Detecting Transitions in Manual Tasks from Wearables: An Unsupervised Labeling Approach †


Abstract
:
1. Introduction
2. Activity Recognition and Related Work
2.1. AR with Inertial Sensors
2.2. AR via Image Processing
2.3. Unsupervised AR: Clustering
2.4. Unsupervised AR: Motif Discovery
2.5. Supervised AR
2.6. Process Recognition
3. System Design
4. Experimental Setup and Evaluation
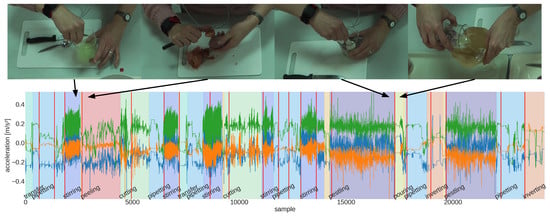
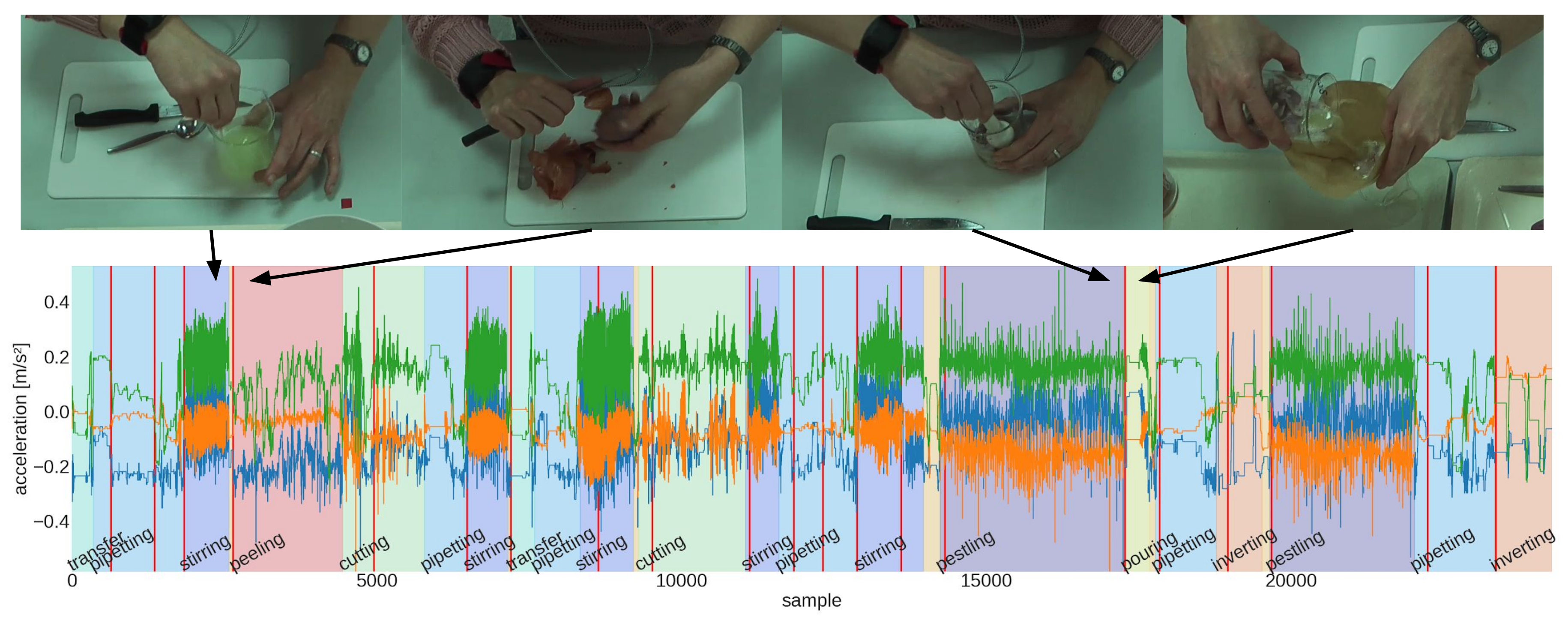
- The DNA Extraction [73] dataset has 13 recordings of a DNA extraction experiments performed in a biological laboratory setting. Motion data from a single wrist accelerometer at 50 are combined with videos from a fixed camera above the experimentation area. Experiments include 9 process steps, which may occur multiple times in one recording and in a semi-variable order.
- CMU’s Kitchen-Brownies [75] dataset contains 9 recordings of participants preparing a simple cookie baking recipe. Motion data from two-arm and two-leg IMUs were recorded at 62 . Video recordings from multiple angles, including a head-mounted camera, are included, as well. In total, the recipes consist of 29 variable actions.
