3.1. Comparison of Aroma Compounds between Graševina Wines and Other Wines from the Same Producers
We analyzed 36 Graševina wine samples and 9 other wine samples (Pinot Gris and Chardonnay) in an attempt to identify VOCs that could potentially contribute to the aromatic typicality of Graševina wines in comparison with wines made from other varieties by the same producers. Wine samples with different vintages (2019, 2020, and 2021) were obtained from 14 producers located in two Croatian sub-regions, namely the Slavonia and Podunavlje sub-regions. The aromatic profile of the analyzed wine samples was determined by quantifying 60 VOCs from five different groups, namely 21 terpenes, 6 norisoprenoids, 6 volatile phenols, 4 C6 alcohols, and 23 esters. Concentration levels of all VOCs are available in
Table S2 in the Supplementary Materials.
Quantification data for each analyzed VOC in each sample (data given in
Supplementary Materials, Table S2) showed no distinct differences between Graševina wine samples and other wine samples (Chardonnay and Pinot gris). The effect of the winemaking protocol could potentially overlap the varietal differences for the targeted aromatic compounds. Interestingly, when comparing Chardonnay and/or Pinot gris wine samples with Graševina wines made by the same producers as shown in
Figure 1, four terpenes, namely α-terpinen, γ-terpinene, 1,4-cineol and 4-terpineol, stood out, since they were predominantly present in higher concentrations in Graševina wines. The sensory impact of these monoterpenes on wine aroma is not well documented, except for 1,4-cineole, which has recently been studied [
10]. Nevertheless, it seems that the concentrations of these monoterpenes in Graševina wines were well below their sensory thresholds, considering the case of γ-terpinene in matrices other than wine [
11]. However, monoterpenes are known to contribute to wine aroma, even when their levels are lower than their sensory threshold, through complex synergistic effects [
12,
13]. Such complex sensory interactions between terpenes and other compounds cannot be excluded and require further investigation.
3.2. Identifying Patterns in the Whole Dataset Using Heatmaps and Hierarchical Clustering
Because the comparison of concentration levels of all analyzed VOCs showed no relevant differences between Graševina wines and other wines, except for the four previously mentioned terpenes, we focused our efforts on the data obtained for Graševina wine samples by applying statistical analysis to obtain a clearer picture of the regional effect on the concentration levels of determined VOCs, as wine samples were sourced from two different sub-regions.
To discern the patterns and trends within our dataset, we employed heatmap analysis to visually depict the relationships between the samples and variables (VOCs). This visualization technique highlighted clusters of correlated samples and variables. Initially, it was important to observe that among the 60 VOCs, β-ionone, 3-carene, and trans-rose oxide were consistently assigned a fixed value of 0.01. Consequently, these three compounds were excluded from further analysis. Furthermore, a correlation matrix, complemented by a correlogram, was employed to visualize the correlations and relationships among a total of 57 VOCs spanning various chemical families. This comprehensive analysis encompasses all samples, irrespective of their geographical regions, and is illustrated in
Figure A1 within
Appendix A.
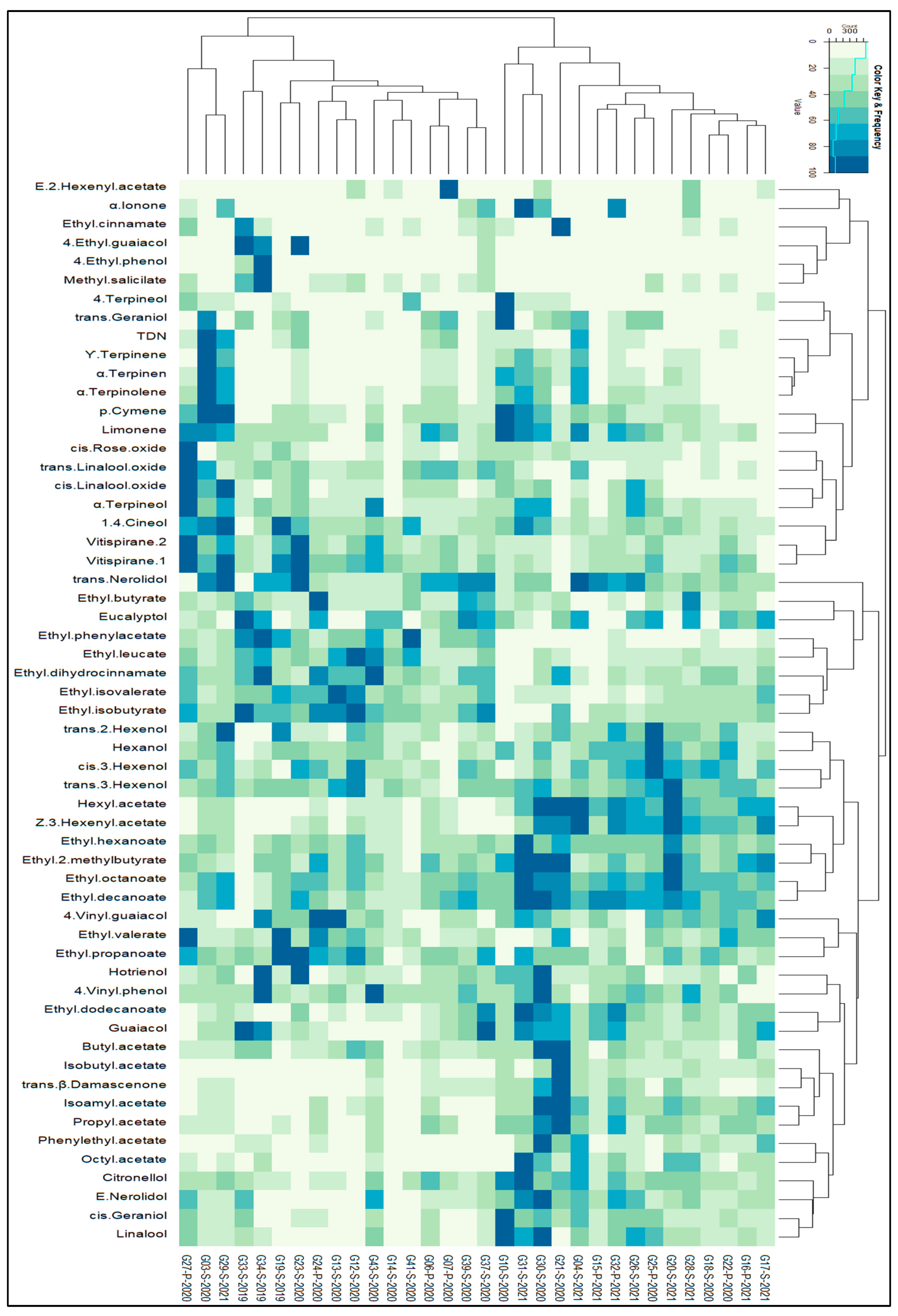
Figure 2 displays a heatmap, which provides a succinct representation of the data by utilizing colors to denote the values of the 57 distinct variables. The columns represent the various samples utilized in our experiments, showcasing their hierarchical clusters, while the rows depict the VOCs and their corresponding hierarchical clusters. The heatmap incorporates all VOCs associated with the 32 Graševina wine samples from 2 distinct geographical regions.
