
Tracing the Evolution of Reviews and Research Articles in the Biomedical Literature: A Multi-Dimensional Analysis of Abstracts

Abstract
:1. Introduction
2. Materials and Methods
- #1 ‘year[dp] NOT Review[pt]’;
- #2 ‘year[dp] AND Review[pt]’.
- #1 Abstracts from Research articles (excluding Reviews), published between 1989 and 2022 (n = 680,000);
- #2 Abstracts from Review articles, published between 1989 and 2022 (n = 680,000).
3. Results and Discussion
3.1. Dimension 1
It was my second clinical placement and I was working on a surgical ward when I was asked to accompany a patient to theatre. [29]
Primary care clinicians treat patients with cancer and cancer pain. It is essential that physicians know how to effectively manage pain including assessment and pharmacologic and nonpharmacologic treatment modalities. [33]
During 8 observation days (with time delay of 10–14 days between each observation day), all adult patients hospitalized at an internal medicine ward of 4 Belgian participating hospitals were screened for AB use. Patients receiving AB on the observation day were included in the study and screened for signs and symptoms of AAD using a period prevalence methodology. [34]
Administration of thioredoxin may have a good potential for anti-aging and anti-stress effects. [36]
3.2. Dimension 2
We investigated expression of the five ssts in various adrenal tumors and in normal adrenal gland. Tissue was obtained from ten pheochromocytomas (PHEOs)… [38]
Several lines of evidence indicate that platelet-activating factor (PAF-acether) is implicated in hypersensitivity reactions. Indeed, PAF-acether reproduces the features of asthma in vivo and in vitro, since it induces bronchoconstriction, hypotension, and hemoconcentration and activates platelets and leukocytes. [39]
Mammalian neonates have been simultaneously described as having particularly poor memory, as evidenced by infantile amnesia, and as being particularly excellent learners. [40]
3.3. Dimension 3
Pancreatic cancer (PC) is characterized by high tumor invasiveness, distant metastasis, and insensitivity to traditional chemotherapeutic drugs… [49]
… the specific mechanisms are blurry, especially the involved immunological pathways, and the roles of beneficial flora have usually been ignored. [49]
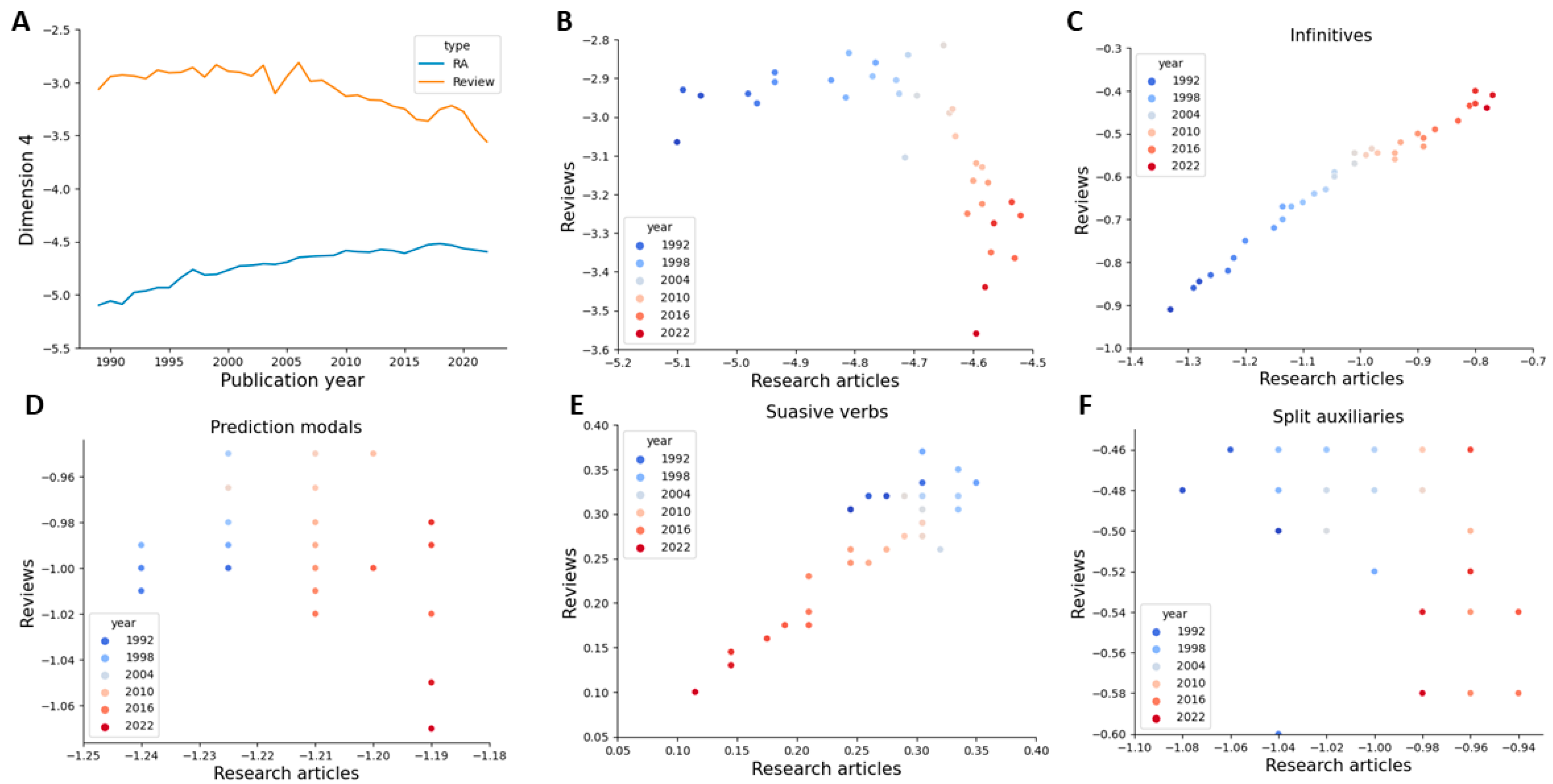
3.4. Dimension 4
