1. Introduction
Prefetching is a basic technique underlying many computer science applications. Its main purpose is to reduce the time needed to access some information by loading it in advance and concurrently with the process that needs this information. From prefetching of data and code in CPUs and memory architectures, to prefetching of web pages and video segments in Internet-based applications, this technique is ubiquitous. Yet, the technique fundamentally involves a tradeoff between access latency and the consumption of resources (memory, network), and the optimization of this tradeoff is not completely understood.
Clearly, the issue here is randomness: the entity in charge of prefetching, let us call it the “controller”, does not know in advance what is the precise data access sequence of the process needing the data. It must therefore make decisions based on the current state of said process and its knowledge of the possible evolution. The adequate formalism for modeling optimal decisions in such a context is that of Markov Decision Processes (MDPs). The principle of using Markov decision processes to optimize prefetching in the context of video applications was first demonstrated in [
1,
2]. The model was extended in [
3,
4] and further extended in [
5].
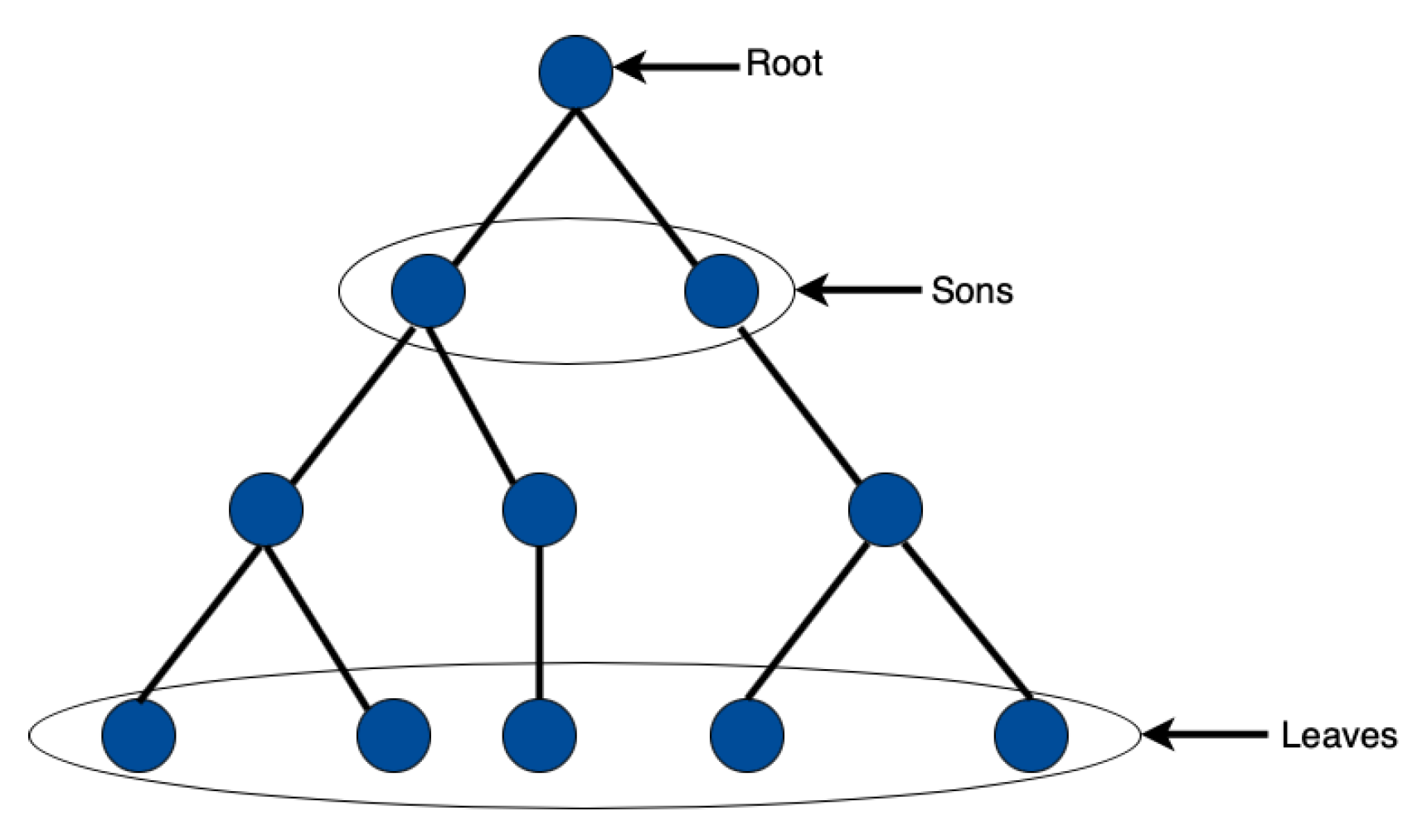
The basic principle of these models is that the set of (video) documents to be viewed is represented by a directed graph. The nodes represent the documents, and the edges represent the possible transitions: which documents can be viewed after the viewing of the current document is completed. The edges can be labeled with probabilities or frequencies. A random “surfer” alternates viewing periods and moves to another node/document according to the probabilities of the edges. The controller knows where the surfer stands and knows all about the graph, but does not know which way the surfer will go: only the odds. Its decision is to choose which nodes to download during the time the surfer views the current document. The amount of nodes that can be downloaded is constrained by network resources and is called the “prefetching budget”. The amount of storage memory available to the controller is assumed to be sufficient: no memory management is involved in the decision. The criterion to be minimized is typically the average number of times the surfer moves to a document that has not been prefetched: this is a measure of the user’s dissatisfaction. The criterion might also involve some measure of the waste of network and memory resources. An optimal policy can, in principle, be computed using dynamic programming.