The dendrograms displayed alongside the heatmap correspond to the hierarchical clustering of columns (i.e., samples) and rows (i.e., VOCs) based on their similarity. To create the heatmap, the data were standardized to a range of 0 to 100, and hierarchical clustering was performed on the sample data using the Euclidean distance between the columns of the standardized data and the default Complete Linkage method.
Based on the discerned patterns in the heatmap and hierarchical cluster analysis, we identified two major classes depicted at the top of the heatmap among the 32 samples. The dendrograms associated with the samples revealed that the initial cluster (situated on the right side) was composed of samples G17-S-2021, G16-P-2021, …, and G10-S-2020, organized based on their similarities, while the second major cluster of samples comprised G37-S-2020, G39-S-2020, …, and G27-P-2020.
The most relevant differences between these two clusters can be observed in these groups of compounds. The first group of compounds, namely ethyl butyrate, ethyl phenylacetate, ethyl leucate, ethyl dihydrocinnamete, ethyl isovalerate, and ethyl isobutyrate, exhibited the highest content in the second cluster of samples, whereas the second group (trans-2-hexenol, hexano, cis-3-hexenol, trans-3-hexenol, hexyl acetate, z-3-hexenxyl acetate, ethyl hexanoate, ethyl 2-methylbutyrate, ethyl octanoate, and ethyl decanoate) and the third group of compounds (butyl acetate, isobutyl acetate, trans--damascenone, isoamyl acetate, propyl acetate, phenyethyl acetate, octyl acetate, citronellol, E-nerolidol, cis-geraniol, and linaool) exhibited the highest content in the first cluster.
From the above two clusters, it can be seen that they are mainly diversified by vintage, since the first cluster encompasses nine samples out of 10 of vintage 2021, while samples from vintage 2019 are present only in cluster 2. Samples from vintage 2020 were also predominant in cluster two as well. These observations are also in agreement with the previously mentioned groups of compounds, as the concentration patterns coincide with the age of the samples. The first group of compounds associated with older wines present in cluster 2 is dominated by ethyl esters of branched acids, which are mainly formed during wine aging [
9]. In contrast, the second and third groups of compounds correlated to cluster 1, with younger wines bringing together ethyl esters of fatty acids with long carbon chain and higher alcohol acetates. These esters have been reported to undergo hydrolysis during aging [
9,
14].
To summarize, the heatmap displayed in
Figure 2 visually depicted mainly vintage relationships between samples and variables (VOCs).
3.3. Relationships between the Groups of VOCs and Samples Using PCA and PLS-DA
To obtain a preliminary overview of similarities and differences among the studied samples and identify possible patterns, all VOCs were subjected to principal component analysis (PCA). In addition, PCA can show whether the geographical region has a remarkable influence on VOCs. From the eigenanalysis of the correlation matrix associated with the PCA, 13 principal components (represented by PC or F) were extracted, and 51.86% of the variance in the dataset was explained by the first three components, as shown in
Appendix B in
Table A1 (F1 = PC1 = 26.9%, F2 = PC2 = 15.25%, and F3 = PC3 = 9.91%). The first 13 principal components (PCs) had eigenvalues greater than 1. These components explained 90.5% of the total variability, which was due to the difference in volatile components of samples from the western and the eastern geographical regions (Slavonia and Podunavlje sub-regions, respectively), as shown in
Figure A2.
We also employed the PCA score scatter plot depicted in
Figure A2 to assess the significance of individual samples in our dataset and to observe the possible clusters in our 32 samples in a reduced-dimensional space. Some differences can be seen between some samples located in Kutjevo district from other samples also originating from the Slavonia as well as Podunavlje sub-regions from the PCA Score Scatter Plot.
Figure A2 also shows how the VOCs in our dataset relate to each other and to the samples, based on the underlying patterns identified. Thus, from both plots in
Figure A2 it can be deduced that just one group of compounds namely terpenes (α-terpinen, γ-terpinene, 1,4-cineol and 4-terpineol, limonen, p-cymene, and α-terpineol) show a faint connection to samples originated from the Slavonia sub-region.
