
Deep Impact: A Study on the Impact of Data Papers and Datasets in the Humanities and Social Sciences
 , , , and
, , , and
Abstract
:1. Introduction
1.1. Data Journals and Data Papers
1.1.1. The Research and Dissemination Ecosystem in Data-Driven Projects
1.1.2. Humanities and Social Sciences Data Journals
1.2. Previous Work
1.3. Research Questions and Contributions of This Study
- (1)
- Do data papers have a positive impact on the metrics of associated research papers?
- (2)
- Do data papers effectively encourage data reuse?
- (3)
- Can social media have a positive impact on the metrics of data papers?
- A.
- Are higher-impact data papers associated with higher-impact datasets and research papers?
- B.
- Do research papers with associated data papers have higher metrics (i.e., citations, Altmetric scores) than the average research paper in the HSS?
- C.
- Do deposited datasets with associated data papers have higher citation and altmetrics scores than the average deposited dataset in HSS?
- D.
- Does tweeting about a paper on JOHD’s Twitter account have a positive impact on its visibility?
- E.
- What is the best strategy to draw the attention of the users towards the contents of the paper mentioned in a tweet?
2. Materials and Methods
- (1)
- A dataset of all articles published in JOHD and RDJ and their respective research fields (Section 2.1);
- (2)
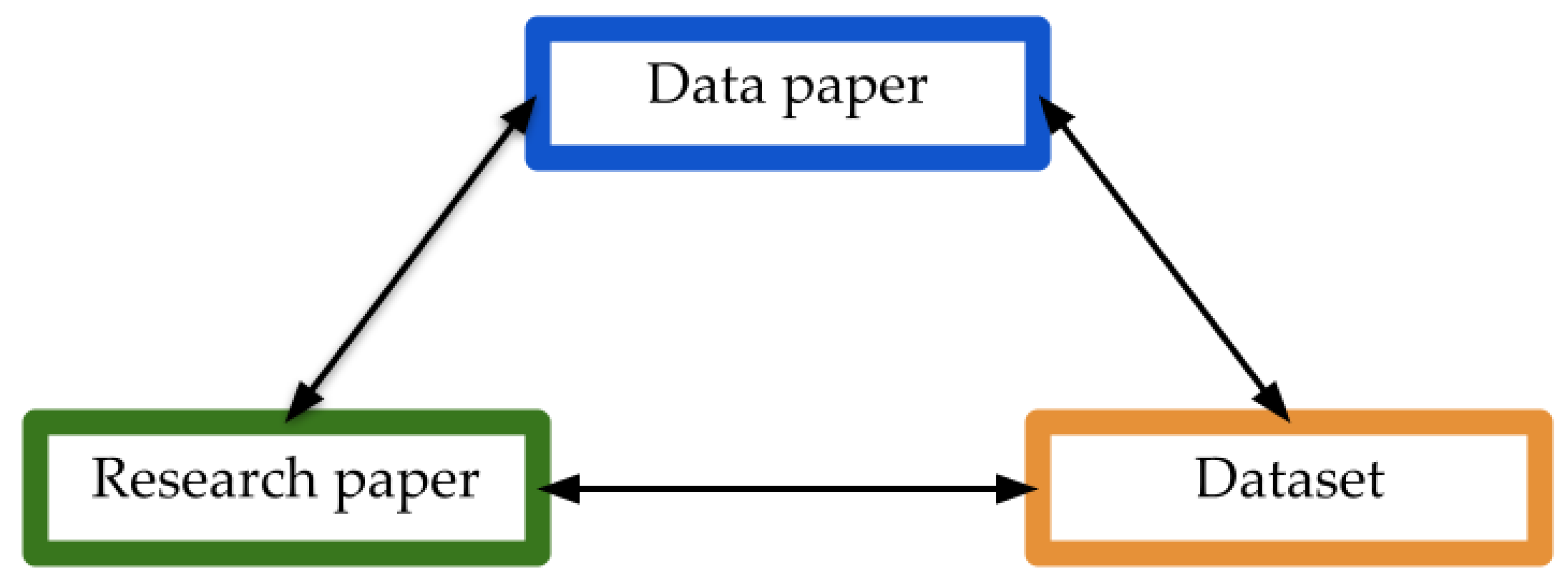
- A dataset linking the three elements of the “deep-impact” triangle in Figure 2: datasets, data papers and research papers provided that all three were produced and published (Section 2.2.1);
- (3)
- The citation and Altmetric counts of articles listed in (2) and those of their corresponding datasets (Section 2.2.2);
- (4)
- A large dataset about the performance of research articles in HSS exported from Dimensions.ai and structured for the purpose of the current study (Section 2.2.3);
- (5)
- A large dataset about the performance of datasets in HSS harvested from the Zenodo REST API and structured for the purpose of the current study (Section 2.2.4);
- (6)
- JOHD’s Twitter activity on newly published articles, updates on the activities of the journal, events related to the journal’s scope and campaigns aimed at encouraging the community to engage in the conversation about Open Humanities data (Section 2.3).
2.1. Publication Data
2.2. Impact of Data Papers, Research Papers and Datasets
2.2.1. Linking Datasets, Data Papers and Research Papers
- (1)
- at least one of the following three conditions was satisfied:
- (a)
- the research paper appeared in the reference list of the data paper;
- (b)
- the research paper was cited in the dataset repository;
- (c)
- the research paper was listed as one citing the data paper on Dimensions [48];
- (2)
- and the following two conditions were also satisfied:
- (a)
- at least one person was an author of both the data and the research paper;
- (b)
- the research paper was a substantial, analytical interpretation of the dataset associated with the data paper.
