

Dental Caries Risk Assessment in Children 5 Years Old and under via Machine Learning

 ,
,  ,
,
Abstract
:1. Introduction
- (a)
- (b)
- Socioeconomic factors: people living in certain districts or belonging to certain ethnic or religious groups may be ‘risk individuals’.
- (c)
2. Materials and Methods
2.1. Data Compilation
2.2. Supervised Classification
3. Results
3.1. Data Compilation
3.2. Supervised Classification
3.2.1. Three Different Risk Levels
3.2.2. Two Different Risk Levels
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alkhasawneh, M.S.; Ngah, U.K.; Tay, L.T.; Mat Isa, N.A.; Al-Batah, M.S. Modeling and testing landslide hazard using decision tree. J. Appl. Math. 2014, 2014, 929768. [Google Scholar] [CrossRef]
- Amirhosseini, M.H.; Kazemian, H. Machine learning approach to personality type prediction based on the myers–briggs type indicator®. Multimodal Technol. Interact. 2020, 4, 9. [Google Scholar] [CrossRef]
- Azeredo, F.N.; Guimarães, L.S.; Luís, W.; Fialho, S.; Antunes, L.A.A.; Antunes, L.S. Estimated prevalence of dental caries in athletes: An epidemiological systematic review and meta-analysis. Indian J. Dent. Res. 2020, 31, 297. [Google Scholar]
- Beck, J.D. Risk revisited. Community Dent. Oral Epidemiol. 1998, 26, 220–225. [Google Scholar] [CrossRef]
- Branger, B.; Camelot, F.; Droz, D.; Houbiers, B.; Marchalot, A.; Bruel, H.; Laczny, E.; Clement, C. Breastfeeding and early childhood caries. Review of the literature, recommendations, and prevention. Arch. Pédiatrie 2019, 26, 497–503. [Google Scholar] [CrossRef]
- Bratthall, D.; Hänsel Petersson, G. Cariogram–a multifactorial risk assessment model for a multifactorial disease. Community Dent. Oral Epidemiol. 2005, 33, 256–264. [Google Scholar] [CrossRef]
- Chatterjee, S.; Simonoff, J.S. Handbook of Regression Analysis with Applications in R; John Wiley & Sons: Hoboken, NJ, USA, 2020; ISBN 1119392373. [Google Scholar]
