A Study of Different Classifier Combination Approaches for Handwritten Indic Script Recognition



Abstract
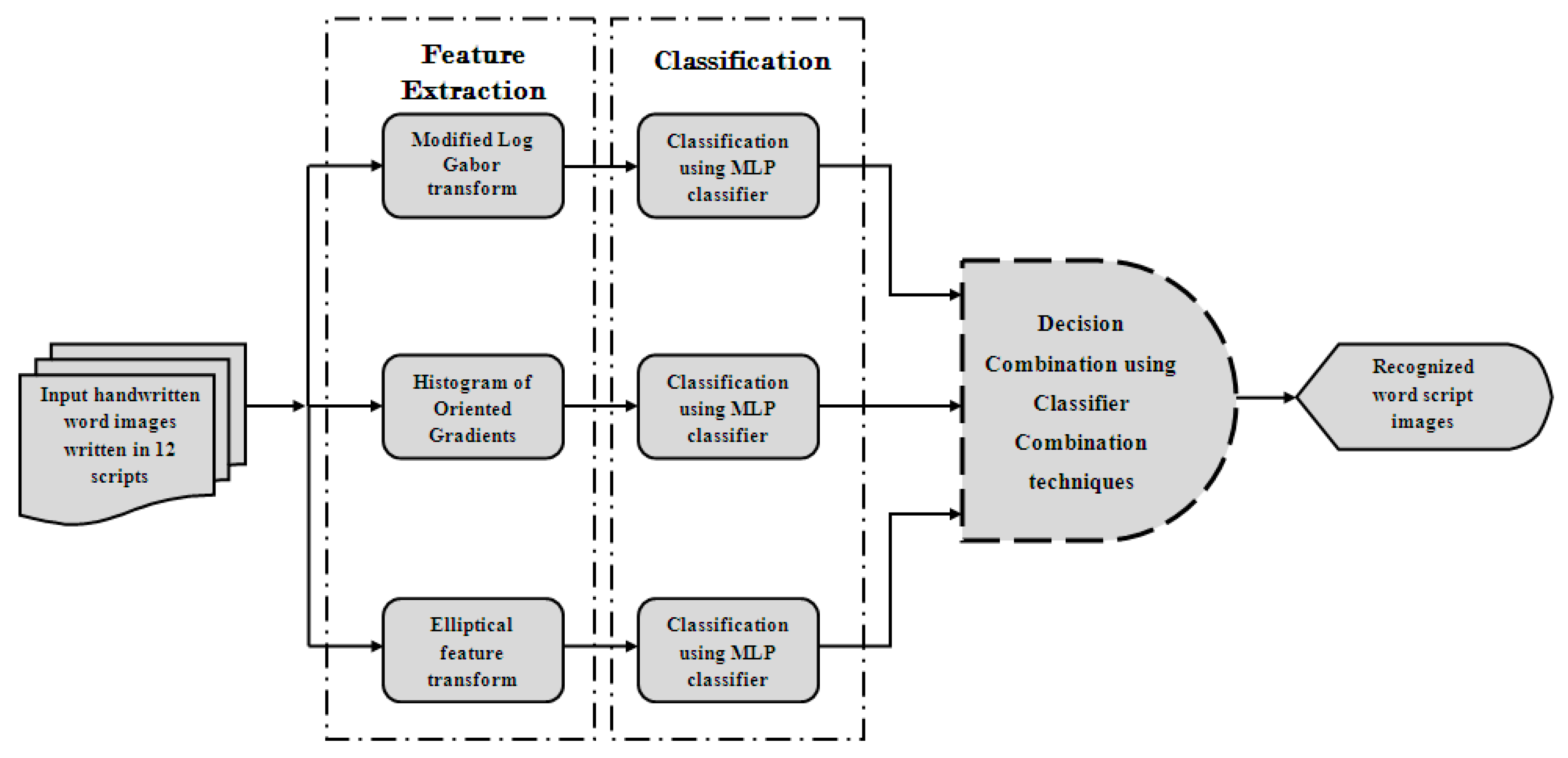
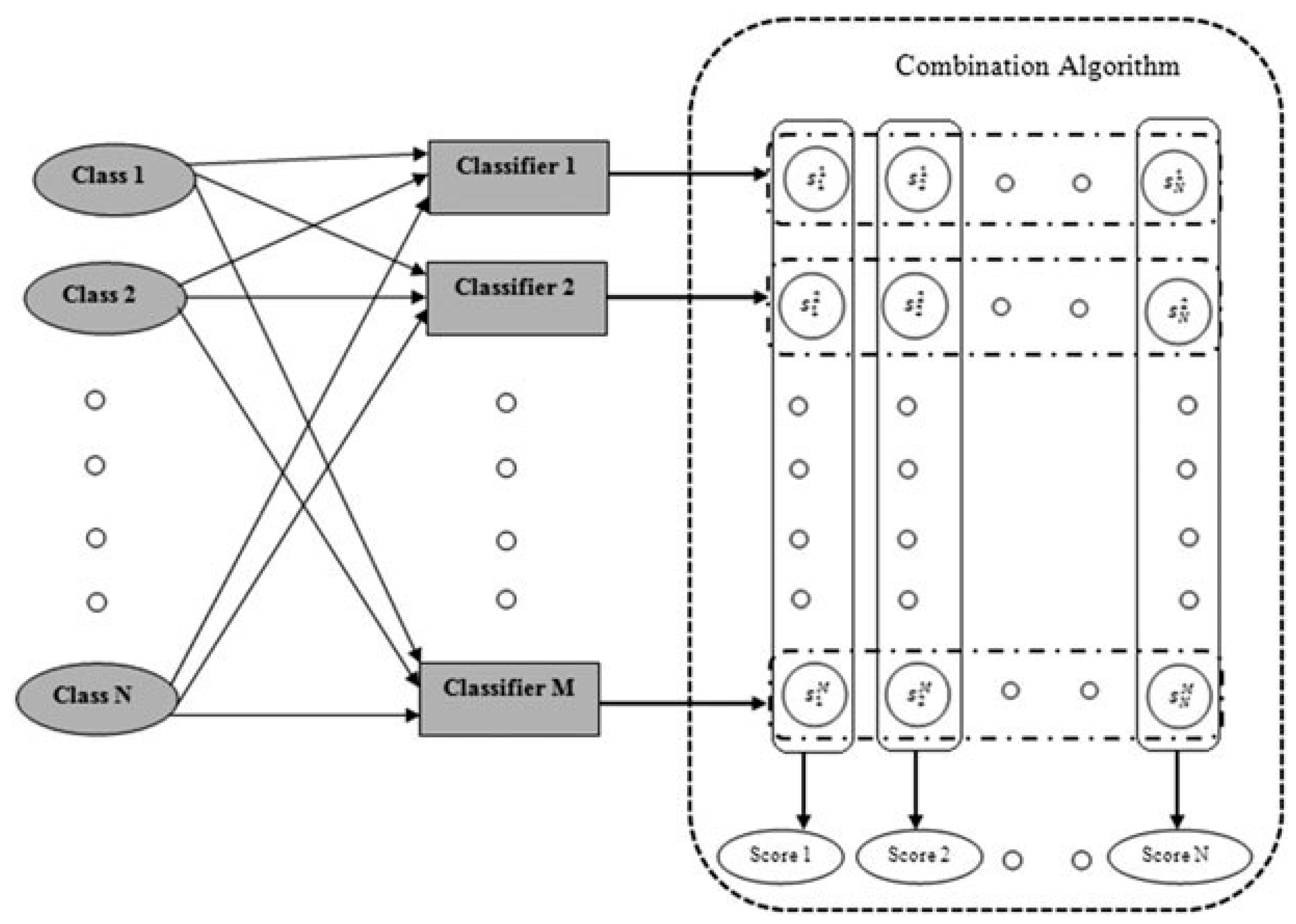
:1. Introduction
2. Feature Extraction
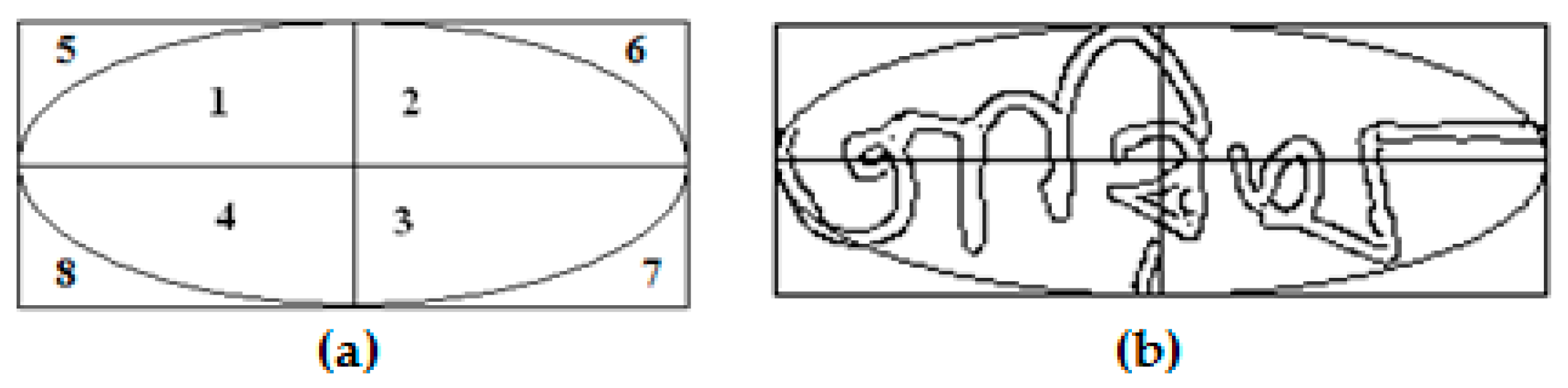
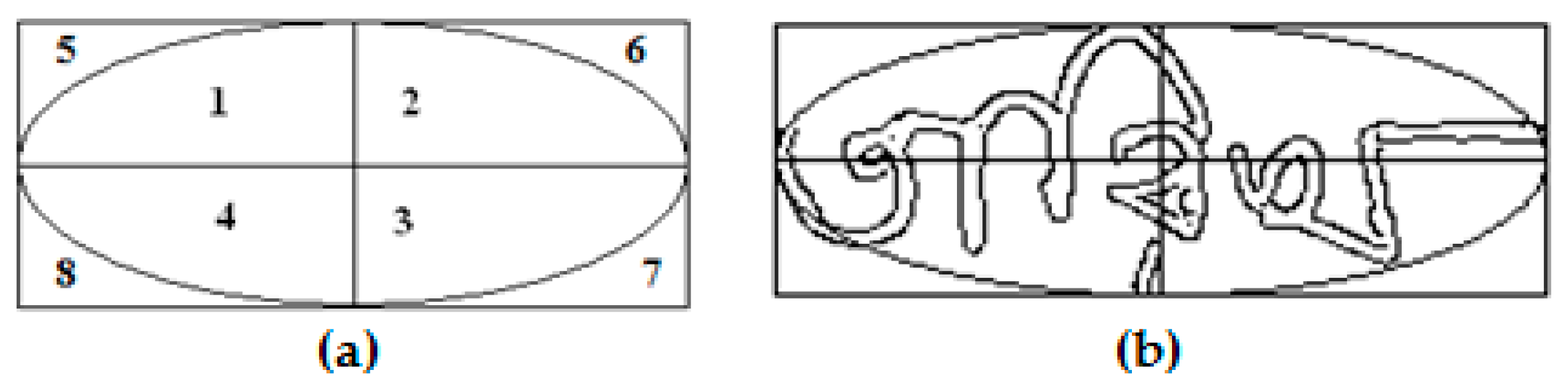
2.1. Elliptical Features
2.1.1. Maximum Inscribed Ellipse
2.1.2. Sectional Inscribed Ellipse
2.1.3. Concentric Ellipses
2.2. Histogram of Oriented Gradients (HOG)
2.3. Modified Log-Gabor Filter Transform (MLG Transform)
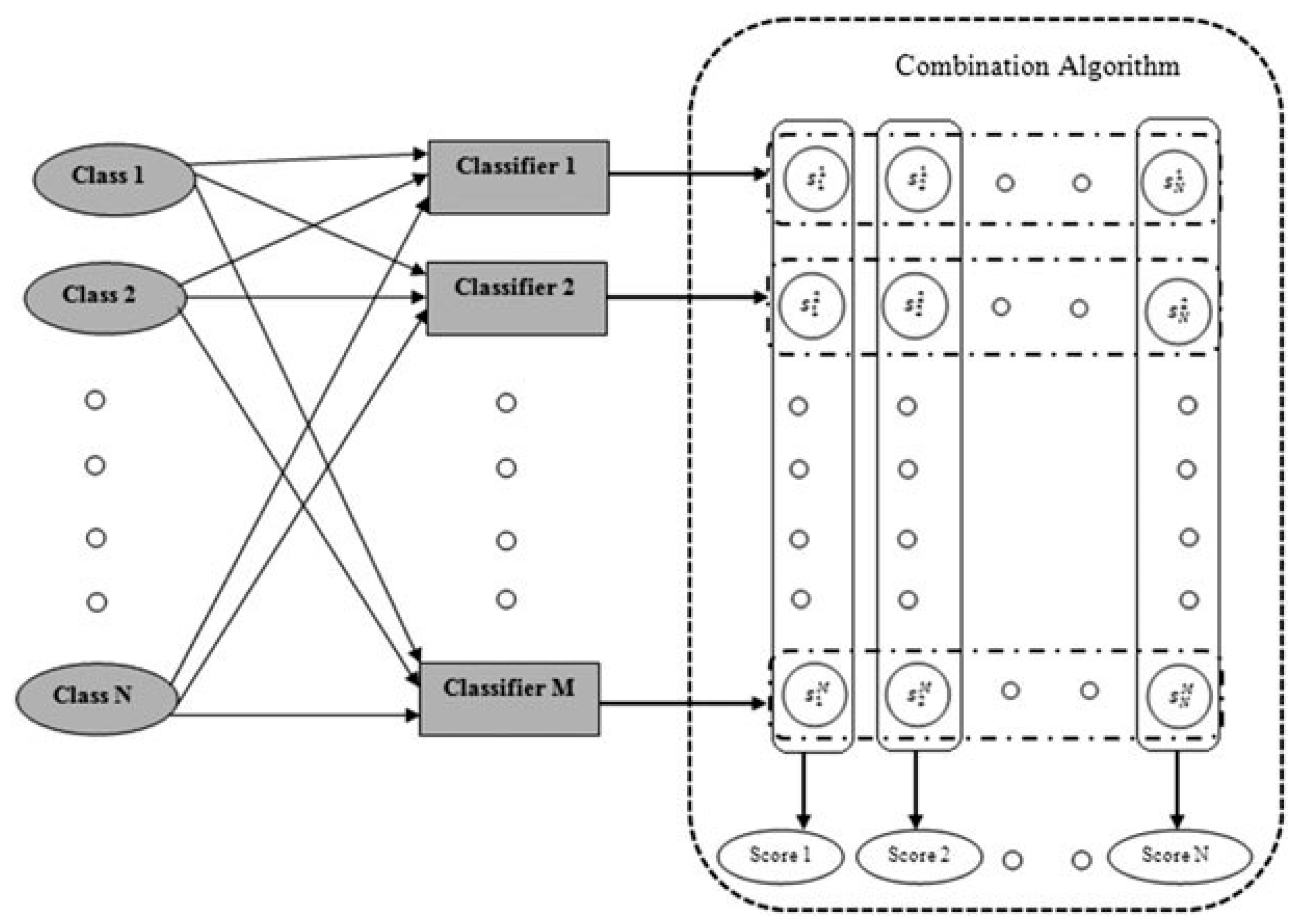
3. Classifier Combination
- Type I (Abstract level): This is the lowest level in a sense that the classifier provides the least amount of information on this level. Classifier output is a single class label informing the decision of the classifier.
- Type II (Rank level): Classifier output on the rank level is an ordered sequence of candidate classes, the so-called n-best list. The candidate classes are ordered from the most likely class at the front and the least likely class index featuring at the last of the list. There are no confidence scores attached to the class labels on rank level and the relative positioning provides the required information.
- Type III (Measurement level): In addition to the ordered n-best lists of candidate classes on the rank level, classifier output on the measurement level has confidence values assigned to each entry of the n-best list. These confidences, or scores, are generally real numbers generated using the internal algorithm for the classifier. This soft-decision information at the measurement level thus provides more information than the other levels.
3.1. Rule Based Combination Techniques
3.1.1. Majority Voting
3.1.2. Borda Count
3.1.3. Elementary Combination Approaches on Measurement Level
3.1.4. Dempster-Shafer Theory of Evidence
3.2. Secondary Classifier Based Combination Techniques
4. Results and Interpretation
4.1. Preparation of Database
4.2. Performance Analysis
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Singh, P.K.; Sarkar, R.; Nasipuri, M. Offline Script Identification from Multilingual Indic-script Documents: A state-of-the-art. Comput. Sci. Rev. 2015, 15–16, 1–28. [Google Scholar] [CrossRef]
- Ubul, K.; Tursun, G.; Aysa, A.; Impedovo, D.; Pirlo, G.; Yibulayin, T. Script Identification of Multi-Script Documents: A Survey. IEEE Access 2017, 5, 6546–6559. [Google Scholar] [CrossRef]
- Spitz, A.L. Determination of the script and language content of document images. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 234–245. [Google Scholar] [CrossRef]
- Tan, T.N. Rotation Invariant Texture Features and their use in Automatic Script Identification. IEEE Tran. Pattern Anal. Mach. Intell. 1998, 20, 751–756. [Google Scholar] [CrossRef]
- Hochberg, J.; Kelly, P.; Thomas, T.; Kerns, L. Automatic script identification from document images using cluster-based templates. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 176–181. [Google Scholar] [CrossRef]
- Hochberg, J.; Bowers, K.; Cannon, M.; Keely, P. Script and language identification for hand-written document images. IJDAR 1999, 2, 45–52. [Google Scholar] [CrossRef]
- Wood, S.; Yao, X.; Krishnamurthi, K.; Dang, L. Language identification for printed text independent of segmentation. In Proceedings of the International Conference on Image Processing, Washington, DC, USA, 23–26 October 1995; pp. 428–431. [Google Scholar]
- Chaudhuri, B.B.; Pal, U. An OCR system to read two Indian language scripts: Bangla and Devnagari (Hindi). In Proceedings of the 4th IEEE International Conference on Document Analysis and Recognition (ICDAR), Ulm, Germany, 18–20 August 1997; pp. 1011–1015. [Google Scholar]
