Domain-Specific Aspect-Sentiment Pair Extraction Using Rules and Compound Noun Lexicon for Customer Reviews


School of Computer Sciences, Universiti Sains Malaysia, Penang 11800, Malaysia
*
Author to whom correspondence should be addressed.
Informatics 2018, 5(4), 45; https://doi.org/10.3390/informatics5040045
Submission received: 27 August 2018
/
Revised: 17 November 2018
/
Accepted: 22 November 2018
/
Published: 29 November 2018
(This article belongs to the Special Issue Data Modeling for Big Data Analytics)
Abstract
:Online reviews are an important source of opinion to measure products’ quality. Hence, automated opinion mining is used to extract important features (aspect) and related comments (sentiment). Extraction of correct aspect-sentiment pairs is critical for overall outcome of opinion mining; however, current works still have limitations in terms of identifying special compound noun and parent-child relationship aspects in the extraction process. To address these problems, an aspect-sentiment pair extraction using the rules and compound noun lexicon (ASPERC) model is proposed. The model consists of three main phases, such as compound noun lexicon generation, aspect-sentiment pair rule generation, and aspect-sentiment pair extraction. The combined approach of rules generated from training sentences and domain specific compound noun lexicon enable extraction of more aspects by firstly identifying special compound noun and parent-child aspects, which eventually contribute to more aspect-sentiment pair extraction. The experiment is conducted with the SemEval 2014 dataset to compare proposed and baseline models. Both ASPERC and its variant, ASPER, result higher in recall (28.58% and 22.55% each) compared to baseline and satisfactorily extract more aspect sentiment pairs. Lastly, the reasonable outcome of ASPER indicates applicability of rules to various domains.
1. Introduction
With the proliferation of the World Wide Web, the way people share and seek opinions has changed. Both customers and organizations can get freely available opinions expressed by people all around the world. Sites, such as blogs, social networks, review sites, forums, and e-commerce websites, provide a better understanding of the customer’s perceptions towards products and services.
Unfortunately, the opinionated texts, which are meant to be helpful, become overwhelming with the passage of time due to the frequency of posts by users. Hence, an automatic way to mine the unstructured contents in text is needed to get a relevant piece of information for better decision making. As a solution to this problem, opinion mining is introduced by researchers.
Opinion mining or sentiment analysis is a field of study that analyzes people’s opinions towards an item (e.g., product) or issue (e.g., service) [1,2]. Aspect based opinion mining relatively gives more detailed insights towards a product or service. This is because a typical customer review will have the description about an aspect of the product or service as well as general feedback about a product or service. The emotion or view expressed in the reviews towards the aspect is known as a sentiment.
Even though the reviews are comprised of vast volumes of sentences, not all the sentences express opinions towards products or services. Therefore, extracting terms that represent opinions in sentences would be useful. The important terms that are present in opinionated sentences are aspect and its corresponding sentiment.
Hence, to represent the opinion of the product or service from a review sentence, aspect-sentiment pair extraction is crucial. The aspect-sentiment pairs extracted from opinion review sentences in Table 1 are represented as the decomposed view as in Table 2. By referring to the decomposed view of opinion review sentences, customers or manufacturers can get a glimpse of the pros and cons of a product or service in a short time.
Aspect-sentiment pair extraction is quite a hard task as it involves processing the sentences written by reviewers in different ways. Hence, there is no predefined solution for this problem. Most of the previous works have extracted aspect-sentiment pairs using syntactic based approaches [3,4]. Syntactic based aspect extraction approaches are usually dependency based [5,6,7,8] and rules based [9,10,11]. Some advanced syntactic based works include [12,13,14]. However, those works still have limitations in identifying multi-word aspects that consist of a parent-child relationship and special compound noun.
Most of the important aspects are missed in the existing works, due to parsing error in the identification of special compound noun aspects. The parsing error causes misidentification of the aspects as sentiments. For example, in the compound noun, “hard disk”, “hard” is identified as a sentiment and “disk” is identified as an aspect. The parent-child aspects are also missed because of inadequate dependency relations and generalized rules are unable to relate the parent-child aspect to their corresponding sentiment. For example, in the sentence, “The screen of laptop is big”, the aspect, “Screen of laptop”, is not extracted as whole, only screen (child) or laptop (parent) is extracted.
To overcome these drawbacks, in this paper, the aspect-sentiment pair extraction model with rules and lexicon is proposed to improve aspect-sentiment pair extraction. Different types of aspects, such as compound nouns, special compound nouns, and parent-child aspects, are identified using rules and compound noun lexicon. With respect to this, the objectives are:
- To determine the optimized number of review sentences to train the aspect-sentiment pair extraction model; and
- To improve the aspect-sentiment pairs extraction via enhancement of rules and compound noun lexicon.
In general, the decomposed view (i.e., the output) that consists of aspect-sentiment pairs of customers’ review sentences can be a beneficial utilization for consumers, organizations, and for opinion mining systems. Consumers are no longer bound to read a lot of reviews and can save time when making decisions before proceeding to purchasing products or services. Similarly, product manufacturers can avoid the trivial job of processing and analyzing review sentences to obtain customers’ feedback. In addition, this decomposed view can also be applied as an input to opinion mining systems, such as the decision making and recommendation system. It could also function as one of the important steps in a sentiment analysis pipeline, e.g., as input for polarity analysis.
In the remainder of this paper, Section 2 gives the definition of aspect-sentiment opinion mining, and a detailed discussion of existing works on aspect-sentiment pair extraction is given in Section 3. Section 4 introduces the proposed model, including all the processes in each phase of the model. Subsequently, Section 5 describes the conducted experiment and discusses the results. Finally, Section 6 concludes the paper.
2. Aspect-Sentiment Opinion Mining
The key tasks in aspect-sentiment opinion mining are aspect and sentiment extraction given an input text. For example, consider a hotel review, “The room was clean and spacious”. The first stage is to detect the aspect which is “room”, followed by identifying aspect related sentiment words, such as “clean” and “spacious”.
In the literature, an aspect is also addressed as a feature, topic, attribute, and target [15]. An aspect can be grouped into two types, which are an explicit aspect and implicit aspect. Explicit aspects are aspects that are directly denoted in sentences and typically represented by noun and noun phrases [1]. For instance, in the sentence, “The screen of iPhone 6 is very big”, the aspect, “screen”, is explicitly indicated. Implicit aspects are the opposite of explicit aspects because they are often expressed indirectly in sentences [1]. For example, in the sentence, “The phone is very expensive”, the aspect is not directly mentioned, but an implicit aspect of “price” can be inferred.
Aspect-based opinion mining yields very fine-grained information, which is useful for applications in various domains [16]. It gives detailed insights towards products or services. This is because a typical customer review will contain a description about the aspect of the product or service and a general view about a product or service.
Alternatively, a sentiment is interchangeably used as an opinion, attitude, appraisal, emotion, and evaluation [1]. It is generally conveyed through the usage of adjectives. Both implicit and explicit aspects as well as sentiment can be analyzed at either the syntactic (or content) or semantic (or concept) level.
The aspect can constitute a single-word or multi-word terms. Single-word aspects are generally represented by a noun, such as “battery”. Whereas, a multi-word aspect is represented by noun phrases, such as “battery life”. Multi-word aspects are usually in the form of compound nouns or parent-child aspects. A compound noun is a fixed expression, which is made up of more than one word [17]. Such expressions are frequently combinations of two nouns or a noun and other part of speech (POS), such as an adjective, verb, particle, cardinal, etc. [17]. For example, “battery life” is a noun-noun compound noun and “hard disk” is a special compound noun.
Parent-child aspects consist of an aspect that is general (parent) and an aspect that is a specific (child) part of the general aspect [18]. For example, in the sentence, “The screen of the laptop is wide”, “laptop” is the parent and “screen” is the child. Besides that, another example of a sentence with a parent-child relationship is “Durability of battery is awesome”, where the parent is “battery” and “durability” is the child.
Although most of the aspect-sentiment opinion mining is performed at the sentence level. It could also be extended to the paragraph or document level when more complex analysis is required. For example, for a sentence, like “It is very cheap.”, the extraction of a meaningful aspect (rather than pronoun) will involve neighboring sentences. Hence, the opinion mining is deemed to be carried out at the paragraph level.
3. Related Work
Aspect-sentiment pair extraction in opinion mining has been around for more than a decade. Over the years, many researchers have come up with various solutions to in the extraction of aspect-sentiment pairs. In this work, a syntactic based aspect extraction approach is utilized. Syntax of a language is its grammar. They are the rules or principles to decide the order of word’s type or vocabulary in a sentence related to a specific language. For example, in the English language, five nouns cannot be simply put together to be assumed as a correct sentence. Appropriate word order should be applied in a sentence for proper syntax. An example of the correct sequence of a sentence in English is “Ali likes durian”, which consists of a subject, verb, and object [19]. However, sequences vary between different languages [19].
Similarly, a syntactic based aspect extraction approach makes use of the sentence structure or term position in a sentence to detect the appearance of an aspect and opinion. There are two ways of using syntax as a measure to extract features, such as dependency parsing and rule based approaches. Some of the related works in dependency parsing are [5,6,7,8]. All these works used dependency relations, such as a mod, rcmod, and advmod, and combine them to produce aspect-sentiment pairs. In the relations, the noun or noun phrase is identified as an aspect whilst the adjective is identified as a sentiment. The noun phrase that has been found is a noun-noun compound noun. Due to usage of a parser, some error results in the extraction of aspect-sentiment pairs. If the sentence consists of terms, like “hard disk”, the parser tagged “hard” is an adjective and “disk” is a noun. “Hard disk” should be extracted as a term as it is a type of compound noun. This issue causes the approaches to produce aspect-sentiment pairs, where “disk” is the aspect and “hard” is a sentiment.
Furthermore, the parent-child aspects’ identification is also less considered in these works. If the parent-child aspect is identified, only either one is assigned to a sentiment. For example, in the sentence, “Customization on Mac is impossible”, the parent is “Mac” and the child is “Customization”. However, only “Mac” is mapped to “impossible”, which is an incomplete mapping of the aspect to its sentiment.
The rule-based method that is most similar to our approach is by [9], this work identifies aspect and sentiment by defining nine rules. The rules contain aspect (noun or noun phrases) and sentiment (adjective) POS tags with their mapping. The rules are the patterns that are learned from sentences of training data. For example, in the (“[DT] NN1 VB [RB] JJ1.1 [CC [RB] JJ1.2]”), aspect “NN1” is mapped to sentiments, “JJ1.1” and “JJ1.2”, resulting in aspect-sentiment pairs of (“NN1, JJ1.1”) and (“NN1, JJ1.2”). The general type of rules is unable to identify aspect-sentiment pairs if the sentences contain a POS tag sequence of (“NN RB RB VB JJ”), since the sentence must follow the exact sequence of POS tags in rules.
Moreover, due to POS tagging error, the misidentification of the aspect-sentiment pair also occurs, such as for the case of “hard disk” that also happens in the dependency parsing based method. Hence, a special compound noun is unable to be identified by using this approach. The general rules also do not address parent-child aspects and their mapping.
The incomplete aspect identification in aspect-sentiment pairs means some of the aspect-sentiment pairs are not extracted. Due to a lack of different types of aspects, such as a special compound noun and parent-child aspects, the sentiments associated with these aspects are also not discovered. Although these aspects are addressed by many researchers, none of the them completely resolve both types of aspect identification in aspect-sentiment pair extraction. A close related work by [20] proposed a multilayer attention network, where each layer consists of a couple of attentions, like attention for extracting aspect terms and attention for extracting opinion terms. The pro of this approach is that it avoids the limitation of parsing, i.e., avoiding the compound noun issue, however, a relatively large number of training sentences are required to train the deep learning model.
Until now, none of the approaches have addressed improving aspect identification in aspect-sentiment pairs in both types of multi-word aspects, such as a special compound noun aspect and parent-child aspects with the consideration of little training sentences; this work will resolve this problem.
4. Aspect Sentiment Pair Extraction using Rules and the Compound Noun Lexicon Model
In this paper, a model known as the aspect-sentiment pair extraction model using rules and compound noun lexicon (ASPERC) is proposed. As shown in Figure 1, the model consists of three main phases, such as compound noun lexicon generation, aspect-sentiment pair rule generation, and aspect-sentiment pair extraction.
4.1. Phase I: Compound Noun Lexicon Generation
The compound noun lexicon used in the aspect-sentiment extraction model is generated based on the corpus based method. The corpus used in lexicon is the training dataset. A total of 500 training sentences are used to compile laptop and restaurant compound noun lexicon. Two-hundred and fifty laptop training sentences are used to build laptop compound noun lexicon and another 250 are used to build restaurant compound noun lexicon. This is because the compound noun lexicon is domain specific. It requires a domain specific compound noun word from training sentences to be applied into testing sentences.
The amount, 250, follows the number of training sentences that are used to create the rules. Since 250 sentences are utilized to create the rules, the same sentences have also been used to create lexicon.
During the Phase I, Step II (POS tagging), the tags of a compound noun detected by the tagger was observed. It was noted that compound nouns do not always consist of noun (“NN”) + noun (“NN”) tags. Basically, compound nouns consist of noun phrases. In the noun phrase, one word is a noun and another word can be either a noun or a different POS. The noun in the compound noun (“NN”) can be modified by an adjective (“JJ”), noun (“NN”), verb (“VB”), particle (“RP”), cardinal (“CD”), etc. [17].
Hence, the compound noun of different types of POS tag is difficult to be detected by works that regard only a (“NN NN”) compound noun to be aspects. However, in this work, besides using (“NN NN”) as aspects, the special compound noun is also identified. The identification of other types of compound nouns can simultaneously help in discovering more aspects. As a result, compilation of compound nouns in the lexicon and using it in the model can help to improve aspect identification. In order to generate compound noun lexicon, there are four steps that are carried out. The four steps are: I) Compound nouns pattern identification, II) compound nouns compilation, III) compound nouns verification, and IV) compound nouns pruning. The POS tagged training sentences used are obtained from Phase II. Each of these steps is discussed in detail in this section.
4.1.1. Step I: Compound Nouns’ Pattern Identification
In the POS tagged training sentences, the pattern of compound noun lexicon was identified through linguistic inspection. The patterns identified includes (“JJ+ NN+”), (“NN+ CD”), (“VB+ NN+”), and (“VB+ RP”). The plus (“+”) sign indicates that the POS tag can have many forms or can have an additional character. For example, the pattern (“NN CD”) can be in another form, such as (“NNS CD”) and (“NNP CD”). This is because a noun (“NN”) can be expressed as singular (“NN”), plural (“NNS”), and a proper noun (“NNP”). Thus, to make a more generic pattern, the common characters are used to represent all the possible forms.
4.1.2. Step II: Compound Nouns Compilation
Using the patterns stated in Table 3, all the occurrences of the words with the POS tags are compiled from the POS tagged training data.
The compound noun patterns are searched using the keyword in context (KWIC) technique [21]. Basically, this technique compiles all the keywords in the dataset and allows the keywords to be searchable with its surrounding words. The AntConc 3.4.4 tool [22] that implements this KWIC technique is used to find compound nouns in the tagged dataset.
Firstly, to search for keywords, the cluster size needs to be defined. Since compound nouns consist of two words, and the tags associated with them are also counted, the cluster size is set to four. For example, “hard_JJ drive_NN” consists of four sequences (“hard”, “JJ”, “drive”, “NN”). Then, the patterns were searched using the search wildcard. For example, to search “hard_JJ drive_NN”, wildcards, such as “*_JJ+ *_NN+*”, are defined in the search. The output is the list of words with its tags.
As seen in the example, the reason why the cluster size is set to four is the word together with its tag is needed to be displayed. Since a compound noun consists of two words, the corresponding tags of the compound noun are also two. Hence, a total of four clusters are defined to represent the two words and the two tags. Also, compound nouns that are considered consist of a two-word compound noun only; other types of compound noun are not part of this work.
4.1.3. Step III: Compound Nouns Verification
The lists of words with its tags obtained in Step II are verified as in Figure 2 and Figure 3 to determine whether those words are compound nouns. This verification is done by comparing the words in the list with Wikipedia Encyclopedia. Wikipedia is used because of its encyclopedic nature [23]. It contains articles with named entities as well as terms, which is large in size for corpus oriented statistical analysis [23].
The compound nouns’ words are maintained in the list if the two words in the compound noun exist in a Wikipedia article. The compound noun words can be part of multi-word terms in Wikipedia. This means that a compound noun can occur as a two-word term or as part of more than two-word terms. As long as the compound noun terms occur in either way, they are maintained in the list with their associated tags.
4.1.4. Step 4: Compound Nouns’ Pruning
The verified compound nouns in the list are stored, and the compound nouns that do not present in Wikipedia are removed from the list. This final list is stored as compound noun lexicon (Table 4).
4.2. Phase II: Aspect-sentiment Pair Rules Generation
The main idea of this phase is to generate rules based on the training sentences dataset. Several steps are carried out, which finally leads to creation of a knowledge base consisting of aspect-sentiment pair rules and aspect-sentiment pair templates. The steps are described in detail in the following section.
4.2.1. Step I: Preprocessing
Reviews are written by humans. Thus, the sentences can contain many irrelevant non-alphabetic characters, such as “:)”, “1)”, “1.”, “- (only for the beginning of a sentence)”. These characters are removed from training sentences so that unnecessary processing during the next phases can be avoided. Besides that, sentence segmentation is also done to split two complete sentences separated by punctuation (e.g., “;”, “,” and etc.).
4.2.2. Step II: POS Tagging
POS tagging is performed by using the Stanford POS Tagger tool to tag all the training sentences, in which, the part of speech, such as a noun (“NN”), verb (“VB”), adjective (“JJ”), adverb (“RB”), etc., are assigned to each of the words in training sentences. Each of the POS tagged sentences has its original words plus its corresponding tag. The POS tagging is illustrated in Example 4.1.
Example 4.1:
Review sentence: The graphics are stunning.
POS tagged sentence: The/DT graphics/NNS are/VBP stunning/JJ./.
4.2.3. Step III: Special Compound Noun Pattern Detection
In this step, the special compound noun patterns, such as (“VB+ NN+”), (“JJ+ NN+”), etc., are searched in the POS tagged sentence. The plus (“+”) sign in the pattern indicates that any one character can exist after the tag. For example, in the operating system POS tag (“VBG NN”), the additional character is “G”.
If the pattern is found, then the tags inside the pattern of the POS tagged sentence will be checked. These tags are checked for its validity through compound noun lexicon. For this purpose, only non-noun (not “NN+”) tags in the pattern will be compared against the tags in compound noun lexicon. Here, both the tag and the associated word in a POS tagged sentence must be the same as in lexicon. If they are the same, then the matching non-noun tag will be changed to a noun (“NN”) tag. Note that only non-noun tags would be changed to nouns if there is a noun tag it remains as it is. This is to enable the application of rules in the sentence. Without changing the non-noun tags to noun tags, the rules cannot be applied to the sentence. If there is no compound noun pattern detected, then, the sentence POS tagged sentence has no changes.
After this process, only the sentences with at least one aspect (“NN”) and one sentiment (“JJ”) are maintained. This step is to avoid processing sentences that do not have an aspect and sentiment mentioned. An example of how compound noun pattern detection is performed is shown in Example 4.2.