- Chen, R.; Zhang, W.; Wang, X. Machine learning in tropical cyclone forecast modeling: A review. Atmosphere 2020, 11, 676. [Google Scholar] [CrossRef]
- Dearing, B.A.; Katz, R.V.; Weitzman, M. Prenatal tobacco and postbirth second-hand smoke exposure and dental caries in children. Community Dent. Oral Epidemiol. 2022, 50, 130–138. [Google Scholar] [CrossRef]
- Devenish, G.; Mukhtar, A.; Begley, A.; Spencer, A.J.; Thomson, W.M.; Ha, D.; Do, L.; Scott, J.A. Early childhood feeding practices and dental caries among Australian preschoolers. Am. J. Clin. Nutr. 2020, 111, 821–828. [Google Scholar] [CrossRef]
- Drummond, B.K.; Milne, T.; Cullinan, M.P.; Meldrum, A.M.; Coates, D. Effects of environmental tobacco smoke on the oral health of preschool children. Eur. Arch. Paediatr. Dent. 2017, 18, 393–398. [Google Scholar]
- Featherstone, J.D.B.; Chaffee, B.W. The evidence for caries management by risk assessment (CAMBRA®). Adv. Dent. Res. 2018, 29, 9–14. [Google Scholar] [CrossRef] [PubMed]
- Fernández, C.E.; González-Cabezas, C.; Fontana, M. Minimum intervention dentistry in the US: An update from a cariology perspective. Br. Dent. J. 2020, 229, 483–486. [Google Scholar] [CrossRef] [PubMed]
- Gerreth, K.; Opydo-Szymaczek, J.; Borysewicz-Lewicka, M. A study of enamel defects and dental caries of permanent dentition in school children with intellectual disability. J. Clin. Med. 2020, 9, 1031. [Google Scholar] [CrossRef] [PubMed]
- Hong, J.; Whelton, H.; Douglas, G.; Kang, J. Consumption frequency of added sugars and UK children’s dental caries. Community Dent. Oral Epidemiol. 2018, 46, 457–464. [Google Scholar] [CrossRef]
- Hung, M.; Voss, M.W.; Rosales, M.N.; Li, W.; Su, W.; Xu, J.; Bounsanga, J.; Ruiz-Negrón, B.; Lauren, E.; Licari, F.W. Application of machine learning for diagnostic prediction of root caries. Gerodontology 2019, 36, 395–404. [Google Scholar] [CrossRef]
- Johnson, M.F. The role of risk factors in the identification of appropriate subjects for caries clinical trials: Design considerations. J. Dent. Res. 2004, 83, 116–118. [Google Scholar] [CrossRef]