- Pal, U.; Sinha, S.; Chaudhuri, B.B. Word-wise Script identification from a document containing English, Devnagari and Telgu Text. In Proceedings of the -Second National Conference on Document Analysis and Recognition, PES, Mandya, Karnataka, India, 11–12 July 2003; pp. 213–220. [Google Scholar]
- Chaudhury, S.; Harit, G.; Madnani, S.; Shet, R.B. Identification of scripts of Indian languages by Combining trainable classifiers. In Proceedings of the Indian Conference on Computer Vision, Graphics and Image Processing, Bangalore, India, 20–22 December 2000; pp. 20–22. [Google Scholar]
- Das, A.; Ferrer, M.; Pal, U.; Pal, S.; Diaz, M.; Blumenstein, M. Multi-script vs. single-script scenarios in automatic off-line signature verification. IET Biom. 2016, 5, 305–313. [Google Scholar] [CrossRef]
- Diaz, M.; Ferrer, M.A.; Sabourin, R. Approaching the Intra-Class Variability in Multi-Script Static Signature Evaluation. In Proceedings of the 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 1147–1152. [Google Scholar]
- Padma, M.C.; Vijaya, P.A. Global Approach for Script Identification using Wavelet Packet Based Features. Int. J. Signal Process. Image Process. Pattern Recognit. 2010, 3, 29–40. [Google Scholar]
- Hiremath, P.S.; Shivshankar, S.; Pujari, J.D.; Mouneswara, V. Script identification in a handwritten document image using texture features. In Proceedings of the 2nd IEEE International Conference on Advance Computing, Patiala, India, 19–20 February 2010; pp. 110–114. [Google Scholar]
- Pati, P.B.; Ramakrishnan, A.G. Word level multi-script identification. Pattern Recognit. Lett. 2008, 29, 1218–1229. [Google Scholar] [CrossRef]
- Dhanya, D.; Ramakrishnan, A.G.; Pati, P.B. Script identification in printed bilingual documents. Sadhana 2002, 27, 73–82. [Google Scholar] [CrossRef]
- Chanda, S.; Pal, S.; Franke, K.; Pal, U. Two-stage Approach for Word-wise Script Identification. In Proceedings of the 10th IEEE International Conference on Document Analysis and Recognition (ICDAR), Barcelona, Spain, 26–29 July 2009; pp. 926–930. [Google Scholar]
- Pal, U.; Chaudhuri, B.B. Identification of different script lines from multi-script documents. Image Vis. Comput. 2002, 20, 945–954. [Google Scholar] [CrossRef]
- Pal, U.; Sinha, S.; Chaudhuri, B.B. Multi-Script Line identification from Indian Documents. In Proceedings of the 7th IEEE International Conference on Document Analysis and Recognition (ICDAR), Edinburgh, UK, 6 August 2003; pp. 880–884. [Google Scholar]
- Singh, P.K.; Chatterjee, I.; Sarkar, R. Page-level Handwritten Script Identification using Modified log-Gabor filter based features. In Proceedings of the 2nd IEEE International Conference on Recent Trends in Information Systems (ReTIS), Kolkata, India, 9–11 July 2015; pp. 225–230. [Google Scholar]
- Singh, P.K.; Sarkar, R.; Nasipuri, M.; Doermann, D. Word-level Script Identification for Handwritten Indic scripts. In Proceedings of the 13th IEEE International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 1106–1110. [Google Scholar]
- Singh, P.K.; Das, S.; Sarkar, R.; Nasipuri, M. Line Parameter based Word-Level Indic Script Identification System. Int. J. Comput. Vis. Image Process. 2016, 6, 18–41. [Google Scholar] [CrossRef]
- Nadal, C.; Legault, R.; Suen, C.Y. Complementary algorithms for the recognition of totally uncontrained handwritten numerals. In Proceedings of the 10th International Conference on Pattern Recognition, Atlantic City, NJ, USA, 16–21 June 1990; Volume A, pp. 434–449. [Google Scholar]
