Abstract
Machine learning algorithms, such as KNN, SVM, MLP, RF, and MLR, are used to extract valuable information from shared digital data on social media platforms through their APIs in an effort to identify anonymous publishers or online users. This can leave these anonymous publishers vulnerable to privacy-related attacks, as identifying information can be revealed. Twitter is an example of such a platform where identifying anonymous users/publishers is made possible by using machine learning techniques. To provide these anonymous users with stronger protection, we have examined the effectiveness of these techniques when critical fields in the metadata are masked or encrypted using tweets (text and images) from Twitter. Our results show that SVM achieved the highest accuracy rate of 95.81% without using data masking or encryption, while SVM achieved the highest identity recognition rate of 50.24% when using data masking and AES encryption algorithm. This indicates that data masking and encryption of metadata of tweets (text and images) can provide promising protection for the anonymity of users’ identities.
1. Introduction
Social media platforms have become an essential part of people’s daily lives, with billions of users generating data and sharing personal information online. However, this has raised concerns about privacy and the potential risks associated with the collection and use of personal data on social media. Research has shown that social media platforms collect a wide range of metadata, including timestamps, geolocation, device information, and user interactions, which can be used to infer sensitive information about users’ identities, preferences, and behaviors [1]. This has led to increasing concerns about privacy, surveillance, and the potential misuse of personal data by third parties, such as advertisers, marketers, and malicious actors [2]. Therefore, there is a need to explore effective techniques to protect the identity and privacy of social media publishers from advanced metadata analysis.
Advanced metadata analysis techniques pose significant risks to the privacy and identity of social media publishers. Metadata, including timestamps, geolocation, device information, and user interactions, can be used to infer sensitive information about social media publishers, even if they have attempted to anonymize or mask their data. For example, studies have shown that metadata from social media posts can reveal users’ real-world identities, interests, and behaviors, allowing potential adversaries to track and profile users with high accuracy [3]. Advanced metadata analysis can also lead to re-identification attacks, where seemingly anonymized data can be de-anonymized using metadata to reveal the identities of social media publishers, leading to privacy breaches and identity exposure [4]. Hence, there is a critical need to assess the effectiveness of masking and encryption techniques in safeguarding social media publishers’ identity from advanced metadata analysis.
More specifically and related to our work, when social media publishers share content, such as images or videos, on social media platforms such as Twitter or Facebook, they inadvertently expose valuable user privacy-related metadata, such as the camera model identification number and Global Positioning System (GPS) coordinates of where the content was created. For instance, authorities were able to locate a fugitive based on the GPS information in a picture taken with an iPhone and published on social media [5]. Applying current natural language processing, artificial intelligence, and machine learning techniques to shared images or videos can reveal additional privacy-related information, such as identifying relationships between individuals featured in the published media content.
Masking and encryption techniques are essential for protecting social media publishers’ identity and privacy from advanced metadata analysis. Masking techniques, such as URL shortening, pseudonymization, and obfuscation, can help hide or distort metadata, making it difficult for adversaries to identify social media publishers. For example, URL shortening services can be used to mask the original URLs of social media posts, preventing adversaries from tracking the source of the posts based on the metadata in the URLs [6]. Encryption techniques, such as cryptographic algorithms and protocols, can secure metadata by transforming it into a ciphertext that can only be decrypted by authorized parties, preventing unauthorized access to sensitive information. These techniques can provide an additional layer of protection against advanced metadata analysis attacks, safeguarding social media publishers’ identity and privacy.
To safeguard the privacy of social media publishers, researchers have explored various techniques for anonymizing metadata, which we elaborate on in the Related Work section. In this study, we demonstrate how different types of metadata from social media accounts can be extracted and used to identify individuals on Twitter. We then show how this identification can be prevented by anonymizing the metadata and evaluating the potential impact on information loss.
1.1. Reasons
1.1.1. Importance of Cybersecurity
Cybersecurity is crucial in today’s digital world for protecting sensitive information, maintaining privacy, safeguarding business continuity, protecting national security, preventing financial losses, safeguarding intellectual property, and ensuring trust in digital systems. With the increasing reliance on digital technologies, cybersecurity measures are necessary to safeguard against unauthorized access, data breaches, financial fraud, disruption of operations, and compromise of national security. Cybersecurity is vital for protecting individuals, businesses, and governments from the growing threat of cyber attacks, ensuring the secure and reliable functioning of digital systems, and maintaining trust in online interactions.
1.1.2. Rule-Based Protection
Traditionally, rule-based software approaches have been used in the field of cybersecurity to safeguard personal data. These approaches typically involve predefined rules and regulations, or policies that are set up to detect and prevent specific types of security threats or data breaches. Rule-based software approaches are effective in detecting known security threats and provide a basic level of protection for personal data. They also do not require extensive computational resources and are relatively simple to implement. For example, a rule-based software approach may involve setting up rules to block access to certain websites or IP addresses known to be associated with malicious activities. However, there are limitations to rule-based software approaches. One key limitation is that they rely on predefined rules, which may not be able to keep up with the rapidly evolving landscape of cybersecurity threats. Rule-based methods may not be effective against new and emerging threats that do not match predefined rules and known patterns, resulting in potential vulnerabilities. Additionally, rule-based approaches may generate a high number of false positives or false negatives, leading to inefficiencies in detecting and mitigating security threats.
1.1.3. Artificial Intelligence and Machine Learning Protection
Machine learning (ML) is a subset of artificial intelligence (AI) that involves the use of algorithms and statistical models to enable computers to learn from and make predictions or decisions based on data without explicit programming. Machine learning algorithms are designed to recognize patterns in data, and they improve their performance over time through a process called training, where they learn from labeled data to make accurate predictions or classifications on unseen data. In general, machine learning works by following a set of steps:
- Data Collection: A large amount of relevant and representative data is collected from various sources, such as social media platforms, online transactions, or user interactions.