Understanding the age-dependent neuromuscular mechanisms underlying force reductions … allows researchers to investigate new interventions to mitigate these reductions. [50]
…an ad hoc committee of the American Venous Forum, working with an international liaison committee, has recommended a number of practical changes. [51]
The data suggest that treatment of H. pylori infection should be considered in children with concomitant GERD. [52]
3.5. Dimension 5
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Narin, F.; Pinski, G.; Gee, H.H. Structure of the Biomedical Literature. J. Am. Soc. Inf. Sci. 1976, 27, 25–45. [Google Scholar] [CrossRef]
- Cartabellotta, A.; Montalto, G.; Notarbartolo, A. Evidence-Based Medicine. How to Use Biomedical Literature to Solve Clinical Problems. Italian Group on Evidence-Based Medicine-GIMBE. Minerva Med. 1998, 89, 105–115. [Google Scholar] [PubMed]
- Hrynaszkiewicz, I. The Need and Drive for Open Data in Biomedical Publishing. Serials 2011, 24, 31–37. [Google Scholar] [CrossRef] [PubMed]
- Sanberg, P.R.; Gharib, M.; Harker, P.T.; Kaler, E.W.; Marchase, R.B.; Sands, T.D.; Arshadi, N.; Sarkar, S. Changing the Academic Culture: Valuing Patents and Commercialization toward Tenure and Career Advancement. Proc. Natl. Acad. Sci. USA 2014, 111, 6542–6547. [Google Scholar] [CrossRef] [PubMed]
- Rice, D.B.; Raffoul, H.; Ioannidis, J.P.A.; Moher, D. Academic Criteria for Promotion and Tenure in Biomedical Sciences Faculties: Cross Sectional Analysis of International Sample of Universities. BMJ 2020, 369, m2081. [Google Scholar] [CrossRef] [PubMed]
- Landhuis, E. Scientific Literature: Information Overload. Nature 2016, 535, 457–458. [Google Scholar] [CrossRef] [PubMed]
- Sharma, H.; Verma, S. Predatory Journals: The Rise of Worthless Biomedical Science. J. Postgrad. Med. 2018, 64, 226. [Google Scholar] [CrossRef]
- Ioannidis, J.P.A. The Mass Production of Redundant, Misleading, and Conflicted Systematic Reviews and Meta-analyses. Milbank Q. 2016, 94, 485–514. [Google Scholar] [CrossRef]
- Pieper, D.; Antoine, S.-L.; Mathes, T.; Neugebauer, E.A.M.; Eikermann, M. Systematic Review Finds Overlapping Reviews Were Not Mentioned in Every Other Overview. J. Clin. Epidemiol. 2014, 67, 368–375. [Google Scholar] [CrossRef]
- Biber, D. On the Complexity of Discourse Complexity: A Multidimensional Analysis. Discourse Process. 1992, 15, 133–163. [Google Scholar] [CrossRef]