- Nakayama, Y.; Ohnishi, H.; Mori, M. Association of environmental tobacco smoke with the risk of severe early childhood caries among 3-year-old Japanese children. Caries Res. 2019, 53, 268–274. [Google Scholar] [CrossRef]
- Pitts, N.B.; Zero, D.T.; Marsh, P.D.; Ekstrand, K.; Weintraub, J.A.; Ramos-Gomez, F.; Tagami, J.; Twetman, S.; Tsakos, G.; Ismail, A. Dental caries. Nat. Rev. Dis. Prim. 2017, 3, 17030. [Google Scholar] [CrossRef]
- Lee, J.-H.; Kim, D.-H.; Jeong, S.-N.; Choi, S.-H. Detection and diagnosis of dental caries using a deep learning-based convolutional neural network algorithm. J. Dent. 2018, 77, 106–111. [Google Scholar] [CrossRef]
- Maltz, M.; Jardim, J.J.; Alves, L.S. Health promotion and dental caries. Braz. Oral Res. 2010, 24, 18–25. [Google Scholar] [CrossRef]
- American Dental Association. ADA Caries Risk Assessment form Completion Instructions. Available online: https://www.ada.org/-/media/project/ada-organization/ada/ada-org/files/resources/public-programs/give-kids-a-smile/gkas_caries_risk_assessment_forms.pdf (accessed on 1 July 2014).
- Michalski, R.; Dziubałtowska, D.; Macek, P. Revealing the character of nodes in a blockchain with supervised learning. Ieee Access 2020, 8, 109639–109647. [Google Scholar] [CrossRef]
- Monte-Santo, A.S.; Viana, S.V.C.; Moreira, K.M.S.; Imparato, J.C.P.; Mendes, F.M.; Bonini, G.A.V.C. Prevalence of early loss of primary molar and its impact in schoolchildren’s quality of life. Int. J. Paediatr. Dent. 2018, 28, 595–601. [Google Scholar] [CrossRef] [PubMed]
- Onyejaka, N.K.; Eboh, O.F.; Amobi, E.O.; Nwamba, N.P. Relationship Between Socio-Demographic Profile, Parity and Dental Caries AMONG a Group of Nursing Mothers in South East, Nigeria. Pesqui. Bras. Odontopediatria Clin. Integr. 2020, 21. [Google Scholar] [CrossRef]
