One-Year Change Methodologies for Fixed-Sum Insurance Contracts

1
Prime Re Solutions, 6340 Zug, Switzerland
2
Department of Mathematics, UAM, Campus de Cantoblanco, 28049 Madrid, Spain
3
SCOR, General Guisan-Quai 26, 8022 Zurich, Switzerland
4
LPSM, Université Paris Diderot, 75013 Paris, France
*
Author to whom correspondence should be addressed.
Risks 2018, 6(3), 75; https://doi.org/10.3390/risks6030075
Submission received: 27 June 2018
/
Revised: 24 July 2018
/
Accepted: 26 July 2018
/
Published: 30 July 2018
Abstract
:We study the dynamics of the one-year change in P&C insurance reserves estimation by analyzing the process that leads to the ultimate risk in the case of “fixed-sum” insurance contracts. The random variable ultimately is supposed to follow a binomial distribution. We compute explicitly various quantities of interest, in particular the Solvency Capital Requirement for one year change and the Risk Margin, using the characteristics of the underlying model. We then compare them with the same figures calculated with existing risk estimation methods. In particular, our study shows that standard methods (Merz–Wüthrich) can lead to materially incorrect results if the assumptions are not fulfilled. This is due to a multiplicative error assumption behind the standard methods, whereas our example has an additive error propagation as often happens in practice.
1. Introduction
In the new solvency regulations, companies are required to estimate their risk over one year and to compute a Risk Margin (RM) for the rest of the time until the ultimate risk margin is reached. Actuaries are not accustomed to do so. Until recently, their task mostly consisted of estimating the ultimate claims and their risk. There are only very few actuarial methods that are designed to look at the risk over one year. Among the most popular ones is the approach proposed by Merz and Wüthrich (2008) as an extension of the Chain–Ladder following Mack’s assumptions (Mack 1993). They obtain an estimation of the mean square error of the one-year change based on the development of the reserve triangles using the Chain–Ladder method. An alternative way to model the one-year risk is developed by Ferriero: the Capital Over Time (COT) method (Ferriero 2016). The latter assumes a modified jump–diffusion Lévy process to the ultimate and gives a formula, based on this process, for determining the one-year risk as a portion of the ultimate risk. In a previous paper, Dacorogna et al. have presented a simple model with a binomial distribution to develop the principles of risk pricing (Dacorogna and Hummel 2008) in insurance. This has been formalized and extended to study the diversification effects in a subsequent work (Busse et al. 2013).
The goal of this paper is to study the time evolution of the risk that leads to the ultimate risk through a simple example that is easy to handle, and so calculate exactly the one year and ultimate risks. This is why we take here the example (as in Busse et al. 2013) of a binomial distribution to model the ultimate loss, and see it as the result of an evolution of different binomials over time. The company is exposed to the risk n times. Different exposures come in different steps, and each exposure has a probability p to incur in a fixed loss, say 1 hundred/thousand/million euros, and, at the end of the n steps, the total number of exposures to the risk is equal to n. In other words, there are n policies each with a probability p of a claim; of the n policies, a number settled at time i either with a claim or with no claim. For simplicity and without loss of meaning, we make the number of policies n coincide with the number of time steps (indeed, in our example, the run-off is complete on average roughly at , as proved in Section 3.3). This type of loss model is similar to the standard collective model widely used in insurance. It can be encountered in reality, for example, for the so-called fixed-sum insurance contracts, for which fixed amounts are paid to the contract owner in case of accident, like the IDA Auto insurance in France, the MRH Multi-Risk Property insurance in France, the Personal Accident insurance in Japan, certain products linked to the the Health insurance in Switzerland, etc.
With the help of such models, we can develop a better understanding of the dynamics at work in the claim triangles. It also allows us to compute explicitly the various variables of interest, like the Solvency Capital Requirement (SCR) based on the one-year change or the Risk Margin (RM) that will account for the cost of holding the capital for this risk during the whole period. It helps also to make more explicit the various variables that need to be considered in the problem, and have an interest on their own.
We then compare them with the capital obtained with existing risk estimation methods. In particular, our results show that the commonly used Merz–Wüthrich method can lead to very wrong estimates in cases where its assumptions are not fulfilled (which is the case for our example). This is due to a multiplicative error assumption. Instead, our example has an additive error propagation as is often the case in practice for many different types of insurance contracts. Indeed, reserving actuaries often estimate the reserves using the Chain–Ladder method for mature underwriting years and the Bornhuetter–Ferguson method (Bornhuetter and Ferguson 1972; Schmidt and Zocher 2008) for young underwriting years. In Mack (2008), Mack has used an additive model for estimating the prediction error of reserves. Hence, claim triangles which have dominant young underwriting years will manifest an additive error propagation structure. The method proposed by Ferriero in Ferriero (2016) (Capital Over Time method, i.e., COT) gives instead good estimates even when its assumptions are not fulfilled and so proves to be more robust than the Merz–Wüthrich method. Our example shows the need of alternative methods beyond Merz–Wüthrich.
The paper is organized as follows. We present in the second section the model defining and explaining the quantities of interest. We then study those quantities in the third section, among which the SCR, first analytically, then their estimates numerically. In the fourth section, we develop a framework for comparing various estimation methods using as a benchmark the regulatory capital requirements computed explicitly by our model. We compare it to the estimates obtained by the Merz–Wüthrich and the COT methods, respectively, and discuss the results. The conclusions are drawn in the last section.
2. The Probabilistic Model
Let us introduce a process described by random variables following binomials’ distribution where the risk of a claim has a probability p and the exposure to this risk is n-times. We use the same probabilistic framework as in Busse et al. (2013). The reader can think of n as the total number of policies and of p as the probability of a claim occurring for any policy.
Let X be a Bernoulli random variable (note that all rv’s introduced in this paper will be defined on the same probability space ) representing the loss obtained when throwing an unbiased dice, i.e., when obtaining a “6”:
Recall that, for , and .
Let be an n-sample with parent rv X, (corresponding to the sequence of exposures n independent exposures we interpret this as a one-step case). The number of losses after n exposures is modelled by , a binomial distribution . Recall that
and that, by independence, . Note that defining the loss as a Bernoulli variable clearly specifies each single loss amount as a fixed quantity. It is the accumulation of these losses that will make the final loss amount stochastic. One could define a different probability distribution for the , but the Bernoulli distribution is the most appropriate choice for the type of exposures in our case, i.e., the case in which the policies offer a lump sum as compensation.
2.1. The Case of a Multi-Step n
We consider now the case where the risk is replicated over n steps, with given . At each step i (for ), the number of exposures is random and represented by a rv that satisfies the condition
which implies that and , .
Condition (H) is part of the assumption that the ultimate loss distribution is fixed and known. This assumption facilitates our objective, which is to study how the risk can materialize over time given the knowledge of the ultimate loss distribution. Actuarial methods have been developed to estimate the ultimate risk. It is thus reasonable to assume that they are doing a good job at this. Our purpose is thus to find ways to decompose this ultimate risk over time (steps).
All over the process, we are exposed to the risk a random number of times at each step independently, and with the same probability p. We keep the same notation as in the one-step case, X being the Bernoulli rv that represents the loss obtained when exposing the contract to the risk with the probability p.
At each intermediate step i, we expose the contract times. For ease of notation, let us define a new rv , which is the sum up to i of all the exposures:
For the process, we obtain losses represented by
in particular, for , after n-steps, the losses are . The variable X will then denote the parent rv of the s. Hence, when looking at the number of exposures and losses, it means that:
- (i)
- at an intermediate step i, the number of exposures is and the number of losses obtained at this step is given by:(the equality in distribution is discussed and proved in Appendix A) setting , and is, conditionally on , a binomial rv , which we denote as
- (ii)
- up to an intermediate step i, the total number of exposures is and the total number of losses is given byand is, conditionally on , a binomial rv:Here, we have and
- (iii)
- at the end of the multi-steps process under condition (H), the total number of exposures is n and the total number of losses is, as in the one-step caseThis is what is called the ultimate loss, once the process is completed.