2.2.2. Impact Metrics of Data Papers and Associated Datasets and Research Papers
2.2.3. Impact Metrics of HSS Research Papers
- 18 Law and Legal Studies
- 20 Language, Communication and Culture
- 21 History and Archaeology
- 22 Philosophy and Religious Studies
2.2.4. Impact Metrics of HSS Datasets
2.3. Twitter Data
- papers tweeted with the hashtag #showmeyourdata and papers that were not;
- papers tweeted with the hashtag #johdpapers and papers that were not. For these, we manually retrieved and added eight papers that were tweeted about without the hashtag.
3. Results
3.1. Publication Data
3.2. Impact of Data Papers and Datasets
3.2.1. Publication Times of Data Papers, Datasets and Research Articles
3.2.2. Impact Metrics
3.2.3. Correlation between the Different Impact Metrics
3.3. Twitter Data
4. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A



Appendix B
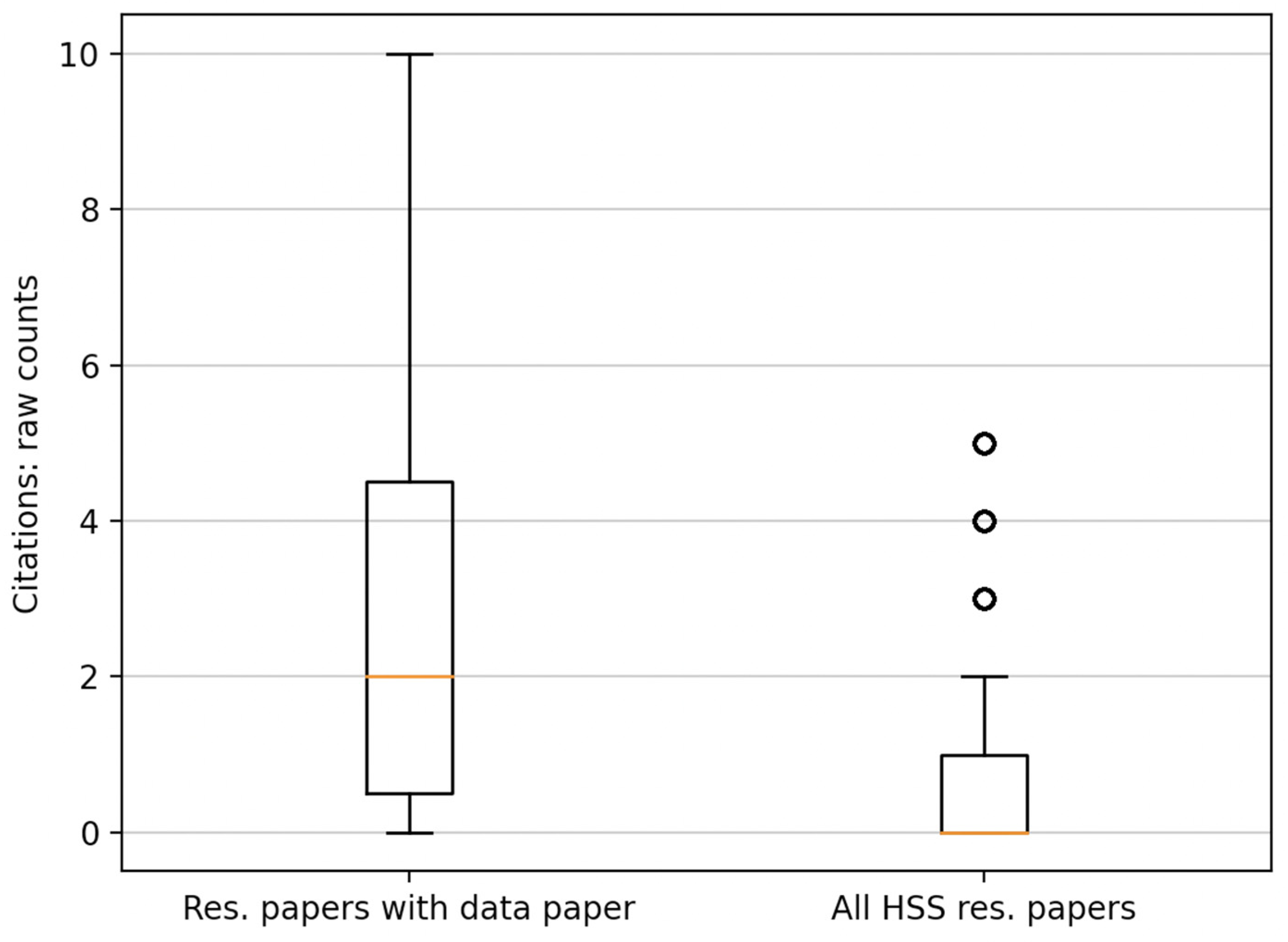
- a box plot representing raw counts, including details on median and mean, lower and upper quartile, and the minima and maxima;
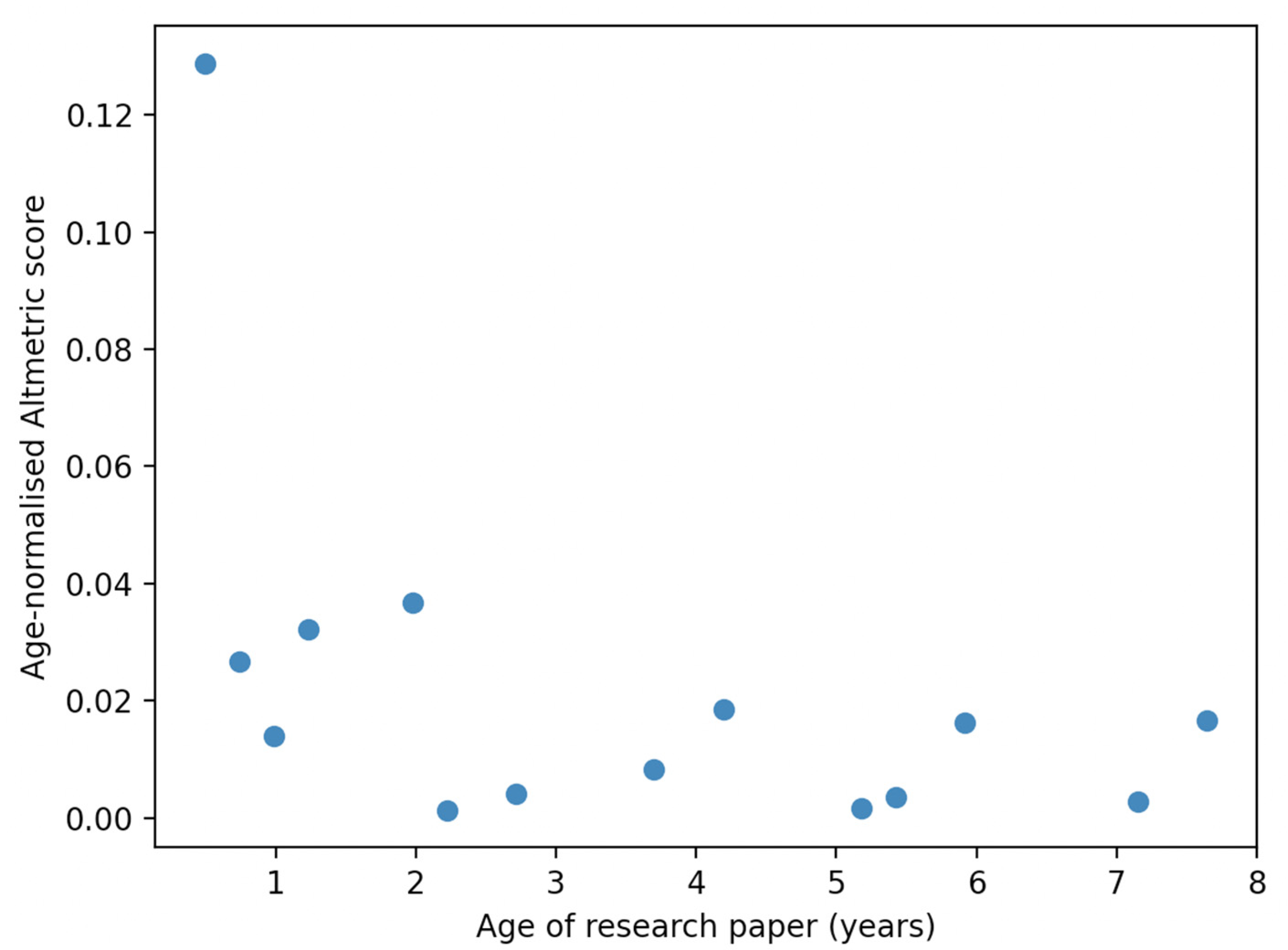
- a scatter plot showing the relative, age-normalised counts of the relevant metrics in papers or datasets of different ages.

- Median: 60
- Mean: 344
- Minimum: 0
- Maximum: 989
- Upper Q: 412
- Lower Q: 16
- Median: 345
- Mean: 553.8
- Minimum: 0
- Maximum: 1367
- Upper Q: 649
- Lower Q: 146


- Median: 2
- Mean: 3.4
- Minimum: 0
- Maximum: 8
- Upper Q: 4
- Lower Q: 1


- Median: 12.5
- Mean: 22
- Minimum: 1
- Maximum: 46
- Upper Q: 26.2
- Lower Q: 7


- Median: 94
- Mean: 469.7
- Minimum: 2
- Maximum: 424
- Upper Q: 244.5
- Lower Q: 26
- Median: 341
- Mean: 933
- Minimum: 35
- Maximum: 1184
- Upper Q: 768.5
- Lower Q: 173.5


- Median: 5
- Mean: 9
- Minimum: 0
- Maximum: 28
- Upper Q: 12
- Lower Q: 1
- Median: 13
- Mean: 18.6
- Minimum: 0
- Maximum: 58
- Lower Q: 6
- Upper Q: 27


- Median: 3
- Mean: 4.6
- Minimum: 1
- Maximum: 13
- Upper Q: 6
- Lower Q: 1
- Median: 3
- Mean: 6
- Minimum: 0
- Maximum: 18
- Upper Q: 8
- Lower Q: 1

| 1. | https://opendefinition.org/, accessed on 12 July 2022. |
| 2. | With regard to types of research output alternative to the academic article, it is worth mentioning the Declaration on Research Assessment (DORA), launched in 2012. Although not specifically focused on open research, it is committed to improving methods for evaluating research outputs in all disciplines, ultimately to decrease inequalities within the academic system. |
