throw points based on a Gaussian distribution of the largest crowding entropy solution (except the boundary solutions). Note that it is more important to find the boundary solutions for the MOPs, and the crowding entropy is infinite at the boundaries. Therefore, we must throw points at the boundary solutions.
The concrete operations are as follows.
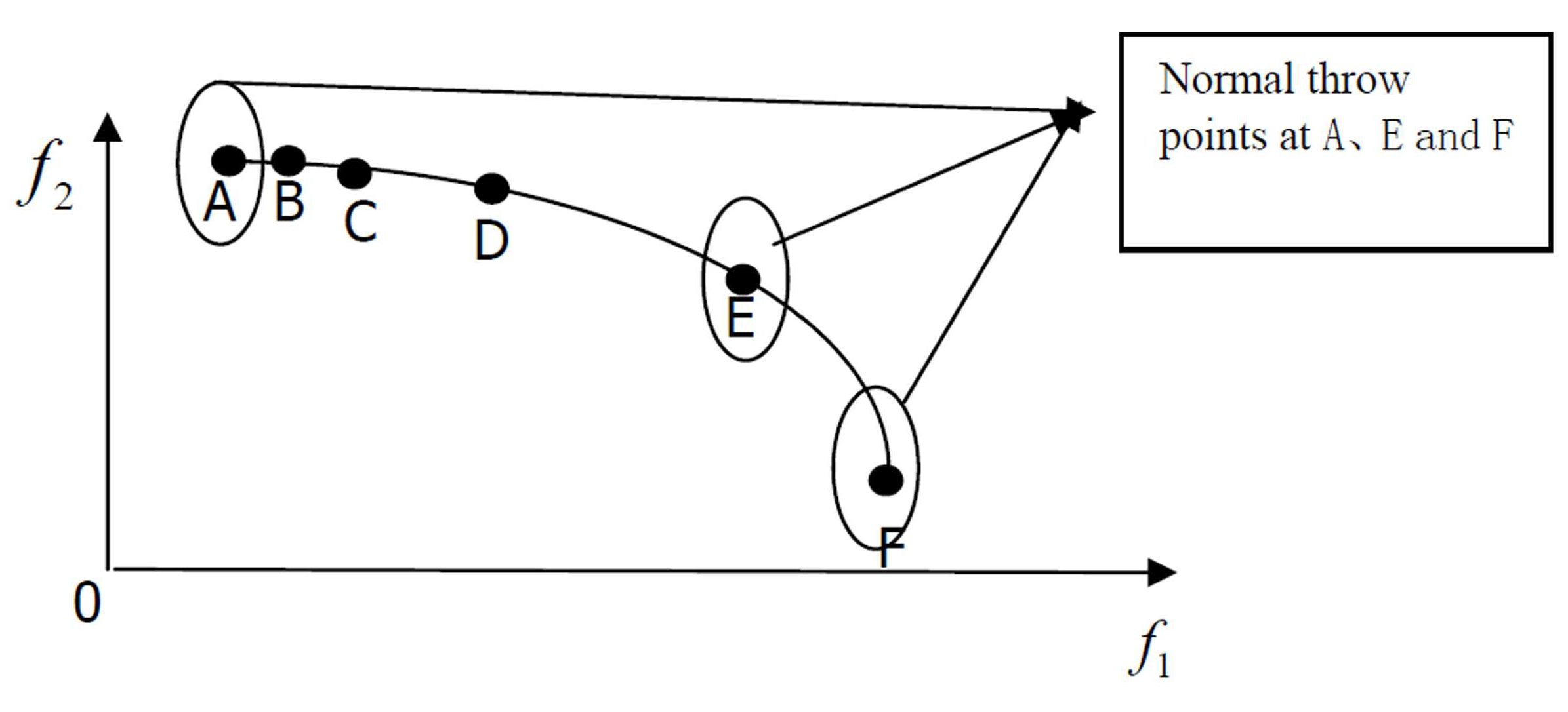
Step 1: Identify a sparse solution based on the crowding entropy, as shown in Figure 1.