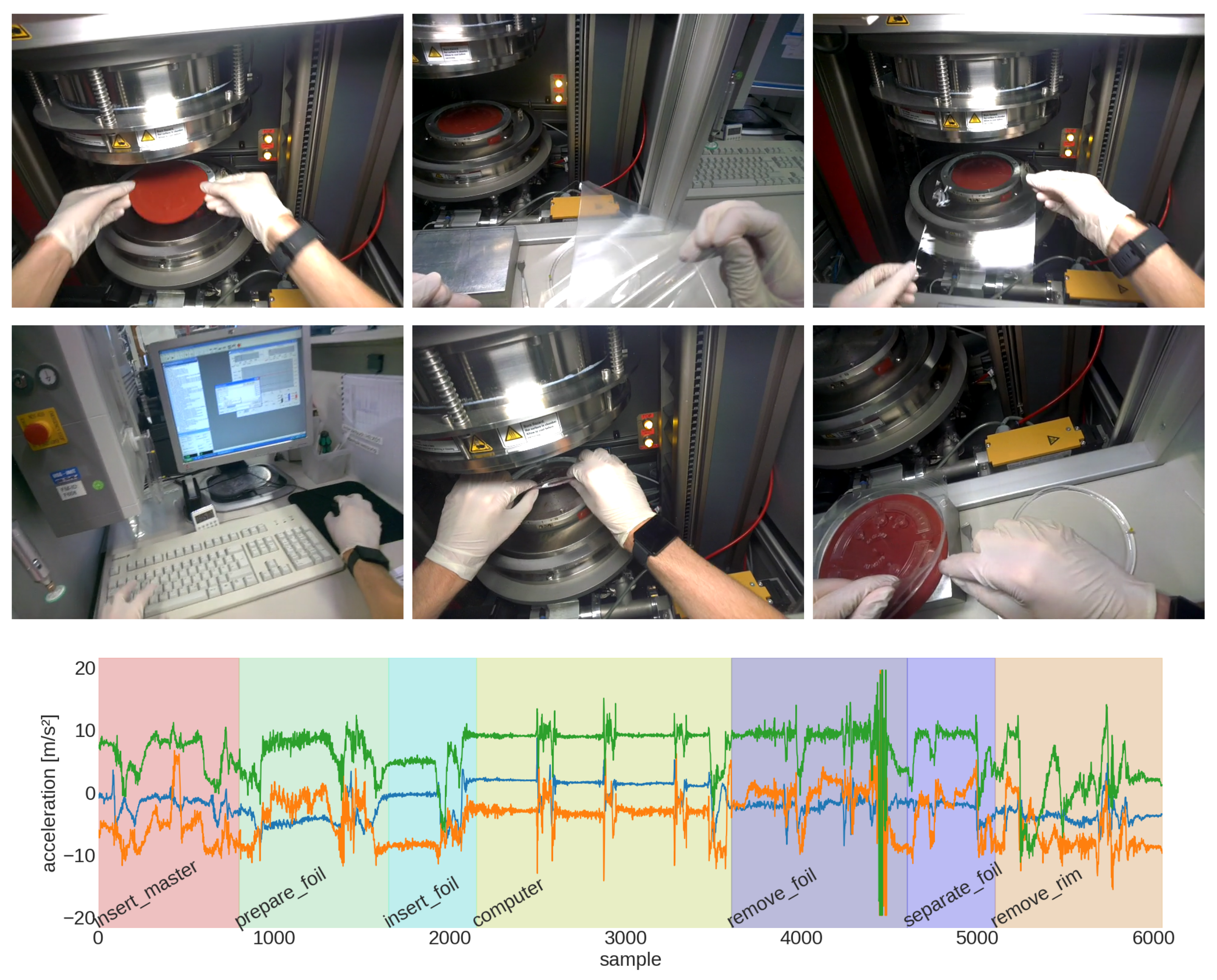
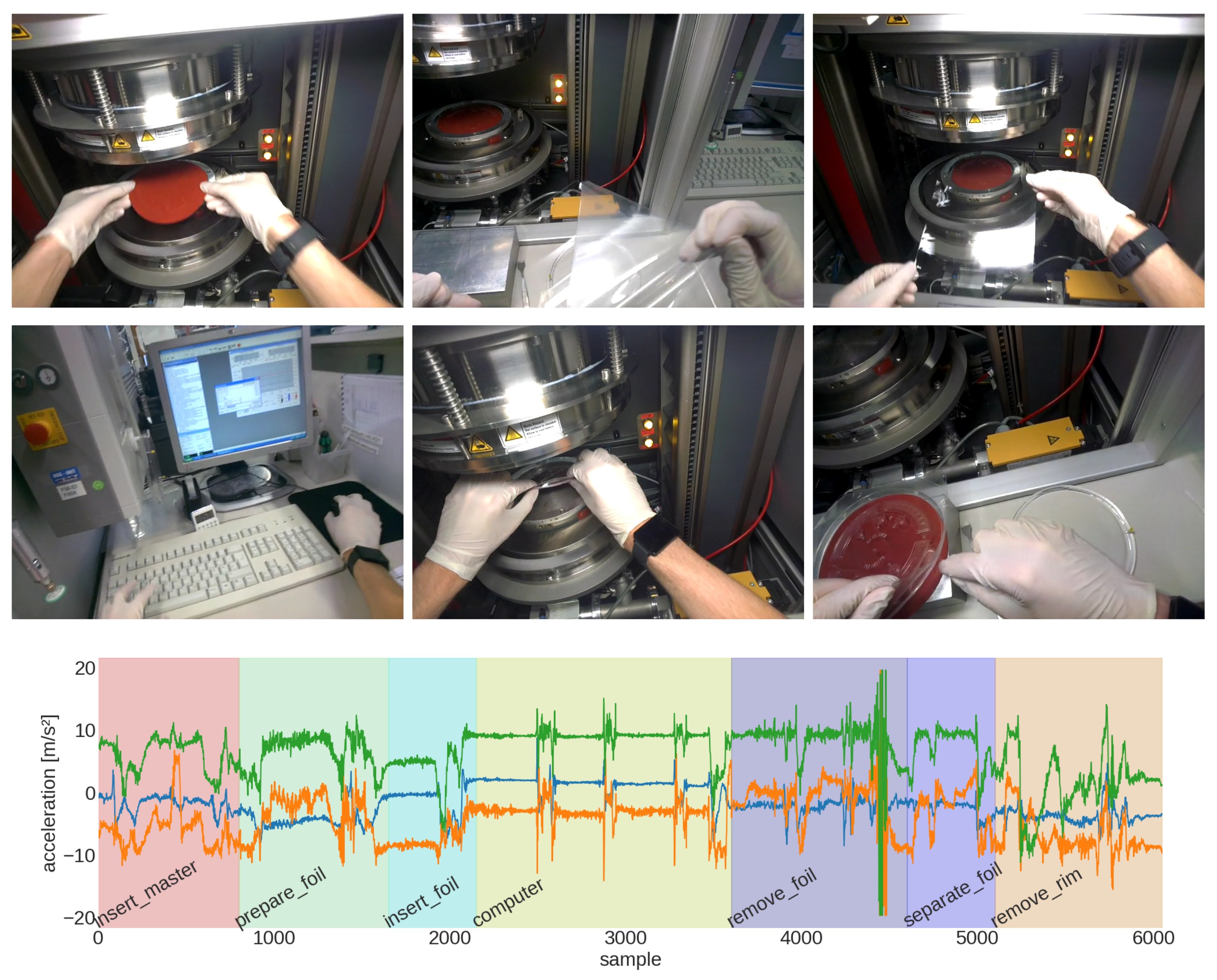
- The Prototype Thermoforming dataset was recorded by ourselves and consists of two recordings of a thermoforming process of a microfluidic ‘lab-on-a-chip’ disk [76]. It combines IMU data at 50 from a smartwatch and Google Glass and video recordings from the Google Glass. The datasets’ process contains 7 fixed process steps in a known order (see Figure 3).
