1. Introduction
Cognitive control systems are characterized by perception, learning, planning and memorization, defining a clear path toward general intelligent systems that are able to optimally handle new, unseen before situations and display adaptability. The best examples of collections of such complex control systems are offered by certain biological systems (living organisms, humans in particular) who intelligently solve complex tasks by combining knowledge gathered through experience via learning and planning mechanisms that are encoded in the brain. As such, the brain acts as a processing unit that is able, at a higher level, to project future strategies in order to achieve goals through reasoning and planning, decompose complex strategies into well-known possibly simpler strategies (planning), memorize new experiences to augment the current knowledge base, and process feedback signals by fusing visual, tactile, auditory, and olfactory information for task execution improvement through learning. Finally, it guides the lower-level neuromuscular control system to act in the environment to achieve higher-level goals.
This intelligence of living organisms has developed without solving explicit mathematical equations; therefore, this kind of complex intelligence serves as inspiration for developing model-free control, learning, and planning techniques. One suitable paradigm for explaining the above techniques is the process of learning neuromotor skills, which rely on well-acknowledged control formulations such as those found in feed-forward- and feedback-based control and predictive-based control. A common trait of all these techniques is that they are almost always posed and solved in optimization-based settings [
1]. In such settings (e.g., taking error-based learning), the error gradient is exploited to improve the control solutions. Alternatively, use-dependent learning addresses the permanent compromise between repeatable tasks whose improved execution is improvable for high-performance and non-repeatable tasks that require a significant relearning effort.
One illustrative natural behavior for some of the above concepts is the imitating behavior of biological systems: the first execution of an imitation task is nearly optimal. The brain can analyze, memorize, and decompose the imitation task into subtasks for each limb and plan for corresponding immediate future tracking tasks. The control of each limb is already encoded in the neuromuscular system through an inverse dynamical model that is not explicitly represented. Another illustrative situation occurs when new neuromotor tasks are solved by first decomposing them into tasks with known solutions and then recomposing the new solution from existing ones. The previously described behavior unites several concepts that can be formally called a primitive-based learning framework [
1].
Primitive-based control has been researched for at least two decades, in various forms, by transforming the time scale [
2,
3], concatenation-based mechanisms [
4,
5,
6], and decomposition/re-composition in time [
7,
8]. More recently, primitive-based control has been studied in [
9,
10,
11,
12,
13], mostly as part of hierarchical learning frameworks [
14,
15,
16,
17,
18]. However, the application of the Iterative Learning Control (ILC, a full list of the acronyms used in the paper is presented in abbreviations part) technique [
19,
20,
21,
22,
23,
24,
25] over linearized feedback closed-loop control systems (CLSs) as a primer mechanism for primitive-based learning was proposed in [
8]. An experiment-driven ILC (EDILC) variant was crafted in a norm-optimal tracking setting to learn reference-input controlled output pairs called primitives. Such a primitive tuple contains a reference input to the CLS (called the input primitive) coupled with its paired control system output (called the output primitive). Subsequently, the output primitive is usually shaped as a Gaussian function, but it can be any shape suitable for approximation purposes. Delayed copies of the output primitives are used to approximate a new trajectory that must be tracked. The coefficients that combine the output primitives linearly to approximate the new trajectory are used to combine the delayed and copied input primitives to obtain the optimal reference input. For the assumed linear CLS, this reconstructed reference input is optimal with respect to the criterion by which the original primitives are learned; therefore, when set as input to the CLS, it leads to theoretically perfect new trajectory tracking. It does this without repetitive-based relearning using the EDILC.
The primitive-based approach is sensible to the CLS’s linearity assumption; therefore, a control that makes the CLS as linear as possible has to be learned. One framework to ensure this linearization is the approximate (adaptive) dynamic programming (ADP) [
26,
27,
28,
29,
30], also known as reinforcement learning (RL) [
31,
32,
33,
34,
35], designed for the output reference model (ORM) paradigm. Specifically, a model-free iterative Value Iteration (IVI) algorithm as a representative ADP/RL approach can serve this goal by using general function approximators such as neural networks (NNs). Hence, it is called the approximated IVI (AIVI).
