Adjustable Robust Singular Value Decomposition: Design, Analysis and Application to Finance

Abstract
:1. Introduction
1.1. Alternating Approach
1.2. The Effect of Noise on SVD
2. Robustness Analysis
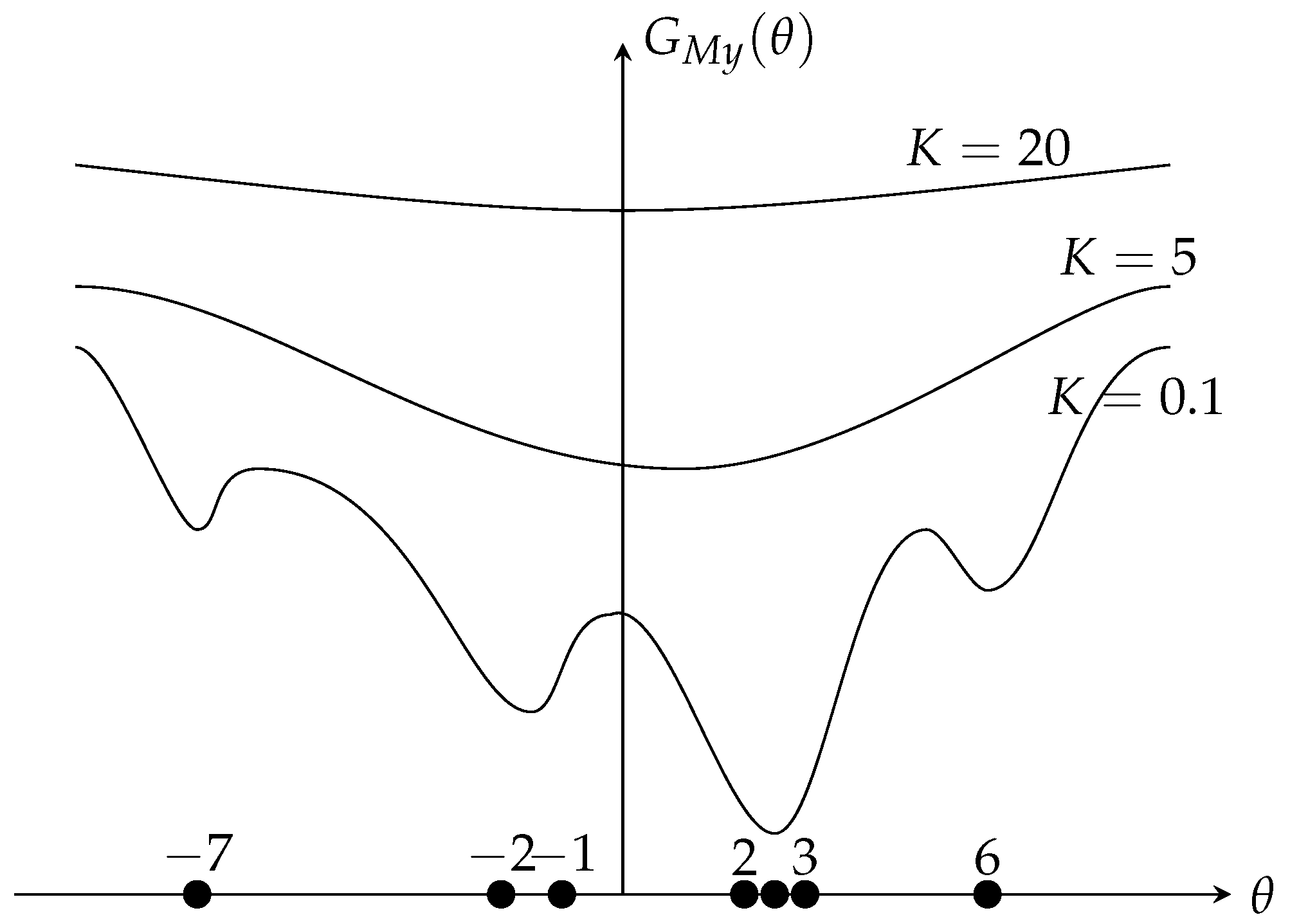
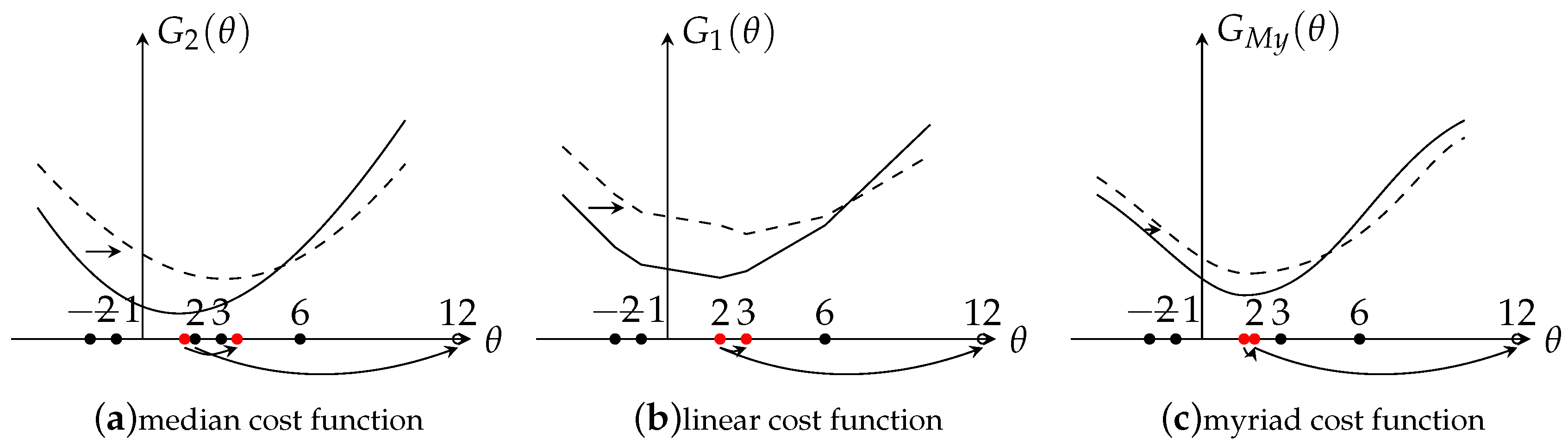
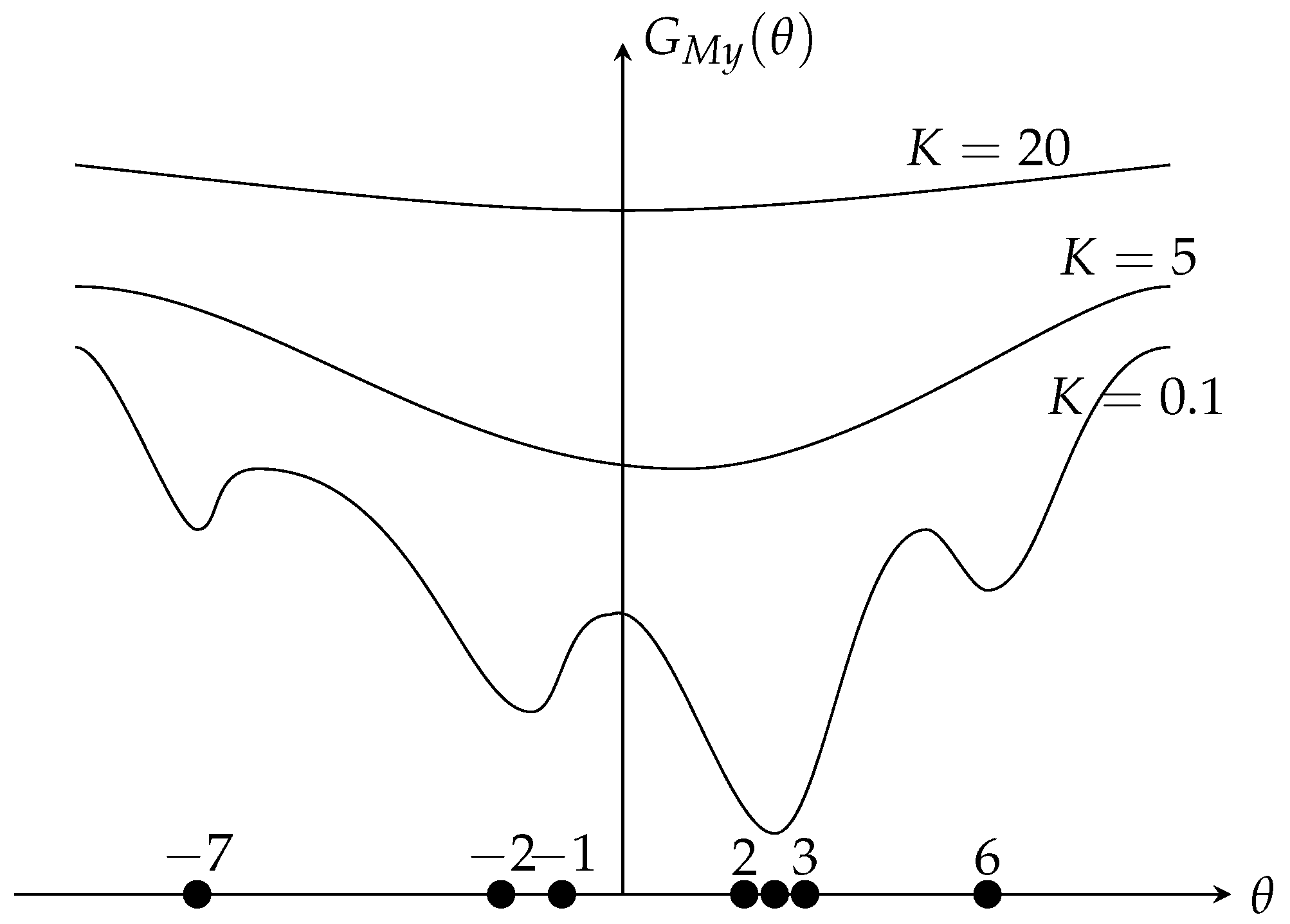
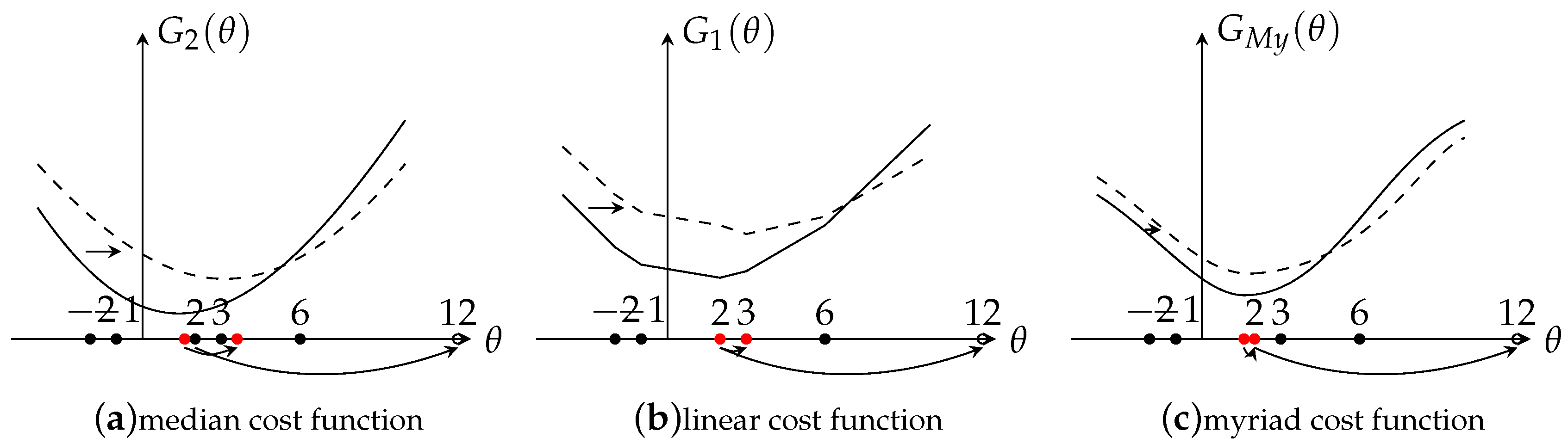
2.1. Robustness Analysis for Different Estimators
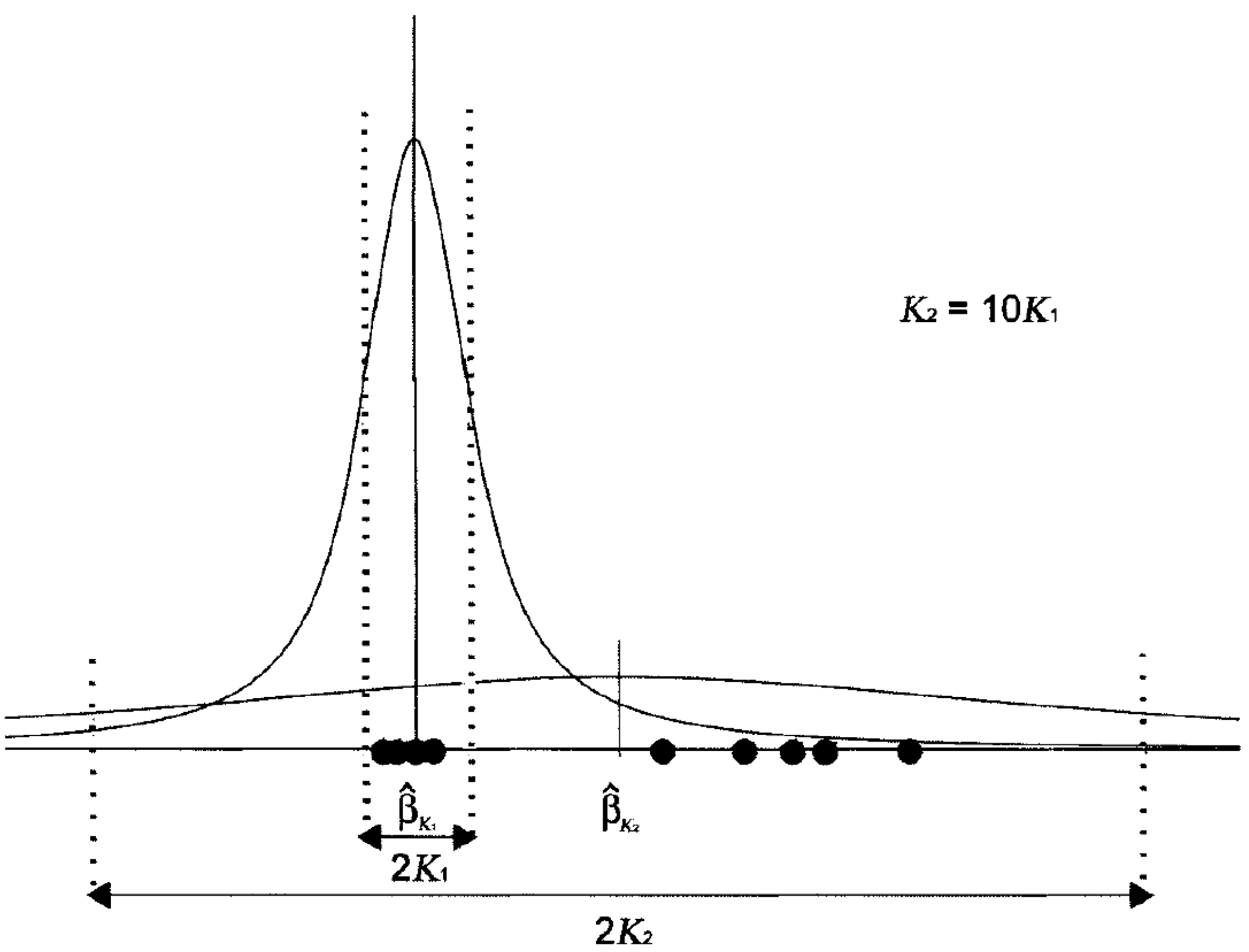
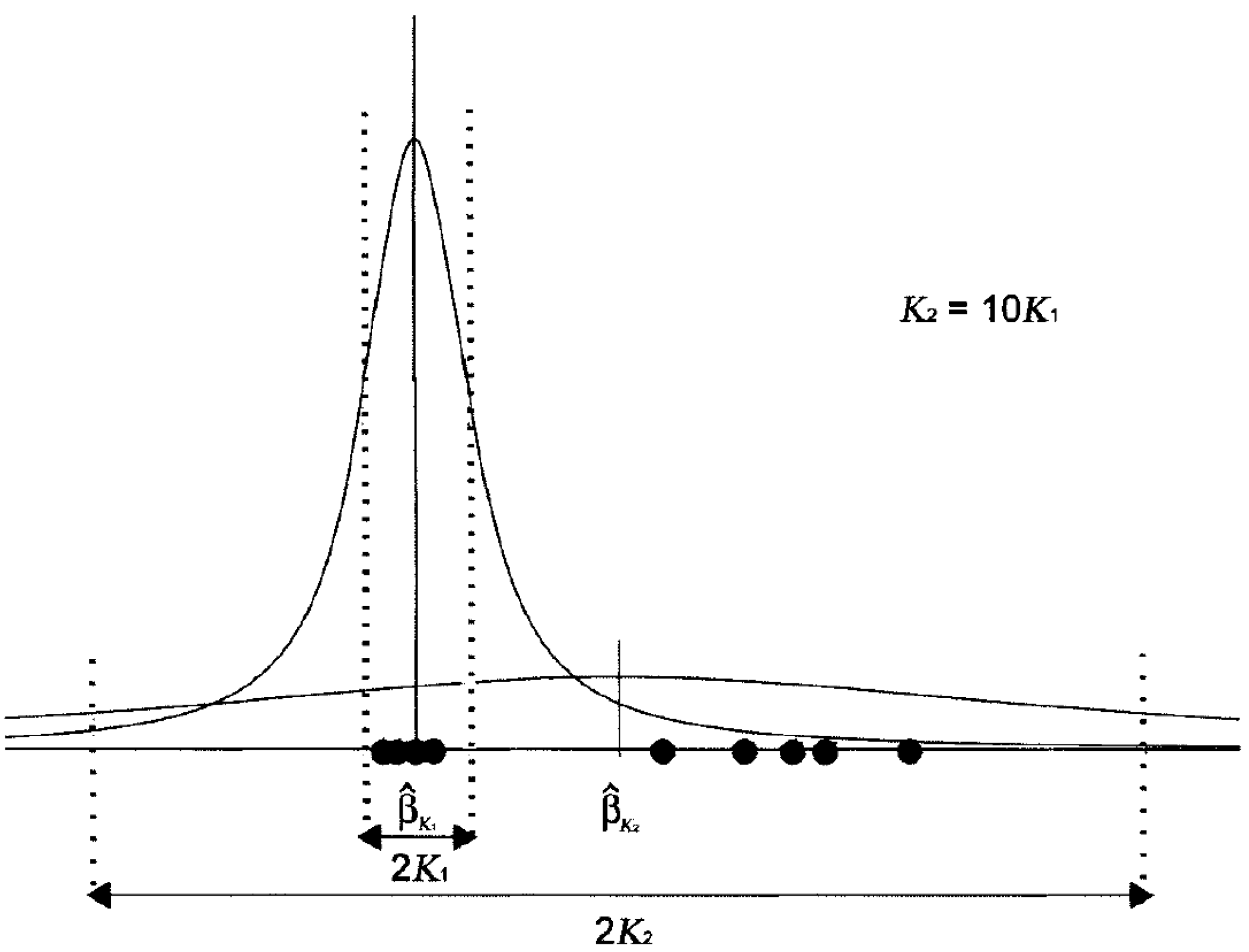
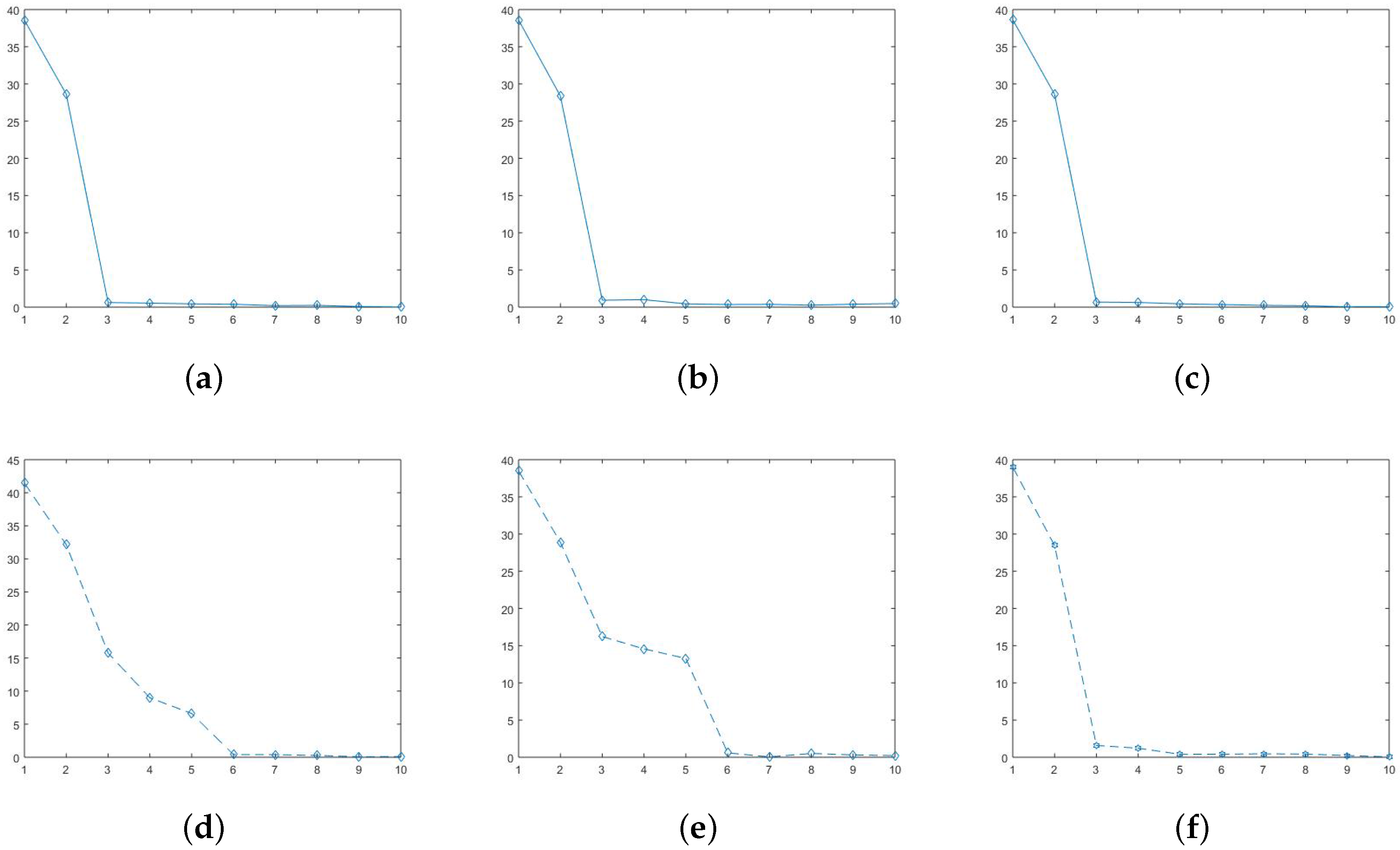
2.2. The Selection of K
3. Adjustable Robust SVD Algorithms
3.1. Myriad Robust SVD (MySVD)
| Algorithm 1 Calculate the first eigentriple |
| Start with an initial guess of the leading left eigenvector and a constant value p |
| repeat |
| for each column j do |
| end for |
| for each row i do |
| end for |
| until Convergence |
3.2. Sequential MySVD