4.2.4. Step IV: POS Tag Grouping
It is observed in the training data that an aspect can be a noun or noun phrases. This means that an aspect can be a single-word or multi-word. Similarly, an intensity word, such as an adverb, also occurs more than one time continuously. Both tags are grouped per number of consecutive occurrences.
After grouping, a general tag (nnx or rbx) is used to represent the grouped noun or adverb tag. Subscript “x” denotes the total number of consecutive occurrences of the noun or adverbs. For example, “also/RB relatively/RB” is grouped “also relatively/rb2”.
This process is conducted to make the rule generated later to be more generic. The example of grouped POS tagged representation for a single occurrence of a noun and adverb is as in Example 4.3. The example of grouped POS tagged representation for multiple occurrences of nouns and adverbs is as in Example 4.4.
Example 4.3 (Single occurrence of noun and adverb):
Review sentence:The battery is really long.
POS tagged sentence:The/DT battery/NN is/VBZ very/RB long/JJ. /.
Grouped POS tagged sentence:The/DT battery/nn1 is/VBZ very/rb1 long/JJ./.
Example 4.4 (Multiple occurrences of noun and adverb):
Review sentence:The battery life is also relatively good.
POS tagged sentence:The/DT battery/NN life/NN is/VBZ also/RB relatively/RB good/JJ. /.
Grouped POS tagged sentence:The/DT battery life/nn2 is/VBZ also relatively/rb2 good/JJ. /.
4.2.5. Step V: Rules’ Generation
In this step, the rules, rules ranking as well as the template to extract the aspect-sentiment pairs are explained. There are five sub steps in this step, such as I) generic rule generation, II) generic rule ranking, III) aspect-sentiment pair rule generation, IV) aspect-sentiment pair rule ranking, and V) aspect-sentiment pair template creation. These steps will be discussed in the following sections.
a) Sub Step I: Generic Rule Generation
Using the grouped POS tagged sentences; the tags that appear in every type of sentence are analyzed using linguistic inspection. It is observed that every type of sentence shares some common POS tags among them. For example, common tag sequences that are observed in the sentences includes (“nn VB JJ”), (“JJ nn”), (“JJ IN nn”), (“nn WD VB JJ”), (“JJ JJ nn”), (“nn IN nn JJ”), (“nn JJ”), (“JJ CC JJ nn”), and (“JJ TO nn”). These common tags are assigned as generic rules.
Next, the position of the tags in generic rules is determined in which the aspect (“nn”), sentiment (“JJ”), and also intensity (“rb”) are denoted by subscript “a” “b”, “c”, and etc. The subscript is used to show the position of the aspect, sentiment, or intensity that occurs at the first position (“a”), second position (“b”), third position (“c”), and etc.
The position shows the arrangement of the aspect (“nn”), sentiment (“JJ”), or intensity (“rb”) POS tag that appears in the generic rules. This is important because if the POS tag, such as (“nn”), (“JJ”), and (“rb”), appear more than one time in the generic rule, then the position is important as it will indicate that there are few occurrences of the (“nn”), (“JJ”), and (“rb”).
For example, in the generic rule, (“JJa JJb nnxa”), the subscript, (“a”), indicates the first occurrence of (“JJ”) and subscript, (“b”), indicates the second occurrence of (“JJ”). This position is important for template creation, where the aspect and sentiment will be matched using the template. This is to determine which aspect matches to which sentiment. As in the example, the aspect, (“nnxa”), will be matched with (“JJa”) as the first aspect-sentiment pair. Next, aspect (“nnxa”) will be matched with (“JJb”) as the second aspect-sentiment pair.
As some generic rules are more important than others, ranking is performed to give weightage to important rules. This is conducted by observing the frequency of appearance of generic rules in the training dataset sentences.
b) Sub Step II: Generic Rule Ranking
Based on the generic rules, all the grouped POS tagged sentences are assigned. The POS tags in generic rules must appear sequentially in the grouped POS tagged sentences and the order must be followed. Table 5 shows the assignment of some sample grouped POS tagged sentences to their generic rules type (Examples 4.5–4.7).
For the assignment by generic rules, only the first two characters of the POS tags are considered. For example, if a grouped POS tagged sentence has POS tag (“DT nn1 VBZ JJ”) as in Example 4.5, only the first two characters, such as “DT nn1 VB JJ”, are used for categorization. This means similar POS tags (e.g., “VBD”, “VBZ”, “VBP”, and etc.) in grouped POS tag sentences can be generalized to be assigned to generic rules.
After all the grouped POS tagged sentences were assigned by generic rules, the frequencies of assigned grouped POS tagged sentences per generic rules are counted. The generic rules are then ranked by their respective assigned grouped POS tagged sentence frequencies. The rank is ordered in ascending order from highest to lowest frequency. Table 6 shows the generic rules with their corresponding frequency.
c) Sub Step III: Aspect-sentiment Pair Rule Generation
After generic rules are obtained, we can proceed to identify unique rules that are associated to each generic rule. For example, the generic rule, (“nnxa VB JJa”), can have associated unique rules, like (“nnxa VB JJa”), (“nnxa VB rbxa JJa”), and (“nnxa VB JJa CC JJb”).
Besides that, the unique rule generation process is also needed to find the stopping criterion for the number of training sentences required. Hence, the iteration method is used during the unique rule generation process. Firstly, the grouped POS tagged sentences are divided into 50 sentences per iteration. The iteration was repeated six times with different grouped POS tagged sentences.
To identify unique rules, duplicate grouped POS tagged sentences are removed in every iteration. For example, the grouped POS tagged sentences associated with generic rule (“nnxa VB JJa”) are (“nnxa VB JJa”), (“nnxa VB rbxa JJa”), and (“nnxa VB JJa CC JJb”). These sentences can occur many times during the iteration. For instance, (“nnxa VB rbxa JJa”) can occur five times during the first iteration. To make it unique, only one occurrence is maintained, and the others are discarded.
The iteration is continued until there is no significant increase in the number of unique grouped POS tagged sentences. Hence, the stopping criterion is at the fifth iteration. The number of training sentences are 250 sentences.
All the unique POS tagged sentences identified until the fifth iteration are assigned as aspect-sentiment pair rules. The number of aspect-sentiment rules in every iteration are shown in Table 7.
For each aspect-sentiment pair generated, the position of the aspect (“nn”), sentiment (“JJ”), and intensity (“rb”) are denoted by subscript (“a”), (“b”), (“c”), and etc. The position is in accordance with the first appearance in the tag (e.g., “a”) until the subsequent appearances (e.g., “b”, “c”, and etc.). Examples of aspect-sentiment pair rules are shown in Table 8.
d) Sub Step IV: Aspect-sentiment Pair Rule Ranking
The aspect-sentiment pair rules are also ranked with the assigned grouped POS tag sentence. However, in this sub step, all the unique assigned grouped POS tag sentence frequencies are counted. These frequencies are used to rank the aspect-sentiment pair rules. The rank is ordered in ascending order from highest to lowest frequency. Table 9 shows some aspect-sentiment pair rules with their corresponding frequency.
e) Sub Step V: Aspect-sentiment Pair Template Creation
In the aspect-sentiment pair rules, the main components are the aspect and its corresponding sentiment. An aspect is a noun or noun phrases (“nnx”), meanwhile, a sentiment is represented by an adjective (“JJ”). Hence, in the rules, there are many tags that are irrelevant, such as (“VB”), (“WD”), etc. In this step, the aspect and its corresponding sentiment will be linked to produce aspect and sentiment pairs. Furthermore, the aspect-sentiment pair rules also have an additional advantage of identifying the intensity (“rbx”), which is usually represented by an adverb.
Basically, an aspect can have one sentiment or more. Similarly, a sentiment can have one aspect or more. Sentiments can also have one or more intensities. Thus, the positions of arrangements of (“a”, “b”, “c”, and etc.) of the aspect, sentiment, and intensity defined in the rules are used in this step to associate the aspect to its corresponding sentiment/s. If an intensity exists before the sentiment, it is also included as additional information. This linking between the aspect and its respective sentiment is obtained through linguistic inspection to produce templates. Examples 4.8–4.10 show the aspect-sentiment pair template created based on the rules.
Example 4.8 (One aspect and one sentiment):
Review sentence:The touchpad is very intuitive
POS tagged sentence:The/DT touchpad/NN is/VBZ very/RB intuitive/JJ
Grouped POS tagged sentence:The/DT touchpad/nn1 is/VBZ very/rb1 intuitive/JJ
Generic rule:nnxa VB JJa
Aspect-sentiment pair rule (R2):nnxa VB rbxa JJa
Aspect-sentiment pair template creation:(nnxa; rbxa; JJa)
Example 4.9 (One sentiment and two aspects):
Review sentence:Amazing colors and resolution.
POS tagged sentence:Amazing/JJ colors/NNS and/CC resolution/NN. /.
Grouped POS tagged sentence:Amazing/JJ (colors/NNS)/nn1 and/CC (resolution/NN)/nn1. /.
Generic rule:JJa nnxa
Aspect-sentiment pair rule (R23):JJa nnxa CC nnxb
Aspect-sentiment pair template creation:(nnxa; ; JJa), (nnxb; ; JJa)
Example 4.10 (Two sentiments and one aspect):
Review sentence:Super fast processor
POS tagged sentence:Super/JJ fast/JJ processor/NN
Grouped POS tagged sentence:Super/JJ fast /JJ (processor/NN)/nn1. /.
Generic rule:JJa JJb nnxa
Aspect-sentiment pair rule (R52):JJa JJb nnxa
Aspect-sentiment pair template creation:(nnxa; ; JJa), (nnxa; ; JJb)
Finally, all the generic rules, aspect-sentiment pair rules, and aspect-sentiment pair template are stored inside a knowledge base as shown in Table 10.
4.3. Phase III: Aspect-sentiment Pair Extraction
The motive of this phase is to extract aspect-sentiment pairs based on testing sentences dataset. Few steps are involved to match the testing sentences to the rules and templates in the knowledge base created in Phase II and produce aspect-sentiment pairs. Step I until Step IV in Phase III is similar with Phase II, except Step V. The difference is, in Phase I, training sentences are used, whereas, in Phase III, testing sentences are used.
4.3.1. Step I: Preprocessing
In this step, a cleaning process is done to the testing sentences in the dataset. Some of the irrelevant tokens, such as “:)”, “1)”, “1.”, “- (only for beginning of sentence)”, are removed from the sentences. Besides that, sentence segmentation is also done to split two complete sentences separated by punctuation (e.g., “;”, “,”, and etc.).
4.3.2. Step II: POS Tagging
The testing sentences are parsed using the Stanford Parser tool to obtain the tagged words for each sentence. For example:
Example 4.11:
Review sentence:The technical support was not helpful as well.
POS tagged sentence: The/DT technical/JJ support/NN was/VBD not/RB helpful/JJ as/IN well/RB. /.
4.3.3. Step III: Compound Noun Pattern Detection
The compound noun pattern is detected in the POS tagged sentence. If the pattern exists, then, the non-noun tag (not “NN+”) is changed to noun tag (“NN”). Next, only the sentences with at least one aspect (“NN”) and one sentiment (“JJ”) are maintained.