With a linear ORM’s output well tracked by the CLS output, an approximate linearized CLS from the reference input to the controlled output is ensured in a wide range, together with some inherent disturbance attenuation ability. Two major problems with ADP/RL are exploration and state knowledge [
36,
37,
38,
39,
40]. The former is still an open issue, although much research is underway. Enhanced and accelerated exploration is achievable with pre-stabilizing controllers, which can also be designed based on the unknown dynamics assumption principles. The state availability was solved with virtual state-space models constructed from input-output (I/O) samples of general unknown but assumed observable nonlinear systems [
41,
42]. Using historical I/O samples from the system as an alternate system, state representation has been used in more complex but unformalized environments, such as video games [
43].
This work aims to integrate the learning control techniques and machine learning techniques previously presented in a hierarchical cognitive-based control framework tailored to extrapolate optimally learned tracking control to novel tracking tasks. Tracking should be achievable without relearning through trials by exploiting the already learned optimal tracking skills. It is obtained through a hierarchical learning architecture where (a) the closed-loop system at a lower level (called L1 level herein) is first linearized using the ORM principle. This is achieved through nonlinear state-feedback control, where a virtual state is built from finite sequences of I/O system data samples. Learning such a controller is performed using AIVI; (b) an EDILC is used at the secondary upper L2 level to learn the optimal tracking skills called primitives, by repetitions; (c) the tertiary and last L3 level is dedicated to extrapolating the optimally learned tracking skills, without repetitions, to new tracking tasks.
Progress and contributions with respect to work [
8] are:
At level L1, CLS linearization is strongly ensured using a virtual state-feedback neuro-controller learned by AIVI. The new state-space representation relies on a virtual transformation empowered by observability theory.
At level L2, the model-free EDILC dedicated to primitive learning is improved in several aspects: (1) the gradient information is extracted using a single gradient experiment in the vicinity of the current iteration nominal trajectory, irrespective of the CLS’s number of controlled outputs; (2) EDILC monotonic convergence is derived by optimally selecting the learning rate parameter in order to trade-off learning speed and robustness. This is achieved using two approximate CLS models for a double-safe mechanism; (3) proper initialization of the gradient-based search specific to EDILC results in fewer iterations for convergence.
The primitive-based mechanism at level L3, for optimally predicting the reference input ensuring theoretical perfect tracking of a previously unseen desired trajectory, is designed to: (1) handle desired trajectories longer than the learned primitives, and (2) indirectly handle constraints on the CLS’s output.
The following bottom-up presentation of the proposed hierarchical learning framework results in an effective validation of a hybrid software-electrical system that is coupled, multivariable, and has a delay. The case study is representative of many mechatronic systems.
2. The Linear ORM Tracking for Observable Systems with Unknown Dynamics
A common and general representation for a deterministic controlled system model in a discrete-time state space is
where
E() is a partially known nonlinear state map,
is the sample index,
lumps the
mu control action inputs of the system within a known domain
. A number of
p measurable system outputs are formally collected in the partial output vector
with known domain
. Another
p measurable system outputs formally complete the remaining output as
with known domain
, to be contextualized later on. The state
lumps three types of state variables stemming from three independent systems. First, a virtual state-space system is defined as follows:
which is a transformation of the true state–space system
where
gathering the
n (which is unknown) true system states that cannot be measured,
ak are the control action inputs of the true system, and the measurable true system outputs are
yk. The system functions as nonlinear maps
,
are unknown and are assumed to be continuously differentiable. Some assumptions regarding (1) were introduced. The pair (
) is entirely state observable, meaning that the true state
from (3) is recoverable from the present and past I/O measurements of
. The observability property is used in the sense defined for linear systems. Further, (3) is assumed to be controllable, and the system’s relative degree (delay included) is known and constant.