- Suen, C.Y.; Nadal, C.; Mai, T.; Legault, R.; Lam, L. Recognition of totally unconstrained handwritten numerals based on the concept of multiple experts. In Proceedings of the International Workshop on Frontiers in Handwriting Recognition, Montreal, QC, Canada, 2–3 April 1990; pp. 131–143. [Google Scholar]
- Ho, T.K. A Theory of Multiple Classifier Systems and Its Application to Visual Word Recognition. Ph.D. Thesis, State University of New York, Buffalo, NY, USA, 1992. [Google Scholar]
- Ho, T.K.; Hull, J.J.; Srihari, S.N. Decision combination in multiple classifier systems. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 66–75. [Google Scholar]
- Xu, L.; Krzyzak, A.; Suen, C. Methods of combining multiple classifiers and their applications to handwritten recognition. IEEE Trans. Syst. Man Cybern. 1992, 22, 418–435. [Google Scholar] [CrossRef]
- Mandler, E.; Schuerman, J. Pattern Recognition and Artificial Intelligence; North-Holland: Amsterdam, The Netherlands, 1988. [Google Scholar]
- Lee, D. A Theory of Classifier Combination: The Neural Network Approach. Ph.D. Thesis, State University of New York, Buffalo, NY, USA, 1995. [Google Scholar]
- Singh, P.K.; Mondal, A.; Bhowmik, S.; Sarkar, R.; Nasipuri, M. Word-level Script Identification from Multi-script Handwritten Documents. In Proceedings of the 3rd International Conference on Frontiers in Intelligent Computing Theory and Applications (FICTA); Springer: Cham, Switzerland, 2014; AISC Volume 1, pp. 551–558. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Daugman, J.G. Uncertainty relation for resolution in space, spatial-frequency and orientation optimized by two-dimensional visual cortical filters. J. Opt. Soc. Am. 1985, 2, 1160–1169. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing; Prentice-Hall: India, 1992; Volume I. [Google Scholar]
- Singh, P.K.; Sarkar, R.; Nasipuri, M. Correlation Based Classifier Combination in the field of Pattern Recognition. Comput. Intell. 2017. [Google Scholar] [CrossRef]
- Tulyakov, S.; Jaeger, S.; Govindaraju, V.; Doermann, D. Review of classifier combination methods. In Machine Learning in Document Analysis and Recognition; Springer: Berlin/Heidelberg, Germany, 2008; pp. 361–386. [Google Scholar]
- Kittler, J. Combining Classifiers: A Theoretical Framework. Pattern Anal. Appl. 1998, 1, 18–27. [Google Scholar] [CrossRef]
- Van Erp, M.; Vuurpijl, L.G.; Schomaker, L. An Overview and Comparison of Voting Methods for Pattern Recognition. In Proceedings of the 8th International Workshop on Frontiers in Handwriting Recognition (IWFHR-8), Niagara-on-the-Lake, ON, Canada; 2002; pp. 195–200. [Google Scholar]
- Kittler, J.; Hatef, M.; Duin, R.; Matas, J. On combining classifiers. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 226–239. [Google Scholar] [CrossRef]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976. [Google Scholar]
- Yager, R.R. On the Dempster-Shafer framework and new combination rules. Inf. Sci. 1987, 41, 93–137. [Google Scholar] [CrossRef]
- Basu, S.; Sarkar, R.; Das, N.; Kundu, M.; Nasipuri, M.; Basu, D.K. Handwritten Bangla Digit Recognition Using Classifier Combination through DS Technique. In Proceedings of the 1st International Conference on Pattern Recognition and Machine Intelligence (PReMI), Kolkata, India, 20–22 December 2005; pp. 236–241. [Google Scholar]
- Shoyaib, M.; Abdullah-Al-Wadud, M.; Chae, O. A Skin detection approach based on the Dempster-Shafer theory of evidence. Int. J. Approx. Reason. 2012, 53, 636–659. [Google Scholar] [CrossRef]
- Ni, J.; Luo, J.; Liu, W. 3D Palmprint Recognition Using Dempster-Shafer Fusion Theory. J. Sens. 2015, 2015, 7. [Google Scholar] [CrossRef]