Summarizing the notation, is the rv of the losses at the intermediate step i, is the rv of the losses up to the intermediate step i and is the rv of the ultimate losses .
For , the -algebra (as usual, or denote the trivial -algebra ) generated by the sequence of the rvs
and let denote the -algebra generated by the sequence of the rvs and the corresponding losses :
Note that , .
The process described here would generate a loss triangle following a Bornhutter–Ferguson (Bornhuetter and Ferguson 1972) type of dynamic, which is essentially linear in the error propagation as in our example, and would lead this way to the ultimate. This type of dynamic is typical of certain lines of business mentioned in the introduction and often used by reserving actuaries to estimate the ultimate loss. Such loss triangle will be generated assuming independency across different underwriting years. This assumption, together with the independency between development periods already mentioned in the introduction of Section 2, are simplifications which allow to calculate explicitly the quantities of interest (below) and are anyway two of the assumptions behind the Merz–Wüthrich methodology, which is the standard actuarial methodology object of our study.
2.2. Random Variables of Interest
Now, let us introduce some variables of interest, namely:
- the ultimate loss , which is ,
- the expected ultimate loss, given the information up to the step i (for :the s being independent of the s. Note that we can also definewhich corresponds to the expected loss at ultimate. Note that Equation (8) defines a martingale. Note also that it is a real number (although the rvs are integer valued).
- the variation of the expected ultimate loss between two successive steps defines exactly the one year change, when choosing yearly steps:Here is also a real rv. When , the is closely related to the solvency capital required as defined in the Solvency II framework, which reflects the risk of changes in the technical provision in one year. The difference lies in that does not take into account the risk margin change. However, this is of minor importance in the SCR estimation because the risk margin change is of a smaller order of magnitude. Indeed, in practice, it is commonly accepted that the risk margin, which represents the risk loading for the market value of the liability, is approximately constant from one year to the other. We note here that the s are the innovation of the martingale defined in Equation (8).
For simplicity, all the quantities of interest are considered undiscounted in our paper. The discounting would anyway not invalidate our findings, but only make the calculations more complex.
Note that, as in (ii), we can express the expected ultimate loss using the conditional expectations, as
The goal of this study is to understand better the behavior of . This means looking for the distribution of .
Using (8) and (10), and the properties of the conditional expectation, we can write, after straightforward computations,
so that
Applying (12) provides
We can see from (13) that depends on but also on the past information via . We can then write the probability distribution of conditional on this information:
using the independence between the s and the s in the equation before the last, and (3) in the last one.
Let us now choose a probability distribution for the s. This choice is arbitrary. We could, for instance, use various distributions typical for modelling frequency or emergence of claims in actuarial modelling, like the Poisson distribution. For simplicity, we will pick first the case of a uniform distribution conditionally to so that, for , we have
We remind the reader that . Strictly speaking, we do not even need to have explicitly. Only their sum matters so that
We can now proceed to compute the expectation of .
Proposition 1.
The expectation of as a function of i is equal to:
Proof of Proposition 1.
Using the property of the conditional expectation, then that is uniformly distributed, and finally the linearity of the expectation, we obtain:
Let us prove the proposition by induction. For , by uniformity of the distribution of the rv N, we have:
The last step has actually the same expectation as the previous one since it is the complementary and is completely conditioned by the sum of the previous steps
We have thus fully characterized the expectation of the number of exposures at each step. (In the Appendix B one can find the distribution of the and also of the .)
3. Analytical Expressions of Quantities to Be Studied
3.1. Incremental Pattern and Capital
Another quantity of interest is the incremental pattern of the expected value of the losses. It can be written, using (4) and (9), as:
For computing the RM, we need to compute the capital requirement (SCR) at each step, using the risk measures and , which we will simply call . We define the capital requirement at step i as
Once we have this quantity, we can then write the RM, , as a function of the number of steps n, as:
where designates the cost of capital.
3.2. Moments of
The properties we present here are specific to our choice of process, but they can be easily generalized in the framework of martingale assumptions. Let us compute the first two conditional moments of the vector given .
Proposition 2.
Let . For k such that , we have
- (i)
- (ii)
- (iii)
- For ,where .
Corollary 1.
From which, we can deduce the following two expressions as corollary:
- (a)
- As a consequence of the Proposition 2, the moments of are given by
- (b)
- The conditional variance of the ultimate is
Proof of Proposition 2.
(ii) The conditional variance of can be obtained in the following way: again, take , and recall the general property of conditional variance, for two random variables X and Y, . By using this result on , we obtain
We now use Equation (13) on both terms of the right side of the last equation. Since ,
which sets the second term of Equation (26) to 0. Let us calculate the first term.
We now consider the following argument: Assuming known, is equivalent in terms of rvs to starting a new process with steps and rvs. A generalization of Equations (16) and (18) therefore gives
and
It follows then that
and that
We also notice that, since is measurable,
This finishes the calculation of the conditional variance.
(iii) Only calculation of the conditional covariance remains. Let and . Since ,
This finishes the characterization of the second moment of . Indeed, we have shown that ,
and
☐
Proof of Corollary 1.
Since the particular case corresponds to the unconditional moments of , we have:
- (a)
- Thus, the unconditional moments of D are given by
- (b)
- As an immediate consequence of Equation (24), one can write the conditional variance of the ultimate as
(This formula can also be derived directly, arguing that .) ☐
3.3. Completion Time
Our process is defined on a finite time scale of n-steps. However, the process will, most of the time, finish much before the n-th step (the ultimate time). It is therefore of interest to know how fast the process reaches the maximum exposures allowed. This is also very important for computational reasons. Indeed, when simulating from the process, one can stop the simulation procedure earlier than the ultimate time thus sparing large amounts of calculations. In order to answer this question, we first consider a type of process that differs slightly from ours in the sense that it has an infinite time range (infinite steps), but is still only allowed a finite number of exposures, n. For an infinite time process with n rvs, let us denote by
the completion time given by the step at which the last exposure is realized. Before trying to approximate a finite process with an infinite process, we need to show that the infinite process finishes with probability 1.
Proposition 3.
The probability of the completion time at infinity is 0:
Proof of Proposition 3.
For , we can argue that
which implies that . Note that is justified by the fact that, since the process is infinite, assuming is equivalent to starting a new infinite process with rvs. This argument is used here with but is explained with general k because we will use it further for other values of k. For , we can do very similar calculations by induction. Assume that , . Then,
which again proves that . ☐
Since the process finishes with probability 1 and the probability of an infinite process with n rvs finishing after time n is very small for n large enough, the approximation is very reasonable.
We would like to find a formula for . By conditioning on the first step, we obtain
Again, assuming is equivalent to starting a new process with rvs. Therefore, , where the 1 takes into account the first step. As only depends on n, let us denote it by . We can then write the following iterative formula
Solving for and realising that , we obtain
which gives by iteration, for :
Note that
Hence, by iterating Equation (30), we obtain the formula
We have now an expression that gives the average completion time of an infinite process as 1 plus the truncated harmonic series, which can itself be approximated by
where is the Euler constant. If n is large enough, we therefore have a simple way to estimate approximately how many steps the process will last on average.