With unknown system functions (), observability and controllability can only be inferred from the working experience with the system, from technical manuals, or from the literature. The system’s relative degree and its non-minimum phase (NMP) type are recognizable from historical I/O response data.
Relying on the system’s (3) complete observability, using
Lemma 1 from [
41] shows how to build transformation (2) whose virtual state vector is defined in terms of I/O samples of (3):
. For a more detailed element-wise correspondence, the indexing
is utilized. Remarkably, knowing
makes
known. The
(ℕ is the set of positive integers) indexes the historical I/O measurements, and its value is related to the order of (3); therefore, it is also correlated with the unknown observability index of (3).
Definition 1. The unknown observability index of (3) is the minimal value τmin of τ for which state sk is fully recoverable from the I/O measurements . The role of this index is similar to that of linear systems.
Under the observability assumption, there exists a minimal value
which makes
fully recovered from I/O data and uniquely associated with
which is a sort of alias for
, but in a different dimensional space [
41]. For
, the size increase of
does not add valuable information about
. In practice,
should be as large as possible without negatively affecting the computational complexity of the subsequent learning of state-feedback control based on high-dimensional
.
Based on transformation (2), system (2) is also I/O controllable, having the same I/O as (1). The main feature of (2) is its complete state availability, making it fully state observable but without entirely known dynamics because the map is partially unknown. Input delay (dead-time) systems also hold transforms such as (2) to render them fully state observable.
The second component of
is the state
of the ORM model which will be matched by the CLS by proper control design; let this known ORM state-space model be
where
gathers the
nm ORM states in known domain
,
lumps the ORM’s inputs in their known domain
;
will also serve as CLS input. The ORM outputs are collected in
introduced in the first place. Note that
completes the definition of
in (1).
The tuple characterizes the linear ORM for which an I/O pulse transfer matrix (t.m.) is (q is the unit time step advance operator). Information about (3), such as relative degree, non-minimum phase character, and bandwidth, must be synthesized within the ORM (4), as dictated by classical control rules. Commonly, this selection is better reflected in a , as it is more straightforward and easier to interpret (bandwidth, overshoot).
To fulfill the Markovian property of (1), the exogenous reference input signal is described by the known generation model dynamics , where acts as a measurable state variable. Note that the extended model (1) has two outputs stemming from (3) and (4). In summary, the dynamics will be partially unknown owing to the partially unknown dynamics of its component . The main feature of (1) is its full state observability, that is, the state is fully measurable, and the domain of is known as .
The ORM tracking problem finally poses as the optimal control search over an infinite-horizon cost
:
The norm
defined as the vector-wise Euclidean distance, penalizes at each sampling instant the CLS’s output deviation from the ORM’s output. Problem (5) is a type of imitation (or apprentice) learning with the ORM (3) acting as a teacher (or expert or supervisor) and with system (1) trying to mimic (or follow) the ORM dynamics. Assuming that (5) is solvable in the following, ADP/RL techniques are well suited for finding closed-form optimal control laws of the type
with the control action input as a nonlinear mapping of the extended state. An AIVI is in fact employed to solve (5) as a competitive alternative to the recently proposed Virtual State-Feedback Reference Tuning (VSFRT) [
42]. This is considered the L1 level control and is presented next.
4. The L2 Level—EDILC for Learning Primitives
The L2 level aims to learn pairs of reference inputs and CLS outputs called primitive pairs or simply primitives, where the CLS outputs have a basis function shape (e.g., Gaussian), to be used later for function approximation. To this end, we search for
which makes
track a desired trajectory
. The CLS is assumed to be reset with each ILC iteration to zero initial conditions. The CLS response to non-zero (but constant) initial conditions and repeated disturbances is easily absorbed into
. At the given ILC iteration
j, the CLS reference input-controlled output relationship is written in lifted (or supervector) notation over an
N-length experiment, as in
where the reference input at iteration
j is
,
, the CLS output at iteration
j is
,
. The impulse response terms of the pulse transfer matrix (t.m.) operator
characterizing the CLS are used to build the matrix
T. To see how
T emerges, the
causal CLS at the current iteration
j is (in time notation)
where
is the iteration index,
is the discrete-time index,
is the
lth output at time
k in iteration
j,
is the
lth input at time
k in iteration
j, and
are the pulse transfer functions (t.f.) from input
i to output
l. The t.m.