Step 2: In the decision space, , , and . We normally throw h points based on centres , , and and variance . The random variable , and we add h random points to the TPS. It should be noted that the value of the variance is the width of each dimension. For example; ; .
2. Throw points into the current population to produce a Gaussian mutation points set (GMPS).
The algorithm chooses R solutions based on the prescribed probability in the current population, and normal throw points are established at R solutions (method based on (i): Step 2). Finally, we obtain a new GMPS.
3.2.3. Improved Learning Strategy
The standard PSO algorithm is used to solve the single-objective optimization problem, therefore, it is difficult to select the value of velocity and update the formula for MOPs. The reason for this issue is that MOPs do not contain the global optimal solution. In many previous articles, researchers have randomly selected a solution from the external archive as the global optimal solution , but this method lacks pertinence and cannot reflect the guidance of . Therefore, this article presents a modified velocity formula, redefines the value of Equation (2) and more efficiently applies to solve MOPs.
(i) When is not in the external archive, all solutions in the archive that dominate can be regarded as global optimal solutions. Therefore, we provide a linear combination of these solutions.
Suppose that there are k archive solutions that dominate . A set of weights is randomly generated, where and . Thus, can be expressed as follows:
Velocity is updated in the formula as follows:
(ii) When is in the external archive, the concept of a global optimal solution is meaningless for because the global optimal solution is a non-dominated solution. Therefore, all other solutions cannot be better than this solution, and does not exist. Hence, the three parts of Equation (2) are unnecessary, and the velocity updating formula is as follows:
The position update formula still uses the original model: .
3.2.4. Update External Archive
The updating process of the external archive is an important problem for MOPs. Researchers typically use the archive update rules to compare the current population and the old external archive and then generate a new external archive to further improve the performance of the external archive. This paper uses three sets to update the old external archive. The specific updating methods are shown in Figure 2.
3.2.5. Population Elitist Incremental Strategy
To increase the convergence rate of the population when the algorithm generates the offspring population, we consider the effect of not only the parent population but also the external archive. This paper proposes an elitist incremental strategy that increases the number of external archive solutions in the offspring population to form a new offspring population. The definition is as follows:
where N is the population size,
T is the number of iterations, and is the external archive of size A at iteration T.
As a result, the population has strong exploration abilities and can find a wider range of non-dominated solutions at the early stage. The population will further explore the known non-dominated solutions and move closer to the true Pareto front in the later stage.
4. Overview of the MOIPSO Algorithm
As previously discussed, the MOIPSO algorithm can be summarized as follows.
Step l: Randomly initialize the position and velocity of each particle within the search space.
(a) Set the following parameters; , , , , , , the Gaussian mutation probability , the maximum generation number , the population size N, and the maximum external archive size .
(b) Randomly initialize the population and the velocity.
Step 2: Calculate the fitness of the particles in the initialized population, and initialize the optimal position of the i-th particle.
Step 3: Initialize an update to the external archive A.
Step 4: For :
(a) Renew the velocities of particles based on Equations (5) and (6) and the position of particles based on Equation (7) to form the middle population;
(b) Select the particles based on the Gaussian mutation probability and throw points using the Gaussian mutation strategy (ii) to produce a GMPS;
(c) Calculate the crowding entropy of the external archive solutions and throw points based on the Gaussian mutation strategy (i) to produce a TPS;
(d) Renew the external archive A based on Section 3.2.4. If , then delete the most crowded particles according to the crowding entropy;
(f) Renew the middle population using the elitist incremental strategy, and form the new offspring population;
(g) Calculate the fitness of the particle in the offspring population;
(h) Renew the optimal position of each particle;
(i) If the termination criterion is satisfied, then output the Pareto optimal solutions. Otherwise, let and go to Step (a).
5. Methods and Simulation Experiments
5.1. Test Problems
To test the performance of MOIPSO, eight unconstrained optimization problems were used in the experiments. The SCH, KUR, and FON functions were suggested by Schaffer in 1985 [25], Kursawe in 1991 [26], and Fonseca in 1998 [27], respectively. The remainders are ZDT problems suggested by Zitzler et al. in 2000 [28]. The optimization problems are described in Table 1.