4.3.4. Step IV: POS Tag Grouping
The POS tags that occur consecutively in the POS tagged sentences are grouped together. These grouped tags are denoted by new tags (e.g., nnx, rbx, and etc.) indicating there are multiple tags inside it.
Example 4.13:
Review sentence:The technical support was not helpful as well.
POS tagged sentence:The/DT (technical/NN support/NN) was/VBD (not/RB) helpful/JJ as/IN (well/RB). /.
Grouped POS tagged sentence:The/DT technical support/nn2 was/VBD not/rb1 helpful/JJ as/IN well/rb1. /.
4.3.5. Step V: Rule and Grouped POS Tagged Sentence Matching
In this step, the grouped POS tagged testing sentences will be used to match the rules in the knowledge base. In the matching process, only the first two characters of the POS tag are used. For example, (“NNS”) in grouped POS tagged sentences have three characters inside the tag, but for matching with rules, only the first two characters, such as (“NN”), are used. This is to allow the testing sentences with various types (“NN”, “NNS”, “NNP”, etc.) of the same tag (“NN”) to match with the rules.
The sub steps involved are: a) Grouped POS tagged sentences and generic rules matching, b) grouped POS tagged sentences and aspect-sentiment pair rules matching, and c) grouped POS tagged sentences and aspect-sentiment template matching.
a) Sub Step I: Grouped POS Tagged Sentence and Generic Rule Matching
In this sub step, the grouped POS tagged sentences will be matched with all the generic rules produced in Phase (II). The purpose is to shortlist the generic rule that can be applied to grouped POS tagged sentences. Matching is performed from the generic rule rank one until the generic rule rank ten. In the matching process, each of the POS tags in grouped POS tagged sentences is compared with the generic rules POS tags.
There can be optional POS tags to the left and right of the matching tag of the sentence with a generic rule tag. In Example 1, there is an optional tag (“DT”) to the left of the matching tag (“nn2”), which matches with the generic rule tag (“nnxa”).
However, when a sentence is matched, the order of the POS tag inside the generic rule must be followed. As in Example 1, the first tag (“nnxa”) must match with the tag of the sentence, and then only the next tag is matched (“VB”).
In short, the sequence of the generic rule POS tags must be in order. All the tags of the sentence must match with the tags of generic rules. This is to shortlist the generic rules that match with the sentence.
Also, for matching purposes, only the first two characters of the POS tag is taken. For example, only (“NN”) is matched in the POS tag (“NNS”). In the POS tag, (“nn2”), only (“nn”) is matched. However, there are no changes made to the original tag. It is retained as it is. The example is as shown.
Example 4.14 (Matching with generic rule rank 1):
Grouped POS tagged sentence:The/DT technical support/nn2 was/VBD not/rb1 helpful/JJ as/IN well/rb1. /.
Matching of POS tag of grouped POS tagged sentence with tags of generic rule is conducted by looping each POS tag in the sentence by the sequence it appears.