- Data Preparation: The collected data are cleaned, pre-processed, and transformed into a suitable format for training machine learning models. This may involve tasks such as data normalization, feature engineering, and data augmentation.
- Model Training: Machine learning models are trained on the prepared data using a variety of algorithms, such as supervised learning, unsupervised learning, or reinforcement learning. During training, the model learns to recognize patterns and relationships in the data.
- Model Evaluation: The trained model is evaluated on a separate set of data, called the validation or test set, to assess its performance, accuracy, and generalization ability. Model parameters may be adjusted and fine-tuned based on the evaluation results.
- Fine-tuning: If necessary, the hyperparameters of the classifier are adjusted to optimize its performance. This can be carried out using techniques such as grid search or randomized search, where different combinations of hyperparameters are evaluated to find the best configuration.
- Model Deployment: Once the model is trained and evaluated, it can be deployed in a real-world environment to make predictions, classifications, or decisions on new, unseen data.
- Model Monitoring and Maintenance: Machine learning models require continuous monitoring to ensure their accuracy and effectiveness. They may need to be updated or retrained periodically with new data to maintain their performance.
ML techniques can be applied to a wide range of applications, including cybersecurity, where they have become indispensable tools for safeguarding identities, protecting personal data, and mitigating security threats in online social networks, as discussed in the following sections. Recent research articles, such as Bhattacharya et al. [7], Dini and Saponara [8], and Kumar et al. [9], highlight the significance of machine learning in addressing security and privacy issues in online social networks.
AI/ML techniques have the potential to address the limitations of traditional rule-based approaches in dealing with the ever-changing landscape of cyber threats. Compared to traditional rule-based software approaches, AI/ML techniques offer several advantages in cybersecurity.
In their recent work, Kumar et al. [9] conducted a comparative review on the use of ML and deep learning (DL) for online social network security. The study concluded that AI/ML can play a crucial role in enhancing online security in various ways. Firstly, by automating processes such as data anonymization, de-identification, and consent management, ML can assist organizations in complying with privacy regulations and standards. Secondly, ML can aid in privacy protection by automating data minimization techniques and ensuring compliance with privacy regulations and best practices. Moreover, ML’s predictive capabilities allow organizations to anticipate and mitigate potential cyber threats before they cause significant damage. Lastly, ML can enhance incident response capabilities, such as threat hunting and forensic analysis, thereby improving the overall cybersecurity posture of organizations. The findings of Kumar et al.’s study highlight the potential of AI/ML in addressing online social network security challenges and promoting robust cybersecurity practices.
In their recent work, Dini and Saponara [8] conducted a comprehensive analysis, design, and comparison of machine learning techniques for networking intrusion detection. The study concluded that AI/ML technologies offer several advantages in the context of intrusion detection. Firstly, their ability to continuously learn and adapt to new and evolving threats in real time makes them highly effective in detecting and mitigating sophisticated and previously unknown cyber threats. Secondly, AI/ML algorithms can learn from large datasets and identify anomalies, behaviors, and patterns that may not be evident to human analysts, enabling proactive threat detection and prevention. These findings highlight the potential of AI/ML in enhancing the accuracy and efficiency of intrusion detection systems, and their ability to provide proactive cybersecurity measures.
In their recent work, Dini et al. [10] proposed a novel one-class classifier based on polynomial interpolation for networking security. The study also concluded that AI/ML technologies can offer significant benefits in the realm of data security and privacy. Firstly, AI/ML can assist in implementing data encryption, anomaly detection, and access control mechanisms, which can safeguard personal data from unauthorized access. Secondly, AI/ML can aid in identifying and mitigating potential privacy breaches by analyzing patterns of data access, detecting suspicious activities, and automating privacy protection mechanisms. These findings highlight the potential of AI/ML in enhancing data security and privacy measures, and their role in safeguarding sensitive information in networking environments.
In their recent work, Bhattacharya et al. [7] conducted a comprehensive survey on online social network security and privacy issues, highlighting threats, ML-based solutions, and open challenges in this context. The study concluded that AI/ML technologies can play a crucial role in addressing these challenges. Firstly, AI/ML can aid in assessing and mitigating bias in data handling and decision-making processes, ensuring that personal data are processed in a fair and equitable manner. Secondly, AI/ML can assist in identifying and mitigating bias in data handling and decision-making processes, promoting fairness and equity in data usage. Moreover, AI/ML can analyze large amounts of data, identify patterns, and detect anomalies that may signal potential cyber attacks, enabling automated threat detection and response, and reducing human errors and response time. Additionally, AI/ML can assist in data breach detection, notification, and recovery, minimizing the impact of data breaches on individuals and organizations. Furthermore, AI/ML can help in identifying and preventing data breaches by detecting unusual patterns of data access, analyzing user behaviors, and identifying potential insider threats. These findings highlight the potential of AI/ML in enhancing the security and privacy of online social networks and mitigating risks associated with cyber threats and data breaches. Despite the numerous benefits, Bhattacharya et al. [7] identified some of the open challenges, including the potential for adversarial attacks on ML models, issues related to explainability and interpretability of ML-based decisions, and concerns about the ethical and legal implications of using AI/ML in cybersecurity. Addressing these challenges requires ongoing research, collaboration, and the development of robust AI/ML techniques that are resilient to attacks and can provide interpretable and explainable results.
Therefore, AI/ML have become indispensable tools in cybersecurity addressing the limitations of traditional rule-based approaches and providing advanced capabilities in threat detection, prevention, and incident response. They play a crucial role in safeguarding personal data by identifying potential threats, protecting privacy, ensuring compliance with regulations, and mitigating bias. However, there are also challenges that need to be addressed in the ethical, legal, and technical aspects of using AI/ML in cybersecurity. Continued research and development in this field are essential to harness the full potential of AI/ML in safeguarding sensitive information and mitigating cyber threats. As cyber threats continue to evolve, the use of AI/ML in cybersecurity is expected to become even more critical in safeguarding digital assets and protecting sensitive information.