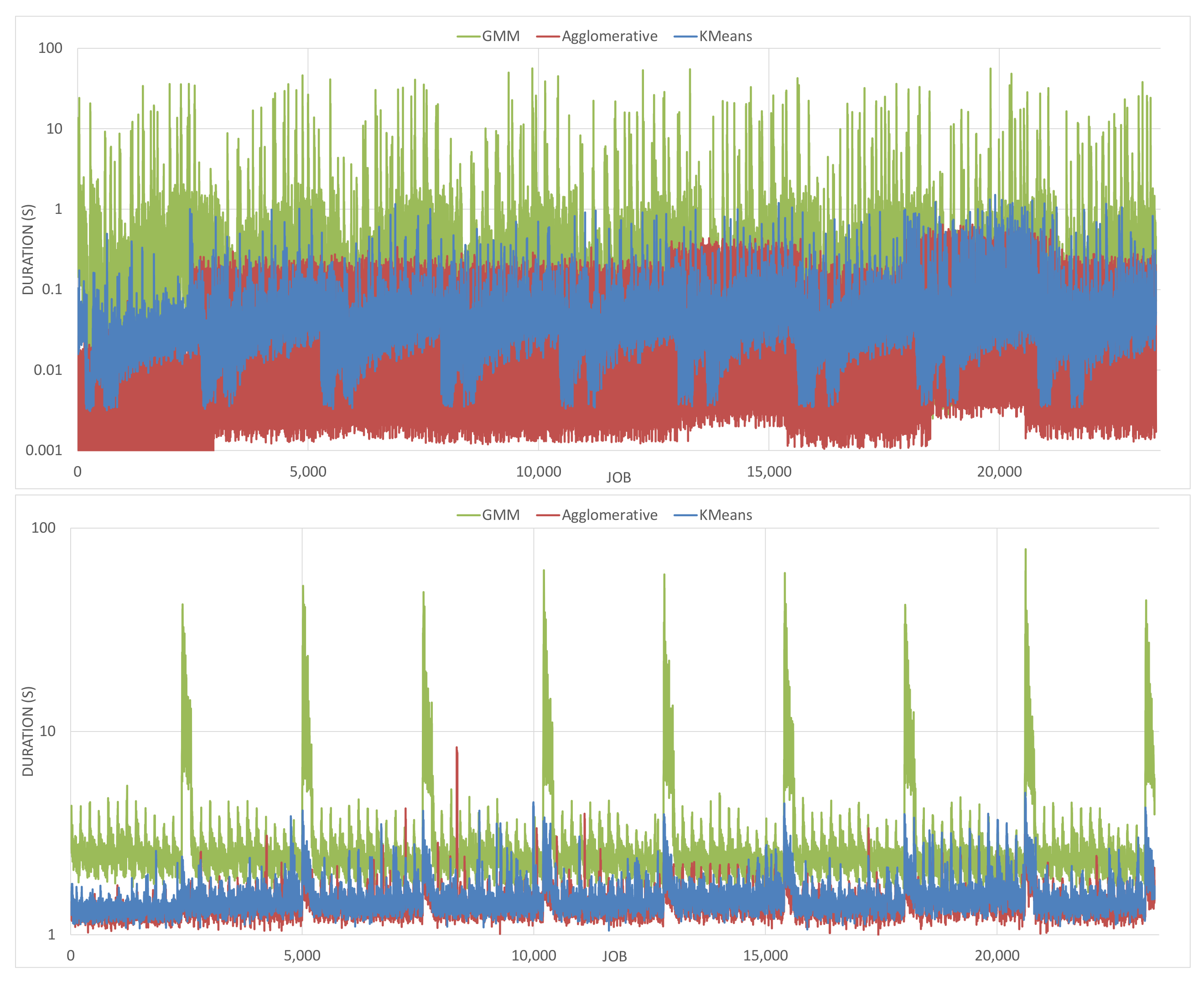
- The results of each method across the three datasets with a recall score of ≥0.75 are intersected across the window, feature and margin parameters, since these are the pipeline parameters applicable to all methods and datasets. The intersection removes duplicates.
- The experiment runs where the three parameters are the same as each parameter combination from the intersection are extracted, per method and dataset and again with recall ≥0.75, which gives three new tables per parameter combination (for each dataset).
- The results are sorted and aggregated according to the recall scores of the DNA extraction dataset, since it provides a large number of individual recordings, simple modality and a relevant set of actions, which makes it the most useful dataset for measuring performance.