encompasses the feedback CLS with some kind of a multiple input multiple output (MIMO) (possibly nonlinear) feedback controller over a MIMO (possibly nonlinear) controlled system. The feedback CLS is square; that is, each reference input drives one controlled output. In general,
was coupled.
With each rational t.f.
admitting an infinite
power series expansion, a truncated lifted notation of length
N for the ILC system is
where each
is built from the impulse response coefficients of
and all the
build the
(note the difference between
T and
).
Let the desired output trajectory be
,
. The learning goal is formally expressed as an optimization problem without constraints as:
where the tracking error in the current iteration is
. The non-zero regularization coefficient
may be useful in cases where, for example,
does not acknowledge a possible NMP
. For simplicity, no regularization is used next (
). Directly working with
T in practice raises several numerical difficulties: ill-conditioning, large size, and its identification is costly. A convenient numerical solution to (11) is
. However, without using
T explicitly, (11) is solved based on an ILC-specific iterative update law as a gradient descent search starting from an initial
:
with a positive-definite matrix
is a user-selectable learning rate. The gradient in (12) computed according to the cost in (11) is
and is based on an unknown
T. The next EDILC Algorithm 1 extracts this gradient information experimentally, and its steps are:
| Algorithm 1 |
| Step 0. Initialize , then for each call the subsequent steps. |
| Step 1. In a nominal experiment, with the current iteration reference input Pj, measure Ej. Flip Ej to obtain udf(Ej): the upside-down flipped version of Ej. |
| Step 2. In a so-called gradient experiment, use μ·udf(Ej) (with scaling factor μ) as an additive disturbance on the current iteration Pj. With the disturbed reference input, the CLS output . It is valid that . Irrespective of the number of control channels p, a single gradient experiment was performed. |
| Step 3. Calculate , since provably holds. |
| Step 4. Call (8) to update . |
| Step 5. Go to Step 1 if j < ϵ, otherwise exit with . |
The output of the model-free EDILC algorithm is the primitive pair
where the
input primitive is ,
the output primitive is
Y. Several such pairs can be learned, and they can be indexed
. Note that
is used instead of
in the primitive because of the following reasons: after the algorithm,
and
are close; it is the pair
that intrinsically encodes the behavior
. In addition,
is not exactly the
solving (11) because EDILC stops after a finite number of iterations. Algorithm 1 runs in a mixed-mode: each iteration requires two real-time experiments which are proportional to the number
N of samples of the desired trajectory. These computations are repeated for a number of iterations
. We conclude that this algorithm complexity is
. Note that the gradient computation has been greatly optimized: it requires a single gradient experiment than the previous variants of the EDILC algorithm in [
8] which required a number of gradient experiments equal to the number of CLS inputs, in which case the complexity would have been
.
Monotonic convergence is desirable for EDILC and is ensured by the proper selection of step size
. The learning level L1 makes the CLS match
to some extent; however, a mismatch is expected. The I/O samples from the EDILC trajectories used to learn
offer the opportunity to identify a linear lower-order model for the CLS, which commonly has low-pass behavior. We denote the model identified from the I/O data as
. Then,
and
are both rough CLS estimates, which can be used to derive suitable step sizes for monotonic EDILC convergence. The most conservative selection of
is selected by solving the subsequent optimization:
where
is the norm calculated as the greatest singular value of a t.m. over the frequency domain, while the identity transfer matrix is
. Derivation of the convergence condition for the t.m. norm inequality constraints in (13) is presented in
Appendix A.
