1. Introduction
Basel II capital accord defines the capital charge as a risk measure obtained on an annual basis at a given confidence level on a loss distribution that integrates the following four sources of information: internal data, external data, scenario analysis, business environment and internal control factors (see
Box 1).
Box 1. Mixing of outcomes from AMA sub-models.
‘258. The Range of Practice Paper recognises that “there are numerous ways that the four data elements have been combined in AMA capital models and a bank should have a clear understanding of the influence of each of these elements in their capital model”. In some cases, it may not be possible to:
(a) Perform separate calculations for each data element; or
(b) Precisely evaluate the effect of gradually introducing the different elements.
259. While, in principle, this may be a useful mathematical approach, certain approaches to modelling may not be amenable to this style of decomposition. However, regardless of the modelling approach, a bank should have a clear understanding of how each of the four data elements influences the capital charge.
260. A bank should avoid arbitrary decisions if they combine the results from different sub-models within an AMA model. For example, in a model where internal and external loss data are modelled separately and then combined, the blending of the output of the two models should be based on a logical and sound statistical methodology. There is no reason to expect that arbitrarily weighted partial capital requirement estimates would represent a bank’s requisite capital requirements commensurate with its operational risk profile. Any approach using weighted capital charge estimates needs to be defensible and supported, for example by thorough sensitivity analysis that considers the impact of different weighting schemes.’
BCBS (
2010)
Basel II and Solvency II require financial institutions to access the capital charge associated with operational risks
BCBS (
2001,
2010). There are three different approaches to measure operational risks, namely the basic, the standard and the advanced measurement approach (AMA), representing increasing levels of control and the difficulty of implementation. The AMA requires a better understanding of the exposure for implementing an internal model.
Basel II capital accord defines the capital charge as a risk measure obtained on an annual basis at a given confidence level on a loss distribution that integrates the following four sources of information: internal data, external data, scenario analysis, business environment and internal control factors. The regulatory capital is given by the 99.9 percentile (99.5 for Solvency II) of the loss distribution, whereas the economic capital is given by a higher percentile related to the rating of the financial institution, which is usually between 99.95% and 99.98%.