5. Discussion
5.1. Limitations
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Böttcher, S.; Scholl, P.M.; Laerhoven, K.V. Detecting Process Transitions from Wearable Sensors: An Unsupervised Labeling Approach. In Proceedings of the 4th International Workshop on Sensor-Based Activity Recognition and Interaction—iWOAR 17, Rostock, Germany, 21–22 September 2017; ACM Press: New York, NY, USA, 2017. [Google Scholar]
- Khan, A.M.; Lee, Y.K.; Lee, S.Y.; Kim, T.S. A Triaxial Accelerometer-Based Physical-Activity Recognition via Augmented-Signal Features and a Hierarchical Recognizer. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 1166–1172. [Google Scholar] [CrossRef] [PubMed]
- Kunze, K.; Lukowicz, P. Dealing with Sensor Displacement in Motion-based Onbody Activity Recognition Systems. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Korea, 21–24 September 2008; ACM: New York, NY, USA, 2008; pp. 20–29. [Google Scholar]
- Lester, J.; Choudhury, T.; Borriello, G. A Practical Approach to Recognizing Physical Activities. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2006; pp. 1–16. [Google Scholar]
- Ravi, N.; Dandekar, N.; Mysore, P.; Littman, M.L. Activity recognition from accelerometer data. In Proceedings of the 17th Conference on Innovative Applications of Artificial Intelligence, Pittsburgh, Pennsylvania, 9–13 July 2005; Volume 5, pp. 1541–1546. [Google Scholar]
- Xu, R.; Zhou, S.; Li, W.J. MEMS Accelerometer Based Nonspecific-User Hand Gesture Recognition. IEEE Sens. J. 2012, 12, 1166–1173. [Google Scholar] [CrossRef]
- Li, Q.; Stankovic, J.A.; Hanson, M.A.; Barth, A.T.; Lach, J.; Zhou, G. Accurate, Fast Fall Detection Using Gyroscopes and Accelerometer-Derived Posture Information. In Proceedings of the 2009 Sixth International Workshop on Wearable and Implantable Body Sensor Networks, Berkeley, CA, USA, 3–5 June 2009. [Google Scholar]
- Shoaib, M.; Bosch, S.; Incel, O.; Scholten, H.; Havinga, P. Complex Human Activity Recognition Using Smartphone and Wrist-Worn Motion Sensors. Sensors 2016, 16, 426. [Google Scholar] [CrossRef] [PubMed]
- Dernbach, S.; Das, B.; Krishnan, N.C.; Thomas, B.L.; Cook, D.J. Simple and Complex Activity Recognition through Smart Phones. In Proceedings of the 2012 8th International Conference on Intelligent Environments (IE), Guanajuato, Mexico, 26–29 June 2012; pp. 214–221. [Google Scholar]
- Büber, E.; Guvensan, A.M. Discriminative time-domain features for activity recognition on a mobile phone. In Proceedings of the 2014 IEEE Ninth International Conference on Intelligent Sensors, Sensor Networks and Information Processing (ISSNIP), Singapore, 21–24 April 2014; pp. 1–6. [Google Scholar]
- Xu, C.; Pathak, P.H.; Mohapatra, P. Finger-writing with Smartwatch: A Case for Finger and Hand Gesture Recognition Using Smartwatch. In Proceedings of the 16th International Workshop on Mobile Computing Systems and Applications, Santa Fe, NM, USA, 12–13 February 2015; ACM: New York, NY, USA, 2015; pp. 9–14. [Google Scholar]
- Berlin, E.; Van Laerhoven, K. Detecting Leisure Activities with Dense Motif Discovery. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; ACM: New York, NY, USA, 2012; pp. 250–259. [Google Scholar]
- Matthies, D.J.; Bieber, G.; Kaulbars, U. AGIS: Automated tool detection & hand-arm vibration estimation using an unmodified smartwatch. In Proceedings of the 3rd International Workshop on Sensor-Based Activity Recognition and Interaction, Rostock, Germany, 23–24 June 2016; ACM: New York, NY, USA, 2016; p. 8. [Google Scholar]
- Trabelsi, D.; Mohammed, S.; Chamroukhi, F.; Oukhellou, L.; Amirat, Y. An Unsupervised Approach for Automatic Activity Recognition Based on Hidden Markov Model Regression. IEEE Trans. Autom. Sci. Eng. 2013, 10, 829–835. [Google Scholar] [CrossRef]
- Zhu, C.; Sheng, W. Human daily activity recognition in robot-assisted living using multi-sensor fusion. In Proceedings of the ICRA ’09. IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 2154–2159. [Google Scholar]
- Trabelsi, D.; Mohammed, S.; Amirat, Y.; Oukhellou, L. Activity recognition using body mounted sensors: An unsupervised learning based approach. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, QLD, Australia, 10–15 June 2012; pp. 1–7. [Google Scholar]