is usually selected diagonally to ensure decoupling between the control channels through controller design, at least in the steady state, for example, by including integral action in the controllers. For example, for a first-order square reference model of size 2-by-2, the continuous-time unitary-gain t.m. is selected as
(
s is the continuous-time Laplace complex argument), where
T1 and
T2 are the time constants that impose the transient behavior,
are delays. The real achieved behavior in continuous time can be modeled as
with
,
,
,
where the second-order t.f.s on the anti-diagonal capture any coupling transient that possibly vanishes in time and oscillates at most, while the second-order t.f.s from the main diagonal captures any transient responses that are oscillatory at most and may or may not achieve the desired unit gains. Time delay and NMP zeros must be included in the ORM definition without difficulty, if present. The equivalent discretized causal behavior model
of the CLS
, identifiable from I/O data, is (where
are the delay steps)
During ILC operation, is identified using I/O data either from the nominal or gradient experiment, or from both. The model can be re-estimated or can be continuously refined with every ILC iteration, with no computational burden, owing to the offline experimental nature of ILC. Model precision is not crucial because uncertainty only affects the monotonic convergence condition, and more cautious learning can be attempted. In any case, using low-order models such as (14) is recommended because the ORM control ensures that the CLS approximately matches .
A better initial value than
in the EDILC law (12) could theoretically be found based on the desired ORM
. This could further improve the convergence speed of the subsequent EDILC. The initialization is expressed as:
where the term
is evaluated by simulation, based on
, on a finite-time scenario with length
N. However, experimental investigations reveal that this initialization renders oscillatory
near its ends because of noncausal filtering involved in the model-based solution of (15).
The EDILC learns primitives under constraints imposed on the operational variables, such as on the control action
(and also on its derivative) and on the system (and also the CLS) output
(and also on its derivative). The reference input constraints are not of interest in this type of tracking problem. These constraints are mostly of the inequality type owing to the underlying dynamical system. They can be directly handled either as hard constraints appended to (7) or as soft constraints by additional terms in the cost function of the optimization (7). It was shown [
44] that inequality-type hard constraint handling is still possible with EDILC in an experimental-driven fashion with unknown system dynamics. For primitive-based learning with EDILC, inequality-type constraints on
are possible, but generally not an issue, as long as the CLS operates in the linearized range resulting from the level L1 learning phase. Any constraints on
(and possibly on its derivative) may negatively impact the level of L2 learning trajectory tracking performance. Therefore, the constraints on
are more interesting, mainly for safety reasons such as saturation, which when violated in mechanical systems could lead to permanent damage. The constraints on
will not be handled explicitly at this level L2, but rather indirectly at the next level L3 and deferred to a later section.
Concluding the level L2 learning aspects discussion, the final tertiary learning level L3 is presented next.
5. The L3 Level—New Desired Trajectories Optimally Tracked by Extrapolating Primitives’ Behavior
Suppose a new desired trajectory
is to be tracked; this time, without relearning by EDILC. This amounts to finding the optimal reference input
to obtain a CLS output that perfectly tracks
. A solution to use and extrapolate the behavior of learned primitive pairs was proposed in [
8]. Because the solution uses delayed copies of the output primitives from the learned pairs serving as basis functions for approximating
, the reason for using EDILC to learn output primitives that have good approximation capability is transparent. Among others, Gaussian shapes are well-known in function approximation theory; therefore, primitive pairs
where the output primitives
have a Gaussian-like shape, are commonly learned with EDILC.
In the following, the desired trajectory
is assumed to start from zero and end in non-zero values, component-wise. To accommodate for fine approximations whenever
ends in a non-zero value and starts from zero with a non-zero slope, both
and the copied primitive pairs
will undergo a time-extension process. The length of
is
N (same as the primitives’ length), and with no generality loss,
N is assumed even. A longer desired trajectory was deferred to a later discussion. The optimal reference input calculation Algorithm 2 is summarized below.