The purpose of using multiple sources of information is building an internal model based on the largest set of data possible to increase the robustness, stability and conservatism of the final capital evaluation. However, different sources of information have different characteristics, which, taken in isolation, can be misleading. Therefore, as clearly stated in the regulation (
BCBS 2010, c.f. above), practitioners should obtain a clear understanding of the impact of each of these elements on the capital charge that is computed. Internal loss data represent the entity risk profile, external loss data characterise the industry risk profile and scenarios offer a forward-looking perspective and enable one to gauge the unexpected loss from an internal point of view (
Guégan and Hassani 2014).
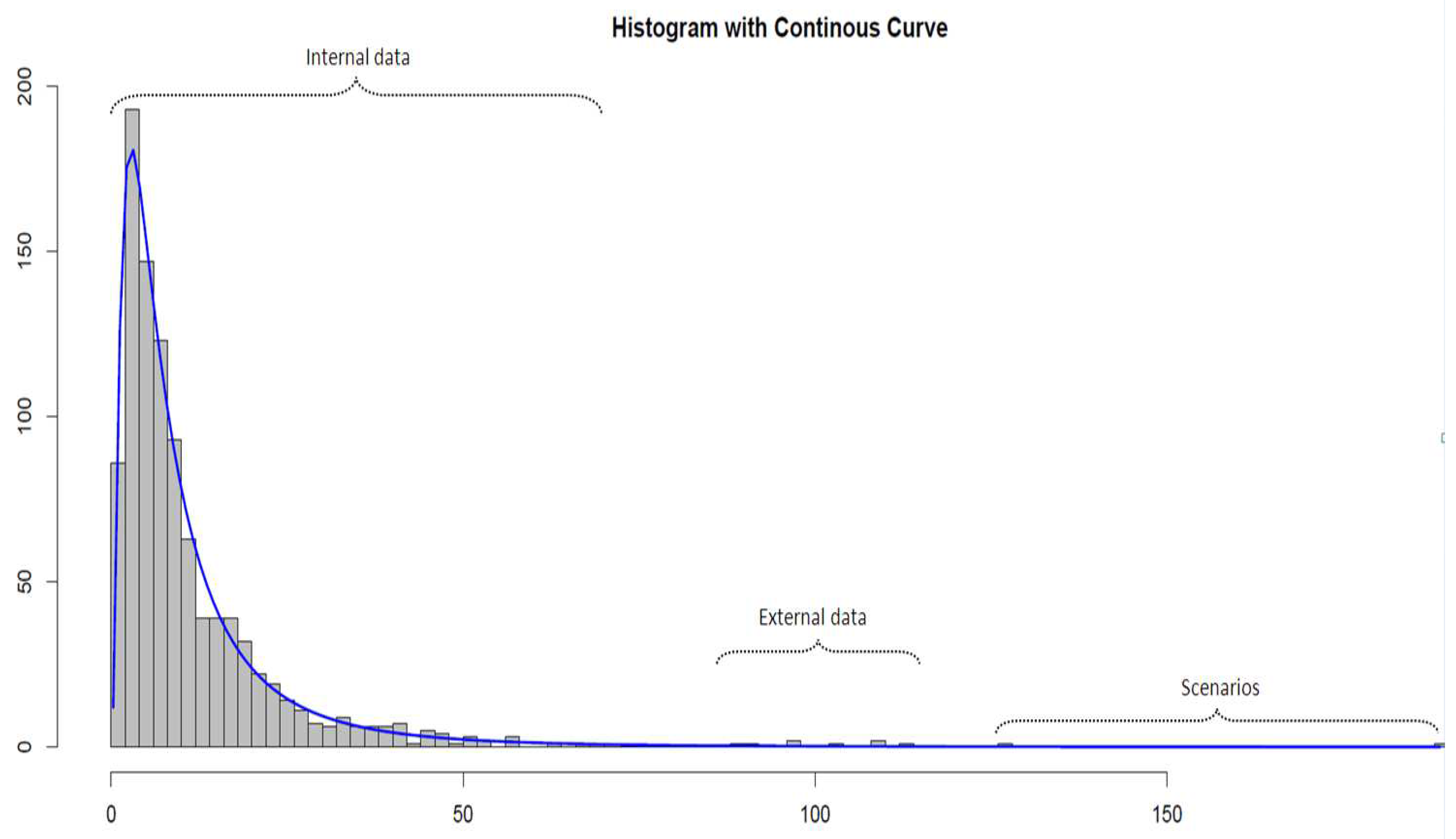
Figure 1 illustrates this point by assuming that the internal loss data tends to represent the body of the severity distribution, the scenarios, the extreme tail, and the external data, the section in between
1.
As presented in
Cruz et al. (
2014) and
Hassani (
2016), operational risk can be modelled considering various approaches depending on the situation, the economical environment, the bank activity, the risk profile of the financial institution, the appetite of the domestic regulator, the legal and the regulatory environment. Indeed, AMA banks are not all using the same methodological frameworks: some are using Bayesian networks (
Cowell et al. 2007), some are relying on an extreme value theory (
Peters and Shevchenko 2015), some are considering Bayesian inference (BI) strategies for parameter estimation and some are implementing traditional frequentist approaches (among others). We observed that the choice of the methodologies were driven by the way components were captured, for instance if the scenarios were captured on a monthly basis and modelled using a generalized extreme value (GEV) distribution (
Guégan and Hassani 2014) or annually capturing only a few points in the tail (this approach led to the scenario assessment used in this paper), whether internal data have been collected over a threshold, if the categories underpinning quantification are combining different types of events (e.g., external fraud may combine credit card fraud, commercial paper fraud, cyber attacks, Ponzi schemes, etc.), how external data have been provided, if loss data are independent (
Guégan and Hassani 2013b), or how the dependencies between risk types are being dealt with. This last point is out of the scope of this paper; however, this methodology is compatible with
Guegan and Hassani (
2013a).
Here, ⊗ denotes the convolution operator. Denoting
g the density of
G, we have
where
and
are respectively representing the sets of parameters of the frequency and the severity distributions considered.
The parameter is estimated by the maximum likelihood of the internal loss data using a Poisson distribution to model the frequencies
2. However, as collection thresholds are being set up, the frequency distribution parameter is adjusted using the parameterised severity distribution.