In practical situations, the probabilities that the surfer moves to some new document after viewing the current document are not known a priori. However, these probabilities can be learned from data using Markov models, as in [
6,
7,
8,
9,
10,
11]. Moreover, the optimal control of a prefetching agent can be approximated using machine learning techniques such as reinforcement learning, as in [
2]. A way to evaluate the efficiency of a machine learning algorithm is to test it on a problem for which the exact solution is known. The purpose of this paper is to provide such a benchmark situation, by determining the optimal policy and the minimal possible cost it induces, to which heuristics and learning algorithms can be compared.
While these previous modeling attempts demonstrated that the MDP formalism is flexible enough to take into account many features of a real system, they also illustrate that finding an optimal policy is a complex problem. Indeed, computing an optimal prefetching policy is very hard in general, that is when the graph of documents does not have a particular property. In [
12], the authors studied the
feasibility variant of the problem. There, it was assumed that the controller has a prefetching budget
k, representing the number of documents that can be prefetched while some document is viewed. The question is to decide whether
k is large enough so that there exists a policy that prefetches all nodes of a graph before the random surfer tries to access them. This is a subproblem of the Markov optimization model: if such a policy exists, the MDP model should find it as a policy that realizes a zero cost. The results of [
12,
13] concluded that finding the minimum possible
k is difficult when the graph is general. Computing the optimal policy in the corresponding MDP must be even more difficult.
However, if the underlying graph is a tree, it was proven in [
12] that the minimal budget
k that ensures the existence of a costless policy can be computed in polynomial time. The corresponding prefetching strategy is also easy to compute and has the feature of being “connected”. This property, which we also call “greedy”, means that the controller can choose the documents to download in the set of neighbors (in the document graph) of the documents already downloaded.
The models and results reviewed thus far assumed that the complete space of documents is known to the controller. This ideal situation may be either unrealistic or undesirable. For instance, if the documents are pages on the global web, storing all the knowledge about this graph is probably impossible and also useless since the web surfer will not visit all the graph during a surfing session. Furthermore, since the complexity of the decision grows exponentially with the size of the graph, it may help the controller to limit, on purpose, the size of the known graph to a neighborhood of the current document.
The current literature lacks a model for the optimal prefetching problem, which features a dynamic graph of documents. It also lacks situations where an optimal control can be formally (and not just numerically) identified, even when the underlying graph of documents is static. We fill these gaps in two ways. First, we propose a new optimal prefetching model in which the graph of documents is dynamic. We focused on trees, since those are the simplest graphs, with the potential for having computable solutions as the literature review suggests. Second, we compute exactly the optimal control for some instances of this model. We proceed with an informal description of the model, then we highlight our contribution.
1.1. The Model
We propose to use the modeling described above, but replace the graph of known documents with a tree of depth d. The root of this tree is the current position of the surfer. The tree represents all the possible sequences of d moves of the surfer. After the surfer has moved to one of the neighbors of its current position, a discovery phase adds a new generation of documents at depth d. The rest of the tree is then ignored: the possibility that the surfer moves back to a node already viewed is neglected, as well as the possibility that several paths exist from one node to another. If any of these possibilities happens in practice, the task will become easier to the controller.
In the discovery phase, we assume that a random number of new documents is attached to every leaf of the current tree, with a uniform distribution between 1 and some integer p, which we refer to as the “fanout”. In practical graphs of documents, this assumption is not very realistic. The advantages of making such an assumption are that the space of possible configurations will remain finite and that probabilities relative to objects in this space will be easier to write.
As in previous models, the controller is assumed to have a fixed prefetching budget: some integer number k. Given a tree of documents with some nodes already downloaded, the problem is to decide which k nodes to download so as to minimize the cost. We chose as criterion the stationary probability that the surfer moves to a node that is not prefetched. All these elements are converted in the specification of a Markov decision process, with criterion the infinite-horizon average cost. The model has only three parameters: the depth d and fanout p of trees and the prefetching budget k. The question is whether there is a simple rule based on these three parameters that leads to an optimal decision.
1.2. Contribution
The first contribution of this paper is the precise specification of this MDP, in
Section 3. This specification is based on sets of trees, presented in
Section 2, together with their basic properties.
We then turn to the identification of optimal prefetching policies, in
Section 5,
Section 6 and
Section 7. The results we obtained include: (a) A bound on the optimal cost in general trees; (b) The characterization of optimal policies in trees with depth 1, arbitrary fanout, and arbitrary budget; (c) The characterization of optimal policies in trees with depth 2, arbitrary fanout, and budget 1; (d) An exploration of the optimal policy in trees with depth 2, budget 2 and fanout less than 5. In the process of obtaining these results, we show, in
Section 4, the properties of underlying Markov chains on the “shape of trees”, which do not depend on the specific policy used and are of independent interest. We discuss the results and the modeling assumptions in
Section 8 and conclude in
Section 9.
The main notation that is used throughout the paper is summarized in
Table A1 in
Appendix A.
2. Preliminaries: Sets of Trees
This section is devoted to the presentation of mathematical objects that are used in the definition of our problem and in its solution.
The state space of the MDP we are about to construct is a set of marked trees. We introduce it now, together with other sets of trees that will be useful in the analysis. We shall use “with fanout p” as a shorthand for “with nodes having between 1 and p sons”.
Definition 1 (Trees and marked trees). Define:
- (a)
the set of rooted trees of depth d with fanout p;
- (b)
the set of rooted trees of depth d with fanout p and a mark in the set;
- (c)
the set of rooted trees of depth d with fanout p and a mark in the setexcept for leaves that have the mark 0.