3.4. Distribution of the
In Section 3.2, we studied analytically the two first moments of the . Here, we simulate 200,000 times the process of size to estimate the empirical distribution of the . We also compute the normal distribution with same mean and variance to compare the distributions. The results are displayed in Figure 1. Let us recall Equation (13), which states . Conditional on , this random variable has centered binomial distribution (i.e., binomial distribution minus its average). The Central Limit Theorem applies to binomial rv X with parameters n, p. Thus, the distribution, f, of a sum of n independent Bernoulli rvs with parameter p will converge to a Gaussian distribution: , for n large enough. Assume that F is a discrete mixture of normal distributions with mean 0, variances and weights . Then, ,
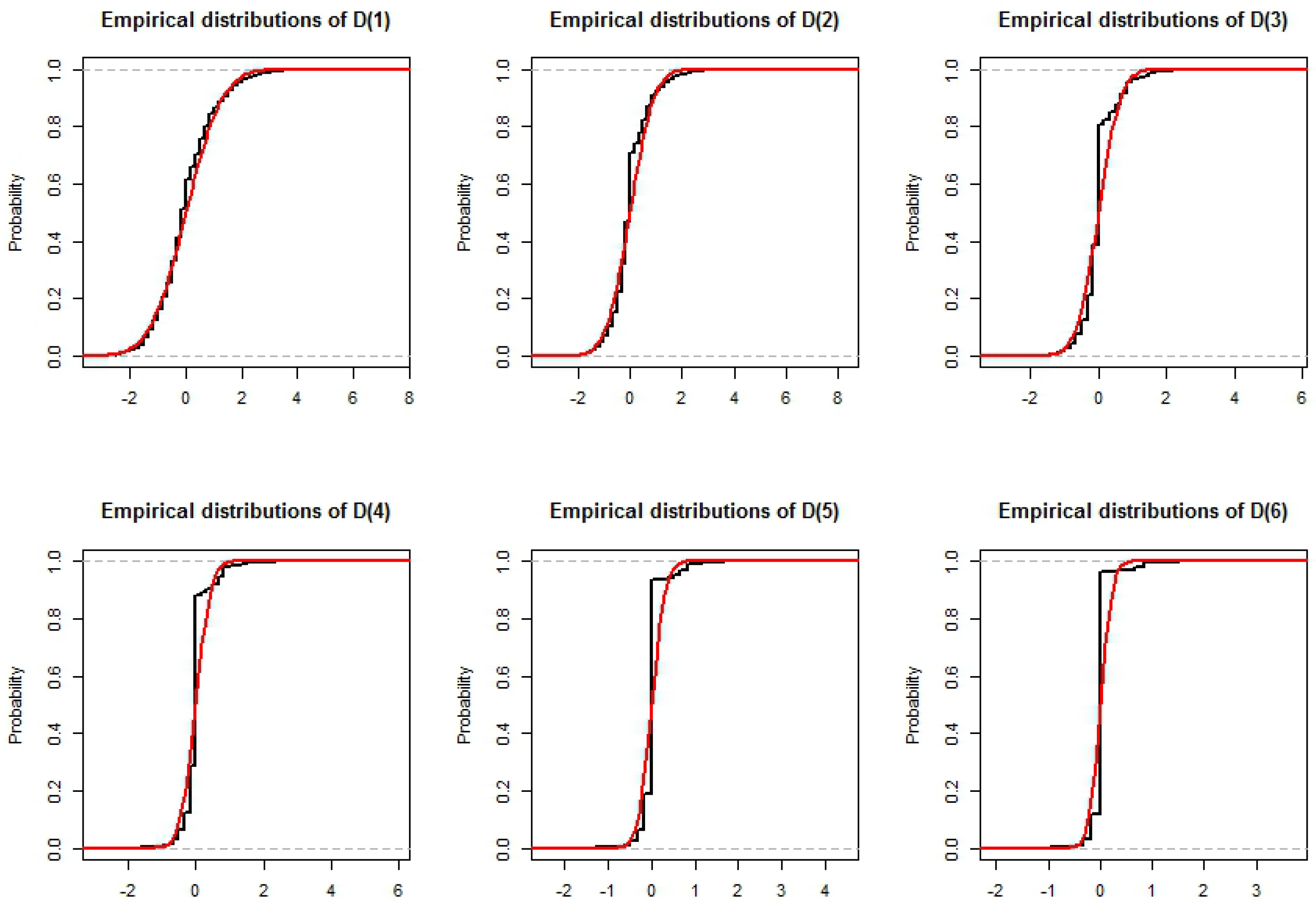
where W is a normal rv . In particular, if for some indices i and j, and are close to each other, then and are also going to be close to each other. In our case, and these values are going to be close when i is large enough. If a sufficiently large part of the weight is on large values of i, our mixture of centred binomial distributions is going to be close to a Normal distribution. In other words, is going to have a distribution that is close to Normal only if the probability of having a large is high. For , as we can see in Figure 1, it is the case. For , the approximation is still reasonable despite a mass larger than normal around 0. For , the fit is rather good for large and small quantiles but not for the middle part of the distribution. We recall from Equation (16) that expectation of is divided by 2 at every step so that small values of and in particular 0 will have a larger probability. It should be noted that, due to the probability mass of small values of , these mixture distributions, even if they are close to a normal distribution, will always have a higher than normal probability density around 0. To verify this intuition empirically, we also simulate 200,000 times the process for sizes and . The results do confirm our intuition. Indeed, for , the approximation is good for and starts failing for , where . For , we can of course go one step further, which makes the normal approximation good also for .
3.5. Simulation of the Completion Time
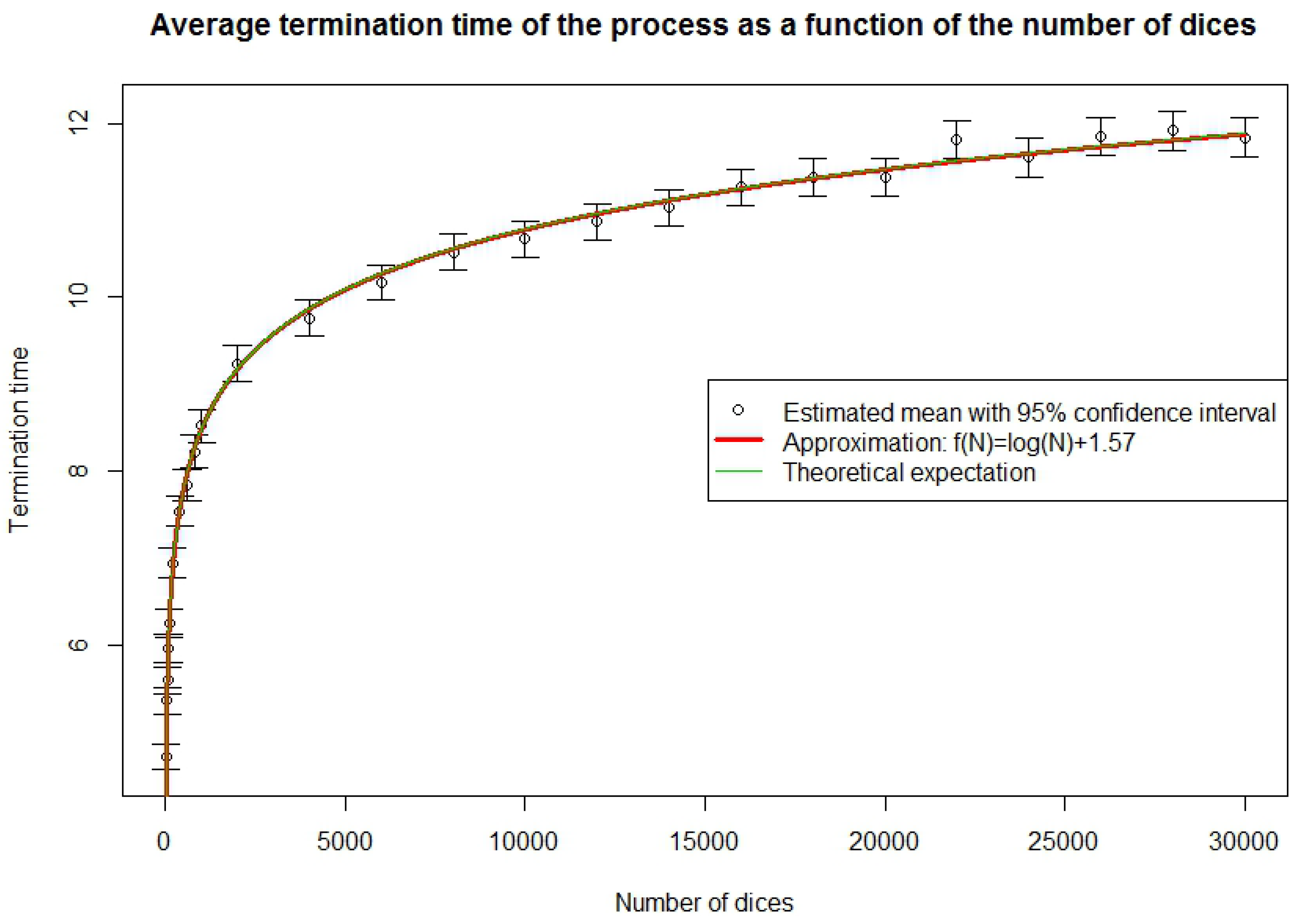
We have seen, in Section 3.3, Equations (31) and (32), how to approximate the average time until the end of the process. We test this result empirically by simulating 10,000 times the process of size n for . For each n, we calculate the average time to complete the total number of exposures and the 95% Gaussian confidence interval given by adding or subtracting 1.96 times the empirical standard deviation of the sample. We also calculate the harmonic series and its approximation by a logarithm. The two approximations are almost identical and fit very well the results. Indeed, in 25 times, the 95% confidence interval misses once, which is what is expected. The approximations should however be expected not to be valid for very short processes because the logarithm approximation is based on convergence and because both the logarithm and harmonic series approximations are based on the approximation of a finite process by an infinite one, which is inaccurate for very short processes. In order to know how long a process must be for the approximation to be valid, we simulate 10,000 times the process of size n for . From the results, displayed in Figure 2, we see that for , the fit is not good. However, from onwards, our approximation is a reasonable and easy way to find the completion time. We shall use this result later when we build loss triangles.