| 3. | https://www.go-fair.org/fair-principles/, accessed on 12 July 2022. |
| 4. | https://www.coalition-s.org/, accessed on 12 July 2022. |
| 5. | https://sshopencloud.eu/about-sshoc, accessed on 12 July 2022. |
| 6. | https://libereurope.eu/, accessed on 12 July 2022. |
| 7. | https://www.ubiquitypress.com/site/publish/, accessed on 12 July 2022. |
| 8. | https://openhumanitiesdata.metajnl.com/, accessed on 12 July 2022. |
| 9. | https://brill.com/view/journals/rdj/rdj-overview.xml, accessed on 12 July 2022. |
| 10. | The first articles were published in RDJ at a later date, on 25 March 2016. |
| 11. | https://meshb.nlm.nih.gov/, accessed on 12 July 2022. |
| 12. | https://help.figshare.com/article/usage-metrics, accessed on 12 July 2022. |
| 13. | See, for example, https://figshare.com/articles/dataset/Comparison_chart_of_Vai_script/5398537, accessed on 12 July 2022. |
| 14. | https://app.dimensions.ai/browse/categories/publication/for, accessed on 12 July 2022. |
| 15. | The documentation of the Zenodo REST API includes instructions for using the ‘records’ endpoint at https://developers.zenodo.org/#records, accessed on 25 August 2022. |
| 16. | https://www.ref.ac.uk/panels/units-of-assessment/, accessed on 12 July 2022. |
| 17. | Prior to the introduction of the hashtags system, the publication of some of the first papers published by JOHD was announced on the journal’s Twitter account. The content of these tweets generally overlaps with the format used in #johdpapers, besides the missing hashtag. Therefore, we manually retrieved and added the papers tweeted in the past to the list of #johdpapers. |
| 18. | https://openhumanitiesdata.metajnl.com/collections/special/humanities-data-in-the-time-of-covid-19/, accessed on 14 July 2022. |
| 19. | https://www.altmetric.com/about-our-data/altmetric-top-100/, accessed on 12 July 2022. |
References
- McGillivray, B.; Alex, B.; Ames, S.; Armstrong, G.; Beavan, D.; Ciula, A.; Colavizza, G.; Cummings, J.; De Roure, D.; Farquhar, A. The challenges and prospects of the intersection of humanities and data science: A White Paper from The Alan Turing Institute. Figshare 2020. [Google Scholar] [CrossRef]