These sets are represented mathematically with the following recursive formulas:
In these expressions,
denotes, in the notation of [
14], a sequence of objects in the set
A, with the length between 1 and
p. In (
1), we associate the constant mark “0” with nodes in unmarked trees. At the risk of being confusing, we shall say that a node in marked trees of
or
is “unmarked” if it has the mark 0. With this convention, we can say that
.
A tree
t in
is represented as follows. If the depth is
,
where
is the mark. If
,
where
or
depending on the set, and
is a list of length
. The elements of
s are called “subtrees”. The root nodes of these subtrees are called “sons” of
t. The following notation will be useful to designate the components of a tree.
Figure 1 illustrates this terminology.
Definition 2 (Mark, subtrees, internal nodes, leaves). For a tree represented as, letdenote the mark of the root anddenote the list of subtrees of t. Let alsodenote the number of internal nodes in t anddenote the number of leaves in t.
The cardinal of the sets defined in Definition 1 is important to know, in case we want to turn to numerical experiments. From the recursive definition of the different sets of trees, the following result is easily established.
Lemma 1. Let, , anddenote respectively the cardinals of sets,and. Then:
,
and for,and for, and for,
Similar formulas can be established for generating functions of the size of trees in each set. We shall not develop this analysis further.
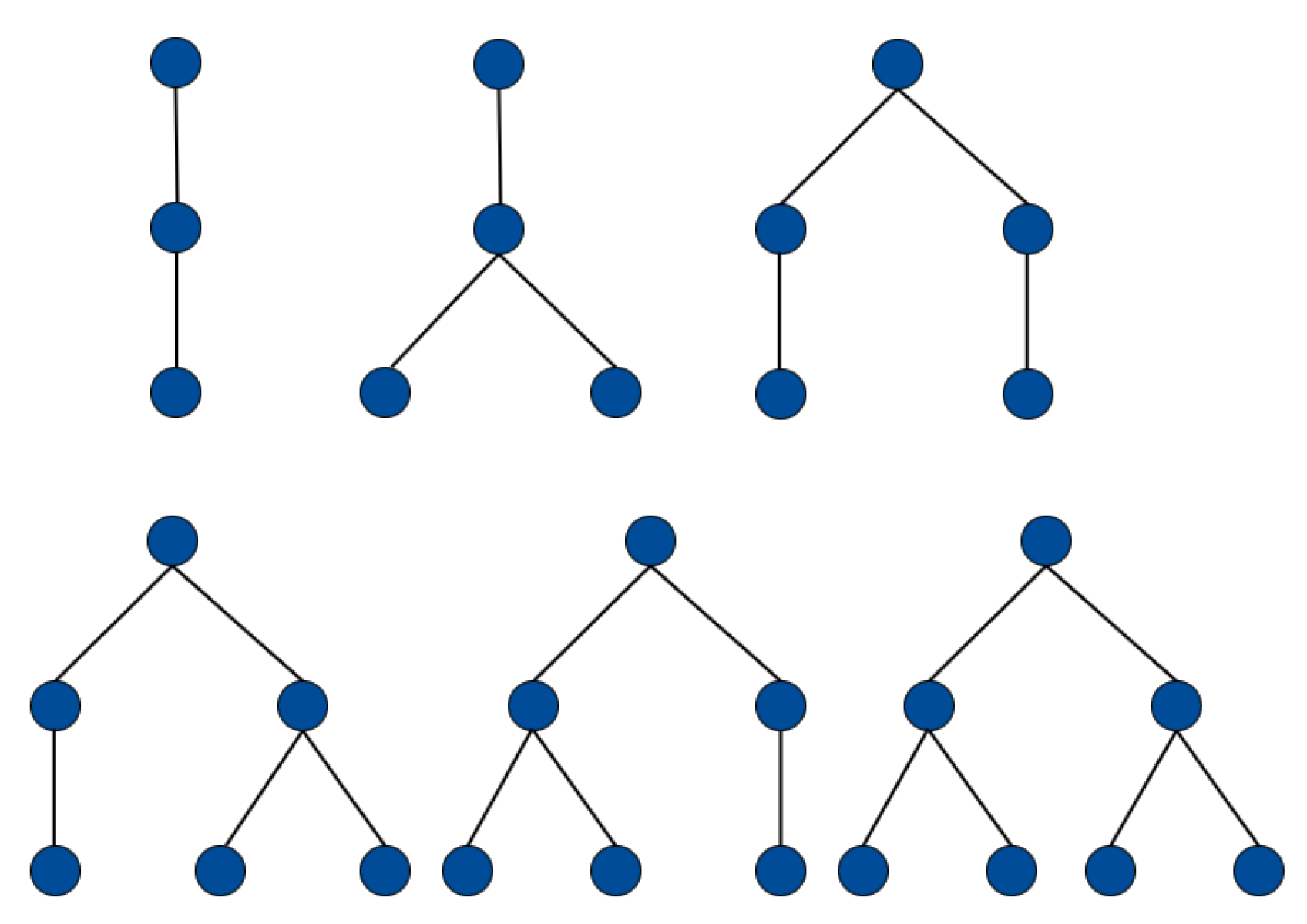
Table 1 shows the values of
,
, and
for small values of
p and
d. Clearly, these numbers grow extremely fast with
d. The sets remain manageable for small values of
p and
d. For instance,
Figure 2 lists the 6 trees of
.