4. Capital Requirements
In this section, we propose a framework to test the accuracy of some of the methods to estimate the one year change. We construct triangles using the model presented in Section 3.4. From these triangles, we estimate the one year change using the classica Merz–Wüthrich method Wüthrich and Merz (2008) and the capital-over-time (COT) method, currently used at SCOR Ferriero (2016). We then compare the results obtained analytically and by simulation based on the specifications of our model to those estimated by the Merz–Wüthrich and with the capital-over-time (COT) method.
4.1. Triangles
Until now, we have only considered the development properties of one process. Actual liability data are generally available in the form of triangles that represent the losses attributed to insurance contracts for each underwriting year after their current numbers of years of development. It is therefore reasonable to compare the results of our model in this framework. We first need to define the notation. Let us consider n representations of the process of size n. We denote their ultimate losses . The ultimate loss of the triangle is then
We denote by the number of exposures realized at each step of the ith process and the losses due to . The cumulated losses of row i up to column j are written . We consider the discrete filtration given by the information available at each calendar year. Formally,
The individual filtrations of each representation of the process are denoted by
We denote the jth one-year change of the ith individual process by and define the one-year changes of the triangle until its completion by
Equation (33) simply writes the global one-year change as the sum of the individual one-year changes. Note that, due to linearity of expectation, Equation (33) also implies that the have expectation 0 and are uncorrelated. Their variances can be calculated by summing the variances of the individual one-year changes that constitute them.
Similarly to the individual process situation, we define the capital requirement for calendar year i as
for some risk measure . The risk-margin associated with these capitals is
for the cost of capital .
4.2. Methodology and Results’ Comparison
We now describe the methodology used to obtain our risk measure results and to compare them with the Merz–Wüthrich and the COT methods, both briefly explained in Appendix D. For convenience, we use the following notation
for the number of exposures remaining to be realized for row i of the triangle after time j. In particular, for . In particular, is an measurable random variable.
4.2.1. First Year Capital Comparison
A first value of interest is the required capital for the first year
The Merz–Wüthrich method only provides , while the COT method was originally designed for (A4). An assumption concerning the link between and is therefore to be made. Since follows a mixture of binomial distributions for a generally large number of rvs, its distribution can be approximated relatively well by a normal distribution (this approximation may lead up to 20% underestimation of the risk depending on the number of exposures n). Note that the number of rvs from the binomial is not a uniform variable but a sum of uniform variables, which diminishes the probability of very large or very low values, thus making the normal approximation better than for a simple uniform number of rvs. Normal distribution fixes the relation between and :
In our case, and
The COT method, such as explained in Appendix D, was designed for real insurance data. In particular, parameter b models the dependence between relative loss increments. In the case of our model, the relative loss increments are uncorrelated, which points to the choice of parameter instead of the value chosen with mean time to payment. The choice of coefficient is also arbitrary. Indeed, determines the proportion of the risk that is due to the jump part of the process. For our process, there is no “special” type of behaviour that the model could have and that would increase the risk. Therefore, we choose . In general, the type of data is not known, in particular the dependency between loss increments is not known. Thus, we are also interested in the results given by the COT method applied the standard way. We therefore also compute the COT estimator with chosen according to Formula (A5). In our case, b cannot be chosen like in the formula, as the pattern used in the mean time to payment computation is a paid pattern that we do not have for our model. For the jump case, we choose as for a long-tail process. Indeed, the (incurred) pattern of our n-step process corresponds generally to the type of patterns that one can find in long (or possibly medium) tail lines of business. We will refer to the two variations of the method as “COT method with jump part” for the version with standard and and “COT method without jump part” for the version with and .
In the case of an n-step Bernoulli model triangle, we notice that the accident-year (incremental) patterns are given by
The first factor is simply the total number of exposures remaining to be realized, the first row not being counted because it is finished. Since, at each step but the last, half of the current exposures of the process are expected to be realized, the number of exposures remaining for each unfinished is expected to be the number of exposures remaining in the original triangle divided by 2 for each past step that is not the last step. Hence, the expected remaining exposures are
for the lines that are not finished after i steps, plus
for the line that finishes precisely after i steps. The pattern designates the results of the binomial random variable and not the number of exposures. However, since the rvs (random variable X) are independent and have the same expectation, the numerator and denominator are both multiplied by p leaving the result unchanged.
In particular, with the help of Equation (37) and after few manipulations, we have that
This result uses the property of martingales that the variance of the sum of martingale increments is equal to the sum of variances. An analogous property is false for the . However, we get for the COT model without jump part, an approximation (see Ferriero 2016)
Moreover, if we assume that the normal approximation is not an approximation but indeed an exact distribution, it can be shown through straightforward calculations that this expression becomes an exact result for the required capital for the first year (see Ferriero 2016).
The Merz–Wüthrich method is the one posing the most problems. Indeed, the triangles generated with our process are very noisy in the sense that the simulated triangles can quite often have many zeros. The Mack hypotheses, on which the Merz–Wüthrich method is based, are multiplicative in nature and, therefore, very sensitive to zeros. If there is a zero in the first column of a triangle, Mack’s estimation fails to compute the parameters . There are more robust ways, such as the one developed in Busse et al. (2010), to calculate these estimators. However, all of them (except removing the line) fail if an entire row of the triangle is 0. This happens quite often for n small. If n is large, the problem becomes, as we explain in Section 3.5, that the process terminates on average in time , which means that the largest part of the triangle shows no variation at all and gives . In order to eliminate all these problems, we simulate our test triangles with n = 100,000 and work on the truncated top side of the triangle of size , where 5 is a safety margin to insure that the run-off of the process is finished or at least almost finished.
We set , which is a more realistic value given the high number of policies, simulate 500 triangles and, for each of them, calculate the first year capital using the theoretical value, the COT method with and without jumps and the Merz–Wüthrich method. We display, in Table 1, the mean capital and the standard deviation of the capital around that mean over the 500 triangles. We also calculate the mean absolute deviation (MAD)
and mean relative absolute deviation (MRAD)
with respect to the theoretical value using standard and robust mean estimation.
Note that, in our example, the relative risk, i.e., the first year capital relative to the reserves volume, is about 18% (the reserves are approximately 100 and the first year capital approximately 18), which is a realistic value. The reserves in our model can be easily computed by the close formula , as proved in Appendix C. As a point of comparison, using the prescription of the Solvency Standard Formula, we find a stand-alone capital intensity (SCR/Reserves) between 14% to 26% for the P&C reserves. Given the type of risks we are considering here, it is logical that the capital intensity should be at the lower end of the range. By the way, we also see, as expected, that the average claim is much smaller than the maximum claim (100,000) given the fact that the chances that 100,000 independent policies claim at the same time with such a low probability of claims () is practically nil.