5.2. Performance Measures
The standard performance measures of multi-objective evolutionary algorithms were used to evaluate the performance of the proposed algorithm. The performance measures are briefly described as follows.
5.2.1. Convergence Measure Indicator
Ideally, the iterative process of MOEA approaches the Pareto front, but in most cases, it is difficult to find the true Pareto front. The proximity of the approximate solutions to the Pareto optimal solutions is a main indicator.
The concept of generational distance was introduced by Van Veldhuizen [29] to measure the proximity of the approximate solutions to the Pareto optimal solutions. This indicator is defined as follows:
where n is the number of non-dominated solutions. When the Pareto fronts of the objective function can be expressed in analytic form, is measured by the Euclidean distance (in objective space) between the i-th non-dominated solution and the nearest member of the Pareto optimal set. Otherwise, is measured by the Euclidean distance between the i-th non-dominated solution and the reference point set. It is clear that a smaller value of is better, and indicates that the non-dominated solution set is located in the true Pareto front.
5.2.2. Distribution Measure Indicator
Typically, we hope that non-dominated solutions are uniformly distributed in the true Pareto front. Two main factors used to measure the distribution are uniformity and width:
(1) Distribution uniformity ()
The indicator [4] is used to measure the uniformity and diversity of the non-dominated solution set. When calculating this indicator, we must sort the obtained non-dominated solutions based on the specified objective function values. This indicator is defined as follows:
where n is the number of non-dominated solutions, is the Euclidean distance between neighbouring solutions in the non-dominated solution set, is the mean of all values, and are the Euclidean distances between the extreme solutions of the Pareto optimal solution set and the boundary solutions of the non-dominated solution set. When the non-dominated solution set is uniformly distributed in the true Pareto front, , , and all , therefore, . A small value of indicates better uniformity in the true Pareto front.
(2) Distribution width ()
Generally, it is favourable if the boundary solutions can be included in the non-dominated solution set. In other words, in these types of problems, researchers hope to find the boundary points of the true Pareto fronts.
The indicator , which measures the distribution width, was proposed by Zitzler et al. [28]. The associated formula is as follows:
where is the non-dominated solution set and M is the dimension of the non-dominated solutions. Notably, can measure the distribution width of the non-dominated solution set, but when the distribution range of the Pareto front is too large or the dimensions of the solutions are large, the value of will be large. Therefore, it is difficult to compare and compile the data.
Based on the aforementioned method, the new indicator, , is provided. The concrete form of this indicator is as follows:
where is the Pareto optimal set or the reference point set. Notably, a small value of reflects a better distribution uniformity for the non-dominated solution set.
5.3. Algorithm Comparison
To validate the MOIPSO algorithm, we compared it to NSGA-II [4] and MOPSO [7] based on the above three performance measures. The source codes of NSGA-II and MOPSO are available at http://delta.cs.cinvestav.mx/~ccoello/EMOO/ (matlab code).
The initial population size is 100 for MOIPSO, NSGA-II and MOPSO. The number of iterations directly affects the time complexity of the algorithm, and the convergence of the problem with different iterations is discussed [30]. It can be found that when the program reaches a stable state, the subsequent iterations can no longer improve the performance of the algorithm, but only increase the running time. Therefore, through a large number of numerical experiments, different iteration numbers were chosen based on the complexity of the problems in the three algorithms. The number of iterations completed was 60 for SCH, 100 for FON and KUR, 300 for ZDT1, ZDT2, and ZDT3, and 1000 for ZDT4 and ZDT6.
The range of the parameter has been discussed in some literature [31], so we took the commonly used parameter values for NSGAII and MOPSO. To make the test and its results more comparable, for MOIPSO, the same parameters as MOPSO took the same values, and other parameters were set after a large number of numerical experiments. In the MOPSO and MOIPSO algorithms, , while and are assigned random values between 0 and 1. In MOPSO, the inertia weight is , and the inertia weight damping ratio . In MOIPSO, the inertia weight w adaptively decreased from to according to the following formula: . In the NSGA-II [4] algorithm, the crossover probability is , and the mutation probability is . To evaluate the statistical performance, all the experiments are run 30 times. The best, worst, mean, and average deviations are shown in Table 2, Table 3 and Table 4, respectively.