Moreover, to condense an extensive discussion on the significance and impact of VOCs on principal components, we present a summary in
Table A2 in
Appendix B. This table, along with the biplot in
Figure A2, outlines the contributions of the variables obtained from PCA, focusing on the VOCs deemed of the highest importance in our analysis.
Table A2 in conjunction with
Figure A2, facilitated the understanding of the relationship between the variables and samples within a reduced-dimensional space. Moreover, it highlighted the primary contributors associated with each Principal Component (PC). For example, it can be observed that variables α-terpinen, γ-terpinene, 1,4-cineol and 4-terpineol, limonen, p-cymene, and α-terpineol have higher loadings in the PCA biplot in
Figure A2; additionally, their associated scores for the contribution of the variables (%) factor loadings in
Table A2 are larger compared to other VOCs.
The cumulative variance of 51.86% in the PCA method across the initial three PCs does not provide a sufficient level of variation for researchers to rely on valid and robust analyses and clustering. Additionally, the PCA score scatter plot failed to exhibit a distinct separation of samples according to their geographical regions. Consequently, to gain deeper insights into the distinctions among samples originating from different geographical locations, a partial least squares discriminant analysis (PLS-DA) model was constructed with a confidence interval of 95%. Furthermore, it should be noted that we have utilized the weighting technique to mitigate the dominance of the larger sample group (i.e., Slavonija (S)) in the analysis solely because of its larger sample size. This methodological approach serves to alleviate the effects of imbalanced sample