The results presented in Table 1 are striking. While the COT method gives answers close to the theoretical value with a slight preference, as expected, for the COT without jumps, the Merz–Wüthrich method is way off (1356.6% off the true value), and the true result is not even within one standard deviation away. The coefficient of variation for this method is more than 59% while in all the other cases it hovers around 21%. There are many explanations for this. Looking at triangles and analysing the properties of the methods allows us to understand those results. The true risk depends on the number of rvs remaining to be realized. In most cases, only the few last underwriting years are truly important in that matter because the others will be almost fully developed. For Merz–Wüthrich, as most of the volatility of the process will appear on the first step, the most crucial part of the triangle is the last line of the triangle, which is the only process representation at this stage of development. If the latter is large, it influences the Merz–Wüthrich capital in the same direction. Merz–Wüthrich interprets a large value as: “Something happened on that accident year, there is going to be more to pay than expected”. The logic behind our model is different, through the “fixed number of rvs” property, it is: “What has been paid already needs not to be paid anymore”. A large value on the last line of the triangle is therefore likely to indicate that few rvs remain to be realized, which implies smaller remaining risk. This explains negative correlation because the same cause has the exact opposite effect on the result.
How can we explain the difference of magnitude in the estimated capitals? This may be due to the fact that our model is additive while Merz–Wüthrich is multiplicative. If a small number appears in the first column and then the situation reestablishes on the second step by realizing a larger number of exposures, we know that this is irrelevant for future risk. However, Mack and subsequently Merz–Wüthrich don’t consider the increase but the ratio. If the first value is small, the ratio may be large. However, the estimated ratio is the mean of the ratios weighted with the value of the first column, i.e., Equation (A2) can be rewritten as
Therefore, cases with large ratios, such as described before, will not appear in but in . The Merz–Wüthrich (Mack) method considers that small and large values are as likely to be multiplied by a factor, which is not the case with our model for which small values are likely to be multiplied by large factors and large values are likely to be multiplied by small factors.
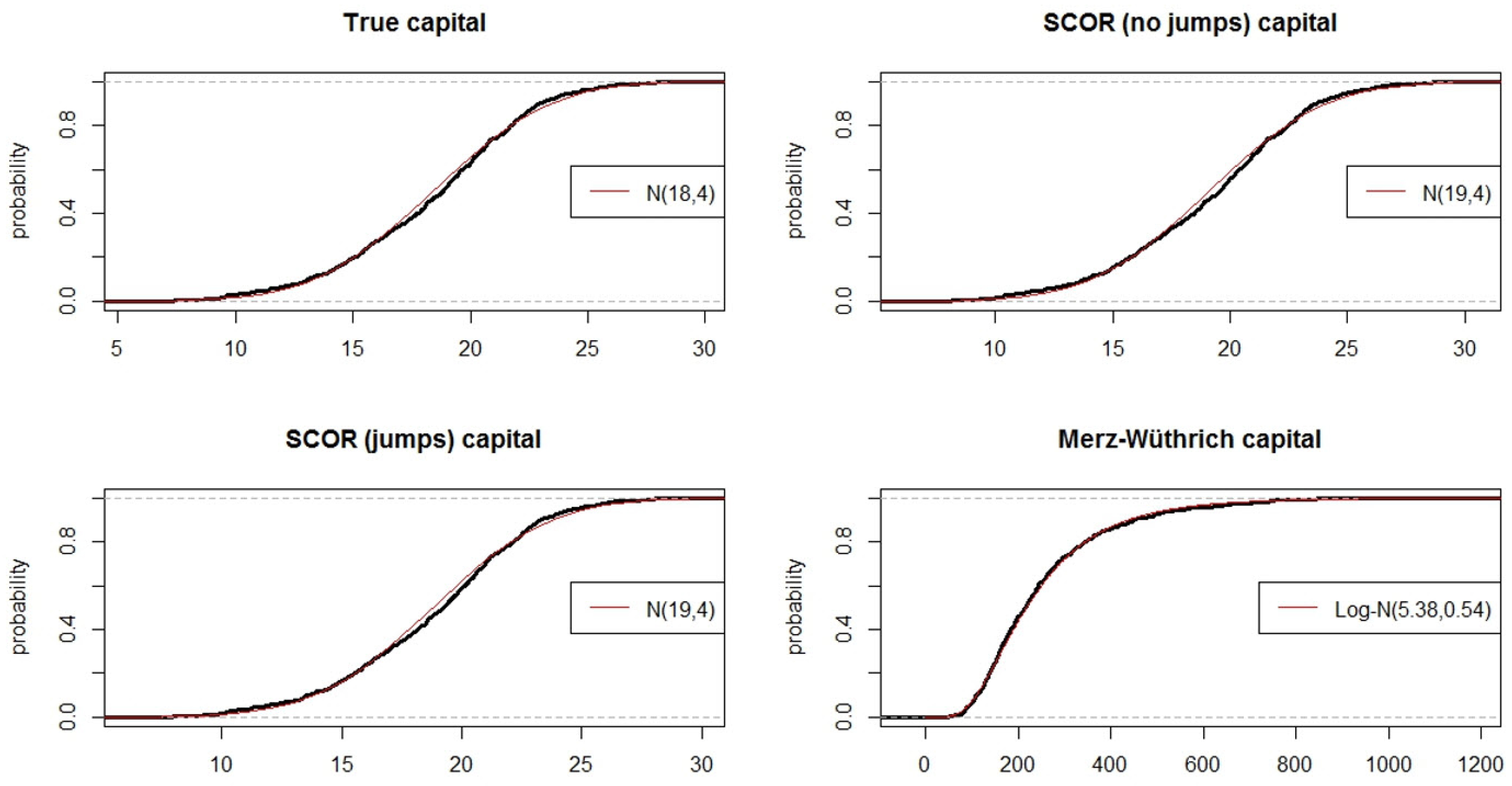
This is confirmed by plotting and comparing the distributions of the different capital measurements (Figure 3), we can notice that, while the true capital and the two COT capitals seem to follow a normal distribution, the distribution of the Merz–Wüthrich capital seems to follow rather a log-normal distribution.
Another interesting statistic to understand how related these capital measurements are is the correlation between them. Computing the correlation matrix yields the results presented in Table 2, we see that the correlation is almost 100% for the two COT estimates and the true value. Indeed, with or without jumps, the COT method is very close to the theoretical result. This is partially due to the fact that the ultimate distribution is known and that all these methods simply multiply the ultimate risk by a constant. The correlation is not exactly 100% due to the stochasticity induced by the simulations used to calculate ultimate risk in the COT methods. The Merz–Wüthrich capital however shows a negative correlation. The standard and robust estimators are very different, which suggests the presence of very large values of Merz–Wüthrich capital and departure from normality. This is confirmed by Figure 3 where the distribution in the bottom right plot is very different from a Gaussian. It indicates in particular that the robust estimator is more representative of the data. A correlation of −46% is rather strong. It is not true though that a small true capital implies a large Merz–Wüthrich capital, nor the opposite, but there is a real tendency among large values of true capital to coincide with relatively small values of Merz–Wüthrich capital.
4.2.2. Risk Margin Comparison
Another important quantity to study is the risk margin defined in Equation (21). We compare here the results obtained with the COT method described in Appendix D to those obtained from theory. Note that we cannot do this for the Merz–Wüthrich method as it is only giving the variation for the first year.
We want to estimate
Our methodology is very close to the one for the first-year capital using normal approximation and Equations (34) and (35). Assume known, we can then generalise Equation (36), to get the following expression
We then use the normality assumption to write
thus obtaining a theoretical form for the tail value at risk, given the triangle developed up to calendar-year . Our methodology, starting from a triangle of realized rvs, is to complete it R times using the Bernoulli model and to calculate on each completed triangle according to the formula of Equation (39). By taking the mean over all R triangles, we obtain the required capital for calendar-year i that we sum up and multiply by the cost of capital (chosen here at 6%, as in the Solvency II directive) to obtain the risk margin.