- Hinrichs, E.; Krauwer, S. ‘The CLARIN Research Infrastructure: Resources and Tools for E-Humanities Scholars. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC-2014), Reykjavik, Iceland, 26–31 May 2014. [Google Scholar]
- Callaghan, S.; Donegan, S.; Pepler, S.; Thorley, M.; Cunningham, N.; Kirsch, P.; Ault, L.; Bell, P.; Bowie, R.; Leadbetter, A.; et al. Making Data a First Class Scientific Output: Data Citation and Publication by NERC’s Environmental Data Centres. Int. J. Digit. Curation 2012, 7, 107–113. [Google Scholar] [CrossRef]
- Schöpfel, J.; Farace, D.; Prost, H.; Zane, A. Data Papers as a New Form of Knowledge Organization in the Field of Research Data. Knowl. Organ. 2019, 46, 622–638. [Google Scholar] [CrossRef] [Green Version]
- Bordelon, D.; Grothkopf, U.; Meakins, S.; Sterzik, M. Trends and developments in VLT data papers as seen through telbib. In Proceedings of the Volume 9910, Observatory Operations: Strategies, Processes, and Systems VI, Edinburgh, UK, 15 July 2016. [Google Scholar] [CrossRef]
- Pärtel, M. Data availability for macroecology: How to get more out of regular ecological papers. Acta Oecologica 2006, 30, 97–99. [Google Scholar] [CrossRef]
- Penev, L.; Chavan, V.; Georgiev, T.; Stoev, P. Data papers as incentives for opening biodiversity data: One year of experience and perspectives for the future. Poster présenté à EU BON: Building the European Biodiversity Observation Network, 2012. Available online: https://pensoft.net/img/upl/file/DataPaperPoster.pdf (accessed on 15 July 2022).
- Marongiu, P.; Pedrazzini, N.; Ribary, M.; McGillivray, B. Le Journal of Open Humanities Data: Enjeux et défis dans la publication de data papers pour les sciences humaines. In Publier, Partager, Réutiliser les Données de la Recherche: Les Data Papers et Leurs enjeux; Kosmopoulos, C., Schopfel, J., Eds.; Presses Universitaires du Septentrion: Villeneuve-d’Ascq, France, 2021; (to be published). [Google Scholar]
- Ribary, M. pyDigest: A GitLab Repository of Scripts, Files and Documentation. Available online: https://gitlab.eps.surrey.ac.uk/mr0048/pydigest (accessed on 18 June 2022).
- Ribary, M. A Relational Database of Roman Law Based on Justinian’s Digest. Available online: https://figshare.com/articles/dataset/A_relational_database_of_Roman_law_based_on_Justinian_s_Digest/12333290 (accessed on 18 June 2022).