A similar way of matching has been performed with all the generic rules. The sentence matches two generic rules with rank one and rank eight. The matched generic rules are taken as a shortlisted rule. The non-matching rules are discarded. Table 11 shows all the matching outcomes with generic rules.
b) Sub Step II: Grouped POS Tagged Sentence and Aspect-sentiment Pair Rule Matching
The aspect-sentiment pair rules associated with the shortlisted generic rules will be used to perform matching with the grouped POS tagged sentence. For this purpose, similarity scores between the sentence and each aspect-sentiment rule are calculated.
A Levenshtein distance [24] is used as the similarity matching technique. This technique computes differences between two sequences. The two sequences are the source sequence and target sequence. In this case, the grouped POS tagged sentence is the source sequence and the aspect-sentiment pair rule is the target sequence.
The Levenshtein distance between two sequences is the minimum number of editing operations required to transform the source sequence to the target sequence [24]. The editing operations involved are insertions, deletions, and substitutions.
Each of the editing operations had their assigned cost. Insertion and deletion has a cost of one, whereas, substitution costs two [24]. This is because substitution involves both deletion and insertion.
The distances between a grouped POS tagged sentence and rules are measured by calculating the total cost involved to transform the sentence into rules. After computing the cost, the similarity score is calculated as follows:
This formula states that, in this work, the preference for a similarity score is low cost and high number of matches. Hence, a higher matching score is desirable when matching the sentence with the rules.
In Sub step III), the shortlisted generic rules are rank one and rank eight generic rules. Rank one and rank eight has their own associated aspect-sentiment rules.
In Example 4.15 a), the calculation of the total cost between a grouped POS tagged sentence and rank two aspect-sentiment pair rule is shown. In Example 4.15 b), the calculation of the total number of matches between a grouped POS tagged sentence and rank two aspect-sentiment pair rule is shown. In Example 4.15 c), the similarity score calculation is shown.
Example 4.15 (Calculation of total cost between grouped POS tagged sentence):
Grouped POS tagged sentence:The/DT technical support/nn2 was/VBD not/rb1 helpful/JJ as/IN well/rb1. /.
a) Total Cost Calculation
POS tags of grouped POS tagged sentence = S
POS tags of aspect-sentiment rule (R2) rank 2 = R2
S: DT nn2 VBD rb1 JJ IN rb1
R2: _ nnxa VB rbxa JJa _ _
Operation: delete (“DT”)
delete (“IN”)
delete (“rb1”)
Total cost = 1 + 1 + 1
= 3

c) Similarity score calculation
Similarity score =
= 1
All the similarity scores between grouped POS tagged sentences and aspect-sentiment rules are calculated in the same way. After comparing all the similarity scores, rule (R2) provides the highest similarity matching value. Hence, rule (R2) is selected as the final rule for the sentence. If two rules have a similar score, then the ranking of aspect-sentiment pair rules will be used to select the final rule.
c) Sub Step III: Grouped POS Tagged Sentence and Aspect-sentiment Template Matching
The aspect-sentiment template associated with the aspect-sentiment pair rule selected in Sub step ii) will be used to match with the POS tags of a grouped POS tagged sentence. After that, the POS tags of a grouped POS tagged sentence will be inserted into the template to produce the aspect-sentiment pair.
Then, the aspect-sentiment pair POS tag will be associated with its words. The words in a grouped POS tagged sentence are aligned to the aspect-sentiment pair. The position, (“a”), (“b”), and etc., is used to indicate the position of the POS tag as appearing as first, second, and etc. Example 4.16 shows the matching between a grouped POS tagged sentence and the aspect-sentiment pair template.
Example 4.16:
Grouped POS tagged sentence:The/DT technical support/nn2 was/VBD not/rb1 helpful/JJ as/IN well/rb1. /.
POS tags of aspect-sentiment rule (R2) rank 2: nnxa VB JJa
The POS tags of the grouped POS tagged sentence are matched with the template. The position is indicated by (“a”) means, that particular POS tag appearing as the first occurrence. Similar to (“b”), means that the tag appears as second and so on.