In this case, we do not need to simulate truncated large triangles to make our comparison. Indeed, both the COT method and the theoretical simulation method work on small triangles. However, for the results to be similar and to avoid too frequent “zero risk left” situations, we still use a truncated large triangle like for the first-year capital comparison, i.e., triangles of size 19 and with rvs. Like for the first-year capital, we simulate 500 triangles from the process and, for each of them, calculate the capital required at each consecutive year and the risk margin using for the theoretical simulation method triangle completions and for the COT and (without jump part) and (long tail) and from Equation (A5) (with “jump part”). In Table 3 and Figure 4, we can observe the results obtained on average and the measures of deviation over the 500 triangles.
As we just saw, assuming normality, the first year capital of the COT method without jump part is an exact result. However, for (still assuming normality), the method gives
However, from Schwarz inequality, which also holds for conditional expectation, for any positive integrable random variable Y and any algebra , the COT method without jumps is systematically overestimating the true capital, as we can see in Figure 4. However, the overestimation is not very big (Table 3) and the method replicates reasonably well the form of the actual yearly capital. The average relative absolute error of the risk margin is 10.57% (see results in Table 3). We do not show the results for the capital at each year, but they lead to a similar message with the error increasing with the years as the capital itself decreases. The same method with jumps has less success with 26.52% of absolute error. This error is always underestimation, which is also true for each year. The error on the capital is always bigger with jumps. It is only at the end (calendar year 13 here) that the capital estimation is better with jumps and these values are almost 0, so they are not very relevant for the risk margin.
In general, one can see (Table 1 and Table 3) that, for our n-steps model, the COT method without jumps is the one that performs the best. If we compute the autocorrelation of consecutive loss increments, we obtain 5% of mean correlation, which is close to independence. The independence situation corresponds to the calibration of the COT method with , thus explaining why the COT method without jumps provides the best results. This raises the question of what value of b would give the risk margin the closest to the benchmark. To answer this, we simulate another 100 triangles and calculate each time the risk margin with the benchmark method and with both COT methods with and without jumps, for all values of parameter b between 0.3 and 1 by steps of 0.01. For the COT method without jumps, we find that the fitted values for b are between 0.52 and 0.53, which is very close to the that we have been using. For the COT method with jumps, the mean best b is also close to 0.5. However, we find some best b observations that are below 0.5, which stands for negative dependence between accident years and is not accepted by the COT method. In this case, the best b is much further than the one that has been used (0.75) by SCOR for real data. This is not unexpected since the method yields rather poor results (Table 3) for our n-steps model. (In the Appendix E we discuss the numerical stability of the above approximations. Furthermore, in the Appendix F we discuss the one-year capital for the first period as proportion to the sum of all the one-year capitals over all the periods.)
5. Conclusions
In this study, we have decomposed the various steps to reach the ultimate loss through a simple, but realistic example, which is used in a variety of line of business all over the World. The goal is to study the one year change required by the new risk based solvency regulations (Solvency II and the Swiss Solvency Test). Our example allows us to compute explicit analytical expressions for the variables of interest and thus test two methods used by actuaries to derive the one year change: the Merz–Wüthrich method and the COT method developed at SCOR. We find that the COT method is able to reproduce quite well the model properties while Merz–Wüthrich is not, even though the assumptions behind both methodologies are not satisfied in the case of our example (therefore the COT methodology is more robust). It is thus dangerous to use the Merz–Wüthrich method without making sure that its assumptions are met by the underlying data. Even though this seems obvious at first, the authors feel the need to warn about the risk of using the Merz–Wüthrich methodology acritically to any non-life portfolio, ignoring the fullfillment of the Merz–Wüthrich method’s assumptions, as this is the tendency among practitioners, regulators and auditors in the last years.
Funding
This research was funded by SCOR, General Guisan-Quai 26, 8022 Zurich, Switzerland.
Acknowledgments
The authors would like to thank Christoph Hummel for suggesting the binomial process and acknowledge his first contribution with a model of tossing a coin. The authors would also like to thank Arthur Charpentier for providing the R code of the Merz–Wüthrich method and for discussions. We also would like to thank anonymous referees for the useful remarks.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of an Equality in Distribution
In this appendix, we examine the equality in distribution formulated in Equation (3):
The reason for it is that both sides are a sum of Bernoulli random variables with the same parameter, so that no matter what the distribution of is, both sides will have the same distribution. This can be proved rigorously by calculating both characteristic functions. The characteristic function of a random variable Y is defined as
and determines uniquely the distribution of a function.
The characteristic function of is
The same calculations and arguments give the characteristic function of :
thus proving the equality in distribution.
The calculations can be pushed forward. Indeed,
Note that, if , and , then we can write
We therefore have a close form for the characteristic function of .
Appendix B. The Distributions of Ni and of D(i)
Proposition A1.
The distribution of , for , is
and .
Proof.
Indeed, the first value of the probability is
Then, we can write, for ,
and, for ,
We can continue iteratively up to and obtain (A1).
We should note here that, because of Condition (H), for the last distribution, we have . Alternatively, reminding that , we come to the same conclusion. ☐
Proposition A2.
The distribution of conditioned to , is equal to
for , and .
Appendix C. The Reserves in Our Model
For our model with only one row, i.e., one rv, the reserves at years (steps) are simply
In case we have a claims triangle with m rows and columns, where each row is our process with n exposures, the reserves at calendar year i are
Appendix D. Presentation of the Methods to Compute the One-Year Change Volatility
We briefly present here the methods we use in Section 4.2.
Appendix D.1. Merz–Wüthrich Method
The Merz–Wüthrich method Wüthrich and Merz (2008) is the most commonly used approach to model one-year change volatility. It is based on the distribution free method developed by Mack (1993) to estimate the ultimate uncertainty of the reserves on a triangle of claims. Using our notation, Mack makes the following assumptions:
- Independence across rows of the triangle.
- There exists a sequence of factors , such that
- There exists a sequence of factors , such that
Under these assumptions, Mack proposes the following unbiased estimators for the factors:
and
For , Mack uses . Furthermore, he uses the estimates to estimate the future parts of the triangle with the estimator
Summing these conditional variances, they obtain an estimator for the first one year change:
The idea behind the Merz–Wüthrich method is to calculate the Chain–Ladder estimation of the ultimate uncertainty at time 0 and at time 1 after adding the next diagonal. They then calculate the uncertainty of the difference to obtain the one-year uncertainty. We illustrate this in Figure A1 by showing the addition of one diagonal.
Figure A1.
The current triangle (left) and the next year triangle (right). The present is outlined in blue and the one-year ahead future in red. The Merz–Wüthrich method allows for computing the ultimate risk on both triangles and calculate the uncertainty of the difference.
Figure A1.
The current triangle (left) and the next year triangle (right). The present is outlined in blue and the one-year ahead future in red. The Merz–Wüthrich method allows for computing the ultimate risk on both triangles and calculate the uncertainty of the difference.

Appendix D.2. The COT Method
The COT formula used at SCOR Ferriero (2016) consists of computing first the ultimate risk, in our case, the of a distribution, and taking a part of it, to be determined, as the required capital for each year. The idea behind the COT formula is to look at the evolution of the risk over time till the ultimate, and thus obtain the one-year period risks as a portion of the ultimate risk. In what follows, we give a brief description of the COT formula; however, the detailed derivation is presented in Ferriero (2016). Here, designates the number of exposures that remain to be included in the whole triangle. This can be written as
where
The vector is called the COT-pattern and is obtained through the following relation:
where designates the incremental calendar year pattern,
and parameters are fixed to the values . Parameter b is set to 0.6 for short-tailed Lines of Business, 0.65 for medium-tailed LoB and 0.75 for long-tailed LoB, where the duration is determined by the notion of mean time to payment . It is defined as
where designates the incremental calendar year paid pattern. A short-tail is defined as , medium-tail by and long-tail by . Once we have the , we can sum them and multiply them by the cost of capital to obtain the risk margin
In short, this model is based on the idea that claims will develop partially with a “good” continuous part and partially according to a “bad” part characterized by sudden jumps, the bad part being modelled as the total rest of the claims realising at once. The variable is a coefficient between [0, 1] that determines in which proportion the evolution is going to be continuous or discrete and models the dependence between different calendar years.