- Huynh, T.; Blanke, U.; Schiele, B. Scalable Recognition of Daily Activities with Wearable Sensors. In Location- and Context-Awareness; Springer: Berlin, Germany, 2007; pp. 50–67. [Google Scholar]
- Peng, H.K.; Wu, P.; Zhu, J.; Zhang, J.Y. Helix: Unsupervised Grammar Induction for Structured Activity Recognition. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining, Vancouver, BC, Canada, 11–14 December 2011; pp. 1194–1199. [Google Scholar]
- Scholl, P.M.; van Laerhoven, K. A Feasibility Study of Wrist-Worn Accelerometer Based Detection of Smoking Habits. In Proceedings of the 2012 Sixth International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing, Palermo, Italy, 4–6 July 2012. [Google Scholar]
- Akyazi, O.; Batmaz, S.; Kosucu, B.; Arnrich, B. SmokeWatch: A smartwatch smoking cessation assistant. In Proceedings of the 2017 25th Signal Processing and Communications Applications Conference (SIU), Antalya, Turkey, 15–18 May 2017. [Google Scholar]
- Mortazavi, B.; Nemati, E.; VanderWall, K.; Flores-Rodriguez, H.; Cai, J.; Lucier, J.; Naeim, A.; Sarrafzadeh, M. Can Smartwatches Replace Smartphones for Posture Tracking? Sensors 2015, 15, 26783–26800. [Google Scholar] [CrossRef] [PubMed]
- Bernaerts, Y.; Druwé, M.; Steensels, S.; Vermeulen, J.; Schöning, J. The office smartwatch: Development and design of a smartwatch app to digitally augment interactions in an office environment. In Proceedings of the 2014 Companion Publication on Designing Interactive Systems–DIS Companion 14, Vancouver, BC, Canada, 21–25 June 2014; ACM Press: New York, NY, USA, 2014. [Google Scholar]
- Ni, B.; Wang, G.; Moulin, P. RGBD-HuDaAct: A Color-Depth Video Database for Human Daily Activity Recognition. In Consumer Depth Cameras for Computer Vision; Springer: London, UK, 2013. [Google Scholar]
- Sung, J.; Ponce, C.; Selman, B.; Saxena, A. Unstructured human activity detection from RGBD images. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation (ICRA), Saint Paul, MN, USA, 14–18 May 2012; pp. 842–849. [Google Scholar]
- Piyathilaka, L.; Kodagoda, S. Gaussian mixture based HMM for human daily activity recognition using 3D skeleton features. In Proceedings of the 2013 8th IEEE Conference on Industrial Electronics and Applications (ICIEA), Melbourne, VIC, Australia, 19–21 June 2013; pp. 567–572. [Google Scholar]
- Eick, C.; Zeidat, N.; Zhao, Z. Supervised clustering—Algorithms and benefits. In Proceedings of the 16th IEEE International Conference on Tools with Artificial Intelligence, Boca Raton, FL, USA, 15–17 November 2004. [Google Scholar]
- Basu, S.; Bilenko, M.; Mooney, R.J. A probabilistic framework for semi-supervised clustering. In Proceedings of the 2004 ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; ACM Press: New York, NY, USA, 2004. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and pRobability; University of California Press: Berkeley, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Jain, A.K.; Dubes, R.C. Algorithms for Clustering Data; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1988. [Google Scholar]
- Jain, A.K. Data Clustering: 50 Years Beyond K-Means. In Machine Learning and Knowledge Discovery in Databases; Springer: Berlin, Germany, 2008; pp. 3–4. [Google Scholar]
- Huynh, T.; Schiele, B. Analyzing Features for Activity Recognition. In Proceedings of the 2005 Joint Conference on Smart Objects and Ambient Intelligence: Innovative Context-aware Services: Usages and Technologies, Grenoble, France, 12–14 October 2005; ACM: New York, NY, USA, 2005; pp. 159–163. [Google Scholar]
- Huynh, T.; Fritz, M.; Schiele, B. Discovery of Activity Patterns Using Topic Models. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Korea, 21–24 September 2008; ACM: New York, NY, USA, 2008; pp. 10–19. [Google Scholar]
- Farrahi, K.; Gatica-Perez, D. Discovering Routines from Large-scale Human Locations Using Probabilistic Topic Models. ACM Trans. Intell. Syst. Technol. 2011, 2, 3:1–3:27. [Google Scholar] [CrossRef]
- Johnson, S.C. Hierarchical clustering schemes. Psychometrika 1967, 32, 241. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.Y.; Chen, Y.P.; Lee, G.Y.; Liou, S.N.; Wang, J.S. Activity Recognition Using One Triaxial Accelerometer: A Neuro-fuzzy Classifier with Feature Reduction. In Proceedings of the Entertainment Computing—ICEC 2007, Shanghai, China, 15–17 September 2007; pp. 395–400. [Google Scholar]