- Biber, D. Variation across Speech and Writing; Cambridge University Press: Cambridge, UK, 1991; ISBN 0521425565. [Google Scholar]
- Stig, J.; Leech, G.N.; Goodluck, H. Manual of Information to Accompany the Lancaster-Oslo: Bergen Corpus of British English, for Use with Digital Computers; Department of English, University of Oslo: Oslo, Norway, 1978. [Google Scholar]
- Põldvere, N.; Johansson, V.; Paradis, C. On the London–Lund Corpus 2: Design, Challenges and Innovations. Engl. Lang. Linguist. 2021, 25, 459–483. [Google Scholar] [CrossRef]
- Biber, D.; Conrad, S.; Reppen, R.; Byrd, P.; Helt, M. Speaking and Writing in the University: A Multidimensional Comparison. TESOL Q. 2002, 36, 9–48. [Google Scholar] [CrossRef]
- Friginal, E.; Mustafa, S.S. A Comparison of US-Based and Iraqi English Research Article Abstracts Using Corpora. J. Engl. Acad. Purp. 2017, 25, 45–57. [Google Scholar] [CrossRef]
- Cao, Y.; Xiao, R. A Multi-Dimensional Contrastive Study of English Abstracts by Native and Non-Native Writers. Corpora 2013, 8, 209–234. [Google Scholar] [CrossRef]
- Nini, A. The Multi-Dimensional Analysis Tagger. In Multi-Dimensional Analysis: Research Methods and Current Issues; Bloomsbury Academic: New York, NY, USA, 2019; pp. 67–94. [Google Scholar]
- Tausczik, Y.R.; Pennebaker, J.W. The Psychological Meaning of Words: LIWC and Computerized Text Analysis Methods. J. Lang. Soc. Psychol. 2010, 29, 24–54. [Google Scholar] [CrossRef]
- Guizzardi, S.; Colangelo, M.T.; Mirandola, P.; Galli, C. The Evolution of Narrativity in Abstracts of the Biomedical Literature between 1989 and 2022. Publications 2023, 11, 26. [Google Scholar] [CrossRef]
- Kluyver, T.; Ragan-Kelley, B.; Pérez, F.; Granger, B.; Bussonnier, M.; Frederic, J.; Kelley, K.; Hamrick, J.; Grout, J.; Corlay, S.; et al. Jupyter Notebooks—A Publishing Format for Reproducible Computational Workflows. In Positioning and Power in Academic Publishing: Players, Agents and Agendas, Proceedings of the 20th International Conference on Electronic Publishing, ELPUB 2016, Göttingen, Germany, 7–9 June 2016; IOS Press BV: Amsterdam, The Netherlands, 2016; pp. 87–90. [Google Scholar]
- Shapiro, A. Littler-Getter. Available online: https://github.com/shapiromatron/litter_getter (accessed on 1 June 2022).