| Algorithm 2 Sequential MySVD |
| Known: |
| Original data , new data |
| Process: |
|
4. Application
4.1. Model Set Up
4.2. Factor Extraction
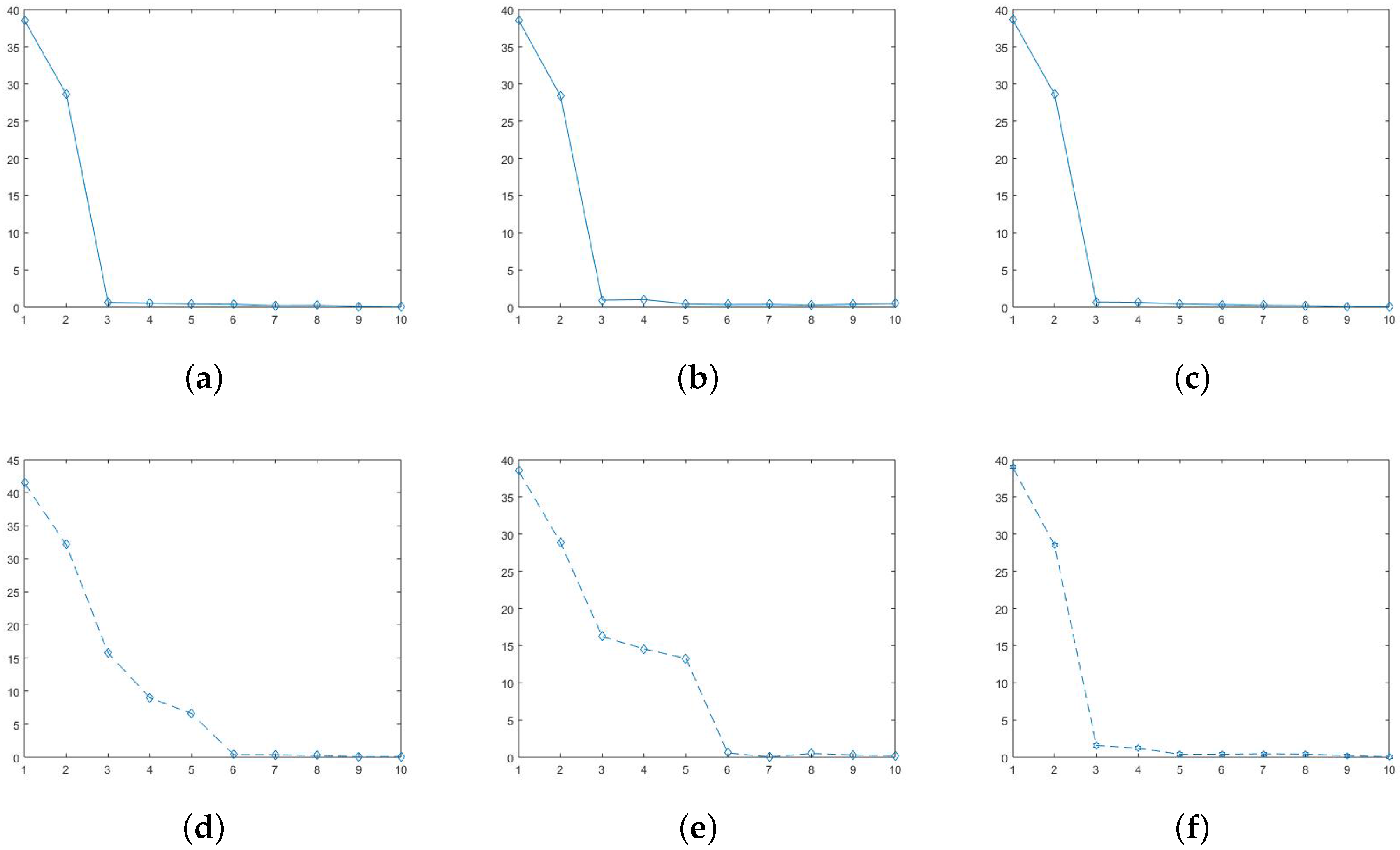
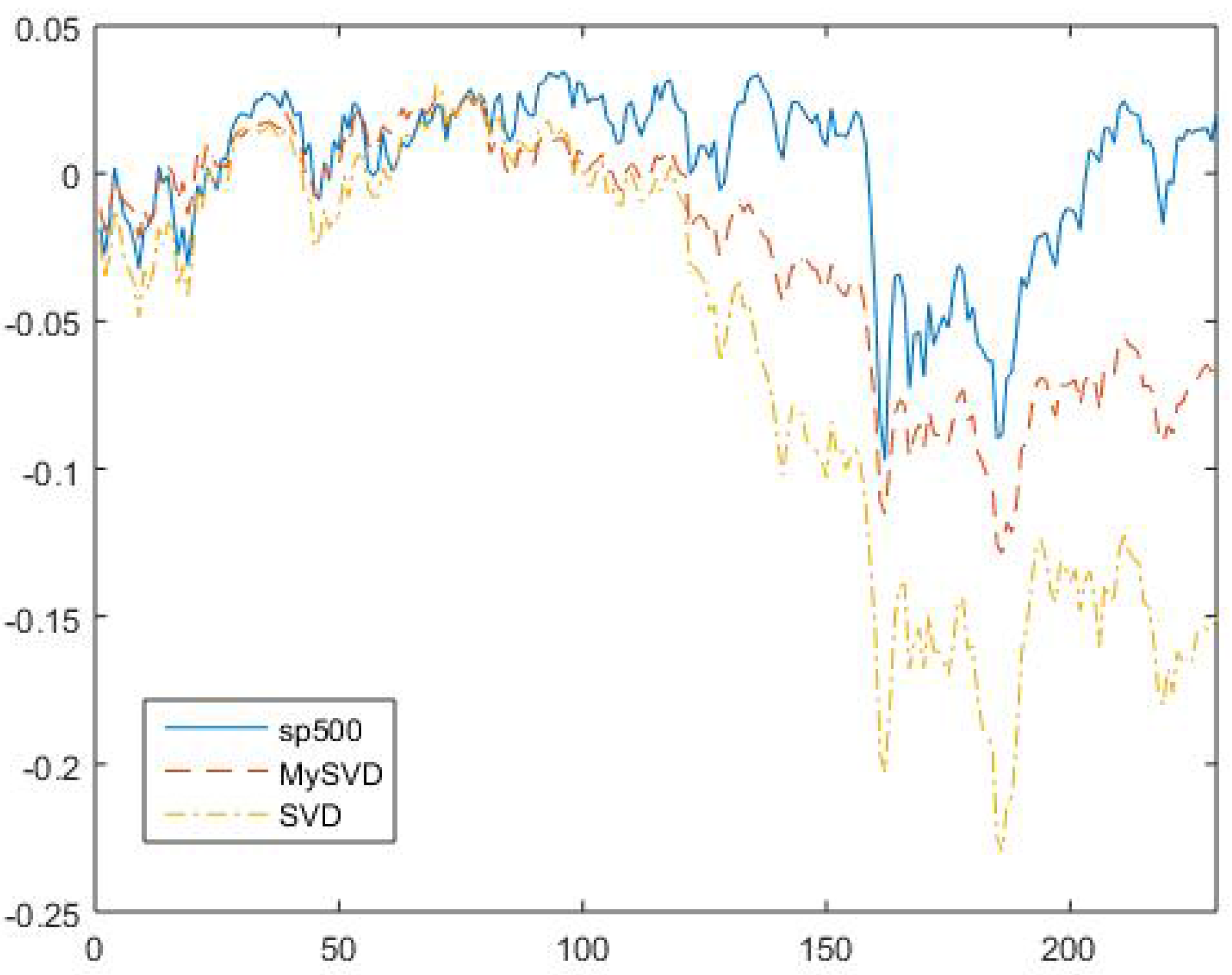
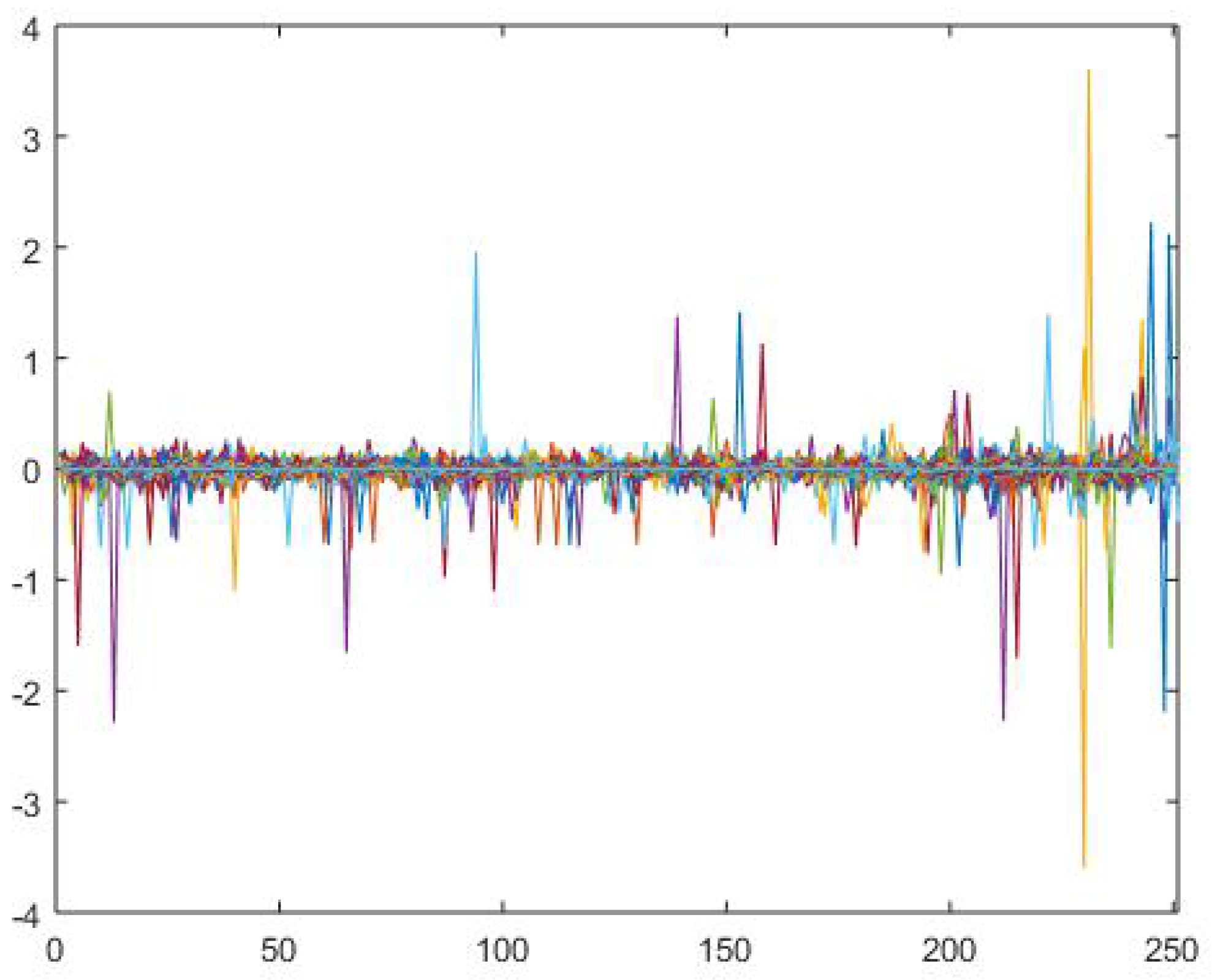
4.3. Numerical Example
5. Conclusion and Future Research
Acknowledgments
Conflicts of Interest
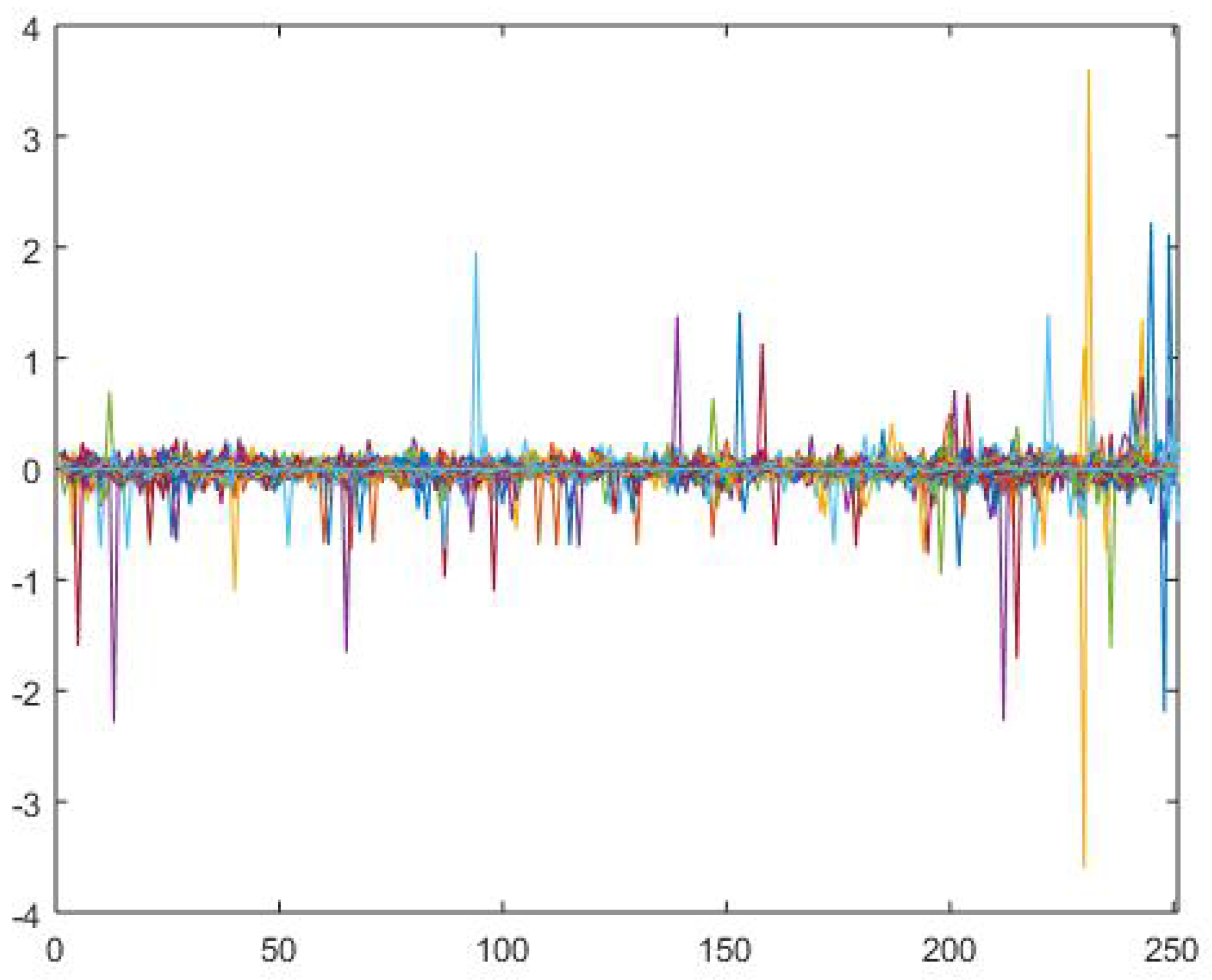
Appendix A. A Simulation Example

References
- Bradu, D.; Gabriel, K.R. The Biplot as a Diagnostic Tool for Models of Two-Way Tables. Technometrics 1978, 20, 47–68. [Google Scholar] [CrossRef]
- Greenacre, M.J. Theory and Applications of Correspondence Analysis; Academic Press: Cambridge, MA, USA, 1984. [Google Scholar]
- Gabriel, K.R.; Zamir, S. Lower Rank Approximation of Matrices by Least Squares with Any Choice of Weights. Technometrics 1979, 21, 489–498. [Google Scholar] [CrossRef]