- Singh, P.K.; Chowdhury, S.P.; Sinha, S.; Eum, S.; Sarkar, R. Page-to-Word Extraction from Unconstrained Handwritten Document Images. In Proceedings of the 1st International Conference on Intelligent Computing and Communication (ICIC2); Springer: Singapore, 2016; AISC Volume 458, pp. 517–524. [Google Scholar]
- Zhang, B.; Srihari, S.N. Class-wise multi-classifier combination based on Dempster-Shafer theory. In Proceedings of the 7th IEEE International Conference on Control, Automation, Robotics and Vision (ICARCV 2002), Singapore, 2–5 December 2002; Volume 2. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | A | B | C | D | E | F | G | H | I | J | K | L | R | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | ||||||||||||||
| A | 345 | 9 | 6 | 22 | 13 | 21 | 64 | 42 | 27 | 0 | 44 | 7 | 27 | |
| B | 27 | 548 | 0 | 7 | 9 | 0 | 1 | 0 | 1 | 0 | 7 | 0 | 0 | |
| C | 0 | 0 | 557 | 0 | 6 | 13 | 1 | 19 | 2 | 1 | 0 | 1 | 38 | |
| D | 38 | 4 | 0 | 516 | 3 | 3 | 4 | 0 | 9 | 0 | 20 | 3 | 10 | |
| E | 10 | 6 | 1 | 12 | 449 | 26 | 5 | 2 | 0 | 0 | 13 | 76 | 30 | |
| F | 30 | 0 | 23 | 3 | 46 | 417 | 33 | 36 | 6 | 1 | 4 | 1 | 27 | |
| G | 27 | 2 | 15 | 10 | 12 | 16 | 446 | 34 | 12 | 1 | 24 | 1 | 10 | |
| H | 10 | 0 | 27 | 17 | 16 | 41 | 8 | 420 | 28 | 11 | 14 | 8 | 38 | |
| I | 38 | 2 | 4 | 16 | 0 | 10 | 34 | 33 | 455 | 0 | 8 | 0 | 0 | |
| J | 0 | 0 | 17 | 0 | 7 | 0 | 0 | 16 | 0 | 553 | 1 | 6 | 38 | |
| K | 38 | 6 | 5 | 35 | 22 | 14 | 42 | 31 | 0 | 2 | 404 | 1 | 2 | |
| L | 2 | 2 | 14 | 6 | 15 | 24 | 1 | 9 | 0 | 13 | 5 | 509 | 0 | |
| Class | A | B | C | D | E | F | G | H | I | J | K | L | R | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | ||||||||||||||
| A | 528 | 0 | 2 | 13 | 1 | 1 | 19 | 9 | 5 | 0 | 12 | 10 | 0 | |
| B | 0 | 576 | 0 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 15 | 1 | |
| C | 1 | 0 | 596 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 2 | |
| D | 2 | 9 | 0 | 574 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 14 | 0 | |
| E | 0 | 0 | 0 | 0 | 592 | 6 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | |
| F | 0 | 0 | 2 | 0 | 16 | 553 | 0 | 20 | 0 | 9 | 0 | 0 | 4 | |
| G | 4 | 0 | 9 | 3 | 0 | 1 | 528 | 15 | 26 | 0 | 10 | 4 | 7 | |
| H | 7 | 0 | 5 | 0 | 5 | 30 | 8 | 512 | 16 | 1 | 8 | 8 | 12 | |
| I | 12 | 0 | 7 | 1 | 0 | 0 | 12 | 2 | 560 | 0 | 4 | 2 | 0 | |
| J | 0 | 0 | 0 | 0 | 3 | 4 | 0 | 5 | 0 | 588 | 0 | 0 | 19 | |
| K | 19 | 3 | 1 | 7 | 2 | 0 | 24 | 2 | 4 | 0 | 527 | 11 | 3 | |
| L | 3 | 2 | 25 | 29 | 24 | 9 | 4 | 21 | 18 | 4 | 13 | 448 | 0 | |
| Class | A | B | C | D | E | F | G | H | I | J | K | L | R | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | ||||||||||||||
| A | 355 | 29 | 49 | 48 | 0 | 25 | 3 | 4 | 42 | 10 | 6 | 29 | 2 | |
| B | 2 | 550 | 0 | 7 | 0 | 1 | 32 | 0 | 0 | 0 | 0 | 8 | 27 | |
| C | 27 | 0 | 479 | 8 | 1 | 19 | 2 | 11 | 31 | 1 | 8 | 13 | 32 | |
| D | 32 | 9 | 0 | 514 | 0 | 13 | 23 | 0 | 3 | 2 | 4 | 0 | 66 | |
| E | 66 | 1 | 2 | 1 | 441 | 42 | 4 | 7 | 10 | 20 | 4 | 2 | 96 | |
| F | 96 | 3 | 6 | 15 | 6 | 397 | 16 | 4 | 19 | 12 | 14 | 12 | 55 | |
| G | 55 | 13 | 7 | 54 | 6 | 17 | 402 | 1 | 3 | 19 | 22 | 1 | 25 | |
| H | 25 | 0 | 2 | 3 | 0 | 26 | 0 | 491 | 28 | 10 | 4 | 11 | 7 | |
| I | 7 | 0 | 23 | 3 | 33 | 8 | 7 | 3 | 493 | 10 | 4 | 9 | 0 | |
| J | 0 | 0 | 1 | 0 | 16 | 5 | 2 | 2 | 9 | 553 | 6 | 6 | 2 | |
| K | 2 | 0 | 16 | 7 | 1 | 7 | 12 | 0 | 2 | 7 | 546 | 0 | 8 | |
| L | 8 | 22 | 1 | 0 | 6 | 6 | 20 | 13 | 6 | 9 | 1 | 508 | 0 | |
| Class | A | B | C | D | E | F | G | H | I | J | K | L | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||||||
| A | 534 | 2 | 3 | 10 | 3 | 2 | 16 | 7 | 13 | 0 | 5 | 5 | |
| B | 1 | 590 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 6 | |
| C | 0 | 0 | 597 | 0 | 0 | 2 | 0 | 0 | 1 | 0 | 0 | 0 | |
| D | 2 | 3 | 0 | 590 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 3 | |