- Greenhalgh, T.; Thorne, S.; Malterud, K. Time to Challenge the Spurious Hierarchy of Systematic over Narrative Reviews? Eur. J. Clin. Investig. 2018, 48, e12931. [Google Scholar] [CrossRef]
- Mckinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 51–56. [Google Scholar]
- Richardson, L. Beautiful Soup Documentation. Available online: https://pypi.org/project/beautifulsoup4/ (accessed on 1 June 2022).
- Curtis, A.; Smith, T.; Ziganshin, B.; Elefteriades, J. The Mystery of the Z-Score. AORTA 2016, 4, 124–130. [Google Scholar] [CrossRef]
- Hunter, J.D. Matplotlib: A 2D Graphics Environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Waskom, M. Seaborn: Statistical Data Visualization. J. Open Source Softw. 2021, 6, 3021. [Google Scholar] [CrossRef]
- Liu, J.; Xiao, L. A Multi-Dimensional Analysis of Conclusions in Research Articles: Variation across Disciplines. Engl. Specif. Purp. 2022, 67, 46–61. [Google Scholar] [CrossRef]
- Andrews, R. My Cheerful Attitude Upset an Anxious Pre-Op Patient. Nurs. Stand. 2009, 24, 27–28. [Google Scholar] [CrossRef]
- Hyland, K. Authority and Invisibility. J. Pragmat. 2002, 34, 1091–1112. [Google Scholar] [CrossRef]
- Hyland, K. Options of Identity in Academic Writing. ELT J. 2002, 56, 351–358. [Google Scholar] [CrossRef]
- Hyland, K.; Jiang, F. Is Academic Writing Becoming More Informal? Engl. Specif. Purp. 2017, 45, 40–51. [Google Scholar] [CrossRef]
- Pathak, S.K.; Salunke, A.A.; Chawla, J.S.; Sharma, A.; Ratna, H.V.K.; Gautam, R.K. Bilateral Radial Head Fracture Secondary to Weighted Push-Up Exercise: Case Report and Review of Literature of a Rare Injury. Indian. J. Orthop. 2021, 56, 162–167. [Google Scholar] [CrossRef]
- Elseviers, M.M.; Van Camp, Y.; Nayaert, S.; Duré, K.; Annemans, L.; Tanghe, A.; Vermeersch, S. Prevalence and Management of Antibiotic Associated Diarrhea in General Hospitals. BMC Infect. Dis. 2015, 15, 129. [Google Scholar] [CrossRef]
- Carrió Pastor, M. Cross-Cultural Variation in the Use of Modal Verbs in Academic English. SKY J. Linguist. 2014, 27, 153–166. [Google Scholar]
- Nakamura, H. Experimental and Clinical Aspects of Oxidative Stress and Redox Regulation. Rinsho Byori 2003, 51, 109–114. [Google Scholar]
- Harris, E.E. Hypothesis and Perception: The Roots of Scientific Method; Routledge: London, UK, 2014; ISBN 1317851609. [Google Scholar]
- Ueberberg, B.; Tourne, H.; Redman, A.; Walz, M.K.; Schmid, K.W.; Mann, K.; Petersenn, S. Differential Expression of the Human Somatostatin Receptor Subtypes Sst1 to Sst5 in Various Adrenal Tumors and Normal Adrenal Gland. Horm. Metab. Res. 2005, 37, 722–728. [Google Scholar] [CrossRef]
- Pretolani, M.; Lellouch-Tubiana, A.; Lefort, J.; Bachelet, M.; Vargaftig, B.B. PAF-Acether and Experimental Anaphylaxis as a Model for Asthma. Int. Arch. Allergy Immunol. 1989, 88, 149–153. [Google Scholar] [CrossRef] [PubMed]
- Wilson, D.A.; Sullivan, R.M. Neurobiology of Associative Learning in the Neonate: Early Olfactory Learning. Behav. Neural Biol. 1994, 61, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Boyd, R.L.; Blackburn, K.G.; Pennebaker, J.W. The Narrative Arc: Revealing Core Narrative Structures through Text Analysis. Sci. Adv. 2020, 6, eaba2196. [Google Scholar] [CrossRef] [PubMed]