- Hawkins, D.M.; Liu, L.; Young, S.S. Robust Singular Value Decomposition; National Institute of Statistical Sciences: Durham, NC, USA, 2001.
- Arce, G.R. Nonlinear Signal Processing: A Statistical Approach; Wiley-Intersecience: Hoboken, NJ, USA, 2004. [Google Scholar]
- Gonzalez, J.G.; Arce, G.R. Optimality of the myriad filter in practical impulsive-noise environments. IEEE Trans. Signal Proc. 2001, 2, 438–441. [Google Scholar] [CrossRef]
- Gonzalez, J.G.; Arce, G.R. Statistically-Efficient Filtering in Impulsive Environments: Weighted Myriad Filters. EURASIP J. Adv. Signal Proc. 2002, 2002, 363195. [Google Scholar] [CrossRef]
- Lim, H.S.; Chuah, T.C.; Chuah, H.T. On the Optimal Alpha-k Curve of the Sample Myriad. IEEE Signal Proc. Lett. 2007, 8, 545–548. [Google Scholar] [CrossRef]
- Gonzalez, J.G.; Griffith, D.W.; Arce, G.R. Matched Myriad Filtering for Robust Communications. In Proceedings of the 30th Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA; 1996. [Google Scholar]
- Fama, E.F.; Roll, R. Parameter Estimates for Symmetric Stable Distributions. J. Am. Stat. Assoc. 1971, 334, 331–338. [Google Scholar] [CrossRef]
- Koutrouvelis, I.A. Regression-Type Estimation of the Parameters of Stable Laws. J. Am. Stat. Assoc. 1980, 372, 918–928. [Google Scholar] [CrossRef]
- McCulloch, J.H. Simple consistent estimators of stable distribution parameters. Commun. Stat. Simul. Comput. 1986, 4, 1109–1136. [Google Scholar] [CrossRef]
- Kalluri, S.; Arce, G.R. Fast Algorithms for Weighted Myriad Computation by Fixed-Point Search. IEEE Trans. Signal Proc. 2000, 1, 159–171. [Google Scholar] [CrossRef]
- Brand, M. Incremental Singular Value Decomposition of Uncertain Data with Missing Values. Proc. 7th Eur. Conf. Comput. Vis. Part I 2002, 14, 707–720. [Google Scholar]