In this work, we use AI/ML to examine the metadata of tweets, which are comprised of text and images to examine the efficiency of encryption and anonymization in protecting the identity of online publishers.
1.2. State of the Art and Related Works
Table 1 lists the pros and cons of recent related works.

Table 1.
Pros and Cons of recent related works.
1.3. Contributions
The main research contributions made in this article are as follows:
- Conducts an analysis of the advantages and disadvantages of the most relevant proposed solutions in the existing literature regarding the security of personal data.
- Provides comprehensive coverage of both textual and image metadata in our proposed work.
- Demonstrates the effectiveness of encryption and obfuscation methods in enhancing user privacy by limiting the accuracy of information obtained from encrypted metadata.
- Provides empirical evidence on the efficacy and precision of different classifiers in identifying online users by assessing their performance pre- and post-encryption of metadata.
- Assesses the potential information loss resulting from metadata encryption and obfuscation, providing insights into the trade-off between privacy and data utility.
- Provides strong experimental evidence that our proposed method minimally compromises data utility, indicating its viability and effectiveness in safeguarding user privacy while maintaining the usefulness of the data.
- Raises awareness about critical privacy issues related to metadata.
- Highlights the increasing importance of privacy concerns as social media platforms provide APIs for accessing data accompanied by metadata.
2. Dataset Collection and Preparation
In this work, we opted to create our own dataset rather than using a standardized one because our research question necessitates a dataset that can be collected in real time. By creating our own dataset, we were able to exercise greater control over the data collection and preparation process, enabling us to tailor the dataset to our specific research needs while ensuring relevance to our study. Next, we will explain how the data were collected and prepared.
Social media platforms such as Twitter provide additional metadata, such as the number of likes/retweets for a tweet, date and time of upload, and the number of mentions, in addition to the data that can be directly extracted from the media content. These metadata are publicly accessible through Twitter’s Application Programming Interface (API). Table 2 shows the metadata offered by Twitter’s API for a tweet containing an image. This metadata, which includes both the information extracted from a shared image and other metadata added by Twitter for a particular online publisher/user, is extracted using Twitter’s Standard v1.1 API [25]. Recent studies [15,16] have demonstrated that this metadata can be subjected to further processing and analysis to extract sensitive data and identify the online publisher/user. Surprisingly, almost every tweet, picture, or status update posted on popular social media platforms such as Twitter or Facebook produces metadata that can be traced back to the user and their location, regardless of how anonymous they believe they are.
Table 2.
The metadata extracted from a shared image on Twitter, using Twitter’s Standard v1.1 API [25].
2.1. Metadata Collection
To collect the User ID or Username of those who supported the hashtag #BlackLivesMatter [26], we used Twitter’s Standard v1.1 API [25]. Using their User IDs, we extracted their tweets from a period of three months (1 December 2020 to 1 March 2021) and only kept those tweets with attached images. This resulted in approximately 500,000 tweets from over 5000 users. We removed any images and their associated tweets if the images were invalid or broken. Using ExifTool [27], we extracted the metadata of these images and appended it to the metadata of their corresponding tweets. ExifTool is a platform-independent command-line application used for downloading, reading, writing, and manipulating metadata of images, audio, video, or PDF files. We used ExifTool to download and store the metadata of all the images in this work. Figure 1 shows the metadata information extracted from an image belonging to a tweet.

Figure 1.
Result of metadata extraction of an image from a tweet using ExifTool.
2.2. Metadata Pruning
Our metadata set consisted of 300,000 images and their corresponding tweets. We refer to a sample in this metadata set as the metadata of one image and its corresponding tweet. At this stage, each sample in the metadata set has 56 features. The metadata pruning was performed as follows:
- We observed that some samples, particularly the metadata of images, were missing values for a common set of 31 features (out of 56 features). Therefore, we removed these samples with more than 31 missing features.
- We removed features with redundant values from the samples. For instance, the value of the MegaPixels feature is the result of the ImageHeight feature multiplied by the value of the ImageWidth feature. Therefore, we removed the ImageHeight and ImageWidth features from each sample in the metadata set. At this stage, each sample in the metadata set has 29 features.
- We adopted a consistent format for the values of the features. For example, if the “Location” feature had values such as “New York City,” “NYC,” and “New York,” we used a common format. Additionally, if the date format in the “User_Creation_Time” and “Tweet_Creation_Time” features was different, we used a common format.
- We removed samples from the metadata set with the source feature (Source = “TweetBot”), which indicates values of tweets placed by bots.
Using Twitter’s API resulted in extracting duplicate tweets for some users. We removed all these duplicates and only considered those users with at least 10 tweets, keeping exactly 10 tweets for each of those users in the metadata set. As a result, we ended up with 7010 samples belonging to 701 online publishers/users.
2.3. Normalization of Dataset
Table 2 shows that each sample in our metadata set consists of 14 features with numeric attributes and the remaining 15 features with non-numeric attributes after removing Image height and Image width. Table 3 shows the 14 features with numeric attributes. Some of these numeric features, such as “from_user_followers_count,” have values ranging from 0 to over 200,000, while others, such as “num_characters,” range from 25 to 280. To account for this disparity when using classification models and prevent certain features from being more influential than others, we explored two normalization techniques: Min-Max Normalization and Z-score Normalization, to determine if normalization of the metadata is needed to improve classification [28]. Normalization ensures that all features have compatible standard deviations. However, Table 4 shows that the best classification accuracy was obtained without any normalization. This is attributed to the fact that the metadata set we are using has more variations. Normalization brings the data points together and destroys such disparities. Therefore, we opted not to use normalization for this metadata set. Accuracy is typically the most important metric for evaluating the performance of normalization techniques; it is often used to determine the best normalization approach as shown in [29].
Table 3.
Feature name, data type, and description of the dataset to be normalized.
Table 4.
Comparison of accuracies from different normalization techniques.