The results are shown in Table 2. MOIPSO exhibits the best values for SCH, KUR, ZDT1 and ZDT4. MOPSO displays the best values for ZDT2, ZDT3, and ZDT6. FON, MOIPSO, and MOPSO exhibit similar results. For the worst , MOIPSO displays high stability and consistently yields the lowest worst value in all test problems. For the mean , MOIPSO produces the best mean values for all test problems except ZDT4, for which FON, MOIPSO, and MOPSO exhibit similar results. With respect to the standard deviation of , MOIPSO exhibits the best solution for KUR, ZDT1, ZDT2, and ZDT3. NSGA-II yields the best results for the other functions. Thus, MOIPSO produces better values of indicators than the other two algorithms in most test problems, and the results of MOIPSO are better than those of the other algorithms by 1∼2 orders of magnitude. This finding indicates that the resulting Pareto fronts obtained via MOIPSO are closer to the true Pareto fronts, and MOIPSO can effectively improve convergence.
Some information for is shown in Table 3. For the SCH and ZDT1 functions, all the solutions of MOIPSO are better than those of the other algorithms. MOPSO exhibits the best, and the mean best, value for KUR. MOIPSO has the minimal worst and the best standard deviation. MOIPSO has the best, the mean best, and the minimal worst values for ZDT2 and ZDT3, but the standard deviation of NSGA-II is the best. MOIPSO displays the best and the mean best values for ZDT4. NSGA-II exhibits the minimal worst , and MOPSO yields the best standard deviation. MOPSO provides the best for ZDT6. MOIPSO has the minimal worst and the mean best , and the minimal standard deviation of NSGA-II is the best. Table 3 shows that MOIPSO provides the best mean solution for all seven functions. Therefore, the MOIPSO results are evenly distributed in the experiments, however, they are not shown for all the functions.
Table 4 shows the results of a new quality indicator—. All the solutions of MOIPSO are better than those of the other algorithms for SCH, KUR, and ZDT1. MOIPSO yields the three best indicators for the FON function, and MOPSO provides the best solution for . NSGA-II exhibits the best solution for ZDT2, and the other indicators of MOIPSO are the best. MOIPSO displays the best and the mean best for ZDT3, and NSGA-II yields the minimal worst and the best standard deviation. NSGA-II exhibits the best for ZDT4, and MOPSO displays the minimal worst . MOIPSO produces the mean best and the minimal standard deviation. For the ZDT6 function, NSGA-II exhibits the minimal standard deviation, and the other indicators of MOIPSO are the best. Similarly, the results in Table 4 show that MOIPSO is able to produce the best distribution of solutions in the Pareto optimal front for most of the test functions.
According to the above statistical analyses, MOIPSO successfully solves the SCH, ZDT1 and ZDT6 problems, as illustrated by Figure 3, Figure 4 and Figure 5. Figure 3 shows that the three algorithms have similar convergence performances for the SCH function, however, MOIPSO exhibits better uniformity. Figure 4 and Figure 5 illustrate the superior convergence and distribution results of MOIPSO compared with those of the other algorithms. Furthermore, by combining the data from Table 4 and the figures, we can see that when the boundary solutions do not exist in non-dominated solutions or solutions do not converge to the true Pareto front, then the value is very large. In the case of NSGAII and MOPSO for ZDT6, because some points are far away from the true optimal pare fronts, their values are , but the values are for MOIPSO and we can find that all the solutions are near the true optimal Pareto fronts in Figure 4. Thus, the indicator can measure the distribution width of the non-dominated solution set.
From the numerical results, we can also see that the MOIPSO algorithm performs better than other algorithms in distribution uniformity and width. This is obviously a good result of the Gaussian mutation throw point strategy. However, this method is not omnipotent. Firstly, when the number of throwing points is too large, the running time will rapidly increase. It is difficult to determine the number, so in this paper, we have done a lot of experiments to determine it. Secondly, for all sparse solutions, we will throw points, so when the Pareto optimal front of optimization problem is very complex and contains a large number of outliers, the effectiveness of our Gaussian mutation throw point strategy will be affected.