In order for the COT method to be exact, the following assumptions must be true:
- The evolutions of the claims losses and of the best estimates are stochastic processes as described in Ferriero (2016); roughly speaking, the relative losses evolve from the start to the end as a Brownian motion, except during a random time interval in which they evolve as a fractional Brownian motion, and the consequently best estimates evolve as the conditional expectation of the ultimate loss plus a sudden reserves jump, which may happen as a result of systematic under-estimations of the losses.
- The volatility, measured in standard deviations, of the attritional claims losses is small relative to the ultimate loss size.
However, the COT method is robust in the sense that gives good estimates even when the assumptions are not fullfilled as we show here with our example.
Appendix E. Numerical Stability
In Section 4.2, we calculate the risk margin by simulating triangle completions according to our n-steps model. It is therefore legitimate to ask if the simulations we use are enough to obtain stable results. To investigate this question, we simulate an n-steps model triangle. We then calculate its risk margin 200 times using our simulation method with a grid of values of R. From these, we calculate the mean and the standard deviation of the computed risk margins for each value of R. The distribution of the calculated risk margin being approximatively normal due to the central limit theorem, the mean and standard deviation fully characterize the distribution allowing us in particular to draw confidence intervals. We chose for this test and obtained the values presented in Table A1.
The results seem to indicate that the standard deviation of the risk margin calculation is inversely proportional to as one would expect. The mean prediction is almost the same no matter what the number of simulations is even though the variation of this mean around 3.28 diminishes as R grows. The value that we have used seems in any case sufficient as, for this value, the 95% confidence interval represents only a variation of around the mean.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
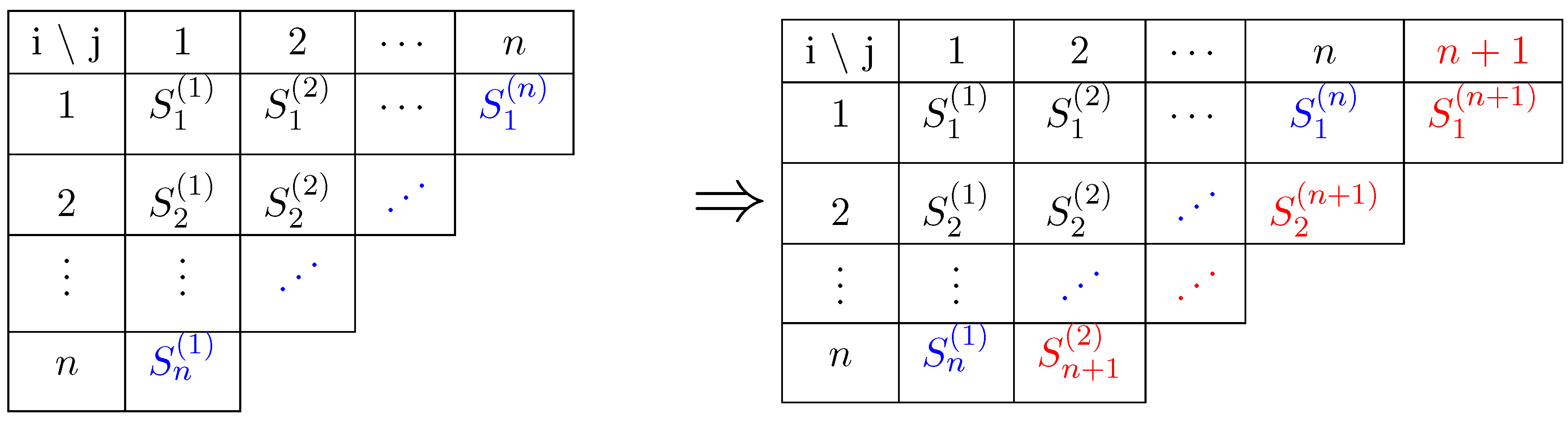{kind=link}
Table A1.
Test of the number R of random triangle completions for the risk margin calculation. The mean and standard deviation allow for constructing a Gaussian 95% confidence interval by adding (resp. subtracting) 1.96 times the standard deviation to the mean to obtain the upper (resp. lower) bound. The “Variation” column designates the variation around the mean that represents the 95% confidence interval, i.e., 1.96 times the standard deviation.
Table A1.
Test of the number R of random triangle completions for the risk margin calculation. The mean and standard deviation allow for constructing a Gaussian 95% confidence interval by adding (resp. subtracting) 1.96 times the standard deviation to the mean to obtain the upper (resp. lower) bound. The “Variation” column designates the variation around the mean that represents the 95% confidence interval, i.e., 1.96 times the standard deviation.
| R | Mean | Standard Dev. | Confidence Interval | Variation |
|---|---|---|---|---|
| 10 | 3.279 | 0.176 | [2.935, 3.624] | |
| 20 | 3.294 | 0.122 | [3.055, 3.533] | |
| 50 | 3.287 | 0.077 | [3.136, 3.438] | |
| 100 | 3.291 | 0.057 | [3.180, 3.402] | |
| 200 | 3.289 | 0.042 | [3.206, 3.372] | |
| 500 | 3.281 | 0.027 | [3.228, 3.333] | |
| 1000 | 3.284 | 0.018 | [3.248, 3.320] | |
| 2000 | 3.283 | 0.013 | [3.258, 3.308] | |
| 5000 | 3.282 | 0.009 | [3.265, 3.300] | |
| 10,000 | 3.283 | 0.006 | [3.272, 3.294] | |
| 20,000 | 3.283 | 0.004 | [3.275, 3.291] |
Appendix F. Capital Properties of the Model
In this section, we discuss the properties of the ratio first year capital divided by the sum of all required capitals. That is the ratio
where m represents the size of the triangle. We would like to know in particular how a variation of the parameter n will influence that ratio. To investigate this question, we simulate 100 triangles with n exposures per line, for values of n in the set . Like for the previous capital requirement calculations, we truncate the triangles to size . This avoids considering triangles of very large sizes without changing the result, as, in most cases, almost all exposures will have been realized before this step. For each triangle, we compute the capital requirements using 2000 random triangle completions, as the study of Appendix E has shown that this is sufficient to have less than 1% error. For convenience reasons, we only show some statistics of the results that are representative of the spread of the whole sample (Table A2), the mean, standard deviation and the two extremal values observed.
Table A2.
Statistics of the proportion of the capital represented by the first year as a function of the number of rvs n. Note that the number of rvs modifies the number of steps .
Table A2.
Statistics of the proportion of the capital represented by the first year as a function of the number of rvs n. Note that the number of rvs modifies the number of steps .
| Number of rvs | Number of Steps | Mean | Standard Dev. | Min. Obs. | Max. Obs. |
|---|---|---|---|---|---|
| 10,000 | 16 | 0.3137 | 0.00395 | 0.3067 | 0.3267 |
| 20,000 | 17 | 0.3129 | 0.00472 | 0.3049 | 0.3286 |
| 30,000 | 17 | 0.3130 | 0.00444 | 0.3056 | 0.3278 |
| 40,000 | 18 | 0.3125 | 0.00372 | 0.3064 | 0.3257 |
| 50,000 | 18 | 0.3129 | 0.00465 | 0.3040 | 0.3244 |
| 60,000 | 18 | 0.3123 | 0.00412 | 0.3041 | 0.3240 |
| 70,000 | 18 | 0.3123 | 0.00422 | 0.3057 | 0.3279 |
| 80,000 | 18 | 0.3118 | 0.00440 | 0.3039 | 0.3264 |
| 90,000 | 18 | 0.3125 | 0.00465 | 0.3041 | 0.3284 |
| 100,000 | 19 | 0.3118 | 0.00383 | 0.3033 | 0.3231 |
The results are quite independent of the number of rvs and show no obvious pattern of development. The size of the changes between different values of n is much smaller than the standard deviation indicating that n has no (or non-significant) effect on the ratio of interest. The standard deviation shows no sign of correlation to the number of realized rvs per line, and the maximal observation is slightly more volatile than the minimal. However, both are very stable, giving no indication that n might have any significant effect on the ratio.