- Ikizler-Cinbis, N.; Sclaroff, S. Object, Scene and Actions: Combining Multiple Features for Human Action Recognition. In Proceedings of the Computer Vision—ECCV 2010, Heraklion, Greece, 5–11 September 2010; pp. 494–507. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the KDD’96 Second International Conference on Knowledge Discovery and Data Mining Pages, Portland, Oregon, 2–4 August 1996. [Google Scholar]
- Kwon, Y.; Kang, K.; Bae, C. Unsupervised learning for human activity recognition using smartphone sensors. Expert Syst. Appl. 2014, 41, 6067–6074. [Google Scholar] [CrossRef]
- Hoque, E.; Stankovic, J. AALO: Activity recognition in smart homes using Active Learning in the presence of Overlapped activities. In Proceedings of the 2012 6th International Conference on Pervasive Computing Technologies for Healthcare (Pervasive Health), San Diego, CA, USA, 21–24 May 2012; pp. 139–146. [Google Scholar]
- Bilmes, J.A. A gentle tutorial of the EM algorithm and its application to parameter estimation for Gaussian mixture and hidden Markov models. Int. Comput. Sci. Inst. 1998, 4, 126. [Google Scholar]
- Rasmussen, C.E. The infinite Gaussian mixture model. In Proceedings of the NIPS’99 12th International Conference on Neural Information Processing Systems NIPS, Denver, CO, USA, 29 November–4 December 1999; Volume 12, pp. 554–560. [Google Scholar]
- Huang, Y.; Englehart, K.B.; Hudgins, B.; Chan, A.D.C. A Gaussian mixture model based classification scheme for myoelectric control of powered upper limb prostheses. IEEE Trans. Biomed. Eng. 2005, 52, 1801–1811. [Google Scholar] [CrossRef] [PubMed]
- Bailey, T.L.; Williams, N.; Misleh, C.; Li, W.W. MEME: discovering and analyzing DNA and protein sequence motifs. Nucleic Acids Res. 2006, 34, W369–W373. [Google Scholar] [CrossRef] [PubMed]
- Chiu, B.; Keogh, E.; Lonardi, S. Probabilistic Discovery of Time Series Motifs. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–27 August 2003; ACM: New York, NY, USA, 2003; pp. 493–498. [Google Scholar]
- Srinivasan, V.; Moghaddam, S.; Mukherji, A.; Rachuri, K.K.; Xu, C.; Tapia, E.M. Mobileminer: Mining your frequent patterns on your phone. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WA, USA, 13–17 September 2014; ACM: New York, NY, USA, 2014; pp. 389–400. [Google Scholar]
- Rawassizadeh, R.; Momeni, E.; Dobbins, C.; Gharibshah, J.; Pazzani, M. Scalable daily human behavioral pattern mining from multivariate temporal data. IEEE Trans. Knowl. Data Eng. 2016, 28, 3098–3112. [Google Scholar] [CrossRef]
- Minnen, D.; Starner, T.; Essa, I.; Isbell, C. Discovering Characteristic Actions from On-Body Sensor Data. In Proceedings of the 2006 10th IEEE International Symposium on Wearable Computers, Montreux, Switzerland, 11–14 October 2006; pp. 11–18. [Google Scholar]
- Vahdatpour, A.; Amini, N.; Sarrafzadeh, M. Toward Unsupervised Activity Discovery Using Multi-Dimensional Motif Detection in Time Series. In Proceedings of the 21st International Jont Conference on Artifical Intelligence, Pasadena, CA, USA, 11–17 July 2009; Volume 9, pp. 1261–1266. [Google Scholar]
- Berlin, E. Early Abstraction of Inertial Sensor Data for Long-Term Deployments. Ph.D. Thesis, Technische Universität, Darmstadt, Germany, 2014. [Google Scholar]
- Quinlan, J.R. C4. 5: Programs for Machine Learning; Elsevier: Amsterdam, The Netherlands, 1993. [Google Scholar]
- Quinlan, J. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Wu, X.; Kumar, V.; Quinlan, J.R.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2007, 14, 1–37. [Google Scholar] [CrossRef]
- Bao, L.; Intille, S.S. Activity Recognition from User-Annotated Acceleration Data. Pervasive Comput. 2004, 1–17. [Google Scholar]
- Lara, Ó.D.; Labrador, M.A. A mobile platform for real-time human activity recognition. In Proceedings of the 2012 IEEE Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 14–17 January 2012; pp. 667–671. [Google Scholar]
- Ho, T.K. Random decision forests. In Proceedings of the Third International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5. [Google Scholar] [CrossRef]
