
Data on Healthy Food Accessibility in Amsterdam, The Netherlands

Abstract
:1. Introduction
2. Data Description
3. Materials and Methods
3.1. Study Area and Analysis Scale
3.2. Data Sources and Pre-Processing
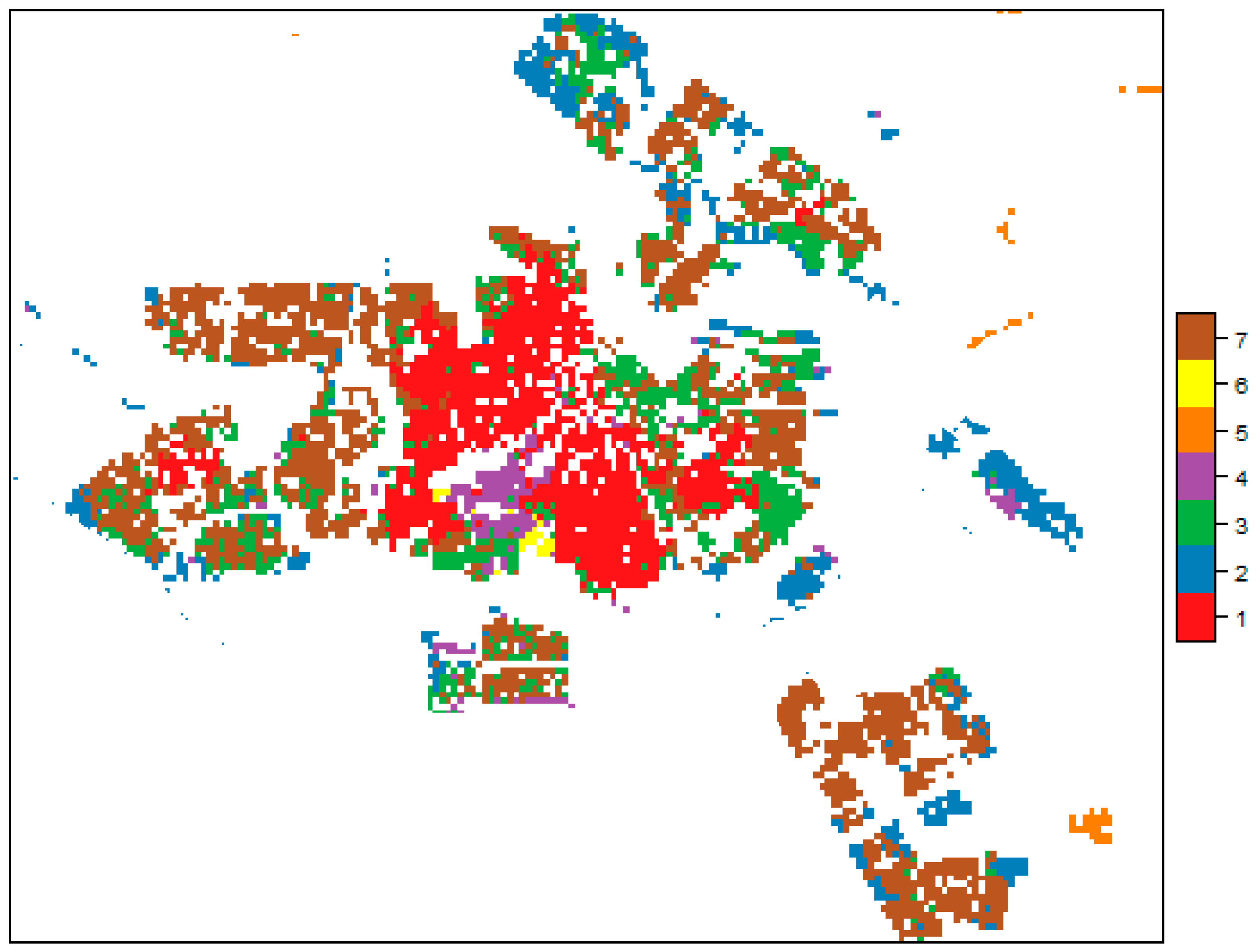
3.2.1. Supermarket Data
3.2.2. Accessibility Measures
3.2.3. Neighborhood Data
4. Data Usage and Application











Acknowledgments
Author Contributions
Conflicts of Interest
References
- Beaulac, J.; Kristjansson, E.; Cummins, S. A systematic review of food deserts: 1966–2007. Prev. Chronic Dis. 2009, 6, 1–10. [Google Scholar]
- Zenk, S.N.; Schulz, A.J.; Israel, B.A.; James, S.A.; Bao, S.; Wilson, M.L. Neighborhood racial composition, neighborhood poverty, and the spatial accessibility of supermarkets in metropolitan Detorit. Am. J. Public Health 2005, 95, 660–667. [Google Scholar] [CrossRef] [PubMed]
- Cummins, S.; Macintyre, S. “Food deserts”—Evidence and assumption in health policy making. Br. Med. J. 2002, 25, 436–438. [Google Scholar] [CrossRef]