| Algorithm 2 |
| Step 0. Initialize , then for each call the subsequent steps. |
| Step 1. Let be the components of . In lifted notation, these trajectories are . |
| Step 2. Extend each to size 2N, padding with the first and last sample of , respectively with N/2 values to the right and to the left, respectively. We denote the extended trajectories . |
| Step 3. Arrange . |
| Step 4. The N-length input primitives and N-length output primitives , from the δth learned pair, are extended to size 2N by padding to the left and right N/2 zeros, respectively. Padding with zeros is employed because both start and end at zero, owing to the Gaussian-like shape of . We denote as the extended primitives. |
| Step 5. Make M copies of the randomly occurring δ extended pairs , let them be called as . |
| Step 6. Delay each component and of the π pairs by an integer uniform number . Because the delay is a non-circular shift, padding is again required to either end, based on the sign of θ. The value used for padding for a number of |θ| samples is the first or last sample value of the unshifted signals. Let be the notation for the delayed input and output primitive of each of the π pairs. |
| Step 7. Obtain and . The basis function matrix is . A visual summary of the extension with padding, delay with padding, and final concatenation is shown for the output primitives in Figure 1. |
| Step 8. Compute as the minimizer of with linear least-squares. Each component of w multiplies a specific . |
| Step 9. Based on Theorem 1 from [8], the optimal reference to ensure the tracking of is:
|
| Step 10. In (16), . To obtain N-length channel-wise optimal reference inputs, the p components are clipped in the middle of their intervals. |
| Step 11. The clipped optimal references are set as CLS inputs, and the CLS output tracks . The algorithm ends. |
Algorithm 2 is entirely performed offline, not impacting the real-time control task. Of course, the planner is allowed sufficient computation time. If the trajectories to be tracked on each subinterval are very long, this may impact performance, but we have tried to solve this particular issue by dividing the longer trajectories in shorter, manageable trajectories. Essentially, Algorithm 2 has two complexity components: the least squares matrices preparation part which has complexity and the least squares regression solution which combines matrix multiplication and the SVD factorization. For this numerical solution, the complexity is where is the size of the regression vector and is the number of examples ( is the experiment length and is the number of CLS inputs and outputs). Hence, the complexity of Algorithm 2 is but since p is usually a small constant, it can be approximated to .
The optimality of in (16) with respect to the tracking performance and its relation to the true optimal solution of (11) is analyzed next.
Theorem 1. When is approximated with a bounded reconstruction error ζ, then can be computed with arbitrary precision.
Proof. The desired trajectory is decomposed as in , where ζ is the bounded reconstruction error. The optimal reference input ensuring perfect tracking is and is expressed as . As , then follows, where applied to a matrix is the induced 2-norm by a vector, which represents the matrix’s largest singular value, applied to a vector is the Euclidean norm. □
Theorem 1 shows that a good approximation of the desired trajectory in terms of a small error leads to a reference input close to the optimal one. This ensures good tracking performance. To achieve a small approximation error, the number of basis functions can be adjusted along with the desired shape.
Managing Longer Desired Trajectories
Suppose that each signal component of Yd has length Ω as a multiple of N (padding is again usable when Ω is not a multiple of N). One solution to obtain the desired optimal reference input that achieves CLS output tracking of Yd is to extend the primitive pairs to length Ω with appropriate padding. In addition, proportionally more M copies of these extended pairs were used. This will increase the size of w and the ill-condition the least squares. An intuitive mitigation is to perform tracking experiments on subintervals of length N as divisions of Yd.
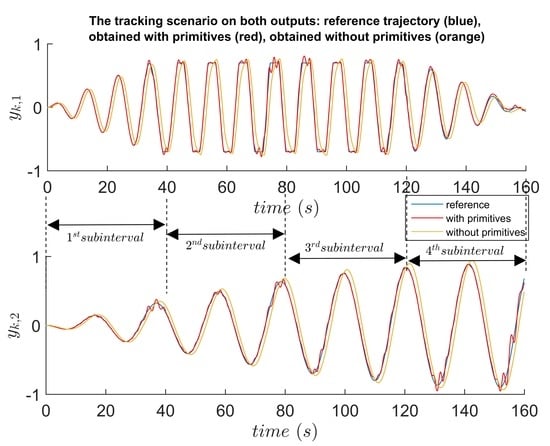
For example, a longer trajectory of length 2
N, comprising two shorter trajectories of length
N, is displayed in
Figure 2 for a single input single output (SISO) system. The end of trajectory
is the start of trajectory
. A base reference frame in discrete-time is
with a discrete-time index
k.
