Deep Learning Dataset for Estimating Burned Areas: Case Study, Indonesia

Abstract
:1. Summary
2. Data Description
2.1. Image Subset
2.2. Burned Area Mask
2.3. Quicklook
3. Methods
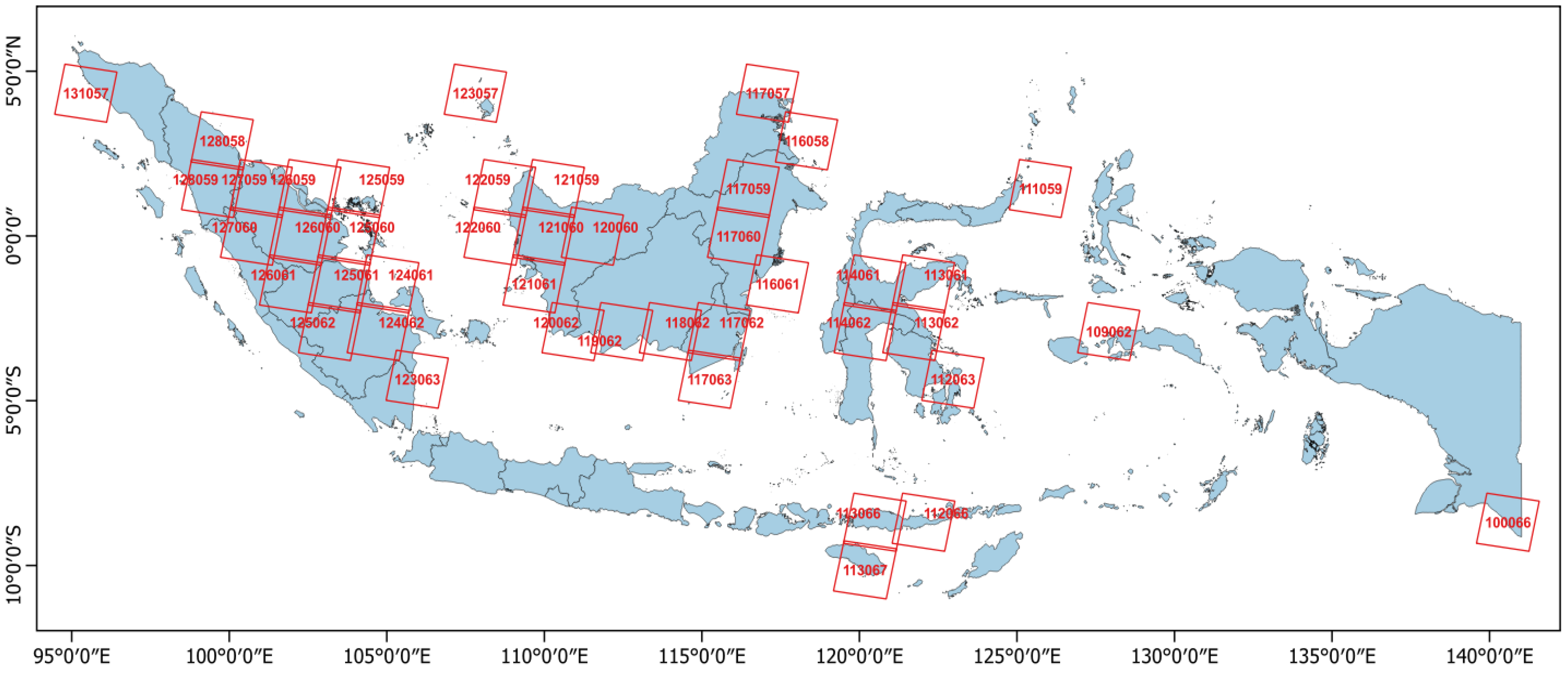
3.1. Scene Selection
3.2. Pre-Processing
3.3. Burned Area Masking
3.3.1. Delineation Process
3.3.2. Cropping and Rasterizing
3.4. Validation
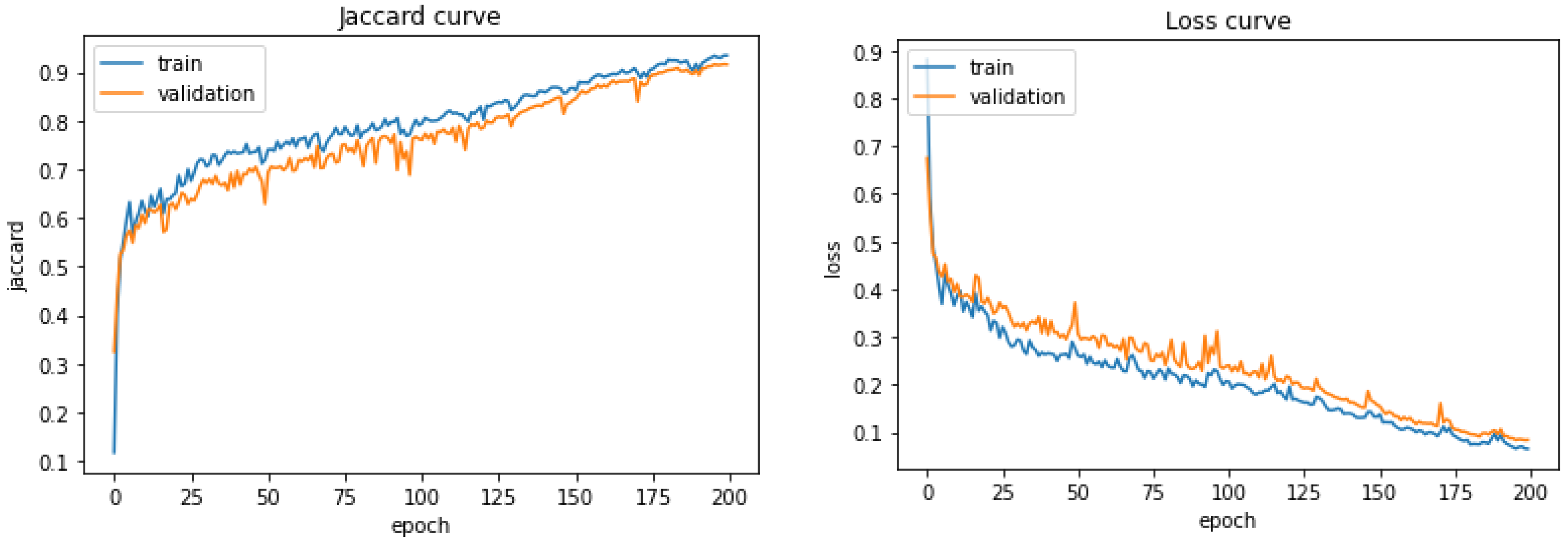
3.5. The Training Performance on the Dataset
4. User Notes
- The released dataset is organized into three folders: “images”, “masks”, and “quicklooks” folders that contain the image subsets, burned area masks, and quicklook images, respectively.
- The name of each file in this dataset indicates the image derived from such a scene.
- File name of image subset: L8_PPPRRR_DDMMYY_XXX.tif
- File name of burned area mask: L8_PPPRRR_DDMMYY_XXX_mask.tif
- File name of quicklook: L8_PPPRRR_DDMMYY_XXX_ql.tif
where:- ▪
- L8 = Landsat-8
- ▪
- PPP = WRS path
- ▪
- RRR = WRS row
- ▪
- DDMMYY = Acquisition date (Day, Month, Year)
- ▪
- XXX = Collection number of dataset (001, 002, …)
- ▪
- mask = Indicates burned area mask file
- ▪
- ql = Indicates quicklook file
- This dataset provides all multispectral bands of Landsat-8 image (see Table 2) to facilitate the users in selecting input bands to obtain the best performance from their model. They may choose one band or more to be used as input for training their model, or a combination of bands using spectral indices, such as Normalized Difference Vegetation Indices (NDVI), Normalized Burn Ratio (NBR), etc.