- Charreire, H.; Casey, R.; Salze, P.; Simon, C.; Chaix, B.; Banos, A.; Badariotti, D.; Weber, C.; Oppert, J.M. Measuring the food environment using geographical information systems: A methodological review. Public Health Nutr. 2010, 13, 1773–1785. [Google Scholar] [CrossRef] [PubMed]
- Apparicio, P.; Cloutier, M.; Shearmur, R. The case of Montreal’s missing food deserts: Evaluation of accessibility to food supermarkets. Int. J. Health Geogr. 2007, 6, 4. [Google Scholar] [CrossRef] [PubMed]
- Russell, S.; Heidkamp, C. “Food desertification”: The loss of a major supermarket in New Haven, Connecticut. Appl. Geogr. 2011, 31, 1197–1209. [Google Scholar] [CrossRef]
- Wang, H.; Qiu, F.; Swallow, B. Can community gardens and farmers’ markets relieve food desert problems? A study of Edmonton, Canada. Appl. Geogr. 2014, 55, 127–137. [Google Scholar] [CrossRef]
- Brunsdon, C. Quantitative methods I: Reproducible research and quantitative geography. Prog. Hum. Geogr. 2015, 1–10. [Google Scholar] [CrossRef]
- Helbich, M.; Schadenberg, B.; Hagenauer, J.; Poelman, M. Food Deserts? Healthy Food Access in Amsterdam. 2017. under revision. [Google Scholar]
- GGD Amsterdam. Amsterdammers Gezond en Wel? Available online: http://www.ggd.amsterdam.nl/beleid-onderzoek/gezondheidsmonitors/amsterdamse/ (accessed on 2 October 2016).
- Centraal Bureau voor de Statistiek. Statistische Gegevens per Vierkant. Den Haag/Heerlen. Available online: http://www.cbs.nl/NR/rdonlyres/E29D852E-0AD5–40AD-AF57-C42F811487B6/0/Statistischegegevenspervierkantupdateoktober2014.pdf (accessed on 2 October 2016).
- Wikipedia. Lijst van Supermarkten. Available online: https://nl.wikipedia.org/wiki/Lijst_van_supermarkten (accessed on 2 October 2016).
- Levensmiddelen Krant. Available online: http://www.levensmiddelenkrant.nl/ (accessed on 2 October 2016).
- BAG. Kadaster. Available online: https://www.kadaster.nl/bag (accessed on 2 October 2016).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria. Available online: http://www.R-project.org/ (accessed on 2 October 2016).