The matched POS tag will be inserted into the aspect-sentiment pair template. The resultant form is the aspect-sentiment pair.
Aspect-sentiment Pair: (nn2; rb1; JJ)
Next, the aspect-sentiment pair is aligned with its associated words as in a grouped POS tagged sentence. Thus, the final product is the aspect-sentiment pair with its associated words.
Aspect-sentiment Pair: (technical support; not; helpful)
5. Results and Discussion
This section elaborates the evaluation of the aspect-sentiment pair extraction with rules and compound noun lexicon (ASPERC) model, the dataset collection, performance measure, results, and result analysis.
5.1. Dataset
The dataset used for the training and testing phase is introduced in the following subsections. In the data collection, the benchmarked data are described in terms of its domain, number of sentences, and proportion of the training and testing dataset. In the benchmarked dataset section, the dataset is described where the reannotation is done by the experts in terms of aspect and sentiment terms.
5.1.1. Data Collection
The dataset used for the experiments are benchmark data from SemEval 2014 Task 4 [25]. The dataset is used for aspect and its polarity identification in SemEval 2014 tasks that involve supervised and unsupervised approaches. We have chosen this dataset because they are the first one tagged at the aspect-level with a multiword aspect and single-word aspect. This dataset consists of two domains, which are laptop and restaurant. Both datasets were divided into a training and testing dataset. The restaurant training data consists of 3041 sentences with annotations of aspect terms for some sentences. The restaurant testing data consists of 800 sentences with annotations of aspect terms for some sentences. The restaurant dataset is a subset of [26] restaurant datasets. Additionally, more sentences are crawled from scratch in the restaurant review. The laptop dataset consists of 3845 training sentences and 800 testing sentences with aspect term annotations for some sentences. This dataset is extracted from the laptop customer review.
In this work, a total of 250 training sentences from 6086 sentences and 126 testing sentences from 1600 sentences are randomly taken from the annotated sentences. A common measure used to split for determining the number of training and testing data is 80: 20 ratios based on the Pareto principle [27]. Hence, for the laptop dataset, the training and testing dataset are 250 and 63. The 250 laptop training dataset is used to train the rules.
To test the rules created using laptop dataset, 63 laptop testing datasets and 63 restaurant testing datasets are used. Table 12 shows the information of the training and testing dataset used.
5.1.2. Benchmarked Dataset
The SemEval 2014 Task 4 dataset consists of datasets that have aspect terms annotated. However, for sentiments, there is no annotation. Thus, two human experts are assigned to annotate the testing dataset to include sentiments and add the missing aspects in annotation. For example, in the sentence, “The specs are pretty good too.”, the sentiment, “good”, is added as a sentiment term. For example, in the sentence, “There restaurant is very casual”, the aspect, “restaurant”, is added as an aspect term.
Each human expert annotates 63 sentences for testing datasets. An explanation and examples of aspects and sentiments are given to the human experts to annotate the aspect and sentiment pairs. This dataset is then used as the golden standard for the experiment evaluation. Refer to Figure 4 and Figure 5 for some of the testing review sentences’ annotation (golden standard) in the laptop and restaurant dataset. The aspect terms and the sentiment terms are the terms annotated by the user.
5.2. Performance Metric
The performance is evaluated by comparing the aspect and sentiment pairs extracted by the approach with the set of gold standard aspect-sentiment pairs. The gold standard is the “true” aspect-sentiment pair that should be extracted by the approach for validation of results. This is to check whether the aspect-sentiment pair extracted by the approach is valid or not valid. The gold standard refers to the annotated testing dataset by the users, where the aspect and sentiment are labelled in the sentences. Hence, to measure the validity of the aspect-sentiment pairs, two measures are used. The two commonly used matrices in opinion mining are utilized, i.e., precision and recall.
Precision is measured to determine the number of correct aspect-sentiment pairs that are extracted by all the approaches. On the other hand, recall is measured to find out the coverage of aspect-sentiment pairs that can be extracted.
5.2.1. Precision
Precision measures the correctness of aspect-sentiment pairs extracted by the approach with the aspect-sentiment pair annotated in the gold standard. The equation of precision is as follows:
- Relevant aspect sentiment pair indicates the correct aspect-sentiment pair that is extracted by the approach as in the gold standard aspect-sentiment pair; and
- retrieved aspect sentiment pair indicates the aspect-sentiment pair in the gold standard that is supposed to be retrieved by the approach, but it is not retrieved. Also, added with the aspect-sentiment pair that is retrieved by the approach, but not present in the gold standard.
5.2.2. Recall
Recall measures the coverage of the aspect-sentiment pair extracted by the approach with the aspect-sentiment pair in the gold standard. The equation of recall is as follows:
5.3. Experimental Result
In this section, the results of the approach used are discussed based on evaluation on two perspectives, which are the optimized number of review sentences to train the aspect-sentiment pair extraction model as well as the precision and recall of aspect-sentiment pair extraction on testing review sentences.
5.3.1. Evaluation on Optimized Number of Review Sentences to Train the Aspect-sentiment Pair Extraction Model
Here, the number of training review sentences that is optimal to train the model is evaluated. The training sentences are divided into 50 sentences per run. In each run, the rules that can be generated from the sentences are recorded. The rules increase per run. The unique rules are stored in an aggregation manner for each of the runs. This means, after one run, there will be some rules produced, and then in the next run, the new rules are added on to the existing rules.
The number of sentences is taken as reasonable until there is no significant increase in the number of rules. As can be seen in Figure 6, after running 250 sentences, there is only a little increase in the number of rules. Thus, for this work, 250 sentences in datasets are used as training sentences.
5.3.2. Evaluation on Precision and Recall of Aspect-sentiment Pair Extraction on Testing Review Sentences
The motivation of doing this evaluation is to measure the performance of our approach and the baseline approach in aspect-sentiment pair extraction. To test the performance, the annotated testing sentences from SemEval 2014 dataset (golden standard) is used to evaluate the baseline (BE), ASPER and ASPERC to ensure validity. About 126 testing sentences are used, where 63 of sentences are from laptop domain and another 63 sentences are from restaurant domain.
The proposed approach (ASPERC) and its variant (ASPER) are tested. The main concern here is to find out whether ASPER and ASPERC can better extract aspect-sentiment pairs without much aspect-sentiment pair loss. In other words, this is to find out the ability of the approach to extract more aspect-sentiment pairs.
The intention of evaluating ASPER is to determine whether the rules of our work can be used across domains. This is to test whether, even if there is no usage of lexicon with the rules, the rules itself are able to better discover aspect-sentiment pairs. The evaluation is carried out to compare the following approaches in aspect-sentiment pair extraction.
Baseline rule based (BE) approach:
- The baseline [8] has nine rules for extraction of aspect-sentiment pairs. The rules consist of a POS tag sequence to extract aspect-sentiment pairs where a noun is extracted as an aspect and an adjective as a sentiment. The position of the aspect and sentiment is denoted by the arrangement of the noun and adjective in rules;
- this approach considers extraction of aspect-sentiment pairs with occurrence of aspect-sentiment pairs, such as one aspect with one sentiment, one aspect with many sentiments, many aspects with one aspect, one sentiment with one aspect, one sentiment with many aspects, and many sentiments with one aspect; and
- for the multi-word, the aspect is only considered a noun-noun compound noun. Special compound noun aspects and parent-child aspects are not identified.
Aspect-sentiment pair extraction with rules and compound noun lexicon (ASPERC) model:
- This model consists of 63 rules and a template for extraction of aspect-sentiment pairs. The position of aspects and sentiments is denoted with respect to the arrangement of nouns and adjectives in the rules and in the template;
- the model considers extraction of aspect-sentiment pairs with the occurrence of aspect-sentiment pairs, such as one aspect with one sentiment, one aspect with many sentiments, many aspects with one aspect, one sentiment with one aspect, one sentiment with many aspects, and many sentiments with one aspect; and
- it is also able to identify multi-word aspects, such as a noun-noun compound noun, special compound noun aspect, and parent-child aspect.