- The quicklook can also be used as an alternative substitute for image subset if the users only need bands SWIR-2, NIR, and Red for their model input. However, it should be noted that the quicklook is a false composite image of band combination SWIR-2, NIR, and Red, which has been performed contrast enhancement using the parameters described in Table 4.
- The dataset can be used by researchers and professionals working on remote sensing or computer vision-based models for image segmentation, object detection, and classification related to the burned area. However, this dataset only supports binary classification for mapping burned areas and non-burned areas. Users are free to utilize the dataset and to contribute by improving the existing dataset or adding new ones.
- The dataset has been collected from some path row locations in Indonesia. Therefore, it can represent different conditions in some regions of Indonesia.
- Finally, some of the data may not be accurate and have errors in interpretation due to visual human error.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ministry of Environment and Forestry Republic of Indonesia (KLHK). Siaran Pers: Hutan dan Deforestasi Indonesia Tahun 2019. Available online: http://ppid.menlhk.go.id/siaran_pers/browse/2435 (accessed on 1 October 2021).
- FAO; UNEP. The State of the World’s Forests (SOFO); FAO and UNEP: Rome, Italy, 2020. [Google Scholar]
- Nurofiq, H.F.; Prihatno, K.B.; Margono, B.A.; Sudijanto, A.; Primiantoro, E.T.; Saputro, T.; Parisy, Y.; Nugroho, D.; Ramdhany, D.; Kumar, K. The State of Indonesia’s Forest 2020; Ministry of Environment and Forestry Republic of Indonesia: Jakarta, Indonesia, 2020.