- Ribary, M. A Relational Database of Roman Law Based on Justinian’s Digest. J. Open Humanit. Data 2020, 6, 5. [Google Scholar] [CrossRef]
- Ribary, M.; McGillivray, B. A Corpus Approach to Roman Law Based on Justinian’s Digest. Informatics 2020, 7, 44. [Google Scholar] [CrossRef]
- García-García, A.; López-Borrull, A.; Peset, F. Data journals: Eclosión de nuevas revistas especializadas en datos. El Prof. de la Inf. 2015, 24, 845. [Google Scholar] [CrossRef] [Green Version]
- Candela, L.; Castelli, D.; Manghi, P.; Tani, A. Data journals: A survey. J. Assoc. Inf. Sci. Technol. 2015, 66, 1747–1762. [Google Scholar] [CrossRef] [Green Version]
- Walters, W.H. Data journals: Incentivizing data access and documentation within the scholarly communication system. Insights 2020, 33, 18. [Google Scholar] [CrossRef]
- Engelhardt, C.; Biernacka, K.; Coffey, A.; Cornet, R.; Danciu, A.; Demchenko, Y.; Downes, S.; Erdmann, C.; Garbuglia, F.; Germer, K.; et al. D7.4 How to Be FAIR with Your Data. A Teaching and Training Handbook for Higher Education Institutions, version V1.2 DRAFT. Zenodo 2022. [Google Scholar] [CrossRef]
- Miguel, E.; Camerer, C.; Casey, K.; Cohen, J.; Esterling, K.M.; Gerber, A.; Glennerster, R.; Green, D.P.; Humphreys, M.; Imbens, G.; et al. Promoting Transparency in Social Science Research. Science 2014, 343, 30–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hrynaszkiewicz, I.; Harney, J.; Cadwallader, L. A Survey of Researchers’ Needs and Priorities for Data Sharing. Data Sci. J. 2021, 20, 31. [Google Scholar] [CrossRef]
- Rousi, A.M.; Laakso, M. Journal research data sharing policies: A study of highly-cited journals in neuroscience, physics, and operations research. Scientometrics 2020, 124, 131–152. [Google Scholar] [CrossRef] [Green Version]
- Haendel, M.A.; Vasilevsky, N.; Wirz, J. Dealing with Data: A Case Study on Information and Data Management Literacy. PLOS Biol. 2012, 10, e1001339. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rouder, J.N. The what, why, and how of born-open data. Behav. Res. Methods 2015, 48, 1062–1069. [Google Scholar] [CrossRef]
- Armbruster, C. Whose metrics? Citation, usage and access metrics as scholarly information service. Learn. Publ. 2010, 23, 33–38. [Google Scholar] [CrossRef]
- Colavizza, G.; Hrynaszkiewicz, I.; Staden, I.; Whitaker, K.; McGillivray, B. The citation advantage of linking publications to research data. PLoS ONE 2020, 15, e0230416. [Google Scholar] [CrossRef] [Green Version]
- Christensen, G.; Dafoe, A.; Miguel, E.; Moore, D.A.; Rose, A.K. A study of the impact of data sharing on article citations using journal policies as a natural experiment. PLoS ONE 2019, 14, e0225883. [Google Scholar] [CrossRef] [Green Version]
- Piwowar, H.A.; Vision, T.J. Data reuse and the open data citation advantage. PeerJ 2013, 1, e175. [Google Scholar] [CrossRef]
- Elmore, S.A. The Altmetric attention score: What does it mean and why should I care? Toxicol. Pathol. 2018, 46, 252–255. [Google Scholar] [CrossRef] [Green Version]
- Robinson, D.B.T.; Powell, A.G.M.T.; Waterman, J.; Hopkins, L.; James, O.P.; Egan, R.J.; Lewis, W.G. Predictive value of Altmetric score on citation rates and bibliometric impact. BJS Open 2021, 5, zraa039. [Google Scholar] [CrossRef] [PubMed]
- Erdt, M.; Nagarajan, A.; Sin, S.-C.J.; Theng, Y.-L. Altmetrics: An analysis of the state-of-the-art in measuring research impact on social media. Scientometrics 2016, 109, 1117–1166. [Google Scholar] [CrossRef]
- Llewellyn, N.M.; Nehl, E.J. Predicting citation impact from altmetric attention in clinical and translational research: Do big splashes lead to ripple effects? CTS 2022, 15, 1387–1392. [Google Scholar] [CrossRef] [PubMed]
- Brody, T.; Harnad, S.; Carr, L. Earlier Web usage statistics as predictors of later citation impact. J. Am. Soc. Inf. Sci. Technol. 2006, 57, 1060–1072. [Google Scholar] [CrossRef]
- Chang, J.; Desai, N.; Gosain, A. Correlation Between Altmetric Score and Citations in Pediatric Surgery Core Journals. J. Surg. Res. 2019, 243, 52–58. [Google Scholar] [CrossRef] [PubMed]
- Collins, C.S.; Singh, N.P.; Ananthasekar, S.; Boyd, C.J.; Brabston, E.; King, T.W. The Correlation Between Altmetric Score and Traditional Bibliometrics in Orthopaedic Literature. J. Surg. Res. 2021, 268, 705–711. [Google Scholar] [CrossRef]
- Kolahi, J.; Khazaei, S.; Iranmanesh, P.; Kim, J.; Bang, H.; Khademi, A. Meta-Analysis of Correlations between Altmetric Attention Score and Citations in Health Sciences. BioMed Res. Int. 2021, 2021, 1–11. [Google Scholar] [CrossRef]