The focal point of this paper is to construct severity distributions by combining the three data sources presented above. As the level of granularity of the risk taxonomy increases, the quantity of data available per risk category tends to decrease. As a result, the traditional estimation methods, such as the maximum likelihood or the method of moments, tend to be less reliable. Consequently, we opted to bring together the three components within the Bayesian inference theoretical framework (
Box and Tiao 1992;
Shevchenko 2011). Despite the numerous hypotheses surrounding BI, it is known to be effective in situations in which there are only a few data points available. Using loss collection thresholds, the empirical frequencies are biased as some incidents are not captured. Therefore, the frequency distribution parameters depend on the shape of the severity distribution obtained once all the elements have been combined, for instance the scenarios, the external data and the internal data conditionally to the collection thresholds. Thus, the frequency distribution parameters are corrected to take into account the censored part of the severity distribution, and as such mechanically integrate some frequency information consistent with the shape of the severities. The fatter the tail, the lower the correction of the frequency distribution, and conversely. Consequently, a model driven by the tail would lead to frequency distribution being not consistent with the risk profile of the target entity. This issue has been dealt with in this paper and the pertaining results are presented in the fourth section.
In statistics, the Bayesian inference is a statistical method of inference in which Bayes’ theorem (
Bayes 1763) is used to update the probability estimate of a proposition as additional information becomes available. The initial degree of confidence is called the prior and the updated degree of confidence, the posterior.
Consider a random vector of loss data
whose joint density for a given vector of parameters
, is
. In the Bayesian approach, both observations and parameters are considered to be random. Then, the joint density is as follows:
where
is the probability density of the parameters, which is known as the prior density function. Typically,
depends on a set of further parameters that are usually called ’hyper’ parameters
3.
is the density of parameters in given data
, which is known as the posterior density,
is the joint density of the observed data and parameters and
is the density of observations for given parameters. This is the same as a likelihood function (as such, and to draw a parallel with the frequentist approach, this component will be referred to as the likelihood component in what follows) if considered as a function of
, i.e.,
.
is the marginal density of
which can be written as
The Bayesian inference approach permits the reliable estimation of distributions’ parameters even if the quantity of data denoted as n is limited. In addition, as n becomes larger, the weight of the likelihood component increases, such that, if , the posterior distribution tends to the likelihood function and, consequently, the parameters obtained from both approaches converge. As a result, the data selected to inform the likelihood component may lead the model and, consequently, the capital charge. Therefore, our two-step approach presents an opportunity for operational risk managers and modellers to integrate all the aforementioned components in a way that they do not have to justify a capital charge increase due to an extreme loss that another entity would have suffered.
This paper employs two Bayesian inference techniques in a sequential manner to obtain the parameter of the statistical distribution that is used to characterise the severity. Scenarios are used to build the prior distributions of the parameters denoted , which is refined using external data Y to inform the likelihood component. This results in an initial posterior function (), which is then used as a prior distribution, and the likelihood part is informed by the internal data. This leads to a second posterior distribution that allows the estimation of the parameters of the severity distribution used to build the loss distribution function in the loss distribution approach (LDA) approach. The first step of the methodology aims, in reality, to bring about the transformation of a first prior containing little information (but not yet non-informative) to a prior containing much more information, leading to the creation of a narrower set of acceptable parameters.
Universally suitable methodologies for operational risk capital modelling are rare if they can be designed at all (
Hassani 2016). With that caveat in mind, our methodology can be useful in several ways. First, our Bayesian cascade approach can be a viable alternative when available internal data is not numerous, in which the risk profile has some similarities with the entities providing the external data and in which the scenarios are only characterised by a few points evaluated by expert judgement for a given set of likelihoods. Indeed, the priors are acting as penalisation functions during the estimation of the parameters and eventually as a weighting function while combining the elements. Here, we would like to reinforce the fact that the objective is to obtain a set of distributions driven by internal data and not distributions driven by losses collected by other banks and therefore not necessarily fully representative of the risk profile of the target entity.
Second, bank management as well as external stakeholders and regulators find transparency of a model highly desirable from a model risk and governance perspective. Our methodology advances this cause in a significant manner through a controlled integration of the three data elements that allows evaluating the marginal impact of each element type on the estimated risk capital. In addition, in the situation considered in this paper, the three elements did not have the same characteristics, indeed external data were only collected above a high threshold, scenarios were only representing by a few points in the right tail of the distributions underpinning quantifications and internal data were collected above different thresholds depending on the type of risks.