6. Conclusions
A new multi-objective PSO algorithm based on Gaussian mutation and an improved learning strategy (MOIPSO) is presented to solve MOPs. First, MOIPSO builds different learning strategies to update the individual positions of the non-dominated and dominated solutions. Then, the Gaussian mutation strategy is used to create throw points at sparse and boundary positions. These updating strategies yield high convergence and a satisfactory distribution. To further measure the distribution width, the indicator is proposed.
The performance of MOIPSO was tested based on different MOP benchmark functions with convex and nonconvex objection functions. To demonstrate the effectiveness of MOIPSO, the results were compared to those of MOPSO and NSGA-II. The experimental results showed that MOIPSO significantly outperforms all other algorithms based on the test problems with respect to three metrics. The resulting data and figures indicate that the proposed indicator is reasonable.
In this article, only two-objective functions are tested. In the near future, we also plan to evaluate MOIPSO using other objective test functions. Furthermore, most parameters in this paper (such as the number of throw points, cognitive coefficient, etc.) have certain values. It would be interesting to study whether these control parameters could adaptively change as the iteration time increases.
Author Contributions
Both authors have contributed equally to this paper. Both authors have read and approved the final manuscript.
Funding
This research was funded by the National Natural Science Foundation of P.R. China (61561001) and First-Class Disciplines Foundation of NingXia (Grant No. NXYLXK2017B09).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MOIPSO | Multi-objective improved PSO algorithm |
| MOPs | Multi-objective optimization problems |
| MOEA | Multi-objective optimization evolutionary algorithm |
| GMPS | Gaussian mutation points set |
| TPS | Thickened point set |
| DW | Distribution width |
References
- Miettinen, K.M. Nonlinear Multi-Objective Optimization; Kluwer Academic Publishers: Boston, MA, USA, 1999. [Google Scholar]
- Deb, K. Multi-Objective Optimization Using Evolutionary Algorithms; John Wiley and Sons: Hoboken, NJ, USA, 2001. [Google Scholar]
- Fonseca, C.M.; Fleming, P.J. Genetic Algorithm for Multi-Objective Optimization: Formulation, Discussion and Generalization; Morgan Kaufmann Publishers: Burlington, MA, USA, 1993. [Google Scholar]
- Deb, K.; Pratap, A.; Agrawal, S.; Meyarivan, T. A fast and elitist multi-objective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Zitzler, E.; Thiele, L. Multi-objective evolutionary algorithms: A comparative case study and the strength pareto approach. IEEE Trans. Evol. Comput. 1999, 3, 257–271. [Google Scholar] [CrossRef]
- Knowles, J.D.; Corne, D.W. Approximating the nondominated front using the Pareto archived evolution strategy. IEEE Trans. Evol. Comput. 2000, 8, 149–172. [Google Scholar] [CrossRef]
- Coello, C.A.C.; Pultdo, G.T.; Lechuga, M.S. Handling multiple objectives with particle swarm optimization. IEEE Trans. Evol. Comput. 2004, 8, 256–279. [Google Scholar] [CrossRef]
- Sierra, M.R.; Coello, C.A.C. Improving PSO-Based Multi-Objective Optimization Using Crowding, Mutation and ε-Dominance; Springer: Berlin/Heidelberg, Germany, 2005; pp. 505–519. [Google Scholar]
- Reddy, M.J.; Kumar, D.N. An efficient multi-objective optimization algorithm based on swarm intelligence for engineering design. Eng. Optim. 2007, 39, 49–68. [Google Scholar] [CrossRef]
- Leong, W.F.; Yen, G.G. PSO-based multi-objective optimization with dynamic population size and adaptive local archives. IEEE Trans. Syst. Man Cybern. Part B 2008, 38, 1270–1293. [Google Scholar] [CrossRef] [PubMed]
- Yen, G.G.; Leong, W.F. Dynamic multiple swarms in multi-objective particle swarm optimization. IEEE Trans. Syst. Man Cybern. Part B 2009, 39, 890–911. [Google Scholar] [CrossRef]