3. The MDP Model
In this section, we formally describe the five elements of the prefetching MDP. An MDP model is formally defined by a state space, an action space, transitions, costs, and an evaluation criterion. The state is usually made of numerical variables or discrete structures that summarize the information needed for the following definitions. Actions and transitions specify what controls are allowed to the controller, how they modify the states, and with what probabilities. The cost function, which depends on the states and actions, quantifies the impact of actions. The costs incurred at different time steps are aggregated into a numerical criterion: the objective is to minimize this criterion.
3.1. Prefetching Process Flow
The prefetching process flow is summarized as follows. The current state of the prefetching program is the currently known graph of depth d, together with the knowledge of nodes that have been already prefetched. This is represented as a marked tree of depth d. The surfer is assumed to stand at the root. The controller then prefetches up to k documents, which is represented by marking the corresponding nodes in the tree. Then, the surfer moves randomly to one of the sons, with uniform probabilities among them. If the document corresponding to this node is not already prefetched, then some cost is incurred. Finally, the controller discovers a new generation of nodes. We assume that every possible exploration/discovery of the current subtree is equally likely. After discovery, the controller is back at the beginning of this decision loop.
3.2. State Space and Action Space
According to the prefetching process flow described previously, the state space S of the MDP is as defined in Definition 1, since the leaves of a state were just discovered and are not prefetched: their mark is 0. For a given tree , the action space is the set of all subsets of the vertices of t with cardinal at most k. An action will have the effect of marking the nodes in a. Some actions will not make much sense: those that mark already marked nodes. We choose to include them nevertheless as possible actions, which greatly simplifies the description of the set . The parameter is called the prefetching budget.
3.3. Transitions
We first formalize the transition between the different trees using random variables and set mappings. Then, we quantify the probabilities of these transitions and the costs.
Definition 3 (Prefetching process random variables). Define:
- (a)
t the random variable denoting the state (tree) of the prefetching MDP; t takes values in;
- (b)
the random variable denoting the tree after some marking action has been performed;takes values in;
- (c)
the random variable denoting the tree after the movement of the surfer and before the exploration of the tree;takes values in.
In the evolution of the controlled process, these three random variables will depend on the time step n. When necessary, we use the notation , , …, , … to denote this (random) succession of trees.
Definition 4 (Discovery).Let denote the mapping such that is the set of trees that can be discovered from tree . Elements of are in and are obtained from the tree t by updating its leaves according to the following rule: for a leaf (i.e., depth-0 tree) in t, update it as: Definition 5 (Successors after discovery). Let be defined by:where ⊔ refers to the disjoint union of sets. The set contains all trees that are the possible results from a combination of surfer movement and the discovery of new leaves.
For a tree
, let
denote the tree after marking according to action
. Then,
is the set of subtrees of
t after marking action
a. The transition probability of moving from a tree
t to a tree
under action
a is:
3.4. Immediate Cost
The immediate cost of moving to tree
by choosing action
a while in tree
t is:
Accordingly, the expected cost incurred when applying action
a to tree
t is:
but a simpler expression is available by substituting the explicit values for the probability term and the cost term, as stated in the next lemma.
Lemma 2. The expected cost can be written as: Given a budget or a specific family of policies, there are states in S that will never feature in the MDP. Thus, we shall focus only on the “usable states”.
Definition 6 (Usable states). The states in S that are attained through transitions given a specific value of budget k or a family of policies are called usable states. Denote this set of states as .
For example, budget dependent states for
,
, and
will not include states where both nodes at depth 1 (if two exist) are marked. We will come back to this in
Section 6.
3.5. Policies and Criterion
We choose as evaluation criterion the expected average cost over an infinite horizon. The class of policies in which we optimize is, in the terminology of [
15] (Section 2.1.4), that of History-dependent, Randomized strategies (HR). However, the classical theory allows focusing on stationary strategies only. Some of our definitions are valid in the general class HR. In this context,
denotes the action prescribed by the policy at time step
n for tree
t.
Definition 7 (Sensible policies, greedy policies). A policyis called:
- Sensible
if, for every state t and every time instant n,marks k unmarked nodes, or the number of unmarked nodes in t;
- Greedy
if it is sensible and if for every t,marks: either k of the unmarked sons of t if these are more than k or else all unmarked sons of t plus possibly nodes at a depth of at least 2.
Sensible policies do not waste the marking budget on marked nodes, unless they have no other possibility. Among them, greedy policies mark sons as priority.
The following observation will be useful. Its proof is immediate by unrolling the marking/surfing/discovering cycle.
Lemma 3. Consider a stationary policy γ such that for any t, marks nodes only up to some depth . Let be the Markov chain generated by this policy. Then, the usable states , and in particular the recurrent classes of , contain only trees with nodes marked up to depth .
Remark 1. Given the rules of surfing (uniform choice) and of discovery (independence of different subtrees), it seems possible to further reduce the size of the state space by exploiting symmetries. For instance, in Figure 2, the fourth and fifth trees will have exactly the same properties. We chose not to exploit these symmetries, because this would lead to an extra complexity in the formalism. Furthermore, it would render the enumeration of state spaces more complex and, as a consequence, complicate the description of the process on tree shapes; see the following section. 4. The Markov Chain of Tree Shapes
In this section, we temporarily forget the control part of the MDP and focus on the process of trees generated by the surfing/discovering mechanism. It turns out to contain two Markov chains, which we identify and analyze.
4.1. Definition and Basic Properties
An important feature of the MDP constructed in
Section 3 is that the
shape of the successive trees does not depend on the marking strategy. In order to formalize this, we first define the shape of trees.
Definition 8 (Shape of trees). Consider the mapping , defined for all p and d recursively with: The tree is called the shape of tree t.
We now state the aforementioned property of the shape of trees in the MDP. Observe that, by the definition of the succession of trees t, , , we have for all n.