- Oshiro, T.M.; Perez, P.S.; Baranauskas, J.A. How many trees in a random forest? In Proceedings of the International Workshop on Machine Learning and Data Mining in Pattern Recognition, Berlin, Germany, 13–20 July 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 154–168. [Google Scholar]
- Saho, H.; Taniguchi-Tabata, A.; Ekuni, D.; Yokoi, A.; Kataoka, K.; Fukuhara, D.; Toyama, N.; Islam, M.M.; Sawada, N.; Nakashima, Y. Association between household exposure to secondhand smoke and dental caries among Japanese young adults: A cross-sectional study. Int. J. Environ. Res. Public Health 2020, 17, 8623. [Google Scholar] [CrossRef]
- Sheiham, A. Dental caries affects body weight, growth and quality of life in pre-school children. Br. Dent. J. 2006, 201, 625–626. [Google Scholar] [CrossRef] [PubMed]
- Shenkin, J.D.; Broffitt, B.; Levy, S.M.; Warren, J.J. The association between environmental tobacco smoke and primary tooth caries. J. Public Health Dent. 2004, 64, 184–186. [Google Scholar] [CrossRef]
- Tanaka, S.; Shinzawa, M.; Tokumasu, H.; Seto, K.; Tanaka, S.; Kawakami, K. Secondhand smoke and incidence of dental caries in deciduous teeth among children in Japan: Population based retrospective cohort study. Bmj 2015, 351, h5397. [Google Scholar] [CrossRef] [PubMed]
- van Palenstein Helderman, W.H.; Van’t Hof, M.A.; Van Loveren, C. Prognosis of caries increment with past caries experience variables. Caries Res. 2001, 35, 186–192. [Google Scholar] [CrossRef]
- Vandal, V.B.; Noorani, H.; Shivaprakash, P.K.; Walikar, B.N. Salivary lead concentration in dental caries among normal and children with cerebral palsy. J. Indian Soc. Pedod. Prev. Dent. 2018, 36, 381. [Google Scholar] [CrossRef]
- Weber, M.; Søvik, J.B.; Mulic, A.; Deeley, K.; Tveit, A.B.; Forella, J.; Shirey, N.; Vieira, A.R. Redefining the phenotype of dental caries. Caries Res. 2018, 52, 263–271. [Google Scholar] [CrossRef]
- Yu, X.; Guo, S.; Guo, J.; Huang, X. An extended support vector machine forecasting framework for customer churn in e-commerce. Expert Syst. Appl. 2011, 38, 1425–1430. [Google Scholar] [CrossRef]