- Freytag, G. Freytag’s Technique of the Drama; Scott Foresman: Northbrook, IL, USA, 1894. [Google Scholar]
- Corver, N.; van Riemsdijk, H. Semi-Lexical Categories: The Function of Content Words and the Content of Function Words; Walter de Gruyter: Berlin, Germany, 2013; Volume 59, ISBN 3110874008. [Google Scholar]
- Alexiadou, A. Nominalizations: A Probe into the Architecture of Grammar Part I: The Nominalization Puzzle. Lang. Linguist. Compass 2010, 4, 496–511. [Google Scholar] [CrossRef]
- Khamesian, M. On Nominalization, A Rhetorical Device in Academic Writing. Armen. Folia Angl. 2015, 11, 42–48. [Google Scholar] [CrossRef]
- Baratta, A.M. Nominalization Development across an Undergraduate Academic Degree Program. J. Pragmat. 2010, 42, 1017–1036. [Google Scholar] [CrossRef]
- Biber, D.; Gray, B. Challenging Stereotypes about Academic Writing: Complexity, Elaboration, Explicitness. J. Engl. Acad. Purp. 2010, 9, 2–20. [Google Scholar] [CrossRef]
- Biber, D.; Gray, B. Nominalizing the Verb Phrase in Academic Science Writing. In The Register-Functional Approach to Grammatical Complexity; Routledge: London, UK, 2021; pp. 176–198. [Google Scholar]
- Wei, X.; Mei, C.; Li, X.; Xie, Y. The Unique Microbiome and Immunity in Pancreatic Cancer. Pancreas 2021, 50, 119–129. [Google Scholar] [CrossRef]
- Orssatto, L.B.d.R.; Wiest, M.J.; Diefenthaeler, F. Neural and Musculotendinous Mechanisms Underpinning Age-Related Force Reductions. Mech. Ageing Dev. 2018, 175, 17–23. [Google Scholar] [CrossRef]
- Eklöf, B.; Rutherford, R.B.; Bergan, J.J.; Carpentier, P.H.; Gloviczki, P.; Kistner, R.L.; Meissner, M.H.; Moneta, G.L.; Myers, K.; Padberg, F.T.; et al. Revision of the CEAP Classification for Chronic Venous Disorders: Consensus Statement. J. Vasc. Surg. 2004, 40, 1248–1252. [Google Scholar] [CrossRef]
- Pollet, S.; Gottrand, F.; Vincent, P.; Kalach, N.; Michaud, L.; Guimber, D.; Turck, D. Gastroesophageal Reflux Disease and Helicobacter Pylori Infection in Neurologically Impaired Children: Inter-Relations and Therapeutic Implications. J. Pediatr. Gastroenterol. Nutr. 2004, 38, 70–74. [Google Scholar] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dimension | Feature |
|---|---|
| 1 | Involved vs. Informational discourse |
| 2 | Narrative vs. Non-Narrative Concerns |
| 3 | Context-Independent Discourse vs. Context-Dependent Discourse |
| 4 | Overt Expression of Persuasion |
| 5 | Abstract and Non-Abstract Information |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guizzardi, S.; Colangelo, M.T.; Mirandola, P.; Galli, C. Tracing the Evolution of Reviews and Research Articles in the Biomedical Literature: A Multi-Dimensional Analysis of Abstracts. Publications 2024, 12, 2. https://doi.org/10.3390/publications12010002
Guizzardi S, Colangelo MT, Mirandola P, Galli C. Tracing the Evolution of Reviews and Research Articles in the Biomedical Literature: A Multi-Dimensional Analysis of Abstracts. Publications. 2024; 12(1):2. https://doi.org/10.3390/publications12010002
Chicago/Turabian StyleGuizzardi, Stefano, Maria Teresa Colangelo, Prisco Mirandola, and Carlo Galli. 2024. "Tracing the Evolution of Reviews and Research Articles in the Biomedical Literature: A Multi-Dimensional Analysis of Abstracts" Publications 12, no. 1: 2. https://doi.org/10.3390/publications12010002