2.4. Feature Selection
To enhance classification accuracy and reduce computational requirements and CPU overheating, we utilized the entire metadata set in Table 3 to implement three feature selection methods: Pearson’s Correlation Matrix, Chi-Square Test of Independence, and the Wrapper method [30,31]. As shown in Table 5, the Wrapper method provided the most optimal feature selection. Table 6 provides a description of the selected 15 features.
Table 5.
Feature Selection.
Table 6.
Description of selected features along with their data type.
3. Classifier Models
A classifier model is a type of machine learning model that is used for classification tasks. It is trained on a labeled dataset where the target variable or class labels are known, and it learns patterns and relationships in the input features to predict the class label of new, unseen instances. Some commonly used classifier models [32] include:
- Support Vector Machines (SVM): SVM is a supervised machine learning algorithm that constructs a hyperplane or set of hyperplanes to separate data points into different classes. It aims to find the optimal decision boundary that maximizes the margin between classes. SVMs can handle both linear and non-linear classification tasks effectively.
- K-Nearest Neighbors (KNN): KNN is a non-parametric supervised learning algorithm that classifies new instances based on their similarity to neighboring instances in the feature space. It assigns a class label to a new data point based on the majority class of its k nearest neighbors.
- Multilayer Perceptron (MLP): MLP is a type of artificial neural network with multiple layers of interconnected neurons. It uses feedforward propagation to classify data by learning the weights and biases associated with each connection. MLPs are capable of learning complex relationships and are widely used for classification tasks.
- Random Forest (RF): RF is an ensemble learning method that combines multiple decision trees. It generates a set of decision trees on different subsets of the training data and combines their predictions to make the final classification. RF is known for its ability to handle large datasets and provide robust performance.
- Multinomial Logistic Regression (MLR): MLR is a regression-based classification algorithm used for categorical dependent variables with more than two classes. It estimates the probabilities of each class using a logistic function and assigns the data point to the class with the highest probability.
3.1. Hyperparameter Tuning
Optimizing parameters and hyperparameters in classifier models plays a crucial role in enhancing model performance, generalization, resource utilization, stability, and customization for specific requirements. Selecting appropriate values for hyperparameters depends on the specific dataset and can help the model to learn more effectively and make better predictions. Several widely used techniques [33,34] are available for this purpose:
- Grid Search: Grid search involves manually specifying a set of values for each hyperparameter and exhaustively evaluating the model’s performance on all possible combinations. It allows you to explore a predefined search space and find the best combination of hyperparameters based on a specified evaluation metric.
- Random Search: In contrast to grid search, random search selects hyperparameters randomly from a predefined distribution. This approach provides a more efficient way to explore the hyperparameter space, especially when certain hyperparameters are expected to have a stronger impact on model performance than others.
- Cross-Validation: Cross-validation is a technique used to estimate the performance of a model on unseen data. By dividing the available data into training and validation sets, you can iteratively train the model on different subsets of the data and evaluate its performance. This helps in assessing the generalizability of the model and can guide the selection of hyperparameters.
3.2. Data Split
Our dataset is split into two portions: the training dataset and the testing dataset. The training dataset comprises 70% of the total data and is used to train the model. The remaining 30% of the data are allocated to the testing dataset, which is used to evaluate the performance of the trained model. This splitting process is achieved using the “train_test_split()” method provided by the sklearn library.
4. Training-Validation and Testing
The tasks in Algorithm 1 and Figure 2 describe the entire process, starting from the preparation of the dataset, and ending with the estimation of the privacy.
| Algorithm 1: Metadata Anonymization |
| Input: Metadata from Tweets and Images Output: Privacy-Preserving Anonymized data
|
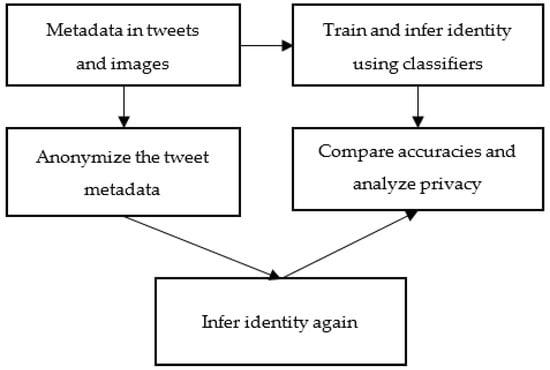
Figure 2.
Proposed methodology.
4.1. Training and Validation
To construct our classification model, we utilized the Python library Sci-kit-learn [35] to apply five algorithms, namely Support Vector Machine (SVM), K-Nearest Neighbor, Random Forest (RF), Multilayer Perceptron (MLP), and Multinomial Logistic Regression (MLR). For each algorithm in our classification model, we trained it on the metadata set provided in Table 3, and subsequently optimized it by fine-tuning its corresponding hyperparameters. Table 7, Table 8 and Table 9 present the best parameter values for the classifiers that achieve optimal results.
Table 7.
Result of parameter fine-tuning for K-NN using GridSearchCV.
Table 8.
Result of parameter fine-tuning for RF using RandomizedSearchCV.
Table 9.
Result of parameter fine-tuning for MLR using GridSearchCV.
A comparison of accuracy obtained before and after hyperparameter fine-tuning of each classification algorithm in our model can be seen in Table 10.
Table 10.
Accuracy comparison before and after hyperparameter tuning.
The best accuracy was observed with the default parameters for SVM, which was 87.58%. However, after hyperparameter tuning, SVM achieved the highest accuracy of 95.81%. The convergence plots for hyperparameter optimization are depicted in Figure 3 which provide valuable information about the behavior and effectiveness of the optimization process, aiding in understanding the performance of the model and guiding the selection of hyperparameters for optimal results.