Aspect-sentiment pair extraction with rules (ASPER) model:
- This model is the variant of ASPERC where the usage of a compound noun is excluded;
- it can identify a multi-word aspect, such as a noun-noun compound noun and parent-child aspect. A special compound noun aspect is not identified; and
- the model is used to test the rules applicability across various domains.
The result on the precision and recall of the aspect-sentiment pair extraction model using rules (ASPER) for the extraction of aspect-sentiment pairs are shown in Figure 7.
The precision of the ASPER model for aspect-sentiment pair extraction in the laptop domain is 4% lower than in the restaurant domain. However, the recall of the ASPER model for the aspect-sentiment pair extraction model in the laptop domain is 9.59%.
The result on precision and recall of the aspect-sentiment pair extraction model using rules and lexicon (ASPERC) for the extraction of aspect-sentiment pairs is shown in Figure 8.
Similarly, the precision of ASPERC for aspect-sentiment pair extraction in the laptop domain is 1.03% lower than in the restaurant domain. However, the recall of the ASPERC model for the aspect-sentiment pair extraction model in the laptop domain is 15.62% higher.
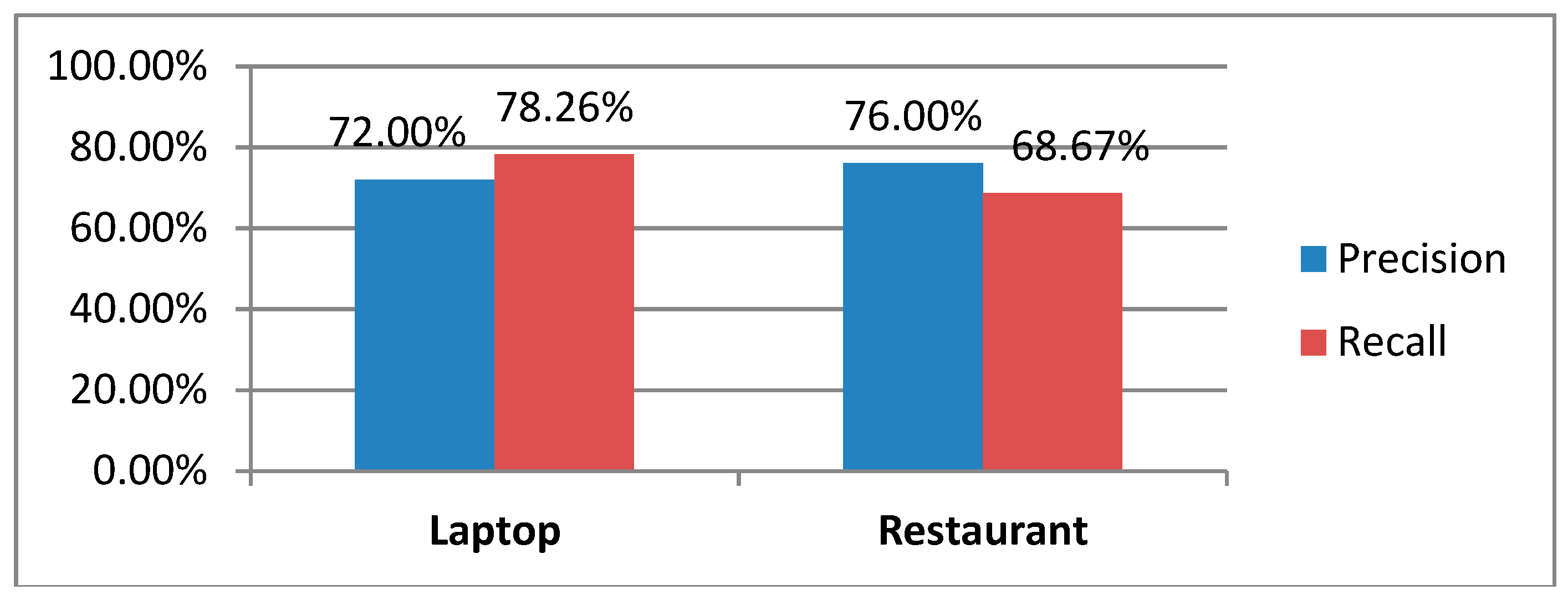
The results on precision and recall of the ASPER model, ASPERC model, and BE baseline on the laptop dataset are shown in Figure 9.
ASPER precision and recall is lower by 4% and 6.03% than ASPERC. The precision of ASPER and ASPERC is slightly lower than the BE baseline. However, both models have higher recall compared to the BE baseline. Even tough precision of ASPER is 6% lower than the BE baseline, yet ASPER still managed to increase by 22.55% higher in terms of recall. In a similar manner, there is a little drop of precision by 2% in ASPERC, but still, it advances the BE baseline in recall by 28.58%.
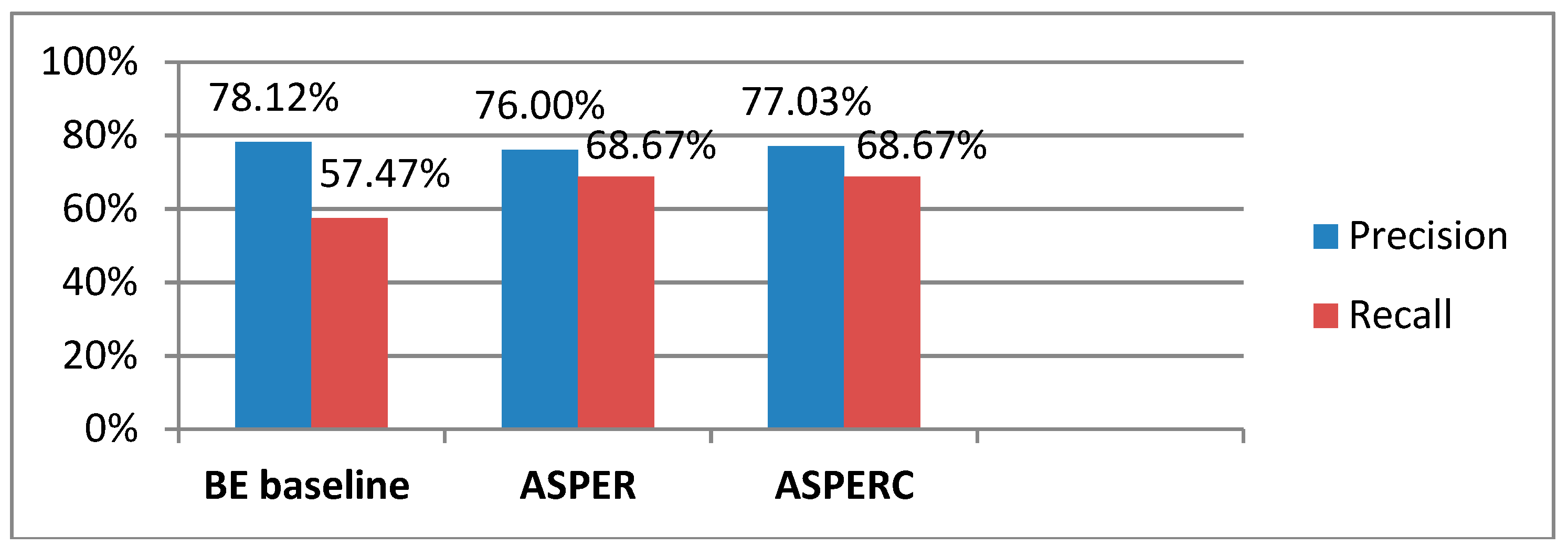
The results on precision and recall of the ASPER model, ASPERC model, and BE baseline on the restaurant dataset are shown in Figure 10.
The precision of ASPER is less by 1.03%, but the recall is the same with ASPERC. The precision of ASPER and ASPERC is slightly lower than the BE baseline. However, both models have higher recall compared to the BE baseline.
Even tough precision of ASPER is 2.12% lower than the BE baseline, yet ASPER still managed to increase by 11.2% in terms of recall. In a similar manner, there is a little drop of precision by 1.09% in ASPERC, but still, it advances the BE baseline in recall by 11.2%.
5.4. Result Analysis
In this section, the results obtained are analyzed. The two main evaluations conducted are discussed in detail.
5.4.1. Optimized Number of Review Sentences to Train the Aspect-sentiment Pair Extraction Model
Determining the number of training sentences helps to set the number of testing sentences. Based on the stopping criterion, the amount of training sentences is set as 250 sentences. Following the proportion of 80:20, the amount of testing sentences is set to 63 corresponding to 250 training sentences. By using 63 testing sentences, the precision and recall of aspect-sentiment pairs extracted in the laptop domain and restaurant domain are obtained.
It is observed that 63 testing sentences can provide a precision of 72.00 (ASPER)% and 76.00 (ASPERC) for the domain. Similarly, a precision of 76.00% (ASPER) and 77.03% (ASPERC) is obtained for the restaurant domain. Meanwhile, a recall of 78.26% (ASPER) and 84.29% (ASPERC) in the laptop dataset and 68.67% (ASPER and ASPERC) is achieved in the restaurant dataset. With the usage of 250 training sentences, a decent performance in terms of precision and recall can be attained in both the laptop and restaurant dataset. Hence, this result obtained from this evaluation can be used as a guideline in terms of the range of the number of training sentences that can be used to train a similar extraction model, especially in the domain of review texts.
5.4.2. Precision of Aspect-sentiment Pair Extraction on Testing Review Sentences
Precision is a measure to find out the correct aspect-sentiment pairs extracted by the approaches. In both the laptop and restaurant domain, the precision of the ASPERC is higher than ASPER because the use of compound noun lexicon has enabled ASPERC to find correct aspect-sentiment pairs.
Due to the complexity and heterogeneity of review sentences written by customers, some irrelevant aspect-sentiment pairs also got extracted in ASPER and ASPERC approaches, which results in a slight decrement as compared to the BE baseline approach. Besides that, ASPER and ASPERC approaches are based on the existence of some specific grammatical language rules, which the sentence structure needs to follow the exact structure of the rules to be selected as an aspect-sentiment pair.
The BE baseline can maintain a slight increment in precision, due to the generality of rules in aspect-sentiment pair extraction. The author combined all the specific rules to form a general rule that can be used in different sentence structures.
5.4.3. Recall of Aspect-sentiment Pair Extraction on Testing Review Sentences
Recall is a measure to find out the coverage of aspect-sentiment pairs extracted by the approaches. In the laptop domain, the recall of the ASPERC is higher than ASPER because the use of compound noun lexicon has enabled ASPERC to find more aspect-sentiment pairs. However, in the restaurant domain, the recall of both ASPER and ASPERC are the same, as in this domain, the compound noun that is needed to be resolved involves a food name. Few food names are not able to be found in the lexicon due to the complexity of the name itself.
We have enhanced the rules and have decent coverage. Hence, ASPER and ASPERC can achieve an improvement in recall compared to the BE baseline. Also, the aspect-sentiment pair template of the rules that associate an aspect to its corresponding sentiment contributes to recall. Another reason of the increase in recall is the use of compound noun lexicon. By utilizing compound noun lexicon, more aspects are discovered, thus resulting in relevant aspect-sentiment pair extraction.
Since the baseline rules do not give enough coverage to various types of aspect extraction, such as a parent-child aspect and special compound noun aspect, it can be concluded that the baseline cannot extract enough aspects. When some of the aspects are not identified, eventually, the sentiment is also not identified. This results in extraction of incomplete aspect-sentiment pairs.
5.5. Comparison of Aspect-sentiment Pair Extraction ASPER Model, ASPERC Model, and BE Baseline
Table 13 shows the comparison of aspect-sentiment pair extraction by all the approaches in both laptop and restaurant training sentences. It is notable that the BE baseline is not able to identify the parent-child aspect, e.g., “Customization on Mac”, with the rules. In addition to that, the special compound noun aspect, like “Set up”, is also not discovered in the baseline. In contrast, ASPER can identify the parent-child aspect with the aspect-sentiment pair rules. With the advantage of compound noun lexicon, ASPERC can identify both the parent-child aspect and special compound noun aspect.
6. Conclusions
In this paper, the motivation was to provide a decomposed view of opinions in review sentences that consist of aspect-sentiment pairs. In the state-of-the-art, there are many researchers who have applied aspect-based opinion mining to extract aspect-sentiment pairs. However, none of the approaches completely resolve the issues of multi-word aspects’ identification, such as special compound noun aspects and parent-child aspects.
Hence, to improve aspect-sentiment pair extraction, aspect identification was enhanced by proposing the aspect-sentiment pair extraction using rules and compound noun lexicon (ASPERC) model. Basically, a total of three phases were included in the model, such as compound noun lexicon generation, aspect-sentiment pair rules generation, and aspect-sentiment pair extraction. The outcome of Phase I was compound noun lexicon for the laptop and restaurant domain. In Phase II, the outcome was the knowledge base consisting of generic rules, aspect-sentiment pair rules, and an aspect-sentiment pair template. In Phase III, the outcome of the model was the aspect-sentiment pair extractions.
With the usage of rules, the parent-child aspect was identified. Different types of order of arrangements in the extraction of aspect-sentiment pairs were also tackled with the rules. The rules have the template to match the aspects to sentiments in which the aspects or sentiments may appear first and later in the sentence. Additionally, the compound noun lexicon helps to identify more aspects.
In the evaluation, the ASPERC model and its variant, ASPER, can decently perform aspect-sentiment pair extraction with reasonable precision and recall. Better precision and recall were obtained after using compound noun lexicon. The models achieved precision of 72.00% (ASPER) and 76.00% (ASPERC) in the laptop domain and precision of 76.00% (ASPER) and 77.03% (ASPERC) for the restaurant domain. The recall was 78.26% (ASPER) and 84.29% (ASPERC) in the laptop domain and 68.67% (ASPER and ASPERC) in the restaurant domain.