- Zero, D.; Fontana, M.; Lennon, Á.M. Clinical applications and outcomes of using indicators of risk in caries management. J. Dent. Educ. 2001, 65, 1126–1132. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
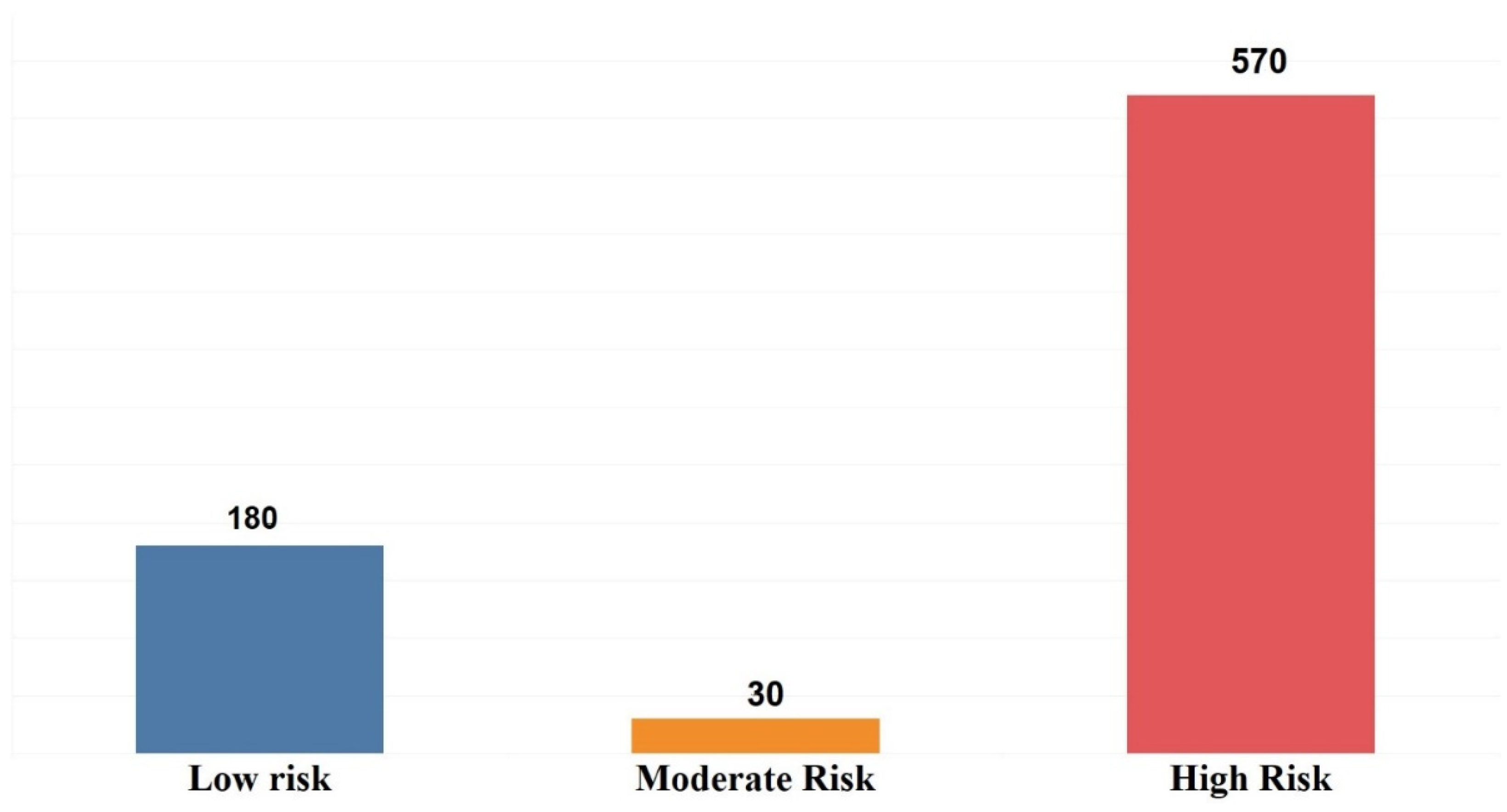
| Categorical Variables | N | % |
|---|---|---|
| Fluoride exposure | ||
| Yes | 180 | 23.08% |
| No | 600 | 76.92% |
| Sugary foods/drinks | ||
| Yes | 550 | 70.51% |
| No | 230 | 29.49% |
| Regular dental visits | ||
| Yes | 330 | 42.31% |
| No | 450 | 57.69% |
| Special needs | ||
| Yes | 10 | 1.28% |
| No | 770 | 98.72% |
| Chemo/radiotherapy | ||
| Yes | 0 | 0.00% |
| No | 780 | 100.00% |
| Eating disorders | ||
| Yes | 0 | 0.00% |
| No | 780 | 100.00% |
| Medications reducing salivary flow | 290 | 16.48% |
| Yes | 0 | 0.00% |
| No | 780 | 100.00% |
| Cavitated/non-cavitated | ||
| Cavitated | 600 | 76.92% |
| Non-cavitated | 180 | 23.08% |
| Carious lesion (visual/radiographically) | ||
| Visual | 600 | 76.92% |
| Radiographically | 180 | 23.08% |
| Teeth extracted due to caries within the past 36 months | ||
| Yes | 250 | 32.05% |
| No | 530 | 67.95% |
| Visible plaque | ||
| Yes | 330 | 42.31% |
| No | 450 | 57.69% |
| Unusual tooth morphology that causes plaque retention | ||
| Yes | 0 | 0.00% |
| No | 780 | 100.00% |
| Proximal restorations | ||
| Yes | 0 | 0.00% |
| No | 780 | 100.00% |
| Dental/orthodontic appliances | ||
| Yes | 0 | 0.00% |
| No | 780 | 100.00% |
| Parents’/carers’ education | ||
| High | 430 | 55.13% |
| Medium | 350 | 44.87% |
| Low | 0 | 0.00% |
| Parents’/carers’ monthly income | ||
| High | 390 | 50.00% |
| Medium | 390 | 50.00% |
| Low | 0 | 0.00% |
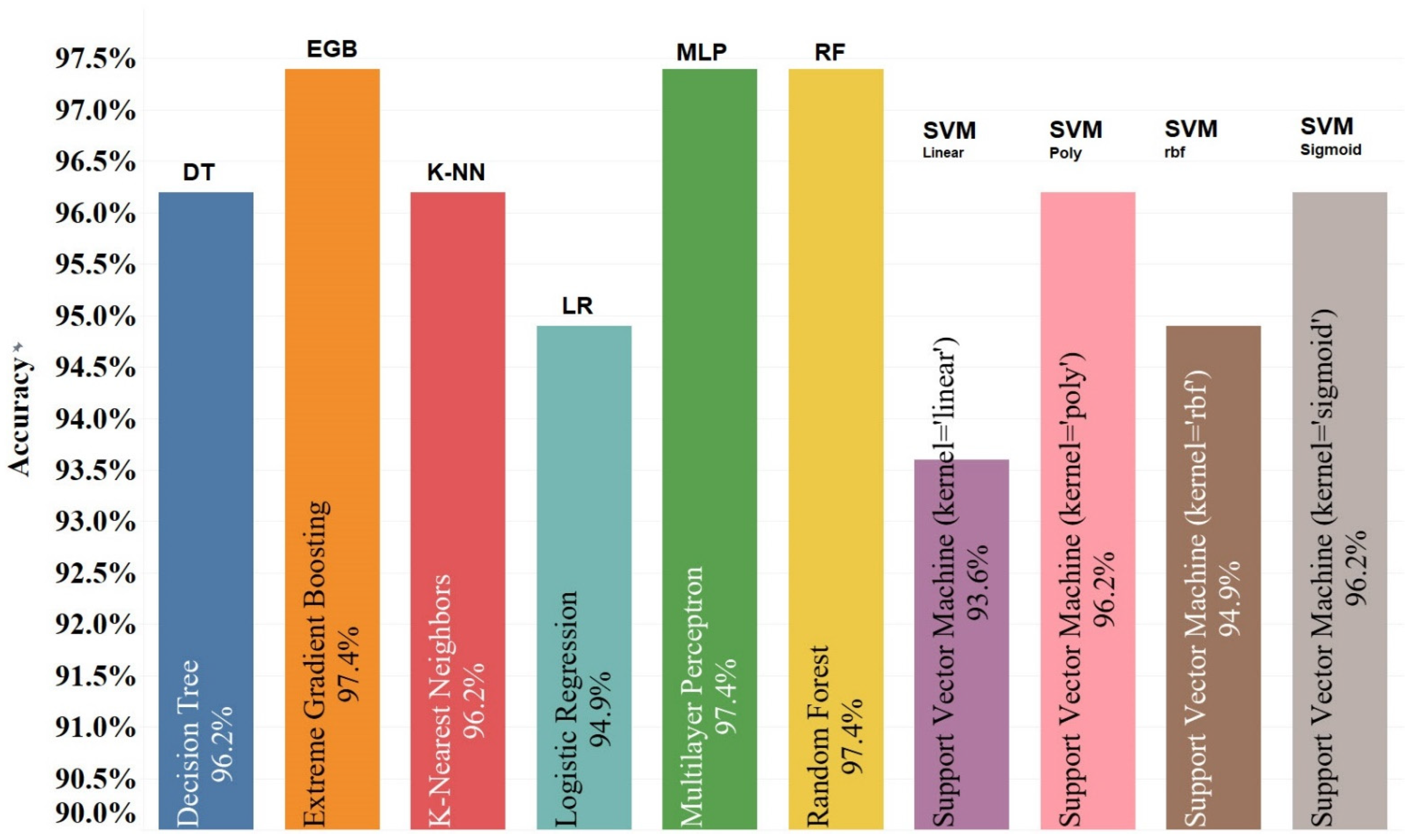
| Classifier | Class | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| Decision Tree | High Risk | 98 | 96 | 97 |
| Moderate Risk | 50 | 67 | 57 | |
| Low Risk | 100 | 100 | 100 | |
| Extreme Gradient Boosting | High Risk | 98 | 98 | 98 |
| Moderate Risk | 67 | 67 | 67 | |
| Low Risk | 100 | 100 | 100 | |