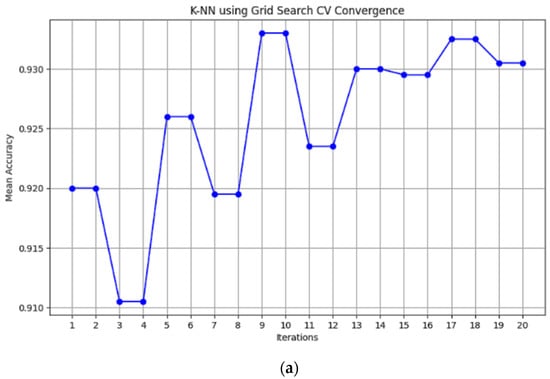
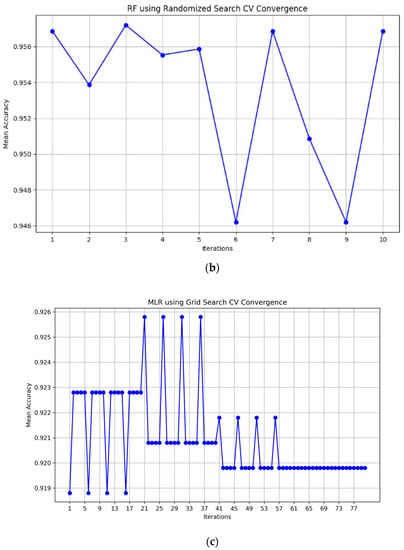
Figure 3.
Hyperparameter optimization convergence plots: K-NN using GridSearchCV (a), Random Forest using RandomizedSearchCV (b), and MLR through GridSearchCV (c).
4.1.1. Runtime
We conducted the experiments using PyCharm on a computer equipped with an Intel Core i7-10510U CPU and 16 GB RAM. For each classifier, we performed 30 dependent runs during the testing phase. The average testing time in milliseconds for each classifier was calculated, as shown in Figure 4. The classifiers were ranked by runtime in ascending order, with SVM being the fastest, followed by KNN, MLR, MLP, and RF.
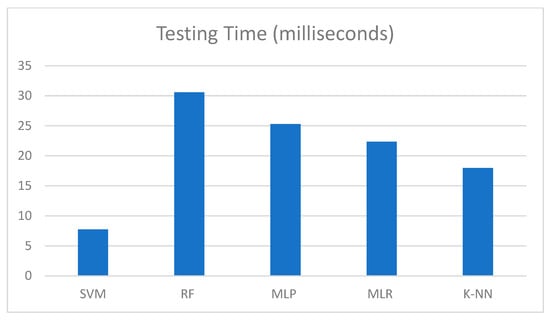
Figure 4.
Average testing time for the five classifiers after performing 30 dependent runs.
4.1.2. Obfuscation
We used data anonymization [36] and advanced encryption standard (AES) [37] to anonymize and encrypt the metadata set in Table 3. Then, we evaluated the accuracy of each classification algorithm for online user identification. Finally, we retrained the classification algorithms using the anonymized and encrypted metadata set.
4.1.3. Data Anonymization
In this work, data anonymization [38] is a privacy protection technique used to encode personally-identifying information from a metadata set and hide the identity of online users, ensuring the individuals described by the data remain anonymous. Data anonymization techniques can include deleting, replacing, or distorting metadata. Generalization, suppression, and aggregation are other forms of data anonymization [38].
In this work, we utilized the “cat.codes” pseudonymization technique from the Pandas library [39,40] to obscure the metadata set features presented in Table 5 by replacing feature values with numbers ranging from 1 to the total number of distinct values in these features. This method was employed to hide sensitive information, primarily the User ID and Location. To reduce the number of different values, the “Location” feature was generalized by converting city names to their corresponding states before pseudonymization. This was carried out manually, using Microsoft Excel’s search and replace functions. The “tweet_creation_time” feature contained data in the form “MMM-DD”, which was generalized to only keep the Month values (MMM). The features with numerical values in the metadata set, specifically “from_user_followers_count”, “from_user_friends_count”, and “favorite_count,” were randomly perturbed by adding a random number between [-average, average] to each value, where the average value for each feature was first calculated for a particular user. If a particular value resulted in a negative number, it was replaced with either the mod value or the average.
4.1.4. Advanced Encryption Standard (AES)
AES [41] has undergone thorough evaluation for security and has proven to be one of the most secure algorithms available with faster encryption and decryption times. Therefore, we utilized AES-256 to encrypt the following features in our metadata set: “Megapixels,” “exif_camera_make,” “exif_aperture_value,” “exif_focal_length,” “longitude,” and “latitude.” The AES function of the “Crypto.Cipher” Python library was used to implement the AES algorithm. The user entered the encryption key which was transformed into a hash value using the “sha256” algorithm in the “hashlib” crypto library. The “AES.new” function was used to pass the key and the metadata feature values, resulting in a 16-byte multiple ciphertext. Cipher Block Chaining Mode, “AES MODE CBC,” was applied as a parameter of the “AES.new” function, chaining each block to the previous block in the stream. This method was utilized to encrypt all image information values. After encryption, the data were in byte form and then converted to numerical form using the “int.from bytes()” method. Since the column values were in extremely large ranges, they were normalized using Z-score normalization [42]. The resulting features had values between 0 and 1. The metadata set was encrypted in increments of 10%, and the encrypted datasets were passed through the five classification algorithms. Table 11 indicates a reduction in accuracy of all classification models used as the data become increasingly encrypted. SVM was the most stable of the five classification algorithms in terms of sensitivity to encryption. MLR was the most vulnerable to data encryption, exhibiting a considerable reduction in accuracy even with a slight percentage of encryption. After full, i.e., 100% encryption, RF proved to be the second-best classifier with an accuracy of 37.65%, followed by MLP and KNN.
Table 11.
Accuracy comparison with increasing % of encryption.
A comparison of accuracies of the five classification algorithms, before and after encryption, can be seen in Figure 5.

Figure 5.
Comparison of accuracies of different classifiers before and after 100% encryption.
4.1.5. Precision, Recall, and F1-Score
The precision, recall, and F1-scores of all the models were compared on both the unencrypted dataset and the fully encrypted dataset.