Third, when one or more data elements for some categories of events are not numerous, the resulting capital estimate can be exorbitantly high and unrealistic depending on how the data elements are combined. In such challenging contexts, our methodology seems relatively more robust in producing sensible capital estimates. As a matter of fact, the sensitivity analysis we performed at the time was providing an increase of 400% of the initial value-at-risk (VaR) on some categories.
Section 2 presents the Cascade strategy and the underlying assumption that allows the implementation of a data-driven model.
Section 3 deals with the implementation in practice, using real data sets.
Section 4 presents the results, and
Section 5 provides the conclusion.
2. A Bayesian Inference in Two Steps for Severity Estimation
This section outlines the two-step approach to parametrise the severity distribution. The cascade implementation of the Bayesian inference approach is justified by the following property (
Berger 1985). The Bayesian posterior distribution implies that the larger the quantity of data used, the larger the weight of the likelihood component. Consequently,
where
f is the density characterising the severity distribution,
, a data point, and
, the set of parameters to be estimated. As a result, the order of the Bayesian integration of the components is significant.
In other words, the information contained in the observed incidents may override the prior (
Parent and Bernier 2007). Splitting the posterior function into two mathematical sets, in which the prior characterises ’observable’ values and the likelihood component, ’observed’ values. Consequently, in our case, three sources of information are available that qualify as ’observable’ (scenarios), ’observed’ outside the target entity (ELD) and ’observed’ inside the entity (ILD). If both ’observed’ components were considered to belong to the same source, then we would have two likelihood components that may be linearly combined as one. Consequently, if the number of data points is limited internally, then the external data would have a major impact on our parameters and would drive the risk measures. Furthermore, ELD only includes incidents that are observed outside the target entity. Therefore, they logically should be considered as ’observable’ internally.
As a consequence, this strategy has been based on the construction of two successive posterior distribution functions. The first uses the scenario values to inform the prior and the external loss data to inform the likelihood function. Using a Markov chain Monte Carlo algorithm (
Gilks et al. 1996), the first posterior empirical distribution is obtained. This is used as a prior distribution in a second Bayesian approach for which the likelihood component is informed by internal loss data. Due to the Bayesian approach property presented above, in the worst case, the final posterior distribution is entirely driven by internal data. The method may be formalised as follows:
f is the density function of the severity distribution,
represent the internal data,
the external data and
the set of parameters to be estimated.
Prior
by the scenarios and the likelihood component by external data as follows:
The aforementioned posterior function
is then sampled and used as prior, and the likelihood component is informed by internal data as follows:
As a result, the first posterior function becomes a prior, and only a prior, limiting the impact of the first two components on the parameters. Another way to describe the process is to present it as a prior transformation. Indeed, the initial parametric prior constructed on tail information, i.e., a non-informative prior or more likely a non-very informative prior, is transformed into a non-parametric informative prior as external data are integrated. The sampling step of the algorithm is crucial, as, otherwise, the entire interest of this method is lost as the external data and internal data would be given the same weight. The Bayesian way of reasoning considers probability as a numerical representation of the information available regarding the level of confidence given to an assumption. Applying a frequentist way of reasoning to the Bayesian inference and, especially, to this method would lead to the consideration that the previous algorithm could be integrated in one single step, disregarding the fundamental distinction between ’observable’ and ’observed’ values and that, by extension, the choice of the prior has no importance.
4. Results
The Cascade Bayesian approach enables the updating of the parameters of the distributions that are considered to model particular risk events.
Table 5 presents the parameters that are estimated, considering the different pieces of information used to build the loss distribution function (LDF), i.e., the parameters of the selected distributions. For instance, the lognormal, the Weibull and the generalized Pareto distribution are estimated on each of these pieces of information without considering the information introduced by the others. It results in a large variance in the parameters, which, once translated into financial values, may be inconsistent with the observations. For example, considering the lognormal distribution for internal fraud, the median is equal to 40,783.42, when considering only the scenarios, 6047.53, using the external data, and 11,472.33, considering the internal data. The parameter implied variance of the losses is also quite different across the different elements. The variation is similar for the Weibull distribution that models external fraud. It may be even worse in the case of the GPD, as the risk measures are extremely sensitive to the shape parameter.
Table 6 shows the evolution of the parameters as they are updated with respect to the different pieces of information.
Scenarios’ severity is derived from the calibration of the prior distributions with the scenario values. The theoretical means obtained from the calibrated priors provide scenario severity estimates.
Intermediate severity refers to the estimation of the severity of the first obtained posterior, i.e., the mean of the posterior distribution obtained from scenario values updated with external loss data.