Proposition 1. - (i)
The distribution of the sequencedoes not depend on the strategy;
- (ii)
The processes, andare homogeneous Markov chains on the state spacesand, respectively.
Proof. The proof of
follows from the fact that transition probabilities in (
9) do not depend on the action
a. Then, the Markov nature of embedded sequences
and
is clear since random moves of the surfer and discoveries depend only on the shape of the current tree. □
We proceed with the identification of the stationary distributions of the Markov chains featured in Proposition 1. We first introduce the family of candidate distributions and state their basic properties. We then prove the result about Markov chains.
Definition 9. Letbe the sequence of functions defined recursively by: Lemma 4. The functionsintroduced in Definition 9 have the following properties:
- (i)
For each fixed d,is a probability distribution on;
- (ii)
The probabilitiescan be expressed as:
The interpretation of Definition 9 and Lemma 4 is that the probability of a tree t is the probability that this tree is generated by a Galton–Watson process with branching probabilities uniform in , stopped at generation d.
Proof. The proof of
proceeds by recurrence. For
, the property is trivial. Assume then the property proven up to
d. Then, selecting the number of sons of a tree and using (12), we have:
We continue with the proof of . Recursively, . The result then follows from the definition (12). □
The following properties of the distribution will be useful. The proofs of the first two of them are straightforward and omitted.
Lemma 5. Let t be a random tree in distributed according to . Then, is uniformly distributed in .
Lemma 6. Let t be a random tree in distributed according to . Then, conditioned on the fact that , the subtrees are independent and uniformly distributed according to .
Proposition 2. Consider the Markov chainsand:
Both chains are ergodic;
The stationary distribution ofis;
The stationary distribution ofis.
Proof. The property is proven if we can show that both chains are irreducible and aperiodic. Irreducibility follows from the fact that there is a sequence of transitions with a nonzero probability leading to, say, the tree that is a chain (all its internal nodes have only one son, let us name it ): if the discovery phase adds just one leaf to every leaf of (this happens with positive probability), after d steps, the tree is , whatever the random surfing moves. The tree itself is . Aperiodicity also follows from this construction since the transition from to has a nonzero probability.
In order to prove
, we check that the distribution
satisfies the equation
. Since
is ergodic, this will be the unique solution. We first identify the set of trees that have a positive probability of transition to a given tree
. To that end, we have to reverse the process of the transformation of one tree into another. Reversing the discovery phase, we are led to define
as the tree deduced from
t by removing the leaves. Then, reversing the surfer movement, we conclude that
can be transformed into
t if and only if
has
as one of its subtrees. Let
be this set. For any
, we have:
Accordingly, it is convenient to partition the set
into “blocks” of states as follows:
Trees that have the same number of sons and the same number of occurrences of
among their sons are grouped together. By construction, we have:
This transition probability is therefore constant in the block
. Then, we can write:
We evaluate the inner sum, which is the total probability of the block
under the distribution
. According to Lemma 6, the distribution of subtrees of
is that of
m independent trees in
. Therefore, the probability, conditioned on
m, that exactly
n subtrees of
are
is the following binomial distribution (resulting from picking the
n locations for trees
among the
m possibilities):
Using this result, we can evaluate the product of the distribution
and the matrix
P through the following computation:
| |
| (16a) |
| |
| |
| (16b) |
| (16c) |
| |
We used (
13) and (
14) to obtain (16a). The binomial expansion theorem was used in (16b). Finally, in (16c), we note that
is the sum of
and
, which gives us the desired result,
.
Finally, we prove . We know that results from through the random choice of a son of t. Invoking again Lemma 6, we have: conditioned on the event , each subtree is with probability , and the probability that a uniform random choice picks has probability as well. Since this does not depend on m, the result is true also when removing the conditioning. □
4.2. Application to Greedy Policies
As an application of Lemma 5, we obtain an upper bound on the optimal cost that can be realized by any policy. This was based on the following result.
Lemma 7. Consider a random variabledistributed as.
Define the random variable: Then,with probability 1 (in particular,) ifand:where: Proof. According to Lemma 5,
is uniformly distributed. Then:
□
We now state the bound announced.
Proposition 3. The optimal expected costof the MDP described in Section 3 satisfies: The cost of any greedy policy satisfies the same bound.
Proof. Consider the policy that marks
k sons of the current tree or all the sons if
k is larger than this. This is a greedy policy, in the sense of Definition 7. The average cost of this policy is precisely given by
as in Lemma 7, which is equal to the right-hand side in (
19). Any greedy policy will mark at least the same nodes: it will necessarily have a smaller average cost. The optimal cost of the MDP is necessarily smaller than the cost of this specific policy. □
4.3. Metrics of Tree Shapes
We applied the results of
Section 4.1 to evaluate several simple metrics in tree shapes generated by the MDP. This may be useful in particular for estimating the quantity of memory needed in a simulation of this process.
4.3.1. Average Number of Nodes
Let
be the average size of a tree
t distributed according to
. According to Lemma 6, we can write, conditional on the event
:
so that:
Since the initial condition is
, the recurrence in (
20) has the solution:
with
. We have proven the following result.
Lemma 8. The average number of nodes in a treedistributed according tois given by (
21).
4.3.2. Average Number of Leaves
Let
be the average number of leaves, in trees
t distributed according to
. The reasoning of
Section 4.3.1 can be reproduced: according to Lemma 6, we can write, conditional on the event
:
. If follows that:
Since , we have the following result.
Lemma 9. The average number of leaves in a treedistributed according tois: Note that the maximal number of leaves of a tree in is .