- Altman, N.S. An Introduction to Kernel and Nearest-Neighbor Nonparametric Regression. Am. Statist. 1992, 46, 175–185. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Altini, M.; Penders, J.; Vullers, R.; Amft, O. Estimating Energy Expenditure Using Body-Worn Accelerometers: A Comparison of Methods, Sensors Number and Positioning. IEEE J. Biomed. Health Inform. 2015, 19, 219–226. [Google Scholar] [CrossRef] [PubMed]
- Cleland, I.; Kikhia, B.; Nugent, C.; Boytsov, A.; Hallberg, J.; Synnes, K.; McClean, S.; Finlay, D. Optimal Placement of Accelerometers for the Detection of Everyday Activities. Sensors 2013, 13, 9183–9200. [Google Scholar] [CrossRef] [PubMed]
- McLachlan, G. Discriminant Analysis and Statistical Pattern Recognition; John Wiley & Sons: Hoboken, NJ, USA, 2004; Volume 544. [Google Scholar]
- Siirtola, P.; Röning, J. Recognizing human activities user-independently on smartphones based on accelerometer data. IJIMAI 2012, 1, 38–45. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A comprehensive foundation. Neural Netw. 2004, 2. [Google Scholar]
- Lara, O.D.; Labrador, M.A. A Survey on Human Activity Recognition using Wearable Sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Bader, S.; Aehnelt, M. Tracking Assembly Processes and Providing Assistance in Smart Factories. In Proceedings of the 6th International Conference on Agents and Artificial Intelligence, Loire Valley, France, 6–8 March 2014; pp. 161–168. [Google Scholar]
- Stiefmeier, T.; Roggen, D.; Ogris, G.; Lukowicz, P.; Tröster, G. Wearable Activity Tracking in Car Manufacturing. IEEE Pervasive Comput. 2008, 7, 42–50. [Google Scholar] [CrossRef]
- Stauffer, C.; Grimson, W.E.L. Learning patterns of activity using real-time tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 747–757. [Google Scholar] [CrossRef]
- Song, B.; Kamal, A.T.; Soto, C.; Ding, C.; Farrell, J.A.; Roy-Chowdhury, A.K. Tracking and Activity Recognition through Consensus in Distributed Camera Networks. IEEE Trans. Image Process. 2010, 19, 2564–2579. [Google Scholar] [CrossRef] [PubMed]
- Funk, M.; Korn, O.; Schmidt, A. An Augmented Workplace for Enabling User-defined Tangibles. In Proceedings of the Extended Abstracts of the 32nd Annual ACM Conference on Human Factors in Computing Systems, Toronto, ON, Canada, 26 April–1 May 2014; ACM: New York, NY, USA, 2014; pp. 1285–1290. [Google Scholar]
- Yordanova, K.; Whitehouse, S.; Paiement, A.; Mirmehdi, M.; Kirste, T.; Craddock, I. Whats cooking and why? Behaviour recognition during unscripted cooking tasks for health monitoring. In Proceedings of the 2017 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kona, HI, USA, 13–17 March 2017; pp. 18–21. [Google Scholar]
- Leelasawassuk, T.; Damen, D.; Mayol-Cuevas, W. Automated Capture and Delivery of Assistive Task Guidance with an Eyewear Computer: The GlaciAR System. In Proceedings of the 8th Augmented Human International Conference, Silicon Valley, CA, USA, 16–18 March 2017; ACM: New York, NY, USA, 2017; pp. 1–9. [Google Scholar]
- Scholl, P.M.; Wille, M.; Van Laerhoven, K. Wearables in the Wet Lab: A Laboratory System for Capturing and Guiding Experiments. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Osaka, Japan, 7–11 September 2015; ACM: New York, NY, USA, 2015; pp. 589–599. [Google Scholar]
- Scholl, P.M. Grtool. 2017. Available online: https://github.com/pscholl/grtool (accessed on 5 January 2017).
- De la Torre, F.; Hodgins, J.; Bargteil, A.; Martin, X.; Macey, J.; Collado, A.; Beltran, P. Guide to the Carnegie Mellon University Multimodal Activity (Cmu-Mmac) Database; Technical Report; Robotic Institute, Carnegie Mellon University: Pittsburgh, PA, USA, 2008. [Google Scholar]
- Faller, M. Hahn-Schickard: Lab-on-a-Chip + Analytics. 2016. Available online: http://www.hahn-schickard.de/en/services/lab-on-a-chip-analytics/ (accessed on 6 December 2016).
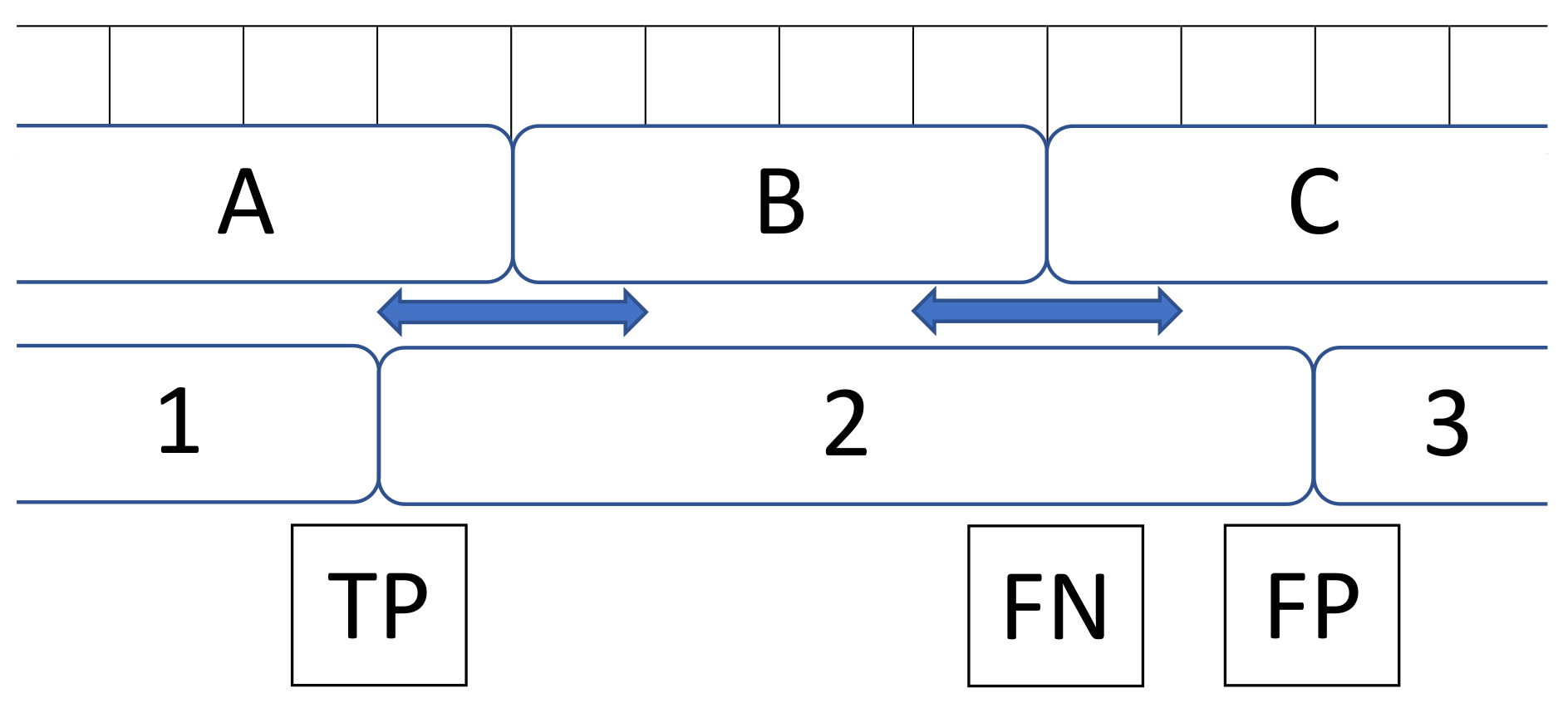
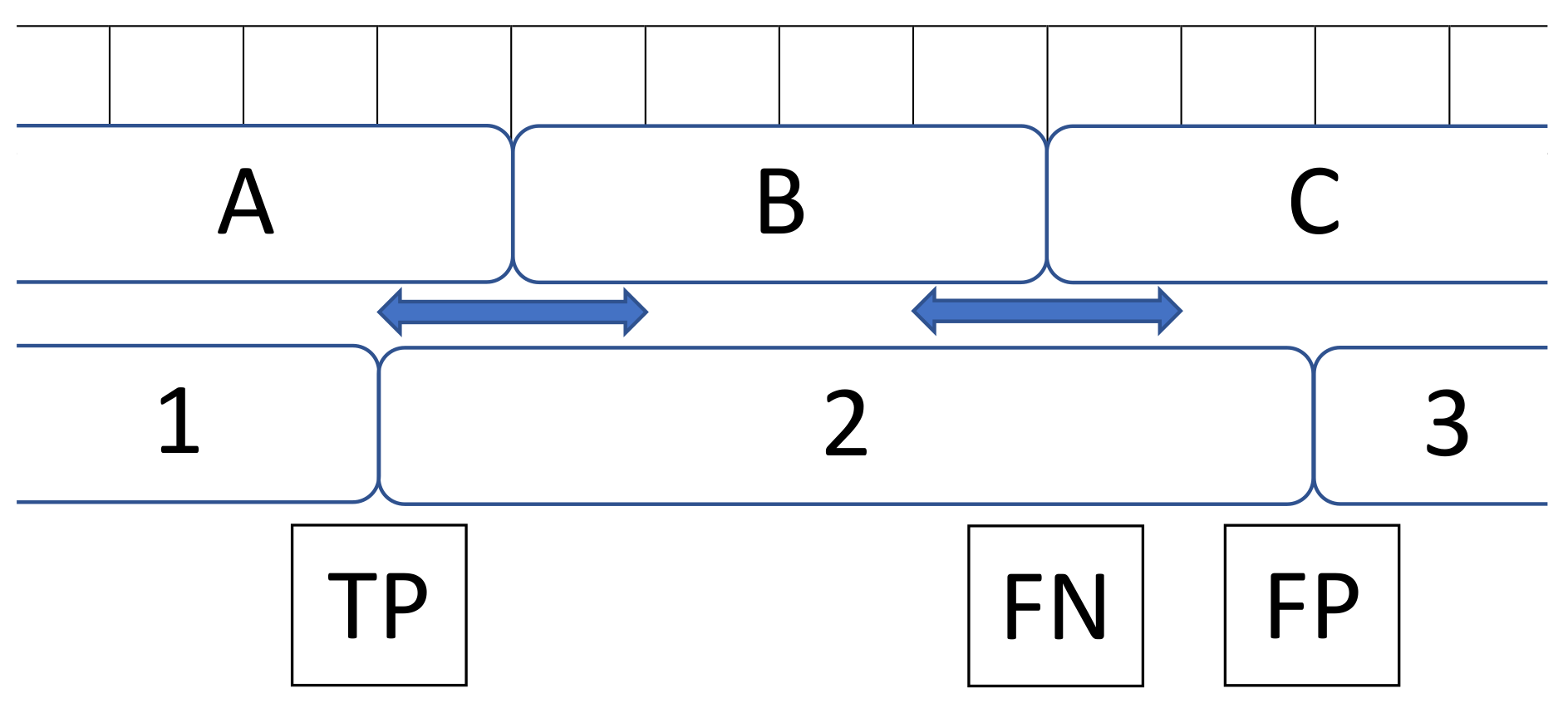
- Ward, J.A.; Lukowicz, P.; Gellersen, H.W. Performance Metrics for Activity Recognition. ACM Trans. Intell. Syst. Technol. 2011, 2, 6. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Modality | Window | Feature | Margin | Accuracy | Recall | Precision | -Score | |
|---|---|---|---|---|---|---|---|---|---|
| Set 1 | k-means | wrist acc | 80 | mean | 4 | 0.92 | 0.92 | 0.92 | 0.92 |
| Agglo. | wrist acc | 90 | time | 5 | 0.92 | 0.93 | 0.92 | 0.93 | |