With respect to the objective and evaluation outcome, we highlight two main contributions from this work. First, the optimal number of sentences to train the ASPERC model were identified. For training the model, usually, a higher number of training sentences would result in higher performance. However, to use fewer sentences, as acquiring sentence datasets can be expensive and time consuming, the rules were used as the stopping criteria. The sentences were categorized according to aspect-sentiment pair rules in every iteration of the experiment. Iteration was repeated until there was only a little increase in the number of rules. The number of sentences that corresponds to the number of rules that were not increasing much were taken as the optimal number of sentences. The number helps to determine a reasonable and minimal size of training sentences that will be giving a reasonable precision and recall.
Second, the ASPERC was proposed to improve the aspect and sentiment extraction through rules and compound noun lexicon. This model utilizes rules for discovering both single-word and multi-word aspects. The multi-word aspect, such as the parent-child aspect, was extracted through the rules. The rules were also able to extract the aspect or sentiment, which appears first or later in sentences, using the template matching between aspect and sentiment. Moreover, compound noun lexicon enabled identification of non-noun-noun compound nouns as the aspect. By enhancing aspect identification in aspect-sentiment pair extraction, more aspect words could be obtained. When the aspect can be obtained, its corresponding sentiment can be discovered. Hence, this results in greater extraction of aspect-sentiment pairs. Both the ASPERC and its variant (ASPER) models are able to extract aspect sentiment pairs in a decent performance in precision and recall. The ASPER model contains rules without compound noun lexicon. Even though these rules were trained in the laptop domain and tested in both the laptop and restaurant domain, we can still achieve a reasonable performance. This indicates that the rules are domain independent and can be applied across different domains.
In conclusion, aspect and sentiment pair extraction is beneficial for both customers and business organization. By extracting aspect-sentiment pairs, the opinion in the sentences can be simplified. Individuals can save time by not reading an overwhelming amount of reviews when looking for an opinion towards an item or matter.
As future work, the model can be enhanced by integrating ontology to discover the hierarchy of the aspects in the aspect-sentiment model. Since our approach is already able to extract parent-child aspects and special compound noun aspects, representing them in a hierarchy with associated sentiments can provide a structured detail of products or services opinions. In terms of the semantics of the aspect-sentiment model, this research can further integrate polarity scores for the extracted aspect-sentiment pair. On top of that, the pair can also be linked to a finer grain of sentiment analysis, such as emotions, like anger, happy, sad, etc.
Currently, besides the aspect-sentiment pairs extraction, there is no grouping of an aspect to its category. Grouping different mentions of aspects makes the aspects extracted be less redundant in the extraction’s output.
Author Contributions
Conceptualization, K.H.G.; Data curation, N.R.A.K.; Formal analysis, K.H.G.; Funding acquisition, K.H.G.; Investigation, N.R.A.K.; Methodology, N.R.A.K.; Supervision, K.H.G.; Validation, N.R.A.K. and E.H.; Writing—review & editing, E.H.
Funding
This research was supported by USM Research University Grant (1001/PKOMP/811335: Mining Unstructured Web Data for Tour Itineraries Construction), Universiti Sains Malaysia.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Liu, B. Sentiment analysis and opinion mining. In Synthesis Lectures on Human Language Technologies; Morgan & Claypool Publishers: San Rafael, CA, USA, 2012; Volume 5, pp. 1–167. [Google Scholar]
- Perikos, I.; Hatzilygeroudis, I. Aspect based sentiment analysis in social media with classifier ensembles. In Proceedings of the IEEE/ACIS 16th International Conference on Computer and Information Science (ICIS), Wuhan, China, 24–26 May 2017; pp. 273–278. [Google Scholar]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–24 August 2004; pp. 168–177. [Google Scholar]
- Popescu, A.M.; Etzioni, O. Extracting product features and opinions from reviews. In Natural Language Processing and Text Mining; Springer: London, UK, 2007; pp. 9–28. [Google Scholar]
- Moghaddam, S.; Ester, M. On the Design of LDA Models for Aspect-based Opinion Mining. In Proceedings of the 12th ACM International Conference on Information & Knowledge Management, Maui, HI, USA, 29 October–2 November 2012; pp. 803–812. [Google Scholar]
- Ravi, K.; Raghuveer, K. Web User Opinion Analysis for Product Features Extraction and Opinion Summarization. Int. J. Web Semant. Technol. 2012, 3, 69–82. [Google Scholar] [CrossRef]
- Chinsha, T.C.; Shibily, J. A Syntactic Approach for Aspect Based Opinion Mining. In Proceedings of the 9th International Workshop on Semantic Evaluation, Denver, CO, USA, 4–5 June 2015; pp. 730–735. [Google Scholar]
- Bancken, W.; Alfarone, D.; Davis, J. Automatically Detecting and Rating Product Aspects from Textual Customer Reviews. In Proceedings of the DMNLP, Workshop at ECML/PKDD, Nancy, France, 15 September 2014. [Google Scholar]
- Bross, J.; Ehrig, H. Automatic construction of domain and aspect specific sentiment lexicons for customer review mining. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 1077–1086. [Google Scholar]
- Veselovská, K.; Tamchyna, A. UFAL: Using Hand-crafted Rules in Aspect Based Sentiment Analysis on Parsed Data. In Proceedings of the 8th International Workshop on Semantic Evaluation, Dublin, Ireland, 23–24 August 2014; pp. 694–698. [Google Scholar]
- Poria, S.; Cambria, E.; Gelbukh, A.; Gui, C. A Rule-Based Approach to Aspect Extraction from Product Reviews. In Proceedings of the Second Workshop on Natural Language Processing for Social Media, Dublin, Ireland, 24 August 2014; pp. 28–37. [Google Scholar]
- Zhao, Q.; Wang, H.; Lv, P.; Zhang, C. A Bootstrapping Based Refinement Framework for Mining Opinion Words and Targets. In Proceedings of the 23rd ACM International Conference On Conference On Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 1995–1998. [Google Scholar]
- Carpenter, T.; Golab, L.; Syed, S. Is the Grass Greener? Mining Electric Vehicle Opinions. In Proceedings of the 5th International Conference on Future Energy Systems, Cambridge, UK, 11–13 June 2014; pp. 241–252. [Google Scholar]
- Li, Y.; Wang, H.; Qin, Z.; Xu, W.; Guo, J. Confidence Estimation and Reputation Analysis in Aspect Extraction. In Proceedings of the 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 3612–3617. [Google Scholar]
- Kim, H.; Ganesan, K.; Parikshit, S.; ChengXiang, Z. Comprehensive review of opinion summarization. 2011; in press. [Google Scholar]
- Schouten, K.; Frasincar, F. Survey on Aspect-Level Sentiment Analysis. IEEE T Knowl. Data En. 2016, 28, 813–830. [Google Scholar] [CrossRef]
- Hurford, J.R. Grammar: A. Student’s Guide; Cambridge University Press: Cambridge, UK, 1994. [Google Scholar]
- Kim, S.; Zhang, J.; Chen, Z.; Oh, A.; Liu, S. A Hierarchical Aspect-Sentiment Model for Online Reviews. In Proceedings of the 27th AAAI Conference on Artifical Intelligence, Bellevue, WA, USA, 14–18 July 2013; pp. 526–533. [Google Scholar]
- Xu, P.; Kang, J.; Ringgaard, M.; Och, F. Using a Dependency Parser to Improve SMT for Subject-Object-Verb Languages. In Proceedings of the Annual Conference of the North American Chapter of ACL, Boulder, CO, USA, 31 May–5 June 2009; pp. 245–253. [Google Scholar]
- Wang, W.; Pan, S.J.; Dahlmeier, D.; Xiao, X. Coupled Multi-Layer Attentions for Co-Extraction of Aspect and Opinion Terms. In Proceedings of the AAAI, San Francisco, CA, USA, 4–9 February 2017; pp. 3316–3322. [Google Scholar]
- Luhn, H.P. Key word-in-context index for technical literature (KWIC index). Am. Doc. 1960, 11, 288–295. [Google Scholar] [CrossRef]
- Anthony, L. AntConc: Design and Development of a Freeware Corpus Analysis Toolkit for the Technical Writing Classroom. In Proceedings of the 2005 International Professional Communication Conference, Limerick, Ireland, 10–13 July 2005; pp. 729–737. [Google Scholar]
- Barri’ere, C.; Ménard, P. Multiword noun compound bracketing using Wikipedia. In Proceedings of the First Workshop on Computational Approaches to Compound Analysis, Dublin, Ireland, 24 August 2014; pp. 72–80. [Google Scholar]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, And Speech Recognition, 2nd ed.; Prentice Hall PTR: Upper Saddle River, NJ, USA, 2014. [Google Scholar]
- Pontiki, M.; Galanis, D.; Pavlopoulos, J.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S. Semeval-2014 Task 4: Aspect Based Sentiment Analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation, Dublin, Ireland, 23–24 August 2014; pp. 27–35. [Google Scholar]
- Ganu, G.; Elhadad, N.; Marian, A. Beyond the Stars: Improving Rating Predictions using Review Text Content. In Proceedings of the 12th International Workshop on the Web and Databases, Providence, RI, USA, 28 June 2009; pp. 1–6. [Google Scholar]
- Kiremire, A.R. The Application of The Pareto Principle in Software Engineering; Louisiana Tech University: Ruston, LA, USA, 2011. [Google Scholar]
Figure 1.
The aspect-sentiment pair extraction using rules and compound noun lexicon (ASPERC) model.
Figure 1.
The aspect-sentiment pair extraction using rules and compound noun lexicon (ASPERC) model.