- Ran, N. Association Between Immediacy of Citations and Altmetrics in COVID-19 Research by Artificial Neural Networks. Disaster Med. Public Health Prep. 2021, 1–6. [Google Scholar] [CrossRef]
- Vaghjiani, N.G.; Lal, V.; Vahidi, N.; Ebadi, A.; Carli, M.; Sima, A.; Coelho, D.H. Social Media and Academic Impact: Do Early Tweets Correlate With Future Citations? Ear Nose Throat J. 2021. [Google Scholar] [CrossRef]
- Drachen, T.M.; Ellegaard, O.; Larsen, A.V.; Dorch, S.B.F. Sharing Data Increases Citations. Liber Q. 2016, 26, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Piwowar, H.A.; Day, R.S.; Fridsma, D.B. Sharing Detailed Research Data Is Associated with Increased Citation Rate. PLoS ONE 2007, 2, e308. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Henneken, E.A.; Accomazzi, A. Linking to data-effect on citation rates in astronomy. arXiv 2011, arXiv:1111.3618. [Google Scholar]
- Sears, J.R.L. Data sharing effect on article citation rate in paleoceanography. In Proceedings of the Fall Meeting, AGU, San Francisco, CA, USA, 5–9 December 2011. [Google Scholar]
- Leitner, F.; Bielza, C.; Hill, S.L.; Larrañaga, P. Data Publications Correlate with Citation Impact. Front. Neurosci. 2016, 10, 419. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, L.; Ma, L. Does open data boost journal impact: Evidence from Chinese economics. Scientometrics 2021, 126, 3393–3419. [Google Scholar] [CrossRef] [PubMed]
- Vandewalle, P. Code Sharing Is Associated with Research Impact in Image Processing. Comput. Sci. Eng. 2012, 14, 42–47. [Google Scholar] [CrossRef] [Green Version]
- Thelwall, M. Data in Brief: Can a mega-journal for data be useful? Scientometrics 2020, 124, 697–709. [Google Scholar] [CrossRef]
- Stuart, D. Data bibliometrics: Metrics before norms. Online Inf. Rev. 2017, 41, 428–435. [Google Scholar] [CrossRef]
- Ilgisonis, E.V.; Pyatnitskiy, M.A.; Tarbeeva, S.N.; Aldushin, A.A.; Ponomarenko, E.A. How to catch trends using MeSH terms analysis? Scientometrics 2022, 127, 1953–1967. [Google Scholar] [CrossRef]
- Leydesdorff, L.; Opthof, T. Citation analysis with medical subject Headings (MeSH) using the Web of Knowledge: A new routine. J. Am. Soc. Inf. Sci. Technol. 2013, 64, 1076–1080. [Google Scholar] [CrossRef] [Green Version]
- AlRyalat, S.A.S.; Malkawi, L.W.; Momani, S.M. Comparing Bibliometric Analysis Using PubMed, Scopus, and Web of Science Databases. J. Vis. Exp. 2019, 152, e58494. [Google Scholar] [CrossRef]
- Bode, C.; Herzog, C.; Hook, D.; McGrath, R. A Guide to the Dimensions Data Approach. Figshare 2019. [Google Scholar] [CrossRef]
- Peters, I.; Kraker, P.; Lex, E.; Gumpenberger, C.; Gorraiz, J. Research data explored: An extended analysis of citations and altmetrics. Scientometrics 2016, 107, 723–744. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bornmann, L. Do altmetrics point to the broader impact of research? An overview of benefits and disadvantages of altmetrics. J. Inf. 2014, 8, 895–903. [Google Scholar] [CrossRef] [Green Version]
- Hwang, L.; Fish, A.; Soito, L.; Smith, M.; Kellogg, L.H. Software and the Scientist: Coding and Citation Practices in Geodynamics. Earth Space Sci. 2017, 4, 670–680. [Google Scholar] [CrossRef]
- Park, H.; You, S.; Wolfram, D. Informal data citation for data sharing and reuse is more common than formal data citation in biomedical fields. J. Assoc. Inf. Sci. Technol. 2018, 69, 1346–1354. [Google Scholar] [CrossRef]
- Park, H.; Wolfram, D. Research software citation in the Data Citation Index: Current practices and implications for research software sharing and reuse. J. Inf. 2019, 13, 574–582. [Google Scholar] [CrossRef]
- Yoon, J.; Chung, E.; Lee, J.Y.; Kim, J. How research data is cited in scholarly literature: A case study of HINTS. Learn. Publ. 2019, 32, 199–206. [Google Scholar] [CrossRef]
- Martone, M. (Ed.) Data Citation Synthesis Group: Joint Declaration of Data Citation Principles; FORCE11: San Diego, CA, USA, 2014. [Google Scholar] [CrossRef]
- Burton, A.; Aryani, A.; Koers, H.; Manghi, P.; La Bruzzo, S.; Stocker, M.; Diepenbroek, M.; Schindler, U.; Fenner, M. The Scholix Framework for Interoperability in Data-Literature Information Exchange. D-Lib Mag. 2017, 23, 1/2. [Google Scholar] [CrossRef]
- Cousijn, H.; Feeney, P.; Lowenberg, D.; Presani, E.; Simons, N. Bringing Citations and Usage Metrics Together to Make Data Count. Data Sci. J. 2019, 18, 1. [Google Scholar] [CrossRef]
- Federer, L. Measuring and Mapping Data Reuse: Findings From an Interactive Workshop on Data Citation and Metrics for Data Reuse. Harv. Data Sci. Rev. 2020, 2, 2. [Google Scholar] [CrossRef]