- Miyazaki, D.; Ikeuchi, K. Photometric Stereo Under Unknown Light Sources Using Robust SVD with Missing Data. In Proceedings of the IEEE 17th International Conference on Imaging Processing, Hong Kong, China, 26–29 September 2010. [Google Scholar]
- Lei, B.; Soon, I.; Tan, E. Robust SVD-Based Audio Watermaking Scheme With Differential Evolution Optimization. IEEE Trans. Audio Speech Lang. Proc. 2013, 21, 2368–2378. [Google Scholar] [CrossRef]
- Loukhaoukha, K.; Nabti, M.; Zebbiche, K. A Robust SVD-Based Image Watermaking Using a Multi-objective Particle Swarm Optimization. Opto-Electron. Rev. 2014, 22, 45–54. [Google Scholar] [CrossRef]
- Caraiani, P. The predictive power of singular value decomposition entropy for stock market dynamics. Physica A 2014, 393, 571–578. [Google Scholar] [CrossRef]
- Fama, E.F.; French, K.R. The Cross-Section of Expected Stock Returns. J. Financ. 1992, 47, 427–465. [Google Scholar] [CrossRef]
- Connor, G. The Three Types of Factor Models: A Comparison of Their Explanatory Power. Financ. Anal. J. 1995, 51, 42–46. [Google Scholar] [CrossRef]
- Connor, G.; Korajczyk, R. Factor Models of Asset Returns. In Encyclopedia of Quantitative Finance; Wiley: Hoboken, NJ, USA, 2009. [Google Scholar]
- Avellaneda, M.; Lee, J. Statistical arbitrage in the US equities market. Quant. Financ. 2010, 10, 761–782. [Google Scholar] [CrossRef]
- Laloux, L.; Cizeau, P.; Potters, M.; Bouchaud, J. Random Matrix Theory and Financial Correlations. Int. J. Theor. Appl. Financ. 2000, 3, 391–397. [Google Scholar] [CrossRef]
- Zivot, E. Factor Models for Asset Returns. In Modeling Financial Time Series with S-PLUS®; Springer: Berlin, Germany, 2006. [Google Scholar]
- Fama, E.F.; MacBeth, J.D. Risk, Return, and Equilibrium: Empirical Tests. J. Political Econ. 1973, 81, 607–636. [Google Scholar] [CrossRef]