sizes, ensuring that each sample contributes proportionally to the analysis, regardless of group size. Notably, this model revealed a clear separation between samples from the Podunavlje and Slavonia sub-regions, which was better than that observed in the Heatmap in
Figure 2. Furthermore, the score scatter plot (
Figure 3) demonstrates the distinct segregation of samples based on their geographical origins. Additionally, the correlation circle plot in
Figure 3 provides a visual representation of Variable Importance in the Projection (VIP) scores. Under the above-mentioned data, yet more distinguished, terpenes can be well associated with samples originating from the Salvonia sub-region, as shown in
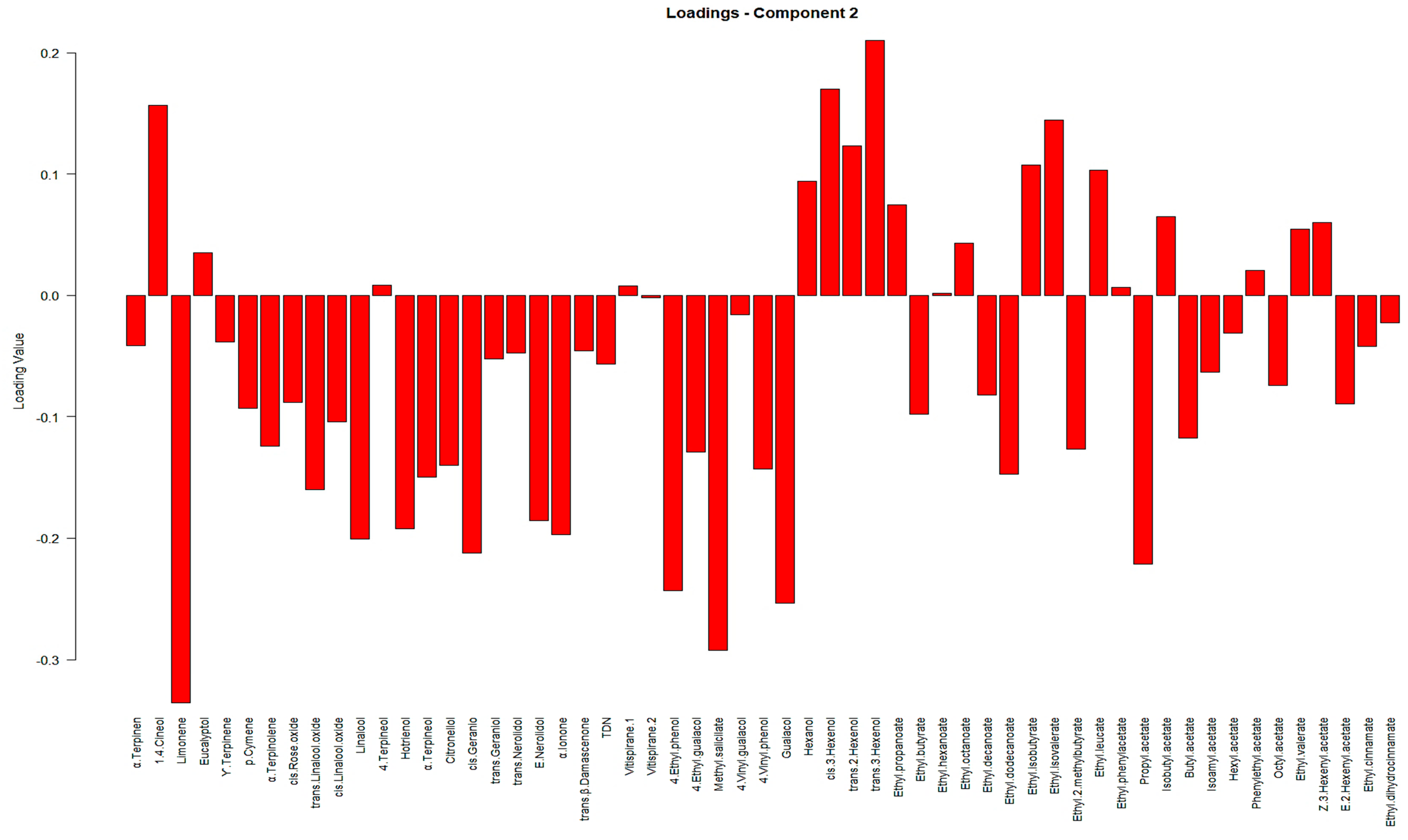
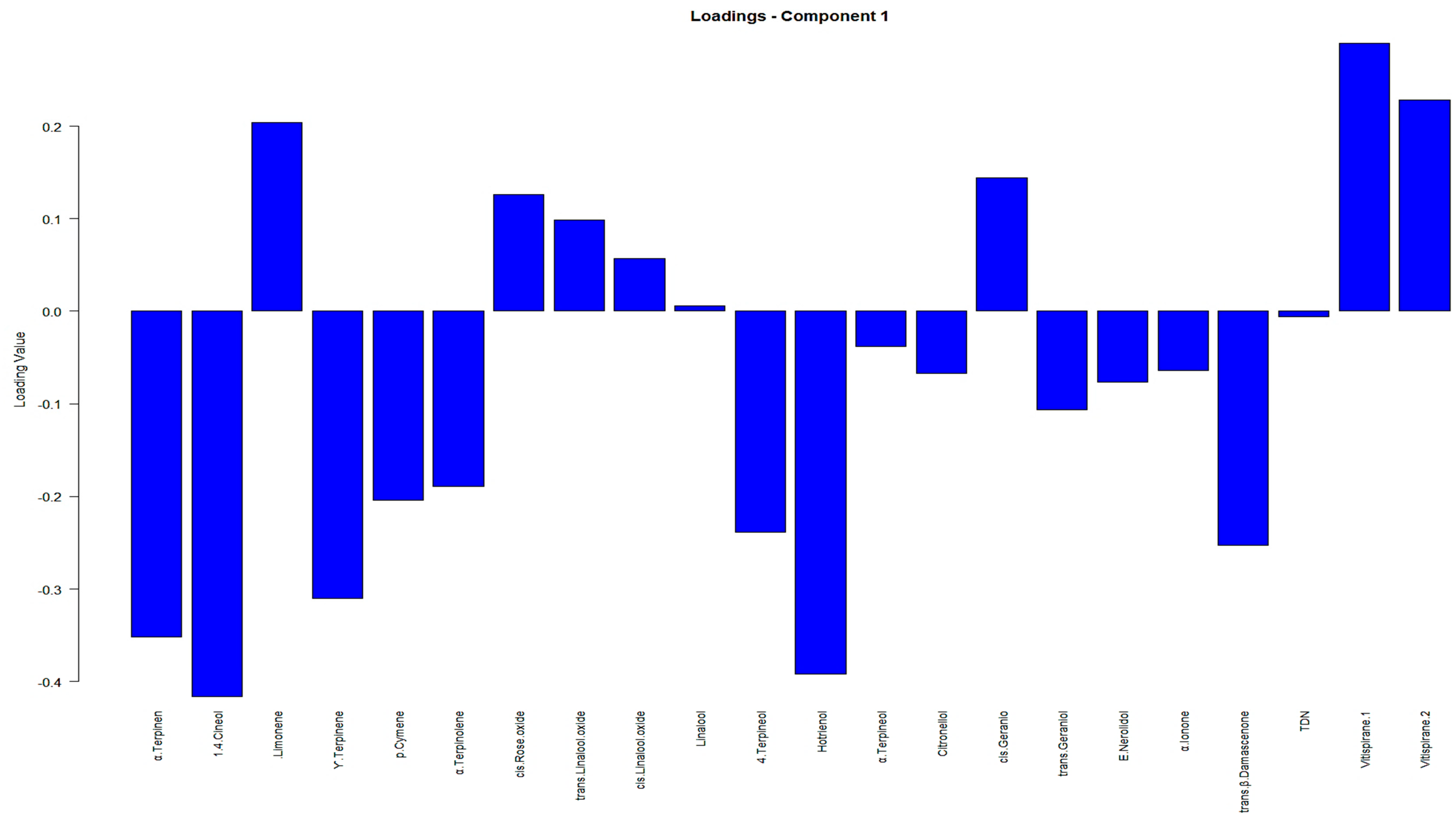
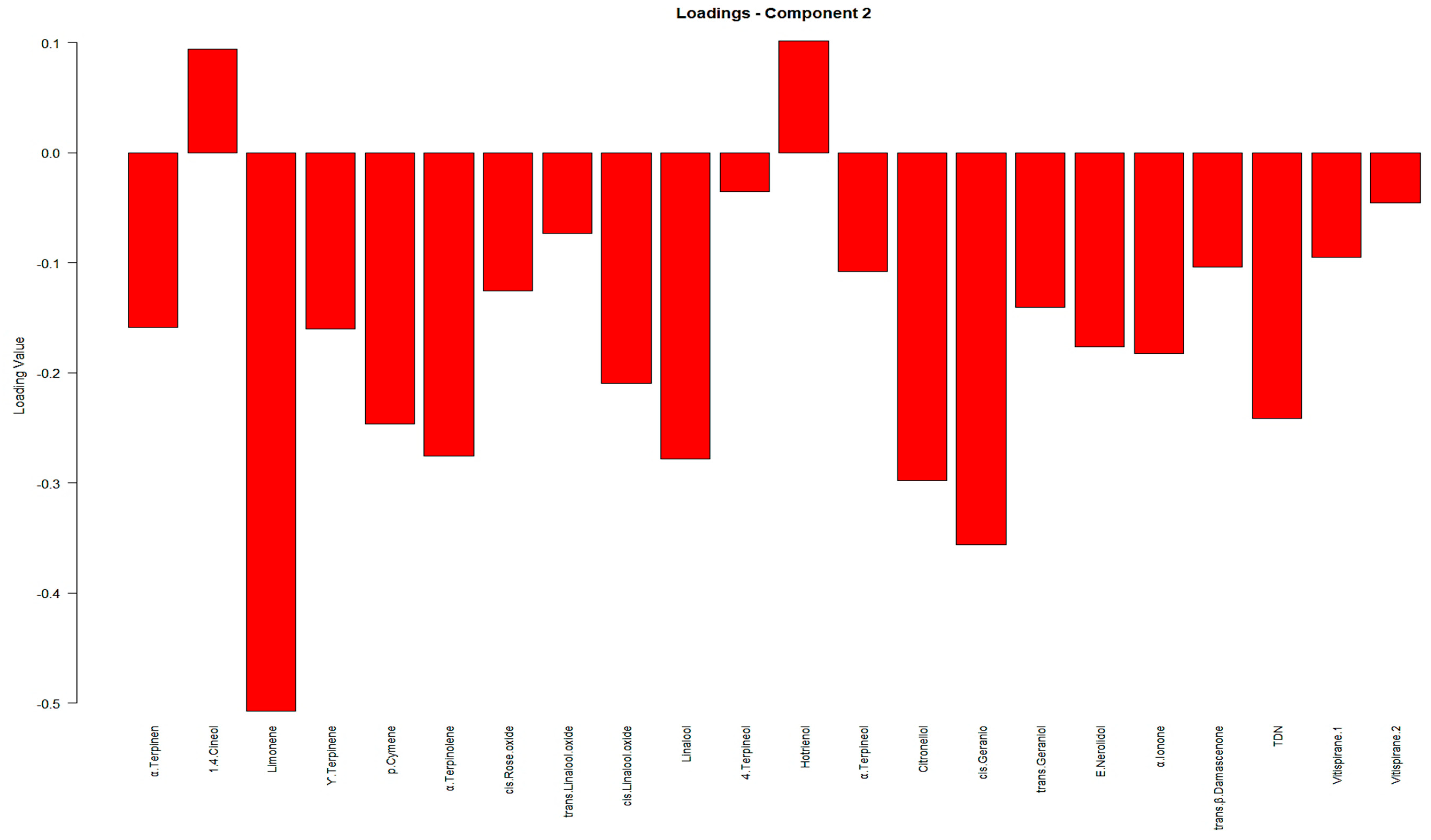
Figure 3. Furthermore, detailed information on the individual loadings of all VOCs in the PLS-DA method can be found in
Appendix C, presented in
Figure A4 and
Figure A5.
3.4. Multivariate Data Analysis Based on 22 VOCs
As the PLS-DA score scatter plot in
Figure 3 shows, some VOCs, namely terpenes and norisoprenoids, were of higher importance in the classification depicted in the correlation circle plot in
Figure 3. Consequently, we focused on 22 terpenes and norisoprenoids, of which 3-carene, β-ionone, and trans-rose oxide were present below the limit of quantification, and therefore, they are not important. Additionally, these 22 VOCs could better represent the profiles of our samples, since four terpenes, i.e., α-terpinene, γ-terpinene, 1,4-cineol, and 4-terpineol, as shown in
Figure 2, are generally found at higher concentration in Graševina wines in comparison to Chardonnay and Pinot Gris wines from the same producers.