- McGillivray, B.; Marongiu, P.; Pedrazzini, N.; Ribary, M.; Zordan, E. JOHD Data Analysis: Scripts and Data. npedrazzini/DataPapersAnalysis, version 1.0.0. Zenodo 2022. [Google Scholar] [CrossRef]
- McGillivray, B.; Marongiu, P.; Pedrazzini, N.; Ribary, M.; Zordan, E. Data Journals and Data Papers in the Humanities. Figshare 2022. [Google Scholar] [CrossRef]
- Dancey Christine, P.; Reidy, J. Statistics without Maths for Psychology, 7th ed.; Pearson Education: London, UK, 2017. [Google Scholar]
- Hall-Lew, L.; Cowie, C.; McNulty, S.J.; Markl, N.; Liu, S.-J.S.; Lai, C.; Llewellyn, C.; Alex, B.; Fang, N.; Elliott, Z.; et al. The Lothian Diary Project: Investigating the Impact of the COVID-19 Pandemic on Edinburgh and Lothian Residents. J. Open Humanit. Data 2021, 7, 4. [Google Scholar] [CrossRef]
- Allés-Torrent, S.; Riande, G.D.R.; Bonnell, J.; Song, D.; Hernández, N. Digital Narratives of COVID-19: A Twitter Dataset for Text Analysis in Spanish. J. Open Humanit. Data 2021, 7, 5. [Google Scholar] [CrossRef]
- Knuutila, A.; Herasimenka, A.; Au, H.; Bright, J.; Howard, P.N. A Dataset of COVID-Related Misinformation Videos and their Spread on Social Media. J. Open Humanit. Data 2021, 7, 1–5. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name of Journal | Year Since Publications | Field | Publications so Far | Publisher | URL |
|---|---|---|---|---|---|
| (CODATA) Data Science Journal | 2002 (relaunch 2014) | Science; Technology; Humanities; Arts | 823 | Ubiquity Press | https://datascience.codata.org/ (accessed on 7 July 2022) |
| Data in Brief | 2014 | All including Humanities | >6000 | Elsevier | https://www.journals.elsevier.com/data-in-brief (accessed on 7 July 2022) |
| F1000Research | 2012 | All including Humanities | >5000 | F1000 Research | https://f1000research.com (accessed on 7 July 2022) |
| Journal of Cognition | 2017 | Cognitive psychology | 222 | Ubiquity Press | https://www.journalofcognition.org/ (accessed on 7 July 2022) |
| Journal of Cultural Analytics | 2016 | Cultural analytics | 109 | Department of Languages, Literatures, and Cultures at McGill University | https://culturalanalytics.org/section/1579-data-sets (accessed on 7 July 2022) |
| Journal of Open Archaeology Data | 2012 | Archaeology | 57 | Ubiquity Press | https://openarchaeologydata.metajnl.com/ (accessed on 7 July 2022) |
| Journal of Open Humanities Data | 2015 | Humanities | 67 | Ubiquity Press | https://openhumanitiesdata.metajnl.com/ (accessed on 7 July 2022) |
| Journal of Open Psychology Data | 2013 | Psychology | 48 | Ubiquity Press | https://openpsychologydata.metajnl.com/ (accessed on 7 July 2022) |
| Research Data Journal for the Humanities and Social Sciences | 2016 | Humanities; Social Sciences | 46 | Brill | https://brill.com/view/journals/rdj/rdj-overview.xml (accessed on 7 July 2022) |
| Total Number of Data Papers with an Associated Dataset | Dataset Download and View Count Available for Associated Dataset | Only Download Count Available for Associated Dataset | Only View Count Available for Associated Dataset | No Total Usage Statistics Available for Associated Dataset |
|---|---|---|---|---|
| 107 | 42 | 14 | 2 | 49 |
| Zenodo | Figshare | Dataverse | Datashare | Kaggle | OSF | |
|---|---|---|---|---|---|---|
| Total views | Yes | Yes | Sometimes | Yes | Yes | No |
| Total downloads | Yes | Yes | Yes | No | Yes | No |
| Type of Publication | Impact Metrics Available | n of Entries |
|---|---|---|
| a. Data papers | Citation counts Total views Total downloads Altmetric score | 107 |
| b. Research associated with a data paper | Citation counts Total views Total downloads Altmetric score | 35 |
| c. Datasets associated with a data paper | Total views Total downloads | 58 |
| d. Humanities and social sciences datasets in Zenodo (2015–2022) | Total views Total downloads | 39,290 |
| e. Humanities and social sciences research papers in Dimensions (2015–2022) | Citation counts Altmetric score | 358,770 |
| Variable 1 | Variable 2 | rho | p-Value | Strength of Correlation | Significant (Alpha = 0.05)? |
|---|---|---|---|---|---|
| tot_cit_datapapers | altmetric_research | 0.68 | <0.01 | Moderate | Y |
| downloads_datapapers | altmetric_research | 0.59 | 0.015 | Moderate | Y |
| altmetric_datapapers | tot_cit_research | 0.39 | 0.063 | Weak | Borderline |
| views_datapapers | altmetric_research | 0.47 | 0.064 | Moderate | Borderline |
| views_dataset | tot_cit_datapapers | 0.51 | 0.014 | Moderate | Y |
| All HSS Res. Papers (Mean Citations) | Res. Papers with Associated Data Paper (Mean Citations) | Welch’s Stats | Welch’s p-Value | Mann–Whitney Stats | Mann–Whitney p-Value |