Figure 2.
Verification of compound nouns.

Figure 3.
Verification of compound nouns (Continued).

Figure 4.
Annotated testing dataset for the laptop domain.

Figure 5.
Annotated testing dataset for the restaurant domain.

Figure 6.
Optimized number of review sentences to train the aspect-sentiment pair extraction model.

Figure 7.
Precision and recall of the ASPER model.

Figure 8.
Precision and recall of the ASPERC model.

Figure 9.
Precision and recall of ASPER model, ASPERC model, and BE baseline in the laptop dataset.

Figure 10.
Precision and recall of the ASPER model, ASPERC model, and BE baseline in the restaurant dataset.
Figure 10.
Precision and recall of the ASPER model, ASPERC model, and BE baseline in the restaurant dataset.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Sample opinion review sentences (Input).
| No | Laptop Review Sentences |
|---|---|
| 1 | Keyboard is great |
| 2 | Mac OS is so simple and easy |
| 3 | Nice appearance |
| 4 | Simple yet stylish design |
| 5 | Design of this laptop is fantastic |
| 6 | The Photo Booth is a great program |
Table 2.
Decomposed view of opinions in review sentences (Output).
| No | Aspect | Sentiment |
|---|---|---|
| 1 | Keyboard | Great |
| 2 | Mac OS | Simple |
| Mac OS | Easy | |
| 3 | Appearance | Nice |
| 4 | Design | Simple |
| Design | Stylish | |
| 5 | Design of laptop | Fantastic |
| 6 | Photo Booth program | Great |
Table 3.
Compound noun patterns.
| Compound Noun Patterns | Example |
|---|---|
| JJ+ NN+ | Hard/JJ disk/NN |
| NN+ CD | Windows/NN 7/CD |
| VB+ NN+ | Operating/VBG system/NN |
| VB+ RP | Boot/VB up/RP |
Table 4.
Compound noun lexicon (only displaying 10 examples each).
| Laptop | Restaurant |
|---|---|
| black_jj model_nn | corned_jj beef_nn |
| blue_jj screen_nn | fried_jj rice_nn |
| casual_jj games_nns | black_jj vinegar_nn |
| chat_jj services_nns | chinese_jj desserts_nns |
| cooling_jj system_nn | creme_jj brulee_nn |
| windows_nnp 7_cd | sweet_jj lassi_nns |
| boot_vb up_rp | smoked_jj salmon_nn |
| shut_vbd down_rp | green_jj curry_nn |
| sound_jj card_nn | condensed_jj milk_nn |
| operating_vbg system_nn | mashed_jj potatoes_nns |
Table 5.
Assignment of grouped POS tagged sentences to generic rules.
| Example No. | Grouped POS Tagged Sentence | Generic Rules |
|---|---|---|
| 4.5 | This/DT speed/nn1 is/VBZ fine/JJ. /. | nnxa VB JJa |
| 4.6 | Good/JJ price/nn1. /. | JJa nnxa |
| 4.7 | It/PRP’s/VBZ wonderful/JJ for/IN computer gaming/nn2 ./. | JJa IN nnxa |
Table 6.
Generic rules with their corresponding frequency.
| Rank | Generic Rules | Frequency of Occurrence |
|---|---|---|
| 1 | nnxa VB JJa | 107 |
| 2 | JJa nnxa | 103 |
| 3 | JJa IN nnxa | 22 |
| 4 | nnxa IN JJa nnxb | 14 |
| 5 | nnxa WD VB JJa | 11 |
| 6 | JJa JJb nnxa | 11 |
| 7 | nnxa IN nnxb JJa | 9 |
| 8 | nnxa JJa | 6 |
| 9 | JJa CC JJa nnxa | 3 |
| 10 | JJa TO nnxa | 2 |
Table 7.
Iteration and the number of aspect-sentiment rules.
| Iteration | Number of Aspect-sentiment Rules |
|---|---|
| 1 | 21 |
| 2 | 14 |
| 3 | 19 |
| 4 | 5 |
| 5 | 4 |
| 6 | 1 |
Table 8.
Generic rules with its corresponding aspect-sentiment pair rule.
| Rule Id | Generic Rule Rank | Generic Rule | Aspect-sentiment Pair Rule (R) |
|---|---|---|---|
| R1 | 1 | nnxa VB JJa | nnxa VB JJa |
| R2 | 1 | nnxa VB JJa | nnxa VB rbxa JJa |
| R3 | 1 | nnxa VB JJa | nnxa VB JJa CC JJb |
Table 9.
Aspect-sentiment pair rule ranking.
| Rule Id | Generic Rule Rank | Generic Rule | Aspect-sentiment Pair Rule Rank | Aspect-sentiment Pair Rule (R) |
|---|---|---|---|---|
| R1 | 1 | nnxa VB JJa | 1 | nnxa VB JJa |
| R2 | 1 | nnxa VB JJa | 2 | nnxa VB rbxa JJa |
| R3 | 1 | nnxa VB JJa | 3 | nnxa VB JJa CC JJb |
Table 10.
Generic rules, aspect-sentiment pair rules, and aspect-sentiment pair templates.
| Rule Id | Generic Rule Rank | Generic Rule | Aspect Sentiment Pair Rule Rank | Aspect Sentiment Pair Rule | Aspect Sentiment Pair Template (Aspect; Intensity; Sentiment) |
|---|---|---|---|---|---|
| R1 | 1 | nnxa VB JJa | 1 | nnxa VB JJa | (nnxa ; ; JJa) |
| R2 | 1 | nnxa VB JJa | 2 | nnxa VB rbxa JJa | (nnxa ; rbxa ; JJa) |
| R3 | 1 | nnxa VB JJa | 3 | nnxa VB JJa CC JJb | (nnxa ; ; JJa), (nnxa ; ; JJb), |
| R4 | 1 | nnxa VB JJa | 4 | nnxa VB DT JJa nnxb | (nnxa nnxb; ; JJa) |
| R5 | 1 | nnxa VB JJa | 5 | nnxa VB rbxa JJa CC JJb | (nnxa ; rbxa ; JJa), (nnxa ; ; JJb) |
| R6 | 1 | nnxa VB JJa | 6 | nnxa VB JJa nnxb | (nnxa nnxb; ; JJa) |
| R7 | 1 | nnxa VB JJa | 7 | nnxa VB DT rbxa JJa | (nnxa ; rbxa ; JJa) |
| R8 | 1 | nnxa VB JJa | 8 | nnxa VB JJa TO nnxb | (nnxa nnxb; ; JJa) |
| R9 | 1 | nnxa VB JJa | 9 | nnxa VB DT JJa | (nnxa ; ; JJa) |
| R10 | 1 | nnxa VB JJa | 10 | nnxa VB rbxa JJa CC rb JJb | (nnxa ; rbxa ; JJa), (nnxa ; rbxb; JJb) |
| R11 | 1 | nnxa VB JJa | 11 | nnxa CC DT nnxb VB JJa | (nnxa ; ; JJa) , (nnxb ; ; JJa) |
| R12 | 1 | nnxa VB JJa | 12 | nnxa CC nnxb VB DT JJa | (nnxa ; ; JJa) , (nnxb ; ; JJa) |
| R13 | 1 | nnxa VB JJa | 13 | nnxa CC nnxb VB rbxa JJa | (nnxa ; rbxa ; JJa) , (nnxb ; rbxa ; JJa) |
| R14 | 1 | nnxa VB JJa | 14 | nnxa VB DT JJa CC JJb | (nnxa ; ; JJa), (nnxa ; ; JJb) |
| R15 | 1 | nnxa VB JJa | 15 | nnxa VB rbxa JJa TO nnxb | (nnxa nnxb; rbxa; JJa) |
| R16 | 1 | nnxa VB JJa | 16 | nnxa VB rbxa DT JJa | (nnxa ; rbxa ; JJa) |
| R17 | 1 | nnxa VB JJa | 17 | nnxa VB rbxa JJa nnxb | (nnxa nnxb; rbxa; JJa) |
| R18 | 2 | JJa nnxa | 1 | JJa nnxa | (nnxa; ; JJa) |
| R19 | 2 | JJa nnxa | 2 | rbxa JJa nnxa | (nnxa; rbxa ; JJa) |
| R20 | 2 | JJa nnxa | 3 | JJa nnxa IN nnxb | (nnxa IN nnxb; ; JJa) |
| R21 | 2 | JJa nnxa | 4 | JJa nnxa IN DT nnxb | (nnxa IN nnxb; ; JJa) |
| R22 | 2 | JJa nnxa | 5 | JJa nnxa IN PR nnxb | (nnxa IN nnxb; ; JJa) |
| R23 | 2 | JJa nnxa | 6 | JJa nnxa CC nnxb | (nnxa; ; JJa), (nnxb; ; JJa) |
| R24 | 2 | JJa nnxa | 7 | JJa nnxa CC nnxb CC nnxc | (nnxa; ; JJa), (nnxb; ; JJa) ,(nnxc; ; JJa) |
| R25 | 2 | JJa nnxa | 8 | JJa nnxa IN nnxb CC nnxc rbxa DT JJa nnxa | (nnxa IN nnxb; ; JJa), (nnxa IN nnxc; ; JJa) |
| R26 | 2 | JJa nnxa | 9 | nnxa VB JJa IN DT nnxb | (nnxa; rbxa ; JJa) |
| R27 | 3 | JJa IN nnxa | 1 | JJa IN nnxa | (nnxa IN nnxb; ; JJa) |
| R28 | 3 | JJa IN nnxa | 2 | nnxa JJa IN nnxb | (nnxa; ; JJa ) |
| R29 | 3 | JJa IN nnxb | 3 | rbxa JJa IN nnxa | (nnxa IN nnxb; ; JJa) |
| R30 | 3 | JJa IN nnxb | 4 | nnxa VB rbxa JJa IN nnxb CC nnxc | (nnxa; rbxa; JJa) |
| R31 | 3 | JJa IN nnxb | 5 | nnxa VB rbxa JJa IN DT nnxb | (nnxa IN nnxb; rbxa; JJa), (nnxa IN nnxc; rbxa; JJa) |
| R32 | 3 | JJa IN nnxb | 6 | nnxa VB rbxa JJa IN DT nnxb | (nnxa IN nnxb; rbxa; JJa) |
| R33 | 3 | JJa IN nnxb | 7 | nnxa rbxa JJa IN DT nnxb | (nnxa IN nnxb; rbxa; JJa) |
| R34 | 3 | JJa IN nnxb | 8 | nnxa VB rbxa JJa IN nnxb | (nnxa IN nnxb; rbxa; JJa) |
| R35 | 3 | JJa IN nnxb | 9 | nnxa rbxa JJa IN nnxb | (nnxa IN nnxb; rbxa; JJa) |
| R36 | 3 | JJa IN nnxb | 10 | nnxa VB JJa IN nnxb | (nnxa IN nnxb; ; JJa) |
| R37 | 3 | JJa IN nnxa | 11 | rbxa JJa IN DT nnxa | (nnxa; rbxa; JJa ) |
| R38 | 3 | JJa IN nnxa | 12 | rbxa JJa IN PR nnxa | (nnxa; rbxa; JJa ) |
| R39 | 3 | JJa IN nnxa | 13 | rbxa JJa nnxa IN nnxb | (nnxa IN nnxb; rbxa; JJa) |
| R40 | 3 | JJa IN nnxb | 14 | JJa IN DT nnxa | (nnxa; ; JJa ) |
| R41 | 4 | nnxa IN JJa nnxb | 1 | nnxa IN JJa nnxb | (nnxa IN nnxb; ; JJa) |
| R42 | 4 | nnxa IN JJa nnxb | 2 | nnxa IN DT JJa nnxb | (nnxa IN nnxb; ; JJa) |
| R43 | 4 | nnxa IN JJa nnxb | 3 | nnxa IN rbxa JJa nnxb | (nnxa IN nnxb; rbxa ; JJa) |
| R44 | 5 | nnxa WD VB JJa | 1 | nnxa WD VB DT JJa nnxb | (nnxa nnxb; ; JJa) |
| R45 | 5 | nnxa WD VB JJa | 2 | nnxa WD VB rbxa JJa | (nnxa ; rbxa ; JJa) |
| R46 | 5 | nnxa WD VB JJa | 3 | nnxa WD VB JJa | (nnxa ; ; JJa) |
| R47 | 5 | nnxa WD VB JJa | 4 | nnxa WD VB IN DT nnxb VB rbxa JJa | (nnxa IN nnxb; rbxa; JJa) |
| R48 | 5 | nnxa WD VB JJa | 5 | nnxa WD VB IN DT JJa | (nnxa ; ; JJa) |
| R49 | 5 | nnxa WD VB JJa | 6 | nnxa WD VB IN JJa nnxb | (nnxa IN nnxb; ; JJa) |
| R50 | 5 | nnxa WD VB JJa | 7 | nnxa WDT VB JJa JJb nnxb | (nnxa nnxb; ; JJa), (nnxa nnxb; ; JJb) |
| R51 | 5 | nnxa WD VB JJa | 8 | nnxa WD VB IN JJa | (nnxa ; ; JJa) |
| R52 | 6 | JJa JJb nnxa | 1 | JJa JJb nnxa | nnxa; ; JJa), (nnxa; ; JJb) |
| R53 | 6 | JJa JJb nnxa | 2 | rbxa DT JJa JJb nnxa | (nnxa; rbxa; JJa), (nnxa; ; JJb) |
| R54 | 7 | nnxa IN nnxb JJa | 1 | nnxa IN DT nnxb VB rbxa JJa | (nnxa IN nnxb; rbxa; JJa) |
| R55 | 7 | nnxa IN nnxb JJa | 2 | nnxa IN DT nnxb VB JJa | (nnxa IN nnxb; ; JJa) |
| R56 | 7 | nnxa IN nnxb JJa | 3 | nnxa IN nnxb VB rbxa DT JJa | (nnxa IN nnxb; rbxa; JJa) |
| R57 | 7 | nnxa IN nnxb JJa | 4 | nnxa IN nnxb rbxa VB JJa | (nnxa IN nnxb; rbxa; JJa) |
| R58 | 8 | nnxa JJa | 1 | nnxa rbxa JJa | (nnxa; rbxa ; JJa) |
| R59 | 8 | nnxa JJa | 2 | nnxa JJa | (nnxa; ; JJa) |
| R60 | 9 | JJa CC JJb nnxa | 1 | JJa CC JJb nnxa | (nnxa; ; JJa), (nnxa; ; JJb) |
| R61 | 9 | JJa CC JJb nnxa | 2 | rbxa JJ a CC JJb nnxa | (nnxa; rbxa; JJa), (nnxa; ; JJb) |
| R62 | 10 | JJ a TO nnxa | 1 | rbxa JJa TO nnxa | (nnxa; rbxa ; JJa) |
| R63 | 10 | JJ a TO nnxa | 2 | JJa TO nnxa | (nnxa; ; JJa) |
Table 11.
Matching of grouped POS tagged sentence with generic rules.
| Grouped POS Tagged Sentence | Generic Rule Rank | Generic Rule | Matching |
|---|---|---|---|
| DT nn2 VBD rb1 JJ IN rb1 | 1 | nnxa VB JJa | Match |
| DT nn2 VBD rb1 JJ IN rb1 | 2 | JJa nnxa | No match |
| DT nn2 VBD rb1 JJ IN rb1 | 3 | JJa IN nnxa | No match |
| DT nn2 VBD rb1 JJ IN rb1 | 4 | nnxa IN JJa nnxb | No match |
| DT nn2 VBD rb1 JJ IN rb1 | 5 | nnxa WD VB JJa | No match |
| DT nn2 VBD rb1 JJ IN rb1 | 6 | JJa JJb nnxa | No match |
| DT nn2 VBD rb1 JJ IN rb1 | 7 | nnxa IN nnxb JJa | No match |
| DT nn2 VBD rb1 JJ IN rb1 | 8 | nnxa JJa | Match |
| DT nn2 VBD rb1 JJ IN rb1 | 9 | JJa CC JJb nnxa | No match |
| DT nn2 VBD rb1 JJ IN rb1 | 10 | JJa TO nnxa | No match |
Table 12.
The information of the training and testing datasets.
| Domain | Training Dataset | Training Dataset Used | Testing Dataset | Testing Dataset Used |
|---|---|---|---|---|
| Laptop | 3041 | 250 | 800 | 63 |
| Restaurant | 3045 | - | 800 | 63 |
| Total | 6086 | 250 | 1600 | 126 |
Table 13.
Comparison of aspect-sentiment pair extraction ASPER model, ASPERC model, and BE baseline.
Table 13.
Comparison of aspect-sentiment pair extraction ASPER model, ASPERC model, and BE baseline.
| No. | Example of Testing Sentence | Approach | ||
|---|---|---|---|---|
| BE Baseline | ASPER | ASPERC | ||
| 1 | Set up was easy | No | No | Yes |
| 2 | MS Office 2011 for Mac is wonderful | No | Yes | Yes |
| 3 | But the Mountain lion is just too slow | No | Yes | Yes |
| 4 | I was extremely happy with the OS itself | No | Yes | Yes |
| 5 | The specs are pretty good too | Yes | Yes | Yes |
| 6 | The technical support was not helpful as well. | No | No | Yes |
| 7 | Greatproduct | Yes | Yes | Yes |
| 8 | Customization on Mac is impossible | No | Yes | Yes |
| 9 | Excellentdurability of battery | No | Yes | Yes |
| 10 | GreatAsian salad | Yes | Yes | Yes |
| 11 | Great and attentive staff | Yes | Yes | Yes |
| 12 | Their twist on a pizza is healthy | No | Yes | Yes |
| 13 | Definitely try the taglierini with truffles it was incredible | No | Yes | Yes |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Ahamed Kabeer, N.R.; Gan, K.H.; Haris, E. Domain-Specific Aspect-Sentiment Pair Extraction Using Rules and Compound Noun Lexicon for Customer Reviews. Informatics 2018, 5, 45. https://doi.org/10.3390/informatics5040045
AMA Style
Ahamed Kabeer NR, Gan KH, Haris E. Domain-Specific Aspect-Sentiment Pair Extraction Using Rules and Compound Noun Lexicon for Customer Reviews. Informatics. 2018; 5(4):45. https://doi.org/10.3390/informatics5040045
Chicago/Turabian StyleAhamed Kabeer, Noor Rizvana, Keng Hoon Gan, and Erum Haris. 2018. "Domain-Specific Aspect-Sentiment Pair Extraction Using Rules and Compound Noun Lexicon for Customer Reviews" Informatics 5, no. 4: 45. https://doi.org/10.3390/informatics5040045
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.