4.3.3. Average Number of Nodes Created
Let
be the average number of nodes created at some time step in the Markov chain
in its stationary regime. It is equal to the expected number of nodes created from some tree
distributed according to
. This number itself is equal to the expected number of leaves in
t, since
t results from the addition of leaves to some
, also distributed according to
. We therefore have, with Lemma 9:
4.3.4. Average Number of Nodes Deleted
Let be the average number of nodes deleted at some time step in the Markov chain in its stationary regime. By stationarity, it is expected that . We verify this with a direct computation.
Consider a tree
. Conditioned on the events
and the surfer moving to the
, the number of nodes deleted is:
(the root and the other subtrees). Using Lemma 5 and the fact that each
is distributed according to
(Lemma 6), we have then:
where the last equality results from (
21). This is equal to the average number of nodes created
, as expected.
5. Trees of Depth with an Arbitrary Marking Budget
In this section, we consider trees of depth 1, and we prove the following result.
Theorem 1. When, any greedy policy is optimal.
It is quite clear intuitively that, indeed, no reasonable alternative exists. The exercise here is to check that the theory does provide a way to prove the result formally. In the process, we identify arguments that will be useful for the proofs of stronger results.
For the purpose of the forthcoming proof, we rename the elements of
as:
. In the notation of
Section 2, we have
. Furthermore, observe that trees
belong to
: these are trees reduced to a root with a mark.
Proof. We shall prove the result using Theorem A1. Define the constant
g and the function
as:
The symbol
was defined in (
18). We shall check that this
satisfies the optimality Equation (
A1). For every state
and every action
a, we write the quantity to be minimized in the right-hand side of this equation:
We obtained (
24) by conditioning the transition
on the value of the tree
. The new notation
stands for the probability of moving from
t to
when action
a is applied. Given the definition of
in (23), we have further:
The actions
a can be grouped according to the number of sons they mark in the tree
: this number ranges from 0 to
. When
has
ℓ sons marked, this determines the cost as:
Finally, the minimization with respect to
a amounts to the following minimization with respect to
ℓ:
The constant
g and the function
f therefore solve Equation (
A1). This function is bounded since the state space is finite. Therefore, there exists an optimal policy
with cost
g. Clearly, this policy consists of marking up to
k sons of any tree: a greedy policy in the sense of Definition 7. □
From the proof of Theorem 1 and also from Lemma 7, we have the corollary:
Corollary 1. The average value of any tree of depth 1 is.
Remark 2. The fact that, in the present case,is a consequence of the fact that the cost of the future treeresulting from the transition is actually independent of the action a.
Remark 3. It was proven in [16] that the finite-horizon, total-cost optimal-value function is given by: and is realized by any greedy policy. We obtained from this result the value ofand the form of function f that must satisfy.
6. Trees of Depth with Marking Budget
In this section, we consider trees of depth 2, and we prove the following result.
Proposition 4. Whenand, any greedy policy is optimal.
We begin with some notation and preliminary results. Then, we provide the proof.
6.1. Preliminaries
As a preliminary, observe that as a consequence of the marking/moving/discovery cycle, the subtrees of that appear have at most one leaf marked. Indeed, at the beginning of the cycle, trees have all leaves unmarked. The marking with budget marks at most one of these leaves. Then, the surfer moves to one subtree , which inherits this property. The discovery phase merely adds unmarked leaves at depth 2. With this observation, we can restrict our attention to the usable set of trees with at most one leaf marked, since only those can appear recurrently when some stationary policy is applied.
A second preparation is to calculate the average cost under some greedy policy
, which therefore marks one node at depth one in any tree
t. The choice of this node does not matter. According to Lemma 3, the Markov chain
generated by this policy has recurrent states with marks only at depth 0, that is at the root. Therefore, the cost (
10) is always given by
. It is then of the form assumed in Lemma 7, and the application of (
17) yields the expected cost for policy
:
6.2. Notation and Terminology
When , the trees of interest are simpler than in the general case, and it is convenient to devise an appropriate notation. For trees in , all subtrees have depth one and unmarked leaves. We shall adopt the simplified notation for such trees: denotes a depth one tree with root marked with and m unmarked leaves. A typical tree of is then denoted by for some .
After marking, the subtrees of depth one will have at most one leaf marked: then will denote this tree with one marked leaf. Which leaf exactly is marked does not make a difference in the following reasoning.
In the analysis, the number of unmarked sons of a tree is a key criterion. Accordingly, we introduce the following typology for
:
6.3. Proof
The proof uses the optimality equations and Theorem A1, as in
Section 5. The “
g” value needed for this was computed as
in (
27). The next step is to evaluate the “
f” function in the optimality Equation (
A1) in Theorem A1. It is sufficient to provide a value to states that are usable in the sense of Definition 6. For other states, the value of
f is defined by (
A1), since the right-hand side only contains values of reachable states.
The function
f that is proposed is the following:
In this last line, is the number of subtrees of t that have exactly one leaf.
Proof of Proposition 4. We apply Theorem A1 by checking that the function
f, in (
28), and the constant
satisfy the optimality equations. To that end, we first evaluate the expected value of trees
in
. Denote by
the transition probability from a tree
to a “discovered” tree
. We can write:
We have, for any
:
From these formulas, the following identities are obtained: for any
and
,
The following result then immediately follows:
Lemma 10. For all,and all,.
We now proceed with checking that f and g solve the optimality equations. We start with Type 1 trees. Let with . The alternative actions are: mark the root or any son already marked; mark an unmarked son k; mark a leaf of subtree . For actions , we denote by the marks of the sons after marking: for and . Clearly, . For actions , which leaf is marked does not matter, so we ignore this information.