| E | 0 | 1 | 0 | 0 | 591 | 2 | 0 | 0 | 0 | 1 | 0 | 5 | |
| F | 12 | 0 | 5 | 0 | 13 | 561 | 1 | 7 | 1 | 0 | 0 | 0 | |
| G | 2 | 0 | 6 | 4 | 5 | 1 | 554 | 14 | 7 | 3 | 4 | 0 | |
| H | 4 | 0 | 4 | 3 | 1 | 6 | 0 | 567 | 7 | 2 | 5 | 1 | |
| I | 9 | 1 | 1 | 2 | 0 | 1 | 7 | 2 | 572 | 0 | 5 | 0 | |
| J | 0 | 0 | 1 | 0 | 2 | 0 | 0 | 3 | 0 | 594 | 0 | 0 | |
| K | 4 | 0 | 2 | 5 | 4 | 1 | 10 | 4 | 1 | 0 | 567 | 2 | |
| L | 0 | 2 | 10 | 3 | 6 | 2 | 1 | 1 | 1 | 5 | 3 | 566 | |
| Class | A | B | C | D | E | F | G | H | I | J | K | L | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||||||
| A | 567 | 0 | 5 | 7 | 0 | 0 | 5 | 4 | 7 | 0 | 3 | 2 | |
| B | 16 | 580 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| C | 1 | 0 | 586 | 0 | 0 | 5 | 0 | 4 | 3 | 0 | 0 | 1 | |
| D | 25 | 1 | 0 | 572 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | |
| E | 6 | 0 | 0 | 0 | 466 | 108 | 0 | 11 | 1 | 0 | 0 | 8 | |
| F | 16 | 0 | 2 | 0 | 7 | 571 | 0 | 1 | 1 | 1 | 0 | 1 | |
| G | 25 | 0 | 4 | 2 | 0 | 2 | 548 | 3 | 1 | 0 | 15 | 0 | |
| H | 30 | 0 | 5 | 0 | 0 | 21 | 0 | 533 | 6 | 0 | 1 | 4 | |
| I | 39 | 0 | 2 | 1 | 0 | 2 | 6 | 6 | 540 | 0 | 4 | 0 | |
| J | 0 | 0 | 2 | 0 | 2 | 0 | 0 | 7 | 0 | 589 | 0 | 0 | |
| K | 5 | 0 | 0 | 3 | 0 | 0 | 12 | 0 | 1 | 0 | 579 | 0 | |
| L | 4 | 0 | 10 | 2 | 2 | 4 | 0 | 1 | 3 | 3 | 3 | 568 | |
| Class | A | B | C | D | E | F | G | H | I | J | K | L | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||||||
| A | 563 | 0 | 4 | 7 | 0 | 0 | 8 | 6 | 7 | 0 | 3 | 2 | |
| B | 14 | 582 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| C | 0 | 0 | 586 | 0 | 0 | 5 | 0 | 5 | 3 | 0 | 0 | 1 | |
| D | 15 | 2 | 0 | 580 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 1 | |
| E | 5 | 0 | 0 | 0 | 466 | 102 | 0 | 17 | 2 | 0 | 0 | 8 | |
| F | 13 | 0 | 0 | 0 | 6 | 576 | 0 | 2 | 1 | 1 | 0 | 1 | |
| G | 14 | 0 | 3 | 2 | 0 | 1 | 558 | 3 | 1 | 0 | 18 | 0 | |
| H | 22 | 0 | 5 | 0 | 0 | 14 | 0 | 546 | 6 | 0 | 1 | 6 | |
| I | 30 | 0 | 2 | 1 | 0 | 1 | 6 | 5 | 551 | 0 | 4 | 0 | |
| J | 0 | 0 | 2 | 0 | 2 | 0 | 0 | 6 | 0 | 590 | 0 | 0 | |
| K | 2 | 0 | 0 | 2 | 0 | 0 | 9 | 0 | 0 | 0 | 587 | 0 | |
| L | 4 | 0 | 10 | 1 | 2 | 4 | 0 | 1 | 2 | 3 | 3 | 570 | |
| Class | A | B | C | D | E | F | G | H | I | J | K | L | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||||||
| A | 549 | 1 | 4 | 6 | 0 | 1 | 13 | 10 | 11 | 0 | 3 | 2 | |
| B | 3 | 589 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 5 | |
| C | 0 | 0 | 597 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | |
| D | 1 | 3 | 0 | 593 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | |
| E | 0 | 0 | 0 | 0 | 595 | 2 | 0 | 0 | 0 | 0 | 0 | 3 | |
| F | 6 | 0 | 2 | 0 | 8 | 576 | 0 | 7 | 0 | 0 | 0 | 1 | |
| G | 3 | 0 | 5 | 3 | 1 | 0 | 568 | 10 | 3 | 2 | 5 | 0 | |
| H | 2 | 0 | 2 | 0 | 0 | 5 | 0 | 582 | 4 | 1 | 3 | 1 | |
| I | 16 | 0 | 1 | 1 | 0 | 1 | 6 | 3 | 569 | 0 | 3 | 0 | |
| J | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 599 | 0 | 0 | |
| K | 0 | 0 | 0 | 2 | 2 | 0 | 5 | 3 | 0 | 0 | 588 | 0 | |
| L | 1 | 0 | 6 | 1 | 3 | 0 | 0 | 0 | 1 | 3 | 2 | 583 | |
| Class | A | B | C | D | E | F | G | H | I | J | K | L | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||||||
| A | 566 | 0 | 4 | 6 | 0 | 0 | 6 | 6 | 9 | 0 | 1 | 2 | |
| B | 7 | 584 | 0 | 8 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | |
| C | 0 | 0 | 597 | 0 | 0 | 2 | 0 | 0 | 1 | 0 | 0 | 0 | |
| D | 5 | 2 | 0 | 591 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | |
| E | 4 | 0 | 0 | 0 | 467 | 97 | 0 | 10 | 2 | 0 | 7 | 13 | |
| F | 8 | 0 | 0 | 0 | 5 | 582 | 0 | 3 | 0 | 1 | 0 | 1 | |
| G | 5 | 0 | 2 | 2 | 0 | 1 | 578 | 3 | 1 | 0 | 8 | 0 | |