- Dassios, I.; Devine, M.T. A macroeconomic mathematical model for the national income of a union of countries with interaction and trade. J. Econ. Struct. 2016, 5, 18. [Google Scholar] [CrossRef]
- Machado, J.A.T.; Mata, M.E.; Lopes, A.M. Fractional State Space Analysis of Economic Systems. Entropy 2015, 17, 5402–5421. [Google Scholar]
- Dassios, I.; Zimbidis, A.A.; Kontzalis, C.P. The Delay Effect in a Stochastic Multiplier–Accelerator Model. J. Econ. Struct. 2014, 3, 7. [Google Scholar] [CrossRef]
- Yang, H.; Li, L.; Wang, D. Research on the Stability of Open Financial System. Entropy 2015, 17, 1734–1754. [Google Scholar] [CrossRef]
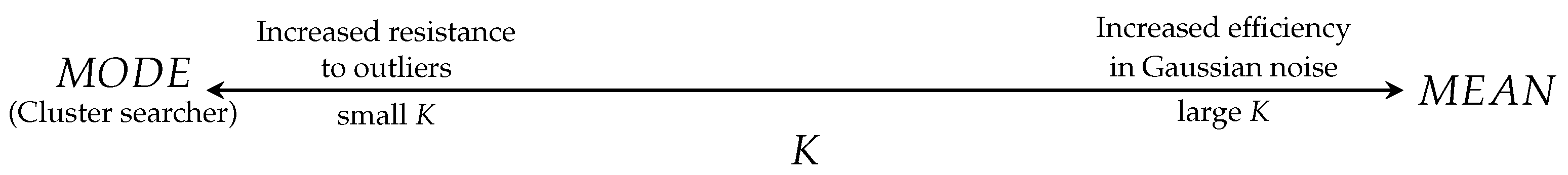

{kind=link}
{kind=link}
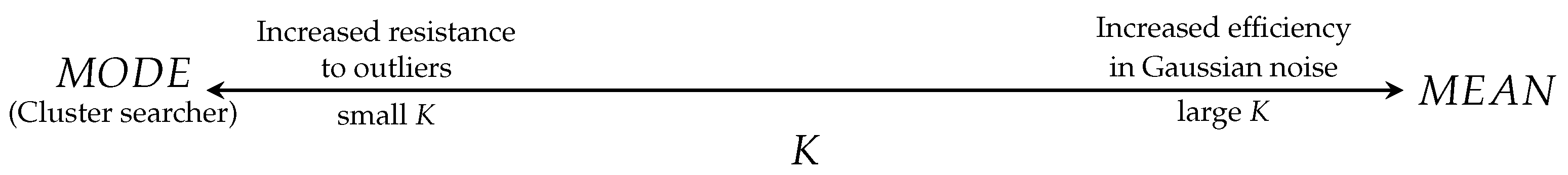{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Estimator | Cost Function | Output, |
|---|---|---|
| Linear | ||
| Median | ||
| Myriad |
| Factors | Conventional SVD | Myriad Robust SVD (MySVD) |
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| All Factors |
| h-value | p-value | |||
|---|---|---|---|---|
| MySVD | 0 | |||
| SVD | 1 |
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, D. Adjustable Robust Singular Value Decomposition: Design, Analysis and Application to Finance. Data 2017, 2, 29. https://doi.org/10.3390/data2030029
Wang D. Adjustable Robust Singular Value Decomposition: Design, Analysis and Application to Finance. Data. 2017; 2(3):29. https://doi.org/10.3390/data2030029
Chicago/Turabian StyleWang, Deshen. 2017. "Adjustable Robust Singular Value Decomposition: Design, Analysis and Application to Finance" Data 2, no. 3: 29. https://doi.org/10.3390/data2030029
APA StyleWang, D. (2017). Adjustable Robust Singular Value Decomposition: Design, Analysis and Application to Finance. Data, 2(3), 29. https://doi.org/10.3390/data2030029