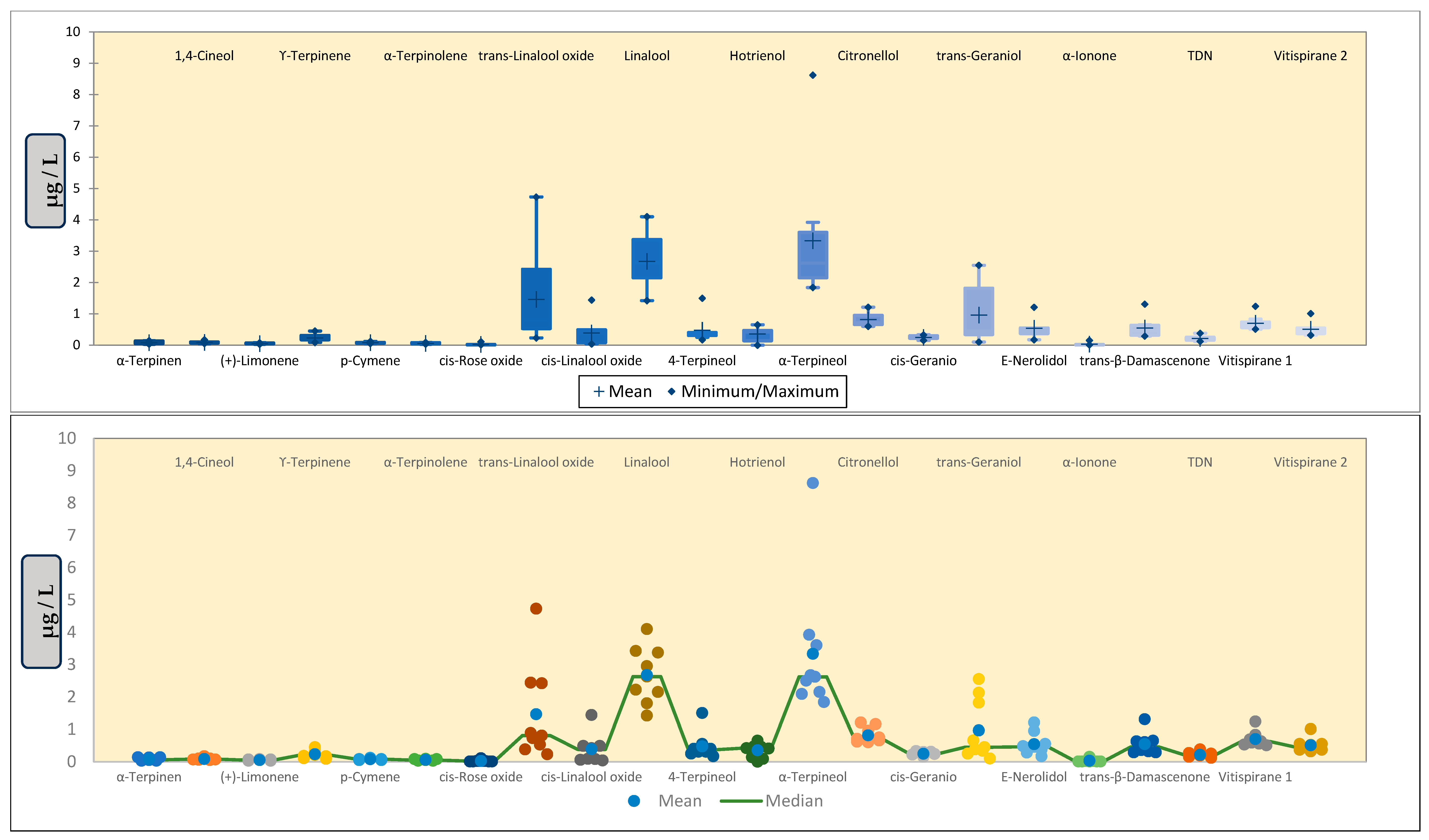
To uncover the patterns and trends in our dataset, we mapped and visualized the relationship between samples and variables (VOCs) using a heatmap, which revealed groups of correlated samples and variables. Additionally, we utilized Boxplots and Scattergrams as two impactful graphical tools to depict the distribution of our 22 VOCs, serving as predictor variables for samples from the Slavonia (S) and Podunavlje (P) sub-regions in the dataset. These visual representations are provided separately in
Appendix D (
Figure A8 and
Figure A9). In the heatmap analysis, we used 22 VOCs associated with 32 different samples from 2 different geographical regions to generate the heatmap.
Based on the heatmap and hierarchical cluster analysis patterns, two major groups of samples were identified. Higher amounts of terpenes and norisoprenoids were present in the first group than in the second group, as shown in the heatmap (
Figure 4). Interestingly, the wines represented in the first group with a higher content of terpenoids mainly originated from the Kutjevo district within the Slavonia sub-region, whereas most of the wines from Podunavlje sub-region were in the second group. Therefore, it appears that the heatmap and hierarchical cluster analysis managed to separate Graševina wine samples according to their geographical origin to a certain extent. The dendrogram from the heatmap depicted in
Figure 4 also shows two major clusters (or three minor clusters in total) of compounds, each cluster being composed of different groups of terpenoids and norisoprenoids without a clear trend.
The sum of terpenes and norisoprenoids (but not individual compounds) showed a connection to the geographical region based on their concentration levels. These data indicate that norisoprenoids and even more terpenes can be used to a certain extent as markers of the geographical origin of Slavonian Graševina wines.