| GMM | wrist acc | 90 | mean | 3 | 0.88 | 0.88 | 0.87 | 0.87 | |
| Set 2 | k-means | l_leg mag | 100 | time | 3 | 0.97 | 0.97 | 0.98 | 0.97 |
| Agglo. | l_leg gyr | 100 | time | 3 | 0.97 | 0.97 | 0.98 | 0.97 | |
| GMM | r_arm acc | 100 | var | 1 | 0.91 | 0.9 | 0.9 | 0.9 | |
| Set 3 | k-means | wrist acc | 80 | mean | 2 | 0.95 | 0.96 | 0.95 | 0.95 |
| Agglo. | head acc | 90 | mean | 2 | 0.95 | 0.96 | 0.95 | 0.95 | |
| GMM | wrist mag | 100 | mean | 2 | 0.95 | 0.95 | 0.95 | 0.95 |
| Method | Modality | Window | Feature | Margin | Accuracy | Recall | Precision | -Score | |
|---|---|---|---|---|---|---|---|---|---|
| Set 1 | SVM | wrist acc | 100 | time | 1 | 0.64 | 0.75 | 0.63 | 0.58 |
| RF | wrist acc | 100 | variance | 1 | 0.63 | 0.78 | 0.62 | 0.56 | |
| LDA | wrist acc | 100 | variance | 1 | 0.68 | 0.78 | 0.67 | 0.64 | |
| QDA | wrist acc | 90 | variance | 1 | 0.67 | 0.78 | 0.66 | 0.62 | |
| Set 2 | SVM | l_arm acc | 90 | time | 1 | 0.71 | 0.7 | 0.69 | 0.68 |
| RF | r_arm acc | 100 | time | 1 | 0.82 | 0.83 | 0.82 | 0.82 | |
| LDA | all | 100 | variance | 1 | 0.75 | 0.77 | 0.73 | 0.73 | |
| QDA | r_arm mag | 50 | time | 1 | 0.67 | 0.79 | 0.66 | 0.63 | |
| Set 3 | SVM | head acc | 100 | time | 3 | 0.88 | 0.87 | 0.88 | 0.87 |
| RF | wrist acc | 100 | mean | 3 | 0.85 | 0.86 | 0.87 | 0.85 | |
| LDA | wrist mag | 100 | mean | 2 | 0.85 | 0.87 | 0.86 | 0.84 | |
| QDA | wrist mag | 60 | mean | 5 | 0.93 | 0.93 | 0.94 | 0.93 |
| Method | Modality | Window | Feature | Margin | Accuracy | Recall | Precision | -Score | |
|---|---|---|---|---|---|---|---|---|---|
| Set 1 | SVM | wrist acc | 20 | time | - | 0.87 | 0.22 | 0.21 | 0.18 |
| RF | wrist acc | 100 | time | - | 0.88 | 0.29 | 0.33 | 0.26 | |
| LDA | wrist acc | 100 | time | - | 0.88 | 0.32 | 0.33 | 0.3 | |
| QDA | wrist acc | 100 | time | - | 0.84 | 0.22 | 0.15 | 0.15 | |
| Set 2 | SVM | r_arm acc | 100 | variance | - | 0.91 | 0.06 | 0.02 | 0.03 |
| RF | r_arm acc | 100 | variance | - | 0.94 | 0.02 | 0.02 | 0.02 | |
| LDA | r_leg acc | 90 | time | - | 0.92 | 0.1 | 0.05 | 0.06 | |
| QDA | l_leg acc | 40 | mean | - | 0.93 | 0.09 | 0.03 | 0.05 | |
| Set 3 | SVM | head acc | 70 | time | - | 0.87 | 0.45 | 0.44 | 0.41 |
| RF | head acc | 100 | time | - | 0.86 | 0.45 | 0.53 | 0.44 | |
| LDA | head acc | 90 | time | - | 0.88 | 0.49 | 0.53 | 0.48 | |
| QDA | head acc | 100 | mean | - | 0.88 | 0.53 | 0.47 | 0.47 |
| Method | Window | Feature | Margin | Accuracy | Recall | Precision | -Score | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | ||||
| k-means | 80 | mean | 4 | 0.92 | 0.88 | 0.95 | 0.92 | 0.88 | 0.95 | 0.92 | 0.89 | 0.95 | 0.92 | 0.88 | 0.95 |
| Agglo. | 90 | time | 5 | 0.93 | 0.89 | 0.95 | 0.93 | 0.88 | 0.95 | 0.94 | 0.91 | 0.95 | 0.93 | 0.88 | 0.95 |
| GMM | 90 | mean | 3 | 0.88 | 0.86 | 0.95 | 0.88 | 0.86 | 0.95 | 0.87 | 0.89 | 0.95 | 0.87 | 0.86 | 0.95 |
| SVM (trans) | 80 | mean | 4 | 0.84 | 0.75 | 0.93 | 0.83 | 0.75 | 0.93 | 0.85 | 0.84 | 0.94 | 0.83 | 0.74 | 0.93 |
| RF (trans) | 100 | variance | 1 | 0.68 | 0.91 | 0.71 | 0.80 | 0.92 | 0.82 | 0.68 | 0.91 | 0.71 | 0.64 | 0.91 | 0.69 |
| Method | Modality | Window | Feature | Margin | Accuracy | Recall | Precision | -Score |
|---|---|---|---|---|---|---|---|---|
| k-means | wrist acc | 90 | mean | 5 | 0.81 | 0.83 | 0.79 | 0.8 |
| Agglo. | wrist acc | 90 | mean | 3 | 0.83 | 0.83 | 0.81 | 0.82 |
| GMM | wrist acc | 90 | mean | 5 | 0.82 | 0.83 | 0.8 | 0.81 |
| SVM (multi) | wrist acc | 90 | time | - | 0.96 | 0.17 | 0.2 | 0.18 |
| RF (multi) | wrist acc | 80 | variance | - | 0.95 | 0.17 | 0.25 | 0.19 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Böttcher, S.; Scholl, P.M.; Van Laerhoven, K. Detecting Transitions in Manual Tasks from Wearables: An Unsupervised Labeling Approach. Informatics 2018, 5, 16. https://doi.org/10.3390/informatics5020016
Böttcher S, Scholl PM, Van Laerhoven K. Detecting Transitions in Manual Tasks from Wearables: An Unsupervised Labeling Approach. Informatics. 2018; 5(2):16. https://doi.org/10.3390/informatics5020016
Chicago/Turabian StyleBöttcher, Sebastian, Philipp M. Scholl, and Kristof Van Laerhoven. 2018. "Detecting Transitions in Manual Tasks from Wearables: An Unsupervised Labeling Approach" Informatics 5, no. 2: 16. https://doi.org/10.3390/informatics5020016