The right-hand side of the optimality equation in the cases
,
, and
are respectively:
Then:
Both differences are negative according to Lemma 10. This implies that action dominates all actions , which in turn dominate action . It therefore realizes the minimum in the right-hand side of the optimality equation. With (32), the right-hand side and the left-hand side coincide.
Next, we consider Type 2 trees. According to the preliminary remark, we can focus our attention on trees with at most one son marked: if this tree is of Type 2 (all sons marked), then it has only one son. Let then
,
be such a tree. The alternative actions are:
mark the root or the son;
mark leaf of the subtree
. The right-hand side of the optimality equation is respectively:
and
. From Lemma 10, we know that action
dominates action
. Further, from Definitions (
28) and (31),
□
Remark 4. It was proven in [16] that, for any tree, in the usable set, namely the set of trees with no sons marked, the finite-horizon total-cost optimal-value function is given by:and that this cost is realized by any greedy policy. From this result, the average cost of this policy in the infinite horizon is then: This matches with (27). Furthermore, it is compatible with the form of the function f in (28). The interpretation ofis the difference in the total expected cost when starting from trees t or.
According to (33), the tree-dependent cost for trees with unmarked sons would be: This is indeed the value in (28) since.
7. Trees of Depth with Marking Budget
This section is devoted to the case where the marking budget is . In this case, we do not present general results, but we focus on the case of trees with depth 2. For small values of p, we describe the optimal policy, and we conjecture that this policy is optimal for general values of p.
We begin with some additional notation, then we introduce the definitions of the policies of interest. This allows us to formulate Conjecture 1. We then present numerical experiments made with small values of p supporting this conjecture.
7.1. Preliminary
Similarly as in
Section 6, we argue that usable states are necessarily such that the marking of sons
takes values in
. Indeed, the sons of a tree are the leaves of a tree at the previous time step, and at most two leaves can be marked at any step.
7.2. Notation and Terminology
We first recall the representation of depth two trees of
from
Section 6.2. Such a tree can be represented as
where
,
and
for all
.
are the markings of the root and the sons,
m is the number of sons, and
are the number of leaves of the depth one subtree
. Based on the number of marked sons of the tree, we classify them into two types:
Type 2 trees are further classified into three subtypes (remember that
cannot exceed 2):
We also introduce some shorthand notation for the different possible actions. Let represent the action of marking two sons ( as in “depth 1”), represent the action of marking a son and a leaf of the tree ( as in “leaf j”), and represent the action of marking a leaf in each of the subtrees and . If , two leaves are marked in this subtree.
7.3. Policies
All policies of interest in our study are greedy in the sense of Definition 7. These policies do not specify what happens when some marking budget is left after marking all unmarked sons of a tree. We therefore specify the following variants of the greedy policy by their precise behavior in this situation. We begin with four simple rules; three of them rely on an order defined on the subtrees. The terms “first” and “second” used in the specification are relative to this order:
Greedy depth 1: Ensure that only the sons of the tree are marked;
Greedy smallest: Ensure that the sons of the tree are marked. If budget remains, then mark the first leaf of the smallest subtree. If budget still remains, mark the second leaf of the smallest subtree, if any. Otherwise, mark the first leaf of the second smallest subtree;
Greedy largest: Ensure that the sons of the tree are marked. If budget remains, then mark the first leaf of the largest subtree. If budget still remains, mark the second leaf of the largest subtree, if any. Otherwise, mark the first leaf of the second largest subtree;
Greedy leftmost: Ensure that the sons of the tree are marked. If budget remains, then mark the first leaf of the leftmost subtree. If budget still remains, mark the second leaf of the leftmost subtree, if any. Otherwise, mark the first leaf of the second leftmost subtree.
The cost of policy “greedy depth 1” is known by Lemma 7:
Finally, we introduce the “greedy finite optimal” policy, a name that we use as a shorthand for “the policy that seems to emerge as optimal with the finite horizon criterion”. Its behavior is specified in
Table 2. It is explained in
Appendix C how the features of this policy are extrapolated from the results obtained with the finite-horizon version of the MDP.
The behavior of the “greedy finite optimal” policy is obvious on Type 1 (more than two unmarked sons) and Type 2c (one son that is marked) trees. On Type 2a (one unmarked son) and Type 2b (two sons, both marked), it introduces a threshold of 3 or 4 on the size of the subtrees. When the tree is of Type 2a, one mark is left for marking subtrees. If all of them have a size less than 2, the largest one is marked. On the other hand, if some of them has a size larger than 3, the smallest of these is marked. When the tree is of Type 2b, two marks are left for marking subtrees. If both of them have a size larger than 4 (), the smallest subtree is marked. In the other case, both subtrees are marked.
A rationale for such a rule is as follows. When a tree has less than two unmarked sons, it can be made costless with the two marks of the budget. Therefore, when considering trees of Type 2a, a subtree that has less than two leaves has less priority than a subtree with more than three leaves, which is more “vulnerable”. Among the vulnerable trees, it is better to mark the smallest ones, in order to reduce future expected costs. Trees of Type 2b have, so to speak, one round in advance since all sons are already marked. Subtrees of a size less than 3 can be “protected” by devoting one mark to them: if the surfer moves to them, the budget of the next round will be used to complete the protection. If both trees are too large to be fully protected, the budget is devoted again to the smallest one.
We can now state the conjecture that is the focus of this section.
Conjecture 1. When and , the “greedy finite optimal” policy is optimal.