One solution is to translate the origin of the base reference frame
to the starting point of each piece of the desired trajectory of length
N. In
Figure 2,
is translated to
. This is equivalent to having the desired trajectory
starting from the origin. Thus, the planner always computes the optimal reference inputs for a desired trajectory starting in zero initial conditions. Considering that the tracked trajectory
does not perfectly track the desired one
and there exists a vertical distance
between the endpoints of
and
, then in the translated reference frame
the closed-loop CS will have a non-zero initial condition in the
-vicinity near
. In practice,
is expected to be small. The CS response due to the non-zero initial condition vanishes over time.
After executing the tracking task on the second subinterval with desired trajectory , the execution is translated back in the base frame for visualization; afterwards, the reference frame is moved in the start of the desired trajectory of the third subinterval, and the entire process repeats itself for all subintervals. After all subinterval tracking tasks are executed, the actual obtained trajectories are translated back to the base reference frame and then concatenated to be presented as a longer tracking task.
Inequality-type constraints on can be handled indirectly at the tertiary learning level. The aim of this learning level is to ensure the theoretical perfect tracking of , meaning that . This implies that any constraint on is imposed on also. We note that inequality constraints on the rate of are again not of particular interest when trajectory tracking is aimed; therefore, the magnitude constraints are more feasible in the lifted form as . As a result, the constraints on are softly handled.
With the discussed aspects of the L3 learning level, the entire hierarchical three-level framework shown in
Figure 3 was validated on a real-world system.
7. Implementation Issues and Analysis of the Primitive-Based Framework
One of the most important aspects affecting the entire hierarchical learning performance is the CLS linearity assumption achieved at level L1. Therefore, it is critical to ensure that the CLS matches the linear ORM as accurately as possible. While the mismatch does not affect the L2 level too much because the EDILC displays good learning ability even for some nonlinear CLS (the perturbation-based gradient experiment performed in the vicinity of the nominal trajectory where linearity holds), the level L3 operations have proven to be more sensitive to this mismatch because the optimal reference reconstruction relies on the superposition principle. Therefore, all efforts in learning AIVI NN controllers are justified, both in terms of NN complexity and in terms of the required database size and exploration effort. Better parameterization (more specifically, a linear one using polynomials as basis functions, as opposed to a more generic, such as, e.g., a NN) of the Q-function may need fewer transition samples for learning; however, the downside is that it requires more insight about the underlying controlled system. This insight is still needed in terms of relative degree, system order, minimum-phase character, and in matching the system bandwidth with the linear ORM’s bandwidth. Together, these impact the virtual state size (hence the learning space complexity and the function approximators architectural complexity). With careful AIVI design, the NN should be preferred because the underlying training management (e.g., early stopping) allows the more complex NN architectures to use just as much as needed in terms of approximation capacity. Another advantage is automatic feature selection, which is inherently encoded in the NN layers. Yet another aspect of offline AIVI learning is that it does not require online computational power (as in e.g., [
46]). The resulting NN controllers take up to a few hours to learn offline; however, they are easily implementable afterwards on hardware with no special computing requirements for typical mechatronic systems. The efforts needed for this L1 level control, also regarded as limitations, are:
- −
a good estimation of the controlled system’s relative degree. A too small degree is equivalent to partial observability and will incur a performance degradation in achieving linearized ORM tracking behavior. A higher degree will add information redundancy which is not a real issue except for the computational costs involving the resulted controller.
- −
some additional required information leading to a degree of subjectiveness in the design: the underlying system’s minimum-phase character, and its bandwidth to be matched with the linear ORM’s bandwidth. This information quantification necessitates some experience from the designer and some insight into the process phenomena.