|---|---|---|---|---|---|
| 0.0005 | 0.0017 | 3.5911 | <0.01 | 87,958 | <0.01 |
| 0.0005 | 0.0017 | 3.5417 | <0.01 | 87,593 | <0.01 |
| 0.0005 | 0.0017 | 3.5756 | <0.01 | 87,779 | <0.01 |
| 0.0005 | 0.0017 | 3.5491 | <0.01 | 87,595 | <0.01 |
| 0.0005 | 0.0017 | 3.5666 | <0.01 | 87,704.5 | <0.01 |
| 0.0005 | 0.0017 | 3.5052 | <0.01 | 87,319.5 | <0.01 |
| 0.0005 | 0.0017 | 3.5174 | <0.01 | 87,434.5 | <0.01 |
| 0.0005 | 0.0017 | 3.5788 | <0.01 | 87,909.5 | <0.01 |
| 0.0005 | 0.0017 | 3.5552 | <0.01 | 87,690.5 | <0.01 |
| 0.0005 | 0.0017 | 3.5329 | <0.01 | 87,569.5 | <0.01 |
| All HSS Res. Papers (Mean Altmetric Score) | Res. Papers with Associated Data Paper (Mean Altmetric Score) | Welch’s Stats | Welch’s p-Value | Mann–Whitney Stats | Mann–Whitney p-Value |
|---|---|---|---|---|---|
| 0.0054 | 0.0142 | 2.7096 | 0.0169 | 55,227.5 | <0.01 |
| 0.0055 | 0.0142 | 2.6809 | 0.0178 | 54,885 | <0.01 |
| 0.0054 | 0.0142 | 2.7060 | 0.0170 | 55,167 | <0.01 |
| 0.0054 | 0.0142 | 2.7028 | 0.0171 | 54,985.5 | <0.01 |
| 0.0053 | 0.0142 | 2.7207 | 0.0165 | 55,342.5 | <0.01 |
| 0.0054 | 0.0142 | 2.7123 | 0.0168 | 55,262.5 | <0.01 |
| 0.0054 | 0.0142 | 2.6967 | 0.0173 | 55,065 | <0.01 |
| 0.0054 | 0.0142 | 2.7027 | 0.0171 | 55,138 | <0.01 |
| 0.0052 | 0.0142 | 2.7566 | 0.0154 | 55,542 | <0.01 |
| 0.0053 | 0.0142 | 2.7220 | 0.0165 | 55,247.5 | <0.01 |
| All HSS Datasets (Mean Downloads) | Datasets with Associated Data Paper (Mean Downloads) | Welch’s Stats | Welch’s p-Value | Mann–Whitney Stats | Mann–Whitney p-Value |
|---|---|---|---|---|---|
| 0.0371 | 0.1807 | 3.6907 | <0.001 | 150,735.5 | <0.001 |
| 0.0333 | 0.1807 | 3.7979 | <0.001 | 150,662.5 | <0.001 |
| 0.0325 | 0.1807 | 3.8184 | <0.001 | 150,606.5 | <0.001 |
| 0.0363 | 0.1807 | 3.6818 | <0.001 | 150,534.5 | <0.001 |
| 0.0358 | 0.1807 | 3.7203 | <0.001 | 149,763.5 | <0.001 |
| 0.0324 | 0.1807 | 3.8213 | <0.001 | 150,502 | <0.001 |
| 0.0415 | 0.1807 | 3.5410 | <0.001 | 150,328.5 | <0.001 |
| 0.0393 | 0.1807 | 3.6093 | <0.001 | 150,285 | <0.001 |
| 0.0360 | 0.1807 | 3.6890 | <0.001 | 150,863.5 | <0.001 |
| 0.0329 | 0.1807 | 3.8062 | <0.001 | 150,091 | <0.001 |
| All HSS Datasets (Mean Views) | Datasets with Associated Data Paper (Mean Views) | Welch’s Stats | Welch’s p-Value | Mann–Whitney Stats | Mann–Whitney p-Value |
|---|---|---|---|---|---|
| 0.0866 | 0.5899 | 6.6730 | <0.001 | 166,320.5 | <0.001 |
| 0.1045 | 0.5899 | 6.3782 | <0.001 | 166,043.5 | <0.001 |
| 0.0915 | 0.5899 | 6.5895 | <0.001 | 166,474 | <0.001 |
| 0.0780 | 0.5899 | 6.7957 | <0.001 | 166,256 | <0.001 |
| 0.0885 | 0.5899 | 6.6488 | <0.001 | 165,853 | <0.001 |
| 0.0954 | 0.5899 | 6.5406 | <0.001 | 166,109 | <0.001 |
| 0.0868 | 0.5899 | 6.6652 | <0.001 | 166,378.5 | <0.001 |
| 0.0903 | 0.5899 | 6.6159 | <0.001 | 166,123.5 | <0.001 |
| 0.0811 | 0.5899 | 6.7502 | <0.001 | 166,266 | <0.001 |
| 0.0813 | 0.5899 | 6.7475 | <0.001 | 166,329.5 | <0.001 |
| #johdpapers | #showmeyourdata | |||
|---|---|---|---|---|
| With Hashtag | Without Hashtag | With Hashtag | Without Hashtag | |
| (1) | (2) | (3) | (4) | |
| Mean downloads | 0.0822 | 0.0893 | 0.1048 | 0.0576 |
| Mean views | 0.6327 | 0.7643 | 0.8471 | 0.4543 |
| Mean citations | 0.0016 | 0.0025 | 0.0020 | 0.0018 |
| With Hashtag | Without Hashtag | Difference in Means | t-Statistic | p-Value |
|---|---|---|---|---|
| downloads | downloads | 0.0472 | 2.0208 | <0.05 |
| views | views | 0.3927 | 2.2143 | <0.05 |
| citations | citations | 0.0002 | 0.2012 | 0.8412 |
| With Hashtag | Without Hashtag | Difference in Means | t-Statistic | p-Value |
|---|---|---|---|---|
| downloads | downloads | −0.0071 | −0.2289 | 0.8204 |
| views | views | −0.1316 | −0.5423 | 0.5916 |
| citations | citations | −0.0009 | −0.6620 | 0.5131 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
McGillivray, B.; Marongiu, P.; Pedrazzini, N.; Ribary, M.; Wigdorowitz, M.; Zordan, E. Deep Impact: A Study on the Impact of Data Papers and Datasets in the Humanities and Social Sciences. Publications 2022, 10, 39. https://doi.org/10.3390/publications10040039
McGillivray B, Marongiu P, Pedrazzini N, Ribary M, Wigdorowitz M, Zordan E. Deep Impact: A Study on the Impact of Data Papers and Datasets in the Humanities and Social Sciences. Publications. 2022; 10(4):39. https://doi.org/10.3390/publications10040039
Chicago/Turabian StyleMcGillivray, Barbara, Paola Marongiu, Nilo Pedrazzini, Marton Ribary, Mandy Wigdorowitz, and Eleonora Zordan. 2022. "Deep Impact: A Study on the Impact of Data Papers and Datasets in the Humanities and Social Sciences" Publications 10, no. 4: 39. https://doi.org/10.3390/publications10040039