3.5. Relationships between the Groups of VOCs and Samples Using PCA and PLS-DA
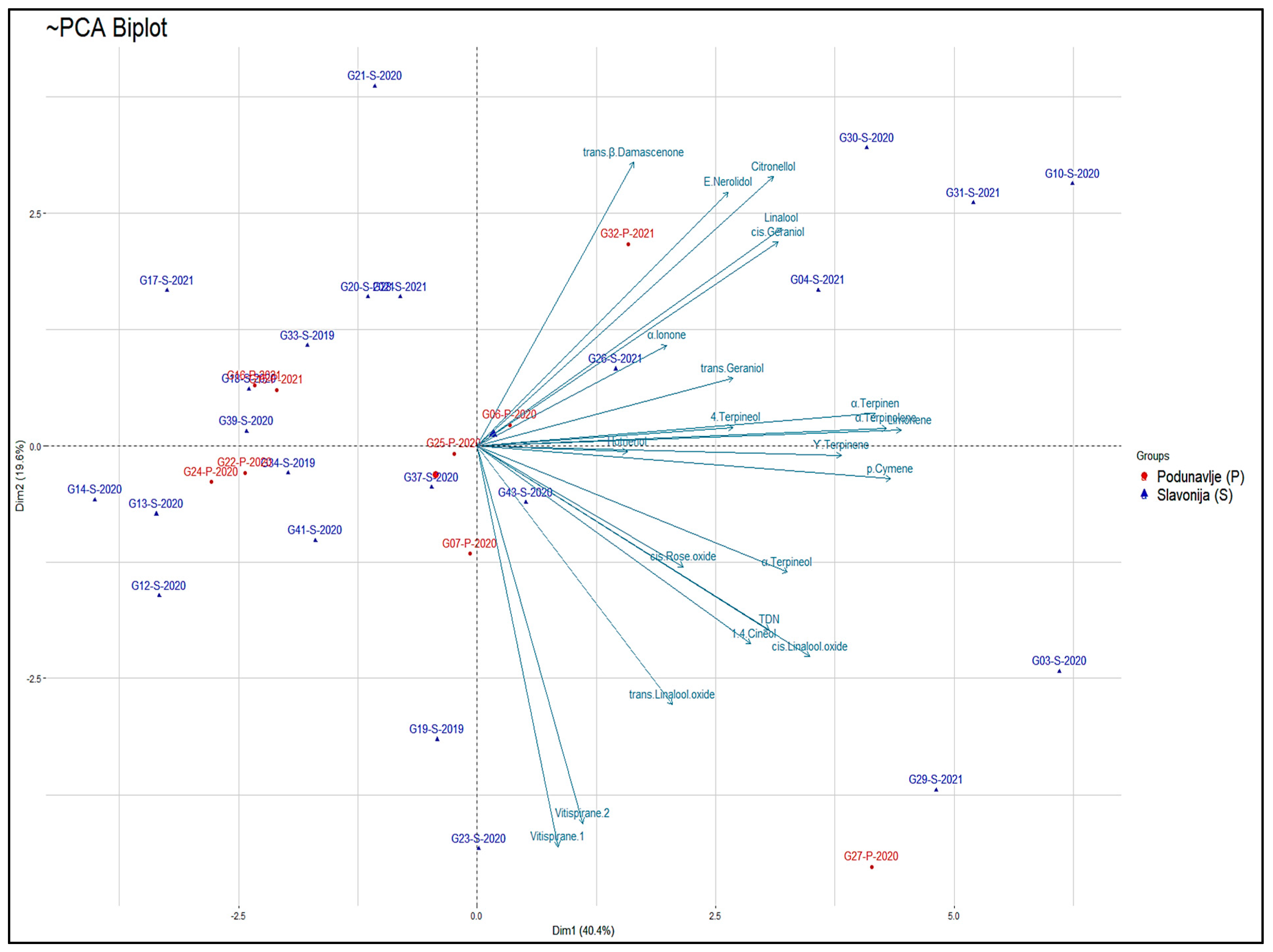
To gain a comprehensive understanding of the similarities and distinctions among the samples and to identify potential patterns, 22 VOCs were subjected to PCA. Through eigenanalysis of the correlation matrix associated with PCA, five principal components (denoted as PC or F) were extracted, each having eigenvalues greater than 1. Notably, these five components effectively accounted for 83.71% of the total variability observed in samples from both the Podunavlje and Salvonia sub-region. The first three principal components (F1 = PC1 = 40.41%, F2 = PC2 = 19.60%, and F3 = PC3 = 10.39%) collectively explained 70.41% of the variance in the dataset. The PCA biplot (
Figure A3 in
Appendix B) again displayed a higher tendency of norisoprenoids and terpenes towards samples originating from the western geographic region.
The PCA score scatter plot failed to exhibit a distinct separation of samples based on geographical sub-regions. Therefore, to gain deeper insights into the differences among samples originating from diverse geographical origins, a new Partial Least Squares-Discriminant Analysis (PLS-DA) model was constructed, incorporating a confidence interval of 95%. In this PLS-DA model, three significant components elucidated 64% of the total variation in predictors (i.e., VOCs). The score scatter plot presented in
Figure 5 did not reveal, however, a clear separation of samples based on geographical sub-regions. Additionally, the correlation circle plot in