- Ministry of Environment and Forestry Republic of Indonesia (KLHK). SiPongi Karhutla Monitoring Sistem. Available online: http://sipongi.menlhk.go.id/hotspot/luas_kebakaran (accessed on 4 October 2021).
- Ongeri, D.; Kenduiywo, B.K. Burnt area detection using medium resolution sentinel 2 and landsat 8 satellites. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. ISPRS Arch. 2020, 43, 131–137. [Google Scholar] [CrossRef]
- Thapa, S.; Vishwas, S.C.; Pradhan, S.; Shakya, B.; Sharma, S.; Regmi, S.; Bajracharya, S.; Adhikari, S.; Dangol, G.S. Forest Fire Detection and Monitoring. In Earth Observation Science and Applications for Risk Reduction and Enhanced Resilience in Hindu Kush Himalaya Region; Birendra, B., Rajesh, B.T., Eds.; Springer Nature: Cham, Switzerland, 2021; pp. 147–167. [Google Scholar]
- Purnomo, E.P.; Ramdani, R.; Agustiyara; Nurmandi, A.; Trisnawati, D.W.; Fathani, A.T. Bureaucratic inertia in dealing with annual forest fires in Indonesia. Int. J. Wildl. Fire 2021, 30, 733–744. [Google Scholar] [CrossRef]
- Roteta, E.; Bastarrika, A.; Padilla, M.; Storm, T.; Chuvieco, E. Development of a Sentinel-2 burned area algorithm: Generation of a small fire database for sub-Saharan Africa. Remote Sens. Environ. 2019, 222, 1–17. [Google Scholar] [CrossRef]
- Sari, I.L.; Weston, C.J.; Newnham, G.J.; Volkova, L. Assessing accuracy of land cover change maps derived from automated digital processing and visual interpretation in tropical forests in indonesia. Remote Sens. 2021, 13, 1446. [Google Scholar] [CrossRef]
- Tarko, A.; Tsendbazar, N.E.; Bruin, S.; Bregt, A.K. Producing consistent visually interpreted land cover reference data: Learning from feedback. Int. J. Digit. Earth. 2021, 14, 52–70. [Google Scholar] [CrossRef]
- Alganci, U.; Soydas, M.; Sertel, E. Comparative research on deep learning approaches for airplane detection from very high-resolution satellite images. Remote Sens. 2020, 12, 458. [Google Scholar] [CrossRef] [Green Version]
- Scott, G.J.; Marcum, R.A.; Davis, C.H.; Nivin, T.W. Fusion of Deep Convolutional Neural Networks for Land Cover Classification of High-Resolution Imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1638–1642. [Google Scholar] [CrossRef]
- USGS. Landsat Missions: Landsat 8. Available online: https://www.usgs.gov/landsat-missions/landsat-8 (accessed on 11 January 2022).
- USGS. Landsat Missions: Landsat Levels of Processing. Available online: https://www.usgs.gov/core-science-systems/nli/landsat/landsat-levels-processing (accessed on 4 October 2021).
- USGS. Landsat Missions: Using the USGS Landsat Level-1 Data Product. Available online: https://www.usgs.gov/core-science-systems/nli/landsat/using-usgs-landsat-level-1-data-product (accessed on 4 October 2021).