Similarly, final severity represents the severity estimation of the second and last posterior distribution, which includes scenarios, external and internal loss data. A 95% Bayesian confidence interval (also known as a credible interval) derived from this final posterior distribution is also provided. It is worth noticing that this interval, which is formally defined as containing 95% of the distribution mass, is not unique and is chosen here as the narrowest possible interval. It is, therefore, not necessarily symmetric around the posterior mean estimator.
Implementation of the Cascade approach results in final parameters located within the range of values obtained from the different elements taken independently. As the dispersion of the information increases, the variance of the theoretical losses tends to increase, as does the theoretical kurtosis. For example, the evolution of the lognormal parameters is significant, as the introduction of data belonging to the body (
Table 5, first line) tends to decrease the mean (the
parameter is the mean of the log-transformed of the data). The parameters of the body part of the risk category for which a GPD is used to model the losses in the tail are provided in
Table 7. However, naturally, the dispersion increases, and, therefore, the variance tends to increase (the
parameter is a representation of the standard deviation of the log-transform of the data) (
Table 6, first line). The impact of the severity on frequency is given in
Table 8. The conditional frequencies naturally increase with respect to the severity distributions.
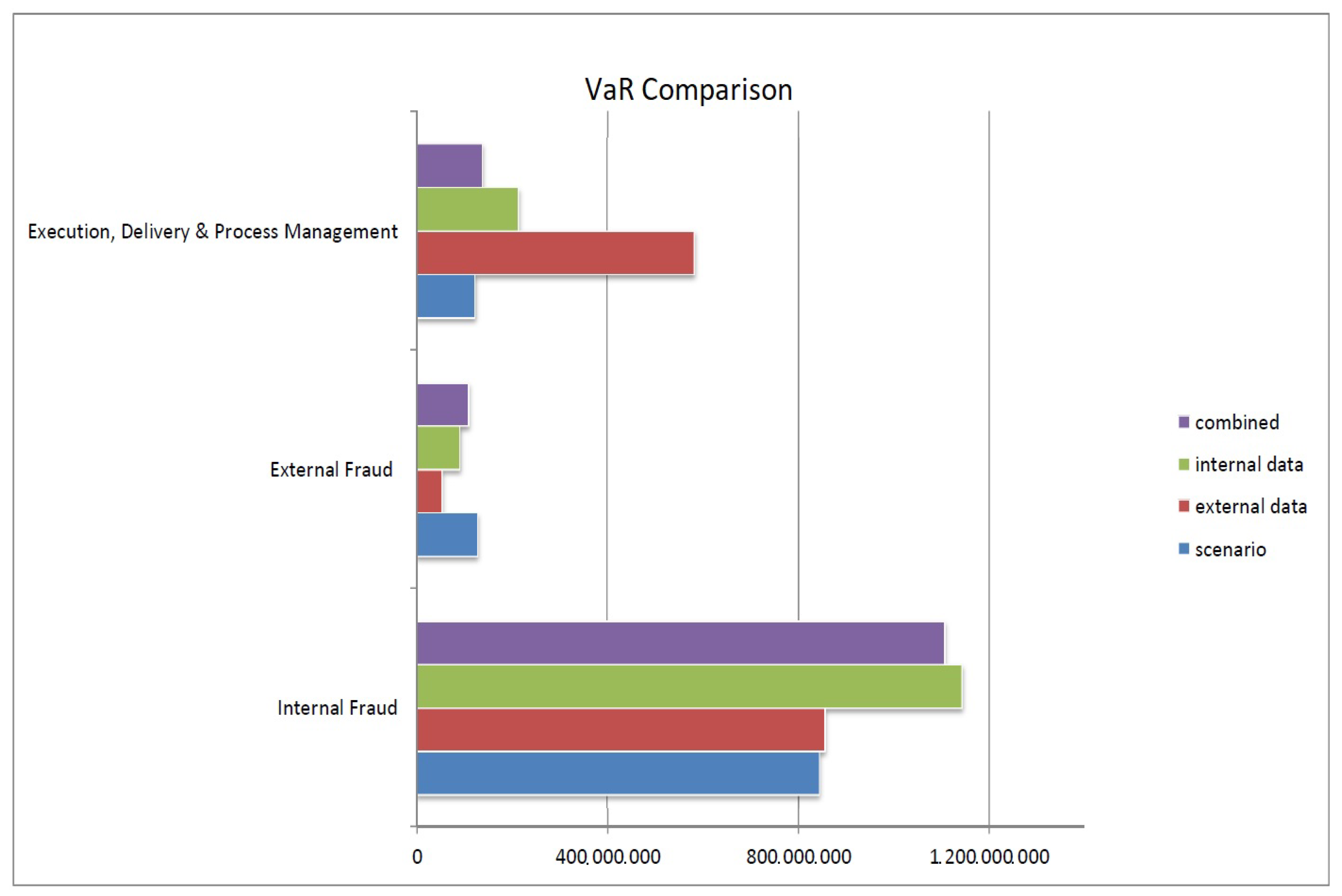
It also results in conservative capital charges, considering the VaR (
Appendix D) obtained from the different elements taken independently, as it tends to be a weighted average of the VaR obtained from each part. The weights are automatically evaluated during the cascade and directly related to the quantity and the quality of information integrated (
Table 9).