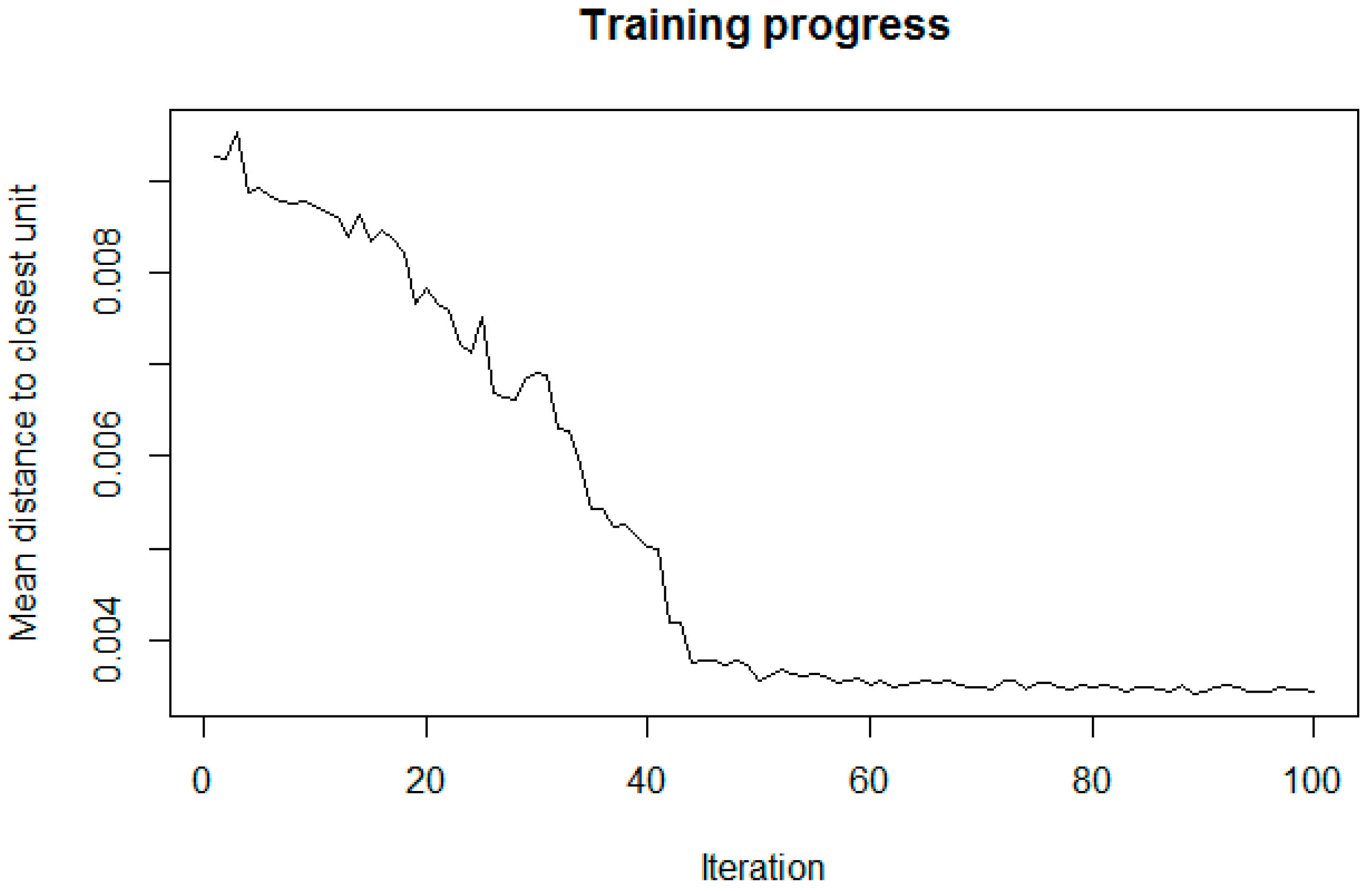
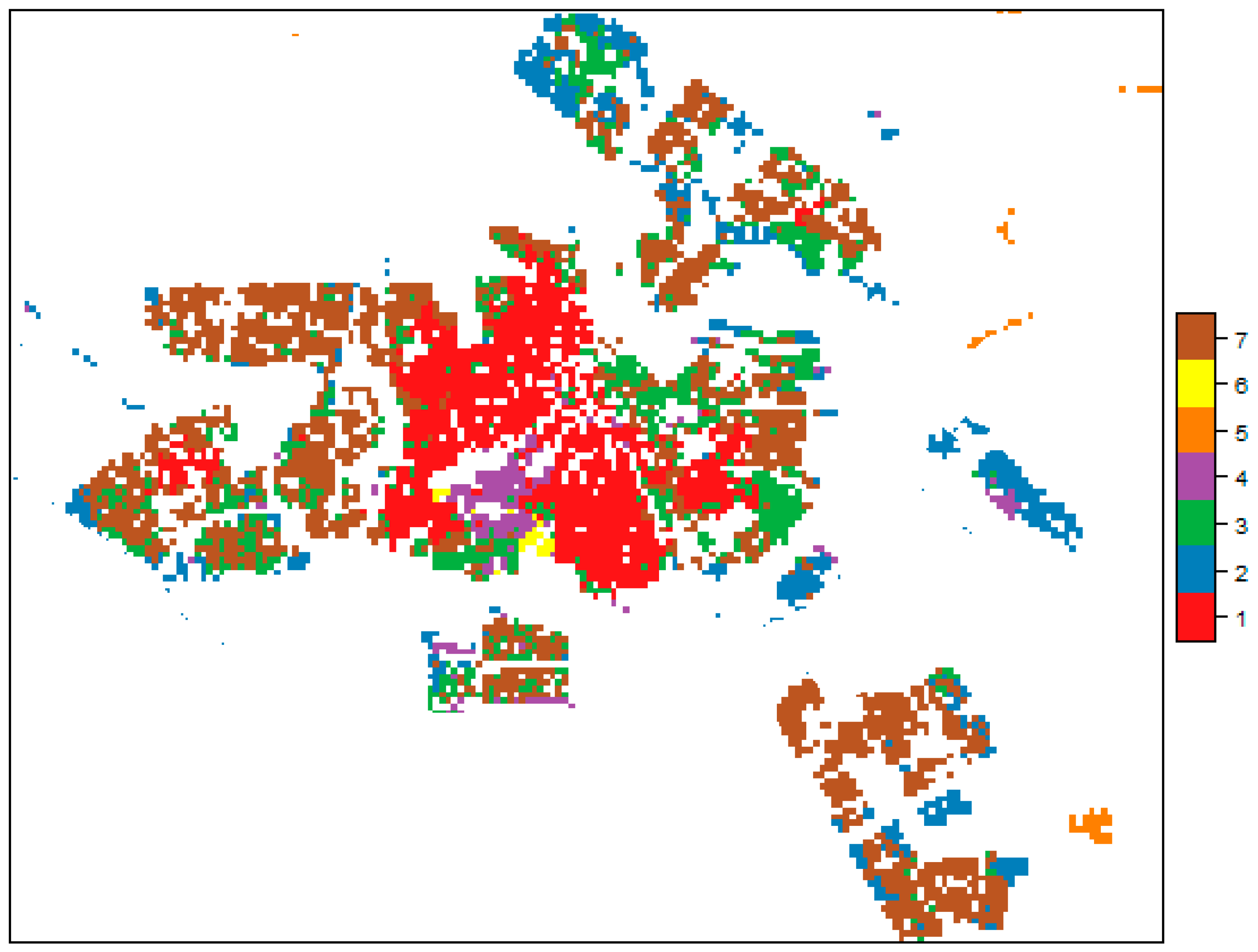
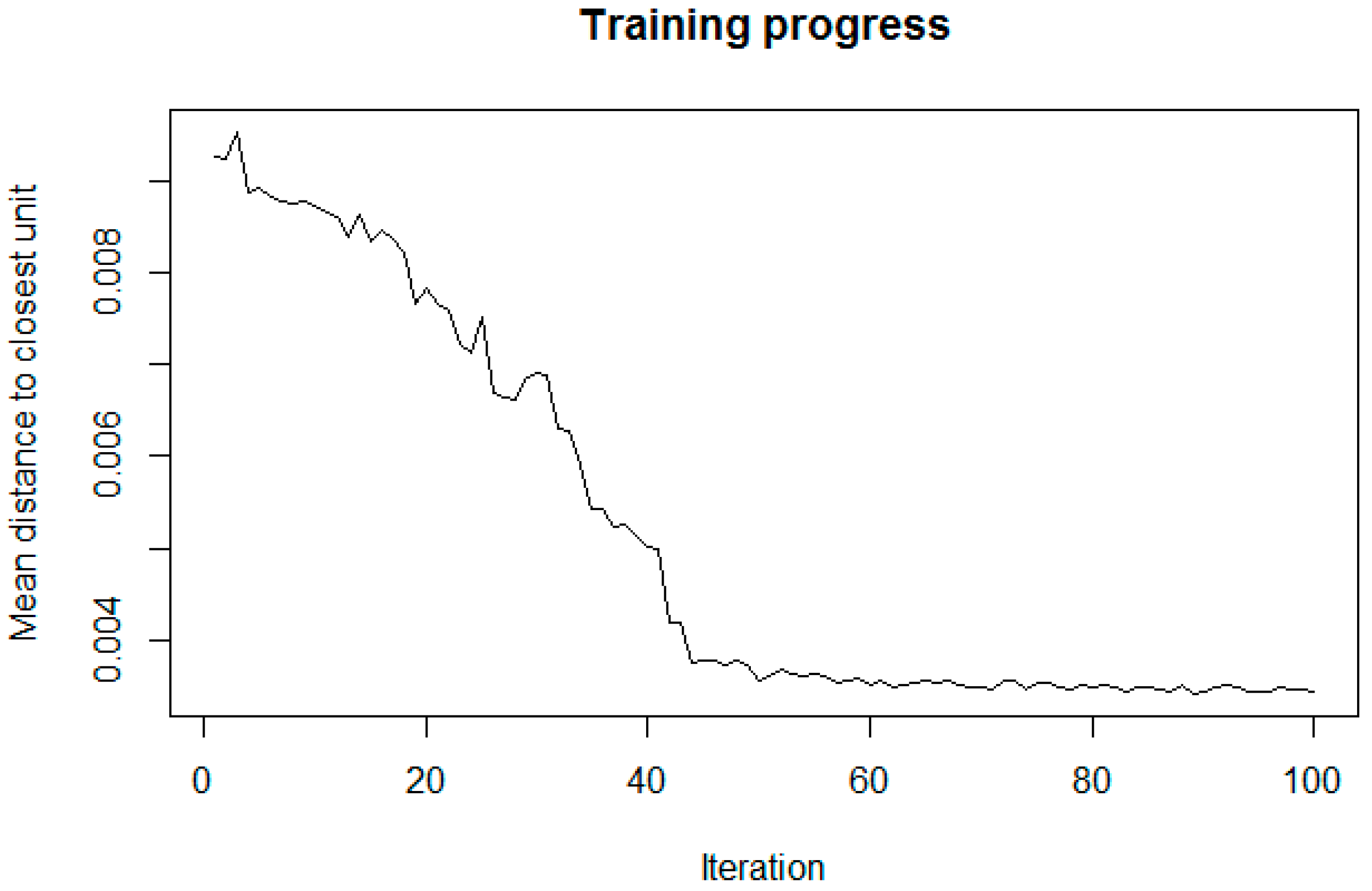
- Hagenauer, J.; Helbich, M. Contextual neural gas for spatial clustering and analysis. Int. J. Geogr. Inf. Sci. 2013, 27, 251–266. [Google Scholar] [CrossRef]
- Hagenauer, J.; Helbich, M. SPAWNN: A toolkit for spatial analysis with self-organizing neural networks. Trans. GIS 2016, 20, 755–774. [Google Scholar] [CrossRef]
- Helbich, M.; Blüml, V.; Leitner, M.; Kapusta, N.; Stadsgeografie, S. Does altitude moderate the impact of lithium on suicide? The case of Austria. Geospat. Health 2013, 7, 209–218. [Google Scholar] [CrossRef] [PubMed]
- Kohonen, T. Self-Organizing Maps; Springer: New York, NY, USA, 2001. [Google Scholar]
- Helbich, M.; Hagenauer, J.; Leitner, M.; Edward, R. Exploration of unstructured narrative crime reports—An unsupervised neural network and point pattern analysis approach. Cartogr. Geogr. Inf. Sci. 2013, 40, 326–336. [Google Scholar] [CrossRef]
- Helbich, M.; Brunauer, W.; Hagenauer, J.; Leitner, M. Data-driven regionalization of housing markets. Ann. Assoc. Am. Geogr. 2013, 103, 871–889. [Google Scholar] [CrossRef]
- Kulldorff, M. A spatial scan statistic. Commun. Stat. Theory Methods 1997, 26, 1481–1496. [Google Scholar] [CrossRef]
- Helbich, M. Beyond postsuburbia? Multifunctional service agglomeration in Vienna’s urban fringe. Tijdschrift voor Economische en Sociale Geografie 2012, 103, 39–52. [Google Scholar] [CrossRef]
- Pebesma, E.; Bivand, R. Classes and methods for spatial data in R. R News 2005, 5. Available online: http://cran.r-project.org/doc/Rnews/ (accessed on 10 October 2016). [Google Scholar]
- Bivand, R.; Keitt, T.; Rowlingson, B. Rgdal: Bindings for the Geospatial Data Abstraction Library. R Package Version 1.1-10. 2016. Available online: https://CRAN.R-project.org/package=rgdal (accessed on 10 October 2016).