- Hawbaker, T.J.; Vanderhoof, M.K.; Schmidt, G.L.; Beal, Y.J.; Picotte, J.J.; Takacs, J.D.; Falgout, J.T.; Dwyer, J.L. The Landsat Burned Area algorithm and products for the conterminous United States. Remote Sens. Environ. 2020, 244, 111801. [Google Scholar] [CrossRef]
- Taner, A.; Oztekin, Y.B.; Duran, H. Performance Analysis of Deep Learning CNN Models for Variety Classification in Hazelnut. Sustainability 2020, 13, 6527. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Specification | Image Subsets | Burned Area Masks | Quicklooks |
|---|---|---|---|
| Image size (in pixel) | 512 × 512 | 512 × 512 | 512 × 512 |
| Number of bands | 8 | 1 | 3 |
| Bit depth | 16 bit (unsigned integer) | 8 bit (unsigned integer) | 8 bit (unsigned integer) |
| File format | GeoTIFF | GeoTIFF | GeoTIFF |
| Georeferenced | Yes | Yes | Yes |
| Total number | 227 | 227 | 227 |
| Band Names | Wavelength [µm] | Resolution (Degree) |
|---|---|---|
| Band 1—Coastal/Aerosol | 0.43–0.45 | 0.00025 |
| Band 2—Blue | 0.45–0.51 | 0.00025 |
| Band 3—Green | 0.53–0.59 | 0.00025 |
| Band 4—Red | 0.64–0.67 | 0.00025 |
| Band 5—Near Infrared (NIR) | 0.85–0.88 | 0.00025 |
| Band 6—Short Wave Infrared (SWIR-1) | 1.57–1.65 | 0.00025 |
| Band 7—Short Wave Infrared (SWIR-2) | 2.11–2.29 | 0.00025 |
| Band 8—Cirrus | 1.36–1.38 | 0.00025 |
| Percentage of Burned Area (%) | Number of Images |
|---|---|
| 0 | 21 |
| 0–10 | 145 |
| 10–20 | 36 |
| 20–30 | 18 |
| 30–40 | 2 |
| 40–50 | 2 |
| 50–60 | 1 |
| 60–70 | 2 |
| >70 | 0 |
| Total | 227 |
| Composite Band | Minimum | Maximum |
|---|---|---|
| Red (Band 7) | 3500 | 15,000 |
| Green (Band 5) | 11,000 | 27,000 |
| Blue (Band 4) | 5000 | 18,000 |
| Path/Row | Number of Images | Path/Row | Number of Images |
|---|---|---|---|
| 100/066 | 1 | 121/059 | 2 |
| 109/062 | 1 | 121/060 | 10 |
| 111/059 | 1 | 121/061 | 16 |
| 112/063 | 2 | 122/059 | 10 |
| 112/066 | 2 | 122/060 | 7 |
| 113/061 | 2 | 123/057 | 1 |
| 113/062 | 1 | 123/063 | 1 |
| 113/066 | 1 | 124/061 | 1 |
| 113/067 | 1 | 124/062 | 3 |
| 114/061 | 1 | 125/059 | 7 |
| 114/062 | 1 | 125/060 | 8 |
| 116/058 | 4 | 125/061 | 20 |
| 116/062 | 1 | 125/062 | 2 |
| 117/057 | 1 | 126/059 | 7 |
| 117/059 | 1 | 126/060 | 7 |
| 117/060 | 11 | 126/061 | 1 |
| 117/062 | 30 | 127/059 | 16 |
| 117/063 | 6 | 127/060 | 1 |
| 118/062 | 17 | 128/058 | 2 |
| 119/062 | 3 | 128/059 | 3 |
| 120/060 | 3 | 131/057 | 1 |
| 120/062 | 10 |
| Evaluation Metric | Equation |
|---|---|
| Precision (P) | |
| Recall (R) | |
| F1-Score (F1) | |
| Accuracy (A) |
| Validator Result | |||
|---|---|---|---|
| Burned Area | Non-Burned Area | ||
| Delineator Result | Burned Area | True Positive (TP) | False Positive (FP) |
| Non-Burned Area | False Negative (FN) | True Negative (TN) | |
| Percentage (%) | Overlap | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|---|
| 90–100 | 218 | 223 | 206 | 223 | 210 |
| 80–90 | 7 | 3 | 12 | 4 | 13 |
| 70–80 | 1 | 1 | 9 | 0 | 4 |
| 60–70 | 1 | 0 | 0 | 0 | 0 |
| 50–60 | 0 | 0 | 0 | 0 | 0 |
| <50 | 0 | 0 | 0 | 0 | 0 |
| Total | 227 | 227 | 227 | 227 | 227 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prabowo, Y.; Sakti, A.D.; Pradono, K.A.; Amriyah, Q.; Rasyidy, F.H.; Bengkulah, I.; Ulfa, K.; Candra, D.S.; Imdad, M.T.; Ali, S. Deep Learning Dataset for Estimating Burned Areas: Case Study, Indonesia. Data 2022, 7, 78. https://doi.org/10.3390/data7060078
Prabowo Y, Sakti AD, Pradono KA, Amriyah Q, Rasyidy FH, Bengkulah I, Ulfa K, Candra DS, Imdad MT, Ali S. Deep Learning Dataset for Estimating Burned Areas: Case Study, Indonesia. Data. 2022; 7(6):78. https://doi.org/10.3390/data7060078
Chicago/Turabian StylePrabowo, Yudhi, Anjar Dimara Sakti, Kuncoro Adi Pradono, Qonita Amriyah, Fadillah Halim Rasyidy, Irwan Bengkulah, Kurnia Ulfa, Danang Surya Candra, Muhammad Thufaili Imdad, and Shadiq Ali. 2022. "Deep Learning Dataset for Estimating Burned Areas: Case Study, Indonesia" Data 7, no. 6: 78. https://doi.org/10.3390/data7060078