- −
the controller computational complexity is not seen as an important issue. Indeed, there is more complexity than with a PI/PID controller with few parameters; however, the used NN architectures are shallow, allowing for less than 1ms inference time on a wide range of embedded devices, which would extend the application range of the control. The benefits in terms of nonlinear control performance well balance the costs.
Concerning level L2 learning, it should be used mostly in cases where does not render the output close to the basis function shape imposed by . Otherwise, the impact on level L3 is not damaging, since essentially just about any shape of will eventually have some approximation capacity. The major question at this stage is how to learn primitives to be useful for level L3. This is discussed among the aspects of the next and final learning levels. The L2 level design is dependent only on the initial solution and the linaerity assumption. The limitations associated with these are
- −
the L2 level CLS requires resetting conditioned which for some system may be more restrictive. ILC solutions for systems without perfect resetting such stochastic resetting exists, but not in a model-free style. However, for most mechatronic systems, this is not an issue.
- −
The initialization for can be optimized using, e.g., (15), for a neal-optimal approximate model-based initialization. This would require fewer EDILC iterations. On the other hand, model-based initialization based on non-causal filtering showed some oscillations at the beginning and at the end of hence it was not applied here.
- −
The linearity assumption about the CLS. This must be ensured with the L1 level virtual state-feedback control. There is a certain degree of tolerance, as EDILC was applied before on smooth nonlinear systems and the underlying linear system’s theory showed effectiveness and learnability.
Most aspects concern level L3 implementation details. The discussion about how to learn the proper primitives starts backward, with the new desired trajectory . From Algorithm 2’s steps, undergoes a transformation process (extrapolation plus padding, then concatenation), resulting in as a single signal. The same is valid when obtaining , except for the additional delay process involved. It is obvious that the final should resemble a basis function (here, Gaussians were used, also known as radial basis functions), which means that only one output channel should be Gaussian and the rest should be zero. Therefore, the practical rule is that if the CLS has p channels, then a number of p primitives should be learned, each time with a different output channel being a Gaussian, while the other outputs are zero.
Learning Gaussian-like shapes as output primitive trajectories is advantageous because a Gaussian is described with only two design parameters: mean (center) and variance (width). With the function approximation, the width of the Gaussian-like output primitive influences the approximation capacity in relation to the shape of : if is non-smooth, more copies of output primitives should be used when their widths are small. Conversely, when is smooth, a good approximation is achievable with fewer copied, wider output primitives. The Gaussian polarity (pointing upward or downward) is not important as long as the CLS linearity holds, because a negative weighting coefficient suitably reverses polarity and helps with the approximation.
Typically, the number of copies (parameter M) does not significantly affect the approximation quality. The number of delay/advance steps for each copied primitive (parameter ) should be chosen from an interval such that the copied and time-shifted output primitives span the entire approximation range of interest for . In summary, the limitations at this particular L3 level include:
- −
correlating the shape of the basis functions with the shape of the desired trajectory to be tracked on each subinterval.
- −
selecting the adequate number of copies for the learned primitives. While more is better in the sense that the approximation quality does not increase past a certain number M of copies, it could increase the computational cost for the underlying regression and reference input recomposition. We still argue that the computations are performed online and manageable.
- −
the tracking has to be of good quality for each subinterval, to avoid large deviations at the end, since this would shift the initial point for trajectory tracking of the next subinterval. This was found to depend largely on the ORM matching (CLS linearization quality) at the level L1.
Concluding, the discussed aspects also reveal the sensitive issues across the proposed framework. At level L1, it is important to ensure exceptional ORM matching for level L3 to accept behavior extrapolation. This is related to AIVI learning, which is strongly tied to exploration quality. This is an open issue in ADP/RL and requires further investigation. At level L2, with an impact on level L3, the basis function shape of the output primitives with respect to the desired trajectory shape is another trade-off and an open issue.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