| H | 12 | 0 | 4 | 0 | 0 | 15 | 0 | 562 | 4 | 0 | 0 | 3 | |
| I | 31 | 0 | 0 | 0 | 0 | 1 | 8 | 2 | 556 | 0 | 2 | 0 | |
| J | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 4 | 0 | 594 | 0 | 0 | |
| K | 2 | 0 | 0 | 1 | 0 | 0 | 4 | 0 | 0 | 0 | 593 | 0 | |
| L | 2 | 0 | 2 | 0 | 0 | 1 | 0 | 1 | 0 | 2 | 3 | 589 | |
| Class | A | B | C | D | E | F | G | H | I | J | K | L | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||||||
| A | 512 | 6 | 4 | 13 | 4 | 2 | 17 | 13 | 17 | 0 | 8 | 4 | |
| B | 1 | 587 | 0 | 3 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 7 | |
| C | 0 | 0 | 599 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| D | 2 | 5 | 0 | 580 | 0 | 0 | 2 | 0 | 3 | 0 | 3 | 5 | |
| E | 1 | 1 | 0 | 4 | 566 | 3 | 0 | 1 | 0 | 1 | 0 | 23 | |
| F | 7 | 0 | 6 | 0 | 10 | 556 | 2 | 12 | 2 | 1 | 1 | 3 | |
| G | 3 | 1 | 6 | 5 | 4 | 1 | 553 | 8 | 7 | 4 | 8 | 0 | |
| H | 3 | 0 | 4 | 4 | 1 | 5 | 0 | 566 | 11 | 2 | 3 | 1 | |
| I | 8 | 1 | 1 | 1 | 2 | 1 | 6 | 5 | 569 | 0 | 5 | 1 | |
| J | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 4 | 0 | 594 | 0 | 0 | |
| K | 3 | 1 | 4 | 5 | 6 | 4 | 5 | 6 | 1 | 0 | 564 | 1 | |
| L | 0 | 3 | 3 | 9 | 5 | 2 | 2 | 2 | 2 | 5 | 2 | 565 | |
| Class | A | B | C | D | E | F | G | H | I | J | K | L | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||||||
| A | 512 | 6 | 4 | 13 | 4 | 2 | 17 | 13 | 17 | 0 | 8 | 4 | |
| B | 1 | 587 | 0 | 3 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 7 | |
| C | 0 | 0 | 599 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| D | 2 | 5 | 0 | 580 | 0 | 0 | 2 | 0 | 3 | 0 | 3 | 5 | |
| E | 1 | 1 | 0 | 4 | 566 | 3 | 0 | 1 | 0 | 1 | 0 | 23 | |
| F | 7 | 0 | 6 | 0 | 10 | 556 | 2 | 12 | 2 | 1 | 1 | 3 | |
| G | 3 | 1 | 6 | 5 | 4 | 1 | 553 | 8 | 7 | 4 | 8 | 0 | |
| H | 3 | 0 | 4 | 4 | 1 | 5 | 0 | 566 | 11 | 2 | 3 | 1 | |
| I | 8 | 1 | 1 | 1 | 2 | 1 | 6 | 5 | 569 | 0 | 5 | 1 | |
| J | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 4 | 0 | 594 | 0 | 0 | |
| K | 3 | 1 | 4 | 5 | 6 | 4 | 5 | 6 | 1 | 0 | 564 | 1 | |
| L | 0 | 3 | 3 | 9 | 5 | 2 | 2 | 2 | 2 | 5 | 2 | 565 | |
| Class | A | B | C | D | E | F | G | H | I | J | K | L | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||||||
| A | 564 | 0 | 3 | 8 | 0 | 1 | 7 | 4 | 8 | 0 | 0 | 5 | |
| B | 0 | 593 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 6 | |
| C | 0 | 0 | 600 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| D | 0 | 7 | 0 | 590 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 2 | |
| E | 1 | 0 | 0 | 0 | 589 | 8 | 0 | 1 | 0 | 1 | 0 | 0 | |
| F | 0 | 0 | 0 | 0 | 5 | 580 | 1 | 7 | 0 | 4 | 1 | 2 | |
| G | 5 | 0 | 4 | 3 | 0 | 0 | 563 | 3 | 10 | 3 | 8 | 1 | |
| H | 3 | 0 | 1 | 0 | 1 | 16 | 0 | 567 | 7 | 2 | 1 | 2 | |
| I | 6 | 0 | 1 | 0 | 2 | 0 | 2 | 1 | 583 | 2 | 1 | 2 | |
| J | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 600 | 0 | 0 | |
| K | 1 | 0 | 1 | 0 | 0 | 0 | 5 | 0 | 1 | 0 | 592 | 0 | |
| L | 3 | 6 | 3 | 3 | 7 | 0 | 4 | 2 | 2 | 2 | 2 | 566 | |
| Class | A | B | C | D | E | F | G | H | I | J | K | L | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||||||
| A | 511 | 2 | 4 | 12 | 5 | 1 | 19 | 19 | 12 | 0 | 8 | 7 | |
| B | 6 | 573 | 0 | 5 | 2 | 0 | 0 | 0 | 0 | 0 | 5 | 9 | |
| C | 1 | 0 | 590 | 0 | 1 | 1 | 0 | 5 | 2 | 0 | 0 | 0 | |
| D | 4 | 4 | 0 | 580 | 0 | 0 | 1 | 0 | 2 | 0 | 4 | 5 | |
| E | 3 | 1 | 1 | 6 | 540 | 6 | 0 | 1 | 0 | 0 | 3 | 39 | |
| F | 7 | 0 | 5 | 0 | 18 | 549 | 1 | 18 | 0 | 2 | 0 | 0 | |
| G | 7 | 1 | 7 | 5 | 2 | 0 | 530 | 21 | 11 | 1 | 13 | 2 | |
| H | 10 | 0 | 10 | 6 | 8 | 13 | 4 | 524 | 11 | 5 | 7 | 2 | |
| I | 26 | 1 | 2 | 4 | 0 | 0 | 17 | 11 | 535 | 0 | 4 | 0 | |
| J | 0 | 0 | 3 | 0 | 5 | 0 | 0 | 9 | 0 | 580 | 0 | 3 | |
| K | 22 | 3 | 4 | 11 | 3 | 1 | 15 | 11 | 3 | 2 | 522 | 3 | |