- Bivand, R.; Piras, G. Comparing implementations of estimation methods for spatial econometrics. J. Stat. Softw. 2015, 63, 1–36. [Google Scholar] [CrossRef]
- Wehrens, R.; Buydens, L. Self- and super-organising maps in R: The kohonen package. J. Stat. Softw. 2007, 21, 1–19. [Google Scholar] [CrossRef]
- Neuwirth, E. RColorBrewer: ColorBrewer Palettes. R Package Version 1.1-2. 2014. Available online: https://CRAN.R-project.org/package=RColorBrewer (accessed on 10 October 2016).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Key Features | Description |
|---|---|
| Subject area | Health, nutrition, geography, transportation |
| Data source location | Amsterdam, The Netherlands |
| Data acquisition | Derived attributes and official data (Statistic Netherlands) |
| Type and format | R object (SpatialPolygonsDataFrame), ESRI™ shapefile |
| Spatial resolution | cells with 100 m widths |
| Dimension | 5242 × 8 |
| Projection and reference system | EPSG code: 28992 |
| Attributes | |
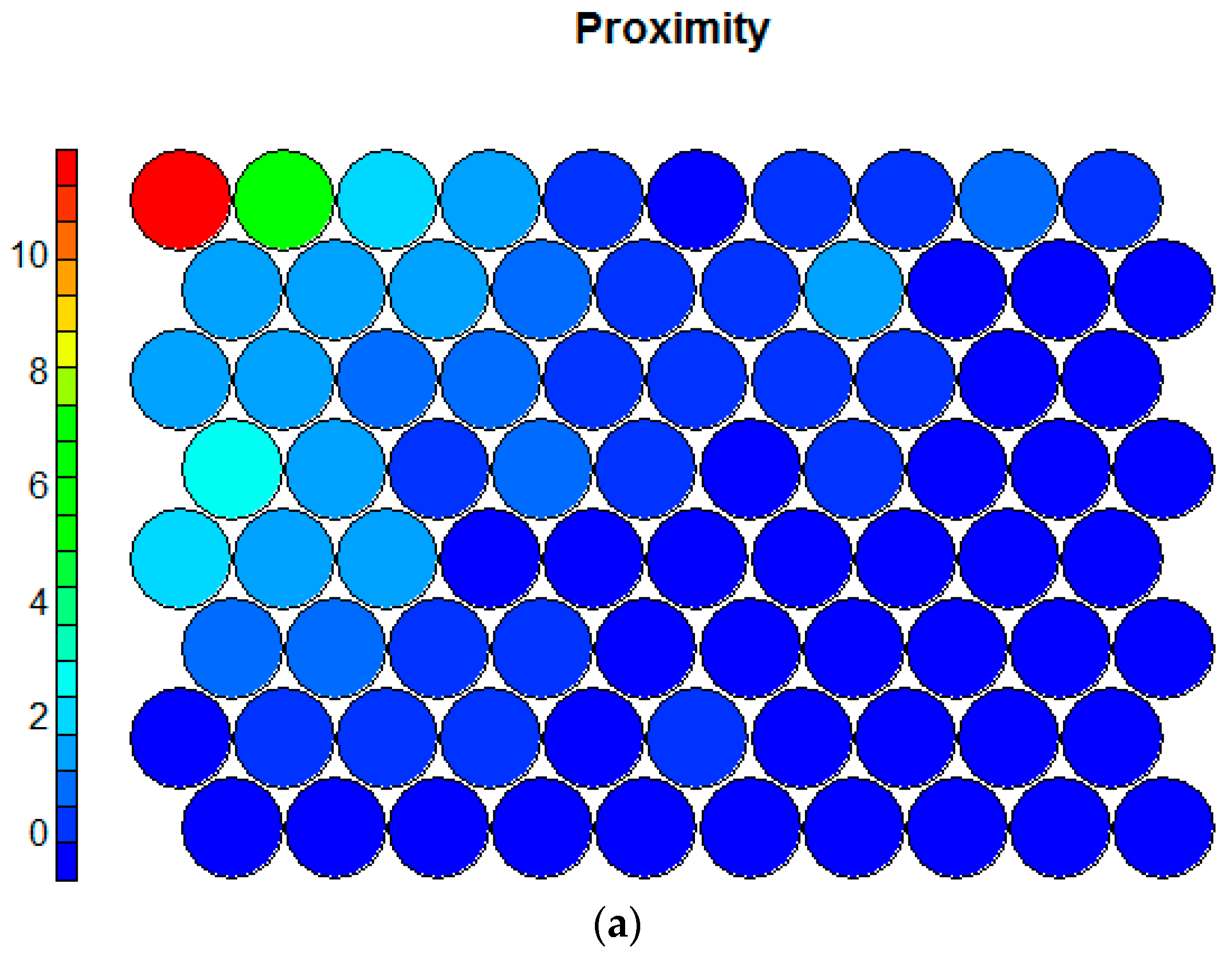
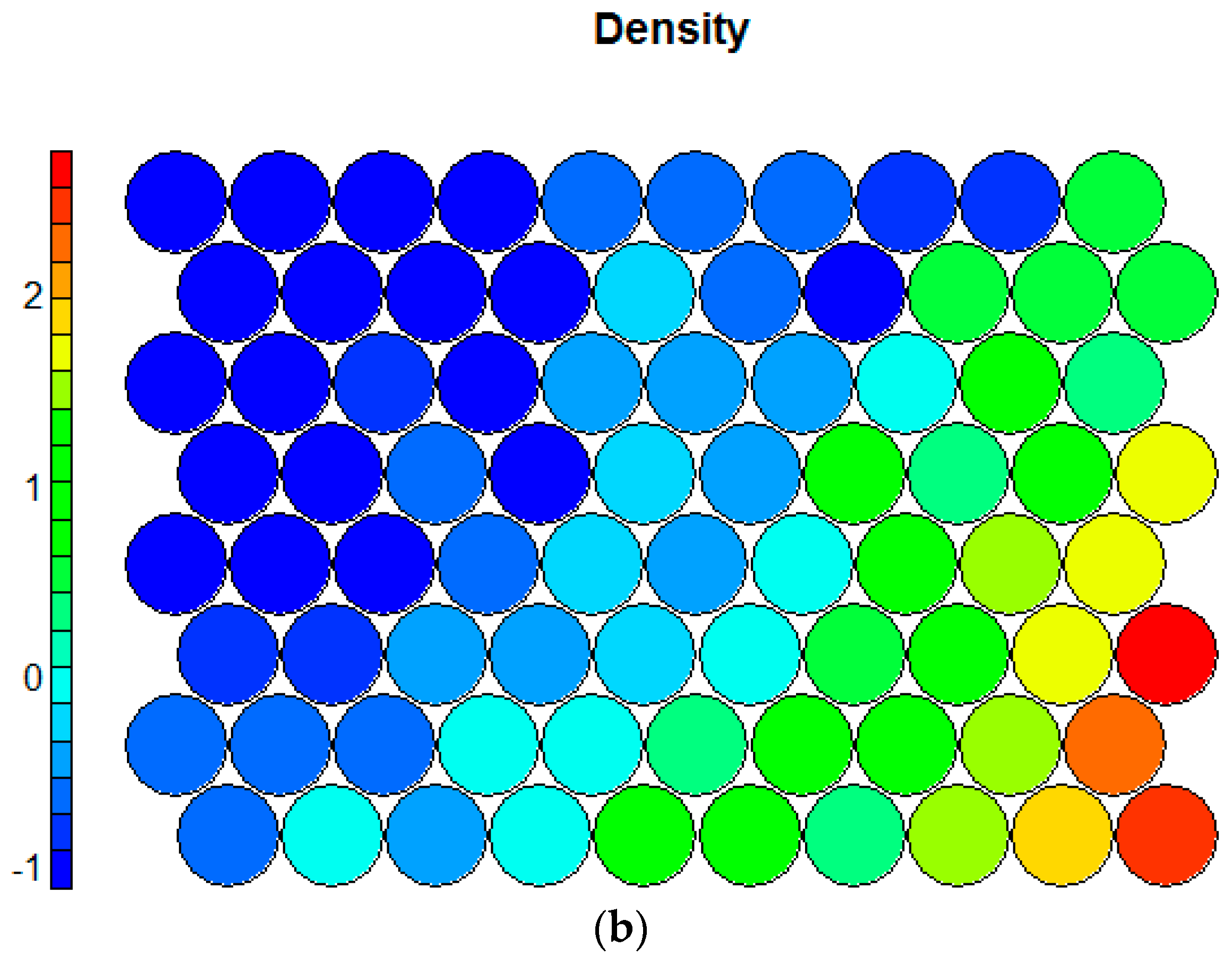
| Proximity (PROX) | Numeric, distance to the closest supermarket from each cell (in meters) |
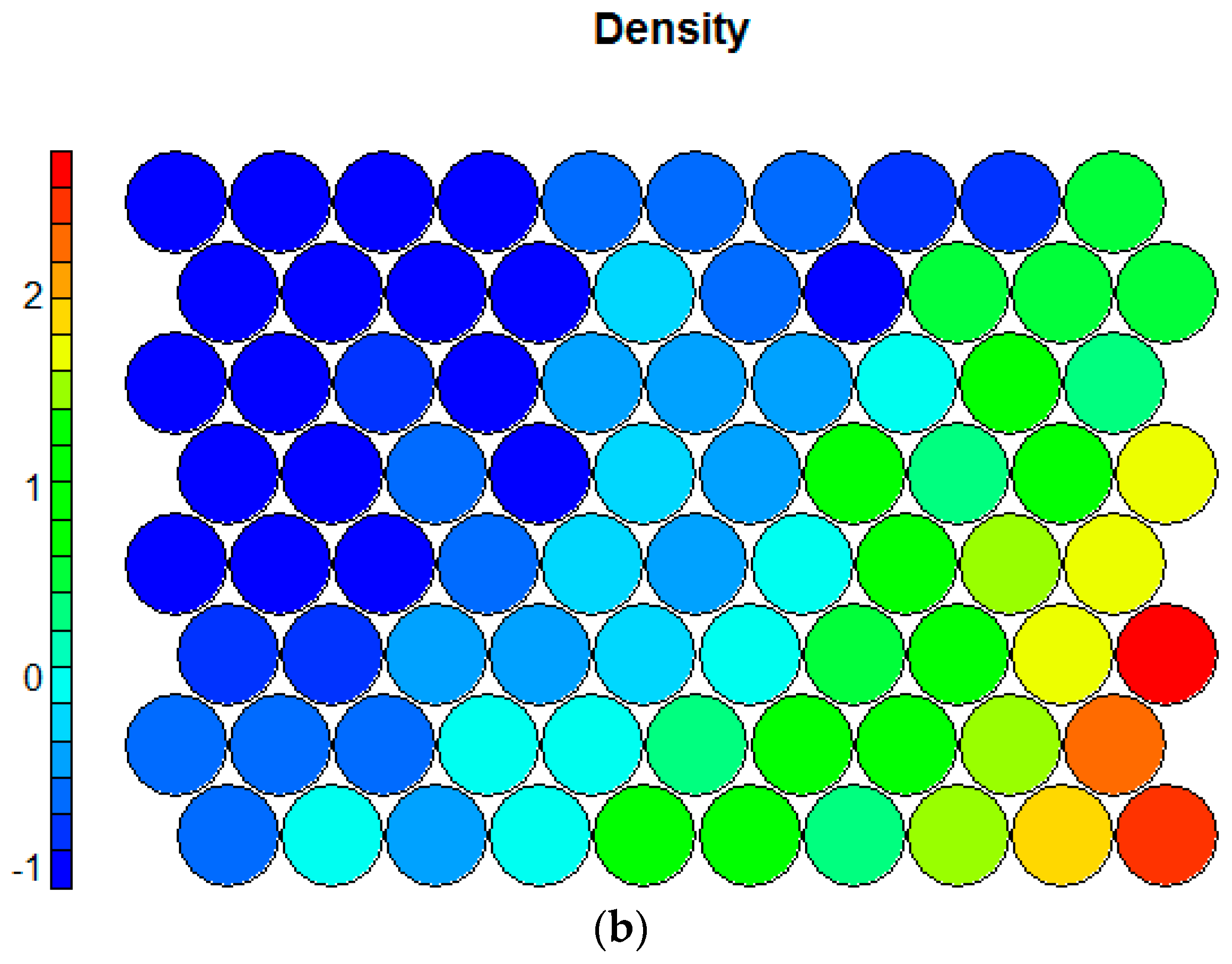
| Density (DENS) | Numeric, number of stores within a 1000 m street network buffer around each cell |
| Variety (VARI) | Numeric, mean distance to three supermarkets of three different chains from each cell (in meters) |
| Ethnicity (NATI) | Numeric, proportion of native Dutch within a cell in the year 2014 (converted to the following numeric values: 5 = >90%, 4 = 75%–90%, 3 = 60%–75%, 2 = 40%–60%, 1 = <40%) |
| Housing (HOUS) | Numeric, average housing price per cell in the year 2011/12 (in €1000) |
| ID | Unique identifier |
| Version 1 | 1.0 |
| Chain | Number of Stores | Chain | Number of Stores |
|---|---|---|---|
| Albert Heijn | 79 | Coop | 3 |
| Dirk | 15 | Plus | 4 |
| Jumbo | 15 | Spar | 3 |
| Lidl | 10 | Dekamarkt | 2 |
| Aldi | 5 | C1000 | 1 |
| Deen | 6 | Boni | 1 |
© 2017 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Helbich, M.; Hagenauer, J. Data on Healthy Food Accessibility in Amsterdam, The Netherlands. Data 2017, 2, 7. https://doi.org/10.3390/data2010007
Helbich M, Hagenauer J. Data on Healthy Food Accessibility in Amsterdam, The Netherlands. Data. 2017; 2(1):7. https://doi.org/10.3390/data2010007
Chicago/Turabian StyleHelbich, Marco, and Julian Hagenauer. 2017. "Data on Healthy Food Accessibility in Amsterdam, The Netherlands" Data 2, no. 1: 7. https://doi.org/10.3390/data2010007
APA StyleHelbich, M., & Hagenauer, J. (2017). Data on Healthy Food Accessibility in Amsterdam, The Netherlands. Data, 2(1), 7. https://doi.org/10.3390/data2010007