4.2. Test Results
Table 12.
Model evaluation before encryption.
Table 13.
Model evaluation after encryption.
Precision refers to the ratio of correctly predicted positive instances to the total predicted positive instances. A precision of 0.9 signifies that 90% of the predicted positive instances are accurate. On the other hand, recall measures the ratio of correctly predicted positive instances to the actual positive instances. A recall of 0.9 indicates that 90% of the actual positive instances are correctly identified by the model. The F1-score combines both precision and recall into a single metric, offering a balanced assessment of the model’s performance. Ranging from 0 to 1, an F1-score of 1 signifies exceptional precision and recall, indicating a model that performs exceedingly well. Conversely, an F1-score of 0 suggests that the model’s performance is no better than random guessing. Accuracy represents the proportion of correctly classified instances out of the total number of instances [41]. Therefore, an accuracy of 0.9 implies that the model accurately predicts 90% of the instances in the dataset. As depicted in Table 11, all values surpass 0.9, indicating that the models are performing well in the classification task [43]. Since the dataset consists of exactly 10 tweets per user, it is a balanced dataset. Therefore, the precision, recall, and F1-score values of each model are close to each other [44].
4.3. Information Loss
4.3.1. Generalization
As mentioned in Section 4.1.3, we applied generalization to the “Location” and “tweet_creation_time” features to reduce their domain space. The number of unique values in the “Location” feature decreased from 550 to 145, and in “tweet_creation_time,” it reduced from 90 to only 3. This led to the creation of 435 equivalent classes, resulting in a k-anonymity [41] of 38, which means that each tweet sample has creation time and location values similar to at least 37 other tweets.
Generalized Information Loss
When a feature value is generalized, it is expected to result in some information loss. If this loss exceeds a certain threshold, the metadata becomes unusable. To evaluate the loss of information due to generalization and determine the usability of the metadata, we computed the amount of forfeit using Equation (1) [42], where T’ represents the generalized metadata set:
In Equation (1), Li and Ui are the lower and upper bounds of feature i, n is the number of features, and |T| is the number of samples. All values in i are generalized between Lij and Uij. After calculation, a total GenILoss of 0.1704 was obtained for the metadata set. The low value of this information loss indicates that the generalization method used here does not degrade the data utility to a great extent, as data utility is proportional to this loss. This indicates that the generalization was quite effective in maintaining data quality, which means that this generalized data can be used for further analysis, without giving away the sensitive details, and also ensures that the important patterns in the dataset are preserved.
Average Equivalence Class Size
This metric describes how the Equivalent Classes are created, where each such class contains at least k records [43]. The total Average Equivalent Class Size (CAVG) for the anonymized dataset is calculated as shown in Equation (2) [41].
where T’ is anonymized data, T is original data, and |T| is the cardinality of table T. |EQs| denotes the total number of equivalence classes formed, and k is privacy value. The obtained total Average Equivalent Class Size CAVG(T*) is 1.0158. The low value of this metric indicates better generalization, which means that the method was successful in preserving privacy. The almost perfect value of 1 can be associated with the fact that all EQs in the dataset had the same number of elements, i.e., the size of EQs was the same, and the fact that the value of k was very high is important. Thus, the high value of k resulted in preserving the privacy better, since the “anonymity” of the dataset is increased. This means that an adversary will have a 1/k, i.e., only 1/38 chance of correctly identifying an individual in this dataset. This generalization has thus been successful in protecting the users’ privacy to a great extent. The above two metrics are collectively used to establish a trade-off between privacy and utility [45].
4.3.2. Perturbation
As mentioned in Section 4.1.3, perturbation was used on the “from_user_followers_count”, “from_user_friends_count” and “favorite_count” columns, to randomize their values. The unified privacy metric, as described in [43], was used to determine the uncertainty in identification, due to the perturbation. To measure this privacy metric across the three features, the features were first generalized using Z-Score generalization, such that the metric results in comparable values. The privacy score calculation is shown in Equation (3) [46].
Here, represents the normalized uncertainty in estimation for user identification. µ and σ are the mean and standard deviations of the original dataset, respectively, N is the number of rows, yi is the value of attribute y for row i, is the perturbed value, and r is the RMSE (Root mean squared error), calculated as shown in Equation (4) [43].
The calculated values of this privacy metric for “from_user_followers_count” was 1.3421, for “from_user_friends_count” it was 2.3642, and for “favorite_count” it was 2.8236. These values indicate high uncertainty in the data, and therefore represent that this perturbation technique hinders attackers from correctly guessing the user, based on the perturbed features.
5. Conclusions and Future Works
This work aimed to develop classification techniques to identify online publishers/users of Twitter by analyzing the association between the metadata of posted tweets and images and user identities. After establishing the extent of privacy breach caused by metadata analysis, we obscured the relevant fields and evaluated the level of privacy protection achieved. We assessed the effectiveness of five machine learning algorithms (KNN, SVM, MLP, RF, and MLR) in identifying users based on the metadata obtained from their tweets and images. Our results show that SVM achieved the highest accuracy of 95.81% in identity recognition. To protect the identity of online publishers/users, we anonymized the metadata related to the tweets and encrypted the metadata related to the images using the AES algorithm. We then evaluated the effectiveness of the five machine learning algorithms on the anonymized and encrypted data. Our results showed that SVM provided the highest accuracy rate of 50.24% in identity recognition.
To avoid biases, it is important to incorporate a wide range of data that covers a broad scenario. However, even after encryption, the most accurate model found was SVM, with an accuracy of 50.24%. This means that there is still a high likelihood of a user’s identity being discovered. To further increase user privacy, a better encryption method, such as Chaotic Encryption, and access policies should be explored in the future. Additionally, a more robust anonymization technique that can withstand attacks such as background knowledge and homogeneity should be developed. More efficient devices that can seamlessly extract, encrypt, and reinsert modified metadata should also be developed. Finally, better access-based de-anonymization algorithms that minimize privacy loss should be developed to address these concerns in the future.