Figure 5 provides a visual representation of Variable Importance in the Projection (VIP) scores. Furthermore, detailed information regarding the individual loadings of all 22 VOCs in the PLS-DA method on various components can be located in
Appendix C, illustrated in
Figure A6 and
Figure A7. Once more, it can be seen that in both PLS-DA plots (
Figure 5), as expected and discussed earlier, most of the chosen 22 VOCs, especially terpenes, are of higher importance in the PLS-DA model and classification. This can be observed by their high loadings in the correlation circle plot in
Figure 5.
3.6. Potential Markers of Graševina Wines’ Regionality
Different statistical approaches led to the same conclusion, suggesting that it was not easy to discriminate between Graševina wines from both studied sub-regions based on the targeted volatiles. Nevertheless, a group of wine samples exclusively from the Kutjevo district in the Slavonia sub-region were systematically correlated to some norisoprenoids and a wide range of monoterpenes, including the four compounds potentially involved in Graševina aromatic signature, namely 4-terpineol, 1,4-cineole, and α- and γ-terpinene. In contrast, wines from the Podunavlje sub-region were grouped together when PLS-DA was applied, and seemed to be correlated with the levels of vitispirane isomers (
Figure 3 and
Figure 5). This consistent result highlights that appropriate statistical analyses can unravel some subtle differences in the composition of wines from different geographical origins. For instance, this approach has recently been used to characterize the regional aromatic signature of Australian Shiraz wines [
15,
16]. More recently, Schartner et al. [
17] managed to predict the origin of Bordeaux red wines from simple GC/MS data with the help of a Machine Learning tool.