| L | 3 | 1 | 19 | 8 | 12 | 4 | 1 | 2 | 2 | 6 | 3 | 539 | |
| Class | A | B | C | D | E | F | G | H | I | J | K | L | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||||||
| A | 548 | 1 | 5 | 7 | 3 | 1 | 12 | 5 | 12 | 0 | 2 | 4 | |
| B | 4 | 584 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 6 | |
| C | 0 | 0 | 598 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | |
| D | 5 | 2 | 0 | 592 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | |
| E | 0 | 1 | 0 | 5 | 548 | 22 | 0 | 3 | 1 | 2 | 3 | 15 | |
| F | 10 | 1 | 2 | 0 | 5 | 572 | 1 | 6 | 0 | 1 | 0 | 2 | |
| G | 10 | 0 | 3 | 3 | 3 | 0 | 556 | 9 | 7 | 1 | 8 | 0 | |
| H | 8 | 0 | 4 | 0 | 2 | 8 | 0 | 568 | 4 | 1 | 4 | 1 | |
| I | 17 | 1 | 1 | 2 | 0 | 0 | 12 | 3 | 561 | 0 | 3 | 0 | |
| J | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 2 | 0 | 597 | 0 | 0 | |
| K | 6 | 0 | 1 | 2 | 0 | 2 | 7 | 0 | 0 | 0 | 582 | 0 | |
| L | 2 | 1 | 5 | 4 | 2 | 0 | 2 | 0 | 0 | 3 | 1 | 580 | |
| Class | A | B | C | D | E | F | G | H | I | J | K | L | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||||||
| A | 573 | 1 | 3 | 5 | 0 | 0 | 8 | 5 | 3 | 0 | 1 | 1 | |
| B | 1 | 597 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| C | 1 | 0 | 598 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | |
| D | 1 | 2 | 0 | 595 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | |
| E | 0 | 0 | 0 | 0 | 599 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | |
| F | 0 | 0 | 0 | 0 | 4 | 590 | 0 | 5 | 0 | 0 | 0 | 1 | |
| G | 7 | 1 | 5 | 3 | 0 | 0 | 571 | 1 | 5 | 1 | 6 | 0 | |
| H | 2 | 0 | 0 | 0 | 0 | 9 | 1 | 585 | 1 | 0 | 2 | 0 | |
| I | 11 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 586 | 0 | 1 | 0 | |
| J | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 598 | 0 | 0 | |
| K | 1 | 0 | 0 | 0 | 1 | 0 | 4 | 0 | 0 | 0 | 594 | 0 | |
| L | 1 | 0 | 3 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 592 | |
| Class | A | B | C | D | E | F | G | H | I | J | K | L | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||||||
| A | 583 | 0 | 1 | 2 | 0 | 0 | 5 | 4 | 2 | 0 | 1 | 2 | |
| B | 0 | 598 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| C | 1 | 0 | 598 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | |
| D | 1 | 2 | 0 | 594 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 2 | |
| E | 1 | 0 | 0 | 0 | 595 | 3 | 0 | 0 | 0 | 0 | 0 | 1 | |
| F | 0 | 0 | 0 | 0 | 4 | 589 | 0 | 5 | 1 | 0 | 0 | 1 | |
| G | 4 | 0 | 3 | 2 | 0 | 0 | 578 | 2 | 3 | 0 | 8 | 0 | |
| H | 3 | 0 | 0 | 0 | 0 | 6 | 1 | 586 | 1 | 0 | 1 | 2 | |
| I | 6 | 0 | 1 | 0 | 0 | 0 | 2 | 3 | 587 | 0 | 1 | 0 | |
| J | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 1 | 0 | 596 | 0 | 1 | |
| K | 1 | 0 | 0 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 594 | 0 | |
| L | 1 | 0 | 1 | 0 | 2 | 0 | 2 | 1 | 0 | 0 | 0 | 593 | |
| Class | A | B | C | D | E | F | G | H | I | J | K | L | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||||||
| A | 575 | 1 | 2 | 4 | 0 | 0 | 4 | 4 | 4 | 0 | 2 | 4 | |
| B | 1 | 597 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| C | 1 | 0 | 598 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | |
| D | 3 | 2 | 0 | 594 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | |
| E | 0 | 0 | 0 | 0 | 599 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | |
| F | 0 | 0 | 0 | 0 | 2 | 594 | 0 | 3 | 0 | 0 | 0 | 1 | |
| G | 7 | 1 | 2 | 1 | 3 | 0 | 577 | 0 | 2 | 1 | 6 | 0 | |
| H | 4 | 0 | 0 | 0 | 1 | 7 | 1 | 583 | 1 | 1 | 0 | 2 | |
| I | 7 | 0 | 2 | 1 | 0 | 0 | 3 | 0 | 586 | 0 | 1 | 0 | |
| J | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 599 | 0 | 0 | |
| K | 0 | 0 | 0 | 0 | 0 | 0 | 7 | 0 | 0 | 0 | 593 | 0 | |