We believe that our work will make a noteworthy contribution in raising awareness about the critical privacy issues related to metadata. As social media platforms continue to provide APIs for accessing data that are often accompanied by metadata, this issue is becoming increasingly pressing. Our study demonstrated that utilizing encryption methods can significantly enhance user privacy by making it harder for attackers to access accurate information from encrypted metadata [47]. Our proposed method provides strong experimental evidence that the data utility is only minimally compromised with this approach. This finding suggests that our method is a viable and effective solution to safeguard user privacy while maintaining the usefulness of the data. We hope that our study will encourage further research and development of more advanced encryption methods and data anonymization techniques to mitigate privacy breaches resulting from metadata analysis.
Author Contributions
Conceptualization, M.K. (Mohammed Khader); methodology, M.K. (Mohammed Khader); software, M.K. (Mohammed Khader); validation, M.K. (Mohammed Khader) and M.K. (Marcel Karam); formal analysis, M.K. (Mohammed Khader) and M.K. (Marcel Karam); investigation, M.K. (Mohammed Khader) and M.K. (Marcel Karam); resources, M.K. (Mohammed Khader) and M.K. (Marcel Karam); data curation, M.K. (Mohammed Khader); writing—original draft preparation, M.K. (Mohammed Khader); writing—review and editing, M.K. (Marcel Karam); visualization, M.K. (Mohammed Khader). All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors are grateful to the Applied Science Private University, Amman, Jordan, for the full financial support granted to cover the publication fee of this research article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mislove, A.; Lehmann, S.; Ahn, Y.Y.; Onnela, J.P.; Rosenquist, J.N. Understanding the demographics of Twitter users. In Proceedings of the Fifth International Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011; pp. 554–557. [Google Scholar]
- Dhir, A.; Kaur, P.; Rajala, R. Social media research in advertising, communication, marketing, and public relations: Evolution and implications. Telemat. Inform. 2017, 34, 1–13. [Google Scholar]
- De Montjoye, Y.A.; Shmueli, E.; Wang, S.S.; Pentland, A.S. openPDS: Protecting the Privacy of Metadata through SafeAnswers. PLoS ONE 2014, 9, e98790. [Google Scholar] [CrossRef] [PubMed]
- Narayanan, A.; Shmatikov, V. Robust de-anonymization of large sparse datasets. In Proceedings of the IEEE Symposium on Security and Privacy, Oakland, CA, USA, 18–22 May 2008; pp. 111–125. [Google Scholar] [CrossRef]
- Cluley, G. Fugitive John McAfee’s Location Revealed by Photo Meta-Data Screw-Up. Available online: https://nakedsecurity.sophos.com/2012/12/03/john-mcafee-location-exif/ (accessed on 4 December 2012).
- Zook, M.; Graham, M.; Shelton, T.; Gorman, S. Volunteered Geographic Information and Crowdsourcing Disaster Relief: A Case Study of the Haitian Earthquake. World Med. Health Policy 2010, 2, 7–33. [Google Scholar] [CrossRef]
- Bhattacharya, M.; Roy, S.; Chattopadhyay, S.; Das, A.K.; Shetty, S. A comprehensive survey on online social networks security and privacy issues: Threats, machine learning-based solutions, and open challenges. Secur. Priv. 2023, 6, e275. [Google Scholar] [CrossRef]
- Dini, P.; Saponara, S. Analysis, Design, and Comparison of Machine-Learning Techniques for Networking Intrusion Detection. Designs 2021, 5, 9. [Google Scholar] [CrossRef]
- Kumar, C.; Bharati, T.S.; Prakash, S. Online Social Network Security: A Comparative Review Using Machine Learning and Deep Learning. Neural Process. Lett. 2021, 53, 843–861. [Google Scholar] [CrossRef]
- Dini, P.; Begni, A.; Ciavarella, S.; De Paoli, E.; Fiorelli, G.; Silvestro, C.; Saponara, S. Design and Testing Novel One-Class Classifier Based on Polynomial Interpolation with Application to Networking Security. IEEE Access 2022, 10, 67910–67924. [Google Scholar] [CrossRef]
- Wijayanto, H.; Riadi, I.; Prayudi, Y. Encryption EXIF Metadata for Protection Photographic Image of Copyright Piracy. IJRCCT 2016, 5, 237–243. [Google Scholar]
- Delgado, J.; Llorente, S. Improving privacy in JPEG images. In Proceedings of the 2016 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Takbiri, N.; Houmansadr, A.; Goeckel, D.L.; Pishro-Nik, H. Limits of location privacy under anonymization and obfuscation. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 764–768. [Google Scholar] [CrossRef]
- Shozi, N.A.; Mtsweni, J. Big data privacy in social media sites. In Proceedings of the IST-Africa Week Conference (IST-Africa), Windhoek, Namibia, 31 May–2 June 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Ghazinour, K.; Ponchak, J. Hidden Privacy Risks in Sharing Pictures on Social Media. Procedia Comput. Sci. 2017, 113, 267–272. [Google Scholar] [CrossRef]
- Perez, B.; Musolesi, M.; Stringhini, G. You are your metadata: Identification and obfuscation of social media users using metadata information. In Proceedings of the AAAI Conference on Web and Social Media (ICWSM), Palo Alto, CA, USA, 25–28 June 2018. [Google Scholar]
- Macwan, K.R.; Patel, S.J. k-NMF Anonymization in Social Network Data Publishing. Comput. J. 2018, 61, 601–613. [Google Scholar] [CrossRef]
- Kim, J. Protecting Metadata of Access Indicator and Region of Interests for Image Files. Secur. Commun. Netw. 2020, 2020, 4836109. [Google Scholar] [CrossRef]
- Fukami, A.; Stoykova, R.; Geradts, Z. A new model for forensic data extraction from encrypted mobile devices. Forensic. Sci. Int. Digit. Investig. 2021, 38, 301169. [Google Scholar] [CrossRef]
- Li, J.; Zhang, X. Large-Scale Social Network Privacy Protection Method for Protecting K-Core. Int. J. Netw. Secur. 2021, 23, 612–622. [Google Scholar]
- Yang, Q.; Wang, C.; Hu, T.; Chen, X.; Jiang, C. Implicit privacy preservation: A framework based on data generation. Secur. Saf. 2022, 1, 2022008. [Google Scholar] [CrossRef]
- Alyousef, A.S.; Srinivasan, K.; Alrahhal, M.S.; Alshammari, M.; Al-Akhras, M. Preserving Location Privacy in the IoT against Advanced Attacks using Deep Learning. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 416–427. [Google Scholar] [CrossRef]
- Maiano, L.; Amerini, I.; Celsi, L.R.; Anagnostopoulos, A. Identification of Social-Media Platform of Videos through the Use of Shared Features. J. Imaging 2021, 7, 140. [Google Scholar] [CrossRef] [PubMed]
- Singh, A.; Singh, M. Social Networks Privacy Preservation: A Novel Framework. Cybern. Syst. 2022, 1–32. [Google Scholar] [CrossRef]
- Twitter Standard Search v1.1 API Documentation. Available online: https://developer.twitter.com/en/docs/twitter-api/v1 (accessed on 4 June 2023).