| K-Nearest Neighbour | High Risk | 98 | 96 | 97 |
| Moderate Risk | 50 | 67 | 57 | |
| Low Risk | 100 | 100 | 100 | |
| Logistic Regression | High Risk | 94 | 98 | 97 |
| Moderate Risk | 0 | 0 | 0 | |
| Low Risk | 100 | 100 | 100 | |
| Multilayer Perceptron | High Risk | 98 | 98 | 98 |
| Moderate Risk | 67 | 67 | 67 | |
| Low Risk | 100 | 100 | 100 | |
| Random Forest | High Risk | 94 | 96 | 96 |
| Moderate Risk | 0 | 0 | 0 | |
| Low Risk | 100 | 100 | 100 | |
| Support Vector Machine (kernel = Linear) | High Risk | 98 | 96 | 97 |
| Moderate Risk | 50 | 67 | 57 | |
| Low Risk | 100 | 100 | 100 | |
| Support Vector Machine (kernel = Poly) | High Risk | 94 | 96 | 96 |
| Moderate Risk | 0 | 0 | 0 | |
| Low Risk | 100 | 100 | 100 | |
| Support Vector Machine (kernel = rbf) | High Risk | 98 | 96 | 97 |
| Moderate Risk | 50 | 67 | 57 | |
| Low Risk | 100 | 100 | 100 | |
| Support Vector Machine (kernel = Sigmoid) | High Risk | 95 | 100 | 97 |
| Moderate Risk | 0 | 0 | 0 | |
| Low Risk | 100 | 100 | 100 |
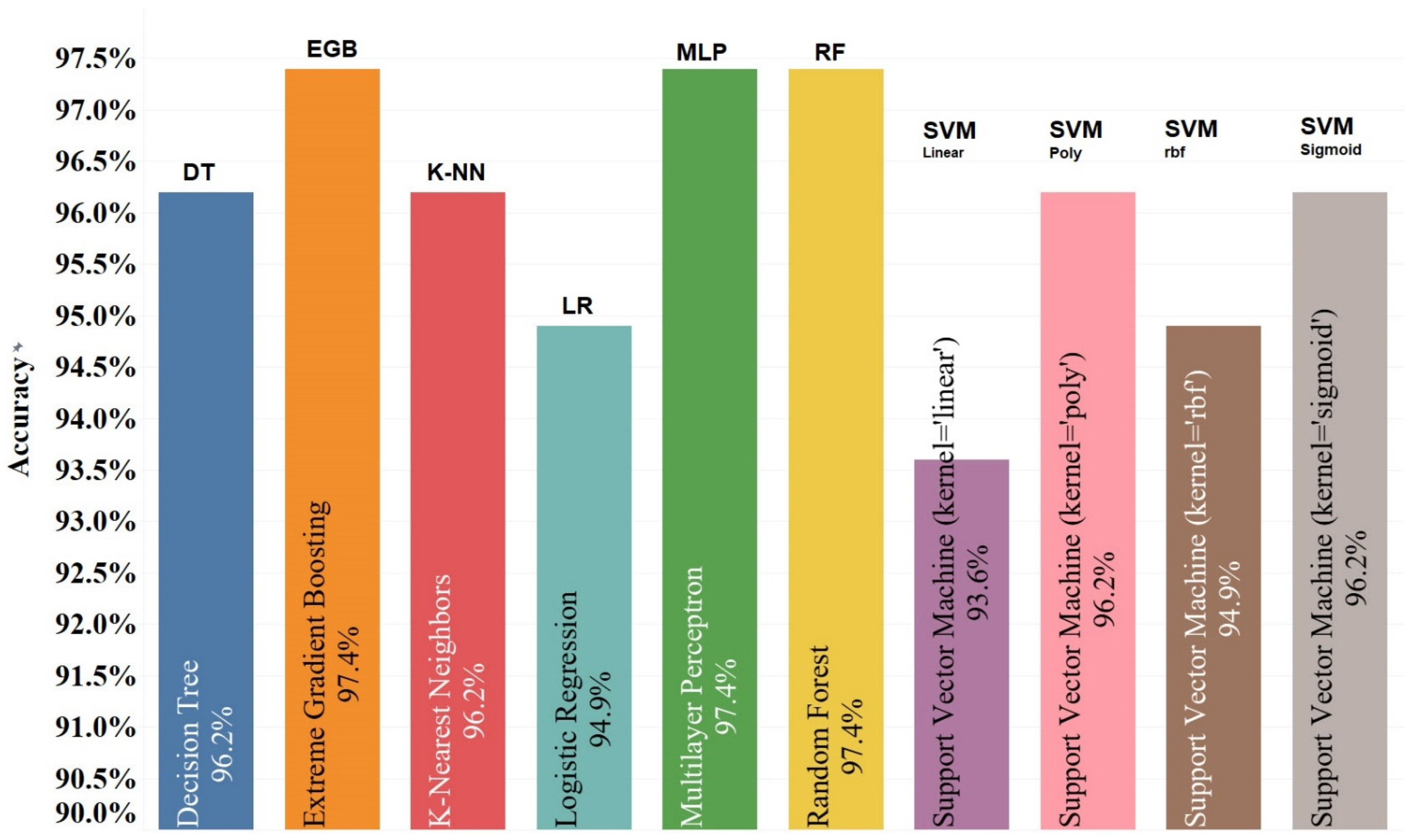
| Classifier | Class | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| Decision Tree | Low & Moderate Risk | 90 | 95 | 93 |
| High Risk | 98 | 96 | 97 | |
| Extreme Gradient Boosting | Low & Moderate Risk | 95 | 86 | 90 |
| High Risk | 95 | 98 | 97 | |
| K-Nearest Neighbour | Low & Moderate Risk | 88 | 100 | 93 |
| High Risk | 100 | 95 | 97 | |
| Logistic Regression | Low & Moderate Risk | 100 | 86 | 92 |
| High Risk | 95 | 100 | 97 | |
| Multilayer Perceptron | Low & Moderate Risk | 95 | 95 | 95 |
| High Risk | 98 | 98 | 98 | |
| Random Forest | Low & Moderate Risk | 95 | 95 | 95 |
| High Risk | 98 | 98 | 98 | |
| Support Vector Machine (kernel = Linear) | Low & Moderate Risk | 90 | 86 | 88 |
| High Risk | 95 | 96 | 96 | |
| Support Vector Machine (kernel = Poly) | Low & Moderate Risk | 87 | 95 | 91 |
| High Risk | 98 | 95 | 96 | |
| Support Vector Machine (kernel = rbf) | Low & Moderate Risk | 95 | 95 | 95 |