- Chen, D.B.; Zou, F.; Wang, J.T. A multi-objective endocrine PSO algorithm and application. Appl. Soft Comput. 2011, 11, 4508–4520. [Google Scholar] [CrossRef]
- Lin, Q.; Li, J.; Du, Z.; Chen, J.; Ming, Z. A novel multi-objective particle swarm optimization with multiple search strategies. Eur. J. Oper. Res. 2015, 247, 732–744. [Google Scholar] [CrossRef]
- Meza, J.; Espitia, H.; Montenegro, C.; Giménez, E.; González-Crespo, R. Movpso: Vortex multi-objective particle swarm optimization. Appl. Soft Comput. 2017, 52, 1042–1057. [Google Scholar] [CrossRef]
- Hu, W.; Yen, G.G. Adaptive multi-objective particle swarm optimization based on parallel cell coordinate system. IEEE Trans. Evol. Comput. 2015, 19, 1–18. [Google Scholar]
- Knight, J.T.; Singer, D.J.; Collette, M.D. Testing of a spreading mechanism to promote diversity in multi-objective particle swarm optimization. IEEE Trans. Evol. Comput. 2015, 16, 279–302. [Google Scholar] [CrossRef]
- Cheng, T.; Chen, M.; Fleming, P.J.; Yang, Z.; Gan, S. A novel hybrid teaching learning based multi-objective particle swarm optimization. Neurocomputing 2017, 222, 11–25. [Google Scholar] [CrossRef]
- Coello, C.A.C. Evolutionary multi-objective optimization: A historical view of the field. IEEE Comput. Intell. Mag. 2006, 1, 28–36. [Google Scholar] [CrossRef]
- Zitzler, E. Evolutionary Algorithm for Multiobjective Optimization: Methods and Application; Swiss Federal Institute of Technology: Zurich, Switzerland, 1999. [Google Scholar]
- Kennedy, J.; Eberhart, R.C. Particle Swarm Optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Wang, Y.N.; Wu, L.H.; Yuan, X.F. Multi-objective self-adaptive differential evolution with elitist archive and crowding entropy-based diversity measure. Soft Comput. 2010, 14, 193–209. [Google Scholar] [CrossRef]
- Higashi, N.; Iba, H. Particle Swarm Optimization with Gaussian Mutation; IEEE: Piscataway, NJ, USA, 2013. [Google Scholar]
- Coelho, L.D.S.; Ayala, V.H.; Alotto, P. A Multiobjective Gaussian Particle Swarm Approach Applied to Electromagnetic Optimization. IEEE Trans. Mag. 2010, 46, 3289–3292. [Google Scholar] [CrossRef]
- Liang, H.M.; Zhang, K.; Yu, H.H. Multi-objective Gaussian particle swarm algorithm optimization based on niche sorting for actuator design. Adv. Mech. Eng. 2015, 7, 1–7. [Google Scholar] [CrossRef]
- Schaffer, J.D. Multiple objective optimization with vector evaluated genetic algorithm. In Proceedings of the 1st International Conference on Genetic Algorithm and Their Applications, Pittsburg, CA, USA, 24–26 July 1985; pp. 93–100. [Google Scholar]
- Kursawe, F. A varant of evolution strategies for vector optimization. In International Conference on Parallel Problem Solving from Nature; Springer: Berlin/Heidelberg, Germany, 1991; pp. 193–197. [Google Scholar]
- Fonseca, C.M.; Fleming, P.J. Multiobjective optimization and multiple constraint handling with evolutionary algorithms, Part II: Application example. IEEE Trans. Syst. Man Cybern. A 1998, 28, 38–47. [Google Scholar] [CrossRef]
- Zitzler, E.; Deb, K.; Thiele, L. Comparison of multi-objective evolutionary algorithms: Empirical results. Evol. Comput. 2000, 8, 173–195. [Google Scholar] [CrossRef]
- Van Veldhuizen, D.A.; Lamont, G.B. Evolutionary computation and convergence to a Pareto front. In Late Breaking Papers at the Genetic Programming 1998 Conference; Standford University: Stanford, CA, USA, 1998; pp. 221–228. [Google Scholar]
- Saraswat, A.; Saini, A. Multi-objective optimal reactive power dispatch considering voltage stability in power systems using HFMOEA. Eng. Appl. Artif. Intell. 2013, 26, 390–404. [Google Scholar] [CrossRef]
- Ding, S.X.; Chen, C.; Xin, B.; Psrdalos, P. A bi-objective load balancing model in a distributed simulation system using NSGA-II and MOPSO approaches. Appl. Soft Comput. 2018, 63, 249–267. [Google Scholar] [CrossRef]
Figure 1.