Practically, implementing the solution presented in this paper, the following remarks should be carefully considered:
Remark 2. The scenarios are defined by the bank. As mentioned previously, eventually all elements have to be combined, though internal data and scenarios are collected by the bank, external data are not. Both external data and scenarios are belonging to the domain of ’observable’ losses and therefore are belonging to the domain of what may happen (either in magnitude, in frequency or in type of incidents). Consequently, in the Bayesian inference philosophy, these should inform the prior functions. On the other hand, internal data are belonging to the domain of what had happened and therefore these should inform what we referred to as the ’likelihood component’.
Remark 3. In our case, the scenarios are representing events located far in the right tail and have been collected given specific percentiles; therefore, if the internal data are not numerous enough, combining them directly in the posterior may lead to very large capital charges. On the contrary, if the internal data set is very large, the scenarios would have a very limited impact on the capital charge.
Remark 4. In this paper, we started form the tail, i.e., the most conservative part of the distribution, using the few largest events to inform the prior. Then, external data are integrated as these are closer to the scenarios. The objective is to avoid a gap too large between scenarios and internal data. Indeed, we observed that a large gap between the element informing the prior and the elements informing the ’likelihood component’ may prevent the MCMC algorithm from converging.
Remark 5. It is noteworthy to mention that some prior distributions have been chosen to constrain the range of parameter’s values. For instance, considering the generalised Pareto distribution, the use of the beta distribution to characterise the shape parameter is justified by the fact that this parameter would mechanically lie between 0 and 1 and therefore this approach would prevent infinite mean models.
As a final step, these results may be illustrated for the whole Bayesian cascade estimation in the simple lognormal case.
Figure 2 shows the final posterior distribution obtained for
and
. This is used to derive the 95% Bayesian credible interval given in
Table 6. We also show the results of the convergence of the posterior mean as a function of the number of MCMC iterations for (
and
). One can see that the values stabilise after 100 to 500 iterations in this example. In the general case, we chose to sample 3000 values and discard the first 1000 MCMC generated values (burn-in period) to ensure the stability of our estimates.
5. Conclusions
This paper presents an intuitive approach to building the loss distribution function using the Bayesian inference framework and combining the different regulatory components. This approach overcomes the problem related to the non-homogeneity of the data.
This approach enables the controlled integration of the different elements through the Bayesian inference. The prior functions have the same role as the penalisation functions on the parameters and, therefore, behave as constraints during the estimation procedure. This results in capital charges being driven by internal data (as shown in
Figure 3), which are not dramatically influenced by external data or extreme scenarios.
Hence, with our approach, the capital requirement calculation is inherently related to the risk profile of the target financial institution and, therefore, provides the senior management with greater assurance of the validity of the results.
As presented in the previous section of this paper, best practices, i.e., practices approved by the regulator for AMA capital calculations, are highly heterogeneous, therefore it is necessary to reinforce the fact that there is no panacea, there are only methodologies or modelling strategies more appropriate than others in particular situation. As such, this methodology can be really interesting in an environment similar to the one presented in this paper.
The next step is to evaluate the financial institutions’ global operational risk capital requirement would involve the construction of the multivariate distribution function, linking the different loss distributions that characterise the various event types through a copula. In this case, the approach developed by
Guegan and Hassani (
2013a) may be of interest.





{kind=link}
{kind=link}
{kind=link}