- Giorgi, S.; Guntuku, S.C.; Rahman, M.; Himelein-Wachowiak, M.; Kwarteng, A.; Curtis, B. Twitter Corpus of the #BlackLivesMatter Movement and Counter Protests: 2013 to 2020. arXiv 2020, arXiv:2009.00596. [Google Scholar] [CrossRef]
- Harvey, P. Exiftoolgui for Windows v12.62. 2023. Available online: https://exiftool.org/exiftool_pod.html (accessed on 4 June 2023).
- Henderi; Wahyuningsih, T.; Rahwanto, E. Comparison of Min-Max normalization and Z-Score Normalization in the K-nearest neighbor (KNN) Algorithm to Test the Accuracy of Types of Breast Cancer. Int. J. Inform. Inf. Syst. 2021, 4, 13–20. [Google Scholar] [CrossRef]
- Singh, D.; Singh, B. Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 2020, 97, 105524. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Nnamoko, N.; Arshad, F.; England, D.; Vora, J.; Norman, J. Evaluation of Filter and Wrapper Methods for Feature Selection in Supervised Machine Learning. In Proceedings of the 15th Annual Postgraduate Symposium on the convergence of Telecommunication, Networking and Broadcasting, Liverpool, UK, 23–24 June 2014. [Google Scholar]
- Markovics, D.; Mayer, M.J. Comparison of machine learning methods for photovoltaic power forecasting based on numerical weather prediction. Renew. Sustain. Energy Rev. 2022, 161, 112364. [Google Scholar] [CrossRef]
- Agrawal, T. Introduction to Hyperparameters. In Hyperparameter Optimization in Machine Learning; Apress: Berkeley, CA, USA, 2020; pp. 1–30. [Google Scholar] [CrossRef]
- Agrawal, T. Hyperparameter optimization using scikit-learn. In Hyperparameter Optimization in Machine Learning; Apress: Berkeley, CA, USA, 2021; pp. 31–51. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Ren, W.; Tong, X.; Du, J.; Wang, N.; Li, S.; Min, G.; Zhao, Z. Privacy Enhancing Techniques in the Internet of Things Using Data Anonymisation. Inf. Syst. Front. 2021. [Google Scholar] [CrossRef]
- Advanced Encryption Standard. Available online: https://www.tutorialspoint.com/cryptography/advanced_encryption_standard.htm (accessed on 4 June 2023).
- Sweeney, L. Achieving k-anonymity privacy protection using generalization and suppression. Int. J. Uncertain. Fuzziness Knowl. -Based Syst. 2002, 10, 571–588. [Google Scholar] [CrossRef]
- Ismael, R.S.; Youail, R.S.; Kareem, S.W. Image encryption by using RC4 algorithm. Eur. Acad. Res. 2014, 4, 5833–5839. [Google Scholar]
- API Reference—Pandas 1.5.3 Documentation (pydata.org). Available online: https://pandas.pydata.org/docs/reference/index.html (accessed on 4 June 2023).
- AES 256 Encryption and Decryption in Python. Available online: https://www.quickprogrammingtips.com/python/aes-256-encryption-and-decryption-in-python.html (accessed on 4 June 2023).
- Narula, D.; Kumar, P.; Upadhyaya, S. Data Utility Metrics for k-anonymization Algorithms. Int. J. Sci. Eng. Res. 2016, 7, 79–83. [Google Scholar]
- Tasnim, A.; Saiduzzaman; Rahman, M.A.; Akhter, J.; Rahaman, A.S.M.M. Performance Evaluation of Multiple Classifiers for Predicting Fake News. J. Comput. Commun. 2022, 10, 1–21. [Google Scholar] [CrossRef]
- Kareem, S.W. A Nature-Inspired Metaheuristic Optimization Algorithm Based on Crocodiles Hunting Search (CHS). Int. J. Swarm Intell. Res. 2022, 13, 1–23. [Google Scholar] [CrossRef]
- LeFevre, K.; DeWitt, D.; Ramakrishnan, R. Mondrian multidimensional k-anonymity. In Proceedings of the 22nd International Conference on Data Engineering (ICDE’06), Atlanta, GA, USA, 3–7 April 2006; p. 25. [Google Scholar]
- Chen, K.; Liu, L. Geometric data perturbation for privacy preserving outsourced data mining. Knowl. Inf. Syst. 2010, 29, 657–695. [Google Scholar] [CrossRef]
- Alemerien, K. User-Friendly Privacy-Preserving Photo Sharing on Online Social Networks. J. Mob. Multimed. 2020, 16, 267–292. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).