7.4. Numerical Experiments
We provide support to Conjecture 1 with results for small
p. We implemented the policy improvement algorithm [
15] (Chapter 8.6), starting with a particular greedy policy. Prior to the implementation of the algorithm, we evaluated the average cost of the four variants of the greedy policy introduced in
Section 7.3, for
. Of course, the greedy policies realize a zero cost for
.
The average costs of the five greedy policies for small values of
p are summarized in
Table 3. The row concerning the “greedy depth 1” policy was evaluated using the exact formula (34), which gave respectively
,
, and
for
, and 5. Several observations can be made from the data of this table. First, there is a substantial gain of marking subtrees after having marked all the sons: there is a larger gap between the performance of greedy depth one and the group of the other ones, than inside this group. Second, the best performance among the four simple policies introduced in
Section 7.3 was achieved by marking the largest subtree, for all values of
p tested. Picking the smallest subtree had the worst performance compared to picking the leftmost/largest subtree. Finally, choosing arbitrarily the leftmost (or, for that matter, the rightmost or a random) subtree resulted in a performance between these extremes.
We used the greedy largest policy as a starting candidate policy for the policy iteration algorithm for
, since it gave the best performance among the simple policies. In each case, the algorithm converged in a few iterations, and the resulting policy was the greedy finite optimal policy. The performance of the policy iteration algorithm is summarized in
Table 4. The execution time figures correspond to an implementation in Python 3.9 running on a 1.4 GHz quad-core processor with 8 GB memory and a 1536 MB graphic card.
We could have also started the algorithm with the greedy finite optimal policy and checked that it solves the optimality equations. Selecting another policy was also a way of checking that our implementation of policy iteration works properly, as well as measuring “how far” from the optimum the greedy largest policy is.
Observe in
Table 3 that the relative performance of the greedy finite optimal policy was more pronounced for
as compared to
. The former MDP had a larger number of Type 2 trees. The greedy largest policy prescribed a suboptimal marking scheme for such trees, which explains the greater cost reduction by switching to the greedy finite optimal policy for
. The greedy finite optimal policy for
coincided with the greedy largest policy, and hence, the costs were identical.
8. Discussion
We proposed a stochastic dynamic decision model for prefetching problems, which is simple in the sense that it has only three integer parameters, and yet can help conceive of optimal strategies in practical situations. The simplicity of the model lies in several assumptions that we discuss now.
We first observe that the modeling we proposed does not look practical for large values of parameters
d and
p. Indeed,
Table 1 clearly shows that the state space sizes that could be handled numerically corresponded to small values of these parameters. On the other hand, the formal results obtained so far suggest that such a numerical solution would be needed in practice. We argue, consistent with our introduction, that large values of
d are not desirable in practice: it may be better not to know the graph at a larger distance, as long as the complexity of the decision grows exponentially with the amount of information. A value
may be a good compromise between excessive shortsightedness and an excess of information. Concerning the parameters
k and
p, practical situations should involve cases where these values are not far from each other. Clearly, if
, the problem is easy, whereas if
, all policies will be bad because the controller is overwhelmed by the number of nodes to control. The modeling we propose is relevant if the network is a bottleneck of the system: in other words, if
k is not very large. Therefore,
p should not be very large either.
The next feature departing from practical cases is about the discovery process. In our model, we assumed a uniform distribution for the new generation of nodes. Practical graphs are known to have different node degree distributions. Here, since we identified this mechanism with a Galton–Watson branching process, it seems possible to use other distributions while conserving the possibility of characterizing the distribution of trees as we did in
Section 4. Therefore, evaluating the performance of simple greedy policies and obtaining bounds might be possible with this generalization. Furthermore, the results we obtained with budget
or depth
were probably insensitive to the distribution of the number of sons.
The assumption we made about the movements of the “surfer” in the graph of documents may also be questioned. We assumed a uniform choice between neighboring documents. In addition to simplicity, we argue that this represents the most difficult situation for the controller, since the amount of information available to it is minimal. In the case where nonuniform movement probabilities are known, they can easily be integrated in the MDP, just as in the models reviewed in the Introduction. It is interesting to note that in such a case, models can be imagined where the optimal policy is not of the greedy type: consider just a case where the probability of moving to some son happens to be zero (or close to zero). The prefetching budget should then be devoted to marking the other sons and their subtrees. Apart from such obvious situations, it is difficult to imagine cases where an optimal policy would be formally identified, since this policy should weight the movement probabilities with the characteristics of the subtrees.
Going back to the simple model we proposed, the results of
Section 7 (the case
and
) and their interpretation suggest a general form for a heuristic policy. The first principle is that sons should be marked as priority. The issue is what to do with the remaining budget. On the one hand, the subtrees that have themselves less than
k sons are easy to deal with and can be ignored. Among the remaining subtrees, those with the smallest number of sons should be marked first. If budget remains, the principle can be applied recursively.
9. Conclusions and Perspectives
Among the results of this paper, we proved that simple greedy policies are optimal in several situations, suggesting that optimal policies are always greedy. One first obvious step in future research will be to prove the following result, generalizing Proposition 4:
Conjecture 2. When , any greedy policy is optimal.
Next, our research will focus on the more challenging case . The first objective will be to prove Conjecture 1 and then determine how to adapt this policy to larger d. Some numerical investigation appears to be possible there for small values of p, despite the large size of the state space. Another line of research on formal solutions will focus on the analysis of Markov chains defined by simple policies with the purpose of providing bounds tighter than that of Proposition 3.
On the practical side, several issues need further investigation. The principal one is to efficiently identify the model and the optimal control from practical data. We plan to develop algorithms that would leverage the knowledge gained with the exact solution of simple models, with the objective of reducing learning time and learning errors.





{kind=link}
{kind=link}