| High Risk | 98 | 98 | 98 | |
| Support Vector Machine (kernel = Sigmoid) | Low & Moderate Risk | 100 | 86 | 92 |
| High Risk | 95 | 100 | 97 |
| Classifier | Mean | Standard Deviation | Best | Worst |
|---|---|---|---|---|
| Decision Tree | 93.58% | 8.04 | 100.00% | 81.25% |
| Extreme Gradient Boosting | 94.92% | 7.3 | 100.00% | 81.25% |
| K-Nearest Neighbours | 92.25% | 7.4 | 100.00% | 81.25% |
| Logistic Regression | 94.92% | 7.3 | 100.00% | 81.25% |
| Multilayer Perceptron | 94.92% | 7.3 | 100.00% | 81.25% |
| Random Forest | 94.92% | 7.3 | 100.00% | 81.25% |
| Support Vector Machine (kernel = ‘linear’) | 93.58% | 8.04 | 100.00% | 81.25% |
| Support Vector Machine (kernel = ‘rbf’) | 93.58% | 6.58 | 100.00% | 81.25% |
| Support Vector Machine (kernel = ‘poly’) | 93.58% | 8.04 | 100.00% | 81.25% |
| Support Vector Machine (kernel = ‘sigmoid’) | 96.25% | 7.5 | 100.00% | 81.25% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sadegh-Zadeh, S.-A.; Rahmani Qeranqayeh, A.; Benkhalifa, E.; Dyke, D.; Taylor, L.; Bagheri, M. Dental Caries Risk Assessment in Children 5 Years Old and under via Machine Learning. Dent. J. 2022, 10, 164. https://doi.org/10.3390/dj10090164
Sadegh-Zadeh S-A, Rahmani Qeranqayeh A, Benkhalifa E, Dyke D, Taylor L, Bagheri M. Dental Caries Risk Assessment in Children 5 Years Old and under via Machine Learning. Dentistry Journal. 2022; 10(9):164. https://doi.org/10.3390/dj10090164
Chicago/Turabian StyleSadegh-Zadeh, Seyed-Ali, Ali Rahmani Qeranqayeh, Elhadj Benkhalifa, David Dyke, Lynda Taylor, and Mahshid Bagheri. 2022. "Dental Caries Risk Assessment in Children 5 Years Old and under via Machine Learning" Dentistry Journal 10, no. 9: 164. https://doi.org/10.3390/dj10090164
APA StyleSadegh-Zadeh, S.-A., Rahmani Qeranqayeh, A., Benkhalifa, E., Dyke, D., Taylor, L., & Bagheri, M. (2022). Dental Caries Risk Assessment in Children 5 Years Old and under via Machine Learning. Dentistry Journal, 10(9), 164. https://doi.org/10.3390/dj10090164