The selection process of the sparse solution.

Figure 2.
The updating process of the external archive.

Figure 3.
For SCH, the comparisons between the true Pareto front and the best ones obtained by three different algorithms.
Figure 3.
For SCH, the comparisons between the true Pareto front and the best ones obtained by three different algorithms.

Figure 4.
For ZDT1, the comparisons between the true Pareto front and the best ones obtained by three different algorithms.
Figure 4.
For ZDT1, the comparisons between the true Pareto front and the best ones obtained by three different algorithms.

Figure 5.
For ZDT6, the comparisons between the true Pareto front and the best ones obtained by three different algorithms.
Figure 5.
For ZDT6, the comparisons between the true Pareto front and the best ones obtained by three different algorithms.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The tested optimization problems.
| Function | Objective Functions | D | Variable Bounds | Characteristics of the Pareto Front |
|---|---|---|---|---|
| SCH | 1 | Convex | ||
| FON | 3 | Nonconvex | ||
| KUR | 3 | Disconnect | ||
| ZDT1 | 30 | Convex | ||
| ZDT2 | 30 | Nonconvex | ||
| ZDT3 | 30 | Convex disconnect | ||
| ZDT4 | 10 | Nonconvex | ||
| ZDT6 | 10 | Nonconvex |
Table 2.
Comparison of the results of multi-objective improved particle swarm optimization algorithm (MOIPSO) and different algorithms based on the indicator, .
Table 2.
Comparison of the results of multi-objective improved particle swarm optimization algorithm (MOIPSO) and different algorithms based on the indicator, .
| Function | Statistic | MOPSO | NSGA-II | MOIPSO |
|---|---|---|---|---|
| SCH | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| FON | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| KUR | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT1 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT2 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT3 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | 1.50 | |||
| ZDT4 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT6 | Best | |||
| Worst | ||||
| Mean | ||||
| Std |
Table 3.
Comparison of the results of MOIPSO and different algorithms based on .
| Function | Statistic | MOPSO | NSGA-II | MOIPSO |
|---|---|---|---|---|
| SCH | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| FON | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| KUR | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT1 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT2 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT3 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT4 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT6 | Best | |||
| Worst | ||||
| Mean | ||||
| Std |
Table 4.
Comparison of the results of MOIPSO and different algorithms based on .
| Function | Statistic | MOPSO | NSGA-II | MOIPSO |
|---|---|---|---|---|
| SCH | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| FON | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| KUR | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT1 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT2 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT3 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT4 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT6 | Best | |||
| Worst | ||||
| Mean | ||||
| Std |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Sun, Y.; Gao, Y. A Multi-Objective Particle Swarm Optimization Algorithm Based on Gaussian Mutation and an Improved Learning Strategy. Mathematics 2019, 7, 148. https://doi.org/10.3390/math7020148
AMA Style
Sun Y, Gao Y. A Multi-Objective Particle Swarm Optimization Algorithm Based on Gaussian Mutation and an Improved Learning Strategy. Mathematics. 2019; 7(2):148. https://doi.org/10.3390/math7020148
Chicago/Turabian StyleSun, Ying, and Yuelin Gao. 2019. "A Multi-Objective Particle Swarm Optimization Algorithm Based on Gaussian Mutation and an Improved Learning Strategy" Mathematics 7, no. 2: 148. https://doi.org/10.3390/math7020148
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.