Let us give some intuition behind these results. In our model, with the exception of the move from penultimate column to ultimate, for which all not yet realized exposures are forced to be realized, each move forward in the triangle means, in expectation, dividing by two the number of remaining rvs to be realized. Since we use 2000 triangle completion, we can assume that we are at the expectation. The variance is proportional to the number of rvs remaining. This means that the , which is proportional to the standard deviation (under normality assumption), is proportional to the square root of the same number. The crucial number in calculating capital is therefore the expectation of the square root of the number of rvs as described in Equations (38) and (40). The expectation of the square root is divided every calendar year by a factor that is almost the same, except near the end. This factor depends on the triangle, unlike the square root of the expected variance (the square root of the expected variance is approximately divided by at every step). However, it is generally close to 0.69. Therefore, the ratio is approximately
This is obviously not an exact result but shows that this quantity has a small sensitivity to m, p, and gives an insight into why the results are so similar every time.
References
- Bornhuetter, Ronald L., and Ronald E. Ferguson. 1972. The Actuary and IBNR. Proceedings of the Casualty Actuarial Society 59: 181–95. [Google Scholar]
- Busse, Marc, Michel M. Dacorogna, and Marie Kratz. 2013. Does Risk Diversification Always Work? The Answer through Simple Modelling. SCOR Paper No 24. Available online: http://www.scor.com/en/sgrc/scor-publications/scor-papers.html (accessed on 10 May 2013).
- Busse, Marc, Ulrich Müller, and Michel Dacorogna. 2010. Robust estimation of reserve risk. Astin Bulletin 40: 453–89. [Google Scholar]
- Dacorogna, Michel M., and Christoph Hummel. 2008. Alea Jacta Est, An Illustrative Example of Pricing Risk. SCOR Technical Newsletter. Zurich: SCOR Global P&C. [Google Scholar]
- Ferriero, Alessandro. 2016. Solvency capital estimation, reserving cycle and ultimate risk. Insurance: Mathematics and Economics 68: 162–68. [Google Scholar] [CrossRef]
- Huber, Peter J. 1981. Robust Statistics. Chichester: Wiley. [Google Scholar]
- Mack, Thomas. 1993. Distribution-free calculation of the standard error of chain ladder reserve estimates. Astin Bulletin 23: 213–55. [Google Scholar] [CrossRef]
- Mack, Thomas. 2008. The Prediction Error of Bornhuetter-Fergusonn. Astin Bulletin 38: 87–103. [Google Scholar] [CrossRef]
- Merz, Michael, and Mario V. Wüthrich. 2008. Modelling the claims development result for solvency purposes. Casualty Actuarial Society, 542–68. [Google Scholar]
- Mikosch, Thomas. 2004. Non-Life Insurance Mathematics: An Introduction with Stochastic Processes. Berlin: Springer Verlag. [Google Scholar]
- Rousseeuw, Peter J., and Annick M. Leroy. 1987. Robust Regression and Outlier Detection. New York: Wiley. [Google Scholar]
- Schmidt, Klaus D., and Mathias Zocher. 2008. The Bornhuetter-Ferguson principle. Variance 2: 85–110. [Google Scholar]
- Wüthrich, Mario V., and Michael Merz. 2008. Stochastic Claims ReservingMethods in Insurance. Chichester: Wiley-Finance. [Google Scholar]
Figure 1.
Simulated distribution of the , for a process of length . A normal distribution with mean 0 and variance set at the value calculated in Section 3 is plotted in red.
Figure 1.
Simulated distribution of the , for a process of length . A normal distribution with mean 0 and variance set at the value calculated in Section 3 is plotted in red.

Figure 2.
Average run-off time of the process for short size processes.

Figure 3.
Simulated distribution of the capital for the different methods.

Figure 4.
Comparison of the average yearly required capital over 500 triangles as proportion of the ultimate.
Figure 4.
Comparison of the average yearly required capital over 500 triangles as proportion of the ultimate.

Table 1.
Statistics for the first year capital on the 500 simulated triangles. The mean first year capital, the standard deviation of the capital around that mean and the mean absolute and relative deviations (MAD/MRAD) from the true value are displayed. The latter are computed using both a standard and the robust Huber M-estimator, Huber (1981). The mean reserves estimated with chain-ladder are 101.87, which are consistent with the reserves calculated with our model, i.e., .
Table 1.
Statistics for the first year capital on the 500 simulated triangles. The mean first year capital, the standard deviation of the capital around that mean and the mean absolute and relative deviations (MAD/MRAD) from the true value are displayed. The latter are computed using both a standard and the robust Huber M-estimator, Huber (1981). The mean reserves estimated with chain-ladder are 101.87, which are consistent with the reserves calculated with our model, i.e., .
| Method | Mean | Std. Dev. | MAD | MRAD | Rob. MAD | Rob. MRAD |
|---|---|---|---|---|---|---|
| Theoretical value | 18.37 | 3.92 | 0 | 0% | 0 | 0% |
| SCOR, without jumps | 19.08 | 3.93 | 0.71 | 4.14% | 0.71 | 3.93% |
| SCOR, with jumps | 18.81 | 3.86 | 0.43 | 2.47% | 0.44 | 2.42% |
| Merz–Wüthrich | 252.89 | 149.6 | 234.5 | 1365.6% | 213.9 | 1217.8% |
Table 2.
Correlation matrix of the different capital measures. Above, the standard correlation estimate and below, the robust “MVE” estimate Rousseeuw and Leroy (1987).
Table 2.
Correlation matrix of the different capital measures. Above, the standard correlation estimate and below, the robust “MVE” estimate Rousseeuw and Leroy (1987).
| Standard Corr | True Value | SCOR, No Jumps | SCOR, Jumps | Merz–Wüthrich |
| True value | 100% | 99.98% | 99.97% | −37.64% |
| SCOR, no jumps | 100% | 99.99% | −37.65% | |
| SCOR, jumps | 100% | −37.64% | ||
| Merz–Wüthrich | 100% | |||
| MVE Corr | True Value | SCOR, No Jumps | SCOR, Jumps | Merz–Wüthrich |
| True value | 100% | 99.98% | 99.97% | −46.56% |
| SCOR, no jumps | 100% | 99.99% | −46.61% | |
| SCOR, jumps | 100% | −46.60% | ||
| Merz–Wüthrich | 100% |
Table 3.
Statistics for the risk margin on the 500 simulated triangles. The average risk margin, the standard deviation of the risk margin around the average and the mean absolute and relative deviation (MAD/MRAD) from the true value are displayed.
Table 3.
Statistics for the risk margin on the 500 simulated triangles. The average risk margin, the standard deviation of the risk margin around the average and the mean absolute and relative deviation (MAD/MRAD) from the true value are displayed.
| Method | Mean | Std. Dev. | MAD | MRAD |
|---|---|---|---|---|
| True value (simulation) | 5.89 | 1.27 | 0 | 0% |
| SCOR, without jumps | 6.49 | 1.34 | 0.61 | 10.57% |
| SCOR, with jumps | 4.32 | 0.89 | 1.57 | 26.52% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Dacorogna, M.; Ferriero, A.; Krief, D. One-Year Change Methodologies for Fixed-Sum Insurance Contracts. Risks 2018, 6, 75. https://doi.org/10.3390/risks6030075
AMA Style
Dacorogna M, Ferriero A, Krief D. One-Year Change Methodologies for Fixed-Sum Insurance Contracts. Risks. 2018; 6(3):75. https://doi.org/10.3390/risks6030075
Chicago/Turabian StyleDacorogna, Michel, Alessandro Ferriero, and David Krief. 2018. "One-Year Change Methodologies for Fixed-Sum Insurance Contracts" Risks 6, no. 3: 75. https://doi.org/10.3390/risks6030075
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.