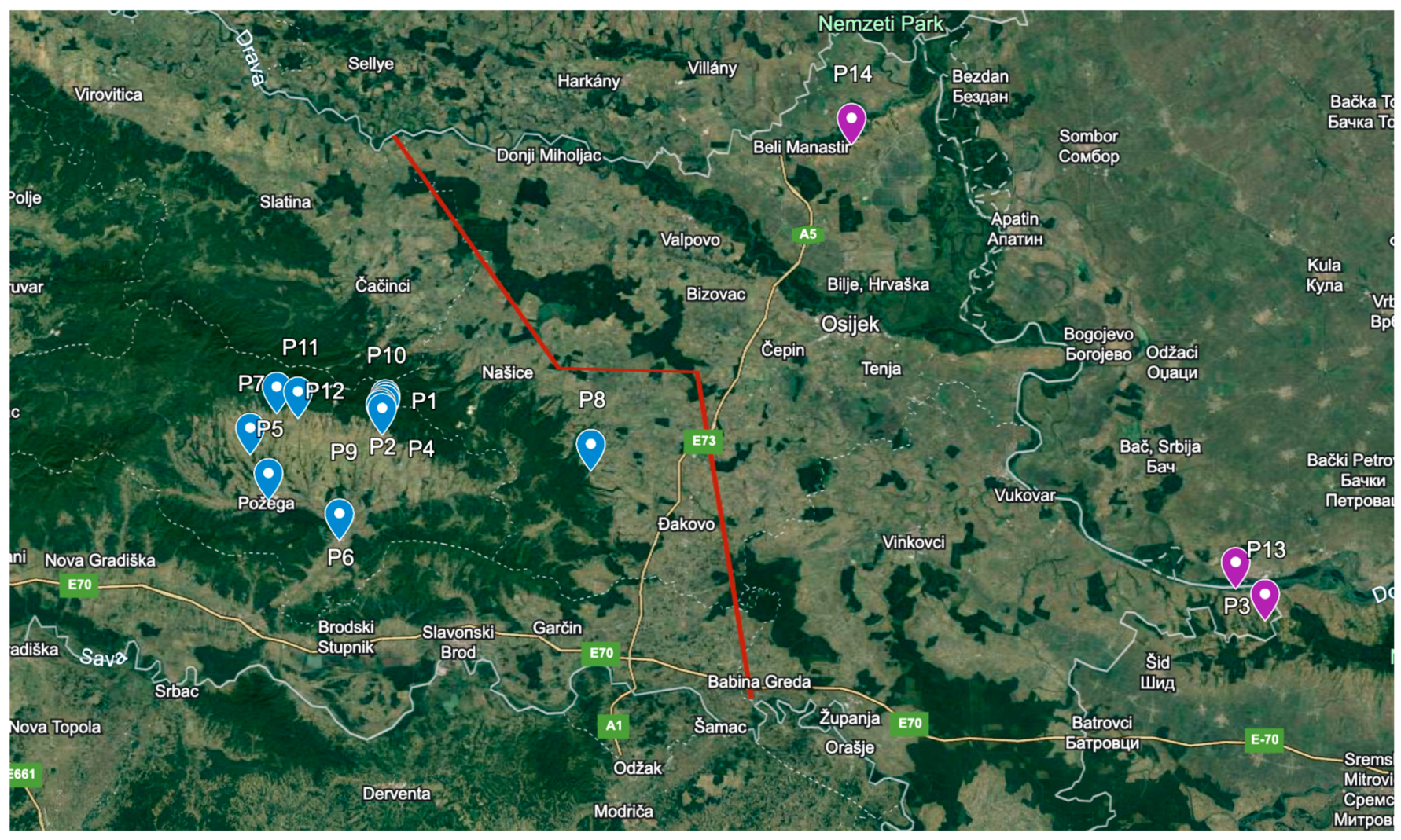
In the case of Graševina wines from northeastern Croatia, as shown in
Figure 6, it seems that the Kutjevo district in the Slavonia sub-region is more prone to favor higher levels of terpenoids. The Podunavlje sub-region has a more continental climate than the Slavonia sub-region, with warmer days and slightly colder nights during the ripening season. Rain precipitation is slightly more abundant during summer and autumn in Slavonia (
www.meteoblue.com, 28 January 2024). This climatic difference is even more pronounced when considering the Kutjevo district, which is located on the slope of the Papuk mountains. Interestingly, Graševina wines from different areas of the Slavonia sub-region, namely Požega Pleternica, and Djakovo, were rather grouped with wines from the Podunavlje sub-region. This was particularly the case for samples from the Djakovo area, located at the border with the Podunavlje sub-region, which has a more continental climate than Kutjevo.
Different studies have reported contradictory results regarding the effects of temperature on norisoprenoids and monoterpenes [
18]. The influence of abiotic factors on these volatiles also depends on the compound [
18]. For norisoprenoids, there is consensus that warmer and sunnier climate favors higher levels of TDN [
18]. This was not the case in the present study, because samples from the cooler Kutjevo district displayed higher levels than those from the warmer Podunavlje sub-region (
Figure 5). β-Damascenone and α-ionone were also associated with samples from Kutjevo area. For these compounds, there is a lack of consensus in the literature regarding the impact of abiotic factors on their contents in grapes and wine [
18]. In contrast, both vitispirane isomers were correlated with wines from the Podunavlje sub-region, indicating that warmer temperatures could potentially stimulate their synthesis in grapes. However, this topic is poorly documented in the literature and further studies are required to confirm this assumption. Monoterpenes were all associated with different degrees of correlation with wines from Kutjevo area. According to Van Leeuwen et al. [
18], the influence of air temperature on monoterpene concentrations in grape and wine is difficult to predict and depends on other factors. In contrast, Suklje et al. [
15] found in Shiraz wines that monoterpenes were associated with cooler regions in Australia. It appears that Graševina, grown in a continental climate, follows the same trend. Interestingly, the compounds that were most discriminative between sub-regions were α-terpinene, γ-terpinene, and 1,4-cineole. Graševina wines from the Kutjevo district showed higher concentrations than Podunavlje wines. Antalick et al. [
10] reported a higher level of 1,4-cineole in Cabernet-Sauvignon wines originating from the Margaret River with milder climates than South Australia. Suklje et al. [
15] found similar results for γ-terpinene in Shiraz wines associated with cooler Australian regions. It is worth highlighting that terpinene isomers and 1,4-cineole followed the same trend, as the three compounds are connected by the same metabolic pathway [
19]. These monoterpenes are also metabolically connected to 4-terpineol [
19], and they seem to be all chemical markers of Graševina wines, as suggested earlier. Their individual odors are described as herbaceous for 1,4-cineole and 4-terpineol [
10,
20] and pine, citrusy, lemon, and lime odor for terpinene isomers [
20]. It is worth noting that lemon and lime are descriptors used by wine experts to characterize the aroma of Graševina wine, particularly in the Kutjevo district, which is considered the most iconic region for this variety in Croatia. Nevertheless, it is too speculative to state that these monoterpenes actually contribute directly or through perceptive interactions to the aromatic typicality of Graševina wine. Further sensory experiments are warranted to confirm this hypothesis.




 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