| L | 1 | 0 | 0 | 0 | 4 | 0 | 1 | 0 | 0 | 0 | 0 | 594 | |
| Class | A | B | C | D | E | F | G | H | I | J | K | L | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||||||
| A | 581 | 0 | 3 | 2 | 0 | 0 | 8 | 1 | 4 | 0 | 0 | 1 | |
| B | 0 | 597 | 0 | 2 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | |
| C | 1 | 0 | 595 | 0 | 0 | 0 | 2 | 0 | 1 | 0 | 0 | 1 | |
| D | 2 | 2 | 0 | 593 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | |
| E | 0 | 0 | 0 | 0 | 598 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | |
| F | 0 | 0 | 0 | 0 | 7 | 585 | 0 | 6 | 0 | 1 | 0 | 1 | |
| G | 3 | 0 | 4 | 1 | 0 | 0 | 585 | 1 | 2 | 0 | 4 | 0 | |
| H | 4 | 0 | 2 | 0 | 0 | 8 | 0 | 582 | 1 | 0 | 1 | 2 | |
| I | 9 | 0 | 1 | 0 | 0 | 0 | 3 | 2 | 584 | 0 | 1 | 0 | |
| J | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 2 | 0 | 595 | 0 | 1 | |
| K | 0 | 0 | 0 | 0 | 0 | 0 | 6 | 0 | 0 | 0 | 593 | 1 | |
| L | 1 | 0 | 4 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 592 | |
| Class | Abstract Level | Rank Level | Measurement Level Combination Rules | DS Theory of Evidence | Secondary Classifier | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Majority Voting | Borda Count | Sum Rule | Product Rule | Max Rule | DS with 2 Sources | DS with 3 Sources | 3-NN | Random Forest | MLP | Logistic Regression | |
| A | 89.0 | 93.8 | 91.5 | 94.3 | 85.3 | 94.0 | 91.3 | 95.5 | 96.8 | 96.5 | 97.1 |
| B | 98.3 | 97.0 | 98.2 | 97.3 | 97.8 | 98.8 | 97.3 | 99.5 | 99.5 | 99.8 | 99.6 |
| C | 99.5 | 97.7 | 99.5 | 99.5 | 99.8 | 100.0 | 99.6 | 99.6 | 99.1 | 99.5 | 99.6 |
| D | 98.3 | 96.7 | 98.8 | 98.5 | 96.6 | 98.3 | 98.6 | 99.1 | 98.8 | 98.8 | 99.0 |
| E | 98.5 | 77.7 | 99.1 | 77.8 | 94.3 | 98.1 | 91.3 | 99.8 | 99.6 | 99.5 | 99.1 |
| F | 93.5 | 96.0 | 96.0 | 97.0 | 92.6 | 96.6 | 95.3 | 98.3 | 97.5 | 98.1 | 98.1 |
| G | 92.3 | 93.0 | 94.6 | 96.3 | 92.1 | 93.8 | 92.6 | 95.1 | 97.5 | 95.5 | 96.3 |
| H | 94.5 | 91.0 | 97.0 | 93.6 | 94.3 | 94.5 | 94.6 | 97.5 | 97.0 | 97.1 | 97.6 |
| I | 95.3 | 91.8 | 94.8 | 92.6 | 94.8 | 97.1 | 93.5 | 97.6 | 97.3 | 97.6 | 97.8 |
| J | 99.0 | 98.3 | 99.8 | 99.0 | 99.0 | 100.0 | 99.5 | 99.6 | 99.1 | 99.5 | 99.3 |
| K | 94.5 | 97.8 | 98.0 | 98.8 | 94.0 | 98.6 | 97.0 | 99.0 | 98.8 | 99.5 | 99.0 |
| L | 94.3 | 95.0 | 97.2 | 98.1 | 94.1 | 94.3 | 96.6 | 98.6 | 98.6 | 98.6 | 98.8 |
| Overall | 95.6 | 94.3 | 97.8 | 95.7 | 94.6 | 97.0 | 95.6 | 98.3 | 98.3 | 98.3 | 98.5 |
| Feature/Methodology | Recognition Accuracy (%) |
|---|---|
| MLG | 91.42 |
| HOG | 78.04 |
| Elliptical | 79.57 |
| MLG + HOG | 86.03 |
| HOG + Elliptical | 86.57 |
| MLG + Elliptical | 93.44 |
| MLG + HOG + Elliptical | 91.03 |
| Best result after classifier combination | 98.45 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mukhopadhyay, A.; Singh, P.K.; Sarkar, R.; Nasipuri, M. A Study of Different Classifier Combination Approaches for Handwritten Indic Script Recognition. J. Imaging 2018, 4, 39. https://doi.org/10.3390/jimaging4020039
Mukhopadhyay A, Singh PK, Sarkar R, Nasipuri M. A Study of Different Classifier Combination Approaches for Handwritten Indic Script Recognition. Journal of Imaging. 2018; 4(2):39. https://doi.org/10.3390/jimaging4020039
Chicago/Turabian StyleMukhopadhyay, Anirban, Pawan Kumar Singh, Ram Sarkar, and Mita Nasipuri. 2018. "A Study of Different Classifier Combination Approaches for Handwritten Indic Script Recognition" Journal of Imaging 4, no. 2: 39. https://doi.org/10.3390/jimaging4020039
APA StyleMukhopadhyay, A., Singh, P. K., Sarkar, R., & Nasipuri, M. (2018). A Study of Different Classifier Combination Approaches for Handwritten Indic Script Recognition. Journal of Imaging, 4(2), 39. https://doi.org/10.3390/jimaging4020039